[GitHub] [flink] twalthr commented on a change in pull request #9174: [FLINK-13330][table-planner-blink] Remove unnecessary to reduce testing time in blink
twalthr commented on a change in pull request #9174:
[FLINK-13330][table-planner-blink] Remove unnecessary to reduce testing time in
blink
URL: https://github.com/apache/flink/pull/9174#discussion_r305225030
##
File path:
flink-table/flink-table-planner-blink/src/test/scala/org/apache/flink/table/runtime/utils/StreamingWithAggTestBase.scala
##
@@ -63,9 +63,11 @@ object StreamingWithAggTestBase {
@Parameterized.Parameters(name = "LocalGlobal={0}, {1}, StateBackend={2}")
def parameters(): util.Collection[Array[java.lang.Object]] = {
+// To avoid too long testing time, we not test all HEAP_BACKEND.
+// If HEAP_BACKEND has changed, please open it manually for testing.
Review comment:
Comments like this get lost in the code base. Tests like this should be
moved to a special manual tests package.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-13002) Expand Concept -> Glossary Section
[ https://issues.apache.org/jira/browse/FLINK-13002?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888587#comment-16888587 ] Jeff Yang commented on FLINK-13002: --- And I think we can added more some terms , as follows: * task slot * parallelism They are all used frequently. > Expand Concept -> Glossary Section > -- > > Key: FLINK-13002 > URL: https://issues.apache.org/jira/browse/FLINK-13002 > Project: Flink > Issue Type: Sub-task > Components: Documentation >Reporter: Konstantin Knauf >Priority: Major > > We use this ticket to collect terms, we would like to add to the Glossary in > the future: > * Snapshot > * Checkpoint > * Savepoint -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system
twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system URL: https://github.com/apache/flink/pull/9161#discussion_r305225956 ## File path: docs/dev/table/types.md ## @@ -0,0 +1,1201 @@ +--- +title: "Data Types" +nav-parent_id: tableapi +nav-pos: 1 +--- + + +Due to historical reasons, the data types of Flink's Table & SQL API were closely coupled to Flink's Review comment: Thanks, I readded DataSet for now because it is not deprecated yet. And this paragraph will be gone until then. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (FLINK-13002) Expand Concept -> Glossary Section
[ https://issues.apache.org/jira/browse/FLINK-13002?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888587#comment-16888587 ] Jeff Yang edited comment on FLINK-13002 at 7/19/19 7:08 AM: And I think we can added more some terms , as follows: * task slot * parallelism They are all used frequently. was (Author: highfei2...@126.com): And I think we can added more some terms , as follows: * task slot * parallelism They are all used frequently. > Expand Concept -> Glossary Section > -- > > Key: FLINK-13002 > URL: https://issues.apache.org/jira/browse/FLINK-13002 > Project: Flink > Issue Type: Sub-task > Components: Documentation >Reporter: Konstantin Knauf >Priority: Major > > We use this ticket to collect terms, we would like to add to the Glossary in > the future: > * Snapshot > * Checkpoint > * Savepoint -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (FLINK-12179) Remove legacy Instance
[
https://issues.apache.org/jira/browse/FLINK-12179?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888596#comment-16888596
]
TisonKun commented on FLINK-12179:
--
[~xleesf] I have attached a patch that you can make use of :- )
> Remove legacy Instance
> --
>
> Key: FLINK-12179
> URL: https://issues.apache.org/jira/browse/FLINK-12179
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.9.0
>Reporter: TisonKun
>Assignee: leesf
>Priority: Major
> Fix For: 1.10.0
>
> Attachments:
> 0001-FLINK-12179-coordination-Remove-legacy-class-Instanc.patch
>
>
> Remove legacy {{Instance}}.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Updated] (FLINK-12179) Remove legacy Instance
[
https://issues.apache.org/jira/browse/FLINK-12179?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
TisonKun updated FLINK-12179:
-
Attachment: 0001-FLINK-12179-coordination-Remove-legacy-class-Instanc.patch
> Remove legacy Instance
> --
>
> Key: FLINK-12179
> URL: https://issues.apache.org/jira/browse/FLINK-12179
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.9.0
>Reporter: TisonKun
>Assignee: leesf
>Priority: Major
> Fix For: 1.10.0
>
> Attachments:
> 0001-FLINK-12179-coordination-Remove-legacy-class-Instanc.patch
>
>
> Remove legacy {{Instance}}.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[GitHub] [flink] twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system
twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add
documentation for the new Table & SQL API type system
URL: https://github.com/apache/flink/pull/9161#discussion_r305227989
##
File path: docs/dev/table/types.md
##
@@ -0,0 +1,1201 @@
+---
+title: "Data Types"
+nav-parent_id: tableapi
+nav-pos: 1
+---
+
+
+Due to historical reasons, the data types of Flink's Table & SQL API were
closely coupled to Flink's
+`TypeInformation` before Flink 1.9. `TypeInformation` is used in DataSet and
DataStream API and is
+sufficient to describe all information needed to serialize and deserialize
JVM-based objects in a
+distributed setting.
+
+However, `TypeInformation` was not designed to properly represent logical
types independent of an
+actual JVM class. In the past, it was difficult to properly map SQL standard
types to this abstraction.
+Furthermore, some types were not SQL-compliant and were introduced without a
bigger picture in mind.
+
+Starting with Flink 1.9, the Table & SQL API will receive a new type system
that serves as a long-term
+solution for API stablility and standard compliance.
+
+Reworking the type system is a major effort that touches almost all
user-facing interfaces. Therefore, its introduction
+spans multiple releases and the community aims to finish this effort by Flink
1.10.
+
+Due to the simultaneous addition of a new planner for table programs (see
[FLINK-11439](https://issues.apache.org/jira/browse/FLINK-11439)),
+not every combination of planner and data type is supported. Furthermore,
planners might not support every
+data type with the desired precision or parameter.
+
+Attention Please see the planner
compatibility table and limitations
+section before using a data type.
+
+* This will be replaced by the TOC
+{:toc}
+
+Data Type
+-
+
+A *data type* describes the data type of a value in the table ecosystem. It
can be used to declare input and/or
+output types of operations.
+
+Flink's data types are similar to the SQL standard's *data type* terminology
but also contain information
+about the nullability of a value for efficient handling of scalar expressions.
+
+Examples of data types are:
+- `INT`
+- `INT NOT NULL`
+- `INTERVAL DAY TO SECOND(3)`
+- `ROW, myOtherField TIMESTAMP(3)>`
+
+A list of all pre-defined data types can be found in
[below](#list-of-data-types).
+
+### Data Types in the Table API
+
+Users of the JVM-based API are dealing with instances of
`org.apache.flink.table.types.DataType` within the Table API or when
Review comment:
The Python Table API has also data types but not in
`org.apache.flink.table.types.DataType` that's why added JVM here. We can add
an additional paragraph for Python users later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-13002) Expand Concept -> Glossary Section
[ https://issues.apache.org/jira/browse/FLINK-13002?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888598#comment-16888598 ] Jeff Yang commented on FLINK-13002: --- Hi,[~knaufk],Could you assignee to me? Thanks . > Expand Concept -> Glossary Section > -- > > Key: FLINK-13002 > URL: https://issues.apache.org/jira/browse/FLINK-13002 > Project: Flink > Issue Type: Sub-task > Components: Documentation >Reporter: Konstantin Knauf >Priority: Major > > We use this ticket to collect terms, we would like to add to the Glossary in > the future: > * Snapshot > * Checkpoint > * Savepoint -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (FLINK-12939) Translate "Apache Kafka Connector" page into Chinese
[ https://issues.apache.org/jira/browse/FLINK-12939?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888599#comment-16888599 ] TisonKun commented on FLINK-12939: -- [~highfei2...@126.com] sure you could file a new JIRA named, for example, " in ". > Translate "Apache Kafka Connector" page into Chinese > > > Key: FLINK-12939 > URL: https://issues.apache.org/jira/browse/FLINK-12939 > Project: Flink > Issue Type: Sub-task > Components: chinese-translation, Documentation >Reporter: Jark Wu >Assignee: Jeff Yang >Priority: Minor > > Translate the page > "https://ci.apache.org/projects/flink/flink-docs-master/dev/connectors/kafka.html"; > into Chinese. > The doc located in "flink/docs/dev/connectors/kafka.zh.md" -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] WeiZhong94 opened a new pull request #9177: [hotfix][docs] Fix loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html
WeiZhong94 opened a new pull request #9177: [hotfix][docs] Fix loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html URL: https://github.com/apache/flink/pull/9177 ## What is the purpose of the change *This pull request fixed the loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html* ## Brief change log - *Set the value of `permalink` in `/docs/redirects/linking_with_optional_modules.md` to `/dev/linking.html`.* ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #9177: [hotfix][docs] Fix loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html
flinkbot commented on issue #9177: [hotfix][docs] Fix loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html URL: https://github.com/apache/flink/pull/9177#issuecomment-513122349 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system
twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add
documentation for the new Table & SQL API type system
URL: https://github.com/apache/flink/pull/9161#discussion_r305229723
##
File path: docs/dev/table/types.md
##
@@ -0,0 +1,1201 @@
+---
+title: "Data Types"
+nav-parent_id: tableapi
+nav-pos: 1
+---
+
+
+Due to historical reasons, the data types of Flink's Table & SQL API were
closely coupled to Flink's
+`TypeInformation` before Flink 1.9. `TypeInformation` is used in DataSet and
DataStream API and is
+sufficient to describe all information needed to serialize and deserialize
JVM-based objects in a
+distributed setting.
+
+However, `TypeInformation` was not designed to properly represent logical
types independent of an
+actual JVM class. In the past, it was difficult to properly map SQL standard
types to this abstraction.
+Furthermore, some types were not SQL-compliant and were introduced without a
bigger picture in mind.
+
+Starting with Flink 1.9, the Table & SQL API will receive a new type system
that serves as a long-term
+solution for API stablility and standard compliance.
+
+Reworking the type system is a major effort that touches almost all
user-facing interfaces. Therefore, its introduction
+spans multiple releases and the community aims to finish this effort by Flink
1.10.
+
+Due to the simultaneous addition of a new planner for table programs (see
[FLINK-11439](https://issues.apache.org/jira/browse/FLINK-11439)),
+not every combination of planner and data type is supported. Furthermore,
planners might not support every
+data type with the desired precision or parameter.
+
+Attention Please see the planner
compatibility table and limitations
+section before using a data type.
+
+* This will be replaced by the TOC
+{:toc}
+
+Data Type
+-
+
+A *data type* describes the data type of a value in the table ecosystem. It
can be used to declare input and/or
+output types of operations.
+
+Flink's data types are similar to the SQL standard's *data type* terminology
but also contain information
+about the nullability of a value for efficient handling of scalar expressions.
+
+Examples of data types are:
+- `INT`
+- `INT NOT NULL`
+- `INTERVAL DAY TO SECOND(3)`
+- `ROW, myOtherField TIMESTAMP(3)>`
+
+A list of all pre-defined data types can be found in
[below](#list-of-data-types).
+
+### Data Types in the Table API
+
+Users of the JVM-based API are dealing with instances of
`org.apache.flink.table.types.DataType` within the Table API or when
+defining connectors, catalogs, or user-defined functions.
+
+A `DataType` instance has two responsibilities:
+- **Declaration of a logical type** which does not imply a concrete physical
representation for transmission
+or storage but defines the boundaries between JVM-based languages and the
table ecosystem.
+- *Optional:* **Giving hints about the physical representation of data to the
planner** which is useful at the edges to other APIs .
+
+For JVM-based languages, all pre-defined data types are available in
`org.apache.flink.table.api.DataTypes`.
+
+It is recommended to add a star import to your table programs for having a
fluent API:
+
+
+
+
+{% highlight java %}
+import static org.apache.flink.table.api.DataTypes.*;
+
+DataType t = INTERVAL(DAY(), SECOND(3));
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+import org.apache.flink.table.api.DataTypes._
+
+val t: DataType = INTERVAL(DAY(), SECOND(3));
+{% endhighlight %}
+
+
+
+
+ Physical Hints
+
+Physical hints are required at the edges of the table ecosystem. Hints
indicate the data format that an implementation
Review comment:
I reworded the sentence to:
```
Physical hints are required at the edges of the table ecosystem where the
SQL-based type system ends and programming-specific data types are required.
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system
twalthr commented on a change in pull request #9161: [FLINK-13262][docs] Add
documentation for the new Table & SQL API type system
URL: https://github.com/apache/flink/pull/9161#discussion_r305229723
##
File path: docs/dev/table/types.md
##
@@ -0,0 +1,1201 @@
+---
+title: "Data Types"
+nav-parent_id: tableapi
+nav-pos: 1
+---
+
+
+Due to historical reasons, the data types of Flink's Table & SQL API were
closely coupled to Flink's
+`TypeInformation` before Flink 1.9. `TypeInformation` is used in DataSet and
DataStream API and is
+sufficient to describe all information needed to serialize and deserialize
JVM-based objects in a
+distributed setting.
+
+However, `TypeInformation` was not designed to properly represent logical
types independent of an
+actual JVM class. In the past, it was difficult to properly map SQL standard
types to this abstraction.
+Furthermore, some types were not SQL-compliant and were introduced without a
bigger picture in mind.
