[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521098509 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14143/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521098509 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14143/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521098503 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
HyukjinKwon commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r313700184
##
File path: dev/run-tests-jenkins
##
@@ -31,4 +31,7 @@ if [[ "$PYTHON_VERSION_CHECK" == "True" ]]; then
exit -1
fi
+export JAVA_HOME=/usr/java/jdk-11.0.1
+export PATH=${JAVA_HOME}/bin:${PATH}
Review comment:
cc @shaneknapp and @srowen FYI Yuming is trying to build it on the top of
https://github.com/apache/spark/pull/25423 . Seems Java 8 is not properly set
so it needs some changes at #25423
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
HyukjinKwon commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r31364
##
File path: dev/run-tests-jenkins
##
@@ -31,4 +31,7 @@ if [[ "$PYTHON_VERSION_CHECK" == "True" ]]; then
exit -1
fi
+export JAVA_HOME=/usr/java/jdk-11.0.1
+export PATH=${JAVA_HOME}/bin:${PATH}
Review comment:
@wangyum, can you try this?
Seems we should pass env at
https://github.com/apache/spark/pull/25423/files#diff-3c9f4fccf7d30ce2e8fa86db2ad1fdadR124
```diff
diff --git a/dev/run-tests-jenkins.py b/dev/run-tests-jenkins.py
index 4b91a5fa423..7a73657138f 100755
--- a/dev/run-tests-jenkins.py
+++ b/dev/run-tests-jenkins.py
@@ -121,7 +121,8 @@ def run_tests(tests_timeout):
test_result_code = subprocess.Popen(['timeout',
tests_timeout,
- os.path.join(SPARK_HOME, 'dev',
'run-tests')]).wait()
+ os.path.join(SPARK_HOME, 'dev',
'run-tests')],
+env=dict(os.environ)).wait()
```
Seems like there's something wrong when environment variables are inherited
(by default).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a change in pull request #25402: [SPARK-28666] Support saveAsTable for V2 tables through Session Catalog
brkyvz commented on a change in pull request #25402: [SPARK-28666] Support
saveAsTable for V2 tables through Session Catalog
URL: https://github.com/apache/spark/pull/25402#discussion_r313698022
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/sources/v2/DataSourceV2DataFrameSessionCatalogSuite.scala
##
@@ -0,0 +1,152 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.sources.v2
+
+import java.util
+import java.util.concurrent.ConcurrentHashMap
+
+import scala.collection.JavaConverters._
+
+import org.scalatest.BeforeAndAfter
+
+import org.apache.spark.sql.{DataFrame, QueryTest}
+import org.apache.spark.sql.catalog.v2.Identifier
+import org.apache.spark.sql.catalog.v2.expressions.Transform
+import org.apache.spark.sql.catalyst.analysis.TableAlreadyExistsException
+import org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SharedSQLContext
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+class DataSourceV2DataFrameSessionCatalogSuite
+ extends QueryTest
+ with SharedSQLContext
+ with BeforeAndAfter {
+ import testImplicits._
+
+ private val v2Format = classOf[InMemoryTableProvider].getName
+
+ before {
+spark.conf.set(SQLConf.V2_SESSION_CATALOG.key,
classOf[TestV2SessionCatalog].getName)
+ }
+
+ override def afterEach(): Unit = {
+super.afterEach()
+spark.catalog("session").asInstanceOf[TestV2SessionCatalog].clearTables()
+ }
+
+ private def verifyTable(tableName: String, expected: DataFrame): Unit = {
+checkAnswer(spark.table(tableName), expected)
+checkAnswer(sql(s"SELECT * FROM $tableName"), expected)
+checkAnswer(sql(s"TABLE $tableName"), expected)
+ }
+
+ test("saveAsTable and v2 table - table doesn't exist") {
+val t1 = "tbl"
+val df = Seq((1L, "a"), (2L, "b"), (3L, "c")).toDF("id", "data")
+df.write.format(v2Format).saveAsTable(t1)
+verifyTable(t1, df)
+ }
+
+ test("saveAsTable: v2 table - table exists") {
+val t1 = "tbl"
+val df = Seq((1L, "a"), (2L, "b"), (3L, "c")).toDF("id", "data")
+spark.sql(s"CREATE TABLE $t1 (id bigint, data string) USING $v2Format")
+intercept[TableAlreadyExistsException] {
+ df.select("id", "data").write.format(v2Format).saveAsTable(t1)
+}
+df.write.format(v2Format).mode("append").saveAsTable(t1)
+verifyTable(t1, df)
+
+// Check that appends are by name
+df.select('data, 'id).write.format(v2Format).mode("append").saveAsTable(t1)
Review comment:
I'll add a test
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a change in pull request #25402: [SPARK-28666] Support saveAsTable for V2 tables through Session Catalog
brkyvz commented on a change in pull request #25402: [SPARK-28666] Support
saveAsTable for V2 tables through Session Catalog
URL: https://github.com/apache/spark/pull/25402#discussion_r313697976
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalog.scala
##
@@ -172,7 +173,7 @@ class V2SessionCatalog(sessionState: SessionState) extends
TableCatalog {
/**
* An implementation of catalog v2 [[Table]] to expose v1 table metadata.
*/
-case class CatalogTableAsV2(v1Table: CatalogTable) extends Table {
+case class CatalogTableAsV2(v1Table: CatalogTable) extends UnresolvedTable {
Review comment:
Oh, I like that a lot more
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a change in pull request #25368: [SPARK-28635][SQL] create CatalogManager to track registered v2 catalogs
brkyvz commented on a change in pull request #25368: [SPARK-28635][SQL] create
CatalogManager to track registered v2 catalogs
URL: https://github.com/apache/spark/pull/25368#discussion_r313697394
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceResolution.scala
##
@@ -45,8 +45,8 @@ case class DataSourceResolution(
import org.apache.spark.sql.catalog.v2.CatalogV2Implicits._
import lookup._
- lazy val v2SessionCatalog: CatalogPlugin = lookup.sessionCatalog
- .getOrElse(throw new AnalysisException("No v2 session catalog
implementation is available"))
+ def v2SessionCatalog: CatalogPlugin = lookup.sessionCatalog
Review comment:
Do we even need `LookupCatalog` anymore?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a change in pull request #25368: [SPARK-28635][SQL] create CatalogManager to track registered v2 catalogs
brkyvz commented on a change in pull request #25368: [SPARK-28635][SQL] create
CatalogManager to track registered v2 catalogs
URL: https://github.com/apache/spark/pull/25368#discussion_r313696942
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalog/v2/CatalogManager.scala
##
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalog.v2
+
+import scala.collection.mutable
+import scala.util.control.NonFatal
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * A thread-safe manager for [[CatalogPlugin]]s. It tracks all the registered
catalogs, and allow
+ * the caller to look up a catalog by name.
