[jira] [Updated] (KAFKA-13512) topicIdsToNames and topicNamesToIds allocate unnecessary maps
[
https://issues.apache.org/jira/browse/KAFKA-13512?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
David Jacot updated KAFKA-13512:
Fix Version/s: 3.1.0
> topicIdsToNames and topicNamesToIds allocate unnecessary maps
> -
>
> Key: KAFKA-13512
> URL: https://issues.apache.org/jira/browse/KAFKA-13512
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 3.1.0
>Reporter: Justine Olshan
>Assignee: Justine Olshan
>Priority: Blocker
> Fix For: 3.1.0
>
>
> Currently we write the methods as follows:
> {{def topicNamesToIds(): util.Map[String, Uuid] = {}}
> {{ new util.HashMap(metadataSnapshot.topicIds.asJava)}}
> {{}}}
> We do not need to allocate a new map however, we can simply use
> {{Collections.unmodifiableMap(metadataSnapshot.topicIds.asJava)}}
> We can do something similar for the topicIdsToNames implementation.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [kafka] itweixiang removed a comment on pull request #9902: KAFKA-12193: Re-resolve IPs after a client disconnects
itweixiang removed a comment on pull request #9902:
URL: https://github.com/apache/kafka/pull/9902#issuecomment-987738907
hi bob-barrett , I hava a quetion about your issue ,can you help me ?
our kafka are deloying in k8s , where kafka cluster restart , result in
producer and consumer will disconnect.
kafka cluster restart will generate new ips, but kafka client store old ips
. so we must restart producer and consumer , so tired.
in kafka client 2.8.1 version ,I see
org.apache.kafka.clients.NetworkClient#initiateConnect , `node.host()` maybe
return a ip instead of domain. if return a ip , will result in lose efficacy
about your updated version .
my english level is match awful , can you know my words?
```
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
try {
connectionStates.connecting(nodeConnectionId, now, node.host(),
clientDnsLookup);
InetAddress address =
connectionStates.currentAddress(nodeConnectionId);
log.debug("Initiating connection to node {} using address {}",
node, address);
selector.connect(nodeConnectionId,
new InetSocketAddress(address, node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
} catch (IOException e) {
log.warn("Error connecting to node {}", node, e);
// Attempt failed, we'll try again after the backoff
connectionStates.disconnected(nodeConnectionId, now);
// Notify metadata updater of the connection failure
metadataUpdater.handleServerDisconnect(now, nodeConnectionId,
Optional.empty());
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon opened a new pull request #11578: KAFKA-13514: reduce consumer count and timeout to speed up the test
showuon opened a new pull request #11578: URL: https://github.com/apache/kafka/pull/11578 Reduce the timeout from 60s to 40s, and reduce the consumer count from 2000 -> 1000. In local env, before change, the time took 44s, after change, time took 16s. If before change, in jenkins we took around 60s, we should now, took around 25s. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-13517) Add ConfigurationKeys to ConfigResource class
Vikas Singh created KAFKA-13517:
---
Summary: Add ConfigurationKeys to ConfigResource class
Key: KAFKA-13517
URL: https://issues.apache.org/jira/browse/KAFKA-13517
Project: Kafka
Issue Type: Improvement
Components: clients
Affects Versions: 3.0.0, 2.8.1
Reporter: Vikas Singh
Assignee: Vikas Singh
Fix For: 2.8.1
A list of {{ConfigResource}} class is passed as argument to
{{AdminClient::describeConfigs}} api to indicate configuration of the entities
to fetch. The {{ConfigResource}} class is made up of two fields, name and type
of entity. Kafka returns *all* configurations for the entities provided to the
admin client api.
This admin api in turn uses {{DescribeConfigsRequest}} kafka api to get the
configuration for the entities in question. In addition to name and type of
entity whose configuration to get, Kafka {{DescribeConfigsResource}} structure
also lets users provide {{ConfigurationKeys}} list, which allows users to fetch
only the configurations that are needed.
However, this field isn't exposed in the {{ConfigResource}} class that is used
by AdminClient, so users of AdminClient have no way to ask for specific
configuration. The API always returns *all* configurations. Then the user of
the {{AdminClient::describeConfigs}} go over the returned list and filter out
the config keys that they are interested in.
This results in boilerplate code for all users of
{{AdminClient::describeConfigs}} api, in addition to being wasteful use of
resource. It becomes painful in large cluster case where to fetch one
configuration of all topics, we need to fetch all configuration of all topics,
which can be huge in size.
Creating this Jira to add same field (i.e. {{{}ConfigurationKeys{}}}) to the
{{ConfigResource}} structure to bring it to parity to
{{DescribeConfigsResource}} Kafka API structure. There should be no backward
compatibility issue as the field will be optional and will behave same way if
it is not specified (i.e. by passing null to backend kafka api)
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [kafka] tamara-skokova commented on pull request #11573: KAFKA-13507: GlobalProcessor ignores user specified names
tamara-skokova commented on pull request #11573: URL: https://github.com/apache/kafka/pull/11573#issuecomment-988484139 @showuon, thanks, added a test that verifies the default names -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jeffkbkim edited a comment on pull request #11571: KAFKA-13496: add reason to LeaveGroupRequest
jeffkbkim edited a comment on pull request #11571: URL: https://github.com/apache/kafka/pull/11571#issuecomment-988460630 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jeffkbkim edited a comment on pull request #11571: KAFKA-13496: add reason to LeaveGroupRequest
jeffkbkim edited a comment on pull request #11571: URL: https://github.com/apache/kafka/pull/11571#issuecomment-988460630 tests calling `adminClient.removeMembersFromConsumerGroup` are failing: ``` ERROR [KafkaApi-2] Unexpected error handling request RequestHeader(apiKey=LEAVE_GROUP, apiVersion=5, clientId=adminclient-1, correlationId=30) -- LeaveGroupRequestData(groupId='test_group_id', memberId='', members=[MemberIdentity(memberId='', groupInstanceId='invalid-instance-id', reason='null')]) with context RequestContext(header=RequestHeader(apiKey=LEAVE_GROUP, apiVersion=5, clientId=adminclient-1, correlationId=30), connectionId='127.0.0.1:58238-127.0.0.1:58241-0', clientAddress=/127.0.0.1, principal=User:ANONYMOUS, listenerName=ListenerName(PLAINTEXT), securityProtocol=PLAINTEXT, clientInformation=ClientInformation(softwareName=apache-kafka-java, softwareVersion=unknown), fromPrivilegedListener=true, principalSerde=Optional[org.apache.kafka.common.security.authenticator.DefaultKafkaPrincipalBuilder@5d777a17]) (kafka.server.KafkaApis:76) org.apache.kafka.common.errors.UnsupportedVersionException: Can't size version 5 of MemberResponse ``` i'm not sure i understand the exception. (key=LEAVE_GROUP,api version=5) requests are valid. the error is from `LeaveGroupResponseData.addSize` - why is the response validating the request api version? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jeffkbkim commented on pull request #11571: KAFKA-13496: add reason to LeaveGroupRequest
jeffkbkim commented on pull request #11571: URL: https://github.com/apache/kafka/pull/11571#issuecomment-988460630 tests calling `adminClient.removeMembersFromConsumerGroup` are failing: ``` ERROR [KafkaApi-2] Unexpected error handling request RequestHeader(apiKey=LEAVE_GROUP, apiVersion=5, clientId=adminclient-1, correlationId=30) -- LeaveGroupRequestData(groupId='test_group_id', memberId='', members=[MemberIdentity(memberId='', groupInstanceId='invalid-instance-id', reason='null')]) with context RequestContext(header=RequestHeader(apiKey=LEAVE_GROUP, apiVersion=5, clientId=adminclient-1, correlationId=30), connectionId='127.0.0.1:58238-127.0.0.1:58241-0', clientAddress=/127.0.0.1, principal=User:ANONYMOUS, listenerName=ListenerName(PLAINTEXT), securityProtocol=PLAINTEXT, clientInformation=ClientInformation(softwareName=apache-kafka-java, softwareVersion=unknown), fromPrivilegedListener=true, principalSerde=Optional[org.apache.kafka.common.security.authenticator.DefaultKafkaPrincipalBuilder@5d777a17]) (kafka.server.KafkaApis:76) org.apache.kafka.common.errors.UnsupportedVersionException: Can't size version 5 of MemberResponse ``` i'm not sure i understand the exception. LEAVE_GROUP/API_VERSION=5 requests are valid. the error is from `LeaveGroupResponseData.addSize` - why is the response validating the request api version? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on a change in pull request #11573: KAFKA-13507: GlobalProcessor ignores user specified names
showuon commented on a change in pull request #11573:
URL: https://github.com/apache/kafka/pull/11573#discussion_r764516991
##
File path:
streams/src/test/java/org/apache/kafka/streams/StreamsBuilderTest.java
##
@@ -998,6 +999,23 @@ public void
shouldUseSpecifiedNameForAggregateOperationGivenTable() {
STREAM_OPERATION_NAME);
}
+@Test
+public void shouldUseSpecifiedNameForGlobalStoreProcessor() {
Review comment:
I didn't see there is tests for `GlobalStoreProcessor` using default
name, right? That is, a test to create global store by `addGlobalStore` with
`Consumed` instance without specifying a custom name, and verify the names.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-10503) MockProducer doesn't throw ClassCastException when no partition for topic
[
https://issues.apache.org/jira/browse/KAFKA-10503?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17454673#comment-17454673
]
Dennis Hunziker edited comment on KAFKA-10503 at 12/8/21, 2:58 AM:
---
[~gmunozfe] This change did break our tests. When using the no-arg constructor
the serializers are null but now that they're referenced in any case we'll just
get an NPE. Was that on purpose? Shouldn't the change made here only be applied
if the serializers aren't null?
Happy to create a separate ticket and fix if you agree.
was (Author: JIRAUSER281343):
This change did break our tests. When using the no-arg constructor the
serializers are null but now that they're referenced in any case we'll just get
an NPE. Was that on purpose? Shouldn't the change made here only be applied if
the serializers aren't null?
Happy to create a separate ticket and fix if you agree.
> MockProducer doesn't throw ClassCastException when no partition for topic
> -
>
> Key: KAFKA-10503
> URL: https://issues.apache.org/jira/browse/KAFKA-10503
> Project: Kafka
> Issue Type: Improvement
> Components: clients, producer
>Affects Versions: 2.6.0
>Reporter: Gonzalo Muñoz Fernández
>Assignee: Gonzalo Muñoz Fernández
>Priority: Minor
> Labels: mock, producer
> Fix For: 2.7.0
>
> Original Estimate: 1h
> Remaining Estimate: 1h
>
> Though {{MockProducer}} admits serializers in its constructors, it doesn't
> check during {{send}} method that those serializers are the proper ones to
> serialize key/value included into the {{ProducerRecord}}.
> [This
> check|https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/producer/MockProducer.java#L499-L500]
> is only done if there is a partition assigned for that topic.
> It would be an enhancement if these serialize methods were also invoked in
> simple scenarios, where no partition is assigned to a topic.
> eg:
> {code:java}
> @Test
> public void shouldThrowClassCastException() {
> MockProducer producer = new MockProducer<>(true, new
> IntegerSerializer(), new StringSerializer());
> ProducerRecord record = new ProducerRecord(TOPIC, "key1", "value1");
> try {
> producer.send(record);
> fail("Should have thrown ClassCastException because record cannot
> be casted with serializers");
> } catch (ClassCastException e) {}
> }
> {code}
> Currently, for obtaining the ClassCastException is needed to define the topic
> into a partition:
> {code:java}
> PartitionInfo partitionInfo = new PartitionInfo(TOPIC, 0, null, null, null);
> Cluster cluster = new Cluster(null, emptyList(), asList(partitionInfo),
> emptySet(), emptySet());
> producer = new MockProducer(cluster,
> true,
> new DefaultPartitioner(),
> new IntegerSerializer(),
> new StringSerializer());
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Assigned] (KAFKA-13514) Flakey test StickyAssignorTest
[
https://issues.apache.org/jira/browse/KAFKA-13514?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Luke Chen reassigned KAFKA-13514:
-
Assignee: Luke Chen
> Flakey test StickyAssignorTest
> --
>
> Key: KAFKA-13514
> URL: https://issues.apache.org/jira/browse/KAFKA-13514
> Project: Kafka
> Issue Type: Test
> Components: clients, unit tests
>Reporter: Matthias J. Sax
>Assignee: Luke Chen
>Priority: Critical
> Labels: flaky-test
>
> org.apache.kafka.clients.consumer.StickyAssignorTest.testLargeAssignmentAndGroupWithNonEqualSubscription()
> No real stack trace, but only:
> {quote}java.util.concurrent.TimeoutException:
> testLargeAssignmentAndGroupWithNonEqualSubscription() timed out after 60
> seconds{quote}
> STDOUT
> {quote}[2021-12-07 01:32:23,920] ERROR Found multiple consumers consumer1 and
> consumer2 claiming the same TopicPartition topic-0 in the same generation -1,
> this will be invalidated and removed from their previous assignment.
> (org.apache.kafka.clients.consumer.internals.AbstractStickyAssignor:150)
> [2021-12-07 01:32:58,964] ERROR Found multiple consumers consumer1 and
> consumer2 claiming the same TopicPartition topic-0 in the same generation -1,
> this will be invalidated and removed from their previous assignment.
> (org.apache.kafka.clients.consumer.internals.AbstractStickyAssignor:150)
> [2021-12-07 01:32:58,976] ERROR Found multiple consumers consumer1 and
> consumer2 claiming the same TopicPartition topic-0 in the same generation -1,
> this will be invalidated and removed from their previous assignment.