+
+Starting with Flink 1.9, the Table & SQL API will receive a new type system
that serves as a long-term
+solution for API stablility and standard compliance.
+
+Reworking the type system is a major effort that touches almost all
user-facing interfaces. Therefore, its introduction
+spans multiple releases and the community aims to finish this effort by Flink
1.10.
+
+Due to the simultaneous addition of a new planner for table programs (see
[FLINK-11439](https://issues.apache.org/jira/browse/FLINK-11439)),
+not every combination of planner and data type is supported. Furthermore,
planners might not support every
+data type with the desired precision or parameter.
+
+Attention Please see the planner
compatibility table and limitations
+section before using a data type.
+
+* This will be replaced by the TOC
+{:toc}
+
+Data Type
+-
+
+A *data type* describes the data type of a value in the table ecosystem. It
can be used to declare input and/or
+output types of operations.
+
+Flink's data types are similar to the SQL standard's *data type* terminology
but also contain information
+about the nullability of a value for efficient handling of scalar expressions.
+
+Examples of data types are:
+- `INT`
+- `INT NOT NULL`
+- `INTERVAL DAY TO SECOND(3)`
+- `ROW, myOtherField TIMESTAMP(3)>`
+
+A list of all pre-defined data types can be found in
[below](#list-of-data-types).
+
+### Data Types in the Table API
+
+Users of the JVM-based API are dealing with instances of
`org.apache.flink.table.types.DataType` within the Table API or when
+defining connectors, catalogs, or user-defined functions.
+
+A `DataType` instance has two responsibilities:
+- **Declaration of a logical type** which does not imply a concrete physical
representation for transmission
+or storage but defines the boundaries between JVM-based languages and the
table ecosystem.
+- *Optional:* **Giving hints about the physical representation of data to the
planner** which is useful at the edges to other APIs .
+
+For JVM-based languages, all pre-defined data types are available in
`org.apache.flink.table.api.DataTypes`.
+
+It is recommended to add a star import to your table programs for having a
fluent API:
+
+
+
+
+{% highlight java %}
+import static org.apache.flink.table.api.DataTypes.*;
+
+DataType t = INTERVAL(DAY(), SECOND(3));
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+import org.apache.flink.table.api.DataTypes._
+
+val t: DataType = INTERVAL(DAY(), SECOND(3));
+{% endhighlight %}
+
+
+
+
+ Physical Hints
+
+Physical hints are required at the edges of the table ecosystem. Hints
indicate the data format that an implementation
Review comment:
I reworded the sentence to:
```Physical hints are required at the edges of the table ecosystem where the
SQL-based type system ends and programming-specific data types are required.
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] TsReaper commented on issue #9139: [FLINK-13304][FLINK-13322][FLINK-13323][table-runtime-blink] Fix implementation of getString and getBinary method in NestedRow, fix serializer resto
TsReaper commented on issue #9139: [FLINK-13304][FLINK-13322][FLINK-13323][table-runtime-blink] Fix implementation of getString and getBinary method in NestedRow, fix serializer restore in BaseArray/Map serializer and add tests for complex data formats URL: https://github.com/apache/flink/pull/9139#issuecomment-513122891 Travis: https://travis-ci.com/TsReaper/flink/jobs/217472587 Note that I reverted the modification about flink-mapr-fs in this travis. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] eamontaaffe opened a new pull request #9178: Typo in `scala_api_quickstart.md`
eamontaaffe opened a new pull request #9178: Typo in `scala_api_quickstart.md` URL: https://github.com/apache/flink/pull/9178 Hey, I just noticed a small typo, so I thought I'd raise a PR. ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluser with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #9178: Typo in `scala_api_quickstart.md`
flinkbot commented on issue #9178: Typo in `scala_api_quickstart.md` URL: https://github.com/apache/flink/pull/9178#issuecomment-513124417 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-13334) Remove legacy implementation of slot sharing
TisonKun created FLINK-13334:
Summary: Remove legacy implementation of slot sharing
Key: FLINK-13334
URL: https://issues.apache.org/jira/browse/FLINK-13334
Project: Flink
Issue Type: Sub-task
Components: Runtime / Coordination
Affects Versions: 1.10.0
Reporter: TisonKun
Fix For: 1.10.0
cc [~till.rohrmann] [~srichter]
>From my investigation currently Flink use {{SlotSharingManager}} and
>{{SlotSharingGroupId}} for achieving slot sharing. And thus
>{{SlotSharingGroupAssignment}} {{SlotSharingGroup}} and {{SharedSlot}} are all
>legacy concept.
Notice that the ongoing scheduler re-design touches frequently tests based on
legacy slot/instance logic or even uses it for testing. I'd like to nudge this
process for totally remove legacy code from our code base.
Also I attach a patch on FLINK-12179 that remove {{Instance}}. With current
contribution workflow your shepherds are significant :- )
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (FLINK-12979) Sending data to kafka with CsvRowSerializationSchema always adding a "\n", "\r","\r\n" at the end of the message
[ https://issues.apache.org/jira/browse/FLINK-12979?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888608#comment-16888608 ] Timo Walther commented on FLINK-12979: -- Yes, I think that is ok. Given that the tests pass. Feel free to open a PR that updates docs, descriptor, factory, and tests. > Sending data to kafka with CsvRowSerializationSchema always adding a "\n", > "\r","\r\n" at the end of the message > > > Key: FLINK-12979 > URL: https://issues.apache.org/jira/browse/FLINK-12979 > Project: Flink > Issue Type: Bug > Components: API / Type Serialization System >Affects Versions: 1.8.0, 1.8.1, 1.8.2, 1.9.0, 2.0.0 >Reporter: chaiyongqiang >Assignee: Hugo Louro >Priority: Major > > When sending data to kafka using CsvRowSerializationSchema, the > CsvRowSerializationSchema#serialize method helps generating value for > KafkaRecord, which will call CsvEncoder#endRow and in which a > _cfgLineSeparator will be added at the end of KafkaRecord.value. > But For CsvRowSerializationSchema#Builder , when you calling the mothod > setLineDelimiter only "\n","\r","\r\n" could be used as the parameter. > It's not friendly when you want to send a message "123,pingpong,21:00" to > kafka but kafka receives a message "123,pingpong,21:00\r\n". > I'm not sure about the reason for limitting the lineDelimiter to > "\n","\r","\r\n" ? In previous version and jackson-databind, there's no > limits on lineDelimiter. > But at least it should let the application developer to set LineDelimiter > with "". -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] twalthr commented on issue #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system
twalthr commented on issue #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system URL: https://github.com/apache/flink/pull/9161#issuecomment-513126194 Thanks @sjwiesman. I updated the PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-13111) FlinkKinesisConsumer fails with endpoint and region used together
[
https://issues.apache.org/jira/browse/FLINK-13111?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888613#comment-16888613
]
Robert Metzger commented on FLINK-13111:
[~carp84] I saw that you've assigned yourself to the ticket. What's your plan?
> FlinkKinesisConsumer fails with endpoint and region used together
> -
>
> Key: FLINK-13111
> URL: https://issues.apache.org/jira/browse/FLINK-13111
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kinesis
>Reporter: Jack Tuck
>Assignee: Yu Li
>Priority: Major
>
> So far I have followed the instructions documented for Flink's kinesis
> connector to use a local Kinesis. (Using Flink 1.8 and Kinesis connector 1.8)
> [https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kinesis.html#using-non-aws-kinesis-endpoints-for-testing]
> {code:java}
> Properties producerConfig = new Properties();
> producerConfig.put(AWSConfigConstants.AWS_REGION, "us-east-1");
> producerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id");
> producerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY,
> "aws_secret_access_key");
> producerConfig.put(AWSConfigConstants.AWS_ENDPOINT,
> "http://localhost:4567";);{code}
> With a Flink producer, these instructions work with a local kinesis (I use
> Kinesalite).
> However, with a Flink consumer, I get an exception that `aws.region` and
> `aws.endpoint` are not *both* allowed.
> {noformat}
> org.apache.flink.client.program.ProgramInvocationException: The main method
> caused an error: For FlinkKinesisConsumer either AWS region ('aws.region') or
> AWS endpoint ('aws.endpoint') must be set in the config.{noformat}
> Is this a bug in the connector? I found the PR which fixed this but maybe for
> only the producer [https://github.com/apache/flink/pull/6045] .
> I found a [workaround on Flink's mailing
> list]([http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Can-t-get-the-FlinkKinesisProducer-to-work-against-Kinesalite-for-tests-td23438.html]),
> but their issue is with the producer rather than the consumer but perhaps
> they got that the wrong way around, it is after all weird how there are two
> codepaths for consumer/producer.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Updated] (FLINK-6962) Add a create table SQL DDL
[ https://issues.apache.org/jira/browse/FLINK-6962?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Timo Walther updated FLINK-6962: Description: This Jira adds support to allow user define the DDL for source and sink tables, including the waterMark(on source table) and emit SLA (on result table). The detailed design doc will be attached soon. This issue covered adding batch DDL support. Streaming-specific DDL support will be added later. was:This Jira adds support to allow user define the DDL for source and sink tables, including the waterMark(on source table) and emit SLA (on result table). The detailed design doc will be attached soon. > Add a create table SQL DDL > -- > > Key: FLINK-6962 > URL: https://issues.apache.org/jira/browse/FLINK-6962 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Reporter: Shaoxuan Wang >Assignee: Danny Chan >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > > This Jira adds support to allow user define the DDL for source and sink > tables, including the waterMark(on source table) and emit SLA (on result > table). The detailed design doc will be attached soon. > This issue covered adding batch DDL support. Streaming-specific DDL support > will be added later. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (FLINK-6962) Add a create table SQL DDL
[ https://issues.apache.org/jira/browse/FLINK-6962?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888615#comment-16888615 ] Timo Walther commented on FLINK-6962: - I updated the issue description to avoid confusion. Currently, we just expose a batch DDL. A streaming-specific DDL is planned for Flink 1.10. > Add a create table SQL DDL > -- > > Key: FLINK-6962 > URL: https://issues.apache.org/jira/browse/FLINK-6962 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Reporter: Shaoxuan Wang >Assignee: Danny Chan >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > > This Jira adds support to allow user define the DDL for source and sink > tables, including the waterMark(on source table) and emit SLA (on result > table). The detailed design doc will be attached soon. > This issue covered adding batch DDL support. Streaming-specific DDL support > will be added later. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Updated] (FLINK-13335) Align the SQL DDL with FLIP-37
[ https://issues.apache.org/jira/browse/FLINK-13335?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Timo Walther updated FLINK-13335: - Fix Version/s: 1.9.0 > Align the SQL DDL with FLIP-37 > -- > > Key: FLINK-13335 > URL: https://issues.apache.org/jira/browse/FLINK-13335 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Reporter: Timo Walther >Assignee: Timo Walther >Priority: Blocker > Fix For: 1.9.0 > > > At a first glance it does not seem that the newly introduced DDL is compliant > with FLIP-37. We should ensure consistent behavior esp. also for corner cases. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Created] (FLINK-13335) Align the SQL DDL with FLIP-37
Timo Walther created FLINK-13335: Summary: Align the SQL DDL with FLIP-37 Key: FLINK-13335 URL: https://issues.apache.org/jira/browse/FLINK-13335 Project: Flink Issue Type: Sub-task Components: Table SQL / API Reporter: Timo Walther Assignee: Timo Walther At a first glance it does not seem that the newly introduced DDL is compliant with FLIP-37. We should ensure consistent behavior esp. also for corner cases. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Updated] (FLINK-13289) Blink Planner JDBCUpsertTableSink : UnsupportedOperationException "JDBCUpsertTableSink can not support "
[
https://issues.apache.org/jira/browse/FLINK-13289?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Robert Metzger updated FLINK-13289:
---
Component/s: Table SQL / Planner
> Blink Planner JDBCUpsertTableSink : UnsupportedOperationException
> "JDBCUpsertTableSink can not support "
>
>
> Key: FLINK-13289
> URL: https://issues.apache.org/jira/browse/FLINK-13289
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / Planner
>Affects Versions: 1.9.0
>Reporter: LakeShen
>Priority: Major
>
> Hi , in flink-jdbc connector module, I change the Flink planner to Blink
> planner to test all test case,because we want to use Blank planner in our
> program. When I test the JDBCUpsertTableSinkITCase class , the method
> testUpsert throw the exception:
> {color:red}java.lang.UnsupportedOperationException: JDBCUpsertTableSink can
> not support {color}
> I saw the src code,in Flink planner , the StreamPlanner set the
> JDBCUpsertTableSink' keyFields,
> but in Blink planner , I didn't find anywhere to set JDBCUpsertTableSink'
> keyFields,so JDBCUpsertTableSink keyFields is null, when execute
> JDBCUpsertTableSink newFormat(),
> it thrown the exception.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (FLINK-12249) Type equivalence check fails for Window Aggregates
[
https://issues.apache.org/jira/browse/FLINK-12249?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888670#comment-16888670
]
Hequn Cheng commented on FLINK-12249:
-
Same with the comments from [~godfreyhe]. I have verified the approach. It
works fine. :) I will update the PR soon. Thank you for every one!
