[GitHub] [flink] zhijiangW commented on issue #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on issue #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition URL: https://github.com/apache/flink/pull/7549#issuecomment-474706964 @azagrebin , thanks for reviews! I submitted a separate fixup commit for addressing the method access modifier. For the other issues I left some comments need to be further confirmed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-11972) The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
[
https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11972:
Description:
Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
`hadoop-shaded` JAR integrated into the dist. It will cause an error when the
end-to-end test cannot be found with `Hadoop` Related classes, such as:
`java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we need
to improve the end-to-end test script, or explicitly stated in the README, i.e.
end-to-end test need to add `flink-shaded-hadoop2-uber-.jar` to the
classpath. So, we will get the exception something like:
{code:java}
[INFO] 3 instance(s) of taskexecutor are already running on
jinchengsunjcs-iMac.local.
Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
at java.lang.Class.getDeclaredFields(Class.java:1916)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
at
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
at
org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
at
org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
at
org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
at
org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at
org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at
org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 22 more
Job () is running.{code}
So, I think we can import the test script or improve the README.
What do you think?
was:
Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
`hadoop-shaded` JAR integrated into the dist. It will cause an error when the
end-to-end test cannot be found with `Hadoop` Related classes, such as:
`java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we need
to improve the end-to-end test script, or explicitly stated in the README, i.e.
end-to-end test need to add `flink-shaded-hadoop2-uber-.jar` to the
classpath. So, we will get the exception something like:
{code:java}
[INFO] 3 instance(s) of taskexecutor are already running on
jinchengsunjcs-iMac.local.
Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
at java.lang.Class.getDeclaredFields(Class.java:1916)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
at
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
at
org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
at
org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
at
org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
at
org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecuti
[jira] [Updated] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Description:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!screenshot-1.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local info
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
was:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!screenshot-1.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local messae
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
> Attachments: screenshot-1.png
>
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !screenshot-1.png!
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local info
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267201040
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ResultPartition.java
##
@@ -19,432 +19,105 @@
package org.apache.flink.runtime.io.network.partition;
import org.apache.flink.api.common.JobID;
-import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
-import org.apache.flink.runtime.io.disk.iomanager.IOManager;
import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
-import org.apache.flink.runtime.io.network.buffer.Buffer;
import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
-import org.apache.flink.runtime.io.network.buffer.BufferPool;
-import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
import org.apache.flink.runtime.io.network.buffer.BufferProvider;
-import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
-import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
-import org.apache.flink.runtime.jobgraph.DistributionPattern;
import org.apache.flink.runtime.taskmanager.TaskActions;
-import org.apache.flink.runtime.taskmanager.TaskManager;
-
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
import java.io.IOException;
-import java.util.concurrent.atomic.AtomicBoolean;
-import java.util.concurrent.atomic.AtomicInteger;
-import static org.apache.flink.util.Preconditions.checkArgument;
-import static org.apache.flink.util.Preconditions.checkElementIndex;
import static org.apache.flink.util.Preconditions.checkNotNull;
-import static org.apache.flink.util.Preconditions.checkState;
/**
- * A result partition for data produced by a single task.
- *
- * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
- * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
- * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
- * number of consuming tasks and the data {@link DistributionPattern}.
- *
- * Tasks, which consume a result partition have to request one of its
subpartitions. The request
- * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
- *
- * Life-cycle
- *
- * The life-cycle of each result partition has three (possibly overlapping)
phases:
- *
- * Produce:
- * Consume:
- * Release:
- *
- *
- * Lazy deployment and updates of consuming tasks
- *
- * Before a consuming task can request the result, it has to be deployed.
The time of deployment
- * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
- * results, receivers are deployed as soon as the first buffer is added to the
result partition.
- * With blocking results on the other hand, receivers are deployed after the
partition is finished.
- *
- * Buffer management
- *
- * State management
+ * A wrapper of result partition writer for handling notification of the
consumable
+ * partition which is added a {@link BufferConsumer} or finished.
*/
-public class ResultPartition implements ResultPartitionWriter, BufferPoolOwner
{
-
- private static final Logger LOG =
LoggerFactory.getLogger(ResultPartition.class);
-
- private final String owningTaskName;
+public class ResultPartition implements ResultPartitionWriter {
private final TaskActions taskActions;
private final JobID jobId;
- private final ResultPartitionID partitionId;
-
- /** Type of this partition. Defines the concrete subpartition
implementation to use. */
private final ResultPartitionType partitionType;
- /** The subpartitions of this partition. At least one. */
- private final ResultSubpartition[] subpartitions;
-
- private final ResultPartitionManager partitionManager;
+ private final ResultPartitionWriter partitionWriter;
Review comment:
In the final form, `ResultPartition` should not implement
`ResultPartitionWriter` and it could be put in the `TaskManager` package
instead of current network package. And the field in `ResultPartition` should
be regular `ResultPartitionWriter` finally.
I could understand your concern. If we keep special `NetworkResultPartition`
in `ResultPartition` temporarily, it would bring other troubles after I have a
try. The mainly involved ones are `Environment` and `RecordWriter`.
- `RecordWriter` -> `ResultPartition` -> `NetworkResultPartition`. There are
many other implementations for `ResultPartitionWriter` used for tests. In
`RecordWriterTest` we could not construct the proper `RecordWriter` based on
`ResultPartition` which contains specific `NetworkResultPartition`.
- `Environment` should keep `ResultPartit
[jira] [Assigned] (FLINK-11970) TableEnvironment#registerFunction should overwrite if the same name function existed.
[ https://issues.apache.org/jira/browse/FLINK-11970?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang reassigned FLINK-11970: Assignee: vinoyang > TableEnvironment#registerFunction should overwrite if the same name function > existed. > -- > > Key: FLINK-11970 > URL: https://issues.apache.org/jira/browse/FLINK-11970 > Project: Flink > Issue Type: Improvement >Reporter: Jeff Zhang >Assignee: vinoyang >Priority: Major > > Currently, it would throw exception if I try to register user function > multiple times. Registering udf multiple times is very common usage in > notebook scenario. And I don't think it would cause issues for users. > e.g. If user happened to register the same udf multiple times (he intend to > register 2 different udf actually), then he would get exception at runtime > where he use the udf that is missing registration. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Description:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!screenshot-1.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local messae
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
was:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!image-2019-03-20-14-02-29-636.png!
!image-2019-03-20-14-04-17-933.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local messae
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
> Attachments: screenshot-1.png
>
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !screenshot-1.png!
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local messae
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Closed] (FLINK-11949) Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink planner
[ https://issues.apache.org/jira/browse/FLINK-11949?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young closed FLINK-11949. -- Resolution: Implemented Fix Version/s: 1.9.0 fixed in 4bd2db2abf73f233632a0f256ac00c30dba0c6ec > Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink > planner > > > Key: FLINK-11949 > URL: https://issues.apache.org/jira/browse/FLINK-11949 > Project: Flink > Issue Type: New Feature > Components: SQL / Planner >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 0.5h > Remaining Estimate: 0h > > Introduce DeclarativeAggregateFunction: Use java Expressions to write a > AggregateFunction, just like Table Api. Then the Table generates the > corresponding CodeGenerator code according to the user's Expression logic. > This avoids the Java object overhead in AggregateFunction before. > Introduce AggsHandlerCodeGenerator: According to multiple AggregateFunctions, > generate a complete aggregation processing Class. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Assigned] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Hequn Cheng reassigned FLINK-11971:
---
Assignee: Hequn Cheng
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
> Attachments: screenshot-1.png
>
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !image-2019-03-20-14-02-29-636.png!
> !image-2019-03-20-14-04-17-933.png!
>
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local messae
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Summary: Fix `Command: start_kubernetes_if_not_ruunning failed` error
(was: The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar`
JAR during the end-to-end test.)
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Priority: Major
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !image-2019-03-20-14-02-29-636.png!
> !image-2019-03-20-14-04-17-933.png!
>
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local messae
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Attachment: screenshot-1.png
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
> Attachments: screenshot-1.png
>
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !image-2019-03-20-14-02-29-636.png!
> !image-2019-03-20-14-04-17-933.png!
>
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local messae
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11971) The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Summary: The classpath is missing the
`flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
(was: Fix `Command: start_kubernetes_if_not_ruunning failed` error)
> The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR
> during the end-to-end test.
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Priority: Major
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !image-2019-03-20-14-02-29-636.png!
> !image-2019-03-20-14-04-17-933.png!
>
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local messae
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11972) The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
[
https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11972:
Summary: The classpath is missing the
`flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
(was: Fix `Command: start_kubernetes_if_not_ruunning failed` error)
> The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR
> during the end-to-end test.
>
>
> Key: FLINK-11972
> URL: https://issues.apache.org/jira/browse/FLINK-11972
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
>
> Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
> `hadoop-shaded` JAR integrated into the dist. It will cause an error when
> the end-to-end test cannot be found with `Hadoop` Related classes, such as:
> `java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we
> need to improve the end-to-end test script, or explicitly stated in the
> README, i.e. end-to-end test need to add `flink-shaded-hadoop2-uber-.jar`
> to the classpath. So, we will get the exception something like:
> {code:java}
> [INFO] 3 instance(s) of taskexecutor are already running on
> jinchengsunjcs-iMac.local.
> Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
> java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
> at java.lang.Class.getDeclaredFields0(Native Method)
> at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
> at java.lang.Class.getDeclaredFields(Class.java:1916)
> at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
> at
> org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
> at
> org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
> at
> org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
> at
> org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
> at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
> at
> org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
> at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
> at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
> at
> org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
> at
> org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
> at
> org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
> at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
> Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
> at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
> ... 22 more
> Job () is running.{code}
> So, I think we can import the test script or import the README.
> What do you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11972:
Description:
Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
`hadoop-shaded` JAR integrated into the dist. It will cause an error when the
end-to-end test cannot be found with `Hadoop` Related classes, such as:
`java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we need
to improve the end-to-end test script, or explicitly stated in the README, i.e.
end-to-end test need to add `flink-shaded-hadoop2-uber-.jar` to the
classpath. So, we will get the exception something like:
{code:java}
[INFO] 3 instance(s) of taskexecutor are already running on
jinchengsunjcs-iMac.local.
Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
at java.lang.Class.getDeclaredFields(Class.java:1916)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
at
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
at
org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
at
org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
at
org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
at
org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at
org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at
org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 22 more
Job () is running.{code}
So, I think we can import the test script or import the README.
What do you think?
was:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!image-2019-03-20-14-02-29-636.png!
!image-2019-03-20-14-04-17-933.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local messae
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11972
> URL: https://issues.apache.org/jira/browse/FLINK-11972
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
> Attachments: image-2019-03-20-14-04-17-933.png
>
>
> Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
> `hadoop-shaded` JAR integrated into the dist. It will cause an error when
> the end-to-end test cannot be found with `Hadoop` Related classes, such as:
> `java.lang.NoClassDefFoundError: Lorg/apache/had
[jira] [Assigned] (FLINK-11972) The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
[
https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Hequn Cheng reassigned FLINK-11972:
---
Assignee: (was: Hequn Cheng)
> The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR
> during the end-to-end test.
>
>
> Key: FLINK-11972
> URL: https://issues.apache.org/jira/browse/FLINK-11972
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Priority: Major
>
> Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
> `hadoop-shaded` JAR integrated into the dist. It will cause an error when
> the end-to-end test cannot be found with `Hadoop` Related classes, such as:
> `java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we
> need to improve the end-to-end test script, or explicitly stated in the
> README, i.e. end-to-end test need to add `flink-shaded-hadoop2-uber-.jar`
> to the classpath. So, we will get the exception something like:
> {code:java}
> [INFO] 3 instance(s) of taskexecutor are already running on
> jinchengsunjcs-iMac.local.
> Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
> java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
> at java.lang.Class.getDeclaredFields0(Native Method)
> at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
> at java.lang.Class.getDeclaredFields(Class.java:1916)
> at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
> at
> org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
> at
> org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
> at
> org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
> at
> org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
> at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
> at
> org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
> at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
> at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
> at
> org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
> at
> org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
> at
> org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
> at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
> Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
> at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
> ... 22 more
> Job () is running.{code}
> So, I think we can import the test script or import the README.
> What do you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11972) The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
[
https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11972:
Attachment: (was: image-2019-03-20-14-04-17-933.png)
> The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR
> during the end-to-end test.
>
>
> Key: FLINK-11972
> URL: https://issues.apache.org/jira/browse/FLINK-11972
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
>
> Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
> `hadoop-shaded` JAR integrated into the dist. It will cause an error when
> the end-to-end test cannot be found with `Hadoop` Related classes, such as:
> `java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we
> need to improve the end-to-end test script, or explicitly stated in the
> README, i.e. end-to-end test need to add `flink-shaded-hadoop2-uber-.jar`
> to the classpath. So, we will get the exception something like:
> {code:java}
> [INFO] 3 instance(s) of taskexecutor are already running on
> jinchengsunjcs-iMac.local.
> Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
> java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
> at java.lang.Class.getDeclaredFields0(Native Method)
> at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
> at java.lang.Class.getDeclaredFields(Class.java:1916)
> at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
> at
> org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
> at
> org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
> at
> org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
> at
> org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
> at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
> at
> org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
> at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
> at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
> at
> org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
> at
> org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
> at
> org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
> at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
> Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
> at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
> ... 22 more
> Job () is running.{code}
> So, I think we can import the test script or import the README.
> What do you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Description:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!image-2019-03-20-14-02-29-636.png!
!image-2019-03-20-14-04-17-933.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local messae
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
was:
Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
`hadoop-shaded` JAR integrated into the dist. It will cause an error when the
end-to-end test cannot be found with `Hadoop` Related classes, such as:
`java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we need
to improve the end-to-end test script, or explicitly stated in the README, i.e.
end-to-end test need to add `flink-shaded-hadoop2-uber-.jar` to the
classpath. So, we will get the exception something like:
{code:java}
[INFO] 3 instance(s) of taskexecutor are already running on
jinchengsunjcs-iMac.local.
Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
at java.lang.Class.getDeclaredFields(Class.java:1916)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
at
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
at
org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
at
org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
at
org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
at
org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at
org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at
org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 22 more
Job () is running.{code}
So, I think we can import the test script or import the README.
What do you think?
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Priority: Major
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
[jira] [Updated] (FLINK-11971) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11971:
Summary: Fix `Command: start_kubernetes_if_not_ruunning failed` error
(was: The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar`
JAR during the end-to-end test.)
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11971
> URL: https://issues.apache.org/jira/browse/FLINK-11971
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Priority: Major
>
> Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
> `hadoop-shaded` JAR integrated into the dist. It will cause an error when
> the end-to-end test cannot be found with `Hadoop` Related classes, such as:
> `java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we
> need to improve the end-to-end test script, or explicitly stated in the
> README, i.e. end-to-end test need to add `flink-shaded-hadoop2-uber-.jar`
> to the classpath. So, we will get the exception something like:
> {code:java}
> [INFO] 3 instance(s) of taskexecutor are already running on
> jinchengsunjcs-iMac.local.
> Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
> java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
> at java.lang.Class.getDeclaredFields0(Native Method)
> at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
> at java.lang.Class.getDeclaredFields(Class.java:1916)
> at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
> at
> org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
> at
> org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
> at
> org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
> at
> org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
> at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
> at
> org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
> at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
> at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
> at
> org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
> at
> org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
> at
> org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
> at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
> Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
> at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
> at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
> ... 22 more
> Job () is running.{code}
> So, I think we can import the test script or import the README.
> What do you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] KurtYoung merged pull request #8001: [FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink planner
KurtYoung merged pull request #8001: [FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink planner URL: https://github.com/apache/flink/pull/8001 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[ https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sunjincheng updated FLINK-11972: Attachment: (was: image-2019-03-20-14-01-05-647.png) > Fix `Command: start_kubernetes_if_not_ruunning failed` error > > > Key: FLINK-11972 > URL: https://issues.apache.org/jira/browse/FLINK-11972 > Project: Flink > Issue Type: Bug > Components: Tests >Affects Versions: 1.8.0, 1.9.0 >Reporter: sunjincheng >Assignee: Hequn Cheng >Priority: Major > > When I did the end-to-end test under Mac OS, I found the following two > problems: > 1. The verification returned for different `minikube status` is not enough > for the robustness. The strings returned by different versions of different > platforms are different. the following misjudgment is caused: > When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, > the `minikube` has actually started successfully. The core reason is that > there is a bug in the `test_kubernetes_embedded_job.sh` script. The error > message as follows: > !image-2019-03-20-14-02-29-636.png! > > So, I think we should improve the check logic of `minikube status`, What do > you think? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Assigned] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[ https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Hequn Cheng reassigned FLINK-11972: --- Assignee: Hequn Cheng > Fix `Command: start_kubernetes_if_not_ruunning failed` error > > > Key: FLINK-11972 > URL: https://issues.apache.org/jira/browse/FLINK-11972 > Project: Flink > Issue Type: Bug > Components: Tests >Affects Versions: 1.8.0, 1.9.0 >Reporter: sunjincheng >Assignee: Hequn Cheng >Priority: Major > > When I did the end-to-end test under Mac OS, I found the following two > problems: > 1. The verification returned for different `minikube status` is not enough > for the robustness. The strings returned by different versions of different > platforms are different. the following misjudgment is caused: > When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, > the `minikube` has actually started successfully. The core reason is that > there is a bug in the `test_kubernetes_embedded_job.sh` script. The error > message as follows: > !image-2019-03-20-14-02-29-636.png! > > So, I think we should improve the check logic of `minikube status`, What do > you think? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[
https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sunjincheng updated FLINK-11972:
Description:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!image-2019-03-20-14-02-29-636.png!
!image-2019-03-20-14-04-17-933.png!
{code:java}
Current check logic: echo ${status} | grep -q "minikube: Running cluster:
Running kubectl: Correctly Configured"
My local messae
jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
So, I think we should improve the check logic of `minikube status`, What do you
think?
was:
When I did the end-to-end test under Mac OS, I found the following two problems:
1. The verification returned for different `minikube status` is not enough for
the robustness. The strings returned by different versions of different
platforms are different. the following misjudgment is caused:
When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the
`minikube` has actually started successfully. The core reason is that there is
a bug in the `test_kubernetes_embedded_job.sh` script. The error message as
follows:
!image-2019-03-20-14-02-29-636.png!
!image-2019-03-20-14-04-17-933.png!
So, I think we should improve the check logic of `minikube status`, What do
you think?
> Fix `Command: start_kubernetes_if_not_ruunning failed` error
>
>
> Key: FLINK-11972
> URL: https://issues.apache.org/jira/browse/FLINK-11972
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.8.0, 1.9.0
>Reporter: sunjincheng
>Assignee: Hequn Cheng
>Priority: Major
> Attachments: image-2019-03-20-14-04-17-933.png
>
>
> When I did the end-to-end test under Mac OS, I found the following two
> problems:
> 1. The verification returned for different `minikube status` is not enough
> for the robustness. The strings returned by different versions of different
> platforms are different. the following misjudgment is caused:
> When the `Command: start_kubernetes_if_not_ruunning failed` error occurs,
> the `minikube` has actually started successfully. The core reason is that
> there is a bug in the `test_kubernetes_embedded_job.sh` script. The error
> message as follows:
> !image-2019-03-20-14-02-29-636.png!
> !image-2019-03-20-14-04-17-933.png!
>
> {code:java}
> Current check logic: echo ${status} | grep -q "minikube: Running cluster:
> Running kubectl: Correctly Configured"
> My local messae
> jinchengsunjcs-iMac:flink-1.8.0 jincheng$ minikube status
> host: Running
> kubelet: Running
> apiserver: Running
> kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.101{code}
> So, I think we should improve the check logic of `minikube status`, What do
> you think?
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[ https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sunjincheng updated FLINK-11972: Description: When I did the end-to-end test under Mac OS, I found the following two problems: 1. The verification returned for different `minikube status` is not enough for the robustness. The strings returned by different versions of different platforms are different. the following misjudgment is caused: When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the `minikube` has actually started successfully. The core reason is that there is a bug in the `test_kubernetes_embedded_job.sh` script. The error message as follows: !image-2019-03-20-14-02-29-636.png! !image-2019-03-20-14-04-17-933.png! So, I think we should improve the check logic of `minikube status`, What do you think? was: When I did the end-to-end test under Mac OS, I found the following two problems: 1. The verification returned for different `minikube status` is not enough for the robustness. The strings returned by different versions of different platforms are different. the following misjudgment is caused: When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the `minikube` has actually started successfully. The core reason is that there is a bug in the `test_kubernetes_embedded_job.sh` script. The error message as follows: !image-2019-03-20-14-02-29-636.png! So, I think we should improve the check logic of `minikube status`, What do you think? > Fix `Command: start_kubernetes_if_not_ruunning failed` error > > > Key: FLINK-11972 > URL: https://issues.apache.org/jira/browse/FLINK-11972 > Project: Flink > Issue Type: Bug > Components: Tests >Affects Versions: 1.8.0, 1.9.0 >Reporter: sunjincheng >Assignee: Hequn Cheng >Priority: Major > Attachments: image-2019-03-20-14-04-17-933.png > > > When I did the end-to-end test under Mac OS, I found the following two > problems: > 1. The verification returned for different `minikube status` is not enough > for the robustness. The strings returned by different versions of different > platforms are different. the following misjudgment is caused: > When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, > the `minikube` has actually started successfully. The core reason is that > there is a bug in the `test_kubernetes_embedded_job.sh` script. The error > message as follows: > !image-2019-03-20-14-02-29-636.png! > !image-2019-03-20-14-04-17-933.png! > So, I think we should improve the check logic of `minikube status`, What do > you think? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[ https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sunjincheng updated FLINK-11972: Attachment: image-2019-03-20-14-04-17-933.png > Fix `Command: start_kubernetes_if_not_ruunning failed` error > > > Key: FLINK-11972 > URL: https://issues.apache.org/jira/browse/FLINK-11972 > Project: Flink > Issue Type: Bug > Components: Tests >Affects Versions: 1.8.0, 1.9.0 >Reporter: sunjincheng >Assignee: Hequn Cheng >Priority: Major > Attachments: image-2019-03-20-14-04-17-933.png > > > When I did the end-to-end test under Mac OS, I found the following two > problems: > 1. The verification returned for different `minikube status` is not enough > for the robustness. The strings returned by different versions of different > platforms are different. the following misjudgment is caused: > When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, > the `minikube` has actually started successfully. The core reason is that > there is a bug in the `test_kubernetes_embedded_job.sh` script. The error > message as follows: > !image-2019-03-20-14-02-29-636.png! > !image-2019-03-20-14-04-17-933.png! > So, I think we should improve the check logic of `minikube status`, What do > you think? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
[ https://issues.apache.org/jira/browse/FLINK-11972?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sunjincheng updated FLINK-11972: Attachment: (was: image-2019-03-20-14-02-29-636.png) > Fix `Command: start_kubernetes_if_not_ruunning failed` error > > > Key: FLINK-11972 > URL: https://issues.apache.org/jira/browse/FLINK-11972 > Project: Flink > Issue Type: Bug > Components: Tests >Affects Versions: 1.8.0, 1.9.0 >Reporter: sunjincheng >Assignee: Hequn Cheng >Priority: Major > > When I did the end-to-end test under Mac OS, I found the following two > problems: > 1. The verification returned for different `minikube status` is not enough > for the robustness. The strings returned by different versions of different > platforms are different. the following misjudgment is caused: > When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, > the `minikube` has actually started successfully. The core reason is that > there is a bug in the `test_kubernetes_embedded_job.sh` script. The error > message as follows: > !image-2019-03-20-14-02-29-636.png! > > So, I think we should improve the check logic of `minikube status`, What do > you think? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-11971) The classpath is missing the `flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
sunjincheng created FLINK-11971:
---
Summary: The classpath is missing the
`flink-shaded-hadoop2-uber-2.8.3-1.8.0.jar` JAR during the end-to-end test.
Key: FLINK-11971
URL: https://issues.apache.org/jira/browse/FLINK-11971
Project: Flink
Issue Type: Bug
Components: Tests
Affects Versions: 1.8.0, 1.9.0
Reporter: sunjincheng
Since the difference between 1.8.0 and 1.7.x is that 1.8.x does not put the
`hadoop-shaded` JAR integrated into the dist. It will cause an error when the
end-to-end test cannot be found with `Hadoop` Related classes, such as:
`java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem`. So we need
to improve the end-to-end test script, or explicitly stated in the README, i.e.
end-to-end test need to add `flink-shaded-hadoop2-uber-.jar` to the
classpath. So, we will get the exception something like:
{code:java}
[INFO] 3 instance(s) of taskexecutor are already running on
jinchengsunjcs-iMac.local.
Starting taskexecutor daemon on host jinchengsunjcs-iMac.local.
java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
at java.lang.Class.getDeclaredFields(Class.java:1916)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:72)
at
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:1558)
at
org.apache.flink.streaming.api.datastream.DataStream.clean(DataStream.java:185)
at
org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1227)
at
org.apache.flink.streaming.tests.BucketingSinkTestProgram.main(BucketingSinkTestProgram.java:80)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
at
org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:423)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at
org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at
org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FileSystem
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 22 more
Job () is running.{code}
So, I think we can import the test script or import the README.
What do you think?
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (FLINK-11972) Fix `Command: start_kubernetes_if_not_ruunning failed` error
sunjincheng created FLINK-11972: --- Summary: Fix `Command: start_kubernetes_if_not_ruunning failed` error Key: FLINK-11972 URL: https://issues.apache.org/jira/browse/FLINK-11972 Project: Flink Issue Type: Bug Components: Tests Affects Versions: 1.8.0, 1.9.0 Reporter: sunjincheng Attachments: image-2019-03-20-14-01-05-647.png, image-2019-03-20-14-02-29-636.png When I did the end-to-end test under Mac OS, I found the following two problems: 1. The verification returned for different `minikube status` is not enough for the robustness. The strings returned by different versions of different platforms are different. the following misjudgment is caused: When the `Command: start_kubernetes_if_not_ruunning failed` error occurs, the `minikube` has actually started successfully. The core reason is that there is a bug in the `test_kubernetes_embedded_job.sh` script. The error message as follows: !image-2019-03-20-14-02-29-636.png! So, I think we should improve the check logic of `minikube status`, What do you think? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-11970) TableEnvironment#registerFunction should overwrite if the same name function existed.
Jeff Zhang created FLINK-11970: -- Summary: TableEnvironment#registerFunction should overwrite if the same name function existed. Key: FLINK-11970 URL: https://issues.apache.org/jira/browse/FLINK-11970 Project: Flink Issue Type: Improvement Reporter: Jeff Zhang Currently, it would throw exception if I try to register user function multiple times. Registering udf multiple times is very common usage in notebook scenario. And I don't think it would cause issues for users. e.g. If user happened to register the same udf multiple times (he intend to register 2 different udf actually), then he would get exception at runtime where he use the udf that is missing registration. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-11912) Expose per partition Kafka lag metric in Flink Kafka connector
[
https://issues.apache.org/jira/browse/FLINK-11912?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16796788#comment-16796788
]
Jiangjie Qin commented on FLINK-11912:
--
[~suez1224] Thanks for bringing this up. The current proposal (and the WIP
patch) seems still having metric leak. Even if the metric objects are removed
from the {{manualRegisteredMetricSet}}, the metric will still be there until
{{MetricRegistry.unregister()}} is invoked. Unfortunately, the {{MetricGroup}}
interface does not expose a method to explicitly remove a single metric. At
this point, in order to unregister the metrics, the metric group has to be
closed.