+ */
+class CatalogManager(conf: SQLConf) extends Logging {
+
+ private val catalogs = mutable.HashMap.empty[String, CatalogPlugin]
+
+ def catalog(name: String): CatalogPlugin = synchronized {
+catalogs.getOrElseUpdate(name, Catalogs.load(name, conf))
+ }
+
+ def defaultCatalog: Option[CatalogPlugin] = {
+conf.defaultV2Catalog.flatMap { catalogName =>
+ try {
+Some(catalog(catalogName))
+ } catch {
+case NonFatal(e) =>
+ logError(s"Cannot load default v2 catalog: $catalogName", e)
+ None
+ }
+}
+ }
+
+ def v2SessionCatalog: Option[CatalogPlugin] = {
+try {
+ Some(catalog(CatalogManager.SESSION_CATALOG_NAME))
+} catch {
+ case NonFatal(e) =>
+logError("Cannot load v2 session catalog", e)
+None
+}
+ }
+
+ private def getDefaultNamespace(c: CatalogPlugin) = c match {
+case c: SupportsNamespaces => c.defaultNamespace()
+case _ => Array.empty[String]
+ }
+
+ private var _currentNamespace = {
+// The builtin catalog use "default" as the default database.
Review comment:
I'm thinking more about whether this should be the duty of the
CatalogManager or the catalog itself...
My thoughts are:
1. Once the V2SessionCatalog `SupportsNamespaces`, it can have the default
namespace `default` set within it
2. When you run a command like `USE foo.bar` where `foo` is the catalog,
we should set the default namespace within that catalog to be `bar`.
3. What if the `default` catalog doesn't support namespaces in the first
place?
I'm a bit worried that having the default namespace setting in the
CatalogManager can lead to a split brain situation.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a change in pull request #25368: [SPARK-28635][SQL] create CatalogManager to track registered v2 catalogs
brkyvz commented on a change in pull request #25368: [SPARK-28635][SQL] create
CatalogManager to track registered v2 catalogs
URL: https://github.com/apache/spark/pull/25368#discussion_r313697462
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceResolution.scala
##
@@ -45,8 +45,8 @@ case class DataSourceResolution(
import org.apache.spark.sql.catalog.v2.CatalogV2Implicits._
import lookup._
- lazy val v2SessionCatalog: CatalogPlugin = lookup.sessionCatalog
- .getOrElse(throw new AnalysisException("No v2 session catalog
implementation is available"))
+ def v2SessionCatalog: CatalogPlugin = lookup.sessionCatalog
Review comment:
Shouldn't this rule just get the `CatalogManager` as an input instead of
`LookupCatalog`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan
AmplabJenkins removed a comment on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan URL: https://github.com/apache/spark/pull/24623#issuecomment-521094084 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan
AmplabJenkins removed a comment on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan URL: https://github.com/apache/spark/pull/24623#issuecomment-521094087 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109069/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan
AmplabJenkins commented on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan URL: https://github.com/apache/spark/pull/24623#issuecomment-521094084 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan
AmplabJenkins commented on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan URL: https://github.com/apache/spark/pull/24623#issuecomment-521094087 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109069/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan
SparkQA removed a comment on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan URL: https://github.com/apache/spark/pull/24623#issuecomment-521059455 **[Test build #109069 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109069/testReport)** for PR 24623 at commit [`f6312c1`](https://github.com/apache/spark/commit/f6312c1cb8bb00c0f8aba3fb677328b46a72523a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #25383: [SPARK-13677][ML] Implement Tree-Based Feature Transformation for ML
zhengruifeng commented on a change in pull request #25383: [SPARK-13677][ML]
Implement Tree-Based Feature Transformation for ML
URL: https://github.com/apache/spark/pull/25383#discussion_r313696881
##
File path: mllib/src/main/scala/org/apache/spark/ml/tree/treeParams.scala
##
@@ -455,7 +508,19 @@ private[ml] object GBTClassifierParams {
Array("logistic").map(_.toLowerCase(Locale.ROOT))
}
-private[ml] trait GBTClassifierParams extends GBTParams with
HasVarianceImpurity {
+private[ml] trait GBTClassifierParams extends GBTParams with
HasVarianceImpurity
+ with ProbabilisticClassifierParams {
+
+ override protected def validateAndTransformSchema(
Review comment:
@mgaido91 I tend to keep current way, that is because the superclasses are
different:
1,the `super.validateAndTransformSchema(schema, fitting, featuresDataType)`
in `GBTClassifierParams` & `RandomForestClassifierParams` are from
`ProbabilisticClassifierParams`, which check cols
probabilityCol,rawPredictionCol,featuresCol,labelCol,weightCol,predictionCol
2,while the super method called in `RandomForestRegressorParams` &
`GBTRegressorParams` are from `PredictorParams`, which only check cols
featuresCol,labelCol,weightCol,predictionCol
We can add another two trait for classification and regression,
respectively. Like `TreeEnsembleClassifierParams` &
`TreeEnsembleRegressorParams`.
