[GitHub] [flink] Airblader commented on pull request #17898: [FLINK-25047][table] Resolve architectural violations
Airblader commented on pull request #17898: URL: https://github.com/apache/flink/pull/17898#issuecomment-981374898 Thanks @wenlong88. Although I think chances are small that anyone is using these exceptions, I would like this to be a non-breaking PR, so it makes sense to do that. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #17845: [FLINK-24352] [flink-table-planner] Add null check for temporal table check on SqlSnapshot
MartijnVisser commented on pull request #17845: URL: https://github.com/apache/flink/pull/17845#issuecomment-981374790 Should we create a follow-up ticket for the issue you've mentioned @godfreyhe ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] AHeise merged pull request #17538: [FLINK-24325][connectors/elasticsearch] Create Elasticsearch 6 Sink
AHeise merged pull request #17538: URL: https://github.com/apache/flink/pull/17538 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] AHeise commented on a change in pull request #17870: [FLINK-24596][kafka] Fix buffered KafkaUpsert sink
AHeise commented on a change in pull request #17870:
URL: https://github.com/apache/flink/pull/17870#discussion_r758107290
##
File path:
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/sink/TopicSelector.java
##
@@ -18,14 +18,12 @@
package org.apache.flink.connector.kafka.sink;
import org.apache.flink.annotation.PublicEvolving;
-
-import java.io.Serializable;
-import java.util.function.Function;
+import org.apache.flink.util.function.SerializableFunction;
/**
* Selects a topic for the incoming record.
*
* @param type of the incoming record
*/
@PublicEvolving
-public interface TopicSelector extends Function, Serializable
{}
+public interface TopicSelector extends SerializableFunction {}
Review comment:
This is a probably breaking change (just double check if user code is
affected or not). Since this PR is aimed as a bugfix to 1.14.0, I'd remove it
for now. Please also double-check the other migrations.
In general, I think that `TopicSelector` should not have inherited from
`Function` to begin with. :/
##
File path:
flink-connectors/flink-connector-kafka/src/test/java/org/apache/flink/streaming/connectors/kafka/table/ReducingUpsertWriterTest.java
##
@@ -320,8 +319,8 @@ public void registerProcessingTimer(
long time, ProcessingTimeCallback
processingTimerCallback) {}
},
enableObjectReuse
-? typeInformation.createSerializer(new
ExecutionConfig())::copy
-: Function.identity());
+? r -> typeInformation.createSerializer(new
ExecutionConfig()).copy(r)
Review comment:
You can revert that line as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17924: [FLINK-25072][streaming] Introduce description on Transformation and …
flinkbot edited a comment on pull request #17924: URL: https://github.com/apache/flink/pull/17924#issuecomment-979870210 ## CI report: * 07174990a0a73184286f32792dda356ea71d96a6 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27174) * 3dab421140db64ac746629e032738a457ae78d99 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27192) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17924: [FLINK-25072][streaming] Introduce description on Transformation and …
flinkbot edited a comment on pull request #17924: URL: https://github.com/apache/flink/pull/17924#issuecomment-979870210 ## CI report: * 07174990a0a73184286f32792dda356ea71d96a6 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27174) * 3dab421140db64ac746629e032738a457ae78d99 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17938: [Flink-25073][streaming] Introduce TreeMode description for vertices
flinkbot edited a comment on pull request #17938: URL: https://github.com/apache/flink/pull/17938#issuecomment-981363546 ## CI report: * d29e331ebbccb61bbb784d4b0e41cf1e591cb9c0 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27191) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #17938: [Flink-25073][streaming] Introduce TreeMode description for vertices
flinkbot commented on pull request #17938: URL: https://github.com/apache/flink/pull/17938#issuecomment-981364305 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit d29e331ebbccb61bbb784d4b0e41cf1e591cb9c0 (Mon Nov 29 07:42:28 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-25073).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #17938: [Flink-25073][streaming] Introduce TreeMode description for vertices
flinkbot commented on pull request #17938: URL: https://github.com/apache/flink/pull/17938#issuecomment-981363546 ## CI report: * d29e331ebbccb61bbb784d4b0e41cf1e591cb9c0 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wenlong88 opened a new pull request #17938: [Flink-25073][streaming] Introduce TreeMode description for vertices
wenlong88 opened a new pull request #17938: URL: https://github.com/apache/flink/pull/17938 ## What is the purpose of the change This PR is a following up PR of FLINK-25072, inits the operatorPrettyName of JobVertex according to the description of operators introduced in FLINK-25072 and exposes the description in web ui. ## Brief change log - init operatorPrettyName of JobVertex in streaming jobs according to description of operators. - introduce an new tree mode description to make the operatorPrettyName easier to understand. - update web ui: display name in DAG of web ui and display description in detail of job vertex. ## Verifying this change This change added tests and can be verified as follows: - *Added unit tests for StreamingJobGraphGeneratorTest to verify the generation of description * - *verified changed in web ui manually, following is the result in examples. * 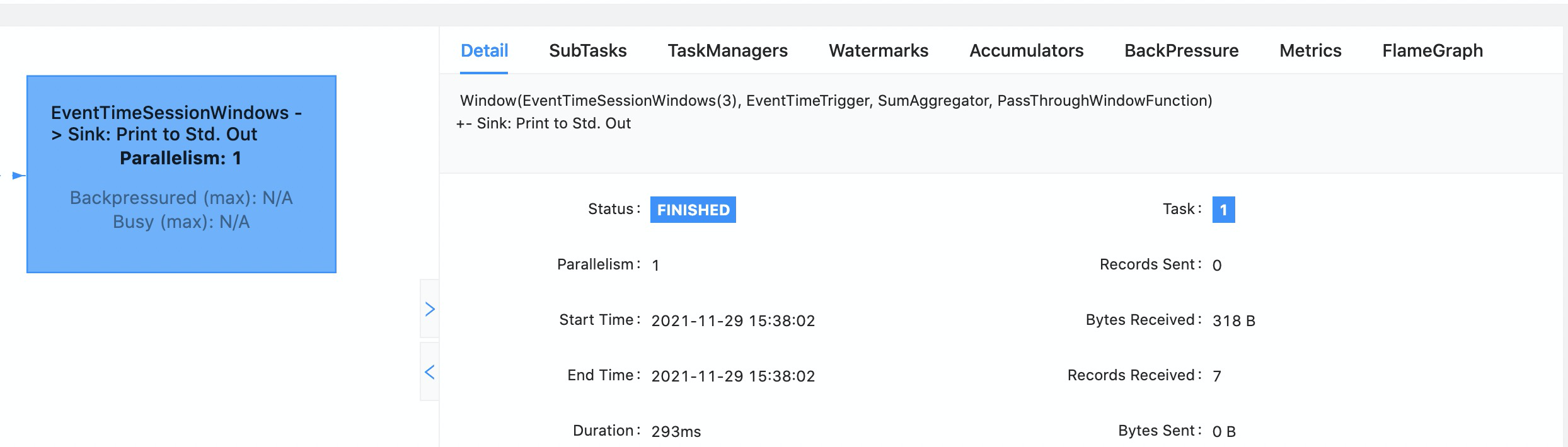 ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (JavaDocs) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17788: [FLINK-15826][Tabel SQL/API] Add renameFunction() to Catalog
flinkbot edited a comment on pull request #17788: URL: https://github.com/apache/flink/pull/17788#issuecomment-968179643 ## CI report: * 4e6d4e3bab6c9fe8caf2363177e74011a175ee72 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=26633) * b6a9b9e36cb882db39de2e5afab9068e86655c2e Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27190) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17867: [FLINK-24592][Table SQL/Client] FlinkSQL Client multiline parser improvements
flinkbot edited a comment on pull request #17867: URL: https://github.com/apache/flink/pull/17867#issuecomment-975551530 ## CI report: * ed90e252cfa8e3fd725ca71473339aafe213a4b3 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=26852) * 4df1c7765d87265518ccb5dd008118a8dbf80f5b Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27189) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17788: [FLINK-15826][Tabel SQL/API] Add renameFunction() to Catalog
flinkbot edited a comment on pull request #17788: URL: https://github.com/apache/flink/pull/17788#issuecomment-968179643 ## CI report: * 4e6d4e3bab6c9fe8caf2363177e74011a175ee72 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=26633) * b6a9b9e36cb882db39de2e5afab9068e86655c2e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] shenzhu removed a comment on pull request #17788: [FLINK-15826][Tabel SQL/API] Add renameFunction() to Catalog
shenzhu removed a comment on pull request #17788: URL: https://github.com/apache/flink/pull/17788#issuecomment-969976164 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17867: [FLINK-24592][Table SQL/Client] FlinkSQL Client multiline parser improvements
flinkbot edited a comment on pull request #17867: URL: https://github.com/apache/flink/pull/17867#issuecomment-975551530 ## CI report: * ed90e252cfa8e3fd725ca71473339aafe213a4b3 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=26852) * 4df1c7765d87265518ccb5dd008118a8dbf80f5b UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-25044) Add More Unit Test For Pulsar Source
[ https://issues.apache.org/jira/browse/FLINK-25044?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Arvid Heise reassigned FLINK-25044: --- Assignee: Yufei Zhang > Add More Unit Test For Pulsar Source > > > Key: FLINK-25044 > URL: https://issues.apache.org/jira/browse/FLINK-25044 > Project: Flink > Issue Type: Improvement > Components: Connectors / Pulsar >Reporter: Yufei Zhang >Assignee: Yufei Zhang >Priority: Minor > Labels: pull-request-available, testing > > We should enhance the pulsar source connector tests by adding more unit tests. > > * SourceReader > * SplitReader > * Enumerator > * SourceBuilder -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] klion26 commented on a change in pull request #10925: [FLINK-15690][core][configuration] Enable configuring ExecutionConfig & CheckpointConfig from flink-conf.yaml
klion26 commented on a change in pull request #10925: URL: https://github.com/apache/flink/pull/10925#discussion_r75800 ## File path: flink-core/src/main/java/org/apache/flink/api/common/ExecutionConfig.java ## @@ -99,7 +99,7 @@ private ClosureCleanerLevel closureCleanerLevel = ClosureCleanerLevel.RECURSIVE; - private int parallelism = PARALLELISM_DEFAULT; + private int parallelism = CoreOptions.DEFAULT_PARALLELISM.defaultValue(); Review comment: @dawidwys this changes the default parallelism from -1(undefined) to 1, is this what we expect? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17666: [FLINK-21327][table-planner-blink] Support window TVF in batch mode
flinkbot edited a comment on pull request #17666: URL: https://github.com/apache/flink/pull/17666#issuecomment-960514675 ## CI report: * cc426ff491234fd94ff50163786c02f9a0e1e5b5 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27188) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-25077) Postgresql connector fails in case column with nested arrays
[
https://issues.apache.org/jira/browse/FLINK-25077?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450228#comment-17450228
]
Sergey Nuyanzin edited comment on FLINK-25077 at 11/29/21, 7:14 AM:
Hi [~jark] thanks for your response.
Yes, I think so
I have a fix for that in my branch [1].
Could you please clarify this question?
The only thing that I noticed: there is no tests for
_org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter_ at
all...
Is there any specific reason for that or just another thing to be improved?
[1]
https://github.com/snuyanzin/flink/commit/bd5e9003c86fcc3ce03b2c109f1feb916029d3c8
was (Author: sergey nuyanzin):
Hi [~jark] thanks for your response.
Yes, I think so
I have a fix for that in my branch [1].
Could you please clarify this question?
The only thing that I noticed: there is no tests for
_org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter_ at
all...
Is there any specific reason for that or just another thing to be improved?
> Postgresql connector fails in case column with nested arrays
>
>
> Key: FLINK-25077
> URL: https://issues.apache.org/jira/browse/FLINK-25077
> Project: Flink
> Issue Type: Bug
> Components: Connectors / JDBC
>Affects Versions: 1.14.0
>Reporter: Sergey Nuyanzin
>Priority: Major
>
> On Postgres
> {code:sql}
> CREATE TABLE sal_emp (
> name VARCHAR,
> pay_by_quarter INT[],
> schedule VARCHAR[][]
> );
> INSERT INTO sal_emp VALUES ('test', ARRAY[1], ARRAY[ARRAY['nested']]);
> {code}
> on Flink
> {code:sql}
> CREATE TABLE flink_sal_emp (
> name STRING,
> pay_by_quarter ARRAY,
> schedule ARRAY>
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:postgresql://localhost:5432/postgres',
> 'table-name' = 'sal_emp',
> 'username' = 'postgres',
> 'password' = 'postgres'
> );
> SELECT * FROM default_catalog.default_database.flink_sal_emp ;
> {code}
> result
> {noformat}
> [ERROR] Could not execute SQL statement. Reason:
> java.lang.ClassCastException: class [Ljava.lang.String; cannot be cast to
> class org.postgresql.jdbc.PgArray ([Ljava.lang.String; is in module java.base
> of loader 'bootstrap'; org.postgresql.jdbc.PgArray is in unnamed module of
> loader 'app')
> at
> org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter.lambda$createPostgresArrayConverter$4f4cdb95$2(PostgresRowConverter.java:104)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.lambda$wrapIntoNullableInternalConverter$ea5b8348$1(AbstractJdbcRowConverter.java:127)
> at
> org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter.lambda$createPostgresArrayConverter$4f4cdb95$2(PostgresRowConverter.java:108)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.lambda$wrapIntoNullableInternalConverter$ea5b8348$1(AbstractJdbcRowConverter.java:127)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.toInternal(AbstractJdbcRowConverter.java:78)
> at
> org.apache.flink.connector.jdbc.table.JdbcRowDataInputFormat.nextRecord(JdbcRowDataInputFormat.java:257)
> at
> org.apache.flink.connector.jdbc.table.JdbcRowDataInputFormat.nextRecord(JdbcRowDataInputFormat.java:56)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:90)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:330)
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-25077) Postgresql connector fails in case column with nested arrays
[
https://issues.apache.org/jira/browse/FLINK-25077?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450228#comment-17450228
]
Sergey Nuyanzin commented on FLINK-25077:
-
Hi [~jark] thanks for your response.
Yes, I think so
I have a fix for that in my branch [1].
Could you please clarify this question?
The only thing that I noticed: there is no tests for
_org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter_ at
all...
Is there any specific reason for that or just another thing to be improved?
> Postgresql connector fails in case column with nested arrays
>
>
> Key: FLINK-25077
> URL: https://issues.apache.org/jira/browse/FLINK-25077
> Project: Flink
> Issue Type: Bug
> Components: Connectors / JDBC
>Affects Versions: 1.14.0
>Reporter: Sergey Nuyanzin
>Priority: Major
>
> On Postgres
> {code:sql}
> CREATE TABLE sal_emp (
> name VARCHAR,
> pay_by_quarter INT[],
> schedule VARCHAR[][]
> );
> INSERT INTO sal_emp VALUES ('test', ARRAY[1], ARRAY[ARRAY['nested']]);
> {code}
> on Flink
> {code:sql}
> CREATE TABLE flink_sal_emp (
> name STRING,
> pay_by_quarter ARRAY,
> schedule ARRAY>
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:postgresql://localhost:5432/postgres',
> 'table-name' = 'sal_emp',
> 'username' = 'postgres',
> 'password' = 'postgres'
> );
> SELECT * FROM default_catalog.default_database.flink_sal_emp ;
> {code}
> result
> {noformat}
> [ERROR] Could not execute SQL statement. Reason:
> java.lang.ClassCastException: class [Ljava.lang.String; cannot be cast to
> class org.postgresql.jdbc.PgArray ([Ljava.lang.String; is in module java.base
> of loader 'bootstrap'; org.postgresql.jdbc.PgArray is in unnamed module of
> loader 'app')
> at
> org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter.lambda$createPostgresArrayConverter$4f4cdb95$2(PostgresRowConverter.java:104)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.lambda$wrapIntoNullableInternalConverter$ea5b8348$1(AbstractJdbcRowConverter.java:127)
> at
> org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter.lambda$createPostgresArrayConverter$4f4cdb95$2(PostgresRowConverter.java:108)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.lambda$wrapIntoNullableInternalConverter$ea5b8348$1(AbstractJdbcRowConverter.java:127)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.toInternal(AbstractJdbcRowConverter.java:78)
> at
> org.apache.flink.connector.jdbc.table.JdbcRowDataInputFormat.nextRecord(JdbcRowDataInputFormat.java:257)
> at
> org.apache.flink.connector.jdbc.table.JdbcRowDataInputFormat.nextRecord(JdbcRowDataInputFormat.java:56)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:90)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:330)
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-25050) Translate "Metrics" page of "Operations" into Chinese
[ https://issues.apache.org/jira/browse/FLINK-25050?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ZhiJie Yang updated FLINK-25050: Component/s: Documentation > Translate "Metrics" page of "Operations" into Chinese > - > > Key: FLINK-25050 > URL: https://issues.apache.org/jira/browse/FLINK-25050 > Project: Flink > Issue Type: Improvement > Components: chinese-translation, Documentation >Reporter: ZhiJie Yang >Assignee: ZhiJie Yang >Priority: Minor > Labels: pull-request-available > > The page url is > https://nightlies.apache.org/flink/flink-docs-master/docs/zh/docs/ops/metrics/ > The markdown file is located in flink/docs/content.zh/docs/ops/metrics.md -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25077) Postgresql connector fails in case column with nested arrays
[
https://issues.apache.org/jira/browse/FLINK-25077?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450222#comment-17450222
]
Jark Wu commented on FLINK-25077:
-
I think this might because JDBC connector with PG dialect just doesn't
supported nested array.
