[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618131621
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -957,22 +890,27 @@ ApiError electLeader(String topic, int partitionId,
boolean unclean,
return ControllerResult.of(records, reply);
}
-int bestLeader(int[] replicas, int[] isr, boolean unclean) {
+static boolean isGoodLeader(int[] isr, int leader) {
+return Replicas.contains(isr, leader);
+}
+
+static int bestLeader(int[] replicas, int[] isr, boolean uncleanOk,
Review comment:
We use NO_LEADER in a lot of different places in the code, so I think
it's reasonable to use it here. it is actually a valid value for the leader of
the partition, so translating to and from OptionalInt would be awkward, I think.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wenbingshen commented on pull request #10558: KAFKA-12684: Fix noop set is incorrectly replaced with succeeded set from LeaderElectionCommand
wenbingshen commented on pull request #10558: URL: https://github.com/apache/kafka/pull/10558#issuecomment-824593661 > @wenbingshen感谢您的更新代码。经过质量检查合格后,我将其合并。 Thank you very much for your guidance and help. :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618132526
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -356,7 +369,8 @@ public void replay(PartitionChangeRecord record) {
brokersToIsrs.update(record.topicId(), record.partitionId(),
prevPartitionInfo.isr, newPartitionInfo.isr,
prevPartitionInfo.leader,
newPartitionInfo.leader);
-log.debug("Applied ISR change record: {}", record.toString());
+String topicPart = topicInfo.name + "-" + record.partitionId();
Review comment:
sorry. added.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618133367
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -172,47 +174,54 @@ String diff(PartitionControlInfo prev) {
StringBuilder builder = new StringBuilder();
String prefix = "";
if (!Arrays.equals(replicas, prev.replicas)) {
-
builder.append(prefix).append("oldReplicas=").append(Arrays.toString(prev.replicas));
+builder.append(prefix).append("replicas: ").
+append(Arrays.toString(prev.replicas)).
+append(" -> ").append(Arrays.toString(replicas));
prefix = ", ";
-
builder.append(prefix).append("newReplicas=").append(Arrays.toString(replicas));
}
if (!Arrays.equals(isr, prev.isr)) {
-
builder.append(prefix).append("oldIsr=").append(Arrays.toString(prev.isr));
+builder.append(prefix).append("isr: ").
+append(Arrays.toString(prev.isr)).
+append(" -> ").append(Arrays.toString(isr));
prefix = ", ";
-
builder.append(prefix).append("newIsr=").append(Arrays.toString(isr));
}
if (!Arrays.equals(removingReplicas, prev.removingReplicas)) {
-builder.append(prefix).append("oldRemovingReplicas=").
-append(Arrays.toString(prev.removingReplicas));
+builder.append(prefix).append("removingReplicas: ").
+append(Arrays.toString(prev.removingReplicas)).
+append(" -> ").append(Arrays.toString(removingReplicas));
prefix = ", ";
-builder.append(prefix).append("newRemovingReplicas=").
-append(Arrays.toString(removingReplicas));
}
if (!Arrays.equals(addingReplicas, prev.addingReplicas)) {
-builder.append(prefix).append("oldAddingReplicas=").
-append(Arrays.toString(prev.addingReplicas));
+builder.append(prefix).append("addingReplicas: ").
+append(Arrays.toString(prev.addingReplicas)).
+append(" -> ").append(Arrays.toString(addingReplicas));
prefix = ", ";
-builder.append(prefix).append("newAddingReplicas=").
-append(Arrays.toString(addingReplicas));
}
if (leader != prev.leader) {
-
builder.append(prefix).append("oldLeader=").append(prev.leader);
+builder.append(prefix).append("leader: ").
+append(prev.leader).append(" -> ").append(leader);
prefix = ", ";
-builder.append(prefix).append("newLeader=").append(leader);
}
if (leaderEpoch != prev.leaderEpoch) {
-
builder.append(prefix).append("oldLeaderEpoch=").append(prev.leaderEpoch);
+builder.append(prefix).append("leaderEpoch: ").
+append(prev.leaderEpoch).append(" ->
").append(leaderEpoch);
prefix = ", ";
-
builder.append(prefix).append("newLeaderEpoch=").append(leaderEpoch);
}
if (partitionEpoch != prev.partitionEpoch) {
-
builder.append(prefix).append("oldPartitionEpoch=").append(prev.partitionEpoch);
-prefix = ", ";
-
builder.append(prefix).append("newPartitionEpoch=").append(partitionEpoch);
+builder.append(prefix).append("partitionEpoch: ").
+append(prev.partitionEpoch).append(" ->
").append(partitionEpoch);
}
return builder.toString();
}
+void maybeLogPartitionChange(Logger log, String description,
PartitionControlInfo prev) {
+if (!electionWasClean(leader, prev.isr)) {
+log.info("UNCLEAN partition change for {}: {}", description,
diff(prev));
+} else if (log.isDebugEnabled()) {
+log.debug("partition change for {}: {}", description,
diff(prev));
Review comment:
I don't think this will be practical as the number of partitions grows.
A 10-node cluster with a million partitions could have tens of thousands of
partition changes when a node goes away or comes back.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618133367
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -172,47 +174,54 @@ String diff(PartitionControlInfo prev) {
StringBuilder builder = new StringBuilder();
String prefix = "";
if (!Arrays.equals(replicas, prev.replicas)) {
-
builder.append(prefix).append("oldReplicas=").append(Arrays.toString(prev.replicas));
+builder.append(prefix).append("replicas: ").
+append(Arrays.toString(prev.replicas)).
+append(" -> ").append(Arrays.toString(replicas));
prefix = ", ";
-
builder.append(prefix).append("newReplicas=").append(Arrays.toString(replicas));
}
if (!Arrays.equals(isr, prev.isr)) {
-
builder.append(prefix).append("oldIsr=").append(Arrays.toString(prev.isr));
+builder.append(prefix).append("isr: ").
+append(Arrays.toString(prev.isr)).
+append(" -> ").append(Arrays.toString(isr));
prefix = ", ";
-
builder.append(prefix).append("newIsr=").append(Arrays.toString(isr));
}
if (!Arrays.equals(removingReplicas, prev.removingReplicas)) {
-builder.append(prefix).append("oldRemovingReplicas=").
-append(Arrays.toString(prev.removingReplicas));
+builder.append(prefix).append("removingReplicas: ").
+append(Arrays.toString(prev.removingReplicas)).
+append(" -> ").append(Arrays.toString(removingReplicas));
prefix = ", ";
-builder.append(prefix).append("newRemovingReplicas=").
-append(Arrays.toString(removingReplicas));
}
if (!Arrays.equals(addingReplicas, prev.addingReplicas)) {
-builder.append(prefix).append("oldAddingReplicas=").
-append(Arrays.toString(prev.addingReplicas));
+builder.append(prefix).append("addingReplicas: ").
+append(Arrays.toString(prev.addingReplicas)).
+append(" -> ").append(Arrays.toString(addingReplicas));
prefix = ", ";
-builder.append(prefix).append("newAddingReplicas=").
-append(Arrays.toString(addingReplicas));
}
if (leader != prev.leader) {
-
builder.append(prefix).append("oldLeader=").append(prev.leader);
+builder.append(prefix).append("leader: ").
+append(prev.leader).append(" -> ").append(leader);
prefix = ", ";
-builder.append(prefix).append("newLeader=").append(leader);
}
if (leaderEpoch != prev.leaderEpoch) {
-
builder.append(prefix).append("oldLeaderEpoch=").append(prev.leaderEpoch);
+builder.append(prefix).append("leaderEpoch: ").
+append(prev.leaderEpoch).append(" ->
").append(leaderEpoch);
prefix = ", ";
-
builder.append(prefix).append("newLeaderEpoch=").append(leaderEpoch);
}
if (partitionEpoch != prev.partitionEpoch) {
-
builder.append(prefix).append("oldPartitionEpoch=").append(prev.partitionEpoch);
-prefix = ", ";
-
builder.append(prefix).append("newPartitionEpoch=").append(partitionEpoch);
+builder.append(prefix).append("partitionEpoch: ").
+append(prev.partitionEpoch).append(" ->
").append(partitionEpoch);
}
return builder.toString();
}
+void maybeLogPartitionChange(Logger log, String description,
PartitionControlInfo prev) {
+if (!electionWasClean(leader, prev.isr)) {
+log.info("UNCLEAN partition change for {}: {}", description,
diff(prev));
+} else if (log.isDebugEnabled()) {
+log.debug("partition change for {}: {}", description,
diff(prev));
Review comment:
I don't think this will be practical as the number of partitions grows.
A 10-node cluster with a million partitions could have hundreds of thousands of
partition changes when a node goes away or comes back.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618135556
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -1119,6 +1057,83 @@ void validateManualPartitionAssignment(List
assignment,
}
}
+/**
+ * Iterate over a sequence of partitions and generate ISR changes and/or
leader
+ * changes if necessary.
+ *
+ * @param context A human-readable context string used in log4j
logging.
+ * @param brokerToRemoveNO_LEADER if no broker is being removed; the
ID of the
+ * broker to remove from the ISR and leadership,
otherwise.
+ * @param brokerToAdd NO_LEADER if no broker is being added; the ID
of the
+ * broker which is now eligible to be a leader,
otherwise.
+ * @param records A list of records which we will append to.
+ * @param iterator The iterator containing the partitions to
examine.
+ */
+void generateLeaderAndIsrUpdates(String context,
+ int brokerToRemove,
+ int brokerToAdd,
+ List records,
+ Iterator iterator) {
+int oldSize = records.size();
+Function isAcceptableLeader =
+r -> r == brokerToAdd || clusterControl.unfenced(r);
Review comment:
In the case of an unclean leader election, I suppose we do need to
consider brokerToRemove, since we'll want to explicitly exclude it. Good catch.
In general the code will work if both brokerToRemove and brokerToAdd are
both set, although we don't plan to do this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618138346
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -1119,6 +1057,83 @@ void validateManualPartitionAssignment(List
assignment,
}
}
+/**
+ * Iterate over a sequence of partitions and generate ISR changes and/or
leader
+ * changes if necessary.
+ *
+ * @param context A human-readable context string used in log4j
logging.
+ * @param brokerToRemoveNO_LEADER if no broker is being removed; the
ID of the
+ * broker to remove from the ISR and leadership,
otherwise.
+ * @param brokerToAdd NO_LEADER if no broker is being added; the ID
of the
+ * broker which is now eligible to be a leader,
otherwise.
+ * @param records A list of records which we will append to.
+ * @param iterator The iterator containing the partitions to
examine.
+ */
+void generateLeaderAndIsrUpdates(String context,
+ int brokerToRemove,
+ int brokerToAdd,
+ List records,
+ Iterator iterator) {
+int oldSize = records.size();
+Function isAcceptableLeader =
+r -> r == brokerToAdd || clusterControl.unfenced(r);
+while (iterator.hasNext()) {
+TopicIdPartition topicIdPart = iterator.next();
+TopicControlInfo topic = topics.get(topicIdPart.topicId());
+if (topic == null) {
+throw new RuntimeException("Topic ID " + topicIdPart.topicId()
+
+" existed in isrMembers, but not in the topics map.");
+}
+PartitionControlInfo partition =
topic.parts.get(topicIdPart.partitionId());
+if (partition == null) {
+throw new RuntimeException("Partition " + topicIdPart +
+" existed in isrMembers, but not in the partitions map.");
+}
+int[] newIsr = Replicas.copyWithout(partition.isr, brokerToRemove);
+int newLeader;
+if (isGoodLeader(newIsr, partition.leader)) {
+// If the current leader is good, don't change.
+newLeader = partition.leader;
+} else {
+// Choose a new leader.
+boolean uncleanOk =
configurationControl.uncleanLeaderElectionEnabledForTopic(topic.name);
+newLeader = bestLeader(partition.replicas, newIsr, uncleanOk,
isAcceptableLeader);
Review comment:
That will block the controlled shutdown from finishing in many cases.
Is the intention to allow for a clean leader election later on if the other
replicas catch up?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10564: MINOR: clean up some replication code
cmccabe commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618138592
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -957,22 +890,27 @@ ApiError electLeader(String topic, int partitionId,
boolean unclean,
return ControllerResult.of(records, reply);
}
-int bestLeader(int[] replicas, int[] isr, boolean unclean) {
+static boolean isGoodLeader(int[] isr, int leader) {
+return Replicas.contains(isr, leader);
+}
+
+static int bestLeader(int[] replicas, int[] isr, boolean uncleanOk,
+ Function isAcceptableLeader) {
+int bestUnclean = NO_LEADER;
for (int i = 0; i < replicas.length; i++) {
int replica = replicas[i];
-if (Replicas.contains(isr, replica)) {
-return replica;
-}
-}
-if (unclean) {
-for (int i = 0; i < replicas.length; i++) {
-int replica = replicas[i];
-if (clusterControl.unfenced(replica)) {
+if (isAcceptableLeader.apply(replica)) {
+if (bestUnclean == NO_LEADER) bestUnclean = replica;
+if (Replicas.contains(isr, replica)) {
return replica;
}
}
}
-return NO_LEADER;
+return uncleanOk ? bestUnclean : NO_LEADER;
+}
+
+static boolean electionWasClean(int newLeader, int[] prevIsr) {
Review comment:
I will just call it isr.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on a change in pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on a change in pull request #9627:
URL: https://github.com/apache/kafka/pull/9627#discussion_r618158921
##
File path:
connect/runtime/src/main/java/org/apache/kafka/connect/runtime/distributed/WorkerGroupMember.java
##
@@ -203,8 +203,8 @@ public void requestRejoin() {
coordinator.requestRejoin();
}
-public void maybeLeaveGroup(String leaveReason) {
-coordinator.maybeLeaveGroup(leaveReason);
+public void maybeLeaveGroup(String leaveReason, boolean shouldWarn) {
Review comment:
Nice suggestion!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on a change in pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on a change in pull request #9627:
URL: https://github.com/apache/kafka/pull/9627#discussion_r618159827
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1001,9 +1001,14 @@ protected void close(Timer timer) {
}
/**
+ * Leave the group. This method also sends LeaveGroupRequest and log
{@code leaveReason} if this is dynamic members
+ * or unknown coordinator or state is not UNJOINED or this generation has
a valid member id.
