[Lldb-commits] [lldb] [LLDB][SaveCore] Add SBCoreDumpOptions Object, and SBProcess::SaveCore() overload (PR #98403)
https://github.com/Jlalond unassigned https://github.com/llvm/llvm-project/pull/98403 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][SaveCore] Add SBCoreDumpOptions Object, and SBProcess::SaveCore() overload (PR #98403)
https://github.com/Jlalond unassigned https://github.com/llvm/llvm-project/pull/98403 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][SaveCore] Add SBCoreDumpOptions Object, and SBProcess::SaveCore() overload (PR #98403)
https://github.com/Jlalond unassigned https://github.com/llvm/llvm-project/pull/98403 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][SaveCore] Add SBCoreDumpOptions Object, and SBProcess::SaveCore() overload (PR #98403)
Jlalond wrote: > > None of the SB API methods return any STL types/containers, like the > > std::optionals returned in this PR. I worry if this will make the bridging > > to other languages more complicated, but it's never something I've thought > > about before. @jimingham @bulbazord @clayborg @JDevlieghere may have a more > > informed opinion on whether this is important or not. > > Yeah, we've been discussing introducing an `SBOptional` type at some point to > be easier to bridge it with python but we should refrain from using the STL > as return types / arguments for now. > > Besides that, I've also noticed that your classes are named `CoreDumpOption`. > On Apple platform, we call these "corefiles" so to be consistent accros > various platform, lets just drop the "Dump" part from the class / method > names and call it `CoreOption` @clayborg actually mentioned this when I started work originally that we should avoid STL types. It seems I forgot while figuring out SWIG. As for `CoreOptions` vs `CoreDumpOptions`, the primary flavors I know of are Window's Kernel/Minidump and the ELF Coredumps. I think `CoreDumpOptions` is less ambiguous for that reason https://github.com/llvm/llvm-project/pull/98403 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/97470
>From 8647eccd35085ab80f978fabb78b016915c5524f Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/8] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId) > 0) {
+ // We only cast to avoid the warning around converting little endian in
printf.
+ error.SetErrorStringWithFormat("duplicate exception stream for tid %"
PRIu32, (uint32_t)exception_stream.ThreadId);
+ return error;
+} else
+ m_exceptions_by_tid[exception_stream.ThreadId] = exception_stream;
+
+
+std::cout << "Adding Exception Stream # " <<
(uint32_t)exception_stream.ThreadId << std::endl;
+std::cout << "Added index " <<
(uint32_t)m_exceptions_by_tid[exception_stream.ThreadId].ExceptionRecord.ExceptionCode
<< std::endl;
+ }
SetUnixSignals(UnixSignals::Create(GetArchitecture()));
@@ -232,60 +245,59 @@ Status
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/97470
>From 8647eccd35085ab80f978fabb78b016915c5524f Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/7] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId) > 0) {
+ // We only cast to avoid the warning around converting little endian in
printf.
+ error.SetErrorStringWithFormat("duplicate exception stream for tid %"
PRIu32, (uint32_t)exception_stream.ThreadId);
+ return error;
+} else
+ m_exceptions_by_tid[exception_stream.ThreadId] = exception_stream;
+
+
+std::cout << "Adding Exception Stream # " <<
(uint32_t)exception_stream.ThreadId << std::endl;
+std::cout << "Added index " <<
(uint32_t)m_exceptions_by_tid[exception_stream.ThreadId].ExceptionRecord.ExceptionCode
<< std::endl;
+ }
SetUnixSignals(UnixSignals::Create(GetArchitecture()));
@@ -232,60 +245,59 @@ Status
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
@@ -82,15 +82,24 @@ class MinidumpFile : public Binary {
return getListStream(minidump::StreamType::ThreadList);
}
- /// Returns the contents of the Exception stream. An error is returned if
the
- /// file does not contain this stream, or the stream is smaller than the size
- /// of the ExceptionStream structure. The internal consistency of the stream
- /// is not checked in any way.
- Expected getExceptionStream() const {
-return getStream(
-minidump::StreamType::Exception);
+ /// Returns the contents of the Exception stream. An error is returned if the
+ /// associated stream is smaller than the size of the ExceptionStream
+ /// structure. Or the directory supplied is not of kind exception stream.
+ Expected
+ getExceptionStream(minidump::Directory Directory) const {
+if (Directory.Type != minidump::StreamType::Exception) {
+ return createError("Not an exception stream");
+}
+
+return getStreamFromDirectory(Directory);
Jlalond wrote:
Fixed.
https://github.com/llvm/llvm-project/pull/97470
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
@@ -109,7 +109,7 @@ class ProcessMinidump : public PostMortemProcess {
private:
lldb::DataBufferSP m_core_data;
llvm::ArrayRef m_thread_list;
- const minidump::ExceptionStream *m_active_exception;
+ std::unordered_map m_exceptions_by_tid;
Jlalond wrote:
This will expose my noviceness in C++, but I struggled that you can't emplace a
list of references, so instead I refactored this to return a vector of const
pointers.
https://github.com/llvm/llvm-project/pull/97470
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
@@ -82,15 +82,24 @@ class MinidumpFile : public Binary {
return getListStream(minidump::StreamType::ThreadList);
}
- /// Returns the contents of the Exception stream. An error is returned if
the
- /// file does not contain this stream, or the stream is smaller than the size
- /// of the ExceptionStream structure. The internal consistency of the stream
- /// is not checked in any way.
- Expected getExceptionStream() const {
-return getStream(
-minidump::StreamType::Exception);
+ /// Returns the contents of the Exception stream. An error is returned if the
+ /// associated stream is smaller than the size of the ExceptionStream
+ /// structure. Or the directory supplied is not of kind exception stream.
+ Expected
+ getExceptionStream(minidump::Directory Directory) const {
+if (Directory.Type != minidump::StreamType::Exception) {
+ return createError("Not an exception stream");
+}
+
+return getStreamFromDirectory(Directory);
}
+ /// Returns the contents of the Exception streams. An error is returned if
+ /// any of the streams are smaller than the size of the ExceptionStream
+ /// structure. The internal consistency of the stream is not checked in any
+ /// way.
+ Expected> getExceptionStreams() const;
Jlalond wrote:
I decided against this for Minidump.h because the existing API's expose
`Expected`, for the Minidumparser I used optional upon your recommendation
https://github.com/llvm/llvm-project/pull/97470
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
Jlalond wrote: > > @jeffreytan81 I think the callout for multiple exception is a good > > question. I made a C# testbed to see what would happen if I had multiple > > simultaneous exceptions. [Gist > > here](https://gist.github.com/Jlalond/467bc990f10fbb75cc9ca7db897a7beb). > > When manually collecting a minidump on my Windows system and then viewing > > it, I do get a warning that my application has multiple exceptions. > >  > > This leads me to believe multiple exceptions is acceptable, albeit rare. > > That's good to know, but this is still an indirectly way to check. We would > feel much convinced if you can copy the minidump generated by lldb to Windows > and give windbg or Visual Studio a try. Okay, I took the same program and then collected a dump with LLDB. As this was .net, we have an issue not collecting information about private core lib or the windows OS version, so Visual studio does encounter some issue. However I can still enter managed debug and see the exception objects on every thread. https://github.com/llvm/llvm-project/pull/97470 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/97470
>From dc4730dcff31c2c9212d2ce5412ecb8a9f4d83c0 Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/6] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId) > 0) {
+ // We only cast to avoid the warning around converting little endian in
printf.
+ error.SetErrorStringWithFormat("duplicate exception stream for tid %"
PRIu32, (uint32_t)exception_stream.ThreadId);
+ return error;
+} else
+ m_exceptions_by_tid[exception_stream.ThreadId] = exception_stream;
+
+
+std::cout << "Adding Exception Stream # " <<
(uint32_t)exception_stream.ThreadId << std::endl;
+std::cout << "Added index " <<
(uint32_t)m_exceptions_by_tid[exception_stream.ThreadId].ExceptionRecord.ExceptionCode
<< std::endl;
+ }
SetUnixSignals(UnixSignals::Create(GetArchitecture()));
@@ -232,60 +245,59 @@ Status
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
Jlalond wrote: @jeffreytan81 I think the callout for multiple exception is a good question. I made a C# testbed to see what would happen if I had multiple simultaneous exceptions. [Gist here](https://gist.github.com/Jlalond/467bc990f10fbb75cc9ca7db897a7beb). When manually collecting a minidump on my Windows system and then viewing it, I do get a warning that my application has multiple exceptions. 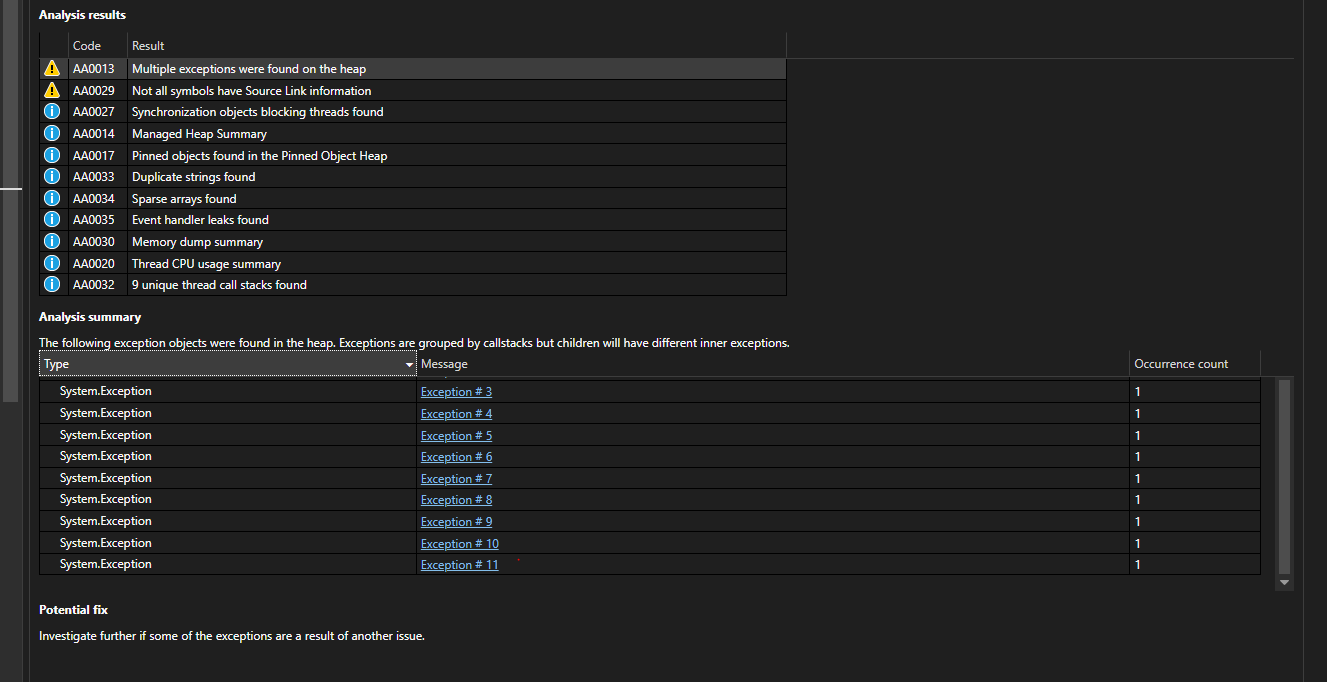 This leads me to believe multiple exceptions is acceptable, albeit rare. https://github.com/llvm/llvm-project/pull/97470 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/97470 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/97470
>From dc4730dcff31c2c9212d2ce5412ecb8a9f4d83c0 Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/5] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId) > 0) {
+ // We only cast to avoid the warning around converting little endian in
printf.