> Postgresql connector fails in case column with nested arrays
>
>
> Key: FLINK-25077
> URL: https://issues.apache.org/jira/browse/FLINK-25077
> Project: Flink
> Issue Type: Bug
> Components: Connectors / JDBC
>Affects Versions: 1.14.0
>Reporter: Sergey Nuyanzin
>Priority: Major
>
> On Postgres
> {code:sql}
> CREATE TABLE sal_emp (
> name VARCHAR,
> pay_by_quarter INT[],
> schedule VARCHAR[][]
> );
> INSERT INTO sal_emp VALUES ('test', ARRAY[1], ARRAY[ARRAY['nested']]);
> {code}
> on Flink
> {code:sql}
> CREATE TABLE flink_sal_emp (
> name STRING,
> pay_by_quarter ARRAY,
> schedule ARRAY>
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:postgresql://localhost:5432/postgres',
> 'table-name' = 'sal_emp',
> 'username' = 'postgres',
> 'password' = 'postgres'
> );
> SELECT * FROM default_catalog.default_database.flink_sal_emp ;
> {code}
> result
> {noformat}
> [ERROR] Could not execute SQL statement. Reason:
> java.lang.ClassCastException: class [Ljava.lang.String; cannot be cast to
> class org.postgresql.jdbc.PgArray ([Ljava.lang.String; is in module java.base
> of loader 'bootstrap'; org.postgresql.jdbc.PgArray is in unnamed module of
> loader 'app')
> at
> org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter.lambda$createPostgresArrayConverter$4f4cdb95$2(PostgresRowConverter.java:104)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.lambda$wrapIntoNullableInternalConverter$ea5b8348$1(AbstractJdbcRowConverter.java:127)
> at
> org.apache.flink.connector.jdbc.internal.converter.PostgresRowConverter.lambda$createPostgresArrayConverter$4f4cdb95$2(PostgresRowConverter.java:108)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.lambda$wrapIntoNullableInternalConverter$ea5b8348$1(AbstractJdbcRowConverter.java:127)
> at
> org.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter.toInternal(AbstractJdbcRowConverter.java:78)
> at
> org.apache.flink.connector.jdbc.table.JdbcRowDataInputFormat.nextRecord(JdbcRowDataInputFormat.java:257)
> at
> org.apache.flink.connector.jdbc.table.JdbcRowDataInputFormat.nextRecord(JdbcRowDataInputFormat.java:56)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:90)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:330)
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #17937: [FLINK-25044][testing][Pulsar Connector] Add More Unit Test For Pulsar Source
flinkbot edited a comment on pull request #17937: URL: https://github.com/apache/flink/pull/17937#issuecomment-981287170 ## CI report: * 1fb86a6233a0fab5a0ef858b40566c3cc76f1a82 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27187) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-25065) Update lookup document for jdbc connector
[ https://issues.apache.org/jira/browse/FLINK-25065?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu reassigned FLINK-25065: --- Assignee: Gaurav Miglani > Update lookup document for jdbc connector > - > > Key: FLINK-25065 > URL: https://issues.apache.org/jira/browse/FLINK-25065 > Project: Flink > Issue Type: Improvement > Components: Documentation >Affects Versions: 1.15.0 >Reporter: Gaurav Miglani >Assignee: Gaurav Miglani >Priority: Minor > Labels: pull-request-available > > Update `lookup.cache.caching-missing-key` document for jdbc connector -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-25065) Update lookup document for jdbc connector
[ https://issues.apache.org/jira/browse/FLINK-25065?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-25065: Component/s: Connectors / JDBC > Update lookup document for jdbc connector > - > > Key: FLINK-25065 > URL: https://issues.apache.org/jira/browse/FLINK-25065 > Project: Flink > Issue Type: Improvement > Components: Connectors / JDBC, Documentation >Affects Versions: 1.15.0 >Reporter: Gaurav Miglani >Assignee: Gaurav Miglani >Priority: Minor > Labels: pull-request-available > > Update `lookup.cache.caching-missing-key` document for jdbc connector -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] wuchong commented on pull request #17918: [FLINK-25065][docs] Update document for jdbc connector
wuchong commented on pull request #17918: URL: https://github.com/apache/flink/pull/17918#issuecomment-98154 @gaurav726 , could you update the content for Chinese documentation as well? The file is located in `docs/content.zh/docs/connectors/table/jdbc.md`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-19358) when submit job on application mode with HA,the jobid will be 0000000000
[ https://issues.apache.org/jira/browse/FLINK-19358?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450220#comment-17450220 ] jocean.shi commented on FLINK-19358: [~trohrmann] I get your concern, In the other word, Whether it's reasonable the code generate JobGraph run twice when failover in "application mode", maybe user code has random code or time code,running twice may be generate different logic. > when submit job on application mode with HA,the jobid will be 00 > > > Key: FLINK-19358 > URL: https://issues.apache.org/jira/browse/FLINK-19358 > Project: Flink > Issue Type: Bug > Components: Runtime / Coordination >Affects Versions: 1.11.0 >Reporter: Jun Zhang >Priority: Minor > Labels: auto-deprioritized-major, usability > > when submit a flink job on application mode with HA ,the flink job id will be > , when I have many jobs ,they have the same > job id , it will be lead to a checkpoint error -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Assigned] (FLINK-25050) Translate "Metrics" page of "Operations" into Chinese
[ https://issues.apache.org/jira/browse/FLINK-25050?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu reassigned FLINK-25050: --- Assignee: ZhiJie Yang > Translate "Metrics" page of "Operations" into Chinese > - > > Key: FLINK-25050 > URL: https://issues.apache.org/jira/browse/FLINK-25050 > Project: Flink > Issue Type: Improvement > Components: chinese-translation >Reporter: ZhiJie Yang >Assignee: ZhiJie Yang >Priority: Minor > Labels: pull-request-available > > The page url is > https://nightlies.apache.org/flink/flink-docs-master/docs/zh/docs/ops/metrics/ > The markdown file is located in flink/docs/content.zh/docs/ops/metrics.md -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25055) Support listen and notify mechanism for PartitionRequest
[ https://issues.apache.org/jira/browse/FLINK-25055?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450218#comment-17450218 ] Shammon commented on FLINK-25055: - [~trohrmann] Thank you for your rely. Yes, your understanding is quite correct, this mechanism helps to optimize the interaction between tasks. And thank you for suggestions, I agree with you that it's necessary and important to delete the specified callback in case of timeout or task deployment failure. I want to add this mechanism in flink when job's tasks are deployed in a same pipelined region, and users can use it in their clusters with a specify config. Could you assign this issue to me? Thanks > Support listen and notify mechanism for PartitionRequest > > > Key: FLINK-25055 > URL: https://issues.apache.org/jira/browse/FLINK-25055 > Project: Flink > Issue Type: Improvement > Components: Runtime / Network >Affects Versions: 1.14.0, 1.12.5, 1.13.3 >Reporter: Shammon >Priority: Major > > We submit batch jobs to flink session cluster with eager scheduler for olap. > JM deploys subtasks to TaskManager independently, and the downstream subtasks > may start before the upstream ones are ready. The downstream subtask sends > PartitionRequest to upstream ones, and may receive PartitionNotFoundException > from them. Then it will retry to send PartitionRequest after a few ms until > timeout. > The current approach raises two problems. First, there will be too many retry > PartitionRequest messages. Each downstream subtask will send PartitionRequest > to all its upstream subtasks and the total number of messages will be O(N*N), > where N is the parallelism of subtasks. Secondly, the interval between > polling retries will increase the delay for upstream and downstream tasks to > confirm PartitionRequest. > We want to support listen and notify mechanism for PartitionRequest when the > job needs no failover. Upstream TaskManager will add the PartitionRequest to > a listen list with a timeout checker, and notify the request when the task > register its partition in the TaskManager. > [~nkubicek] I noticed that your scenario of using flink is similar to ours. > What do you think? And hope to hear from you [~trohrmann] THX -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25049) sql-client.sh execute batch job in async mode failed with java.io.FileNotFoundException
[
https://issues.apache.org/jira/browse/FLINK-25049?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450217#comment-17450217
]
Jark Wu commented on FLINK-25049:
-
[~macdoor615], could you share the DDL of the tables used in your DMLs?
cc [~lzljs3620320]
> sql-client.sh execute batch job in async mode failed with
> java.io.FileNotFoundException
> ---
>
> Key: FLINK-25049
> URL: https://issues.apache.org/jira/browse/FLINK-25049
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem, Table SQL / Ecosystem
>Affects Versions: 1.14.0
>Reporter: macdoor615
>Priority: Major
>
> execute multi simple sql in a sql file, like
>
> {code:java}
> insert overwrite bnpmp.p_biz_hcd_5m select * from bnpmp.p_biz_hcd_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hjr_5m select * from bnpmp.p_biz_hjr_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hswtv_5m select * from bnpmp.p_biz_hswtv_5m
> where dt='2021-11-22';
> ...
> {code}
>
> if
> {code:java}
> SET table.dml-sync = true;{code}
> execute properly.
> if
> {code:java}
> SET table.dml-sync = false;{code}
> some SQL Job failed with the following error
>
> {code:java}
> Caused by: java.lang.Exception: Failed to finalize execution on master ...
> 37 more Caused by: org.apache.flink.table.api.TableException: Exception in
> finalizeGlobal at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:91)
> at
> org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.finalizeOnMaster(InputOutputFormatVertex.java:148)
> at
> org.apache.flink.runtime.executiongraph.DefaultExecutionGraph.vertexFinished(DefaultExecutionGraph.java:1086)
> ... 36 more Caused by: java.io.FileNotFoundException: File
> hdfs://service1/user/hive/warehouse/bnpmp.db/p_snmp_f5_traffic_5m/.staging_1637821441497
> does not exist. at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatusInternal(DistributedFileSystem.java:901)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.access$600(DistributedFileSystem.java:112)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:961)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:958)
> at
> org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatus(DistributedFileSystem.java:958)
> at
> org.apache.flink.hive.shaded.fs.hdfs.HadoopFileSystem.listStatus(HadoopFileSystem.java:170)
> at
> org.apache.flink.table.filesystem.PartitionTempFileManager.listTaskTemporaryPaths(PartitionTempFileManager.java:104)
> at
> org.apache.flink.table.filesystem.FileSystemCommitter.commitPartitions(FileSystemCommitter.java:77)
> at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:89)
> ... 38 more
>
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-25049) sql-client.sh execute batch job in async mode failed with java.io.FileNotFoundException
[
https://issues.apache.org/jira/browse/FLINK-25049?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-25049:
Component/s: Table SQL / Ecosystem
> sql-client.sh execute batch job in async mode failed with
> java.io.FileNotFoundException
> ---
>
> Key: FLINK-25049
> URL: https://issues.apache.org/jira/browse/FLINK-25049
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem, Table SQL / Ecosystem
>Affects Versions: 1.14.0
>Reporter: macdoor615
>Priority: Major
>
> execute multi simple sql in a sql file, like
>
> {code:java}
> insert overwrite bnpmp.p_biz_hcd_5m select * from bnpmp.p_biz_hcd_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hjr_5m select * from bnpmp.p_biz_hjr_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hswtv_5m select * from bnpmp.p_biz_hswtv_5m
> where dt='2021-11-22';
> ...
> {code}
>
> if
> {code:java}
> SET table.dml-sync = true;{code}
> execute properly.
> if
> {code:java}
> SET table.dml-sync = false;{code}
> some SQL Job failed with the following error
>
> {code:java}
> Caused by: java.lang.Exception: Failed to finalize execution on master ...
> 37 more Caused by: org.apache.flink.table.api.TableException: Exception in
> finalizeGlobal at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:91)
> at
> org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.finalizeOnMaster(InputOutputFormatVertex.java:148)
> at
> org.apache.flink.runtime.executiongraph.DefaultExecutionGraph.vertexFinished(DefaultExecutionGraph.java:1086)
> ... 36 more Caused by: java.io.FileNotFoundException: File
> hdfs://service1/user/hive/warehouse/bnpmp.db/p_snmp_f5_traffic_5m/.staging_1637821441497
> does not exist. at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatusInternal(DistributedFileSystem.java:901)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.access$600(DistributedFileSystem.java:112)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:961)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:958)
> at
> org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatus(DistributedFileSystem.java:958)
> at
> org.apache.flink.hive.shaded.fs.hdfs.HadoopFileSystem.listStatus(HadoopFileSystem.java:170)
> at
> org.apache.flink.table.filesystem.PartitionTempFileManager.listTaskTemporaryPaths(PartitionTempFileManager.java:104)
> at
> org.apache.flink.table.filesystem.FileSystemCommitter.commitPartitions(FileSystemCommitter.java:77)
> at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:89)
> ... 38 more
>
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-25049) sql-client.sh execute batch job in async mode failed with java.io.FileNotFoundException
[
https://issues.apache.org/jira/browse/FLINK-25049?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-25049:
Environment: (was: {code:java}
//代码占位符
{code})
> sql-client.sh execute batch job in async mode failed with
> java.io.FileNotFoundException
> ---
>
> Key: FLINK-25049
> URL: https://issues.apache.org/jira/browse/FLINK-25049
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem
>Affects Versions: 1.14.0
>Reporter: macdoor615
>Priority: Major
>
> execute multi simple sql in a sql file, like
>
> {code:java}
> insert overwrite bnpmp.p_biz_hcd_5m select * from bnpmp.p_biz_hcd_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hjr_5m select * from bnpmp.p_biz_hjr_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hswtv_5m select * from bnpmp.p_biz_hswtv_5m
> where dt='2021-11-22';
> ...
> {code}
>
> if
> {code:java}
> SET table.dml-sync = true;{code}
> execute properly.
> if
> {code:java}
> SET table.dml-sync = false;{code}
> some SQL Job failed with the following error
>
> {code:java}
> Caused by: java.lang.Exception: Failed to finalize execution on master ...
> 37 more Caused by: org.apache.flink.table.api.TableException: Exception in
> finalizeGlobal at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:91)
> at
> org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.finalizeOnMaster(InputOutputFormatVertex.java:148)
> at
> org.apache.flink.runtime.executiongraph.DefaultExecutionGraph.vertexFinished(DefaultExecutionGraph.java:1086)
> ... 36 more Caused by: java.io.FileNotFoundException: File
> hdfs://service1/user/hive/warehouse/bnpmp.db/p_snmp_f5_traffic_5m/.staging_1637821441497
> does not exist. at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatusInternal(DistributedFileSystem.java:901)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.access$600(DistributedFileSystem.java:112)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:961)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:958)
> at
> org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatus(DistributedFileSystem.java:958)
> at
> org.apache.flink.hive.shaded.fs.hdfs.HadoopFileSystem.listStatus(HadoopFileSystem.java:170)
> at
> org.apache.flink.table.filesystem.PartitionTempFileManager.listTaskTemporaryPaths(PartitionTempFileManager.java:104)
> at
> org.apache.flink.table.filesystem.FileSystemCommitter.commitPartitions(FileSystemCommitter.java:77)
> at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:89)
> ... 38 more
>
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-25049) sql-client.sh execute batch job in async mode failed with java.io.FileNotFoundException
[
https://issues.apache.org/jira/browse/FLINK-25049?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-25049:
Component/s: Connectors / FileSystem
(was: Table SQL / Client)
> sql-client.sh execute batch job in async mode failed with
> java.io.FileNotFoundException
> ---
>
> Key: FLINK-25049
> URL: https://issues.apache.org/jira/browse/FLINK-25049
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem
>Affects Versions: 1.14.0
> Environment: {code:java}
> //代码占位符
> {code}
>Reporter: macdoor615
>Priority: Major
>
> execute multi simple sql in a sql file, like
>
> {code:java}
> insert overwrite bnpmp.p_biz_hcd_5m select * from bnpmp.p_biz_hcd_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hjr_5m select * from bnpmp.p_biz_hjr_5m where
> dt='2021-11-22';
> insert overwrite bnpmp.p_biz_hswtv_5m select * from bnpmp.p_biz_hswtv_5m
> where dt='2021-11-22';
> ...
> {code}
>
> if
> {code:java}
> SET table.dml-sync = true;{code}
> execute properly.
> if
> {code:java}
> SET table.dml-sync = false;{code}
> some SQL Job failed with the following error
>
> {code:java}
> Caused by: java.lang.Exception: Failed to finalize execution on master ...
