[jira] [Commented] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053923#comment-17053923
]
Hive QA commented on HIVE-22962:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995953/HIVE-22962.06.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:green}SUCCESS:{color} +1 due to 18102 tests passed
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20993/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20993/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20993/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995953 - PreCommit-HIVE-Build
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.06.patch, HIVE-22962.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053913#comment-17053913
]
Hive QA commented on HIVE-22962:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 1m
39s{color} | {color:blue} Maven dependency ordering for branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 7m
35s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
56s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 1m
11s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 3m
39s{color} | {color:blue} ql in master has 1531 extant Findbugs warnings.
{color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
40s{color} | {color:blue} service in master has 51 extant Findbugs warnings.
{color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
28s{color} | {color:blue} cli in master has 9 extant Findbugs warnings. {color}
|
| {color:red}-1{color} | {color:red} findbugs {color} | {color:red} 3m
11s{color} | {color:red} branch/itests/hive-jmh cannot run convertXmlToText
from findbugs {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
35s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
27s{color} | {color:blue} Maven dependency ordering for patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 2m
43s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 2m
1s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 2m
1s{color} | {color:green} the patch passed {color} |
| {color:red}-1{color} | {color:red} checkstyle {color} | {color:red} 0m
40s{color} | {color:red} ql: The patch generated 90 new + 141 unchanged - 0
fixed = 231 total (was 141) {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:red}-1{color} | {color:red} findbugs {color} | {color:red} 3m
7s{color} | {color:red} patch/itests/hive-jmh cannot run convertXmlToText from
findbugs {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
32s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
14s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 39m 19s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20993/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| findbugs |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20993/yetus/branch-findbugs-itests_hive-jmh.txt
|
| checkstyle |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20993/yetus/diff-checkstyle-ql.txt
|
| findbugs |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20993/yetus/patch-findbugs-itests_hive-jmh.txt
|
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20993/yetus/patch-asflicense-problems.txt
|
| modules | C: ql service cli itests/hive-jmh U: . |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20993/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: J
[jira] [Commented] (HIVE-22978) Fix decimal precision and scale inference for aggregate rewriting in Calcite
[
https://issues.apache.org/jira/browse/HIVE-22978?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053899#comment-17053899
]
Hive QA commented on HIVE-22978:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995800/HIVE-22978.01.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:green}SUCCESS:{color} +1 due to 18102 tests passed
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20992/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20992/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20992/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995800 - PreCommit-HIVE-Build
> Fix decimal precision and scale inference for aggregate rewriting in Calcite
>
>
> Key: HIVE-22978
> URL: https://issues.apache.org/jira/browse/HIVE-22978
> Project: Hive
> Issue Type: Bug
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22978.01.patch, HIVE-22978.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Calcite rules can do rewritings of aggregate functions, e.g., {{avg}} into
> {{sum/count}}. When type of {{avg}} is decimal, inference of intermediate
> precision and scale for the division is not done correctly. The reason is
> that we miss support for some types in method {{getDefaultPrecision}} in
> {{HiveTypeSystemImpl}}. Additionally, {{deriveSumType}} should be overridden
> in {{HiveTypeSystemImpl}} to abide by the Hive semantics for sum aggregate
> type inference.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22987) ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
[ https://issues.apache.org/jira/browse/HIVE-22987?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ashutosh Chauhan updated HIVE-22987: Fix Version/s: 4.0.0 Resolution: Fixed Status: Resolved (was: Patch Available) Pushed to master. Thanks, Ramesh! > ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null > --- > > Key: HIVE-22987 > URL: https://issues.apache.org/jira/browse/HIVE-22987 > Project: Hive > Issue Type: Bug >Reporter: Ramesh Kumar Thangarajan >Assignee: Ramesh Kumar Thangarajan >Priority: Major > Fix For: 4.0.0 > > Attachments: HIVE-22987.1.patch > > > ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22987) ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
[ https://issues.apache.org/jira/browse/HIVE-22987?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053891#comment-17053891 ] Ashutosh Chauhan commented on HIVE-22987: - +1 > ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null > --- > > Key: HIVE-22987 > URL: https://issues.apache.org/jira/browse/HIVE-22987 > Project: Hive > Issue Type: Bug >Reporter: Ramesh Kumar Thangarajan >Assignee: Ramesh Kumar Thangarajan >Priority: Major > Attachments: HIVE-22987.1.patch > > > ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053890#comment-17053890 ] Gopal Vijayaraghavan commented on HIVE-22996: - +1 tests pending > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Labels: pull-request-available > Attachments: HIVE-22996.patch > > Time Spent: 10m > Remaining Estimate: 0h > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22978) Fix decimal precision and scale inference for aggregate rewriting in Calcite
[
https://issues.apache.org/jira/browse/HIVE-22978?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053889#comment-17053889
]
Hive QA commented on HIVE-22978:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 1m
36s{color} | {color:blue} Maven dependency ordering for branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 7m
42s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
41s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
56s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 3m
35s{color} | {color:blue} ql in master has 1531 extant Findbugs warnings.
{color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
41s{color} | {color:blue} itests/hive-unit in master has 2 extant Findbugs
warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
17s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
27s{color} | {color:blue} Maven dependency ordering for patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
59s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
42s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 1m
42s{color} | {color:green} the patch passed {color} |
| {color:red}-1{color} | {color:red} checkstyle {color} | {color:red} 0m
40s{color} | {color:red} ql: The patch generated 4 new + 19 unchanged - 1 fixed
= 23 total (was 20) {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 4m
31s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
21s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
15s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 29m 35s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20992/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| checkstyle |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20992/yetus/diff-checkstyle-ql.txt
|
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20992/yetus/patch-asflicense-problems.txt
|
| modules | C: ql itests/hive-unit U: . |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20992/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> Fix decimal precision and scale inference for aggregate rewriting in Calcite
>
>
> Key: HIVE-22978
> URL: https://issues.apache.org/jira/browse/HIVE-22978
> Project: Hive
> Issue Type: Bug
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22978.01.patch, HIVE-22978.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Calcite rules can do rewritings of aggregate functions, e.g., {{avg}} into
> {{sum/count}}. When type of {{avg}} is decimal, inference of intermediate
> precision and scale for the division is not done correctly. The reason is
> that we miss support for some types in method {{getDefaultPrecision}} in
> {{HiveTypeSystemImpl}}. Additionally
[jira] [Commented] (HIVE-22986) Prevent Decimal64 to Decimal conversion when other operations support Decimal64
[
https://issues.apache.org/jira/browse/HIVE-22986?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053878#comment-17053878
]
Hive QA commented on HIVE-22986:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995798/HIVE-22986.1.patch
{color:red}ERROR:{color} -1 due to build exiting with an error
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20991/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20991/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20991/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Tests exited with: NonZeroExitCodeException
Command 'bash /data/hiveptest/working/scratch/source-prep.sh' failed with exit
status 1 and output '+ date '+%Y-%m-%d %T.%3N'
2020-03-07 04:25:01.282
+ [[ -n /usr/lib/jvm/java-8-openjdk-amd64 ]]
+ export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
+ JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
+ export
PATH=/usr/lib/jvm/java-8-openjdk-amd64/bin/:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
+
PATH=/usr/lib/jvm/java-8-openjdk-amd64/bin/:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
+ export 'ANT_OPTS=-Xmx1g -XX:MaxPermSize=256m '
+ ANT_OPTS='-Xmx1g -XX:MaxPermSize=256m '
+ export 'MAVEN_OPTS=-Xmx1g '
+ MAVEN_OPTS='-Xmx1g '
+ cd /data/hiveptest/working/
+ tee /data/hiveptest/logs/PreCommit-HIVE-Build-20991/source-prep.txt
+ [[ false == \t\r\u\e ]]
+ mkdir -p maven ivy
+ [[ git = \s\v\n ]]
+ [[ git = \g\i\t ]]
+ [[ -z master ]]
+ [[ -d apache-github-source-source ]]
+ [[ ! -d apache-github-source-source/.git ]]
+ [[ ! -d apache-github-source-source ]]
+ date '+%Y-%m-%d %T.%3N'
2020-03-07 04:25:01.284
+ cd apache-github-source-source
+ git fetch origin
+ git reset --hard HEAD
HEAD is now at 1b50b70 HIVE-22673: Replace Base64 in contrib Package (David
Mollitor, reviewed by Zoltan Haindrich)
+ git clean -f -d
Removing standalone-metastore/metastore-server/src/gen/
+ git checkout master
Already on 'master'
Your branch is up-to-date with 'origin/master'.
+ git reset --hard origin/master
HEAD is now at 1b50b70 HIVE-22673: Replace Base64 in contrib Package (David
Mollitor, reviewed by Zoltan Haindrich)
+ git merge --ff-only origin/master
Already up-to-date.
+ date '+%Y-%m-%d %T.%3N'
2020-03-07 04:25:03.050
+ rm -rf ../yetus_PreCommit-HIVE-Build-20991
+ mkdir ../yetus_PreCommit-HIVE-Build-20991
+ git gc
+ cp -R . ../yetus_PreCommit-HIVE-Build-20991
+ mkdir /data/hiveptest/logs/PreCommit-HIVE-Build-20991/yetus
+ patchCommandPath=/data/hiveptest/working/scratch/smart-apply-patch.sh
+ patchFilePath=/data/hiveptest/working/scratch/build.patch
+ [[ -f /data/hiveptest/working/scratch/build.patch ]]
+ chmod +x /data/hiveptest/working/scratch/smart-apply-patch.sh
+ /data/hiveptest/working/scratch/smart-apply-patch.sh
/data/hiveptest/working/scratch/build.patch
Trying to apply the patch with -p0
error: a/itests/src/test/resources/testconfiguration.properties: does not exist
in index
error:
a/ql/src/java/org/apache/hadoop/hive/ql/exec/vector/VectorizationContext.java:
does not exist in index
Trying to apply the patch with -p1
error: patch failed: itests/src/test/resources/testconfiguration.properties:876
Falling back to three-way merge...
Applied patch to 'itests/src/test/resources/testconfiguration.properties' with
conflicts.
Going to apply patch with: git apply -p1
/data/hiveptest/working/scratch/build.patch:234: trailing whitespace.
Map 1
/data/hiveptest/working/scratch/build.patch:265: trailing whitespace.
null sort order:
/data/hiveptest/working/scratch/build.patch:266: trailing whitespace.
sort order:
/data/hiveptest/working/scratch/build.patch:291: trailing whitespace.
Reducer 2
/data/hiveptest/working/scratch/build.patch:296: trailing whitespace.
reduceColumnNullOrder:
error: patch failed: itests/src/test/resources/testconfiguration.properties:876
Falling back to three-way merge...
Applied patch to 'itests/src/test/resources/testconfiguration.properties' with
conflicts.
U itests/src/test/resources/testconfiguration.properties
warning: squelched 7 whitespace errors
warning: 12 lines add whitespace errors.
+ result=1
+ '[' 1 -ne 0 ']'
+ rm -rf yetus_PreCommit-HIVE-Build-20991
+ exit 1
'
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995798 - PreCommit-HIVE-Build
> Prevent Decimal64 to Decimal conversion when other operations support
> Decimal64
> ---
>
> Key: HIVE-22986
> URL: https://issues.apache.org/jira/browse/HIVE-22986
> Project: Hive
> Issue Type: Bug
> Components: Vectorization
>Reporter: Rames
[jira] [Commented] (HIVE-22987) ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
[
https://issues.apache.org/jira/browse/HIVE-22987?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053876#comment-17053876
]
Hive QA commented on HIVE-22987:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995797/HIVE-22987.1.patch
{color:red}ERROR:{color} -1 due to no test(s) being added or modified.
{color:green}SUCCESS:{color} +1 due to 18102 tests passed
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20990/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20990/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20990/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995797 - PreCommit-HIVE-Build
> ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
> ---
>
> Key: HIVE-22987
> URL: https://issues.apache.org/jira/browse/HIVE-22987
> Project: Hive
> Issue Type: Bug
>Reporter: Ramesh Kumar Thangarajan
>Assignee: Ramesh Kumar Thangarajan
>Priority: Major
> Attachments: HIVE-22987.1.patch
>
>
> ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David McGinnis updated HIVE-21218: -- Attachment: HIVE-21218.8.patch > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.8.patch, HIVE-21218.patch > > Time Spent: 14h 20m > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22955) PreUpgradeTool can fail because access to CharsetDecoder is not synchronized
[
https://issues.apache.org/jira/browse/HIVE-22955?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053822#comment-17053822
]
Hive QA commented on HIVE-22955:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995775/HIVE-22955.1.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:red}ERROR:{color} -1 due to 1 failed/errored test(s), 18103 tests
executed
*Failed tests:*
{noformat}
org.apache.hive.minikdc.TestJdbcWithMiniKdcSQLAuthBinary.testAuthorization1
(batchId=307)
{noformat}
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20985/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20985/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20985/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
Tests exited with: TestsFailedException: 1 tests failed
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995775 - PreCommit-HIVE-Build
> PreUpgradeTool can fail because access to CharsetDecoder is not synchronized
>
>
> Key: HIVE-22955
> URL: https://issues.apache.org/jira/browse/HIVE-22955
> Project: Hive
> Issue Type: Bug
> Components: Transactions
>Affects Versions: 4.0.0
>Reporter: Hankó Gergely
>Assignee: Hankó Gergely
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22955.1.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> {code:java}
> 2020-02-26 20:22:49,683 ERROR [main] acid.PreUpgradeTool
> (PreUpgradeTool.java:main(150)) - PreUpgradeTool failed
> org.apache.hadoop.hive.ql.metadata.HiveException at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.prepareAcidUpgradeInternal(PreUpgradeTool.java:283)
> at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.main(PreUpgradeTool.java:146)
> Caused by: java.lang.RuntimeException:
> java.util.concurrent.ExecutionException: java.lang.RuntimeException:
> java.lang.RuntimeException: java.lang.RuntimeException:
> java.lang.IllegalStateException: Current state = RESET, new state = FLUSHED
> ...
> Caused by: java.lang.IllegalStateException: Current state = RESET, new state
> = FLUSHED at
> java.nio.charset.CharsetDecoder.throwIllegalStateException(CharsetDecoder.java:992)
> at java.nio.charset.CharsetDecoder.flush(CharsetDecoder.java:675) at
> java.nio.charset.CharsetDecoder.decode(CharsetDecoder.java:804) at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.needsCompaction(PreUpgradeTool.java:606)
> at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.needsCompaction(PreUpgradeTool.java:567)
> at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.getCompactionCommands(PreUpgradeTool.java:464)
> at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.processTable(PreUpgradeTool.java:374)
> {code}
> This is probably caused by HIVE-21948.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-21778) CBO: "Struct is not null" gets evaluated as `nullable` always causing filter miss in the query
[
https://issues.apache.org/jira/browse/HIVE-21778?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Vineet Garg updated HIVE-21778:
---
Status: Patch Available (was: Open)
> CBO: "Struct is not null" gets evaluated as `nullable` always causing filter
> miss in the query
> --
>
> Key: HIVE-21778
> URL: https://issues.apache.org/jira/browse/HIVE-21778
> Project: Hive
> Issue Type: Bug
> Components: CBO
>Affects Versions: 2.3.5, 4.0.0
>Reporter: Rajesh Balamohan
>Assignee: Vineet Garg
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-21778.1.patch, HIVE-21778.2.patch,
> HIVE-21778.3.patch, HIVE-21778.4.patch, HIVE-21778.5.patch,
> HIVE-21778.6.patch, HIVE-21778.7.patch, test_null.q, test_null.q.out
>
> Time Spent: 40m
> Remaining Estimate: 0h
>
> {noformat}
> drop table if exists test_struct;
> CREATE external TABLE test_struct
> (
> f1 string,
> demo_struct struct,
> datestr string
> );
> set hive.cbo.enable=true;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: (datestr = '2019-01-01') (type: boolean) <- Note
> that demo_struct filter is not added here
> Filter Operator
> predicate: (datestr = '2019-01-01') (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
> outputColumnNames: _col0, _col1, _col2
> ListSink
> set hive.cbo.enable=false;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: ((datestr = '2019-01-01') and demo_struct is not null)
> (type: boolean) <- Note that demo_struct filter is added when CBO is
> turned off
> Filter Operator
> predicate: ((datestr = '2019-01-01') and demo_struct is not null)
> (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
> outputColumnNames: _col0, _col1, _col2
> ListSink
> {noformat}
> In CalcitePlanner::genFilterRelNode, the following code misses to evaluate
> this filter.
> {noformat}
> RexNode factoredFilterExpr = RexUtil
> .pullFactors(cluster.getRexBuilder(), convertedFilterExpr);
> {noformat}
> Note that even if we add `demo_struct.f1` it would end up pushing the filter
> correctly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22995) Add support for location for managed tables on database
[
https://issues.apache.org/jira/browse/HIVE-22995?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Thejas Nair updated HIVE-22995:
---
Description:
I have attached the initial spec to this jira.
Default location for database would be the external table base directory.
Managed location can be optionally specified.
{code}
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
ALTER (DATABASE|SCHEMA) database_name SET
MANAGEDLOCATION
hdfs_path;
{code}
was:
I have attached the initial spec to this jira.