+ *
+ * @param leaveReason the reason to leave the group for logging
+ * @param shouldWarn should log as WARN level or INFO
* @throws KafkaException if the rebalance callback throws exception
*/
-public synchronized RequestFuture maybeLeaveGroup(String
leaveReason) {
+public synchronized RequestFuture maybeLeaveGroup(String
leaveReason, boolean shouldWarn) throws KafkaException {
Review comment:
Cool! And, it cannot change to `protected` method since we used this
method in `KafkaConsumer`, which is in different package.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-824620099 @chia7712 , thanks for the good suggestion! You make the change simpler!! :) Please help check again. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-12708) Rewrite org.apache.kafka.test.Microbenchmarks by JMH
Chia-Ping Tsai created KAFKA-12708: -- Summary: Rewrite org.apache.kafka.test.Microbenchmarks by JMH Key: KAFKA-12708 URL: https://issues.apache.org/jira/browse/KAFKA-12708 Project: Kafka Issue Type: Task Reporter: Chia-Ping Tsai The benchmark code is a bit obsolete and it would be better to rewrite it by JMH -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (KAFKA-12528) kafka-configs.sh does not work while changing the sasl jaas configurations.
[
https://issues.apache.org/jira/browse/KAFKA-12528?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chia-Ping Tsai resolved KAFKA-12528.
Resolution: Duplicate
see KAFKA-12530
> kafka-configs.sh does not work while changing the sasl jaas configurations.
> ---
>
> Key: KAFKA-12528
> URL: https://issues.apache.org/jira/browse/KAFKA-12528
> Project: Kafka
> Issue Type: Bug
> Components: admin, core
>Reporter: kaushik srinivas
>Priority: Major
>
> We are trying to modify the sasl jaas configurations for the kafka broker
> runtime using the dynamic config update functionality using the
> kafka-configs.sh script. But we are unable to get it working.
> Below is our command:
> ./kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers
> --entity-name 59 --alter --add-config 'sasl.jaas.config=KafkaServer \{\n
> org.apache.kafka.common.security.plain.PlainLoginModule required \n
> username=\"test\" \n password=\"test\"; \n };'
>
> command is exiting with error:
> requirement failed: Invalid entity config: all configs to be added must be in
> the format "key=val".
>
> we also tried below format as well:
> kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers
> --entity-name 59 --alter --add-config
> 'sasl.jaas.config=[username=test,password=test]'
> command does not return but the kafka broker logs prints the below error
> messages.
> org.apache.kafka.common.security.authenticator.SaslServerAuthenticator - Set
> SASL server state to FAILED during authentication"}}
> {"type":"log", "host":"kf-kaudynamic-0", "level":"INFO",
> "neid":"kafka-cfd5ccf2af7f47868e83471a5b603408", "system":"kafka",
> "time":"2021-03-23T08:29:00.946", "timezone":"UTC",
> "log":\{"message":"data-plane-kafka-network-thread-1001-ListenerName(SASL_PLAINTEXT)-SASL_PLAINTEXT-2
> - org.apache.kafka.common.network.Selector - [SocketServer brokerId=1001]
> Failed authentication with /127.0.0.1 (Unexpected Kafka request of type
> METADATA during SASL handshake.)"}}
>
> 1. If one has SASL enabled and with a single listener, how are we supposed to
> change the sasl credentials using this command ?
> 2. can anyone point us out to some example commands for modifying the sasl
> jaas configurations ?
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (KAFKA-12529) kafka-configs.sh does not work while changing the sasl jaas configurations.
[
https://issues.apache.org/jira/browse/KAFKA-12529?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chia-Ping Tsai resolved KAFKA-12529.
Resolution: Duplicate
see KAFKA-12530
> kafka-configs.sh does not work while changing the sasl jaas configurations.
> ---
>
> Key: KAFKA-12529
> URL: https://issues.apache.org/jira/browse/KAFKA-12529
> Project: Kafka
> Issue Type: Bug
>Reporter: kaushik srinivas
>Priority: Major
>
> We are trying to use kafka-configs script to modify the sasl jaas
> configurations, but unable to do so.
> Command used:
> ./kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers
> --entity-name 59 --alter --add-config 'sasl.jaas.config=KafkaServer \{\n
> org.apache.kafka.common.security.plain.PlainLoginModule required \n
> username=\"test\" \n password=\"test\"; \n };'
> error:
> requirement failed: Invalid entity config: all configs to be added must be in
> the format "key=val".
> command 2:
> kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers
> --entity-name 59 --alter --add-config
> 'sasl.jaas.config=[username=test,password=test]'
> output:
> command does not return , but kafka broker logs below error:
> DEBUG", "neid":"kafka-cfd5ccf2af7f47868e83471a5b603408", "system":"kafka",
> "time":"2021-03-23T08:29:00.946", "timezone":"UTC",
> "log":\{"message":"data-plane-kafka-network-thread-1001-ListenerName(SASL_PLAINTEXT)-SASL_PLAINTEXT-2
> - org.apache.kafka.common.security.authenticator.SaslServerAuthenticator -
> Set SASL server state to FAILED during authentication"}}
> {"type":"log", "host":"kf-kaudynamic-0", "level":"INFO",
> "neid":"kafka-cfd5ccf2af7f47868e83471a5b603408", "system":"kafka",
> "time":"2021-03-23T08:29:00.946", "timezone":"UTC",
> "log":\{"message":"data-plane-kafka-network-thread-1001-ListenerName(SASL_PLAINTEXT)-SASL_PLAINTEXT-2
> - org.apache.kafka.common.network.Selector - [SocketServer brokerId=1001]
> Failed authentication with /127.0.0.1 (Unexpected Kafka request of type
> METADATA during SASL handshake.)"}}
> We have below issues:
> 1. If one installs kafka broker with SASL mechanism and wants to change the
> SASL jaas config via kafka-configs scripts, how is it supposed to be done ?
> does kafka-configs needs client credentials to do the same ?
> 2. Can anyone point us to example commands of kafka-configs to alter the
> sasl.jaas.config property of kafka broker. We do not see any documentation or
> examples for the same.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (KAFKA-12371) MirrorMaker 2.0 documentation is incorrect
[ https://issues.apache.org/jira/browse/KAFKA-12371?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chia-Ping Tsai resolved KAFKA-12371. Resolution: Duplicate > MirrorMaker 2.0 documentation is incorrect > -- > > Key: KAFKA-12371 > URL: https://issues.apache.org/jira/browse/KAFKA-12371 > Project: Kafka > Issue Type: Improvement > Components: docs, documentation >Affects Versions: 2.7.0 >Reporter: Scott Kirkpatrick >Priority: Minor > > There are a few places in the official MirrorMaker 2.0 docs that are either > confusing or incorrect. Here are a few examples I've found: > The documentation for the 'sync.group.offsets.enabled' config states that > it's enabled by default > [here|https://github.com/apache/kafka-site/blob/61f4707381c369a98a7a77e1a7c3a11d5983909c/27/ops.html#L802], > but the actual source code indicates that it's disabled by default > [here|https://github.com/apache/kafka/blob/f75efb96fae99a22eb54b5d0ef4e23b28fe8cd2d/connect/mirror/src/main/java/org/apache/kafka/connect/mirror/MirrorConnectorConfig.java#L185]. > I'm unsure if the intent is to have it enabled or disabled by default. > There are also some numerical typos, > [here|https://github.com/apache/kafka-site/blob/61f4707381c369a98a7a77e1a7c3a11d5983909c/27/ops.html#L791] > and > [here|https://github.com/apache/kafka-site/blob/61f4707381c369a98a7a77e1a7c3a11d5983909c/27/ops.html#L793]. > These lines state that the default is 6000 seconds (and incorrectly that > it's equal to 10 minutes), but the actual default is 600 seconds, shown > [here|https://github.com/apache/kafka/blob/f75efb96fae99a22eb54b5d0ef4e23b28fe8cd2d/connect/mirror/src/main/java/org/apache/kafka/connect/mirror/MirrorConnectorConfig.java#L145] > and > [here|https://github.com/apache/kafka/blob/f75efb96fae99a22eb54b5d0ef4e23b28fe8cd2d/connect/mirror/src/main/java/org/apache/kafka/connect/mirror/MirrorConnectorConfig.java#L152] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] chia7712 commented on pull request #10547: KAFKA-12284: increase request timeout to make tests reliable
chia7712 commented on pull request #10547: URL: https://github.com/apache/kafka/pull/10547#issuecomment-824640807 @showuon Could you merge trunk to trigger QA again? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10547: KAFKA-12284: increase request timeout to make tests reliable
showuon commented on pull request #10547: URL: https://github.com/apache/kafka/pull/10547#issuecomment-824644809 Done. Let's wait and see :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
cadonna commented on pull request #10548:
URL: https://github.com/apache/kafka/pull/10548#issuecomment-824665014
>
> * prefixScan() (prefix should not be `null` either I guess? \cc
@guozhangwang @cadonna
>
Yes! Actually, the implementations in `RocksDBStore` and
`InMemoryKeyValueStore` already have a `null` check.
```
public , P> KeyValueIterator
prefixScan(final P prefix,
final PS prefixKeySerializer) {
Objects.requireNonNull(prefix, "prefix cannot be null");
Objects.requireNonNull(prefixKeySerializer, "prefixKeySerializer
cannot be null");
```
I think it would make sense to move them to the `MeteredKeyValueStore`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r618221025
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/AbstractApiMessageAndVersionSerde.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage.serialization;
+
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ByteBufferAccessor;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+
+import java.nio.ByteBuffer;
+
+/**
+ * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}.
+ *
+ * Implementors need to extend this class and implement {@link
#apiMessageFor(short)} method to return a respective
+ * {@code ApiMessage} for the given {@code apiKey}. This is required to
deserialize the bytes to build the respective
+ * {@code ApiMessage} instance.
+ */
+public abstract class AbstractApiMessageAndVersionSerde {
+
+public byte[] serialize(ApiMessageAndVersion messageAndVersion) {
+ObjectSerializationCache cache = new ObjectSerializationCache();
+short version = messageAndVersion.version();
+ApiMessage message = messageAndVersion.message();
+
+// Add header containing apiKey and apiVersion,
+// headerSize is 1 byte for apiKey and 1 byte for apiVersion
+int headerSize = 1 + 1;
+int messageSize = message.size(cache, version);
+ByteBufferAccessor writable = new
ByteBufferAccessor(ByteBuffer.allocate(headerSize + messageSize));
+
+// Write apiKey and version
+writable.writeUnsignedVarint(message.apiKey());
Review comment:
It adds one more indirection but it is good to have a standardized
serialization mechanism for different metadata logs.
We can introduce `AbsatrctMetadataRecordSerde` which is mostly the current
`MetadataRecordSerde` excluding RAFT related `ApiMessage` generation or a given
`apiKey`. I prefer not to share the `apiKey `space across different modules
but they can implement their own serde derived from
`AbstractMetadataRecordSerde` by providing `ApiMessage` instances for the
respective `apiKey`s.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r618227233
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/AbstractApiMessageAndVersionSerde.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage.serialization;
+
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ByteBufferAccessor;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+
+import java.nio.ByteBuffer;
+
+/**
+ * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}.
+ *
+ * Implementors need to extend this class and implement {@link
#apiMessageFor(short)} method to return a respective
+ * {@code ApiMessage} for the given {@code apiKey}. This is required to
deserialize the bytes to build the respective
+ * {@code ApiMessage} instance.
+ */
+public abstract class AbstractApiMessageAndVersionSerde {
+
+public byte[] serialize(ApiMessageAndVersion messageAndVersion) {
+ObjectSerializationCache cache = new ObjectSerializationCache();
+short version = messageAndVersion.version();
+ApiMessage message = messageAndVersion.message();
+
+// Add header containing apiKey and apiVersion,
+// headerSize is 1 byte for apiKey and 1 byte for apiVersion
+int headerSize = 1 + 1;
+int messageSize = message.size(cache, version);
+ByteBufferAccessor writable = new
ByteBufferAccessor(ByteBuffer.allocate(headerSize + messageSize));
+
+// Write apiKey and version
+writable.writeUnsignedVarint(message.apiKey());
Review comment:
@junrao I gave a shot at introducing the mentioned changes in the
earlier comment.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r618228663
##
File path: build.gradle
##
@@ -1410,6 +1410,7 @@ project(':storage') {
implementation project(':storage:api')
implementation project(':clients')
implementation project(':metadata')
+implementation project(':raft')
Review comment:
I will remove this dependency once `AbstractMetadataRecordSerde` is
moved to `clients` module. I plan to do that in a followup PR if we go with
this approach.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r618229816
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/AbstractMetadataMessageSerde.java
##
@@ -19,52 +19,41 @@
import org.apache.kafka.common.protocol.ApiMessage;
import org.apache.kafka.common.protocol.ByteBufferAccessor;
import org.apache.kafka.common.protocol.ObjectSerializationCache;
-import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.common.protocol.Readable;
import org.apache.kafka.metadata.ApiMessageAndVersion;
-
+import org.apache.kafka.raft.metadata.AbstractMetadataRecordSerde;
import java.nio.ByteBuffer;
/**
- * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}.
+ * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}. This can be used as
+ * serialization/deserialization protocol for any metadata records derived of
{@code ApiMessage}s.
*
* Implementors need to extend this class and implement {@link
#apiMessageFor(short)} method to return a respective
* {@code ApiMessage} for the given {@code apiKey}. This is required to
deserialize the bytes to build the respective
* {@code ApiMessage} instance.
*/
-public abstract class AbstractApiMessageAndVersionSerde {
+public abstract class AbstractMetadataMessageSerde {
Review comment:
I could not find a better name here. Pl let me know if you have any.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r618227233
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/AbstractApiMessageAndVersionSerde.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage.serialization;
+
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ByteBufferAccessor;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+
+import java.nio.ByteBuffer;
+
+/**
+ * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}.
+ *
+ * Implementors need to extend this class and implement {@link
#apiMessageFor(short)} method to return a respective
+ * {@code ApiMessage} for the given {@code apiKey}. This is required to
deserialize the bytes to build the respective
+ * {@code ApiMessage} instance.
+ */
+public abstract class AbstractApiMessageAndVersionSerde {
+
+public byte[] serialize(ApiMessageAndVersion messageAndVersion) {
+ObjectSerializationCache cache = new ObjectSerializationCache();
+short version = messageAndVersion.version();
+ApiMessage message = messageAndVersion.message();
+
+// Add header containing apiKey and apiVersion,
+// headerSize is 1 byte for apiKey and 1 byte for apiVersion
+int headerSize = 1 + 1;
+int messageSize = message.size(cache, version);
+ByteBufferAccessor writable = new
ByteBufferAccessor(ByteBuffer.allocate(headerSize + messageSize));
+
+// Write apiKey and version
+writable.writeUnsignedVarint(message.apiKey());
Review comment:
@junrao I gave a shot at introducing the mentioned changes in the
earlier comment with
https://github.com/apache/kafka/pull/10271/commits/e962ddf01894118655776e93907eb41a9e04a8e7.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10493) KTable out-of-order updates are not being ignored
[ https://issues.apache.org/jira/browse/KAFKA-10493?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17327212#comment-17327212 ] Bruno Cadonna commented on KAFKA-10493: --- The options that I see are: # verify the order during restoration # disable the source topic optimization entirely # live with the inconsistency and warn users when they enable the source topic optimization # let users enable/disable dropping out-of-order updates per table # let users enable/disable source topic optimizaton per table (that has been already under discussion if I remember correctly) I think a mix of 3, 4, and 5 would be the most flexible solution. By default, I would enable dropping out-of-order updates and disabling the source topic optimization. > KTable out-of-order updates are not being ignored > - > > Key: KAFKA-10493 > URL: https://issues.apache.org/jira/browse/KAFKA-10493 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Pedro Gontijo >Assignee: Matthias J. Sax >Priority: Blocker > Fix For: 3.0.0 > > Attachments: KTableOutOfOrderBug.java > > > On a materialized KTable, out-of-order records for a given key (records which > timestamp are older than the current value in store) are not being ignored > but used to update the local store value and also being forwarded. > I believe the bug is here: > [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/state/internals/ValueAndTimestampSerializer.java#L77] > It should return true, not false (see javadoc) > The bug impacts here: > [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KTableSource.java#L142-L148] > I have attached a simple stream app that shows the issue happening. > Thank you! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] showuon commented on pull request #10547: KAFKA-12284: increase request timeout to make tests reliable
showuon commented on pull request #10547: URL: https://github.com/apache/kafka/pull/10547#issuecomment-824789512 Failed tests are ``` Build / JDK 8 and Scala 2.12 / org.apache.kafka.connect.mirror.integration.MirrorConnectorsIntegrationSSLTest.testReplication() Build / JDK 8 and Scala 2.12 / kafka.server.RaftClusterTest.testCreateClusterAndCreateAndManyTopicsWithManyPartitions() Build / JDK 15 and Scala 2.13 / org.apache.kafka.connect.integration.RebalanceSourceConnectorsIntegrationTest.testDeleteConnector Build / JDK 15 and Scala 2.13 / org.apache.kafka.streams.integration.KTableKTableForeignKeyInnerJoinMultiIntegrationTest.shouldInnerJoinMultiPartitionQueryable ``` The failed `MirrorConnectorsIntegrationSSLTest.testReplication()` is not request timeout anymore. ``` org.opentest4j.AssertionFailedError: Condition not met within timeout 2. Offsets not translated downstream to primary cluster. ==> expected: but was: ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tombentley commented on a change in pull request #9441: KAFKA-10614: Ensure group state (un)load is executed in the submitted order
tombentley commented on a change in pull request #9441:
URL: https://github.com/apache/kafka/pull/9441#discussion_r618358643
##
File path: core/src/main/scala/kafka/coordinator/group/GroupCoordinator.scala
##
@@ -905,19 +908,32 @@ class GroupCoordinator(val brokerId: Int,
*
* @param offsetTopicPartitionId The partition we are now leading
*/
- def onElection(offsetTopicPartitionId: Int): Unit = {
-info(s"Elected as the group coordinator for partition
$offsetTopicPartitionId")
-groupManager.scheduleLoadGroupAndOffsets(offsetTopicPartitionId,
onGroupLoaded)
+ def onElection(offsetTopicPartitionId: Int, coordinatorEpoch: Int): Unit = {
+val currentEpoch = Option(epochForPartitionId.get(offsetTopicPartitionId))
+if (currentEpoch.forall(currentEpoch => coordinatorEpoch > currentEpoch)) {
+ info(s"Elected as the group coordinator for partition
$offsetTopicPartitionId in epoch $coordinatorEpoch")
+ groupManager.scheduleLoadGroupAndOffsets(offsetTopicPartitionId,
onGroupLoaded)
+ epochForPartitionId.put(offsetTopicPartitionId, coordinatorEpoch)
+} else {
+ warn(s"Ignored election as group coordinator for partition
$offsetTopicPartitionId " +
+s"in epoch $coordinatorEpoch since current epoch is $currentEpoch")
+}
}
/**
* Unload cached state for the given partition and stop handling requests
for groups which map to it.
*
* @param offsetTopicPartitionId The partition we are no longer leading
*/
- def onResignation(offsetTopicPartitionId: Int): Unit = {
-info(s"Resigned as the group coordinator for partition
$offsetTopicPartitionId")
-groupManager.removeGroupsForPartition(offsetTopicPartitionId,
onGroupUnloaded)
+ def onResignation(offsetTopicPartitionId: Int, coordinatorEpoch:
Option[Int]): Unit = {
+val currentEpoch = Option(epochForPartitionId.get(offsetTopicPartitionId))
+if (currentEpoch.forall(currentEpoch => currentEpoch <=
coordinatorEpoch.getOrElse(Int.MaxValue))) {
Review comment:
This one doesn't do an update any more (following your other comment).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-824786063 All failed tests are flaky and unrelated. ``` Build / JDK 11 and Scala 2.13 / kafka.server.RaftClusterTest.testCreateClusterAndCreateListDeleteTopic() Build / JDK 15 and Scala 2.13 / org.apache.kafka.connect.mirror.integration.MirrorConnectorsIntegrationSSLTest.testReplicationWithEmptyPartition() Build / JDK 15 and Scala 2.13 / org.apache.kafka.connect.mirror.integration.MirrorConnectorsIntegrationSSLTest.testOneWayReplicationWithAutoOffsetSync() Build / JDK 15 and Scala 2.13 / org.apache.kafka.connect.mirror.integration.MirrorConnectorsIntegrationSSLTest.testReplicationWithEmptyPartition() Build / JDK 8 and Scala 2.12 / org.apache.kafka.connect.mirror.integration.MirrorConnectorsIntegrationTest.testReplication() ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tombentley commented on a change in pull request #10530: KAFKA-10231 fail bootstrap of Rest server if the host name in the adv…
tombentley commented on a change in pull request #10530:
URL: https://github.com/apache/kafka/pull/10530#discussion_r618372208
##
File path:
connect/runtime/src/main/java/org/apache/kafka/connect/runtime/rest/RestServer.java
##
@@ -357,21 +358,53 @@ public URI advertisedUrl() {
ServerConnector serverConnector =
findConnector(advertisedSecurityProtocol);
builder.scheme(advertisedSecurityProtocol);
-String advertisedHostname =
config.getString(WorkerConfig.REST_ADVERTISED_HOST_NAME_CONFIG);
-if (advertisedHostname != null && !advertisedHostname.isEmpty())
-builder.host(advertisedHostname);
-else if (serverConnector != null && serverConnector.getHost() != null
&& serverConnector.getHost().length() > 0)
-builder.host(serverConnector.getHost());
+String hostNameOverride = hostNameOverride(serverConnector);
+if (hostNameOverride != null) {
+builder.host(hostNameOverride);
+}
Integer advertisedPort =
config.getInt(WorkerConfig.REST_ADVERTISED_PORT_CONFIG);
if (advertisedPort != null)
builder.port(advertisedPort);
else if (serverConnector != null && serverConnector.getPort() > 0)
builder.port(serverConnector.getPort());
-log.info("Advertised URI: {}", builder.build());
+URI uri = builder.build();
+maybeThrowInvalidHostNameException(uri, hostNameOverride);
+log.info("Advertised URI: {}", uri);
-return builder.build();
+return uri;
+}
+
+private String hostNameOverride(ServerConnector serverConnector) {
+String advertisedHostname =
config.getString(WorkerConfig.REST_ADVERTISED_HOST_NAME_CONFIG);
+if (advertisedHostname != null && !advertisedHostname.isEmpty())
+return advertisedHostname;
+else if (serverConnector != null && serverConnector.getHost() != null
&& serverConnector.getHost().length() > 0)
+return serverConnector.getHost();
+return null;
+}
+
+/**
+ * Parses the uri and throws a more definitive error
+ * when the internal node to node communication can't happen due to an
invalid host name.
+ */
+static void maybeThrowInvalidHostNameException(URI uri, String
hostNameOverride) {
+//java URI parsing will fail silently returning null in the host if
the host name contains invalid characters like _
+//this bubbles up later when the Herder tries to communicate on the
advertised url and the current HttpClient fails with an ambiguous message
+if (uri.getHost() == null) {
+String errorMsg = "Could not parse host from advertised URL: '" +
uri.toString() + "'";
+if (hostNameOverride != null) {
+//validate hostname using IDN class to see if it can bubble up
the real cause and we can show the user a more detailed exception
+try {
+IDN.toASCII(hostNameOverride, IDN.USE_STD3_ASCII_RULES);
+} catch (IllegalArgumentException e) {
+errorMsg += ", as it doesn't conform to RFC 1123
specification: " + e.getMessage();
Review comment:
If we're going to mention the RFC let's mention section 2.1
specifically. We're referring the user to a nearly 100 page document and it's
only a tiny part of it which is relevant here.