> 37 more Caused by: org.apache.flink.table.api.TableException: Exception in
> finalizeGlobal at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:91)
> at
> org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.finalizeOnMaster(InputOutputFormatVertex.java:148)
> at
> org.apache.flink.runtime.executiongraph.DefaultExecutionGraph.vertexFinished(DefaultExecutionGraph.java:1086)
> ... 36 more Caused by: java.io.FileNotFoundException: File
> hdfs://service1/user/hive/warehouse/bnpmp.db/p_snmp_f5_traffic_5m/.staging_1637821441497
> does not exist. at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatusInternal(DistributedFileSystem.java:901)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.access$600(DistributedFileSystem.java:112)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:961)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:958)
> at
> org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
> at
> org.apache.hadoop.hdfs.DistributedFileSystem.listStatus(DistributedFileSystem.java:958)
> at
> org.apache.flink.hive.shaded.fs.hdfs.HadoopFileSystem.listStatus(HadoopFileSystem.java:170)
> at
> org.apache.flink.table.filesystem.PartitionTempFileManager.listTaskTemporaryPaths(PartitionTempFileManager.java:104)
> at
> org.apache.flink.table.filesystem.FileSystemCommitter.commitPartitions(FileSystemCommitter.java:77)
> at
> org.apache.flink.table.filesystem.FileSystemOutputFormat.finalizeGlobal(FileSystemOutputFormat.java:89)
> ... 38 more
>
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-25054) Improve exception message for unsupported hashLength for SHA2 function
[ https://issues.apache.org/jira/browse/FLINK-25054?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450215#comment-17450215 ] Jark Wu commented on FLINK-25054: - Yes, I think the exception message should be improved. > Improve exception message for unsupported hashLength for SHA2 function > -- > > Key: FLINK-25054 > URL: https://issues.apache.org/jira/browse/FLINK-25054 > Project: Flink > Issue Type: Improvement > Components: Table SQL / API >Affects Versions: 1.12.3 >Reporter: chenbowen >Priority: Major > Attachments: image-2021-11-25-16-59-56-699.png > > Original Estimate: 1h > Remaining Estimate: 1h > > 【exception sql】 > SELECT > SHA2(, 128) > FROM > > 【effect】 > when sql is long , it`s hard to clear where is the problem on this issue > 【reason】 > build-in function SHA2, hashLength do not support “128”, but I could not > understand from > 【Exception log】 > !image-2021-11-25-16-59-56-699.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25054) Improve exception message for unsupported hashLength for SHA2 function
[ https://issues.apache.org/jira/browse/FLINK-25054?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450216#comment-17450216 ] Jark Wu commented on FLINK-25054: - Yes, I think the exception message should be improved. > Improve exception message for unsupported hashLength for SHA2 function > -- > > Key: FLINK-25054 > URL: https://issues.apache.org/jira/browse/FLINK-25054 > Project: Flink > Issue Type: Improvement > Components: Table SQL / API >Affects Versions: 1.12.3 >Reporter: chenbowen >Priority: Major > Attachments: image-2021-11-25-16-59-56-699.png > > Original Estimate: 1h > Remaining Estimate: 1h > > 【exception sql】 > SELECT > SHA2(, 128) > FROM > > 【effect】 > when sql is long , it`s hard to clear where is the problem on this issue > 【reason】 > build-in function SHA2, hashLength do not support “128”, but I could not > understand from > 【Exception log】 > !image-2021-11-25-16-59-56-699.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-25054) Improve exception message for unsupported hashLength for SHA2 function
[ https://issues.apache.org/jira/browse/FLINK-25054?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-25054: Language: (was: JAVA) > Improve exception message for unsupported hashLength for SHA2 function > -- > > Key: FLINK-25054 > URL: https://issues.apache.org/jira/browse/FLINK-25054 > Project: Flink > Issue Type: Improvement > Components: Table SQL / API >Affects Versions: 1.12.3 >Reporter: chenbowen >Priority: Major > Attachments: image-2021-11-25-16-59-56-699.png > > Original Estimate: 1h > Remaining Estimate: 1h > > 【exception sql】 > SELECT > SHA2(, 128) > FROM > > 【effect】 > when sql is long , it`s hard to clear where is the problem on this issue > 【reason】 > build-in function SHA2, hashLength do not support “128”, but I could not > understand from > 【Exception log】 > !image-2021-11-25-16-59-56-699.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-25054) Improve exception message for unsupported hashLength for SHA2 function
[ https://issues.apache.org/jira/browse/FLINK-25054?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-25054: Summary: Improve exception message for unsupported hashLength for SHA2 function (was: flink sql System (Built-in) Functions 【SHA2】,hashLength validation Unsurpport) > Improve exception message for unsupported hashLength for SHA2 function > -- > > Key: FLINK-25054 > URL: https://issues.apache.org/jira/browse/FLINK-25054 > Project: Flink > Issue Type: Improvement > Components: Build System >Affects Versions: 1.12.3 >Reporter: chenbowen >Priority: Major > Attachments: image-2021-11-25-16-59-56-699.png > > Original Estimate: 1h > Remaining Estimate: 1h > > 【exception sql】 > SELECT > SHA2(, 128) > FROM > > 【effect】 > when sql is long , it`s hard to clear where is the problem on this issue > 【reason】 > build-in function SHA2, hashLength do not support “128”, but I could not > understand from > 【Exception log】 > !image-2021-11-25-16-59-56-699.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-25054) Improve exception message for unsupported hashLength for SHA2 function
[ https://issues.apache.org/jira/browse/FLINK-25054?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-25054: Component/s: Table SQL / API (was: Build System) > Improve exception message for unsupported hashLength for SHA2 function > -- > > Key: FLINK-25054 > URL: https://issues.apache.org/jira/browse/FLINK-25054 > Project: Flink > Issue Type: Improvement > Components: Table SQL / API >Affects Versions: 1.12.3 >Reporter: chenbowen >Priority: Major > Attachments: image-2021-11-25-16-59-56-699.png > > Original Estimate: 1h > Remaining Estimate: 1h > > 【exception sql】 > SELECT > SHA2(, 128) > FROM > > 【effect】 > when sql is long , it`s hard to clear where is the problem on this issue > 【reason】 > build-in function SHA2, hashLength do not support “128”, but I could not > understand from > 【Exception log】 > !image-2021-11-25-16-59-56-699.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25029) Hadoop Caller Context Setting In Flink
[ https://issues.apache.org/jira/browse/FLINK-25029?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450209#comment-17450209 ] 刘方奇 commented on FLINK-25029: - Sorry to bother. Could someone help to look this issue? In my opinion, this issue do not go the end. [~lzljs3620320] [~arvid] [~dmvk] [~jark] > Hadoop Caller Context Setting In Flink > -- > > Key: FLINK-25029 > URL: https://issues.apache.org/jira/browse/FLINK-25029 > Project: Flink > Issue Type: Improvement > Components: Runtime / Task >Reporter: 刘方奇 >Priority: Major > > For a given HDFS operation (e.g. delete file), it's very helpful to track > which upper level job issues it. The upper level callers may be specific > Oozie tasks, MR jobs, and hive queries. One scenario is that the namenode > (NN) is abused/spammed, the operator may want to know immediately which MR > job should be blamed so that she can kill it. To this end, the caller context > contains at least the application-dependent "tracking id". > The above is the main effect of the Caller Context. HDFS Client set Caller > Context, then name node get it in audit log to do some work. > Now the Spark and hive have the Caller Context to meet the HDFS Job Audit > requirement. > In my company, flink jobs often cause some problems for HDFS, so we did it > for preventing some cases. > If the feature is general enough. Should we support it, then I can submit a > PR for this. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #32: [FLINK-24817] Add Naive Bayes implementation
yunfengzhou-hub commented on a change in pull request #32:
URL: https://github.com/apache/flink-ml/pull/32#discussion_r758054855
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/classification/naivebayes/NaiveBayesModelData.java
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.classification.naivebayes;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.serialization.Encoder;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.connector.file.src.reader.SimpleStreamFormat;
+import org.apache.flink.core.fs.FSDataInputStream;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.types.Row;
+
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+
+import java.io.IOException;
+import java.io.OutputStream;
+import java.io.Serializable;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * The model data of {@link NaiveBayesModel}.
+ *
+ * This class also provides methods to convert model data between Table and
Datastream, and
+ * classes to save/load model data.
+ */
+public class NaiveBayesModelData implements Serializable {
+public final Map[][] theta;
+public final double[] piArray;
+public final int[] labels;
+
+public NaiveBayesModelData(Map[][] theta, double[]
piArray, int[] labels) {
+this.theta = theta;
+this.piArray = piArray;
+this.labels = labels;
+}
+
+/** Converts the provided modelData Datastream into corresponding Table. */
+public static Table getModelDataTable(
+StreamTableEnvironment tEnv, DataStream
stream) {
Review comment:
Yes. it makes sense. I'll make the change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (FLINK-25089) KafkaSourceITCase.testBasicRead hangs on azure
Yun Gao created FLINK-25089: --- Summary: KafkaSourceITCase.testBasicRead hangs on azure Key: FLINK-25089 URL: https://issues.apache.org/jira/browse/FLINK-25089 Project: Flink Issue Type: Bug Components: Connectors / Kafka Affects Versions: 1.13.4 Reporter: Yun Gao https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=27180=logs=1fc6e7bf-633c-5081-c32a-9dea24b05730=80a658d1-f7f6-5d93-2758-53ac19fd5b19=6933 -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-24764) pyflink/table/tests/test_udf.py hang on Azure
[
https://issues.apache.org/jira/browse/FLINK-24764?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450202#comment-17450202
]
Yun Gao commented on FLINK-24764:
-
[https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=27181=logs=821b528f-1eed-5598-a3b4-7f748b13f261=6bb545dd-772d-5d8c-f258-f5085fba3295=22361]
> pyflink/table/tests/test_udf.py hang on Azure
> -
>
> Key: FLINK-24764
> URL: https://issues.apache.org/jira/browse/FLINK-24764
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.14.0, 1.12.5, 1.15.0
>Reporter: Till Rohrmann
>Priority: Critical
> Labels: test-stability
> Fix For: 1.15.0, 1.14.1, 1.13.4
>
>
> {{pyflink/table/tests/test_udf.py}} seems to hang on Azure.
> {code}
> 2021-11-04T03:12:01.4537829Z py36-cython run-test: commands[3] | pytest
> --durations=20
> 2021-11-04T03:12:03.6955063Z = test session
> starts ==
> 2021-11-04T03:12:03.6957461Z platform linux -- Python 3.6.13, pytest-6.2.5,
> py-1.10.0, pluggy-1.0.0
> 2021-11-04T03:12:03.6959285Z cachedir: .tox/py36-cython/.pytest_cache
> 2021-11-04T03:12:03.6960653Z rootdir: /__w/1/s/flink-python
> 2021-11-04T03:12:03.6961356Z collected 690 items
> 2021-11-04T03:12:03.6961755Z
> 2021-11-04T03:12:04.6615796Z pyflink/common/tests/test_configuration.py
> ..[ 1%]
> 2021-11-04T03:12:04.9315499Z pyflink/common/tests/test_execution_config.py
> ...[ 4%]
> 2021-11-04T03:12:05.4226061Z
> pyflink/common/tests/test_serialization_schemas.py ... [
> 5%]
> 2021-11-04T03:12:05.8920762Z pyflink/common/tests/test_typeinfo.py ...
> [ 5%]
> 2021-11-04T03:12:10.3843622Z
> pyflink/dataset/tests/test_execution_environment.py ...s.[
> 6%]
> 2021-11-04T03:12:10.4385641Z
> pyflink/dataset/tests/test_execution_environment_completeness.py . [
> 7%]
> 2021-11-04T03:12:10.5390180Z
> pyflink/datastream/tests/test_check_point_config.py ... [
> 8%]
> 2021-11-04T03:12:20.1148835Z pyflink/datastream/tests/test_connectors.py ...
> [ 9%]
> 2021-11-04T03:13:12.4436977Z pyflink/datastream/tests/test_data_stream.py
> ... [ 13%]
> 2021-11-04T03:13:22.6815256Z
> [ 14%]
> 2021-11-04T03:13:22.9777981Z pyflink/datastream/tests/test_state_backend.py
> ..[ 16%]
> 2021-11-04T03:13:33.4281095Z
> pyflink/datastream/tests/test_stream_execution_environment.py .. [
> 18%]
> 2021-11-04T03:13:45.3707210Z .s.
> [ 21%]
> 2021-11-04T03:13:45.5100419Z
> pyflink/datastream/tests/test_stream_execution_environment_completeness.py .
> [ 21%]
> 2021-11-04T03:13:45.5107357Z
> [ 21%]
> 2021-11-04T03:13:45.5824541Z pyflink/fn_execution/tests/test_coders.py
> s [ 24%]
> 2021-11-04T03:13:45.6311670Z pyflink/fn_execution/tests/test_fast_coders.py
> ... [ 27%]
> 2021-11-04T03:13:45.6480686Z
> pyflink/fn_execution/tests/test_flink_fn_execution_pb2_synced.py . [
> 27%]
> 2021-11-04T03:13:48.3033527Z
> pyflink/fn_execution/tests/test_process_mode_boot.py ... [
> 28%]
> 2021-11-04T03:13:48.3169538Z pyflink/metrics/tests/test_metric.py .
> [ 28%]
> 2021-11-04T03:13:48.3928810Z pyflink/ml/tests/test_ml_environment.py ...
> [ 29%]
> 2021-11-04T03:13:48.4381082Z pyflink/ml/tests/test_ml_environment_factory.py
> ... [ 29%]
> 2021-11-04T03:13:48.4696143Z pyflink/ml/tests/test_params.py .
> [ 31%]
> 2021-11-04T03:13:48.5140301Z pyflink/ml/tests/test_pipeline.py
> [ 32%]
> 2021-11-04T03:13:50.2573824Z pyflink/ml/tests/test_pipeline_it_case.py ...
> [ 32%]
> 2021-11-04T03:13:50.3598135Z pyflink/ml/tests/test_pipeline_stage.py ..
> [ 32%]
> 2021-11-04T03:14:18.5397420Z pyflink/table/tests/test_aggregate.py .
> [ 34%]
> 2021-11-04T03:14:20.1852937Z pyflink/table/tests/test_calc.py ...
> [ 35%]
> 2021-11-04T03:14:21.3674525Z pyflink/table/tests/test_catalog.py
> [ 40%]
> 2021-11-04T03:14:22.4375814Z ...
> [ 46%]
> 2021-11-04T03:14:22.4966492Z
[jira] [Created] (FLINK-25088) KafkaSinkITCase failed on azure due to Container did not start correctly
Yun Gao created FLINK-25088:
---
Summary: KafkaSinkITCase failed on azure due to Container did not
start correctly
Key: FLINK-25088
URL: https://issues.apache.org/jira/browse/FLINK-25088
Project: Flink
Issue Type: Bug
Components: Build System / Azure Pipelines, Connectors / Kafka
Affects Versions: 1.14.1
Reporter: Yun Gao
{code:java}
Nov 29 03:38:00 at
org.junit.vintage.engine.VintageTestEngine.executeAllChildren(VintageTestEngine.java:82)
Nov 29 03:38:00 at
org.junit.vintage.engine.VintageTestEngine.execute(VintageTestEngine.java:73)
Nov 29 03:38:00 at
org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:220)
Nov 29 03:38:00 at
org.junit.platform.launcher.core.DefaultLauncher.lambda$execute$6(DefaultLauncher.java:188)
Nov 29 03:38:00 at
org.junit.platform.launcher.core.DefaultLauncher.withInterceptedStreams(DefaultLauncher.java:202)
Nov 29 03:38:00 at
org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:181)
Nov 29 03:38:00 at
org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:128)
Nov 29 03:38:00 at
org.apache.maven.surefire.junitplatform.JUnitPlatformProvider.invokeAllTests(JUnitPlatformProvider.java:150)
Nov 29 03:38:00 at
org.apache.maven.surefire.junitplatform.JUnitPlatformProvider.invoke(JUnitPlatformProvider.java:120)
Nov 29 03:38:00 at
org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
Nov 29 03:38:00 at
org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
Nov 29 03:38:00 at
org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
Nov 29 03:38:00 at
org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
Nov 29 03:38:00 Caused by: org.rnorth.ducttape.RetryCountExceededException:
Retry limit hit with exception
Nov 29 03:38:00 at
org.rnorth.ducttape.unreliables.Unreliables.retryUntilSuccess(Unreliables.java:88)
Nov 29 03:38:00 at
org.testcontainers.containers.GenericContainer.doStart(GenericContainer.java:327)
Nov 29 03:38:00 ... 33 more
Nov 29 03:38:00 Caused by:
org.testcontainers.containers.ContainerLaunchException: Could not create/start
container
Nov 29 03:38:00 at
org.testcontainers.containers.GenericContainer.tryStart(GenericContainer.java:523)
Nov 29 03:38:00 at
org.testcontainers.containers.GenericContainer.lambda$doStart$0(GenericContainer.java:329)
Nov 29 03:38:00 at
org.rnorth.ducttape.unreliables.Unreliables.retryUntilSuccess(Unreliables.java:81)
Nov 29 03:38:00 ... 34 more
Nov 29 03:38:00 Caused by: java.lang.IllegalStateException: Container did not
start correctly.
