[GitHub] [flink] yunfengzhou-hub commented on a diff in pull request #20454: [FLINK-28639][Runtime/Checkpointing] Preserve consistency of events from subtask to OC
yunfengzhou-hub commented on code in PR #20454:
URL: https://github.com/apache/flink/pull/20454#discussion_r943118408
##
flink-runtime/src/main/java/org/apache/flink/runtime/operators/coordination/OperatorCoordinatorHolder.java:
##
@@ -299,9 +352,67 @@ public void resetToCheckpoint(long checkpointId, @Nullable
byte[] checkpointData
}
private void checkpointCoordinatorInternal(
-final long checkpointId, final CompletableFuture result) {
+long checkpointId, CompletableFuture result) {
mainThreadExecutor.assertRunningInMainThread();
+try {
+subtaskGatewayMap.forEach(
+(subtask, gateway) ->
gateway.markForCheckpoint(checkpointId));
+
+if (currentPendingCheckpointId != NO_CHECKPOINT
+&& currentPendingCheckpointId != checkpointId) {
+throw new IllegalStateException(
+String.format(
+"Cannot checkpoint coordinator for checkpoint
%d, "
++ "since checkpoint %d has already
started.",
+checkpointId, currentPendingCheckpointId));
+}
+
+if (latestAttemptedCheckpointId >= checkpointId) {
+throw new IllegalStateException(
+String.format(
+"Regressing checkpoint IDs. Previous
checkpointId = %d, new checkpointId = %d",
+latestAttemptedCheckpointId, checkpointId));
+}
+
+
Preconditions.checkState(acknowledgeCloseGatewayFutureMap.isEmpty());
+} catch (Throwable t) {
+ExceptionUtils.rethrowIfFatalErrorOrOOM(t);
+result.completeExceptionally(t);
+globalFailureHandler.handleGlobalFailure(t);
+return;
+}
+
+currentPendingCheckpointId = checkpointId;
+latestAttemptedCheckpointId = checkpointId;
+
+for (int subtask : subtaskGatewayMap.keySet()) {
+acknowledgeCloseGatewayFutureMap.put(subtask, new
CompletableFuture<>());
+final OperatorEvent closeGatewayEvent = new
CloseGatewayEvent(checkpointId, subtask);
+subtaskGatewayMap
+.get(subtask)
+.sendEventWithCallBackOnCompletion(
+closeGatewayEvent,
+(success, failure) -> {
+if (failure != null) {
+// If the close gateway event failed to
reach the subtask for
+// some reason, the coordinator would
trigger a fail-over on
+// the subtask if the subtask is still
running. This behavior
+// also guarantees that the coordinator
won't receive more
+// events from this subtask before the
current checkpoint
+// finishes, which is equivalent to
receiving ACK from this
+// subtask.
+if (!(failure instanceof
TaskNotRunningException)) {
+subtaskGatewayMap
+.get(subtask)
+
.tryTriggerTaskFailover(closeGatewayEvent, failure);
+}
+
+
completeAcknowledgeCloseGatewayFuture(subtask, checkpointId);
Review Comment:
According to our offline discussion, I'll make it complete with exception
when the attempt to trigger task fail-over succeeded, otherwise we'll still
complete it normally.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (FLINK-28840) Introduce roadmap document of Flink Table Store
[ https://issues.apache.org/jira/browse/FLINK-28840?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee closed FLINK-28840. Assignee: Nicholas Jiang Resolution: Fixed master: 26786fad4df2fb889bc339cf93e5ce08e3ee8652 > Introduce roadmap document of Flink Table Store > --- > > Key: FLINK-28840 > URL: https://issues.apache.org/jira/browse/FLINK-28840 > Project: Flink > Issue Type: Improvement > Components: Table Store >Reporter: Nicholas Jiang >Assignee: Nicholas Jiang >Priority: Minor > Labels: pull-request-available > Fix For: table-store-0.3.0 > > > The Flink Table Store subproject needs its own roadmap document to present an > overview of the general direction. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-table-store] JingsongLi merged pull request #263: [FLINK-28840] Introduce roadmap document of Flink Table Store
JingsongLi merged PR #263: URL: https://github.com/apache/flink-table-store/pull/263 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-28794) Publish flink-table-store snapshot artifacts
[ https://issues.apache.org/jira/browse/FLINK-28794?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee closed FLINK-28794. Resolution: Fixed master: 49491377b93223e914f5656d8d2c2f7ade7999bb > Publish flink-table-store snapshot artifacts > > > Key: FLINK-28794 > URL: https://issues.apache.org/jira/browse/FLINK-28794 > Project: Flink > Issue Type: Improvement > Components: Table Store >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: table-store-0.3.0 > > > It is better to publish the Maven artifacts, so that downstream Java projects > can use this. > See FLINK-26639 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-28903) flink-table-store-hive-catalog could not shade hive-shims-0.23
[
https://issues.apache.org/jira/browse/FLINK-28903?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578248#comment-17578248
]
Jingsong Lee commented on FLINK-28903:
--
We can change this to `support hive 2.1&2.2`
> flink-table-store-hive-catalog could not shade hive-shims-0.23
> --
>
> Key: FLINK-28903
> URL: https://issues.apache.org/jira/browse/FLINK-28903
> Project: Flink
> Issue Type: Bug
> Components: Table Store
>Affects Versions: table-store-0.3.0
>Reporter: Nicholas Jiang
>Priority: Major
> Labels: pull-request-available
> Fix For: table-store-0.3.0
>
>
> flink-table-store-hive-catalog could not shade hive-shims-0.23 because
> artifactSet doesn't include hive-shims-0.23 and the minimizeJar is set to
> true. The exception is as follows:
> {code:java}
> Caused by: java.lang.RuntimeException: Unable to instantiate
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.HiveMetaStoreClient
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1708)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.(RetryingMetaStoreClient.java:83)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:133)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:97)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.hive.HiveCatalog.createClient(HiveCatalog.java:380)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.hive.HiveCatalog.(HiveCatalog.java:80)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.hive.HiveCatalogFactory.create(HiveCatalogFactory.java:51)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.file.catalog.CatalogFactory.createCatalog(CatalogFactory.java:93)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.connector.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:62)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.connector.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:57)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.connector.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:31)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.factories.FactoryUtil.createCatalog(FactoryUtil.java:428)
> ~[flink-table-api-java-uber-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.createCatalog(TableEnvironmentImpl.java:1356)
> ~[flink-table-api-java-uber-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:)
> ~[flink-table-api-java-uber-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.client.gateway.local.LocalExecutor.lambda$executeOperation$3(LocalExecutor.java:209)
> ~[flink-sql-client-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.client.gateway.context.ExecutionContext.wrapClassLoader(ExecutionContext.java:88)
> ~[flink-sql-client-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.client.gateway.local.LocalExecutor.executeOperation(LocalExecutor.java:209)
> ~[flink-sql-client-1.15.1.jar:1.15.1]
> ... 10 more
> Caused by: java.lang.reflect.InvocationTargetException
> at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
> ~[?:1.8.0_181]
> at
> sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
> ~[?:1.8.0_181]
> at
> sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
> ~[?:1.8.0_181]
> at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
> ~[?:1.8.0_181]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1706)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
>
[GitHub] [flink-table-store] JingsongLi merged pull request #261: [FLINK-28794] Publish flink-table-store snapshot artifacts
JingsongLi merged PR #261: URL: https://github.com/apache/flink-table-store/pull/261 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-28754) Document that Java 8 is required to build table store
[ https://issues.apache.org/jira/browse/FLINK-28754?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee closed FLINK-28754. Fix Version/s: table-store-0.2.0 Assignee: Nicholas Jiang Resolution: Fixed master: d29f41a2e4cabe37083ee0faf0bbd776db7fd9d8 release-0.2: 3f3f7ece3563a19654882db066a4c79e44c67dfe > Document that Java 8 is required to build table store > - > > Key: FLINK-28754 > URL: https://issues.apache.org/jira/browse/FLINK-28754 > Project: Flink > Issue Type: Improvement > Components: Documentation, Table Store >Reporter: David Anderson >Assignee: Nicholas Jiang >Priority: Major > Labels: pull-request-available > Fix For: table-store-0.2.0 > > > The table store can not be built with Java 11, but the "build from source" > instructions don't mention this restriction. > https://nightlies.apache.org/flink/flink-table-store-docs-master/docs/engines/build/ -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-28897) Fail to use udf in added jar when enabling checkpoint
[
https://issues.apache.org/jira/browse/FLINK-28897?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu reassigned FLINK-28897:
---
Assignee: dalongliu
> Fail to use udf in added jar when enabling checkpoint
> -
>
> Key: FLINK-28897
> URL: https://issues.apache.org/jira/browse/FLINK-28897
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Client
>Affects Versions: 1.16.0
>Reporter: Liu
>Assignee: dalongliu
>Priority: Critical
> Fix For: 1.16.0
>
>
> The problem can be reproduced when enabling checkpoint for that
> StreamingJobGraphGenerator.preValidate is called actually in this case. Maybe
> this is a classloader problem.
> The reproduced steps are as following:
> {code:java}
> // Enable checkpoint first and execute the command in sql client.
> ADD JAR
> '~/flink/flink-end-to-end-tests/flink-sql-client-test/target/SqlToolbox.jar';
> create function func1 as
> 'org.apache.flink.table.toolbox.StringRegexReplaceFunction' LANGUAGE JAVA;
> SELECT id, func1(str, 'World', 'Flink') FROM (VALUES (1, 'Hello World')) AS
> T(id, str); {code}
> The output is as following:
> {code:java}
> /* 1 */
> /* 2 */ public class StreamExecCalc$11 extends
> org.apache.flink.table.runtime.operators.TableStreamOperator
> /* 3 */ implements
> org.apache.flink.streaming.api.operators.OneInputStreamOperator {
> /* 4 */
> /* 5 */ private final Object[] references;
> /* 6 */ private transient
> org.apache.flink.table.runtime.typeutils.StringDataSerializer
> typeSerializer$4;
> /* 7 */
> /* 8 */ private final
> org.apache.flink.table.data.binary.BinaryStringData str$6 =
> org.apache.flink.table.data.binary.BinaryStringData.fromString("World");
> /* 9 */
> /* 10 */
> /* 11 */ private final
> org.apache.flink.table.data.binary.BinaryStringData str$7 =
> org.apache.flink.table.data.binary.BinaryStringData.fromString("Flink");
> /* 12 */
> /* 13 */ private transient
> org.apache.flink.table.toolbox.StringRegexReplaceFunction
> function_org$apache$flink$table$toolbox$StringRegexReplaceFunction;
> /* 14 */ private transient
> org.apache.flink.table.data.conversion.StringStringConverter converter$8;
> /* 15 */ org.apache.flink.table.data.BoxedWrapperRowData out = new
> org.apache.flink.table.data.BoxedWrapperRowData(2);
> /* 16 */ private final
> org.apache.flink.streaming.runtime.streamrecord.StreamRecord outElement = new
> org.apache.flink.streaming.runtime.streamrecord.StreamRecord(null);
> /* 17 */
> /* 18 */ public StreamExecCalc$11(
> /* 19 */ Object[] references,
> /* 20 */ org.apache.flink.streaming.runtime.tasks.StreamTask task,
> /* 21 */ org.apache.flink.streaming.api.graph.StreamConfig config,
> /* 22 */ org.apache.flink.streaming.api.operators.Output output,
> /* 23 */
> org.apache.flink.streaming.runtime.tasks.ProcessingTimeService
> processingTimeService) throws Exception {
> /* 24 */ this.references = references;
> /* 25 */ typeSerializer$4 =
> (((org.apache.flink.table.runtime.typeutils.StringDataSerializer)
> references[0]));
> /* 26 */
> function_org$apache$flink$table$toolbox$StringRegexReplaceFunction =
> (((org.apache.flink.table.toolbox.StringRegexReplaceFunction) references[1]));
> /* 27 */ converter$8 =
> (((org.apache.flink.table.data.conversion.StringStringConverter)
> references[2]));
> /* 28 */ this.setup(task, config, output);
> /* 29 */ if (this instanceof
> org.apache.flink.streaming.api.operators.AbstractStreamOperator) {
> /* 30 */
> ((org.apache.flink.streaming.api.operators.AbstractStreamOperator) this)
> /* 31 */ .setProcessingTimeService(processingTimeService);
> /* 32 */ }
> /* 33 */ }
> /* 34 */
> /* 35 */ @Override
> /* 36 */ public void open() throws Exception {
> /* 37 */ super.open();
> /* 38 */
> /* 39 */
> function_org$apache$flink$table$toolbox$StringRegexReplaceFunction.open(new
> org.apache.flink.table.functions.FunctionContext(getRuntimeContext()));
> /* 40 */
> /* 41 */
> /* 42 */
> converter$8.open(getRuntimeContext().getUserCodeClassLoader());
> /* 43 */
> /* 44 */ }
> /* 45 */
> /* 46 */ @Override
> /* 47 */ public void
> processElement(org.apache.flink.streaming.runtime.streamrecord.StreamRecord
> element) throws Exception {
> /* 48 */ org.apache.flink.table.data.RowData in1 =
> (org.apache.flink.table.data.RowData) element.getValue();
> /* 49 */
> /* 50 */ int field$2;
> /* 51 */ boolean isNull$2;
> /* 52 */ org.apache.flink.table.data.binary.BinaryStringData field$3;
> /* 53 */ boolean
[jira] [Updated] (FLINK-27492) Flink table scala example does not including the scala-api jars
[ https://issues.apache.org/jira/browse/FLINK-27492?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-27492: Priority: Major (was: Critical) > Flink table scala example does not including the scala-api jars > --- > > Key: FLINK-27492 > URL: https://issues.apache.org/jira/browse/FLINK-27492 > Project: Flink > Issue Type: Bug > Components: Table SQL / API >Affects Versions: 1.15.0, 1.16.0 >Reporter: Yun Gao >Assignee: Timo Walther >Priority: Major > Labels: pull-request-available, stale-assigned > Fix For: 1.16.0, 1.15.2 > > > Currently it seems the flink-scala-api, flink-table-api-scala-bridge is not > including from the binary package[1]. However, currently the scala table > examples seems not include the scala-api classes in the generated jar, If we > start a standalone cluster from the binary distribution package and then > submit a table / sql job in scala, it would fail due to not found the > StreamTableEnvironment class. > > [1] > https://nightlies.apache.org/flink/flink-docs-master/docs/dev/configuration/advanced/#anatomy-of-table-dependencies -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-table-store] JingsongLi merged pull request #264: [FLINK-28754] Document that Java 8 is required to build table store
JingsongLi merged PR #264: URL: https://github.com/apache/flink-table-store/pull/264 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #265: [FLINK-28903] flink-table-store-hive-catalog could not shade hive-shims-0.23
JingsongLi commented on code in PR #265: URL: https://github.com/apache/flink-table-store/pull/265#discussion_r943089140 ## flink-table-store-hive/flink-table-store-hive-catalog/pom.xml: ## @@ -476,7 +476,6 @@ under the License. shade -true Review Comment: Does this need? Can we add jar what we need? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-28883) Fix HiveTableSink failed to report metrics to hive metastore
[ https://issues.apache.org/jira/browse/FLINK-28883?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578245#comment-17578245 ] luoyuxia edited comment on FLINK-28883 at 8/11/22 4:28 AM: --- I'll try to fix it. [~jark] Could you please assign it to me. was (Author: luoyuxia): I'll try to fix it. > Fix HiveTableSink failed to report metrics to hive metastore > > > Key: FLINK-28883 > URL: https://issues.apache.org/jira/browse/FLINK-28883 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Affects Versions: 1.16.0 >Reporter: Liu >Priority: Critical > Fix For: 1.16.0 > > > Currently, HiveTableSink is failed to report metrics to metastores, like file > number, total line number and total size. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-28883) Fix HiveTableSink failed to report metrics to hive metastore
[ https://issues.apache.org/jira/browse/FLINK-28883?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578245#comment-17578245 ] luoyuxia commented on FLINK-28883: -- I'll try to fix it. > Fix HiveTableSink failed to report metrics to hive metastore > > > Key: FLINK-28883 > URL: https://issues.apache.org/jira/browse/FLINK-28883 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Affects Versions: 1.16.0 >Reporter: Liu >Priority: Critical > Fix For: 1.16.0 > > > Currently, HiveTableSink is failed to report metrics to metastores, like file > number, total line number and total size. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-27622) Make `AsyncDataStream.OutputMode` configurable for table module
[
https://issues.apache.org/jira/browse/FLINK-27622?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
lincoln lee closed FLINK-27622.