So it seems we need to add a {{remove(String MetricName)}} method to the
{{MetricGroup}} interface to ensure the metrics are properly unregistered.
> Expose per partition Kafka lag metric in Flink Kafka connector
> --
>
> Key: FLINK-11912
> URL: https://issues.apache.org/jira/browse/FLINK-11912
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Kafka
>Affects Versions: 1.6.4, 1.7.2
>Reporter: Shuyi Chen
>Assignee: Shuyi Chen
>Priority: Major
>
> In production, it's important that we expose the Kafka lag by partition
> metric in order for users to diagnose which Kafka partition is lagging.
> However, although the Kafka lag by partition metrics are available in
> KafkaConsumer after 0.10.2, Flink was not able to properly register it
> because the metrics are only available after the consumer start polling data
> from partitions. I would suggest the following fix:
> 1) In KafkaConsumerThread.run(), allocate a manualRegisteredMetricSet.
> 2) in the fetch loop, as KafkaConsumer discovers new partitions, manually add
> MetricName for those partitions that we want to register into
> manualRegisteredMetricSet.
> 3) in the fetch loop, check if manualRegisteredMetricSet is empty. If not,
> try to search for the metrics available in KafkaConsumer, and if found,
> register it and remove the entry from manualRegisteredMetricSet.
> The overhead of the above approach is bounded and only incur when discovering
> new partitions, and registration is done once the KafkaConsumer have the
> metrics exposed.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] TisonKun commented on issue #7971: [FLINK-11897][tests] should wait all submitTask methods executed,befo…
TisonKun commented on issue #7971: [FLINK-11897][tests] should wait all submitTask methods executed,befo… URL: https://github.com/apache/flink/pull/7971#issuecomment-474678271 @chummyhe89 I think the community is busy with releasing 1.8 and ASF Project consists of all volunteers. Sorry for the long delay but be aware of that there is no guarantee for reviewing all prs. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267179415
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ResultPartition.java
##
@@ -19,432 +19,105 @@
package org.apache.flink.runtime.io.network.partition;
import org.apache.flink.api.common.JobID;
-import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
-import org.apache.flink.runtime.io.disk.iomanager.IOManager;
import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
-import org.apache.flink.runtime.io.network.buffer.Buffer;
import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
-import org.apache.flink.runtime.io.network.buffer.BufferPool;
-import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
import org.apache.flink.runtime.io.network.buffer.BufferProvider;
-import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
-import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
-import org.apache.flink.runtime.jobgraph.DistributionPattern;
import org.apache.flink.runtime.taskmanager.TaskActions;
-import org.apache.flink.runtime.taskmanager.TaskManager;
-
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
import java.io.IOException;
-import java.util.concurrent.atomic.AtomicBoolean;
-import java.util.concurrent.atomic.AtomicInteger;
-import static org.apache.flink.util.Preconditions.checkArgument;
-import static org.apache.flink.util.Preconditions.checkElementIndex;
import static org.apache.flink.util.Preconditions.checkNotNull;
-import static org.apache.flink.util.Preconditions.checkState;
/**
- * A result partition for data produced by a single task.
- *
- * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
- * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
- * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
- * number of consuming tasks and the data {@link DistributionPattern}.
- *
- * Tasks, which consume a result partition have to request one of its
subpartitions. The request
- * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
- *
- * Life-cycle
- *
- * The life-cycle of each result partition has three (possibly overlapping)
phases:
- *
- * Produce:
- * Consume:
- * Release:
- *
- *
- * Lazy deployment and updates of consuming tasks
- *
- * Before a consuming task can request the result, it has to be deployed.
The time of deployment
- * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
- * results, receivers are deployed as soon as the first buffer is added to the
result partition.
- * With blocking results on the other hand, receivers are deployed after the
partition is finished.
- *
- * Buffer management
- *
- * State management
+ * A wrapper of result partition writer for handling notification of the
consumable
+ * partition which is added a {@link BufferConsumer} or finished.
*/
-public class ResultPartition implements ResultPartitionWriter, BufferPoolOwner
{
-
- private static final Logger LOG =
LoggerFactory.getLogger(ResultPartition.class);
-
- private final String owningTaskName;
+public class ResultPartition implements ResultPartitionWriter {
Review comment:
Yes, I agree with your point.
But currently it still implements `ResultPartitionWriter`, so we could keep
it as current way? In future this class might not need implement the interface,
then we could further refactor it as you said. Or you think we should rename
this class and change the package now?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267178927
##
File path:
flink-streaming-java/src/test/java/org/apache/flink/streaming/runtime/io/benchmark/StreamNetworkBenchmarkEnvironment.java
##
@@ -236,21 +237,23 @@ protected ResultPartitionWriter createResultPartition(
NetworkEnvironment environment,
int channels) throws Exception {
- ResultPartition resultPartition = new ResultPartition(
+ NetworkResultPartition networkResultPartition = new
NetworkResultPartition(
"sender task",
- new NoOpTaskActions(),
- jobId,
partitionId,
ResultPartitionType.PIPELINED_BOUNDED,
channels,
1,
environment.getResultPartitionManager(),
+ ioManager);
+ environment.setupPartition(networkResultPartition);
+
+ ResultPartition resultPartition = new ResultPartition(
Review comment:
From functional aspect, I agree with your point. But it seems reasonable to
reflect the real path for performance sensitive benchmark. If there are extra
overheads executed in `ResultPartition`, it could be detected in the benchmark.
What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] Matrix42 commented on issue #8011: [FLINK-11958][on-yarn] fix flink on windows yarn deploy failed
Matrix42 commented on issue #8011: [FLINK-11958][on-yarn] fix flink on windows yarn deploy failed URL: https://github.com/apache/flink/pull/8011#issuecomment-474674276 before: 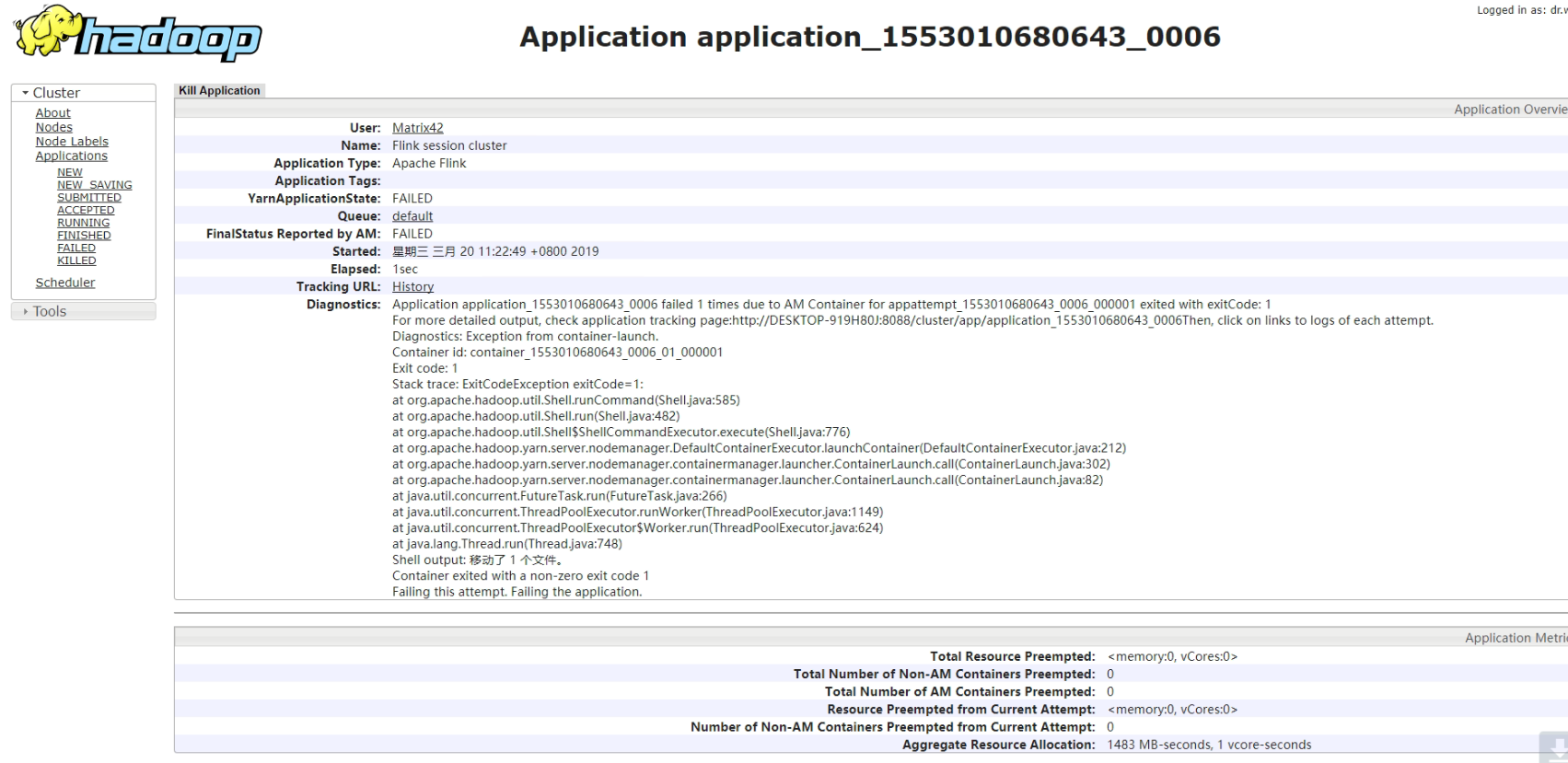 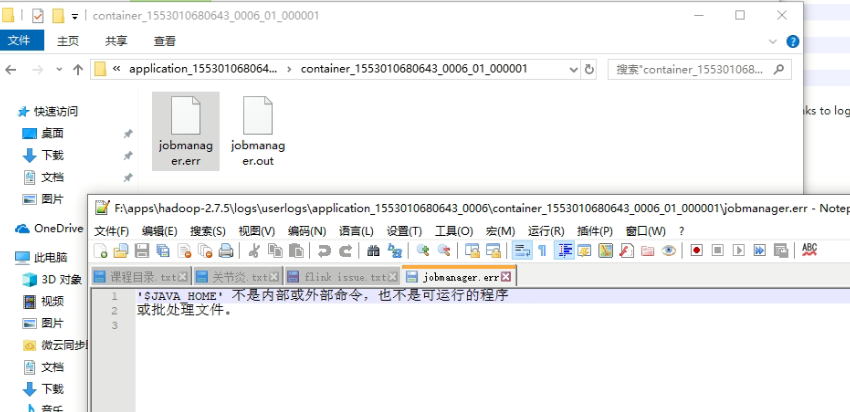 after:   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267177872
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/partition/ResultPartitionTest.java
##
@@ -148,15 +148,17 @@ public void testAddOnReleasedBlockingPartition() throws
Exception {
/**
* Tests {@link ResultPartition#addBufferConsumer} on a partition which
has already been released.
*
-* @param pipelined the result partition type to set up
+* @param partitionType the result partition type to set up
*/
- protected void testAddOnReleasedPartition(final ResultPartitionType
pipelined)
+ protected void testAddOnReleasedPartition(final ResultPartitionType
partitionType)
throws Exception {
BufferConsumer bufferConsumer =
createFilledBufferConsumer(BufferBuilderTestUtils.BUFFER_SIZE);
ResultPartitionConsumableNotifier notifier =
mock(ResultPartitionConsumableNotifier.class);
try {
- ResultPartition partition = createPartition(notifier,
pipelined, true);
- partition.release();
+ NetworkResultPartition networkPartition =
createNetworkResultPartition(partitionType);
+ ResultPartition partition = new ResultPartition(
Review comment:
I think we might still need the `ResultPartition`.
This test wants to verify the notification logic after releasing partition.
The `partition.addBufferConsumer` would return false after released, then it
would never trigger notification which is verified in finally path. And the
notification logic is removed from `networkPartition`, so it can not be
verified directly.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267176818
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/partition/ResultPartitionTest.java
##
@@ -67,7 +67,7 @@ public void testSendScheduleOrUpdateConsumersMessage()
throws Exception {
partition.addBufferConsumer(createFilledBufferConsumer(BufferBuilderTestUtils.BUFFER_SIZE),
0);
verify(notifier, times(1))
.notifyPartitionConsumable(
- eq(partition.getJobId()),
+ any(JobID.class),
Review comment:
Yes, it can be package private method.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267176272
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/partition/ResultPartitionTest.java
##
@@ -148,15 +148,17 @@ public void testAddOnReleasedBlockingPartition() throws
Exception {
/**
* Tests {@link ResultPartition#addBufferConsumer} on a partition which
has already been released.
*
-* @param pipelined the result partition type to set up
+* @param partitionType the result partition type to set up
*/
- protected void testAddOnReleasedPartition(final ResultPartitionType
pipelined)
+ protected void testAddOnReleasedPartition(final ResultPartitionType
partitionType)
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267174747
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ResultPartition.java
##
@@ -19,432 +19,105 @@
package org.apache.flink.runtime.io.network.partition;
import org.apache.flink.api.common.JobID;
-import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
-import org.apache.flink.runtime.io.disk.iomanager.IOManager;
import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
-import org.apache.flink.runtime.io.network.buffer.Buffer;
import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
-import org.apache.flink.runtime.io.network.buffer.BufferPool;
-import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
import org.apache.flink.runtime.io.network.buffer.BufferProvider;
-import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
-import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
-import org.apache.flink.runtime.jobgraph.DistributionPattern;
import org.apache.flink.runtime.taskmanager.TaskActions;
-import org.apache.flink.runtime.taskmanager.TaskManager;
-
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
import java.io.IOException;
-import java.util.concurrent.atomic.AtomicBoolean;
-import java.util.concurrent.atomic.AtomicInteger;
-import static org.apache.flink.util.Preconditions.checkArgument;
-import static org.apache.flink.util.Preconditions.checkElementIndex;
import static org.apache.flink.util.Preconditions.checkNotNull;
-import static org.apache.flink.util.Preconditions.checkState;
/**
- * A result partition for data produced by a single task.