Nov 29 03:38:00 at
org.testcontainers.containers.GenericContainer.tryStart(GenericContainer.java:461)
Nov 29 03:38:00 ... 36 more
Nov 29 03:38:00
Nov 29 03:38:01 [INFO] Running
org.apache.flink.connector.kafka.sink.FlinkKafkaInternalProducerITCase
Nov 29 03:38:16 [INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time
elapsed: 14.442 s - in
org.apache.flink.connector.kafka.sink.FlinkKafkaInternalProducerITCase
Nov 29 03:38:16 [INFO]
Nov 29 03:38:16 [INFO] Results:
Nov 29 03:38:16 [INFO]
Nov 29 03:38:16 [ERROR] Errors:
Nov 29 03:38:16 [ERROR] KafkaSinkITCase » ContainerLaunch Container startup
failed
Nov 29 03:38:16 [INFO]
Nov 29 03:38:16 [ERROR] Tests run: 186, Failures: 0, Errors: 1, Skipped: 0
{code}
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=27181=logs=b0097207-033c-5d9a-b48c-6d4796fbe60d=8338a7d2-16f7-52e5-f576-4b7b3071eb3d=7151
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-24935) Python module failed to compile due to "Could not create local repository"
[
https://issues.apache.org/jira/browse/FLINK-24935?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450200#comment-17450200
]
Yun Gao commented on FLINK-24935:
-
[https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=27179=logs=a29bcfe1-064d-50b9-354f-07802213a3c0=47ff6576-c9dc-5eab-9db8-183dcca3bede]
Hi [~chesnay] sorry this issue seems to still pop up, does disabling the repo
sync already take effect~?
> Python module failed to compile due to "Could not create local repository"
> --
>
> Key: FLINK-24935
> URL: https://issues.apache.org/jira/browse/FLINK-24935
> Project: Flink
> Issue Type: Bug
> Components: Build System / Azure Pipelines
>Affects Versions: 1.12.5
>Reporter: Yun Gao
>Priority: Critical
> Labels: test-stability
>
> {code:java}
> Invoking mvn with 'mvn -Dmaven.wagon.http.pool=false --settings
> /__w/1/s/tools/ci/google-mirror-settings.xml
> -Dorg.slf4j.simpleLogger.showDateTime=true
> -Dorg.slf4j.simpleLogger.dateTimeFormat=HH:mm:ss.SSS
> -Dorg.slf4j.simpleLogger.log.org.apache.maven.cli.transfer.Slf4jMavenTransferListener=warn
> --no-snapshot-updates -B -Dhadoop.version=2.8.3 -Dinclude_hadoop_aws
> -Dscala-2.11 clean deploy
> -DaltDeploymentRepository=validation_repository::default::file:/tmp/flink-validation-deployment
> -Dmaven.repo.local=/home/vsts/work/1/.m2/repository
> -Dflink.convergence.phase=install -Pcheck-convergence -Dflink.forkCount=2
> -Dflink.forkCountTestPackage=2 -Dmaven.javadoc.skip=true -U -DskipTests'
> [ERROR] Could not create local repository at /home/vsts/work/1/.m2/repository
> -> [Help 1]
> [ERROR]
> [ERROR] To see the full stack trace of the errors, re-run Maven with the -e
> switch.
> [ERROR] Re-run Maven using the -X switch to enable full debug logging.
> [ERROR]
> [ERROR] For more information about the errors and possible solutions, please
> read the following articles:
> [ERROR] [Help 1]
> http://cwiki.apache.org/confluence/display/MAVEN/LocalRepositoryNotAccessibleException
> {code}
> [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=26625=logs=a29bcfe1-064d-50b9-354f-07802213a3c0=47ff6576-c9dc-5eab-9db8-183dcca3bede]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-23391) KafkaSourceReaderTest.testKafkaSourceMetrics fails on azure
[
https://issues.apache.org/jira/browse/FLINK-23391?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450198#comment-17450198
]
Yun Gao commented on FLINK-23391:
-
[https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=27178=logs=c5f0071e-1851-543e-9a45-9ac140befc32=15a22db7-8faa-5b34-3920-d33c9f0ca23c=6861]
The ci is running against c40bbf1e87cc62880905cd567dca05a4e15aff35, which seems
to contains c461338d0009a164d9c236aeab691677384d1d9f on master, [~renqs] could
you have a double look~?
> KafkaSourceReaderTest.testKafkaSourceMetrics fails on azure
> ---
>
> Key: FLINK-23391
> URL: https://issues.apache.org/jira/browse/FLINK-23391
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0, 1.13.1
>Reporter: Xintong Song
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available, test-stability
> Fix For: 1.15.0, 1.14.1, 1.13.4
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=20456=logs=c5612577-f1f7-5977-6ff6-7432788526f7=53f6305f-55e6-561c-8f1e-3a1dde2c77df=6783
> {code}
> Jul 14 23:00:26 [ERROR] Tests run: 10, Failures: 0, Errors: 1, Skipped: 0,
> Time elapsed: 99.93 s <<< FAILURE! - in
> org.apache.flink.connector.kafka.source.reader.KafkaSourceReaderTest
> Jul 14 23:00:26 [ERROR]
> testKafkaSourceMetrics(org.apache.flink.connector.kafka.source.reader.KafkaSourceReaderTest)
> Time elapsed: 60.225 s <<< ERROR!
> Jul 14 23:00:26 java.util.concurrent.TimeoutException: Offsets are not
> committed successfully. Dangling offsets:
> {15213={KafkaSourceReaderTest-0=OffsetAndMetadata{offset=10,
> leaderEpoch=null, metadata=''}}}
> Jul 14 23:00:26 at
> org.apache.flink.core.testutils.CommonTestUtils.waitUtil(CommonTestUtils.java:210)
> Jul 14 23:00:26 at
> org.apache.flink.connector.kafka.source.reader.KafkaSourceReaderTest.testKafkaSourceMetrics(KafkaSourceReaderTest.java:275)
> Jul 14 23:00:26 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> Jul 14 23:00:26 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> Jul 14 23:00:26 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> Jul 14 23:00:26 at java.lang.reflect.Method.invoke(Method.java:498)
> Jul 14 23:00:26 at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
> Jul 14 23:00:26 at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> Jul 14 23:00:26 at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> Jul 14 23:00:26 at
> org.junit.rules.ExpectedException$ExpectedExceptionStatement.evaluate(ExpectedException.java:239)
> Jul 14 23:00:26 at
> org.apache.flink.util.TestNameProvider$1.evaluate(TestNameProvider.java:45)
> Jul 14 23:00:26 at
> org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:55)
> Jul 14 23:00:26 at org.junit.rules.RunRules.evaluate(RunRules.java:20)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
> Jul 14 23:00:26 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
> Jul 14 23:00:26 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.run(ParentRunner.java:363)
> Jul 14 23:00:26 at org.junit.runners.Suite.runChild(Suite.java:128)
> Jul 14 23:00:26 at org.junit.runners.Suite.runChild(Suite.java:27)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
> Jul 14 23:00:26 at
>
[jira] [Reopened] (FLINK-23391) KafkaSourceReaderTest.testKafkaSourceMetrics fails on azure
[
https://issues.apache.org/jira/browse/FLINK-23391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yun Gao reopened FLINK-23391:
-
> KafkaSourceReaderTest.testKafkaSourceMetrics fails on azure
> ---
>
> Key: FLINK-23391
> URL: https://issues.apache.org/jira/browse/FLINK-23391
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0, 1.13.1
>Reporter: Xintong Song
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available, test-stability
> Fix For: 1.15.0, 1.14.1, 1.13.4
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=20456=logs=c5612577-f1f7-5977-6ff6-7432788526f7=53f6305f-55e6-561c-8f1e-3a1dde2c77df=6783
> {code}
> Jul 14 23:00:26 [ERROR] Tests run: 10, Failures: 0, Errors: 1, Skipped: 0,
> Time elapsed: 99.93 s <<< FAILURE! - in
> org.apache.flink.connector.kafka.source.reader.KafkaSourceReaderTest
> Jul 14 23:00:26 [ERROR]
> testKafkaSourceMetrics(org.apache.flink.connector.kafka.source.reader.KafkaSourceReaderTest)
> Time elapsed: 60.225 s <<< ERROR!
> Jul 14 23:00:26 java.util.concurrent.TimeoutException: Offsets are not
> committed successfully. Dangling offsets:
> {15213={KafkaSourceReaderTest-0=OffsetAndMetadata{offset=10,
> leaderEpoch=null, metadata=''}}}
> Jul 14 23:00:26 at
> org.apache.flink.core.testutils.CommonTestUtils.waitUtil(CommonTestUtils.java:210)
> Jul 14 23:00:26 at
> org.apache.flink.connector.kafka.source.reader.KafkaSourceReaderTest.testKafkaSourceMetrics(KafkaSourceReaderTest.java:275)
> Jul 14 23:00:26 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> Jul 14 23:00:26 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> Jul 14 23:00:26 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> Jul 14 23:00:26 at java.lang.reflect.Method.invoke(Method.java:498)
> Jul 14 23:00:26 at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
> Jul 14 23:00:26 at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> Jul 14 23:00:26 at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> Jul 14 23:00:26 at
> org.junit.rules.ExpectedException$ExpectedExceptionStatement.evaluate(ExpectedException.java:239)
> Jul 14 23:00:26 at
> org.apache.flink.util.TestNameProvider$1.evaluate(TestNameProvider.java:45)
> Jul 14 23:00:26 at
> org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:55)
> Jul 14 23:00:26 at org.junit.rules.RunRules.evaluate(RunRules.java:20)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
> Jul 14 23:00:26 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
> Jul 14 23:00:26 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> Jul 14 23:00:26 at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.run(ParentRunner.java:363)
> Jul 14 23:00:26 at org.junit.runners.Suite.runChild(Suite.java:128)
> Jul 14 23:00:26 at org.junit.runners.Suite.runChild(Suite.java:27)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
> Jul 14 23:00:26 at
> org.junit.runners.ParentRunner.run(ParentRunner.java:363)
> Jul 14 23:00:26 at
>
[GitHub] [flink] flinkbot edited a comment on pull request #17666: [FLINK-21327][table-planner-blink] Support window TVF in batch mode
flinkbot edited a comment on pull request #17666: URL: https://github.com/apache/flink/pull/17666#issuecomment-960514675 ## CI report: * 51b6f01db6e073d4f943fca2d0aba057bbabac72 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=26917) * cc426ff491234fd94ff50163786c02f9a0e1e5b5 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27188) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17666: [FLINK-21327][table-planner-blink] Support window TVF in batch mode
flinkbot edited a comment on pull request #17666: URL: https://github.com/apache/flink/pull/17666#issuecomment-960514675 ## CI report: * 51b6f01db6e073d4f943fca2d0aba057bbabac72 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=26917) * cc426ff491234fd94ff50163786c02f9a0e1e5b5 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #17937: [FLINK-25044][testing][Pulsar Connector] Add More Unit Test For Pulsar Source
flinkbot commented on pull request #17937: URL: https://github.com/apache/flink/pull/17937#issuecomment-981288048 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 1fb86a6233a0fab5a0ef858b40566c3cc76f1a82 (Mon Nov 29 04:44:08 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-25044).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17937: [FLINK-25044][testing][Pulsar Connector] Add More Unit Test For Pulsar Source
flinkbot edited a comment on pull request #17937: URL: https://github.com/apache/flink/pull/17937#issuecomment-981287170 ## CI report: * 1fb86a6233a0fab5a0ef858b40566c3cc76f1a82 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27187) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #17937: [FLINK-25044][testing][Pulsar Connector] Add More Unit Test For Pulsar Source
flinkbot commented on pull request #17937: URL: https://github.com/apache/flink/pull/17937#issuecomment-981287170 ## CI report: * 1fb86a6233a0fab5a0ef858b40566c3cc76f1a82 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-25044) Add More Unit Test For Pulsar Source
[ https://issues.apache.org/jira/browse/FLINK-25044?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-25044: --- Labels: pull-request-available testing (was: testing) > Add More Unit Test For Pulsar Source > > > Key: FLINK-25044 > URL: https://issues.apache.org/jira/browse/FLINK-25044 > Project: Flink > Issue Type: Improvement > Components: Connectors / Pulsar >Reporter: Yufei Zhang >Priority: Minor > Labels: pull-request-available, testing > > We should enhance the pulsar source connector tests by adding more unit tests. > > * SourceReader > * SplitReader > * Enumerator > * SourceBuilder -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] imaffe opened a new pull request #17937: [FLINK-25044][testing][Pulsar Connector] Add More Unit Test For Pulsar Source
imaffe opened a new pull request #17937: URL: https://github.com/apache/flink/pull/17937 ## What is the purpose of the change Enhance the pulsar source unit test for the following classes - PulsarSourceReader - PulsarPartitionSplitReader - PulsarSourceEnumerator - PulsarSourceBuilder ## Brief change log One bug fix with this test enhancement: 1. [BUG FIX] Fix overflow when stopCursor is latest and use exclusive start cursor . 2. Added tests for Ordered and Unordered version of PulsarSourceReader and PulsarPartitionSplitReader 3. Improved tests for PulsarSourceEnumerator and PulsarSourceBuilder ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluser with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-25087) Move heartbeats from akka to the dedicated thread pool in JM
Shammon created FLINK-25087: --- Summary: Move heartbeats from akka to the dedicated thread pool in JM Key: FLINK-25087 URL: https://issues.apache.org/jira/browse/FLINK-25087 Project: Flink Issue Type: Sub-task Components: Runtime / Coordination Affects Versions: 1.13.3, 1.12.5, 1.14.0 Reporter: Shammon There're heartbeats in jm, such as heartbeat between jm and tm, jm and rm. These heartbeats are scheduled in akka thread pool. They should be moved to the dedicated thread pool in jm, and job remove them when jm reaches termination. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Created] (FLINK-25086) Move resource timeout checkers in JM from akka executors to the dedicated thread pool
Shammon created FLINK-25086: --- Summary: Move resource timeout checkers in JM from akka executors to the dedicated thread pool Key: FLINK-25086 URL: https://issues.apache.org/jira/browse/FLINK-25086 Project: Flink Issue Type: Sub-task Components: Runtime / Coordination Affects Versions: 1.13.3, 1.12.5, 1.14.0 Reporter: Shammon Move the resource timeout checkers from akka executors to the dedicated thread pool in jm, and these checkers will be removed when the job termitates. The timeout checker includes PhysicalSlotRequestBulkCheckerImpl, timeout checker of `pending request`/`checkIdleSlotTimeout`/`checkBatchSlotTimeout` in DeclarativeSlotPoolBridge and some other resource timeout checkers. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Created] (FLINK-25085) Add a scheduled thread pool in JM and close it when job terminates
Shammon created FLINK-25085: --- Summary: Add a scheduled thread pool in JM and close it when job terminates Key: FLINK-25085 URL: https://issues.apache.org/jira/browse/FLINK-25085 Project: Flink Issue Type: Sub-task Components: Runtime / Coordination Affects Versions: 1.13.3, 1.12.5, 1.14.0 Reporter: Shammon Add a dedicated thread pool in JM to schedule tasks that have a long delay such as PhysicalSlotRequestBulkCheckerImpl, heatbeat checker and some other timeout checker. Job should shut down the thread pool and all the pending tasks will be removed when it terminates. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink-ml] zhipeng93 commented on a change in pull request #32: [FLINK-24817] Add Naive Bayes implementation
zhipeng93 commented on a change in pull request #32:
URL: https://github.com/apache/flink-ml/pull/32#discussion_r758021592
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/classification/naivebayes/NaiveBayesModelData.java
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.classification.naivebayes;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.serialization.Encoder;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.connector.file.src.reader.SimpleStreamFormat;
+import org.apache.flink.core.fs.FSDataInputStream;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.types.Row;
+
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+
+import java.io.IOException;
+import java.io.OutputStream;
+import java.io.Serializable;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * The model data of {@link NaiveBayesModel}.
+ *
+ * This class also provides methods to convert model data between Table and
Datastream, and
+ * classes to save/load model data.
+ */
+public class NaiveBayesModelData implements Serializable {
+public final Map[][] theta;
+public final double[] piArray;
+public final int[] labels;
+
+public NaiveBayesModelData(Map[][] theta, double[]
piArray, int[] labels) {
+this.theta = theta;
+this.piArray = piArray;
+this.labels = labels;
+}
+
+/** Converts the provided modelData Datastream into corresponding Table. */
+public static Table getModelDataTable(
+StreamTableEnvironment tEnv, DataStream
stream) {
Review comment:
Can we get `tEnv` from the input data stream rather than passing it as a
param?
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/classification/naivebayes/NaiveBayesModelData.java
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.classification.naivebayes;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.serialization.Encoder;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.connector.file.src.reader.SimpleStreamFormat;
+import org.apache.flink.core.fs.FSDataInputStream;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.types.Row;
+
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+
+import java.io.IOException;
+import java.io.OutputStream;
+import java.io.Serializable;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * The model data of {@link NaiveBayesModel}.
+ *
+ * This class also provides methods to convert model data between Table and
Datastream, and
+ * classes to save/load model data.