> Type equivalence check fails for Window Aggregates
> --
>
> Key: FLINK-12249
> URL: https://issues.apache.org/jira/browse/FLINK-12249
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Legacy Planner, Tests
>Affects Versions: 1.9.0
>Reporter: Dawid Wysakowicz
>Assignee: Hequn Cheng
>Priority: Critical
> Fix For: 1.9.0
>
>
> Creating Aggregate node fails in rules: {{LogicalWindowAggregateRule}} and
> {{ExtendedAggregateExtractProjectRule}} if the only grouping expression is a
> window and
> we compute aggregation on NON NULLABLE field.
> The root cause for that, is how return type inference strategies in calcite
> work and how we handle window aggregates. Take
> {{org.apache.calcite.sql.type.ReturnTypes#AGG_SUM}} as an example, based on
> {{groupCount}} it adjusts type nullability based on groupCount.
> Though we pass a false information as we strip down window aggregation from
> groupSet (in {{LogicalWindowAggregateRule}}).
> One can reproduce this problem also with a unit test like this:
> {code}
> @Test
> def testTumbleFunction2() = {
>
> val innerQuery =
> """
> |SELECT
> | CASE a WHEN 1 THEN 1 ELSE 99 END AS correct,
> | rowtime
> |FROM MyTable
> """.stripMargin
> val sql =
> "SELECT " +
> " SUM(correct) as cnt, " +
> " TUMBLE_START(rowtime, INTERVAL '15' MINUTE) as wStart " +
> s"FROM ($innerQuery) " +
> "GROUP BY TUMBLE(rowtime, INTERVAL '15' MINUTE)"
> val expected = ""
> streamUtil.verifySql(sql, expected)
> }
> {code}
> This causes e2e tests to fail:
> https://travis-ci.org/apache/flink/builds/521183361?utm_source=slack&utm_medium=notificationhttps://travis-ci.org/apache/flink/builds/521183361?utm_source=slack&utm_medium=notification
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Updated] (FLINK-13335) Align the SQL CREATE TABLE DDL with FLIP-37
[ https://issues.apache.org/jira/browse/FLINK-13335?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Timo Walther updated FLINK-13335: - Summary: Align the SQL CREATE TABLE DDL with FLIP-37 (was: Align the SQL DDL with FLIP-37) > Align the SQL CREATE TABLE DDL with FLIP-37 > --- > > Key: FLINK-13335 > URL: https://issues.apache.org/jira/browse/FLINK-13335 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Reporter: Timo Walther >Assignee: Timo Walther >Priority: Blocker > Fix For: 1.9.0 > > > At a first glance it does not seem that the newly introduced DDL is compliant > with FLIP-37. We should ensure consistent behavior esp. also for corner cases. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Updated] (FLINK-13336) Remove the legacy batch fault tolerance page and redirect it to the new task failure recovery page
[ https://issues.apache.org/jira/browse/FLINK-13336?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zhu Zhu updated FLINK-13336: Description: The [batch fault tolerance page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]] is describing a deprecated way to configure restart strategies. We should remove it and redirect it to the [task failure recovery page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]] for latest description of the fault tolerance configurations, including restart strategies and failover strategies. was:The [batch fault tolerance page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]] is describing a deprecated way to configure restart strategies. We should remove it and redirect it to the [task failure recovery page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]] for latest description of the fault tolerance configurations, including restart strategies and failover strategies. > Remove the legacy batch fault tolerance page and redirect it to the new task > failure recovery page > -- > > Key: FLINK-13336 > URL: https://issues.apache.org/jira/browse/FLINK-13336 > Project: Flink > Issue Type: Task > Components: Documentation >Affects Versions: 1.9.0 >Reporter: Zhu Zhu >Priority: Minor > > The [batch fault tolerance > page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]] > is describing a deprecated way to configure restart strategies. > We should remove it and redirect it to the [task failure recovery > page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]] > for latest description of the fault tolerance configurations, including > restart strategies and failover strategies. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Created] (FLINK-13336) Remove the legacy batch fault tolerance page and redirect it to the new task failure recovery page
Zhu Zhu created FLINK-13336: --- Summary: Remove the legacy batch fault tolerance page and redirect it to the new task failure recovery page Key: FLINK-13336 URL: https://issues.apache.org/jira/browse/FLINK-13336 Project: Flink Issue Type: Task Components: Documentation Affects Versions: 1.9.0 Reporter: Zhu Zhu The [batch fault tolerance page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]] is describing a deprecated way to configure restart strategies. We should remove it and redirect it to the [task failure recovery page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]] for latest description of the fault tolerance configurations, including restart strategies and failover strategies. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Updated] (FLINK-13336) Remove the legacy batch fault tolerance page and redirect it to the new task failure recovery page
[ https://issues.apache.org/jira/browse/FLINK-13336?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zhu Zhu updated FLINK-13336: Description: The batch fault tolerance page([https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]) is describing a deprecated way to configure restart strategies. We should remove it and redirect it to the task failure recovery page ([https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]) for latest description of the fault tolerance configurations, including restart strategies and failover strategies. was: The [batch fault tolerance page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]] is describing a deprecated way to configure restart strategies. We should remove it and redirect it to the [task failure recovery page|[https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]] for latest description of the fault tolerance configurations, including restart strategies and failover strategies. > Remove the legacy batch fault tolerance page and redirect it to the new task > failure recovery page > -- > > Key: FLINK-13336 > URL: https://issues.apache.org/jira/browse/FLINK-13336 > Project: Flink > Issue Type: Task > Components: Documentation >Affects Versions: 1.9.0 >Reporter: Zhu Zhu >Priority: Minor > > The batch fault tolerance > page([https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/batch/fault_tolerance.html]) > is describing a deprecated way to configure restart strategies. > We should remove it and redirect it to the task failure recovery page > ([https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/restart_strategies.html]) > for latest description of the fault tolerance configurations, including > restart strategies and failover strategies. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] zhuzhurk commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
zhuzhurk commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305246912 ## File path: docs/dev/task_failure_recovery.md ## @@ -1,5 +1,5 @@ --- -title: "Restart Strategies" +title: "Task Failure Recovery" Review comment: I opened a ticket for it: https://issues.apache.org/jira/browse/FLINK-13336 . Can start working on it once this PR is merged. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] godfreyhe commented on issue #9168: [FLINK-13286][table-api] Port connector related validators to api-java-bridge
godfreyhe commented on issue #9168: [FLINK-13286][table-api] Port connector related validators to api-java-bridge URL: https://github.com/apache/flink/pull/9168#issuecomment-513139000 > Hi @JingsongLi , I think we should also move the corresponding tests to table-api or table-common, because they do not depend on planner. What do you think? > > `FileSystemTest` -> `flink-table-common` > `RowtimeTest` -> `flink-table-api-java-bridge` > `SchemaValidator` -> `flink-table-api-java-bridge` I think we can move java test, and scala test could be port to java in another commit. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] hequn8128 commented on issue #9141: [FLINK-12249][table] Fix type equivalence check problems for Window Aggregates
hequn8128 commented on issue #9141: [FLINK-12249][table] Fix type equivalence check problems for Window Aggregates URL: https://github.com/apache/flink/pull/9141#issuecomment-513142925 @dawidwys @godfreyhe @wuchong @sunjincheng121 Hi, I have updated the PR with the latest solution: Change the types to the inferred types in the Aggregate and then cast back in the Project after Aggregate. I think this makes sure the right semantics and also brings minor changes to the under-released Flink. The long term solution as we discussed in the jira ticket should be considered later after 1.9. Would be great if you can take a look. Best, Hequn This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] hequn8128 edited a comment on issue #9141: [FLINK-12249][table] Fix type equivalence check problems for Window Aggregates
hequn8128 edited a comment on issue #9141: [FLINK-12249][table] Fix type equivalence check problems for Window Aggregates URL: https://github.com/apache/flink/pull/9141#issuecomment-513142925 @dawidwys @godfreyhe @wuchong @sunjincheng121 Hi, I have updated the PR with the latest solution: In the LogicalWindowAggregateRule, change the types to the inferred types in the Aggregate and then cast back in the Project after Aggregate. I think this makes sure the right semantics and also brings minor changes to the under-released Flink. The long term solution as we discussed in the jira ticket should be considered later after 1.9. Would be great if you can take a look. Best, Hequn This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-13337) Do not need to backup and restore streamEnv config in BatchExecutor
XuPingyong created FLINK-13337: -- Summary: Do not need to backup and restore streamEnv config in BatchExecutor Key: FLINK-13337 URL: https://issues.apache.org/jira/browse/FLINK-13337 Project: Flink Issue Type: Task Components: Table SQL / Planner Affects Versions: 1.9.0, 1.10.0 Reporter: XuPingyong Fix For: 1.9.0, 1.10.0 -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink
table config to documentation
URL: https://github.com/apache/flink/pull/9024#discussion_r305214830
##
File path: docs/dev/table/blink.md
##
@@ -0,0 +1,33 @@
+---
+title: "Blink Table"
+nav-id: "config"
+nav-parent_id: tableapi
+nav-pos: 4
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+### Blink Table Optimizer
+ {% include generated/optimizer_config_configuration.html %}
+
+### Blink Table Execution
Review comment:
Execution Options
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink
table config to documentation
URL: https://github.com/apache/flink/pull/9024#discussion_r305214755
##
File path: docs/dev/table/blink.md
##
@@ -0,0 +1,33 @@
+---
+title: "Blink Table"
+nav-id: "config"
+nav-parent_id: tableapi
+nav-pos: 4
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+### Blink Table Optimizer
Review comment:
Optimizer Options
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink
table config to documentation
URL: https://github.com/apache/flink/pull/9024#discussion_r305254580
##
File path:
flink-docs/src/test/java/org/apache/flink/docs/configuration/ConfigOptionsDocsCompletenessITCase.java
##
@@ -177,7 +177,8 @@ private static void
compareDocumentedAndExistingOptions(Map
element.getElementsByTag("tbody").get(0))
.flatMap(element ->
element.getElementsByTag("tr").stream())
.map(tableRow -> {
- String key = tableRow.child(0).text();
+ // split space to exclude document tags.