+ error.SetErrorStringWithFormat("duplicate exception stream for tid %"
PRIu32, (uint32_t)exception_stream.ThreadId);
+ return error;
+} else
+ m_exceptions_by_tid[exception_stream.ThreadId] = exception_stream;
+
+
+std::cout << "Adding Exception Stream # " <<
(uint32_t)exception_stream.ThreadId << std::endl;
+std::cout << "Added index " <<
(uint32_t)m_exceptions_by_tid[exception_stream.ThreadId].ExceptionRecord.ExceptionCode
<< std::endl;
+ }
SetUnixSignals(UnixSignals::Create(GetArchitecture()));
@@ -232,60 +245,59 @@ Status
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/97470 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
@@ -0,0 +1,39 @@ +--- !minidump +Streams: + - Type:ThreadList +Threads: + - Thread Id: 0x1B4F23 +Context: 0B001000330006020100100010A234EBFC7F10A234EBFC7FF09C34EBFC7FC0A91ABCE97FA0163FBCE97F4602921C400030A434EBFC7FC61D40007F03801F0000FF00252525252525252525252525252525250000FF00FF00 +Stack: + Start of Memory Range: 0x7FFFD348 + Content: '' + - Thread Id: 0x1B6D22 +Context:
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond ready_for_review https://github.com/llvm/llvm-project/pull/97470 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/97470
>From e8d1f3a7f978bd3c5767f0b0cacea60146a257f7 Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/4] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId) > 0) {
+ // We only cast to avoid the warning around converting little endian in
printf.
+ error.SetErrorStringWithFormat("duplicate exception stream for tid %"
PRIu32, (uint32_t)exception_stream.ThreadId);
+ return error;
+} else
+ m_exceptions_by_tid[exception_stream.ThreadId] = exception_stream;
+
+
+std::cout << "Adding Exception Stream # " <<
(uint32_t)exception_stream.ThreadId << std::endl;
+std::cout << "Added index " <<
(uint32_t)m_exceptions_by_tid[exception_stream.ThreadId].ExceptionRecord.ExceptionCode
<< std::endl;
+ }
SetUnixSignals(UnixSignals::Create(GetArchitecture()));
@@ -232,60 +245,59 @@ Status
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/97470 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [DRAFT][LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/97470
>From 7e41ca79a09d67ff7bb76a9d95dda4e7ccfdba8b Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/3] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId) > 0) {
+ // We only cast to avoid the warning around converting little endian in
printf.
+ error.SetErrorStringWithFormat("duplicate exception stream for tid %"
PRIu32, (uint32_t)exception_stream.ThreadId);
+ return error;
+} else
+ m_exceptions_by_tid[exception_stream.ThreadId] = exception_stream;
+
+
+std::cout << "Adding Exception Stream # " <<
(uint32_t)exception_stream.ThreadId << std::endl;
+std::cout << "Added index " <<
(uint32_t)m_exceptions_by_tid[exception_stream.ThreadId].ExceptionRecord.ExceptionCode
<< std::endl;
+ }
SetUnixSignals(UnixSignals::Create(GetArchitecture()));
@@ -232,60 +245,59 @@ Status
[Lldb-commits] [lldb] [llvm] [DRAFT][LLDB][Minidump] Support minidumps where there are multiple exception streams (PR #97470)
https://github.com/Jlalond created
https://github.com/llvm/llvm-project/pull/97470
Currently, LLDB assumes all minidumps will have unique sections. This is
intuitive because almost all of the minidump sections are themselves lists.
Exceptions including Signals are unique in that they are all individual
sections with their own directory.
This means LLDB fails to load minidumps with multiple exceptions due to them
not being unique. This behavior is erroneous and this PR introduces support for
an arbitrary number of exception streams. Additionally, stop info was
calculated on for a single thread before, and now we properly support mapping
exceptions to threads.
This PR is starting in DRAFT because implementing testing is still required.
>From 7e41ca79a09d67ff7bb76a9d95dda4e7ccfdba8b Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Tue, 2 Jul 2024 12:41:02 -0700
Subject: [PATCH 1/2] Add support to read multiple exception streams in
minidumps
---
.../Process/minidump/MinidumpParser.cpp | 11 +-
.../Plugins/Process/minidump/MinidumpParser.h | 2 +-
.../Process/minidump/ProcessMinidump.cpp | 122 ++
.../Process/minidump/ProcessMinidump.h| 2 +-
.../Process/minidump/ThreadMinidump.cpp | 14 +-
.../Plugins/Process/minidump/ThreadMinidump.h | 3 +-
.../Process/minidump/MinidumpParserTest.cpp | 11 +-
llvm/include/llvm/Object/Minidump.h | 34 -
llvm/lib/Object/Minidump.cpp | 37 ++
llvm/lib/ObjectYAML/MinidumpYAML.cpp | 4 +-
10 files changed, 162 insertions(+), 78 deletions(-)
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
index be9fae938e227..ac487a5ed0c0a 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.cpp
@@ -408,7 +408,7 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
continue;
}
// This module has been seen. Modules are sometimes mentioned multiple
- // times when they are mapped discontiguously, so find the module with
+ // times when they are mapped discontiguously, so find the module with
// the lowest "base_of_image" and use that as the filtered module.
if (module.BaseOfImage < dup_module->BaseOfImage)
filtered_modules[iter->second] =
@@ -417,14 +417,15 @@ std::vector
MinidumpParser::GetFilteredModuleList() {
return filtered_modules;
}
-const minidump::ExceptionStream *MinidumpParser::GetExceptionStream() {
- auto ExpectedStream = GetMinidumpFile().getExceptionStream();
+const std::vector
MinidumpParser::GetExceptionStreams() {
+ auto ExpectedStream = GetMinidumpFile().getExceptionStreams();
if (ExpectedStream)
-return &*ExpectedStream;
+return ExpectedStream.get();
LLDB_LOG_ERROR(GetLog(LLDBLog::Process), ExpectedStream.takeError(),
"Failed to read minidump exception stream: {0}");
- return nullptr;
+ // return empty on failure.
+ return std::vector();
}
std::optional
diff --git a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
index 050ba086f46f5..e552c7210e330 100644
--- a/lldb/source/Plugins/Process/minidump/MinidumpParser.h
+++ b/lldb/source/Plugins/Process/minidump/MinidumpParser.h
@@ -82,7 +82,7 @@ class MinidumpParser {
// have the same name, it keeps the copy with the lowest load address.
std::vector GetFilteredModuleList();
- const llvm::minidump::ExceptionStream *GetExceptionStream();
+ const std::vector GetExceptionStreams();
std::optional FindMemoryRange(lldb::addr_t addr);
diff --git a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
index 13599f4a1553f..9f707c0d8a7a7 100644
--- a/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
+++ b/lldb/source/Plugins/Process/minidump/ProcessMinidump.cpp
@@ -39,6 +39,7 @@
#include
#include
+#include
using namespace lldb;
using namespace lldb_private;
@@ -157,7 +158,7 @@ ProcessMinidump::ProcessMinidump(lldb::TargetSP target_sp,
const FileSpec _file,
DataBufferSP core_data)
: PostMortemProcess(target_sp, listener_sp, core_file),
- m_core_data(std::move(core_data)), m_active_exception(nullptr),
+ m_core_data(std::move(core_data)),
m_is_wow64(false) {}
ProcessMinidump::~ProcessMinidump() {
@@ -209,7 +210,19 @@ Status ProcessMinidump::DoLoadCore() {
GetTarget().SetArchitecture(arch, true /*set_platform*/);
m_thread_list = m_minidump_parser->GetThreads();
- m_active_exception = m_minidump_parser->GetExceptionStream();
+ std::vector exception_streams =
m_minidump_parser->GetExceptionStreams();
+ for (const auto _stream : exception_streams) {
+if (m_exceptions_by_tid.count(exception_stream.ThreadId)
[Lldb-commits] [lldb] [LLDB] DebugInfoD tests: attempt to fix Fuchsia build (PR #96802)
Jlalond wrote: @petrhosek Is there a way you can help @kevinfrei validate this on Fuschia? https://github.com/llvm/llvm-project/pull/96802 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][Minidump] Change expected directories to the correct type; size_t (PR #96564)
Jlalond wrote: @DavidSpickett We'll be fine with 32b size_t. Directories in minidumps have to all have their offsets be 32b addressable, so if you were to fill the directory list up to the `size_t` max, it would be a corrupted minidump https://github.com/llvm/llvm-project/pull/96564 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][Windows Build]Removed header and validated on new windows machine (PR #96724)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/96724 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Removed header and validated on new windows machine (PR #96724)
https://github.com/Jlalond closed https://github.com/llvm/llvm-project/pull/96724 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Removed header and validated on new windows machine (PR #96724)
Jlalond wrote: Hey @petrhosek @vvereschaka apologies about the delay, I had to get a Windows machine up to validate this. https://github.com/llvm/llvm-project/pull/96724 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Removed header and validated on new windows machine (PR #96724)
https://github.com/Jlalond created https://github.com/llvm/llvm-project/pull/96724  In #95312 uint and `#include ` were introduced. These broke the windows build. I addressed uint in #96564, but include went unfixed. So I acquired myself a windows machine to validate. >From aa9c8fae63f9124c59332cbfd4e84e3e229b1956 Mon Sep 17 00:00:00 2001 From: Jacob Lalonde Date: Tue, 25 Jun 2024 20:04:13 -0700 Subject: [PATCH] Removed header and validated on new windows machine --- lldb/source/Plugins/ObjectFile/Minidump/ObjectFileMinidump.cpp | 1 - 1 file changed, 1 deletion(-) diff --git a/lldb/source/Plugins/ObjectFile/Minidump/ObjectFileMinidump.cpp b/lldb/source/Plugins/ObjectFile/Minidump/ObjectFileMinidump.cpp index 3668c37c5191d..7c875aa3223ed 100644 --- a/lldb/source/Plugins/ObjectFile/Minidump/ObjectFileMinidump.cpp +++ b/lldb/source/Plugins/ObjectFile/Minidump/ObjectFileMinidump.cpp @@ -18,7 +18,6 @@ #include "lldb/Utility/Log.h" #include "llvm/Support/FileSystem.h" -#include using namespace lldb; using namespace lldb_private; ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
Jlalond wrote: @petrhosek I am working on this. I think it's only the header thankfully https://github.com/llvm/llvm-project/pull/95312 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
Jlalond wrote: @vvereschaka I'll work on this today. Is it time pressing enough you would want everything reverted? https://github.com/llvm/llvm-project/pull/95312 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][Minidump] Change expected directories to the correct type; size_t (PR #96564)
https://github.com/Jlalond closed https://github.com/llvm/llvm-project/pull/96564 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
Jlalond wrote: Fixed uint issue in #96564 https://github.com/llvm/llvm-project/pull/95312 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][Minidump] Change expected directories to the correct type; size_t (PR #96564)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/96564 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][Minidump] Change expected directories to the correct type; size_t (PR #96564)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/96564 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB][Minidum] Change expected directories to the correct type; size_t (PR #96564)
https://github.com/Jlalond created
https://github.com/llvm/llvm-project/pull/96564
In !95312 I incorrectly set `m_expected_directories` to uint, this broke the
windows build and is the incorrect type.