However, I think this maybe not worthwhile, since there will be only two
subclasses for each, and this will make the hierarchy more complex.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan
SparkQA commented on issue #24623: [SPARK-27739][SQL] df.persist should save stats from optimized plan URL: https://github.com/apache/spark/pull/24623#issuecomment-521093828 **[Test build #109069 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109069/testReport)** for PR 24623 at commit [`f6312c1`](https://github.com/apache/spark/commit/f6312c1cb8bb00c0f8aba3fb677328b46a72523a). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on issue #25424: [SPARK-28543][DOCS][WebUI] Document Spark Jobs page
zhengruifeng commented on issue #25424: [SPARK-28543][DOCS][WebUI] Document Spark Jobs page URL: https://github.com/apache/spark/pull/25424#issuecomment-521090758 @srowen I had some offline discussion with @gatorsmile , and the expected doc seems to be something like 1, https://www.cloudera.com/documentation/enterprise/5-9-x/topics/operation_spark_applications.html#spark_monitoring 2, https://www.ibm.com/support/knowledgecenter/en/SS3H8V_1.1.0/com.ibm.izoda.v1r1.azka100/topics/azkic_c_webUIs.htm the first step in my opinion is to add some basic explanation, example and figure for each tab, and we can refine it in the future. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521090259 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109077/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521090256 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109076/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521090255 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521090252 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521090255 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521090259 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109077/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521090256 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109076/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page
SparkQA commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521090220 **[Test build #109077 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109077/testReport)** for PR 25430 at commit [`0098e68`](https://github.com/apache/spark/commit/0098e6871fc9f0fa031336d747998b439fd93a95). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
SparkQA commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521090215 **[Test build #109076 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109076/testReport)** for PR 25445 at commit [`bdc796c`](https://github.com/apache/spark/commit/bdc796c397c05dcaebfa52b3d95b9acf3d3fd41a). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page
SparkQA removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521088432 **[Test build #109077 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109077/testReport)** for PR 25430 at commit [`0098e68`](https://github.com/apache/spark/commit/0098e6871fc9f0fa031336d747998b439fd93a95). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521090252 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page
SparkQA removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521088431 **[Test build #109076 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109076/testReport)** for PR 25445 at commit [`bdc796c`](https://github.com/apache/spark/commit/bdc796c397c05dcaebfa52b3d95b9acf3d3fd41a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25427: [SPARK-28705][Test]drop table after being used
SparkQA commented on issue #25427: [SPARK-28705][Test]drop table after being used URL: https://github.com/apache/spark/pull/25427#issuecomment-521089644 **[Test build #109078 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109078/testReport)** for PR 25427 at commit [`139c98a`](https://github.com/apache/spark/commit/139c98ab32f2783a5ea5b1523df873f76d54). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521089319 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25427: [SPARK-28705][Test]drop table after being used
AmplabJenkins removed a comment on issue #25427: [SPARK-28705][Test]drop table after being used URL: https://github.com/apache/spark/pull/25427#issuecomment-521089348 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25427: [SPARK-28705][Test]drop table after being used
AmplabJenkins removed a comment on issue #25427: [SPARK-28705][Test]drop table after being used URL: https://github.com/apache/spark/pull/25427#issuecomment-521089351 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14142/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins removed a comment on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521089321 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14141/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25427: [SPARK-28705][Test]drop table after being used
AmplabJenkins commented on issue #25427: [SPARK-28705][Test]drop table after being used URL: https://github.com/apache/spark/pull/25427#issuecomment-521089351 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14142/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521089321 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14141/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25427: [SPARK-28705][Test]drop table after being used
AmplabJenkins commented on issue #25427: [SPARK-28705][Test]drop table after being used URL: https://github.com/apache/spark/pull/25427#issuecomment-521089348 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page
AmplabJenkins commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521089319 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
wangyum commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r313692809
##
File path: dev/run-tests-jenkins
##
@@ -31,4 +31,7 @@ if [[ "$PYTHON_VERSION_CHECK" == "True" ]]; then
exit -1
fi
+export JAVA_HOME=/usr/java/jdk-11.0.1
+export PATH=${JAVA_HOME}/bin:${PATH}
Review comment:
Seems it works:
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521088078 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
SparkQA commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521088431 **[Test build #109076 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109076/testReport)** for PR 25445 at commit [`bdc796c`](https://github.com/apache/spark/commit/bdc796c397c05dcaebfa52b3d95b9acf3d3fd41a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins removed a comment on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521088084 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14140/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on a change in pull request #25115: [SPARK-28351][SQL] Support DELETE in DataSource V2
xianyinxin commented on a change in pull request #25115: [SPARK-28351][SQL] Support DELETE in DataSource V2 URL: https://github.com/apache/spark/pull/25115#discussion_r313692144 ## File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceResolution.scala ## @@ -173,6 +173,19 @@ case class DataSourceResolution( // only top-level adds are supported using AlterTableAddColumnsCommand AlterTableAddColumnsCommand(table, newColumns.map(convertToStructField)) +case DeleteFromStatement(AsTableIdentifier(table), tableAlias, condition) => + throw new AnalysisException( Review comment: Saw the code in #25402 . I think it's the best choice. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page
SparkQA commented on issue #25430: [SPARK-28540][WEBUI] Document Environment page URL: https://github.com/apache/spark/pull/25430#issuecomment-521088432 **[Test build #109077 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109077/testReport)** for PR 25430 at commit [`0098e68`](https://github.com/apache/spark/commit/0098e6871fc9f0fa031336d747998b439fd93a95). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on a change in pull request #25402: [SPARK-28666] Support saveAsTable for V2 tables through Session Catalog
xianyinxin commented on a change in pull request #25402: [SPARK-28666] Support saveAsTable for V2 tables through Session Catalog URL: https://github.com/apache/spark/pull/25402#discussion_r313691951 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala ## @@ -650,8 +648,11 @@ class Analyzer( if catalog.isTemporaryTable(ident) => u // temporary views take precedence over catalog table names - case u @ UnresolvedRelation(CatalogObjectIdentifier(Some(catalogPlugin), ident)) => -loadTable(catalogPlugin, ident).map(DataSourceV2Relation.create).getOrElse(u) + case u @ UnresolvedRelation(CatalogObjectIdentifier(maybeCatalog, ident)) => +maybeCatalog.orElse(sessionCatalog) + .flatMap(loadTable(_, ident)) + .map(DataSourceV2Relation.create) + .getOrElse(u) Review comment: A +1 on this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #25427: [SPARK-28705][Test]drop table after being used
sandeep-katta commented on a change in pull request #25427:
[SPARK-28705][Test]drop table after being used
URL: https://github.com/apache/spark/pull/25427#discussion_r313691983
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisExternalCatalogSuite.scala