+ String key = tableRow.child(0).text().split("
")[0];;
Review comment:
What's the case to fix?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation URL: https://github.com/apache/flink/pull/9024#discussion_r305214636 ## File path: docs/dev/table/blink.md ## @@ -0,0 +1,33 @@ +--- +title: "Blink Table" Review comment: Configuration This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation URL: https://github.com/apache/flink/pull/9024#discussion_r305214636 ## File path: docs/dev/table/blink.md ## @@ -0,0 +1,33 @@ +--- +title: "Blink Table" Review comment: Configuration This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink
table config to documentation
URL: https://github.com/apache/flink/pull/9024#discussion_r305214755
##
File path: docs/dev/table/blink.md
##
@@ -0,0 +1,33 @@
+---
+title: "Blink Table"
+nav-id: "config"
+nav-parent_id: tableapi
+nav-pos: 4
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+### Blink Table Optimizer
Review comment:
Optimizer Options
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on a change in pull request #9024: [FLINK-13119] add blink
table config to documentation
URL: https://github.com/apache/flink/pull/9024#discussion_r305214830
##
File path: docs/dev/table/blink.md
##
@@ -0,0 +1,33 @@
+---
+title: "Blink Table"
+nav-id: "config"
+nav-parent_id: tableapi
+nav-pos: 4
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+### Blink Table Optimizer
+ {% include generated/optimizer_config_configuration.html %}
+
+### Blink Table Execution
Review comment:
Execution Options
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on issue #9024: [FLINK-13119] add blink table config to documentation
wuchong commented on issue #9024: [FLINK-13119] add blink table config to documentation URL: https://github.com/apache/flink/pull/9024#issuecomment-513146074 I think we need to refactor the config page. I wrote a draft for this and pushed the commit to my repo: https://github.com/wuchong/flink/tree/pull/9024. Can you pick the commit to your branch @XuPingyong and continue the reviewing? Here is a preview. 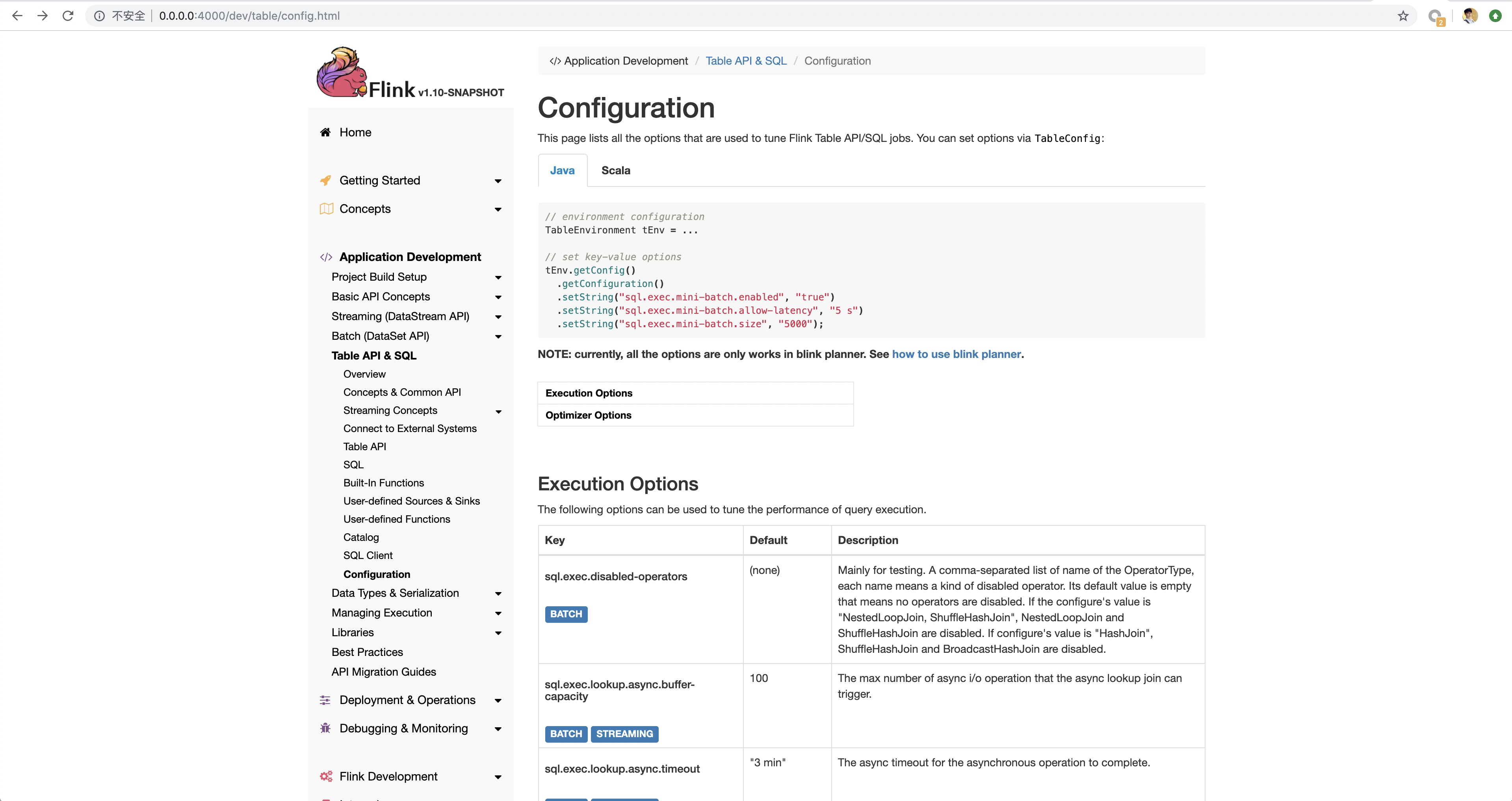 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] XuPingyong opened a new pull request #9179: [FLINK-13117][table-planner-blink] Do not need to backup and restore …
XuPingyong opened a new pull request #9179: [FLINK-13117][table-planner-blink] Do not need to backup and restore … URL: https://github.com/apache/flink/pull/9179 …streamEnv config in BatchExecutor ## What is the purpose of the change Because streamEnv can not be reuse for batch table job, streamEnv config is no need to backup and restore. ## Brief change log Minor fix in BatchExecutor. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): ( no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: ( no) - The serializers: ( no ) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: ( no ) - The S3 file system connector: ( no) ## Documentation - Does this pull request introduce a new feature? ( no) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-13117) Serialize Issue when restoring from savepoint
[ https://issues.apache.org/jira/browse/FLINK-13117?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-13117: --- Labels: pull-request-available (was: ) > Serialize Issue when restoring from savepoint > - > > Key: FLINK-13117 > URL: https://issues.apache.org/jira/browse/FLINK-13117 > Project: Flink > Issue Type: Bug >Reporter: dmgkeke >Priority: Major > Labels: pull-request-available > > Hi, I have one question. > My application should be maintained without loss of data. > So I use savepoint to deploy a new application. > > Normally there is no problem in restarting. > However, when the schema of some case classes is changed, a serialize error > occurs at restart. > > How can I resolve this? > Flink version is 1.8.0 > Here is the error log. > Thank you. > > org.apache.flink.util.StateMigrationException: The new state serializer > cannot be incompatible. > at > org.apache.flink.contrib.streaming.state.RocksDBKeyedStateBackend.updateRestoredStateMetaInfo(RocksDBKeyedStateBackend.java:527) > at > org.apache.flink.contrib.streaming.state.RocksDBKeyedStateBackend.tryRegisterKvStateInformation(RocksDBKeyedStateBackend.java:475) > at > org.apache.flink.contrib.streaming.state.RocksDBKeyedStateBackend.createInternalState(RocksDBKeyedStateBackend.java:613) > at > org.apache.flink.runtime.state.KeyedStateFactory.createInternalState(KeyedStateFactory.java:47) > at > org.apache.flink.runtime.state.ttl.TtlStateFactory.createStateAndWrapWithTtlIfEnabled(TtlStateFactory.java:72) > at > org.apache.flink.runtime.state.AbstractKeyedStateBackend.getOrCreateKeyedState(AbstractKeyedStateBackend.java:286) > at > org.apache.flink.streaming.api.operators.AbstractStreamOperator.getOrCreateKeyedState(AbstractStreamOperator.java:568) > at > org.apache.flink.streaming.runtime.operators.windowing.WindowOperator.open(WindowOperator.java:240) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.openAllOperators(StreamTask.java:424) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:290) > at org.apache.flink.runtime.taskmanager.Task.run(Task.java:711) > at java.lang.Thread.run(Thread.java:748) > -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] flinkbot commented on issue #9179: [FLINK-13117][table-planner-blink] Do not need to backup and restore …
flinkbot commented on issue #9179: [FLINK-13117][table-planner-blink] Do not need to backup and restore … URL: https://github.com/apache/flink/pull/9179#issuecomment-513147622 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-13331) Add TestMiniClusters to maintain cache share cluster between Tests
[ https://issues.apache.org/jira/browse/FLINK-13331?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888701#comment-16888701 ] Jingsong Lee commented on FLINK-13331: -- [~jark] Can you assign this one to me? > Add TestMiniClusters to maintain cache share cluster between Tests > -- > > Key: FLINK-13331 > URL: https://issues.apache.org/jira/browse/FLINK-13331 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Planner >Reporter: Jingsong Lee >Priority: Major > Fix For: 1.9.0, 1.10.0 > > -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (FLINK-12578) Use secure URLs for Maven repositories
[ https://issues.apache.org/jira/browse/FLINK-12578?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888702#comment-16888702 ] Chesnay Schepler commented on FLINK-12578: -- Additional fix for travis_controller.sh: master: 1869c2892785bd471c2ca8b27851f000fd489f8b 1.9: eb3d00a5a5d7ba1b9c375ff66a689438e6c7972e 1.8: 330516c08b33c8ca9c29563a8406e1a89c9e39ae 1.7: 7758cddca734b37dcc794a096f2c63e17ad9acc5 > Use secure URLs for Maven repositories > -- > > Key: FLINK-12578 > URL: https://issues.apache.org/jira/browse/FLINK-12578 > Project: Flink > Issue Type: Improvement > Components: Build System >Affects Versions: 1.6.4, 1.7.2, 1.8.0, 1.9.0 >Reporter: Jungtaek Lim >Assignee: Jungtaek Lim >Priority: Blocker > Labels: pull-request-available > Fix For: 1.7.3, 1.8.2, 1.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > > Currently, some of repository URLs in Maven pom.xml are http scheme. Ideally > they should have been https scheme. > Below is the list of repositories which use http scheme in pom files for now: > * Confluent > * HWX > * MapR -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] JingsongLi opened a new pull request #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases
JingsongLi opened a new pull request #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases URL: https://github.com/apache/flink/pull/9180 ## What is the purpose of the change Add CachedMiniClusterWithClientResource to share cluster between ITCases. This should reduce a lot of test time. ## Verifying this change This change is already covered by existing tests. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? JavaDocs This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-13331) Add TestMiniClusters to maintain cache share cluster between Tests
[ https://issues.apache.org/jira/browse/FLINK-13331?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-13331: --- Labels: pull-request-available (was: ) > Add TestMiniClusters to maintain cache share cluster between Tests > -- > > Key: FLINK-13331 > URL: https://issues.apache.org/jira/browse/FLINK-13331 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Planner >Reporter: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0, 1.10.0 > > -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (FLINK-12728) taskmanager container can't launch on nodemanager machine because of kerberos
[ https://issues.apache.org/jira/browse/FLINK-12728?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888705#comment-16888705 ] wgcn commented on FLINK-12728: -- hi Tao Yang,Andrey Zagrebin it's does work by setting yarn.resourcemanager.proxy-user-privileges.enabled =true ,hadoop.proxyuser.yarn.hosts=*,hadoop.proxyuser.yarn.groups=* ,and it may be useful for other user if it's recorded in flink document. > taskmanager container can't launch on nodemanager machine because of > kerberos > --- > > Key: FLINK-12728 > URL: https://issues.apache.org/jira/browse/FLINK-12728 > Project: Flink > Issue Type: Bug > Components: Deployment / YARN >Affects Versions: 1.7.2 > Environment: linux > jdk8 > hadoop 2.7.2 > flink 1.7.2 >Reporter: wgcn >Priority: Major > Attachments: AM.log, NM.log > > > job can't restart when flink job has been running for a long time and > then taskmanager restarting ,i find log in AM that AM request > containers taskmanager all the time . the log in NodeManager show > that the new requested containers can't downloading file from hdfs because > of kerberos . I configed the keytab config that > security.kerberos.login.use-ticket-cache: false > security.kerberos.login.keytab: /data/sysdir/knit/user/.flink.keytab > security.kerberos.login.principal: > at flink-client machine and keytab is exist. > I showed the logs at AM and NodeManager below. > > > > -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] flinkbot commented on issue #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases
flinkbot commented on issue #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases URL: https://github.com/apache/flink/pull/9180#issuecomment-513149650 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (FLINK-12728) taskmanager container can't launch on nodemanager machine because of kerberos
[ https://issues.apache.org/jira/browse/FLINK-12728?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] wgcn closed FLINK-12728. Resolution: Resolved *in core-site.xml* hadoop.proxyuser.yarn.hosts * hadoop.proxyuser.yarn.groups * in *yarn**-site.xml* yarn.resourcemanager.proxy-user-privileges.enabled true > taskmanager container can't launch on nodemanager machine because of > kerberos > --- > > Key: FLINK-12728 > URL: https://issues.apache.org/jira/browse/FLINK-12728 > Project: Flink > Issue Type: Bug > Components: Deployment / YARN >Affects Versions: 1.7.2 > Environment: linux > jdk8 > hadoop 2.7.2 > flink 1.7.2 >Reporter: wgcn >Priority: Major > Attachments: AM.log, NM.log > > > job can't restart when flink job has been running for a long time and > then taskmanager restarting ,i find log in AM that AM request > containers taskmanager all the time . the log in NodeManager show > that the new requested containers can't downloading file from hdfs because > of kerberos . I configed the keytab config that > security.kerberos.login.use-ticket-cache: false > security.kerberos.login.keytab: /data/sysdir/knit/user/.flink.keytab > security.kerberos.login.principal: > at flink-client machine and keytab is exist. > I showed the logs at AM and NodeManager below. > > > > -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (FLINK-13335) Align the SQL CREATE TABLE DDL with FLIP-37
[ https://issues.apache.org/jira/browse/FLINK-13335?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888709#comment-16888709 ] Danny Chan commented on FLINK-13335: [~twalthr] May i take this issue ? I would like to fix the compliant problems. And, what corner cases do you mean above so far. > Align the SQL CREATE TABLE DDL with FLIP-37 > --- > > Key: FLINK-13335 > URL: https://issues.apache.org/jira/browse/FLINK-13335 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Reporter: Timo Walther >Assignee: Timo Walther >Priority: Blocker > Fix For: 1.9.0 > > > At a first glance it does not seem that the newly introduced DDL is compliant > with FLIP-37. We should ensure consistent behavior esp. also for corner cases. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] wuchong commented on a change in pull request #9139: [FLINK-13304][FLINK-13322][FLINK-13323][table-runtime-blink] Fix implementation of getString and getBinary method in NestedRow, fi
wuchong commented on a change in pull request #9139:
[FLINK-13304][FLINK-13322][FLINK-13323][table-runtime-blink] Fix implementation
of getString and getBinary method in NestedRow, fix serializer restore in
BaseArray/Map serializer and add tests for complex data formats
URL: https://github.com/apache/flink/pull/9139#discussion_r305261075
##
File path:
flink-table/flink-table-runtime-blink/src/test/java/org/apache/flink/table/dataformat/DataFormatTestHelper.java
##
@@ -0,0 +1,73 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.dataformat;
+
+import org.apache.flink.core.memory.MemorySegment;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+
+/**
+ * Helper class for testing data formats.