> (org.apache.kafka.clients.consumer.internals.AbstractStickyAssignor:150){quote}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [kafka] Loyilee closed pull request #10781: MINOR: Reduce duplicate authentication check
Loyilee closed pull request #10781: URL: https://github.com/apache/kafka/pull/10781 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Loyilee closed pull request #10601: KAFKA-12723: Fix potential NPE in HashTier
Loyilee closed pull request #10601: URL: https://github.com/apache/kafka/pull/10601 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #11562: KAFKA-12648: extend IQ APIs to work with named topologies
ableegoldman commented on pull request #11562: URL: https://github.com/apache/kafka/pull/11562#issuecomment-988400580 Hey @tolgadur can we also add one more thing to this -- see https://github.com/tolgadur/kafka/pull/1 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] florin-akermann commented on pull request #11456: KAFKA-13351: Add possibility to write kafka headers in Kafka Console Producer
florin-akermann commented on pull request #11456: URL: https://github.com/apache/kafka/pull/11456#issuecomment-988371209 Hi again, @dajac @mimaison I made the adjustments based on your inputs. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] florin-akermann commented on a change in pull request #11456: KAFKA-13351: Add possibility to write kafka headers in Kafka Console Producer
florin-akermann commented on a change in pull request #11456:
URL: https://github.com/apache/kafka/pull/11456#discussion_r764457132
##
File path: core/src/main/scala/kafka/tools/ConsoleProducer.scala
##
@@ -206,11 +210,25 @@ object ConsoleProducer {
.describedAs("size")
.ofType(classOf[java.lang.Integer])
.defaultsTo(1024*100)
-val propertyOpt = parser.accepts("property", "A mechanism to pass
user-defined properties in the form key=value to the message reader. " +
- "This allows custom configuration for a user-defined message reader.
Default properties include:\n" +
- "\tparse.key=true|false\n" +
- "\tkey.separator=\n" +
- "\tignore.error=true|false")
+val propertyOpt = parser.accepts("property",
+ """A mechanism to pass user-defined properties in the form key=value to
the message reader. This allows custom configuration for a user-defined message
reader.
+|Default properties include:
+| parse.key=false
+| parse.headers=false
+| ignore.error=false
+| key.separator=\t
+| headers.delimiter=\t
+| headers.separator=,
+| headers.key.separator=:
+|Default parsing pattern when:
+| parse.headers=true & parse.key=true:
Review comment:
Now i remember the reason why I chose &
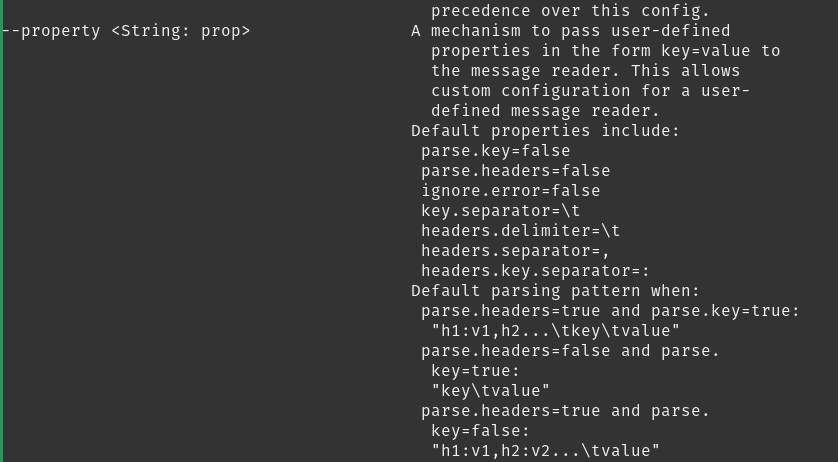
The lines break in an unfortunate way if and is used. What do you think?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (KAFKA-13516) Connection level metrics are not closed
Aman Agarwal created KAFKA-13516: Summary: Connection level metrics are not closed Key: KAFKA-13516 URL: https://issues.apache.org/jira/browse/KAFKA-13516 Project: Kafka Issue Type: Bug Components: clients Affects Versions: 3.0.0 Reporter: Aman Agarwal Connection level metrics are not closed by the Selector on connection close, hence leaking the sensors. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [kafka] cmccabe opened a new pull request #11577: KAFKA-13515: Fix KRaft config validation issues
cmccabe opened a new pull request #11577: URL: https://github.com/apache/kafka/pull/11577 Require that topics exist before topic configurations can be created for them. Merge the code from ConfigurationControlManager#checkConfigResource into ControllerConfigurationValidator to avoid duplication. Add KRaft support to DynamicConfigChangeTest. Split out tests in DynamicConfigChangeTest that don't require a cluster into DynamicConfigChangeUnitTest to save test time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-13515) Fix KRaft config validation issues
Colin McCabe created KAFKA-13515: Summary: Fix KRaft config validation issues Key: KAFKA-13515 URL: https://issues.apache.org/jira/browse/KAFKA-13515 Project: Kafka Issue Type: Bug Reporter: Colin McCabe -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [kafka] rondagostino commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
rondagostino commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764387735
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -2018,12 +2025,103 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
"offsets.commit.required.acks must be greater or equal -1 and less or
equal to offsets.topic.replication.factor")
require(BrokerCompressionCodec.isValid(compressionType), "compression.type
: " + compressionType + " is not valid." +
" Valid options are " +
BrokerCompressionCodec.brokerCompressionOptions.mkString(","))
-require(!processRoles.contains(ControllerRole) ||
controllerListeners.nonEmpty,
- s"${KafkaConfig.ControllerListenerNamesProp} cannot be empty if the
server has the controller role")
+val advertisedListenerNames =
effectiveAdvertisedListeners.map(_.listenerName).toSet
+
+// validate KRaft-related configs
+val voterAddressSpecsByNodeId =
RaftConfig.parseVoterConnections(quorumVoters)
+def validateNonEmptyQuorumVotersForKRaft(): Unit = {
+ if (voterAddressSpecsByNodeId.isEmpty) {
+throw new ConfigException(s"If using ${KafkaConfig.ProcessRolesProp},
${KafkaConfig.QuorumVotersProp} must contain a parseable set of voters.")
+ }
+}
+def validateControlPlaneListenerEmptyForKRaft(): Unit = {
+ require(controlPlaneListenerName.isEmpty,
+s"${KafkaConfig.ControlPlaneListenerNameProp} is not supported in
KRaft mode. KRaft uses ${KafkaConfig.ControllerListenerNamesProp} instead.")
+}
+val sourceOfAdvertisedListeners: String =
+ if (getString(KafkaConfig.AdvertisedListenersProp) != null)
+s"${KafkaConfig.AdvertisedListenersProp}"
+ else
+s"${KafkaConfig.ListenersProp}"
+def
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker():
Unit = {
+ require(!advertisedListenerNames.exists(aln =>
controllerListenerNames.contains(aln.value())),
+s"$sourceOfAdvertisedListeners must not contain KRaft controller
listeners from ${KafkaConfig.ControllerListenerNamesProp} when
${KafkaConfig.ProcessRolesProp} contains the broker role because Kafka clients
that send requests via advertised listeners do not send requests to KRaft
controllers -- they only send requests to KRaft brokers.")
+}
+def validateControllerQuorumVotersMustContainNodeIDForKRaftController():
Unit = {
+ require(voterAddressSpecsByNodeId.containsKey(nodeId),
+s"If ${KafkaConfig.ProcessRolesProp} contains the 'controller' role,
the node id $nodeId must be included in the set of voters
${KafkaConfig.QuorumVotersProp}=${voterAddressSpecsByNodeId.asScala.keySet.toSet}")
+}
+def validateControllerListenerExistsForKRaftController(): Unit = {
+ require(controllerListeners.nonEmpty,
+s"${KafkaConfig.ControllerListenerNamesProp} must contain at least one
value appearing in the '${KafkaConfig.ListenersProp}' configuration when
running the KRaft controller role")
+}
+def
validateControllerListenerNamesMustAppearInListenersForKRaftController(): Unit
= {
+ val listenerNameValues = listeners.map(_.listenerName.value).toSet
+ require(controllerListenerNames.forall(cln =>
listenerNameValues.contains(cln)),
+s"${KafkaConfig.ControllerListenerNamesProp} must only contain values
appearing in the '${KafkaConfig.ListenersProp}' configuration when running the
KRaft controller role")
+}
+def validateAdvertisedListenersNonEmptyForBroker(): Unit = {
+ require(advertisedListenerNames.nonEmpty,
+"There must be at least one advertised listener." + (
+ if (processRoles.contains(BrokerRole)) s" Perhaps all listeners
appear in ${ControllerListenerNamesProp}?" else ""))
+}
+if (processRoles == Set(BrokerRole)) {
+ // KRaft broker-only
+ validateNonEmptyQuorumVotersForKRaft()
+ validateControlPlaneListenerEmptyForKRaft()
+
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker()
+ // nodeId must not appear in controller.quorum.voters
+ require(!voterAddressSpecsByNodeId.containsKey(nodeId),
+s"If ${KafkaConfig.ProcessRolesProp} contains just the 'broker' role,
the node id $nodeId must not be included in the set of voters
${KafkaConfig.QuorumVotersProp}=${voterAddressSpecsByNodeId.asScala.keySet.toSet}")
+ // controller.listener.names must be non-empty...
+ require(controllerListenerNames.exists(_.nonEmpty),
+s"${KafkaConfig.ControllerListenerNamesProp} must contain at least one
value when running KRaft with just the broker role")
+ // controller.listener.names are forbidden in listeners...
+ require(controllerListeners.isEmpty,
+s"${KafkaConfig.ControllerListenerNamesProp} must not contain a value
appearing in the '${KafkaConfig.ListenersProp}' configuration when running
KRaft with just
[GitHub] [kafka] dajac commented on pull request #11576: KAFKA-13512: topicIdsToNames and topicNamesToIds allocate unnecessary maps
dajac commented on pull request #11576: URL: https://github.com/apache/kafka/pull/11576#issuecomment-988280848 The MetadataSnapshot is immutable so this seems fine to me as well. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] C0urante commented on a change in pull request #11046: KAFKA-12980: Return empty record batch from Consumer::poll when position advances due to aborted transactions
C0urante commented on a change in pull request #11046:
URL: https://github.com/apache/kafka/pull/11046#discussion_r764381476
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/Fetcher.java
##
@@ -725,17 +725,13 @@ public void onFailure(RuntimeException e) {
completedFetch.nextFetchOffset,
completedFetch.lastEpoch,
position.currentLeader);
-log.trace("Update fetching position to {} for partition
{}", nextPosition, completedFetch.partition);
+log.trace("Updating fetch position from {} to {} for
partition {} and returning {} records from `poll()`",
+position, nextPosition, completedFetch.partition,
partRecords.size());
subscriptions.position(completedFetch.partition,
nextPosition);
positionAdvanced = true;
if (partRecords.isEmpty()) {
-log.debug(
-"Advanced position for partition {} without
receiving any user-visible records. "
-+ "This is likely due to skipping over
control records in the current fetch, "
-+ "and may result in the consumer
returning an empty record batch when "
-+ "polled before its poll timeout has
elapsed.",
-completedFetch.partition
-);
+log.trace("Returning empty records from `poll()` "
++ "since the consumer's position has advanced
for at least one topic partition");
Review comment:
Moved it to `KafkaConsumer`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jolshan opened a new pull request #11576: KAFKA-13512: topicIdsToNames and topicNamesToIds allocate unnecessary maps
jolshan opened a new pull request #11576: URL: https://github.com/apache/kafka/pull/11576 We are creating a new map unnecessarily for these methods. Remove the extra map creation and simply wrap in unmodifiable map. I've also added a benchmark for the map method. Here are some results when I limited partitions to 20 only. Before change: ``` Benchmark (partitionCount) (topicCount) Mode Cnt Score Error Units MetadataRequestBenchmark.testTopicIdInfo20 500 avgt 15 16.942 ± 0.306 ns/op MetadataRequestBenchmark.testTopicIdInfo20 1000 avgt 15 19.476 ± 0.339 ns/op MetadataRequestBenchmark.testTopicIdInfo20 5000 avgt 15 18.989 ± 0.482 ns/op ``` After change: ``` Benchmark (partitionCount) (topicCount) Mode Cnt Score Error Units MetadataRequestBenchmark.testTopicIdInfo20 500 avgt 15 11.120 ± 0.336 ns/op MetadataRequestBenchmark.testTopicIdInfo20 1000 avgt 15 11.173 ± 0.489 ns/op MetadataRequestBenchmark.testTopicIdInfo20 5000 avgt 15 11.003 ± 0.042 ns/op ``` ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rondagostino commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
rondagostino commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764369935
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -2018,12 +2025,103 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
"offsets.commit.required.acks must be greater or equal -1 and less or
equal to offsets.topic.replication.factor")
require(BrokerCompressionCodec.isValid(compressionType), "compression.type
: " + compressionType + " is not valid." +
" Valid options are " +
BrokerCompressionCodec.brokerCompressionOptions.mkString(","))
-require(!processRoles.contains(ControllerRole) ||
controllerListeners.nonEmpty,
- s"${KafkaConfig.ControllerListenerNamesProp} cannot be empty if the
server has the controller role")
+val advertisedListenerNames =
effectiveAdvertisedListeners.map(_.listenerName).toSet
+
+// validate KRaft-related configs
+val voterAddressSpecsByNodeId =
RaftConfig.parseVoterConnections(quorumVoters)
+def validateNonEmptyQuorumVotersForKRaft(): Unit = {
+ if (voterAddressSpecsByNodeId.isEmpty) {
+throw new ConfigException(s"If using ${KafkaConfig.ProcessRolesProp},
${KafkaConfig.QuorumVotersProp} must contain a parseable set of voters.")
+ }
+}
+def validateControlPlaneListenerEmptyForKRaft(): Unit = {
+ require(controlPlaneListenerName.isEmpty,
+s"${KafkaConfig.ControlPlaneListenerNameProp} is not supported in
KRaft mode. KRaft uses ${KafkaConfig.ControllerListenerNamesProp} instead.")