##
@@ -57,6 +57,7 @@ class AnalysisExternalCatalogSuite extends AnalysisTest with
Matchers {
val plan = Project(Seq(func), testRelation)
analyzer.execute(plan)
verifyZeroInteractions(catalog)
+catalog.dropTable("default", "t1", true, false)
Review comment:
I will add in afterEach, table created in "query builtin functions don't
call the external catalog" is affecting the testcase "check the existence of
builtin functions don't call the external catalog". As per SPARK-25464,
database can only be created to empty location. So it is requried to delete the
table created in every testcase
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521088078 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
AmplabJenkins commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521088084 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14140/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request #25445: [SPARK-28541][WEBUI] Document Storage page
zhengruifeng opened a new pull request #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445 ## What changes were proposed in this pull request? add an example for storage tab ## How was this patch tested? locally building This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page
zhengruifeng commented on issue #25445: [SPARK-28541][WEBUI] Document Storage page URL: https://github.com/apache/spark/pull/25445#issuecomment-521087793 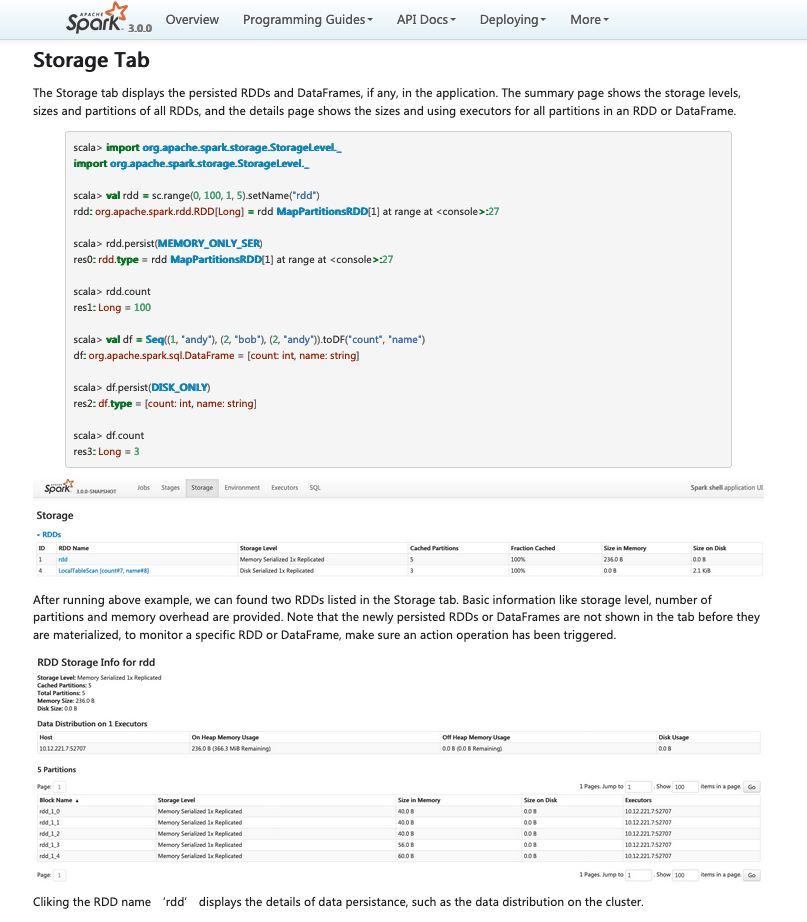 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
HyukjinKwon commented on a change in pull request #25412:
[SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r313691392
##
File path:
examples/src/main/scala/org/apache/spark/examples/streaming/DirectKerberizedKafkaWordCount.scala
##
@@ -0,0 +1,90 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.streaming
+
+import org.apache.kafka.clients.CommonClientConfigs
+import org.apache.kafka.clients.consumer.ConsumerConfig
+import org.apache.kafka.common.security.auth.SecurityProtocol
+import org.apache.kafka.common.serialization.StringDeserializer
+
+import org.apache.spark.SparkConf
+import org.apache.spark.streaming._
+import org.apache.spark.streaming.kafka010._
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: DirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ *$ bin/run-example --files ${path}/kafka_jaas.conf \
Review comment:
Where is `kafka_jaas.conf` file? Can we describe how to execute this example
from the very first bash command?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25121: [SPARK-28356][SQL] Do not reduce the number of partitions for repartition in adaptive execution
cloud-fan commented on a change in pull request #25121: [SPARK-28356][SQL] Do
not reduce the number of partitions for repartition in adaptive execution
URL: https://github.com/apache/spark/pull/25121#discussion_r313691232
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/ReduceNumShufflePartitions.scala
##
@@ -76,12 +82,7 @@ case class ReduceNumShufflePartitions(conf: SQLConf)
extends Rule[SparkPlan] {
// `ShuffleQueryStageExec` gives null mapOutputStatistics when the input
RDD has 0 partitions,
// we should skip it when calculating the `partitionStartIndices`.
val validMetrics = shuffleMetrics.filter(_ != null)
- // We may get different pre-shuffle partition number if user calls
repartition manually.
- // We don't reduce shuffle partition number in that case.
- val distinctNumPreShufflePartitions =
-validMetrics.map(stats => stats.bytesByPartitionId.length).distinct
-
- if (validMetrics.nonEmpty && distinctNumPreShufflePartitions.length ==
1) {
+ if (validMetrics.nonEmpty) {
Review comment:
ah `SinglePartition` is an exception. So it's still possible to hit
`distinctNumPreShufflePartitions.length > 1` here. Let's add back this check
@carsonwang @maryannxue
thanks for reporting it!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
HyukjinKwon commented on a change in pull request #25412:
[SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r313691175
##
File path:
examples/src/main/java/org/apache/spark/examples/streaming/JavaDirectKerberizedKafkaWordCount.java
##
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.streaming;
+
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Arrays;
+import java.util.Map;
+import java.util.Set;
+import java.util.regex.Pattern;
+
+import scala.Tuple2;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.serialization.StringDeserializer;
+
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.api.java.*;
+import org.apache.spark.streaming.kafka010.ConsumerStrategies;
+import org.apache.spark.streaming.kafka010.KafkaUtils;
+import org.apache.spark.streaming.kafka010.LocationStrategies;
+import org.apache.spark.streaming.Durations;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaDirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ *$ bin/run-example --files ${path}/kafka_jaas.conf \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ */
+
+public final class JavaDirectKerberizedKafkaWordCount {
+ private static final Pattern SPACE = Pattern.compile(" ");
+
+ public static void main(String[] args) throws Exception {
+if (args.length < 3) {
+ System.err.println(
+ "Usage: JavaDirectKerberizedKafkaWordCount
\n" +
+ " is a list of one or more Kafka brokers\n" +
+ " is a consumer group name to consume from
topics\n" +
+ " is a list of one or more kafka topics to
consume from\n\n");
+ System.exit(1);
+}
+
+StreamingExamples.setStreamingLogLevels();
+
+String brokers = args[0];
+String groupId = args[1];
+String topics = args[2];
+
+// Create context with a 2 seconds batch interval
+SparkConf sparkConf = new
SparkConf().setAppName("JavaDirectKerberizedKafkaWordCount");
+JavaStreamingContext jssc = new JavaStreamingContext(sparkConf,
Durations.seconds(2));
+
+Set topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
+Map kafkaParams = new HashMap<>();
+kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
+kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
+kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
+kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
+kafkaParams.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG,
+
SecurityProtocol.SASL_PLAINTEXT.name);
Review comment:
I think you can just explain why `SASL_PLAINTEXT` is discouraged (SSL
encryption is disabled and why it's dangerous) in a comment.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail:
[GitHub] [spark] dongjoon-hyun commented on issue #25444: [SPARK-28719][BUILD] [FOLLOWUP] Add JDK11 for Github Actions
dongjoon-hyun commented on issue #25444: [SPARK-28719][BUILD] [FOLLOWUP] Add JDK11 for Github Actions URL: https://github.com/apache/spark/pull/25444#issuecomment-521086708 +1, LGTM. Wow, so fast! :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dbtsai closed pull request #25444: [SPARK-28719][BUILD] [FOLLOWUP] Add JDK11 for Github Actions
dbtsai closed pull request #25444: [SPARK-28719][BUILD] [FOLLOWUP] Add JDK11 for Github Actions URL: https://github.com/apache/spark/pull/25444 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dbtsai opened a new pull request #25444: [SPARK-28719][BUILD] [FOLLOWUP] Add JDK11 for Github Actions
dbtsai opened a new pull request #25444: [SPARK-28719][BUILD] [FOLLOWUP] Add JDK11 for Github Actions URL: https://github.com/apache/spark/pull/25444 ## What changes were proposed in this pull request? Add JDK11 for Github Actions This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
SparkQA commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521085932 **[Test build #109075 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109075/testReport)** for PR 25443 at commit [`6821aa5`](https://github.com/apache/spark/commit/6821aa5f898c2cf7937618f7fca7010ade7f1620). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521085607 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14139/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521085603 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521085607 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14139/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521085603 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
HyukjinKwon commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r313689496
##
File path: dev/run-tests-jenkins
##
@@ -31,4 +31,7 @@ if [[ "$PYTHON_VERSION_CHECK" == "True" ]]; then
exit -1
fi
+export JAVA_HOME=/usr/java/jdk-11.0.1
+export PATH=${JAVA_HOME}/bin:${PATH}
Review comment:
if it doesn't work, you can even try within `build/mvn`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25402: [SPARK-28666] Support saveAsTable for V2 tables through Session Catalog
cloud-fan commented on a change in pull request #25402: [SPARK-28666] Support
saveAsTable for V2 tables through Session Catalog
URL: https://github.com/apache/spark/pull/25402#discussion_r313688836
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalog.scala
##
@@ -172,7 +173,7 @@ class V2SessionCatalog(sessionState: SessionState) extends
TableCatalog {
/**
* An implementation of catalog v2 [[Table]] to expose v1 table metadata.