`size_t` is more accurate because this value only ever represents the expected
upper bound of the directory vector.
>From d675ccf2313d6605c28357029e4a2014a9591dcd Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Mon, 24 Jun 2024 14:51:03 -0700
Subject: [PATCH] Change expected directories to the correct type; size_t
---
lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp | 2 +-
lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.h | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
b/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
index 7a09c6104d08c..de212c6b20da7 100644
--- a/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
+++ b/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
@@ -109,7 +109,7 @@ Status MinidumpFileBuilder::AddDirectory(StreamType type,
if (m_directories.size() + 1 > m_expected_directories) {
error.SetErrorStringWithFormat(
"Unable to add directory for stream type %x, exceeded expected number "
-"of directories %d.",
+"of directories %zu.",
(uint32_t)type, m_expected_directories);
return error;
}
diff --git a/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.h
b/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.h
index b606f925f9912..20564e0661f2a 100644
--- a/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.h
+++ b/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.h
@@ -146,7 +146,7 @@ class MinidumpFileBuilder {
lldb_private::DataBufferHeap m_data;
lldb::ProcessSP m_process_sp;
- uint m_expected_directories = 0;
+ size_t m_expected_directories = 0;
uint64_t m_saved_data_size = 0;
lldb::offset_t m_thread_list_start = 0;
// We set the max write amount to 128 mb, this is arbitrary
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
Jlalond wrote: @petrhosek because it's just going to be a change to something like `size_t`, would you mind if I just did a quick commit to fix this and assign you as the reviewer? https://github.com/llvm/llvm-project/pull/95312 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -791,26 +807,101 @@ void MinidumpFileBuilder::AddLinuxFileStreams(
size_t size = memory_buffer->getBufferSize();
if (size == 0)
continue;
- AddDirectory(stream, size);
+ error = AddDirectory(stream, size);
+ if (error.Fail())
+return error;
m_data.AppendData(memory_buffer->getBufferStart(), size);
}
}
+
+ return error;
}
-Status MinidumpFileBuilder::Dump(lldb::FileUP _file) const {
- constexpr size_t header_size = sizeof(llvm::minidump::Header);
- constexpr size_t directory_size = sizeof(llvm::minidump::Directory);
+Status MinidumpFileBuilder::AddMemoryList(SaveCoreStyle core_style) {
+ Status error;
+
+ // We first save the thread stacks to ensure they fit in the first UINT32_MAX
+ // bytes of the core file. Thread structures in minidump files can only use
+ // 32 bit memory descriptiors, so we emit them first to ensure the memory is
+ // in accessible with a 32 bit offset.
+ Process::CoreFileMemoryRanges ranges_32;
+ Process::CoreFileMemoryRanges ranges_64;
+ error = m_process_sp->CalculateCoreFileSaveRanges(
+ SaveCoreStyle::eSaveCoreStackOnly, ranges_32);
+ if (error.Fail())
+return error;
+ uint64_t total_size =
+ ranges_32.size() * sizeof(llvm::minidump::MemoryDescriptor);
+ std::unordered_set stack_start_addresses;
+ for (const auto _range : ranges_32) {
+stack_start_addresses.insert(core_range.range.start());
+total_size += core_range.range.size();
+ }
+
+ if (total_size >= UINT32_MAX) {
+error.SetErrorStringWithFormat("Unable to write minidump. Stack memory "
+ "exceeds 32b limit. (Num Stacks %zu)",
+ ranges_32.size());
+return error;
+ }
+
+ Process::CoreFileMemoryRanges all_core_memory_ranges;
+ if (core_style != SaveCoreStyle::eSaveCoreStackOnly) {
+error = m_process_sp->CalculateCoreFileSaveRanges(core_style,
+ all_core_memory_ranges);
+if (error.Fail())
+ return error;
+ }
+
+ // After saving the stacks, we start packing as much as we can into 32b.
+ // We apply a generous padding here so that the Directory, MemoryList and
+ // Memory64List sections all begin in 32b addressable space.
+ // Then anything overflow extends into 64b addressable space.
+ total_size +=
+ 256 + (all_core_memory_ranges.size() - stack_start_addresses.size()) *
+sizeof(llvm::minidump::MemoryDescriptor_64);
Jlalond wrote:
This actually works, because we'll never enter the loop unless
`all_core_memory_ranges` is non empty, where total_size will actually be used.
Prior to code review feedback we always called to get memory ranges, even when
it's just stacks, ensuring we would always have at least stacks in
`all_core_memory_ranges`.
I have added the check for empty and an explanation comment as well.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -858,10 +953,247 @@ Status MinidumpFileBuilder::Dump(lldb::FileUP
_file) const {
return error;
}
-size_t MinidumpFileBuilder::GetDirectoriesNum() const {
- return m_directories.size();
+static size_t GetLargestRange(const Process::CoreFileMemoryRanges ) {
+ size_t max_size = 0;
+ for (const auto _range : ranges) {
+max_size = std::max(max_size, core_range.range.size());
+ }
+ return max_size;
}
-size_t MinidumpFileBuilder::GetCurrentDataEndOffset() const {
- return sizeof(llvm::minidump::Header) + m_data.GetByteSize();
+Status MinidumpFileBuilder::AddMemoryList_32(
+ Process::CoreFileMemoryRanges ) {
+ std::vector descriptors;
+ Status error;
+ if (ranges.size() == 0)
+return error;
+
+ Log *log = GetLog(LLDBLog::Object);
+ size_t region_index = 0;
+ auto data_up = std::make_unique(GetLargestRange(ranges), 0);
+ for (const auto _range : ranges) {
+// Take the offset before we write.
+const size_t offset_for_data = GetCurrentDataEndOffset();
+const addr_t addr = core_range.range.start();
+const addr_t size = core_range.range.size();
+const addr_t end = core_range.range.end();
+
+LLDB_LOGF(log,
+ "AddMemoryList %zu/%zu reading memory for region "
+ "(%zu bytes) [%zx, %zx)",
+ region_index, ranges.size(), size, addr, addr + size);
+++region_index;
+
+const size_t bytes_read =
+m_process_sp->ReadMemory(addr, data_up->GetBytes(), size, error);
+if (error.Fail() || bytes_read == 0) {
+ LLDB_LOGF(log, "Failed to read memory region. Bytes read: %zu, error:
%s",
+bytes_read, error.AsCString());
+ // Just skip sections with errors or zero bytes in 32b mode
+ continue;
+} else if (bytes_read != size) {
+ LLDB_LOGF(log, "Memory region at: %zu failed to read %zu bytes", addr,
+size);
+}
+
+MemoryDescriptor descriptor;
+descriptor.StartOfMemoryRange =
+static_cast(addr);
+descriptor.Memory.DataSize =
+static_cast(bytes_read);
+descriptor.Memory.RVA =
+static_cast(offset_for_data);
Jlalond wrote:
Messaged offline, but it doesn't appear all the little endian types support
conversion. Specifically ulittle64_t and ulittle_t for the stream type. I think
we should fix this in a followup, and add a formatter for little endian types.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -858,10 +923,224 @@ Status MinidumpFileBuilder::Dump(lldb::FileUP
_file) const {
return error;
}
-size_t MinidumpFileBuilder::GetDirectoriesNum() const {
- return m_directories.size();
+Status MinidumpFileBuilder::AddMemoryList_32(
+const Process::CoreFileMemoryRanges ) {
+ std::vector descriptors;
+ Status error;
+ Log *log = GetLog(LLDBLog::Object);
+ size_t region_index = 0;
Jlalond wrote:
Done. Albeit the `m_data` buffer that the class uses does get used and then
reallocated when we call `Clear()` in flush to disk. May want to look into
keeping a write index and a range...
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -858,10 +953,247 @@ Status MinidumpFileBuilder::Dump(lldb::FileUP
_file) const {
return error;
}
-size_t MinidumpFileBuilder::GetDirectoriesNum() const {
- return m_directories.size();
+static size_t GetLargestRange(const Process::CoreFileMemoryRanges ) {
+ size_t max_size = 0;
+ for (const auto _range : ranges) {
+max_size = std::max(max_size, core_range.range.size());
+ }
+ return max_size;
}
-size_t MinidumpFileBuilder::GetCurrentDataEndOffset() const {
- return sizeof(llvm::minidump::Header) + m_data.GetByteSize();
+Status MinidumpFileBuilder::AddMemoryList_32(
+ Process::CoreFileMemoryRanges ) {
+ std::vector descriptors;
+ Status error;
+ if (ranges.size() == 0)
+return error;
+
+ Log *log = GetLog(LLDBLog::Object);
+ size_t region_index = 0;
+ auto data_up = std::make_unique(GetLargestRange(ranges), 0);
+ for (const auto _range : ranges) {
+// Take the offset before we write.
+const size_t offset_for_data = GetCurrentDataEndOffset();
+const addr_t addr = core_range.range.start();
+const addr_t size = core_range.range.size();
+const addr_t end = core_range.range.end();
+
+LLDB_LOGF(log,
+ "AddMemoryList %zu/%zu reading memory for region "
+ "(%zu bytes) [%zx, %zx)",
+ region_index, ranges.size(), size, addr, addr + size);
+++region_index;
+
+const size_t bytes_read =
+m_process_sp->ReadMemory(addr, data_up->GetBytes(), size, error);
+if (error.Fail() || bytes_read == 0) {
+ LLDB_LOGF(log, "Failed to read memory region. Bytes read: %zu, error:
%s",
+bytes_read, error.AsCString());
+ // Just skip sections with errors or zero bytes in 32b mode
+ continue;
+} else if (bytes_read != size) {
+ LLDB_LOGF(log, "Memory region at: %zu failed to read %zu bytes", addr,
+size);
+}
+
+MemoryDescriptor descriptor;
+descriptor.StartOfMemoryRange =
+static_cast(addr);
+descriptor.Memory.DataSize =
+static_cast(bytes_read);
+descriptor.Memory.RVA =
+static_cast(offset_for_data);
+descriptors.push_back(descriptor);
+if (m_thread_by_range_end.count(end) > 0)
+ m_thread_by_range_end[end].Stack = descriptor;
+
+// Add the data to the buffer, flush as needed.
+error = AddData(data_up->GetBytes(), bytes_read);
+if (error.Fail())
+ return error;
+ }
+
+ // Add a directory that references this list
+ // With a size of the number of ranges as a 32 bit num
+ // And then the size of all the ranges
+ error = AddDirectory(StreamType::MemoryList,
+ sizeof(llvm::support::ulittle32_t) +
+ descriptors.size() *
+ sizeof(llvm::minidump::MemoryDescriptor));
+ if (error.Fail())
+return error;
+
+ llvm::support::ulittle32_t memory_ranges_num =
+ static_cast(descriptors.size());
Jlalond wrote:
I'm torn on the static casts. I know the little endian support types can
support big endian assignment, but I think the static cast makes it very
explicit that these values have to be little endian
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/95312 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -797,20 +822,75 @@ void MinidumpFileBuilder::AddLinuxFileStreams(
}
}
-Status MinidumpFileBuilder::Dump(lldb::FileUP _file) const {
- constexpr size_t header_size = sizeof(llvm::minidump::Header);
- constexpr size_t directory_size = sizeof(llvm::minidump::Directory);
+Status MinidumpFileBuilder::AddMemory(const ProcessSP _sp,
+ SaveCoreStyle core_style) {
+ Status error;
+
+ Process::CoreFileMemoryRanges ranges_for_memory_list;
+ error = process_sp->CalculateCoreFileSaveRanges(
+ SaveCoreStyle::eSaveCoreStackOnly, ranges_for_memory_list);
+ if (error.Fail()) {
+return error;
+ }
+
+ std::set stack_ranges;
+ for (const auto _range : ranges_for_memory_list) {
+stack_ranges.insert(core_range.range.start());
+ }
Jlalond wrote:
I would say we should error, especially with the reduced stacks since !92002 if
the stacks did exceed 4gb this would be a case where we wouldn't fully be able
to support the user.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -59,39 +68,67 @@ class MinidumpFileBuilder {
// Add ThreadList stream, containing information about all threads running
// at the moment of core saving. Contains information about thread
// contexts.
