[jira] [Commented] (FLINK-11779) CLI ignores -m parameter if high-availability is ZOOKEEPER
[
https://issues.apache.org/jira/browse/FLINK-11779?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784201#comment-16784201
]
TisonKun commented on FLINK-11779:
--
[~gjy]
Isn't "-m" ignored because it is run in a yarn-cluster? If so, what we need to
do is excluding "-m" option from yarn-cluster mode document.
>From {{FlinkYarnSessionCli#applyCommandLineOptionsToConfiguration}}.
{code:java}
@Override
protected Configuration
applyCommandLineOptionsToConfiguration(CommandLine commandLine) throws
FlinkException {
// we ignore the addressOption because it can only contain
"yarn-cluster"
...
{code}
> CLI ignores -m parameter if high-availability is ZOOKEEPER
> ---
>
> Key: FLINK-11779
> URL: https://issues.apache.org/jira/browse/FLINK-11779
> Project: Flink
> Issue Type: Bug
> Components: Command Line Client
>Affects Versions: 1.7.2, 1.8.0
>Reporter: Gary Yao
>Assignee: leesf
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> *Description*
> The CLI will ignores the host/port provided by the {{-m}} parameter if
> {{high-availability: ZOOKEEPER}} is configured in {{flink-conf.yaml}}
> *Expected behavior*
> * TBD: either document this behavior or give precedence to {{-m}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (FLINK-7129) Support dynamically changing CEP patterns
[ https://issues.apache.org/jira/browse/FLINK-7129?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dawid Wysakowicz reassigned FLINK-7129: --- Assignee: (was: Dawid Wysakowicz) > Support dynamically changing CEP patterns > - > > Key: FLINK-7129 > URL: https://issues.apache.org/jira/browse/FLINK-7129 > Project: Flink > Issue Type: New Feature > Components: Library / CEP >Reporter: Dawid Wysakowicz >Priority: Major > > An umbrella task for introducing mechanism for injecting patterns through > coStream -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-11821) fix the error package location of KafkaDeserializationSchemaWrapper.java file
lamber-ken created FLINK-11821: -- Summary: fix the error package location of KafkaDeserializationSchemaWrapper.java file Key: FLINK-11821 URL: https://issues.apache.org/jira/browse/FLINK-11821 Project: Flink Issue Type: Bug Components: Connectors / Kafka Reporter: lamber-ken Assignee: lamber-ken fix the error package location of KafkaDeserializationSchemaWrapper.java -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] lamber-ken opened a new pull request #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken opened a new pull request #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902 ## What is the purpose of the change fix the error package location of KafkaDeserializationSchemaWrapper.java ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (yes) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
flinkbot commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469587374 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-11821) fix the error package location of KafkaDeserializationSchemaWrapper.java file
[ https://issues.apache.org/jira/browse/FLINK-11821?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-11821: --- Labels: pull-request-available (was: ) > fix the error package location of KafkaDeserializationSchemaWrapper.java file > -- > > Key: FLINK-11821 > URL: https://issues.apache.org/jira/browse/FLINK-11821 > Project: Flink > Issue Type: Bug > Components: Connectors / Kafka >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Blocker > Labels: pull-request-available > > fix the error package location of KafkaDeserializationSchemaWrapper.java -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] aljoscha commented on issue #7781: [FLINK-8354] Add KafkaDeserializationSchema that directly uses ConsumerRecord
aljoscha commented on issue #7781: [FLINK-8354] Add KafkaDeserializationSchema that directly uses ConsumerRecord URL: https://github.com/apache/flink/pull/7781#issuecomment-469591040 @lamber-ken How do you mean? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken commented on issue #7781: [FLINK-8354] Add KafkaDeserializationSchema that directly uses ConsumerRecord
lamber-ken commented on issue #7781: [FLINK-8354] Add KafkaDeserializationSchema that directly uses ConsumerRecord URL: https://github.com/apache/flink/pull/7781#issuecomment-469594239 @aljoscha, hi, the mismatch between KafkaDeserializationSchemaWrapper class's package name and file's location. #7902 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-11779) CLI ignores -m parameter if high-availability is ZOOKEEPER
[
https://issues.apache.org/jira/browse/FLINK-11779?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784246#comment-16784246
]
Gary Yao commented on FLINK-11779:
--
[~Tison] I am not sure what you are proposing. It does not make sense to
specify a host:port when submitting to a per-job cluster but if the user
submits to a yarn session cluster with the {{-m host:port}} option, the client
could respect the specified host:port.
> CLI ignores -m parameter if high-availability is ZOOKEEPER
> ---
>
> Key: FLINK-11779
> URL: https://issues.apache.org/jira/browse/FLINK-11779
> Project: Flink
> Issue Type: Bug
> Components: Command Line Client
>Affects Versions: 1.7.2, 1.8.0
>Reporter: Gary Yao
>Assignee: leesf
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> *Description*
> The CLI will ignores the host/port provided by the {{-m}} parameter if
> {{high-availability: ZOOKEEPER}} is configured in {{flink-conf.yaml}}
> *Expected behavior*
> * TBD: either document this behavior or give precedence to {{-m}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (FLINK-11822) Introduce Flink metadata handler
godfrey he created FLINK-11822: -- Summary: Introduce Flink metadata handler Key: FLINK-11822 URL: https://issues.apache.org/jira/browse/FLINK-11822 Project: Flink Issue Type: New Feature Components: API / Table SQL Reporter: godfrey he Assignee: godfrey he Calcite has defined various metadata handlers(e.g. `RowCount`, `Selectivity`) and provided default implementation(e.g. `RelMdRowCount`, `RelMdSelectivity`). However, the default implementation can't completely meet our requirements, e.g. some of its logic is incomplete,and some `RelNode`s are not considered. There are two options to meet our requirements: option 1. Extends from default implementation, overrides method to improve its logic, add new methods for new `RelNode`. The advantage of this option is we just need to focus on the additions and modifications. However, its shortcomings are also obvious: we have no control over the code of non-override methods in default implementation classes especially when upgrading the Calcite version. option 2. Extends from metadata handler interfaces, reimplement all the logic. Its shortcomings are very obvious, however we can control all the code logic that's what we want. so we choose option 2! In this jira, only basic metadata handles will be introduce, including: `FlinkRelMdPercentageOriginalRow`, `FlinkRelMdNonCumulativeCost`, `FlinkRelMdCumulativeCost`, `FlinkRelMdRowCount`, `FlinkRelMdSize`, `FlinkRelMdSelectivity`, `FlinkRelMdDistinctRowCoun`, `FlinkRelMdPopulationSize`, `FlinkRelMdColumnUniqueness`, `FlinkRelMdUniqueKeys` -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11822) Introduce Flink metadata handlers
[ https://issues.apache.org/jira/browse/FLINK-11822?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] godfrey he updated FLINK-11822: --- Summary: Introduce Flink metadata handlers (was: Introduce Flink metadata handler) > Introduce Flink metadata handlers > - > > Key: FLINK-11822 > URL: https://issues.apache.org/jira/browse/FLINK-11822 > Project: Flink > Issue Type: New Feature > Components: API / Table SQL >Reporter: godfrey he >Assignee: godfrey he >Priority: Major > > Calcite has defined various metadata handlers(e.g. `RowCount`, `Selectivity`) > and provided default implementation(e.g. `RelMdRowCount`, > `RelMdSelectivity`). However, the default implementation can't completely > meet our requirements, e.g. some of its logic is incomplete,and some > `RelNode`s are not considered. > There are two options to meet our requirements: > option 1. Extends from default implementation, overrides method to improve > its logic, add new methods for new `RelNode`. The advantage of this option is > we just need to focus on the additions and modifications. However, its > shortcomings are also obvious: we have no control over the code of > non-override methods in default implementation classes especially when > upgrading the Calcite version. > option 2. Extends from metadata handler interfaces, reimplement all the > logic. Its shortcomings are very obvious, however we can control all the code > logic that's what we want. > so we choose option 2! > In this jira, only basic metadata handles will be introduce, including: > `FlinkRelMdPercentageOriginalRow`, > `FlinkRelMdNonCumulativeCost`, > `FlinkRelMdCumulativeCost`, > `FlinkRelMdRowCount`, > `FlinkRelMdSize`, > `FlinkRelMdSelectivity`, > `FlinkRelMdDistinctRowCoun`, > `FlinkRelMdPopulationSize`, > `FlinkRelMdColumnUniqueness`, > `FlinkRelMdUniqueKeys` -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11822) Introduce Flink metadata handlers
[
https://issues.apache.org/jira/browse/FLINK-11822?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
godfrey he updated FLINK-11822:
---
Description:
Calcite has defined various metadata handlers(e.g. {{RowCoun}}, {{Selectivity}}
and provided default implementation(e.g. {{RelMdRowCount}},
{{RelMdSelectivity}}). However, the default implementation can't completely
meet our requirements, e.g. some of its logic is incomplete,and some
{{RelNode}}s are not considered.
There are two options to meet our requirements:
option 1. Extends from default implementation, overrides method to improve its
logic, add new methods for new {{RelNode}}. The advantage of this option is we
just need to focus on the additions and modifications. However, its
shortcomings are also obvious: we have no control over the code of non-override
methods in default implementation classes especially when upgrading the Calcite
version.
option 2. Extends from metadata handler interfaces, reimplement all the logic.
Its shortcomings are very obvious, however we can control all the code logic
that's what we want.
so we choose option 2!
In this jira, only basic metadata handles will be introduced, including:
{{FlinkRelMdPercentageOriginalRow}},
{{FlinkRelMdNonCumulativeCost}},
{{FlinkRelMdCumulativeCost}},
{{FlinkRelMdRowCount}},
{{FlinkRelMdSize}},
{{FlinkRelMdSelectivity}},
{{FlinkRelMdDistinctRowCoun}},
{{FlinkRelMdPopulationSize}},
{{FlinkRelMdColumnUniqueness}},
{{FlinkRelMdUniqueKeys}}
was:
Calcite has defined various metadata handlers(e.g. `RowCount`, `Selectivity`)
and provided default implementation(e.g. `RelMdRowCount`, `RelMdSelectivity`).
However, the default implementation can't completely meet our requirements,
e.g. some of its logic is incomplete,and some `RelNode`s are not considered.
There are two options to meet our requirements:
option 1. Extends from default implementation, overrides method to improve its
logic, add new methods for new `RelNode`. The advantage of this option is we
just need to focus on the additions and modifications. However, its
shortcomings are also obvious: we have no control over the code of non-override
methods in default implementation classes especially when upgrading the Calcite
version.
option 2. Extends from metadata handler interfaces, reimplement all the logic.
Its shortcomings are very obvious, however we can control all the code logic
that's what we want.
so we choose option 2!
In this jira, only basic metadata handles will be introduce, including:
`FlinkRelMdPercentageOriginalRow`,
`FlinkRelMdNonCumulativeCost`,
`FlinkRelMdCumulativeCost`,
`FlinkRelMdRowCount`,
`FlinkRelMdSize`,
`FlinkRelMdSelectivity`,
`FlinkRelMdDistinctRowCoun`,
`FlinkRelMdPopulationSize`,
`FlinkRelMdColumnUniqueness`,
`FlinkRelMdUniqueKeys`
> Introduce Flink metadata handlers
> -
>
> Key: FLINK-11822
> URL: https://issues.apache.org/jira/browse/FLINK-11822
> Project: Flink
> Issue Type: New Feature
> Components: API / Table SQL
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
>
> Calcite has defined various metadata handlers(e.g. {{RowCoun}},
> {{Selectivity}} and provided default implementation(e.g. {{RelMdRowCount}},
> {{RelMdSelectivity}}). However, the default implementation can't completely
> meet our requirements, e.g. some of its logic is incomplete,and some
> {{RelNode}}s are not considered.
> There are two options to meet our requirements:
> option 1. Extends from default implementation, overrides method to improve
> its logic, add new methods for new {{RelNode}}. The advantage of this option
> is we just need to focus on the additions and modifications. However, its
> shortcomings are also obvious: we have no control over the code of
> non-override methods in default implementation classes especially when
> upgrading the Calcite version.
> option 2. Extends from metadata handler interfaces, reimplement all the
> logic. Its shortcomings are very obvious, however we can control all the code
> logic that's what we want.
> so we choose option 2!
> In this jira, only basic metadata handles will be introduced, including:
> {{FlinkRelMdPercentageOriginalRow}},
> {{FlinkRelMdNonCumulativeCost}},
> {{FlinkRelMdCumulativeCost}},
> {{FlinkRelMdRowCount}},
> {{FlinkRelMdSize}},
> {{FlinkRelMdSelectivity}},
> {{FlinkRelMdDistinctRowCoun}},
> {{FlinkRelMdPopulationSize}},
> {{FlinkRelMdColumnUniqueness}},
> {{FlinkRelMdUniqueKeys}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11822) Introduce Flink metadata handlers
[
https://issues.apache.org/jira/browse/FLINK-11822?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
godfrey he updated FLINK-11822:
---
Description:
Calcite has defined various metadata handlers(e.g. {{RowCoun}}, {{Selectivity}}
and provided default implementation(e.g. {{RelMdRowCount}},
{{RelMdSelectivity}}). However, the default implementation can't completely
meet our requirements, e.g. some of its logic is incomplete,and some RelNodes
are not considered.
There are two options to meet our requirements:
option 1. Extends from default implementation, overrides method to improve its
logic, add new methods for new {{RelNode}}. The advantage of this option is we
just need to focus on the additions and modifications. However, its
shortcomings are also obvious: we have no control over the code of non-override
methods in default implementation classes especially when upgrading the Calcite
version.
option 2. Extends from metadata handler interfaces, reimplement all the logic.
Its shortcomings are very obvious, however we can control all the code logic
that's what we want.
so we choose option 2!
In this jira, only basic metadata handles will be introduced, including:
{{FlinkRelMdPercentageOriginalRow}},
{{FlinkRelMdNonCumulativeCost}},
{{FlinkRelMdCumulativeCost}},
{{FlinkRelMdRowCount}},
{{FlinkRelMdSize}},
{{FlinkRelMdSelectivity}},
{{FlinkRelMdDistinctRowCoun}},
{{FlinkRelMdPopulationSize}},
{{FlinkRelMdColumnUniqueness}},
{{FlinkRelMdUniqueKeys}}
was:
Calcite has defined various metadata handlers(e.g. {{RowCoun}}, {{Selectivity}}
and provided default implementation(e.g. {{RelMdRowCount}},
{{RelMdSelectivity}}). However, the default implementation can't completely
meet our requirements, e.g. some of its logic is incomplete,and some
{{RelNode}}s are not considered.