*/
-case class CatalogTableAsV2(v1Table: CatalogTable) extends Table {
+case class CatalogTableAsV2(v1Table: CatalogTable) extends UnresolvedTable {
Review comment:
It's defined in catalyst:
`org.apache.spark.sql.catalyst.catalog.CatalogTable` in file
`org/apache/spark/sql/catalyst/catalog/interface.scala`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25402: [SPARK-28666] Support saveAsTable for V2 tables through Session Catalog
cloud-fan commented on a change in pull request #25402: [SPARK-28666] Support
saveAsTable for V2 tables through Session Catalog
URL: https://github.com/apache/spark/pull/25402#discussion_r313688836
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalog.scala
##
@@ -172,7 +173,7 @@ class V2SessionCatalog(sessionState: SessionState) extends
TableCatalog {
/**
* An implementation of catalog v2 [[Table]] to expose v1 table metadata.
*/
-case class CatalogTableAsV2(v1Table: CatalogTable) extends Table {
+case class CatalogTableAsV2(v1Table: CatalogTable) extends UnresolvedTable {
Review comment:
It's defined in catalyst:
`org.apache.spark.sql.catalyst.catalog.CatalogTable` in file
`sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/interface.scala`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25115: [SPARK-28351][SQL] Support DELETE in DataSource V2
cloud-fan commented on a change in pull request #25115: [SPARK-28351][SQL] Support DELETE in DataSource V2 URL: https://github.com/apache/spark/pull/25115#discussion_r313688614 ## File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceResolution.scala ## @@ -173,6 +173,19 @@ case class DataSourceResolution( // only top-level adds are supported using AlterTableAddColumnsCommand AlterTableAddColumnsCommand(table, newColumns.map(convertToStructField)) +case DeleteFromStatement(AsTableIdentifier(table), tableAlias, condition) => + throw new AnalysisException( Review comment: We can remove this case after https://github.com/apache/spark/pull/25402, which updates `ResolveTable` to fallback to v2 session catalog. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521084337 Hmm. It's a little confusing. The current Jenkins passes this module. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521084337 Hmm. It's a little confusing. The current Jenkins passes this module, too. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521084337 Hmm. Maybe not. The current Jenkins passes this module. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521083767 If we build and test with both JDK11, it will pass. The current Jenkins is building with JDK8 and running on JDK11 and hit this known issue. ``` $ build/sbt "core/testOnly *.ExternalSorterSuite" [info] ExternalSorterSuite: WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/Users/dhyun/PRS/SPARK-HIVE-2.3.6/common/unsafe/target/scala-2.12/spark-unsafe_2.12-3.0.0-SNAPSHOT.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release [info] - empty data stream with kryo ser (1 second, 457 milliseconds) [info] - empty data stream with java ser (89 milliseconds) [info] - few elements per partition with kryo ser (89 milliseconds) [info] - few elements per partition with java ser (74 milliseconds) [info] - empty partitions with spilling with kryo ser (329 milliseconds) [info] - empty partitions with spilling with java ser (156 milliseconds) [info] - spilling in local cluster with kryo ser (4 seconds, 296 milliseconds) [info] - spilling in local cluster with java ser (4 seconds, 372 milliseconds) [info] - spilling in local cluster with many reduce tasks with kryo ser (5 seconds, 718 milliseconds) [info] - spilling in local cluster with many reduce tasks with java ser (6 seconds, 51 milliseconds) [info] - cleanup of intermediate files in sorter (113 milliseconds) [info] - cleanup of intermediate files in sorter with failures (111 milliseconds) [info] - cleanup of intermediate files in shuffle (297 milliseconds) [info] - cleanup of intermediate files in shuffle with failures (121 milliseconds) [info] - no sorting or partial aggregation with kryo ser (58 milliseconds) [info] - no sorting or partial aggregation with java ser (53 milliseconds) [info] - no sorting or partial aggregation with spilling with kryo ser (62 milliseconds) [info] - no sorting or partial aggregation with spilling with java ser (68 milliseconds) [info] - sorting, no partial aggregation with kryo ser (63 milliseconds) [info] - sorting, no partial aggregation with java ser (54 milliseconds) [info] - sorting, no partial aggregation with spilling with kryo ser (58 milliseconds) [info] - sorting, no partial aggregation with spilling with java ser (61 milliseconds) [info] - partial aggregation, no sorting with kryo ser (52 milliseconds) [info] - partial aggregation, no sorting with java ser (51 milliseconds) [info] - partial aggregation, no sorting with spilling with kryo ser (55 milliseconds) [info] - partial aggregation, no sorting with spilling with java ser (49 milliseconds) [info] - partial aggregation and sorting with kryo ser (44 milliseconds) [info] - partial aggregation and sorting with java ser (44 milliseconds) [info] - partial aggregation and sorting with spilling with kryo ser (48 milliseconds) [info] - partial aggregation and sorting with spilling with java ser (49 milliseconds) [info] - sort without breaking sorting contracts with kryo ser (1 second, 904 milliseconds) [info] - sort without breaking sorting contracts with java ser (1 second, 860 milliseconds) [info] - sort without breaking timsort contracts for large arrays !!! IGNORED !!! [info] - spilling with hash collisions (208 milliseconds) [info] - spilling with many hash collisions (589 milliseconds) [info] - spilling with hash collisions using the Int.MaxValue key (168 milliseconds) [info] - spilling with null keys and values (226 milliseconds) [info] - sorting updates peak execution memory (1 second, 347 milliseconds) [info] - force to spill for external sorter (800 milliseconds) [info] ScalaTest [info] Run completed in 34 seconds, 99 milliseconds. [info] Total number of tests run: 38 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 38, failed 0, canceled 0, ignored 1, pending 0 [info] All tests passed. ``` cc @srowen This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun edited a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521083767 If we build and test with both JDK11, it will pass. The current Jenkins seems to build with JDK8 and running on JDK11 and hit this known issue. ``` $ build/sbt "core/testOnly *.ExternalSorterSuite" [info] ExternalSorterSuite: WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/Users/dhyun/PRS/SPARK-HIVE-2.3.6/common/unsafe/target/scala-2.12/spark-unsafe_2.12-3.0.0-SNAPSHOT.