---
Resolution: Fixed
> Make `AsyncDataStream.OutputMode` configurable for table module
> ---
>
> Key: FLINK-27622
> URL: https://issues.apache.org/jira/browse/FLINK-27622
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / API
>Reporter: lincoln lee
>Assignee: lincoln lee
>Priority: Major
> Fix For: 1.16.0
>
>
> The `AsyncDataStream.OutputMode` is hardcoded to
> 'AsyncDataStream.OutputMode.ORDERED' for now:
> {code}
> //
> org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecLookupJoin
> // force ORDERED output mode currently, optimize it to UNORDERED
> // when the downstream do not need orderness
> return new AsyncWaitOperatorFactory<>(
> asyncFunc, asyncTimeout, asyncBufferCapacity,
> AsyncDataStream.OutputMode.ORDERED);
> {code}
> It should be configurable to users same as the other two async options
> 'table.exec.async-lookup.buffer-capacity' & 'table.exec.async-lookup.timeout'.
> Also, there must be some plan validation for correctness concern when output
> mode is unordered(that's the reason I know why not be exposed before).
> Further, we should offer more precisely control for async join operation more
> than job level config, e.g., an async lookup join hint can do this per-join
> operation.
> It's the time to get this work!
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #20543: [FLINK-28027][connectors] Implement slow start for AIMDRateLimitingSt…
flinkbot commented on PR #20543: URL: https://github.com/apache/flink/pull/20543#issuecomment-1211541061 ## CI report: * e7ea1da8a04947eb501c702e1f5280af009a5530 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] hlteoh37 opened a new pull request, #20543: [FLINK-28027][connectors] Implement slow start for AIMDRateLimitingSt…
hlteoh37 opened a new pull request, #20543: URL: https://github.com/apache/flink/pull/20543 …rategy ## What is the purpose of the change Implement slow start for `AIMDRateLimitingStrategy` by starting from the `maxBatchSize` specified as the `initialRate`. ## Brief change log - Reduce the `initialRate` for `AIMDRateLimitingStrategy` to `maxBatchSize`. ## Verifying this change This change is already covered by existing tests, such as `AsyncSinkWriter` unit tests. Sinks extending `AsyncSinkWriter` have their own integration tests (e.g. AwsKinesisFirehoseSink, AwsKinesisStreamsSink) ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20542: [FLINK-28910]CDC From Mysql To Hbase Bugs
flinkbot commented on PR #20542: URL: https://github.com/apache/flink/pull/20542#issuecomment-1211531027 ## CI report: * 6983e1350a69cfa945b353fe51efe5ab64c27946 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fredia commented on pull request #20405: [FLINK-28010][state] Use deleteRange to optimize the clear method of RocksDBMapState.
fredia commented on PR #20405: URL: https://github.com/apache/flink/pull/20405#issuecomment-1211529169 > Do you mean that the performance of Point Lookups and Range Scans should be verified again in Flink's benchmark? Not Flink's benchmark, the tests in Flink bechmark are fine-grained. If we have some jobs that use MapState, we can observe the overall TPS of these jobs before and after optimization. BTW, I'm just curious, I'm absolutely fine with this PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ganlute closed pull request #20542: [FLINK-28910]CDC From Mysql To Hbase Bugs
ganlute closed pull request #20542: [FLINK-28910]CDC From Mysql To Hbase Bugs URL: https://github.com/apache/flink/pull/20542 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ganlute opened a new pull request, #20542: [FLINK-28910]CDC From Mysql To Hbase Bugs
ganlute opened a new pull request, #20542: URL: https://github.com/apache/flink/pull/20542 ## What is the purpose of the change https://issues.apache.org/jira/browse/FLINK-28910 ## Brief change log - *Add reduce when hbase connector process mutation. ## Verifying this change CI passed ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-28915) Flink Native k8s mode jar localtion support s3 schema
hjw created FLINK-28915: --- Summary: Flink Native k8s mode jar localtion support s3 schema Key: FLINK-28915 URL: https://issues.apache.org/jira/browse/FLINK-28915 Project: Flink Issue Type: Improvement Components: Deployment / Kubernetes, flink-contrib Affects Versions: 1.15.1, 1.15.0 Reporter: hjw As the Flink document show , local is the only supported scheme in Native k8s deployment. Is there have a plan to support s3 filesystem? thx. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] wangyang0918 commented on a diff in pull request #20516: [FLINK-27856][flink-kubernetes]solve the NPE error of no spec field in taskmanager pod template.
wangyang0918 commented on code in PR #20516:
URL: https://github.com/apache/flink/pull/20516#discussion_r943071236
##
flink-kubernetes/src/main/java/org/apache/flink/kubernetes/utils/KubernetesUtils.java:
##
@@ -419,12 +420,18 @@ public static FlinkPod loadPodFromTemplateFile(
final List otherContainers = new ArrayList<>();
Container mainContainer = null;
-for (Container container :
pod.getInternalResource().getSpec().getContainers()) {
-if (mainContainerName.equals(container.getName())) {
-mainContainer = container;
-} else {
-otherContainers.add(container);
+if (null != pod.getInternalResource().getSpec()) {
+for (Container container :
pod.getInternalResource().getSpec().getContainers()) {
+if (mainContainerName.equals(container.getName())) {
+mainContainer = container;
+} else {
+otherContainers.add(container);
+}
}
+pod.getInternalResource().getSpec().setContainers(otherContainers);
+} else {
+// Set empty spec for taskmanager pod template
Review Comment:
This is not only for taskmanger pod template.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] JesseAtSZ commented on pull request #20091: [FLINK-27570][runtime] Fix checkFailureCounter in CheckpointFailureManager for finalize failure
JesseAtSZ commented on PR #20091: URL: https://github.com/apache/flink/pull/20091#issuecomment-1211521274 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-28909) Add ribbon filter policy option in RocksDBConfiguredOptions
[
https://issues.apache.org/jira/browse/FLINK-28909?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578235#comment-17578235
]
Yanfei Lei commented on FLINK-28909:
Hi [~zlzhang0122], {{rocksjni}} does not support [Ribbon filter
policy|https://github.com/facebook/rocksdb/blob/main/java/rocksjni/filter.cc]
yet, we should let rocks-jni support it first, and then pick the commits to
frocksdb.
> Add ribbon filter policy option in RocksDBConfiguredOptions
> ---
>
> Key: FLINK-28909
> URL: https://issues.apache.org/jira/browse/FLINK-28909
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / State Backends
>Affects Versions: 1.14.2, 1.15.1
>Reporter: zlzhang0122
>Priority: Minor
> Fix For: 1.16.0, 1.15.2
>
>
> Ribbon filter can efficiently enhance the read and reduce the disk and memory
> usage on RocksDB, it's supported by rocksdb since 6.15. (more details see
> [http://rocksdb.org/blog/2021/12/29/ribbon-filter.html|http://rocksdb.org/blog/2021/12/29/ribbon-filter.html])
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Comment Edited] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
[
https://issues.apache.org/jira/browse/FLINK-28913?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578226#comment-17578226
]
luoyuxia edited comment on FLINK-28913 at 8/11/22 3:32 AM:
---
The workaround way is to swap `opt/flink-table-planner` and
`lib/flink-table-planner-loader` as flink-table-planner contains calcite
dependency.
But to fix it, I think we can lazy init the `Hive` class, only when we need to
call method `loadTable` / `loadPartition`.
I think it's fine for only in Hive dialect, do we need `Hive` class, and when
user want to use Hive dialect, they need to swap
`lib/flink-table-planner-loader` and `opt/flink-table-planner` so that the
calcite will exist in class path.
was (Author: luoyuxia):
The workaround way is to swap `opt/flink-table-planner` and
`lib/flink-table-planner-loader` as flink-table-planner contains calcite
dependency.
But to fix it, I think we can lazy init the `Hive`, only when we need to call
method `loadTable` / `loadPartition`.
I think it's fine for only in Hive dialect, do we need `Hive`, and when user
want to use Hive dialect, they need to swap `lib/flink-table-planner-loader`
and `opt/flink-table-planner` so that the calcite will exist in class path.
> Fix fail to open HiveCatalog when it's for hive3
>
>
> Key: FLINK-28913
> URL: https://issues.apache.org/jira/browse/FLINK-28913
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
>Reporter: luoyuxia
>Priority: Critical
> Fix For: 1.16.0
>
>
> When use HiveCatalog for hive3, it will throw such exception:
> {code:java}
> java.lang.NoClassDefFoundError: org/apache/calcite/plan/RelOptRule
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:91)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:79)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:32)
> at
> org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:306)
> at
> org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:211)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:382)
> {code}
> The failure is introduced by
> [FLINK-26413|https://issues.apache.org/jira/browse/FLINK-26413], which
> introduces `Hive.get(hiveConf);` in method
> `HiveMetastoreClientFactory.create` to support Hive's "load data inpath`
> syntax.
> But the class `Hive` will import class 'org.apache.calcite.plan.RelOptRule',
> then when try to load the class `Hive`, it'll throw class not found exception
> since this class is not in class path.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] wangyang0918 commented on pull request #20516: [FLINK-27856][flink-kubernetes]solve the NPE error of no spec field in taskmanager pod template.
wangyang0918 commented on PR #20516: URL: https://github.com/apache/flink/pull/20516#issuecomment-1211516437 My bad. I will take closer look now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a diff in pull request #140: [FLINK-28894] Add Transformer for Interaction
yunfengzhou-hub commented on code in PR #140:
URL: https://github.com/apache/flink-ml/pull/140#discussion_r943061498
##
flink-ml-lib/src/test/java/org/apache/flink/ml/feature/InteractionTest.java:
##
@@ -0,0 +1,180 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature;
+
+import org.apache.flink.api.common.restartstrategy.RestartStrategies;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.ml.feature.interaction.Interaction;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.SparseVector;
+import org.apache.flink.ml.linalg.Vectors;
+import org.apache.flink.ml.util.TestUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import
org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.test.util.AbstractTestBase;
+import org.apache.flink.types.Row;
+
+import org.apache.commons.collections.IteratorUtils;
+import org.junit.Before;
+import org.junit.Test;
+
+import java.util.Arrays;
+import java.util.List;
+
+import static org.junit.Assert.assertArrayEquals;
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertNull;
+
+/** Tests {@link Interaction}. */
+public class InteractionTest extends AbstractTestBase {
+
+private StreamTableEnvironment tEnv;
+private Table inputDataTable;
+
+private static final List INPUT_DATA =
+Arrays.asList(
+Row.of(
+1,
+Vectors.dense(1, 2),
+Vectors.dense(3, 4),
+Vectors.sparse(17, new int[] {0, 3, 9}, new
double[] {1.0, 2.0, 7.0})),
+Row.of(
+2,
+Vectors.dense(2, 8),
+Vectors.dense(3, 4, 5),
+Vectors.sparse(17, new int[] {0, 2, 14}, new
double[] {5.0, 4.0, 1.0})),
+Row.of(3, null, null, null));
+
+private static final double[] EXPECTED_OUTPUT_DENSE_VEC_ARRAY_1 =
+new double[] {3.0, 4.0, 6.0, 8.0};
Review Comment:
Could you please add some documents to explain the order of the resulting
vector? For example, why should users get `3.0, 4.0, 6.0, 8.0`, instead of
`3.0, 6.0, 4.0, 8.0` here? If users want to get the latter result, what should
they do?