There are two options to meet our requirements:
option 1. Extends from default implementation, overrides method to improve its
logic, add new methods for new {{RelNode}}. The advantage of this option is we
just need to focus on the additions and modifications. However, its
shortcomings are also obvious: we have no control over the code of non-override
methods in default implementation classes especially when upgrading the Calcite
version.
option 2. Extends from metadata handler interfaces, reimplement all the logic.
Its shortcomings are very obvious, however we can control all the code logic
that's what we want.
so we choose option 2!
In this jira, only basic metadata handles will be introduced, including:
{{FlinkRelMdPercentageOriginalRow}},
{{FlinkRelMdNonCumulativeCost}},
{{FlinkRelMdCumulativeCost}},
{{FlinkRelMdRowCount}},
{{FlinkRelMdSize}},
{{FlinkRelMdSelectivity}},
{{FlinkRelMdDistinctRowCoun}},
{{FlinkRelMdPopulationSize}},
{{FlinkRelMdColumnUniqueness}},
{{FlinkRelMdUniqueKeys}}
> Introduce Flink metadata handlers
> -
>
> Key: FLINK-11822
> URL: https://issues.apache.org/jira/browse/FLINK-11822
> Project: Flink
> Issue Type: New Feature
> Components: API / Table SQL
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
>
> Calcite has defined various metadata handlers(e.g. {{RowCoun}},
> {{Selectivity}} and provided default implementation(e.g. {{RelMdRowCount}},
> {{RelMdSelectivity}}). However, the default implementation can't completely
> meet our requirements, e.g. some of its logic is incomplete,and some RelNodes
> are not considered.
> There are two options to meet our requirements:
> option 1. Extends from default implementation, overrides method to improve
> its logic, add new methods for new {{RelNode}}. The advantage of this option
> is we just need to focus on the additions and modifications. However, its
> shortcomings are also obvious: we have no control over the code of
> non-override methods in default implementation classes especially when
> upgrading the Calcite version.
> option 2. Extends from metadata handler interfaces, reimplement all the
> logic. Its shortcomings are very obvious, however we can control all the code
> logic that's what we want.
> so we choose option 2!
> In this jira, only basic metadata handles will be introduced, including:
> {{FlinkRelMdPercentageOriginalRow}},
> {{FlinkRelMdNonCumulativeCost}},
> {{FlinkRelMdCumulativeCost}},
> {{FlinkRelMdRowCount}},
> {{FlinkRelMdSize}},
> {{FlinkRelMdSelectivity}},
> {{FlinkRelMdDistinctRowCoun}},
> {{FlinkRelMdPopulationSize}},
> {{FlinkRelMdColumnUniqueness}},
> {{FlinkRelMdUniqueKeys}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] azagrebin commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
azagrebin commented on a change in pull request #7880: [FLINK-11336][zk] Delete
ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
URL: https://github.com/apache/flink/pull/7880#discussion_r262417205
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/highavailability/zookeeper/ZooKeeperHaServicesTest.java
##
@@ -0,0 +1,250 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.highavailability.zookeeper;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.HighAvailabilityOptions;
+import org.apache.flink.runtime.blob.BlobKey;
+import org.apache.flink.runtime.blob.BlobStoreService;
+import org.apache.flink.runtime.concurrent.Executors;
+import org.apache.flink.runtime.highavailability.RunningJobsRegistry;
+import org.apache.flink.runtime.leaderelection.LeaderElectionService;
+import org.apache.flink.runtime.leaderelection.TestingContender;
+import org.apache.flink.runtime.leaderelection.TestingListener;
+import org.apache.flink.runtime.leaderretrieval.LeaderRetrievalService;
+import org.apache.flink.runtime.util.ZooKeeperUtils;
+import org.apache.flink.runtime.zookeeper.ZooKeeperResource;
+import org.apache.flink.util.TestLogger;
+import org.apache.flink.util.function.ThrowingConsumer;
+
+import org.apache.curator.framework.CuratorFramework;
+import org.apache.curator.framework.CuratorFrameworkFactory;
+import org.apache.curator.retry.RetryForever;
+import org.junit.AfterClass;
+import org.junit.Before;
+import org.junit.BeforeClass;
+import org.junit.ClassRule;
+import org.junit.Test;
+
+import javax.annotation.Nonnull;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+
+import static org.hamcrest.Matchers.empty;
+import static org.hamcrest.Matchers.equalTo;
+import static org.hamcrest.Matchers.is;
+import static org.hamcrest.Matchers.not;
+import static org.hamcrest.Matchers.notNullValue;
+import static org.hamcrest.Matchers.nullValue;
+import static org.junit.Assert.assertThat;
+
+/**
+ * Tests for the {@link ZooKeeperHaServices}.
+ */
+public class ZooKeeperHaServicesTest extends TestLogger {
+
+ @ClassRule
+ public static final ZooKeeperResource ZOO_KEEPER_RESOURCE = new
ZooKeeperResource();
+
+ private static CuratorFramework client;
+
+ @BeforeClass
+ public static void setupClass() {
+ client = startCuratorFramework();
+ client.start();
+ }
+
+ @Before
+ public void setup() throws Exception {
+ final List children = client.getChildren().forPath("/");
+
+ for (String child : children) {
+ if (!child.equals("zookeeper")) {
+
client.delete().deletingChildrenIfNeeded().forPath('/' + child);
+ }
+ }
+ }
+
+ @AfterClass
+ public static void teardownClass() {
+ if (client != null) {
+ client.close();
+ }
+ }
+
+ /**
+* Tests that a simple {@link ZooKeeperHaServices#close()} does not
delete ZooKeeper paths.
+*/
+ @Test
+ public void testSimpleClose() throws Exception {
+ final String rootPath = "/foo/bar/flink";
+ final Configuration configuration =
createConfiguration(rootPath);
+
+ final TestingBlobStoreService blobStoreService = new
TestingBlobStoreService();
+
+ runCleanupTest(
+ configuration,
+ blobStoreService,
+ ZooKeeperHaServices::close);
+
+ assertThat(blobStoreService.isClosed(), is(true));
+ assertThat(blobStoreService.isClosedAndCleanedUpAllData(),
is(false));
+
+ final List children =
client.getChildren().forPath(rootPath);
+ assertThat(children, is(not(empty(;
+ }
+
+ /**
+* Tests that the {@link ZooKeeperHaServices} cleans up all paths if
+* it is closed via {@link
ZooKeeperHaServices#closeAndCleanupAllData()}.
+*/
+ @T
[GitHub] [flink] azagrebin commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
azagrebin commented on a change in pull request #7880: [FLINK-11336][zk] Delete
ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
URL: https://github.com/apache/flink/pull/7880#discussion_r262164377
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/highavailability/zookeeper/ZooKeeperHaServicesTest.java
##
@@ -0,0 +1,250 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.highavailability.zookeeper;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.HighAvailabilityOptions;
+import org.apache.flink.runtime.blob.BlobKey;
+import org.apache.flink.runtime.blob.BlobStoreService;
+import org.apache.flink.runtime.concurrent.Executors;
+import org.apache.flink.runtime.highavailability.RunningJobsRegistry;
+import org.apache.flink.runtime.leaderelection.LeaderElectionService;
+import org.apache.flink.runtime.leaderelection.TestingContender;
+import org.apache.flink.runtime.leaderelection.TestingListener;
+import org.apache.flink.runtime.leaderretrieval.LeaderRetrievalService;
+import org.apache.flink.runtime.util.ZooKeeperUtils;
+import org.apache.flink.runtime.zookeeper.ZooKeeperResource;
+import org.apache.flink.util.TestLogger;
+import org.apache.flink.util.function.ThrowingConsumer;
+
+import org.apache.curator.framework.CuratorFramework;
+import org.apache.curator.framework.CuratorFrameworkFactory;
+import org.apache.curator.retry.RetryForever;
+import org.junit.AfterClass;
+import org.junit.Before;
+import org.junit.BeforeClass;
+import org.junit.ClassRule;
+import org.junit.Test;
+
+import javax.annotation.Nonnull;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+
+import static org.hamcrest.Matchers.empty;
+import static org.hamcrest.Matchers.equalTo;
+import static org.hamcrest.Matchers.is;
+import static org.hamcrest.Matchers.not;
+import static org.hamcrest.Matchers.notNullValue;
+import static org.hamcrest.Matchers.nullValue;
+import static org.junit.Assert.assertThat;
+
+/**
+ * Tests for the {@link ZooKeeperHaServices}.
+ */
+public class ZooKeeperHaServicesTest extends TestLogger {
+
+ @ClassRule
+ public static final ZooKeeperResource ZOO_KEEPER_RESOURCE = new
ZooKeeperResource();
+
+ private static CuratorFramework client;
+
+ @BeforeClass
+ public static void setupClass() {
+ client = startCuratorFramework();
+ client.start();
+ }
+
+ @Before
+ public void setup() throws Exception {
+ final List children = client.getChildren().forPath("/");
+
+ for (String child : children) {
+ if (!child.equals("zookeeper")) {
+
client.delete().deletingChildrenIfNeeded().forPath('/' + child);
+ }
+ }
+ }
+
+ @AfterClass
+ public static void teardownClass() {
+ if (client != null) {
+ client.close();
+ }
+ }
+
+ /**
+* Tests that a simple {@link ZooKeeperHaServices#close()} does not
delete ZooKeeper paths.
+*/
+ @Test
+ public void testSimpleClose() throws Exception {
+ final String rootPath = "/foo/bar/flink";
+ final Configuration configuration =
createConfiguration(rootPath);
+
+ final TestingBlobStoreService blobStoreService = new
TestingBlobStoreService();
+
+ runCleanupTest(
+ configuration,
+ blobStoreService,
+ ZooKeeperHaServices::close);
+
+ assertThat(blobStoreService.isClosed(), is(true));
+ assertThat(blobStoreService.isClosedAndCleanedUpAllData(),
is(false));
+
+ final List children =
client.getChildren().forPath(rootPath);
+ assertThat(children, is(not(empty(;
+ }
+
+ /**
+* Tests that the {@link ZooKeeperHaServices} cleans up all paths if
+* it is closed via {@link
ZooKeeperHaServices#closeAndCleanupAllData()}.
+*/
+ @T
[GitHub] [flink] azagrebin commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
azagrebin commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData URL: https://github.com/apache/flink/pull/7880#discussion_r262162846 ## File path: flink-runtime/src/test/resources/log4j-test.properties ## @@ -18,7 +18,7 @@ # Set root logger level to OFF to not flood build logs # set manually to INFO for debugging purposes -log4j.rootLogger=OFF, testlogger +log4j.rootLogger=INFO, testlogger Review comment: needs to be reverted? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] mxm commented on issue #7762: [FLINK-11146] Remove invalid codes in ClusterClient
mxm commented on issue #7762: [FLINK-11146] Remove invalid codes in ClusterClient URL: https://github.com/apache/flink/pull/7762#issuecomment-469615045 I'd merge. Anything blocking this from being merged? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] klion26 commented on a change in pull request #7895: [FLINK-11126][YARN][security] Filter out AMRMToken in TaskManager‘s credentials
klion26 commented on a change in pull request #7895: [FLINK-11126][YARN][security] Filter out AMRMToken in TaskManager‘s credentials URL: https://github.com/apache/flink/pull/7895#discussion_r262423416 ## File path: flink-yarn/src/test/java/org/apache/flink/yarn/UtilsTest.java ## @@ -18,25 +18,54 @@ package org.apache.flink.yarn; +import org.apache.flink.configuration.Configuration; +import org.apache.flink.core.testutils.CommonTestUtils; +import org.apache.flink.runtime.clusterframework.ContaineredTaskManagerParameters; import org.apache.flink.util.TestLogger; +import org.apache.hadoop.io.Text; +import org.apache.hadoop.security.Credentials; +import org.apache.hadoop.security.token.Token; +import org.apache.hadoop.security.token.TokenIdentifier; +import org.apache.hadoop.yarn.api.records.ContainerLaunchContext; +import org.apache.hadoop.yarn.conf.YarnConfiguration; import org.junit.Rule; import org.junit.Test; import org.junit.rules.TemporaryFolder; +import org.mockito.Mockito; +import org.mockito.invocation.InvocationOnMock; +import org.mockito.stubbing.Answer; +import org.slf4j.Logger; +import org.slf4j.LoggerFactory; +import java.io.ByteArrayInputStream; +import java.io.DataInputStream; +import java.io.File; import java.nio.file.Files; import java.nio.file.Path; +import java.util.Collection; import java.util.Collections; +import java.util.HashMap; +import java.util.Map; import java.util.stream.Stream; import static org.hamcrest.Matchers.equalTo; +import static org.junit.Assert.assertEquals; +import static org.junit.Assert.assertFalse; import static org.junit.Assert.assertThat; +import static org.junit.Assert.assertTrue; +import static org.mockito.ArgumentMatchers.anyInt; +import static org.mockito.ArgumentMatchers.anyString; +import static org.mockito.Mockito.doAnswer; +import static org.mockito.Mockito.mock; Review comment: Using mock may cause the test instability, I think. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #7903: [FLINK-11822][table-planner-blink] Introduce Flink metadata handlers
flinkbot commented on issue #7903: [FLINK-11822][table-planner-blink] Introduce Flink metadata handlers URL: https://github.com/apache/flink/pull/7903#issuecomment-469617035 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-11822) Introduce Flink metadata handlers
[
https://issues.apache.org/jira/browse/FLINK-11822?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-11822:
---
Labels: pull-request-available (was: )
> Introduce Flink metadata handlers
> -
>
> Key: FLINK-11822
> URL: https://issues.apache.org/jira/browse/FLINK-11822
> Project: Flink
> Issue Type: New Feature
> Components: API / Table SQL
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
> Labels: pull-request-available
>
> Calcite has defined various metadata handlers(e.g. {{RowCoun}},
> {{Selectivity}} and provided default implementation(e.g. {{RelMdRowCount}},
> {{RelMdSelectivity}}). However, the default implementation can't completely
> meet our requirements, e.g. some of its logic is incomplete,and some RelNodes
> are not considered.
> There are two options to meet our requirements:
> option 1. Extends from default implementation, overrides method to improve
> its logic, add new methods for new {{RelNode}}. The advantage of this option
> is we just need to focus on the additions and modifications. However, its
> shortcomings are also obvious: we have no control over the code of
> non-override methods in default implementation classes especially when
> upgrading the Calcite version.
> option 2. Extends from metadata handler interfaces, reimplement all the
> logic. Its shortcomings are very obvious, however we can control all the code
> logic that's what we want.