- lldb_private::Status AddThreadList(const lldb::ProcessSP _sp);
- // Add Exception streams for any threads that stopped with exceptions.
- void AddExceptions(const lldb::ProcessSP _sp);
- // Add MemoryList stream, containing dumps of important memory segments
- lldb_private::Status AddMemoryList(const lldb::ProcessSP _sp,
- lldb::SaveCoreStyle core_style);
// Add MiscInfo stream, mainly providing ProcessId
void AddMiscInfo(const lldb::ProcessSP _sp);
// Add informative files about a Linux process
void AddLinuxFileStreams(const lldb::ProcessSP _sp);
+ // Add Exception streams for any threads that stopped with exceptions.
+ void AddExceptions(const lldb::ProcessSP _sp);
// Dump the prepared data into file. In case of the failure data are
// intact.
- lldb_private::Status Dump(lldb::FileUP _file) const;
- // Returns the current number of directories(streams) that have been so far
- // created. This number of directories will be dumped when calling Dump()
- size_t GetDirectoriesNum() const;
+ lldb_private::Status AddThreadList(const lldb::ProcessSP _sp);
+
+ lldb_private::Status AddMemory(const lldb::ProcessSP _sp,
+ lldb::SaveCoreStyle core_style);
+
+ lldb_private::Status DumpToFile();
Jlalond wrote:
To start, this is not a good name, but we need at least two methods:
- One method to just write data from the buffer to the current end of the file
- One method to finalize and run header/directory cleanup.
When trying to get this done I couldn't come up with a good name, so I am
soliciting ideas. I think going forward some better version could be
`CompleteFile()` `FinalizeFile()` `WriteAndFinish()` but I don't like any of
them
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -59,39 +68,67 @@ class MinidumpFileBuilder {
// Add ThreadList stream, containing information about all threads running
// at the moment of core saving. Contains information about thread
// contexts.
- lldb_private::Status AddThreadList(const lldb::ProcessSP _sp);
- // Add Exception streams for any threads that stopped with exceptions.
- void AddExceptions(const lldb::ProcessSP _sp);
- // Add MemoryList stream, containing dumps of important memory segments
- lldb_private::Status AddMemoryList(const lldb::ProcessSP _sp,
- lldb::SaveCoreStyle core_style);
// Add MiscInfo stream, mainly providing ProcessId
void AddMiscInfo(const lldb::ProcessSP _sp);
// Add informative files about a Linux process
void AddLinuxFileStreams(const lldb::ProcessSP _sp);
+ // Add Exception streams for any threads that stopped with exceptions.
+ void AddExceptions(const lldb::ProcessSP _sp);
// Dump the prepared data into file. In case of the failure data are
// intact.
- lldb_private::Status Dump(lldb::FileUP _file) const;
- // Returns the current number of directories(streams) that have been so far
- // created. This number of directories will be dumped when calling Dump()
- size_t GetDirectoriesNum() const;
+ lldb_private::Status AddThreadList(const lldb::ProcessSP _sp);
+
+ lldb_private::Status AddMemory(const lldb::ProcessSP _sp,
+ lldb::SaveCoreStyle core_style);
+
+ lldb_private::Status DumpToFile();
private:
+ // Add data to the end of the buffer, if the buffer exceeds the flush level,
+ // trigger a flush.
+ lldb_private::Status AddData(const void *data, size_t size);
+ // Add MemoryList stream, containing dumps of important memory segments
+ lldb_private::Status
+ AddMemoryList_64(const lldb::ProcessSP _sp,
+ const lldb_private::Process::CoreFileMemoryRanges );
+ lldb_private::Status
+ AddMemoryList_32(const lldb::ProcessSP _sp,
+ const lldb_private::Process::CoreFileMemoryRanges );
+ lldb_private::Status FixThreads();
+ lldb_private::Status FlushToDisk();
+
+ lldb_private::Status DumpHeader() const;
+ lldb_private::Status DumpDirectories() const;
+ bool CheckIf_64Bit(const size_t size);
// Add directory of StreamType pointing to the current end of the prepared
// file with the specified size.
- void AddDirectory(llvm::minidump::StreamType type, size_t stream_size);
- size_t GetCurrentDataEndOffset() const;
-
- // Stores directories to later put them at the end of minidump file
+ void AddDirectory(llvm::minidump::StreamType type, uint64_t stream_size);
+ lldb::addr_t GetCurrentDataEndOffset() const;
+ // Stores directories to fill in later
std::vector m_directories;
+ // When we write off the threads for the first time, we need to clean them up
+ // and give them the correct RVA once we write the stack memory list.
+ std::map m_thread_by_range_start;
// Main data buffer consisting of data without the minidump header and
// directories
lldb_private::DataBufferHeap m_data;
+ uint m_expected_directories = 0;
+ uint64_t m_saved_data_size = 0;
+ size_t m_thread_list_start = 0;
+ // We set the max write amount to 128 mb
+ // Linux has a signed 32b - some buffer on writes
+ // and we have guarauntee a user memory region / 'object' could be over 2gb
+ // now that we support 64b memory dumps.
+ static constexpr size_t m_write_chunk_max = (1024 * 1024 * 128);
Jlalond wrote:
Avoiding OS limitations was the goal. Originally when I was testing large
minidumps, I created a large array, that was 5.2gb in size. Linux has a max
write byte size that is slightly less than `SSIZE_T` max. However that also
ends up being platform specific, and we should probably make the write size the
architecture byte width max value for `SSIZE_T`.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -797,20 +822,75 @@ void MinidumpFileBuilder::AddLinuxFileStreams(
}
}
-Status MinidumpFileBuilder::Dump(lldb::FileUP _file) const {
- constexpr size_t header_size = sizeof(llvm::minidump::Header);
- constexpr size_t directory_size = sizeof(llvm::minidump::Directory);
+Status MinidumpFileBuilder::AddMemory(const ProcessSP _sp,
+ SaveCoreStyle core_style) {
+ Status error;
+
+ Process::CoreFileMemoryRanges ranges_for_memory_list;
+ error = process_sp->CalculateCoreFileSaveRanges(
+ SaveCoreStyle::eSaveCoreStackOnly, ranges_for_memory_list);
+ if (error.Fail()) {
+return error;
+ }
+
+ std::set stack_ranges;
+ for (const auto _range : ranges_for_memory_list) {
+stack_ranges.insert(core_range.range.start());
+ }
+ // We leave a little padding for dictionary and any other metadata we would
+ // want. Also so that we can put the header of the memory list 64 in 32b
land,
+ // because the directory requires a 32b RVA.
+ Process::CoreFileMemoryRanges ranges;
+ error = process_sp->CalculateCoreFileSaveRanges(core_style, ranges);
+ if (error.Fail()) {
+return error;
+ }
+
+ uint64_t total_size =
+ 256 + (ranges.size() * sizeof(llvm::minidump::MemoryDescriptor_64));
Jlalond wrote:
It's actually arbitrary. I wanted to make sure we had some byte aligned padding
before the end of the file, so that all the MemoryDescriptors64 could be 32b
addressable with the data after them.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -59,39 +68,67 @@ class MinidumpFileBuilder {
// Add ThreadList stream, containing information about all threads running
// at the moment of core saving. Contains information about thread
// contexts.
- lldb_private::Status AddThreadList(const lldb::ProcessSP _sp);
- // Add Exception streams for any threads that stopped with exceptions.
- void AddExceptions(const lldb::ProcessSP _sp);
- // Add MemoryList stream, containing dumps of important memory segments
- lldb_private::Status AddMemoryList(const lldb::ProcessSP _sp,
- lldb::SaveCoreStyle core_style);
// Add MiscInfo stream, mainly providing ProcessId
void AddMiscInfo(const lldb::ProcessSP _sp);
// Add informative files about a Linux process
void AddLinuxFileStreams(const lldb::ProcessSP _sp);
+ // Add Exception streams for any threads that stopped with exceptions.
+ void AddExceptions(const lldb::ProcessSP _sp);
// Dump the prepared data into file. In case of the failure data are
// intact.
- lldb_private::Status Dump(lldb::FileUP _file) const;
- // Returns the current number of directories(streams) that have been so far
- // created. This number of directories will be dumped when calling Dump()
- size_t GetDirectoriesNum() const;
+ lldb_private::Status AddThreadList(const lldb::ProcessSP _sp);
+
+ lldb_private::Status AddMemory(const lldb::ProcessSP _sp,
+ lldb::SaveCoreStyle core_style);
+
+ lldb_private::Status DumpToFile();
private:
+ // Add data to the end of the buffer, if the buffer exceeds the flush level,
+ // trigger a flush.
+ lldb_private::Status AddData(const void *data, size_t size);
+ // Add MemoryList stream, containing dumps of important memory segments
+ lldb_private::Status
+ AddMemoryList_64(const lldb::ProcessSP _sp,
+ const lldb_private::Process::CoreFileMemoryRanges );
+ lldb_private::Status
+ AddMemoryList_32(const lldb::ProcessSP _sp,
+ const lldb_private::Process::CoreFileMemoryRanges );
+ lldb_private::Status FixThreads();
+ lldb_private::Status FlushToDisk();
+
+ lldb_private::Status DumpHeader() const;
+ lldb_private::Status DumpDirectories() const;
+ bool CheckIf_64Bit(const size_t size);
// Add directory of StreamType pointing to the current end of the prepared
// file with the specified size.
- void AddDirectory(llvm::minidump::StreamType type, size_t stream_size);
- size_t GetCurrentDataEndOffset() const;
-
- // Stores directories to later put them at the end of minidump file
+ void AddDirectory(llvm::minidump::StreamType type, uint64_t stream_size);
+ lldb::addr_t GetCurrentDataEndOffset() const;
+ // Stores directories to fill in later
std::vector m_directories;
+ // When we write off the threads for the first time, we need to clean them up
+ // and give them the correct RVA once we write the stack memory list.