##
File path:
connect/runtime/src/main/java/org/apache/kafka/connect/runtime/rest/RestServer.java
##
@@ -357,21 +358,53 @@ public URI advertisedUrl() {
ServerConnector serverConnector =
findConnector(advertisedSecurityProtocol);
builder.scheme(advertisedSecurityProtocol);
-String advertisedHostname =
config.getString(WorkerConfig.REST_ADVERTISED_HOST_NAME_CONFIG);
-if (advertisedHostname != null && !advertisedHostname.isEmpty())
-builder.host(advertisedHostname);
-else if (serverConnector != null && serverConnector.getHost() != null
&& serverConnector.getHost().length() > 0)
-builder.host(serverConnector.getHost());
+String hostNameOverride = hostNameOverride(serverConnector);
+if (hostNameOverride != null) {
+builder.host(hostNameOverride);
+}
Integer advertisedPort =
config.getInt(WorkerConfig.REST_ADVERTISED_PORT_CONFIG);
if (advertisedPort != null)
builder.port(advertisedPort);
else if (serverConnector != null && serverConnector.getPort() > 0)
builder.port(serverConnector.getPort());
-log.info("Advertised URI: {}", builder.build());
+URI uri = builder.build();
+maybeThrowInvalidHostNameException(uri, hostNameOverride);
+log.info("Advertised URI: {}", uri);
-return builder.build();
+return uri;
+}
+
+private String hostNameOverride(ServerConnector serverConnector) {
+String advertisedHostname =
con
[GitHub] [kafka] tombentley commented on pull request #9441: KAFKA-10614: Ensure group state (un)load is executed in the submitted order
tombentley commented on pull request #9441: URL: https://github.com/apache/kafka/pull/9441#issuecomment-824800741 Thanks @hachikuji, it's much simpler now, if you could take another look? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna opened a new pull request #10587: KAFKA-8897: Upgrade RocksDB to 6.8.1
cadonna opened a new pull request #10587: URL: https://github.com/apache/kafka/pull/10587 RocksDB 6.8.1 is the newest version I could upgrade without running into a SIGABRT issue with error message "Pure virtual function called!" during Gradle builds. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] C0urante commented on pull request #10530: KAFKA-10231 fail bootstrap of Rest server if the host name in the adv…
C0urante commented on pull request #10530: URL: https://github.com/apache/kafka/pull/10530#issuecomment-824847306 I've just realized--this may not be a safe change to make. Although we should fail fast on startup if a worker tries to join an existing cluster with a bad hostname, it's still possible right now to run a single worker in that scenario. Although running a single worker in distributed mode may sound like an anti-pattern, there are still benefits to such a setup, such as persistent storage of configurations in a Kafka topic. It's also possible that there are Dockerized quickstarts and demos that use a single Connect worker and may have a bad hostname; these would suddenly break on upgrade if we merge this change. At the very least, I think we should be more explicit about _why_ we're failing workers on startup with our error message, try to give users a better picture of how workers with a bad hostname can be dangerous (since right now they don't fail on startup but instead begin to fail silently when forwarding user requests or task configs to the leader), and even call out Dockerized setups with instructions on how to fix the worker config in that case by changing the advertised URL to use a valid hostname and, if running a multi-node cluster, making sure that the worker is reachable from other workers with that advertised URL. But I think at this point we're doing a fair bit of work to try to circumvent this issue instead of addressing it head-on. Using a different HTTP client has already been discussed as an option but punted on in favor of a smaller, simpler change; given that this change seems less simple now, I wonder if it's worth reconsidering. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Nathan22177 edited a comment on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 edited a comment on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-824837667 > Seems, `put(final Windowed sessionKey,...)` and `remove(final Windowed sessionKey)` don't check for `sessionKey.key() != null` though? Can we add this check? They do? Since 2017 according to annotations? Might be that we're talking different classes? 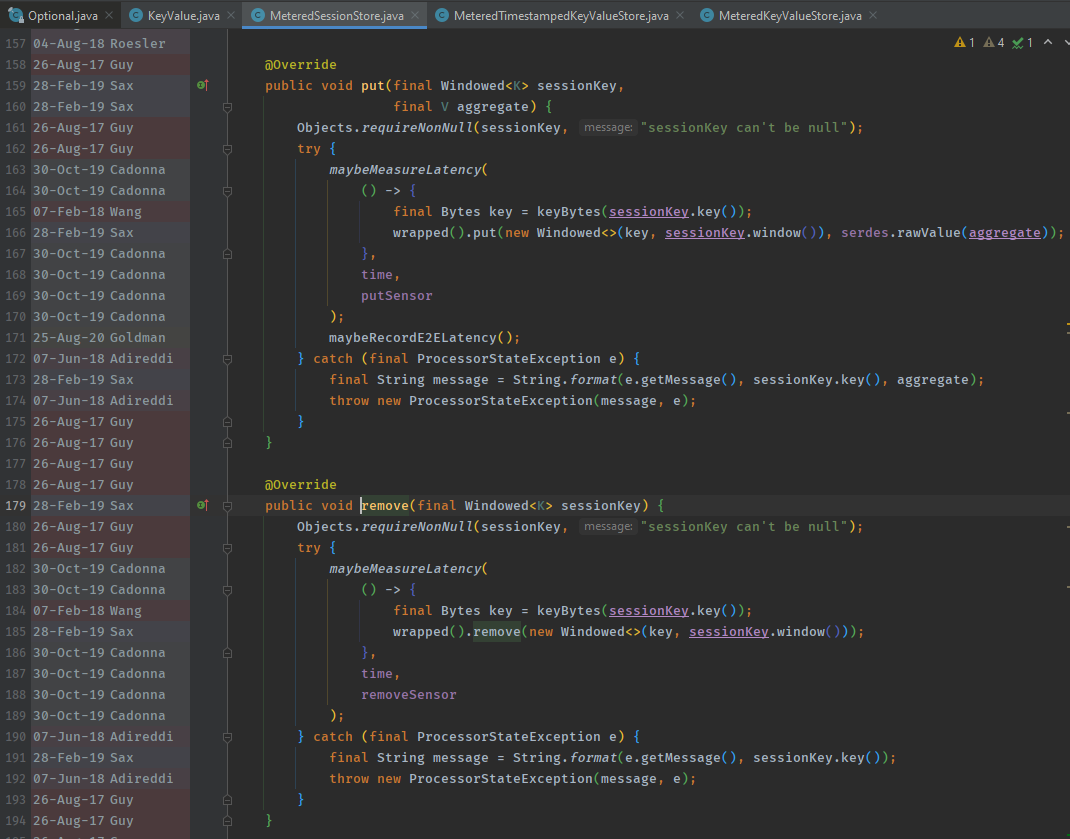 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Nathan22177 commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 commented on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-824837667 > > All of them already had the checks. > > Sweet. I did not double check the code before. > > Seems, `put(final Windowed sessionKey,...)` and `remove(final Windowed sessionKey)` don't check for `sessionKey.key() != null` though? Can we add this check? They do? Might be that we're talking different classes?  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Nathan22177 commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 commented on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-824839639 And both are covered with tests.  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] C0urante commented on pull request #10074: KAFKA-12305: Fix Flatten SMT for array types
C0urante commented on pull request #10074: URL: https://github.com/apache/kafka/pull/10074#issuecomment-824801861 Thanks @tombentley--good call on updating the docs; I've done that. RE a test for the recursive case--I don't think it'll hurt, so I updated the existing tests to include it. Probably not too valuable right now since arrays are just passed through unmodified but it might save someone else that bit of legwork in the future if we decide we want bona fide flattening for array types as well. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Nathan22177 commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 commented on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-824842899 Tests for aforementioned checks were added here: https://github.com/apache/kafka/pull/9520/files#diff-dc416cbdf3efca7ee284fe1e27110e737c4178b7a1cc0696d9d7a72bb8e6e764 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tombentley commented on pull request #10530: KAFKA-10231 fail bootstrap of Rest server if the host name in the adv…
tombentley commented on pull request #10530: URL: https://github.com/apache/kafka/pull/10530#issuecomment-824864967 Great spot @C0urante! I completely agree we shouldn't break working single-node distributed installs and that trying to fix this validation approach is going to end up being a lot of work. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kpatelatwork commented on pull request #10530: KAFKA-10231 fail bootstrap of Rest server if the host name in the adv…
kpatelatwork commented on pull request #10530: URL: https://github.com/apache/kafka/pull/10530#issuecomment-824873571 Great catch @C0urante . Let me investigate what it takes to upgrade to an Apache HttpClient and how much of an effort it is. I Agree a seemingly simple change doesn't seem simple anymore so why not put the effort in the right future direction to use a client that supports IDNs. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kkonstantine commented on a change in pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
kkonstantine commented on a change in pull request #9627:
URL: https://github.com/apache/kafka/pull/9627#discussion_r618521825
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1023,9 +1023,14 @@ protected void close(Timer timer) {
}
/**
+ * Leaving the group. This method also sends LeaveGroupRequest and log
{@code leaveReason} if this is dynamic members
+ * or unknown coordinator or state is not UNJOINED or this generation has
a valid member id.
+ *
+ * @param leaveReason the reason to leave the group for logging
+ * @param shouldWarn should log as WARN level or INFO
* @throws KafkaException if the rebalance callback throws exception
*/
-public synchronized RequestFuture maybeLeaveGroup(String
leaveReason) {
+public synchronized RequestFuture maybeLeaveGroup(String
leaveReason, boolean shouldWarn) throws KafkaException {
Review comment:
`KafkaException` is a runtime exception and therefore should only be
included in the javadoc. In the method signature we include checked exceptions.
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1051,6 +1061,10 @@ protected void close(Timer timer) {
return future;
}
+public synchronized RequestFuture maybeLeaveGroup(String
leaveReason) throws KafkaException {
Review comment:
same here
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] tang7526 opened a new pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 opened a new pull request #10588: URL: https://github.com/apache/kafka/pull/10588 https://issues.apache.org/jira/browse/KAFKA-12662 ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #10483: KAFKA-12586; Add `DescribeTransactions` Admin API
hachikuji commented on pull request #10483: URL: https://github.com/apache/kafka/pull/10483#issuecomment-824996875 @dajac Thanks for reviewing. I will go ahead and merge since the only failures look like the usual MM ones. @chia7712 Feel free to leave additional comments and I can address them in a separate PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji merged pull request #10483: KAFKA-12586; Add `DescribeTransactions` Admin API
hachikuji merged pull request #10483: URL: https://github.com/apache/kafka/pull/10483 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (KAFKA-12586) Admin API for DescribeTransactions
[ https://issues.apache.org/jira/browse/KAFKA-12586?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jason Gustafson resolved KAFKA-12586. - Resolution: Fixed > Admin API for DescribeTransactions > -- > > Key: KAFKA-12586 > URL: https://issues.apache.org/jira/browse/KAFKA-12586 > Project: Kafka > Issue Type: Sub-task >Reporter: Jason Gustafson >Assignee: Jason Gustafson >Priority: Major > > Add the Admin API for DescribeTransactions documented on KIP-664: > https://cwiki.apache.org/confluence/display/KAFKA/KIP-664%3A+Provide+tooling+to+detect+and+abort+hanging+transactions. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12709) Admin API for ListTransactions
Jason Gustafson created KAFKA-12709: --- Summary: Admin API for ListTransactions Key: KAFKA-12709 URL: https://issues.apache.org/jira/browse/KAFKA-12709 Project: Kafka Issue Type: Sub-task Reporter: Jason Gustafson Assignee: Jason Gustafson Add the `listTransactions` API described in KIP-664: https://cwiki.apache.org/confluence/display/KAFKA/KIP-664%3A+Provide+tooling+to+detect+and+abort+hanging+transactions. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] jolshan commented on pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
jolshan commented on pull request #10584: URL: https://github.com/apache/kafka/pull/10584#issuecomment-825041572 Test failures look unrelated. Some of the usual suspects like `RaftClusterTest.testCreateClusterAndCreateAndManyTopicsWithManyPartitions()` and `MirrorConnectorsIntegrationSSLTest`/`MirrorConnectorsIntegrationTest`tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-9895) Truncation request on broker start up may cause OffsetOutOfRangeException
[
https://issues.apache.org/jira/browse/KAFKA-9895?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329317#comment-17329317
]
Konstantin commented on KAFKA-9895:
---
We bumped into this as well on kafka 2.4.1.
Here's the sequence of events, which I believe leads to this error:
1. Leader of partition test-3 (broker 2) stops due to graceful shutdown with hw
502921625, but is has ongoing unreplicated transaction, starting from
502921626, so it writes this transaction to producer snapshot.
{code:java}
[2021-04-11 23:27:44,313] INFO [ProducerStateManager partition=topic-3] Writing
producer snapshot at offset 502921627 (kafka.log.ProducerStateManager){code}
2. Another broker (1) becomes leader and starts partition from hw 502921625
{code:java}
[2021-04-11 23:27:43,081] INFO [Partition topic-3 broker=1] topic-3 starts at
leader epoch 30 from offset 502921625 with high watermark 502921625. Previous
leader epoch was 29. (kafka.cluster.Partition){code}
3. Broker 2 starts again, loads that transaction's start offset as first
unstable offset and tries to become follower. Then it tries to truncate to last
replicated offset - 502921625.
{code:java}
[2021-04-11 23:28:31,447] INFO [ProducerStateManager partition=topic-3] Loading
producer state from snapshot file
'/KAFKADATA/topic-3/000502921627.snapshot'
(kafka.log.ProducerStateManager)
[2021-04-11 23:28:31,454] INFO [Log partition=topic-3, dir=/KAFKADATA]
Completed load of log with 25 segments, log start offset 496341849 and log end
offset 502921627 in 29 ms (kafka.log.Log)
[2021-04-11 23:28:33,776] INFO [Partition topic-3 broker=2] Log loaded for
partition topic-3 with initial high watermark 502921625
(kafka.cluster.Partition)
[2021-04-11 23:28:33,885] INFO [ReplicaFetcherManager on broker 2] Added
fetcher to broker BrokerEndPoint(id=1, host=***:9093) for partitions
Map(topic-3 -> (offset=502921625, leaderEpoch=30), ***)
(kafka.server.ReplicaFetcherManager)
[2021-04-11 23:28:34,002] INFO [Log partition=topic-3, dir=/KAFKADATA]
Truncating to offset 502921625 (kafka.log.Log)
{code}
4. During truncation it updates logEndOffset, which leads to updating hw and
incrementing first unstable offset here:
{code:java}
private def maybeIncrementFirstUnstableOffset(): Unit = lock synchronized {
checkIfMemoryMappedBufferClosed()
val updatedFirstStableOffset = producerStateManager.firstUnstableOffset match
{
case Some(logOffsetMetadata) if logOffsetMetadata.messageOffsetOnly ||
logOffsetMetadata.messageOffset < logStartOffset =>
val offset = math.max(logOffsetMetadata.messageOffset, logStartOffset)
Some(convertToOffsetMetadataOrThrow(offset))
case other => other
}
if (updatedFirstStableOffset != this.firstUnstableOffsetMetadata) {
debug(s"First unstable offset updated to $updatedFirstStableOffset")
this.firstUnstableOffsetMetadata = updatedFirstStableOffset
}
}
{code}
It finds producerStateManager.firstUnstableOffset (502921626, loaded from
producer snapshot) and calls convertToOffsetMetadataOrThrow(), which tries to
read the log at 502921626 and fails, because log end offset is already
truncated to 502921625.
{code:java}
[2021-04-11 23:28:34,003] ERROR [ReplicaFetcher replicaId=2, leaderId=1,
fetcherId=2] Unexpected error occurred during truncation for topic-3 at offset
502921625
(kafka.server.ReplicaFetcherThread)org.apache.kafka.common.errors.OffsetOutOfRangeException:
Received request for offset 502921626 for partition topic-3, but we only have
log segments in the range 496341849 to 502921625.
[2021-04-11 23:28:34,004] WARN [ReplicaFetcher replicaId=2, leaderId=1,
fetcherId=2] Partition topic-3 marked as failed
{code}
We didn't manage to reproduce this as is, but it can be emulated via writing
transaction to only one replica, shutting it down and starting another one with
unclean leader election.
So, the steps to reproduce are:
# Start 2 brokers, create a topic with 1 partition and replication factor of
2. Let's say end offset is 5.
# Stop broker 1
# Write any record (to offset 5), then start transaction and write another one
(to offset 6) - transaction start offset should be greater than end offset of
1st broker's replica, or it won't be out of range.