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release [info] - empty data stream with kryo ser (1 second, 457 milliseconds) [info] - empty data stream with java ser (89 milliseconds) [info] - few elements per partition with kryo ser (89 milliseconds) [info] - few elements per partition with java ser (74 milliseconds) [info] - empty partitions with spilling with kryo ser (329 milliseconds) [info] - empty partitions with spilling with java ser (156 milliseconds) [info] - spilling in local cluster with kryo ser (4 seconds, 296 milliseconds) [info] - spilling in local cluster with java ser (4 seconds, 372 milliseconds) [info] - spilling in local cluster with many reduce tasks with kryo ser (5 seconds, 718 milliseconds) [info] - spilling in local cluster with many reduce tasks with java ser (6 seconds, 51 milliseconds) [info] - cleanup of intermediate files in sorter (113 milliseconds) [info] - cleanup of intermediate files in sorter with failures (111 milliseconds) [info] - cleanup of intermediate files in shuffle (297 milliseconds) [info] - cleanup of intermediate files in shuffle with failures (121 milliseconds) [info] - no sorting or partial aggregation with kryo ser (58 milliseconds) [info] - no sorting or partial aggregation with java ser (53 milliseconds) [info] - no sorting or partial aggregation with spilling with kryo ser (62 milliseconds) [info] - no sorting or partial aggregation with spilling with java ser (68 milliseconds) [info] - sorting, no partial aggregation with kryo ser (63 milliseconds) [info] - sorting, no partial aggregation with java ser (54 milliseconds) [info] - sorting, no partial aggregation with spilling with kryo ser (58 milliseconds) [info] - sorting, no partial aggregation with spilling with java ser (61 milliseconds) [info] - partial aggregation, no sorting with kryo ser (52 milliseconds) [info] - partial aggregation, no sorting with java ser (51 milliseconds) [info] - partial aggregation, no sorting with spilling with kryo ser (55 milliseconds) [info] - partial aggregation, no sorting with spilling with java ser (49 milliseconds) [info] - partial aggregation and sorting with kryo ser (44 milliseconds) [info] - partial aggregation and sorting with java ser (44 milliseconds) [info] - partial aggregation and sorting with spilling with kryo ser (48 milliseconds) [info] - partial aggregation and sorting with spilling with java ser (49 milliseconds) [info] - sort without breaking sorting contracts with kryo ser (1 second, 904 milliseconds) [info] - sort without breaking sorting contracts with java ser (1 second, 860 milliseconds) [info] - sort without breaking timsort contracts for large arrays !!! IGNORED !!! [info] - spilling with hash collisions (208 milliseconds) [info] - spilling with many hash collisions (589 milliseconds) [info] - spilling with hash collisions using the Int.MaxValue key (168 milliseconds) [info] - spilling with null keys and values (226 milliseconds) [info] - sorting updates peak execution memory (1 second, 347 milliseconds) [info] - force to spill for external sorter (800 milliseconds) [info] ScalaTest [info] Run completed in 34 seconds, 99 milliseconds. [info] Total number of tests run: 38 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 38, failed 0, canceled 0, ignored 1, pending 0 [info] All tests passed. ``` cc @srowen This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For
[GitHub] [spark] dongjoon-hyun commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521083767 If we build and test with both JDK11, it will pass. The current Jenkins is building with JDK8 and running on JDK11 and hit this known issue. ``` [info] ExternalSorterSuite: WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/Users/dhyun/PRS/SPARK-HIVE-2.3.6/common/unsafe/target/scala-2.12/spark-unsafe_2.12-3.0.0-SNAPSHOT.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release [info] - empty data stream with kryo ser (1 second, 457 milliseconds) [info] - empty data stream with java ser (89 milliseconds) [info] - few elements per partition with kryo ser (89 milliseconds) [info] - few elements per partition with java ser (74 milliseconds) [info] - empty partitions with spilling with kryo ser (329 milliseconds) [info] - empty partitions with spilling with java ser (156 milliseconds) [info] - spilling in local cluster with kryo ser (4 seconds, 296 milliseconds) [info] - spilling in local cluster with java ser (4 seconds, 372 milliseconds) [info] - spilling in local cluster with many reduce tasks with kryo ser (5 seconds, 718 milliseconds) [info] - spilling in local cluster with many reduce tasks with java ser (6 seconds, 51 milliseconds) [info] - cleanup of intermediate files in sorter (113 milliseconds) [info] - cleanup of intermediate files in sorter with failures (111 milliseconds) [info] - cleanup of intermediate files in shuffle (297 milliseconds) [info] - cleanup of intermediate files in shuffle with failures (121 milliseconds) [info] - no sorting or partial aggregation with kryo ser (58 milliseconds) [info] - no sorting or partial aggregation with java ser (53 milliseconds) [info] - no sorting or partial aggregation with spilling with kryo ser (62 milliseconds) [info] - no sorting or partial aggregation with spilling with java ser (68 milliseconds) [info] - sorting, no partial aggregation with kryo ser (63 milliseconds) [info] - sorting, no partial aggregation with java ser (54 milliseconds) [info] - sorting, no partial aggregation with spilling with kryo ser (58 milliseconds) [info] - sorting, no partial aggregation with spilling with java ser (61 milliseconds) [info] - partial aggregation, no sorting with kryo ser (52 milliseconds) [info] - partial aggregation, no sorting with java ser (51 milliseconds) [info] - partial aggregation, no sorting with spilling with kryo ser (55 milliseconds) [info] - partial aggregation, no sorting with spilling with java ser (49 milliseconds) [info] - partial aggregation and sorting with kryo ser (44 milliseconds) [info] - partial aggregation and sorting with java ser (44 milliseconds) [info] - partial aggregation and sorting with spilling with kryo ser (48 milliseconds) [info] - partial aggregation and sorting with spilling with java ser (49 milliseconds) [info] - sort without breaking sorting contracts with kryo ser (1 second, 904 milliseconds) [info] - sort without breaking sorting contracts with java ser (1 second, 860 milliseconds) [info] - sort without breaking timsort contracts for large arrays !!! IGNORED !!! [info] - spilling with hash collisions (208 milliseconds) [info] - spilling with many hash collisions (589 milliseconds) [info] - spilling with hash collisions using the Int.MaxValue key (168 milliseconds) [info] - spilling with null keys and values (226 milliseconds) [info] - sorting updates peak execution memory (1 second, 347 milliseconds) [info] - force to spill for external sorter (800 milliseconds) [info] ScalaTest [info] Run completed in 34 seconds, 99 milliseconds. [info] Total number of tests run: 38 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 38, failed 0, canceled 0, ignored 1, pending 0 [info] All tests passed. ``` cc @srowen This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on issue #24983: [SPARK-27714][SQL][CBO] Support Genetic Algorithm based join reorder
xianyinxin commented on issue #24983: [SPARK-27714][SQL][CBO] Support Genetic Algorithm based join reorder URL: https://github.com/apache/spark/pull/24983#issuecomment-521082932 Gentle ping @yeshengm This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