+}
+val sourceOfAdvertisedListeners: String =
+ if (getString(KafkaConfig.AdvertisedListenersProp) != null)
+s"${KafkaConfig.AdvertisedListenersProp}"
+ else
+s"${KafkaConfig.ListenersProp}"
+def
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker():
Unit = {
+ require(!advertisedListenerNames.exists(aln =>
controllerListenerNames.contains(aln.value())),
+s"$sourceOfAdvertisedListeners must not contain KRaft controller
listeners from ${KafkaConfig.ControllerListenerNamesProp} when
${KafkaConfig.ProcessRolesProp} contains the broker role because Kafka clients
that send requests via advertised listeners do not send requests to KRaft
controllers -- they only send requests to KRaft brokers.")
+}
+def validateControllerQuorumVotersMustContainNodeIDForKRaftController():
Unit = {
+ require(voterAddressSpecsByNodeId.containsKey(nodeId),
+s"If ${KafkaConfig.ProcessRolesProp} contains the 'controller' role,
the node id $nodeId must be included in the set of voters
${KafkaConfig.QuorumVotersProp}=${voterAddressSpecsByNodeId.asScala.keySet.toSet}")
+}
+def validateControllerListenerExistsForKRaftController(): Unit = {
+ require(controllerListeners.nonEmpty,
+s"${KafkaConfig.ControllerListenerNamesProp} must contain at least one
value appearing in the '${KafkaConfig.ListenersProp}' configuration when
running the KRaft controller role")
+}
+def
validateControllerListenerNamesMustAppearInListenersForKRaftController(): Unit
= {
+ val listenerNameValues = listeners.map(_.listenerName.value).toSet
+ require(controllerListenerNames.forall(cln =>
listenerNameValues.contains(cln)),
+s"${KafkaConfig.ControllerListenerNamesProp} must only contain values
appearing in the '${KafkaConfig.ListenersProp}' configuration when running the
KRaft controller role")
+}
+def validateAdvertisedListenersNonEmptyForBroker(): Unit = {
+ require(advertisedListenerNames.nonEmpty,
+"There must be at least one advertised listener." + (
+ if (processRoles.contains(BrokerRole)) s" Perhaps all listeners
appear in ${ControllerListenerNamesProp}?" else ""))
+}
+if (processRoles == Set(BrokerRole)) {
+ // KRaft broker-only
+ validateNonEmptyQuorumVotersForKRaft()
+ validateControlPlaneListenerEmptyForKRaft()
+
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker()
+ // nodeId must not appear in controller.quorum.voters
+ require(!voterAddressSpecsByNodeId.containsKey(nodeId),
+s"If ${KafkaConfig.ProcessRolesProp} contains just the 'broker' role,
the node id $nodeId must not be included in the set of voters
${KafkaConfig.QuorumVotersProp}=${voterAddressSpecsByNodeId.asScala.keySet.toSet}")
+ // controller.listener.names must be non-empty...
+ require(controllerListenerNames.exists(_.nonEmpty),
+s"${KafkaConfig.ControllerListenerNamesProp} must contain at least one
value when running KRaft with just the broker role")
+ // controller.listener.names are forbidden in listeners...
+ require(controllerListeners.isEmpty,
+s"${KafkaConfig.ControllerListenerNamesProp} must not contain a value
appearing in the '${KafkaConfig.ListenersProp}' configuration when running
KRaft with just
[GitHub] [kafka] rondagostino commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
rondagostino commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764367910
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -2018,12 +2025,103 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
"offsets.commit.required.acks must be greater or equal -1 and less or
equal to offsets.topic.replication.factor")
require(BrokerCompressionCodec.isValid(compressionType), "compression.type
: " + compressionType + " is not valid." +
" Valid options are " +
BrokerCompressionCodec.brokerCompressionOptions.mkString(","))
-require(!processRoles.contains(ControllerRole) ||
controllerListeners.nonEmpty,
- s"${KafkaConfig.ControllerListenerNamesProp} cannot be empty if the
server has the controller role")
+val advertisedListenerNames =
effectiveAdvertisedListeners.map(_.listenerName).toSet
+
+// validate KRaft-related configs
+val voterAddressSpecsByNodeId =
RaftConfig.parseVoterConnections(quorumVoters)
+def validateNonEmptyQuorumVotersForKRaft(): Unit = {
+ if (voterAddressSpecsByNodeId.isEmpty) {
+throw new ConfigException(s"If using ${KafkaConfig.ProcessRolesProp},
${KafkaConfig.QuorumVotersProp} must contain a parseable set of voters.")
+ }
+}
+def validateControlPlaneListenerEmptyForKRaft(): Unit = {
+ require(controlPlaneListenerName.isEmpty,
+s"${KafkaConfig.ControlPlaneListenerNameProp} is not supported in
KRaft mode. KRaft uses ${KafkaConfig.ControllerListenerNamesProp} instead.")
+}
+val sourceOfAdvertisedListeners: String =
+ if (getString(KafkaConfig.AdvertisedListenersProp) != null)
+s"${KafkaConfig.AdvertisedListenersProp}"
+ else
+s"${KafkaConfig.ListenersProp}"
+def
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker():
Unit = {
+ require(!advertisedListenerNames.exists(aln =>
controllerListenerNames.contains(aln.value())),
+s"$sourceOfAdvertisedListeners must not contain KRaft controller
listeners from ${KafkaConfig.ControllerListenerNamesProp} when
${KafkaConfig.ProcessRolesProp} contains the broker role because Kafka clients
that send requests via advertised listeners do not send requests to KRaft
controllers -- they only send requests to KRaft brokers.")
+}
+def validateControllerQuorumVotersMustContainNodeIDForKRaftController():
Unit = {
+ require(voterAddressSpecsByNodeId.containsKey(nodeId),
+s"If ${KafkaConfig.ProcessRolesProp} contains the 'controller' role,
the node id $nodeId must be included in the set of voters
${KafkaConfig.QuorumVotersProp}=${voterAddressSpecsByNodeId.asScala.keySet.toSet}")
+}
+def validateControllerListenerExistsForKRaftController(): Unit = {
+ require(controllerListeners.nonEmpty,
+s"${KafkaConfig.ControllerListenerNamesProp} must contain at least one
value appearing in the '${KafkaConfig.ListenersProp}' configuration when
running the KRaft controller role")
+}
+def
validateControllerListenerNamesMustAppearInListenersForKRaftController(): Unit
= {
+ val listenerNameValues = listeners.map(_.listenerName.value).toSet
+ require(controllerListenerNames.forall(cln =>
listenerNameValues.contains(cln)),
+s"${KafkaConfig.ControllerListenerNamesProp} must only contain values
appearing in the '${KafkaConfig.ListenersProp}' configuration when running the
KRaft controller role")
+}
+def validateAdvertisedListenersNonEmptyForBroker(): Unit = {
+ require(advertisedListenerNames.nonEmpty,
+"There must be at least one advertised listener." + (
+ if (processRoles.contains(BrokerRole)) s" Perhaps all listeners
appear in ${ControllerListenerNamesProp}?" else ""))
+}
+if (processRoles == Set(BrokerRole)) {
+ // KRaft broker-only
+ validateNonEmptyQuorumVotersForKRaft()
+ validateControlPlaneListenerEmptyForKRaft()
+
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker()
+ // nodeId must not appear in controller.quorum.voters
+ require(!voterAddressSpecsByNodeId.containsKey(nodeId),
+s"If ${KafkaConfig.ProcessRolesProp} contains just the 'broker' role,
the node id $nodeId must not be included in the set of voters
${KafkaConfig.QuorumVotersProp}=${voterAddressSpecsByNodeId.asScala.keySet.toSet}")
+ // controller.listener.names must be non-empty...
+ require(controllerListenerNames.exists(_.nonEmpty),
+s"${KafkaConfig.ControllerListenerNamesProp} must contain at least one
value when running KRaft with just the broker role")
+ // controller.listener.names are forbidden in listeners...
+ require(controllerListeners.isEmpty,
+s"${KafkaConfig.ControllerListenerNamesProp} must not contain a value
appearing in the '${KafkaConfig.ListenersProp}' configuration when running
KRaft with just
[GitHub] [kafka] rondagostino commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
rondagostino commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764367513
##
File path: core/src/test/scala/unit/kafka/server/KafkaConfigTest.scala
##
@@ -1000,46 +1139,78 @@ class KafkaConfigTest {
}
}
- def assertDistinctControllerAndAdvertisedListeners(): Unit = {
-val props = TestUtils.createBrokerConfig(0, TestUtils.MockZkConnect, port
= TestUtils.MockZkPort)
-val listeners = "PLAINTEXT://A:9092,SSL://B:9093,SASL_SSL://C:9094"
-props.put(KafkaConfig.ListenersProp, listeners)
-props.put(KafkaConfig.AdvertisedListenersProp,
"PLAINTEXT://A:9092,SSL://B:9093")
+ @Test
+ def assertDistinctControllerAndAdvertisedListenersAllowedForKRaftBroker():
Unit = {
+val props = new Properties()
+props.put(KafkaConfig.ProcessRolesProp, "broker")
+props.put(KafkaConfig.ListenersProp,
"PLAINTEXT://A:9092,SSL://B:9093,SASL_SSL://C:9094")
+props.put(KafkaConfig.AdvertisedListenersProp,
"PLAINTEXT://A:9092,SSL://B:9093") // explicitly setting it in KRaft
+props.put(KafkaConfig.ControllerListenerNamesProp, "SASL_SSL")
+props.put(KafkaConfig.NodeIdProp, "2")
+props.put(KafkaConfig.QuorumVotersProp, "3@localhost:9094")
+
+// invalid due to extra listener also appearing in controller listeners
+assertBadConfigContainingMessage(props,
+ "controller.listener.names must not contain a value appearing in the
'listeners' configuration when running KRaft with just the broker role")
+
// Valid now
-assertTrue(isValidKafkaConfig(props))
+props.put(KafkaConfig.ListenersProp, "PLAINTEXT://A:9092,SSL://B:9093")
+KafkaConfig.fromProps(props)
-// Still valid
-val controllerListeners = "SASL_SSL"
-props.put(KafkaConfig.ControllerListenerNamesProp, controllerListeners)
-assertTrue(isValidKafkaConfig(props))
+// Also valid if we let advertised listeners be derived from
listeners/controller.listener.names
+// since listeners and advertised.listeners are explicitly identical at
this point
+props.remove(KafkaConfig.AdvertisedListenersProp)
+KafkaConfig.fromProps(props)
}
@Test
- def assertAllControllerListenerCannotBeAdvertised(): Unit = {
-val props = TestUtils.createBrokerConfig(0, TestUtils.MockZkConnect, port
= TestUtils.MockZkPort)
+ def assertControllerListenersCannotBeAdvertisedForKRaftBroker(): Unit = {
+val props = new Properties()
+props.put(KafkaConfig.ProcessRolesProp, "broker,controller")
val listeners = "PLAINTEXT://A:9092,SSL://B:9093,SASL_SSL://C:9094"
props.put(KafkaConfig.ListenersProp, listeners)
-props.put(KafkaConfig.AdvertisedListenersProp, listeners)
+props.put(KafkaConfig.AdvertisedListenersProp, listeners) // explicitly
setting it in KRaft
+props.put(KafkaConfig.InterBrokerListenerNameProp, "SASL_SSL")
+props.put(KafkaConfig.ControllerListenerNamesProp, "PLAINTEXT,SSL")
+props.put(KafkaConfig.NodeIdProp, "2")
+props.put(KafkaConfig.QuorumVotersProp, "2@localhost:9092")
+assertBadConfigContainingMessage(props,
+ "advertised.listeners must not contain KRaft controller listeners from
controller.listener.names when process.roles contains the broker role")
+
// Valid now
-assertTrue(isValidKafkaConfig(props))
+props.put(KafkaConfig.AdvertisedListenersProp, "SASL_SSL://C:9094")
+KafkaConfig.fromProps(props)
-// Invalid now
-props.put(KafkaConfig.ControllerListenerNamesProp,
"PLAINTEXT,SSL,SASL_SSL")
-assertFalse(isValidKafkaConfig(props))
+// Also valid if we allow advertised listeners to derive from
listeners/controller.listener.names
+props.remove(KafkaConfig.AdvertisedListenersProp)
+KafkaConfig.fromProps(props)
}
@Test
- def assertEvenOneControllerListenerCannotBeAdvertised(): Unit = {
-val props = TestUtils.createBrokerConfig(0, TestUtils.MockZkConnect, port
= TestUtils.MockZkPort)
+ def assertAdvertisedListenersDisallowedForKRaftControllerOnlyRole(): Unit = {
Review comment:
> do we have a test for the scenario where SSL/SASL are in use and no
controller listener security mapping is defined
Yes, testControllerListenerNameMapsToPlaintextByDefaultForKRaft() has this
case.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] bbejeck commented on pull request #11573: KAFKA-13507: GlobalProcessor ignores user specified names
bbejeck commented on pull request #11573: URL: https://github.com/apache/kafka/pull/11573#issuecomment-988225508 Failures unrelated to this PR - kicked off another build - JDK 8 and Scala 2.12 / kafka.admin.LeaderElectionCommandTest.[1] Type=Raft, Name=testTopicPartition, Security=PLAINTEXT - JDK 11 and Scala 2.13 / org.apache.kafka.streams.integration.EosV2UpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosV2[true] - JDK 17 and Scala 2.13 / kafka.server.ReplicaManagerTest.[1] usesTopicIds=true -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #11513: feat: Write and restore position to/from changelog
vvcephei commented on a change in pull request #11513:
URL: https://github.com/apache/kafka/pull/11513#discussion_r764279791
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ProcessorContextImpl.java
##
@@ -110,17 +121,27 @@ public RecordCollector recordCollector() {
public void logChange(final String storeName,
final Bytes key,
final byte[] value,
- final long timestamp) {
+ final long timestamp,
+ final Position position) {
throwUnsupportedOperationExceptionIfStandby("logChange");
final TopicPartition changelogPartition =
stateManager().registeredChangelogPartitionFor(storeName);
-// Sending null headers to changelog topics (KIP-244)
+Headers headers = new RecordHeaders();
Review comment:
nit: I'd make this final with no assignment, then assign it in both
branches below.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #11513: feat: Write and restore position to/from changelog
vvcephei commented on a change in pull request #11513:
URL: https://github.com/apache/kafka/pull/11513#discussion_r764278336
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ChangelogRecordDeserializationHelper.java
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.processor.internals;
+
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.header.Header;
+import org.apache.kafka.common.header.internals.RecordHeader;
+import org.apache.kafka.streams.errors.StreamsException;
+import org.apache.kafka.streams.query.Position;
+import org.apache.kafka.streams.state.internals.PositionSerde;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.nio.ByteBuffer;
+
+/**
+ * Changelog records without any headers are considered old format.