> so we choose option 2!
> In this jira, only basic metadata handles will be introduced, including:
> {{FlinkRelMdPercentageOriginalRow}},
> {{FlinkRelMdNonCumulativeCost}},
> {{FlinkRelMdCumulativeCost}},
> {{FlinkRelMdRowCount}},
> {{FlinkRelMdSize}},
> {{FlinkRelMdSelectivity}},
> {{FlinkRelMdDistinctRowCoun}},
> {{FlinkRelMdPopulationSize}},
> {{FlinkRelMdColumnUniqueness}},
> {{FlinkRelMdUniqueKeys}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] godfreyhe opened a new pull request #7903: [FLINK-11822][table-planner-blink] Introduce Flink metadata handlers
godfreyhe opened a new pull request #7903: [FLINK-11822][table-planner-blink] Introduce Flink metadata handlers URL: https://github.com/apache/flink/pull/7903 ## What is the purpose of the change *Introduce Flink metadata handlers* ## Brief change log - *adds Flink metadata handlers, including `FlinkRelMdPercentageOriginalRow`, `FlinkRelMdNonCumulativeCost`, `FlinkRelMdCumulativeCost`, `FlinkRelMdRowCount`, `FlinkRelMdSize`, `FlinkRelMdSelectivity`, `FlinkRelMdDistinctRowCoun`, `FlinkRelMdPopulationSize`, `FlinkRelMdColumnUniqueness`, `FlinkRelMdUniqueKeys`* - *adds dependent classes: `FlinkCalciteCatalogReader`, `FlinkRelBuilder`, `FlinkRelOptClusterFactory`, `FlinkTypeSystem` and `FlinkRelOptTable` for test* ## Verifying this change This change added tests and can be verified as follows: - *Added test for each metadata handler* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zentol commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
zentol commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469618123 Why do you consider the current package to be wrong? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-11823) TrySerializer#duplicate does not create a proper duplication
Dawid Wysakowicz created FLINK-11823: Summary: TrySerializer#duplicate does not create a proper duplication Key: FLINK-11823 URL: https://issues.apache.org/jira/browse/FLINK-11823 Project: Flink Issue Type: Bug Components: API / Type Serialization System Affects Versions: 1.7.2 Reporter: Dawid Wysakowicz Fix For: 1.7.3, 1.8.0 In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and throwableSerializer, which additionally is a KryoSerializer and therefore should always be duplicated. It was fixed in 1.8/master with 186b8df4155a4c171d71f1c806290bd94374416c -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11823) TrySerializer#duplicate does not create a proper duplicate
[ https://issues.apache.org/jira/browse/FLINK-11823?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dawid Wysakowicz updated FLINK-11823: - Summary: TrySerializer#duplicate does not create a proper duplicate (was: TrySerializer#duplicate does not create a proper duplication) > TrySerializer#duplicate does not create a proper duplicate > -- > > Key: FLINK-11823 > URL: https://issues.apache.org/jira/browse/FLINK-11823 > Project: Flink > Issue Type: Bug > Components: API / Type Serialization System >Affects Versions: 1.7.2 >Reporter: Dawid Wysakowicz >Priority: Major > Fix For: 1.7.3, 1.8.0 > > > In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and > throwableSerializer, which additionally is a KryoSerializer and therefore > should always be duplicated. > It was fixed in 1.8/master with 186b8df4155a4c171d71f1c806290bd94374416c -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-11823) TrySerializer#duplicate does not create a proper duplicate
[ https://issues.apache.org/jira/browse/FLINK-11823?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784280#comment-16784280 ] Dawid Wysakowicz commented on FLINK-11823: -- Fixed in master: 186b8df4155a4c171d71f1c806290bd94374416c 1.8: 186b8df4155a4c171d71f1c806290bd94374416c > TrySerializer#duplicate does not create a proper duplicate > -- > > Key: FLINK-11823 > URL: https://issues.apache.org/jira/browse/FLINK-11823 > Project: Flink > Issue Type: Bug > Components: API / Type Serialization System >Affects Versions: 1.7.2 >Reporter: Dawid Wysakowicz >Priority: Major > Fix For: 1.7.3, 1.8.0 > > > In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and > throwableSerializer, which additionally is a KryoSerializer and therefore > should always be duplicated. > It was fixed in 1.8/master with 186b8df4155a4c171d71f1c806290bd94374416c -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11823) TrySerializer#duplicate does not create a proper duplicate
[ https://issues.apache.org/jira/browse/FLINK-11823?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dawid Wysakowicz updated FLINK-11823: - Description: In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and throwableSerializer, which additionally is a KryoSerializer and therefore should always be duplicated. was: In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and throwableSerializer, which additionally is a KryoSerializer and therefore should always be duplicated. It was fixed in 1.8/master with 186b8df4155a4c171d71f1c806290bd94374416c > TrySerializer#duplicate does not create a proper duplicate > -- > > Key: FLINK-11823 > URL: https://issues.apache.org/jira/browse/FLINK-11823 > Project: Flink > Issue Type: Bug > Components: API / Type Serialization System >Affects Versions: 1.7.2 >Reporter: Dawid Wysakowicz >Priority: Major > Fix For: 1.7.3, 1.8.0 > > > In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and > throwableSerializer, which additionally is a KryoSerializer and therefore > should always be duplicated. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-46962 > Why do you consider the current package to be wrong? hi, the mismatch between KafkaDeserializationSchemaWrapper class's package name and file's location This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469622874 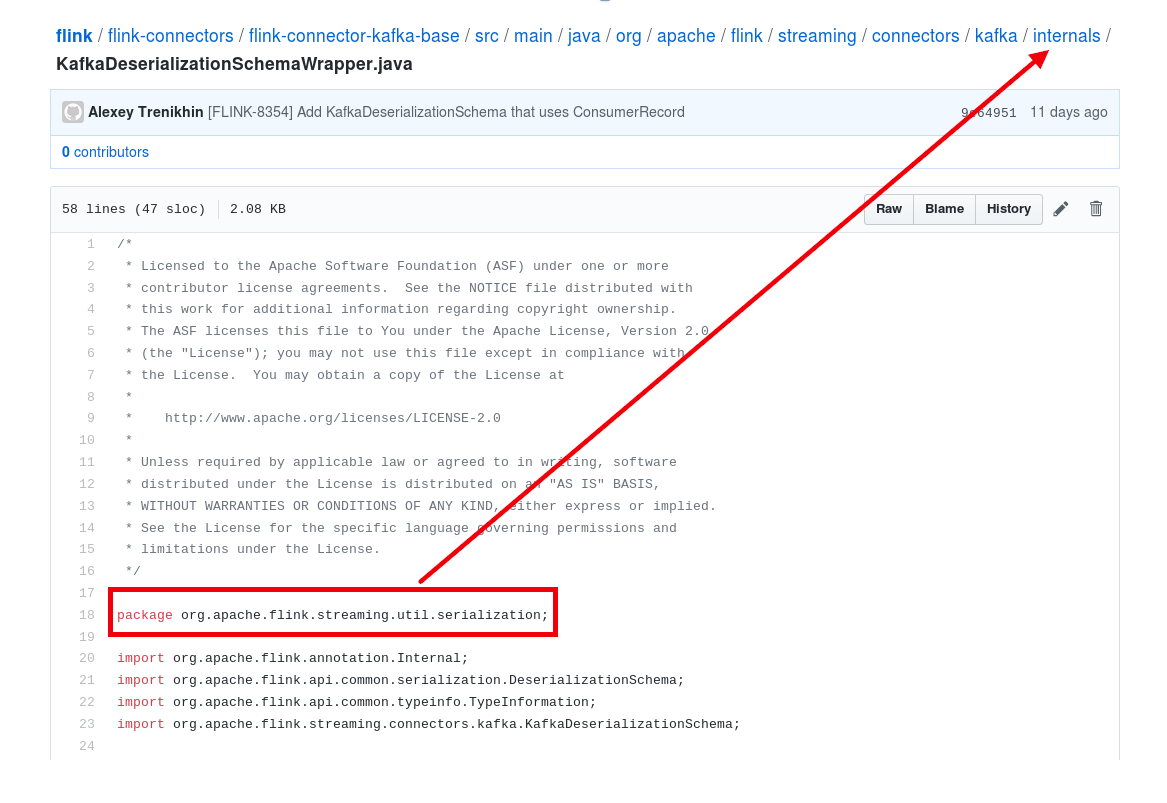 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken removed a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken removed a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-46962 > Why do you consider the current package to be wrong? hi, the mismatch between KafkaDeserializationSchemaWrapper class's package name and file's location This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469622874 > Why do you consider the current package to be wrong? hi, the mismatch between KafkaDeserializationSchemaWrapper class's package name and file's location  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469622874 > Why do you consider the current package to be wrong? @zentol hi, the mismatch between KafkaDeserializationSchemaWrapper class's package name and file's location  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] carp84 commented on issue #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
carp84 commented on issue #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern URL: https://github.com/apache/flink/pull/7899#issuecomment-469627041 Checked the travis build and confirmed the failure is irrelative with change here. And a [local travis check](https://travis-ci.org/carp84/flink/builds/501881135) with the same commit passed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on issue #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
zhijiangW commented on issue #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode URL: https://github.com/apache/flink/pull/7713#issuecomment-469631030 @pnowojski , thanks for your review and suggestions! I have updated the codes for addressing the comments. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-11824) Event-time attribute cannot have same name as in original format
Fabian Hueske created FLINK-11824:
-
Summary: Event-time attribute cannot have same name as in original
format
Key: FLINK-11824
URL: https://issues.apache.org/jira/browse/FLINK-11824
Project: Flink
Issue Type: Bug
Components: API / Table SQL
Affects Versions: 1.7.2, 1.8.0
Reporter: Fabian Hueske
When a table is defined, event-time attributes are typically defined by linking
them to an existing field in the original format (e.g., CSV, Avro, JSON, ...).
However, right now, the event-time attribute in the defined table cannot have
the same name as the original field.
The following table definition fails with an exception:
{code}
// set up execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = StreamTableEnvironment.create(env)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val names: Array[String] = Array("name", "t")
val types: Array[TypeInformation[_]] = Array(Types.STRING, Types.LONG)
tEnv.connect(new Kafka()
.version("universal")
.topic("namesTopic")
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
.property("group.id", "testGroup"))
.withFormat(new Csv()
.schema(Types.ROW(names, types)))
.withSchema(new Schema()
.field("name", Types.STRING)
.field("t", Types.SQL_TIMESTAMP) // changing "t" to "t2" works
.rowtime(new Rowtime()
.timestampsFromField("t")
.watermarksPeriodicAscending()))
.inAppendMode()
.registerTableSource("Names")
{code}
{code}
Exception in thread "main" org.apache.flink.table.api.ValidationException:
Field 't' could not be resolved by the field mapping.
at
org.apache.flink.table.sources.TableSourceUtil$.org$apache$flink$table$sources$TableSourceUtil$$resolveInputField(TableSourceUtil.scala:491)
at
org.apache.flink.table.sources.TableSourceUtil$$anonfun$org$apache$flink$table$sources$TableSourceUtil$$resolveInputFields$1.apply(TableSourceUtil.scala:521)
at
org.apache.flink.table.sources.TableSourceUtil$$anonfun$org$apache$flink$table$sources$TableSourceUtil$$resolveInputFields$1.apply(TableSourceUtil.scala:521)
at
scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at
scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at
scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
at
org.apache.flink.table.sources.TableSourceUtil$.org$apache$flink$table$sources$TableSourceUtil$$resolveInputFields(TableSourceUtil.scala:521)
at
org.apache.flink.table.sources.TableSourceUtil$.validateTableSource(TableSourceUtil.scala:127)
at
org.apache.flink.table.plan.schema.StreamTableSourceTable.(StreamTableSourceTable.scala:33)
at
org.apache.flink.table.api.StreamTableEnvironment.registerTableSourceInternal(StreamTableEnvironment.scala:150)
at
org.apache.flink.table.api.TableEnvironment.registerTableSource(TableEnvironment.scala:541)
at
org.apache.flink.table.descriptors.ConnectTableDescriptor.registerTableSource(ConnectTableDescriptor.scala:47)
{code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] azagrebin commented on issue #7186: [FLINK-10941] Keep slots which contain unconsumed result partitions
azagrebin commented on issue #7186: [FLINK-10941] Keep slots which contain unconsumed result partitions URL: https://github.com/apache/flink/pull/7186#issuecomment-469636966 @zhijiangW I agree we need to revisit this topic after shuffle refactoring @QiLuo-BD What do you think if we keep releasing of partitions as it is now but add a separate `isClosed` flag to subpartition/partition and use it instead of `isReleased`? The `PartitionRequestQueue.close` and `PartitionRequestQueue.channelInactive` could notify read view and subsequently subpartition/partition that it is closed. The task/slot could use `partition.isClosed` flag instead of `isReeleased` to report to resource manager that task executor can be released the same way as it is now in PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-11825) Resolve name clash of StateTTL TimeCharacteristic class
Fabian Hueske created FLINK-11825:
-
Summary: Resolve name clash of StateTTL TimeCharacteristic class
Key: FLINK-11825
URL: https://issues.apache.org/jira/browse/FLINK-11825
Project: Flink
Issue Type: Improvement
Components: Runtime / State Backends
Affects Versions: 1.7.2
Reporter: Fabian Hueske
The StateTTL feature introduced the class
\{{org.apache.flink.api.common.state.TimeCharacteristic}} which clashes with
\{{org.apache.flink.streaming.api.TimeCharacteristic}}.
This is a problem for two reasons:
1. Users get confused because the mistakenly import
\{{org.apache.flink.api.common.state.TimeCharacteristic}}.
2. When using the StateTTL feature, users need to spell out the package name
for \{{org.apache.flink.api.common.state.TimeCharacteristic}} because the other
class is most likely already imported.
Since \{{org.apache.flink.streaming.api.TimeCharacteristic}} is one of the most
used classes of the DataStream API, we should make sure that users can use it
without import problems.
These error are hard to spot and confusing for many users.
I see two ways to resolve the issue:
1. drop \{{org.apache.flink.api.common.state.TimeCharacteristic}} and use
\{{org.apache.flink.streaming.api.TimeCharacteristic}} throwing an exception if
an incorrect characteristic is used.
2. rename the class \{{org.apache.flink.api.common.state.TimeCharacteristic}}
to some other name.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
StefanRRichter commented on a change in pull request #7899: [FLINK-11731]
[State Backends] Make DefaultOperatorStateBackend follow the builder pattern
URL: https://github.com/apache/flink/pull/7899#discussion_r262438032
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackendBuilder.java
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.runtime.state;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.core.fs.CloseableRegistry;
+import org.apache.flink.util.IOUtils;
+
+import java.io.Serializable;
+import java.util.Collection;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Builder class for {@link DefaultOperatorStateBackend} which handles all
necessary initializations and clean ups.