+ std::map m_thread_by_range_start;
Jlalond wrote:
In this case, the map is the start of the memory range, and the corresponding
thread. So I think addr_t is more clear. If it is not, I'll take map name
recommendations.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -797,20 +822,75 @@ void MinidumpFileBuilder::AddLinuxFileStreams(
}
}
-Status MinidumpFileBuilder::Dump(lldb::FileUP _file) const {
- constexpr size_t header_size = sizeof(llvm::minidump::Header);
- constexpr size_t directory_size = sizeof(llvm::minidump::Directory);
+Status MinidumpFileBuilder::AddMemory(const ProcessSP _sp,
+ SaveCoreStyle core_style) {
+ Status error;
+
+ Process::CoreFileMemoryRanges ranges_for_memory_list;
Jlalond wrote:
I responded above on this, I tried to minimize allocating vectors and reduce
iterations by just removing what will fit in 32b.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -797,20 +822,75 @@ void MinidumpFileBuilder::AddLinuxFileStreams(
}
}
-Status MinidumpFileBuilder::Dump(lldb::FileUP _file) const {
- constexpr size_t header_size = sizeof(llvm::minidump::Header);
- constexpr size_t directory_size = sizeof(llvm::minidump::Directory);
+Status MinidumpFileBuilder::AddMemory(const ProcessSP _sp,
+ SaveCoreStyle core_style) {
+ Status error;
+
+ Process::CoreFileMemoryRanges ranges_for_memory_list;
+ error = process_sp->CalculateCoreFileSaveRanges(
+ SaveCoreStyle::eSaveCoreStackOnly, ranges_for_memory_list);
+ if (error.Fail()) {
+return error;
+ }
+
+ std::set stack_ranges;
+ for (const auto _range : ranges_for_memory_list) {
+stack_ranges.insert(core_range.range.start());
+ }
+ // We leave a little padding for dictionary and any other metadata we would
+ // want. Also so that we can put the header of the memory list 64 in 32b
land,
+ // because the directory requires a 32b RVA.
+ Process::CoreFileMemoryRanges ranges;
+ error = process_sp->CalculateCoreFileSaveRanges(core_style, ranges);
+ if (error.Fail()) {
+return error;
+ }
+
+ uint64_t total_size =
+ 256 + (ranges.size() * sizeof(llvm::minidump::MemoryDescriptor_64));
+ // Take all the memory that will fit in the 32b range.
+ for (int i = ranges.size() - 1; i >= 0; i--) {
Jlalond wrote:
The reverse is so that I can remove them in place, this was so that I could use
two lists. The reason being is I already get the stacks in my first call to
process, and then I call process again with the user specific style. This is so
stacks are the first items in the memory list for the thread RVA's.
So I remove anything from the second call to process and instead move it to the
list of ranges I pass to memorylist, and the remaining go to memorylist64.
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
@@ -40,7 +46,7 @@ lldb_private::Status WriteString(const std::string _write,
/// the data on heap.
class MinidumpFileBuilder {
public:
- MinidumpFileBuilder() = default;
+ MinidumpFileBuilder(lldb::FileUP&& core_file):
m_core_file(std::move(core_file)) {};
Jlalond wrote:
I agree with this. I also think it reduces the split responsibility with
`ObjectfileMinidump`
https://github.com/llvm/llvm-project/pull/95312
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [llvm] [LLDB][Minidump] Add 64b support to LLDB's minidump file builder. (PR #95312)
https://github.com/Jlalond created
https://github.com/llvm/llvm-project/pull/95312
Currently, LLDB does not support taking a minidump over the 4.2gb limit imposed
by uint32. In fact, currently it writes the RVA's and the headers to the end of
the file, which can become corrupted due to the header offset only supporting a
32b offset.
This change reorganizes how the file structure is laid out. LLDB will
precalculate the number of directories required and preallocate space at the
top of the file to fill in later. Additionally, thread stacks require a 32b
offset, and we provision empty descriptors and keep track of them to clean up
once we write the 32b memory list.
For
[MemoryList64](https://learn.microsoft.com/en-us/windows/win32/api/minidumpapiset/ns-minidumpapiset-minidump_memory64_list),
the RVA to the start of the section itself will remain in a 32b addressable
space. We achieve this by predetermining the space the memory regions will
take, and only writing up to 4.2 gb of data with some buffer to allow all the
MemoryDescriptor64s to also still be 32b addressable.
I did not add any explicit tests to this PR because allocating 4.2gb+ to test
is very expensive. However, we have 32b automation tests and I validated with
in several ways, including with 5gb+ array/object and would be willing to add
this as a test case.
>From 810865580a4d8ea3f48e56f3964602fba6087ddf Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Wed, 12 Jun 2024 13:57:10 -0700
Subject: [PATCH 1/5] Squash minidump-64-protoype.
This is a change to reorder LLDB's minidumps to support 64b memory
lists/minidumps while still keeping all directories under the 32b limit.
Better O(N), not N^2 cleanup code
---
.../Minidump/MinidumpFileBuilder.cpp | 520 ++
.../ObjectFile/Minidump/MinidumpFileBuilder.h | 55 +-
.../Minidump/ObjectFileMinidump.cpp | 38 +-
llvm/include/llvm/BinaryFormat/Minidump.h | 11 +
llvm/include/llvm/Object/Minidump.h | 7 +
llvm/lib/ObjectYAML/MinidumpEmitter.cpp | 7 +
6 files changed, 482 insertions(+), 156 deletions(-)
diff --git a/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
b/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
index 7231433619ffb..c08b5206720ab 100644
--- a/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
+++ b/lldb/source/Plugins/ObjectFile/Minidump/MinidumpFileBuilder.cpp
@@ -20,35 +20,106 @@
#include "lldb/Target/RegisterContext.h"
#include "lldb/Target/StopInfo.h"
#include "lldb/Target/ThreadList.h"
+#include "lldb/Utility/DataBufferHeap.h"
#include "lldb/Utility/DataExtractor.h"
#include "lldb/Utility/LLDBLog.h"
#include "lldb/Utility/Log.h"
+#include "lldb/Utility/LLDBLog.h"
#include "lldb/Utility/RegisterValue.h"
#include "llvm/ADT/StringRef.h"
#include "llvm/BinaryFormat/Minidump.h"
#include "llvm/Support/ConvertUTF.h"
+#include "llvm/Support/Endian.h"
#include "llvm/Support/Error.h"
#include "Plugins/Process/minidump/MinidumpTypes.h"
+#include "lldb/lldb-enumerations.h"
+#include "lldb/lldb-forward.h"
+#include "lldb/lldb-types.h"
#include
+#include
+#include
+#include
+#include
+#include
using namespace lldb;
using namespace lldb_private;
using namespace llvm::minidump;
-void MinidumpFileBuilder::AddDirectory(StreamType type, size_t stream_size) {
+Status MinidumpFileBuilder::AddHeaderAndCalculateDirectories(const
lldb_private::Target , const lldb::ProcessSP _sp) {
+ // First set the offset on the file, and on the bytes saved
+ //TODO: advance the core file.
+ m_saved_data_size += header_size;
+ // We know we will have at least Misc, SystemInfo, Modules, and ThreadList
(corresponding memory list for stacks)
+ // And an additional memory list for non-stacks.
+ m_expected_directories = 6;
+ // Check if OS is linux
+ if (target.GetArchitecture().GetTriple().getOS() ==
+ llvm::Triple::OSType::Linux)
+m_expected_directories += 9;
+
+ // Go through all of the threads and check for exceptions.
+ lldb_private::ThreadList thread_list = process_sp->GetThreadList();
+ const uint32_t num_threads = thread_list.GetSize();
+ for (uint32_t thread_idx = 0; thread_idx < num_threads; ++thread_idx) {
+ThreadSP thread_sp(thread_list.GetThreadAtIndex(thread_idx));
+StopInfoSP stop_info_sp = thread_sp->GetStopInfo();
+if (stop_info_sp && stop_info_sp->GetStopReason() ==
StopReason::eStopReasonException) {
+ m_expected_directories++;
+}
+ }
+
+ // Now offset the file by the directores so we can write them in later.
+ offset_t directory_offset = m_expected_directories * directory_size;
+ //TODO: advance the core file.
+ m_saved_data_size += directory_offset;
+ // Replace this when we make a better way to do this.
+ Status error;
+ Header empty_header;
+ size_t bytes_written;
+ bytes_written = header_size;
+ error = m_core_file->Write(_header, bytes_written);
+ if (error.Fail() || bytes_written !=
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -254,13 +254,17 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+
+ // We have to check for host address here
+ // because GetAddressOf returns INVALID for all non load addresses.
+ // But we can still format strings in host memory.
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
Jlalond wrote:
> Make sense to fix GetAddressOf to take advantage of the API it is
> implementing. If the address kind can be host and we can return a valid host
> address value, I would say we use it. We will need to look over all uses of
> this API internally if we do change it.
If we decide to go forward with this refactor, I think we should probably split
this out into it's own independent PR and put this one on pause. As Jim
mentioned above there are currently places that make assumptions based on the
value object being host and getting back an invalid address, and we would need
to correct for that.
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -254,13 +254,17 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+
+ // We have to check for host address here
+ // because GetAddressOf returns INVALID for all non load addresses.
+ // But we can still format strings in host memory.
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
Jlalond wrote:
We could take the approach you provided. Greg and I originally talked and
mentioned how `GetAddressOf` will return the pointer within a buffer in certain
cases. I'm not enough of an expert here to have strong opinions but I think
we're in a confusing middleground, where GetAddressOf works for Load addresses,
but fails for a host address even if we have a pointer internally to a data
buffer.
I think solving that is more fundamental to my (2nd?) PR in lldb, but if we can
all agree on the returning invaild for host addresses. I'm okay with that, as
long as we also add a comment/documentation to the call that HostAddress
addresses are invalid and to instead use a data extractor. My only opinion on
that as a new contributor is the API to work with ValueObject's data is clunky,
because I can seemingly only construct a copy via `GetData`.
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -17,6 +17,15 @@ def setUp(self):
# Find the line number to break at.
self.line = line_number("main.cpp", "// Set break point at this line.")
+# This is the function to remove the custom formats in order to have a
Jlalond wrote:
This PR is already old enough that we can lump it in!
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -2763,10 +2763,10 @@ ValueObjectSP ValueObject::Cast(const CompilerType
_type) {
ExecutionContextScope *exe_scope
= ExecutionContext(GetExecutionContextRef())
.GetBestExecutionContextScope();
- if (compiler_type.GetByteSize(exe_scope)
- <= GetCompilerType().GetByteSize(exe_scope)
- || m_value.GetValueType() == Value::ValueType::LoadAddress)
-return DoCast(compiler_type);
+ if (compiler_type.GetByteSize(exe_scope) <=
Jlalond wrote:
Hmm, yeah I ran `git-clang-format` against this.
Specifically, `git fetch upstream; git-clang-format upstream/main` and it
produced this. I'll manually revert this one
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
Jlalond wrote: @jimingham it turned out when created by data, the value object's address points to it's buffer which itself contains the char* of the string. I'm not sure how we can support the small string optimization if this is the case, my testing was against a small string "test2", and it was always saved as a char* for the value object. I think for this PR we can probably ignore it and open an issue to support the small string optimization. Please review when you have time https://github.com/llvm/llvm-project/pull/89110 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/89110
>From 5955863f22d5048cad91f089e96b10ea15c05446 Mon Sep 17 00:00:00 2001
From: Jacob John Lalonde
Date: Wed, 10 Apr 2024 14:33:40 -0700
Subject: [PATCH 1/7] Fix bug where an sbvalue containing a std::string created
from data would not use the built in summary provider, but default to the
valueobjectprinter
std::string children are normally formatted as their summary [my_string_prop] =
"hello world".
Sbvalues created from data do not follow the same summary formatter path and
instead hit the value object printer.