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/interaction/Interaction.java:
##
@@ -0,0 +1,178 @@
+/*
Review Comment:
Let's add documents to the description of this PR, explaining that nominal
features should be one-hot encoded before inputting to this algorithm. You can
refer to #139 's description.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] liming30 commented on pull request #20405: [FLINK-28010][state] Use deleteRange to optimize the clear method of RocksDBMapState.
liming30 commented on PR #20405: URL: https://github.com/apache/flink/pull/20405#issuecomment-1211512386 @fredia If we want to test the performance of RocksDB after `deleteRange`, the conclusion should have been given in the last part of this [blog](https://rocksdb.org/blog/2018/11/21/delete-range.html). Do you mean that the performance of `Point Lookups` and `Range Scans` should be verified again in Flink's benchmark? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20541: [hotfix][docs] Fix some formatting errors in Chinese documents.
flinkbot commented on PR #20541: URL: https://github.com/apache/flink/pull/20541#issuecomment-1211512020 ## CI report: * 32b13f534278fa93d96f55c96f707ad6dbce595e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943054862
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerParams.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.ml.param.IntParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.StringParam;
+
+/**
+ * Params for {@link KBinsDiscretizer}.
+ *
+ * @param The class type of this instance.
+ */
+public interface KBinsDiscretizerParams extends
KBinsDiscretizerModelParams {
Review Comment:
Setting `HasSeed` has two possible indications for users:
- Using same seed can have reproduciable outputs
- Using different seed can have different outputs.
However, our implementation does not provide reproduciable outputs due to
the complexity of reproduciable distributed sampling --- We always provide
different outputs in each run. As a result, it seems meaningless to provide
`HasSeed` here.
If we add `HasSeed` now, we may mislead users. However, we can add `HasSeed`
later if we can provide reproduciable distributed sampling.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (FLINK-28914) Could not find any factories that implement
Dongming WU created FLINK-28914: --- Summary: Could not find any factories that implement Key: FLINK-28914 URL: https://issues.apache.org/jira/browse/FLINK-28914 Project: Flink Issue Type: Bug Components: Table SQL / Gateway Affects Versions: 1.16.0 Reporter: Dongming WU Fix For: 1.16.0 2022-08-11 11:09:53,135 ERROR org.apache.flink.table.gateway.SqlGateway [] - Failed to start the endpoints. org.apache.flink.table.api.ValidationException: Could not find any factories that implement 'org.apache.flink.table.gateway.api.endpoint.SqlGatewayEndpointFactory' in the classpath. - I packaged Flink-Master and tried to start sql-gateway, but some problems arise. I found tow problem with Factory under resources of flink-sql-gateway module. META-INF.services should not be a folder name, ti should be ... /META-INF/services/... The `` org.apache.flink.table.gateway.rest.SqlGatewayRestEndpointFactory `` in the org.apache.flink.table.factories.Factory file should be `` org.apache.flink.table.gateway.rest.util.SqlGatewayRestEndpointFactory `` . -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] liuzhuang2017 commented on pull request #20541: [hotfix][docs] Fix some formatting errors in Chinese documents.
liuzhuang2017 commented on PR #20541: URL: https://github.com/apache/flink/pull/20541#issuecomment-1211509812 @MartijnVisser , Sorry to bother you again, can you help me review this pr? Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 opened a new pull request, #20541: [hotfix][docs] Fix some formatting errors in Chinese documents.
liuzhuang2017 opened a new pull request, #20541: URL: https://github.com/apache/flink/pull/20541 ## What is the purpose of the change - **In english document:** 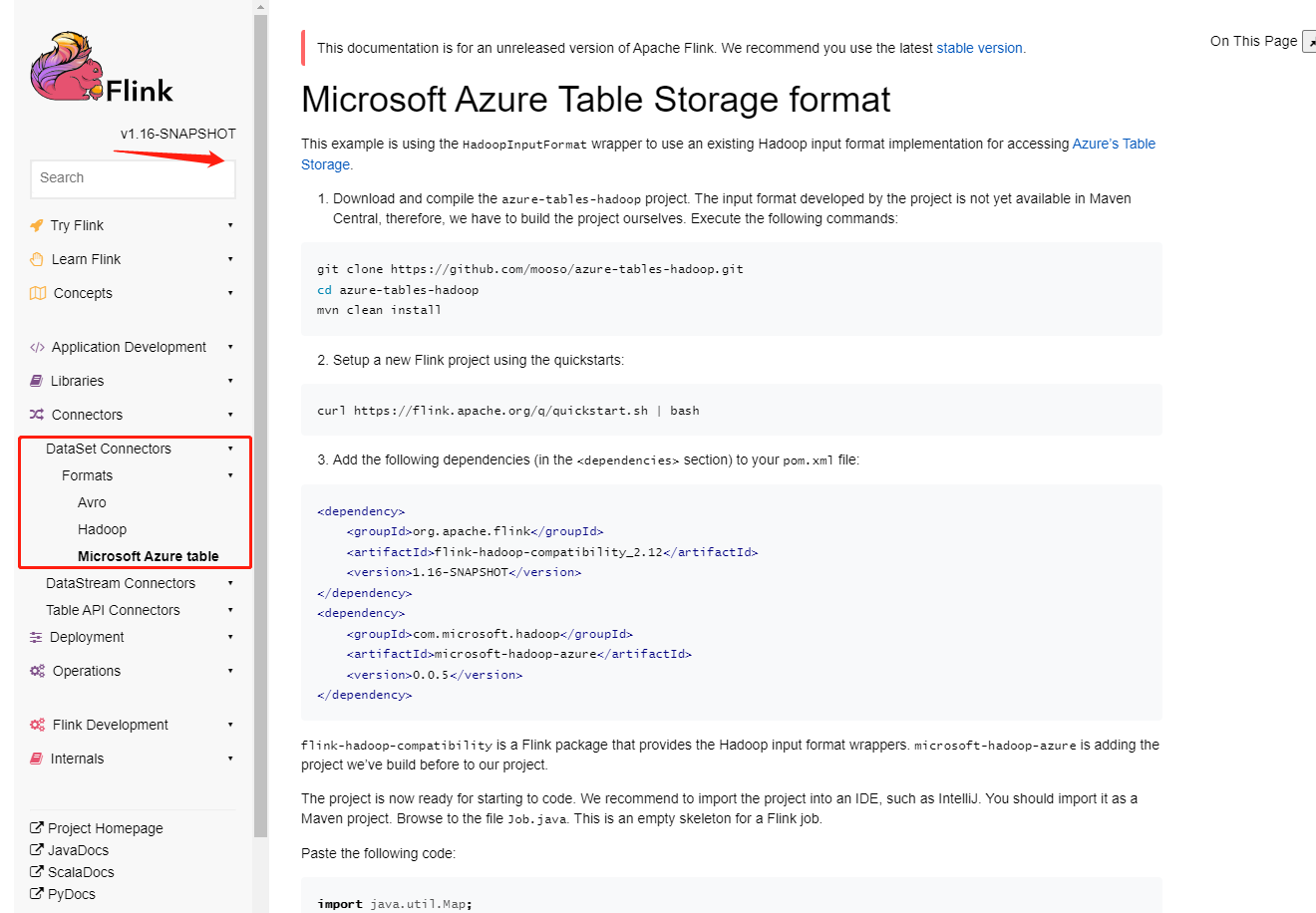 - **In chinese document:** 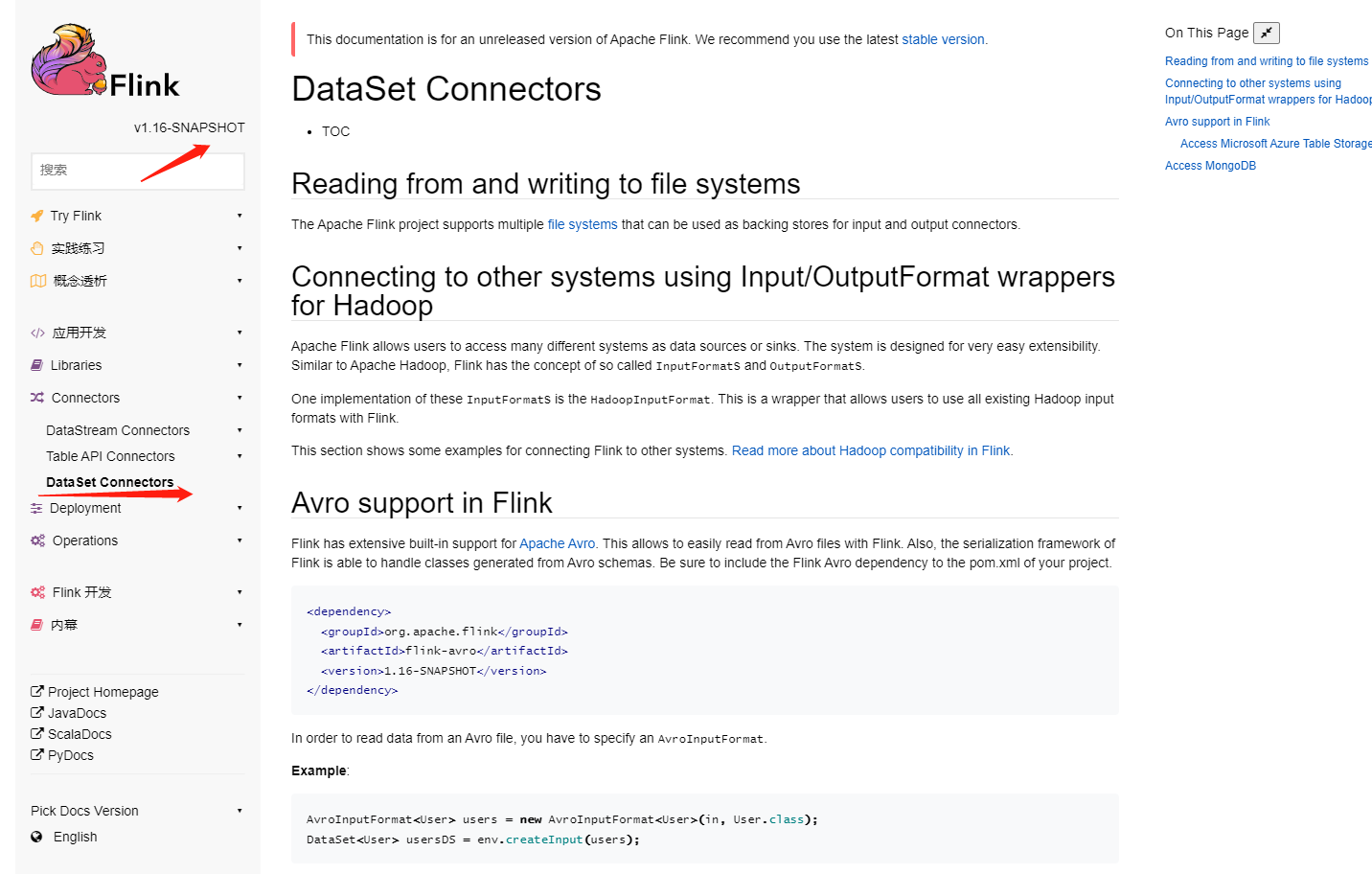 ## Brief change log - Fix some formatting errors in Chinese documents. ## Verifying this change - No need to test. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-22679) code optimization:Transformation.equals
[
https://issues.apache.org/jira/browse/FLINK-22679?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
huzeming updated FLINK-22679:
-
Priority: Minor (was: Not a Priority)
> code optimization:Transformation.equals
>
>
> Key: FLINK-22679
> URL: https://issues.apache.org/jira/browse/FLINK-22679
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Affects Versions: 1.13.0
>Reporter: huzeming
>Priority: Minor
> Labels: auto-deprioritized-minor, pull-request-available
>
> code optimization:Transformation.equals , line : 550
> {code:java}
> // old
> return outputType != null ? outputType.equals(that.outputType) :
> that.outputType == null;
> // new
> return Objects.equals(outputType, that.outputType);{code}
> I think after change it will be more readable
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-26771) Fix incomparable exception between boolean type and numeric type in Hive dialect
[
https://issues.apache.org/jira/browse/FLINK-26771?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
luoyuxia updated FLINK-26771:
-
Priority: Critical (was: Major)
> Fix incomparable exception between boolean type and numeric type in Hive
> dialect
>
>
> Key: FLINK-26771
> URL: https://issues.apache.org/jira/browse/FLINK-26771
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Hive
>Reporter: luoyuxia
>Assignee: luoyuxia
>Priority: Critical
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> Hive support compare boolean type with numeric type, for example such sql can
> be excuted in Hive:
> {code:java}
> // the data type for `status` is `int`
> select * from employee where status = true; {code}
> But in Flink, with Hive dialect, it'll throw "Incomparable types: BOOLEAN
> and INT NOT NULL" exception.