# Stop broker 2
# Start broker 1 with unclean leader election. It will start from offset 5.
# Start broker 2 and it will throw OffsetOutOfRangeException during truncation
to 5 for transaction start offset 6.
Works (or rather fails) like a charm on any kafka from 2.4.1 to 2.7.0.
> Truncation request on broker start up may cause OffsetOutOfRangeException
> -
>
> Key: KAFKA-9895
> URL: https://issues.apache.org/jira/browse/KAFKA-9895
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 2.4.0
>Reporte
[GitHub] [kafka] tang7526 commented on pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on pull request #10588: URL: https://github.com/apache/kafka/pull/10588#issuecomment-825051567 @chia7712 Could you help to review this PR? Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tang7526 commented on pull request #10534: KAFKA-806: Index may not always observe log.index.interval.bytes
tang7526 commented on pull request #10534: URL: https://github.com/apache/kafka/pull/10534#issuecomment-825051965 @chia7712 Could you help to review this PR? Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
mjsax commented on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-825070459 > They do? Since 2017 according to annotations? Might be that we're talking different classes? The input parameter is `Windowed sessionKey` and the check is if `sessionKey != null` -- however, `sessionKey` wraps a `key` object, and my ask was to also check if the wrapped key is not null, ie, to add `sessionKey.key() != null` check (note the `.get()` call that extract the wrapped `key` from `sessionKey` parameter). Sorry for the confusion. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10582: MINOR: Bump latest 2.6 version to 2.6.2
ableegoldman commented on a change in pull request #10582: URL: https://github.com/apache/kafka/pull/10582#discussion_r618639618 ## File path: tests/docker/Dockerfile ## @@ -60,7 +60,7 @@ RUN mkdir -p "/opt/kafka-2.2.2" && chmod a+rw /opt/kafka-2.2.2 && curl -s "$KAFK RUN mkdir -p "/opt/kafka-2.3.1" && chmod a+rw /opt/kafka-2.3.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.3.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.3.1" RUN mkdir -p "/opt/kafka-2.4.1" && chmod a+rw /opt/kafka-2.4.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.4.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.4.1" RUN mkdir -p "/opt/kafka-2.5.1" && chmod a+rw /opt/kafka-2.5.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.5.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.5.1" -RUN mkdir -p "/opt/kafka-2.6.1" && chmod a+rw /opt/kafka-2.6.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.6.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.6.1" +RUN mkdir -p "/opt/kafka-2.6.2" && chmod a+rw /opt/kafka-2.6.2 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.6.2.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.6.2" Review comment: Is it possible you just don't have access to view it? I myself get an `access denied` when I click on that link directly, but if you go to [https://s3-us-west-2.amazonaws.com/kafka-packages/](https://s3-us-west-2.amazonaws.com/kafka-packages/) and search for `kafka_2.12-2.6.2.tgz` it shows up with all the other versions -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10800) Validate the snapshot id when the state machine creates a snapshot
[ https://issues.apache.org/jira/browse/KAFKA-10800?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329364#comment-17329364 ] Jose Armando Garcia Sancio commented on KAFKA-10800: 1) What does "the state machine" mean here? I assume it's the KafkaRaftClient? And "attempts to create a snapshot writer", I assume this refers to `log.createSnapshot(snapshotId)`? Sorry, by state machine, I mean users of `interface RaftClient`. This basically means snapshots created through `SnapshotWriter`. In general there are two ways of creating a snapshot. One is by the state machine through `RaftClient::createSnapshot` and `SnapshotWriter`. Another way is by the `KafkaRaftClient` itself downloading the snapshot from the quorum leader. In the second case we want to trust the leader's snapshot and not perform the validation described in this issue. 2) "The end offset and epoch of the snapshot is less than the high-watermark", does the "high-watermark" refer to the leader's highwatermark or the follower's highwatermark? If it is the former, shouldn't it be the leader's responsibility to satisfy this ? If it's the latter, then I think the snapshotId can actually be larger than itself's highwatermark, say the follower has been lagged too much, and its highwatermark == its logEndOffset, which is smaller than the leader's logStartOffset, in this case, the follower's highwatermark will be updated to the snapshotId's endOffset when the snapshot fetching has completed, did I miss anything? See my answer to 1) but in this issue we are only concern with snapshot created locally by either the leader or the follower. Note that both the leader and the followers are responsible for creating snapshot based on the state of the local log. Having said that, high watermark means the local high watermark this is the high watermark reported by the quorum state object. 3) "validation should not be performed when the raft client creates the snapshot writer ", if my assumption in Question 1) is correct, then this seems to be in conflict with 1) The KafkaRaftClient can download a snapshot from the leader when it is too far behind. In this case, those snapshots don't need to get validated against the local quorum state and the local log. When KafkaRaftClient downloads snapshots from the leader the snapshotId will always be greater than the local LEO (and high-watermark). Instead the KafkaRaftClient will write the snapshot to local disk, fully truncate the local log and update the high watermark accordingly. > Validate the snapshot id when the state machine creates a snapshot > -- > > Key: KAFKA-10800 > URL: https://issues.apache.org/jira/browse/KAFKA-10800 > Project: Kafka > Issue Type: Sub-task > Components: replication >Reporter: Jose Armando Garcia Sancio >Assignee: Haoran Xuan >Priority: Major > > When the state machine attempts to create a snapshot writer we should > validate that the following is true: > # The end offset and epoch of the snapshot is less than the high-watermark. > # The end offset and epoch of the snapshot is valid based on the leader > epoch cache. > Note that this validation should not be performed when the raft client > creates the snapshot writer because in that case the local log is out of date > and the follower should trust the snapshot id sent by the partition leader. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10800) Validate the snapshot id when the state machine creates a snapshot
[
https://issues.apache.org/jira/browse/KAFKA-10800?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329364#comment-17329364
]
Jose Armando Garcia Sancio edited comment on KAFKA-10800 at 4/22/21, 7:05 PM:
--
{quote}1) What does "the state machine" mean here? I assume it's the
KafkaRaftClient? And "attempts to create a snapshot writer", I assume this
refers to `log.createSnapshot(snapshotId)`?
{quote}
Sorry, by state machine, I mean users of `interface RaftClient`. This basically
means snapshots created through `SnapshotWriter`.
In general there are two ways of creating a snapshot. One is by the state
machine through `RaftClient::createSnapshot` and `SnapshotWriter`. Another way
is by the `KafkaRaftClient` itself downloading the snapshot from the quorum
leader. In the second case we want to trust the leader's snapshot and not
perform the validation described in this issue.
{quote}2) "The end offset and epoch of the snapshot is less than the
high-watermark", does the "high-watermark" refer to the leader's highwatermark
or the follower's highwatermark? If it is the former, shouldn't it be the
leader's responsibility to satisfy this ? If it's the latter, then I think the
snapshotId can actually be larger than itself's highwatermark, say the follower
has been lagged too much, and its highwatermark == its logEndOffset, which is
smaller than the leader's logStartOffset, in this case, the follower's
highwatermark will be updated to the snapshotId's endOffset when the snapshot
fetching has completed, did I miss anything?
{quote}
See my answer to 1) but in this issue we are only concern with snapshot created
locally by either the leader or the follower. Note that both the leader and the
followers are responsible for creating snapshot based on the state of the local
log. Having said that, high watermark means the local high watermark this is
the high watermark reported by the quorum state object.
{quote}3) "validation should not be performed when the raft client creates the
snapshot writer ", if my assumption in Question 1) is correct, then this seems
to be in conflict with 1)
{quote}
The KafkaRaftClient can download a snapshot from the leader when it is too far
behind. In this case, those snapshots don't need to get validated against the
local quorum state and the local log. When KafkaRaftClient downloads snapshots
from the leader the snapshotId will always be greater than the local LEO (and
high-watermark). Instead the KafkaRaftClient will write the snapshot to local
disk, fully truncate the local log and update the high watermark accordingly.
was (Author: jagsancio):
1) What does "the state machine" mean here? I assume it's the KafkaRaftClient?
And "attempts to create a snapshot writer", I assume this refers to
`log.createSnapshot(snapshotId)`?
Sorry, by state machine, I mean users of `interface RaftClient`. This basically
means snapshots created through `SnapshotWriter`.
In general there are two ways of creating a snapshot. One is by the state
machine through `RaftClient::createSnapshot` and `SnapshotWriter`. Another way
is by the `KafkaRaftClient` itself downloading the snapshot from the quorum
leader. In the second case we want to trust the leader's snapshot and not
perform the validation described in this issue.
2) "The end offset and epoch of the snapshot is less than the high-watermark",
does the "high-watermark" refer to the leader's highwatermark or the follower's
highwatermark? If it is the former, shouldn't it be the leader's responsibility
to satisfy this ? If it's the latter, then I think the snapshotId can actually
be larger than itself's highwatermark, say the follower has been lagged too
much, and its highwatermark == its logEndOffset, which is smaller than the
leader's logStartOffset, in this case, the follower's highwatermark will be
updated to the snapshotId's endOffset when the snapshot fetching has completed,
did I miss anything?
See my answer to 1) but in this issue we are only concern with snapshot created
locally by either the leader or the follower. Note that both the leader and the
followers are responsible for creating snapshot based on the state of the local
log. Having said that, high watermark means the local high watermark this is
the high watermark reported by the quorum state object.
3) "validation should not be performed when the raft client creates the
snapshot writer ", if my assumption in Question 1) is correct, then this seems
to be in conflict with 1)
The KafkaRaftClient can download a snapshot from the leader when it is too far
behind. In this case, those snapshots don't need to get validated against the
local quorum state and the local log. When KafkaRaftClient downloads snapshots
from the leader the snapshotId will always be greater than the local LEO (and
high-watermark). Instead the Kaf
[jira] [Commented] (KAFKA-10493) KTable out-of-order updates are not being ignored
[
https://issues.apache.org/jira/browse/KAFKA-10493?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329373#comment-17329373
]
Matthias J. Sax commented on KAFKA-10493:
-
{quote}verify the order during restoration
{quote}
I don't think this would work. If we have input ` ` and process
the records first, we would discard the second record. However, after log
compaction run, the topic would only contain the second record `` and
thus we don't recognize it as an out-of-order record any longer.
{quote}disable the source topic optimization entirely
{quote}
Sounds like a step backwards?
{quote}live with the inconsistency and warn users when they enable the source
topic optimization
{quote}
I would rather not do this, because we should make it simpler to users, not
harder.
{quote}let users enable/disable dropping out-of-order updates per table
{quote}
If we believe that dropping out-of-order message is the right thing to do
semantically, it seems not a good option to let users enable "incorrect"
behavior? IMHO it's ok if the DSL is opinionated – if users need different
semantics, they can fall back to the processor API.
Another "trick" they could apply is, to use a custom timestamp extractor, and
`return max(r.tx, partitionTime)` to modify timestamps.
{quote}let users enable/disable source topic optimizaton per table (that has
been already under discussion if I remember correctly)
{quote}
On a per table basis maybe. And it's even possible to today to avoid it by
rewriting the program from `builder.table()` to `builder.stream().toTable()` –
But similarly to the point above, it put a lot of burden on the user to
understand the details.
{quote}By default, I would enable dropping out-of-order updates and disabling
the source topic optimization.
{quote}
Topology optimization is already disabled by default.
> KTable out-of-order updates are not being ignored
> -
>
> Key: KAFKA-10493
> URL: https://issues.apache.org/jira/browse/KAFKA-10493
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.6.0
>Reporter: Pedro Gontijo
>Assignee: Matthias J. Sax
>Priority: Blocker
> Fix For: 3.0.0
>
> Attachments: KTableOutOfOrderBug.java
>
>
> On a materialized KTable, out-of-order records for a given key (records which
> timestamp are older than the current value in store) are not being ignored
> but used to update the local store value and also being forwarded.
> I believe the bug is here:
> [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/state/internals/ValueAndTimestampSerializer.java#L77]
> It should return true, not false (see javadoc)
> The bug impacts here:
> [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KTableSource.java#L142-L148]
> I have attached a simple stream app that shows the issue happening.
> Thank you!
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-10493) KTable out-of-order updates are not being ignored
[
https://issues.apache.org/jira/browse/KAFKA-10493?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329387#comment-17329387
]
Bruno Cadonna commented on KAFKA-10493:
---
Good point about the compaction!
{quote}Sounds like a step backwards?
{quote}
What is worse not dropping out-of-order records or not having the source topic
optimization? It seems like they are not compatible.
{quote}After
[KIP-280|https://cwiki.apache.org/confluence/display/KAFKA/KIP-280%3A+Enhanced+log+compaction]
is done, we could drop out-or-order records also with source-table
materialization enabled.
{quote}
Streams does not have control over the source topic. So even if KIP-280 is
done, Streams cannot impose a compaction strategy on the source topic.
{quote}Topology optimization is already disabled by default.
{quote}
I know. that was just to state the defaults in the case of per-table knobs. Of
course, I would regard the knobs for source topic optimization and dropping
out-of-order records as expert mode.
> KTable out-of-order updates are not being ignored
> -
>
> Key: KAFKA-10493
> URL: https://issues.apache.org/jira/browse/KAFKA-10493
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.6.0
>Reporter: Pedro Gontijo
>Assignee: Matthias J. Sax
>Priority: Blocker
> Fix For: 3.0.0
>
> Attachments: KTableOutOfOrderBug.java
>
>
> On a materialized KTable, out-of-order records for a given key (records which
> timestamp are older than the current value in store) are not being ignored
> but used to update the local store value and also being forwarded.
> I believe the bug is here:
> [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/state/internals/ValueAndTimestampSerializer.java#L77]
> It should return true, not false (see javadoc)
> The bug impacts here:
> [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KTableSource.java#L142-L148]
> I have attached a simple stream app that shows the issue happening.