Proposed syntax -
{code}
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
ALTER (DATABASE|SCHEMA) database_name SET
MANAGEDLOCATION
hdfs_path;
{code}
> Add support for location for managed tables on database
> ---
>
> Key: HIVE-22995
> URL: https://issues.apache.org/jira/browse/HIVE-22995
> Project: Hive
> Issue Type: Improvement
> Components: Hive
>Affects Versions: 3.1.0
>Reporter: Naveen Gangam
>Assignee: Naveen Gangam
>Priority: Major
> Attachments: Hive Metastore Support for Tenant-based storage
> heirarchy.pdf
>
>
> I have attached the initial spec to this jira.
> Default location for database would be the external table base directory.
> Managed location can be optionally specified.
> {code}
> CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
> [COMMENT database_comment]
> [LOCATION hdfs_path]
> [MANAGEDLOCATION hdfs_path]
> [WITH DBPROPERTIES (property_name=property_value, ...)];
> ALTER (DATABASE|SCHEMA) database_name SET
> MANAGEDLOCATION
> hdfs_path;
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jesus Camacho Rodriguez updated HIVE-22962:
---
Attachment: HIVE-22962.06.patch
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.06.patch, HIVE-22962.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-21778) CBO: "Struct is not null" gets evaluated as `nullable` always causing filter miss in the query
[
https://issues.apache.org/jira/browse/HIVE-21778?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Vineet Garg updated HIVE-21778:
---
Status: Open (was: Patch Available)
> CBO: "Struct is not null" gets evaluated as `nullable` always causing filter
> miss in the query
> --
>
> Key: HIVE-21778
> URL: https://issues.apache.org/jira/browse/HIVE-21778
> Project: Hive
> Issue Type: Bug
> Components: CBO
>Affects Versions: 2.3.5, 4.0.0
>Reporter: Rajesh Balamohan
>Assignee: Vineet Garg
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-21778.1.patch, HIVE-21778.2.patch,
> HIVE-21778.3.patch, HIVE-21778.4.patch, HIVE-21778.5.patch,
> HIVE-21778.6.patch, HIVE-21778.7.patch, test_null.q, test_null.q.out
>
> Time Spent: 40m
> Remaining Estimate: 0h
>
> {noformat}
> drop table if exists test_struct;
> CREATE external TABLE test_struct
> (
> f1 string,
> demo_struct struct,
> datestr string
> );
> set hive.cbo.enable=true;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: (datestr = '2019-01-01') (type: boolean) <- Note
> that demo_struct filter is not added here
> Filter Operator
> predicate: (datestr = '2019-01-01') (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
> outputColumnNames: _col0, _col1, _col2
> ListSink
> set hive.cbo.enable=false;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: ((datestr = '2019-01-01') and demo_struct is not null)
> (type: boolean) <- Note that demo_struct filter is added when CBO is
> turned off
> Filter Operator
> predicate: ((datestr = '2019-01-01') and demo_struct is not null)
> (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
> outputColumnNames: _col0, _col1, _col2
> ListSink
> {noformat}
> In CalcitePlanner::genFilterRelNode, the following code misses to evaluate
> this filter.
> {noformat}
> RexNode factoredFilterExpr = RexUtil
> .pullFactors(cluster.getRexBuilder(), convertedFilterExpr);
> {noformat}
> Note that even if we add `demo_struct.f1` it would end up pushing the filter
> correctly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jesus Camacho Rodriguez updated HIVE-22962:
---
Attachment: (was: HIVE-22962.06.patch)
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.06.patch, HIVE-22962.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22987) ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
[
https://issues.apache.org/jira/browse/HIVE-22987?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053861#comment-17053861
]
Hive QA commented on HIVE-22987:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 9m
1s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
0s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
42s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 3m
48s{color} | {color:blue} ql in master has 1531 extant Findbugs warnings.
{color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
54s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
17s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 0m
59s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 0m
59s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
43s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 3m
56s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
53s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
15s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 23m 58s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20990/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20990/yetus/patch-asflicense-problems.txt
|
| modules | C: ql U: ql |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20990/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
> ---
>
> Key: HIVE-22987
> URL: https://issues.apache.org/jira/browse/HIVE-22987
> Project: Hive
> Issue Type: Bug
>Reporter: Ramesh Kumar Thangarajan
>Assignee: Ramesh Kumar Thangarajan
>Priority: Major
> Attachments: HIVE-22987.1.patch
>
>
> ClassCastException in VectorCoalesce when DataTypePhysicalVariation is null
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22760) Add Clock caching eviction based strategy
[ https://issues.apache.org/jira/browse/HIVE-22760?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Slim Bouguerra updated HIVE-22760: -- Attachment: HIVE-22760.patch > Add Clock caching eviction based strategy > - > > Key: HIVE-22760 > URL: https://issues.apache.org/jira/browse/HIVE-22760 > Project: Hive > Issue Type: New Feature > Components: llap >Reporter: Slim Bouguerra >Assignee: Slim Bouguerra >Priority: Major > Attachments: HIVE-22760.patch > > > LRFU is the current default right now. > The main issue with such Strategy is that it has a very high memory overhead, > in addition to that, most of the accounting has to happen under locks thus > can be source of contentions. > Add Simpler policy like clock, can help with both issues. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22760) Add Clock caching eviction based strategy
[ https://issues.apache.org/jira/browse/HIVE-22760?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Slim Bouguerra updated HIVE-22760: -- Status: Patch Available (was: Open) > Add Clock caching eviction based strategy > - > > Key: HIVE-22760 > URL: https://issues.apache.org/jira/browse/HIVE-22760 > Project: Hive > Issue Type: New Feature > Components: llap >Reporter: Slim Bouguerra >Assignee: Slim Bouguerra >Priority: Major > Attachments: HIVE-22760.patch > > > LRFU is the current default right now. > The main issue with such Strategy is that it has a very high memory overhead, > in addition to that, most of the accounting has to happen under locks thus > can be source of contentions. > Add Simpler policy like clock, can help with both issues. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-21851) FireEventResponse should include event id when available
[
https://issues.apache.org/jira/browse/HIVE-21851?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053835#comment-17053835
]
Hive QA commented on HIVE-21851:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995788/HIVE-21851.06.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:green}SUCCESS:{color} +1 due to 18102 tests passed
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20986/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20986/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20986/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995788 - PreCommit-HIVE-Build
> FireEventResponse should include event id when available
>
>
> Key: HIVE-21851
> URL: https://issues.apache.org/jira/browse/HIVE-21851
> Project: Hive
> Issue Type: Improvement
>Reporter: Vihang Karajgaonkar
>Assignee: Vihang Karajgaonkar
>Priority: Minor
> Attachments: HIVE-21851.01.patch, HIVE-21851.02.patch,
> HIVE-21851.03.patch, HIVE-21851.04.patch, HIVE-21851.05.patch,
> HIVE-21851.06.patch
>
>
> The metastore API {{fire_listener_event}} gives clients the ability to fire a
> INSERT event on DML operations. However, the returned response is empty
> struct. It would be useful to sent back the event id information in the
> response so that clients can take actions based of the event id.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053729#comment-17053729 ] Jesus Camacho Rodriguez commented on HIVE-22996: [~kgyrtkirk], could you take a look? Thanks > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Labels: pull-request-available > Attachments: HIVE-22996.patch > > Time Spent: 10m > Remaining Estimate: 0h > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399460&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399460 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 07/Mar/20 00:28 Start Date: 07/Mar/20 00:28 Worklog Time Spent: 10m Work Description: cricket007 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-596019430 I think that is a side effect of the Avro Maven Plugin on that configuration block... You can put `Charsequence` or `String`, I think, but the default is `Utf8` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399460) Time Spent: 13.5h (was: 13h 20m) > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.patch > > Time Spent: 13.5h > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22954) Schedule Repl Load using Hive Scheduler
[
https://issues.apache.org/jira/browse/HIVE-22954?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053787#comment-17053787
]
Hive QA commented on HIVE-22954:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995811/HIVE-22954.20.patch
{color:green}SUCCESS:{color} +1 due to 23 test(s) being added or modified.
{color:green}SUCCESS:{color} +1 due to 18093 tests passed
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20984/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20984/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20984/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995811 - PreCommit-HIVE-Build
> Schedule Repl Load using Hive Scheduler
> ---
>
> Key: HIVE-22954
> URL: https://issues.apache.org/jira/browse/HIVE-22954
> Project: Hive
> Issue Type: Task
>Reporter: Aasha Medhi
>Assignee: Aasha Medhi
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22954.01.patch, HIVE-22954.02.patch,
> HIVE-22954.03.patch, HIVE-22954.04.patch, HIVE-22954.05.patch,
> HIVE-22954.06.patch, HIVE-22954.07.patch, HIVE-22954.08.patch,
> HIVE-22954.09.patch, HIVE-22954.10.patch, HIVE-22954.11.patch,
> HIVE-22954.12.patch, HIVE-22954.13.patch, HIVE-22954.15.patch,
> HIVE-22954.16.patch, HIVE-22954.17.patch, HIVE-22954.18.patch,
> HIVE-22954.19.patch, HIVE-22954.20.patch, HIVE-22954.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> [https://github.com/apache/hive/pull/932]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-21851) FireEventResponse should include event id when available
[
https://issues.apache.org/jira/browse/HIVE-21851?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053827#comment-17053827
]
Hive QA commented on HIVE-21851:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 2m
2s{color} | {color:blue} Maven dependency ordering for branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 7m
34s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
20s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
41s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 2m
32s{color} | {color:blue} standalone-metastore/metastore-common in master has
35 extant Findbugs warnings. {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 1m
15s{color} | {color:blue} standalone-metastore/metastore-server in master has
185 extant Findbugs warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
29s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
28s{color} | {color:blue} Maven dependency ordering for patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
28s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
17s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 1m
17s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
44s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:red}-1{color} | {color:red} findbugs {color} | {color:red} 1m
24s{color} | {color:red} standalone-metastore/metastore-server generated 1 new
+ 185 unchanged - 0 fixed = 186 total (was 185) {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
28s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
14s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 27m 21s{color} |
{color:black} {color} |
\\
\\
|| Reason || Tests ||
| FindBugs | module:standalone-metastore/metastore-server |
| | Boxing/unboxing to parse a primitive
org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.fire_listener_event(FireEventRequest)
At
HiveMetaStore.java:org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.fire_listener_event(FireEventRequest)
At HiveMetaStore.java:[line 8623] |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20986/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.0 |
| findbugs |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20986/yetus/new-findbugs-standalone-metastore_metastore-server.html
|
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20986/yetus/patch-asflicense-problems.txt
|
| modules | C: standalone-metastore/metastore-common
standalone-metastore/metastore-server itests/hcatalog-unit U: . |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20986/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> FireEventResponse should include event id when available
>
>
> Key: HIVE-21851
> URL: https://issues.apache.org/jira/browse/HIVE-21851
> Project: Hive
> Issue Type: Improvement
>Reporter: Vihang Karajgaonkar
>Assignee: Vihang Karajgaonkar
>Priority: Mino
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399396&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399396 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 06/Mar/20 22:19 Start Date: 06/Mar/20 22:19 Worklog Time Spent: 10m Work Description: davidov541 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-595988456 OK, I was able to successfully test this build using a Confluent single-node cluster and a Hive pseudo-standalone cluster. I was able to create a topic with a simple Avro schema and a few records, and then read that from Hive successfully. Confluent Cluster Production:  Hive Table Creation and Querying: 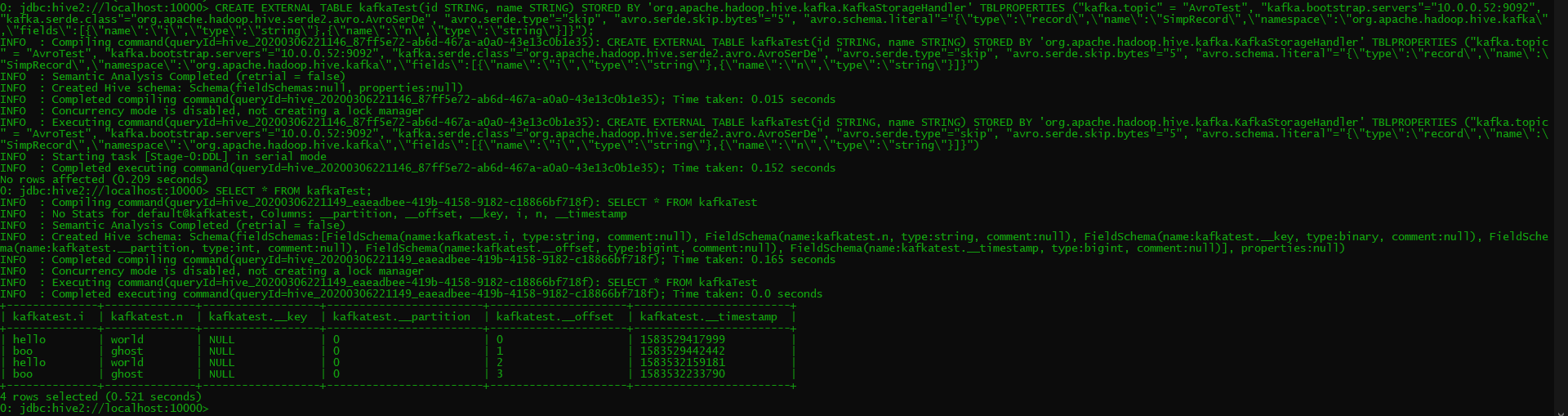 One thing I noticed was that on the Hive side, if I used the exact same schema as the SimpleRecord schema which we use for testing, I got the following error. As you can see in the screenshots, I was able to edit the field and schema names, and avoid this error, so it was specifically due to Hive pulling in the SimpleRecord class which we use for testing. ``` 2020-03-06T22:05:23,739 WARN [HiveServer2-Handler-Pool: Thread-165] thrift.ThriftCLIService: Error fetching results: org.apache.hive.service.cli.HiveSQLException: java.io.IOException: java.lang.ClassCastException: org.apache.avro.util.Utf8 cannot be cast to java.lang.String at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:481) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:331) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:946) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:567) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:801) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1837) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1822) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_242] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_242] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_242] Caused by: java.io.IOException: java.lang.ClassCastException: org.apache.avro.util.Utf8 cannot be cast to java.lang.String at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:638) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:545) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:150) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:880) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:241) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:476) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] ... 13 more Caused by: java.lang.ClassCastException: org.apache.avro.util.Utf8 cannot be cast to java.lang.String at org.apache.hadoop.hive.kafka.SimpleRecord.put(SimpleRecord.java:88) ~[kafka-handler-4.0.0-SNAPSHOT.jar:4.0.0
[jira] [Updated] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HIVE-22996: -- Labels: pull-request-available (was: ) > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Labels: pull-request-available > Attachments: HIVE-22996.patch > > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?focusedWorklogId=399331&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399331 ] ASF GitHub Bot logged work on HIVE-22996: - Author: ASF GitHub Bot Created on: 06/Mar/20 19:48 Start Date: 06/Mar/20 19:48 Worklog Time Spent: 10m Work Description: jcamachor commented on pull request #942: HIVE-22996 URL: https://github.com/apache/hive/pull/942 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399331) Remaining Estimate: 0h Time Spent: 10m > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Labels: pull-request-available > Attachments: HIVE-22996.patch > > Time Spent: 10m > Remaining Estimate: 0h > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22126) hive-exec packaging should shade guava
[ https://issues.apache.org/jira/browse/HIVE-22126?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053747#comment-17053747 ] Eugene Chung commented on HIVE-22126: - If common-complier and janino modules are included in hive-exec, jar signing error is occurred. Execution default-test of goal org.apache.maven.plugins:maven-surefire-plugin:2.21.0:test failed: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:215) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:156) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:148) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81) at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56) at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192) at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105) at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957) at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289) at org.apache.maven.cli.MavenCli.main (MavenCli.java:193) at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke (Method.java:498) at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282) at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225) at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406) at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347) Caused by: org.apache.maven.plugin.PluginExecutionException: Execution default-test of goal org.apache.maven.plugins:maven-surefire-plugin:2.21.0:test failed: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:148) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:210) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:156) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:148) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81) at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56) at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192) at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105) at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957) at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289) at org.apache.maven.cli.MavenCli.main (MavenCli.java:193) at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke (Method.java:498) at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282) at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225) at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406) at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347) Caused by: org.apache.maven.surefire.util.SurefireReflectionException: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at org.apache.maven.surefire.util.ReflectionUtils.invokeMethodWithArray (ReflectionUtils.java:197) at org.apache.maven.surefire.util.ReflectionUtils.invokeGetter (ReflectionUtils.java:76) at org.apache.maven.surefire.util.ReflectionUtils.invokeGetter (ReflectionUtils.java:70) at org.apache.maven.surefire.booter.ProviderFactory$ProviderProxy.getSuites (ProviderFactory.java:144) at org.apache.maven.plugin.surefire.booterclient.ForkStarter.getSuitesIterator (ForkStarter.java:699) at org.apach