- *
- * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
- * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
- * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
- * number of consuming tasks and the data {@link DistributionPattern}.
- *
- * Tasks, which consume a result partition have to request one of its
subpartitions. The request
- * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
- *
- * Life-cycle
- *
- * The life-cycle of each result partition has three (possibly overlapping)
phases:
- *
- * Produce:
- * Consume:
- * Release:
- *
- *
- * Lazy deployment and updates of consuming tasks
- *
- * Before a consuming task can request the result, it has to be deployed.
The time of deployment
- * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
- * results, receivers are deployed as soon as the first buffer is added to the
result partition.
- * With blocking results on the other hand, receivers are deployed after the
partition is finished.
- *
- * Buffer management
- *
- * State management
+ * A wrapper of result partition writer for handling notification of the
consumable
+ * partition which is added a {@link BufferConsumer} or finished.
*/
-public class ResultPartition implements ResultPartitionWriter, BufferPoolOwner
{
-
- private static final Logger LOG =
LoggerFactory.getLogger(ResultPartition.class);
-
- private final String owningTaskName;
+public class ResultPartition implements ResultPartitionWriter {
private final TaskActions taskActions;
private final JobID jobId;
- private final ResultPartitionID partitionId;
-
- /** Type of this partition. Defines the concrete subpartition
implementation to use. */
private final ResultPartitionType partitionType;
- /** The subpartitions of this partition. At least one. */
- private final ResultSubpartition[] subpartitions;
-
- private final ResultPartitionManager partitionManager;
+ private final ResultPartitionWriter partitionWriter;
private final ResultPartitionConsumableNotifier
partitionConsumableNotifier;
- public final int numTargetKeyGroups;
-
private final boolean sendScheduleOrUpdateConsumersMessage;
- // - Runtime state
-
- private final AtomicBoolean isReleased = new AtomicBoolean();
-
- /**
-* The total number of references to subpartitions of this result. The
result partition can be
-* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
-* result partition has been released.
-*/
- private final AtomicInteger pendingReferences = new AtomicInteger();
-
- private BufferPool bufferPool;
-
private boolean hasNotifiedPipelinedConsumers;
- private boolean isFinished;
-
-
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267174747
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ResultPartition.java
##
@@ -19,432 +19,105 @@
package org.apache.flink.runtime.io.network.partition;
import org.apache.flink.api.common.JobID;
-import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
-import org.apache.flink.runtime.io.disk.iomanager.IOManager;
import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
-import org.apache.flink.runtime.io.network.buffer.Buffer;
import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
-import org.apache.flink.runtime.io.network.buffer.BufferPool;
-import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
import org.apache.flink.runtime.io.network.buffer.BufferProvider;
-import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
-import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
-import org.apache.flink.runtime.jobgraph.DistributionPattern;
import org.apache.flink.runtime.taskmanager.TaskActions;
-import org.apache.flink.runtime.taskmanager.TaskManager;
-
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
import java.io.IOException;
-import java.util.concurrent.atomic.AtomicBoolean;
-import java.util.concurrent.atomic.AtomicInteger;
-import static org.apache.flink.util.Preconditions.checkArgument;
-import static org.apache.flink.util.Preconditions.checkElementIndex;
import static org.apache.flink.util.Preconditions.checkNotNull;
-import static org.apache.flink.util.Preconditions.checkState;
/**
- * A result partition for data produced by a single task.
- *
- * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
- * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
- * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
- * number of consuming tasks and the data {@link DistributionPattern}.
- *
- * Tasks, which consume a result partition have to request one of its
subpartitions. The request
- * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
- *
- * Life-cycle
- *
- * The life-cycle of each result partition has three (possibly overlapping)
phases:
- *
- * Produce:
- * Consume:
- * Release:
- *
- *
- * Lazy deployment and updates of consuming tasks
- *
- * Before a consuming task can request the result, it has to be deployed.
The time of deployment
- * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
- * results, receivers are deployed as soon as the first buffer is added to the
result partition.
- * With blocking results on the other hand, receivers are deployed after the
partition is finished.
- *
- * Buffer management
- *
- * State management
+ * A wrapper of result partition writer for handling notification of the
consumable
+ * partition which is added a {@link BufferConsumer} or finished.
*/
-public class ResultPartition implements ResultPartitionWriter, BufferPoolOwner
{
-
- private static final Logger LOG =
LoggerFactory.getLogger(ResultPartition.class);
-
- private final String owningTaskName;
+public class ResultPartition implements ResultPartitionWriter {
private final TaskActions taskActions;
private final JobID jobId;
- private final ResultPartitionID partitionId;
-
- /** Type of this partition. Defines the concrete subpartition
implementation to use. */
private final ResultPartitionType partitionType;
- /** The subpartitions of this partition. At least one. */
- private final ResultSubpartition[] subpartitions;
-
- private final ResultPartitionManager partitionManager;
+ private final ResultPartitionWriter partitionWriter;
private final ResultPartitionConsumableNotifier
partitionConsumableNotifier;
- public final int numTargetKeyGroups;
-
private final boolean sendScheduleOrUpdateConsumersMessage;
- // - Runtime state
-
- private final AtomicBoolean isReleased = new AtomicBoolean();
-
- /**
-* The total number of references to subpartitions of this result. The
result partition can be
-* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
-* result partition has been released.
-*/
- private final AtomicInteger pendingReferences = new AtomicInteger();
-
- private BufferPool bufferPool;
-
private boolean hasNotifiedPipelinedConsumers;
- private boolean isFinished;
-
-
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267174001
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/NetworkResultPartition.java
##
@@ -0,0 +1,414 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.io.network.partition;
+
+import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
+import org.apache.flink.runtime.io.disk.iomanager.IOManager;
+import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
+import org.apache.flink.runtime.io.network.buffer.Buffer;
+import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
+import org.apache.flink.runtime.io.network.buffer.BufferPool;
+import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
+import org.apache.flink.runtime.io.network.buffer.BufferProvider;
+import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
+import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
+import org.apache.flink.runtime.jobgraph.DistributionPattern;
+import org.apache.flink.runtime.taskmanager.TaskManager;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkArgument;
+import static org.apache.flink.util.Preconditions.checkElementIndex;
+import static org.apache.flink.util.Preconditions.checkNotNull;
+import static org.apache.flink.util.Preconditions.checkState;
+
+/**
+ * A result partition for data produced by a single task.
+ *
+ * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
+ * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
+ * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
+ * number of consuming tasks and the data {@link DistributionPattern}.
+ *
+ * Tasks, which consume a result partition have to request one of its
subpartitions. The request
+ * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
+ *
+ * Life-cycle
+ *
+ * The life-cycle of each result partition has three (possibly overlapping)
phases:
+ *
+ * Produce:
+ * Consume:
+ * Release:
+ *
+ *
+ * Lazy deployment and updates of consuming tasks
+ *
+ * Before a consuming task can request the result, it has to be deployed.
The time of deployment
+ * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
+ * results, receivers are deployed as soon as the first buffer is added to the
result partition.
+ * With blocking results on the other hand, receivers are deployed after the
partition is finished.
+ *
+ * Buffer management
+ *
+ * State management
+ */
+public class NetworkResultPartition implements ResultPartitionWriter,
BufferPoolOwner {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(NetworkResultPartition.class);
+
+ private final String owningTaskName;
+
+ private final ResultPartitionID partitionId;
+
+ /** Type of this partition. Defines the concrete subpartition
implementation to use. */
+ private final ResultPartitionType partitionType;
+
+ /** The subpartitions of this partition. At least one. */
+ private final ResultSubpartition[] subpartitions;
+
+ private final ResultPartitionManager partitionManager;
+
+ public final int numTargetKeyGroups;
+
+ // - Runtime state
+
+ private final AtomicBoolean isReleased = new AtomicBoolean();
+
+ /**
+* The total number of references to subpartitions of this result. The
result partition can be
+* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
+* result partition has been released.
+*/
+
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267173820
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/NetworkResultPartition.java
##
@@ -0,0 +1,414 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.io.network.partition;
+
+import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
+import org.apache.flink.runtime.io.disk.iomanager.IOManager;
+import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
+import org.apache.flink.runtime.io.network.buffer.Buffer;
+import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
+import org.apache.flink.runtime.io.network.buffer.BufferPool;
+import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
+import org.apache.flink.runtime.io.network.buffer.BufferProvider;
+import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
+import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
+import org.apache.flink.runtime.jobgraph.DistributionPattern;
+import org.apache.flink.runtime.taskmanager.TaskManager;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkArgument;
+import static org.apache.flink.util.Preconditions.checkElementIndex;
+import static org.apache.flink.util.Preconditions.checkNotNull;
+import static org.apache.flink.util.Preconditions.checkState;
+
+/**
+ * A result partition for data produced by a single task.
+ *
+ * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
+ * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
+ * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
+ * number of consuming tasks and the data {@link DistributionPattern}.
+ *
+ * Tasks, which consume a result partition have to request one of its
subpartitions. The request
+ * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
+ *
+ * Life-cycle
+ *
+ * The life-cycle of each result partition has three (possibly overlapping)
phases:
+ *
+ * Produce:
+ * Consume:
+ * Release:
+ *
+ *
+ * Lazy deployment and updates of consuming tasks
+ *
+ * Before a consuming task can request the result, it has to be deployed.
The time of deployment
+ * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
+ * results, receivers are deployed as soon as the first buffer is added to the
result partition.
+ * With blocking results on the other hand, receivers are deployed after the
partition is finished.
+ *
+ * Buffer management
+ *
+ * State management
+ */
+public class NetworkResultPartition implements ResultPartitionWriter,
BufferPoolOwner {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(NetworkResultPartition.class);
+
+ private final String owningTaskName;
+
+ private final ResultPartitionID partitionId;
+
+ /** Type of this partition. Defines the concrete subpartition
implementation to use. */
+ private final ResultPartitionType partitionType;
+
+ /** The subpartitions of this partition. At least one. */
+ private final ResultSubpartition[] subpartitions;
+
+ private final ResultPartitionManager partitionManager;
+
+ public final int numTargetKeyGroups;
+
+ // - Runtime state
+
+ private final AtomicBoolean isReleased = new AtomicBoolean();
+
+ /**
+* The total number of references to subpartitions of this result. The
result partition can be
+* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
+* result partition has been released.
+*/
+
[GitHub] [flink] zhijiangW commented on a change in pull request #7549: [FLINK-11403][network] Remove ResultPartitionConsumableNotifier from ResultPartition
zhijiangW commented on a change in pull request #7549: [FLINK-11403][network]
Remove ResultPartitionConsumableNotifier from ResultPartition
URL: https://github.com/apache/flink/pull/7549#discussion_r267173879
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/NetworkResultPartition.java
##
@@ -0,0 +1,414 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.io.network.partition;
+
+import org.apache.flink.runtime.executiongraph.IntermediateResultPartition;
+import org.apache.flink.runtime.io.disk.iomanager.IOManager;
+import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
+import org.apache.flink.runtime.io.network.buffer.Buffer;
+import org.apache.flink.runtime.io.network.buffer.BufferConsumer;
+import org.apache.flink.runtime.io.network.buffer.BufferPool;
+import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
+import org.apache.flink.runtime.io.network.buffer.BufferProvider;
+import
org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel;
+import
org.apache.flink.runtime.io.network.partition.consumer.RemoteInputChannel;
+import org.apache.flink.runtime.jobgraph.DistributionPattern;
+import org.apache.flink.runtime.taskmanager.TaskManager;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkArgument;
+import static org.apache.flink.util.Preconditions.checkElementIndex;
+import static org.apache.flink.util.Preconditions.checkNotNull;
+import static org.apache.flink.util.Preconditions.checkState;
+
+/**
+ * A result partition for data produced by a single task.
+ *
+ * This class is the runtime part of a logical {@link
IntermediateResultPartition}. Essentially,
+ * a result partition is a collection of {@link Buffer} instances. The buffers
are organized in one
+ * or more {@link ResultSubpartition} instances, which further partition the
data depending on the
+ * number of consuming tasks and the data {@link DistributionPattern}.
+ *
+ * Tasks, which consume a result partition have to request one of its
subpartitions. The request
+ * happens either remotely (see {@link RemoteInputChannel}) or locally (see
{@link LocalInputChannel})
+ *
+ * Life-cycle
+ *
+ * The life-cycle of each result partition has three (possibly overlapping)
phases:
+ *
+ * Produce:
+ * Consume:
+ * Release:
+ *
+ *
+ * Lazy deployment and updates of consuming tasks
+ *
+ * Before a consuming task can request the result, it has to be deployed.
The time of deployment
+ * depends on the PIPELINED vs. BLOCKING characteristic of the result
partition. With pipelined
+ * results, receivers are deployed as soon as the first buffer is added to the
result partition.
+ * With blocking results on the other hand, receivers are deployed after the
partition is finished.