> For such case, it should be consistent with Hive while using Hive dialect in
> Flink.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-28883) Fix HiveTableSink failed to report metrics to hive metastore
[ https://issues.apache.org/jira/browse/FLINK-28883?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] luoyuxia updated FLINK-28883: - Fix Version/s: 1.16.0 > Fix HiveTableSink failed to report metrics to hive metastore > > > Key: FLINK-28883 > URL: https://issues.apache.org/jira/browse/FLINK-28883 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Affects Versions: 1.16.0 >Reporter: Liu >Priority: Critical > Fix For: 1.16.0 > > > Currently, HiveTableSink is failed to report metrics to metastores, like file > number, total line number and total size. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-28883) Fix HiveTableSink failed to report metrics to hive metastore
[ https://issues.apache.org/jira/browse/FLINK-28883?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] luoyuxia updated FLINK-28883: - Priority: Critical (was: Major) > Fix HiveTableSink failed to report metrics to hive metastore > > > Key: FLINK-28883 > URL: https://issues.apache.org/jira/browse/FLINK-28883 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Affects Versions: 1.16.0 >Reporter: Liu >Priority: Critical > > Currently, HiveTableSink is failed to report metrics to metastores, like file > number, total line number and total size. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
[
https://issues.apache.org/jira/browse/FLINK-28913?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578226#comment-17578226
]
luoyuxia commented on FLINK-28913:
--
The workaround way is to swap `opt/flink-table-planner` and
`lib/flink-table-planner-loader` as flink-table-planner contains calcite
dependency.
But to fix it, I think we can lazy init the `Hive`, only when we need to call
method `loadTable` / `loadPartition`.
I think it's fine for only in Hive dialect, do we need `Hive`, and when user
want to use Hive dialect, they need to swap `lib/flink-table-planner-loader`
and `opt/flink-table-planner` so that the calcite will exist in class path.
> Fix fail to open HiveCatalog when it's for hive3
>
>
> Key: FLINK-28913
> URL: https://issues.apache.org/jira/browse/FLINK-28913
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
>Reporter: luoyuxia
>Priority: Critical
> Fix For: 1.16.0
>
>
> When use HiveCatalog for hive3, it will throw such exception:
> {code:java}
> java.lang.NoClassDefFoundError: org/apache/calcite/plan/RelOptRule
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:91)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:79)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:32)
> at
> org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:306)
> at
> org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:211)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:382)
> {code}
> The failure is introduced by
> [FLINK-26413|https://issues.apache.org/jira/browse/FLINK-26413], which
> introduces `Hive.get(hiveConf);` in method
> `HiveMetastoreClientFactory.create` to support Hive's "load data inpath`
> syntax.
> But the class `Hive` will import class 'org.apache.calcite.plan.RelOptRule',
> then when try to load the class `Hive`, it'll throw class not found exception
> since this class is not in class path.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943059908
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerModel.java:
##
@@ -0,0 +1,172 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.ml.api.Model;
+import org.apache.flink.ml.common.broadcast.BroadcastUtils;
+import org.apache.flink.ml.common.datastream.TableUtils;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.commons.lang3.ArrayUtils;
+
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * A Model which transforms continuous features into discrete features using
the model data computed
+ * by {@link KBinsDiscretizer}.
+ *
+ * A feature value {v} should be mapped to a bin with edges as {left,
right} if {v} is in [left,
Review Comment:
Thanks for pointing this out. I have replaced `{}` with `` following [1]
[1]
https://github.com/apache/spark/blob/5dadf52beb822f67bf294dfda0e0380e46674656/mllib/src/main/scala/org/apache/spark/ml/feature/Interaction.scala#L42
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943059908
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerModel.java:
##
@@ -0,0 +1,172 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.ml.api.Model;
+import org.apache.flink.ml.common.broadcast.BroadcastUtils;
+import org.apache.flink.ml.common.datastream.TableUtils;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.commons.lang3.ArrayUtils;
+
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * A Model which transforms continuous features into discrete features using
the model data computed
+ * by {@link KBinsDiscretizer}.
+ *
+ * A feature value {v} should be mapped to a bin with edges as {left,
right} if {v} is in [left,
Review Comment:
Thanks for pointing this out. I have replaced `{}` with `` following [1]
[1]
https://github.com/apache/spark/blob/e17d8ecabcad6e84428752b977120ff355a4007a/mllib/src/main/scala/org/apac
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943059908
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerModel.java:
##
@@ -0,0 +1,172 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.ml.api.Model;
+import org.apache.flink.ml.common.broadcast.BroadcastUtils;
+import org.apache.flink.ml.common.datastream.TableUtils;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.commons.lang3.ArrayUtils;
+
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * A Model which transforms continuous features into discrete features using
the model data computed
+ * by {@link KBinsDiscretizer}.
+ *
+ * A feature value {v} should be mapped to a bin with edges as {left,
right} if {v} is in [left,
Review Comment:
Thanks for pointing this out. I have replaced `{}` with `\`\`` following [1]
[1]
https://github.com/apache/spark/blob/e17d8ecabcad6e84428752b977120ff355a4007a/mllib/src/main/scala/org/apac
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerModel.java:
##
@@ -0,0 +1,172 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.ml.api.Model;
+import org.apache.flink.ml.common.broadcast.BroadcastUtils;
+import org.apache.flink.ml.common.datastream.TableUtils;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.commons.lang3.ArrayUtils;
+
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * A Model which transforms continuous features into discrete features using
the model data computed
+ * by {@link KBinsDiscretizer}.
+ *
+ * A feature value {v} should be mapped to a bin with edges as {left,
right} if {v} is in [left,
[jira] [Updated] (FLINK-23944) PulsarSourceITCase.testTaskManagerFailure is instable
[
https://issues.apache.org/jira/browse/FLINK-23944?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Huang Xingbo updated FLINK-23944:
-
Priority: Critical (was: Major)
> PulsarSourceITCase.testTaskManagerFailure is instable
> -
>
> Key: FLINK-23944
> URL: https://issues.apache.org/jira/browse/FLINK-23944
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Pulsar
>Affects Versions: 1.14.0
>Reporter: Dian Fu
>Assignee: Yufan Sheng
>Priority: Critical
> Labels: pull-request-available, stale-assigned, test-stability
> Fix For: 1.16.0, 1.14.6
>
>
> [https://dev.azure.com/dianfu/Flink/_build/results?buildId=430=logs=f3dc9b18-b77a-55c1-591e-264c46fe44d1=2d3cd81e-1c37-5c31-0ee4-f5d5cdb9324d]
> It's from my personal azure pipeline, however, I'm pretty sure that I have
> not touched any code related to this.
> {code:java}
> Aug 24 10:44:13 [ERROR] testTaskManagerFailure{TestEnvironment,
> ExternalContext, ClusterControllable}[1] Time elapsed: 258.397 s <<< FAILURE!
> Aug 24 10:44:13 java.lang.AssertionError: Aug 24 10:44:13 Aug 24 10:44:13
> Expected: Records consumed by Flink should be identical to test data and
> preserve the order in split Aug 24 10:44:13 but: Mismatched record at
> position 7: Expected '0W6SzacX7MNL4xLL3BZ8C3ljho4iCydbvxIl' but was
> 'wVi5JaJpNvgkDEOBRC775qHgw0LyRW2HBxwLmfONeEmr' Aug 24 10:44:13 at
> org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) Aug 24 10:44:13
> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:8) Aug 24
> 10:44:13 at
> org.apache.flink.connectors.test.common.testsuites.SourceTestSuiteBase.testTaskManagerFailure(SourceTestSuiteBase.java:271)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943059550
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
+ *
+ *
+ * When the input values of one column are all the same, then they
should be mapped to the
+ * same bin (i.e., the zero-th bin). Thus the corresponding bin edges
are {Double.MIN_VALUE,
+ * Double.MAX_VALUE}.
+ * When the number of distinct values of one column is less than the
specified number of bins
+ * and the {@link KBinsDiscretizerParams#STRATEGY} is set as {@link
+ * KBinsDiscretizerParams#KMEANS}, we switch to {@link
KBinsDiscretizerParams#UNIFORM}.
+ * When the width of one output bin is zero, i.e., the left edge equals
to the right edge of
+ * the bin, we remove it.
+ *
+ */
+public class KBinsDiscretizer
+implements Estimator,
+KBinsDiscretizerParams {
+private static final Logger LOG =
LoggerFactory.getLogger(KBinsDiscretizer.class);
+private final Map, Object> paramMap = new HashMap<>();
+
+public KBinsDiscretizer() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public KBinsDiscretizerModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+
+String inputCol = getInputCol();
+String strategy = getStrategy();
+int numBins = getNumBins();
+
+DataStream inputData =
+tEnv.toDataStream(inputs[0])
+.map(
+(MapFunction)
+value -> ((Vector)
value.getField(inputCol)).toDense());
+
+DataStream preprocessedData;
+if (strategy.equals(UNIFORM)) {
+preprocessedData =
+inputData
+.transform(
+"reduceInEachPartition",
+inputData.getType(),
+new MinMaxReduceFunctionOperator())
+.transform(
+
[jira] [Commented] (FLINK-23944) PulsarSourceITCase.testTaskManagerFailure is instable
[
https://issues.apache.org/jira/browse/FLINK-23944?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578225#comment-17578225
]
Huang Xingbo commented on FLINK-23944:
--
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=39856=logs=298e20ef-7951-5965-0e79-ea664ddc435e=d4c90338-c843-57b0-3232-10ae74f00347
> PulsarSourceITCase.testTaskManagerFailure is instable
> -
>
> Key: FLINK-23944
> URL: https://issues.apache.org/jira/browse/FLINK-23944
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Pulsar
>Affects Versions: 1.14.0
>Reporter: Dian Fu
>Assignee: Yufan Sheng
>Priority: Major
> Labels: pull-request-available, stale-assigned, test-stability
> Fix For: 1.16.0, 1.14.6
>
>
> [https://dev.azure.com/dianfu/Flink/_build/results?buildId=430=logs=f3dc9b18-b77a-55c1-591e-264c46fe44d1=2d3cd81e-1c37-5c31-0ee4-f5d5cdb9324d]
> It's from my personal azure pipeline, however, I'm pretty sure that I have
> not touched any code related to this.
> {code:java}
> Aug 24 10:44:13 [ERROR] testTaskManagerFailure{TestEnvironment,
> ExternalContext, ClusterControllable}[1] Time elapsed: 258.397 s <<< FAILURE!
> Aug 24 10:44:13 java.lang.AssertionError: Aug 24 10:44:13 Aug 24 10:44:13
> Expected: Records consumed by Flink should be identical to test data and
> preserve the order in split Aug 24 10:44:13 but: Mismatched record at
> position 7: Expected '0W6SzacX7MNL4xLL3BZ8C3ljho4iCydbvxIl' but was
> 'wVi5JaJpNvgkDEOBRC775qHgw0LyRW2HBxwLmfONeEmr' Aug 24 10:44:13 at
> org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) Aug 24 10:44:13
> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:8) Aug 24
> 10:44:13 at
> org.apache.flink.connectors.test.common.testsuites.SourceTestSuiteBase.testTaskManagerFailure(SourceTestSuiteBase.java:271)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943058613
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
+ *
+ *
+ * When the input values of one column are all the same, then they
should be mapped to the
+ * same bin (i.e., the zero-th bin). Thus the corresponding bin edges
are {Double.MIN_VALUE,
+ * Double.MAX_VALUE}.
+ * When the number of distinct values of one column is less than the
specified number of bins
+ * and the {@link KBinsDiscretizerParams#STRATEGY} is set as {@link
+ * KBinsDiscretizerParams#KMEANS}, we switch to {@link
KBinsDiscretizerParams#UNIFORM}.
+ * When the width of one output bin is zero, i.e., the left edge equals
to the right edge of
+ * the bin, we remove it.
+ *
+ */
+public class KBinsDiscretizer
+implements Estimator,
+KBinsDiscretizerParams {
+private static final Logger LOG =
LoggerFactory.getLogger(KBinsDiscretizer.class);
+private final Map, Object> paramMap = new HashMap<>();
+
+public KBinsDiscretizer() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public KBinsDiscretizerModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+
+String inputCol = getInputCol();
+String strategy = getStrategy();
+int numBins = getNumBins();
+
+DataStream inputData =
+tEnv.toDataStream(inputs[0])
+.map(
+(MapFunction)
+value -> ((Vector)
value.getField(inputCol)).toDense());
+
+DataStream preprocessedData;
+if (strategy.equals(UNIFORM)) {
+preprocessedData =
+inputData
+.transform(
+"reduceInEachPartition",
+inputData.getType(),
+new MinMaxReduceFunctionOperator())
+.transform(
+
[GitHub] [flink] fredia commented on pull request #20405: [FLINK-28010][state] Use deleteRange to optimize the clear method of RocksDBMapState.
fredia commented on PR #20405: URL: https://github.com/apache/flink/pull/20405#issuecomment-1211500562 @liming30 This optimization may increase the number of tombstones. As the [blog](https://rocksdb.org/blog/2018/11/21/delete-range.html) says, `deleteRange` would bring some regression on `Point Lookups` and `Range Scans`, could you please share the performance of other operations after this optimization? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] Grypse commented on pull request #20516: [FLINK-27856][flink-kubernetes]solve the NPE error of no spec field in taskmanager pod template.