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399394&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399394 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 06/Mar/20 22:17 Start Date: 06/Mar/20 22:17 Worklog Time Spent: 10m Work Description: davidov541 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-595988456 OK, I was able to successfully test this build using a Confluent single-node cluster and a Hive pseudo-standalone cluster. I was able to create a topic with a simple Avro schema and a few records, and then read that from Hive successfully. Confluent Cluster Production:  Hive Table Creation and Querying:  One thing I noticed was that on the Hive side, if I used the exact same schema as the SimpleRecord schema which we use for testing, I got the following error. ``` 2020-03-06T22:05:23,739 WARN [HiveServer2-Handler-Pool: Thread-165] thrift.ThriftCLIService: Error fetching results: org.apache.hive.service.cli.HiveSQLException: java.io.IOException: java.lang.ClassCastException: org.apache.avro.util.Utf8 cannot be cast to java.lang.String at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:481) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:331) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:946) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:567) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:801) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1837) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1822) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_242] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_242] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_242] Caused by: java.io.IOException: java.lang.ClassCastException: org.apache.avro.util.Utf8 cannot be cast to java.lang.String at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:638) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:545) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:150) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:880) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:241) ~[hive-exec-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:476) ~[hive-service-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] ... 13 more Caused by: java.lang.ClassCastException: org.apache.avro.util.Utf8 cannot be cast to java.lang.String at org.apache.hadoop.hive.kafka.SimpleRecord.put(SimpleRecord.java:88) ~[kafka-handler-4.0.0-SNAPSHOT.jar:4.0.0-SNAPSHOT] at org.apache.avro.generic.GenericData.setField(GenericData.java:690) ~[avro-1.8.2.jar:1.8.2] at org.apache.avro.specific.SpecificDatumReader.readField(SpecificDatum
[jira] [Updated] (HIVE-22953) Update Apache Arrow and flatbuffer versions
[ https://issues.apache.org/jira/browse/HIVE-22953?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jesus Camacho Rodriguez updated HIVE-22953: --- Attachment: HIVE-22953.patch > Update Apache Arrow and flatbuffer versions > --- > > Key: HIVE-22953 > URL: https://issues.apache.org/jira/browse/HIVE-22953 > Project: Hive > Issue Type: Improvement > Components: Serializers/Deserializers >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Attachments: HIVE-22953.patch, HIVE-22953.patch > > > HIVE-22827 updated flatbuffer version to 1.6.0.1. Current Arrow version > consumed by Hive uses 1.2.0 (com.vlkan:flatbuffers version). > This issue is to update Arrow and flatbuffers (from official flatbuffers > release, same version used by Arrow). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22760) Add Clock caching eviction based strategy
[ https://issues.apache.org/jira/browse/HIVE-22760?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053844#comment-17053844 ] Slim Bouguerra commented on HIVE-22760: --- [~szita] can you take a look at this ? > Add Clock caching eviction based strategy > - > > Key: HIVE-22760 > URL: https://issues.apache.org/jira/browse/HIVE-22760 > Project: Hive > Issue Type: New Feature > Components: llap >Reporter: Slim Bouguerra >Assignee: Slim Bouguerra >Priority: Major > Attachments: HIVE-22760.patch > > > LRFU is the current default right now. > The main issue with such Strategy is that it has a very high memory overhead, > in addition to that, most of the accounting has to happen under locks thus > can be source of contentions. > Add Simpler policy like clock, can help with both issues. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22974) Metastore's table location check should be applied when location changed
[
https://issues.apache.org/jira/browse/HIVE-22974?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053730#comment-17053730
]
Hive QA commented on HIVE-22974:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 1m
52s{color} | {color:blue} Maven dependency ordering for branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 8m
19s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
14s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
41s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 1m
21s{color} | {color:blue} standalone-metastore/metastore-server in master has
185 extant Findbugs warnings. {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
43s{color} | {color:blue} itests/hive-unit in master has 2 extant Findbugs
warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
48s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
28s{color} | {color:blue} Maven dependency ordering for patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
21s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
11s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 1m
11s{color} | {color:green} the patch passed {color} |
| {color:red}-1{color} | {color:red} checkstyle {color} | {color:red} 0m
23s{color} | {color:red} standalone-metastore/metastore-server: The patch
generated 2 new + 375 unchanged - 0 fixed = 377 total (was 375) {color} |
| {color:red}-1{color} | {color:red} checkstyle {color} | {color:red} 0m
21s{color} | {color:red} itests/hive-unit: The patch generated 1 new + 190
unchanged - 0 fixed = 191 total (was 190) {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 2m
16s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
49s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
15s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 22m 48s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20983/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.0 |
| checkstyle |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20983/yetus/diff-checkstyle-standalone-metastore_metastore-server.txt
|
| checkstyle |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20983/yetus/diff-checkstyle-itests_hive-unit.txt
|
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20983/yetus/patch-asflicense-problems.txt
|
| modules | C: standalone-metastore/metastore-server itests/hive-unit U: . |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20983/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> Metastore's table location check should be applied when location changed
>
>
> Key: HIVE-22974
> URL: https://issues.apache.org/jira/browse/HIVE-22974
> Project: Hive
> Issue Type: Sub-task
> Components: Metastore
>Reporter: Attila Magyar
>Assignee: Attila Magyar
>Priority: Major
> Fix For: 4.0.0
>
> Attachments: HIVE-22974
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399498&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399498 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 07/Mar/20 01:39 Start Date: 07/Mar/20 01:39 Worklog Time Spent: 10m Work Description: cricket007 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-596029870 > since it will use the one built into the system, instead of theirs. Move the Avro schema to src/test/resources and scope the plugin to the test lifecycle, and you shouldn't have that problem This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399498) Time Spent: 13h 50m (was: 13h 40m) > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.patch > > Time Spent: 13h 50m > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22972) Allow table id to be set for table creation requests
[
https://issues.apache.org/jira/browse/HIVE-22972?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053855#comment-17053855
]
Hive QA commented on HIVE-22972:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995792/HIVE-22972.03.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:red}ERROR:{color} -1 due to 1 failed/errored test(s), 18102 tests
executed
*Failed tests:*
{noformat}
org.apache.hive.beeline.TestBeeLineWithArgs.testRowsAffected (batchId=286)
{noformat}
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20988/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20988/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20988/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
Tests exited with: TestsFailedException: 1 tests failed
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995792 - PreCommit-HIVE-Build
> Allow table id to be set for table creation requests
>
>
> Key: HIVE-22972
> URL: https://issues.apache.org/jira/browse/HIVE-22972
> Project: Hive
> Issue Type: Bug
> Components: Hive
>Reporter: Miklos Gergely
>Assignee: Miklos Gergely
>Priority: Major
> Fix For: 4.0.0
>
> Attachments: HIVE-22972.01.patch, HIVE-22972.02.patch,
> HIVE-22972.03.patch
>
>
> Hive Metastore should accept requests for table creation where the id is set,
> ignoring it.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399495&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399495 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 07/Mar/20 01:31 Start Date: 07/Mar/20 01:31 Worklog Time Spent: 10m Work Description: davidov541 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-596028873 @cricket007 That makes sense. I'm still concerned that the schema is present at all in the build. I'm currently rebuilding some things due to mistakes on my end, but I expect that this issue prevents anyone from using an Avro schema with the name "SimpleRecord" at all, since it will use the one built into the system, instead of theirs. I'll test it, but I do think that's something we can solve separately, since the schema management piece is separate from the skipping of bytes that this PR implements. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399495) Time Spent: 13h 40m (was: 13.5h) > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.patch > > Time Spent: 13h 40m > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22126) hive-exec packaging should shade guava
[ https://issues.apache.org/jira/browse/HIVE-22126?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eugene Chung updated HIVE-22126: Attachment: HIVE-22126.08.patch Status: Patch Available (was: Open) [^HIVE-22126.08.patch] Because of my lack of knowledge with maven-shade-plugin, my previous approach (07.patch) was undesirable that I tried to include all the dependent modules of calcite-core in hive-exec.jar. Now only calcite-core is included in the list of maven-shade-plugin to shade its guava usages. Then the modules which are required for calcite-core itself are listed in maven dependencies of hive-exec. > hive-exec packaging should shade guava > -- > > Key: HIVE-22126 > URL: https://issues.apache.org/jira/browse/HIVE-22126 > Project: Hive > Issue Type: Bug >Reporter: Vihang Karajgaonkar >Assignee: Eugene Chung >Priority: Major > Fix For: 4.0.0 > > Attachments: HIVE-22126.01.patch, HIVE-22126.02.patch, > HIVE-22126.03.patch, HIVE-22126.04.patch, HIVE-22126.05.patch, > HIVE-22126.06.patch, HIVE-22126.07.patch, HIVE-22126.08.patch > > > The ql/pom.xml includes complete guava library into hive-exec.jar > https://github.com/apache/hive/blob/master/ql/pom.xml#L990 This causes a > problems for downstream clients of hive which have hive-exec.jar in their > classpath since they are pinned to the same guava version as that of hive. > We should shade guava classes so that other components which depend on > hive-exec can independently use a different version of guava as needed. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jesus Camacho Rodriguez updated HIVE-22996: --- Attachment: HIVE-22996.patch > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Attachments: HIVE-22996.patch > > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22995) Add support for location for managed tables on database
[
https://issues.apache.org/jira/browse/HIVE-22995?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Thejas Nair updated HIVE-22995:
---
Description:
I have attached the initial spec to this jira.
Proposed syntax -
{code}
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
ALTER (DATABASE|SCHEMA) database_name SET
MANAGEDLOCATION
hdfs_path;
{code}
was:I have attached the initial spec to this jira.
> Add support for location for managed tables on database
> ---
>
> Key: HIVE-22995
> URL: https://issues.apache.org/jira/browse/HIVE-22995
> Project: Hive
> Issue Type: Improvement
> Components: Hive
>Affects Versions: 3.1.0
>Reporter: Naveen Gangam
>Assignee: Naveen Gangam
>Priority: Major
> Attachments: Hive Metastore Support for Tenant-based storage
> heirarchy.pdf
>
>
> I have attached the initial spec to this jira.
> Proposed syntax -
> {code}
> CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
> [COMMENT database_comment]
> [LOCATION hdfs_path]
> [MANAGEDLOCATION hdfs_path]
> [WITH DBPROPERTIES (property_name=property_value, ...)];
> ALTER (DATABASE|SCHEMA) database_name SET
> MANAGEDLOCATION
> hdfs_path;
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jesus Camacho Rodriguez updated HIVE-22996: --- Status: Patch Available (was: In Progress) > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > Attachments: HIVE-22996.patch > > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jesus Camacho Rodriguez reassigned HIVE-22996: -- > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work started] (HIVE-22996) BasicStats parsing should check proactively for null or empty string
[ https://issues.apache.org/jira/browse/HIVE-22996?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HIVE-22996 started by Jesus Camacho Rodriguez. -- > BasicStats parsing should check proactively for null or empty string > > > Key: HIVE-22996 > URL: https://issues.apache.org/jira/browse/HIVE-22996 > Project: Hive > Issue Type: Bug > Components: Statistics >Reporter: Jesus Camacho Rodriguez >Assignee: Jesus Camacho Rodriguez >Priority: Major > > Rather than throwing an Exception for control flow, which will create > unnecessary overhead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22974) Metastore's table location check should be applied when location changed
[
https://issues.apache.org/jira/browse/HIVE-22974?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053746#comment-17053746
]
Hive QA commented on HIVE-22974:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995773/HIVE-22974.3.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:red}ERROR:{color} -1 due to 8 failed/errored test(s), 18103 tests
executed
*Failed tests:*
{noformat}
org.apache.hadoop.hive.cli.TestMiniLlapLocalCliDriver.testCliDriver[sysdb_schq]
(batchId=182)
org.apache.hadoop.hive.metastore.TestHiveMetaStoreWithEnvironmentContext.testEnvironmentContext
(batchId=236)
org.apache.hadoop.hive.metastore.TestMetaStoreEventListener.testListener
(batchId=237)
org.apache.hadoop.hive.metastore.client.TestGetTableMeta.testGetTableMetaNullNoDbNoTbl[Remote]
(batchId=230)
org.apache.hadoop.hive.metastore.client.TestGetTableMeta.testGetTableMetaNullOrEmptyDb[Remote]
(batchId=230)
org.apache.hadoop.hive.metastore.client.TestGetTableMeta.testGetTableMetaNullOrEmptyTbl[Remote]
(batchId=230)
org.apache.hadoop.hive.metastore.client.TestGetTableMeta.testGetTableMetaNullOrEmptyTypes[Remote]
(batchId=230)
org.apache.hadoop.hive.metastore.client.TestGetTableMeta.testGetTableMeta[Remote]
(batchId=230)
{noformat}
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20983/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20983/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20983/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
Tests exited with: TestsFailedException: 8 tests failed
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995773 - PreCommit-HIVE-Build
> Metastore's table location check should be applied when location changed
>
>
> Key: HIVE-22974
> URL: https://issues.apache.org/jira/browse/HIVE-22974
> Project: Hive
> Issue Type: Sub-task
> Components: Metastore
>Reporter: Attila Magyar
>Assignee: Attila Magyar
>Priority: Major
> Fix For: 4.0.0
>
> Attachments: HIVE-22974.2.patch, HIVE-22974.3.patch
>
>
> In HIVE-22189 a check was introduced to make sure managed and external tables
> are located at the proper space. This condition cannot be satisfied during an
> upgrade.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22126) hive-exec packaging should shade guava
[ https://issues.apache.org/jira/browse/HIVE-22126?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eugene Chung updated HIVE-22126: Status: Open (was: Patch Available) > hive-exec packaging should shade guava > -- > > Key: HIVE-22126 > URL: https://issues.apache.org/jira/browse/HIVE-22126 > Project: Hive > Issue Type: Bug >Reporter: Vihang Karajgaonkar >Assignee: Eugene Chung >Priority: Major > Fix For: 4.0.0 > > Attachments: HIVE-22126.01.patch, HIVE-22126.02.patch, > HIVE-22126.03.patch, HIVE-22126.04.patch, HIVE-22126.05.patch, > HIVE-22126.06.patch, HIVE-22126.07.patch > > > The ql/pom.xml includes complete guava library into hive-exec.jar > https://github.com/apache/hive/blob/master/ql/pom.xml#L990 This causes a > problems for downstream clients of hive which have hive-exec.jar in their > classpath since they are pinned to the same guava version as that of hive. > We should shade guava classes so that other components which depend on > hive-exec can independently use a different version of guava as needed. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22945) Hive ACID Data Corruption: Update command mess the other column data and produces incorrect result
[
https://issues.apache.org/jira/browse/HIVE-22945?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053837#comment-17053837
]
Hive QA commented on HIVE-22945:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995790/HIVE-22945.1.patch
{color:red}ERROR:{color} -1 due to build exiting with an error
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20987/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20987/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20987/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Tests exited with: NonZeroExitCodeException
Command 'bash /data/hiveptest/working/scratch/source-prep.sh' failed with exit
status 1 and output '+ date '+%Y-%m-%d %T.%3N'
2020-03-07 01:23:55.627
+ [[ -n /usr/lib/jvm/java-8-openjdk-amd64 ]]
+ export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
+ JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
+ export
PATH=/usr/lib/jvm/java-8-openjdk-amd64/bin/:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
+
PATH=/usr/lib/jvm/java-8-openjdk-amd64/bin/:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
+ export 'ANT_OPTS=-Xmx1g -XX:MaxPermSize=256m '
+ ANT_OPTS='-Xmx1g -XX:MaxPermSize=256m '
+ export 'MAVEN_OPTS=-Xmx1g '
+ MAVEN_OPTS='-Xmx1g '
+ cd /data/hiveptest/working/
+ tee /data/hiveptest/logs/PreCommit-HIVE-Build-20987/source-prep.txt
+ [[ false == \t\r\u\e ]]
+ mkdir -p maven ivy
+ [[ git = \s\v\n ]]
+ [[ git = \g\i\t ]]
+ [[ -z master ]]
+ [[ -d apache-github-source-source ]]
+ [[ ! -d apache-github-source-source/.git ]]
+ [[ ! -d apache-github-source-source ]]
+ date '+%Y-%m-%d %T.%3N'
2020-03-07 01:23:55.629
+ cd apache-github-source-source
+ git fetch origin
+ git reset --hard HEAD
HEAD is now at 1b50b70 HIVE-22673: Replace Base64 in contrib Package (David
Mollitor, reviewed by Zoltan Haindrich)
+ git clean -f -d
Removing itests/${project.basedir}/
Removing standalone-metastore/metastore-server/src/gen/
+ git checkout master
Already on 'master'
Your branch is up-to-date with 'origin/master'.
+ git reset --hard origin/master
HEAD is now at 1b50b70 HIVE-22673: Replace Base64 in contrib Package (David
Mollitor, reviewed by Zoltan Haindrich)
+ git merge --ff-only origin/master
Already up-to-date.