+ */
+class DataFormatTestHelper {
Review comment:
DataFormatTestUtil?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9139: [FLINK-13304][FLINK-13322][FLINK-13323][table-runtime-blink] Fix implementation of getString and getBinary method in NestedRow, fi
wuchong commented on a change in pull request #9139:
[FLINK-13304][FLINK-13322][FLINK-13323][table-runtime-blink] Fix implementation
of getString and getBinary method in NestedRow, fix serializer restore in
BaseArray/Map serializer and add tests for complex data formats
URL: https://github.com/apache/flink/pull/9139#discussion_r305261402
##
File path:
flink-core/src/test/java/org/apache/flink/api/common/typeutils/SerializerTestBase.java
##
@@ -124,30 +124,8 @@ public void testSnapshotConfigurationAndReconfigure()
throws Exception {
final TypeSerializer serializer = getSerializer();
final TypeSerializerSnapshot configSnapshot =
serializer.snapshotConfiguration();
- byte[] serializedConfig;
- try (ByteArrayOutputStream out = new ByteArrayOutputStream()) {
-
TypeSerializerSnapshotSerializationUtil.writeSerializerSnapshot(
- new DataOutputViewStreamWrapper(out),
configSnapshot, serializer);
- serializedConfig = out.toByteArray();
- }
-
- TypeSerializerSnapshot restoredConfig;
- try (ByteArrayInputStream in = new
ByteArrayInputStream(serializedConfig)) {
- restoredConfig =
TypeSerializerSnapshotSerializationUtil.readSerializerSnapshot(
- new DataInputViewStreamWrapper(in),
Thread.currentThread().getContextClassLoader(), getSerializer());
- }
-
- TypeSerializerSchemaCompatibility strategy =
restoredConfig.resolveSchemaCompatibility(getSerializer());
- final TypeSerializer restoreSerializer;
- if (strategy.isCompatibleAsIs()) {
- restoreSerializer = restoredConfig.restoreSerializer();
- }
- else if (strategy.isCompatibleWithReconfiguredSerializer()) {
- restoreSerializer =
strategy.getReconfiguredSerializer();
- }
- else {
- throw new AssertionError("Unable to restore serializer
with " + strategy);
- }
+ final TypeSerializer restoreSerializer =
snapshotAndReconfigure(
Review comment:
Is this a bug of this class? Is there any way do not touch this file?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] JingsongLi commented on issue #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases
JingsongLi commented on issue #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases URL: https://github.com/apache/flink/pull/9180#issuecomment-513150285 We need do some work to override false reuseForks from https://github.com/apache/flink/pull/2003 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi edited a comment on issue #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases
JingsongLi edited a comment on issue #9180: [FLINK-13331][table-planner-blink] Add CachedMiniCluster to share cluster between ITCases URL: https://github.com/apache/flink/pull/9180#issuecomment-513150285 Do we need some work to override false reuseForks from https://github.com/apache/flink/pull/2003 ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-10819) JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure is unstable
[ https://issues.apache.org/jira/browse/FLINK-10819?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guowei Ma updated FLINK-10819: -- Attachment: image-2019-07-19-16-59-10-178.png > JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure is > unstable > - > > Key: FLINK-10819 > URL: https://issues.apache.org/jira/browse/FLINK-10819 > Project: Flink > Issue Type: Bug > Components: Runtime / Coordination, Tests >Affects Versions: 1.7.0 >Reporter: sunjincheng >Assignee: Guowei Ma >Priority: Critical > Labels: test-stability > Fix For: 1.9.0 > > Attachments: image-2019-07-19-16-59-10-178.png > > > Found the following error in the process of CI: > Results : > Tests in error: > JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure:331 » > IllegalArgument > Tests run: 1463, Failures: 0, Errors: 1, Skipped: 29 > 18:40:55.828 [INFO] > > 18:40:55.829 [INFO] BUILD FAILURE > 18:40:55.829 [INFO] > > 18:40:55.830 [INFO] Total time: 30:19 min > 18:40:55.830 [INFO] Finished at: 2018-11-07T18:40:55+00:00 > 18:40:56.294 [INFO] Final Memory: 92M/678M > 18:40:56.294 [INFO] > > 18:40:56.294 [WARNING] The requested profile "include-kinesis" could not be > activated because it does not exist. > 18:40:56.295 [ERROR] Failed to execute goal > org.apache.maven.plugins:maven-surefire-plugin:2.18.1:test > (integration-tests) on project flink-tests_2.11: There are test failures. > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] Please refer to > /home/travis/build/sunjincheng121/flink/flink-tests/target/surefire-reports > for the individual test results. > 18:40:56.295 [ERROR] -> [Help 1] > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] To see the full stack trace of the errors, re-run Maven > with the -e switch. > 18:40:56.295 [ERROR] Re-run Maven using the -X switch to enable full debug > logging. > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] For more information about the errors and possible > solutions, please read the following articles: > 18:40:56.295 [ERROR] [Help 1] > http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException > MVN exited with EXIT CODE: 1. > Trying to KILL watchdog (11329). > ./tools/travis_mvn_watchdog.sh: line 269: 11329 Terminated watchdog > PRODUCED build artifacts. > But after the rerun, the error disappeared. > Currently,no specific reasons are found, and will continue to pay attention. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] JingsongLi commented on issue #9168: [FLINK-13286][table-api] Port connector related validators to api-java-bridge
JingsongLi commented on issue #9168: [FLINK-13286][table-api] Port connector related validators to api-java-bridge URL: https://github.com/apache/flink/pull/9168#issuecomment-513152929 > move the corresponding tests to table-api or table-common Good suggestion, and previous `RowtimeTest` and `SchemaTest` need port too. @godfreyhe will port them together in the next PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-10819) JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure is unstable
[ https://issues.apache.org/jira/browse/FLINK-10819?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guowei Ma updated FLINK-10819: -- Attachment: image-2019-07-19-17-00-17-194.png > JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure is > unstable > - > > Key: FLINK-10819 > URL: https://issues.apache.org/jira/browse/FLINK-10819 > Project: Flink > Issue Type: Bug > Components: Runtime / Coordination, Tests >Affects Versions: 1.7.0 >Reporter: sunjincheng >Assignee: Guowei Ma >Priority: Critical > Labels: test-stability > Fix For: 1.9.0 > > Attachments: image-2019-07-19-16-59-10-178.png, > image-2019-07-19-17-00-17-194.png > > > Found the following error in the process of CI: > Results : > Tests in error: > JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure:331 » > IllegalArgument > Tests run: 1463, Failures: 0, Errors: 1, Skipped: 29 > 18:40:55.828 [INFO] > > 18:40:55.829 [INFO] BUILD FAILURE > 18:40:55.829 [INFO] > > 18:40:55.830 [INFO] Total time: 30:19 min > 18:40:55.830 [INFO] Finished at: 2018-11-07T18:40:55+00:00 > 18:40:56.294 [INFO] Final Memory: 92M/678M > 18:40:56.294 [INFO] > > 18:40:56.294 [WARNING] The requested profile "include-kinesis" could not be > activated because it does not exist. > 18:40:56.295 [ERROR] Failed to execute goal > org.apache.maven.plugins:maven-surefire-plugin:2.18.1:test > (integration-tests) on project flink-tests_2.11: There are test failures. > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] Please refer to > /home/travis/build/sunjincheng121/flink/flink-tests/target/surefire-reports > for the individual test results. > 18:40:56.295 [ERROR] -> [Help 1] > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] To see the full stack trace of the errors, re-run Maven > with the -e switch. > 18:40:56.295 [ERROR] Re-run Maven using the -X switch to enable full debug > logging. > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] For more information about the errors and possible > solutions, please read the following articles: > 18:40:56.295 [ERROR] [Help 1] > http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException > MVN exited with EXIT CODE: 1. > Trying to KILL watchdog (11329). > ./tools/travis_mvn_watchdog.sh: line 269: 11329 Terminated watchdog > PRODUCED build artifacts. > But after the rerun, the error disappeared. > Currently,no specific reasons are found, and will continue to pay attention. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Updated] (FLINK-10819) JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure is unstable
[ https://issues.apache.org/jira/browse/FLINK-10819?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guowei Ma updated FLINK-10819: -- Attachment: image-2019-07-19-17-01-19-758.png > JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure is > unstable > - > > Key: FLINK-10819 > URL: https://issues.apache.org/jira/browse/FLINK-10819 > Project: Flink > Issue Type: Bug > Components: Runtime / Coordination, Tests >Affects Versions: 1.7.0 >Reporter: sunjincheng >Assignee: Guowei Ma >Priority: Critical > Labels: test-stability > Fix For: 1.9.0 > > Attachments: image-2019-07-19-16-59-10-178.png, > image-2019-07-19-17-00-17-194.png, image-2019-07-19-17-01-19-758.png > > > Found the following error in the process of CI: > Results : > Tests in error: > JobManagerHAProcessFailureRecoveryITCase.testDispatcherProcessFailure:331 » > IllegalArgument > Tests run: 1463, Failures: 0, Errors: 1, Skipped: 29 > 18:40:55.828 [INFO] > > 18:40:55.829 [INFO] BUILD FAILURE > 18:40:55.829 [INFO] > > 18:40:55.830 [INFO] Total time: 30:19 min > 18:40:55.830 [INFO] Finished at: 2018-11-07T18:40:55+00:00 > 18:40:56.294 [INFO] Final Memory: 92M/678M > 18:40:56.294 [INFO] > > 18:40:56.294 [WARNING] The requested profile "include-kinesis" could not be > activated because it does not exist. > 18:40:56.295 [ERROR] Failed to execute goal > org.apache.maven.plugins:maven-surefire-plugin:2.18.1:test > (integration-tests) on project flink-tests_2.11: There are test failures. > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] Please refer to > /home/travis/build/sunjincheng121/flink/flink-tests/target/surefire-reports > for the individual test results. > 18:40:56.295 [ERROR] -> [Help 1] > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] To see the full stack trace of the errors, re-run Maven > with the -e switch. > 18:40:56.295 [ERROR] Re-run Maven using the -X switch to enable full debug > logging. > 18:40:56.295 [ERROR] > 18:40:56.295 [ERROR] For more information about the errors and possible > solutions, please read the following articles: > 18:40:56.295 [ERROR] [Help 1] > http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException > MVN exited with EXIT CODE: 1. > Trying to KILL watchdog (11329). > ./tools/travis_mvn_watchdog.sh: line 269: 11329 Terminated watchdog > PRODUCED build artifacts. > But after the rerun, the error disappeared. > Currently,no specific reasons are found, and will continue to pay attention. -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] wuchong merged pull request #9177: [hotfix][docs] Fix loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html
wuchong merged pull request #9177: [hotfix][docs] Fix loop redirection in https://ci.apache.org/projects/flink/flink-docs-master/dev/projectsetup/dependencies.html URL: https://github.com/apache/flink/pull/9177 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] 1u0 commented on a change in pull request #9169: [FLINK-12998][docs] Update documentation for file systems loading as plugins
1u0 commented on a change in pull request #9169: [FLINK-12998][docs] Update
documentation for file systems loading as plugins
URL: https://github.com/apache/flink/pull/9169#discussion_r305265446
##
File path: docs/ops/filesystems/index.md
##
@@ -35,32 +35,50 @@ File system instances are instantiated once per process
and then cached/pooled,
* This will be replaced by the TOC
{:toc}
-## Built-in File Systems
+## Local File System
-Flink ships with implementations for the following file systems:
+Flink has built-in support for the file system of the local machine, including
any NFS or SAN drives mounted into that local file system.
+It can be used by default without additional configuration. Local files are
referenced with the *file://* URI scheme.
- - **local**: This file system is used when the scheme is *"file://"*, and it
represents the file system of the local machine, including any NFS or SAN
drives mounted into that local file system.
+## Pluggable File Systems
- - **S3**: Flink directly provides file systems to talk to Amazon S3 with two
alternative implementations, `flink-s3-fs-presto` and `flink-s3-fs-hadoop`.
Both implementations are self-contained with no dependency footprint.
-
- - **MapR FS**: The MapR file system *"maprfs://"* is automatically available
when the MapR libraries are in the classpath.
+Apache Flink project supports the following file systems as plugins:
+
+ - [**Amazon S3**](./s3.html) object storage is supported by two alternative
implementations, `flink-s3-fs-presto` and `flink-s3-fs-hadoop`.
+ Both implementations are self-contained with no dependency footprint.
+
+ - **MapR FS**: The MapR file system *maprfs://* is automatically available
when the MapR libraries are in the classpath.
+ Note You'd need to build from sources
the `flink-mapr-fs` JAR file.
Review comment:
I've removed this notice sentence, but I need to restructure this
documentation or mention somehow that this MapR FS is not pluggable as others
in this list.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Assigned] (FLINK-13331) Add TestMiniClusters to maintain cache share cluster between Tests
[ https://issues.apache.org/jira/browse/FLINK-13331?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu reassigned FLINK-13331: --- Assignee: Jingsong Lee > Add TestMiniClusters to maintain cache share cluster between Tests > -- > > Key: FLINK-13331 > URL: https://issues.apache.org/jira/browse/FLINK-13331 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Planner >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0, 1.10.0 > > Time Spent: 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[GitHub] [flink] 1u0 commented on a change in pull request #9169: [FLINK-12998][docs] Update documentation for file systems loading as plugins
1u0 commented on a change in pull request #9169: [FLINK-12998][docs] Update
documentation for file systems loading as plugins
URL: https://github.com/apache/flink/pull/9169#discussion_r305267673
##
File path: docs/ops/filesystems/index.md
##
@@ -35,32 +35,50 @@ File system instances are instantiated once per process
and then cached/pooled,
* This will be replaced by the TOC
{:toc}
-## Built-in File Systems
+## Local File System
-Flink ships with implementations for the following file systems:
+Flink has built-in support for the file system of the local machine, including
any NFS or SAN drives mounted into that local file system.