Grypse commented on PR #20516:
URL: https://github.com/apache/flink/pull/20516#issuecomment-1211500213
> Could we fix this issue in the `KubernetesUtils#loadPodFromTemplateFile`?
Set an empty spec if not specified.
This PR fixes the issue in KubernetesUtils#loadPodFromTemplateFile. When no
spec field is specified, set an empty one.
Code:
`public static FlinkPod loadPodFromTemplateFile(
FlinkKubeClient kubeClient, File podTemplateFile, String
mainContainerName) {
final KubernetesPod pod =
kubeClient.loadPodFromTemplateFile(podTemplateFile);
final List otherContainers = new ArrayList<>();
Container mainContainer = null;
if (null != pod.getInternalResource().getSpec()) {
for (Container container :
pod.getInternalResource().getSpec().getContainers()) {
if (mainContainerName.equals(container.getName())) {
mainContainer = container;
} else {
otherContainers.add(container);
}
}
pod.getInternalResource().getSpec().setContainers(otherContainers);
} else {
// Set empty spec for taskmanager pod template
pod.getInternalResource().setSpec(new PodSpecBuilder().build());
}
if (mainContainer == null) {
LOG.info(
"Could not find main container {} in pod template, using
empty one to initialize.",
mainContainerName);
mainContainer = new ContainerBuilder().build();
}
return new FlinkPod(pod.getInternalResource(), mainContainer);
}`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20540: [FLINK-28887][python] Fix the bug of custom metrics in Thread Mode
flinkbot commented on PR #20540: URL: https://github.com/apache/flink/pull/20540#issuecomment-1211497477 ## CI report: * 00fd582ca5f2a7d429428f72158c4b18e844d12f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943055570
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
+ *
+ *
+ * When the input values of one column are all the same, then they
should be mapped to the
+ * same bin (i.e., the zero-th bin). Thus the corresponding bin edges
are {Double.MIN_VALUE,
+ * Double.MAX_VALUE}.
+ * When the number of distinct values of one column is less than the
specified number of bins
+ * and the {@link KBinsDiscretizerParams#STRATEGY} is set as {@link
+ * KBinsDiscretizerParams#KMEANS}, we switch to {@link
KBinsDiscretizerParams#UNIFORM}.
+ * When the width of one output bin is zero, i.e., the left edge equals
to the right edge of
+ * the bin, we remove it.
+ *
+ */
+public class KBinsDiscretizer
+implements Estimator,
+KBinsDiscretizerParams {
+private static final Logger LOG =
LoggerFactory.getLogger(KBinsDiscretizer.class);
+private final Map, Object> paramMap = new HashMap<>();
+
+public KBinsDiscretizer() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public KBinsDiscretizerModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+
+String inputCol = getInputCol();
+String strategy = getStrategy();
+int numBins = getNumBins();
+
+DataStream inputData =
+tEnv.toDataStream(inputs[0])
+.map(
+(MapFunction)
+value -> ((Vector)
value.getField(inputCol)).toDense());
+
+DataStream preprocessedData;
+if (strategy.equals(UNIFORM)) {
+preprocessedData =
+inputData
+.transform(
+"reduceInEachPartition",
+inputData.getType(),
+new MinMaxReduceFunctionOperator())
+.transform(
+
[jira] [Updated] (FLINK-28887) Fix the bug of custom metrics in Thread Mode
[ https://issues.apache.org/jira/browse/FLINK-28887?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-28887: --- Labels: pull-request-available (was: ) > Fix the bug of custom metrics in Thread Mode > > > Key: FLINK-28887 > URL: https://issues.apache.org/jira/browse/FLINK-28887 > Project: Flink > Issue Type: Bug > Components: API / Python >Affects Versions: 1.16.0 >Reporter: Huang Xingbo >Assignee: Huang Xingbo >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] HuangXingBo opened a new pull request, #20540: [FLINK-28887][python] Fix the bug of custom metrics in Thread Mode
HuangXingBo opened a new pull request, #20540: URL: https://github.com/apache/flink/pull/20540 ## What is the purpose of the change *This pull request will fix the bug of custom metrics in Thread Mode* ## Brief change log - *Fix the bug of custom metrics in Thread Mode* ## Verifying this change This change added tests and can be verified as follows: - *`test_metrics` in `test_data_stream.py`* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943054862
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerParams.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.ml.param.IntParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.StringParam;
+
+/**
+ * Params for {@link KBinsDiscretizer}.
+ *
+ * @param The class type of this instance.
+ */
+public interface KBinsDiscretizerParams extends
KBinsDiscretizerModelParams {
Review Comment:
Setting `HasSeed` has two possible indications:
- Using same seed can have reproduciable outputs
- Using different seed can have different outputs.
However, our implementation does not provide reproduciable outputs due to
the complexity of reproduciable distributed sampling --- We always provide
different outputs in each run. As a result, it seems meaningless to provide
`HasSeed` here.
If we add `HasSeed` now, we may mislead users. However, we can add `HasSeed`
later if we can provide reproduciable distributed sampling.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943054862
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerParams.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.ml.param.IntParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.StringParam;
+
+/**
+ * Params for {@link KBinsDiscretizer}.
+ *
+ * @param The class type of this instance.
+ */
+public interface KBinsDiscretizerParams extends
KBinsDiscretizerModelParams {
Review Comment:
Setting `HasSeed` has two possible indications:
- Using same seed can have reproduciable outputs
- Using different seed can have different outputs.
However, our implementation does not provide reproduciable outputs due to
the complexity of reproduciable distributed sampling --- We always provide
different outputs in each run. As a result, it seems meaningless to provide
`HasSeed` here.
However, we can add `HasSeed` later if we can provide reproduciable
distributed sampling.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
[
https://issues.apache.org/jira/browse/FLINK-28913?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
luoyuxia updated FLINK-28913:
-
Priority: Critical (was: Major)
> Fix fail to open HiveCatalog when it's for hive3
>
>
> Key: FLINK-28913
> URL: https://issues.apache.org/jira/browse/FLINK-28913
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
>Reporter: luoyuxia
>Priority: Critical
> Fix For: 1.16.0
>
>
> When use HiveCatalog for hive3, it will throw such exception:
> {code:java}
> java.lang.NoClassDefFoundError: org/apache/calcite/plan/RelOptRule
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:91)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:79)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:32)
> at
> org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:306)
> at
> org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:211)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:382)
> {code}
> The failure is introduced by
> [FLINK-26413|https://issues.apache.org/jira/browse/FLINK-26413], which
> introduces `Hive.get(hiveConf);` in method
> `HiveMetastoreClientFactory.create` to support Hive's "load data inpath`
> syntax.
> But the class `Hive` will import class 'org.apache.calcite.plan.RelOptRule',
> then when try to load the class `Hive`, it'll throw class not found exception
> since this class is not in class path.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
[
https://issues.apache.org/jira/browse/FLINK-28913?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
luoyuxia updated FLINK-28913:
-
Fix Version/s: 1.16.0
> Fix fail to open HiveCatalog when it's for hive3
>
>
> Key: FLINK-28913
> URL: https://issues.apache.org/jira/browse/FLINK-28913
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
>Reporter: luoyuxia
>Priority: Major
> Fix For: 1.16.0
>
>
> When use HiveCatalog for hive3, it will throw such exception:
> {code:java}
> java.lang.NoClassDefFoundError: org/apache/calcite/plan/RelOptRule
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:91)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:79)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:32)
> at
> org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:306)
> at
> org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:211)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:382)
> {code}
> The failure is introduced by
> [FLINK-26413|https://issues.apache.org/jira/browse/FLINK-26413], which
> introduces `Hive.get(hiveConf);` in method
> `HiveMetastoreClientFactory.create` to support Hive's "load data inpath`
> syntax.
> But the class `Hive` will import class 'org.apache.calcite.plan.RelOptRule',
> then when try to load the class `Hive`, it'll throw class not found exception
> since this class is not in class path.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943053798
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerParams.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.ml.param.IntParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.StringParam;
+
+/**
+ * Params for {@link KBinsDiscretizer}.
+ *
+ * @param The class type of this instance.
+ */
+public interface KBinsDiscretizerParams extends
KBinsDiscretizerModelParams {
+String UNIFORM = "uniform";
+String QUANTILE = "quantile";
+String KMEANS = "kmeans";
+
+/**
+ * Supported options to define the widths of the bins are listed as
follows.
+ *
+ *
+ * uniform: all bins in each feature have identical widths.
+ * quantile: all bins in each feature have the same number of points.
+ * kmeans: values in each bin have the same nearest center of a 1D
kmeans cluster.
+ *
+ */
+Param STRATEGY =
+new StringParam(
+"strategy",
+"Strategy used to define the width of the bin.",
+QUANTILE,
+ParamValidators.inArray(UNIFORM, QUANTILE, KMEANS));
+
+Param NUM_BINS =
+new IntParam("numBins", "Number of bins to produce.", 5,
ParamValidators.gtEq(2));
+
+Param SUB_SAMPLES =
+new IntParam(
+"subSamples",
+"Maximum number of samples used to fit the model.",
+20,
+ParamValidators.gt(0));
Review Comment:
Setting the value as `None` is useless here. If users want to use all of the
samples, they can set the value as `Integer.MAX_VALUE`.
In our implementation, if `numSamples` is greater than number of input data,
all of the data are used in quantile/kmeans.
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizerParams.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.ml.param.IntParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.StringParam;
+
+/**
+ * Params for {@link KBinsDiscretizer}.
+ *
+ * @param The class type of this instance.
+ */
+public interface KBinsDiscretizerParams extends
KBinsDiscretizerModelParams {
+String UNIFORM = "uniform";
+String QUANTILE = "quantile";
+String KMEANS = "kmeans";
+
+/**
+ * Supported options to define the widths of the bins are listed as
follows.
+ *
+ *
+ * uniform: all bins in each feature have identical widths.
+ * quantile: all bins in each feature have the same number of points.
+ * kmeans: values in each bin have the same nearest center of a 1D
kmeans cluster.
+ *
+ */
+Param STRATEGY =
+new StringParam(
+"strategy",
+"Strategy used to define the width of the bin.",
+QUANTILE,
+ParamValidators.inArray(UNIFORM, QUANTILE, KMEANS));
+
+Param
[jira] [Updated] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
[
https://issues.apache.org/jira/browse/FLINK-28913?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
luoyuxia updated FLINK-28913:
-
Description:
When use HiveCatalog for hive3, it will throw such exception:
{code:java}
java.lang.NoClassDefFoundError: org/apache/calcite/plan/RelOptRule
at
org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:91)
at
org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:79)
at
org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:32)
at
org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:306)
at
org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:211)
at
org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:382)
{code}
The failure is introduced by
[FLINK-26413|https://issues.apache.org/jira/browse/FLINK-26413], which
introduces `Hive.get(hiveConf);` in method `HiveMetastoreClientFactory.create`
to support Hive's "load data inpath` syntax.
But the class `Hive` will import class 'org.apache.calcite.plan.RelOptRule',
then when try to load the class `Hive`, it'll throw class not found exception
since this class is not in class path.
> Fix fail to open HiveCatalog when it's for hive3
>
>
> Key: FLINK-28913
> URL: https://issues.apache.org/jira/browse/FLINK-28913
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
>Reporter: luoyuxia
>Priority: Major
>
> When use HiveCatalog for hive3, it will throw such exception:
> {code:java}
> java.lang.NoClassDefFoundError: org/apache/calcite/plan/RelOptRule
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:91)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:79)
> at
> org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:32)
> at
> org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:306)
> at
> org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:211)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:382)
> {code}
> The failure is introduced by
> [FLINK-26413|https://issues.apache.org/jira/browse/FLINK-26413], which
> introduces `Hive.get(hiveConf);` in method
> `HiveMetastoreClientFactory.create` to support Hive's "load data inpath`
> syntax.
> But the class `Hive` will import class 'org.apache.calcite.plan.RelOptRule',
> then when try to load the class `Hive`, it'll throw class not found exception
> since this class is not in class path.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943052952
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
+ *
+ *
+ * When the input values of one column are all the same, then they
should be mapped to the
+ * same bin (i.e., the zero-th bin). Thus the corresponding bin edges
are {Double.MIN_VALUE,
+ * Double.MAX_VALUE}.
+ * When the number of distinct values of one column is less than the
specified number of bins
+ * and the {@link KBinsDiscretizerParams#STRATEGY} is set as {@link
+ * KBinsDiscretizerParams#KMEANS}, we switch to {@link
KBinsDiscretizerParams#UNIFORM}.
+ * When the width of one output bin is zero, i.e., the left edge equals
to the right edge of
Review Comment:
Removing bins whose width is less than a non-zero value (e.g., `1e-8`) is
ambiguous to users --- Consider the following case:
Suppose we have four consecutive bins with width {6e-9, 6e-9, 6e-9, 6e-9}
and the minimum bin width is `1e-8`, we may get different results: {1.2e-8,
1.2e-8} and {2.4e-8}, both of which are reasonable.
Setting minimum bin width as zero does not incur the above problem.