This change fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
---
.../Plugins/Language/CPlusPlus/LibStdcpp.cpp | 31 ++--
.../string/ConvertToDataFormatter.py | 50 +++
.../string/TestDataFormatterStdString.py | 28 +++
.../libstdcpp/string/main.cpp | 13 +
4 files changed, 118 insertions(+), 4 deletions(-)
create mode 100644
lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
diff --git a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
index 86bb575af5ca3..0da01e9ca07fb 100644
--- a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
+++ b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
switch (addr_type) {
case eAddressTypeLoad: {
ProcessSP process_sp(valobj.GetProcessSP());
if (!process_sp)
return false;
-
StringPrinter::ReadStringAndDumpToStreamOptions options(valobj);
Status error;
lldb::addr_t addr_of_data =
@@ -287,8 +287,31 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+ // We have the host address of our std::string
+ // But we need to read the pointee data from the debugged process.
+ ProcessSP process_sp(valobj.GetProcessSP());
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+ // We want to read the address from std::string, which is the first 8
bytes.
+ lldb::offset_t offset = 0;
+ lldb::addr_t addr = data.GetAddress();
+ if (!addr)
+ {
+stream.Printf("nullptr");
+return true;
+ }
+
+ std::string contents;
+ process_sp->ReadCStringFromMemory(addr, contents, error);
+ if (error.Fail())
+return false;
+ stream.Printf("%s", contents.c_str());
+ return true;
+} break;
case eAddressTypeInvalid:
case eAddressTypeFile:
break;
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
new file mode 100644
index 0..57e42c920f829
--- /dev/null
+++
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
@@ -0,0 +1,50 @@
+# coding=utf8
+"""
+Helper formmater to verify Std::String by created via SBData
+"""
+
+import lldb
+
+class SyntheticFormatter:
+def __init__(self, valobj, dict):
+self.valobj = valobj
+
+def num_children(self):
+return 6
+
+def has_children(self):
+return True
+
+def get_child_at_index(self, index):
+name = None
+match index:
+case 0:
+name = "short_string"
+case 1:
+name = "long_string"
+case 2:
+name = "short_string_ptr"
+case 3:
+name = "long_string_ptr"
+case 4:
+name = "short_string_ref"
+case 5:
+name = "long_string_ref"
+case _:
+return None
+
+child = self.valobj.GetChildMemberWithName(name)
+valType = child.GetType()
+return self.valobj.CreateValueFromData(name,
+child.GetData(),
+valType)
+
+
+def __lldb_init_module(debugger, dict):
+typeName = "string_container"
+debugger.HandleCommand(
+'type synthetic add -x "'
++ typeName
++ '" --python-class '
++ f"{__name__}.SyntheticFormatter"
+)
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/TestDataFormatterStdString.py
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/89110
>From e0316188d22605c670079e37855d3d8b5c944cee Mon Sep 17 00:00:00 2001
From: Jacob John Lalonde
Date: Wed, 10 Apr 2024 14:33:40 -0700
Subject: [PATCH 1/5] Fix bug where an sbvalue containing a std::string created
from data would not use the built in summary provider, but default to the
valueobjectprinter
std::string children are normally formatted as their summary [my_string_prop] =
"hello world".
Sbvalues created from data do not follow the same summary formatter path and
instead hit the value object printer.
This change fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
---
.../Plugins/Language/CPlusPlus/LibStdcpp.cpp | 31 ++--
.../string/ConvertToDataFormatter.py | 50 +++
.../string/TestDataFormatterStdString.py | 28 +++
.../libstdcpp/string/main.cpp | 13 +
4 files changed, 118 insertions(+), 4 deletions(-)
create mode 100644
lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
diff --git a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
index 86bb575af5ca3..0da01e9ca07fb 100644
--- a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
+++ b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
switch (addr_type) {
case eAddressTypeLoad: {
ProcessSP process_sp(valobj.GetProcessSP());
if (!process_sp)
return false;
-
StringPrinter::ReadStringAndDumpToStreamOptions options(valobj);
Status error;
lldb::addr_t addr_of_data =
@@ -287,8 +287,31 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+ // We have the host address of our std::string
+ // But we need to read the pointee data from the debugged process.
+ ProcessSP process_sp(valobj.GetProcessSP());
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+ // We want to read the address from std::string, which is the first 8
bytes.
+ lldb::offset_t offset = 0;
+ lldb::addr_t addr = data.GetAddress();
+ if (!addr)
+ {
+stream.Printf("nullptr");
+return true;
+ }
+
+ std::string contents;
+ process_sp->ReadCStringFromMemory(addr, contents, error);
+ if (error.Fail())
+return false;
+ stream.Printf("%s", contents.c_str());
+ return true;
+} break;
case eAddressTypeInvalid:
case eAddressTypeFile:
break;
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
new file mode 100644
index 0..57e42c920f829
--- /dev/null
+++
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
@@ -0,0 +1,50 @@
+# coding=utf8
+"""
+Helper formmater to verify Std::String by created via SBData
+"""
+
+import lldb
+
+class SyntheticFormatter:
+def __init__(self, valobj, dict):
+self.valobj = valobj
+
+def num_children(self):
+return 6
+
+def has_children(self):
+return True
+
+def get_child_at_index(self, index):
+name = None
+match index:
+case 0:
+name = "short_string"
+case 1:
+name = "long_string"
+case 2:
+name = "short_string_ptr"
+case 3:
+name = "long_string_ptr"
+case 4:
+name = "short_string_ref"
+case 5:
+name = "long_string_ref"
+case _:
+return None
+
+child = self.valobj.GetChildMemberWithName(name)
+valType = child.GetType()
+return self.valobj.CreateValueFromData(name,
+child.GetData(),
+valType)
+
+
+def __lldb_init_module(debugger, dict):
+typeName = "string_container"
+debugger.HandleCommand(
+'type synthetic add -x "'
++ typeName
++ '" --python-class '
++ f"{__name__}.SyntheticFormatter"
+)
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/TestDataFormatterStdString.py
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from stack start to the stackpointer + red_zone (PR #92002)
@@ -3857,8 +3857,8 @@ thread_result_t Process::RunPrivateStateThread(bool
is_secondary_thread) {
// case we should tell it to stop doing that. Normally, we don't NEED
// to do that because we will next close the communication to the stub
// and that will get it to shut down. But there are remote debugging
-// cases where relying on that side-effect causes the shutdown to be
-// flakey, so we should send a positive signal to interrupt the wait.
+// cases where relying on that side-effect causes the shutdown to be
+// flakey, so we should send a positive signal to interrupt the wait.
Jlalond wrote:
This got pulled back in by running clang-formatter on this file. Several
different places were reformatted, do you want me to manually revert this still?
https://github.com/llvm/llvm-project/pull/92002
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from stack start to the stackpointer + red_zone (PR #92002)
@@ -6335,16 +6335,51 @@ static void AddRegion(const MemoryRegionInfo ,
bool try_dirty_pages,
ranges.push_back(CreateCoreFileMemoryRange(region));
}
+static void
+SaveOffRegionsWithStackPointers(Process ,
+ const MemoryRegionInfos ,
+ Process::CoreFileMemoryRanges ,
+ std::set _ends) {
+ const bool try_dirty_pages = true;
+
+ // Before we take any dump, we want to save off the used portions of the
stacks
+ // and mark those memory regions as saved. This prevents us from saving the
unused portion
+ // of the stack below the stack pointer. Saving space on the dump.
+ for (lldb::ThreadSP thread_sp : process.GetThreadList().Threads()) {
+if (!thread_sp)
+ continue;
+StackFrameSP frame_sp = thread_sp->GetStackFrameAtIndex(0);
+if (!frame_sp)
+ continue;
+RegisterContextSP reg_ctx_sp = frame_sp->GetRegisterContext();
+if (!reg_ctx_sp)
+ continue;
+const addr_t sp = reg_ctx_sp->GetSP();
+const size_t red_zone = process.GetABI()->GetRedZoneSize();
+lldb_private::MemoryRegionInfo sp_region;
+if (process.GetMemoryRegionInfo(sp, sp_region).Success()) {
+const size_t stack_head = (sp - red_zone);
+const size_t stack_size = sp_region.GetRange().GetRangeEnd() -
stack_head;
+sp_region.GetRange().SetRangeBase(stack_head);
+sp_region.GetRange().SetByteSize(stack_size);
+stack_ends.insert(sp_region.GetRange().GetRangeEnd());
+AddRegion(sp_region, try_dirty_pages, ranges);
+}
Jlalond wrote:
Done, also made sure we do this in `MinidumpFileBuilder`
https://github.com/llvm/llvm-project/pull/92002
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from stack start to the stackpointer + red_zone (PR #92002)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/92002
>From 2d192f640b332c2f1381cf96b75be60ad18de3ac Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Fri, 10 May 2024 09:35:11 -0700
Subject: [PATCH 1/5] change core dump stacks to only include up to the stack
pointer (+ red zone) Add python tests to verify we can read up to sp +
redzone - 1.
---
lldb/source/Target/Process.cpp | 14 +++---
.../TestProcessSaveCoreMinidump.py | 12
2 files changed, 23 insertions(+), 3 deletions(-)
diff --git a/lldb/source/Target/Process.cpp b/lldb/source/Target/Process.cpp
index 25afade9a8275..a11e45909202f 100644
--- a/lldb/source/Target/Process.cpp
+++ b/lldb/source/Target/Process.cpp
@@ -3857,8 +3857,8 @@ thread_result_t Process::RunPrivateStateThread(bool
is_secondary_thread) {
// case we should tell it to stop doing that. Normally, we don't NEED
// to do that because we will next close the communication to the stub
// and that will get it to shut down. But there are remote debugging
-// cases where relying on that side-effect causes the shutdown to be
-// flakey, so we should send a positive signal to interrupt the wait.
+// cases where relying on that side-effect causes the shutdown to be
+// flakey, so we should send a positive signal to interrupt the wait.
Status error = HaltPrivate();
BroadcastEvent(eBroadcastBitInterrupt, nullptr);
} else if (StateIsRunningState(m_last_broadcast_state)) {
@@ -6410,12 +6410,20 @@ GetCoreFileSaveRangesStackOnly(Process ,
if (!reg_ctx_sp)
continue;
const addr_t sp = reg_ctx_sp->GetSP();
+const size_t red_zone = process.GetABI()->GetRedZoneSize();
lldb_private::MemoryRegionInfo sp_region;
if (process.GetMemoryRegionInfo(sp, sp_region).Success()) {
// Only add this region if not already added above. If our stack pointer
// is pointing off in the weeds, we will want this range.
- if (stack_bases.count(sp_region.GetRange().GetRangeBase()) == 0)
+ if (stack_bases.count(sp_region.GetRange().GetRangeBase()) == 0) {
+// Take only the start of the stack to the stack pointer and include
the redzone.
+// Because stacks grow 'down' to include the red_zone we have to
subtract it from the sp.