+It can be used by default without additional configuration. Local files are
referenced with the *file://* URI scheme.
- - **local**: This file system is used when the scheme is *"file://"*, and it
represents the file system of the local machine, including any NFS or SAN
drives mounted into that local file system.
+## Pluggable File Systems
- - **S3**: Flink directly provides file systems to talk to Amazon S3 with two
alternative implementations, `flink-s3-fs-presto` and `flink-s3-fs-hadoop`.
Both implementations are self-contained with no dependency footprint.
-
- - **MapR FS**: The MapR file system *"maprfs://"* is automatically available
when the MapR libraries are in the classpath.
+Apache Flink project supports the following file systems as plugins:
+
+ - [**Amazon S3**](./s3.html) object storage is supported by two alternative
implementations, `flink-s3-fs-presto` and `flink-s3-fs-hadoop`.
+ Both implementations are self-contained with no dependency footprint.
+
+ - **MapR FS**: The MapR file system *maprfs://* is automatically available
when the MapR libraries are in the classpath.
+ Note You'd need to build from sources
the `flink-mapr-fs` JAR file.
- - **OpenStack Swift FS**: Flink directly provides a file system to talk to
the OpenStack Swift file system, registered under the scheme *"swift://"*.
- The implementation of `flink-swift-fs-hadoop` is based on the [Hadoop
Project](https://hadoop.apache.org/) but is self-contained with no dependency
footprint.
- To use it when using Flink as a library, add the respective maven dependency
(`org.apache.flink:flink-swift-fs-hadoop:{{ site.version }}`
- When starting a Flink application from the Flink binaries, copy or move the
respective jar file from the `opt` folder to the `lib` folder.
+ - **OpenStack Swift FS** is supported by `flink-swift-fs-hadoop` and
registered under the *swift://* URI scheme.
+ The implementation is based on the [Hadoop
Project](https://hadoop.apache.org/) but is self-contained with no dependency
footprint.
+ To use it when using Flink as a library, add the respective maven dependency
(`org.apache.flink:flink-swift-fs-hadoop:{{ site.version }}`).
- - **Azure Blob Storage**:
-Flink directly provides a file system to work with Azure Blob Storage.
-This filesystem is registered under the scheme *"wasb(s)://"*.
-The implementation is self-contained with no dependency footprint.
+ - **[Aliyun Object Storage Service](./oss.html)** is supported by
`flink-oss-fs-hadoop` and registered under the *oss://* URI scheme.
+ The implementation is based on the [Hadoop
Project](https://hadoop.apache.org/) but is self-contained with no dependency
footprint.
+
+ - **[Azure Blob Storage](./azure.html)** is supported by
`flink-azure-fs-hadoop` and registered under the *wasb(s)://* URI schemes.
+ The implementation is based on the [Hadoop
Project](https://hadoop.apache.org/) but is self-contained with no dependency
footprint.
+
+To use a pluggable file systems, copy the corresponding JAR file from the
`opt` directory to a directory under `plugins` directory
+of your Flink distribution before starting Flink, e.g.
+
+{% highlight bash %}
+mkdir ./plugins/s3-fs-hadoop
+cp ./opt/flink-s3-fs-hadoop-{{ site.version }}.jar ./plugins/s3-fs-hadoop/
+{% endhighlight %}
+
+Attention The plugin mechanism for
file systems was introduced since Flink version `1.9` to
+support dedicated Java class loaders per file system and move away from class
shading mechanism. You can still use the provided file systems
+(or your own implementations) via the old mechanism by copying corresponding
JAR file into `lib` directory.
+
+The non plugin-based loading mechanism is deprecated and will be not supported
in the future.
Review comment:
Not removing it now.
But in my understanding the plan (introducing and using plugins effort) is
to move away from shared (lib based) class loader and shading.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Gi
[GitHub] [flink] 1u0 commented on a change in pull request #9169: [FLINK-12998][docs] Update documentation for file systems loading as plugins
1u0 commented on a change in pull request #9169: [FLINK-12998][docs] Update documentation for file systems loading as plugins URL: https://github.com/apache/flink/pull/9169#discussion_r305269463 ## File path: docs/ops/filesystems/index.md ## @@ -83,17 +101,21 @@ fs.hdfs.hadoopconf: /path/to/etc/hadoop This registers `/path/to/etc/hadoop` as Hadoop's configuration directory and is where Flink will look for the `core-site.xml` and `hdfs-site.xml` files. -## Adding new File System Implementations +## Adding a new pluggable File System implementation -File systems are represented via the `org.apache.flink.core.fs.FileSystem` class, which captures the ways to access and modify files and objects in that file system. -Implementations are discovered by Flink through Java's service abstraction, making it easy to add new file system implementations. Review comment: I've removed it because it was not exact: * it is not, that `FileSystem` classes are discovered by Java's service loading mechanism, but `FileSystemFactory`; * there is still reference left to Java's service loading in the `Add a service entry` step. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9174: [FLINK-13330][table-planner-blink] Remove unnecessary to reduce testing time in blink
wuchong commented on a change in pull request #9174:
[FLINK-13330][table-planner-blink] Remove unnecessary to reduce testing time in
blink
URL: https://github.com/apache/flink/pull/9174#discussion_r305270009
##
File path:
flink-table/flink-table-runtime-blink/src/test/java/org/apache/flink/table/runtime/sort/BinaryExternalSorterTest.java
##
@@ -76,11 +75,14 @@ public BinaryExternalSorterTest(
@Parameterized.Parameters(name = "spillCompress-{0} asyncMerge-{1}")
public static Collection parameters() {
- return Arrays.asList(
- new Boolean[]{false, false},
- new Boolean[]{false, true},
- new Boolean[]{true, false},
- new Boolean[]{true, true});
+ // To avoid too long testing time, we only tested the default
configuration.
+ // If BinaryExternalSorter has changed, please open it manually
for testing.
+// return Arrays.asList(
+// new Boolean[]{false, false},
+// new Boolean[]{false, true},
+// new Boolean[]{true, false},
+// new Boolean[]{true, true});
Review comment:
Manually testing is hard to guarantee the correctness. I think we need to
find a way to add these tests to nightly tests in this pull request.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9174: [FLINK-13330][table-planner-blink] Remove unnecessary to reduce testing time in blink
wuchong commented on a change in pull request #9174:
[FLINK-13330][table-planner-blink] Remove unnecessary to reduce testing time in
blink
URL: https://github.com/apache/flink/pull/9174#discussion_r305270009
##
File path:
flink-table/flink-table-runtime-blink/src/test/java/org/apache/flink/table/runtime/sort/BinaryExternalSorterTest.java
##
@@ -76,11 +75,14 @@ public BinaryExternalSorterTest(
@Parameterized.Parameters(name = "spillCompress-{0} asyncMerge-{1}")
public static Collection parameters() {
- return Arrays.asList(
- new Boolean[]{false, false},
- new Boolean[]{false, true},
- new Boolean[]{true, false},
- new Boolean[]{true, true});
+ // To avoid too long testing time, we only tested the default
configuration.
+ // If BinaryExternalSorter has changed, please open it manually
for testing.
+// return Arrays.asList(
+// new Boolean[]{false, false},
+// new Boolean[]{false, true},
+// new Boolean[]{true, false},
+// new Boolean[]{true, true});
Review comment:
Manually testing is hard to guarantee the correctness. I think we need to
find a way to add this to nightly tests in this pull request.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add
documentation for failover strategy option
URL: https://github.com/apache/flink/pull/9113#discussion_r305270103
##
File path: docs/dev/task_failure_recovery.md
##
@@ -264,4 +268,51 @@ The cluster defined restart strategy is used.
This is helpful for streaming programs which enable checkpointing.
By default, a fixed delay restart strategy is chosen if there is no other
restart strategy defined.
+## Failover Strategies
+
+Flink supports different failover strategies which can be configured via the
configuration parameter
+*jobmanager.execution.failover-strategy* in Flink's configuration file
`flink-conf.yaml`.
+
+
+
+
+ Failover Strategy
+ Value for
jobmanager.execution.failover-strategy
+
+
+
+
+Restart all
+full
+
+
+Restart pipelined region
+region
+
+
+
+
+### Restart All Failover Strategy
+
+With this strategy, all tasks in the job will be restarted to recover from a
task failure.
+
+### Restart Pipelined Region Failover Strategy
+
+With this strategy, tasks to restart depend on the regions to restart.
+
+A region is defined by this strategy as tasks that communicate via pipelined
data exchanges.
+- All data exchanges in a DataStream job or Streaming Table job are pipelined.
+- All data exchanges in a Batch Table job are batched.
+- Types of data exchanges in a DataSet job is decided with the
+ [ExecutionMode]({{ site.javadocs_baseurl
}}/api/java/org/apache/flink/api/common/ExecutionMode.html) set in
+ [ExecutionConfig]({{ site.baseurl }}/dev/execution_configuration.html).
+
+Regions to restart are decided as below:
+1. The region containing the failed task should be restarted.
Review comment:
I'd change: *should be restarted* -> *is restarted*
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add
documentation for failover strategy option
URL: https://github.com/apache/flink/pull/9113#discussion_r305271732
##
File path:
flink-core/src/main/java/org/apache/flink/configuration/JobManagerOptions.java
##
@@ -105,18 +105,27 @@
/**
* This option specifies the failover strategy, i.e. how the job
computation recovers from task failures.
+* The option "individual" and "region-legacy" are intentionally not
included
+* as they have some known limitations or issues.
+* "individual" strategy only works when all tasks are not connected,
in which case the "region"
+* failover strategy would also restart failed tasks individually.
+* "region-legacy" strategy is not able to backtrack missing input
result partitions.
+* The new "region" strategy supersedes "individual" and
"region-legacy" strategies and should always work.
*/
- @Documentation.ExcludeFromDocumentation("The failover strategy feature
is highly experimental.")
public static final ConfigOption EXECUTION_FAILOVER_STRATEGY =
key("jobmanager.execution.failover-strategy")
.defaultValue("full")
.withDescription(Description.builder()
.text("This option specifies how the job
computation recovers from task failures. " +
"Accepted values are:")
.list(
- text("'full': Restarts all tasks."),
- text("'individual': Restarts only the
failed task. Should only be used if all tasks are independent components."),
- text("'region': Restarts all tasks that
could be affected by the task failure.")
+ text("'full': Restarts all tasks to
recover the job."),
+ text("'region': Restarts all tasks that
could be affected by the task failure. " +
Review comment:
Maybe we can omit some details here, and place a hyperlink to the *Task
Failure Recovery* page using `LinkElement`. WDYT?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add
documentation for failover strategy option
URL: https://github.com/apache/flink/pull/9113#discussion_r305270062
##
File path: docs/dev/task_failure_recovery.md
##
@@ -264,4 +268,51 @@ The cluster defined restart strategy is used.
This is helpful for streaming programs which enable checkpointing.
By default, a fixed delay restart strategy is chosen if there is no other
restart strategy defined.
+## Failover Strategies
+
+Flink supports different failover strategies which can be configured via the
configuration parameter
+*jobmanager.execution.failover-strategy* in Flink's configuration file
`flink-conf.yaml`.
+
+
+
+
+ Failover Strategy
+ Value for
jobmanager.execution.failover-strategy
+
+
+
+
+Restart all
+full
+
+
+Restart pipelined region
+region
+
+
+
+
+### Restart All Failover Strategy
+
+With this strategy, all tasks in the job will be restarted to recover from a
task failure.
+
+### Restart Pipelined Region Failover Strategy
+
+With this strategy, tasks to restart depend on the regions to restart.
+
+A region is defined by this strategy as tasks that communicate via pipelined
data exchanges.
+- All data exchanges in a DataStream job or Streaming Table job are pipelined.
+- All data exchanges in a Batch Table job are batched.
+- Types of data exchanges in a DataSet job is decided with the
+ [ExecutionMode]({{ site.javadocs_baseurl
}}/api/java/org/apache/flink/api/common/ExecutionMode.html) set in
+ [ExecutionConfig]({{ site.baseurl }}/dev/execution_configuration.html).
+
+Regions to restart are decided as below:
+1. The region containing the failed task should be restarted.
+2. If a result partition is not available while it is required by a region
that will be restarted,
+ the region producing the result partition should be restarted as well.
+3. If a region is to be restarted, all of its consumer regions should also be
restarted. This is to guarantee
+ data consistency. Because nondeterministic processing or partitioning can
result in that a partition
Review comment:
*[...] data consistency because nondeterministic [...]*
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305239559 ## File path: docs/dev/task_failure_recovery.md ## @@ -264,4 +268,51 @@ The cluster defined restart strategy is used. This is helpful for streaming programs which enable checkpointing. By default, a fixed delay restart strategy is chosen if there is no other restart strategy defined. +## Failover Strategies + +Flink supports different failover strategies which can be configured via the configuration parameter +*jobmanager.execution.failover-strategy* in Flink's configuration file `flink-conf.yaml`. + + + + + Failover Strategy + Value for jobmanager.execution.failover-strategy + + + + +Restart all +full + + +Restart pipelined region +region + + + + +### Restart All Failover Strategy + +With this strategy, all tasks in the job will be restarted to recover from a task failure. Review comment: Maybe simplify: *This strategy restarts all tasks in the job to recover from a task failure.* This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305237186 ## File path: flink-core/src/main/java/org/apache/flink/configuration/JobManagerOptions.java ## @@ -105,18 +105,27 @@ /** * This option specifies the failover strategy, i.e. how the job computation recovers from task failures. +* The option "individual" and "region-legacy" are intentionally not included Review comment: *The option**s** [...]* This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add
documentation for failover strategy option
URL: https://github.com/apache/flink/pull/9113#discussion_r305271784
##
File path: docs/dev/task_failure_recovery.md
##
@@ -264,4 +268,51 @@ The cluster defined restart strategy is used.