+ */
+public class DefaultOperatorStateBackendBuilder implements
+ StateBackendBuilder {
+ /** The user code classloader. */
+ @VisibleForTesting
+ protected final ClassLoader userClassloader;
+ /** The execution configuration. */
+ @VisibleForTesting
+ protected final ExecutionConfig executionConfig;
+ /** Flag to de/activate asynchronous snapshots. */
+ @VisibleForTesting
+ protected final boolean asynchronousSnapshots;
+ /** State handles for restore. */
+ @VisibleForTesting
+ protected final Collection restoreStateHandles;
+ @VisibleForTesting
+ protected final CloseableRegistry cancelStreamRegistry;
+
+
+ public DefaultOperatorStateBackendBuilder(
+ ClassLoader userClassloader,
+ ExecutionConfig executionConfig,
+ boolean asynchronousSnapshots,
+ Collection stateHandles,
+ CloseableRegistry cancelStreamRegistry) {
+ this.userClassloader = userClassloader;
+ this.executionConfig = executionConfig;
+ this.asynchronousSnapshots = asynchronousSnapshots;
+ this.restoreStateHandles = stateHandles;
+ this.cancelStreamRegistry = cancelStreamRegistry;
+ }
+
+ @Override
+ public DefaultOperatorStateBackend build() throws
BackendBuildingException {
+ JavaSerializer serializer = new
JavaSerializer<>();
Review comment:
One more comment about this `JavaSerializer`. This is one exception where I
would initialize the field inside the constructor of
`DefaultOperatorStateBackend` and not pass it in. The reasons are, that this
member has a similar intent as a `static final` field, only the class does not
support concurrency so we must create a new instance per object. This field is
always assigned the same type of object and it is also only used in the context
of a deprecated method. No new code or tests would ever be interested to pass
in something different here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern URL: https://github.com/apache/flink/pull/7899#discussion_r262439351 ## File path: flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java ## @@ -85,25 +73,15 @@ private final CloseableRegistry closeStreamOnCancelRegistry; /** -* Default serializer. Only used for the default operator state. -*/ - private final JavaSerializer javaSerializer; - - /** -* The user code classloader. +* Default typeSerializer. Only used for the default operator state. */ - private final ClassLoader userClassloader; + private final TypeSerializer typeSerializer; Review comment: I suggest to change the name of this field. `typeSerializer` is general and makes it look like this is a very commonly used field. However, this is more like a very static field, that always gets assigned the same type of serializer and is only used in deprecated context (see one of my other comments in the builder about this). I suggest something like `deprecatedDefaultJavaSerializer`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
StefanRRichter commented on a change in pull request #7899: [FLINK-11731]
[State Backends] Make DefaultOperatorStateBackend follow the builder pattern
URL: https://github.com/apache/flink/pull/7899#discussion_r262437095
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackendBuilder.java
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.runtime.state;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.core.fs.CloseableRegistry;
+import org.apache.flink.util.IOUtils;
+
+import java.io.Serializable;
+import java.util.Collection;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Builder class for {@link DefaultOperatorStateBackend} which handles all
necessary initializations and clean ups.
+ */
+public class DefaultOperatorStateBackendBuilder implements
+ StateBackendBuilder {
+ /** The user code classloader. */
+ @VisibleForTesting
+ protected final ClassLoader userClassloader;
+ /** The execution configuration. */
+ @VisibleForTesting
+ protected final ExecutionConfig executionConfig;
+ /** Flag to de/activate asynchronous snapshots. */
+ @VisibleForTesting
+ protected final boolean asynchronousSnapshots;
+ /** State handles for restore. */
+ @VisibleForTesting
+ protected final Collection restoreStateHandles;
+ @VisibleForTesting
+ protected final CloseableRegistry cancelStreamRegistry;
+
+
+ public DefaultOperatorStateBackendBuilder(
+ ClassLoader userClassloader,
+ ExecutionConfig executionConfig,
+ boolean asynchronousSnapshots,
+ Collection stateHandles,
+ CloseableRegistry cancelStreamRegistry) {
+ this.userClassloader = userClassloader;
+ this.executionConfig = executionConfig;
+ this.asynchronousSnapshots = asynchronousSnapshots;
+ this.restoreStateHandles = stateHandles;
+ this.cancelStreamRegistry = cancelStreamRegistry;
+ }
+
+ @Override
+ public DefaultOperatorStateBackend build() throws
BackendBuildingException {
+ JavaSerializer serializer = new
JavaSerializer<>();
Review comment:
I suggest to move some of the local variables (like this one) further down,
closer to their first usage. First, it is better to keep the scope of variables
as small as possible, second if we run in the exceptional case, those objects
have been constructed for nothing.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
StefanRRichter commented on a change in pull request #7899: [FLINK-11731]
[State Backends] Make DefaultOperatorStateBackend follow the builder pattern
URL: https://github.com/apache/flink/pull/7899#discussion_r262434116
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackendBuilder.java
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.runtime.state;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.core.fs.CloseableRegistry;
+import org.apache.flink.util.IOUtils;
+
+import java.io.Serializable;
+import java.util.Collection;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Builder class for {@link DefaultOperatorStateBackend} which handles all
necessary initializations and clean ups.
+ */
+public class DefaultOperatorStateBackendBuilder implements
+ StateBackendBuilder {
+ /** The user code classloader. */
+ @VisibleForTesting
+ protected final ClassLoader userClassloader;
+ /** The execution configuration. */
+ @VisibleForTesting
+ protected final ExecutionConfig executionConfig;
+ /** Flag to de/activate asynchronous snapshots. */
+ @VisibleForTesting
+ protected final boolean asynchronousSnapshots;
+ /** State handles for restore. */
+ @VisibleForTesting
+ protected final Collection restoreStateHandles;
+ @VisibleForTesting
+ protected final CloseableRegistry cancelStreamRegistry;
+
+
+ public DefaultOperatorStateBackendBuilder(
+ ClassLoader userClassloader,
+ ExecutionConfig executionConfig,
+ boolean asynchronousSnapshots,
+ Collection stateHandles,
+ CloseableRegistry cancelStreamRegistry) {
+ this.userClassloader = userClassloader;
+ this.executionConfig = executionConfig;
+ this.asynchronousSnapshots = asynchronousSnapshots;
+ this.restoreStateHandles = stateHandles;
+ this.cancelStreamRegistry = cancelStreamRegistry;
+ }
+
+ @Override
+ public DefaultOperatorStateBackend build() throws
BackendBuildingException {
+ JavaSerializer serializer = new
JavaSerializer<>();
+ Map> registeredOperatorStates
= new HashMap<>();
+ Map>
registeredBroadcastStates = new HashMap<>();
+ Map> accessedStatesByName =
new HashMap<>();
+ Map>
accessedBroadcastStatesByName = new HashMap<>();
+ CloseableRegistry cancelStreamRegistryForBackend = new
CloseableRegistry();
+ AbstractSnapshotStrategy snapshotStrategy =
+ new DefaultOperatorStateBackendSnapshotStrategy(
+ userClassloader,
+ asynchronousSnapshots,
+ registeredOperatorStates,
+ registeredBroadcastStates,
+ cancelStreamRegistryForBackend);
+ OperatorStateRestoreOperation restoreOperation = new
OperatorStateRestoreOperation(
+ cancelStreamRegistry,
+ userClassloader,
+ registeredOperatorStates,
+ registeredBroadcastStates,
+ restoreStateHandles
+ );
+ try {
+ restoreOperation.restore();
+ } catch (Throwable e) {
Review comment:
I would suggest to only catch `Exception` here, not `Throwable`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] tillrohrmann commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
tillrohrmann commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData URL: https://github.com/apache/flink/pull/7880#discussion_r262455867 ## File path: flink-runtime/src/test/resources/log4j-test.properties ## @@ -18,7 +18,7 @@ # Set root logger level to OFF to not flood build logs # set manually to INFO for debugging purposes -log4j.rootLogger=OFF, testlogger +log4j.rootLogger=INFO, testlogger Review comment: Good catch. Will revert it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] tillrohrmann commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
tillrohrmann commented on a change in pull request #7880: [FLINK-11336][zk]
Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
URL: https://github.com/apache/flink/pull/7880#discussion_r262457417
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/highavailability/zookeeper/ZooKeeperHaServicesTest.java
##
@@ -0,0 +1,250 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.highavailability.zookeeper;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.HighAvailabilityOptions;
+import org.apache.flink.runtime.blob.BlobKey;
+import org.apache.flink.runtime.blob.BlobStoreService;
+import org.apache.flink.runtime.concurrent.Executors;
+import org.apache.flink.runtime.highavailability.RunningJobsRegistry;
+import org.apache.flink.runtime.leaderelection.LeaderElectionService;
+import org.apache.flink.runtime.leaderelection.TestingContender;
+import org.apache.flink.runtime.leaderelection.TestingListener;
+import org.apache.flink.runtime.leaderretrieval.LeaderRetrievalService;
+import org.apache.flink.runtime.util.ZooKeeperUtils;
+import org.apache.flink.runtime.zookeeper.ZooKeeperResource;
+import org.apache.flink.util.TestLogger;
+import org.apache.flink.util.function.ThrowingConsumer;
+
+import org.apache.curator.framework.CuratorFramework;
+import org.apache.curator.framework.CuratorFrameworkFactory;
+import org.apache.curator.retry.RetryForever;
+import org.junit.AfterClass;
+import org.junit.Before;
+import org.junit.BeforeClass;
+import org.junit.ClassRule;
+import org.junit.Test;
+
+import javax.annotation.Nonnull;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+
+import static org.hamcrest.Matchers.empty;
+import static org.hamcrest.Matchers.equalTo;
+import static org.hamcrest.Matchers.is;
+import static org.hamcrest.Matchers.not;
+import static org.hamcrest.Matchers.notNullValue;
+import static org.hamcrest.Matchers.nullValue;
+import static org.junit.Assert.assertThat;
+
+/**
+ * Tests for the {@link ZooKeeperHaServices}.
+ */
+public class ZooKeeperHaServicesTest extends TestLogger {
+
+ @ClassRule
+ public static final ZooKeeperResource ZOO_KEEPER_RESOURCE = new
ZooKeeperResource();
+
+ private static CuratorFramework client;
+
+ @BeforeClass
+ public static void setupClass() {
+ client = startCuratorFramework();
+ client.start();
+ }
+
+ @Before
+ public void setup() throws Exception {
+ final List children = client.getChildren().forPath("/");
+
+ for (String child : children) {
+ if (!child.equals("zookeeper")) {
+
client.delete().deletingChildrenIfNeeded().forPath('/' + child);
+ }
+ }
+ }
+
+ @AfterClass
+ public static void teardownClass() {
+ if (client != null) {
+ client.close();
+ }
+ }
+
+ /**
+* Tests that a simple {@link ZooKeeperHaServices#close()} does not
delete ZooKeeper paths.
+*/
+ @Test
+ public void testSimpleClose() throws Exception {
+ final String rootPath = "/foo/bar/flink";
+ final Configuration configuration =
createConfiguration(rootPath);
+
+ final TestingBlobStoreService blobStoreService = new
TestingBlobStoreService();
+
+ runCleanupTest(
+ configuration,
+ blobStoreService,
+ ZooKeeperHaServices::close);
+
+ assertThat(blobStoreService.isClosed(), is(true));
+ assertThat(blobStoreService.isClosedAndCleanedUpAllData(),
is(false));
+
+ final List children =
client.getChildren().forPath(rootPath);
+ assertThat(children, is(not(empty(;
+ }
+
+ /**
+* Tests that the {@link ZooKeeperHaServices} cleans up all paths if
+* it is closed via {@link
ZooKeeperHaServices#closeAndCleanupAllData()}.
+*/
+
[GitHub] [flink] tillrohrmann commented on a change in pull request #7880: [FLINK-11336][zk] Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
tillrohrmann commented on a change in pull request #7880: [FLINK-11336][zk]
Delete ZNodes when ZooKeeperHaServices#closeAndCleanupAllData
URL: https://github.com/apache/flink/pull/7880#discussion_r262457623
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/highavailability/zookeeper/ZooKeeperHaServicesTest.java
##
@@ -0,0 +1,250 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.highavailability.zookeeper;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.HighAvailabilityOptions;
+import org.apache.flink.runtime.blob.BlobKey;
+import org.apache.flink.runtime.blob.BlobStoreService;
+import org.apache.flink.runtime.concurrent.Executors;
+import org.apache.flink.runtime.highavailability.RunningJobsRegistry;
+import org.apache.flink.runtime.leaderelection.LeaderElectionService;
+import org.apache.flink.runtime.leaderelection.TestingContender;
+import org.apache.flink.runtime.leaderelection.TestingListener;
+import org.apache.flink.runtime.leaderretrieval.LeaderRetrievalService;
+import org.apache.flink.runtime.util.ZooKeeperUtils;
+import org.apache.flink.runtime.zookeeper.ZooKeeperResource;
+import org.apache.flink.util.TestLogger;
+import org.apache.flink.util.function.ThrowingConsumer;
+
+import org.apache.curator.framework.CuratorFramework;
+import org.apache.curator.framework.CuratorFrameworkFactory;
+import org.apache.curator.retry.RetryForever;
+import org.junit.AfterClass;
+import org.junit.Before;
+import org.junit.BeforeClass;
+import org.junit.ClassRule;
+import org.junit.Test;
+
+import javax.annotation.Nonnull;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+
+import static org.hamcrest.Matchers.empty;
+import static org.hamcrest.Matchers.equalTo;
+import static org.hamcrest.Matchers.is;
+import static org.hamcrest.Matchers.not;
+import static org.hamcrest.Matchers.notNullValue;
+import static org.hamcrest.Matchers.nullValue;
+import static org.junit.Assert.assertThat;
+
+/**
+ * Tests for the {@link ZooKeeperHaServices}.
+ */
+public class ZooKeeperHaServicesTest extends TestLogger {
+
+ @ClassRule
+ public static final ZooKeeperResource ZOO_KEEPER_RESOURCE = new
ZooKeeperResource();
+
+ private static CuratorFramework client;
+
+ @BeforeClass
+ public static void setupClass() {
+ client = startCuratorFramework();
+ client.start();
+ }
+
+ @Before
+ public void setup() throws Exception {
+ final List children = client.getChildren().forPath("/");
+
+ for (String child : children) {
+ if (!child.equals("zookeeper")) {
+
client.delete().deletingChildrenIfNeeded().forPath('/' + child);
+ }
+ }
+ }
+
+ @AfterClass
+ public static void teardownClass() {
+ if (client != null) {
+ client.close();
+ }
+ }
+
+ /**
+* Tests that a simple {@link ZooKeeperHaServices#close()} does not
delete ZooKeeper paths.