> Thank you!
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] Nathan22177 commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 commented on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-825160003 Ooo. I see yea sorry I also completely looked over the wrapped key part. I'll fix it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Nathan22177 edited a comment on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 edited a comment on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-825160003 Ooo. I see. Yea, sorry, I also completely overlooked the wrapped key part. I'll fix it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kpatelatwork commented on pull request #10530: KAFKA-10231 fail bootstrap of Rest server if the host name in the adv…
kpatelatwork commented on pull request #10530:
URL: https://github.com/apache/kafka/pull/10530#issuecomment-825190538
@tombentley and @C0urante Thanks for the above comment.
I peeked at the code for upgrading to Apache HttpClient and this seems like
a big work especially around the SSL factory and other parameters. This has the
potential to cause even bigger disruption. I am a new committer and the
benefits of doing this upgrade don't seem worth it to me as this bug seems like
a very corner case. All we want to do is report a better error message to the
user that he needs to fix the hostname.
At this point, my suggestion is to pick between the below two choices:
1. close the PR, given it's a corner case, and revisit in the future.
2. Go back to the original PR where the plan was to validate the URL when
Herder tries to forward the request to another node here
https://github.com/kpatelatwork/kafka/blob/7c8fb346a976903cc67e66c4ccfe6cc9858b5048/connect/runtime/src/main/java/org/apache/kafka/connect/runtime/rest/RestClient.java#L107
. This would require parsing the URL to create a URI and see if the host is
null then parse the host out of the URL. I tried
`System.out.println(new
java.net.URL("http://kafka_connect-0.dev-2:8080";).getHost());`
and it seems to do return the proper hostname.
What do you think if we go #2 approach?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] kpatelatwork edited a comment on pull request #10530: KAFKA-10231 fail bootstrap of Rest server if the host name in the adv…
kpatelatwork edited a comment on pull request #10530:
URL: https://github.com/apache/kafka/pull/10530#issuecomment-825190538
@tombentley and @C0urante Thanks for the above comment.
I peeked at the code for upgrading to Apache HttpClient and this seems like
a big work especially around the SSL factory and other parameters. This has the
potential to cause even bigger disruption. I am a new committer and the
benefits of doing this upgrade don't seem worth it to me as this bug seems like
a very corner case. All we want to do is report a better error message to the
user that he needs to fix the hostname.
At this point, my suggestion is to pick between the below two choices:
1. close the PR, given it's a corner case, and revisit in the future.
2. Go back to the original PR where the plan was to validate the URL when
Herder tries to forward the request to another node here
https://github.com/kpatelatwork/kafka/blob/7c8fb346a976903cc67e66c4ccfe6cc9858b5048/connect/runtime/src/main/java/org/apache/kafka/connect/runtime/rest/RestClient.java#L107
. This would require parsing the URL to create a URI and see if the host is
null then parse the host out of the URL. I tried
`System.out.println(new
java.net.URL("http://kafka_connect-0.dev-2:8080";).getHost());`
and it seems to do return the proper hostname that later we can validate
using IDN class.
What do you think if we go #2 approach?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10582: MINOR: Bump latest 2.6 version to 2.6.2
ableegoldman commented on a change in pull request #10582: URL: https://github.com/apache/kafka/pull/10582#discussion_r618753516 ## File path: tests/docker/Dockerfile ## @@ -60,7 +60,7 @@ RUN mkdir -p "/opt/kafka-2.2.2" && chmod a+rw /opt/kafka-2.2.2 && curl -s "$KAFK RUN mkdir -p "/opt/kafka-2.3.1" && chmod a+rw /opt/kafka-2.3.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.3.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.3.1" RUN mkdir -p "/opt/kafka-2.4.1" && chmod a+rw /opt/kafka-2.4.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.4.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.4.1" RUN mkdir -p "/opt/kafka-2.5.1" && chmod a+rw /opt/kafka-2.5.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.5.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.5.1" -RUN mkdir -p "/opt/kafka-2.6.1" && chmod a+rw /opt/kafka-2.6.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.6.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.6.1" +RUN mkdir -p "/opt/kafka-2.6.2" && chmod a+rw /opt/kafka-2.6.2 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.6.2.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.6.2" Review comment: @chia7712 it should be fixed now. Thanks for bringing this up -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] junrao commented on a change in pull request #10564: MINOR: clean up some replication code
junrao commented on a change in pull request #10564:
URL: https://github.com/apache/kafka/pull/10564#discussion_r618761439
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -1119,6 +1057,83 @@ void validateManualPartitionAssignment(List
assignment,
}
}
+/**
+ * Iterate over a sequence of partitions and generate ISR changes and/or
leader
+ * changes if necessary.
+ *
+ * @param context A human-readable context string used in log4j
logging.
+ * @param brokerToRemoveNO_LEADER if no broker is being removed; the
ID of the
Review comment:
What about this place? It seems that Instead of relying upon NO_LEADER,
it might be clearer to make brokerToRemove and brokerToAdd optional int?
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -1119,6 +1057,83 @@ void validateManualPartitionAssignment(List
assignment,
}
}
+/**
+ * Iterate over a sequence of partitions and generate ISR changes and/or
leader
+ * changes if necessary.
+ *
+ * @param context A human-readable context string used in log4j
logging.
+ * @param brokerToRemoveNO_LEADER if no broker is being removed; the
ID of the
+ * broker to remove from the ISR and leadership,
otherwise.
+ * @param brokerToAdd NO_LEADER if no broker is being added; the ID
of the
+ * broker which is now eligible to be a leader,
otherwise.
+ * @param records A list of records which we will append to.
+ * @param iterator The iterator containing the partitions to
examine.
+ */
+void generateLeaderAndIsrUpdates(String context,
+ int brokerToRemove,
+ int brokerToAdd,
+ List records,
+ Iterator iterator) {
+int oldSize = records.size();
+Function isAcceptableLeader =
+r -> r == brokerToAdd || clusterControl.unfenced(r);
+while (iterator.hasNext()) {
+TopicIdPartition topicIdPart = iterator.next();
+TopicControlInfo topic = topics.get(topicIdPart.topicId());
+if (topic == null) {
+throw new RuntimeException("Topic ID " + topicIdPart.topicId()
+
+" existed in isrMembers, but not in the topics map.");
+}
+PartitionControlInfo partition =
topic.parts.get(topicIdPart.partitionId());
+if (partition == null) {
+throw new RuntimeException("Partition " + topicIdPart +
+" existed in isrMembers, but not in the partitions map.");
+}
+int[] newIsr = Replicas.copyWithout(partition.isr, brokerToRemove);
+int newLeader;
+if (isGoodLeader(newIsr, partition.leader)) {
+// If the current leader is good, don't change.
+newLeader = partition.leader;
+} else {
+// Choose a new leader.
+boolean uncleanOk =
configurationControl.uncleanLeaderElectionEnabledForTopic(topic.name);
+newLeader = bestLeader(partition.replicas, newIsr, uncleanOk,
isAcceptableLeader);
Review comment:
Yes, it probably doesn't make a big difference and it happens rarely.
So, we could just keep the logic in this PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] mjsax commented on a change in pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
mjsax commented on a change in pull request #10548:
URL: https://github.com/apache/kafka/pull/10548#discussion_r618760487
##
File path:
streams/src/main/java/org/apache/kafka/streams/state/internals/MeteredKeyValueStore.java
##
@@ -219,11 +224,19 @@ public V putIfAbsent(final K key,
@Override
public void putAll(final List> entries) {
+final List> possiblyNullKeys = entries
Review comment:
I think we could simplify this to a one liner?
```
entries.forEach(entry -> Objects.requireNonNull(entry.key, "key cannot be
null"));
```
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/MeteredSessionStoreTest.java
##
@@ -472,11 +472,26 @@ public void shouldThrowNullPointerOnRemoveIfKeyIsNull() {
assertThrows(NullPointerException.class, () -> store.remove(null));
}
+@Test
+public void shouldThrowNullPointerOnPutIfWrappedKeyIsNull() {
+assertThrows(NullPointerException.class, () -> store.put(new
Windowed<>(null, new SessionWindow(0, 0)), "a"));
Review comment:
This test remind me, that the `SessionWindow` what is wrapped should not
be `null` either.
##
File path:
streams/src/main/java/org/apache/kafka/streams/state/internals/MeteredKeyValueStore.java
##
@@ -234,13 +247,15 @@ public V delete(final K key) {
@Override
public , P> KeyValueIterator
prefixScan(final P prefix, final PS prefixKeySerializer) {
-
+Objects.requireNonNull(prefix, "key cannot be null");
Review comment:
As mentioned by @cadonna the wrapped stores, also check
`prefixKeySerializer` for null -- thus might be good to move both check here.
I think we can also remove both checks in `RocksDBStore` and
`InMemoryKeyValueStore` -- they seems to be redundant now?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] mjsax commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
mjsax commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-825210429 @ableegoldman Can you have a look into this PR -- you are familiar with the consumer code. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Nathan22177 commented on a change in pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 commented on a change in pull request #10548:
URL: https://github.com/apache/kafka/pull/10548#discussion_r618783595
##
File path:
streams/src/main/java/org/apache/kafka/streams/state/internals/MeteredKeyValueStore.java
##
@@ -234,13 +247,15 @@ public V delete(final K key) {
@Override
public , P> KeyValueIterator
prefixScan(final P prefix, final PS prefixKeySerializer) {
-
+Objects.requireNonNull(prefix, "key cannot be null");
Review comment:
>I think we can also remove both checks in RocksDBStore and
InMemoryKeyValueStore -- they seem to be redundant now?
they are both different implementations, aren't they?
I don't understand how they will be checked if we only leave it in
`MeteredKeyValueStore.`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] Nathan22177 commented on a change in pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
Nathan22177 commented on a change in pull request #10548:
URL: https://github.com/apache/kafka/pull/10548#discussion_r618795692
##
File path:
streams/src/main/java/org/apache/kafka/streams/state/internals/MeteredKeyValueStore.java
##
@@ -234,13 +247,15 @@ public V delete(final K key) {
@Override
public , P> KeyValueIterator
prefixScan(final P prefix, final PS prefixKeySerializer) {
-
+Objects.requireNonNull(prefix, "key cannot be null");
Review comment:
I wrote a quick test to see if it still throws NPE in
`InMemoryKeyValueStore` without the check - it did, I am confused, but they
are, indeed, redundant.
I'll leave the tests in both `RocksDBStoreTest` and `InMemoryKeyValueStore`
bc why not.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10493) KTable out-of-order updates are not being ignored
[ https://issues.apache.org/jira/browse/KAFKA-10493?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329888#comment-17329888 ] A. Sophie Blee-Goldman commented on KAFKA-10493: Imo we should find a way to fix this that doesn't prevent users from leveraging the source topic optimization. As I've mentioned before, the additional storage footprint from changelogs is a very real complaint and has been cited as the reason for not using Kafka Streams in the past. And it sounds to me like this would make it even worse, as we would need to not only use a dedicated changelog for all source KTables but also disable compaction entirely IIUC. That just does not sound like a feasible path forward I haven't fully digested this current discussion about the impact of dropping out-of-order updates with a compacted changelog, but perhaps we could store some information in the committed offset metadata to help us here? > KTable out-of-order updates are not being ignored > - > > Key: KAFKA-10493 > URL: https://issues.apache.org/jira/browse/KAFKA-10493 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Pedro Gontijo >Assignee: Matthias J. Sax >Priority: Blocker > Fix For: 3.0.0 > > Attachments: KTableOutOfOrderBug.java > > > On a materialized KTable, out-of-order records for a given key (records which > timestamp are older than the current value in store) are not being ignored > but used to update the local store value and also being forwarded. > I believe the bug is here: > [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/state/internals/ValueAndTimestampSerializer.java#L77] > It should return true, not false (see javadoc) > The bug impacts here: > [https://github.com/apache/kafka/blob/2.6.0/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KTableSource.java#L142-L148] > I have attached a simple stream app that shows the issue happening. > Thank you! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12710) Consider enabling (at least some) optimizations by default
A. Sophie Blee-Goldman created KAFKA-12710: -- Summary: Consider enabling (at least some) optimizations by default Key: KAFKA-12710 URL: https://issues.apache.org/jira/browse/KAFKA-12710 Project: Kafka Issue Type: Improvement Components: streams Reporter: A. Sophie Blee-Goldman Topology optimizations such as the repartition consolidation and source topic changelog are extremely useful at reducing the footprint of a Kafka Streams application on the broker. The additional storage and resource utilization due to changelogs and repartitions is a very real pain point, and has even been cited as the reason for turning to other stream processing frameworks in the past (though of course I question that judgement) The repartition topic optimization, at the very least, should be enabled by default. The problem is that we can't just flip the switch without breaking existing applications during upgrade, since the location and name of such topics in the topology may change. One possibility is to just detect this situation and disable the optimization if we find that it would produce an incompatible topology for an existing application. We can determine that this is the case simply by looking for pre-existing repartition topics. If any such topics are present, and match the set of repartition topics in the un-optimized topology, then we know we need to switch the optimization off. If we don't find any repartition topics, or they match the optimized topology, then we're safe to enable it by default. Alternatively, we could just do a KIP to indicate that we intend to change the default in the next breaking release and that existing applications should override this config if necessary. We should be able to implement a fail-safe and shut down if a user misses or forgets to do so, using the method mentioned above. The source topic optimization is perhaps more controversial, as there have been a few issues raised with regards to things like [restoring bad data and asymmetric serdes|https://issues.apache.org/jira/browse/KAFKA-8037], or more recently the bug discovered in the [emit-on-change semantics for KTables|https://issues.apache.org/jira/browse/KAFKA-12508?focusedCommentId=17306323&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17306323]. However for this case at least there are no compatibility concerns. It's safe to upgrade from using a separate changelog for a source KTable to just using that source topic directly, although the reverse is not true. We could even automatically delete the no-longer-necessary changelog for upgrading applications -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] chia7712 commented on a change in pull request #10582: MINOR: Bump latest 2.6 version to 2.6.2
chia7712 commented on a change in pull request #10582: URL: https://github.com/apache/kafka/pull/10582#discussion_r618815048 ## File path: tests/docker/Dockerfile ## @@ -60,7 +60,7 @@ RUN mkdir -p "/opt/kafka-2.2.2" && chmod a+rw /opt/kafka-2.2.2 && curl -s "$KAFK RUN mkdir -p "/opt/kafka-2.3.1" && chmod a+rw /opt/kafka-2.3.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.3.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.3.1" RUN mkdir -p "/opt/kafka-2.4.1" && chmod a+rw /opt/kafka-2.4.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.4.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.4.1" RUN mkdir -p "/opt/kafka-2.5.1" && chmod a+rw /opt/kafka-2.5.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.5.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.5.1" -RUN mkdir -p "/opt/kafka-2.6.1" && chmod a+rw /opt/kafka-2.6.1 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.6.1.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.6.1" +RUN mkdir -p "/opt/kafka-2.6.2" && chmod a+rw /opt/kafka-2.6.2 && curl -s "$KAFKA_MIRROR/kafka_2.12-2.6.2.tgz" | tar xz --strip-components=1 -C "/opt/kafka-2.6.2" Review comment: @ableegoldman thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
ableegoldman commented on a change in pull request #9627:
URL: https://github.com/apache/kafka/pull/9627#discussion_r618821079
##
File path:
connect/runtime/src/main/java/org/apache/kafka/connect/runtime/distributed/WorkerGroupMember.java
##
@@ -202,7 +202,7 @@ public void requestRejoin() {
}
public void maybeLeaveGroup(String leaveReason) {
-coordinator.maybeLeaveGroup(leaveReason);
+coordinator.maybeLeaveGroup(leaveReason, true);
Review comment:
The only invocation of `WorkerGroupMember#maybeLeaveGroup` in fact
already does log a warning as to why instead of relying on `maybeLeaveGroup` to
do so. Imo we should do something similar for the "consumer poll timeout has
expired" case
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1023,9 +1023,14 @@ protected void close(Timer timer) {
}
/**
+ * Leaving the group. This method also sends LeaveGroupRequest and log
{@code leaveReason} if this is dynamic members
+ * or unknown coordinator or state is not UNJOINED or this generation has
a valid member id.