wangyum commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521082061 Failed with these errors: ```java ExternalSorterSuite: - empty data stream with kryo ser - empty data stream with java ser - few elements per partition with kryo ser - few elements per partition with java ser - empty partitions with spilling with kryo ser - empty partitions with spilling with java ser - spilling in local cluster with kryo ser *** FAILED *** org.apache.spark.SparkException: Job aborted due to stage failure: Task serialization failed: java.lang.NoSuchMethodError: java.nio.ByteBuffer.flip()Ljava/nio/ByteBuffer; java.lang.NoSuchMethodError: java.nio.ByteBuffer.flip()Ljava/nio/ByteBuffer; at org.apache.spark.util.io.ChunkedByteBufferOutputStream.toChunkedByteBuffer(ChunkedByteBufferOutputStream.scala:115) at org.apache.spark.broadcast.TorrentBroadcast$.blockifyObject(TorrentBroadcast.scala:307) at org.apache.spark.broadcast.TorrentBroadcast.writeBlocks(TorrentBroadcast.scala:137) at org.apache.spark.broadcast.TorrentBroadcast.(TorrentBroadcast.scala:91) at org.apache.spark.broadcast.TorrentBroadcastFactory.newBroadcast(TorrentBroadcastFactory.scala:34) at org.apache.spark.broadcast.BroadcastManager.newBroadcast(BroadcastManager.scala:74) at org.apache.spark.SparkContext.broadcast(SparkContext.scala:1470) at org.apache.spark.scheduler.DAGScheduler.submitMissingTasks(DAGScheduler.scala:1182) at org.apache.spark.scheduler.DAGScheduler.submitStage(DAGScheduler.scala:1086) at org.apache.spark.scheduler.DAGScheduler.$anonfun$submitStage$5(DAGScheduler.scala:1089) at org.apache.spark.scheduler.DAGScheduler.$anonfun$submitStage$5$adapted(DAGScheduler.scala:1088) at scala.collection.immutable.List.foreach(List.scala:392) at org.apache.spark.scheduler.DAGScheduler.submitStage(DAGScheduler.scala:1088) at org.apache.spark.scheduler.DAGScheduler.handleJobSubmitted(DAGScheduler.scala:1030) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2129) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2121) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2110) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on issue #25440: [SPARK-28719] [Build] Enable Github Actions for master
HyukjinKwon edited a comment on issue #25440: [SPARK-28719] [Build] Enable Github Actions for master URL: https://github.com/apache/spark/pull/25440#issuecomment-521080338 That's cool if possible. I will take a look when I fine some more time. For a quick FYI to share, actually Spark build on Windows is dependent on some environment of AppVeyor such as Cygwin (Spark build is not supported in a native Windows machine) sadly so might not be easy I guess .. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521081623 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109074/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521081620 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
SparkQA removed a comment on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521078178 **[Test build #109074 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109074/testReport)** for PR 25443 at commit [`540d6da`](https://github.com/apache/spark/commit/540d6daef3cecbec195333d5aec7595853f2c94d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
SparkQA commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521081612 **[Test build #109074 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109074/testReport)** for PR 25443 at commit [`540d6da`](https://github.com/apache/spark/commit/540d6daef3cecbec195333d5aec7595853f2c94d). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521081620 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521081585 @wangyum . I believe we should do https://github.com/apache/spark/pull/25443#issuecomment-521078239 in this PR to be complete. cc @gatorsmile This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521081623 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109074/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r313686024
##
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveUtils.scala
##
@@ -59,7 +59,7 @@ private[spark] object HiveUtils extends Logging {
val isHive23: Boolean = hiveVersion.startsWith("2.3")
/** The version of hive used internally by Spark SQL. */
- val builtinHiveVersion: String = if (isHive23) hiveVersion else "1.2.1"
+ val builtinHiveVersion: String = if (isHive23) "2.3.5" else "1.2.1"
Review comment:
Oops. Yes. It's the same with @HyukjinKwon 's comment.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r313685898
##
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveUtils.scala
##
@@ -59,7 +59,7 @@ private[spark] object HiveUtils extends Logging {
val isHive23: Boolean = hiveVersion.startsWith("2.3")
/** The version of hive used internally by Spark SQL. */
- val builtinHiveVersion: String = if (isHive23) hiveVersion else "1.2.1"
+ val builtinHiveVersion: String = if (isHive23) "2.3.5" else "1.2.1"
Review comment:
`2.3.5` -> `2.3.6` to test `Hive 2.3.6` fully?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
HyukjinKwon commented on a change in pull request #25443:
[WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive
2.3.6 on jenkins
URL: https://github.com/apache/spark/pull/25443#discussion_r313685852
##
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveUtils.scala
##
@@ -59,7 +59,7 @@ private[spark] object HiveUtils extends Logging {
val isHive23: Boolean = hiveVersion.startsWith("2.3")
/** The version of hive used internally by Spark SQL. */
- val builtinHiveVersion: String = if (isHive23) hiveVersion else "1.2.1"
+ val builtinHiveVersion: String = if (isHive23) "2.3.5" else "1.2.1"
Review comment:
https://github.com/apache/spark/pull/25443#issuecomment-521078239 - yeah,
otherwise people might keep asking why it's 2.3.5.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25440: [SPARK-28719] [Build] Enable Github Actions for master
HyukjinKwon commented on issue #25440: [SPARK-28719] [Build] Enable Github Actions for master URL: https://github.com/apache/spark/pull/25440#issuecomment-521080338 That's cool if possible. I will take a look when I fine some more time. For a quick FYI to share, actually Appveyor build is dependent on some environment such as Cygwin (Spark build is not supported in a native Windows machine) sadly so might not be easy I guess .. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
wangyum commented on issue #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521080175 Will do it later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES]
Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r313683650
##
File path:
examples/src/main/java/org/apache/spark/examples/streaming/JavaDirectKerberizedKafkaWordCount.java
##
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.streaming;
+
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Arrays;
+import java.util.Map;
+import java.util.Set;
+import java.util.regex.Pattern;
+
+import scala.Tuple2;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.serialization.StringDeserializer;
+
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.api.java.*;
+import org.apache.spark.streaming.kafka010.ConsumerStrategies;
+import org.apache.spark.streaming.kafka010.KafkaUtils;