+const size_t stack_head = (sp - red_zone);
+const size_t stack_size = sp_region.GetRange().GetRangeEnd() -
(stack_head);
+sp_region.GetRange().SetRangeBase(stack_head);
+sp_region.GetRange().SetByteSize(stack_size);
AddRegion(sp_region, try_dirty_pages, ranges);
+ }
}
}
}
diff --git
a/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
b/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
index 9fe5e89142987..123bbd472be05 100644
---
a/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
+++
b/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
@@ -14,6 +14,7 @@ class ProcessSaveCoreMinidumpTestCase(TestBase):
def verify_core_file(
self, core_path, expected_pid, expected_modules, expected_threads
):
+breakpoint()
# To verify, we'll launch with the mini dump
target = self.dbg.CreateTarget(None)
process = target.LoadCore(core_path)
@@ -36,11 +37,22 @@ def verify_core_file(
self.assertEqual(module_file_name, expected_file_name)
self.assertEqual(module.GetUUIDString(), expected.GetUUIDString())
+red_zone = process.GetTarget().GetStackRedZoneSize()
for thread_idx in range(process.GetNumThreads()):
thread = process.GetThreadAtIndex(thread_idx)
self.assertTrue(thread.IsValid())
thread_id = thread.GetThreadID()
self.assertIn(thread_id, expected_threads)
+oldest_frame = thread.GetFrameAtIndex(thread.GetNumFrames() - 1)
+stack_start =
oldest_frame.GetSymbol().GetStartAddress().GetFileAddress()
+frame = thread.GetFrameAtIndex(0)
+sp = frame.GetSP()
+stack_size = stack_start - (sp - red_zone)
+byte_array = process.ReadMemory(sp - red_zone + 1, stack_size,
error)
+self.assertTrue(error.Success(), "Failed to read stack")
+self.assertEqual(stack_size - 1, len(byte_array), "Incorrect stack
size read"),
+
+
self.dbg.DeleteTarget(target)
@skipUnlessArch("x86_64")
>From aa6d0a24b64816c328c7c4c3d00c7563407a3deb Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Fri, 10 May 2024 14:51:12 -0700
Subject: [PATCH 2/5] Refactor test to read the top and bottom stack frame's
respective pointers instead of trying to take the entire range
---
.../TestProcessSaveCoreMinidump.py | 14 +++---
1 file
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from stack start to the stackpointer + red_zone (PR #92002)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/92002 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from start start to the stackpointer + red_zone (PR #92002)
@@ -6410,12 +6410,20 @@ GetCoreFileSaveRangesStackOnly(Process , if (!reg_ctx_sp) continue; const addr_t sp = reg_ctx_sp->GetSP(); +const size_t red_zone = process.GetABI()->GetRedZoneSize(); Jlalond wrote: Correct, but on systems where it would be greater than 0, we ensure we capture it for the memory dump as well. https://github.com/llvm/llvm-project/pull/92002 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from start start to the stackpointer + red_zone (PR #92002)
Jlalond wrote: @clayborg Could you take a look at this? https://github.com/llvm/llvm-project/pull/92002 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] [LLDB/Coredump] Only take the Pthread from start start to the stackpointer + red_zone (PR #92002)
https://github.com/Jlalond created
https://github.com/llvm/llvm-project/pull/92002
Currently in Core dumps, the entire pthread is copied, including the unused
space beyond the stack pointer. This causes large amounts of core dump
inflation when the number of threads is high, but the stack usage is low. Such
as when an application is using a thread pool.
This change will optimize for these situations in addition to generally
improving the core dump performance for all of lldb.
>From 2d192f640b332c2f1381cf96b75be60ad18de3ac Mon Sep 17 00:00:00 2001
From: Jacob Lalonde
Date: Fri, 10 May 2024 09:35:11 -0700
Subject: [PATCH 1/3] change core dump stacks to only include up to the stack
pointer (+ red zone) Add python tests to verify we can read up to sp +
redzone - 1.
---
lldb/source/Target/Process.cpp | 14 +++---
.../TestProcessSaveCoreMinidump.py | 12
2 files changed, 23 insertions(+), 3 deletions(-)
diff --git a/lldb/source/Target/Process.cpp b/lldb/source/Target/Process.cpp
index 25afade9a8275..a11e45909202f 100644
--- a/lldb/source/Target/Process.cpp
+++ b/lldb/source/Target/Process.cpp
@@ -3857,8 +3857,8 @@ thread_result_t Process::RunPrivateStateThread(bool
is_secondary_thread) {
// case we should tell it to stop doing that. Normally, we don't NEED
// to do that because we will next close the communication to the stub
// and that will get it to shut down. But there are remote debugging
-// cases where relying on that side-effect causes the shutdown to be
-// flakey, so we should send a positive signal to interrupt the wait.
+// cases where relying on that side-effect causes the shutdown to be
+// flakey, so we should send a positive signal to interrupt the wait.
Status error = HaltPrivate();
BroadcastEvent(eBroadcastBitInterrupt, nullptr);
} else if (StateIsRunningState(m_last_broadcast_state)) {
@@ -6410,12 +6410,20 @@ GetCoreFileSaveRangesStackOnly(Process ,
if (!reg_ctx_sp)
continue;
const addr_t sp = reg_ctx_sp->GetSP();
+const size_t red_zone = process.GetABI()->GetRedZoneSize();
lldb_private::MemoryRegionInfo sp_region;
if (process.GetMemoryRegionInfo(sp, sp_region).Success()) {
// Only add this region if not already added above. If our stack pointer
// is pointing off in the weeds, we will want this range.
- if (stack_bases.count(sp_region.GetRange().GetRangeBase()) == 0)
+ if (stack_bases.count(sp_region.GetRange().GetRangeBase()) == 0) {
+// Take only the start of the stack to the stack pointer and include
the redzone.
+// Because stacks grow 'down' to include the red_zone we have to
subtract it from the sp.
+const size_t stack_head = (sp - red_zone);
+const size_t stack_size = sp_region.GetRange().GetRangeEnd() -
(stack_head);
+sp_region.GetRange().SetRangeBase(stack_head);
+sp_region.GetRange().SetByteSize(stack_size);
AddRegion(sp_region, try_dirty_pages, ranges);
+ }
}
}
}
diff --git
a/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
b/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
index 9fe5e89142987..123bbd472be05 100644
---
a/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
+++
b/lldb/test/API/functionalities/process_save_core_minidump/TestProcessSaveCoreMinidump.py
@@ -14,6 +14,7 @@ class ProcessSaveCoreMinidumpTestCase(TestBase):
def verify_core_file(
self, core_path, expected_pid, expected_modules, expected_threads
):
+breakpoint()
# To verify, we'll launch with the mini dump
target = self.dbg.CreateTarget(None)
process = target.LoadCore(core_path)
@@ -36,11 +37,22 @@ def verify_core_file(
self.assertEqual(module_file_name, expected_file_name)
self.assertEqual(module.GetUUIDString(), expected.GetUUIDString())
+red_zone = process.GetTarget().GetStackRedZoneSize()
for thread_idx in range(process.GetNumThreads()):
thread = process.GetThreadAtIndex(thread_idx)
self.assertTrue(thread.IsValid())
thread_id = thread.GetThreadID()
self.assertIn(thread_id, expected_threads)
+oldest_frame = thread.GetFrameAtIndex(thread.GetNumFrames() - 1)
+stack_start =
oldest_frame.GetSymbol().GetStartAddress().GetFileAddress()
+frame = thread.GetFrameAtIndex(0)
+sp = frame.GetSP()
+stack_size = stack_start - (sp - red_zone)
+byte_array = process.ReadMemory(sp - red_zone + 1, stack_size,
error)
+self.assertTrue(error.Success(), "Failed to read stack")
+self.assertEqual(stack_size - 1, len(byte_array), "Incorrect stack
size read"),
+
+
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/89110
>From e0316188d22605c670079e37855d3d8b5c944cee Mon Sep 17 00:00:00 2001
From: Jacob John Lalonde
Date: Wed, 10 Apr 2024 14:33:40 -0700
Subject: [PATCH 1/4] Fix bug where an sbvalue containing a std::string created
from data would not use the built in summary provider, but default to the
valueobjectprinter
std::string children are normally formatted as their summary [my_string_prop] =
"hello world".
Sbvalues created from data do not follow the same summary formatter path and
instead hit the value object printer.
This change fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
---
.../Plugins/Language/CPlusPlus/LibStdcpp.cpp | 31 ++--
.../string/ConvertToDataFormatter.py | 50 +++
.../string/TestDataFormatterStdString.py | 28 +++
.../libstdcpp/string/main.cpp | 13 +
4 files changed, 118 insertions(+), 4 deletions(-)
create mode 100644
lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
diff --git a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
index 86bb575af5ca34..0da01e9ca07fb6 100644
--- a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
+++ b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
switch (addr_type) {
case eAddressTypeLoad: {
ProcessSP process_sp(valobj.GetProcessSP());
if (!process_sp)
return false;
-
StringPrinter::ReadStringAndDumpToStreamOptions options(valobj);
Status error;
lldb::addr_t addr_of_data =
@@ -287,8 +287,31 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+ // We have the host address of our std::string
+ // But we need to read the pointee data from the debugged process.
+ ProcessSP process_sp(valobj.GetProcessSP());
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+ // We want to read the address from std::string, which is the first 8
bytes.
+ lldb::offset_t offset = 0;
+ lldb::addr_t addr = data.GetAddress();
+ if (!addr)
+ {
+stream.Printf("nullptr");
+return true;
+ }
+
+ std::string contents;
+ process_sp->ReadCStringFromMemory(addr, contents, error);
+ if (error.Fail())
+return false;
+ stream.Printf("%s", contents.c_str());
+ return true;
+} break;
case eAddressTypeInvalid:
case eAddressTypeFile:
break;
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
new file mode 100644
index 00..57e42c920f8294
--- /dev/null
+++
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
@@ -0,0 +1,50 @@
+# coding=utf8
+"""
+Helper formmater to verify Std::String by created via SBData
+"""
+
+import lldb
+
+class SyntheticFormatter:
+def __init__(self, valobj, dict):
+self.valobj = valobj
+
+def num_children(self):
+return 6
+
+def has_children(self):
+return True
+
+def get_child_at_index(self, index):
+name = None
+match index:
+case 0:
+name = "short_string"
+case 1:
+name = "long_string"
+case 2:
+name = "short_string_ptr"
+case 3:
+name = "long_string_ptr"
+case 4:
+name = "short_string_ref"
+case 5:
+name = "long_string_ref"
+case _:
+return None
+
+child = self.valobj.GetChildMemberWithName(name)
+valType = child.GetType()
+return self.valobj.CreateValueFromData(name,
+child.GetData(),
+valType)
+
+
+def __lldb_init_module(debugger, dict):
+typeName = "string_container"
+debugger.HandleCommand(
+'type synthetic add -x "'
++ typeName
++ '" --python-class '
++ f"{__name__}.SyntheticFormatter"
+)
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/TestDataFormatterStdString.py
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -254,13 +254,17 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+
+ // We have to check for host address here
+ // because GetAddressOf returns INVALID for all non load addresses.
+ // But we can still format strings in host memory.
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
Jlalond wrote:
That I don't know. ValueObject does [explicitly
return](https://github.com/llvm/llvm-project/blob/main/lldb/source/Core/ValueObject.cpp#L1408C12-L1408C32)
`LLDB_INVALID_ADDRESS` when `addressType == eAddressTypeHost`. I thought this
was weird and potentially returning the address of the in memory buffer made
more sense, but that seemed like a major refactor for a minor string issue
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -287,8 +291,52 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+
Jlalond wrote:
Wouldn't short string optimization be covered by the check at the address type
of children (Line 303)? If the children are host we directly read the
std::string from the data extractor
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/89110
>From e0316188d22605c670079e37855d3d8b5c944cee Mon Sep 17 00:00:00 2001
From: Jacob John Lalonde
Date: Wed, 10 Apr 2024 14:33:40 -0700
Subject: [PATCH 1/3] Fix bug where an sbvalue containing a std::string created
from data would not use the built in summary provider, but default to the
valueobjectprinter
std::string children are normally formatted as their summary [my_string_prop] =
"hello world".