Review comment:
I think it may be more useful to describe the cases where it will _not_
send a LeaveGroup and describe what this actually means (also it should have
been 'and' not 'or' in the original):
```suggestion
* Sends LeaveGroupRequest and logs the {@code leaveReason}, unless this
member is using
* static membership or is already not part of the group (ie does not
have a valid member id,
* is in the UNJOINED state, or the coordinator is unknown).
```
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1386,7 +1400,7 @@ public void run() {
"the poll loop is spending
too much time processing messages. " +
"You can address this
either by increasing max.poll.interval.ms or by reducing " +
"the maximum size of
batches returned in poll() with max.poll.records.";
-maybeLeaveGroup(leaveReason);
+maybeLeaveGroup(leaveReason, true);
Review comment:
I think it would be simpler to just log the current `leaveReason` right
here at the warn level, and then pass in a more brief description to
`maybeLeaveGroup` rather than add a flag to that method just for this one case
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618823378
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
+mkEntry(UUIDDeserializer.class, 36)
+);
+
+public ListDeserializer() {}
+
+public > ListDeserializer(Class listClass,
Deserializer innerDeserializer) {
+this.listClass = listClass;
+this.inner = innerDeserializer;
+if (innerDeserializer != null) {
+this.primitiveSize =
fixedLengthDeserializers.get(innerDeserializer.getClass());
+}
+}
+
+public Deserializer getInnerDeserializer() {
+return inner;
+}
+
+@Override
+public void configure(Map configs, boolean isKey) {
+if (listClass == null) {
Review comment:
Yes, I think we should. And it's not even a diversion from the approach
elsewhere because there's a KIP in progress to do so in classes like
`SessionWindowedSerializer` as well
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618823669
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
+mkEntry(UUIDDeserializer.class, 36)
+);
+
+public ListDeserializer() {}
+
+public > ListDeserializer(Class listClass,
Deserializer innerDeserializer) {
+this.listClass = listClass;
+this.inner = innerDeserializer;
+if (innerDeserializer != null) {
+this.primitiveSize =
fixedLengthDeserializers.get(innerDeserializer.getClass());
+}
+}
+
+public Deserializer getInnerDeserializer() {
+return inner;
+}
+
+@Override
+public void configure(Map configs, boolean isKey) {
+if (listClass == null) {
+configureListClass(configs, isKey);
+}
+if (inner == null) {
+configureInnerSerde(configs, isKey);
+}
+}
+
+private void configureListClass(Map configs, boolean isKey) {
+String listTypePropertyName = isKey ?
CommonClientConfigs.DEFAULT_LIST_KEY_SERDE_TYPE_CLASS :
CommonClientConfigs.DEFAULT_LIST_VALUE_SERDE_TYPE_CLASS;
+final Object listClassOrName = configs.get(listTypePropertyName);
+if (listClassOrName == null) {
+throw new ConfigException("Not able to determine the list class
because it was neither passed via the constructor nor set in the config.");
+}
+try {
+if (listClassOrName instanceof String) {
+listClass = Utils.loadClass((String) listClassOrName,
Object.class);
+} else if (listClassOrName instanceof Class) {
+listClass = (Class) listClassOrName;
+} else {
+throw new KafkaException("Could not determine the list class
instance using \"" + listTypePropertyName + "\" property.");
+}
+} catch (final ClassNotFoundException e) {
+throw new ConfigException(listTypePropertyName, listClassOrName,
"Deserializer's list class \"" + listClassOrName + "\" could not be found.");
+}
+}
+
+@SuppressWarnings("unchecked")
+private void configureInnerSerde(Map configs, boolean isKey) {
+String innerSerdePropertyName = isKey ?
CommonClientConfigs.DEFAULT_LIST_KEY_SERDE_INNER_CLASS :
CommonClientConfigs.DEFAULT_LIST_VALUE_SERDE_INNER_CLASS;
Review comment:
Cool. I think the fewer configs overall, the better. If we can get away
with just the Serde configs then let's do so to keep the API surface area
smaller for users 👍
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618824127
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
Review comment:
Ah, my bad. I think the variable I had in mind is actually called
`Double.BYTES`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618824127
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
Review comment:
Ah, my bad. I think the variable I had in mind is actually called
`Double.BYTES`. Not 100% sure it's defined for all possible primitive types,
but I don't see why it wouldn't be
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618824127
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
Review comment:
Ah, my bad. I think the variable I had in mind is actually called
`Double.BYTES`. Not 100% sure it's defined for all possible primitive types,
but I would hope so
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618824748
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
+mkEntry(UUIDDeserializer.class, 36)
+);
+
+public ListDeserializer() {}
+
+public > ListDeserializer(Class listClass,
Deserializer innerDeserializer) {
+this.listClass = listClass;
+this.inner = innerDeserializer;
+if (innerDeserializer != null) {
Review comment:
That sounds good to me 👍
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618826368
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Awesome. Maybe I misunderstood this comment:
>Even if we are dealing with primitives, and a user chooses
SerializationStrategy.NEGATIVE_SIZE, we would have to encode each primitive's
size in our payload.
or maybe you just wrote that a while ago and it's out of date. Anyways what
we're doing now sounds good, no reason to encode extra data even if the user
selects this strategy for some reason. But I do think we should at least log a
warning telling them they made a bad choice and it will be ignored. Most likely
they just didn't understand what the parameter meant, and it's a good
opportunity to enlighten them
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618826641
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/Serdes.java
##
@@ -128,13 +128,27 @@ public UUIDSerde() {
static public final class ListSerde extends
WrapperSerde> {
+final static int NEGATIVE_SIZE_VALUE = -1;
Review comment:
Ooooh ok, that makes a lot more sense now. I think your suggestion for
the name sounds good
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #9821: KAFKA-5876: Apply UnknownStateStoreException for Interactive Queries
ableegoldman commented on a change in pull request #9821: URL: https://github.com/apache/kafka/pull/9821#discussion_r618828160 ## File path: docs/streams/upgrade-guide.html ## @@ -93,6 +93,9 @@ Upgrade Guide and API Changes Streams API changes in 3.0.0 + +We applyed UnknownStateStoreException to KafkaStreams#store(): If the specified store name does not exist in the topology, UnknownStateStoreException will be thrown instead InvalidStateStoreException(https://cwiki.apache.org/confluence/display/KAFKA/KIP-216%3A+IQ+should+throw+different+exceptions+for+different+errors";>KIP-216). Review comment: ```suggestion A new exception may be thrown from KafkaStreams#store(). If the specified store name does not exist in the topology, an UnknownStateStoreException will be thrown instead of the former InvalidStateStoreException. See https://cwiki.apache.org/confluence/display/KAFKA/KIP-216%3A+IQ+should+throw+different+exceptions+for+different+errors";>KIP-216 for more information. ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #10482: KAFKA-12499: add transaction timeout verification
ableegoldman commented on pull request #10482: URL: https://github.com/apache/kafka/pull/10482#issuecomment-825278618 @abbccdda it looks like some eos test failed in the PR build, guessing it's related -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng commented on a change in pull request #9821: KAFKA-5876: Apply UnknownStateStoreException for Interactive Queries
vitojeng commented on a change in pull request #9821: URL: https://github.com/apache/kafka/pull/9821#discussion_r618840083 ## File path: docs/streams/upgrade-guide.html ## @@ -93,6 +93,9 @@ Upgrade Guide and API Changes Streams API changes in 3.0.0 + +We applyed UnknownStateStoreException to KafkaStreams#store(): If the specified store name does not exist in the topology, UnknownStateStoreException will be thrown instead InvalidStateStoreException(https://cwiki.apache.org/confluence/display/KAFKA/KIP-216%3A+IQ+should+throw+different+exceptions+for+different+errors";>KIP-216). Review comment: Thanks @ableegoldman ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10619) Producer will enable EOS by default
[ https://issues.apache.org/jira/browse/KAFKA-10619?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17329915#comment-17329915 ] Soumyajit Sahu commented on KAFKA-10619: Hi Cheng, I would like to raise an issue with making enable.idempotence=true by default. Recently, we hit an issue where a producer app of ours was using enable.idempotence=true, but was creating a producer object for each message. We ended up in having thousands of producer ids for our log segment, and the broker crashed with OutOfMemory exception while trying to take a snapshot. I am not aware of any way to monitor this or check on such behavior. Hence, setting this to true could break many clusters with a surprise. It would be ideal to come up with a monitoring or controlling mechanism for this before we set it to true by default. > Producer will enable EOS by default > --- > > Key: KAFKA-10619 > URL: https://issues.apache.org/jira/browse/KAFKA-10619 > Project: Kafka > Issue Type: Improvement >Reporter: Cheng Tan >Assignee: Cheng Tan >Priority: Major > Fix For: 3.0.0 > > > This is an after-work for KIP-185. > In the producer config, > # the default value of `acks` will change to `all` > # `enable.idempotence` will change to `true` > [An analysis of the impact of max.in.flight.requests.per.connection and acks > on Producer > performance|https://cwiki.apache.org/confluence/display/KAFKA/An+analysis+of+the+impact+of+max.in.flight.requests.per.connection+and+acks+on+Producer+performance] > indicates that changing `acks` from `1` to `all` won't increase the latency > and decrease the throughput in a significant way. > > KIP: > https://cwiki.apache.org/confluence/display/KAFKA/KIP-679%3A+Producer+will+enable+the+strongest+delivery+guarantee+by+default -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dengziming commented on pull request #10576: KAFKA-12701: Remove topicId from MetadataReq since it was not supported in 2.8.0
dengziming commented on pull request #10576: URL: https://github.com/apache/kafka/pull/10576#issuecomment-825322789 Thank you @junrao @jolshan , move to #10584 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dengziming closed pull request #10576: KAFKA-12701: Remove topicId from MetadataReq since it was not supported in 2.8.0
dengziming closed pull request #10576: URL: https://github.com/apache/kafka/pull/10576 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dengziming commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
dengziming commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r618874302
##
File path: build.gradle
##
@@ -1485,7 +1485,7 @@ project(':tools') {
testImplementation libs.junitJupiter
testImplementation project(':clients').sourceSets.test.output
testImplementation libs.mockitoInline // supports mocking static methods,
final classes, etc.
-
+testImplementation libs.easymock
Review comment:
We'd better use Mockito rather than EasyMock in new PRs.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe opened a new pull request #10589: MINOR: add defaults to TopicConfig.java
cmccabe opened a new pull request #10589: URL: https://github.com/apache/kafka/pull/10589 Add default values for the configurations to TopicConfig.java. Eventually we want to move all of the log configurations into TopicConfig.java, and this is a good step along the way. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on a change in pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on a change in pull request #9627:
URL: https://github.com/apache/kafka/pull/9627#discussion_r618893986
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1023,9 +1023,14 @@ protected void close(Timer timer) {
}
/**
+ * Leaving the group. This method also sends LeaveGroupRequest and log
{@code leaveReason} if this is dynamic members
+ * or unknown coordinator or state is not UNJOINED or this generation has
a valid member id.