+*/
+ @Test
+ public void testSimpleClose() throws Exception {
+ final String rootPath = "/foo/bar/flink";
+ final Configuration configuration =
createConfiguration(rootPath);
+
+ final TestingBlobStoreService blobStoreService = new
TestingBlobStoreService();
+
+ runCleanupTest(
+ configuration,
+ blobStoreService,
+ ZooKeeperHaServices::close);
+
+ assertThat(blobStoreService.isClosed(), is(true));
+ assertThat(blobStoreService.isClosedAndCleanedUpAllData(),
is(false));
+
+ final List children =
client.getChildren().forPath(rootPath);
+ assertThat(children, is(not(empty(;
+ }
+
+ /**
+* Tests that the {@link ZooKeeperHaServices} cleans up all paths if
+* it is closed via {@link
ZooKeeperHaServices#closeAndCleanupAllData()}.
+*/
+
[GitHub] [flink] hequn8128 commented on a change in pull request #6787: [FLINK-8577][table] Implement proctime DataStream to Table upsert conversion
hequn8128 commented on a change in pull request #6787: [FLINK-8577][table]
Implement proctime DataStream to Table upsert conversion
URL: https://github.com/apache/flink/pull/6787#discussion_r262459081
##
File path:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/runtime/UpsertToRetractionProcessFunction.scala
##
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.table.runtime
+
+import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
+import org.apache.flink.api.java.typeutils.RowTypeInfo
+import org.apache.flink.configuration.Configuration
+import org.apache.flink.streaming.api.functions.ProcessFunction
+import org.apache.flink.table.api.StreamQueryConfig
+import org.apache.flink.table.runtime.aggregate.ProcessFunctionWithCleanupState
+import org.apache.flink.table.runtime.types.CRow
+import org.apache.flink.table.util.Logging
+import org.apache.flink.types.Row
+import org.apache.flink.util.Collector
+
+/**
+ * Function used to convert upsert to retractions.
+ *
+ * @param rowTypeInfo the output row type info.
+ * @param queryConfig the configuration for the query.
+ */
+class UpsertToRetractionProcessFunction(
Review comment:
I haven't found related descriptions in SQL standard. I found these
descriptions in some popular sql systems, such
as[[1]](https://docs.microsoft.com/en-us/sql/t-sql/functions/aggregate-functions-transact-sql?view=sql-server-2017)[[2]](https://docs.oracle.com/database/121/SQLRF/functions003.htm#SQLRF20035).
>Except for COUNT, aggregate functions ignore null values.
I'm fine if we decide to reuse aggregate operator and I prefer reuse all
aggregate operator including planing instead only runtime part to make it more
clear. What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] hequn8128 commented on a change in pull request #6787: [FLINK-8577][table] Implement proctime DataStream to Table upsert conversion
hequn8128 commented on a change in pull request #6787: [FLINK-8577][table]
Implement proctime DataStream to Table upsert conversion
URL: https://github.com/apache/flink/pull/6787#discussion_r262459081
##
File path:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/runtime/UpsertToRetractionProcessFunction.scala
##
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.table.runtime
+
+import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
+import org.apache.flink.api.java.typeutils.RowTypeInfo
+import org.apache.flink.configuration.Configuration
+import org.apache.flink.streaming.api.functions.ProcessFunction
+import org.apache.flink.table.api.StreamQueryConfig
+import org.apache.flink.table.runtime.aggregate.ProcessFunctionWithCleanupState
+import org.apache.flink.table.runtime.types.CRow
+import org.apache.flink.table.util.Logging
+import org.apache.flink.types.Row
+import org.apache.flink.util.Collector
+
+/**
+ * Function used to convert upsert to retractions.
+ *
+ * @param rowTypeInfo the output row type info.
+ * @param queryConfig the configuration for the query.
+ */
+class UpsertToRetractionProcessFunction(
Review comment:
I haven't found related descriptions in SQL standard. I found these
descriptions in some popular sql systems, such
as[[1]](https://docs.microsoft.com/en-us/sql/t-sql/functions/aggregate-functions-transact-sql?view=sql-server-2017)[[2]](https://docs.oracle.com/database/121/SQLRF/functions003.htm#SQLRF20035).
>Except for COUNT, aggregate functions ignore null values.
I'm fine if we decide to reuse aggregate operator and I prefer reuse all
aggregate operator including planing instead of only runtime part to make it
more clear. What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] hequn8128 commented on a change in pull request #6787: [FLINK-8577][table] Implement proctime DataStream to Table upsert conversion
hequn8128 commented on a change in pull request #6787: [FLINK-8577][table]
Implement proctime DataStream to Table upsert conversion
URL: https://github.com/apache/flink/pull/6787#discussion_r262459081
##
File path:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/runtime/UpsertToRetractionProcessFunction.scala
##
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.table.runtime
+
+import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
+import org.apache.flink.api.java.typeutils.RowTypeInfo
+import org.apache.flink.configuration.Configuration
+import org.apache.flink.streaming.api.functions.ProcessFunction
+import org.apache.flink.table.api.StreamQueryConfig
+import org.apache.flink.table.runtime.aggregate.ProcessFunctionWithCleanupState
+import org.apache.flink.table.runtime.types.CRow
+import org.apache.flink.table.util.Logging
+import org.apache.flink.types.Row
+import org.apache.flink.util.Collector
+
+/**
+ * Function used to convert upsert to retractions.
+ *
+ * @param rowTypeInfo the output row type info.
+ * @param queryConfig the configuration for the query.
+ */
+class UpsertToRetractionProcessFunction(
Review comment:
I haven't found related descriptions in SQL standard. I found these
descriptions in some popular sql systems, such
as[[1]](https://docs.microsoft.com/en-us/sql/t-sql/functions/aggregate-functions-transact-sql?view=sql-server-2017)[[2]](https://docs.oracle.com/database/121/SQLRF/functions003.htm#SQLRF20035).
>Except for COUNT, aggregate functions ignore null values.
I'm fine if we decide to reuse aggregate operator and I prefer to reuse all
aggregate operator including planing instead of only runtime part to make it
more clear. What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (FLINK-11826) Kafka09ITCase.testRateLimitedConsumer fails on Travis
Till Rohrmann created FLINK-11826:
-
Summary: Kafka09ITCase.testRateLimitedConsumer fails on Travis
Key: FLINK-11826
URL: https://issues.apache.org/jira/browse/FLINK-11826
Project: Flink
Issue Type: Bug
Components: Connectors / Kafka, Tests
Affects Versions: 1.8.0
Reporter: Till Rohrmann
The {{Kafka09ITCase.testRateLimitedConsumer}} fails on Travis with:
{code}
20:33:49.887 [ERROR] Errors:
20:33:49.887 [ERROR] Kafka09ITCase.testRateLimitedConsumer:204 »
JobExecution Job execution failed.
{code}
https://api.travis-ci.org/v3/job/501660504/log.txt
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-11826) Kafka09ITCase.testRateLimitedConsumer fails on Travis
[
https://issues.apache.org/jira/browse/FLINK-11826?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784344#comment-16784344
]
Till Rohrmann commented on FLINK-11826:
---
cc [~glaksh100]
> Kafka09ITCase.testRateLimitedConsumer fails on Travis
> -
>
> Key: FLINK-11826
> URL: https://issues.apache.org/jira/browse/FLINK-11826
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Tests
>Affects Versions: 1.8.0
>Reporter: Till Rohrmann
>Priority: Critical
> Labels: test-stability
>
> The {{Kafka09ITCase.testRateLimitedConsumer}} fails on Travis with:
> {code}
> 20:33:49.887 [ERROR] Errors:
> 20:33:49.887 [ERROR] Kafka09ITCase.testRateLimitedConsumer:204 »
> JobExecution Job execution failed.
> {code}
> https://api.travis-ci.org/v3/job/501660504/log.txt
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-11826) Kafka09ITCase.testRateLimitedConsumer fails on Travis
[
https://issues.apache.org/jira/browse/FLINK-11826?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784345#comment-16784345
]
Till Rohrmann commented on FLINK-11826:
---
The test also runs 30s on my machine. Can we try to speed it up?
> Kafka09ITCase.testRateLimitedConsumer fails on Travis
> -
>
> Key: FLINK-11826
> URL: https://issues.apache.org/jira/browse/FLINK-11826
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Tests
>Affects Versions: 1.8.0
>Reporter: Till Rohrmann
>Priority: Critical
> Labels: test-stability
>
> The {{Kafka09ITCase.testRateLimitedConsumer}} fails on Travis with:
> {code}
> 20:33:49.887 [ERROR] Errors:
> 20:33:49.887 [ERROR] Kafka09ITCase.testRateLimitedConsumer:204 »
> JobExecution Job execution failed.
> {code}
> https://api.travis-ci.org/v3/job/501660504/log.txt
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] TisonKun commented on issue #7762: [FLINK-11146] Remove invalid codes in ClusterClient
TisonKun commented on issue #7762: [FLINK-11146] Remove invalid codes in ClusterClient URL: https://github.com/apache/flink/pull/7762#issuecomment-469659626 @mxm No from my side if you can double check the removals of `endSession(JobID)` are safe. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Assigned] (FLINK-5080) Cassandra connector ignores saveAsync result onSuccess
[
https://issues.apache.org/jira/browse/FLINK-5080?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Aleksandr Salatich reassigned FLINK-5080:
-
Assignee: Aleksandr Salatich
> Cassandra connector ignores saveAsync result onSuccess
> --
>
> Key: FLINK-5080
> URL: https://issues.apache.org/jira/browse/FLINK-5080
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Cassandra
>Affects Versions: 1.1.3
>Reporter: Jakub Nowacki
>Assignee: Aleksandr Salatich
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> When a record is saved to Cassandra it may return a ResultSet to the callback
> given in the saveAsync; e.g. when we do {{INSERT ... IF NOT EXISTS}}, a
> ResultSet is returned with column {{applied: false}} if the record exists and
> the new record has not been inserted. Thus, we loose data in such case.
> The minimal solution would be to log the result. The best solution would be
> to add possibility of passing a custom callback; in this way we could deal
> with a success or failure in more custom way. Other solution is to add a
> possibility to pass onSuccess and onFailure functions, which would be
> executed inside the callback.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11826) Kafka09ITCase.testRateLimitedConsumer fails on Travis
[
https://issues.apache.org/jira/browse/FLINK-11826?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Till Rohrmann updated FLINK-11826:
--
Affects Version/s: (was: 1.8.0)
1.9.0
> Kafka09ITCase.testRateLimitedConsumer fails on Travis
> -
>
> Key: FLINK-11826
> URL: https://issues.apache.org/jira/browse/FLINK-11826
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Tests
>Affects Versions: 1.9.0
>Reporter: Till Rohrmann
>Priority: Critical
> Labels: test-stability
>
> The {{Kafka09ITCase.testRateLimitedConsumer}} fails on Travis with:
> {code}
> 20:33:49.887 [ERROR] Errors:
> 20:33:49.887 [ERROR] Kafka09ITCase.testRateLimitedConsumer:204 »
> JobExecution Job execution failed.
> {code}
> https://api.travis-ci.org/v3/job/501660504/log.txt
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] StefanRRichter commented on issue #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
StefanRRichter commented on issue #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern URL: https://github.com/apache/flink/pull/7899#issuecomment-469665230 Changes to this point look good to me now 👍 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #6787: [FLINK-8577][table] Implement proctime DataStream to Table upsert conversion
pnowojski commented on a change in pull request #6787: [FLINK-8577][table]
Implement proctime DataStream to Table upsert conversion
URL: https://github.com/apache/flink/pull/6787#discussion_r262481756
##
File path:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/runtime/UpsertToRetractionProcessFunction.scala
##
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.table.runtime
+
+import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
+import org.apache.flink.api.java.typeutils.RowTypeInfo
+import org.apache.flink.configuration.Configuration
+import org.apache.flink.streaming.api.functions.ProcessFunction
+import org.apache.flink.table.api.StreamQueryConfig
+import org.apache.flink.table.runtime.aggregate.ProcessFunctionWithCleanupState
+import org.apache.flink.table.runtime.types.CRow
+import org.apache.flink.table.util.Logging
+import org.apache.flink.types.Row
+import org.apache.flink.util.Collector
+
+/**
+ * Function used to convert upsert to retractions.
+ *
+ * @param rowTypeInfo the output row type info.
+ * @param queryConfig the configuration for the query.
+ */
+class UpsertToRetractionProcessFunction(
Review comment:
The only reference in SQL standard that I have found was this `SQL:2016-2:
§10.9, General Rule 12gii, note 510.`, which explicitly states that `array_agg`
can not ignore nulls. Also I haven't found in the standard references to
something stating the opposite, so I would be inclined to re-use aggregation
node in planning as well if you are fine with that.
Next question would be wether to simply create an aggregation node or to
extend either `Aggregate` or `FlinkLogicalAggregate` classes (to re-use all of
their logic), but to keep the distinct name of the node `UpsertToRetraction`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Closed] (FLINK-11823) TrySerializer#duplicate does not create a proper duplicate
[ https://issues.apache.org/jira/browse/FLINK-11823?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dawid Wysakowicz closed FLINK-11823. Resolution: Fixed Assignee: Dawid Wysakowicz Fixed in 1.7.3 : 70bc26c330bb719d5fec3745605eaf5f530d18f0 > TrySerializer#duplicate does not create a proper duplicate > -- > > Key: FLINK-11823 > URL: https://issues.apache.org/jira/browse/FLINK-11823 > Project: Flink > Issue Type: Bug > Components: API / Type Serialization System >Affects Versions: 1.7.2 >Reporter: Dawid Wysakowicz >Assignee: Dawid Wysakowicz >Priority: Major > Fix For: 1.7.3, 1.8.0 > > > In flink 1.7.x TrySerializer#duplicate does not duplicate elemSerializer and > throwableSerializer, which additionally is a KryoSerializer and therefore > should always be duplicated. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11420) Serialization of case classes containing a Map[String, Any] sometimes throws ArrayIndexOutOfBoundsException
[
https://issues.apache.org/jira/browse/FLINK-11420?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Dawid Wysakowicz updated FLINK-11420:
-
Fix Version/s: 1.7.3
> Serialization of case classes containing a Map[String, Any] sometimes throws
> ArrayIndexOutOfBoundsException
> ---
>
> Key: FLINK-11420
> URL: https://issues.apache.org/jira/browse/FLINK-11420
> Project: Flink
> Issue Type: Bug
> Components: API / Type Serialization System
>Affects Versions: 1.7.1
>Reporter: Jürgen Kreileder
>Assignee: Dawid Wysakowicz
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 1.7.3, 1.8.0
>
> Time Spent: 1h
> Remaining Estimate: 0h
>
> We frequently run into random ArrayIndexOutOfBounds exceptions when flink
> tries to serialize Scala case classes containing a Map[String, Any] (Any
> being String, Long, Int, or Boolean) with the FsStateBackend. (This probably
> happens with any case class containing a type requiring Kryo, see this thread
> for instance:
> [http://mail-archives.apache.org/mod_mbox/flink-user/201710.mbox/%3cCANNGFpjX4gjV=df6tlfeojsb_rhwxs_ruoylqcqv2gvwqtt...@mail.gmail.com%3e])
> Disabling asynchronous snapshots seems to work around the problem, so maybe
> something is not thread-safe in CaseClassSerializer.