Moreover, if the users found the width of a bin is too small, they may decrease
number of bins to achieve the same goal.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20539: [FLINK-28908][python] Coder for LIST type is incorrectly chosen
flinkbot commented on PR #20539: URL: https://github.com/apache/flink/pull/20539#issuecomment-1211492362 ## CI report: * ff8cfa1ac0d586f0e7575c772d53181e4bdf1e19 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943052952
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
+ *
+ *
+ * When the input values of one column are all the same, then they
should be mapped to the
+ * same bin (i.e., the zero-th bin). Thus the corresponding bin edges
are {Double.MIN_VALUE,
+ * Double.MAX_VALUE}.
+ * When the number of distinct values of one column is less than the
specified number of bins
+ * and the {@link KBinsDiscretizerParams#STRATEGY} is set as {@link
+ * KBinsDiscretizerParams#KMEANS}, we switch to {@link
KBinsDiscretizerParams#UNIFORM}.
+ * When the width of one output bin is zero, i.e., the left edge equals
to the right edge of
Review Comment:
Removing bins whose width is less than a non-zero value (e.g., `1e-8`) is
ambiguous to users --- Consider the following case:
Suppose we have four consecutive bins with width {6e-9, 6e-9, 6e-9, 6e-9}
and the minimum bin width is `1e-8`, we may get different results: {1.2e-8,
1.2e-8} and {2.4e-8}, both of which are reasonable.
Setting minimum bin width as zero does not incur the above problem. If the
users found the bin is too small, they may decrease number of bins.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
zhipeng93 commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943052952
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
+ *
+ *
+ * When the input values of one column are all the same, then they
should be mapped to the
+ * same bin (i.e., the zero-th bin). Thus the corresponding bin edges
are {Double.MIN_VALUE,
+ * Double.MAX_VALUE}.
+ * When the number of distinct values of one column is less than the
specified number of bins
+ * and the {@link KBinsDiscretizerParams#STRATEGY} is set as {@link
+ * KBinsDiscretizerParams#KMEANS}, we switch to {@link
KBinsDiscretizerParams#UNIFORM}.
+ * When the width of one output bin is zero, i.e., the left edge equals
to the right edge of
Review Comment:
Removing bins whose width is less than `1e-8` is ambiguous to users ---
Consider the following case:
Suppose we have four consecutive bins with width {6e-9, 6e-9, 6e-9, 6e-9}
and the minimum bin width is `1e-8`, we may get different results: {1.2e-8,
1.2e-8} and {2.4e-8}, both of which are reasonable.
Setting minimum bin width as zero does not incur the above problem. If the
users found the bin is too small, they may decrease number of bins.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-28908) Coder for LIST type is incorrectly chosen is PyFlink
[
https://issues.apache.org/jira/browse/FLINK-28908?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-28908:
---
Labels: pull-request-available (was: )
> Coder for LIST type is incorrectly chosen is PyFlink
>
>
> Key: FLINK-28908
> URL: https://issues.apache.org/jira/browse/FLINK-28908
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.14.5, 1.15.1
>Reporter: Juntao Hu
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.16.0, 1.15.2, 1.14.6
>
>
> Code to reproduce this bug, the result is `[None, None, None]`:
> {code:python}
> jvm = get_gateway().jvm
> env = StreamExecutionEnvironment.get_execution_environment()
> j_item = jvm.java.util.ArrayList()
> j_item.add(1)
> j_item.add(2)
> j_item.add(3)
> j_list = jvm.java.util.ArrayList()
> j_list.add(j_item)
> type_info = Types.LIST(Types.INT())
> ds = DataStream(env._j_stream_execution_environment.fromCollection(j_list,
> type_info.get_java_type_info()))
> ds.map(lambda e: print(e))
> env.execute() {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Created] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
luoyuxia created FLINK-28913: Summary: Fix fail to open HiveCatalog when it's for hive3 Key: FLINK-28913 URL: https://issues.apache.org/jira/browse/FLINK-28913 Project: Flink Issue Type: Bug Reporter: luoyuxia -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-28913) Fix fail to open HiveCatalog when it's for hive3
[ https://issues.apache.org/jira/browse/FLINK-28913?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] luoyuxia updated FLINK-28913: - Component/s: Connectors / Hive > Fix fail to open HiveCatalog when it's for hive3 > > > Key: FLINK-28913 > URL: https://issues.apache.org/jira/browse/FLINK-28913 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Reporter: luoyuxia >Priority: Major > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] Vancior opened a new pull request, #20539: [FLINK-28908][python] Coder for LIST type is incorrectly chosen
Vancior opened a new pull request, #20539: URL: https://github.com/apache/flink/pull/20539 ## What is the purpose of the change This PR fixes incorrect coder for deserializing `Types.LIST` data from Java. This needs to be cherry-picked to release-1.14 too. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a diff in pull request #139: [FLINK-28803] Add Transformer and Estimator for KBinsDiscretizer
yunfengzhou-hub commented on code in PR #139:
URL: https://github.com/apache/flink-ml/pull/139#discussion_r943030312
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/**
+ * An Estimator which implements discretization (also known as quantization or
binning), which
+ * transforms continuous features into discrete ones. The output values are in
[0, numBins).
+ *
+ * KBinsDiscretizer implements three different binning strategies, and it
can be set by {@link
+ * KBinsDiscretizerParams#STRATEGY}. If the strategy is set as {@link
KBinsDiscretizerParams#KMEANS}
+ * or {@link KBinsDiscretizerParams#QUANTILE}, users should further set {@link
+ * KBinsDiscretizerParams#SUB_SAMPLES} for better performance.
+ *
+ * There are several cornel cases for different inputs as listed below:
Review Comment:
nit: "corner"
##
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/kbinsdiscretizer/KBinsDiscretizer.java:
##
@@ -0,0 +1,340 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.kbinsdiscretizer;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.DataStreamUtils;
+import
org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler.MinMaxReduceFunctionOperator;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.Vector;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import
[GitHub] [flink] tweise commented on pull request #20530: [FLINK-28817] NullPointerException in HybridSource when restoring from checkpoint
tweise commented on PR #20530: URL: https://github.com/apache/flink/pull/20530#issuecomment-1211466504 @zhongqishang thanks for the PR, I'm going to take a look soon. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-28903) flink-table-store-hive-catalog could not shade hive-shims-0.23
[
https://issues.apache.org/jira/browse/FLINK-28903?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-28903:
---
Labels: pull-request-available (was: )
> flink-table-store-hive-catalog could not shade hive-shims-0.23
> --
>
> Key: FLINK-28903
> URL: https://issues.apache.org/jira/browse/FLINK-28903
> Project: Flink
> Issue Type: Bug
> Components: Table Store
>Affects Versions: table-store-0.3.0
>Reporter: Nicholas Jiang
>Priority: Major
> Labels: pull-request-available
> Fix For: table-store-0.3.0
>
>
> flink-table-store-hive-catalog could not shade hive-shims-0.23 because
> artifactSet doesn't include hive-shims-0.23 and the minimizeJar is set to
> true. The exception is as follows:
> {code:java}
> Caused by: java.lang.RuntimeException: Unable to instantiate
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.HiveMetaStoreClient
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1708)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.(RetryingMetaStoreClient.java:83)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:133)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:97)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.hive.HiveCatalog.createClient(HiveCatalog.java:380)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.hive.HiveCatalog.(HiveCatalog.java:80)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.hive.HiveCatalogFactory.create(HiveCatalogFactory.java:51)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.file.catalog.CatalogFactory.createCatalog(CatalogFactory.java:93)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.connector.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:62)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.connector.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:57)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.store.connector.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:31)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
> org.apache.flink.table.factories.FactoryUtil.createCatalog(FactoryUtil.java:428)
> ~[flink-table-api-java-uber-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.createCatalog(TableEnvironmentImpl.java:1356)
> ~[flink-table-api-java-uber-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:)
> ~[flink-table-api-java-uber-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.client.gateway.local.LocalExecutor.lambda$executeOperation$3(LocalExecutor.java:209)
> ~[flink-sql-client-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.client.gateway.context.ExecutionContext.wrapClassLoader(ExecutionContext.java:88)
> ~[flink-sql-client-1.15.1.jar:1.15.1]
> at
> org.apache.flink.table.client.gateway.local.LocalExecutor.executeOperation(LocalExecutor.java:209)
> ~[flink-sql-client-1.15.1.jar:1.15.1]
> ... 10 more
> Caused by: java.lang.reflect.InvocationTargetException
> at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
> ~[?:1.8.0_181]
> at
> sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
> ~[?:1.8.0_181]
> at
> sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
> ~[?:1.8.0_181]
> at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
> ~[?:1.8.0_181]
> at
> org.apache.flink.table.store.shaded.org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1706)
> ~[flink-table-store-dist-0.3-SNAPSHOT.jar:0.3-SNAPSHOT]
> at
>
[GitHub] [flink-table-store] SteNicholas opened a new pull request, #265: [FLINK-28903] flink-table-store-hive-catalog could not shade hive-shims-0.23
SteNicholas opened a new pull request, #265: URL: https://github.com/apache/flink-table-store/pull/265 flink-table-store-hive-catalog could not shade hive-shims-0.23 because `artifactSet` doesn't include `hive-shims-0.23` and the `minimizeJar` is set to true. **The brief change log** - The `artifactSet` of flink-table-store-hive-catalog module includes the `hive-shims-0.23`. - The `minimizeJar` label is removed for default value to false. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] luoyuxia commented on pull request #20536: [FLINK-28905][hive] Fix HiveCatalog can't get statistic for Hive timestamp partition column
luoyuxia commented on PR #20536: URL: https://github.com/apache/flink/pull/20536#issuecomment-1211461202 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] luoyuxia commented on a diff in pull request #20469: [FLINK-28773][hive] Fix Hive sink not write a success file after finish writing in batch mode
luoyuxia commented on code in PR #20469:
URL: https://github.com/apache/flink/pull/20469#discussion_r943034014
##
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemOutputFormat.java:
##
@@ -81,11 +91,29 @@ private FileSystemOutputFormat(
this.formatFactory = formatFactory;
this.computer = computer;
this.outputFileConfig = outputFileConfig;
+this.identifier = identifier;
+this.policyKind = policyKind;
+this.customClass = customClass;
+this.successFileName = successFileName;
}
@Override
public void finalizeGlobal(int parallelism) {
try {
+List policies =
+PartitionCommitPolicy.createPolicyChain(
+Thread.currentThread().getContextClassLoader(),
Review Comment:
Use `Thread.currentThread().getContextClassLoader()` to load user class may
casue class not found issue.
I think we can make `FileSystemOutputFormat` extend `RichOutputFormat` and
use `getRuntimeContext().getUserCodeClassLoader()`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-18631) Serializer for scala sealed trait hierarchies
[
https://issues.apache.org/jira/browse/FLINK-18631?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-18631:
---
Labels: auto-deprioritized-major performance pull-request-available
stale-minor (was: auto-deprioritized-major performance pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Minor but is unassigned and neither itself nor its Sub-Tasks have been updated
for 180 days. I have gone ahead and marked it "stale-minor". If this ticket is
still Minor, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Serializer for scala sealed trait hierarchies
> -
>
> Key: FLINK-18631
> URL: https://issues.apache.org/jira/browse/FLINK-18631
> Project: Flink
> Issue Type: Improvement
> Components: API / Type Serialization System
>Affects Versions: 1.11.0
>Reporter: Roman Grebennikov
>Priority: Minor
> Labels: auto-deprioritized-major, performance,
> pull-request-available, stale-minor
>
> Currently, when flink serialization system spots an ADT-style class hierarchy
> in the Scala code, it falls back to GenericType and kryo serialization, which
> may introduce performance issues. For example, for code:
> {{sealed trait ADT}}
> {{case class Foo(a: String) extends ADT}}
> {{case class Bar(b: Int) extends ADT}}
> {{env.fromCollection(List[ADT](Foo("a"),Bar(1))).collect()}}
>
> It will fall back to Kryo even if there is no problem with dealing with
> List[Foo] or List[Bar] separately. Using ADTs is a convenient way in Scala to
> model different types of messages, but Flink type system performance limits
> it to only a non performance-critical paths.
>
> It would be nice to have a sealed trait hierarchies support out of the box
> without kryo fallback.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] dannycranmer commented on pull request #20522: [kinesis][glue] Updating AWS SDK dependencies to latest versions
dannycranmer commented on PR #20522: URL: https://github.com/apache/flink/pull/20522#issuecomment-1211234037 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dannycranmer merged pull request #20521: [kinesis][glue] Updating AWS SDK dependencies to latest versions
dannycranmer merged PR #20521: URL: https://github.com/apache/flink/pull/20521 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-28900) RecreateOnResetOperatorCoordinatorTest compile failed in jdk11
[
https://issues.apache.org/jira/browse/FLINK-28900?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Dong Lin reassigned FLINK-28900:
Assignee: Yunfeng Zhou
> RecreateOnResetOperatorCoordinatorTest compile failed in jdk11
> --
>
> Key: FLINK-28900
> URL: https://issues.apache.org/jira/browse/FLINK-28900
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.16.0
>Reporter: Xingbo Huang
>Assignee: Yunfeng Zhou
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.16.0
>
>
> {code:java}
> 2022-08-10T00:19:25.3221073Z [ERROR] COMPILATION ERROR :
> 2022-08-10T00:19:25.3221634Z [INFO]
> -
> 2022-08-10T00:19:25.3222878Z [ERROR]
> /__w/1/s/flink-runtime/src/test/java/org/apache/flink/runtime/operators/coordination/RecreateOnResetOperatorCoordinatorTest.java:[241,58]
> method containsExactly in class
> org.assertj.core.api.AbstractIterableAssert
> cannot be applied to given types;
> 2022-08-10T00:19:25.3223786Z required: capture#1 of ? extends
> java.lang.Integer[]
> 2022-08-10T00:19:25.3224245Z found: int
> 2022-08-10T00:19:25.3224684Z reason: varargs mismatch; int cannot be
> converted to capture#1 of ? extends java.lang.Integer
> 2022-08-10T00:19:25.3225128Z [INFO] 1 error
> {code}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=39795=logs=946871de-358d-5815-3994-8175615bc253=e0240c62-4570-5d1c-51af-dd63d2093da1
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Closed] (FLINK-28900) RecreateOnResetOperatorCoordinatorTest compile failed in jdk11
[
https://issues.apache.org/jira/browse/FLINK-28900?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Dong Lin closed FLINK-28900.