+ */
+public class NaiveBayesModelData implements Serializable {
+public final Map[][] theta;
+public final double[] piArray;
+public final int[] labels;
+
+public
[GitHub] [flink] beyond1920 commented on a change in pull request #17666: [FLINK-21327][table-planner-blink] Support window TVF in batch mode
beyond1920 commented on a change in pull request #17666: URL: https://github.com/apache/flink/pull/17666#discussion_r758020898 ## File path: flink-table/flink-table-planner/src/test/resources/org/apache/flink/table/planner/plan/rules/logical/ProjectWindowTableFunctionTransposeRuleTest.xml ## @@ -16,7 +16,43 @@ See the License for the specific language governing permissions and limitations under the License. --> - + Review comment: Existed UT `WindowTableFunctionTest#testCascadingWindowAggregate` in `WindowTableFunctionTest` already cover this case, you could find a projection node after TableSourceScan. We could find this way is not so explicit. I think there is no harm to add extra UTs in `ProjectWindowTableFunctionTransposeRuleTest` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-25057) Streaming File Sink writing to HDFS
[ https://issues.apache.org/jira/browse/FLINK-25057?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450177#comment-17450177 ] hanjie commented on FLINK-25057: [~zhisheng] Task start with savepoint. Task often throw FileNotFoundException. We also want to starting previous savepoint. But Task Resuming, method `HadoopRecoverableFsDataOutputStream. revokeLeaseByFileSystem` change expire file and this file has been renamed. I think task does not throw exception. We need check recovered file exist. > Streaming File Sink writing to HDFS > > > Key: FLINK-25057 > URL: https://issues.apache.org/jira/browse/FLINK-25057 > Project: Flink > Issue Type: Improvement > Components: Connectors / FileSystem >Affects Versions: 1.12.1 >Reporter: hanjie >Priority: Major > > Env: Flink 1.12.1 > kafka --> hdfs > hdfs : Streaming File Sink > When I first start flink task: > *First part file example:* > part-0-0 > part-0-1 > .part-0-2.inprogress.952eb958-dac9-4f2c-b92f-9084ed536a1c > I cancel flink task. then, i restart task without savepoint or checkpoint. > Task run for a while. > *Second part file example:* > part-0-0 > part-0-1 > .part-0-2.inprogress.952eb958-dac9-4f2c-b92f-9084ed536a1c > .part-0-0.inprogress.0e2f234b-042d-4232-a5f7-c980f04ca82d > 'part-0-2.inprogress.952eb958-dac9-4f2c-b92f-9084ed536a1c' not rename > file and bucketIndex will start zero. > I view related code. Start task need savepoint or checkpoint. I choose > savepoint.The above question disappears, when i start third test. > But, if i use expire savepoint. Task will throw exception. > java.io.FileNotFoundException: File does not exist: > /ns-hotel/hotel_sa_log/stream/sa_cpc_ad_log_list_detail_dwd/2021-11-25/.part-6-1537.inprogress.cd9c756a-1756-4dc5-9325-485fe99a2803\n\tat > > org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1309)\n\tat > > org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301)\n\tat > > org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)\n\tat > > org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1317)\n\tat > org.apache.hadoop.fs.FileSystem.resolvePath(FileSystem.java:752)\n\tat > org.apache.hadoop.fs.FilterFileSystem.resolvePath(FilterFileSystem.java:153)\n\tat > > org.apache.hadoop.fs.viewfs.ChRootedFileSystem.resolvePath(ChRootedFileSystem.java:373)\n\tat > > org.apache.hadoop.fs.viewfs.ViewFileSystem.resolvePath(ViewFileSystem.java:243)\n\tat > > org.apache.flink.runtime.fs.hdfs.HadoopRecoverableFsDataOutputStream.revokeLeaseByFileSystem(HadoopRecoverableFsDataOutputStream.java:327)\n\tat > > org.apache.flink.runtime.fs.hdfs.HadoopRecoverableFsDataOutputStream.safelyTruncateFile(HadoopRecoverableFsDataOutputStream.java:163)\n\tat > > org.apache.flink.runtime.fs.hdfs.HadoopRecoverableFsDataOutputStream.(HadoopRecoverableFsDataOutputStream.java:88)\n\tat > > org.apache.flink.runtime.fs.hdfs.HadoopRecoverableWriter.recover(HadoopRecoverableWriter.java:86)\n\tat > > org.apache.flink.streaming.api.functions.sink.filesystem.OutputStreamBasedPartFileWriter$OutputStreamBasedBucketWriter.resumeInProgressFileFrom(OutputStreamBasedPartFileWriter.java:104)\n\tat > org.apache.flink.streaming.api.functions.sink.filesyst > Task set 'execution.checkpointing.interval': 1min, I invoke savepoint > every fifth minutes. > Consult next everybody solution. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Assigned] (FLINK-24897) Enable application mode on YARN to use usrlib
[ https://issues.apache.org/jira/browse/FLINK-24897?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yang Wang reassigned FLINK-24897: - Assignee: Biao Geng > Enable application mode on YARN to use usrlib > - > > Key: FLINK-24897 > URL: https://issues.apache.org/jira/browse/FLINK-24897 > Project: Flink > Issue Type: Improvement > Components: Deployment / YARN >Reporter: Biao Geng >Assignee: Biao Geng >Priority: Major > > Hi there, > I am working to utilize application mode to submit flink jobs to YARN cluster > but I find that currently there is no easy way to ship my user-defined > jars(e.g. some custom connectors or udf jars that would be shared by some > jobs) and ask the FlinkUserCodeClassLoader to load classes in these jars. > I checked some relevant jiras, like FLINK-21289. In k8s mode, there is a > solution that users can use `usrlib` directory to store their user-defined > jars and these jars would be loaded by FlinkUserCodeClassLoader when the job > is executed on JM/TM. > But on YARN mode, `usrlib` does not work as that: > In this method(org.apache.flink.yarn.YarnClusterDescriptor#addShipFiles), if > I want to use `yarn.ship-files` to ship `usrlib` from my flink client(in my > local machine) to remote cluster, I must not set UserJarInclusion to > DISABLED due to the checkArgument(). However, if I do not set that option to > DISABLED, the user jars to be shipped will be added into systemClassPaths. As > a result, classes in those user jars will be loaded by AppClassLoader. > But if I do not ship these jars, there is no convenient way to utilize these > jars in my flink run command. Currently, all I can do seems to use `-C` > option, which means I have to upload my jars to some shared store first and > then use these remote paths. It is not so perfect as we have already make it > possible to ship jars or files directly and we also introduce `usrlib` in > application mode on YARN. It would be more user-friendly if we can allow > shipping `usrlib` from local to remote cluster while using > FlinkUserCodeClassLoader to load classes in the jars in `usrlib`. > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-17782) Add array,map,row types support for parquet row writer
[ https://issues.apache.org/jira/browse/FLINK-17782?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450174#comment-17450174 ] Jingsong Lee commented on FLINK-17782: -- CC: [~jark] > Add array,map,row types support for parquet row writer > -- > > Key: FLINK-17782 > URL: https://issues.apache.org/jira/browse/FLINK-17782 > Project: Flink > Issue Type: Sub-task > Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile) >Reporter: Jingsong Lee >Assignee: sujun >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-15826) Add renameFunction() to Catalog
[
https://issues.apache.org/jira/browse/FLINK-15826?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450175#comment-17450175
]
Jingsong Lee commented on FLINK-15826:
--
CC: [~jark]
> Add renameFunction() to Catalog
> ---
>
> Key: FLINK-15826
> URL: https://issues.apache.org/jira/browse/FLINK-15826
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / API
>Affects Versions: 1.11.0
>Reporter: Fabian Hueske
>Assignee: Shen Zhu
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> pull-request-available
>
> The {{Catalog}} interface lacks a method to rename a function.
> It is possible to change all properties (via {{alterFunction()}}) but it is
> not possible to rename a function.
> A {{renameTable()}} method is exists.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-17782) Add array,map,row types support for parquet row writer
[ https://issues.apache.org/jira/browse/FLINK-17782?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450173#comment-17450173 ] Runkang He commented on FLINK-17782: Hi, [~sujun1020], I am interested in your contribution and need it. When do you merge it into flink repo? > Add array,map,row types support for parquet row writer > -- > > Key: FLINK-17782 > URL: https://issues.apache.org/jira/browse/FLINK-17782 > Project: Flink > Issue Type: Sub-task > Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile) >Reporter: Jingsong Lee >Assignee: sujun >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-19358) when submit job on application mode with HA,the jobid will be 0000000000
[
https://issues.apache.org/jira/browse/FLINK-19358?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450172#comment-17450172
]
Yang Wang commented on FLINK-19358:
---
IIUC, whether to recover or submit a new job is determined in
{{{}EmbeddedExecutor#execute{}}}. If the HA is enabled, we could rely on the
submitted jobs from {{JobGraphStore}} and have a simpler behavior like
following.
{code:java}
if (submittedJobIds.size() > 0) {
// We expect only 1 recovered job here
return getJobClientFuture(submittedJobIds.iterator().next(),
userCodeClassloader);
} else {
return submitAndGetJobClientFuture(pipeline, configuration,
userCodeClassloader);
}{code}
Of cause, we also need to change a bit {{ApplicationDispatcherBootstrap}} about
not to set the {{PIPELINE_FIXED_JOB_ID}} to ZERO internally.
> when submit job on application mode with HA,the jobid will be 00
>
>
> Key: FLINK-19358
> URL: https://issues.apache.org/jira/browse/FLINK-19358
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.11.0
>Reporter: Jun Zhang
>Priority: Minor
> Labels: auto-deprioritized-major, usability
>
> when submit a flink job on application mode with HA ,the flink job id will be
> , when I have many jobs ,they have the same
> job id , it will be lead to a checkpoint error
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] JingsongLi merged pull request #17699: [FLINK-20370][table] part1: Fix wrong results when sink primary key is not the same with query result's changelog upsert key
JingsongLi merged pull request #17699: URL: https://github.com/apache/flink/pull/17699 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingsongLi commented on pull request #17788: [FLINK-15826][Tabel SQL/API] Add renameFunction() to Catalog
JingsongLi commented on pull request #17788: URL: https://github.com/apache/flink/pull/17788#issuecomment-981247459 Maybe in `HiveCatalogUdfITCase`? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingsongLi commented on a change in pull request #17897: [FLINK-24687][table] Move FileSystemTableSource/Sink in flink-connector-files
JingsongLi commented on a change in pull request #17897: URL: https://github.com/apache/flink/pull/17897#discussion_r758008970 ## File path: flink-table/flink-table-planner/src/main/scala/org/apache/flink/table/planner/plan/rules/physical/batch/BatchPhysicalLegacySinkRule.scala ## @@ -53,12 +52,14 @@ class BatchPhysicalLegacySinkRule extends ConverterRule( val dynamicPartIndices = dynamicPartFields.map(partitionSink.getTableSchema.getFieldNames.indexOf(_)) +// TODO This option is hardcoded to remove the dependency of planner from Review comment: I know of others who use it because we don't have the `partition by` syntax on SQL. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-21823) RocksDB on FreeBSD
[
https://issues.apache.org/jira/browse/FLINK-21823?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yun Tang closed FLINK-21823.
Resolution: Information Provided
Closing this issue due to inactivity.
> RocksDB on FreeBSD
> --
>
> Key: FLINK-21823
> URL: https://issues.apache.org/jira/browse/FLINK-21823
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Affects Versions: 1.11.3
>Reporter: Mårten Lindblad
>Priority: Minor
> Labels: auto-deprioritized-major, stale-minor
>
> Can't use the RocksDB backend in FreeBSD 12.2:
>
> {color:#00}java.lang.{color}{color:#ff}Exception{color}{color:#00}:
> {color}{color:#ff}Exception{color}
> {color:#ff}while{color}{color:#00} creating
> {color}{color:#008080}StreamOperatorStateContext{color}{color:#00}.{color}
> {color:#00}at
> org.apache.flink.streaming.api.operators.{color}{color:#008080}StreamTaskStateInitializerImpl{color}{color:#00}.streamOperatorStateContext({color}{color:#008080}StreamTaskStateInitializerImpl{color}{color:#00}.java:{color}{color:#09885a}222{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.api.operators.{color}{color:#008080}AbstractStreamOperator{color}{color:#00}.initializeState({color}{color:#008080}AbstractStreamOperator{color}{color:#00}.java:{color}{color:#09885a}248{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.runtime.tasks.{color}{color:#008080}OperatorChain{color}{color:#00}.initializeStateAndOpenOperators({color}{color:#008080}OperatorChain{color}{color:#00}.java:{color}{color:#09885a}290{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.runtime.tasks.{color}{color:#008080}StreamTask{color}{color:#00}.lambda$beforeInvoke$1({color}{color:#008080}StreamTask{color}{color:#00}.java:{color}{color:#09885a}506{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.runtime.tasks.{color}{color:#008080}StreamTaskActionExecutor$1{color}{color:#00}.runThrowing({color}{color:#008080}StreamTaskActionExecutor{color}{color:#00}.java:{color}{color:#09885a}47{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.runtime.tasks.{color}{color:#008080}StreamTask{color}{color:#00}.beforeInvoke({color}{color:#008080}StreamTask{color}{color:#00}.java:{color}{color:#09885a}475{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.runtime.tasks.{color}{color:#008080}StreamTask{color}{color:#00}.invoke({color}{color:#008080}StreamTask{color}{color:#00}.java:{color}{color:#09885a}526{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.runtime.taskmanager.{color}{color:#008080}Task{color}{color:#00}.doRun({color}{color:#008080}Task{color}{color:#00}.java:{color}{color:#09885a}721{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.runtime.taskmanager.{color}{color:#008080}Task{color}{color:#00}.run({color}{color:#008080}Task{color}{color:#00}.java:{color}{color:#09885a}546{color}{color:#00}){color}
> {color:#00}at
> java.lang.{color}{color:#008080}Thread{color}{color:#00}.run({color}{color:#008080}Thread{color}{color:#00}.java:{color}{color:#09885a}748{color}{color:#00}){color}
> {color:#008080}Caused{color} {color:#ff}by{color}{color:#00}:
> org.apache.flink.util.{color}{color:#008080}FlinkException{color}{color:#00}:
> {color}{color:#008080}Could{color} {color:#ff}not{color}{color:#00}
> restore keyed state backend {color}{color:#ff}for{color}
> {color:#008080}KeyedProcessOperator_bb679bef01a6dead9d79d979cc95234a_{color}{color:#00}({color}{color:#09885a}1{color}{color:#00}/{color}{color:#09885a}1{color}{color:#00})
> {color}{color:#ff}from{color} {color:#ff}any{color}
> {color:#ff}of{color}{color:#00} the
> {color}{color:#09885a}1{color}{color:#00} provided restore options.{color}
> {color:#00}at
> org.apache.flink.streaming.api.operators.{color}{color:#008080}BackendRestorerProcedure{color}{color:#00}.createAndRestore({color}{color:#008080}BackendRestorerProcedure{color}{color:#00}.java:{color}{color:#09885a}135{color}{color:#00}){color}
> {color:#00}at
> org.apache.flink.streaming.api.operators.{color}{color:#008080}StreamTaskStateInitializerImpl{color}{color:#00}.keyedStatedBackend({color}{color:#008080}StreamTaskStateInitializerImpl{color}{color:#00}.java:{color}{color:#09885a}335{color}{color:#00}){color}
> {color:#00}at
>
[GitHub] [flink] Myasuka commented on a change in pull request #17874: [FLINK-24046] Refactor the EmbeddedRocksDBStateBackend configuration logic
Myasuka commented on a change in pull request #17874:
URL: https://github.com/apache/flink/pull/17874#discussion_r758006843
##
File path:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/EmbeddedRocksDBStateBackend.java
##
@@ -521,6 +532,16 @@ private RocksDBOptionsFactory configureOptionsFactory(
((ConfigurableRocksDBOptionsFactory)
optionsFactory).configure(config);
}
LOG.info("Using configured options factory: {}.",
optionsFactory);
+if
(DefaultConfigurableOptionsFactory.class.isAssignableFrom(clazz)) {
+LOG.warn(
+"{} is extending from {}, which is deprecated and
will be removed in "
++ "future. It is highly recommended to
directly implement the "
++ "ConfigurableRocksDBOptionsFactory
without extending the {}. "
++ "For more information, please refer to
FLINK-24046.",
+optionsFactory,
+DefaultConfigurableOptionsFactory.class.getName(),
+DefaultConfigurableOptionsFactory.class.getName());
Review comment:
My previous comment is that we might could use same method to check
optionsFactory whether extending `DefaultConfigurableOptionsFactory` and print
the warning both in line 502~507 and 535~543.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-23798) Avoid using reflection to get filter when partition filter is enabled
[ https://issues.apache.org/jira/browse/FLINK-23798?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yun Tang updated FLINK-23798: - Release Note: (was: Merged master: 7d7a97477a50753e38e5b499effc62bb00dfcfe2 release-1.14: f7c0381eb202819b9c1ecc1e3693b31377fe2a9a) > Avoid using reflection to get filter when partition filter is enabled > - > > Key: FLINK-23798 > URL: https://issues.apache.org/jira/browse/FLINK-23798 > Project: Flink > Issue Type: Improvement > Components: Runtime / State Backends >Reporter: Yun Tang >Assignee: PengFei Li >Priority: Minor > Labels: pull-request-available > Fix For: 1.15.0, 1.14.1 > > > FLINK-20496 introduce partitioned index & filter to Flink. However, RocksDB > only support new full format of filter in this feature, and we need to > replace previous filter if user enabled. [Previous implementation use > reflection to get the > filter|https://github.com/apache/flink/blob/7ff4cbdc25aa971dccaf5ce02aaf46dc1e7345cc/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBResourceContainer.java#L251-L258] > and we could use API to get that after upgrading to newer version. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-23798) Avoid using reflection to get filter when partition filter is enabled
[ https://issues.apache.org/jira/browse/FLINK-23798?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450169#comment-17450169 ] Yun Tang commented on FLINK-23798: -- Merged master: 7d7a97477a50753e38e5b499effc62bb00dfcfe2 release-1.14: f7c0381eb202819b9c1ecc1e3693b31377fe2a9a > Avoid using reflection to get filter when partition filter is enabled > - > > Key: FLINK-23798 > URL: https://issues.apache.org/jira/browse/FLINK-23798 > Project: Flink > Issue Type: Improvement > Components: Runtime / State Backends >Reporter: Yun Tang >Assignee: PengFei Li >Priority: Minor > Labels: pull-request-available > Fix For: 1.15.0, 1.14.1 > > > FLINK-20496 introduce partitioned index & filter to Flink. However, RocksDB > only support new full format of filter in this feature, and we need to > replace previous filter if user enabled. [Previous implementation use > reflection to get the > filter|https://github.com/apache/flink/blob/7ff4cbdc25aa971dccaf5ce02aaf46dc1e7345cc/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBResourceContainer.java#L251-L258] > and we could use API to get that after upgrading to newer version. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Resolved] (FLINK-23798) Avoid using reflection to get filter when partition filter is enabled
[ https://issues.apache.org/jira/browse/FLINK-23798?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yun Tang resolved FLINK-23798. -- Release Note: Merged master: 7d7a97477a50753e38e5b499effc62bb00dfcfe2 release-1.14: f7c0381eb202819b9c1ecc1e3693b31377fe2a9a Resolution: Fixed > Avoid using reflection to get filter when partition filter is enabled > - > > Key: FLINK-23798 > URL: https://issues.apache.org/jira/browse/FLINK-23798 > Project: Flink > Issue Type: Improvement > Components: Runtime / State Backends >Reporter: Yun Tang >Assignee: PengFei Li >Priority: Minor > Labels: pull-request-available > Fix For: 1.15.0, 1.14.1 > > > FLINK-20496 introduce partitioned index & filter to Flink. However, RocksDB > only support new full format of filter in this feature, and we need to > replace previous filter if user enabled. [Previous implementation use > reflection to get the > filter|https://github.com/apache/flink/blob/7ff4cbdc25aa971dccaf5ce02aaf46dc1e7345cc/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBResourceContainer.java#L251-L258] > and we could use API to get that after upgrading to newer version. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-23798) Avoid using reflection to get filter when partition filter is enabled
[ https://issues.apache.org/jira/browse/FLINK-23798?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yun Tang updated FLINK-23798: - Fix Version/s: 1.14.1 > Avoid using reflection to get filter when partition filter is enabled > - > > Key: FLINK-23798 > URL: https://issues.apache.org/jira/browse/FLINK-23798 > Project: Flink > Issue Type: Improvement > Components: Runtime / State Backends >Reporter: Yun Tang >Assignee: PengFei Li >Priority: Minor > Labels: pull-request-available > Fix For: 1.15.0, 1.14.1 > > > FLINK-20496 introduce partitioned index & filter to Flink. However, RocksDB > only support new full format of filter in this feature, and we need to > replace previous filter if user enabled. [Previous implementation use > reflection to get the > filter|https://github.com/apache/flink/blob/7ff4cbdc25aa971dccaf5ce02aaf46dc1e7345cc/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBResourceContainer.java#L251-L258] > and we could use API to get that after upgrading to newer version. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] Myasuka merged pull request #17921: [FLINK-23798][state] Avoid using reflection to get filter when partition filter is enable
Myasuka merged pull request #17921: URL: https://github.com/apache/flink/pull/17921 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-25084) Field names must be unique. Found duplicates
[
https://issues.apache.org/jira/browse/FLINK-25084?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jing Zhang closed FLINK-25084.