This is helpful for streaming programs which enable checkpointing.
By default, a fixed delay restart strategy is chosen if there is no other
restart strategy defined.
+## Failover Strategies
+
+Flink supports different failover strategies which can be configured via the
configuration parameter
+*jobmanager.execution.failover-strategy* in Flink's configuration file
`flink-conf.yaml`.
+
+
+
+
+ Failover Strategy
+ Value for
jobmanager.execution.failover-strategy
+
+
+
+
+Restart all
+full
+
+
+Restart pipelined region
+region
+
+
+
+
+### Restart All Failover Strategy
+
+With this strategy, all tasks in the job will be restarted to recover from a
task failure.
+
+### Restart Pipelined Region Failover Strategy
+
+With this strategy, tasks to restart depend on the regions to restart.
+
+A region is defined by this strategy as tasks that communicate via pipelined
data exchanges.
+- All data exchanges in a DataStream job or Streaming Table job are pipelined.
+- All data exchanges in a Batch Table job are batched.
+- Types of data exchanges in a DataSet job is decided with the
+ [ExecutionMode]({{ site.javadocs_baseurl
}}/api/java/org/apache/flink/api/common/ExecutionMode.html) set in
+ [ExecutionConfig]({{ site.baseurl }}/dev/execution_configuration.html).
+
+Regions to restart are decided as below:
Review comment:
***The** regions to restart [...]*
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305255474 ## File path: docs/dev/task_failure_recovery.md ## @@ -264,4 +268,51 @@ The cluster defined restart strategy is used. This is helpful for streaming programs which enable checkpointing. By default, a fixed delay restart strategy is chosen if there is no other restart strategy defined. +## Failover Strategies + +Flink supports different failover strategies which can be configured via the configuration parameter +*jobmanager.execution.failover-strategy* in Flink's configuration file `flink-conf.yaml`. + + + + + Failover Strategy + Value for jobmanager.execution.failover-strategy + + + + +Restart all +full + + +Restart pipelined region +region + + + + +### Restart All Failover Strategy + +With this strategy, all tasks in the job will be restarted to recover from a task failure. + +### Restart Pipelined Region Failover Strategy + +With this strategy, tasks to restart depend on the regions to restart. + +A region is defined by this strategy as tasks that communicate via pipelined data exchanges. +- All data exchanges in a DataStream job or Streaming Table job are pipelined. +- All data exchanges in a Batch Table job are batched. +- Types of data exchanges in a DataSet job is decided with the Review comment: I'd rephrase it to: *The data exchange types in a DataSet job are determined by the ExecutionMode which can be set through the ExecutionConfig* This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305260467 ## File path: docs/dev/task_failure_recovery.md ## @@ -264,4 +268,51 @@ The cluster defined restart strategy is used. This is helpful for streaming programs which enable checkpointing. By default, a fixed delay restart strategy is chosen if there is no other restart strategy defined. +## Failover Strategies + +Flink supports different failover strategies which can be configured via the configuration parameter +*jobmanager.execution.failover-strategy* in Flink's configuration file `flink-conf.yaml`. + + + + + Failover Strategy + Value for jobmanager.execution.failover-strategy + + + + +Restart all +full + + +Restart pipelined region +region + + + + +### Restart All Failover Strategy + +With this strategy, all tasks in the job will be restarted to recover from a task failure. + +### Restart Pipelined Region Failover Strategy + +With this strategy, tasks to restart depend on the regions to restart. + +A region is defined by this strategy as tasks that communicate via pipelined data exchanges. Review comment: I'd rephrase this to: *"A region is the set of tasks that [...]."* Maybe add *"That is, batch data exchanges denote the boundaries of a region."* This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add
documentation for failover strategy option
URL: https://github.com/apache/flink/pull/9113#discussion_r305236342
##
File path: docs/dev/task_failure_recovery.md
##
@@ -22,14 +22,20 @@ specific language governing permissions and limitations
under the License.
-->
-Flink supports different restart strategies which control how the jobs are
restarted in case of a failure.
-The cluster can be started with a default restart strategy which is always
used when no job specific restart strategy has been defined.
-In case that the job is submitted with a restart strategy, this strategy
overrides the cluster's default setting.
+When a task failure happens, Flink needs to restart the failed task and other
affected tasks to recover the job to a normal state.
+
+Restart strategies and failover strategies are used to control the task
restarting.
+Restart strategies decide whether and when the failed/affected tasks can be
restarted.
+Failover strategies decide which tasks should be restarted to recover the job.
* This will be replaced by the TOC
{:toc}
-## Overview
+## Restart Strategies
+
+Flink supports different restart strategies.
Review comment:
Maybe remove *"Flink supports different restart strategies."*
I don't think the sentence adds any information.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305254441 ## File path: docs/dev/task_failure_recovery.md ## @@ -264,4 +268,51 @@ The cluster defined restart strategy is used. This is helpful for streaming programs which enable checkpointing. By default, a fixed delay restart strategy is chosen if there is no other restart strategy defined. +## Failover Strategies + +Flink supports different failover strategies which can be configured via the configuration parameter +*jobmanager.execution.failover-strategy* in Flink's configuration file `flink-conf.yaml`. + + + + + Failover Strategy + Value for jobmanager.execution.failover-strategy + + + + +Restart all +full + + +Restart pipelined region +region + + + + +### Restart All Failover Strategy + +With this strategy, all tasks in the job will be restarted to recover from a task failure. + +### Restart Pipelined Region Failover Strategy + +With this strategy, tasks to restart depend on the regions to restart. + +A region is defined by this strategy as tasks that communicate via pipelined data exchanges. +- All data exchanges in a DataStream job or Streaming Table job are pipelined. +- All data exchanges in a Batch Table job are batched. Review comment: Maybe *"[...] in a DataSet Table job"* to be consistent with the bullet point below. Disclaimer: I don't know a lot about the table API. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305237712 ## File path: flink-core/src/main/java/org/apache/flink/configuration/JobManagerOptions.java ## @@ -105,18 +105,27 @@ /** * This option specifies the failover strategy, i.e. how the job computation recovers from task failures. +* The option "individual" and "region-legacy" are intentionally not included +* as they have some known limitations or issues. +* "individual" strategy only works when all tasks are not connected, in which case the "region" Review comment: nit: Maybe format with `` For example: ``` /** * This option specifies the failover strategy, i.e. how the job computation recovers from task failures. * * The options "individual" and "region-legacy" are intentionally not included * as they have some known limitations or issues: * * "individual" strategy only works when all tasks are not connected, * in which case the "region" failover strategy would also restart failed tasks individually * "region-legacy" strategy is not able to backtrack missing input result partitions * * The new "region" strategy supersedes "individual" and "region-legacy" strategies and should always work. */ ``` https://user-images.githubusercontent.com/1681921/61518527-0a41f380-aa0a-11e9-9d9f-fd1162733144.png";> This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option
GJL commented on a change in pull request #9113: [FLINK-13222] [runtime] Add documentation for failover strategy option URL: https://github.com/apache/flink/pull/9113#discussion_r305271856 ## File path: docs/dev/task_failure_recovery.md ## @@ -264,4 +268,51 @@ The cluster defined restart strategy is used. This is helpful for streaming programs which enable checkpointing. By default, a fixed delay restart strategy is chosen if there is no other restart strategy defined. +## Failover Strategies + +Flink supports different failover strategies which can be configured via the configuration parameter +*jobmanager.execution.failover-strategy* in Flink's configuration file `flink-conf.yaml`. + + + + + Failover Strategy + Value for jobmanager.execution.failover-strategy + + + + +Restart all +full + + +Restart pipelined region +region + + + + +### Restart All Failover Strategy + +With this strategy, all tasks in the job will be restarted to recover from a task failure. + +### Restart Pipelined Region Failover Strategy + +With this strategy, tasks to restart depend on the regions to restart. Review comment: I'd rephrase this and add a few more details: > This strategy groups tasks into disjoint regions. When a task failure is detected, this strategy computes the smallest set of regions that must be restarted to recover from the failure. For some jobs this can result in fewer tasks that will be restarted compared to the *Restart All Failover Strategy*.\ WDYT? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (FLINK-13279) not able to query table registered in catalogs in SQL CLI
[
https://issues.apache.org/jira/browse/FLINK-13279?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888732#comment-16888732
]
Timo Walther edited comment on FLINK-13279 at 7/19/19 9:20 AM:
---
Hi [~xuefuz],
thanks for your valuable feedback. Your concerns are valid. [~dawidwys]'s PR
makes the API more user-friendly but we are also messing up the lookup design
here.
I think the root cause of this discussion is that we don't have a proper
separation between tables that need to be persisted in a catalog and temporary
tables that are only available in the current session.
I did some research for future discussions:
MySQL: https://dev.mysql.com/doc/refman/8.0/en/create-temporary-table.html
{code}
TEMPORARY tables have a very loose relationship with databases (schemas).
Dropping a database does not automatically drop any TEMPORARY tables created
within that database. Also, you can create a TEMPORARY table in a nonexistent
database if you qualify the table name with the database name in the CREATE
TABLE statement. In this case, all subsequent references to the table must be
qualified with the database name.
{code}
SQL Server:
https://docs.microsoft.com/de-de/sql/relational-databases/databases/tempdb-database?view=sql-server-2017
{code}
Tempdb is used to hold: Temporary user objects that are explicitly created,
such as: global or local temporary tables
{code}
We have two options: either we force users to fully specify the path or
maintain a separate Map as MySQL does it. I think we can avoid the exception of
this JIRA ticket easily by changing the SQL Client {{insertInto}} statement to
a fully qualified one and stick to the current behavior for now.
was (Author: twalthr):
Hi [~xuefuz],
thanks for your valuable feedback. Your concerns are valid. [~dawidwys]'s PR
makes the API more user-friendly but we are also messing up the lookup design
here.
I think the root cause of this discussion is that we don't have a proper
separation between tables that need to be persisted in a catalog and temporary
tables that are only available in the current session.
I did some research for future discussions:
MySQL: https://dev.mysql.com/doc/refman/8.0/en/create-temporary-table.html
{code}
TEMPORARY tables have a very loose relationship with databases (schemas).
Dropping a database does not automatically drop any TEMPORARY tables created
within that database. Also, you can create a TEMPORARY table in a nonexistent
database if you qualify the table name with the database name in the CREATE
TABLE statement. In this case, all subsequent references to the table must be
qualified with the database name.
{code}
https://docs.microsoft.com/de-de/sql/relational-databases/databases/tempdb-database?view=sql-server-2017
{code}
Tempdb is used to hold: Temporary user objects that are explicitly created,
such as: global or local temporary tables
{code}
We have two options: either we force users to fully specify the path or
maintain a separate Map as MySQL does it. I think we can avoid the exception of
this JIRA ticket easily by changing the SQL Client {{insertInto}} statement to
a fully qualified one and stick to the current behavior for now.
> not able to query table registered in catalogs in SQL CLI
> -
>
> Key: FLINK-13279
> URL: https://issues.apache.org/jira/browse/FLINK-13279
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API, Table SQL / Client, Table SQL / Legacy
> Planner, Table SQL / Planner
>Affects Versions: 1.9.0
>Reporter: Bowen Li
>Assignee: Dawid Wysakowicz
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 1.9.0
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> When querying a simple table in catalog, SQL CLI reports
> "org.apache.flink.table.api.TableException: No table was registered under the
> name ArrayBuffer(default: select * from hivetable)."
> [~ykt836] can you please help to triage this ticket to proper person?
> Repro steps in SQL CLI (to set up dependencies of HiveCatalog, please refer
> to dev/table/catalog.md):
> {code:java}
> Flink SQL> show catalogs;
> default_catalog
> myhive
> Flink SQL> use catalog myhive
> > ;
> Flink SQL> show databases;
> default
> Flink SQL> show tables;
> hivetable
> products
> test
> Flink SQL> describe hivetable;
> root
> |-- name: STRING
> |-- score: DOUBLE
> Flink SQL> select * from hivetable;
> [ERROR] Could not execute SQL statement. Reason:
> org.apache.flink.table.api.TableException: No table was registered under the
> name ArrayBuffer(default: select * from hivetable).
> {code}
> Exception in log:
> {code:java}
> 2019-07-15 14:59:12,273 WARN org.apache.flink.table.client.cli.CliClient
> - Cou
[jira] [Commented] (FLINK-13279) not able to query table registered in catalogs in SQL CLI
[
https://issues.apache.org/jira/browse/FLINK-13279?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16888732#comment-16888732
]
Timo Walther commented on FLINK-13279:
--
Hi [~xuefuz],
thanks for your valuable feedback. Your concerns are valid. [~dawidwys]'s PR
makes the API more user-friendly but we are also messing up the lookup design
here.