+ date '+%Y-%m-%d %T.%3N'
2020-03-07 01:23:56.853
+ rm -rf ../yetus_PreCommit-HIVE-Build-20987
+ mkdir ../yetus_PreCommit-HIVE-Build-20987
+ git gc
+ cp -R . ../yetus_PreCommit-HIVE-Build-20987
+ mkdir /data/hiveptest/logs/PreCommit-HIVE-Build-20987/yetus
+ patchCommandPath=/data/hiveptest/working/scratch/smart-apply-patch.sh
+ patchFilePath=/data/hiveptest/working/scratch/build.patch
+ [[ -f /data/hiveptest/working/scratch/build.patch ]]
+ chmod +x /data/hiveptest/working/scratch/smart-apply-patch.sh
+ /data/hiveptest/working/scratch/smart-apply-patch.sh
/data/hiveptest/working/scratch/build.patch
Trying to apply the patch with -p0
error:
a/ql/src/java/org/apache/hadoop/hive/ql/optimizer/ConstantPropagateProcFactory.java:
does not exist in index
error:
a/ql/src/test/queries/clientpositive/constant_prop_timestamp_date_cast.q: does
not exist in index
error:
a/ql/src/test/results/clientpositive/constant_prop_timestamp_date_cast.q.out:
does not exist in index
Trying to apply the patch with -p1
error: ql/src/test/queries/clientpositive/constant_prop_timestamp_date_cast.q:
does not exist in index
error:
ql/src/test/results/clientpositive/constant_prop_timestamp_date_cast.q.out:
does not exist in index
Trying to apply the patch with -p2
error:
src/java/org/apache/hadoop/hive/ql/optimizer/ConstantPropagateProcFactory.java:
does not exist in index
error: src/test/queries/clientpositive/constant_prop_timestamp_date_cast.q:
does not exist in index
error: src/test/results/clientpositive/constant_prop_timestamp_date_cast.q.out:
does not exist in index
The patch does not appear to apply with p0, p1, or p2
+ result=1
+ '[' 1 -ne 0 ']'
+ rm -rf yetus_PreCommit-HIVE-Build-20987
+ exit 1
'
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995790 - PreCommit-HIVE-Build
> Hive ACID Data Corruption: Update command mess the other column data and
> produces incorrect result
> --
>
> Key: HIVE-22945
> URL: https://issues.apache.org/jira/browse/HIVE-22945
> Project: Hive
> Issue Type: Bug
> Components: Hive, Transactions
>Affects Versions: 3.2.0
>Reporter: Rajkumar Singh
>Assignee: Denys Kuzmenko
>Priority: Critical
> Attachments: HIVE-22945.1.patch
>
>
> Hive Update Operation update the other column incorrectly and produces
> incorrect results:
> Steps t
[jira] [Issue Comment Deleted] (HIVE-22126) hive-exec packaging should shade guava
[ https://issues.apache.org/jira/browse/HIVE-22126?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eugene Chung updated HIVE-22126: Comment: was deleted (was: If common-complier and janino modules are included in hive-exec, jar signing error is occurred. Execution default-test of goal org.apache.maven.plugins:maven-surefire-plugin:2.21.0:test failed: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:215) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:156) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:148) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81) at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56) at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192) at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105) at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957) at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289) at org.apache.maven.cli.MavenCli.main (MavenCli.java:193) at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke (Method.java:498) at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282) at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225) at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406) at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347) Caused by: org.apache.maven.plugin.PluginExecutionException: Execution default-test of goal org.apache.maven.plugins:maven-surefire-plugin:2.21.0:test failed: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:148) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:210) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:156) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:148) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81) at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56) at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192) at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105) at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957) at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289) at org.apache.maven.cli.MavenCli.main (MavenCli.java:193) at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke (Method.java:498) at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282) at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225) at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406) at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347) Caused by: org.apache.maven.surefire.util.SurefireReflectionException: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at org.apache.maven.surefire.util.ReflectionUtils.invokeMethodWithArray (ReflectionUtils.java:197) at org.apache.maven.surefire.util.ReflectionUtils.invokeGetter (ReflectionUtils.java:76) at org.apache.maven.surefire.util.ReflectionUtils.invokeGetter (ReflectionUtils.java:70) at org.apache.maven.surefire.booter.ProviderFactory$ProviderProxy.getSuites (ProviderFactory.java:144) at org.apache.maven.plugin.surefire.booterclient.ForkStarter.getSuitesIterator (ForkStarter.java:699) at org.apache.maven.plugin.surefire.bo
[jira] [Commented] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053800#comment-17053800
]
Jesus Camacho Rodriguez commented on HIVE-22962:
[~gopalv], [~rajesh.balamohan], [~vgarg], could you take a look? Thanks
https://github.com/apache/hive/pull/943
Preliminary results are quite promising (posted above). I also implemented the
warm up for the cache when HS2 comes up. The reason why I kept
{{RelFieldTrimmer}} around instead of merging {{RelFieldTrimmer}} and
{{HiveRelFieldTrimmer}} is that I do not know when I will be able to merge
these changes into Calcite, hence it will make easier to bring new version of
field trimmer whenever Calcite is upgraded (basically {{RelFieldTrimmer}} is
almost unchanged wrt Calcite version).
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.06.patch, HIVE-22962.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399509&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399509 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 07/Mar/20 02:02 Start Date: 07/Mar/20 02:02 Worklog Time Spent: 10m Work Description: davidov541 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-596032664 Agreed. It isn't difficult to do. The guidance I've been given in the past is to keep PRs tight and focused on the JIRA. Given that this is something that could be user-facing, it's easy enough to make a JIRA for this and a separate PR. I'll let @b-slim or a committer chime in on which direction we should go here. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399509) Time Spent: 14h (was: 13h 50m) > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.patch > > Time Spent: 14h > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HIVE-22962:
--
Labels: pull-request-available (was: )
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.patch
>
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jesus Camacho Rodriguez updated HIVE-22962:
---
Attachment: HIVE-22962.06.patch
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.06.patch, HIVE-22962.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22962) Reuse HiveRelFieldTrimmer instance across queries
[
https://issues.apache.org/jira/browse/HIVE-22962?focusedWorklogId=399412&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399412
]
ASF GitHub Bot logged work on HIVE-22962:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 22:54
Start Date: 06/Mar/20 22:54
Worklog Time Spent: 10m
Work Description: jcamachor commented on pull request #943: HIVE-22962
URL: https://github.com/apache/hive/pull/943
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399412)
Remaining Estimate: 0h
Time Spent: 10m
> Reuse HiveRelFieldTrimmer instance across queries
> -
>
> Key: HIVE-22962
> URL: https://issues.apache.org/jira/browse/HIVE-22962
> Project: Hive
> Issue Type: Improvement
> Components: CBO
>Reporter: Jesus Camacho Rodriguez
>Assignee: Jesus Camacho Rodriguez
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22962.01.patch, HIVE-22962.02.patch,
> HIVE-22962.03.patch, HIVE-22962.04.patch, HIVE-22962.05.patch,
> HIVE-22962.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Currently we create multiple {{HiveRelFieldTrimmer}} instances per query.
> {{HiveRelFieldTrimmer}} uses a method dispatcher that has a built-in caching
> mechanism: given a certain object, it stores the method that was called for
> the object class. However, by instantiating the trimmer multiple times per
> query and across queries, we create a new dispatcher with each instantiation,
> thus effectively removing the caching mechanism that is built within the
> dispatcher.
> This issue is to reutilize the same {{HiveRelFieldTrimmer}} instance within a
> single query and across queries.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22972) Allow table id to be set for table creation requests
[
https://issues.apache.org/jira/browse/HIVE-22972?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053845#comment-17053845
]
Hive QA commented on HIVE-22972:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 9m
4s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 0m
30s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
23s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 1m
16s{color} | {color:blue} standalone-metastore/metastore-server in master has
185 extant Findbugs warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
21s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 0m
34s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 0m
26s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 0m
26s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
22s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 1m
23s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
21s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
14s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 15m 27s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20988/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.0 |
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20988/yetus/patch-asflicense-problems.txt
|
| modules | C: standalone-metastore/metastore-server U:
standalone-metastore/metastore-server |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20988/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> Allow table id to be set for table creation requests
>
>
> Key: HIVE-22972
> URL: https://issues.apache.org/jira/browse/HIVE-22972
> Project: Hive
> Issue Type: Bug
> Components: Hive
>Reporter: Miklos Gergely
>Assignee: Miklos Gergely
>Priority: Major
> Fix For: 4.0.0
>
> Attachments: HIVE-22972.01.patch, HIVE-22972.02.patch,
> HIVE-22972.03.patch
>
>
> Hive Metastore should accept requests for table creation where the id is set,
> ignoring it.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399511&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399511 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 07/Mar/20 02:11 Start Date: 07/Mar/20 02:11 Worklog Time Spent: 10m Work Description: davidov541 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-596033740 Ah you're right, sorry. There are other uses of Avro in the Hive codebase, and I thought this was one of them, but this was included with the original changeset. I'll fix that now. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399511) Time Spent: 14h 20m (was: 14h 10m) > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.patch > > Time Spent: 14h 20m > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (HIVE-22760) Add Clock caching eviction based strategy
[ https://issues.apache.org/jira/browse/HIVE-22760?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053844#comment-17053844 ] Slim Bouguerra edited comment on HIVE-22760 at 3/7/20, 1:50 AM: [~szita] can please you take a look at this ? was (Author: bslim): [~szita] can you take a look at this ? > Add Clock caching eviction based strategy > - > > Key: HIVE-22760 > URL: https://issues.apache.org/jira/browse/HIVE-22760 > Project: Hive > Issue Type: New Feature > Components: llap >Reporter: Slim Bouguerra >Assignee: Slim Bouguerra >Priority: Major > Attachments: HIVE-22760.patch > > > LRFU is the current default right now. > The main issue with such Strategy is that it has a very high memory overhead, > in addition to that, most of the accounting has to happen under locks thus > can be source of contentions. > Add Simpler policy like clock, can help with both issues. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22865) Include data in replication staging directory
[ https://issues.apache.org/jira/browse/HIVE-22865?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] PRAVIN KUMAR SINHA updated HIVE-22865: -- Attachment: HIVE-22865.14.patch > Include data in replication staging directory > - > > Key: HIVE-22865 > URL: https://issues.apache.org/jira/browse/HIVE-22865 > Project: Hive > Issue Type: Task >Reporter: PRAVIN KUMAR SINHA >Assignee: PRAVIN KUMAR SINHA >Priority: Major > Labels: pull-request-available > Attachments: HIVE-22865.1.patch, HIVE-22865.10.patch, > HIVE-22865.11.patch, HIVE-22865.12.patch, HIVE-22865.13.patch, > HIVE-22865.14.patch, HIVE-22865.2.patch, HIVE-22865.3.patch, > HIVE-22865.4.patch, HIVE-22865.5.patch, HIVE-22865.6.patch, > HIVE-22865.7.patch, HIVE-22865.8.patch, HIVE-22865.9.patch > > Time Spent: 4h 40m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22954) Schedule Repl Load using Hive Scheduler
[
https://issues.apache.org/jira/browse/HIVE-22954?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053764#comment-17053764
]
Hive QA commented on HIVE-22954:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 1m
46s{color} | {color:blue} Maven dependency ordering for branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 7m
55s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 2m
7s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 1m
21s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
55s{color} | {color:blue} parser in master has 3 extant Findbugs warnings.
{color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 3m
43s{color} | {color:blue} ql in master has 1531 extant Findbugs warnings.
{color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
42s{color} | {color:blue} itests/hive-unit in master has 2 extant Findbugs
warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
44s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
28s{color} | {color:blue} Maven dependency ordering for patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 2m
34s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 2m
10s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 2m
10s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
10s{color} | {color:green} The patch parser passed checkstyle {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
42s{color} | {color:green} ql: The patch generated 0 new + 38 unchanged - 6
fixed = 38 total (was 44) {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
29s{color} | {color:green} itests/hive-unit: The patch generated 0 new + 1317
unchanged - 11 fixed = 1317 total (was 1328) {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 5m
55s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
43s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
14s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 35m 40s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20984/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20984/yetus/patch-asflicense-problems.txt
|
| modules | C: parser ql itests/hive-unit U: . |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20984/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> Schedule Repl Load using Hive Scheduler
> ---
>
> Key: HIVE-22954
> URL: https://issues.apache.org/jira/browse/HIVE-22954
> Project: Hive
> Issue Type: Task
>Reporter: Aasha Medhi
>Assignee: Aasha Medhi
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22954.01.patch, HIVE-22954.02.patch,
> HIVE-22954.03.patch, HIVE-22954.04.patch, HIVE-22954.05.patch,
> HIVE-22954.06.
[jira] [Work logged] (HIVE-21004) Less object creation for Hive Kafka reader
[ https://issues.apache.org/jira/browse/HIVE-21004?focusedWorklogId=399483&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399483 ] ASF GitHub Bot logged work on HIVE-21004: - Author: ASF GitHub Bot Created on: 07/Mar/20 01:04 Start Date: 07/Mar/20 01:04 Worklog Time Spent: 10m Work Description: b-slim commented on pull request #502: HIVE-21004: Reduce the amount of not needed object creation at Kafka … URL: https://github.com/apache/hive/pull/502 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399483) Remaining Estimate: 0h Time Spent: 10m > Less object creation for Hive Kafka reader > -- > > Key: HIVE-21004 > URL: https://issues.apache.org/jira/browse/HIVE-21004 > Project: Hive > Issue Type: Improvement > Components: kafka integration >Reporter: Slim Bouguerra >Assignee: Slim Bouguerra >Priority: Major > Labels: pull-request-available > Fix For: 4.0.0 > > Attachments: HIVE-21004.2.patch, HIVE-21004.2.patch, HIVE-21004.patch > > Time Spent: 10m > Remaining Estimate: 0h > > Reduce the amount of un-needed object allocation by using a row boat as way > to carry data around. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-21218) KafkaSerDe doesn't support topics created via Confluent Avro serializer
[ https://issues.apache.org/jira/browse/HIVE-21218?focusedWorklogId=399510&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399510 ] ASF GitHub Bot logged work on HIVE-21218: - Author: ASF GitHub Bot Created on: 07/Mar/20 02:06 Start Date: 07/Mar/20 02:06 Worklog Time Spent: 10m Work Description: cricket007 commented on issue #933: HIVE-21218: Adding support for Confluent Kafka Avro message format URL: https://github.com/apache/hive/pull/933#issuecomment-596033178 What do you mean? The Avro file and Maven plugin are part of this PR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399510) Time Spent: 14h 10m (was: 14h) > KafkaSerDe doesn't support topics created via Confluent Avro serializer > --- > > Key: HIVE-21218 > URL: https://issues.apache.org/jira/browse/HIVE-21218 > Project: Hive > Issue Type: Bug > Components: kafka integration, Serializers/Deserializers >Affects Versions: 3.1.1 >Reporter: Milan Baran >Assignee: David McGinnis >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21218.2.patch, HIVE-21218.3.patch, > HIVE-21218.4.patch, HIVE-21218.5.patch, HIVE-21218.6.patch, > HIVE-21218.7.patch, HIVE-21218.patch > > Time Spent: 14h 10m > Remaining Estimate: 0h > > According to [Google > groups|https://groups.google.com/forum/#!topic/confluent-platform/JYhlXN0u9_A] > the Confluent avro serialzier uses propertiary format for kafka value - > <4 bytes of schema ID> conforms to schema>. > This format does not cause any problem for Confluent kafka deserializer which > respect the format however for hive kafka handler its bit a problem to > correctly deserialize kafka value, because Hive uses custom deserializer from > bytes to objects and ignores kafka consumer ser/deser classes provided via > table property. > It would be nice to support Confluent format with magic byte. > Also it would be great to support Schema registry as well. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22254) Mappings.NoElementException: no target in mapping, in `MaterializedViewAggregateRule
[
https://issues.apache.org/jira/browse/HIVE-22254?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053763#comment-17053763
]
Vineet Garg commented on HIVE-22254:
This case also fails
{code:sql}
create materialized view av2 stored as orc as select f1, f2, m1 from fact group
by f1, f2, m1;
explain cbo extended select f1,pk1 from fact inner join dim1 on fact.f1 =
dim1.pk1 group by f1, pk1;
{code}
Problem seems to be in the logic which is creating Mappings from view's top
project to query's. In this particular case since both of the query columns map
to the same column in view's project, one mapping overrides the other. Later
this mapping is inversed to create a project which results into accessing
negative index.
Query with aggregate also fails in rewrite albeit due to slightly different
reason, the aggregate doesn't exist in the view rel node resulting in negative
mapping for the aggregate. While trying to introduce aggregate on top of view
this fails due to missing index in mapping.
I am still working on how to properly fix this.
> Mappings.NoElementException: no target in mapping, in
> `MaterializedViewAggregateRule
>
>
> Key: HIVE-22254
> URL: https://issues.apache.org/jira/browse/HIVE-22254
> Project: Hive
> Issue Type: Sub-task
> Components: CBO, Materialized views
>Affects Versions: 3.1.2
>Reporter: Steve Carlin
>Priority: Minor
> Attachments: ojoin_full.sql
>
>
> A Mappings.NoElementException happens on an edge condition for a query using
> a materialized view.
> The query contains a "group by" clause which contains fields from both sides
> of a join. There is no real reason to group by this same field twice, but
> there is also no reason that this shouldn't succeed.