Resolution: Fixed
> RecreateOnResetOperatorCoordinatorTest compile failed in jdk11
> --
>
> Key: FLINK-28900
> URL: https://issues.apache.org/jira/browse/FLINK-28900
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.16.0
>Reporter: Xingbo Huang
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.16.0
>
>
> {code:java}
> 2022-08-10T00:19:25.3221073Z [ERROR] COMPILATION ERROR :
> 2022-08-10T00:19:25.3221634Z [INFO]
> -
> 2022-08-10T00:19:25.3222878Z [ERROR]
> /__w/1/s/flink-runtime/src/test/java/org/apache/flink/runtime/operators/coordination/RecreateOnResetOperatorCoordinatorTest.java:[241,58]
> method containsExactly in class
> org.assertj.core.api.AbstractIterableAssert
> cannot be applied to given types;
> 2022-08-10T00:19:25.3223786Z required: capture#1 of ? extends
> java.lang.Integer[]
> 2022-08-10T00:19:25.3224245Z found: int
> 2022-08-10T00:19:25.3224684Z reason: varargs mismatch; int cannot be
> converted to capture#1 of ? extends java.lang.Integer
> 2022-08-10T00:19:25.3225128Z [INFO] 1 error
> {code}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=39795=logs=946871de-358d-5815-3994-8175615bc253=e0240c62-4570-5d1c-51af-dd63d2093da1
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] reswqa commented on pull request #20529: [FLINK-28884] Downstream task may never be notified of data available in hybrid shuffle when number of credits is zero.
reswqa commented on PR #20529: URL: https://github.com/apache/flink/pull/20529#issuecomment-1210961697 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lindong28 merged pull request #20532: [FLINK-28900] Fix RecreateOnResetOperatorCoordinatorTest compilation failure
lindong28 merged PR #20532: URL: https://github.com/apache/flink/pull/20532 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lindong28 commented on pull request #20532: [FLINK-28900] Fix RecreateOnResetOperatorCoordinatorTest compilation failure
lindong28 commented on PR #20532: URL: https://github.com/apache/flink/pull/20532#issuecomment-1210958640 Thanks for the PR. LGTM. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-28898) ChangelogRecoverySwitchStateBackendITCase.testSwitchFromEnablingToDisablingWithRescalingOut failed
[
https://issues.apache.org/jira/browse/FLINK-28898?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Roman Khachatryan closed FLINK-28898.
-
Resolution: Fixed
Merged as 3268ec6a7ce0e060eb401917f7d169969334d07d.
> ChangelogRecoverySwitchStateBackendITCase.testSwitchFromEnablingToDisablingWithRescalingOut
> failed
> --
>
> Key: FLINK-28898
> URL: https://issues.apache.org/jira/browse/FLINK-28898
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing, Runtime / State Backends
>Affects Versions: 1.16.0
>Reporter: Xingbo Huang
>Assignee: Hangxiang Yu
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.16.0
>
>
> {code:java}
> 2022-08-10T02:48:19.5711924Z Aug 10 02:48:19 [ERROR]
> ChangelogRecoverySwitchStateBackendITCase.testSwitchFromEnablingToDisablingWithRescalingOut
> Time elapsed: 6.064 s <<< ERROR!
> 2022-08-10T02:48:19.5712815Z Aug 10 02:48:19
> org.apache.flink.runtime.JobException: Recovery is suppressed by
> FixedDelayRestartBackoffTimeStrategy(maxNumberRestartAttempts=0,
> backoffTimeMS=0)
> 2022-08-10T02:48:19.5714530Z Aug 10 02:48:19 at
> org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:139)
> 2022-08-10T02:48:19.5716211Z Aug 10 02:48:19 at
> org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:83)
> 2022-08-10T02:48:19.5717627Z Aug 10 02:48:19 at
> org.apache.flink.runtime.scheduler.DefaultScheduler.recordTaskFailure(DefaultScheduler.java:256)
> 2022-08-10T02:48:19.5718885Z Aug 10 02:48:19 at
> org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:247)
> 2022-08-10T02:48:19.5720430Z Aug 10 02:48:19 at
> org.apache.flink.runtime.scheduler.DefaultScheduler.onTaskFailed(DefaultScheduler.java:240)
> 2022-08-10T02:48:19.5721733Z Aug 10 02:48:19 at
> org.apache.flink.runtime.scheduler.SchedulerBase.onTaskExecutionStateUpdate(SchedulerBase.java:738)
> 2022-08-10T02:48:19.5722680Z Aug 10 02:48:19 at
> org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:715)
> 2022-08-10T02:48:19.5723612Z Aug 10 02:48:19 at
> org.apache.flink.runtime.scheduler.SchedulerNG.updateTaskExecutionState(SchedulerNG.java:78)
> 2022-08-10T02:48:19.5724389Z Aug 10 02:48:19 at
> org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:477)
> 2022-08-10T02:48:19.5725046Z Aug 10 02:48:19 at
> sun.reflect.GeneratedMethodAccessor20.invoke(Unknown Source)
> 2022-08-10T02:48:19.5725708Z Aug 10 02:48:19 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> 2022-08-10T02:48:19.5726374Z Aug 10 02:48:19 at
> java.lang.reflect.Method.invoke(Method.java:498)
> 2022-08-10T02:48:19.5727065Z Aug 10 02:48:19 at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRpcInvocation$1(AkkaRpcActor.java:309)
> 2022-08-10T02:48:19.5727932Z Aug 10 02:48:19 at
> org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:83)
> 2022-08-10T02:48:19.5729087Z Aug 10 02:48:19 at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:307)
> 2022-08-10T02:48:19.5730134Z Aug 10 02:48:19 at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:222)
> 2022-08-10T02:48:19.5731536Z Aug 10 02:48:19 at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:84)
> 2022-08-10T02:48:19.5732549Z Aug 10 02:48:19 at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:168)
> 2022-08-10T02:48:19.5735018Z Aug 10 02:48:19 at
> akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
> 2022-08-10T02:48:19.5735821Z Aug 10 02:48:19 at
> akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
> 2022-08-10T02:48:19.5736465Z Aug 10 02:48:19 at
> scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
> 2022-08-10T02:48:19.5737234Z Aug 10 02:48:19 at
> scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
> 2022-08-10T02:48:19.5737895Z Aug 10 02:48:19 at
> akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
> 2022-08-10T02:48:19.5738574Z Aug 10 02:48:19 at
> scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
> 2022-08-10T02:48:19.5739276Z Aug 10 02:48:19 at
> scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> 2022-08-10T02:48:19.5740315Z Aug 10 02:48:19 at
> scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
>
[GitHub] [flink] rkhachatryan merged pull request #20537: [FLINK-28898][state/changelog] Fix unstable ChangelogRecoverySwitchStateBackendITCase#testSwitchFromEnablingToDisablingWithRescalingOut
rkhachatryan merged PR #20537: URL: https://github.com/apache/flink/pull/20537 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-28694) Set pipeline.name to resource name by default for application deployments
[ https://issues.apache.org/jira/browse/FLINK-28694?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gyula Fora closed FLINK-28694. -- Resolution: Fixed Merged to main 0a1a68c9a88ad3055dcf6630e23ce89df7d23a97 > Set pipeline.name to resource name by default for application deployments > - > > Key: FLINK-28694 > URL: https://issues.apache.org/jira/browse/FLINK-28694 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Nicholas Jiang >Priority: Minor > Labels: Starter, pull-request-available > Fix For: kubernetes-operator-1.2.0 > > > I think it would be nice to set pipeline.name by default to the resource name > for application deployments. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] gyfora merged pull request #345: [FLINK-28694] Set pipeline.name to resource name by default for application deployments
gyfora merged PR #345: URL: https://github.com/apache/flink-kubernetes-operator/pull/345 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-elasticsearch] zentol commented on pull request #28: [FLINK-28911] Ensure the SerializationSchema has been opened.
zentol commented on PR #28: URL: https://github.com/apache/flink-connector-elasticsearch/pull/28#issuecomment-1210806450 Have a look at https://github.com/apache/flink/commit/fb95798b1c301152b912c4b8ec4a737ea16d8641 how I solved it for the version in Flink. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-28027) Initialise Async Sink maximum number of in flight messages to low number for rate limiting strategy
[
https://issues.apache.org/jira/browse/FLINK-28027?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17578007#comment-17578007
]
Danny Cranmer commented on FLINK-28027:
---
This is fixed by FLINK-28487 in 1.16.
> Initialise Async Sink maximum number of in flight messages to low number for
> rate limiting strategy
> ---
>
> Key: FLINK-28027
> URL: https://issues.apache.org/jira/browse/FLINK-28027
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Common, Connectors / Kinesis
>Affects Versions: 1.15.0, 1.15.1
>Reporter: Zichen Liu
>Assignee: Hong Liang Teoh
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.15.2
>
>
> *Background*
> In the AsyncSinkWriter, we implement a rate limiting strategy.
> The initial value for the maximum number of in flight messages is set
> extremely high ({{{}maxBatchSize * maxInFlightRequests{}}}).
> However, in accordance with the AIMD strategy, the TCP implementation for
> congestion control has found a small value to start with [is
> better]([https://en.wikipedia.org/wiki/TCP_congestion_control#Slow_start]).
> *Suggestion*
> A better default might be:
> * maxBatchSize
> * maxBatchSize / parallelism
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-28027) Initialise Async Sink maximum number of in flight messages to low number for rate limiting strategy
[
https://issues.apache.org/jira/browse/FLINK-28027?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Cranmer updated FLINK-28027:
--
Affects Version/s: 1.15.1
> Initialise Async Sink maximum number of in flight messages to low number for
> rate limiting strategy
> ---
>
> Key: FLINK-28027
> URL: https://issues.apache.org/jira/browse/FLINK-28027
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Common, Connectors / Kinesis
>Affects Versions: 1.15.0, 1.15.1
>Reporter: Zichen Liu
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.15.2
>
>
> *Background*
> In the AsyncSinkWriter, we implement a rate limiting strategy.
> The initial value for the maximum number of in flight messages is set
> extremely high ({{{}maxBatchSize * maxInFlightRequests{}}}).
> However, in accordance with the AIMD strategy, the TCP implementation for
> congestion control has found a small value to start with [is
> better]([https://en.wikipedia.org/wiki/TCP_congestion_control#Slow_start]).
> *Suggestion*
> A better default might be:
> * maxBatchSize
> * maxBatchSize / parallelism
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Assigned] (FLINK-28027) Initialise Async Sink maximum number of in flight messages to low number for rate limiting strategy
[
https://issues.apache.org/jira/browse/FLINK-28027?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Cranmer reassigned FLINK-28027:
-
Assignee: Hong Liang Teoh
> Initialise Async Sink maximum number of in flight messages to low number for
> rate limiting strategy
> ---
>
> Key: FLINK-28027
> URL: https://issues.apache.org/jira/browse/FLINK-28027
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Common, Connectors / Kinesis
>Affects Versions: 1.15.0, 1.15.1
>Reporter: Zichen Liu
>Assignee: Hong Liang Teoh
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.15.2
>
>
> *Background*
> In the AsyncSinkWriter, we implement a rate limiting strategy.
> The initial value for the maximum number of in flight messages is set
> extremely high ({{{}maxBatchSize * maxInFlightRequests{}}}).
> However, in accordance with the AIMD strategy, the TCP implementation for
> congestion control has found a small value to start with [is
> better]([https://en.wikipedia.org/wiki/TCP_congestion_control#Slow_start]).
> *Suggestion*
> A better default might be:
> * maxBatchSize
> * maxBatchSize / parallelism
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-28027) Initialise Async Sink maximum number of in flight messages to low number for rate limiting strategy
[
https://issues.apache.org/jira/browse/FLINK-28027?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Cranmer updated FLINK-28027:
--
Fix Version/s: 1.15.2
(was: 1.16.0)
> Initialise Async Sink maximum number of in flight messages to low number for
> rate limiting strategy
> ---
>
> Key: FLINK-28027
> URL: https://issues.apache.org/jira/browse/FLINK-28027
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Common, Connectors / Kinesis
>Affects Versions: 1.15.0
>Reporter: Zichen Liu
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.15.2
>
>
> *Background*
> In the AsyncSinkWriter, we implement a rate limiting strategy.
> The initial value for the maximum number of in flight messages is set
> extremely high ({{{}maxBatchSize * maxInFlightRequests{}}}).
> However, in accordance with the AIMD strategy, the TCP implementation for
> congestion control has found a small value to start with [is
> better]([https://en.wikipedia.org/wiki/TCP_congestion_control#Slow_start]).