Sbvalues created from data do not follow the same summary formatter path and
instead hit the value object printer.
This change fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
---
.../Plugins/Language/CPlusPlus/LibStdcpp.cpp | 31 ++--
.../string/ConvertToDataFormatter.py | 50 +++
.../string/TestDataFormatterStdString.py | 28 +++
.../libstdcpp/string/main.cpp | 13 +
4 files changed, 118 insertions(+), 4 deletions(-)
create mode 100644
lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
diff --git a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
index 86bb575af5ca34..0da01e9ca07fb6 100644
--- a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
+++ b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
switch (addr_type) {
case eAddressTypeLoad: {
ProcessSP process_sp(valobj.GetProcessSP());
if (!process_sp)
return false;
-
StringPrinter::ReadStringAndDumpToStreamOptions options(valobj);
Status error;
lldb::addr_t addr_of_data =
@@ -287,8 +287,31 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+ // We have the host address of our std::string
+ // But we need to read the pointee data from the debugged process.
+ ProcessSP process_sp(valobj.GetProcessSP());
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+ // We want to read the address from std::string, which is the first 8
bytes.
+ lldb::offset_t offset = 0;
+ lldb::addr_t addr = data.GetAddress();
+ if (!addr)
+ {
+stream.Printf("nullptr");
+return true;
+ }
+
+ std::string contents;
+ process_sp->ReadCStringFromMemory(addr, contents, error);
+ if (error.Fail())
+return false;
+ stream.Printf("%s", contents.c_str());
+ return true;
+} break;
case eAddressTypeInvalid:
case eAddressTypeFile:
break;
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
new file mode 100644
index 00..57e42c920f8294
--- /dev/null
+++
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
@@ -0,0 +1,50 @@
+# coding=utf8
+"""
+Helper formmater to verify Std::String by created via SBData
+"""
+
+import lldb
+
+class SyntheticFormatter:
+def __init__(self, valobj, dict):
+self.valobj = valobj
+
+def num_children(self):
+return 6
+
+def has_children(self):
+return True
+
+def get_child_at_index(self, index):
+name = None
+match index:
+case 0:
+name = "short_string"
+case 1:
+name = "long_string"
+case 2:
+name = "short_string_ptr"
+case 3:
+name = "long_string_ptr"
+case 4:
+name = "short_string_ref"
+case 5:
+name = "long_string_ref"
+case _:
+return None
+
+child = self.valobj.GetChildMemberWithName(name)
+valType = child.GetType()
+return self.valobj.CreateValueFromData(name,
+child.GetData(),
+valType)
+
+
+def __lldb_init_module(debugger, dict):
+typeName = "string_container"
+debugger.HandleCommand(
+'type synthetic add -x "'
++ typeName
++ '" --python-class '
++ f"{__name__}.SyntheticFormatter"
+)
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/TestDataFormatterStdString.py
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond updated
https://github.com/llvm/llvm-project/pull/89110
>From e0316188d22605c670079e37855d3d8b5c944cee Mon Sep 17 00:00:00 2001
From: Jacob John Lalonde
Date: Wed, 10 Apr 2024 14:33:40 -0700
Subject: [PATCH 1/2] Fix bug where an sbvalue containing a std::string created
from data would not use the built in summary provider, but default to the
valueobjectprinter
std::string children are normally formatted as their summary [my_string_prop] =
"hello world".
Sbvalues created from data do not follow the same summary formatter path and
instead hit the value object printer.
This change fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
---
.../Plugins/Language/CPlusPlus/LibStdcpp.cpp | 31 ++--
.../string/ConvertToDataFormatter.py | 50 +++
.../string/TestDataFormatterStdString.py | 28 +++
.../libstdcpp/string/main.cpp | 13 +
4 files changed, 118 insertions(+), 4 deletions(-)
create mode 100644
lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
diff --git a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
index 86bb575af5ca34..0da01e9ca07fb6 100644
--- a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
+++ b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
switch (addr_type) {
case eAddressTypeLoad: {
ProcessSP process_sp(valobj.GetProcessSP());
if (!process_sp)
return false;
-
StringPrinter::ReadStringAndDumpToStreamOptions options(valobj);
Status error;
lldb::addr_t addr_of_data =
@@ -287,8 +287,31 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+ // We have the host address of our std::string
+ // But we need to read the pointee data from the debugged process.
+ ProcessSP process_sp(valobj.GetProcessSP());
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+ // We want to read the address from std::string, which is the first 8
bytes.
+ lldb::offset_t offset = 0;
+ lldb::addr_t addr = data.GetAddress();
+ if (!addr)
+ {
+stream.Printf("nullptr");
+return true;
+ }
+
+ std::string contents;
+ process_sp->ReadCStringFromMemory(addr, contents, error);
+ if (error.Fail())
+return false;
+ stream.Printf("%s", contents.c_str());
+ return true;
+} break;
case eAddressTypeInvalid:
case eAddressTypeFile:
break;
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
new file mode 100644
index 00..57e42c920f8294
--- /dev/null
+++
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
@@ -0,0 +1,50 @@
+# coding=utf8
+"""
+Helper formmater to verify Std::String by created via SBData
+"""
+
+import lldb
+
+class SyntheticFormatter:
+def __init__(self, valobj, dict):
+self.valobj = valobj
+
+def num_children(self):
+return 6
+
+def has_children(self):
+return True
+
+def get_child_at_index(self, index):
+name = None
+match index:
+case 0:
+name = "short_string"
+case 1:
+name = "long_string"
+case 2:
+name = "short_string_ptr"
+case 3:
+name = "long_string_ptr"
+case 4:
+name = "short_string_ref"
+case 5:
+name = "long_string_ref"
+case _:
+return None
+
+child = self.valobj.GetChildMemberWithName(name)
+valType = child.GetType()
+return self.valobj.CreateValueFromData(name,
+child.GetData(),
+valType)
+
+
+def __lldb_init_module(debugger, dict):
+typeName = "string_container"
+debugger.HandleCommand(
+'type synthetic add -x "'
++ typeName
++ '" --python-class '
++ f"{__name__}.SyntheticFormatter"
+)
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/TestDataFormatterStdString.py
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
Jlalond wrote: @jimingham What should we do if the child address type is File? I don't know how that could ever happen, and should we support it? Because currently we didn't support summarizing host or file. https://github.com/llvm/llvm-project/pull/89110 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
Jlalond wrote:
Yes, the switch statement is within the if block, if we don't add this
exception we will return false and fall back to the ValueObjectPrinter
https://github.com/llvm/llvm-project/pull/89110
___
lldb-commits mailing list
lldb-commits@lists.llvm.org
https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/89110 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/89110 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::string's when created from data. (PR #89110)
https://github.com/Jlalond edited https://github.com/llvm/llvm-project/pull/89110 ___ lldb-commits mailing list lldb-commits@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/lldb-commits
[Lldb-commits] [lldb] Summarize std::sting's when created from data. (PR #89110)
https://github.com/Jlalond created
https://github.com/llvm/llvm-project/pull/89110
std::string children are normally formatted as their summary [my_string_prop] =
"hello world". Sbvalues/ValueObjects created from data do not follow the same
summary formatter path and instead hit the value object printer. This change
fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
>From e0316188d22605c670079e37855d3d8b5c944cee Mon Sep 17 00:00:00 2001
From: Jacob John Lalonde
Date: Wed, 10 Apr 2024 14:33:40 -0700
Subject: [PATCH] Fix bug where an sbvalue containing a std::string created
from data would not use the built in summary provider, but default to the
valueobjectprinter
std::string children are normally formatted as their summary [my_string_prop] =
"hello world".
Sbvalues created from data do not follow the same summary formatter path and
instead hit the value object printer.
This change fixes that and adds tests for the future.
Added tests in TestDataFormatterStdString.py and a formatter for a custom
struct.
---
.../Plugins/Language/CPlusPlus/LibStdcpp.cpp | 31 ++--
.../string/ConvertToDataFormatter.py | 50 +++
.../string/TestDataFormatterStdString.py | 28 +++
.../libstdcpp/string/main.cpp | 13 +
4 files changed, 118 insertions(+), 4 deletions(-)
create mode 100644
lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
diff --git a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
index 86bb575af5ca34..0da01e9ca07fb6 100644
--- a/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
+++ b/lldb/source/Plugins/Language/CPlusPlus/LibStdcpp.cpp
@@ -254,13 +254,13 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
addr_of_string =
valobj.GetAddressOf(scalar_is_load_addr, _type);
- if (addr_of_string != LLDB_INVALID_ADDRESS) {
+ if (addr_of_string != LLDB_INVALID_ADDRESS ||
+addr_type == eAddressTypeHost) {
switch (addr_type) {
case eAddressTypeLoad: {
ProcessSP process_sp(valobj.GetProcessSP());
if (!process_sp)
return false;
-
StringPrinter::ReadStringAndDumpToStreamOptions options(valobj);
Status error;
lldb::addr_t addr_of_data =
@@ -287,8 +287,31 @@ bool
lldb_private::formatters::LibStdcppStringSummaryProvider(
} else
return true;
} break;
-case eAddressTypeHost:
- break;
+case eAddressTypeHost: {
+ // We have the host address of our std::string
+ // But we need to read the pointee data from the debugged process.
+ ProcessSP process_sp(valobj.GetProcessSP());
+ DataExtractor data;
+ Status error;
+ valobj.GetData(data, error);
+ if (error.Fail())
+return false;
+ // We want to read the address from std::string, which is the first 8
bytes.
+ lldb::offset_t offset = 0;
+ lldb::addr_t addr = data.GetAddress();
+ if (!addr)
+ {
+stream.Printf("nullptr");
+return true;
+ }
+
+ std::string contents;
+ process_sp->ReadCStringFromMemory(addr, contents, error);
+ if (error.Fail())
+return false;
+ stream.Printf("%s", contents.c_str());
+ return true;
+} break;
case eAddressTypeInvalid:
case eAddressTypeFile:
break;
diff --git
a/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
new file mode 100644
index 00..57e42c920f8294
--- /dev/null
+++
b/lldb/test/API/functionalities/data-formatter/data-formatter-stl/libstdcpp/string/ConvertToDataFormatter.py
@@ -0,0 +1,50 @@
+# coding=utf8
+"""
+Helper formmater to verify Std::String by created via SBData
+"""
+
+import lldb
+
+class SyntheticFormatter:
+def __init__(self, valobj, dict):
+self.valobj = valobj
+
+def num_children(self):
+return 6
+
+def has_children(self):
+return True
+
+def get_child_at_index(self, index):
+name = None
+match index:
+case 0:
+name = "short_string"
+case 1:
+name = "long_string"
+case 2:
+name = "short_string_ptr"
+case 3:
+name = "long_string_ptr"
+case 4:
+name = "short_string_ref"
+case 5:
+name = "long_string_ref"
+case _:
+return None
+
+child = self.valobj.GetChildMemberWithName(name)
+valType = child.GetType()
+return self.valobj.CreateValueFromData(name,
+child.GetData(),
+valType)
+
+
+def