> Attached is a script which causes this failure. The query causing the
> problem looks like this:
> explain extended select sum(1)
> from fact inner join dim1
> on fact.f1 = dim1.pk1
> group by f1, pk1;
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (HIVE-22254) Mappings.NoElementException: no target in mapping, in `MaterializedViewAggregateRule
[ https://issues.apache.org/jira/browse/HIVE-22254?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Vineet Garg reassigned HIVE-22254: -- Assignee: Vineet Garg > Mappings.NoElementException: no target in mapping, in > `MaterializedViewAggregateRule > > > Key: HIVE-22254 > URL: https://issues.apache.org/jira/browse/HIVE-22254 > Project: Hive > Issue Type: Sub-task > Components: CBO, Materialized views >Affects Versions: 3.1.2 >Reporter: Steve Carlin >Assignee: Vineet Garg >Priority: Minor > Attachments: ojoin_full.sql > > > A Mappings.NoElementException happens on an edge condition for a query using > a materialized view. > The query contains a "group by" clause which contains fields from both sides > of a join. There is no real reason to group by this same field twice, but > there is also no reason that this shouldn't succeed. > Attached is a script which causes this failure. The query causing the > problem looks like this: > explain extended select sum(1) > from fact inner join dim1 > on fact.f1 = dim1.pk1 > group by f1, pk1; -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22955) PreUpgradeTool can fail because access to CharsetDecoder is not synchronized
[
https://issues.apache.org/jira/browse/HIVE-22955?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053796#comment-17053796
]
Hive QA commented on HIVE-22955:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 9m
14s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 0m
13s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
9s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
22s{color} | {color:blue} upgrade-acid/pre-upgrade in master has 1 extant
Findbugs warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
9s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 0m
14s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 0m
12s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 0m
12s{color} | {color:green} the patch passed {color} |
| {color:red}-1{color} | {color:red} checkstyle {color} | {color:red} 0m
9s{color} | {color:red} upgrade-acid/pre-upgrade: The patch generated 2 new +
52 unchanged - 1 fixed = 54 total (was 53) {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 0m
25s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
11s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
13s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 12m 2s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20985/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| checkstyle |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20985/yetus/diff-checkstyle-upgrade-acid_pre-upgrade.txt
|
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20985/yetus/patch-asflicense-problems.txt
|
| modules | C: upgrade-acid/pre-upgrade U: upgrade-acid/pre-upgrade |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20985/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> PreUpgradeTool can fail because access to CharsetDecoder is not synchronized
>
>
> Key: HIVE-22955
> URL: https://issues.apache.org/jira/browse/HIVE-22955
> Project: Hive
> Issue Type: Bug
> Components: Transactions
>Affects Versions: 4.0.0
>Reporter: Hankó Gergely
>Assignee: Hankó Gergely
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22955.1.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> {code:java}
> 2020-02-26 20:22:49,683 ERROR [main] acid.PreUpgradeTool
> (PreUpgradeTool.java:main(150)) - PreUpgradeTool failed
> org.apache.hadoop.hive.ql.metadata.HiveException at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.prepareAcidUpgradeInternal(PreUpgradeTool.java:283)
> at
> org.apache.hadoop.hive.upgrade.acid.PreUpgradeTool.main(PreUpgradeTool.java:146)
> Caused by: java.lang.RuntimeException:
> java.util.concurrent.ExecutionException: java.lang.RuntimeException:
> java.lang.RuntimeException: java.lang.RuntimeException:
> java.lang.IllegalStateException: Current state = RESET, new state = FLUSHED
> ...
> Caused by: java.lang.IllegalStateException: Current state = RESET, new stat
[jira] [Commented] (HIVE-21778) CBO: "Struct is not null" gets evaluated as `nullable` always causing filter miss in the query
[
https://issues.apache.org/jira/browse/HIVE-21778?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053712#comment-17053712
]
Hive QA commented on HIVE-21778:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995770/HIVE-21778.7.patch
{color:green}SUCCESS:{color} +1 due to 1 test(s) being added or modified.
{color:red}ERROR:{color} -1 due to 1 failed/errored test(s), 18099 tests
executed
*Failed tests:*
{noformat}
org.apache.hadoop.hive.ql.parse.TestStatsReplicationScenariosNoAutogather.org.apache.hadoop.hive.ql.parse.TestStatsReplicationScenariosNoAutogather
(batchId=278)
{noformat}
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20982/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20982/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20982/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
Tests exited with: TestsFailedException: 1 tests failed
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995770 - PreCommit-HIVE-Build
> CBO: "Struct is not null" gets evaluated as `nullable` always causing filter
> miss in the query
> --
>
> Key: HIVE-21778
> URL: https://issues.apache.org/jira/browse/HIVE-21778
> Project: Hive
> Issue Type: Bug
> Components: CBO
>Affects Versions: 4.0.0, 2.3.5
>Reporter: Rajesh Balamohan
>Assignee: Vineet Garg
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-21778.1.patch, HIVE-21778.2.patch,
> HIVE-21778.3.patch, HIVE-21778.4.patch, HIVE-21778.5.patch,
> HIVE-21778.6.patch, HIVE-21778.7.patch, test_null.q, test_null.q.out
>
> Time Spent: 40m
> Remaining Estimate: 0h
>
> {noformat}
> drop table if exists test_struct;
> CREATE external TABLE test_struct
> (
> f1 string,
> demo_struct struct,
> datestr string
> );
> set hive.cbo.enable=true;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: (datestr = '2019-01-01') (type: boolean) <- Note
> that demo_struct filter is not added here
> Filter Operator
> predicate: (datestr = '2019-01-01') (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
> outputColumnNames: _col0, _col1, _col2
> ListSink
> set hive.cbo.enable=false;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: ((datestr = '2019-01-01') and demo_struct is not null)
> (type: boolean) <- Note that demo_struct filter is added when CBO is
> turned off
> Filter Operator
> predicate: ((datestr = '2019-01-01') and demo_struct is not null)
> (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
> outputColumnNames: _col0, _col1, _col2
> ListSink
> {noformat}
> In CalcitePlanner::genFilterRelNode, the following code misses to evaluate
> this filter.
> {noformat}
> RexNode factoredFilterExpr = RexUtil
> .pullFactors(cluster.getRexBuilder(), convertedFilterExpr);
> {noformat}
> Note that even if we add `demo_struct.f1` it would end up pushing the filter
> correctly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (HIVE-22995) Add support for location for managed tables on database
[ https://issues.apache.org/jira/browse/HIVE-22995?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Naveen Gangam reassigned HIVE-22995: > Add support for location for managed tables on database > --- > > Key: HIVE-22995 > URL: https://issues.apache.org/jira/browse/HIVE-22995 > Project: Hive > Issue Type: Improvement > Components: Hive >Affects Versions: 3.1.0 >Reporter: Naveen Gangam >Assignee: Naveen Gangam >Priority: Major > Attachments: Hive Metastore Support for Tenant-based storage > heirarchy.pdf > > > I have attached the initial spec to this jira. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22974) Metastore's table location check should be applied when location changed
[ https://issues.apache.org/jira/browse/HIVE-22974?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Naveen Gangam updated HIVE-22974: - Parent: HIVE-21663 Issue Type: Sub-task (was: Bug) > Metastore's table location check should be applied when location changed > > > Key: HIVE-22974 > URL: https://issues.apache.org/jira/browse/HIVE-22974 > Project: Hive > Issue Type: Sub-task > Components: Metastore >Reporter: Attila Magyar >Assignee: Attila Magyar >Priority: Major > Fix For: 4.0.0 > > Attachments: HIVE-22974.2.patch, HIVE-22974.3.patch > > > In HIVE-22189 a check was introduced to make sure managed and external tables > are located at the proper space. This condition cannot be satisfied during an > upgrade. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22974) Metastore's table location check should be applied when location changed
[ https://issues.apache.org/jira/browse/HIVE-22974?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053701#comment-17053701 ] Naveen Gangam commented on HIVE-22974: -- Will do. > Metastore's table location check should be applied when location changed > > > Key: HIVE-22974 > URL: https://issues.apache.org/jira/browse/HIVE-22974 > Project: Hive > Issue Type: Bug > Components: Metastore >Reporter: Attila Magyar >Assignee: Attila Magyar >Priority: Major > Fix For: 4.0.0 > > Attachments: HIVE-22974.2.patch, HIVE-22974.3.patch > > > In HIVE-22189 a check was introduced to make sure managed and external tables > are located at the proper space. This condition cannot be satisfied during an > upgrade. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[
https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399284&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399284
]
ASF GitHub Bot logged work on HIVE-22959:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 18:26
Start Date: 06/Mar/20 18:26
Worklog Time Spent: 10m
Work Description: pgaref commented on pull request #931: HIVE-22959
Expose FilterContext as part of Hive storage-api
URL: https://github.com/apache/hive/pull/931#discussion_r389068042
##
File path:
storage-api/src/java/org/apache/hadoop/hive/ql/io/filter/MutableFilterContext.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.io.filter;
+
+import java.util.Arrays;
+
+/**
+ * A representation of a Filter applied on the rows of a VectorizedRowBatch
+ * {@link org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch}.
+ *
+ * Each FilterContext consists of an array with the ids (int) of rows that are
selected by the
+ * filter, an integer representing the number of selected rows, and a boolean
showing if the filter
+ * actually selected any rows.
+ *
+ */
+public class MutableFilterContext extends FilterContext {
+
+ /**
+ * Set context with the given values by reference
+ *
+ * @param isSelectedInUse if the filter is applied
+ * @param selected an array of the selected rows
+ * @param selectedSize the number of the selected rows
+ */
+ public void setFilterContext(boolean isSelectedInUse, int[] selected, int
selectedSize) {
+this.currBatchIsSelectedInUse = isSelectedInUse;
+this.currBatchSelected = selected;
+this.currBatchSelectedSize = selectedSize;
+// Avoid selected.length < selectedSize since we can borrow a larger array
for selected
+// debug loop for checking if selected is in order without duplicates (i.e
[1,1,1] is illegal)
+for (int i = 0; i < selectedSize-1; i++)
+ assert selected[i] < selected[i+1];
Review comment:
Added a separate validate method that is checked with an assertion (the
idea here is to use it only as part of testing)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399284)
Time Spent: 1h 10m (was: 1h)
> Extend storage-api to expose FilterContext
> --
>
> Key: HIVE-22959
> URL: https://issues.apache.org/jira/browse/HIVE-22959
> Project: Hive
> Issue Type: Sub-task
> Components: storage-api
>Reporter: Panagiotis Garefalakis
>Assignee: Panagiotis Garefalakis
>Priority: Major
> Labels: pull-request-available
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> To enable row-level filtering at the ORC level ORC-577, or as an extension
> ProDecode MapJoin HIVE-22731 we need a common context class that will hold
> all the needed information for the filter.
> I propose this class to be part of the storage-api – similar to
> VectorizedRowBatch class and hold the information below:
> * A boolean variable showing if the filter is enabled
> * A int array storing the row Ids that are actually selected (passing the
> filter)
> * An int variable storing the the number or rows that passed the filter
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[
https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399285&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399285
]
ASF GitHub Bot logged work on HIVE-22959:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 18:26
Start Date: 06/Mar/20 18:26
Worklog Time Spent: 10m
Work Description: pgaref commented on pull request #931: HIVE-22959
Expose FilterContext as part of Hive storage-api
URL: https://github.com/apache/hive/pull/931#discussion_r389068224
##
File path:
storage-api/src/java/org/apache/hadoop/hive/ql/io/filter/MutableFilterContext.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.io.filter;
+
+import java.util.Arrays;
+
+/**
+ * A representation of a Filter applied on the rows of a VectorizedRowBatch
+ * {@link org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch}.
+ *
+ * Each FilterContext consists of an array with the ids (int) of rows that are
selected by the
+ * filter, an integer representing the number of selected rows, and a boolean
showing if the filter
+ * actually selected any rows.
+ *
+ */
+public class MutableFilterContext extends FilterContext {
+
+ /**
+ * Set context with the given values by reference
+ *
+ * @param isSelectedInUse if the filter is applied
+ * @param selected an array of the selected rows
+ * @param selectedSize the number of the selected rows
+ */
+ public void setFilterContext(boolean isSelectedInUse, int[] selected, int
selectedSize) {
+this.currBatchIsSelectedInUse = isSelectedInUse;
+this.currBatchSelected = selected;
+this.currBatchSelectedSize = selectedSize;
+// Avoid selected.length < selectedSize since we can borrow a larger array
for selected
+// debug loop for checking if selected is in order without duplicates (i.e
[1,1,1] is illegal)
+for (int i = 0; i < selectedSize-1; i++)
+ assert selected[i] < selected[i+1];
+ }
+
+ /**
+ * Copy context variables from the a given FilterContext.
+ * Always does a deep copy of the data.
+ *
+ * @param other FilterContext to copy from
+ */
+ public void copyFilterContextFrom(MutableFilterContext other) {
+// assert if copying into self
Review comment:
Makes sense, added an extra condition here
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399285)
Time Spent: 1h 20m (was: 1h 10m)
> Extend storage-api to expose FilterContext
> --
>
> Key: HIVE-22959
> URL: https://issues.apache.org/jira/browse/HIVE-22959
> Project: Hive
> Issue Type: Sub-task
> Components: storage-api
>Reporter: Panagiotis Garefalakis
>Assignee: Panagiotis Garefalakis
>Priority: Major
> Labels: pull-request-available
> Time Spent: 1h 20m
> Remaining Estimate: 0h
>
> To enable row-level filtering at the ORC level ORC-577, or as an extension
> ProDecode MapJoin HIVE-22731 we need a common context class that will hold
> all the needed information for the filter.
> I propose this class to be part of the storage-api – similar to
> VectorizedRowBatch class and hold the information below:
> * A boolean variable showing if the filter is enabled
> * A int array storing the row Ids that are actually selected (passing the
> filter)
> * An int variable storing the the number or rows that passed the filter
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22974) Metastore's table location check should be applied when location changed
[ https://issues.apache.org/jira/browse/HIVE-22974?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053680#comment-17053680 ] Attila Magyar commented on HIVE-22974: -- [~ngangam], ok, could you push it to master once CI finishes? > Metastore's table location check should be applied when location changed > > > Key: HIVE-22974 > URL: https://issues.apache.org/jira/browse/HIVE-22974 > Project: Hive > Issue Type: Bug > Components: Metastore >Reporter: Attila Magyar >Assignee: Attila Magyar >Priority: Major > Fix For: 4.0.0 > > Attachments: HIVE-22974.2.patch, HIVE-22974.3.patch > > > In HIVE-22189 a check was introduced to make sure managed and external tables > are located at the proper space. This condition cannot be satisfied during an > upgrade. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[ https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399283&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399283 ] ASF GitHub Bot logged work on HIVE-22959: - Author: ASF GitHub Bot Created on: 06/Mar/20 18:25 Start Date: 06/Mar/20 18:25 Worklog Time Spent: 10m Work Description: pgaref commented on pull request #931: HIVE-22959 Expose FilterContext as part of Hive storage-api URL: https://github.com/apache/hive/pull/931#discussion_r389067478 ## File path: ql/src/test/org/apache/hadoop/hive/ql/io/filter/TestFilterContext.java ## @@ -0,0 +1,107 @@ +package org.apache.hadoop.hive.ql.io.filter; Review comment: Fixed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399283) Time Spent: 1h (was: 50m) > Extend storage-api to expose FilterContext > -- > > Key: HIVE-22959 > URL: https://issues.apache.org/jira/browse/HIVE-22959 > Project: Hive > Issue Type: Sub-task > Components: storage-api >Reporter: Panagiotis Garefalakis >Assignee: Panagiotis Garefalakis >Priority: Major > Labels: pull-request-available > Time Spent: 1h > Remaining Estimate: 0h > > To enable row-level filtering at the ORC level ORC-577, or as an extension > ProDecode MapJoin HIVE-22731 we need a common context class that will hold > all the needed information for the filter. > I propose this class to be part of the storage-api – similar to > VectorizedRowBatch class and hold the information below: > * A boolean variable showing if the filter is enabled > * A int array storing the row Ids that are actually selected (passing the > filter) > * An int variable storing the the number or rows that passed the filter > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-21778) CBO: "Struct is not null" gets evaluated as `nullable` always causing filter miss in the query
[
https://issues.apache.org/jira/browse/HIVE-21778?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053672#comment-17053672
]
Hive QA commented on HIVE-21778:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 9m
18s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
2s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
39s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 3m
44s{color} | {color:blue} ql in master has 1531 extant Findbugs warnings.
{color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
54s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
25s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
4s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 1m
4s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
41s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 4m
1s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
56s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
14s{color} | {color:red} The patch generated 2 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 24m 38s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20982/dev-support/hive-personality.sh
|
| git revision | master / 1b50b70 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20982/yetus/patch-asflicense-problems.txt
|
| modules | C: ql U: ql |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20982/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> CBO: "Struct is not null" gets evaluated as `nullable` always causing filter
> miss in the query
> --
>
> Key: HIVE-21778
> URL: https://issues.apache.org/jira/browse/HIVE-21778
> Project: Hive
> Issue Type: Bug
> Components: CBO
>Affects Versions: 4.0.0, 2.3.5
>Reporter: Rajesh Balamohan
>Assignee: Vineet Garg
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-21778.1.patch, HIVE-21778.2.patch,
> HIVE-21778.3.patch, HIVE-21778.4.patch, HIVE-21778.5.patch,
> HIVE-21778.6.patch, HIVE-21778.7.patch, test_null.q, test_null.q.out
>
> Time Spent: 40m
> Remaining Estimate: 0h
>
> {noformat}
> drop table if exists test_struct;
> CREATE external TABLE test_struct
> (
> f1 string,
> demo_struct struct,
> datestr string
> );
> set hive.cbo.enable=true;
> explain select * from etltmp.test_struct where datestr='2019-01-01' and
> demo_struct is not null;
> STAGE PLANS:
> Stage: Stage-0
> Fetch Operator
> limit: -1
> Processor Tree:
> TableScan
> alias: test_struct
> filterExpr: (datestr = '2019-01-01') (type: boolean) <- Note
> that demo_struct filter is not added here
> Filter Operator
> predicate: (datestr = '2019-01-01') (type: boolean)
> Select Operator
> expressions: f1 (type: string), demo_struct (type:
> struct), '2019-01-01' (type: string)
>
[jira] [Updated] (HIVE-22437) LLAP Metadata cache NPE on locking metadata.
[
https://issues.apache.org/jira/browse/HIVE-22437?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Slim Bouguerra updated HIVE-22437:
--
Attachment: HIVE-22437.patch
> LLAP Metadata cache NPE on locking metadata.