+ * New format changelog records will have a version in their headers.
+ * Version 0: This indicates that the changelog records have consistency
information.
+ */
+public class ChangelogRecordDeserializationHelper {
+public static final Logger log =
LoggerFactory.getLogger(ChangelogRecordDeserializationHelper.class);
+private static final byte[] V_0_CHANGELOG_VERSION_HEADER_VALUE = {(byte)
0};
+public static final String CHANGELOG_VERSION_HEADER_KEY = "v";
+public static final String CHANGELOG_POSITION_HEADER_KEY = "c";
+public static final RecordHeader
CHANGELOG_VERSION_HEADER_RECORD_CONSISTENCY = new RecordHeader(
+CHANGELOG_VERSION_HEADER_KEY, V_0_CHANGELOG_VERSION_HEADER_VALUE);
+
+public static Position applyChecksAndUpdatePosition(
+final ConsumerRecord record,
+final boolean consistencyEnabled,
+final Position position
+) {
+Position restoredPosition = Position.emptyPosition();
+if (!consistencyEnabled) {
+return Position.emptyPosition();
Review comment:
Even though I think this is a bit off, I'm going to go ahead and merge
it, so we can fix forward. The overall feature isn't fully implemented yet
anyway, so this will have no negative effects if we release the branch right
now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #11513: feat: Write and restore position to/from changelog
vvcephei commented on a change in pull request #11513:
URL: https://github.com/apache/kafka/pull/11513#discussion_r764277280
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ChangelogRecordDeserializationHelper.java
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.processor.internals;
+
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.header.Header;
+import org.apache.kafka.common.header.internals.RecordHeader;
+import org.apache.kafka.streams.errors.StreamsException;
+import org.apache.kafka.streams.query.Position;
+import org.apache.kafka.streams.state.internals.PositionSerde;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.nio.ByteBuffer;
+
+/**
+ * Changelog records without any headers are considered old format.
+ * New format changelog records will have a version in their headers.
+ * Version 0: This indicates that the changelog records have consistency
information.
+ */
+public class ChangelogRecordDeserializationHelper {
+public static final Logger log =
LoggerFactory.getLogger(ChangelogRecordDeserializationHelper.class);
+private static final byte[] V_0_CHANGELOG_VERSION_HEADER_VALUE = {(byte)
0};
+public static final String CHANGELOG_VERSION_HEADER_KEY = "v";
+public static final String CHANGELOG_POSITION_HEADER_KEY = "c";
+public static final RecordHeader
CHANGELOG_VERSION_HEADER_RECORD_CONSISTENCY = new RecordHeader(
+CHANGELOG_VERSION_HEADER_KEY, V_0_CHANGELOG_VERSION_HEADER_VALUE);
+
+public static Position applyChecksAndUpdatePosition(
+final ConsumerRecord record,
+final boolean consistencyEnabled,
+final Position position
+) {
+Position restoredPosition = Position.emptyPosition();
+if (!consistencyEnabled) {
+return Position.emptyPosition();
Review comment:
Shouldn't these be returning `position`? This method's contract is to
"update" the position, not "replace" it, right?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #11513: feat: Write and restore position to/from changelog
vvcephei commented on a change in pull request #11513:
URL: https://github.com/apache/kafka/pull/11513#discussion_r764271813
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ChangelogRecordDeserializationHelper.java
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.processor.internals;
+
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.header.Header;
+import org.apache.kafka.common.header.internals.RecordHeader;
+import org.apache.kafka.streams.errors.StreamsException;
+import org.apache.kafka.streams.query.Position;
+import org.apache.kafka.streams.state.internals.PositionSerde;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.nio.ByteBuffer;
+
+/**
+ * Changelog records without any headers are considered old format.
+ * New format changelog records will have a version in their headers.
+ * Version 0: This indicates that the changelog records have consistency
information.
+ */
+public class ChangelogRecordDeserializationHelper {
+public static final Logger log =
LoggerFactory.getLogger(ChangelogRecordDeserializationHelper.class);
+private static final byte[] V_0_CHANGELOG_VERSION_HEADER_VALUE = {(byte)
0};
+public static final String CHANGELOG_VERSION_HEADER_KEY = "v";
+public static final String CHANGELOG_POSITION_HEADER_KEY = "c";
+public static final RecordHeader
CHANGELOG_VERSION_HEADER_RECORD_CONSISTENCY = new RecordHeader(
+CHANGELOG_VERSION_HEADER_KEY, V_0_CHANGELOG_VERSION_HEADER_VALUE);
+
+public static Position applyChecksAndUpdatePosition(
+final ConsumerRecord record,
+final boolean consistencyEnabled,
+final Position position
+) {
+Position restoredPosition = Position.emptyPosition();
+if (!consistencyEnabled) {
Review comment:
Good point! @vpapavas , can you handle stuff like this in a follow-on
PR? I'm doing a final pass to try and get this one merged.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #11046: KAFKA-12980: Return empty record batch from Consumer::poll when position advances due to aborted transactions
hachikuji commented on a change in pull request #11046:
URL: https://github.com/apache/kafka/pull/11046#discussion_r764255533
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/Fetcher.java
##
@@ -725,17 +725,13 @@ public void onFailure(RuntimeException e) {
completedFetch.nextFetchOffset,
completedFetch.lastEpoch,
position.currentLeader);
-log.trace("Update fetching position to {} for partition
{}", nextPosition, completedFetch.partition);
+log.trace("Updating fetch position from {} to {} for
partition {} and returning {} records from `poll()`",
+position, nextPosition, completedFetch.partition,
partRecords.size());
subscriptions.position(completedFetch.partition,
nextPosition);
positionAdvanced = true;
if (partRecords.isEmpty()) {
-log.debug(
-"Advanced position for partition {} without
receiving any user-visible records. "
-+ "This is likely due to skipping over
control records in the current fetch, "
-+ "and may result in the consumer
returning an empty record batch when "
-+ "polled before its poll timeout has
elapsed.",
-completedFetch.partition
-);
+log.trace("Returning empty records from `poll()` "
++ "since the consumer's position has advanced
for at least one topic partition");
Review comment:
I'm inclined to either remove the log line entirely or move it back to
its former location in `KafkaConsumer`. Will leave it up to you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
hachikuji commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764232658
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -1959,10 +1962,26 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
}
}
- def listenerSecurityProtocolMap: Map[ListenerName, SecurityProtocol] = {
-getMap(KafkaConfig.ListenerSecurityProtocolMapProp,
getString(KafkaConfig.ListenerSecurityProtocolMapProp))
+ def effectiveListenerSecurityProtocolMap: Map[ListenerName,
SecurityProtocol] = {
+val mapValue = getMap(KafkaConfig.ListenerSecurityProtocolMapProp,
getString(KafkaConfig.ListenerSecurityProtocolMapProp))
.map { case (listenerName, protocolName) =>
- ListenerName.normalised(listenerName) ->
getSecurityProtocol(protocolName, KafkaConfig.ListenerSecurityProtocolMapProp)
+ListenerName.normalised(listenerName) ->
getSecurityProtocol(protocolName, KafkaConfig.ListenerSecurityProtocolMapProp)
+ }
+if (usesSelfManagedQuorum &&
!originals.containsKey(ListenerSecurityProtocolMapProp)) {
+ // Nothing was specified explicitly for listener.security.protocol.map,
so we are using the default value,
+ // and we are using KRaft.
+ // Add PLAINTEXT mappings for controller listeners as long as there is
no SSL or SASL_{PLAINTEXT,SSL} in use
+ def isSslOrSasl(name: String) : Boolean =
name.equals(SecurityProtocol.SSL.name) ||
name.equals(SecurityProtocol.SASL_SSL.name) ||
name.equals(SecurityProtocol.SASL_PLAINTEXT.name)
+ if (controllerListenerNames.exists(isSslOrSasl) ||
Review comment:
Checking my understanding. Is the first clause here necessary for the
broker-only case in which the controller listener names are not included in
`listeners`? A comment to that effect might be useful.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
hachikuji commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764221288
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -748,7 +749,8 @@ object KafkaConfig {
"Different security (SSL and SASL) settings can be configured for each
listener by adding a normalised " +
"prefix (the listener name is lowercased) to the config name. For example,
to set a different keystore for the " +
"INTERNAL listener, a config with name
listener.name.internal.ssl.keystore.location would be set. " +
-"If the config for the listener name is not set, the config will fallback
to the generic config (i.e. ssl.keystore.location). "
+"If the config for the listener name is not set, the config will fallback
to the generic config (i.e. ssl.keystore.location). " +
+"Note that in KRaft an additional default mapping CONTROLLER to PLAINTEXT
is added."
Review comment:
How about this?
> Note that in KRaft, a default mapping from the listener names defined by
`controller.listener.names` to PLAINTEXT is assumed if no explicit mapping is
provided and no other security protocol is in use.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
hachikuji commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764232658
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -1959,10 +1962,26 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
}
}
- def listenerSecurityProtocolMap: Map[ListenerName, SecurityProtocol] = {
-getMap(KafkaConfig.ListenerSecurityProtocolMapProp,
getString(KafkaConfig.ListenerSecurityProtocolMapProp))
+ def effectiveListenerSecurityProtocolMap: Map[ListenerName,
SecurityProtocol] = {
+val mapValue = getMap(KafkaConfig.ListenerSecurityProtocolMapProp,
getString(KafkaConfig.ListenerSecurityProtocolMapProp))
.map { case (listenerName, protocolName) =>
- ListenerName.normalised(listenerName) ->
getSecurityProtocol(protocolName, KafkaConfig.ListenerSecurityProtocolMapProp)
+ListenerName.normalised(listenerName) ->
getSecurityProtocol(protocolName, KafkaConfig.ListenerSecurityProtocolMapProp)
+ }
+if (usesSelfManagedQuorum &&
!originals.containsKey(ListenerSecurityProtocolMapProp)) {
+ // Nothing was specified explicitly for listener.security.protocol.map,
so we are using the default value,
+ // and we are using KRaft.
+ // Add PLAINTEXT mappings for controller listeners as long as there is
no SSL or SASL_{PLAINTEXT,SSL} in use
+ def isSslOrSasl(name: String) : Boolean =
name.equals(SecurityProtocol.SSL.name) ||
name.equals(SecurityProtocol.SASL_SSL.name) ||
name.equals(SecurityProtocol.SASL_PLAINTEXT.name)
+ if (controllerListenerNames.exists(isSslOrSasl) ||
Review comment:
Checking my understanding. Is the first clause here necessary for the
broker-only case in which the controller listener names are not included in
`listeners`? A comment to that effect that might be useful.
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -2018,12 +2025,103 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
"offsets.commit.required.acks must be greater or equal -1 and less or
equal to offsets.topic.replication.factor")
require(BrokerCompressionCodec.isValid(compressionType), "compression.type
: " + compressionType + " is not valid." +
" Valid options are " +
BrokerCompressionCodec.brokerCompressionOptions.mkString(","))
-require(!processRoles.contains(ControllerRole) ||
controllerListeners.nonEmpty,
- s"${KafkaConfig.ControllerListenerNamesProp} cannot be empty if the
server has the controller role")
+val advertisedListenerNames =
effectiveAdvertisedListeners.map(_.listenerName).toSet
+
+// validate KRaft-related configs
+val voterAddressSpecsByNodeId =
RaftConfig.parseVoterConnections(quorumVoters)
+def validateNonEmptyQuorumVotersForKRaft(): Unit = {
+ if (voterAddressSpecsByNodeId.isEmpty) {
+throw new ConfigException(s"If using ${KafkaConfig.ProcessRolesProp},
${KafkaConfig.QuorumVotersProp} must contain a parseable set of voters.")
+ }
+}
+def validateControlPlaneListenerEmptyForKRaft(): Unit = {
+ require(controlPlaneListenerName.isEmpty,
+s"${KafkaConfig.ControlPlaneListenerNameProp} is not supported in
KRaft mode. KRaft uses ${KafkaConfig.ControllerListenerNamesProp} instead.")
+}
+val sourceOfAdvertisedListeners: String =
+ if (getString(KafkaConfig.AdvertisedListenersProp) != null)
+s"${KafkaConfig.AdvertisedListenersProp}"
+ else
+s"${KafkaConfig.ListenersProp}"
+def
validateAdvertisedListenersDoesNotContainControllerListenersForKRaftBroker():
Unit = {
+ require(!advertisedListenerNames.exists(aln =>
controllerListenerNames.contains(aln.value())),
+s"$sourceOfAdvertisedListeners must not contain KRaft controller
listeners from ${KafkaConfig.ControllerListenerNamesProp} when
${KafkaConfig.ProcessRolesProp} contains the broker role because Kafka clients
that send requests via advertised listeners do not send requests to KRaft
controllers -- they only send requests to KRaft brokers.")