+ *
+ * Buffer management
+ *
+ * State management
+ */
+public class NetworkResultPartition implements ResultPartitionWriter,
BufferPoolOwner {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(NetworkResultPartition.class);
+
+ private final String owningTaskName;
+
+ private final ResultPartitionID partitionId;
+
+ /** Type of this partition. Defines the concrete subpartition
implementation to use. */
+ private final ResultPartitionType partitionType;
+
+ /** The subpartitions of this partition. At least one. */
+ private final ResultSubpartition[] subpartitions;
+
+ private final ResultPartitionManager partitionManager;
+
+ public final int numTargetKeyGroups;
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] Matrix42 commented on issue #8011: [FLINK-11958][on-yarn] fix flink on windows yarn deploy failed
Matrix42 commented on issue #8011: [FLINK-11958][on-yarn] fix flink on windows yarn deploy failed URL: https://github.com/apache/flink/pull/8011#issuecomment-474666240 > Apart from `AbstractYarnClusterDescriptor`, [`BootstrapTools`](https://github.com/apache/flink/blob/master/flink-runtime/src/main/java/org/apache/flink/runtime/clusterframework/BootstrapTools.java#L424) also has such kind of hard-coded java command to start task manager. Are you sure the Flink job could be launched well on Windows even without changes to `BootstrapTools`? > Waht's more, how to verify this patch seems a problem, would you please paste some pictures before and after your changes so that YARN could deploy Flink job well. I just find this bug on I start a cluster on windows yarn, I haven't submit a job yet, one PR can only solve on problem, I will reappear the problem of running a job and start a new PR,I will past some pictures of before and after my changes ,thanks for your review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (FLINK-11966) Add support for generating optimized logical plan for simple query(Project, Filter, Values and Union all)
[
https://issues.apache.org/jira/browse/FLINK-11966?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young closed FLINK-11966.
--
Resolution: Implemented
Fix Version/s: 1.9.0
fixed in d15171ffdbb036c54b5aa33c1bf041f1c2372445
> Add support for generating optimized logical plan for simple query(Project,
> Filter, Values and Union all)
> -
>
> Key: FLINK-11966
> URL: https://issues.apache.org/jira/browse/FLINK-11966
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.9.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> Add support for generating optimized logical plan for simple query,
> 1. Project and Filter: SELECT a, b + 1 FROM MyTable WHERE b > 2
> 2. Values: SELECT * FROM (VALUES (1, 2, 3)) AS T(a, b, c)
> 3. Union all: SELECT a, c FROM (SELECT a, c FROM MyTable1 UNION ALL SELECT a,
> c FROM MyTable2)
> {{Union}} depends on {{Aggregate}} to eliminate duplicates, so it will be
> introduced after {{Aggregate}} spported.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] maqingxiang commented on a change in pull request #8008: [FLINK-11963][History Server]Add time-based cleanup mechanism in history server
maqingxiang commented on a change in pull request #8008: [FLINK-11963][History
Server]Add time-based cleanup mechanism in history server
URL: https://github.com/apache/flink/pull/8008#discussion_r267170836
##
File path:
flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/history/HistoryServerArchiveFetcher.java
##
@@ -153,9 +157,15 @@ public void run() {
continue;
}
boolean updateOverview = false;
+ long now = System.currentTimeMillis();
for (FileStatus jobArchive :
jobArchives) {
Path jobArchivePath =
jobArchive.getPath();
String jobID =
jobArchivePath.getName();
+ if (retainedApplicationsMillis
!= 0L && now - jobArchive.getModificationTime() > retainedApplicationsMillis) {
Review comment:
Thank you for the review @klion26 , negative or zero value number is
considered to disable the cleanup mechanism.
Add the hint statements in a log.warn fashion.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] KurtYoung merged pull request #8009: [FLINK-11966] [table-planner-blink] Add support for generating optimized logical plan for simple query(Project, Filter, Values and Union all)
KurtYoung merged pull request #8009: [FLINK-11966] [table-planner-blink] Add support for generating optimized logical plan for simple query(Project, Filter, Values and Union all) URL: https://github.com/apache/flink/pull/8009 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] Matrix42 commented on a change in pull request #8011: [FLINK-11958][on-yarn] fix flink on windows yarn deploy failed
Matrix42 commented on a change in pull request #8011: [FLINK-11958][on-yarn]
fix flink on windows yarn deploy failed
URL: https://github.com/apache/flink/pull/8011#discussion_r267170561
##
File path:
flink-yarn/src/main/java/org/apache/flink/yarn/AbstractYarnClusterDescriptor.java
##
@@ -1555,7 +1555,15 @@ protected ContainerLaunchContext
setupApplicationMasterContainer(
ContainerLaunchContext amContainer =
Records.newRecord(ContainerLaunchContext.class);
final Map startCommandValues = new HashMap<>();
- startCommandValues.put("java", "$JAVA_HOME/bin/java");
+ String osName = System.getProperty("os.name");
+ String javaHome;
+ if (osName.startsWith("Windows")) {
+ javaHome = "%JAVA_HOME%";
+ } else {
+ javaHome = "$JAVA_HOME";
+ }
+ String javaCommand = javaHome + "/bin/java";
Review comment:
It's legal use `/` on Windows
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] Matrix42 commented on a change in pull request #8011: [FLINK-11958][on-yarn] fix flink on windows yarn deploy failed
Matrix42 commented on a change in pull request #8011: [FLINK-11958][on-yarn]
fix flink on windows yarn deploy failed
URL: https://github.com/apache/flink/pull/8011#discussion_r267170387
##
File path:
flink-yarn/src/main/java/org/apache/flink/yarn/AbstractYarnClusterDescriptor.java
##
@@ -1555,7 +1555,15 @@ protected ContainerLaunchContext
setupApplicationMasterContainer(
ContainerLaunchContext amContainer =
Records.newRecord(ContainerLaunchContext.class);
final Map startCommandValues = new HashMap<>();
- startCommandValues.put("java", "$JAVA_HOME/bin/java");
+ String osName = System.getProperty("os.name");
+ String javaHome;
+ if (osName.startsWith("Windows")) {
+ javaHome = "%JAVA_HOME%";
Review comment:
There can't use the value of $JAVA_HOME, because the JAVA_HOME may
different between the machine submmit job and the machine running job.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] chummyhe89 commented on issue #7992: [FLINK-11929][runtime] remove not used transientBlobCache
chummyhe89 commented on issue #7992: [FLINK-11929][runtime] remove not used transientBlobCache URL: https://github.com/apache/flink/pull/7992#issuecomment-474663255 @tillrohrmann can you help me to review this pr? thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] chummyhe89 commented on issue #7971: [FLINK-11897][tests] should wait all submitTask methods executed,befo…
chummyhe89 commented on issue #7971: [FLINK-11897][tests] should wait all submitTask methods executed,befo… URL: https://github.com/apache/flink/pull/7971#issuecomment-474662453 Please take a look. @tillrohrmann @zentol This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-11960) Verify builtin Blink Table API functions and operators are reasonable
[
https://issues.apache.org/jira/browse/FLINK-11960?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11960:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Verify builtin Blink Table API functions and operators are reasonable
> -
>
> Key: FLINK-11960
> URL: https://issues.apache.org/jira/browse/FLINK-11960
> Project: Flink
> Issue Type: Task
> Components: SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> We introduced a lot of functions and operators in
> {{flink-table-planner-blink}}. Most of them are not discussed in the
> community, some of them may break the behavior of current Flink SQL.
> We should re-visit the functions and operators to accept the reasonable ones
> and remove the un-standard ones.
> Here is a list of all the Blink SQL functions and operators:
> https://github.com/apache/flink/blob/master/flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/functions/sql/FlinkSqlOperatorTable.java
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (FLINK-11968) Fix runtime SingleElementIterator.iterator and remove table.SingleElementIterator
Jingsong Lee created FLINK-11968:
Summary: Fix runtime SingleElementIterator.iterator and remove
table.SingleElementIterator
Key: FLINK-11968
URL: https://issues.apache.org/jira/browse/FLINK-11968
Project: Flink
Issue Type: Bug
Components: Runtime / Operators
Reporter: Jingsong Lee
{code:java}
@Override
public Iterator iterator() {
return this;
}
{code}
In iterator we need set available to true otherwise we can only iterator once.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11854) Introduce batch physical nodes
[ https://issues.apache.org/jira/browse/FLINK-11854?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young updated FLINK-11854: --- Component/s: (was: API / Table SQL) SQL / Planner > Introduce batch physical nodes > -- > > Key: FLINK-11854 > URL: https://issues.apache.org/jira/browse/FLINK-11854 > Project: Flink > Issue Type: New Feature > Components: SQL / Planner >Reporter: godfrey he >Assignee: godfrey he >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-11969) Add end2end stream sql test for unbounded operators
Hequn Cheng created FLINK-11969: --- Summary: Add end2end stream sql test for unbounded operators Key: FLINK-11969 URL: https://issues.apache.org/jira/browse/FLINK-11969 Project: Flink Issue Type: Sub-task Components: API / Table SQL, Tests Affects Versions: 1.9.0 Reporter: Hequn Cheng Assignee: Hequn Cheng Currently, there is an end2end test for streaming SQL. This test covers bounded operators such as Group Window and Window join. I think it would be nice if we add end2end tests for unbounded operators, so that unbouded group by and stream-stream join can be covered in end-to-end tests as well. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (FLINK-11946) Introduce ExecNode
[ https://issues.apache.org/jira/browse/FLINK-11946?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young closed FLINK-11946. -- Resolution: Implemented Assignee: Jing Zhang Fix Version/s: 1.9.0 fixed in 475a88c26a0c487bbf07cd51c16599911ab4a740 > Introduce ExecNode > -- > > Key: FLINK-11946 > URL: https://issues.apache.org/jira/browse/FLINK-11946 > Project: Flink > Issue Type: Task > Components: API / Table SQL >Reporter: Jing Zhang >Assignee: Jing Zhang >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 10m > Remaining Estimate: 0h > > This issue introduces ExecNode. ExecNode and FlinkPhysicalRel plays different > role. FlinkPhysicalRel is a physical relational expression, while ExecNode is > a representation of execution information, such as how much resource the node > will take, how to convert to StreamTransformation. > It should be noticed that FlinkPhysicalRel and ExecNode could be implemented > by a same concrete physical node, such as StreamExecCalc, StreamExecScan, > etc. The interface exposed by a concrete physical node is different at > different stages. A FlinkPhysicalRel DAG is generated after physical > optimization, then translate the plan to ExecNode DAG. All post processors > all apply on ExecNode DAG, such as detect deadlock, set heap/memory/cpu, etc. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11946) Introduce ExecNode
[ https://issues.apache.org/jira/browse/FLINK-11946?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young updated FLINK-11946: --- Component/s: (was: API / Table SQL) SQL / Planner > Introduce ExecNode > -- > > Key: FLINK-11946 > URL: https://issues.apache.org/jira/browse/FLINK-11946 > Project: Flink > Issue Type: Task > Components: SQL / Planner >Reporter: Jing Zhang >Assignee: Jing Zhang >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 10m > Remaining Estimate: 0h > > This issue introduces ExecNode. ExecNode and FlinkPhysicalRel plays different > role. FlinkPhysicalRel is a physical relational expression, while ExecNode is > a representation of execution information, such as how much resource the node > will take, how to convert to StreamTransformation. > It should be noticed that FlinkPhysicalRel and ExecNode could be implemented > by a same concrete physical node, such as StreamExecCalc, StreamExecScan, > etc. The interface exposed by a concrete physical node is different at > different stages. A FlinkPhysicalRel DAG is generated after physical > optimization, then translate the plan to ExecNode DAG. All post processors > all apply on ExecNode DAG, such as detect deadlock, set heap/memory/cpu, etc. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] JingsongLi commented on a change in pull request #8001: [FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink planner
JingsongLi commented on a change in pull request #8001:
[FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and
AggsHandlerCodeGenerator to blink planner
URL: https://github.com/apache/flink/pull/8001#discussion_r267166984
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/codegen/agg/ImperativeAggCodeGen.scala
##
@@ -0,0 +1,502 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.flink.table.codegen.agg
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.runtime.util.SingleElementIterator
+import
org.apache.flink.table.`type`.TypeConverters.createInternalTypeFromTypeInfo
+import org.apache.flink.table.`type`.{InternalType, RowType, TypeUtils}
+import org.apache.flink.table.codegen.CodeGenUtils._
+import org.apache.flink.table.codegen.GenerateUtils.generateFieldAccess
+import
org.apache.flink.table.codegen.agg.AggsHandlerCodeGenerator.{CONTEXT_TERM,
CURRENT_KEY, DISTINCT_KEY_TERM, NAMESPACE_TERM, addReusableStateDataViews,
createDataViewBackupTerm, createDataViewTerm}
+import org.apache.flink.table.codegen.{CodeGenException, CodeGeneratorContext,
ExprCodeGenerator, GeneratedExpression}
+import org.apache.flink.table.dataformat.{GenericRow, UpdatableRow}
+import org.apache.flink.table.dataview.DataViewSpec
+import org.apache.flink.table.expressions.{Expression,
ResolvedAggInputReference, ResolvedDistinctKeyReference,
RexNodeGenExpressionVisitor}
+import org.apache.flink.table.functions.AggregateFunction
+import
org.apache.flink.table.functions.utils.UserDefinedFunctionUtils.{getAggFunctionUDIMethod,
getAggUserDefinedInputTypes, getUserDefinedMethod, internalTypesToClasses,
signatureToString}
+import org.apache.flink.table.plan.util.AggregateInfo
+import org.apache.flink.table.typeutils.BaseRowTypeInfo
+
+import org.apache.calcite.tools.RelBuilder
+
+import java.lang.reflect.ParameterizedType
+import java.lang.{Iterable => JIterable}
+
+import scala.collection.mutable.ArrayBuffer
+
+/**
+ * It is for code generate aggregation functions that are specified in terms
of
+ * accumulate(), retract() and merge() functions. The aggregate accumulator is
+ * embedded inside of a larger shared aggregation buffer.