> Our objects look like this:
> {code}
> case class Event(timestamp: Long, [...], content: Map[String, Any]
> case class EnrichedEvent(event: Event, additionalInfo: Map[String, Any])
> {code}
> I've looked at a few of the exceptions in a debugger. It always happens when
> serializing the right-hand side a tuple from EnrichedEvent -> Event ->
> content, e.g: 13 from ("foo", 13) or false from ("bar", false).
> Stacktrace:
> {code:java}
> java.lang.ArrayIndexOutOfBoundsException: Index -1 out of bounds for length 0
> at com.esotericsoftware.kryo.util.IntArray.pop(IntArray.java:157)
> at com.esotericsoftware.kryo.Kryo.reference(Kryo.java:822)
> at com.esotericsoftware.kryo.Kryo.copy(Kryo.java:863)
> at
> org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer.copy(KryoSerializer.java:217)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:101)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:32)
> at
> org.apache.flink.api.scala.typeutils.TraversableSerializer.$anonfun$copy$1(TraversableSerializer.scala:69)
> at scala.collection.immutable.HashMap$HashMap1.foreach(HashMap.scala:234)
> at scala.collection.immutable.HashMap$HashTrieMap.foreach(HashMap.scala:465)
> at scala.collection.immutable.HashMap$HashTrieMap.foreach(HashMap.scala:465)
> at
> org.apache.flink.api.scala.typeutils.TraversableSerializer.copy(TraversableSerializer.scala:69)
> at
> org.apache.flink.api.scala.typeutils.TraversableSerializer.copy(TraversableSerializer.scala:33)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:101)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:32)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:101)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:32)
> at
> org.apache.flink.api.common.typeutils.base.ListSerializer.copy(ListSerializer.java:99)
> at
> org.apache.flink.api.common.typeutils.base.ListSerializer.copy(ListSerializer.java:42)
> at
> org.apache.flink.runtime.state.heap.CopyOnWriteStateTable.get(CopyOnWriteStateTable.java:287)
> at
> org.apache.flink.runtime.state.heap.CopyOnWriteStateTable.get(CopyOnWriteStateTable.java:311)
> at
> org.apache.flink.runtime.state.heap.HeapListState.add(HeapListState.java:95)
> at
> org.apache.flink.streaming.runtime.operators.windowing.WindowOperator.processElement(WindowOperator.java:391)
> at
> org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:202)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:105)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:300)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:704)
> at java.base/java.lang.Thread.run(Thread.java:834){code}
>
>
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
StefanRRichter commented on a change in pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern URL: https://github.com/apache/flink/pull/7899#discussion_r262484441 ## File path: flink-streaming-java/src/main/java/org/apache/flink/streaming/api/operators/BackendRestorerProcedure.java ## @@ -50,7 +49,7 @@ * @param type of the supplied snapshots from which the backend restores. */ public class BackendRestorerProcedure< - T extends Closeable & Disposable & Snapshotable>, + T extends Closeable & Disposable & SnapshotStrategy, Review comment: We can remove the `& SnapshotStrategy` part here, becaues we don't invoke anymore methods from that interface. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-11420) Serialization of case classes containing a Map[String, Any] sometimes throws ArrayIndexOutOfBoundsException
[
https://issues.apache.org/jira/browse/FLINK-11420?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784395#comment-16784395
]
Dawid Wysakowicz commented on FLINK-11420:
--
Fixed in 1.7.3 via: 54cf610494c0601ddbfde91ea62a07dc080feeb1
> Serialization of case classes containing a Map[String, Any] sometimes throws
> ArrayIndexOutOfBoundsException
> ---
>
> Key: FLINK-11420
> URL: https://issues.apache.org/jira/browse/FLINK-11420
> Project: Flink
> Issue Type: Bug
> Components: API / Type Serialization System
>Affects Versions: 1.7.1
>Reporter: Jürgen Kreileder
>Assignee: Dawid Wysakowicz
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 1.7.3, 1.8.0
>
> Time Spent: 1h
> Remaining Estimate: 0h
>
> We frequently run into random ArrayIndexOutOfBounds exceptions when flink
> tries to serialize Scala case classes containing a Map[String, Any] (Any
> being String, Long, Int, or Boolean) with the FsStateBackend. (This probably
> happens with any case class containing a type requiring Kryo, see this thread
> for instance:
> [http://mail-archives.apache.org/mod_mbox/flink-user/201710.mbox/%3cCANNGFpjX4gjV=df6tlfeojsb_rhwxs_ruoylqcqv2gvwqtt...@mail.gmail.com%3e])
> Disabling asynchronous snapshots seems to work around the problem, so maybe
> something is not thread-safe in CaseClassSerializer.
> Our objects look like this:
> {code}
> case class Event(timestamp: Long, [...], content: Map[String, Any]
> case class EnrichedEvent(event: Event, additionalInfo: Map[String, Any])
> {code}
> I've looked at a few of the exceptions in a debugger. It always happens when
> serializing the right-hand side a tuple from EnrichedEvent -> Event ->
> content, e.g: 13 from ("foo", 13) or false from ("bar", false).
> Stacktrace:
> {code:java}
> java.lang.ArrayIndexOutOfBoundsException: Index -1 out of bounds for length 0
> at com.esotericsoftware.kryo.util.IntArray.pop(IntArray.java:157)
> at com.esotericsoftware.kryo.Kryo.reference(Kryo.java:822)
> at com.esotericsoftware.kryo.Kryo.copy(Kryo.java:863)
> at
> org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer.copy(KryoSerializer.java:217)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:101)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:32)
> at
> org.apache.flink.api.scala.typeutils.TraversableSerializer.$anonfun$copy$1(TraversableSerializer.scala:69)
> at scala.collection.immutable.HashMap$HashMap1.foreach(HashMap.scala:234)
> at scala.collection.immutable.HashMap$HashTrieMap.foreach(HashMap.scala:465)
> at scala.collection.immutable.HashMap$HashTrieMap.foreach(HashMap.scala:465)
> at
> org.apache.flink.api.scala.typeutils.TraversableSerializer.copy(TraversableSerializer.scala:69)
> at
> org.apache.flink.api.scala.typeutils.TraversableSerializer.copy(TraversableSerializer.scala:33)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:101)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:32)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:101)
> at
> org.apache.flink.api.scala.typeutils.CaseClassSerializer.copy(CaseClassSerializer.scala:32)
> at
> org.apache.flink.api.common.typeutils.base.ListSerializer.copy(ListSerializer.java:99)
> at
> org.apache.flink.api.common.typeutils.base.ListSerializer.copy(ListSerializer.java:42)
> at
> org.apache.flink.runtime.state.heap.CopyOnWriteStateTable.get(CopyOnWriteStateTable.java:287)
> at
> org.apache.flink.runtime.state.heap.CopyOnWriteStateTable.get(CopyOnWriteStateTable.java:311)
> at
> org.apache.flink.runtime.state.heap.HeapListState.add(HeapListState.java:95)
> at
> org.apache.flink.streaming.runtime.operators.windowing.WindowOperator.processElement(WindowOperator.java:391)
> at
> org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:202)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:105)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:300)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:704)
> at java.base/java.lang.Thread.run(Thread.java:834){code}
>
>
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] KurtYoung merged pull request #7898: [FLINK-11803][table-planner-blink] Improve FlinkTypeFactory for Blink
KurtYoung merged pull request #7898: [FLINK-11803][table-planner-blink] Improve FlinkTypeFactory for Blink URL: https://github.com/apache/flink/pull/7898 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (FLINK-11803) Improve FlinkTypeFactory for Blink
[ https://issues.apache.org/jira/browse/FLINK-11803?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young closed FLINK-11803. -- Resolution: Fixed Fix Version/s: 1.9.0 fixed in fb256d48e52c490b6a899c17c1225d30f7a6c92f > Improve FlinkTypeFactory for Blink > -- > > Key: FLINK-11803 > URL: https://issues.apache.org/jira/browse/FLINK-11803 > Project: Flink > Issue Type: New Feature >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > > We need change TypeInformation to InternalType. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-11827) Introduce DataFormatConverters to convert internal data format and java format
Jingsong Lee created FLINK-11827: Summary: Introduce DataFormatConverters to convert internal data format and java format Key: FLINK-11827 URL: https://issues.apache.org/jira/browse/FLINK-11827 Project: Flink Issue Type: New Feature Reporter: Jingsong Lee Assignee: Jingsong Lee We have introduced a new internal data format, but if user interact with Source, sink and Udx, they prefer to use the traditional Java data format. So we introduce DataFormat Converters to convert the internal efficient binary data format into more general Java data format when source, sink and UDX are used. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] JingsongLi opened a new pull request #7904: Converter
JingsongLi opened a new pull request #7904: Converter URL: https://github.com/apache/flink/pull/7904 ## What is the purpose of the change Introduce DataFormatConverters java class to convert internal data format and java format ## Verifying this change ut ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (JavaDocs) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #7904: [FLINK-11827][table-runtime-blink] Introduce DataFormatConverters to convert internal data format and java format
flinkbot commented on issue #7904: [FLINK-11827][table-runtime-blink] Introduce DataFormatConverters to convert internal data format and java format URL: https://github.com/apache/flink/pull/7904#issuecomment-469680063 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-11827) Introduce DataFormatConverters to convert internal data format and java format
[ https://issues.apache.org/jira/browse/FLINK-11827?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784426#comment-16784426 ] Jingsong Lee commented on FLINK-11827: -- implemented in https://github.com/apache/flink/pull/7904 > Introduce DataFormatConverters to convert internal data format and java format > -- > > Key: FLINK-11827 > URL: https://issues.apache.org/jira/browse/FLINK-11827 > Project: Flink > Issue Type: New Feature >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > > We have introduced a new internal data format, but if user interact with > Source, sink and Udx, they prefer to use the traditional Java data format. > So we introduce DataFormat Converters to convert the internal efficient > binary data format into more general Java data format when source, sink and > UDX are used. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-11819) Additional attribute for order by not support by flink sql, but told supported in doc
[
https://issues.apache.org/jira/browse/FLINK-11819?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16784452#comment-16784452
]
Xingcan Cui commented on FLINK-11819:
-
Hi [~hustclf], I think "additional" means you should first sort on a time
attribute and then use other attributes, e.g., "order by rowtime, tenantId".
> Additional attribute for order by not support by flink sql, but told
> supported in doc
> -
>
> Key: FLINK-11819
> URL: https://issues.apache.org/jira/browse/FLINK-11819
> Project: Flink
> Issue Type: Bug
> Components: Documentation
>Affects Versions: 1.7.2
>Reporter: Lifei Chen
>Assignee: Lifei Chen
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.7.3
>
> Original Estimate: 3h
> Time Spent: 10m
> Remaining Estimate: 2h 50m
>
> I am using flink v1.7.1, when I use flink sql to order by an attribute (not
> time attribute), the error logs is as follow.
>
> sql:
> {quote}"SELECT * FROM events order by tenantId"
> {quote}
>
> error logs:
> {quote}Exception in thread "main" org.apache.flink.table.api.TableException:
> Cannot generate a valid execution plan for the given query:
> FlinkLogicalSort(sort0=[$2], dir0=[ASC])
> FlinkLogicalNativeTableScan(table=[[_DataStreamTable_0]])
> This exception indicates that the query uses an unsupported SQL feature.
> Please check the documentation for the set of currently supported SQL
> features.
> at
> org.apache.flink.table.api.TableEnvironment.runVolcanoPlanner(TableEnvironment.scala:377)
> at
> org.apache.flink.table.api.TableEnvironment.optimizePhysicalPlan(TableEnvironment.scala:302)
> at
> org.apache.flink.table.api.StreamTableEnvironment.optimize(StreamTableEnvironment.scala:814)
> at
> org.apache.flink.table.api.StreamTableEnvironment.translate(StreamTableEnvironment.scala:860)
> at
> org.apache.flink.table.api.java.StreamTableEnvironment.toRetractStream(StreamTableEnvironment.scala:305)
> at
> org.apache.flink.table.api.java.StreamTableEnvironment.toRetractStream(StreamTableEnvironment.scala:248)
> {quote}
>
> So as for now, only time attribute is supported by flink for command `order
> by`, additional attribute is not supported yet, Is that right ?
> If so, there is a mistake, indicated that other attribute except for `time
> attribute` is supported .
> related links:
> [https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/table/sql.html#orderby--limit]
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262484842
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/RecordWriterTest.java
##
@@ -196,10 +198,152 @@ public void testSerializerClearedAfterClearBuffers()
throws Exception {
}
/**
-* Tests broadcasting events when no records have been emitted yet.
+* Tests broadcasting events when no records have been emitted yet in
{@link BroadcastRecordWriter}.
*/
@Test
- public void testBroadcastEventNoRecords() throws Exception {
+ public void testBroadcastWriterBroadcastEventNoRecord() throws
Exception {
Review comment:
I would move `BroadcastRecordWriter`s test to `BroadcastRecordWriterTest`
class, that would extend from `RecordWriterTest`. `BroadcastRecordWriterTest`
could either override some `createRecordWriter()` method or pass different flag
in the constructor like:
```
public BroadcastRecordWriterTest() {
super(isBroadcastWriter = true);
}
```
It would simplify the code and would avoid the need for defining each test
method three times (broadcast, non broadcast, generic).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262504889
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/api/writer/BroadcastRecordWriter.java
##
@@ -44,4 +52,67 @@ public BroadcastRecordWriter(
public void emit(T record) throws IOException, InterruptedException {
broadcastEmit(record);
}
+
+ @Override
+ public void broadcastEmit(T record) throws IOException,
InterruptedException {
Review comment:
I see couple of issues/potential issues here:
1. I'm not sure if I like the `randomTriggered` state field and how it's
value affects the logic in different methods. It took quite some time to
understand two successive `randomEmit` one after another work correctly (and
how they actually work), because `requestNewBufferBuilder` behaves differently
for `randomTriggered = true`.