>
>
> Key: HIVE-22437
> URL: https://issues.apache.org/jira/browse/HIVE-22437
> Project: Hive
> Issue Type: Bug
> Components: llap
>Reporter: Slim Bouguerra
>Assignee: Slim Bouguerra
>Priority: Major
> Attachments: HIVE-22437.patch, HIVE-22437.patch
>
>
> {code}
> java.lang.NullPointerException
> at
> org.apache.hadoop.hive.llap.io.metadata.MetadataCache.unlockSingleBuffer(MetadataCache.java:464)
> at
> org.apache.hadoop.hive.llap.io.metadata.MetadataCache.lockBuffer(MetadataCache.java:409)
> at
> org.apache.hadoop.hive.llap.io.metadata.MetadataCache.lockOldVal(MetadataCache.java:314)
> at
> org.apache.hadoop.hive.llap.io.metadata.MetadataCache.putInternal(MetadataCache.java:287)
> at
> org.apache.hadoop.hive.llap.io.metadata.MetadataCache.putFileMetadata(MetadataCache.java:199)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22979) Support total file size in statistics annotation
[ https://issues.apache.org/jira/browse/HIVE-22979?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053645#comment-17053645 ] Jesus Camacho Rodriguez commented on HIVE-22979: Sounds like a good idea, thanks! > Support total file size in statistics annotation > > > Key: HIVE-22979 > URL: https://issues.apache.org/jira/browse/HIVE-22979 > Project: Hive > Issue Type: Improvement >Affects Versions: 4.0.0 >Reporter: Prasanth Jayachandran >Assignee: Prasanth Jayachandran >Priority: Minor > Labels: pull-request-available > Attachments: HIVE-22979.1.patch, HIVE-22979.2.patch > > Time Spent: 50m > Remaining Estimate: 0h > > Hive statistics annotation provide estimated Statistics for each operator. > The data size provided in TableScanOperator is raw data size (after > decompression and decoding), but there are some optimizations that can be > performed based on total file size on disk (scan cost estimation). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22979) Support total file size in statistics annotation
[ https://issues.apache.org/jira/browse/HIVE-22979?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053639#comment-17053639 ] Prasanth Jayachandran commented on HIVE-22979: -- [~jcamachorodriguez] thanks for the review! I agree that this will certainly be very useful for debugging issues and will be good to have it in explain (all levels of explain) as this is sort of give a single place to look at on-disk file size and estimated raw data size (to know the compression factor maybe?). Created HIVE-22994 to tackle it separately after this patch as it will touch almost all explain out files. > Support total file size in statistics annotation > > > Key: HIVE-22979 > URL: https://issues.apache.org/jira/browse/HIVE-22979 > Project: Hive > Issue Type: Improvement >Affects Versions: 4.0.0 >Reporter: Prasanth Jayachandran >Assignee: Prasanth Jayachandran >Priority: Minor > Labels: pull-request-available > Attachments: HIVE-22979.1.patch, HIVE-22979.2.patch > > Time Spent: 50m > Remaining Estimate: 0h > > Hive statistics annotation provide estimated Statistics for each operator. > The data size provided in TableScanOperator is raw data size (after > decompression and decoding), but there are some optimizations that can be > performed based on total file size on disk (scan cost estimation). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22979) Support total file size in statistics annotation
[ https://issues.apache.org/jira/browse/HIVE-22979?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Prasanth Jayachandran updated HIVE-22979: - Attachment: HIVE-22979.2.patch > Support total file size in statistics annotation > > > Key: HIVE-22979 > URL: https://issues.apache.org/jira/browse/HIVE-22979 > Project: Hive > Issue Type: Improvement >Affects Versions: 4.0.0 >Reporter: Prasanth Jayachandran >Assignee: Prasanth Jayachandran >Priority: Minor > Labels: pull-request-available > Attachments: HIVE-22979.1.patch, HIVE-22979.2.patch > > Time Spent: 50m > Remaining Estimate: 0h > > Hive statistics annotation provide estimated Statistics for each operator. > The data size provided in TableScanOperator is raw data size (after > decompression and decoding), but there are some optimizations that can be > performed based on total file size on disk (scan cost estimation). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22901) Variable substitution can lead to OOM on circular references
[
https://issues.apache.org/jira/browse/HIVE-22901?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053630#comment-17053630
]
Hive QA commented on HIVE-22901:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995754/HIVE-22901.2.patch
{color:green}SUCCESS:{color} +1 due to 2 test(s) being added or modified.
{color:red}ERROR:{color} -1 due to 1 failed/errored test(s), 18098 tests
executed
*Failed tests:*
{noformat}
org.apache.hadoop.hive.ql.parse.TestReplAcidTablesBootstrapWithJsonMessage.org.apache.hadoop.hive.ql.parse.TestReplAcidTablesBootstrapWithJsonMessage
(batchId=259)
{noformat}
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20981/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20981/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20981/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
Tests exited with: TestsFailedException: 1 tests failed
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995754 - PreCommit-HIVE-Build
> Variable substitution can lead to OOM on circular references
>
>
> Key: HIVE-22901
> URL: https://issues.apache.org/jira/browse/HIVE-22901
> Project: Hive
> Issue Type: Bug
> Components: HiveServer2
>Affects Versions: 3.1.2
>Reporter: Daniel Voros
>Assignee: Daniel Voros
>Priority: Major
> Attachments: HIVE-22901.1.patch, HIVE-22901.2.patch
>
>
> {{SystemVariables#substitute()}} is dealing with circular references between
> variables by only doing the substitution 40 times by default. If the
> substituted part is sufficiently large though, it's possible that the
> substitution will produce a string bigger than the heap size within the 40
> executions.
> Take the following test case that fails with OOM in current master (third
> round of execution would need 10G heap, while running with only 2G):
> {code}
> @Test
> public void testSubstitute() {
> String randomPart = RandomStringUtils.random(100_000);
> String reference = "${hiveconf:myTestVariable}";
> StringBuilder longStringWithReferences = new StringBuilder();
> for(int i = 0; i < 10; i ++) {
> longStringWithReferences.append(randomPart).append(reference);
> }
> SystemVariables uut = new SystemVariables();
> HiveConf conf = new HiveConf();
> conf.set("myTestVariable", longStringWithReferences.toString());
> uut.substitute(conf, longStringWithReferences.toString(), 40);
> }
> {code}
> Produces:
> {code}
> java.lang.OutOfMemoryError: Java heap space
> at java.util.Arrays.copyOf(Arrays.java:3332)
> at
> java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
> at
> java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
> at java.lang.StringBuilder.append(StringBuilder.java:136)
> at
> org.apache.hadoop.hive.conf.SystemVariables.substitute(SystemVariables.java:110)
> at
> org.apache.hadoop.hive.conf.SystemVariablesTest.testSubstitute(SystemVariablesTest.java:27)
> {code}
> We should check the size of the substituted query and bail out earlier.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22979) Support total file size in statistics annotation
[ https://issues.apache.org/jira/browse/HIVE-22979?focusedWorklogId=399258&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399258 ] ASF GitHub Bot logged work on HIVE-22979: - Author: ASF GitHub Bot Created on: 06/Mar/20 17:44 Start Date: 06/Mar/20 17:44 Worklog Time Spent: 10m Work Description: prasanthj commented on pull request #941: HIVE-22979: Support total file size in statistics annotation URL: https://github.com/apache/hive/pull/941#discussion_r389048770 ## File path: ql/src/java/org/apache/hadoop/hive/ql/stats/StatsUtils.java ## @@ -147,7 +147,7 @@ * - hive configuration * @param partList * - partition list - * @param table + * @param tablebasicStats.getNumRows() Review comment: Yup. Fixed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399258) Time Spent: 50m (was: 40m) > Support total file size in statistics annotation > > > Key: HIVE-22979 > URL: https://issues.apache.org/jira/browse/HIVE-22979 > Project: Hive > Issue Type: Improvement >Affects Versions: 4.0.0 >Reporter: Prasanth Jayachandran >Assignee: Prasanth Jayachandran >Priority: Minor > Labels: pull-request-available > Attachments: HIVE-22979.1.patch > > Time Spent: 50m > Remaining Estimate: 0h > > Hive statistics annotation provide estimated Statistics for each operator. > The data size provided in TableScanOperator is raw data size (after > decompression and decoding), but there are some optimizations that can be > performed based on total file size on disk (scan cost estimation). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22979) Support total file size in statistics annotation
[
https://issues.apache.org/jira/browse/HIVE-22979?focusedWorklogId=399257&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399257
]
ASF GitHub Bot logged work on HIVE-22979:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 17:44
Start Date: 06/Mar/20 17:44
Worklog Time Spent: 10m
Work Description: prasanthj commented on pull request #941: HIVE-22979:
Support total file size in statistics annotation
URL: https://github.com/apache/hive/pull/941#discussion_r389048647
##
File path: ql/src/java/org/apache/hadoop/hive/ql/plan/Statistics.java
##
@@ -53,19 +53,21 @@ public State merge(State otherState) {
private long numRows;
private long runTimeNumRows;
private long dataSize;
+ private long totalFileSize;
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399257)
Time Spent: 40m (was: 0.5h)
> Support total file size in statistics annotation
>
>
> Key: HIVE-22979
> URL: https://issues.apache.org/jira/browse/HIVE-22979
> Project: Hive
> Issue Type: Improvement
>Affects Versions: 4.0.0
>Reporter: Prasanth Jayachandran
>Assignee: Prasanth Jayachandran
>Priority: Minor
> Labels: pull-request-available
> Attachments: HIVE-22979.1.patch
>
> Time Spent: 40m
> Remaining Estimate: 0h
>
> Hive statistics annotation provide estimated Statistics for each operator.
> The data size provided in TableScanOperator is raw data size (after
> decompression and decoding), but there are some optimizations that can be
> performed based on total file size on disk (scan cost estimation).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22979) Support total file size in statistics annotation
[
https://issues.apache.org/jira/browse/HIVE-22979?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053629#comment-17053629
]
Jesus Camacho Rodriguez commented on HIVE-22979:
Left a couple of minor comments in the PR.
Just another idea. I understand we may not want to expose this number in
explain as it would change all plans, but maybe we want to do it in extended
explain as it would help debugging any issues? There are already two different
methods for user vs default/extended explain.
{code}
...
@Override
@Explain(displayName = "Statistics")
public String toString() {
...
@Explain(displayName = "Statistics", explainLevels = { Level.USER })
public String toUserLevelExplainString() {
...
{code}
We could create a third one, specific for extended explain that includes this
number. We can tackle that in follow-up though.
Other than that, LGTM, +1
> Support total file size in statistics annotation
>
>
> Key: HIVE-22979
> URL: https://issues.apache.org/jira/browse/HIVE-22979
> Project: Hive
> Issue Type: Improvement
>Affects Versions: 4.0.0
>Reporter: Prasanth Jayachandran
>Assignee: Prasanth Jayachandran
>Priority: Minor
> Labels: pull-request-available
> Attachments: HIVE-22979.1.patch
>
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Hive statistics annotation provide estimated Statistics for each operator.
> The data size provided in TableScanOperator is raw data size (after
> decompression and decoding), but there are some optimizations that can be
> performed based on total file size on disk (scan cost estimation).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22979) Support total file size in statistics annotation
[ https://issues.apache.org/jira/browse/HIVE-22979?focusedWorklogId=399252&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399252 ] ASF GitHub Bot logged work on HIVE-22979: - Author: ASF GitHub Bot Created on: 06/Mar/20 17:37 Start Date: 06/Mar/20 17:37 Worklog Time Spent: 10m Work Description: jcamachor commented on pull request #941: HIVE-22979: Support total file size in statistics annotation URL: https://github.com/apache/hive/pull/941#discussion_r389044259 ## File path: ql/src/java/org/apache/hadoop/hive/ql/stats/StatsUtils.java ## @@ -147,7 +147,7 @@ * - hive configuration * @param partList * - partition list - * @param table + * @param tablebasicStats.getNumRows() Review comment: Unintended change? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399252) Time Spent: 0.5h (was: 20m) > Support total file size in statistics annotation > > > Key: HIVE-22979 > URL: https://issues.apache.org/jira/browse/HIVE-22979 > Project: Hive > Issue Type: Improvement >Affects Versions: 4.0.0 >Reporter: Prasanth Jayachandran >Assignee: Prasanth Jayachandran >Priority: Minor > Labels: pull-request-available > Attachments: HIVE-22979.1.patch > > Time Spent: 0.5h > Remaining Estimate: 0h > > Hive statistics annotation provide estimated Statistics for each operator. > The data size provided in TableScanOperator is raw data size (after > decompression and decoding), but there are some optimizations that can be > performed based on total file size on disk (scan cost estimation). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22979) Support total file size in statistics annotation
[
https://issues.apache.org/jira/browse/HIVE-22979?focusedWorklogId=399251&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399251
]
ASF GitHub Bot logged work on HIVE-22979:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 17:37
Start Date: 06/Mar/20 17:37
Worklog Time Spent: 10m
Work Description: jcamachor commented on pull request #941: HIVE-22979:
Support total file size in statistics annotation
URL: https://github.com/apache/hive/pull/941#discussion_r389043859
##
File path: ql/src/java/org/apache/hadoop/hive/ql/plan/Statistics.java
##
@@ -53,19 +53,21 @@ public State merge(State otherState) {
private long numRows;
private long runTimeNumRows;
private long dataSize;
+ private long totalFileSize;
Review comment:
Could you add a comment on what dataSize and totalFileSize mean? It will
prevent us from getting confused when we check the code back after some time :)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399251)
Time Spent: 20m (was: 10m)
> Support total file size in statistics annotation
>
>
> Key: HIVE-22979
> URL: https://issues.apache.org/jira/browse/HIVE-22979
> Project: Hive
> Issue Type: Improvement
>Affects Versions: 4.0.0
>Reporter: Prasanth Jayachandran
>Assignee: Prasanth Jayachandran
>Priority: Minor
> Labels: pull-request-available
> Attachments: HIVE-22979.1.patch
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> Hive statistics annotation provide estimated Statistics for each operator.
> The data size provided in TableScanOperator is raw data size (after
> decompression and decoding), but there are some optimizations that can be
> performed based on total file size on disk (scan cost estimation).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22992) ZkRegistryBase caching mechanism only caches the first instance
[ https://issues.apache.org/jira/browse/HIVE-22992?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053619#comment-17053619 ] Prasanth Jayachandran commented on HIVE-22992: -- To make the patch little bit clearer (viewing the patch diff in browser is hard to follow), can you just move the "instanceSet.add(instance); " outside of the if condition and leave the cache.put outside if condition as well. Just a little bit more readability (always add and put instead of operating on references). lgtm otherwise, +1 > ZkRegistryBase caching mechanism only caches the first instance > --- > > Key: HIVE-22992 > URL: https://issues.apache.org/jira/browse/HIVE-22992 > Project: Hive > Issue Type: Bug > Components: llap >Affects Versions: 4.0.0 >Reporter: Antal Sinkovits >Assignee: Antal Sinkovits >Priority: Minor > Attachments: HIVE-22992.01.patch > > > ZkRegistryBase caching mechanism only caches the first instance of the llap > node running on the same host. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (HIVE-22993) Include Bloom Filter in Column Statistics to Better Estimate nDV
[
https://issues.apache.org/jira/browse/HIVE-22993?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053609#comment-17053609
]
Gopal Vijayaraghavan edited comment on HIVE-22993 at 3/6/20, 5:28 PM:
--
HIVE-13567
Also, I don't know if describe prints it - but I know the query planning does
use it.
was (Author: gopalv):
HIVE-13567
> Include Bloom Filter in Column Statistics to Better Estimate nDV
>
>
> Key: HIVE-22993
> URL: https://issues.apache.org/jira/browse/HIVE-22993
> Project: Hive
> Issue Type: Improvement
> Components: CBO, Statistics
>Reporter: David Mollitor
>Priority: Major
>
> When performing an INSERT statement, Hive has no way to determine the number
> of distinct values since the distinct values themselves are not recorded.
> {code:sql}
> create table test_mm(`id` int, `my_dt` date);
> insert into test_mm values (1, "2018-10-01"), (2, "2018-10-01"), (3,
> "2018-10-01"),
> (4, "2017-10-01"), (5, "2017-10-01"), (6, "2017-10-01"),
> (7, "2010-10-01"), (8, "2010-10-01"), (9, "2010-10-01"),
> (10, "1998-10-01"), (11, "1998-10-01"), (12, "1998-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> insert into test_mm values (13, "2030-10-01"), (14, "2030-10-01"), (15,
> "2030-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> {code}
> The first INSERT statement sees that there are 0 records, so it makes sense
> that any distinct values marked in the statistics. However, for the second
> INSERT, Hive has no idea if "2030-10-01" is distinct, so the distinct_count
> is unchanged. By introducing a bloom filter for column statistics, the
> second INSERT may be able to determine that "2030-10-01" is indeed unique and
> update the distinct_count accordingly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (HIVE-22993) Include Bloom Filter in Column Statistics to Better Estimate nDV
[
https://issues.apache.org/jira/browse/HIVE-22993?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053607#comment-17053607
]
David Mollitor edited comment on HIVE-22993 at 3/6/20, 5:24 PM:
[~gopalv] Thanks. Do you know what JIRA introduced this change? I have been
testing on HDP 3.1
Edit: Can this BIT_VECTOR field be applied to this request for better stats on
INSERT?
was (Author: belugabehr):
[~gopalv] Thanks. Do you know what JIRA introduced this change? I have been
testing on HDP 3.1
> Include Bloom Filter in Column Statistics to Better Estimate nDV
>
>
> Key: HIVE-22993
> URL: https://issues.apache.org/jira/browse/HIVE-22993
> Project: Hive
> Issue Type: Improvement
> Components: CBO, Statistics
>Reporter: David Mollitor
>Priority: Major
>
> When performing an INSERT statement, Hive has no way to determine the number
> of distinct values since the distinct values themselves are not recorded.