+ *
+ * @param ctx the code gen context
+ * @param aggInfo the aggregate information
+ * @param filterExpression filter argument access expression, none if no
filter
+ * @param mergedAccOffset the mergedAcc may come from local aggregate,
+ *this is the first buffer offset in the row
+ * @param aggBufferOffset the offset in the buffers of this aggregate
+ * @param aggBufferSize the total size of aggregate buffers
+ * @param inputTypes the input field type infos
+ * @param constantExprs the constant expressions
+ * @param relBuilder the rel builder to translate expressions to calcite rex
nodes
+ * @param hasNamespace whether the accumulators state has namespace
+ * @param inputFieldCopycopy input field element if true (only mutable
type will be copied)
+ */
+class ImperativeAggCodeGen(
+ctx: CodeGeneratorContext,
+aggInfo: AggregateInfo,
+filterExpression: Option[Expression],
+mergedAccOffset: Int,
+aggBufferOffset: Int,
+aggBufferSize: Int,
+inputTypes: Seq[InternalType],
+constantExprs: Seq[GeneratedExpression],
+relBuilder: RelBuilder,
+hasNamespace: Boolean,
+mergedAccOnHeap: Boolean,
+mergedAccExternalType: TypeInformation[_],
+inputFieldCopy: Boolean)
+ extends AggCodeGen {
+
+ private val SINGLE_ITERABLE = className[SingleElementIterator[_]]
Review comment:
First table-blink has own `SingleElementIterator ` too.
created JIRA to fix it: https://issues.apache.org/jira/browse/FLINK-11968
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (FLINK-11712) Add cost model for both batch and streaming
[ https://issues.apache.org/jira/browse/FLINK-11712?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young updated FLINK-11712: --- Component/s: (was: API / Table SQL) SQL / Planner > Add cost model for both batch and streaming > --- > > Key: FLINK-11712 > URL: https://issues.apache.org/jira/browse/FLINK-11712 > Project: Flink > Issue Type: New Feature > Components: SQL / Planner >Reporter: godfrey he >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11822) Introduce Flink metadata handlers
[
https://issues.apache.org/jira/browse/FLINK-11822?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11822:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Introduce Flink metadata handlers
> -
>
> Key: FLINK-11822
> URL: https://issues.apache.org/jira/browse/FLINK-11822
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Calcite has defined various metadata handlers(e.g. {{RowCoun}},
> {{Selectivity}} and provided default implementation(e.g. {{RelMdRowCount}},
> {{RelMdSelectivity}}). However, the default implementation can't completely
> meet our requirements, e.g. some of its logic is incomplete,and some RelNodes
> are not considered.
> There are two options to meet our requirements:
> option 1. Extends from default implementation, overrides method to improve
> its logic, add new methods for new {{RelNode}}. The advantage of this option
> is we just need to focus on the additions and modifications. However, its
> shortcomings are also obvious: we have no control over the code of
> non-override methods in default implementation classes especially when
> upgrading the Calcite version.
> option 2. Extends from metadata handler interfaces, reimplement all the
> logic. Its shortcomings are very obvious, however we can control all the code
> logic that's what we want.
> so we choose option 2!
> In this jira, only basic metadata handles will be introduced, including:
> {{FlinkRelMdPercentageOriginalRow}},
> {{FlinkRelMdNonCumulativeCost}},
> {{FlinkRelMdCumulativeCost}},
> {{FlinkRelMdRowCount}},
> {{FlinkRelMdSize}},
> {{FlinkRelMdSelectivity}},
> {{FlinkRelMdDistinctRowCoun}},
> {{FlinkRelMdPopulationSize}},
> {{FlinkRelMdColumnUniqueness}},
> {{FlinkRelMdUniqueKeys}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11842) Introduce FlinkLogicalMatch
[
https://issues.apache.org/jira/browse/FLINK-11842?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11842:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Introduce FlinkLogicalMatch
> ---
>
> Key: FLINK-11842
> URL: https://issues.apache.org/jira/browse/FLINK-11842
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
>
> {{FlinkLogicalMatch}} supports output timeout events in Blink, which does not
> support in Flink. However this nuances involves quite a few changes in
> Calcite, include parser, sql validation, RelBuilder and so on.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11840) Introduce FlinkLogicalSnapshot
[
https://issues.apache.org/jira/browse/FLINK-11840?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11840:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Introduce FlinkLogicalSnapshot
> --
>
> Key: FLINK-11840
> URL: https://issues.apache.org/jira/browse/FLINK-11840
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
>
> {{Snapshot}} hasn't been introduced into Calcite yet. It's a whole new
> feature. Related changes include parser, sql validator, relational expression
> and so on.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11841) Introduce FlinkLogicalSemiJoin
[
https://issues.apache.org/jira/browse/FLINK-11841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11841:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Introduce FlinkLogicalSemiJoin
> --
>
> Key: FLINK-11841
> URL: https://issues.apache.org/jira/browse/FLINK-11841
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
>
> {{SemiJoin}} in Calcite should support anti-join. Related changes include
> rules about SemiJoin, sub-classes of SemiJoin, RelBuilder and so on.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11896) Introduce stream physical nodes
[
https://issues.apache.org/jira/browse/FLINK-11896?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11896:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Introduce stream physical nodes
> ---
>
> Key: FLINK-11896
> URL: https://issues.apache.org/jira/browse/FLINK-11896
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.9.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> This issues aims to introduce flink stream physical RelNode, such as
> {{StreamExecCalc}}, {{StreamExecExchange}}, {{StreamExecExpand}} etc.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11945) Support Over aggregation for SQL
[
https://issues.apache.org/jira/browse/FLINK-11945?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11945:
---
Component/s: (was: API / Table SQL)
SQL / Planner
Runtime / Operators
> Support Over aggregation for SQL
>
>
> Key: FLINK-11945
> URL: https://issues.apache.org/jira/browse/FLINK-11945
> Project: Flink
> Issue Type: New Feature
> Components: Runtime / Operators, SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> This is a simple port the over aggregation implementation from
> {{flink-table-planner}} to {{flink-table-planner-blink}}.
> Note: please also convert the over function implementation from Scala to Java.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11943) Support TopN feature for SQL
[
https://issues.apache.org/jira/browse/FLINK-11943?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11943:
---
Component/s: (was: API / Table SQL)
SQL / Planner
Runtime / Operators
> Support TopN feature for SQL
>
>
> Key: FLINK-11943
> URL: https://issues.apache.org/jira/browse/FLINK-11943
> Project: Flink
> Issue Type: New Feature
> Components: Runtime / Operators, SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> TopN is a frequently used feature in data analysis. We can use ORDER BY +
> LIMIT to easily express a TopN query, e.g. {{SELECT * FROM T ORDER BY amount
> DESC LIMIT 10}}.
> But this is a global TopN, there is a great requirement for per-group TopN.
> For example, top 10 shops for each category. In order to avoid introducing
> new syntax for this, we would like to use traditional syntax to express it by
> using {{ROW_NUMBER}} over window + {{FILTER}} to limit the numbers.
> For example:
> SELECT *
> FROM (
> SELECT category, shopId, sales,
> [ROW_NUMBER()|RANK()|DENSE_RANK()] OVER
> (PARTITION BY category ORDER BY sales ASC) as rownum
> FROM shop_sales
> )
> WHERE rownum <= 10
> This issue is aiming to optimize this query to an {{Rank}} node instead of
> {{Over}} plus {{Calc}}. And translate the {{Rank}} node into physical
> operators.
> There are some optimization for rank operator based on the different input of
> the Rank. We would like to implement the basic and one-fit-all
> implementation. And do the performance improvement later.
> Here is a brief design doc:
> https://docs.google.com/document/d/14JCV6X6hcpoA51loprgntZNxQ2NmnDLucxgGY8xVDuI/edit#
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11932) Add support for generating optimized logical plan for 'select * from mytable'
[
https://issues.apache.org/jira/browse/FLINK-11932?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11932:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Add support for generating optimized logical plan for 'select * from mytable'
> -
>
> Key: FLINK-11932
> URL: https://issues.apache.org/jira/browse/FLINK-11932
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.9.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> Add support for generating optimized logical plan for 'select * from
> mytable', including:
> 1. add {{BatchTableEnvironment}}
> 2. introduce {{Optimizer}} interface and implements for batch and stream
> 3. add rules and programs for batch and stream
> 4. add {{registerTableSource}}, {{optimize}}, {{explain}} methods in
> {{TableEnvironment}}
> 5. add plan test infrastructure (is duplicated by
> https://issues.apache.org/jira/browse/FLINK-11685)
> 6. add {{RelTreeWriterImpl}} to make query plan easier to read (is duplicated
> by https://issues.apache.org/jira/browse/FLINK-11680)
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11944) Support FirstRow and LastRow for SQL
[
https://issues.apache.org/jira/browse/FLINK-11944?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11944:
---
Component/s: (was: API / Table SQL)
SQL / Planner
Runtime / Operators
> Support FirstRow and LastRow for SQL
>
>
> Key: FLINK-11944
> URL: https://issues.apache.org/jira/browse/FLINK-11944
> Project: Flink
> Issue Type: New Feature
> Components: Runtime / Operators, SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> Usually there are some duplicate data in the source due to some reasons. In
> order to get a correct result, we need to do deduplication. FirstRow and
> LastRow are two different strategy for deduplication. The syntax of FirstRow
> and LastRow is similar to TopN, but order by a time attribute. For example:
> SELECT *
> FROM (
> SELECT *,
> ROW_NUMBER() OVER (PARTITION BY id ORDER BY proctime DESC) as rownum
> FROM T
> )
> WHERE rownum = 1
> Some information about FirstRow & LastRow.
> 1. the partition by key is the deduplicate key
> 2. can only order by a time attribute (either proctime or rowtime)
> 3. the rownum filter must be {{= 1}} or {{<= 1}}
> 4. it is FirstRow when order direction is ASC, LastRow when order direction
> is DESC
> This issue is aiming to optimize this query to a FirstLastRow node instead of
> Over plus Calc. And translate the it into physical operators.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11966) Add support for generating optimized logical plan for simple query(Project, Filter, Values and Union all)
[
https://issues.apache.org/jira/browse/FLINK-11966?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-11966:
---
Component/s: (was: API / Table SQL)
SQL / Planner
> Add support for generating optimized logical plan for simple query(Project,
> Filter, Values and Union all)
> -
>
> Key: FLINK-11966
> URL: https://issues.apache.org/jira/browse/FLINK-11966
> Project: Flink
> Issue Type: New Feature
> Components: SQL / Planner
>Reporter: godfrey he
>Assignee: godfrey he
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Add support for generating optimized logical plan for simple query,
> 1. Project and Filter: SELECT a, b + 1 FROM MyTable WHERE b > 2
> 2. Values: SELECT * FROM (VALUES (1, 2, 3)) AS T(a, b, c)
> 3. Union all: SELECT a, c FROM (SELECT a, c FROM MyTable1 UNION ALL SELECT a,
> c FROM MyTable2)
> {{Union}} depends on {{Aggregate}} to eliminate duplicates, so it will be
> introduced after {{Aggregate}} spported.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-11946) Introduce ExecNode
[ https://issues.apache.org/jira/browse/FLINK-11946?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-11946: --- Labels: pull-request-available (was: ) > Introduce ExecNode > -- > > Key: FLINK-11946 > URL: https://issues.apache.org/jira/browse/FLINK-11946 > Project: Flink > Issue Type: Task > Components: API / Table SQL >Reporter: Jing Zhang >Priority: Major > Labels: pull-request-available > > This issue introduces ExecNode. ExecNode and FlinkPhysicalRel plays different > role. FlinkPhysicalRel is a physical relational expression, while ExecNode is > a representation of execution information, such as how much resource the node > will take, how to convert to StreamTransformation. > It should be noticed that FlinkPhysicalRel and ExecNode could be implemented > by a same concrete physical node, such as StreamExecCalc, StreamExecScan, > etc. The interface exposed by a concrete physical node is different at > different stages. A FlinkPhysicalRel DAG is generated after physical > optimization, then translate the plan to ExecNode DAG. All post processors > all apply on ExecNode DAG, such as detect deadlock, set heap/memory/cpu, etc. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] KurtYoung merged pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
KurtYoung merged pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner URL: https://github.com/apache/flink/pull/8010 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8001: [FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink planner
JingsongLi commented on a change in pull request #8001:
[FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and
AggsHandlerCodeGenerator to blink planner
URL: https://github.com/apache/flink/pull/8001#discussion_r267165448
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/typeutils/MapViewSerializer.scala
##
@@ -0,0 +1,123 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils
+
+import org.apache.flink.api.common.typeutils._
+import
org.apache.flink.api.common.typeutils.base.{MapSerializerConfigSnapshot,
MapSerializerSnapshot}
+import org.apache.flink.core.memory.{DataInputView, DataOutputView}
+import org.apache.flink.table.api.dataview.MapView
+
+/**
+ * A serializer for [[MapView]]. The serializer relies on a key serializer
and a value
+ * serializer for the serialization of the map's key-value pairs.
+ *
+ * The serialization format for the map is as follows: four bytes for the
length of the map,
+ * followed by the serialized representation of each key-value pair. To allow
null values,
+ * each value is prefixed by a null marker.
+ *
+ * @param mapSerializer Map serializer.
+ * @tparam K The type of the keys in the map.
+ * @tparam V The type of the values in the map.