2. I'm not sure, but I think that `BroadcastRecordWriter`'s logic would be
actually easier to follow, if it didn't have `bufferBuilders` array, but single
`bufferBuilder` field. Maybe it would be worth creating `AbstractRecordWriter`
without `bufferBuilders`/`bufferBuilder` field and then have two concrete
implementations of `RecordWriter` and `BroadcastRecordWriter` with one two
different implementations?
3. `LatencyMarker`s are a bit broken here, since effectively they will be
flushed on the very first next emit following the `LatencyMarker`, so they do
not measure the actual latency. This might not be the critical issue, but it
would be good to have correct metric for that.
Point 1. is not that difficult to address (for 1. `randomEmit()` could flush
the current buffer, request a new one for one `randomEmit()` and immediately
finish it, so that this special handling of `randomTriggered = true` wouldn't
leak outside of the `randomEmit()` method).
Point 2. Might be not worth doing so.
Point 3. is the more problematic one I guess.
a) One way to deal with it, would be to broadcast `LatencyMarker`. Easy to
do, but with huge number of output channels and multiple broadcasts channels
one after another, would result with gigantic cascade/avalanche of the
`LatencyMarkers`.
b) Another idea would be to broadcast the `LatencyMarker` to everybody, but
add some kind of marker to let the receiver know, that it should ignore it,
because it was targeted to someone else.
c) Maybe there are other solutions that I haven't thought about?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262483359
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/api/writer/RecordWriter.java
##
@@ -329,8 +333,12 @@ public static RecordWriter createRecordWriter(
return createRecordWriter(writer, channelSelector, -1,
taskName);
}
- //
+ public static RecordWriter createRecordWriter(
+ ResultPartitionWriter writer) {
Review comment:
nit: one tab missing?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262486384
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/RecordWriterTest.java
##
@@ -247,136 +388,121 @@ public void testBroadcastEventMixedRecords() throws
Exception {
}
TestPooledBufferProvider bufferProvider = new
TestPooledBufferProvider(Integer.MAX_VALUE, bufferSize);
-
ResultPartitionWriter partitionWriter = new
CollectingPartitionWriter(queues, bufferProvider);
- RecordWriter writer = new
RecordWriter<>(partitionWriter);
- CheckpointBarrier barrier = new
CheckpointBarrier(Integer.MAX_VALUE + 1292L, Integer.MAX_VALUE + 199L,
CheckpointOptions.forCheckpointWithDefaultLocation());
+ RecordWriter writer = isBroadcastWriter ?
+ RecordWriter.createRecordWriter(partitionWriter, new
OutputEmitter(ShipStrategyType.BROADCAST, 0), "test") :
+ RecordWriter.createRecordWriter(partitionWriter);
+
+ CheckpointBarrier barrier = new CheckpointBarrier(0, 0,
CheckpointOptions.forCheckpointWithDefaultLocation());
// Emit records on some channels first (requesting buffers),
then
// broadcast the event. The record buffers should be emitted
first, then
// the event. After the event, no new buffer should be
requested.
- // (i) Smaller than the buffer size (single buffer request => 1)
+ // (i) Smaller than the buffer size
byte[] bytes = new byte[bufferSize / 2];
rand.nextBytes(bytes);
writer.emit(new ByteArrayIO(bytes));
- // (ii) Larger than the buffer size (two buffer requests => 1 +
2)
+ // (ii) Larger than the buffer size
bytes = new byte[bufferSize + 1];
rand.nextBytes(bytes);
writer.emit(new ByteArrayIO(bytes));
- // (iii) Exactly the buffer size (single buffer request => 1 +
2 + 1)
+ // (iii) Exactly the buffer size
bytes = new byte[bufferSize - lenBytes];
rand.nextBytes(bytes);
writer.emit(new ByteArrayIO(bytes));
- // (iv) Nothing on the 4th channel (no buffer request => 1 + 2
+ 1 + 0 = 4)
-
- // (v) Broadcast the event
+ // (iv) Broadcast the event
writer.broadcastEvent(barrier);
- assertEquals(4, bufferProvider.getNumberOfCreatedBuffers());
+ if (isBroadcastWriter) {
Review comment:
with `BroadcastRecordWriterTest` class, this if could be changed to
overloaded method.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262487320
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/RecordWriterTest.java
##
@@ -247,136 +388,121 @@ public void testBroadcastEventMixedRecords() throws
Exception {
}
TestPooledBufferProvider bufferProvider = new
TestPooledBufferProvider(Integer.MAX_VALUE, bufferSize);
-
ResultPartitionWriter partitionWriter = new
CollectingPartitionWriter(queues, bufferProvider);
- RecordWriter writer = new
RecordWriter<>(partitionWriter);
- CheckpointBarrier barrier = new
CheckpointBarrier(Integer.MAX_VALUE + 1292L, Integer.MAX_VALUE + 199L,
CheckpointOptions.forCheckpointWithDefaultLocation());
+ RecordWriter writer = isBroadcastWriter ?
+ RecordWriter.createRecordWriter(partitionWriter, new
OutputEmitter(ShipStrategyType.BROADCAST, 0), "test") :
+ RecordWriter.createRecordWriter(partitionWriter);
+
+ CheckpointBarrier barrier = new CheckpointBarrier(0, 0,
CheckpointOptions.forCheckpointWithDefaultLocation());
// Emit records on some channels first (requesting buffers),
then
// broadcast the event. The record buffers should be emitted
first, then
// the event. After the event, no new buffer should be
requested.
- // (i) Smaller than the buffer size (single buffer request => 1)
+ // (i) Smaller than the buffer size
byte[] bytes = new byte[bufferSize / 2];
rand.nextBytes(bytes);
writer.emit(new ByteArrayIO(bytes));
- // (ii) Larger than the buffer size (two buffer requests => 1 +
2)
+ // (ii) Larger than the buffer size
bytes = new byte[bufferSize + 1];
rand.nextBytes(bytes);
writer.emit(new ByteArrayIO(bytes));
- // (iii) Exactly the buffer size (single buffer request => 1 +
2 + 1)
+ // (iii) Exactly the buffer size
bytes = new byte[bufferSize - lenBytes];
rand.nextBytes(bytes);
writer.emit(new ByteArrayIO(bytes));
- // (iv) Nothing on the 4th channel (no buffer request => 1 + 2
+ 1 + 0 = 4)
-
- // (v) Broadcast the event
+ // (iv) Broadcast the event
writer.broadcastEvent(barrier);
- assertEquals(4, bufferProvider.getNumberOfCreatedBuffers());
+ if (isBroadcastWriter) {
+ assertEquals(3,
bufferProvider.getNumberOfCreatedBuffers());
- BufferOrEvent boe;
- assertEquals(2, queues[0].size()); // 1 buffer + 1 event
- assertTrue(parseBuffer(queues[0].remove(), 0).isBuffer());
- assertEquals(3, queues[1].size()); // 2 buffers + 1 event
- assertTrue(parseBuffer(queues[1].remove(), 1).isBuffer());
- assertTrue(parseBuffer(queues[1].remove(), 1).isBuffer());
- assertEquals(2, queues[2].size()); // 1 buffer + 1 event
- assertTrue(parseBuffer(queues[2].remove(), 2).isBuffer());
- assertEquals(1, queues[3].size()); // 0 buffers + 1 event
+ for (int i = 0; i < numberOfChannels; i++) {
+ assertEquals(4, queues[i].size()); // 3 buffer
+ 1 event
- // every queue's last element should be the event
- for (int i = 0; i < numberOfChannels; i++) {
- boe = parseBuffer(queues[i].remove(), i);
- assertTrue(boe.isEvent());
- assertEquals(barrier, boe.getEvent());
+ for (int j = 0; j < 3; j++) {
+
assertTrue(parseBuffer(queues[i].remove(), 0).isBuffer());
+ }
+
+ BufferOrEvent boe =
parseBuffer(queues[i].remove(), i);
+ assertTrue(boe.isEvent());
+ assertEquals(barrier, boe.getEvent());
+ }
+ } else {
+ assertEquals(4,
bufferProvider.getNumberOfCreatedBuffers());
+
+ assertEquals(2, queues[0].size()); // 1 buffer + 1 event
+ assertTrue(parseBuffer(queues[0].remove(),
0).isBuffer());
+ assertEquals(3, queues[1].size()); // 2 buffers + 1
event
+ assertTrue(parseBuffer(queues[1].remove(),
1).isBuffer());
+ assertTrue(parseBuffer(queues[1].remove(),
1).isBuffer());
+ ass
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode URL: https://github.com/apache/flink/pull/7713#discussion_r262483453 ## File path: flink-runtime/src/main/java/org/apache/flink/runtime/io/network/api/writer/RecordWriter.java ## @@ -329,8 +333,12 @@ public static RecordWriter createRecordWriter( return createRecordWriter(writer, channelSelector, -1, taskName); } - // + public static RecordWriter createRecordWriter( Review comment: this slowly deservers for a `Builder` pattern. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262485390
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/RecordWriterTest.java
##
@@ -210,10 +354,12 @@ public void testBroadcastEventNoRecords() throws
Exception {
}
TestPooledBufferProvider bufferProvider = new
TestPooledBufferProvider(Integer.MAX_VALUE, bufferSize);
-
ResultPartitionWriter partitionWriter = new
CollectingPartitionWriter(queues, bufferProvider);
- RecordWriter writer = new
RecordWriter<>(partitionWriter);
- CheckpointBarrier barrier = new
CheckpointBarrier(Integer.MAX_VALUE + 919192L, Integer.MAX_VALUE + 18828228L,
CheckpointOptions.forCheckpointWithDefaultLocation());
+ RecordWriter writer = isBroadcastWriter ?
+ RecordWriter.createRecordWriter(partitionWriter, new
OutputEmitter(ShipStrategyType.BROADCAST, 0), "test") :
+ RecordWriter.createRecordWriter(partitionWriter);
+
+ CheckpointBarrier barrier = new CheckpointBarrier(0, 0,
CheckpointOptions.forCheckpointWithDefaultLocation());
Review comment:
Why have you changed the constants to `0`? Was there some reason behind that?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] pnowojski commented on a change in pull request #7713: [FLINK-10995][network] Copy intermediate serialization results only once for broadcast mode
pnowojski commented on a change in pull request #7713: [FLINK-10995][network]
Copy intermediate serialization results only once for broadcast mode
URL: https://github.com/apache/flink/pull/7713#discussion_r262493971
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/RecordWriterTest.java
##
@@ -461,6 +572,56 @@ private void
emitRecordWithBroadcastPartitionerOrBroadcastEmitRecord(boolean isB
}
}
+ private void randomEmitMixedBroadcastBufferOrEvent(boolean
isBroadcastEvent) throws Exception {
Review comment:
I'm not sure if I understand the idea behind the unit tests in this file.
What's the point of asserting the count and the size of buffers? In doesn't
check for the correctness, nor it checks for the performance it just checks for
some private implementation detail.
For performance testing we have micro benchmarks.
For correctness we should only check that certain scenarios like, writing x,
y, z records or events and/or mixed with broadcasting
records/events/watermarks, result with the correct output content of the
buffers, regardless of the number/size of the buffers on the output. Otherwise
if we optimise/refactor something, all of those tests will start yielding false
positive errors.