> {code:sql}
> create table test_mm(`id` int, `my_dt` date);
> insert into test_mm values (1, "2018-10-01"), (2, "2018-10-01"), (3,
> "2018-10-01"),
> (4, "2017-10-01"), (5, "2017-10-01"), (6, "2017-10-01"),
> (7, "2010-10-01"), (8, "2010-10-01"), (9, "2010-10-01"),
> (10, "1998-10-01"), (11, "1998-10-01"), (12, "1998-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> insert into test_mm values (13, "2030-10-01"), (14, "2030-10-01"), (15,
> "2030-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> {code}
> The first INSERT statement sees that there are 0 records, so it makes sense
> that any distinct values marked in the statistics. However, for the second
> INSERT, Hive has no idea if "2030-10-01" is distinct, so the distinct_count
> is unchanged. By introducing a bloom filter for column statistics, the
> second INSERT may be able to determine that "2030-10-01" is indeed unique and
> update the distinct_count accordingly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22993) Include Bloom Filter in Column Statistics to Better Estimate nDV
[
https://issues.apache.org/jira/browse/HIVE-22993?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053609#comment-17053609
]
Gopal Vijayaraghavan commented on HIVE-22993:
-
HIVE-13567
> Include Bloom Filter in Column Statistics to Better Estimate nDV
>
>
> Key: HIVE-22993
> URL: https://issues.apache.org/jira/browse/HIVE-22993
> Project: Hive
> Issue Type: Improvement
> Components: CBO, Statistics
>Reporter: David Mollitor
>Priority: Major
>
> When performing an INSERT statement, Hive has no way to determine the number
> of distinct values since the distinct values themselves are not recorded.
> {code:sql}
> create table test_mm(`id` int, `my_dt` date);
> insert into test_mm values (1, "2018-10-01"), (2, "2018-10-01"), (3,
> "2018-10-01"),
> (4, "2017-10-01"), (5, "2017-10-01"), (6, "2017-10-01"),
> (7, "2010-10-01"), (8, "2010-10-01"), (9, "2010-10-01"),
> (10, "1998-10-01"), (11, "1998-10-01"), (12, "1998-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> insert into test_mm values (13, "2030-10-01"), (14, "2030-10-01"), (15,
> "2030-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> {code}
> The first INSERT statement sees that there are 0 records, so it makes sense
> that any distinct values marked in the statistics. However, for the second
> INSERT, Hive has no idea if "2030-10-01" is distinct, so the distinct_count
> is unchanged. By introducing a bloom filter for column statistics, the
> second INSERT may be able to determine that "2030-10-01" is indeed unique and
> update the distinct_count accordingly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22992) ZkRegistryBase caching mechanism only caches the first instance
[ https://issues.apache.org/jira/browse/HIVE-22992?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053608#comment-17053608 ] Prasanth Jayachandran commented on HIVE-22992: -- [~asinkovits] can you provide more description about when and how this happens? If llap daemon restarts with same host name and port but with different uniqueID (worker identity) does it not cache the new llap daemon? > ZkRegistryBase caching mechanism only caches the first instance > --- > > Key: HIVE-22992 > URL: https://issues.apache.org/jira/browse/HIVE-22992 > Project: Hive > Issue Type: Bug > Components: llap >Affects Versions: 4.0.0 >Reporter: Antal Sinkovits >Assignee: Antal Sinkovits >Priority: Minor > Attachments: HIVE-22992.01.patch > > > ZkRegistryBase caching mechanism only caches the first instance of the llap > node running on the same host. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22993) Include Bloom Filter in Column Statistics to Better Estimate nDV
[
https://issues.apache.org/jira/browse/HIVE-22993?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053607#comment-17053607
]
David Mollitor commented on HIVE-22993:
---
[~gopalv] Thanks. Do you know what JIRA introduced this change? I have been
testing on HDP 3.1
> Include Bloom Filter in Column Statistics to Better Estimate nDV
>
>
> Key: HIVE-22993
> URL: https://issues.apache.org/jira/browse/HIVE-22993
> Project: Hive
> Issue Type: Improvement
> Components: CBO, Statistics
>Reporter: David Mollitor
>Priority: Major
>
> When performing an INSERT statement, Hive has no way to determine the number
> of distinct values since the distinct values themselves are not recorded.
> {code:sql}
> create table test_mm(`id` int, `my_dt` date);
> insert into test_mm values (1, "2018-10-01"), (2, "2018-10-01"), (3,
> "2018-10-01"),
> (4, "2017-10-01"), (5, "2017-10-01"), (6, "2017-10-01"),
> (7, "2010-10-01"), (8, "2010-10-01"), (9, "2010-10-01"),
> (10, "1998-10-01"), (11, "1998-10-01"), (12, "1998-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> insert into test_mm values (13, "2030-10-01"), (14, "2030-10-01"), (15,
> "2030-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> {code}
> The first INSERT statement sees that there are 0 records, so it makes sense
> that any distinct values marked in the statistics. However, for the second
> INSERT, Hive has no idea if "2030-10-01" is distinct, so the distinct_count
> is unchanged. By introducing a bloom filter for column statistics, the
> second INSERT may be able to determine that "2030-10-01" is indeed unique and
> update the distinct_count accordingly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22673) Replace Base64 in contrib Package
[ https://issues.apache.org/jira/browse/HIVE-22673?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David Mollitor updated HIVE-22673: -- Resolution: Fixed Status: Resolved (was: Patch Available) Pushed to master. Thanks [~kgyrtkirk] for the review! > Replace Base64 in contrib Package > - > > Key: HIVE-22673 > URL: https://issues.apache.org/jira/browse/HIVE-22673 > Project: Hive > Issue Type: Sub-task >Reporter: David Mollitor >Assignee: David Mollitor >Priority: Minor > Attachments: HIVE-22673.1.patch, HIVE-22673.1.patch > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[
https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399232&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399232
]
ASF GitHub Bot logged work on HIVE-22959:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 17:08
Start Date: 06/Mar/20 17:08
Worklog Time Spent: 10m
Work Description: t3rmin4t0r commented on pull request #931: HIVE-22959
Expose FilterContext as part of Hive storage-api
URL: https://github.com/apache/hive/pull/931#discussion_r389020914
##
File path:
storage-api/src/java/org/apache/hadoop/hive/ql/io/filter/MutableFilterContext.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.io.filter;
+
+import java.util.Arrays;
+
+/**
+ * A representation of a Filter applied on the rows of a VectorizedRowBatch
+ * {@link org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch}.
+ *
+ * Each FilterContext consists of an array with the ids (int) of rows that are
selected by the
+ * filter, an integer representing the number of selected rows, and a boolean
showing if the filter
+ * actually selected any rows.
+ *
+ */
+public class MutableFilterContext extends FilterContext {
+
+ /**
+ * Set context with the given values by reference
+ *
+ * @param isSelectedInUse if the filter is applied
+ * @param selected an array of the selected rows
+ * @param selectedSize the number of the selected rows
+ */
+ public void setFilterContext(boolean isSelectedInUse, int[] selected, int
selectedSize) {
+this.currBatchIsSelectedInUse = isSelectedInUse;
+this.currBatchSelected = selected;
+this.currBatchSelectedSize = selectedSize;
+// Avoid selected.length < selectedSize since we can borrow a larger array
for selected
+// debug loop for checking if selected is in order without duplicates (i.e
[1,1,1] is illegal)
+for (int i = 0; i < selectedSize-1; i++)
+ assert selected[i] < selected[i+1];
Review comment:
Add extra assert comment (assuming we'll be looking at the qtest log or
something)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399232)
Time Spent: 0.5h (was: 20m)
> Extend storage-api to expose FilterContext
> --
>
> Key: HIVE-22959
> URL: https://issues.apache.org/jira/browse/HIVE-22959
> Project: Hive
> Issue Type: Sub-task
> Components: storage-api
>Reporter: Panagiotis Garefalakis
>Assignee: Panagiotis Garefalakis
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> To enable row-level filtering at the ORC level ORC-577, or as an extension
> ProDecode MapJoin HIVE-22731 we need a common context class that will hold
> all the needed information for the filter.
> I propose this class to be part of the storage-api – similar to
> VectorizedRowBatch class and hold the information below:
> * A boolean variable showing if the filter is enabled
> * A int array storing the row Ids that are actually selected (passing the
> filter)
> * An int variable storing the the number or rows that passed the filter
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22673) Replace Base64 in contrib Package
[ https://issues.apache.org/jira/browse/HIVE-22673?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David Mollitor updated HIVE-22673: -- Attachment: (was: HIVE-22673.1.patch) > Replace Base64 in contrib Package > - > > Key: HIVE-22673 > URL: https://issues.apache.org/jira/browse/HIVE-22673 > Project: Hive > Issue Type: Sub-task >Reporter: David Mollitor >Assignee: David Mollitor >Priority: Minor > Attachments: HIVE-22673.1.patch, HIVE-22673.1.patch > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[
https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399234&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399234
]
ASF GitHub Bot logged work on HIVE-22959:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 17:08
Start Date: 06/Mar/20 17:08
Worklog Time Spent: 10m
Work Description: t3rmin4t0r commented on pull request #931: HIVE-22959
Expose FilterContext as part of Hive storage-api
URL: https://github.com/apache/hive/pull/931#discussion_r389029434
##
File path:
storage-api/src/java/org/apache/hadoop/hive/ql/io/filter/MutableFilterContext.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.io.filter;
+
+import java.util.Arrays;
+
+/**
+ * A representation of a Filter applied on the rows of a VectorizedRowBatch
+ * {@link org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch}.
+ *
+ * Each FilterContext consists of an array with the ids (int) of rows that are
selected by the
+ * filter, an integer representing the number of selected rows, and a boolean
showing if the filter
+ * actually selected any rows.
+ *
+ */
+public class MutableFilterContext extends FilterContext {
+
+ /**
+ * Set context with the given values by reference
+ *
+ * @param isSelectedInUse if the filter is applied
+ * @param selected an array of the selected rows
+ * @param selectedSize the number of the selected rows
+ */
+ public void setFilterContext(boolean isSelectedInUse, int[] selected, int
selectedSize) {
+this.currBatchIsSelectedInUse = isSelectedInUse;
+this.currBatchSelected = selected;
+this.currBatchSelectedSize = selectedSize;
+// Avoid selected.length < selectedSize since we can borrow a larger array
for selected
+// debug loop for checking if selected is in order without duplicates (i.e
[1,1,1] is illegal)
+for (int i = 0; i < selectedSize-1; i++)
+ assert selected[i] < selected[i+1];
Review comment:
Also move it to a different method so that the profiler will show it as a
separate cost
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399234)
Time Spent: 50m (was: 40m)
> Extend storage-api to expose FilterContext
> --
>
> Key: HIVE-22959
> URL: https://issues.apache.org/jira/browse/HIVE-22959
> Project: Hive
> Issue Type: Sub-task
> Components: storage-api
>Reporter: Panagiotis Garefalakis
>Assignee: Panagiotis Garefalakis
>Priority: Major
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> To enable row-level filtering at the ORC level ORC-577, or as an extension
> ProDecode MapJoin HIVE-22731 we need a common context class that will hold
> all the needed information for the filter.
> I propose this class to be part of the storage-api – similar to
> VectorizedRowBatch class and hold the information below:
> * A boolean variable showing if the filter is enabled
> * A int array storing the row Ids that are actually selected (passing the
> filter)
> * An int variable storing the the number or rows that passed the filter
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[
https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399231&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399231
]
ASF GitHub Bot logged work on HIVE-22959:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 17:08
Start Date: 06/Mar/20 17:08
Worklog Time Spent: 10m
Work Description: t3rmin4t0r commented on pull request #931: HIVE-22959
Expose FilterContext as part of Hive storage-api
URL: https://github.com/apache/hive/pull/931#discussion_r389020620
##
File path:
storage-api/src/java/org/apache/hadoop/hive/ql/io/filter/MutableFilterContext.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.io.filter;
+
+import java.util.Arrays;
+
+/**
+ * A representation of a Filter applied on the rows of a VectorizedRowBatch
+ * {@link org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch}.
+ *
+ * Each FilterContext consists of an array with the ids (int) of rows that are
selected by the
+ * filter, an integer representing the number of selected rows, and a boolean
showing if the filter
+ * actually selected any rows.
+ *
+ */
+public class MutableFilterContext extends FilterContext {
+
+ /**
+ * Set context with the given values by reference
+ *
+ * @param isSelectedInUse if the filter is applied
+ * @param selected an array of the selected rows
+ * @param selectedSize the number of the selected rows
+ */
+ public void setFilterContext(boolean isSelectedInUse, int[] selected, int
selectedSize) {
+this.currBatchIsSelectedInUse = isSelectedInUse;
+this.currBatchSelected = selected;
+this.currBatchSelectedSize = selectedSize;
+// Avoid selected.length < selectedSize since we can borrow a larger array
for selected
+// debug loop for checking if selected is in order without duplicates (i.e
[1,1,1] is illegal)
+for (int i = 0; i < selectedSize-1; i++)
+ assert selected[i] < selected[i+1];
+ }
+
+ /**
+ * Copy context variables from the a given FilterContext.
+ * Always does a deep copy of the data.
+ *
+ * @param other FilterContext to copy from
+ */
+ public void copyFilterContextFrom(MutableFilterContext other) {
+// assert if copying into self
Review comment:
We don't run with -ea in prod, so this is a bit of a "won't fail in prod,
but will hit in testing"
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399231)
Time Spent: 20m (was: 10m)
> Extend storage-api to expose FilterContext
> --
>
> Key: HIVE-22959
> URL: https://issues.apache.org/jira/browse/HIVE-22959
> Project: Hive
> Issue Type: Sub-task
> Components: storage-api
>Reporter: Panagiotis Garefalakis
>Assignee: Panagiotis Garefalakis
>Priority: Major
> Labels: pull-request-available
> Time Spent: 20m
> Remaining Estimate: 0h
>
> To enable row-level filtering at the ORC level ORC-577, or as an extension
> ProDecode MapJoin HIVE-22731 we need a common context class that will hold
> all the needed information for the filter.
> I propose this class to be part of the storage-api – similar to
> VectorizedRowBatch class and hold the information below:
> * A boolean variable showing if the filter is enabled
> * A int array storing the row Ids that are actually selected (passing the
> filter)
> * An int variable storing the the number or rows that passed the filter
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[ https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399235&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399235 ] ASF GitHub Bot logged work on HIVE-22959: - Author: ASF GitHub Bot Created on: 06/Mar/20 17:08 Start Date: 06/Mar/20 17:08 Worklog Time Spent: 10m Work Description: t3rmin4t0r commented on pull request #931: HIVE-22959 Expose FilterContext as part of Hive storage-api URL: https://github.com/apache/hive/pull/931#discussion_r389021429 ## File path: ql/src/test/org/apache/hadoop/hive/ql/io/filter/TestFilterContext.java ## @@ -0,0 +1,107 @@ +package org.apache.hadoop.hive.ql.io.filter; Review comment: ASF license nit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 399235) Time Spent: 50m (was: 40m) > Extend storage-api to expose FilterContext > -- > > Key: HIVE-22959 > URL: https://issues.apache.org/jira/browse/HIVE-22959 > Project: Hive > Issue Type: Sub-task > Components: storage-api >Reporter: Panagiotis Garefalakis >Assignee: Panagiotis Garefalakis >Priority: Major > Labels: pull-request-available > Time Spent: 50m > Remaining Estimate: 0h > > To enable row-level filtering at the ORC level ORC-577, or as an extension > ProDecode MapJoin HIVE-22731 we need a common context class that will hold > all the needed information for the filter. > I propose this class to be part of the storage-api – similar to > VectorizedRowBatch class and hold the information below: > * A boolean variable showing if the filter is enabled > * A int array storing the row Ids that are actually selected (passing the > filter) > * An int variable storing the the number or rows that passed the filter > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work logged] (HIVE-22959) Extend storage-api to expose FilterContext
[
https://issues.apache.org/jira/browse/HIVE-22959?focusedWorklogId=399233&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399233
]
ASF GitHub Bot logged work on HIVE-22959:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 17:08
Start Date: 06/Mar/20 17:08
Worklog Time Spent: 10m
Work Description: t3rmin4t0r commented on pull request #931: HIVE-22959
Expose FilterContext as part of Hive storage-api
URL: https://github.com/apache/hive/pull/931#discussion_r389029685
##
File path:
storage-api/src/java/org/apache/hadoop/hive/ql/io/filter/MutableFilterContext.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.io.filter;
+
+import java.util.Arrays;
+
+/**
+ * A representation of a Filter applied on the rows of a VectorizedRowBatch
+ * {@link org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch}.
+ *
+ * Each FilterContext consists of an array with the ids (int) of rows that are
selected by the
+ * filter, an integer representing the number of selected rows, and a boolean
showing if the filter
+ * actually selected any rows.