Review comment:
nit: The generality here seems misleading. We explicitly allow the
controller listeners to be included among `listeners` even when
`advertised.listeners` is empty. Hence I don't think it would ever be possible
for `sourceOfAdvertisedListeners` to refer to `listeners` here.
##
File path: core/src/test/scala/unit/kafka/server/KafkaConfigTest.scala
##
@@ -1000,46 +1139,78 @@ class KafkaConfigTest {
}
}
- def assertDistinctControllerAndAdvertisedListeners(): Unit = {
-val props = TestUtils.createBrokerConfig(0, TestUtils.MockZkConnect, port
= TestUtils.MockZkPort)
-val listeners = "PLAINTEXT://A:9092,SSL://B:9093,SASL_SSL://C:9094"
-props.put(KafkaConfig.ListenersProp, listeners)
-props.put(KafkaConfig.AdvertisedListenersProp,
[jira] [Created] (KAFKA-13514) Flakey test StickyAssignorTest
Matthias J. Sax created KAFKA-13514:
---
Summary: Flakey test StickyAssignorTest
Key: KAFKA-13514
URL: https://issues.apache.org/jira/browse/KAFKA-13514
Project: Kafka
Issue Type: Test
Components: clients, unit tests
Reporter: Matthias J. Sax
org.apache.kafka.clients.consumer.StickyAssignorTest.testLargeAssignmentAndGroupWithNonEqualSubscription()
No real stack trace, but only:
{quote}java.util.concurrent.TimeoutException:
testLargeAssignmentAndGroupWithNonEqualSubscription() timed out after 60
seconds{quote}
STDOUT
{quote}[2021-12-07 01:32:23,920] ERROR Found multiple consumers consumer1 and
consumer2 claiming the same TopicPartition topic-0 in the same generation -1,
this will be invalidated and removed from their previous assignment.
(org.apache.kafka.clients.consumer.internals.AbstractStickyAssignor:150)
[2021-12-07 01:32:58,964] ERROR Found multiple consumers consumer1 and
consumer2 claiming the same TopicPartition topic-0 in the same generation -1,
this will be invalidated and removed from their previous assignment.
(org.apache.kafka.clients.consumer.internals.AbstractStickyAssignor:150)
[2021-12-07 01:32:58,976] ERROR Found multiple consumers consumer1 and
consumer2 claiming the same TopicPartition topic-0 in the same generation -1,
this will be invalidated and removed from their previous assignment.
(org.apache.kafka.clients.consumer.internals.AbstractStickyAssignor:150){quote}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Created] (KAFKA-13513) Flaky test AdjustStreamThreadCountTest
Matthias J. Sax created KAFKA-13513:
---
Summary: Flaky test AdjustStreamThreadCountTest
Key: KAFKA-13513
URL: https://issues.apache.org/jira/browse/KAFKA-13513
Project: Kafka
Issue Type: Test
Components: streams, unit tests
Reporter: Matthias J. Sax
org.apache.kafka.streams.integration.AdjustStreamThreadCountTest.testConcurrentlyAccessThreads
{quote}java.lang.AssertionError: expected null, but
was: at
org.junit.Assert.fail(Assert.java:89) at
org.junit.Assert.failNotNull(Assert.java:756) at
org.junit.Assert.assertNull(Assert.java:738) at
org.junit.Assert.assertNull(Assert.java:748) at
org.apache.kafka.streams.integration.AdjustStreamThreadCountTest.testConcurrentlyAccessThreads(AdjustStreamThreadCountTest.java:367)
{quote}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Created] (KAFKA-13512) topicIdsToNames and topicNamesToIds allocate unnecessary maps
Justine Olshan created KAFKA-13512:
--
Summary: topicIdsToNames and topicNamesToIds allocate unnecessary
maps
Key: KAFKA-13512
URL: https://issues.apache.org/jira/browse/KAFKA-13512
Project: Kafka
Issue Type: Bug
Affects Versions: 3.1.0
Reporter: Justine Olshan
Assignee: Justine Olshan
Currently we write the methods as follows:
{{def topicNamesToIds(): util.Map[String, Uuid] = {}}
{{ new util.HashMap(metadataSnapshot.topicIds.asJava)}}
{{}}}
We do not need to allocate a new map however, we can simply use
{{Collections.unmodifiableMap(metadataSnapshot.topicIds.asJava)}}
We can do something similar for the topicIdsToNames implementation.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [kafka] cadonna merged pull request #11561: MINOR: Bump version of grgit to 4.1.1
cadonna merged pull request #11561: URL: https://github.com/apache/kafka/pull/11561 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna merged pull request #11574: MINOR: Fix internal topic manager tests
cadonna merged pull request #11574: URL: https://github.com/apache/kafka/pull/11574 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on pull request #11574: MINOR: Fix internal topic manager tests
cadonna commented on pull request #11574: URL: https://github.com/apache/kafka/pull/11574#issuecomment-988124933 Test failures are not related. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] C0urante commented on a change in pull request #11046: KAFKA-12980: Return empty record batch from Consumer::poll when position advances due to aborted transactions
C0urante commented on a change in pull request #11046:
URL: https://github.com/apache/kafka/pull/11046#discussion_r764163807
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/Fetcher.java
##
@@ -725,17 +725,13 @@ public void onFailure(RuntimeException e) {
completedFetch.nextFetchOffset,
completedFetch.lastEpoch,
position.currentLeader);
-log.trace("Update fetching position to {} for partition
{}", nextPosition, completedFetch.partition);
+log.trace("Updating fetch position from {} to {} for
partition {} and returning {} records from `poll()`",
+position, nextPosition, completedFetch.partition,
partRecords.size());
subscriptions.position(completedFetch.partition,
nextPosition);
positionAdvanced = true;
if (partRecords.isEmpty()) {
-log.debug(
-"Advanced position for partition {} without
receiving any user-visible records. "
-+ "This is likely due to skipping over
control records in the current fetch, "
-+ "and may result in the consumer
returning an empty record batch when "
-+ "polled before its poll timeout has
elapsed.",
-completedFetch.partition
-);
+log.trace("Returning empty records from `poll()` "
++ "since the consumer's position has advanced
for at least one topic partition");
Review comment:
This is true. I was hoping we could have something in here that
explicitly states that this can happen because of the change in behavior
implemented in this PR (i.e., skipping control records or aborted
transactions). If you think it's worth it to call that out in a log message we
can do that here, otherwise the entire `if (partRecords.isEmpty())` branch is
unnecessary.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] C0urante commented on a change in pull request #11046: KAFKA-12980: Return empty record batch from Consumer::poll when position advances due to aborted transactions
C0urante commented on a change in pull request #11046:
URL: https://github.com/apache/kafka/pull/11046#discussion_r764161918
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/KafkaConsumer.java
##
@@ -1176,7 +1176,8 @@ public void assign(Collection partitions)
{
* offset for the subscribed list of partitions
*
*
- * This method returns immediately if there are records available or if
the position advances past control records.
+ * This method returns immediately if there are records available or if
the position advances past control records
+ * or aborted transactions when isolation.level=READ_COMMITTED.
Review comment:
```suggestion
* or aborted transactions when isolation.level=read_committed.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rondagostino commented on a change in pull request #11503: KAFKA-13456: Tighten KRaft config checks/constraints
rondagostino commented on a change in pull request #11503:
URL: https://github.com/apache/kafka/pull/11503#discussion_r764161713
##
File path: core/src/main/scala/kafka/server/KafkaConfig.scala
##
@@ -1959,10 +1961,18 @@ class KafkaConfig private(doLog: Boolean, val props:
java.util.Map[_, _], dynami
}
}
- def listenerSecurityProtocolMap: Map[ListenerName, SecurityProtocol] = {
-getMap(KafkaConfig.ListenerSecurityProtocolMapProp,
getString(KafkaConfig.ListenerSecurityProtocolMapProp))
+ def effectiveListenerSecurityProtocolMap: Map[ListenerName,
SecurityProtocol] = {
+val mapValue = getMap(KafkaConfig.ListenerSecurityProtocolMapProp,
getString(KafkaConfig.ListenerSecurityProtocolMapProp))
.map { case (listenerName, protocolName) =>
- ListenerName.normalised(listenerName) ->
getSecurityProtocol(protocolName, KafkaConfig.ListenerSecurityProtocolMapProp)
+ListenerName.normalised(listenerName) ->
getSecurityProtocol(protocolName, KafkaConfig.ListenerSecurityProtocolMapProp)
+ }
+if (usesSelfManagedQuorum &&
!originals.containsKey(ListenerSecurityProtocolMapProp)) {
+ // Nothing was specified explicitly, so we are using the default value;
therefore, since we are using KRaft,
+ // add the PLAINTEXT mappings for all controller listener names that are
not security protocols
+ mapValue ++ controllerListenerNames.filter(cln => cln.nonEmpty &&
!SecurityProtocol.values().exists(_.name.equals(cln))).map(
Review comment:
> I'm inclined to be stricter if other security protocols are in use.
What do you think?
Yeah, I agree that we should only map when SSL and SASL_{SSL,PLAINTEXT} are
not in use. I've pushed a commit that implement this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] C0urante commented on a change in pull request #11046: KAFKA-12980: Return empty record batch from Consumer::poll when position advances due to aborted transactions
C0urante commented on a change in pull request #11046:
URL: https://github.com/apache/kafka/pull/11046#discussion_r764161599
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/KafkaConsumer.java
##
@@ -1176,7 +1176,8 @@ public void assign(Collection partitions)
{
* offset for the subscribed list of partitions
*
*
- * This method returns immediately if there are records available or if
the position advances past control records.
+ * This method returns immediately if there are records available or if
the position advances past control records
+ * or aborted transactions when isolation.level=READ_COMMITTED.
Review comment:
Sure,
https://github.com/apache/kafka/blob/a2da309f134ec2930f70f1a3917eaade7548132f/clients/src/main/java/org/apache/kafka/clients/consumer/ConsumerConfig.java#L557.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ccding commented on a change in pull request #11345: Allow empty last segment to have missing offset index during recovery
ccding commented on a change in pull request #11345:
URL: https://github.com/apache/kafka/pull/11345#discussion_r764130805
##
File path: core/src/main/scala/kafka/log/UnifiedLog.scala
##
@@ -1498,28 +1498,44 @@ class UnifiedLog(@volatile var logStartOffset: Long,
producerStateManager.takeSnapshot()
updateHighWatermarkWithLogEndOffset()
// Schedule an asynchronous flush of the old segment
-scheduler.schedule("flush-log", () => flush(newSegment.baseOffset))
+scheduler.schedule("flush-log", () =>
flushUptoOffsetExclusive(newSegment.baseOffset))
newSegment
}
/**
* Flush all local log segments
+ *
+ * @param forceFlushActiveSegment should be true during a clean shutdown,
and false otherwise. The reason is that
+ * we have to pass logEndOffset + 1 to the `localLog.flush(offset: Long):
Unit` function to flush empty
+ * active segments, which is important to make sure we persist the active
segment file during shutdown, particularly
+ * when it's empty.
*/
- def flush(): Unit = flush(logEndOffset)
+ def flush(forceFlushActiveSegment: Boolean): Unit = flush(logEndOffset,
forceFlushActiveSegment)
Review comment:
If we have 50MB/s produce input in a three-broker cluster and
segment.size is 100MB, it is on average 1 extra fsync every 2 seconds. Given
the extra fsync is to sync an empty file, it may not be a big deal.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] twobeeb commented on pull request #11575: KAFKA-13511: Update TimestampConverter support unix epoch as millis, micros, and seconds
twobeeb commented on pull request #11575: URL: https://github.com/apache/kafka/pull/11575#issuecomment-988049565 @mimaison @rhauch before considering going further with this PR, any chance I could to get your opinion on this subject ? The main idea behind this PR is that Avro logical types are not fully supported in Kafka Connect but even if they were, it would not help schema-less messages that need to convert epoch with a precision different than ms. For this reason, I consider this would be an interesting addition. Thanks for your help. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] twobeeb opened a new pull request #11575: KAFKA-13511: Update TimestampConverter support unix epoch as millis, micros, and seconds
twobeeb opened a new pull request #11575: URL: https://github.com/apache/kafka/pull/11575 Currently, the SMT TimestampConverter can convert Timestamp from either source String, Long or Date into target String, Long or Date. The problem is that Long source or target is required to be epoch in milliseconds. In many cases, epoch is represented with different precisions. This leads to several Jira tickets : [KAFKA-12364](https://issues.apache.org/jira/browse/KAFKA-12364): add support for date from int32 to timestampconverter [KAFKA-10561](https://issues.apache.org/jira/browse/KAFKA-10561): Support microseconds precision for Timestamps I propose to add a new config to TimestampConverter called "epoch.precision" which defaults to "millis" so as to not impact existing code, and allows for more precisions : seconds, millis, micros. json "transforms": "TimestampConverter", "transforms.TimestampConverter.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value", "transforms.TimestampConverter.field": "event_date", "transforms.TimestampConverter.epoch.precision": "micros", "transforms.TimestampConverter.target.type": "Timestamp" Exactly like "format" field which is used as input when the source in String and output when the target.type is string, this new field would be used as input when the field is Long, and as output when the target.type is "unix" *Summary of testing strategy (including rationale) for the feature or bug fix. Unit and/or integration tests are expected for any behaviour change and system tests should be considered for larger changes.* ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-13511) Update TimestampConverter SMT to support unix epoch as millis, micros, and seconds
[
https://issues.apache.org/jira/browse/KAFKA-13511?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Julien Chanaud updated KAFKA-13511:
---
Description:
Currently, the SMT TimestampConverter can convert Timestamp from either source
String, Long or Date into target String, Long or Date.
The problem is that Long source or target is required to be epoch in
milliseconds.