I'm not sure if you understand my concern/agree with it. If yes, and If you
do not want to fix the old tests, could you please at least re-write the new
test? This `randomEmitMixedBroadcastBufferOrEvent` test shouldn't care for
number of `getNumberOfCreatedBuffers`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] carp84 commented on issue #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
carp84 commented on issue #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern URL: https://github.com/apache/flink/pull/7899#issuecomment-469696744 Thanks for the review and help @StefanRRichter ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] aljoscha commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
aljoscha commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469710038 Very strange that this even compiles ... The correct way of fixing this is to change the `package ...` statement, though. I think the file is in the right location. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] aljoscha commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
aljoscha commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469710148 @flinkbot approve consensus This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] aljoscha commented on issue #7781: [FLINK-8354] Add KafkaDeserializationSchema that directly uses ConsumerRecord
aljoscha commented on issue #7781: [FLINK-8354] Add KafkaDeserializationSchema that directly uses ConsumerRecord URL: https://github.com/apache/flink/pull/7781#issuecomment-469710299 Now I see, yes, we need to fix this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
flinkbot edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469587374 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ✅ 2. There is [consensus] that the contribution should go into to Flink. - Approved by @aljoscha [PMC] * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469712927 @aljoscha you mean just need to fix the `package ...` not move it to `org.apache.flink.streaming.util.serialization`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken edited a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469712927 @aljoscha you mean just fix the `package ...` not move it to `org.apache.flink.streaming.util.serialization`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken removed a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken removed a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469712927 @aljoscha you mean just fix the `package ...` not move it to `org.apache.flink.streaming.util.serialization`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] mikeholler commented on issue #7897: [FLINK-11817] Uses aggregate function in DataStream API Tutorial
mikeholler commented on issue #7897: [FLINK-11817] Uses aggregate function in DataStream API Tutorial URL: https://github.com/apache/flink/pull/7897#issuecomment-469716062 I'm a beginner at Flink, and the creator of the original issue FLINK-11817. First of all, HUGE thank you for responding and opening an MR so quickly. Secondly, it strikes me as a beginner that this new `aggregate` API is much more complicated than the very simple `fold` function. Again as a novice, it seems like the experience of coding with the deprecated function is easier than with the new one. So, the question I have, which has nothing to do with the quality of this merge request, is whether there's somewhere I can go to learn about why this change was made? I can only assume that this was done for reasons beneficial to the Flink backend, since the same thing became harder for the end user. I'm only starting to grasp how Flink works and this seems like a good way for me to dive a little deeper. Thanks again for the quick fix! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] mikeholler edited a comment on issue #7897: [FLINK-11817] Uses aggregate function in DataStream API Tutorial
mikeholler edited a comment on issue #7897: [FLINK-11817] Uses aggregate function in DataStream API Tutorial URL: https://github.com/apache/flink/pull/7897#issuecomment-469716062 I'm a beginner at Flink, and the creator of the original issue FLINK-11817. First of all, HUGE thank you for responding and opening an MR so quickly. Secondly, it strikes me as a beginner that this new `aggregate` API is much more complicated than the very simple `fold` function. Again as a novice, it seems like the experience of coding with the deprecated function is easier than with the new one. So, the question I have, which has nothing to do with the quality of this merge request, is whether there's somewhere I can go to learn about why this change was made? I am guessing that this was done for reasons beneficial to the Flink backend, since the same thing became harder for the end user. I'm only starting to grasp how Flink works and this seems like a good way for me to dive a little deeper. Thanks again for the quick fix! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469719771 @aljoscha, it's ok to let the `KafkaDeserializationSchemaWrapper` under package `...util.serialization` and there is not much need to move it to package `...internals` from my side. 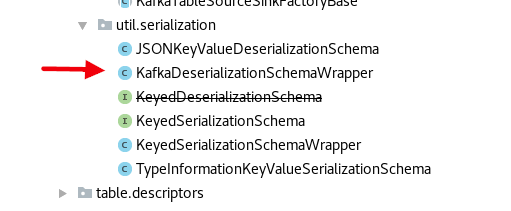 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] mikeholler commented on a change in pull request #7897: [FLINK-11817] Uses aggregate function in DataStream API Tutorial
mikeholler commented on a change in pull request #7897: [FLINK-11817] Uses
aggregate function in DataStream API Tutorial
URL: https://github.com/apache/flink/pull/7897#discussion_r262546713
##
File path: docs/tutorials/datastream_api.md
##
@@ -240,13 +255,28 @@ public class WikipediaAnalysis {
DataStream> result = keyedEdits
.timeWindow(Time.seconds(5))
- .fold(new Tuple2<>("", 0L), new FoldFunction>() {
+ .aggregate(new AggregateFunction, Tuple2>() {
@Override
-public Tuple2 fold(Tuple2 acc,
WikipediaEditEvent event) {
- acc.f0 = event.getUser();
- acc.f1 += event.getByteDiff();
- return acc;
-}
+ public Tuple2 createAccumulator() {
+ return new Tuple2<>("", 0L);
+ }
+
+ @Override
+ public Tuple2 add(WikipediaEditEvent value,
Tuple2 accumulator) {
+ accumulator.f0 = value.getUser();
+ accumulator.f1 += value.getByteDiff();
+ return accumulator;
+ }
+
+ @Override
+ public Tuple2 getResult(Tuple2 accumulator)
{
+ return accumulator;
+ }
+
+ @Override
+ public Tuple2 merge(Tuple2 a,
Tuple2 b) {
Review comment:
Why isn't `b` used here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] asfgit closed pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern
asfgit closed pull request #7899: [FLINK-11731] [State Backends] Make DefaultOperatorStateBackend follow the builder pattern URL: https://github.com/apache/flink/pull/7899 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262542959
##
File path:
flink-core/src/test/java/org/apache/flink/configuration/ConfigurationTest.java
##
@@ -403,4 +405,43 @@ public void testRemove(){
assertEquals("Wrong expectation about size",
cfg.keySet().size(), 0);
assertFalse("Expected 'unexistedOption' is not removed",
cfg.removeConfig(unexistedOption));
}
+
+ @Test
+ public void testShouldParseValidStringToEnum() {
+ final ConfigOption validOption = ConfigOptions
+ .key("test-string-key")
+ .noDefaultValue();
+
+ final Configuration configuration = new Configuration();
+ configuration.setString(validOption.key(),
TestEnum.VALUE1.toString());
+
+ final TestEnum parsedEnumValue =
configuration.getAsEnum(TestEnum.class, validOption);
+ assertEquals(TestEnum.VALUE1, parsedEnumValue);
+ }
+
+ @Test
+ public void testThrowsExceptionIfTryingToParseInvalidStringForEnum() {
+ final ConfigOption validOption = ConfigOptions
+ .key("test-string-key")
+ .noDefaultValue();
+
+ final Configuration configuration = new Configuration();
+ final String invalidValueForTestEnum =
"InvalidValueForTestEnum";
+ configuration.setString(validOption.key(),
invalidValueForTestEnum);
+
+ try {
+ configuration.getAsEnum(TestEnum.class, validOption);
+ fail("Expected exception not thrown");
+ } catch (IllegalArgumentException e) {
+ final String expectedMessage = "Value for config option
" +
Review comment:
nit: Personally prefer the approach with `@Rule`
```
@Rule
public ExpectedException thrown = ExpectedException.none();
@Test
public testMethod() {
...
thrown.expect(IllegalArgumentException.class);
thrown.message();
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262539633
##
File path:
flink-core/src/main/java/org/apache/flink/configuration/Configuration.java
##
@@ -608,6 +610,33 @@ public String getValue(ConfigOption configOption) {
return o == null ? null : o.toString();
}
+ /**
+* Returns the value associated with the given config option as an enum.
+*
+* @param enumClassThe return enum class
+* @param configOption The configuration option
+* @throws IllegalArgumentException If the string associated with the
given config option cannot
+* be parsed as a value of the
provided enum class.
+*/
+ @PublicEvolving
+ public > T getAsEnum(
Review comment:
nit: This would be more consistent with other getters.
```suggestion
public > T getEnum(
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262546655
##
File path:
flink-yarn/src/test/java/org/apache/flink/yarn/YarnClusterDescriptorTest.java
##
@@ -89,6 +91,27 @@ public static void tearDownClass() {
yarnClient.stop();
}
+ /**
+* @see https://issues.apache.org/jira/browse/FLINK-11781";>FLINK-11781
+*/
+ @Test
+ public void
testThrowsExceptionIfUserTriesToDisableUserJarInclusionInSystemClassPath() {
+ final Configuration configuration = new Configuration();
+
configuration.setString(YarnConfigOptions.CLASSPATH_INCLUDE_USER_JAR,
"DISABLED");
+
+ try {
+ new YarnClusterDescriptor(
+ configuration,
+ yarnConfiguration,
+ temporaryFolder.getRoot().getAbsolutePath(),
+ yarnClient,
+ true);
+ fail("Expected exception not thrown");
+ } catch (final IllegalArgumentException e) {
+ assertThat(e.getMessage(), containsString("cannot be
set to DISABLED anymore"));
Review comment:
nit: As before -> I prefer the `@Rule` approach.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262539328
##
File path:
flink-core/src/main/java/org/apache/flink/configuration/Configuration.java
##
@@ -608,6 +610,33 @@ public String getValue(ConfigOption configOption) {
return o == null ? null : o.toString();
}
+ /**
+* Returns the value associated with the given config option as an enum.
+*
+* @param enumClassThe return enum class
+* @param configOption The configuration option
+* @throws IllegalArgumentException If the string associated with the
given config option cannot
+* be parsed as a value of the
provided enum class.
+*/
+ @PublicEvolving
+ public > T getAsEnum(
+ final Class enumClass,
+ final ConfigOption configOption) {
+ checkNotNull(enumClass, "enumClass must not be null");
+ checkNotNull(configOption, "configOption must not be null");
+
+ final String configValue = getString(configOption);
+ try {
+ return T.valueOf(enumClass, configValue);
Review comment:
nit:
```suggestion
return Enum.valueOf(enumClass, configValue);
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262550173
##
File path:
flink-core/src/main/java/org/apache/flink/configuration/Configuration.java
##
@@ -608,6 +610,33 @@ public String getValue(ConfigOption configOption) {
return o == null ? null : o.toString();
}
+ /**
+* Returns the value associated with the given config option as an enum.
+*
+* @param enumClassThe return enum class
+* @param configOption The configuration option
+* @throws IllegalArgumentException If the string associated with the
given config option cannot
+* be parsed as a value of the
provided enum class.
+*/
+ @PublicEvolving
+ public > T getAsEnum(
+ final Class enumClass,
+ final ConfigOption configOption) {
+ checkNotNull(enumClass, "enumClass must not be null");
+ checkNotNull(configOption, "configOption must not be null");
+
+ final String configValue = getString(configOption);
+ try {
+ return T.valueOf(enumClass, configValue);
Review comment:
Shouldn't we call `toUpperCase` on `configValue`? At least for the scope of
`yarn.per-job-cluster.include-user-jar` we tried to be case insensitive so far,
which seems fair.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262540281
##
File path:
flink-core/src/main/java/org/apache/flink/configuration/Configuration.java
##
@@ -608,6 +610,33 @@ public String getValue(ConfigOption configOption) {
return o == null ? null : o.toString();
}
+ /**
+* Returns the value associated with the given config option as an enum.
+*
+* @param enumClassThe return enum class
+* @param configOption The configuration option
+* @throws IllegalArgumentException If the string associated with the
given config option cannot
+* be parsed as a value of the
provided enum class.
+*/
+ @PublicEvolving
+ public > T getAsEnum(
+ final Class enumClass,
+ final ConfigOption configOption) {
+ checkNotNull(enumClass, "enumClass must not be null");
+ checkNotNull(configOption, "configOption must not be null");
+
+ final String configValue = getString(configOption);
+ try {
+ return T.valueOf(enumClass, configValue);
+ } catch (final IllegalArgumentException | NullPointerException
e) {
+ final String errorMessage = String.format("Value for
config option %s must be one of %s (was %s)",
+ configOption.key(),
+ Arrays.asList(enumClass.getEnumConstants()),
Review comment:
nit:
```suggestion
Arrays.toString(enumClass.getEnumConstants()),
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on a change in pull request #7883: [FLINK-11781][yarn]
Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
URL: https://github.com/apache/flink/pull/7883#discussion_r262551151
##
File path:
flink-yarn/src/main/java/org/apache/flink/yarn/configuration/YarnConfigOptions.java
##
@@ -156,7 +155,6 @@ private YarnConfigOptions() {}
/** @see YarnConfigOptions#CLASSPATH_INCLUDE_USER_JAR */
public enum UserJarInclusion {
- DISABLED,
Review comment:
+1 for throwing exception rather than just logging, when mismatch.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Resolved] (FLINK-11731) Make DefaultOperatorStateBackend follow the builder pattern
[
https://issues.apache.org/jira/browse/FLINK-11731?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Stefan Richter resolved FLINK-11731.
Resolution: Implemented
Fix Version/s: 1.8.0
Merged in:
master: 94f84a5c
release-1.8: 2f62b890
> Make DefaultOperatorStateBackend follow the builder pattern
> ---
>
> Key: FLINK-11731
> URL: https://issues.apache.org/jira/browse/FLINK-11731
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / State Backends
>Reporter: Yu Li
>Assignee: Yu Li
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.8.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> This subtask is to introduce a builder for \{{DefaultOperatorStateBackend}}
> and move all necessary initialization work including restore operation to the
> building process.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Resolved] (FLINK-11729) Make all state backends follow builder pattern
[
https://issues.apache.org/jira/browse/FLINK-11729?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Stefan Richter resolved FLINK-11729.
Resolution: Implemented
Fix Version/s: 1.8.0
Merged in:
master: 94f84a5c
release-1.8: 2f62b890
> Make all state backends follow builder pattern
> --
>
> Key: FLINK-11729
> URL: https://issues.apache.org/jira/browse/FLINK-11729
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / State Backends
>Reporter: Yu Li
>Assignee: Yu Li
>Priority: Major
> Fix For: 1.8.0
>
>
> In FLINK-10043 we have introduced builder pattern for
> {{RocksDBKeyedStateBackend}} and moved all necessary initialization of the
> backend into the builder, out of which the most important part is the
> {{restore}} operation. None of the backends could actually supply service
> before the restore operation is done, so it's native to make restore part of
> the _building phase_.
> In this JIRA we propose to make all backends follow the builder pattern. More
> specifically, create builders for {{HeapKeyedStateBackend}} and
> {{DefaultOperatorStateBackend}} and move their {{restore}} operations into
> the builders. Will create sub-tasks for each of them.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Issue Comment Deleted] (FLINK-11729) Make all state backends follow builder pattern
[
https://issues.apache.org/jira/browse/FLINK-11729?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Stefan Richter updated FLINK-11729:
---
Comment: was deleted
(was: Merged in:
master: 94f84a5c
release-1.8: 2f62b890)
> Make all state backends follow builder pattern
> --
>
> Key: FLINK-11729
> URL: https://issues.apache.org/jira/browse/FLINK-11729
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / State Backends
>Reporter: Yu Li
>Assignee: Yu Li
>Priority: Major
> Fix For: 1.8.0
>
>
> In FLINK-10043 we have introduced builder pattern for
> {{RocksDBKeyedStateBackend}} and moved all necessary initialization of the
> backend into the builder, out of which the most important part is the
> {{restore}} operation. None of the backends could actually supply service
> before the restore operation is done, so it's native to make restore part of
> the _building phase_.
> In this JIRA we propose to make all backends follow the builder pattern. More
> specifically, create builders for {{HeapKeyedStateBackend}} and
> {{DefaultOperatorStateBackend}} and move their {{restore}} operations into
> the builders. Will create sub-tasks for each of them.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] dawidwys commented on issue #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar
dawidwys commented on issue #7883: [FLINK-11781][yarn] Remove "DISABLED" as possible value for yarn.per-job-cluster.include-user-jar URL: https://github.com/apache/flink/pull/7883#issuecomment-469726624 @flinkbot approve until architecture This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken commented on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469726573 @flinkbot approve all This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lamber-ken removed a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java
lamber-ken removed a comment on issue #7902: [FLINK-11821] fix the error package location of KafkaDeserializationSchemaWrapper.java URL: https://github.com/apache/flink/pull/7902#issuecomment-469726573 @flinkbot approve all This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Resolved] (FLINK-11796) Remove Snapshotable interface
[
https://issues.apache.org/jira/browse/FLINK-11796?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Stefan Richter resolved FLINK-11796.
Resolution: Implemented
Fix Version/s: 1.8.0
Merged in:
master: e8daa49a
release-1.8: ce2d65d8
> Remove Snapshotable interface
> -
>
> Key: FLINK-11796
> URL: https://issues.apache.org/jira/browse/FLINK-11796
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / State Backends
>Reporter: Yu Li
>Assignee: Yu Li
>Priority: Major
> Fix For: 1.8.0
>
>
> With FLINK-10043 and FLINK-11729 we have made all backends follow the builder
> pattern and moved all restore operations into the backend building process,
> with a newly introduced {{RestoreOperation}} interface for the abstraction.
> So we only need to implement the {{SnapshotStrategy}} interface in backends
> and could safely remove the {{Snapshotable}} interface.
> We will also remove the relative call of {{Snapshotable#restore}} in
> {{BackendRestorerProcedure#attemptCreateAndRestore}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)