+ *
+ */
+public class MutableFilterContext extends FilterContext {
+
+ /**
+ * Set context with the given values by reference
+ *
+ * @param isSelectedInUse if the filter is applied
+ * @param selected an array of the selected rows
+ * @param selectedSize the number of the selected rows
+ */
+ public void setFilterContext(boolean isSelectedInUse, int[] selected, int
selectedSize) {
+this.currBatchIsSelectedInUse = isSelectedInUse;
+this.currBatchSelected = selected;
+this.currBatchSelectedSize = selectedSize;
+// Avoid selected.length < selectedSize since we can borrow a larger array
for selected
+// debug loop for checking if selected is in order without duplicates (i.e
[1,1,1] is illegal)
+for (int i = 0; i < selectedSize-1; i++)
+ assert selected[i] < selected[i+1];
+ }
+
+ /**
+ * Copy context variables from the a given FilterContext.
+ * Always does a deep copy of the data.
+ *
+ * @param other FilterContext to copy from
+ */
+ public void copyFilterContextFrom(MutableFilterContext other) {
+// assert if copying into self
Review comment:
Needs to be an if(), because if this == other, then we overwrite instance
variables in assignment etc.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399233)
Time Spent: 40m (was: 0.5h)
> Extend storage-api to expose FilterContext
> --
>
> Key: HIVE-22959
> URL: https://issues.apache.org/jira/browse/HIVE-22959
> Project: Hive
> Issue Type: Sub-task
> Components: storage-api
>Reporter: Panagiotis Garefalakis
>Assignee: Panagiotis Garefalakis
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> To enable row-level filtering at the ORC level ORC-577, or as an extension
> ProDecode MapJoin HIVE-22731 we need a common context class that will hold
> all the needed information for the filter.
> I propose this class to be part of the storage-api – similar to
> VectorizedRowBatch class and hold the information below:
> * A boolean variable showing if the filter is enabled
> * A int array storing the row Ids that are actually selected (passing the
> filter)
> * An int variable storing the the number or rows that passed the filter
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22993) Include Bloom Filter in Column Statistics to Better Estimate nDV
[
https://issues.apache.org/jira/browse/HIVE-22993?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053599#comment-17053599
]
Gopal Vijayaraghavan commented on HIVE-22993:
-
{code}
HIVESTATSCOLAUTOGATHER("hive.stats.column.autogather", true,
"A flag to gather column statistics automatically."),
{code}
should populate a metastore BIT_VECTOR column with a HyperLogLog bitset
automatically.
https://github.com/apache/hive/blob/master/standalone-metastore/metastore-server/src/main/sql/postgres/hive-schema-4.0.0.postgres.sql#L551
> Include Bloom Filter in Column Statistics to Better Estimate nDV
>
>
> Key: HIVE-22993
> URL: https://issues.apache.org/jira/browse/HIVE-22993
> Project: Hive
> Issue Type: Improvement
> Components: CBO, Statistics
>Reporter: David Mollitor
>Priority: Major
>
> When performing an INSERT statement, Hive has no way to determine the number
> of distinct values since the distinct values themselves are not recorded.
> {code:sql}
> create table test_mm(`id` int, `my_dt` date);
> insert into test_mm values (1, "2018-10-01"), (2, "2018-10-01"), (3,
> "2018-10-01"),
> (4, "2017-10-01"), (5, "2017-10-01"), (6, "2017-10-01"),
> (7, "2010-10-01"), (8, "2010-10-01"), (9, "2010-10-01"),
> (10, "1998-10-01"), (11, "1998-10-01"), (12, "1998-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> insert into test_mm values (13, "2030-10-01"), (14, "2030-10-01"), (15,
> "2030-10-01");
> DESCRIBE FORMATTED test_mm my_dt;
> -- distinct_count: 4
> {code}
> The first INSERT statement sees that there are 0 records, so it makes sense
> that any distinct values marked in the statistics. However, for the second
> INSERT, Hive has no idea if "2030-10-01" is distinct, so the distinct_count
> is unchanged. By introducing a bloom filter for column statistics, the
> second INSERT may be able to determine that "2030-10-01" is indeed unique and
> update the distinct_count accordingly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22821) Add necessary endpoints for proactive cache eviction
[
https://issues.apache.org/jira/browse/HIVE-22821?focusedWorklogId=399228&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399228
]
ASF GitHub Bot logged work on HIVE-22821:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 16:56
Start Date: 06/Mar/20 16:56
Worklog Time Spent: 10m
Work Description: b-slim commented on pull request #909: HIVE-22821
URL: https://github.com/apache/hive/pull/909#discussion_r389021342
##
File path: common/src/java/org/apache/hadoop/hive/conf/HiveConf.java
##
@@ -4215,6 +4215,12 @@ private static void
populateLlapDaemonVarsSet(Set llapDaemonVarsSetLocal
LLAP_IO_CVB_BUFFERED_SIZE("hive.llap.io.cvb.memory.consumption.", 1L << 30,
"The amount of bytes used to buffer CVB between IO and Processor
Threads default to 1GB, "
+ "this will be used to compute a best effort queue size for VRBs
produced by a LLAP IO thread."),
+
LLAP_IO_PROACTIVE_EVICTION_ENABLED("hive.llap.io.proactive.eviction.enabled",
true,
+"If true proactive cache eviction is enabled, thus LLAP will
proactively evict buffers" +
+ " that belong to dropped Hive entities (DBs, tables, partitions, or
temp tables."),
+LLAP_IO_PROACTIVE_EVICTION_ASYNC("hive.llap.io.proactive.eviction.async",
true,
Review comment:
please see comment above, the RPC pool is meant to do that.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399228)
Time Spent: 2h (was: 1h 50m)
> Add necessary endpoints for proactive cache eviction
>
>
> Key: HIVE-22821
> URL: https://issues.apache.org/jira/browse/HIVE-22821
> Project: Hive
> Issue Type: Sub-task
> Components: llap
>Reporter: Ádám Szita
>Assignee: Ádám Szita
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22821.0.patch, HIVE-22821.1.patch,
> HIVE-22821.2.patch
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> Implement the parts required for iHS2 -> LLAP daemons communication:
> * protobuf message schema and endpoints
> * Hive configuration
> * for use cases:
> ** dropping db
> ** dropping table
> ** dropping partition from a table
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (HIVE-22821) Add necessary endpoints for proactive cache eviction
[
https://issues.apache.org/jira/browse/HIVE-22821?focusedWorklogId=399226&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399226
]
ASF GitHub Bot logged work on HIVE-22821:
-
Author: ASF GitHub Bot
Created on: 06/Mar/20 16:55
Start Date: 06/Mar/20 16:55
Worklog Time Spent: 10m
Work Description: b-slim commented on pull request #909: HIVE-22821
URL: https://github.com/apache/hive/pull/909#discussion_r389020955
##
File path:
llap-server/src/java/org/apache/hadoop/hive/llap/io/api/impl/LlapIoImpl.java
##
@@ -221,6 +227,9 @@ public void debugDumpShort(StringBuilder sb) {
metadataCache, dataCache, bufferManagerOrc, conf, cacheMetrics,
ioMetrics, tracePool);
this.genericCvp = isEncodeEnabled ? new GenericColumnVectorProducer(
serdeCache, bufferManagerGeneric, conf, cacheMetrics, ioMetrics,
tracePool) : null;
+proactiveEvictionExecutor = Executors.newSingleThreadExecutor(
Review comment:
@szlta , if for every new feature we add a new thread pool then the code
will become a huge burden to maintain. The RPC thread pool is meant for that
doing the stuff within thread of the pool that can be increased if needed. By
creating a new pool we are not changing anything just adding more burden from
code perspective. Same on the HS2I user will need to wait and see the result
of the command same with the purge.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399226)
Time Spent: 1h 50m (was: 1h 40m)
> Add necessary endpoints for proactive cache eviction
>
>
> Key: HIVE-22821
> URL: https://issues.apache.org/jira/browse/HIVE-22821
> Project: Hive
> Issue Type: Sub-task
> Components: llap
>Reporter: Ádám Szita
>Assignee: Ádám Szita
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-22821.0.patch, HIVE-22821.1.patch,
> HIVE-22821.2.patch
>
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> Implement the parts required for iHS2 -> LLAP daemons communication:
> * protobuf message schema and endpoints
> * Hive configuration
> * for use cases:
> ** dropping db
> ** dropping table
> ** dropping partition from a table
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HIVE-22901) Variable substitution can lead to OOM on circular references
[
https://issues.apache.org/jira/browse/HIVE-22901?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053586#comment-17053586
]
Hive QA commented on HIVE-22901:
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Comment ||
|| || || || {color:brown} Prechecks {color} ||
| {color:green}+1{color} | {color:green} @author {color} | {color:green} 0m
0s{color} | {color:green} The patch does not contain any @author tags. {color} |
|| || || || {color:brown} master Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 1m
39s{color} | {color:blue} Maven dependency ordering for branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 8m
1s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
2s{color} | {color:green} master passed {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 0m
33s{color} | {color:green} master passed {color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
35s{color} | {color:blue} common in master has 63 extant Findbugs warnings.
{color} |
| {color:blue}0{color} | {color:blue} findbugs {color} | {color:blue} 0m
41s{color} | {color:blue} itests/hive-unit in master has 2 extant Findbugs
warnings. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
41s{color} | {color:green} master passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
29s{color} | {color:blue} Maven dependency ordering for patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
3s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 0m
59s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 0m
59s{color} | {color:green} the patch passed {color} |
| {color:red}-1{color} | {color:red} checkstyle {color} | {color:red} 0m
15s{color} | {color:red} common: The patch generated 37 new + 376 unchanged - 0
fixed = 413 total (was 376) {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green} The patch has no whitespace issues. {color} |
| {color:green}+1{color} | {color:green} findbugs {color} | {color:green} 1m
28s{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
41s{color} | {color:green} the patch passed {color} |
|| || || || {color:brown} Other Tests {color} ||
| {color:red}-1{color} | {color:red} asflicense {color} | {color:red} 0m
14s{color} | {color:red} The patch generated 3 ASF License warnings. {color} |
| {color:black}{color} | {color:black} {color} | {color:black} 19m 22s{color} |
{color:black} {color} |
\\
\\
|| Subsystem || Report/Notes ||
| Optional Tests | asflicense javac javadoc findbugs checkstyle compile |
| uname | Linux hiveptest-server-upstream 3.16.0-4-amd64 #1 SMP Debian
3.16.43-2+deb8u5 (2017-09-19) x86_64 GNU/Linux |
| Build tool | maven |
| Personality |
/data/hiveptest/working/yetus_PreCommit-HIVE-Build-20981/dev-support/hive-personality.sh
|
| git revision | master / 5ff8655 |
| Default Java | 1.8.0_111 |
| findbugs | v3.0.1 |
| checkstyle |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20981/yetus/diff-checkstyle-common.txt
|
| asflicense |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20981/yetus/patch-asflicense-problems.txt
|
| modules | C: common itests/hive-unit U: . |
| Console output |
http://104.198.109.242/logs//PreCommit-HIVE-Build-20981/yetus.txt |
| Powered by | Apache Yetushttp://yetus.apache.org |
This message was automatically generated.
> Variable substitution can lead to OOM on circular references
>
>
> Key: HIVE-22901
> URL: https://issues.apache.org/jira/browse/HIVE-22901
> Project: Hive
> Issue Type: Bug
> Components: HiveServer2
>Affects Versions: 3.1.2
>Reporter: Daniel Voros
>Assignee: Daniel Voros
>Priority: Major
> Attachments: HIVE-22901.1.patch, HIVE-22901.2.patch
>
>
> {{SystemVariables#substitute()}} is dealing with circular references between
> variables by only doing the substitution 40 times by default. If the
> substituted part is sufficiently large though, it's possible that the
> substitution will produce a string bigger than the heap size within the 40
> executions.
> Take the following test case that fails with OOM in current master (third
> round of execution would need 10G heap, while r
[jira] [Commented] (HIVE-22985) Failed compaction always throws TxnAbortedException
[
https://issues.apache.org/jira/browse/HIVE-22985?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053569#comment-17053569
]
Hive QA commented on HIVE-22985:
Here are the results of testing the latest attachment:
https://issues.apache.org/jira/secure/attachment/12995738/HIVE-22985.01.patch
{color:red}ERROR:{color} -1 due to no test(s) being added or modified.
{color:green}SUCCESS:{color} +1 due to 18102 tests passed
Test results:
https://builds.apache.org/job/PreCommit-HIVE-Build/20980/testReport
Console output: https://builds.apache.org/job/PreCommit-HIVE-Build/20980/console
Test logs: http://104.198.109.242/logs/PreCommit-HIVE-Build-20980/
Messages:
{noformat}
Executing org.apache.hive.ptest.execution.TestCheckPhase
Executing org.apache.hive.ptest.execution.PrepPhase
Executing org.apache.hive.ptest.execution.YetusPhase
Executing org.apache.hive.ptest.execution.ExecutionPhase
Executing org.apache.hive.ptest.execution.ReportingPhase
{noformat}
This message is automatically generated.
ATTACHMENT ID: 12995738 - PreCommit-HIVE-Build
> Failed compaction always throws TxnAbortedException
> ---
>
> Key: HIVE-22985
> URL: https://issues.apache.org/jira/browse/HIVE-22985
> Project: Hive
> Issue Type: Bug
>Reporter: Karen Coppage
>Assignee: Karen Coppage
>Priority: Major
> Labels: compaction
> Attachments: HIVE-22985.01.patch
>
>
> If compaction fails, its txn is aborted, however Worker attempts to commit it
> again in a finally statement. This results in a TxnAbortedException [1]
> thrown from TxnHandler#commitTxn
> We need to add a check and only try to commit at the end if the txn is not
> aborted.(TxnHandler#commitTxn does nothing if txn is already committed.)
> [1]
> {code:java}
> ERROR org.apache.hadoop.hive.metastore.RetryingHMSHandler -
> TxnAbortedException(message:Transaction txnid:16 already aborted)
> at
> org.apache.hadoop.hive.metastore.txn.TxnHandler.raiseTxnUnexpectedState(TxnHandler.java:4843)
> at
> org.apache.hadoop.hive.metastore.txn.TxnHandler.commitTxn(TxnHandler.java:1141)
> at
> org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.commit_txn(HiveMetaStore.java:8101)
> ...
> at
> org.apache.hadoop.hive.ql.txn.compactor.Worker.commitTxn(Worker.java:291)
> at org.apache.hadoop.hive.ql.txn.compactor.Worker.run(Worker.java:269)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HIVE-22971) Eliminate file rename in insert-only compactor
[ https://issues.apache.org/jira/browse/HIVE-22971?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Karen Coppage updated HIVE-22971: - Attachment: HIVE-22971.01.patch Status: Patch Available (was: Open) > Eliminate file rename in insert-only compactor > -- > > Key: HIVE-22971 > URL: https://issues.apache.org/jira/browse/HIVE-22971 > Project: Hive > Issue Type: Improvement >Reporter: Karen Coppage >Assignee: Karen Coppage >Priority: Major > Labels: ACID, compaction > Attachments: HIVE-22971.01.patch > > > File rename is expensive for object stores, so MM (insert-only) compaction > should skip that step when committing and write directly to base_x_cZ or > delta_x_y_cZ. > This also fixes the issue that for MM QB compaction the temp tables were > stored under the table directory, and these temp dirs were never cleaned up. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HIVE-22907) Break up DDLSemanticAnalyzer - extract the rest of the Alter Table analyzers
[ https://issues.apache.org/jira/browse/HIVE-22907?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Miklos Gergely updated HIVE-22907: -- Resolution: Fixed Status: Resolved (was: Patch Available) > Break up DDLSemanticAnalyzer - extract the rest of the Alter Table analyzers > > > Key: HIVE-22907 > URL: https://issues.apache.org/jira/browse/HIVE-22907 > Project: Hive > Issue Type: Sub-task >Reporter: Miklos Gergely >Assignee: Miklos Gergely >Priority: Major > Labels: refactor-ddl > Attachments: HIVE-22907.01.patch, HIVE-22907.02.patch, > HIVE-22907.03.patch > > > DDLSemanticAnalyzer is a huge class, more than 4000 lines long. The goal is > to refactor it in order to have everything cut into more handleable classes > under the package org.apache.hadoop.hive.ql.exec.ddl: > * have a separate class for each analyzers > * have a package for each operation, containing an analyzer, a description, > and an operation, so the amount of classes under a package is more manageable > Step #15: extract the rest of the alter table analyzers from > DDLSemanticAnalyzer, and move them under the new package. Remove > DDLSemanticAnalyzer. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HIVE-22988) LLAP: If consistent splits is disabled ordering instances is not required
[ https://issues.apache.org/jira/browse/HIVE-22988?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17053559#comment-17053559 ] Slim Bouguerra commented on HIVE-22988: --- +1 > LLAP: If consistent splits is disabled ordering instances is not required > - > > Key: HIVE-22988 > URL: https://issues.apache.org/jira/browse/HIVE-22988 > Project: Hive > Issue Type: Bug >Affects Versions: 4.0.0 >Reporter: Prasanth Jayachandran >Assignee: Prasanth Jayachandran >Priority: Major > Labels: pull-request-available > Attachments: HIVE-22988.1.patch > > Time Spent: 20m > Remaining Estimate: 0h > > LlapTaskSchedulerService always gets consistent ordered list of all LLAP > instances even if consistent splits is disabled. When consistent split is > disabled ordering isn't really useful as there is no cache locality. -- This message was sent by Atlassian Jira (v8.3.4#803005)