--
Fix Version/s: 1.15.0
1.14.1
1.13.4
Resolution: Fixed
> Field names must be unique. Found duplicates
>
>
> Key: FLINK-25084
> URL: https://issues.apache.org/jira/browse/FLINK-25084
> Project: Flink
> Issue Type: Bug
> Components: API / DataStream
>Affects Versions: 1.13.2
> Environment: AWS Kinesis Application in Zeppelin
> Apache Flink 1.13, Apache Zeppelin 0.9
>
>Reporter: Ivan Budanaev
>Priority: Major
> Fix For: 1.15.0, 1.14.1, 1.13.4
>
> Attachments: Screenshot 2021-11-28 at 13.10.57.png
>
>
> I am getting a "Field names must be unique. Found duplicates" error when
> trying to aggregate a column used as a descriptor in HOP windowing.
> Imagine this example, with *events_table* reading from kinesis stream, the
> definition given below, I am getting the "Field names must be unique. Found
> duplicates: [ts]" when trying to run the following SQL in Kinesis Data
> Analytics Application in Zeppelin:
> {code:sql}
> %flink.ssql(type=update)
> -- insert into learn_actions_deduped
> SELECT window_start, window_end, uuid, event_type, max(ts) as max_event_ts
> FROM TABLE(HOP(TABLE events_table, DESCRIPTOR(ts), INTERVAL '5' SECONDS,
> INTERVAL '15' MINUTES))
> GROUP BY window_start, window_end, uuid, event_type;
> {code}
> The question is how can I use the descriptor column in aggregation without
> having to duplicate it?
> The error details:
> java.io.IOException: Fail to run stream sql job
> at
> org.apache.zeppelin.flink.sql.AbstractStreamSqlJob.run(AbstractStreamSqlJob.java:172)
> at
> org.apache.zeppelin.flink.sql.AbstractStreamSqlJob.run(AbstractStreamSqlJob.java:105)
> at
> org.apache.zeppelin.flink.FlinkStreamSqlInterpreter.callInnerSelect(FlinkStreamSqlInterpreter.java:89)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.callSelect(FlinkSqlInterrpeter.java:503)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.callCommand(FlinkSqlInterrpeter.java:266)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.runSqlList(FlinkSqlInterrpeter.java:160)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.internalInterpret(FlinkSqlInterrpeter.java:112)
> at
> org.apache.zeppelin.interpreter.AbstractInterpreter.interpret(AbstractInterpreter.java:47)
> at
> org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:110)
> at
> org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:852)
> at
> org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:744)
> at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
> at
> org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:132)
> at
> org.apache.zeppelin.scheduler.ParallelScheduler.lambda$runJobInScheduler$0(ParallelScheduler.java:46)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
> at java.base/java.lang.Thread.run(Thread.java:829)
> Caused by: java.lang.RuntimeException: Error while applying rule
> PullUpWindowTableFunctionIntoWindowAggregateRule, args
> [rel#1172:StreamPhysicalWindowAggregate.STREAM_PHYSICAL.any.None:
> 0.[NONE].[NONE](input=RelSubset#1170,groupBy=uuid,
> event_type,window=HOP(win_start=[window_start], win_end=[window_end],
> size=[15 min], slide=[5 s]),select=uuid, event_type, MAX(ts) AS max_event_ts,
> start('w$) AS window_start, end('w$) AS window_end),
> rel#1179:StreamPhysicalExchange.STREAM_PHYSICAL.hash[2, 3]true.None:
> 0.[NONE].[NONE](input=RelSubset#1169,distribution=hash[uuid, event_type]),
> rel#1168:StreamPhysicalCalc.STREAM_PHYSICAL.any.None:
> 0.[NONE].[NONE](input=RelSubset#1167,select=window_start, window_end, uuid,
> event_type, CAST(ts) AS ts),
> rel#1166:StreamPhysicalWindowTableFunction.STREAM_PHYSICAL.any.None:
> 0.[NONE].[NONE](input=RelSubset#1165,window=HOP(time_col=[ts], size=[15 min],
> slide=[5 s]))]
> at
> org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
> at
> org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
> at
> org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
> at
> org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
> at
>
[jira] [Commented] (FLINK-25084) Field names must be unique. Found duplicates
[
https://issues.apache.org/jira/browse/FLINK-25084?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450167#comment-17450167
]
Jing Zhang commented on FLINK-25084:
[~ibuda] Thanks for reporting this BUG. It seems to be a duplicate with
[FLINK-23919|https://issues.apache.org/jira/browse/FLINK-23919] which would
been solved in 1.13.4.
> Field names must be unique. Found duplicates
>
>
> Key: FLINK-25084
> URL: https://issues.apache.org/jira/browse/FLINK-25084
> Project: Flink
> Issue Type: Bug
> Components: API / DataStream
>Affects Versions: 1.13.2
> Environment: AWS Kinesis Application in Zeppelin
> Apache Flink 1.13, Apache Zeppelin 0.9
>
>Reporter: Ivan Budanaev
>Priority: Major
> Attachments: Screenshot 2021-11-28 at 13.10.57.png
>
>
> I am getting a "Field names must be unique. Found duplicates" error when
> trying to aggregate a column used as a descriptor in HOP windowing.
> Imagine this example, with *events_table* reading from kinesis stream, the
> definition given below, I am getting the "Field names must be unique. Found
> duplicates: [ts]" when trying to run the following SQL in Kinesis Data
> Analytics Application in Zeppelin:
> {code:sql}
> %flink.ssql(type=update)
> -- insert into learn_actions_deduped
> SELECT window_start, window_end, uuid, event_type, max(ts) as max_event_ts
> FROM TABLE(HOP(TABLE events_table, DESCRIPTOR(ts), INTERVAL '5' SECONDS,
> INTERVAL '15' MINUTES))
> GROUP BY window_start, window_end, uuid, event_type;
> {code}
> The question is how can I use the descriptor column in aggregation without
> having to duplicate it?
> The error details:
> java.io.IOException: Fail to run stream sql job
> at
> org.apache.zeppelin.flink.sql.AbstractStreamSqlJob.run(AbstractStreamSqlJob.java:172)
> at
> org.apache.zeppelin.flink.sql.AbstractStreamSqlJob.run(AbstractStreamSqlJob.java:105)
> at
> org.apache.zeppelin.flink.FlinkStreamSqlInterpreter.callInnerSelect(FlinkStreamSqlInterpreter.java:89)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.callSelect(FlinkSqlInterrpeter.java:503)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.callCommand(FlinkSqlInterrpeter.java:266)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.runSqlList(FlinkSqlInterrpeter.java:160)
> at
> org.apache.zeppelin.flink.FlinkSqlInterrpeter.internalInterpret(FlinkSqlInterrpeter.java:112)
> at
> org.apache.zeppelin.interpreter.AbstractInterpreter.interpret(AbstractInterpreter.java:47)
> at
> org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:110)
> at
> org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:852)
> at
> org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:744)
> at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
> at
> org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:132)
> at
> org.apache.zeppelin.scheduler.ParallelScheduler.lambda$runJobInScheduler$0(ParallelScheduler.java:46)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
> at java.base/java.lang.Thread.run(Thread.java:829)
> Caused by: java.lang.RuntimeException: Error while applying rule
> PullUpWindowTableFunctionIntoWindowAggregateRule, args
> [rel#1172:StreamPhysicalWindowAggregate.STREAM_PHYSICAL.any.None:
> 0.[NONE].[NONE](input=RelSubset#1170,groupBy=uuid,
> event_type,window=HOP(win_start=[window_start], win_end=[window_end],
> size=[15 min], slide=[5 s]),select=uuid, event_type, MAX(ts) AS max_event_ts,
> start('w$) AS window_start, end('w$) AS window_end),
> rel#1179:StreamPhysicalExchange.STREAM_PHYSICAL.hash[2, 3]true.None:
> 0.[NONE].[NONE](input=RelSubset#1169,distribution=hash[uuid, event_type]),
> rel#1168:StreamPhysicalCalc.STREAM_PHYSICAL.any.None:
> 0.[NONE].[NONE](input=RelSubset#1167,select=window_start, window_end, uuid,
> event_type, CAST(ts) AS ts),
> rel#1166:StreamPhysicalWindowTableFunction.STREAM_PHYSICAL.any.None:
> 0.[NONE].[NONE](input=RelSubset#1165,window=HOP(time_col=[ts], size=[15 min],
> slide=[5 s]))]
> at
> org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
> at
> org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
> at
> org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
> at
> org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
> at
>
[GitHub] [flink] godfreyhe commented on a change in pull request #17666: [FLINK-21327][table-planner-blink] Support window TVF in batch mode
godfreyhe commented on a change in pull request #17666: URL: https://github.com/apache/flink/pull/17666#discussion_r758001359 ## File path: flink-table/flink-table-planner/src/test/resources/org/apache/flink/table/planner/plan/rules/logical/ProjectWindowTableFunctionTransposeRuleTest.xml ## @@ -16,7 +16,43 @@ See the License for the specific language governing permissions and limitations under the License. --> - + Review comment: just add tests for project-transpose in WindowTableFunctionTest which is enough I think. We need e2e plan test for this case instead of function test for ProjectWindowTableFunctionTransposeRule -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong merged pull request #17707: [hotfix][datastream][docs]
wuchong merged pull request #17707: URL: https://github.com/apache/flink/pull/17707 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] mans2singh commented on pull request #17707: [hotfix][datastream][docs]
mans2singh commented on pull request #17707: URL: https://github.com/apache/flink/pull/17707#issuecomment-981234896 @wuchong - Can you please review this doc PR ? Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] lindong28 commented on pull request #30: [FLINK-24845] Add allreduce utility function in FlinkML
lindong28 commented on pull request #30: URL: https://github.com/apache/flink-ml/pull/30#issuecomment-981232579 Thanks for the update! The PR looks good overall. I have only two remaining comments regarding the `TRANSFER_BUFFER_SIZE ` and the support for AllRound. Let's wait for @gaoyunhaii 's review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] lindong28 commented on a change in pull request #30: [FLINK-24845] Add allreduce utility function in FlinkML
lindong28 commented on a change in pull request #30:
URL: https://github.com/apache/flink-ml/pull/30#discussion_r757997408
##
File path:
flink-ml-lib/src/test/java/org/apache/flink/ml/common/datastream/AllReduceUtilsTest.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.common.datastream;
+
+import org.apache.flink.api.common.functions.FlatMapFunction;
+import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.streaming.api.functions.sink.SinkFunction;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.NumberSequenceIterator;
+
+import org.junit.Test;
+import org.junit.experimental.runners.Enclosed;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+import java.util.Arrays;
+import java.util.Collection;
+
+import static org.junit.Assert.assertEquals;
+
+/** Tests the {@link org.apache.flink.ml.common.datastream.AllReduceUtils}. */
+@RunWith(Enclosed.class)
+public class AllReduceUtilsTest {
+
+private static final int parallelism = 4;
+
+/** Parameterized test for {@link
org.apache.flink.ml.common.datastream.AllReduceUtils}. */
+@RunWith(Parameterized.class)
+public static class ParameterizedTest {
+private static int numElements;
+
+@Parameterized.Parameters
+public static Collection params() {
+return Arrays.asList(new Object[][] {{0}, {100}, {1},
{10}, {1000}});
Review comment:
Sounds good. Thanks for the update.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-22240) Sanity/phrasing pass for ExternalResourceUtils
[
https://issues.apache.org/jira/browse/FLINK-22240?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yangze Guo updated FLINK-22240:
---
Labels: pull-request-available (was: auto-deprioritized-major
pull-request-available stale-assigned)
> Sanity/phrasing pass for ExternalResourceUtils
> --
>
> Key: FLINK-22240
> URL: https://issues.apache.org/jira/browse/FLINK-22240
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Coordination
>Reporter: Chesnay Schepler
>Assignee: Yangze Guo
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.15.0
>
>
> We should do a pass over the {{ExternalResourceUtils}}, because various
> phrases could use some refinement (e.g., "The amount of the {} should be
> positive while finding {}. Will ignore that resource."), some log messages
> are misleading (resources are logged as enabled on both the JM/TM, but this
> actually doesn't happen on the JM; and on the TM the driver discovery may
> subsequently fail), and we may want to rethink whether we shouldn't fail if a
> driver could not be discovered.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] ZhijieYang commented on pull request #17902: [FLINK-25050][docs-zh] Translate "Metrics" page of "Operations" into Chinese
ZhijieYang commented on pull request #17902: URL: https://github.com/apache/flink/pull/17902#issuecomment-981223568 @RocMarshal Hi, can you review it? thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-24763) ParquetFileSystemITCase.testLimitableBulkFormat failed on Azure
[
https://issues.apache.org/jira/browse/FLINK-24763?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee closed FLINK-24763.
Resolution: Fixed
Ignore case in:
master(1.15): c1b119290bea3bcf8de85b357a357e6181edb040
> ParquetFileSystemITCase.testLimitableBulkFormat failed on Azure
> ---
>
> Key: FLINK-24763
> URL: https://issues.apache.org/jira/browse/FLINK-24763
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem, Formats (JSON, Avro, Parquet,
> ORC, SequenceFile)
>Affects Versions: 1.15.0
>Reporter: Till Rohrmann
>Assignee: Jingsong Lee
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.15.0
>
>
> The test {{ParquetFileSystemITCase.testLimitableBulkFormat}} fails with
> {code}
> 2021-11-03T22:10:11.5106075Z Nov 03 22:10:11 [ERROR]
> testLimitableBulkFormat[false] Time elapsed: 9.177 s <<< ERROR!