> *Suggestion*
> A better default might be:
> * maxBatchSize
> * maxBatchSize / parallelism
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-28609) Flink-Pulsar connector fails on larger schemas
[ https://issues.apache.org/jira/browse/FLINK-28609?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17577980#comment-17577980 ] Aleksandra Sarna commented on FLINK-28609: -- Hi [~martijnvisser] , Could you please confirm that the fix for this issue is still in scope of 1.16 release? Regards, Aleksandra > Flink-Pulsar connector fails on larger schemas > -- > > Key: FLINK-28609 > URL: https://issues.apache.org/jira/browse/FLINK-28609 > Project: Flink > Issue Type: Bug > Components: Connectors / Pulsar >Affects Versions: 1.14.3, 1.14.4, 1.14.5, 1.15.1 >Reporter: Jacek Wislicki >Priority: Major > Labels: pull-request-available > Attachments: > [FLINK-28609][Connector_Pulsar]_PulsarSchema_didn't_get_properly_serialized_.patch, > exception.txt > > > When a model results in a larger schema (this seems to be related to its byte > array representation), the number of expected bytes to read is different than > the number of actually read bytes: [^exception.txt]. The "read" is such a > case is always 1018 while the expected "byteLen" gives a greater value. For > smaller schemata, the numbers are equal (less than 1018) and no issue occurs. > The problem reproduction is on > [GitHub|https://github.com/JacekWislicki/vp-test2]. There are 2 simple jobs > (SimpleJob1 and SimpleJob2) using basic models for the Pulsar source > definition (PulsarMessage1 and PulsarMessage2, respectively). Each of the > corresponding schemata is properly serialised and deserialised, unless an > effective byte array length becomes excessive (marked with "the problem > begins" in model classes). The fail condition can be achieved by a number of > fields (PulsarMessage1) or just longer field names (PulsarMessage2). The > problem occurs on either Avro or a JSON schema set in the Pulsar source > definition. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] sthm closed pull request #20509: [FLINK-28027][connectors/async-sink] Implement slow start strategy fo…
sthm closed pull request #20509: [FLINK-28027][connectors/async-sink] Implement slow start strategy fo… URL: https://github.com/apache/flink/pull/20509 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] sthm commented on pull request #20509: [FLINK-28027][connectors/async-sink] Implement slow start strategy fo…
sthm commented on PR #20509: URL: https://github.com/apache/flink/pull/20509#issuecomment-1210619982 This is superseded by FLINK-28487. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on a diff in pull request #20469: [FLINK-28773][hive] Fix Hive sink not write a success file after finish writing in batch mode
wuchong commented on code in PR #20469:
URL: https://github.com/apache/flink/pull/20469#discussion_r942380136
##
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/HiveOptions.java:
##
@@ -95,6 +95,20 @@ public class HiveOptions {
+ " When the value is over estimated,
Flink will tend to pack Hive's data into less splits, which will be helpful
when Hive's table contains many small files."
+ " And vice versa. It only works for the
Hive table stored as ORC format.");
+public static final ConfigOption SINK_PARTITION_COMMIT_POLICY_KIND
=
+key("sink.partition-commit.policy.kind")
+.stringType()
+.defaultValue("metastore,success-file")
+.withDescription(
+"Policy to commit a partition is to notify the
downstream"
++ " application that the partition has
finished writing, the partition"
++ " is ready to be read."
++ " metastore: add partition to metastore.
"
++ " success-file: add '_success' file to
directory."
Review Comment:
```
success-file: add a success file to the partition directory. The success
file name can be configured by the 'sink.partition-commit.success-file.name'
option.
```
##
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/HiveOptions.java:
##
@@ -95,6 +95,20 @@ public class HiveOptions {
+ " When the value is over estimated,
Flink will tend to pack Hive's data into less splits, which will be helpful
when Hive's table contains many small files."
+ " And vice versa. It only works for the
Hive table stored as ORC format.");
+public static final ConfigOption SINK_PARTITION_COMMIT_POLICY_KIND
=
Review Comment:
Add a comment to explain why we need to re-define a same configuration here,
e.g.,
```java
/**
* Hive users usually commit partition for metastore and a _SUCCESS
file. That's why we
* create a same option with {@link
* FileSystemConnectorOptions#SINK_PARTITION_COMMIT_POLICY_KIND} with
different default value.
*/
```
##
flink-connectors/flink-connector-files/src/test/java/org/apache/flink/connector/file/table/FileSystemCommitterTest.java:
##
@@ -173,7 +206,14 @@ void testEmptyPartition() throws Exception {
assertThat(emptyPartitionFile).exists();
assertThat(emptyPartitionFile).isDirectory();
-assertThat(emptyPartitionFile).isEmptyDirectory();
+files =
+FileUtils.listFilesInDirectory(
+Paths.get(emptyPartitionFile.getPath()),
+(path) ->
+!path.toFile().isHidden()
+&&
!path.toFile().getName().startsWith("_"))
Review Comment:
I think this can be simplified into
```java
assertThat(emptyPartitionFile)
.isDirectoryNotContaining(file ->
!file.getName().equals("_SUCCESS"));
```
There shouldn't be hidden files in the directory, right?
##
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/HiveTableSink.java:
##
@@ -337,6 +340,12 @@ private DataStreamSink createBatchSink(
builder.setTempPath(
new
org.apache.flink.core.fs.Path(toStagingDir(stagingParentDir, jobConf)));
builder.setOutputFileConfig(fileNaming);
+builder.setIdentifier(identifier);
+
builder.setPolicyKind(conf.get(HiveOptions.SINK_PARTITION_COMMIT_POLICY_KIND));
+builder.setCustomClass(
+
conf.get(FileSystemConnectorOptions.SINK_PARTITION_COMMIT_POLICY_CLASS));
+builder.setSuccessFileName(
+
conf.get(FileSystemConnectorOptions.SINK_PARTITION_COMMIT_SUCCESS_FILE_NAME));
Review Comment:
Please only options of `HiveOptions` in the Hive connector. Otherwise, it's
error-prone to use `FileSystemConnectorOptions`, e.g., unexpected default
value. You can reuse the options by referring the definition from
`FileSystemConnectorOptions`, for example, in `HiveOptions.java`:
```java
public static final ConfigOption SINK_PARTITION_COMMIT_POLICY_CLASS =
FileSystemConnectorOptions.SINK_PARTITION_COMMIT_POLICY_CLASS;
public static final ConfigOption
SINK_PARTITION_COMMIT_SUCCESS_FILE_NAME =
FileSystemConnectorOptions.SINK_PARTITION_COMMIT_SUCCESS_FILE_NAME;
```
##
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemCommitter.java:
##
[GitHub] [flink] ganlute closed pull request #20538: [FLINK-28910][connector/hbase]CDC From Mysql To Hbase Bugs
ganlute closed pull request #20538: [FLINK-28910][connector/hbase]CDC From Mysql To Hbase Bugs URL: https://github.com/apache/flink/pull/20538 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-28912) Add Part of "Who Use Flink" In ReadMe file and https://flink.apache.org/
Zhou Yao created FLINK-28912: Summary: Add Part of "Who Use Flink" In ReadMe file and https://flink.apache.org/ Key: FLINK-28912 URL: https://issues.apache.org/jira/browse/FLINK-28912 Project: Flink Issue Type: Improvement Components: Documentation Reporter: Zhou Yao Attachments: image-2022-08-10-20-15-10-418.png May be ,we can learn from website of [Apache Kylin|https://kylin.apache.org/], add part of "Who Use Flink" in Readme or website. This can make Flink more frendly !image-2022-08-10-20-15-10-418.png|width=147,height=99! -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-28694) Set pipeline.name to resource name by default for application deployments
[ https://issues.apache.org/jira/browse/FLINK-28694?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yang Wang reassigned FLINK-28694: - Assignee: Nicholas Jiang > Set pipeline.name to resource name by default for application deployments > - > > Key: FLINK-28694 > URL: https://issues.apache.org/jira/browse/FLINK-28694 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Nicholas Jiang >Priority: Minor > Labels: Starter, pull-request-available > Fix For: kubernetes-operator-1.2.0 > > > I think it would be nice to set pipeline.name by default to the resource name > for application deployments. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-28694) Set pipeline.name to resource name by default for application deployments
[ https://issues.apache.org/jira/browse/FLINK-28694?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-28694: --- Labels: Starter pull-request-available (was: Starter) > Set pipeline.name to resource name by default for application deployments > - > > Key: FLINK-28694 > URL: https://issues.apache.org/jira/browse/FLINK-28694 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Priority: Minor > Labels: Starter, pull-request-available > Fix For: kubernetes-operator-1.2.0 > > > I think it would be nice to set pipeline.name by default to the resource name > for application deployments. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] wuchong commented on a diff in pull request #20469: [FLINK-28773][hive] Fix Hive sink not write a success file after finish writing in batch mode
wuchong commented on code in PR #20469: URL: https://github.com/apache/flink/pull/20469#discussion_r942374166 ## flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/HiveTableSink.java: ## @@ -337,6 +340,12 @@ private DataStreamSink createBatchSink( builder.setTempPath( new org.apache.flink.core.fs.Path(toStagingDir(stagingParentDir, jobConf))); builder.setOutputFileConfig(fileNaming); +builder.setIdentifier(identifier); + builder.setPolicyKind(conf.get(HiveOptions.SINK_PARTITION_COMMIT_POLICY_KIND)); Review Comment: `FileSystemOutputFormat` is also used for DataStream users. We should decouple it with table options. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] SteNicholas opened a new pull request, #345: [FLINK-28694] Set pipeline.name to resource name by default for application deployments
SteNicholas opened a new pull request, #345: URL: https://github.com/apache/flink-kubernetes-operator/pull/345 ## What is the purpose of the change `pipeline.name` should be set to the resource name by default for application deployments. ## Brief change log - Sets the `pipeline.name` with the resource name in `applyFlinkConfiguration`. ## Verifying this change - Updates the `FlinkConfigBuilder#testApplyFlinkConfiguration` to verify whether the default value of `pipeline.name` is the resource name. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changes to the `CustomResourceDescriptors`: (yes / **no**) - Core observer or reconciler logic that is regularly executed: (yes / **no**) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (**not applicable** / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] rkhachatryan commented on a diff in pull request #20523: [WIP][FLINK-26372][runtime][state] Allow to configure Changelog Storage per program
rkhachatryan commented on code in PR #20523:
URL: https://github.com/apache/flink/pull/20523#discussion_r942373536
##
flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobGraph.java:
##
@@ -634,14 +634,19 @@ public void writeUserArtifactEntriesToConfiguration() {
}
}
-public void setChangelogStateBackendEnabled(TernaryBoolean
changelogStateBackendEnabled) {
+public void setChangelogStateBackendEnabled(
+TernaryBoolean changelogStateBackendEnabled, Configuration
changelogConfiguration) {
if (changelogStateBackendEnabled == null
||
TernaryBoolean.UNDEFINED.equals(changelogStateBackendEnabled)) {
return;
}
this.jobConfiguration.setBoolean(
StateChangelogOptionsInternal.ENABLE_CHANGE_LOG_FOR_APPLICATION,
changelogStateBackendEnabled.getAsBoolean());
+if (changelogStateBackendEnabled.getOrDefault(false)) {
+StateChangelogOptionsInternal.putConfiguration(
+jobConfiguration, changelogConfiguration);
+}
Review Comment:
Here, changelog configuration is passed from JM to TM inside the
`jobGraph.jobConfiguration`. It is then merged on TM with its "local" TM
configuration.
It's not strongly typed (something like `ChangelogConfig`) because different
implementations might have different parameters. And it's not a serialized
factory because passing a string map seems safer and easier.
It's added to `jobConfiguration` as serialized value under a single key
(rather than merged) because semantically they are different.
`jobConfiguration` is some internal Flink config, while changelog configuration
contains some user-facing keys; so they might clash.
@zentol WDYT about this approach?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] rkhachatryan commented on a diff in pull request #20523: [WIP][FLINK-26372][runtime][state] Allow to configure Changelog Storage per program
rkhachatryan commented on code in PR #20523:
URL: https://github.com/apache/flink/pull/20523#discussion_r942373004
##
flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobGraph.java:
##
@@ -634,14 +634,19 @@ public void writeUserArtifactEntriesToConfiguration() {
}
}
-public void setChangelogStateBackendEnabled(TernaryBoolean
changelogStateBackendEnabled) {
+public void setChangelogStateBackendEnabled(
+TernaryBoolean changelogStateBackendEnabled, Configuration
changelogConfiguration) {
if (changelogStateBackendEnabled == null
||
TernaryBoolean.UNDEFINED.equals(changelogStateBackendEnabled)) {
return;
}
this.jobConfiguration.setBoolean(
StateChangelogOptionsInternal.ENABLE_CHANGE_LOG_FOR_APPLICATION,
changelogStateBackendEnabled.getAsBoolean());
+if (changelogStateBackendEnabled.getOrDefault(false)) {
+StateChangelogOptionsInternal.putConfiguration(
+jobConfiguration, changelogConfiguration);
+}
Review Comment:
Here, changelog configuration is passed from JM to TM inside the
`jobGraph.jobConfiguration`. It is then merged on TM with its "local" TM
configuration.
It's not strongly typed (something like `ChangelogConfig`) because different
implementations might have different parameters. And it's not a serialized
factory because passing a string map seems safer and easier.
It's added to `jobConfiguration` as serialized value under a single key
(rather than merged) because semantically they are different.
`jobConfiguration` is some internal Flink config, while changelog configuration
contains some user-facing keys; so they might clash.
@zentol WDYT about this approach?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org