+ *
+ * @param leaveReason the reason to leave the group for logging
+ * @param shouldWarn should log as WARN level or INFO
* @throws KafkaException if the rebalance callback throws exception
*/
-public synchronized RequestFuture maybeLeaveGroup(String
leaveReason) {
+public synchronized RequestFuture maybeLeaveGroup(String
leaveReason, boolean shouldWarn) throws KafkaException {
Review comment:
Thanks, updated.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-825339296 @ableegoldman @kkonstantine , thanks for the good comments. It makes the change smaller and simpler. Please help check again. Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on a change in pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on a change in pull request #9627:
URL: https://github.com/apache/kafka/pull/9627#discussion_r618894302
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -1386,7 +1400,7 @@ public void run() {
"the poll loop is spending
too much time processing messages. " +
"You can address this
either by increasing max.poll.interval.ms or by reducing " +
"the maximum size of
batches returned in poll() with max.poll.records.";
-maybeLeaveGroup(leaveReason);
+maybeLeaveGroup(leaveReason, true);
Review comment:
Good suggestion!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wenbingshen commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
wenbingshen commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r618900520
##
File path: tools/src/main/java/org/apache/kafka/tools/ProducerPerformance.java
##
@@ -190,6 +166,51 @@ public static void main(String[] args) throws Exception {
}
+public KafkaProducer createKafkaProducer(Properties props)
{
+return new KafkaProducer<>(props);
+}
+
+public static Properties readProps(List producerProps, String
producerConfig, String transactionalId,
+boolean transactionsEnabled) throws IOException {
+Properties props = new Properties();
+if (producerConfig != null) {
+props.putAll(Utils.loadProps(producerConfig));
+}
+if (producerProps != null)
+for (String prop : producerProps) {
+String[] pieces = prop.split("=");
+if (pieces.length != 2)
+throw new IllegalArgumentException("Invalid property: " +
prop);
+props.put(pieces[0], pieces[1]);
+}
+
+props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.ByteArraySerializer");
+props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.ByteArraySerializer");
+if (transactionsEnabled)
+props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionalId);
+return props;
+}
+
+public static List readPayloadFile(String payloadFilePath, String
payloadDelimiter) throws IOException {
+List payloadByteList = new ArrayList<>();
+if (payloadFilePath != null) {
+Path path = Paths.get(payloadFilePath);
+System.out.println("Reading payloads from: " +
path.toAbsolutePath());
+if (Files.notExists(path) || Files.size(path) == 0) {
+throw new IllegalArgumentException("File does not exist or
empty file provided.");
Review comment:
A simple format point, can you delete the extra spaces which before
IllegalArgumentException. :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-825354532 @ableegoldman , thank you very much! I'll ping @chia7712 when the build tests completed. He is in the same timezone with me. :) And @chia7712 , thanks for following up for this long lying PR. I believe some users are still suffering for this. Thank you. :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
ableegoldman commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-825355637 > I'll ping @chia7712 when the build tests completed. He is in the same timezone with me. :) Perfect. Go team -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r618910174
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
Review comment:
Yep, that checks out.
Only for `UUID` I'd have to leave hardcoded `36`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573:
URL: https://github.com/apache/kafka/pull/10573#discussion_r618911355
##
File path:
clients/src/main/java/org/apache/kafka/clients/producer/KafkaProducer.java
##
@@ -642,9 +647,13 @@ public void beginTransaction() throws
ProducerFencedException {
* to the partition leader. See the exception for more details
* @throws KafkaException if the producer has encountered a previous fatal
or abortable error, or for any
* other unexpected error
+ *
+ * @deprecated Since 3.0.0, will be removed in 4.0. Use {@link
#sendOffsetsToTransaction(Map, ConsumerGroupMetadata)} instead.
*/
+@Deprecated
public void sendOffsetsToTransaction(Map offsets,
String consumerGroupId) throws
ProducerFencedException {
+log.warn("This method has been deprecated and will be removed in 4.0,
please use #sendOffsetsToTransaction(Map, ConsumerGroupMetadata) instead");
Review comment:
Oh I thought Ismael had said we were meant to do so during the KIP
discussion, but I just re-read his message and I think he meant just for
configs. I'll take this out
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573: URL: https://github.com/apache/kafka/pull/10573#discussion_r618912357 ## File path: docs/streams/developer-guide/config-streams.html ## @@ -667,12 +668,14 @@ probing.rebalance.interval.msprocessing.guarantee The processing guarantee that should be used. - Possible values are "at_least_once" (default), - "exactly_once" (for EOS version 1), - and "exactly_once_beta" (for EOS version 2). - Using "exactly_once" requires broker - version 0.11.0 or newer, while using "exactly_once_beta" - requires broker version 2.5 or newer. + Possible values are "at_least_once" (default) + and "exactly_once_v2" (for EOS version 2). + Deprecated config options are "exactly_once" (for EOS alpha), Review comment: I think given we have just rolled this out, and many users are likely still in the process of upgrading their brokers to a sufficient version, we should continue to mention EOS alpha. And then we may as well mention beta as well for consistency. Don't feel too strongly though -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573: URL: https://github.com/apache/kafka/pull/10573#discussion_r618912905 ## File path: docs/streams/upgrade-guide.html ## @@ -53,17 +53,19 @@ Upgrade Guide and API Changes -Starting in Kafka Streams 2.6.x, a new processing mode is available, named EOS version 2, which is configurable by setting -processing.guarantee to "exactly_once_beta". -NOTE: The "exactly_once_beta" processing mode is ready for production (i.e., it's not "beta" software). +Starting in Kafka Streams 2.6.x, a new processing mode is available, named EOS version 2. This can be configured +by setting StreamsConfig.PROCESSING_GUARANTEE to StreamsConfig.EXACTLY_ONCE_V2 for +application versions 3.0+, or setting it to StreamsConfig.EXACTLY_ONCE_BETA for versions between 2.6 and 3.0. To use this new feature, your brokers must be on version 2.5.x or newer. -A switch from "exactly_once" to "exactly_once_beta" (or the other way around) is -only possible if the application is on version 2.6.x. -If you want to upgrade your application from an older version and enable this feature, -you first need to upgrade your application to version 2.6.x, staying on "exactly_once", -and then do second round of rolling bounces to switch to "exactly_once_beta". -For a downgrade, do the reverse: first switch the config from "exactly_once_beta" to -"exactly_once" to disable the feature in your 2.6.x application. +If you want to upgrade your EOS application from an older version and enable this feature, +you first need to upgrade your application to version 2.6.x, staying on StreamsConfig.EXACTLY_ONCE, Review comment: I just copied over the old instructions for upgrading to beta, and then mentioned how to upgrade to V2 down below. But since V2 is now the "real" version I suppose it should be the main one mentioned here ## File path: docs/streams/upgrade-guide.html ## @@ -53,17 +53,19 @@ Upgrade Guide and API Changes -Starting in Kafka Streams 2.6.x, a new processing mode is available, named EOS version 2, which is configurable by setting -processing.guarantee to "exactly_once_beta". -NOTE: The "exactly_once_beta" processing mode is ready for production (i.e., it's not "beta" software). +Starting in Kafka Streams 2.6.x, a new processing mode is available, named EOS version 2. This can be configured +by setting StreamsConfig.PROCESSING_GUARANTEE to StreamsConfig.EXACTLY_ONCE_V2 for +application versions 3.0+, or setting it to StreamsConfig.EXACTLY_ONCE_BETA for versions between 2.6 and 3.0. To use this new feature, your brokers must be on version 2.5.x or newer. -A switch from "exactly_once" to "exactly_once_beta" (or the other way around) is -only possible if the application is on version 2.6.x. -If you want to upgrade your application from an older version and enable this feature, -you first need to upgrade your application to version 2.6.x, staying on "exactly_once", -and then do second round of rolling bounces to switch to "exactly_once_beta". -For a downgrade, do the reverse: first switch the config from "exactly_once_beta" to -"exactly_once" to disable the feature in your 2.6.x application. +If you want to upgrade your EOS application from an older version and enable this feature, +you first need to upgrade your application to version 2.6.x, staying on StreamsConfig.EXACTLY_ONCE, +and then do second round of rolling bounces to switch to StreamsConfig.EXACTLY_ONCE_BETA. If you Review comment: see comment above ## File path: docs/streams/upgrade-guide.html ## @@ -53,17 +53,19 @@ Upgrade Guide and API Changes -Starting in Kafka Streams 2.6.x, a new processing mode is available, named EOS version 2, which is configurable by setting -processing.guarantee to "exactly_once_beta". -NOTE: The "exactly_once_beta" processing mode is ready for production (i.e., it's not "beta" software). +Starting in Kafka Streams 2.6.x, a new processing mode is available, named EOS version 2. This can be configured +by setting StreamsConfig.PROCESSING_GUARANTEE to StreamsConfig.EXACTLY_ONCE_V2 for +application versions 3.0+, or setting it to StreamsConfig.EXACTLY_ONCE_BETA for versions between 2.6 and 3.0. To use this new feature, your brokers must be on version 2.5.x or newer. -A switch from "exactly_once" to "exactly_once_beta" (or the other way around) is -only possible if the application is on version 2.6.x. -If you want to upgrade your application from an older version and enable this feature, -you first need to upgrade your app
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573:
URL: https://github.com/apache/kafka/pull/10573#discussion_r618914490
##
File path: streams/src/main/java/org/apache/kafka/streams/StreamsConfig.java
##
@@ -1010,18 +1026,51 @@ public StreamsConfig(final Map props) {
protected StreamsConfig(final Map props,
final boolean doLog) {
super(CONFIG, props, doLog);
-eosEnabled = StreamThread.eosEnabled(this);
+eosEnabled = eosEnabled();
+
+final String processingModeConfig =
getString(StreamsConfig.PROCESSING_GUARANTEE_CONFIG);
+if (processingModeConfig.equals(EXACTLY_ONCE)) {
+log.warn("Configuration parameter `{}` is deprecated and will be
removed in the 4.0.0 release. " +
+ "Please use `{}` instead. Note that this requires
broker version 2.5+ so you should prepare "
+ + "to upgrade your brokers if necessary.",
EXACTLY_ONCE, EXACTLY_ONCE_V2);
+}
+if (processingModeConfig.equals(EXACTLY_ONCE_BETA)) {
+log.warn("Configuration parameter `{}` is deprecated and will be
removed in the 4.0.0 release. " +
+ "Please use `{}` instead.", EXACTLY_ONCE_BETA,
EXACTLY_ONCE_V2);
+}
+
if (props.containsKey(RETRIES_CONFIG)) {
-log.warn("Configuration parameter `{}` is deprecated and will be
removed in 3.0.0 release.", RETRIES_CONFIG);
+log.warn("Configuration parameter `{}` is deprecated and will be
removed in the 4.0.0 release.", RETRIES_CONFIG);
+}
+}
+
+public ProcessingMode processingMode() {
+if
(EXACTLY_ONCE.equals(getString(StreamsConfig.PROCESSING_GUARANTEE_CONFIG))) {
+return StreamThread.ProcessingMode.EXACTLY_ONCE_ALPHA;
+} else if
(EXACTLY_ONCE_BETA.equals(getString(StreamsConfig.PROCESSING_GUARANTEE_CONFIG)))
{
+return StreamThread.ProcessingMode.EXACTLY_ONCE_V2;
+} else if
(EXACTLY_ONCE_V2.equals(getString(StreamsConfig.PROCESSING_GUARANTEE_CONFIG))) {
+return StreamThread.ProcessingMode.EXACTLY_ONCE_V2;
+} else {
+return StreamThread.ProcessingMode.AT_LEAST_ONCE;
}
}
+public boolean eosEnabled() {
Review comment:
Ohh, I forgot this was public. Now the current code makes much more
sense, I moved it because I thought it was so awkward. I'll just put it back
and leave a comment so the next person doesn't fall into the same trap. Thanks
for the explanation 😅
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on pull request #10573: URL: https://github.com/apache/kafka/pull/10573#issuecomment-825367328 @mjsax thanks for the review, addressed your comments please give it another pass -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
showuon commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-825382213 Failed test cases are unrelated and flaky (all passed in my local env). Thanks. ``` Build / JDK 15 and Scala 2.13 / kafka.network.DynamicConnectionQuotaTest.testDynamicListenerConnectionCreationRateQuota() Build / JDK 15 and Scala 2.13 / kafka.server.RaftClusterTest.testCreateClusterAndCreateAndManyTopicsWithManyPartitions() Build / JDK 15 and Scala 2.13 / kafka.server.RaftClusterTest.testCreateClusterAndCreateAndManyTopicsWithManyPartitions() Build / JDK 8 and Scala 2.12 / org.apache.kafka.connect.mirror.integration.MirrorConnectorsIntegrationTest.testReplication() Build / JDK 8 and Scala 2.12 / kafka.admin.TopicCommandWithAdminClientTest.testDescribeUnderMinIsrPartitionsMixed() ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #9640: KAFKA-10283; Consolidate client-level and consumer-level assignment within ClientState
guozhangwang commented on pull request #9640: URL: https://github.com/apache/kafka/pull/9640#issuecomment-825384541 @highluck I'm re-triggering the unit test again, at the mean time, could you also run them locally and see if the failed tests are consistent? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng commented on pull request #9821: KAFKA-5876: Apply UnknownStateStoreException for Interactive Queries
vitojeng commented on pull request #9821: URL: https://github.com/apache/kafka/pull/9821#issuecomment-825407840 @ableegoldman The PR build is done, please talk a look. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] highluck commented on pull request #9640: KAFKA-10283; Consolidate client-level and consumer-level assignment within ClientState
highluck commented on pull request #9640: URL: https://github.com/apache/kafka/pull/9640#issuecomment-825427682 @guozhangwang Yes, I checked, but the logic was not changed except for assignActiveToConsumer, so the test is consistent. There seems to be no problem locally! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org