In many cases, epoch is represented with different precisions. This leads to
several Jira tickets :
* KAFKA-12364
* KAFKA-10561
I propose to add a new config to TimestampConverter called "epoch.precision"
which defaults to "millis" so as to not impact existing code, and allows for
more precisions : seconds, millis, micros.
{code:json}
"transforms": "TimestampConverter",
"transforms.TimestampConverter.type":
"org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.field": "event_date",
"transforms.TimestampConverter.epoch.precision": "micros",
"transforms.TimestampConverter.target.type": "Timestamp"
{code}
Exactly like "format" field which is used as input when the source in String
and output when the target.type is string, this new field would be used as
input when the field is Long, and as output when the target.type is "unix"
was:
Currently, the SMT TimestampConverter can convert Timestamp from either source
String, Long or Date into target String, Long or Date.
The problem is that Long source or target is required to be epoch in
milliseconds.
In many cases, epoch is represented with different precisions. This leads to
several Jira tickets :
* KAFKA-12364
* KAFKA-10561
I propose to add a new config to TimestampConverter called "epoch.precision"
which defaults to "millis" so as to not impact existing code, and allows for
more precisions : seconds, millis, micros.
{code:json}
"transforms": "TimestampConverter",
"transforms.TimestampConverter.type":
"org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.field": "event_date",
"transforms.TimestampConverter.epoch.precision": "micros",
"transforms.TimestampConverter.target.type": "Timestamp"
{code}
> Update TimestampConverter SMT to support unix epoch as millis, micros, and
> seconds
> --
>
> Key: KAFKA-13511
> URL: https://issues.apache.org/jira/browse/KAFKA-13511
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Julien Chanaud
>Priority: Minor
>
> Currently, the SMT TimestampConverter can convert Timestamp from either
> source String, Long or Date into target String, Long or Date.
> The problem is that Long source or target is required to be epoch in
> milliseconds.
> In many cases, epoch is represented with different precisions. This leads to
> several Jira tickets :
> * KAFKA-12364
> * KAFKA-10561
> I propose to add a new config to TimestampConverter called "epoch.precision"
> which defaults to "millis" so as to not impact existing code, and allows for
> more precisions : seconds, millis, micros.
> {code:json}
> "transforms": "TimestampConverter",
> "transforms.TimestampConverter.type":
> "org.apache.kafka.connect.transforms.TimestampConverter$Value",
> "transforms.TimestampConverter.field": "event_date",
> "transforms.TimestampConverter.epoch.precision": "micros",
> "transforms.TimestampConverter.target.type": "Timestamp"
> {code}
> Exactly like "format" field which is used as input when the source in String
> and output when the target.type is string, this new field would be used as
> input when the field is Long, and as output when the target.type is "unix"
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (KAFKA-13511) Update TimestampConverter SMT to support unix epoch as millis, micros, and seconds
[
https://issues.apache.org/jira/browse/KAFKA-13511?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Julien Chanaud updated KAFKA-13511:
---
Description:
Currently, the SMT TimestampConverter can convert Timestamp from either source
String, Long or Date into target String, Long or Date.
The problem is that Long source or target is required to be epoch in
milliseconds.
In many cases, epoch is represented with different precisions. This leads to
several Jira tickets :
* KAFKA-12364
* KAFKA-10561
I propose to add a new config to TimestampConverter called "epoch.precision"
which defaults to "millis" so as to not impact existing code, and allows for
more precisions : seconds, millis, micros.
{code:json}
"transforms": "TimestampConverter",
"transforms.TimestampConverter.type":
"org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.field": "event_date",
"transforms.TimestampConverter.epoch.precision": "micros",
"transforms.TimestampConverter.target.type": "Timestamp"
{code}
was:
Currently, the SMT TimestampConverter can convert Timestamp from either source
String, Long or any target Date to String, Long or Date.
The problem is that Long source or target is required to be epoch in
milliseconds.
In many cases, epoch is represented with different precisions. This leads to
several Jira tickets :
* KAFKA-12364
* KAFKA-10561
I propose to add a new config to TimestampConverter called "epoch.precision"
which defaults to "millis" so as to not impact existing code, and allows for
more precisions : seconds, millis, micros.
{code:json}
"transforms": "TimestampConverter",
"transforms.TimestampConverter.type":
"org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.field": "event_date",
"transforms.TimestampConverter.epoch.precision": "micros",
"transforms.TimestampConverter.target.type": "Timestamp"
{code}
> Update TimestampConverter SMT to support unix epoch as millis, micros, and
> seconds
> --
>
> Key: KAFKA-13511
> URL: https://issues.apache.org/jira/browse/KAFKA-13511
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Julien Chanaud
>Priority: Minor
>
> Currently, the SMT TimestampConverter can convert Timestamp from either
> source String, Long or Date into target String, Long or Date.
> The problem is that Long source or target is required to be epoch in
> milliseconds.
> In many cases, epoch is represented with different precisions. This leads to
> several Jira tickets :
> * KAFKA-12364
> * KAFKA-10561
> I propose to add a new config to TimestampConverter called "epoch.precision"
> which defaults to "millis" so as to not impact existing code, and allows for
> more precisions : seconds, millis, micros.
> {code:json}
> "transforms": "TimestampConverter",
> "transforms.TimestampConverter.type":
> "org.apache.kafka.connect.transforms.TimestampConverter$Value",
> "transforms.TimestampConverter.field": "event_date",
> "transforms.TimestampConverter.epoch.precision": "micros",
> "transforms.TimestampConverter.target.type": "Timestamp"
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (KAFKA-10503) MockProducer doesn't throw ClassCastException when no partition for topic
[
https://issues.apache.org/jira/browse/KAFKA-10503?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17454673#comment-17454673
]
Dennis Hunziker commented on KAFKA-10503:
-
This change did break our tests. When using the no-arg constructor the
serializers are null but now that they're referenced in any case we'll just get
an NPE. Was that on purpose? Shouldn't the change made here only be applied if
the serializers aren't null?
Happy to create a separate ticket and fix if you agree.
> MockProducer doesn't throw ClassCastException when no partition for topic
> -
>
> Key: KAFKA-10503
> URL: https://issues.apache.org/jira/browse/KAFKA-10503
> Project: Kafka
> Issue Type: Improvement
> Components: clients, producer
>Affects Versions: 2.6.0
>Reporter: Gonzalo Muñoz Fernández
>Assignee: Gonzalo Muñoz Fernández
>Priority: Minor
> Labels: mock, producer
> Fix For: 2.7.0
>
> Original Estimate: 1h
> Remaining Estimate: 1h
>
> Though {{MockProducer}} admits serializers in its constructors, it doesn't
> check during {{send}} method that those serializers are the proper ones to
> serialize key/value included into the {{ProducerRecord}}.
> [This
> check|https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/producer/MockProducer.java#L499-L500]
> is only done if there is a partition assigned for that topic.
> It would be an enhancement if these serialize methods were also invoked in
> simple scenarios, where no partition is assigned to a topic.
> eg:
> {code:java}
> @Test
> public void shouldThrowClassCastException() {
> MockProducer producer = new MockProducer<>(true, new
> IntegerSerializer(), new StringSerializer());
> ProducerRecord record = new ProducerRecord(TOPIC, "key1", "value1");
> try {
> producer.send(record);
> fail("Should have thrown ClassCastException because record cannot
> be casted with serializers");
> } catch (ClassCastException e) {}
> }
> {code}
> Currently, for obtaining the ClassCastException is needed to define the topic
> into a partition:
> {code:java}
> PartitionInfo partitionInfo = new PartitionInfo(TOPIC, 0, null, null, null);
> Cluster cluster = new Cluster(null, emptyList(), asList(partitionInfo),
> emptySet(), emptySet());
> producer = new MockProducer(cluster,
> true,
> new DefaultPartitioner(),
> new IntegerSerializer(),
> new StringSerializer());
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (KAFKA-13511) Update TimestampConverter SMT to support unix epoch as millis, micros, and seconds
[
https://issues.apache.org/jira/browse/KAFKA-13511?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Julien Chanaud updated KAFKA-13511:
---
Description:
Currently, the SMT TimestampConverter can convert Timestamp from either source
String, Long or any target Date to String, Long or Date.
The problem is that Long source or target is required to be epoch in
milliseconds.
In many cases, epoch is represented with different precisions. This leads to
several Jira tickets :
* KAFKA-12364
* KAFKA-10561
I propose to add a new config to TimestampConverter called "epoch.precision"
which defaults to "millis" so as to not impact existing code, and allows for
more precisions : seconds, millis, micros.
{code:json}
"transforms": "TimestampConverter",
"transforms.TimestampConverter.type":
"org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.field": "event_date",
"transforms.TimestampConverter.epoch.precision": "micros",
"transforms.TimestampConverter.target.type": "Timestamp"
{code}
was:
Currently, the SMT TimestampConverter can convert Timestamp from either source
String, Long or any target Date to String, Long or Date.
The problem is that Long source or target is required to be epoch in
milliseconds.
In many cases, epoch is represented with different precisions. This leads to
several Jira tickets :
* KAFKA-12364
* KAFKA-10561
I propose to add a new config to TimestampConverter called "epoch.precision"
which defaults to "millis" so as to not impact existing code, and allows for
more precisions : seconds, millis, micros.
"transforms": "TimestampConverter",
"transforms.TimestampConverter.type":
"org.apache.kafka.connect.transforms.TimestampConverter$Value","transforms.TimestampConverter.field":
"event_date"
*"transforms.TimestampConverter.epoch.precision": "micros"*
"transforms.TimestampConverter.target.type": "Timestamp"
> Update TimestampConverter SMT to support unix epoch as millis, micros, and
> seconds
> --
>
> Key: KAFKA-13511
> URL: https://issues.apache.org/jira/browse/KAFKA-13511
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Julien Chanaud
>Priority: Minor
>
> Currently, the SMT TimestampConverter can convert Timestamp from either
> source String, Long or any target Date to String, Long or Date.
> The problem is that Long source or target is required to be epoch in
> milliseconds.
> In many cases, epoch is represented with different precisions. This leads to
> several Jira tickets :
> * KAFKA-12364
> * KAFKA-10561
> I propose to add a new config to TimestampConverter called "epoch.precision"
> which defaults to "millis" so as to not impact existing code, and allows for
> more precisions : seconds, millis, micros.
> {code:json}
> "transforms": "TimestampConverter",
> "transforms.TimestampConverter.type":
> "org.apache.kafka.connect.transforms.TimestampConverter$Value",
> "transforms.TimestampConverter.field": "event_date",
> "transforms.TimestampConverter.epoch.precision": "micros",
> "transforms.TimestampConverter.target.type": "Timestamp"
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Created] (KAFKA-13511) Update TimestampConverter SMT to support unix epoch as millis, micros, and seconds
Julien Chanaud created KAFKA-13511: -- Summary: Update TimestampConverter SMT to support unix epoch as millis, micros, and seconds Key: KAFKA-13511 URL: https://issues.apache.org/jira/browse/KAFKA-13511 Project: Kafka Issue Type: Improvement Components: KafkaConnect Reporter: Julien Chanaud Currently, the SMT TimestampConverter can convert Timestamp from either source String, Long or any target Date to String, Long or Date. The problem is that Long source or target is required to be epoch in milliseconds. In many cases, epoch is represented with different precisions. This leads to several Jira tickets : * KAFKA-12364 * KAFKA-10561 I propose to add a new config to TimestampConverter called "epoch.precision" which defaults to "millis" so as to not impact existing code, and allows for more precisions : seconds, millis, micros. "transforms": "TimestampConverter", "transforms.TimestampConverter.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value","transforms.TimestampConverter.field": "event_date" *"transforms.TimestampConverter.epoch.precision": "micros"* "transforms.TimestampConverter.target.type": "Timestamp" -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [kafka] showuon commented on a change in pull request #11566: KAFKA-13495: add reason to JoinGroupRequest
showuon commented on a change in pull request #11566:
URL: https://github.com/apache/kafka/pull/11566#discussion_r764003611
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/KafkaConsumer.java
##
@@ -2303,18 +2303,24 @@ public ConsumerGroupMetadata groupMetadata() {
* @throws java.lang.IllegalStateException if the consumer does not use
group subscription
*/
@Override
-public void enforceRebalance() {
+public void enforceRebalance(final String reason) {
Review comment:
Why does the new API not have new java doc for it?