+ */
+@SerialVersionUID(-9007142882049098705L)
+class MapViewSerializer[K, V](val mapSerializer:
TypeSerializer[java.util.Map[K, V]])
+extends TypeSerializer[MapView[K, V]]
+with LegacySerializerSnapshotTransformer[MapView[K, V]] {
+
+ override def isImmutableType: Boolean = false
+
+ override def duplicate(): TypeSerializer[MapView[K, V]] =
+new MapViewSerializer[K, V](mapSerializer.duplicate())
+
+ override def createInstance(): MapView[K, V] = {
+new MapView[K, V]()
+ }
+
+ override def copy(from: MapView[K, V]): MapView[K, V] = {
+new MapView[K, V](null, null, mapSerializer.copy(from.map))
+ }
+
+ override def copy(from: MapView[K, V], reuse: MapView[K, V]): MapView[K, V]
= copy(from)
+
+ override def getLength: Int = -1 // var length
+
+ override def serialize(record: MapView[K, V], target: DataOutputView): Unit
= {
+mapSerializer.serialize(record.map, target)
+ }
+
+ override def deserialize(source: DataInputView): MapView[K, V] = {
+new MapView[K, V](null, null, mapSerializer.deserialize(source))
+ }
+
+ override def deserialize(reuse: MapView[K, V], source: DataInputView):
MapView[K, V] =
+deserialize(source)
+
+ override def copy(source: DataInputView, target: DataOutputView): Unit =
+mapSerializer.copy(source, target)
+
+ override def hashCode(): Int = mapSerializer.hashCode()
+
+ override def equals(obj: Any): Boolean =
+mapSerializer.equals(obj.asInstanceOf[MapViewSerializer[_,
_]].mapSerializer)
+
+ override def snapshotConfiguration(): MapViewSerializerSnapshot[K, V] =
Review comment:
OK
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-11848) Delete outdated kafka topics caused UNKNOWN_TOPIC_EXCEPTIION
[
https://issues.apache.org/jira/browse/FLINK-11848?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16796694#comment-16796694
]
frank wang commented on FLINK-11848:
props.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS,
"120");
Set the time to small, try that
> Delete outdated kafka topics caused UNKNOWN_TOPIC_EXCEPTIION
>
>
> Key: FLINK-11848
> URL: https://issues.apache.org/jira/browse/FLINK-11848
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.6.4
>Reporter: Shengnan YU
>Assignee: frank wang
>Priority: Major
>
> Recently we are doing some streaming jobs with apache flink. There are
> multiple KAFKA topics with a format as xx_yy-mm-dd. We used a topic regex
> pattern to let a consumer to consume those topics. However, if we delete some
> older topics, it seems that the metadata in consumer does not update properly
> so It still remember those outdated topic in its topic list, which leads to
> *UNKNOWN_TOPIC_EXCEPTION*. We must restart the consumer job to recovery. It
> seems to occur in producer as well. Any idea to solve this problem? Thank you
> very much!
>
> Example to reproduce problem:
> There are multiple kafka topics which are
> "test20190310","test20190311","test20190312" for instance. I run the job and
> everything is ok. Then if I delete topic "test20190310", the consumer does
> not perceive the topic is deleted, it will still go fetching metadata of that
> topic. In taskmanager's log, unknown errors display.
> {code:java}
> public static void main(String []args) throws Exception {
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment();
> Properties props = new Properties();
> props.put("bootstrap.servers", "localhost:9092\n");
> props.put("group.id", "test10");
> props.put("enable.auto.commit", "true");
> props.put("auto.commit.interval.ms", "1000");
> props.put("auto.offset.rest", "earliest");
> props.put("key.deserializer",
> "org.apache.kafka.common.serialization.StringDeserializer");
> props.put("value.deserializer",
> "org.apache.kafka.common.serialization.StringDeserializer");
>
> props.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS,
>"120");
> Pattern topics = Pattern.compile("^test.*$");
> FlinkKafkaConsumer011 consumer = new
> FlinkKafkaConsumer011<>(topics, new SimpleStringSchema(), props);
> DataStream stream = env.addSource(consumer);
> stream.writeToSocket("localhost", 4, new SimpleStringSchema());
> env.execute("test");
> }
> }
> {code}
>
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] klion26 commented on a change in pull request #8008: [FLINK-11963][History Server]Add time-based cleanup mechanism in history server
klion26 commented on a change in pull request #8008: [FLINK-11963][History
Server]Add time-based cleanup mechanism in history server
URL: https://github.com/apache/flink/pull/8008#discussion_r267163437
##
File path:
flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/history/HistoryServerArchiveFetcher.java
##
@@ -153,9 +157,15 @@ public void run() {
continue;
}
boolean updateOverview = false;
+ long now = System.currentTimeMillis();
for (FileStatus jobArchive :
jobArchives) {
Path jobArchivePath =
jobArchive.getPath();
String jobID =
jobArchivePath.getName();
+ if (retainedApplicationsMillis
!= 0L && now - jobArchive.getModificationTime() > retainedApplicationsMillis) {
Review comment:
Sorry for the ambiguous description, what I mean is "If a user sets a
negative number, what will the behavior be?"
Maybe we should add a check logic
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8001: [FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and AggsHandlerCodeGenerator to blink planner
JingsongLi commented on a change in pull request #8001:
[FLINK-11949][table-planner-blink] Introduce DeclarativeAggregateFunction and
AggsHandlerCodeGenerator to blink planner
URL: https://github.com/apache/flink/pull/8001#discussion_r267162956
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/expressions/RexNodeGenExpressionVisitor.java
##
@@ -0,0 +1,206 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.expressions;
+
+import org.apache.flink.table.calcite.FlinkTypeFactory;
+import org.apache.flink.table.calcite.RexAggLocalVariable;
+import org.apache.flink.table.calcite.RexDistinctKeyVariable;
+import org.apache.flink.table.type.DecimalType;
+import org.apache.flink.table.type.InternalType;
+import org.apache.flink.table.type.InternalTypes;
+
+import org.apache.calcite.rel.type.RelDataType;
+import org.apache.calcite.rex.RexBuilder;
+import org.apache.calcite.rex.RexInputRef;
+import org.apache.calcite.rex.RexNode;
+import org.apache.calcite.sql.fun.SqlStdOperatorTable;
+import org.apache.calcite.sql.type.SqlTypeName;
+import org.apache.calcite.tools.RelBuilder;
+
+import java.math.BigDecimal;
+import java.util.List;
+import java.util.stream.Collectors;
+
+import static org.apache.calcite.sql.type.SqlTypeName.VARCHAR;
+import static org.apache.flink.table.calcite.FlinkTypeFactory.toInternalType;
+import static
org.apache.flink.table.type.TypeConverters.createInternalTypeFromTypeInfo;
+import static org.apache.flink.table.typeutils.TypeCheckUtils.isString;
+import static org.apache.flink.table.typeutils.TypeCheckUtils.isTemporal;
+import static org.apache.flink.table.typeutils.TypeCheckUtils.isTimeInterval;
+
+/**
+ * Visit expression to generator {@link RexNode}.
+ */
+public class RexNodeGenExpressionVisitor implements ExpressionVisitor
{
+
+ private final RelBuilder relBuilder;
+ private final FlinkTypeFactory typeFactory;
+
+ public RexNodeGenExpressionVisitor(RelBuilder relBuilder) {
+ this.relBuilder = relBuilder;
+ this.typeFactory = (FlinkTypeFactory)
relBuilder.getRexBuilder().getTypeFactory();
+ }
+
+ @Override
+ public RexNode visitCall(CallExpression call) {
+ List child = call.getChildren().stream()
+ .map(expression ->
expression.accept(RexNodeGenExpressionVisitor.this))
+ .collect(Collectors.toList());
+ switch (call.getFunctionDefinition().getType()) {
+ case SCALAR_FUNCTION:
+ return
visitScalarFunc(call.getFunctionDefinition(), child);
+ default: throw new UnsupportedOperationException();
+ }
+ }
+
+ private RexNode visitScalarFunc(FunctionDefinition def, List
child) {
+ switch (def.getName()) {
Review comment:
`if else` is OK, prefer Java code
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Assigned] (FLINK-7391) Normalize release entries
[ https://issues.apache.org/jira/browse/FLINK-7391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] dong reassigned FLINK-7391: --- Assignee: (was: dong) > Normalize release entries > - > > Key: FLINK-7391 > URL: https://issues.apache.org/jira/browse/FLINK-7391 > Project: Flink > Issue Type: Improvement > Components: Project Website >Reporter: Chesnay Schepler >Priority: Major > Labels: starter > > The release list at http://flink.apache.org/downloads.html is inconsistent in > regards to the java/scala docs links. For 1.1.3 and below we only include a > docs link for the latest version (i.e 1.1.3, but not for 1.1.2), for higher > versions we have a docs link for every release. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] KurtYoung commented on issue #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
KurtYoung commented on issue #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner URL: https://github.com/apache/flink/pull/8010#issuecomment-474653633 LGTM, +1 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on issue #8003: [FLINK-11951][table-common] Enhance UserDefinedFunction interface to allow more user defined types
JingsongLi commented on issue #8003: [FLINK-11951][table-common] Enhance UserDefinedFunction interface to allow more user defined types URL: https://github.com/apache/flink/pull/8003#issuecomment-474653408 > Merging this change to `flink-table-common` would introduce instant legacy as we are also thinking about dropping the existing `getResultType` methods and add proper operand type inference and return type strategies, similar to how Calcite functions work. I understand the necessity of this change but I would postpone it a little bit until we have a full type system picture. I see what you mean. It makes sense. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Assigned] (FLINK-7391) Normalize release entries
[ https://issues.apache.org/jira/browse/FLINK-7391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] dong reassigned FLINK-7391: --- Assignee: dong (was: Neelesh Srinivas Salian) > Normalize release entries > - > > Key: FLINK-7391 > URL: https://issues.apache.org/jira/browse/FLINK-7391 > Project: Flink > Issue Type: Improvement > Components: Project Website >Reporter: Chesnay Schepler >Assignee: dong >Priority: Major > Labels: starter > > The release list at http://flink.apache.org/downloads.html is inconsistent in > regards to the java/scala docs links. For 1.1.3 and below we only include a > docs link for the latest version (i.e 1.1.3, but not for 1.1.2), for higher > versions we have a docs link for every release. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] yanghua commented on issue #6489: [FLINK-10054] Add getMaxParallelism/setMaxParallelism API for PythonStreamExecutionEnvironment
yanghua commented on issue #6489: [FLINK-10054] Add getMaxParallelism/setMaxParallelism API for PythonStreamExecutionEnvironment URL: https://github.com/apache/flink/pull/6489#issuecomment-474651884 closing this PR... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yanghua closed pull request #6489: [FLINK-10054] Add getMaxParallelism/setMaxParallelism API for PythonStreamExecutionEnvironment
yanghua closed pull request #6489: [FLINK-10054] Add getMaxParallelism/setMaxParallelism API for PythonStreamExecutionEnvironment URL: https://github.com/apache/flink/pull/6489 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yanghua commented on issue #6487: [FLINK-10053] Add getParallelism API for PythonStreamExecutionEnvironment
yanghua commented on issue #6487: [FLINK-10053] Add getParallelism API for PythonStreamExecutionEnvironment URL: https://github.com/apache/flink/pull/6487#issuecomment-474651774 Closing this PR cc @zentol This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yanghua closed pull request #6487: [FLINK-10053] Add getParallelism API for PythonStreamExecutionEnvironment
yanghua closed pull request #6487: [FLINK-10053] Add getParallelism API for PythonStreamExecutionEnvironment URL: https://github.com/apache/flink/pull/6487 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] beyond1920 commented on a change in pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
beyond1920 commented on a change in pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner URL: https://github.com/apache/flink/pull/8010#discussion_r267159417 ## File path: flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/plan/nodes/exec/StreamExecNode.scala ## @@ -0,0 +1,26 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.table.plan.nodes.exec + +import org.apache.flink.table.api.StreamTableEnvironment +import org.apache.flink.table.dataformat.BaseRow + +trait StreamExecNode[T] extends ExecNode[StreamTableEnvironment, T] + +trait RowStreamExecNode extends StreamExecNode[BaseRow] Review comment: done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] beyond1920 commented on a change in pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
beyond1920 commented on a change in pull request #8010:
[FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
URL: https://github.com/apache/flink/pull/8010#discussion_r267159307
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/plan/nodes/exec/BatchExecNode.scala
##
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.plan.nodes.exec
+
+import org.apache.flink.runtime.operators.DamBehavior
+import org.apache.flink.table.api.BatchTableEnvironment
+import org.apache.flink.table.dataformat.BaseRow
+
+trait BatchExecNode[T] extends ExecNode[BatchTableEnvironment, T] {
+
+ /**
+* Returns [[DamBehavior]] of this node.
+*/
+ def getDamBehavior: DamBehavior
+
+}
+
+trait RowBatchExecNode extends BatchExecNode[BaseRow]
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] KurtYoung commented on a change in pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
KurtYoung commented on a change in pull request #8010:
[FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
URL: https://github.com/apache/flink/pull/8010#discussion_r267157093
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/plan/nodes/exec/BatchExecNode.scala
##
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.plan.nodes.exec
+
+import org.apache.flink.runtime.operators.DamBehavior
+import org.apache.flink.table.api.BatchTableEnvironment
+import org.apache.flink.table.dataformat.BaseRow
+
+trait BatchExecNode[T] extends ExecNode[BatchTableEnvironment, T] {
+
+ /**
+* Returns [[DamBehavior]] of this node.