I think the root cause of this discussion is that we don't have a proper
separation between tables that need to be persisted in a catalog and temporary
tables that are only available in the current session.
I did some research for future discussions:
MySQL: https://dev.mysql.com/doc/refman/8.0/en/create-temporary-table.html
{code}
TEMPORARY tables have a very loose relationship with databases (schemas).
Dropping a database does not automatically drop any TEMPORARY tables created
within that database. Also, you can create a TEMPORARY table in a nonexistent
database if you qualify the table name with the database name in the CREATE
TABLE statement. In this case, all subsequent references to the table must be
qualified with the database name.
{code}
https://docs.microsoft.com/de-de/sql/relational-databases/databases/tempdb-database?view=sql-server-2017
{code}
Tempdb is used to hold: Temporary user objects that are explicitly created,
such as: global or local temporary tables
{code}
We have two options: either we force users to fully specify the path or
maintain a separate Map as MySQL does it. I think we can avoid the exception of
this JIRA ticket easily by changing the SQL Client {{insertInto}} statement to
a fully qualified one and stick to the current behavior for now.
> not able to query table registered in catalogs in SQL CLI
> -
>
> Key: FLINK-13279
> URL: https://issues.apache.org/jira/browse/FLINK-13279
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API, Table SQL / Client, Table SQL / Legacy
> Planner, Table SQL / Planner
>Affects Versions: 1.9.0
>Reporter: Bowen Li
>Assignee: Dawid Wysakowicz
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 1.9.0
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> When querying a simple table in catalog, SQL CLI reports
> "org.apache.flink.table.api.TableException: No table was registered under the
> name ArrayBuffer(default: select * from hivetable)."
> [~ykt836] can you please help to triage this ticket to proper person?
> Repro steps in SQL CLI (to set up dependencies of HiveCatalog, please refer
> to dev/table/catalog.md):
> {code:java}
> Flink SQL> show catalogs;
> default_catalog
> myhive
> Flink SQL> use catalog myhive
> > ;
> Flink SQL> show databases;
> default
> Flink SQL> show tables;
> hivetable
> products
> test
> Flink SQL> describe hivetable;
> root
> |-- name: STRING
> |-- score: DOUBLE
> Flink SQL> select * from hivetable;
> [ERROR] Could not execute SQL statement. Reason:
> org.apache.flink.table.api.TableException: No table was registered under the
> name ArrayBuffer(default: select * from hivetable).
> {code}
> Exception in log:
> {code:java}
> 2019-07-15 14:59:12,273 WARN org.apache.flink.table.client.cli.CliClient
> - Could not execute SQL statement.
> org.apache.flink.table.client.gateway.SqlExecutionException: Invalid SQL
> query.
> at
> org.apache.flink.table.client.gateway.local.LocalExecutor.executeQueryInternal(LocalExecutor.java:485)
> at
> org.apache.flink.table.client.gateway.local.LocalExecutor.executeQuery(LocalExecutor.java:317)
> at
> org.apache.flink.table.client.cli.CliClient.callSelect(CliClient.java:469)
> at
> org.apache.flink.table.client.cli.CliClient.callCommand(CliClient.java:291)
> at java.util.Optional.ifPresent(Optional.java:159)
> at org.apache.flink.table.client.cli.CliClient.open(CliClient.java:200)
> at org.apache.flink.table.client.SqlClient.openCli(SqlClient.java:123)
> at org.apache.flink.table.client.SqlClient.start(SqlClient.java:105)
> at org.apache.flink.table.client.SqlClient.main(SqlClient.java:194)
> Caused by: org.apache.flink.table.api.TableException: No table was registered
> under the name ArrayBuffer(default: select * from hivetable).
> at
> org.apache.flink.table.api.internal.TableEnvImpl.insertInto(TableEnvImpl.scala:529)
> at
> org.apache.flink.table.api.internal.TableEnvImpl.insertInto(TableEnvImpl.scala:507)
> at
> org.apache.flink.table.api.internal.BatchTableEnvImpl.insertInto(BatchTableEnvImpl.scala:58)
> at
> org.apache.flink.table.api.internal.TableImpl.insertInto(TableImpl.java:428)
> at
> org.apache.flink.table.api.internal.TableImpl.insertInto(TableImpl.java:416)
> at
> org.apache.flink.table.client.gatewa
[GitHub] [flink] flinkbot edited a comment on issue #9152: [FLINK-13314][table-planner-blink] Correct resultType of some PlannerExpression when operands contains DecimalTypeInfo or BigDecimalTypeInfo
flinkbot edited a comment on issue #9152: [FLINK-13314][table-planner-blink] Correct resultType of some PlannerExpression when operands contains DecimalTypeInfo or BigDecimalTypeInfo in Blink planner URL: https://github.com/apache/flink/pull/9152#issuecomment-512640394 ## CI report: * 7187e4872abf0c514523a00cc9525d82f80bec6e : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/119569472) * 70aa6a8c439590b3249a8957ee7c07e806c83d25 : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/119584126) * da73323bd2ee055e540a767be217271280a29fbc : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/119585224) * f99ef456e514e0321d92f19ef4c3f7a5ff5458ae : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119595384) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9153: [FLINK-13315][table-api] Port wmstrategies to api-java-bridge
flinkbot edited a comment on issue #9153: [FLINK-13315][table-api] Port wmstrategies to api-java-bridge URL: https://github.com/apache/flink/pull/9153#issuecomment-512644370 ## CI report: * a520fe727f09dbf4f2d0a9f8cf91506ef90e4e3d : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/119570552) * d40db82b937ada2d425889aef28e93e3612eb662 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119612022) * 716f4f3d0a13319fc38270549b14d286e0637bf6 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119627016) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9129: [FLINK-13287][table-api] Port ExistingField to api-java and use new Expression in FieldComputer
flinkbot edited a comment on issue #9129: [FLINK-13287][table-api] Port ExistingField to api-java and use new Expression in FieldComputer URL: https://github.com/apache/flink/pull/9129#issuecomment-511810897 ## CI report: * c3a620e6d2abbe5faac85b2ebcdb5340d06f8e8c : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119414043) * 56811a683c5905dba453933022e39cf61773f1b2 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119441086) * b83051e20c73fb600a548478c5ceb794cb73aafc : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119466658) * e6eaad2f1a5fa1d04a192e20570c17519fe0f05c : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/119570139) * a6f042a9d89750513037b5ea083fd7e129fc5fba : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/119592093) * 139fb6dd515bd8effb30e47e6b77f4e305f28230 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119611149) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9130: [FLINK-13274]Refactor HiveTableSourceTest using HiveRunner
flinkbot edited a comment on issue #9130: [FLINK-13274]Refactor HiveTableSourceTest using HiveRunner URL: https://github.com/apache/flink/pull/9130#issuecomment-511810910 ## CI report: * 979a2e7f99fc3c479c65f58dcd06df2943b6a7e3 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119311556) * 07f36fd9d97dbab3a1a84a566ebdc4fb782eaaab : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119573450) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9163: [FLINK-13086]add Chinese documentation for catalogs
flinkbot edited a comment on issue #9163: [FLINK-13086]add Chinese documentation for catalogs URL: https://github.com/apache/flink/pull/9163#issuecomment-512791684 ## CI report: * 6a8b4bc4fb1256cfd8ae00eb757b5145c8053eed : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119626040) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system
flinkbot edited a comment on issue #9161: [FLINK-13262][docs] Add documentation for the new Table & SQL API type system URL: https://github.com/apache/flink/pull/9161#issuecomment-512771034 ## CI report: * d0b22a54669df50558efd1b9d16b94403e5146bf : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119617241) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9154: [FLINK-13304][table-runtime-blink] Fix implementation of getString and getBinary method in NestedRow and add tests for complex data formats
flinkbot edited a comment on issue #9154: [FLINK-13304][table-runtime-blink] Fix implementation of getString and getBinary method in NestedRow and add tests for complex data formats URL: https://github.com/apache/flink/pull/9154#issuecomment-512650847 ## CI report: * cb3568112c5f74d14b192fa49b78029937e94623 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119572579) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] xuyang1706 commented on a change in pull request #9082: [FLINK-13207][ml] Add the algorithm of Fast Fourier Transformation(FFT)
xuyang1706 commented on a change in pull request #9082: [FLINK-13207][ml] Add
the algorithm of Fast Fourier Transformation(FFT)
URL: https://github.com/apache/flink/pull/9082#discussion_r305273154
##
File path:
flink-ml-parent/flink-ml-lib/src/main/java/org/apache/flink/ml/common/utils/FFT.java
##
@@ -0,0 +1,199 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.ml.common.utils;
+
+import org.apache.commons.math3.complex.Complex;
+
+/**
+ * Fast Fourier Transformation(FFT).
+ * Provides 2 algorithms:
+ * 1. Cooley-Tukey algorithm, high performance, but only supports length of
power-of-2.
+ * 2. Chirp-Z algorithm, can perform FFT with any length.
+ */
+public class FFT {
+ /**
+* Helper for root of unity. Returns the group for power "length".
+*/
+ public static Complex[] getOmega(int length) throws Exception {
Review comment:
Thanks for your advice.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9038: [FLINK-13169][tests][coordination] IT test for fine-grained recovery (task executor failures)
flinkbot edited a comment on issue #9038: [FLINK-13169][tests][coordination] IT test for fine-grained recovery (task executor failures) URL: https://github.com/apache/flink/pull/9038#issuecomment-510467775 ## CI report: * b8a762441d69da24f9041b2159ae0bbda334 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/118861397) * f1aeda132a7775e26d74b6f5a2fd74e2d9e1bb63 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119501275) * 0a1b9c3c4c7d7c8068f8812e70841eec760368a1 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119587098) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9122: [FLINK-13269] [table] copy RelDecorrelator & FlinkFilterJoinRule to flink planner to fix CALCITE-3169 & CALCITE-3170
flinkbot edited a comment on issue #9122: [FLINK-13269] [table] copy RelDecorrelator & FlinkFilterJoinRule to flink planner to fix CALCITE-3169 & CALCITE-3170 URL: https://github.com/apache/flink/pull/9122#issuecomment-511645215 ## CI report: * 2f968ce7ffc295992471254265a1feef450a63f3 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119436681) * c1ac76cfbc2c0d812173614fe67f382cc15bb6eb : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119441295) * 7bbbcc00a0133a73aa783bdcb934ff1a56bef5c1 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119466673) * 983da06e83b7b49284a1e3add48eb6e7d5b73a52 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119567573) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9167: [FLINK-13279][table] Fallback to the builtin catalog when looking for registered tables.
flinkbot edited a comment on issue #9167: [FLINK-13279][table] Fallback to the builtin catalog when looking for registered tables. URL: https://github.com/apache/flink/pull/9167#issuecomment-512809275 ## CI report: * 3474c2ca9de8f21af1c6e7e724291743594ee7e8 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119634208) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9162: [FLINK-13321][table-planner-blink] Fix bug in Blink Planner, Join a udf with constant arguments or without argument in TableAPI query does no
flinkbot edited a comment on issue #9162: [FLINK-13321][table-planner-blink] Fix bug in Blink Planner, Join a udf with constant arguments or without argument in TableAPI query does not work now URL: https://github.com/apache/flink/pull/9162#issuecomment-512787783 ## CI report: * b81c975f6a7a2527e3f224a36eef638b7bfdf330 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119624287) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9168: [FLINK-13286][table-api] Port connector related validators to api-java-bridge
flinkbot edited a comment on issue #9168: [FLINK-13286][table-api] Port connector related validators to api-java-bridge URL: https://github.com/apache/flink/pull/9168#issuecomment-512812254 ## CI report: * 88c12379a5787697e9952d96069b0dbdbb114313 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119635237) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9157: [FLINK-13086]add Chinese documentation for catalogs
flinkbot edited a comment on issue #9157: [FLINK-13086]add Chinese documentation for catalogs URL: https://github.com/apache/flink/pull/9157#issuecomment-512668282 ## CI report: * bc17aec9efac2a454b51e5a6f53196a7d78f0cb9 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/119578288) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9166: [FLINK-12901][docs] Update Hadoop build instructions
flinkbot edited a comment on issue #9166: [FLINK-12901][docs] Update Hadoop build instructions URL: https://github.com/apache/flink/pull/9166#issuecomment-512801972 ## CI report: * d5474e43be6941d0c7bb0e2913a6073b18c13851 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119630857) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9164: [FLINK-12894]add Chinese documentation of how to configure and use catalogs in SQL CLI
flinkbot edited a comment on issue #9164: [FLINK-12894]add Chinese documentation of how to configure and use catalogs in SQL CLI URL: https://github.com/apache/flink/pull/9164#issuecomment-512791689 ## CI report: * ec05105250b5d6ac9ebe3747aa74ca72a8c455e4 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119626033) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9169: [FLINK-12998][docs] Update documentation for file systems loading as plugins
flinkbot edited a comment on issue #9169: [FLINK-12998][docs] Update documentation for file systems loading as plugins URL: https://github.com/apache/flink/pull/9169#issuecomment-512820058 ## CI report: * a7bfcd7a2605fe9299655cb26d3f829b4751ecd6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119638448) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services