##
File path: core/src/main/scala/kafka/coordinator/group/GroupCoordinator.scala
##
@@ -181,6 +182,7 @@ class GroupCoordinator(val brokerId: Int,
responseCallback(JoinGroupResult(memberId, Errors.UNKNOWN_MEMBER_ID))
case Some(group) =>
group.inLock {
+info(s"memberId=$memberId with groupInstanceId=$groupInstanceId is
attempting to join groupId=$groupId due to: $reason")
Review comment:
Since the consumer might be in the old version, the `reason` might be
`null`. I think we should not output the log when the `reason` is null. i.e.:
`memberId=1 with groupInstanceId=2 is attempting to join groupId=3 due to:
null`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vpapavas commented on a change in pull request #11513: feat: Write and restore position to/from changelog
vpapavas commented on a change in pull request #11513:
URL: https://github.com/apache/kafka/pull/11513#discussion_r764012303
##
File path:
streams/src/test/java/org/apache/kafka/streams/integration/ConsistencyVectorIntegrationTest.java
##
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.integration;
+
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.producer.ProducerConfig;
+import org.apache.kafka.common.serialization.IntegerSerializer;
+import org.apache.kafka.common.serialization.Serdes;
+import org.apache.kafka.common.utils.Bytes;
+import org.apache.kafka.common.utils.MockTime;
+import org.apache.kafka.streams.KafkaStreams;
+import org.apache.kafka.streams.KeyValue;
+import org.apache.kafka.streams.StreamsBuilder;
+import org.apache.kafka.streams.StreamsConfig;
+import org.apache.kafka.streams.StreamsConfig.InternalConfig;
+import org.apache.kafka.streams.integration.utils.EmbeddedKafkaCluster;
+import org.apache.kafka.streams.integration.utils.IntegrationTestUtils;
+import org.apache.kafka.streams.kstream.Consumed;
+import org.apache.kafka.streams.kstream.Materialized;
+import org.apache.kafka.streams.state.KeyValueBytesStoreSupplier;
+import org.apache.kafka.streams.state.KeyValueStore;
+import org.apache.kafka.streams.state.QueryableStoreType;
+import org.apache.kafka.streams.state.ReadOnlyKeyValueStore;
+import org.apache.kafka.streams.state.internals.Position;
+import org.apache.kafka.streams.state.internals.RocksDBStore;
+import org.apache.kafka.test.IntegrationTest;
+import org.apache.kafka.test.TestUtils;
+import org.junit.After;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.experimental.categories.Category;
+import org.junit.rules.TestName;
+
+import java.io.File;
+import java.io.IOException;
+import java.time.Duration;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.LinkedList;
+import java.util.List;
+import java.util.Objects;
+import java.util.Properties;
+import java.util.concurrent.Semaphore;
+import java.util.concurrent.TimeUnit;
+import java.util.concurrent.atomic.AtomicInteger;
+import java.util.stream.Collectors;
+import java.util.stream.IntStream;
+
+import static
org.apache.kafka.streams.integration.utils.IntegrationTestUtils.getStore;
+import static
org.apache.kafka.streams.integration.utils.IntegrationTestUtils.safeUniqueTestName;
+import static
org.apache.kafka.streams.integration.utils.IntegrationTestUtils.startApplicationAndWaitUntilRunning;
+import static org.apache.kafka.streams.state.QueryableStoreTypes.keyValueStore;
+import static org.hamcrest.MatcherAssert.assertThat;
+import static org.hamcrest.Matchers.equalTo;
+import static org.hamcrest.Matchers.hasEntry;
+import static org.hamcrest.Matchers.is;
+import static org.hamcrest.Matchers.notNullValue;
+
+@Category({IntegrationTest.class})
+public class ConsistencyVectorIntegrationTest {
+
+private static final int NUM_BROKERS = 1;
+private static int port = 0;
+private static final String INPUT_TOPIC_NAME = "input-topic";
+private static final String TABLE_NAME = "source-table";
+
+public final EmbeddedKafkaCluster cluster = new
EmbeddedKafkaCluster(NUM_BROKERS);
+
+@Rule
+public TestName testName = new TestName();
+
+private final List streamsToCleanup = new ArrayList<>();
+private final MockTime mockTime = cluster.time;
+
+@Before
+public void before() throws InterruptedException, IOException {
+cluster.start();
+cluster.createTopic(INPUT_TOPIC_NAME, 2, 1);
+}
+
+@After
+public void after() {
+for (final KafkaStreams kafkaStreams : streamsToCleanup) {
+kafkaStreams.close();
+}
+cluster.stop();
+}
+
+@Test
+public void shouldHaveSamePositionBoundActiveAndStandBy() throws Exception
{
+final int batch1NumMessages = 100;
Review comment:
I updated the test to check that it sees the last record of the batch in
the standby store
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use
[GitHub] [kafka] cadonna opened a new pull request #11574: MINOR: Fix internal topic manager tests
cadonna opened a new pull request #11574: URL: https://github.com/apache/kafka/pull/11574 When the unit tests of the internal topic manager test are executed on a slow machine (like sometimes in automatic builds) they sometimes fail with a timeout exception instead of the expected exception. To fix this behavior, this commit replaces the use of system time with mock time. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-13077) Replication failing after unclean shutdown of ZK and all brokers
[
https://issues.apache.org/jira/browse/KAFKA-13077?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17454611#comment-17454611
]
Shivakumar Kedlaya edited comment on KAFKA-13077 at 12/7/21, 12:05 PM:
---
[~causton] we have a similar issue in our cluster
did you get any temporary solution as of now?
[~junrao] can you please support us here
was (Author: shivakumar):
[~causton] we have a similar issue in our cluster
did you get any temporary solution as of now?
[~junrao] could you please support here
> Replication failing after unclean shutdown of ZK and all brokers
>
>
> Key: KAFKA-13077
> URL: https://issues.apache.org/jira/browse/KAFKA-13077
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 2.8.0
>Reporter: Christopher Auston
>Priority: Minor
>
> I am submitting this in the spirit of what can go wrong when an operator
> violates the constraints Kafka depends on. I don't know if Kafka could or
> should handle this more gracefully. I decided to file this issue because it
> was easy to get the problem I'm reporting with Kubernetes StatefulSets (STS).
> By "easy" I mean that I did not go out of my way to corrupt anything, I just
> was not careful when restarting ZK and brokers.
> I violated the constraints of keeping Zookeeper stable and at least one
> running in-sync replica.
> I am running the bitnami/kafka helm chart on Amazon EKS.
> {quote}% kubectl get po kaf-kafka-0 -ojson |jq .spec.containers'[].image'
> "docker.io/bitnami/kafka:2.8.0-debian-10-r43"
> {quote}
> I started with 3 ZK instances and 3 brokers (both STS). I changed the
> cpu/memory requests on both STS and kubernetes proceeded to restart ZK and
> kafka instances at the same time. If I recall correctly there were some
> crashes and several restarts but eventually all the instances were running
> again. It's possible all ZK nodes and all brokers were unavailable at various
> points.
> The problem I noticed was that two of the brokers were just continually
> spitting out messages like:
> {quote}% kubectl logs kaf-kafka-0 --tail 10
> [2021-07-13 14:26:08,871] INFO [ProducerStateManager
> partition=__transaction_state-0] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-0/0001.snapshot,1)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,871] WARN [Log partition=__transaction_state-0,
> dir=/bitnami/kafka/data] *Non-monotonic update of high watermark from
> (offset=2744 segment=[0:1048644]) to (offset=1 segment=[0:169])*
> (kafka.log.Log)
> [2021-07-13 14:26:08,874] INFO [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Truncating to offset 2 (kafka.log.Log)
> [2021-07-13 14:26:08,877] INFO [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Loading producer state till offset 2 with message
> format version 2 (kafka.log.Log)
> [2021-07-13 14:26:08,877] INFO [ProducerStateManager
> partition=__transaction_state-10] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-10/0002.snapshot,2)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,877] WARN [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Non-monotonic update of high watermark from
> (offset=2930 segment=[0:1048717]) to (offset=2 segment=[0:338])
> (kafka.log.Log)
> [2021-07-13 14:26:08,880] INFO [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Truncating to offset 1 (kafka.log.Log)
> [2021-07-13 14:26:08,882] INFO [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Loading producer state till offset 1 with message
> format version 2 (kafka.log.Log)
> [2021-07-13 14:26:08,882] INFO [ProducerStateManager
> partition=__transaction_state-20] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-20/0001.snapshot,1)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,883] WARN [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Non-monotonic update of high watermark from
> (offset=2956 segment=[0:1048608]) to (offset=1 segment=[0:169])
> (kafka.log.Log)
> {quote}
> If I describe that topic I can see that several partitions have a leader of 2
> and the ISR is just 2 (NOTE I added two more brokers and tried to reassign
> the topic onto brokers 2,3,4 which you can see below). The new brokers also
> spit out the messages about "non-monotonic update" just like the original
> followers. This describe output is from the following day.
> {{% kafka-topics.sh ${=BS} -topic __transaction_state -describe}}
> {{Topic: __transaction_state TopicId: i7bBNCeuQMWl-ZMpzrnMAw PartitionCount:
> 50 ReplicationFactor: 3 Configs:
>
[jira] [Comment Edited] (KAFKA-13077) Replication failing after unclean shutdown of ZK and all brokers
[
https://issues.apache.org/jira/browse/KAFKA-13077?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17454611#comment-17454611
]
Shivakumar Kedlaya edited comment on KAFKA-13077 at 12/7/21, 12:03 PM:
---
[~causton] we have a similar issue in our cluster
did you get any temporary solution as of now?
[~junrao] could you please support here
was (Author: shivakumar):
[~causton] we have a similar issue in our cluster
did you get any temporary solution as of now?
> Replication failing after unclean shutdown of ZK and all brokers
>
>
> Key: KAFKA-13077
> URL: https://issues.apache.org/jira/browse/KAFKA-13077
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 2.8.0
>Reporter: Christopher Auston
>Priority: Minor
>
> I am submitting this in the spirit of what can go wrong when an operator
> violates the constraints Kafka depends on. I don't know if Kafka could or
> should handle this more gracefully. I decided to file this issue because it
> was easy to get the problem I'm reporting with Kubernetes StatefulSets (STS).
> By "easy" I mean that I did not go out of my way to corrupt anything, I just
> was not careful when restarting ZK and brokers.
> I violated the constraints of keeping Zookeeper stable and at least one
> running in-sync replica.
> I am running the bitnami/kafka helm chart on Amazon EKS.
> {quote}% kubectl get po kaf-kafka-0 -ojson |jq .spec.containers'[].image'
> "docker.io/bitnami/kafka:2.8.0-debian-10-r43"
> {quote}
> I started with 3 ZK instances and 3 brokers (both STS). I changed the
> cpu/memory requests on both STS and kubernetes proceeded to restart ZK and
> kafka instances at the same time. If I recall correctly there were some
> crashes and several restarts but eventually all the instances were running
> again. It's possible all ZK nodes and all brokers were unavailable at various
> points.
> The problem I noticed was that two of the brokers were just continually
> spitting out messages like:
> {quote}% kubectl logs kaf-kafka-0 --tail 10
> [2021-07-13 14:26:08,871] INFO [ProducerStateManager
> partition=__transaction_state-0] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-0/0001.snapshot,1)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,871] WARN [Log partition=__transaction_state-0,
> dir=/bitnami/kafka/data] *Non-monotonic update of high watermark from
> (offset=2744 segment=[0:1048644]) to (offset=1 segment=[0:169])*
> (kafka.log.Log)
> [2021-07-13 14:26:08,874] INFO [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Truncating to offset 2 (kafka.log.Log)
> [2021-07-13 14:26:08,877] INFO [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Loading producer state till offset 2 with message
> format version 2 (kafka.log.Log)
> [2021-07-13 14:26:08,877] INFO [ProducerStateManager
> partition=__transaction_state-10] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-10/0002.snapshot,2)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,877] WARN [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Non-monotonic update of high watermark from
> (offset=2930 segment=[0:1048717]) to (offset=2 segment=[0:338])
> (kafka.log.Log)
> [2021-07-13 14:26:08,880] INFO [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Truncating to offset 1 (kafka.log.Log)
> [2021-07-13 14:26:08,882] INFO [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Loading producer state till offset 1 with message
> format version 2 (kafka.log.Log)
> [2021-07-13 14:26:08,882] INFO [ProducerStateManager
> partition=__transaction_state-20] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-20/0001.snapshot,1)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,883] WARN [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Non-monotonic update of high watermark from
> (offset=2956 segment=[0:1048608]) to (offset=1 segment=[0:169])
> (kafka.log.Log)
> {quote}
> If I describe that topic I can see that several partitions have a leader of 2
> and the ISR is just 2 (NOTE I added two more brokers and tried to reassign
> the topic onto brokers 2,3,4 which you can see below). The new brokers also
> spit out the messages about "non-monotonic update" just like the original
> followers. This describe output is from the following day.
> {{% kafka-topics.sh ${=BS} -topic __transaction_state -describe}}
> {{Topic: __transaction_state TopicId: i7bBNCeuQMWl-ZMpzrnMAw PartitionCount:
> 50 ReplicationFactor: 3 Configs:
>
[GitHub] [kafka] tamara-skokova opened a new pull request #11573: KAFKA-13507: GlobalProcessor ignores user specified names
tamara-skokova opened a new pull request #11573: URL: https://github.com/apache/kafka/pull/11573 Use the name specified via `consumed` parameter in `InternalStreamsBuilder#addGlobalStore` method for initializing the source name and processor name. If not specified, the names are generated. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-13077) Replication failing after unclean shutdown of ZK and all brokers
[
https://issues.apache.org/jira/browse/KAFKA-13077?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17454611#comment-17454611
]
Shivakumar Kedlaya commented on KAFKA-13077:
[~causton] we have a similar issue in our cluster
did you get any temporary solution as of now?
> Replication failing after unclean shutdown of ZK and all brokers
>
>
> Key: KAFKA-13077
> URL: https://issues.apache.org/jira/browse/KAFKA-13077
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 2.8.0
>Reporter: Christopher Auston
>Priority: Minor
>
> I am submitting this in the spirit of what can go wrong when an operator
> violates the constraints Kafka depends on. I don't know if Kafka could or
> should handle this more gracefully. I decided to file this issue because it
> was easy to get the problem I'm reporting with Kubernetes StatefulSets (STS).
> By "easy" I mean that I did not go out of my way to corrupt anything, I just
> was not careful when restarting ZK and brokers.
> I violated the constraints of keeping Zookeeper stable and at least one
> running in-sync replica.
> I am running the bitnami/kafka helm chart on Amazon EKS.
> {quote}% kubectl get po kaf-kafka-0 -ojson |jq .spec.containers'[].image'
> "docker.io/bitnami/kafka:2.8.0-debian-10-r43"
> {quote}
> I started with 3 ZK instances and 3 brokers (both STS). I changed the
> cpu/memory requests on both STS and kubernetes proceeded to restart ZK and
> kafka instances at the same time. If I recall correctly there were some
> crashes and several restarts but eventually all the instances were running
> again. It's possible all ZK nodes and all brokers were unavailable at various
> points.