> 2021-11-03T22:10:11.5106643Z Nov 03 22:10:11 java.lang.RuntimeException:
> Failed to fetch next result
> 2021-11-03T22:10:11.5107213Z Nov 03 22:10:11 at
> org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:109)
> 2021-11-03T22:10:11.5111034Z Nov 03 22:10:11 at
> org.apache.flink.streaming.api.operators.collect.CollectResultIterator.hasNext(CollectResultIterator.java:80)
> 2021-11-03T22:10:11.5112190Z Nov 03 22:10:11 at
> org.apache.flink.table.planner.connectors.CollectDynamicSink$CloseableRowIteratorWrapper.hasNext(CollectDynamicSink.java:188)
> 2021-11-03T22:10:11.5112892Z Nov 03 22:10:11 at
> java.util.Iterator.forEachRemaining(Iterator.java:115)
> 2021-11-03T22:10:11.5113393Z Nov 03 22:10:11 at
> org.apache.flink.util.CollectionUtil.iteratorToList(CollectionUtil.java:109)
> 2021-11-03T22:10:11.5114157Z Nov 03 22:10:11 at
> org.apache.flink.formats.parquet.ParquetFileSystemITCase.testLimitableBulkFormat(ParquetFileSystemITCase.java:128)
> 2021-11-03T22:10:11.5114951Z Nov 03 22:10:11 at
> sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> 2021-11-03T22:10:11.5115568Z Nov 03 22:10:11 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> 2021-11-03T22:10:11.5116115Z Nov 03 22:10:11 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> 2021-11-03T22:10:11.5116591Z Nov 03 22:10:11 at
> java.lang.reflect.Method.invoke(Method.java:498)
> 2021-11-03T22:10:11.5117088Z Nov 03 22:10:11 at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
> 2021-11-03T22:10:11.5117807Z Nov 03 22:10:11 at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> 2021-11-03T22:10:11.5118821Z Nov 03 22:10:11 at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
> 2021-11-03T22:10:11.5119417Z Nov 03 22:10:11 at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> 2021-11-03T22:10:11.5119944Z Nov 03 22:10:11 at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> 2021-11-03T22:10:11.5120427Z Nov 03 22:10:11 at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> 2021-11-03T22:10:11.5120919Z Nov 03 22:10:11 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> 2021-11-03T22:10:11.5121571Z Nov 03 22:10:11 at
> org.apache.flink.util.TestNameProvider$1.evaluate(TestNameProvider.java:45)
> 2021-11-03T22:10:11.5122526Z Nov 03 22:10:11 at
> org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:61)
> 2021-11-03T22:10:11.5123245Z Nov 03 22:10:11 at
> org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> 2021-11-03T22:10:11.5123804Z Nov 03 22:10:11 at
> org.junit.runners.BlockJUnit4ClassRunner$1.evaluate(BlockJUnit4ClassRunner.java:100)
> 2021-11-03T22:10:11.5124314Z Nov 03 22:10:11 at
> org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:366)
> 2021-11-03T22:10:11.5124806Z Nov 03 22:10:11 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:103)
> 2021-11-03T22:10:11.5125313Z Nov 03 22:10:11 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:63)
> 2021-11-03T22:10:11.5125810Z Nov 03 22:10:11 at
> org.junit.runners.ParentRunner$4.run(ParentRunner.java:331)
> 2021-11-03T22:10:11.5126281Z Nov 03 22:10:11 at
> org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:79)
> 2021-11-03T22:10:11.5126739Z Nov 03 22:10:11 at
> org.junit.runners.ParentRunner.runChildren(ParentRunner.java:329)
> 2021-11-03T22:10:11.5127349Z Nov 03 22:10:11 at
> org.junit.runners.ParentRunner.access$100(ParentRunner.java:66)
> 2021-11-03T22:10:11.5128092Z Nov 03
[GitHub] [flink] JingsongLi merged pull request #17923: [FLINK-24763][parquet] Ignore ParquetFileSystemITCase.testLimitableBulkFormat
JingsongLi merged pull request #17923: URL: https://github.com/apache/flink/pull/17923 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-25066) Support using multi hdfs cluster to resolved dependences when submitting job to yarn
[ https://issues.apache.org/jira/browse/FLINK-25066?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] jocean.shi updated FLINK-25066: --- Summary: Support using multi hdfs cluster to resolved dependences when submitting job to yarn (was: Support using multi hdfs namenode to resolved dependences when submitting job to yarn) > Support using multi hdfs cluster to resolved dependences when submitting job > to yarn > > > Key: FLINK-25066 > URL: https://issues.apache.org/jira/browse/FLINK-25066 > Project: Flink > Issue Type: Improvement > Components: Client / Job Submission >Reporter: jocean.shi >Priority: Not a Priority > > if the hdfs-site.xml like this > > dfs.nameservices > cluster1,cluster2 > > > and the core-site.xml like this > > fs.defaultFS > hdfs://cluster1 > > > flink only can use cluster1 to resolve dependences when we submit job to > yarn(include yarn session, yarn per job, yarn application-mode) -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-24939) Support 'SHOW CREATE CATALOG' syntax
[
https://issues.apache.org/jira/browse/FLINK-24939?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450161#comment-17450161
]
Shen Zhu commented on FLINK-24939:
--
Thanks for your explanation [~liyubin117] !
Hey [~jark] , I checked the code and seems currently the properties are not
stored within *Catalog* class itself, do you think we should save these
properties in *Catalog* and add a function *getProperties()* to retrieve them
from {*}Catalog{*}?
> Support 'SHOW CREATE CATALOG' syntax
>
>
> Key: FLINK-24939
> URL: https://issues.apache.org/jira/browse/FLINK-24939
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / API
>Affects Versions: 1.14.0
>Reporter: Yubin Li
>Priority: Major
>
> SHOW CREATE CATALOG ;
>
> `Catalog` is playing a more import role in flink, it would be great to get
> existing catalog detail information
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Comment Edited] (FLINK-22014) Flink JobManager failed to restart after failure in kubernetes HA setup
[
https://issues.apache.org/jira/browse/FLINK-22014?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450147#comment-17450147
]
Adrian Vasiliu edited comment on FLINK-22014 at 11/28/21, 10:54 PM:
Hello [~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be
reopened or should we open a new issue?
was (Author: JIRAUSER280892):
Hello [~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be
reopened or should a new issue be open?
> Flink JobManager failed to restart after failure in kubernetes HA setup
> ---
>
> Key: FLINK-22014
> URL: https://issues.apache.org/jira/browse/FLINK-22014
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.11.3, 1.12.2, 1.13.0
>Reporter: Mikalai Lushchytski
>Priority: Major
> Labels: k8s-ha, pull-request-available
> Attachments: flink-logs.txt.zip, image-2021-04-19-11-17-58-215.png,
> scalyr-logs (1).txt
>
>
> After the JobManager pod failed and the new one started, it was not able to
> recover jobs due to the absence of recovery data in storage - config map
> pointed at not existing file.
>
> Due to this the JobManager pod entered into the `CrashLoopBackOff`state and
> was not able to recover - each attempt failed with the same error so the
> whole cluster became unrecoverable and not operating.
>
> I had to manually delete the config map and start the jobs again without the
> save point.
>
> If I tried to emulate the failure further by deleting job manager pod
> manually, the new pod every time recovered well and issue was not
> reproducible anymore artificially.
>
> Below is the failure log:
> {code:java}
> 2021-03-26 08:22:57,925 INFO
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl [] -
> Starting the SlotManager.
> 2021-03-26 08:22:57,928 INFO
> org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] -
> Starting DefaultLeaderRetrievalService with KubernetesLeaderRetrievalDriver
> {configMapName='stellar-flink-cluster-dispatcher-leader'}.
> 2021-03-26 08:22:57,931 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Retrieved job
> ids [198c46bac791e73ebcc565a550fa4ff6, 344f5ebc1b5c3a566b4b2837813e4940,
> 96c4603a0822d10884f7fe536703d811, d9ded24224aab7c7041420b3efc1b6ba] from
> KubernetesStateHandleStore{configMapName='stellar-flink-cluster-dispatcher-leader'}
> 2021-03-26 08:22:57,933 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Trying to recover job with job id 198c46bac791e73ebcc565a550fa4ff6.
> 2021-03-26 08:22:58,029 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Stopping SessionDispatcherLeaderProcess.
> 2021-03-26 08:28:22,677 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Stopping
> DefaultJobGraphStore. 2021-03-26 08:28:22,681 ERROR
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Fatal error
> occurred in the cluster entrypoint.
[jira] [Comment Edited] (FLINK-22014) Flink JobManager failed to restart after failure in kubernetes HA setup
[
https://issues.apache.org/jira/browse/FLINK-22014?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450147#comment-17450147
]
Adrian Vasiliu edited comment on FLINK-22014 at 11/28/21, 10:53 PM:
Hello [~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be
reopened or should a new issue be open?
was (Author: JIRAUSER280892):
Hello [~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
> Flink JobManager failed to restart after failure in kubernetes HA setup
> ---
>
> Key: FLINK-22014
> URL: https://issues.apache.org/jira/browse/FLINK-22014
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.11.3, 1.12.2, 1.13.0
>Reporter: Mikalai Lushchytski
>Priority: Major
> Labels: k8s-ha, pull-request-available
> Attachments: flink-logs.txt.zip, image-2021-04-19-11-17-58-215.png,
> scalyr-logs (1).txt
>
>
> After the JobManager pod failed and the new one started, it was not able to
> recover jobs due to the absence of recovery data in storage - config map
> pointed at not existing file.
>
> Due to this the JobManager pod entered into the `CrashLoopBackOff`state and
> was not able to recover - each attempt failed with the same error so the
> whole cluster became unrecoverable and not operating.
>
> I had to manually delete the config map and start the jobs again without the
> save point.
>
> If I tried to emulate the failure further by deleting job manager pod
> manually, the new pod every time recovered well and issue was not
> reproducible anymore artificially.
>
> Below is the failure log:
> {code:java}
> 2021-03-26 08:22:57,925 INFO
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl [] -
> Starting the SlotManager.
> 2021-03-26 08:22:57,928 INFO
> org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] -
> Starting DefaultLeaderRetrievalService with KubernetesLeaderRetrievalDriver
> {configMapName='stellar-flink-cluster-dispatcher-leader'}.
> 2021-03-26 08:22:57,931 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Retrieved job
> ids [198c46bac791e73ebcc565a550fa4ff6, 344f5ebc1b5c3a566b4b2837813e4940,
> 96c4603a0822d10884f7fe536703d811, d9ded24224aab7c7041420b3efc1b6ba] from
> KubernetesStateHandleStore{configMapName='stellar-flink-cluster-dispatcher-leader'}
> 2021-03-26 08:22:57,933 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Trying to recover job with job id 198c46bac791e73ebcc565a550fa4ff6.
> 2021-03-26 08:22:58,029 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Stopping SessionDispatcherLeaderProcess.
> 2021-03-26 08:28:22,677 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Stopping
> DefaultJobGraphStore. 2021-03-26 08:28:22,681 ERROR
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Fatal error
> occurred in the cluster entrypoint.
[jira] [Comment Edited] (FLINK-22014) Flink JobManager failed to restart after failure in kubernetes HA setup
[
https://issues.apache.org/jira/browse/FLINK-22014?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450147#comment-17450147
]
Adrian Vasiliu edited comment on FLINK-22014 at 11/28/21, 10:52 PM:
Hello [~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
was (Author: JIRAUSER280892):
[~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
> Flink JobManager failed to restart after failure in kubernetes HA setup
> ---
>
> Key: FLINK-22014
> URL: https://issues.apache.org/jira/browse/FLINK-22014
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.11.3, 1.12.2, 1.13.0
>Reporter: Mikalai Lushchytski
>Priority: Major
> Labels: k8s-ha, pull-request-available
> Attachments: flink-logs.txt.zip, image-2021-04-19-11-17-58-215.png,
> scalyr-logs (1).txt
>
>
> After the JobManager pod failed and the new one started, it was not able to
> recover jobs due to the absence of recovery data in storage - config map
> pointed at not existing file.
>
> Due to this the JobManager pod entered into the `CrashLoopBackOff`state and
> was not able to recover - each attempt failed with the same error so the
> whole cluster became unrecoverable and not operating.
>
> I had to manually delete the config map and start the jobs again without the
> save point.
>
> If I tried to emulate the failure further by deleting job manager pod
> manually, the new pod every time recovered well and issue was not
> reproducible anymore artificially.
>
> Below is the failure log:
> {code:java}
> 2021-03-26 08:22:57,925 INFO
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl [] -
> Starting the SlotManager.
> 2021-03-26 08:22:57,928 INFO
> org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] -
> Starting DefaultLeaderRetrievalService with KubernetesLeaderRetrievalDriver
> {configMapName='stellar-flink-cluster-dispatcher-leader'}.
> 2021-03-26 08:22:57,931 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Retrieved job
> ids [198c46bac791e73ebcc565a550fa4ff6, 344f5ebc1b5c3a566b4b2837813e4940,
> 96c4603a0822d10884f7fe536703d811, d9ded24224aab7c7041420b3efc1b6ba] from
> KubernetesStateHandleStore{configMapName='stellar-flink-cluster-dispatcher-leader'}
> 2021-03-26 08:22:57,933 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Trying to recover job with job id 198c46bac791e73ebcc565a550fa4ff6.
> 2021-03-26 08:22:58,029 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Stopping SessionDispatcherLeaderProcess.
> 2021-03-26 08:28:22,677 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Stopping
> DefaultJobGraphStore. 2021-03-26 08:28:22,681 ERROR
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Fatal error
> occurred in the cluster entrypoint.
[jira] [Comment Edited] (FLINK-22014) Flink JobManager failed to restart after failure in kubernetes HA setup
[
https://issues.apache.org/jira/browse/FLINK-22014?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450147#comment-17450147
]
Adrian Vasiliu edited comment on FLINK-22014 at 11/28/21, 10:51 PM:
[~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00)
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
was (Author: JIRAUSER280892):
[~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
> Flink JobManager failed to restart after failure in kubernetes HA setup
> ---
>
> Key: FLINK-22014
> URL: https://issues.apache.org/jira/browse/FLINK-22014
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.11.3, 1.12.2, 1.13.0
>Reporter: Mikalai Lushchytski
>Priority: Major
> Labels: k8s-ha, pull-request-available
> Attachments: flink-logs.txt.zip, image-2021-04-19-11-17-58-215.png,
> scalyr-logs (1).txt
>
>
> After the JobManager pod failed and the new one started, it was not able to
> recover jobs due to the absence of recovery data in storage - config map
> pointed at not existing file.
>
> Due to this the JobManager pod entered into the `CrashLoopBackOff`state and
> was not able to recover - each attempt failed with the same error so the
> whole cluster became unrecoverable and not operating.
>
> I had to manually delete the config map and start the jobs again without the
> save point.
>
> If I tried to emulate the failure further by deleting job manager pod
> manually, the new pod every time recovered well and issue was not
> reproducible anymore artificially.
>
> Below is the failure log:
> {code:java}
> 2021-03-26 08:22:57,925 INFO
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl [] -
> Starting the SlotManager.
> 2021-03-26 08:22:57,928 INFO
> org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] -
> Starting DefaultLeaderRetrievalService with KubernetesLeaderRetrievalDriver
> {configMapName='stellar-flink-cluster-dispatcher-leader'}.
> 2021-03-26 08:22:57,931 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Retrieved job
> ids [198c46bac791e73ebcc565a550fa4ff6, 344f5ebc1b5c3a566b4b2837813e4940,
> 96c4603a0822d10884f7fe536703d811, d9ded24224aab7c7041420b3efc1b6ba] from
> KubernetesStateHandleStore{configMapName='stellar-flink-cluster-dispatcher-leader'}
> 2021-03-26 08:22:57,933 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Trying to recover job with job id 198c46bac791e73ebcc565a550fa4ff6.
> 2021-03-26 08:22:58,029 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Stopping SessionDispatcherLeaderProcess.
> 2021-03-26 08:28:22,677 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Stopping
> DefaultJobGraphStore. 2021-03-26 08:28:22,681 ERROR
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Fatal error
> occurred in the cluster entrypoint.
[jira] [Comment Edited] (FLINK-22014) Flink JobManager failed to restart after failure in kubernetes HA setup
[
https://issues.apache.org/jira/browse/FLINK-22014?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450147#comment-17450147
]
Adrian Vasiliu edited comment on FLINK-22014 at 11/28/21, 10:50 PM:
[~trohrmann] [~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
was (Author: JIRAUSER280892):
[~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
> Flink JobManager failed to restart after failure in kubernetes HA setup
> ---
>
> Key: FLINK-22014
> URL: https://issues.apache.org/jira/browse/FLINK-22014
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.11.3, 1.12.2, 1.13.0
>Reporter: Mikalai Lushchytski
>Priority: Major
> Labels: k8s-ha, pull-request-available
> Attachments: flink-logs.txt.zip, image-2021-04-19-11-17-58-215.png,
> scalyr-logs (1).txt
>
>
> After the JobManager pod failed and the new one started, it was not able to
> recover jobs due to the absence of recovery data in storage - config map
> pointed at not existing file.
>
> Due to this the JobManager pod entered into the `CrashLoopBackOff`state and
> was not able to recover - each attempt failed with the same error so the
> whole cluster became unrecoverable and not operating.
>
> I had to manually delete the config map and start the jobs again without the
> save point.
>
> If I tried to emulate the failure further by deleting job manager pod
> manually, the new pod every time recovered well and issue was not
> reproducible anymore artificially.
>
> Below is the failure log:
> {code:java}
> 2021-03-26 08:22:57,925 INFO
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl [] -
> Starting the SlotManager.
> 2021-03-26 08:22:57,928 INFO
> org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] -
> Starting DefaultLeaderRetrievalService with KubernetesLeaderRetrievalDriver
> {configMapName='stellar-flink-cluster-dispatcher-leader'}.