+*/
+ def getDamBehavior: DamBehavior
+
+}
+
+trait RowBatchExecNode extends BatchExecNode[BaseRow]
Review comment:
Let's remove this, to make further declaration more explicitly. Like
`BatchExecCalc extend BatchExecNode[BaseRow]`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] KurtYoung commented on a change in pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner
KurtYoung commented on a change in pull request #8010: [FLINK-11946][table-planner-blink] Introduce ExecNode to blink planner URL: https://github.com/apache/flink/pull/8010#discussion_r267157193 ## File path: flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/plan/nodes/exec/StreamExecNode.scala ## @@ -0,0 +1,26 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.table.plan.nodes.exec + +import org.apache.flink.table.api.StreamTableEnvironment +import org.apache.flink.table.dataformat.BaseRow + +trait StreamExecNode[T] extends ExecNode[StreamTableEnvironment, T] + +trait RowStreamExecNode extends StreamExecNode[BaseRow] Review comment: same with RowBatchExecNode This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] KurtYoung commented on issue #8010: [FLINK-11949][table-planner-blink] Introduce ExecNode to blink planner
KurtYoung commented on issue #8010: [FLINK-11949][table-planner-blink] Introduce ExecNode to blink planner URL: https://github.com/apache/flink/pull/8010#issuecomment-474645882 I think you attached to a wrong jira number This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #8013: Minor example typo fix
flinkbot commented on issue #8013: Minor example typo fix URL: https://github.com/apache/flink/pull/8013#issuecomment-474627783 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] angoenka opened a new pull request #8013: Minor example typo fix
angoenka opened a new pull request #8013: Minor example typo fix URL: https://github.com/apache/flink/pull/8013 ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluser with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Resolved] (FLINK-5182) Implement SSL file-shipping
[ https://issues.apache.org/jira/browse/FLINK-5182?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eron Wright resolved FLINK-5182. - Resolution: Won't Fix Closing as unimportant. > Implement SSL file-shipping > --- > > Key: FLINK-5182 > URL: https://issues.apache.org/jira/browse/FLINK-5182 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Eron Wright >Priority: Major > > The current handling of keystore and truststore is, the config entry is > treated as a local file path always, and the files aren't shipped > automatically.The behavior is problematic in YARN/Mesos deployments, > where such an assumption doesn't always hold. > Change the behavior to automatically ship the files and update the config > automatically. That behavior is consistent with how keytabs are handled. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (FLINK-3931) Implement Transport Encryption (SSL/TLS)
[ https://issues.apache.org/jira/browse/FLINK-3931?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eron Wright resolved FLINK-3931. - Resolution: Fixed > Implement Transport Encryption (SSL/TLS) > > > Key: FLINK-3931 > URL: https://issues.apache.org/jira/browse/FLINK-3931 > Project: Flink > Issue Type: New Feature > Components: Runtime / Coordination >Reporter: Eron Wright >Assignee: Eron Wright >Priority: Major > Labels: security > Original Estimate: 1,008h > Remaining Estimate: 1,008h > > _This issue is part of a series of improvements detailed in the [Secure Data > Access|https://docs.google.com/document/d/1-GQB6uVOyoaXGwtqwqLV8BHDxWiMO2WnVzBoJ8oPaAs/edit?usp=sharing] > design doc._ > To assure privacy and data integrity between Flink components, enable TLS for > all communication channels. As described in the design doc: > - Accept a configured certificate or generate a certificate. > - Enable Akka SSL > - Implement Data Transfer SSL > - Implement Blob Server SSL > - Implement Web UI HTTPS -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (FLINK-5029) Implement KvState SSL
[ https://issues.apache.org/jira/browse/FLINK-5029?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eron Wright resolved FLINK-5029. - Resolution: Won't Fix > Implement KvState SSL > - > > Key: FLINK-5029 > URL: https://issues.apache.org/jira/browse/FLINK-5029 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Eron Wright >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > The KVState endpoint is new to 1.2 and should support SSL as the others do. > Note that, with FLINK-4898, the SSL support code is decoupled from the > NettyClient/NettyServer, so can be used by the KvState code by simply > installing the `SSLProtocolHandler`. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-5029) Implement KvState SSL
[ https://issues.apache.org/jira/browse/FLINK-5029?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16796554#comment-16796554 ] Eron Wright commented on FLINK-5029: - Any objection to resolving this as won't-fix? Seems to me that queryable state is an experimental feature that isn't worth investing in. > Implement KvState SSL > - > > Key: FLINK-5029 > URL: https://issues.apache.org/jira/browse/FLINK-5029 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Eron Wright >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > The KVState endpoint is new to 1.2 and should support SSL as the others do. > Note that, with FLINK-4898, the SSL support code is decoupled from the > NettyClient/NettyServer, so can be used by the KvState code by simply > installing the `SSLProtocolHandler`. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-5029) Implement KvState SSL
[ https://issues.apache.org/jira/browse/FLINK-5029?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eron Wright updated FLINK-5029: Labels: (was: pull-request-available) > Implement KvState SSL > - > > Key: FLINK-5029 > URL: https://issues.apache.org/jira/browse/FLINK-5029 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Eron Wright >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > The KVState endpoint is new to 1.2 and should support SSL as the others do. > Note that, with FLINK-4898, the SSL support code is decoupled from the > NettyClient/NettyServer, so can be used by the KvState code by simply > installing the `SSLProtocolHandler`. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] EronWright commented on issue #6626: [FLINK-5029] [QueryableState] SSL Support
EronWright commented on issue #6626: [FLINK-5029] [QueryableState] SSL Support URL: https://github.com/apache/flink/pull/6626#issuecomment-474597145 Closed the PR as "won't fix". This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Assigned] (FLINK-5029) Implement KvState SSL
[ https://issues.apache.org/jira/browse/FLINK-5029?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eron Wright reassigned FLINK-5029: --- Assignee: (was: Eron Wright ) > Implement KvState SSL > - > > Key: FLINK-5029 > URL: https://issues.apache.org/jira/browse/FLINK-5029 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Eron Wright >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > The KVState endpoint is new to 1.2 and should support SSL as the others do. > Note that, with FLINK-4898, the SSL support code is decoupled from the > NettyClient/NettyServer, so can be used by the KvState code by simply > installing the `SSLProtocolHandler`. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] EronWright closed pull request #6626: [FLINK-5029] [QueryableState] SSL Support
EronWright closed pull request #6626: [FLINK-5029] [QueryableState] SSL Support URL: https://github.com/apache/flink/pull/6626 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] suez1224 commented on issue #7978: [FLINK-11910] [Yarn] add customizable yarn application type
suez1224 commented on issue #7978: [FLINK-11910] [Yarn] add customizable yarn application type URL: https://github.com/apache/flink/pull/7978#issuecomment-474586356 Instead of customize just the version, can we just let user override the entire application type, which is more flexible? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #7978: [FLINK-11910] [Yarn] add customizable yarn application type
flinkbot edited a comment on issue #7978: [FLINK-11910] [Yarn] add customizable yarn application type URL: https://github.com/apache/flink/pull/7978#issuecomment-472607121 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ✅ 1. The [description] looks good. - Approved by @suez1224 * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] suez1224 commented on issue #7978: [FLINK-11910] [Yarn] add customizable yarn application type
suez1224 commented on issue #7978: [FLINK-11910] [Yarn] add customizable yarn application type URL: https://github.com/apache/flink/pull/7978#issuecomment-474584787 @flinkbot approve description This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #7986: [FLINK-10517][rest] Add stability test
GJL commented on a change in pull request #7986: [FLINK-10517][rest] Add
stability test
URL: https://github.com/apache/flink/pull/7986#discussion_r267077674
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/rest/compatibility/CompatibilityRoutine.java
##
@@ -0,0 +1,114 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.rest.compatibility;
+
+import org.apache.flink.runtime.rest.messages.MessageHeaders;
+
+import org.junit.Assert;
+
+import java.util.Optional;
+import java.util.function.BiConsumer;
+import java.util.function.Function;
+
+import static
org.apache.flink.runtime.rest.compatibility.Compatibility.COMPATIBLE;
+import static
org.apache.flink.runtime.rest.compatibility.Compatibility.IDENTICAL;
+import static
org.apache.flink.runtime.rest.compatibility.Compatibility.INCOMPATIBLE;
+
+/**
+ * Routine for checking the compatibility of a {@link MessageHeaders} pair.
+ *
+ * The 'extractor' {@link Function} generates a 'container', a
jackson-compatible object containing the data that
+ * the routine bases it's compatibility-evaluation on.
+ * The 'assertion' {@link BiConsumer} accepts a pair of containers and asserts
the compatibility. Incompatibilities are
+ * signaled by throwing an {@link AssertionError}. This implies that the
method body will typically contain jUnit
+ * assertions.
+ */
+final class CompatibilityRoutine {
+
+ private final String key;
+ private final Class containerClass;
+ private final Function, C> extractor;
+ private final BiConsumer assertion;
+
+ CompatibilityRoutine(
+ final String key,
+ final Class containerClass,
+ final Function, C> extractor,
+ final BiConsumer assertion) {
+ this.key = key;
+ this.containerClass = containerClass;
+ this.extractor = extractor;
+ this.assertion = assertion;
+ }
+
+ String getKey() {
+ return key;
+ }
+
+ Class getContainerClass() {
+ return containerClass;
+ }
+
+ C getContainer(final MessageHeaders header) {
+ final C container = extractor.apply(header);
+ Assert.assertNotNull("Implementation error: Extractor returned
null.", container);
+ return container;
+ }
+
+ public CompatibilityCheckResult checkCompatibility(final Optional
old, final Optional cur) {
+ if (!old.isPresent() && !cur.isPresent()) {
+ Assert.fail(String.format(
+ "Implementation error: Compatibility check
container for routine %s for both old and new version is null.", key));
+ }
+ if (!old.isPresent()) {
+ // allow addition of new compatibility routines
+ return new CompatibilityCheckResult(COMPATIBLE);
+ }
+ if (!cur.isPresent()) {
+ // forbid removal of compatibility routines
+ return new CompatibilityCheckResult(
+ new AssertionError(String.format(
+ "Compatibility check container for
routine %s not found in current version.", key)));
+ }
+
+ Compatibility backwardCompatibility;
+ AssertionError backwardIncompatibilityCause = null;
+ try {
+ assertion.accept(old.get(), cur.get());
+ backwardCompatibility = COMPATIBLE;
+ } catch (final Exception | AssertionError e) {
+ backwardCompatibility = INCOMPATIBLE;
+ backwardIncompatibilityCause = new AssertionError(key +
": " + e.getMessage());
+ }
+
+ Compatibility forwardCompatibility;
+ try {
+ assertion.accept(cur.get(), old.get());
+ forwardCompatibility = COMPATIBLE;
+ } catch (final Exception | AssertionError e) {
Review comment:
It's not ideal that t
[GitHub] [flink] GJL commented on a change in pull request #7986: [FLINK-10517][rest] Add stability test
GJL commented on a change in pull request #7986: [FLINK-10517][rest] Add
stability test
URL: https://github.com/apache/flink/pull/7986#discussion_r267077674
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/rest/compatibility/CompatibilityRoutine.java
##
@@ -0,0 +1,114 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.rest.compatibility;
+
+import org.apache.flink.runtime.rest.messages.MessageHeaders;
+
+import org.junit.Assert;
+
+import java.util.Optional;
+import java.util.function.BiConsumer;
+import java.util.function.Function;
+
+import static
org.apache.flink.runtime.rest.compatibility.Compatibility.COMPATIBLE;
+import static
org.apache.flink.runtime.rest.compatibility.Compatibility.IDENTICAL;
+import static
org.apache.flink.runtime.rest.compatibility.Compatibility.INCOMPATIBLE;
+
+/**
+ * Routine for checking the compatibility of a {@link MessageHeaders} pair.
+ *
+ * The 'extractor' {@link Function} generates a 'container', a
jackson-compatible object containing the data that
+ * the routine bases it's compatibility-evaluation on.
+ * The 'assertion' {@link BiConsumer} accepts a pair of containers and asserts
the compatibility. Incompatibilities are
+ * signaled by throwing an {@link AssertionError}. This implies that the
method body will typically contain jUnit
+ * assertions.
+ */
+final class CompatibilityRoutine {
+
+ private final String key;
+ private final Class containerClass;
+ private final Function, C> extractor;
+ private final BiConsumer assertion;
+
+ CompatibilityRoutine(
+ final String key,
+ final Class containerClass,
+ final Function, C> extractor,
+ final BiConsumer assertion) {
+ this.key = key;
+ this.containerClass = containerClass;
+ this.extractor = extractor;
+ this.assertion = assertion;
+ }
+
+ String getKey() {
+ return key;
+ }
+
+ Class getContainerClass() {
+ return containerClass;
+ }
+
+ C getContainer(final MessageHeaders header) {
+ final C container = extractor.apply(header);
+ Assert.assertNotNull("Implementation error: Extractor returned
null.", container);
+ return container;
+ }
+
+ public CompatibilityCheckResult checkCompatibility(final Optional
old, final Optional cur) {
+ if (!old.isPresent() && !cur.isPresent()) {
+ Assert.fail(String.format(
+ "Implementation error: Compatibility check
container for routine %s for both old and new version is null.", key));
+ }
+ if (!old.isPresent()) {
+ // allow addition of new compatibility routines
+ return new CompatibilityCheckResult(COMPATIBLE);
+ }
+ if (!cur.isPresent()) {
+ // forbid removal of compatibility routines
+ return new CompatibilityCheckResult(
+ new AssertionError(String.format(
+ "Compatibility check container for
routine %s not found in current version.", key)));
+ }
+
+ Compatibility backwardCompatibility;
+ AssertionError backwardIncompatibilityCause = null;
+ try {
+ assertion.accept(old.get(), cur.get());
+ backwardCompatibility = COMPATIBLE;
+ } catch (final Exception | AssertionError e) {
+ backwardCompatibility = INCOMPATIBLE;
+ backwardIncompatibilityCause = new AssertionError(key +
": " + e.getMessage());
+ }
+
+ Compatibility forwardCompatibility;
+ try {
+ assertion.accept(cur.get(), old.get());
+ forwardCompatibility = COMPATIBLE;
+ } catch (final Exception | AssertionError e) {
Review comment:
It's not ideal that t