> The problem I noticed was that two of the brokers were just continually
> spitting out messages like:
> {quote}% kubectl logs kaf-kafka-0 --tail 10
> [2021-07-13 14:26:08,871] INFO [ProducerStateManager
> partition=__transaction_state-0] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-0/0001.snapshot,1)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,871] WARN [Log partition=__transaction_state-0,
> dir=/bitnami/kafka/data] *Non-monotonic update of high watermark from
> (offset=2744 segment=[0:1048644]) to (offset=1 segment=[0:169])*
> (kafka.log.Log)
> [2021-07-13 14:26:08,874] INFO [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Truncating to offset 2 (kafka.log.Log)
> [2021-07-13 14:26:08,877] INFO [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Loading producer state till offset 2 with message
> format version 2 (kafka.log.Log)
> [2021-07-13 14:26:08,877] INFO [ProducerStateManager
> partition=__transaction_state-10] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-10/0002.snapshot,2)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,877] WARN [Log partition=__transaction_state-10,
> dir=/bitnami/kafka/data] Non-monotonic update of high watermark from
> (offset=2930 segment=[0:1048717]) to (offset=2 segment=[0:338])
> (kafka.log.Log)
> [2021-07-13 14:26:08,880] INFO [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Truncating to offset 1 (kafka.log.Log)
> [2021-07-13 14:26:08,882] INFO [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Loading producer state till offset 1 with message
> format version 2 (kafka.log.Log)
> [2021-07-13 14:26:08,882] INFO [ProducerStateManager
> partition=__transaction_state-20] Loading producer state from snapshot file
> 'SnapshotFile(/bitnami/kafka/data/__transaction_state-20/0001.snapshot,1)'
> (kafka.log.ProducerStateManager)
> [2021-07-13 14:26:08,883] WARN [Log partition=__transaction_state-20,
> dir=/bitnami/kafka/data] Non-monotonic update of high watermark from
> (offset=2956 segment=[0:1048608]) to (offset=1 segment=[0:169])
> (kafka.log.Log)
> {quote}
> If I describe that topic I can see that several partitions have a leader of 2
> and the ISR is just 2 (NOTE I added two more brokers and tried to reassign
> the topic onto brokers 2,3,4 which you can see below). The new brokers also
> spit out the messages about "non-monotonic update" just like the original
> followers. This describe output is from the following day.
> {{% kafka-topics.sh ${=BS} -topic __transaction_state -describe}}
> {{Topic: __transaction_state TopicId: i7bBNCeuQMWl-ZMpzrnMAw PartitionCount:
> 50 ReplicationFactor: 3 Configs:
> compression.type=uncompressed,min.insync.replicas=3,cleanup.policy=compact,flush.ms=1000,segment.bytes=104857600,flush.messages=1,max.message.bytes=112,unclean.leader.election.enable=false,retention.bytes=1073741824}}
> {{ Topic: __transaction_state
[GitHub] [kafka] mimaison opened a new pull request #11572: KAFKA-13510: Connect APIs to list all connector plugins and retrieve …
mimaison opened a new pull request #11572: URL: https://github.com/apache/kafka/pull/11572 …their configdefs Implements KIP-769 ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-13510) KIP-769: Connect APIs to list all connector plugins and retrieve their configuration definitions
Mickael Maison created KAFKA-13510: -- Summary: KIP-769: Connect APIs to list all connector plugins and retrieve their configuration definitions Key: KAFKA-13510 URL: https://issues.apache.org/jira/browse/KAFKA-13510 Project: Kafka Issue Type: Bug Reporter: Mickael Maison Assignee: Mickael Maison -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [kafka] patrickstuedi commented on a change in pull request #11513: feat: Write and restore position to/from changelog
patrickstuedi commented on a change in pull request #11513:
URL: https://github.com/apache/kafka/pull/11513#discussion_r763810277
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ChangelogRecordDeserializationHelper.java
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.processor.internals;
+
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.header.Header;
+import org.apache.kafka.common.header.internals.RecordHeader;
+import org.apache.kafka.streams.errors.StreamsException;
+import org.apache.kafka.streams.query.Position;
+import org.apache.kafka.streams.state.internals.PositionSerde;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.nio.ByteBuffer;
+
+/**
+ * Changelog records without any headers are considered old format.
+ * New format changelog records will have a version in their headers.
+ * Version 0: This indicates that the changelog records have consistency
information.
+ */
+public class ChangelogRecordDeserializationHelper {
+public static final Logger log =
LoggerFactory.getLogger(ChangelogRecordDeserializationHelper.class);
+private static final byte[] V_0_CHANGELOG_VERSION_HEADER_VALUE = {(byte)
0};
+public static final String CHANGELOG_VERSION_HEADER_KEY = "v";
+public static final String CHANGELOG_POSITION_HEADER_KEY = "c";
+public static final RecordHeader
CHANGELOG_VERSION_HEADER_RECORD_CONSISTENCY = new RecordHeader(
+CHANGELOG_VERSION_HEADER_KEY, V_0_CHANGELOG_VERSION_HEADER_VALUE);
+
+public static Position applyChecksAndUpdatePosition(
+final ConsumerRecord record,
+final boolean consistencyEnabled,
+final Position position
+) {
+Position restoredPosition = Position.emptyPosition();
+if (!consistencyEnabled) {
Review comment:
nit: creating restoredPosition is not required if !constinceyEnabled
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] itweixiang commented on a change in pull request #9902: KAFKA-12193: Re-resolve IPs after a client disconnects
itweixiang commented on a change in pull request #9902:
URL: https://github.com/apache/kafka/pull/9902#discussion_r763795681
##
File path: clients/src/test/java/org/apache/kafka/clients/NetworkClientTest.java
##
@@ -81,6 +85,19 @@
private final NetworkClient clientWithNoExponentialBackoff =
createNetworkClient(reconnectBackoffMsTest);
private final NetworkClient clientWithStaticNodes =
createNetworkClientWithStaticNodes();
private final NetworkClient clientWithNoVersionDiscovery =
createNetworkClientWithNoVersionDiscovery();
+private ArrayList initialAddresses = new
ArrayList<>(Arrays.asList(
Review comment:
hi bob-barrett , I hava a quetion about your issue ,can you help me ?
our kafka are deloying in k8s , where kafka cluster restart , result in
producer and consumer will disconnect.
kafka cluster restart will generate new ips, but kafka client store old ips
. so we must restart producer and consumer , so tired.
in kafka client 2.8.1 version ,I see
org.apache.kafka.clients.NetworkClient#initiateConnect , `node.host()` maybe
return a ip instead of domain. if return a ip , will result in lose efficacy
about your updated version .
my english level is match awful , can you know my words?
```
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
try {
connectionStates.connecting(nodeConnectionId, now, node.host(),
clientDnsLookup);
InetAddress address =
connectionStates.currentAddress(nodeConnectionId);
log.debug("Initiating connection to node {} using address {}",
node, address);
selector.connect(nodeConnectionId,
new InetSocketAddress(address, node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
} catch (IOException e) {
log.warn("Error connecting to node {}", node, e);
// Attempt failed, we'll try again after the backoff
connectionStates.disconnected(nodeConnectionId, now);
// Notify metadata updater of the connection failure
metadataUpdater.handleServerDisconnect(now, nodeConnectionId,
Optional.empty());
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] itweixiang commented on pull request #9902: KAFKA-12193: Re-resolve IPs after a client disconnects
itweixiang commented on pull request #9902:
URL: https://github.com/apache/kafka/pull/9902#issuecomment-987738907
hi bob-barrett , I hava a quetion about your issue ,can you help me ?
our kafka are deloying in k8s , where kafka cluster restart , result in
producer and consumer will disconnect.
kafka cluster restart will generate new ips, but kafka client store old ips
. so we must restart producer and consumer , so tired.
in kafka client 2.8.1 version ,I see
org.apache.kafka.clients.NetworkClient#initiateConnect , `node.host()` maybe
return a ip instead of domain. if return a ip , will result in lose efficacy
about your updated version .
my english level is match awful , can you know my words?
```
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
try {
connectionStates.connecting(nodeConnectionId, now, node.host(),
clientDnsLookup);
InetAddress address =
connectionStates.currentAddress(nodeConnectionId);
log.debug("Initiating connection to node {} using address {}",
node, address);
selector.connect(nodeConnectionId,
new InetSocketAddress(address, node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
} catch (IOException e) {
log.warn("Error connecting to node {}", node, e);
// Attempt failed, we'll try again after the backoff
connectionStates.disconnected(nodeConnectionId, now);
// Notify metadata updater of the connection failure
metadataUpdater.handleServerDisconnect(now, nodeConnectionId,
Optional.empty());
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] xuchenxin commented on pull request #9902: KAFKA-12193: Re-resolve IPs after a client disconnects
xuchenxin commented on pull request #9902: URL: https://github.com/apache/kafka/pull/9902#issuecomment-987730869 您好,我已收到您的来信,会尽快回复。谢谢! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] itweixiang commented on a change in pull request #9902: KAFKA-12193: Re-resolve IPs after a client disconnects
itweixiang commented on a change in pull request #9902:
URL: https://github.com/apache/kafka/pull/9902#discussion_r763795681
##
File path: clients/src/test/java/org/apache/kafka/clients/NetworkClientTest.java
##
@@ -81,6 +85,19 @@
private final NetworkClient clientWithNoExponentialBackoff =
createNetworkClient(reconnectBackoffMsTest);
private final NetworkClient clientWithStaticNodes =
createNetworkClientWithStaticNodes();
private final NetworkClient clientWithNoVersionDiscovery =
createNetworkClientWithNoVersionDiscovery();
+private ArrayList initialAddresses = new
ArrayList<>(Arrays.asList(
Review comment:
hi bob-barrett , I hava a quetion about your issue ,can you help me ?
our kafka are deloying in k8s , where kafka cluster restart , result in
producer and consumer will disconnect.
kafka cluster restart will generate new ips, but kafka client store old ips
. so we must restart producer and consumer , so tired.
in kafka client 2.8.1 version ,I see
org.apache.kafka.clients.NetworkClient#initiateConnect , `node.host()` maybe
return a ip instead of domain. if return a ip , will result in lose efficacy
about your updated version .
my english level is match awful , can you know my words?
```
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
try {
connectionStates.connecting(nodeConnectionId, now, node.host(),
clientDnsLookup);
InetAddress address =
connectionStates.currentAddress(nodeConnectionId);
log.debug("Initiating connection to node {} using address {}",
node, address);
selector.connect(nodeConnectionId,
new InetSocketAddress(address, node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
} catch (IOException e) {
log.warn("Error connecting to node {}", node, e);
// Attempt failed, we'll try again after the backoff
connectionStates.disconnected(nodeConnectionId, now);
// Notify metadata updater of the connection failure
metadataUpdater.handleServerDisconnect(now, nodeConnectionId,
Optional.empty());
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dengziming commented on a change in pull request #11173: KAFKA-13509: Support max timestamp in GetOffsetShell
dengziming commented on a change in pull request #11173:
URL: https://github.com/apache/kafka/pull/11173#discussion_r763752790
##
File path: core/src/main/scala/kafka/tools/GetOffsetShell.scala
##
@@ -72,10 +73,10 @@ object GetOffsetShell {
.ofType(classOf[String])
val timeOpt = parser.accepts("time", "timestamp of the offsets before
that. [Note: No offset is returned, if the timestamp greater than recently
committed record timestamp is given.]")
.withRequiredArg
- .describedAs("timestamp/-1(latest)/-2(earliest)")
+
.describedAs("timestamp/-1(latest)/-2(earliest)/-3(max timestamp)")
.ofType(classOf[java.lang.Long])
.defaultsTo(-1L)
-val commandConfigOpt = parser.accepts("command-config", s"Property file
containing configs to be passed to Consumer Client.")
+val commandConfigOpt = parser.accepts("command-config", s"Property file
containing configs to be passed to Admin Client.")
Review comment:
@showuon , Thank you for your remainders, I inspected
`AdminClientConfig` carefully and I found the only config not presented in
`ConsumerConfig` is `RETRIES_CONFIG`, and those consumer configs which can't
work with admin config will be ignored. So, fortunately, this change is
backward compatible thanks to the good design of `KafkaConfig`.
`RETRIES_CONFIG` is a new config for `GetOffsetShell`, but I don't think we
would need a KIP for this change though, It's better to add this as an addendum
to KIP-734 since they are related.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on a change in pull request #11173: KAFKA-13509: Support max timestamp in GetOffsetShell
showuon commented on a change in pull request #11173:
URL: https://github.com/apache/kafka/pull/11173#discussion_r763706440
##
File path: core/src/main/scala/kafka/tools/GetOffsetShell.scala
##
@@ -72,10 +73,10 @@ object GetOffsetShell {
.ofType(classOf[String])
val timeOpt = parser.accepts("time", "timestamp of the offsets before
that. [Note: No offset is returned, if the timestamp greater than recently
committed record timestamp is given.]")
.withRequiredArg
- .describedAs("timestamp/-1(latest)/-2(earliest)")
+
.describedAs("timestamp/-1(latest)/-2(earliest)/-3(max timestamp)")
.ofType(classOf[java.lang.Long])
.defaultsTo(-1L)
-val commandConfigOpt = parser.accepts("command-config", s"Property file
containing configs to be passed to Consumer Client.")
+val commandConfigOpt = parser.accepts("command-config", s"Property file
containing configs to be passed to Admin Client.")
Review comment:
@dengziming , I think it is OK to extend the KIP-734 without another KIP
to support max timestamp in `GetOffsetShell`. And, it's good. But I don't think
changing the `commandConfigOpt` from `Consumer client` into `Admin client`
doesn't need KIP to address it. It'll cause backward compatibility issue
because some some consumer configs won't work in admin config obviously.
If the change from using `Consumer` into `AdminClient` is necessary (I think
it's necessary because KIP-734 added the max timestamp support in
`AdminClient`), I think you should have a KIP, to let everyone knows this is
the change (and why we need it) that will break backward compatibility.
@dajac , what do you think?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org