> 2021-03-26 08:22:57,931 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Retrieved job
> ids [198c46bac791e73ebcc565a550fa4ff6, 344f5ebc1b5c3a566b4b2837813e4940,
> 96c4603a0822d10884f7fe536703d811, d9ded24224aab7c7041420b3efc1b6ba] from
> KubernetesStateHandleStore{configMapName='stellar-flink-cluster-dispatcher-leader'}
> 2021-03-26 08:22:57,933 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Trying to recover job with job id 198c46bac791e73ebcc565a550fa4ff6.
> 2021-03-26 08:22:58,029 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Stopping SessionDispatcherLeaderProcess.
> 2021-03-26 08:28:22,677 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Stopping
> DefaultJobGraphStore. 2021-03-26 08:28:22,681 ERROR
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Fatal error
> occurred in the cluster entrypoint.
[jira] [Commented] (FLINK-22014) Flink JobManager failed to restart after failure in kubernetes HA setup
[
https://issues.apache.org/jira/browse/FLINK-22014?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17450147#comment-17450147
]
Adrian Vasiliu commented on FLINK-22014:
[~mlushchytski] or anyone knowing:
In our company, we observe symptoms similar to those reported in this issue
while using Flink 1.13.2. That is, job managers in CrashLoopbackOff with
similar errors in their logs. The storage is in a ReadWriteMany PV using
rook-cephfs storage class.
The Flink version information from the log of job manager:
Starting StandaloneSessionClusterEntrypoint (Version: 1.13.2, Scala: 2.11,
Rev:5f007ff, Date:2021-07-23T04:35:55+02:00
The issue happens in a non-systematic manner, but observed it in at least 3
deployments on different OpenShift clusters.
Reducing the number of Flink job managers from 3 (HA) to 1 (non-HA) avoids the
CrashloopbackOff.
For some reason, while previously the "Fix version(s)" field of this issue has
been assigned different values, it presently shows "None".
Has this been observed by others with Flink 1.13.2? Should this issue be reopen
or should a new issue be open?
> Flink JobManager failed to restart after failure in kubernetes HA setup
> ---
>
> Key: FLINK-22014
> URL: https://issues.apache.org/jira/browse/FLINK-22014
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.11.3, 1.12.2, 1.13.0
>Reporter: Mikalai Lushchytski
>Priority: Major
> Labels: k8s-ha, pull-request-available
> Attachments: flink-logs.txt.zip, image-2021-04-19-11-17-58-215.png,
> scalyr-logs (1).txt
>
>
> After the JobManager pod failed and the new one started, it was not able to
> recover jobs due to the absence of recovery data in storage - config map
> pointed at not existing file.
>
> Due to this the JobManager pod entered into the `CrashLoopBackOff`state and
> was not able to recover - each attempt failed with the same error so the
> whole cluster became unrecoverable and not operating.
>
> I had to manually delete the config map and start the jobs again without the
> save point.
>
> If I tried to emulate the failure further by deleting job manager pod
> manually, the new pod every time recovered well and issue was not
> reproducible anymore artificially.
>
> Below is the failure log:
> {code:java}
> 2021-03-26 08:22:57,925 INFO
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl [] -
> Starting the SlotManager.
> 2021-03-26 08:22:57,928 INFO
> org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] -
> Starting DefaultLeaderRetrievalService with KubernetesLeaderRetrievalDriver
> {configMapName='stellar-flink-cluster-dispatcher-leader'}.
> 2021-03-26 08:22:57,931 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Retrieved job
> ids [198c46bac791e73ebcc565a550fa4ff6, 344f5ebc1b5c3a566b4b2837813e4940,
> 96c4603a0822d10884f7fe536703d811, d9ded24224aab7c7041420b3efc1b6ba] from
> KubernetesStateHandleStore{configMapName='stellar-flink-cluster-dispatcher-leader'}
> 2021-03-26 08:22:57,933 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Trying to recover job with job id 198c46bac791e73ebcc565a550fa4ff6.
> 2021-03-26 08:22:58,029 INFO
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess []
> - Stopping SessionDispatcherLeaderProcess.
> 2021-03-26 08:28:22,677 INFO
> org.apache.flink.runtime.jobmanager.DefaultJobGraphStore [] - Stopping
> DefaultJobGraphStore. 2021-03-26 08:28:22,681 ERROR
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Fatal error
> occurred in the cluster entrypoint. java.util.concurrent.CompletionException:
> org.apache.flink.util.FlinkRuntimeException: Could not recover job with job
> id 198c46bac791e73ebcc565a550fa4ff6.
>at java.util.concurrent.CompletableFuture.encodeThrowable(Unknown Source)
> ~[?:?]
>at java.util.concurrent.CompletableFuture.completeThrowable(Unknown
> Source) [?:?]
>at java.util.concurrent.CompletableFuture$AsyncSupply.run(Unknown Source)
> [?:?]
>at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) [?:?]
>at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) [?:?]
>at java.lang.Thread.run(Unknown Source) [?:?] Caused by:
> org.apache.flink.util.FlinkRuntimeException: Could not recover job with job
> id 198c46bac791e73ebcc565a550fa4ff6.
>at
> org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess.recoverJob(SessionDispatcherLeaderProcess.java:144
> undefined) ~[flink-dist_2.12-1.12.2.jar:1.12.2]
>at
>
[jira] [Updated] (FLINK-8380) Dynamic BucketingSink paths based on ingested Kafka topics
[
https://issues.apache.org/jira/browse/FLINK-8380?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-8380:
--
Labels: auto-deprioritized-major stale-minor (was:
auto-deprioritized-major)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Minor but is unassigned and neither itself nor its Sub-Tasks have been updated
for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is
still Minor, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Dynamic BucketingSink paths based on ingested Kafka topics
> --
>
> Key: FLINK-8380
> URL: https://issues.apache.org/jira/browse/FLINK-8380
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Affects Versions: 1.4.0
>Reporter: Kyle Hamlin
>Priority: Minor
> Labels: auto-deprioritized-major, stale-minor
>
> Flink 1.4 released a feature that allows Kafka consumers to dynamically
> ingest topics based on a regex pattern. If a user wanted to use Flink as a
> simple (no transformations) but dynamic (auto topic discovery & auto output
> path generation) data persister they would currently only have half the tools
> to do so. I believe it would be a beneficial feature to allow users to not
> only define automatic topic discovery but also a way to dynamically
> incorporate those topics into a BucketingSink output path. For example:
> If I had three Kafka topics
> {code:java}
> select-topic-1
> ignore-topic-1
> select-topic-2
> {code}
> And my Kafka consumers regex only selected two topics
> {code:java}
> val consumer = new
> FlinkKafkaConsumer010[GenericRecord](Pattern.compile("select-.*?"), new
> MyDeserializer(), props)
> {code}
> Then the selected topics would appended to the beginning of the BucketingSink
> output path and any Bucketers partitions would follow
> {code:java}
> val sink = new BucketingSink[GenericRecord]("s3://my-bucket/")
> sink.setBucketer(new DateTimeBucketer[GenericRecord]("MMdd"))
> {code}
> The resulting output paths would be
> {code:java}
> s3://my-bucket/selected-topic1/MMdd/
> s3://my-bucket/selected-topic2/MMdd/
> {code}
> As new topics are discovered via the regex pattern (while the app is running)
> the set of BucketingSink output paths would grow.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-8377) Document DataViews for user-defined aggregate functions
[
https://issues.apache.org/jira/browse/FLINK-8377?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-8377:
--
Labels: auto-deprioritized-major stale-minor (was:
auto-deprioritized-major)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Minor but is unassigned and neither itself nor its Sub-Tasks have been updated
for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is
still Minor, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Document DataViews for user-defined aggregate functions
> ---
>
> Key: FLINK-8377
> URL: https://issues.apache.org/jira/browse/FLINK-8377
> Project: Flink
> Issue Type: Improvement
> Components: Documentation, Table SQL / API
>Reporter: Timo Walther
>Priority: Minor
> Labels: auto-deprioritized-major, stale-minor
>
> The {{DataView}} feature that has been implemented with FLINK-7206 has not
> been documented on our website. We should add some examples and explain the
> differences and limitations (where Flink state is used and where regular Java
> data structures are used).
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-8526) When use parallelism equals to half of the number of cpu, join and shuffle operators will easly cause deadlock.
[ https://issues.apache.org/jira/browse/FLINK-8526?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-8526: -- Labels: auto-deprioritized-major stale-minor (was: auto-deprioritized-major) I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help the community manage its development. I see this issues has been marked as Minor but is unassigned and neither itself nor its Sub-Tasks have been updated for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is still Minor, please either assign yourself or give an update. Afterwards, please remove the label or in 7 days the issue will be deprioritized. > When use parallelism equals to half of the number of cpu, join and shuffle > operators will easly cause deadlock. > --- > > Key: FLINK-8526 > URL: https://issues.apache.org/jira/browse/FLINK-8526 > Project: Flink > Issue Type: Bug > Components: API / DataSet, Runtime / Task >Affects Versions: 1.4.0 > Environment: 8 machines(96GB and 24 cores) and 20 taskslot per > taskmanager. twitter-2010 dataset. And parallelism setting to 80. I run my > code in standalone mode. >Reporter: zhu.qing >Priority: Minor > Labels: auto-deprioritized-major, stale-minor > Attachments: T2AdjActiveV.java, T2AdjMessage.java > > Original Estimate: 72h > Remaining Estimate: 72h > > The next program attached will stuck at some special parallelism in some > situation. When parallelism is 80 in previous setting, The program will > always stuck. And when parallelism is 100, everything goes well. According > to my research I found when the parallelism equals to number of taskslots. > The program is not fastest and probably caused network buffer not enough. How > networker buffer related to parallelism and how parallelism relate to > running task (In other words we have 160 taskslots but running task can be > far more than taskslots). > Parallelism cannot be equals to half of the cpu. > Or will casuse "java.io.FileNotFoundException". You can repeat exception on > your pc and set your parallelism equals to half of your cpu core. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-8542) Do not indefinitely store closed shard's state in the FlinkKinesisConsumer
[
https://issues.apache.org/jira/browse/FLINK-8542?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-8542:
--
Labels: auto-deprioritized-major stale-minor (was:
auto-deprioritized-major)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Minor but is unassigned and neither itself nor its Sub-Tasks have been updated
for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is
still Minor, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Do not indefinitely store closed shard's state in the FlinkKinesisConsumer
> --
>
> Key: FLINK-8542
> URL: https://issues.apache.org/jira/browse/FLINK-8542
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / Kinesis
>Reporter: Tzu-Li (Gordon) Tai
>Priority: Minor
> Labels: auto-deprioritized-major, stale-minor
>
> See original discussion here:
> [https://github.com/apache/flink/pull/5337|https://github.com/apache/flink/pull/5337#issuecomment-362227711]
> Currently, the Kinesis consumer keeps a list of {{(StreamShardMetadata,
> SequenceNumber)}} as its state. That list also contains all shards that have
> been closed already, and is kept in the state indefinitely so that on
> restore, we know that a closed shard is already fully consumed,
> The downside of this, is that the state size of the Kinesis consumer can
> basically grow without bounds, as the consumed Kinesis streams are resharded
> and more and more closed shards are present.
> Some possible solutions have been discussed in the linked PR comments.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-8444) Rework dependency setup docs
[
https://issues.apache.org/jira/browse/FLINK-8444?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-8444:
--
Labels: auto-deprioritized-major stale-minor (was:
auto-deprioritized-major)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Minor but is unassigned and neither itself nor its Sub-Tasks have been updated
for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is
still Minor, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Rework dependency setup docs
>
>
> Key: FLINK-8444
> URL: https://issues.apache.org/jira/browse/FLINK-8444
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Affects Versions: 1.4.0, 1.5.0
>Reporter: Chesnay Schepler
>Priority: Minor
> Labels: auto-deprioritized-major, stale-minor
>
> Taken from https://github.com/apache/flink/pull/5303:
> {quote}
> I would suggest to start thinking about the dependencies the following way:
> There are pure user-code projects where the Flink runtime is "provided"
> and they are started using an existing Flink setup (bin/flink run or REST
> entry point). This is the Framework Style.
> In the future, we will have "Flink as a Library" deployments, where users
> add something like flink-dist as a library to their program and then simply
> dockerize that Java application.
> Code can be run in the IDE or other similar style embedded forms. This is
> in some sense also a "Flink as a Library" deployment, but with selective
> (fewer) dependencies. The RocksDB issue applies only to this scenario here.
> To make this simpler for the users, it would be great to have not N different
> models that we talk about, but ideally only two: Framework Style and Library
> Style. We could for example start to advocate and document that users should
> always use flink-dist as their standard dependency - "provided" in the
> framework style deployment, "compile" in the library style deployment. That
> might be a really easy way to work with that. The only problem for the time
> being is that flink-dist is quite big and contains for example also optional
> dependencies like flink-table, which makes it more heavyweight for
> quickstarts. Maybe we can accept that as a trade-off for dependency
> simplicity.
> {quote}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-8534: -- Labels: auto-deprioritized-major stale-minor (was: auto-deprioritized-major) I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help the community manage its development. I see this issues has been marked as Minor but is unassigned and neither itself nor its Sub-Tasks have been updated for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is still Minor, please either assign yourself or give an update. Afterwards, please remove the label or in 7 days the issue will be deprioritized. > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Runtime / Task > Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink > 1.4.0, and parallelism = 2 will cause problem and others will not. >Reporter: zhu.qing >Priority: Minor > Labels: auto-deprioritized-major, stale-minor > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable insertBucketEntry() > line 1054 more than 255) will cause spillPartition() (HashPartition line > 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google(SNAP) as dataset. > > Exception in thread "main" > org.apache.flink.runtime.client.JobExecutionException: Job execution failed. > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply$mcV$sp(JobManager.scala:897) > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply(JobManager.scala:840) > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply(JobManager.scala:840) > at > scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) > at > scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) > at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39) > at > akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415) > at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) > at > scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) > at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) > at > scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) > Caused by: java.io.IOException: Channel to path > 'C:\Users\sanquan.qz\AppData\Local\Temp\flink-io-5af23edc-1ec0-4718-87a5-916ee022a8be\fc08af25b6f879b8e7bb24291c47ea1d.18.channel' > could not be opened. > at > org.apache.flink.runtime.io.disk.iomanager.AbstractFileIOChannel.(AbstractFileIOChannel.java:61) > at > org.apache.flink.runtime.io.disk.iomanager.AsynchronousFileIOChannel.(AsynchronousFileIOChannel.java:86) > at > org.apache.flink.runtime.io.disk.iomanager.AsynchronousBulkBlockReader.(AsynchronousBulkBlockReader.java:46) > at > org.apache.flink.runtime.io.disk.iomanager.AsynchronousBulkBlockReader.(AsynchronousBulkBlockReader.java:39) > at > org.apache.flink.runtime.io.disk.iomanager.IOManagerAsync.createBulkBlockChannelReader(IOManagerAsync.java:294) > at > org.apache.flink.runtime.operators.hash.MutableHashTable.buildTableFromSpilledPartition(MutableHashTable.java:880) > at > org.apache.flink.runtime.operators.hash.MutableHashTable.prepareNextPartition(MutableHashTable.java:637) > at > org.apache.flink.runtime.operators.hash.ReOpenableMutableHashTable.prepareNextPartition(ReOpenableMutableHashTable.java:170) > at > org.apache.flink.runtime.operators.hash.MutableHashTable.nextRecord(MutableHashTable.java:675) > at > org.apache.flink.runtime.operators.hash.NonReusingBuildFirstHashJoinIterator.callWithNextKey(NonReusingBuildFirstHashJoinIterator.java:117) > at > org.apache.flink.runtime.operators.AbstractCachedBuildSideJoinDriver.run(AbstractCachedBuildSideJoinDriver.java:176) > at
[jira] [Updated] (FLINK-8457) Documentation for Building from Source is broken
[
https://issues.apache.org/jira/browse/FLINK-8457?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-8457:
--
Labels: auto-deprioritized-major stale-minor (was:
auto-deprioritized-major)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Minor but is unassigned and neither itself nor its Sub-Tasks have been updated
for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is
still Minor, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Documentation for Building from Source is broken
>
>
> Key: FLINK-8457
> URL: https://issues.apache.org/jira/browse/FLINK-8457
> Project: Flink
> Issue Type: Bug
> Components: Documentation
>Affects Versions: 1.3.0, 1.4.0
>Reporter: Fabian Hueske
>Priority: Minor
> Labels: auto-deprioritized-major, stale-minor
>
> The documentation for how to build Flink from source is broken for all
> released versions.
> It only explains how to build the latest master branch which is only correct
> for the docs of the latest master but not for the docs of a release version.
> For example the [build docs for Flink
> 1.4|https://ci.apache.org/projects/flink/flink-docs-release-1.4/start/building.html]
> say
> {quote}This page covers how to build Flink 1.4.0 from sources.
> {quote}
> but explain how to build the {{master}} branch.
> I think we should rewrite this page to explain how to build specific versions
> and also explain how to build the SNAPSHOT branches of released versions (for
> example {{release-1.4}}, the latest dev branch for Flink 1.4 with all merged
> bug fix).
> I guess the same holds for Flink 1.3 as well.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)