+import org.apache.spark.streaming.kafka010.LocationStrategies;
+import org.apache.spark.streaming.Durations;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaDirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ *$ bin/run-example --files ${path}/kafka_jaas.conf \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ */
+
+public final class JavaDirectKerberizedKafkaWordCount {
+ private static final Pattern SPACE = Pattern.compile(" ");
+
+ public static void main(String[] args) throws Exception {
+if (args.length < 3) {
+ System.err.println(
+ "Usage: JavaDirectKerberizedKafkaWordCount
\n" +
+ " is a list of one or more Kafka brokers\n" +
+ " is a consumer group name to consume from
topics\n" +
+ " is a list of one or more kafka topics to
consume from\n\n");
+ System.exit(1);
+}
+
+StreamingExamples.setStreamingLogLevels();
+
+String brokers = args[0];
+String groupId = args[1];
+String topics = args[2];
+
+// Create context with a 2 seconds batch interval
+SparkConf sparkConf = new
SparkConf().setAppName("JavaDirectKerberizedKafkaWordCount");
+JavaStreamingContext jssc = new JavaStreamingContext(sparkConf,
Durations.seconds(2));
+
+Set topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
+Map kafkaParams = new HashMap<>();
+kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
+kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
+kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
+kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
+kafkaParams.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG,
+
SecurityProtocol.SASL_PLAINTEXT.name);
Review comment:
> I'm not questioning whether `SASL_PLAINTEXT` works or not, it is. I'm
telling that using kerberos on plain text channel is coming from evil from
security perspective. Somehow we should tell the users it's not the advised way
because credentials can be sniffed.
I agree it's not completely secure. It's just for testing, if only
`SASL_PLAINTEXT` used. But, I don't think it's only for testing with kerbreos.
@dongjoon-hyun @srowen @HyukjinKwon ,can you give some advice.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and
[GitHub] [spark] HyukjinKwon commented on issue #25380: [SPARK-28649][INFRA] Add Python .eggs to .gitignore
HyukjinKwon commented on issue #25380: [SPARK-28649][INFRA] Add Python .eggs to .gitignore URL: https://github.com/apache/spark/pull/25380#issuecomment-521078769 oh I missed it. LGTM too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES]
Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r313683650
##
File path:
examples/src/main/java/org/apache/spark/examples/streaming/JavaDirectKerberizedKafkaWordCount.java
##
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.streaming;
+
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Arrays;
+import java.util.Map;
+import java.util.Set;
+import java.util.regex.Pattern;
+
+import scala.Tuple2;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.serialization.StringDeserializer;
+
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.api.java.*;
+import org.apache.spark.streaming.kafka010.ConsumerStrategies;
+import org.apache.spark.streaming.kafka010.KafkaUtils;
+import org.apache.spark.streaming.kafka010.LocationStrategies;
+import org.apache.spark.streaming.Durations;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaDirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ *$ bin/run-example --files ${path}/kafka_jaas.conf \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ */
+
+public final class JavaDirectKerberizedKafkaWordCount {
+ private static final Pattern SPACE = Pattern.compile(" ");
+
+ public static void main(String[] args) throws Exception {
+if (args.length < 3) {
+ System.err.println(
+ "Usage: JavaDirectKerberizedKafkaWordCount
\n" +
+ " is a list of one or more Kafka brokers\n" +
+ " is a consumer group name to consume from
topics\n" +
+ " is a list of one or more kafka topics to
consume from\n\n");
+ System.exit(1);
+}
+
+StreamingExamples.setStreamingLogLevels();
+
+String brokers = args[0];
+String groupId = args[1];
+String topics = args[2];
+
+// Create context with a 2 seconds batch interval
+SparkConf sparkConf = new
SparkConf().setAppName("JavaDirectKerberizedKafkaWordCount");
+JavaStreamingContext jssc = new JavaStreamingContext(sparkConf,
Durations.seconds(2));
+
+Set topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
+Map kafkaParams = new HashMap<>();
+kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
+kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
+kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
+kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
+kafkaParams.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG,
+
SecurityProtocol.SASL_PLAINTEXT.name);
Review comment:
> I'm not questioning whether `SASL_PLAINTEXT` works or not, it is. I'm
telling that using kerberos on plain text channel is coming from evil from
security perspective. Somehow we should tell the users it's not the advised way
because credentials can be sniffed.
I agree it's not completely secure. It's just for testing, if only
`SASL_PLAINTEXT` used. But, I don't think it's just for testing with kerbreos.
@dongjoon-hyun @srowen @HyukjinKwon ,can you give some advice.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and
[GitHub] [spark] dongjoon-hyun commented on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
dongjoon-hyun commented on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521078239 Since the test is parallel, could you add the following, too? ``` sql/hive/src/main/scala/org/apache/spark/sql/hive/client/IsolatedClientLoader.scala -case "2.3" | "2.3.0" | "2.3.1" | "2.3.2" | "2.3.3" | "2.3.4" | "2.3.5" => hive.v2_3 +case "2.3" | "2.3.0" | "2.3.1" | "2.3.2" | "2.3.3" | "2.3.4" | "2.3.5" | "2.3.6" => hive.v2_3 ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521077935 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109073/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
SparkQA commented on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521078178 **[Test build #109074 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109074/testReport)** for PR 25443 at commit [`540d6da`](https://github.com/apache/spark/commit/540d6daef3cecbec195333d5aec7595853f2c94d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans
AmplabJenkins removed a comment on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans URL: https://github.com/apache/spark/pull/25434#issuecomment-521077856 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109067/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans
AmplabJenkins removed a comment on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans URL: https://github.com/apache/spark/pull/25434#issuecomment-521077853 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins removed a comment on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521077930 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
SparkQA removed a comment on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521075539 **[Test build #109073 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109073/testReport)** for PR 25443 at commit [`540d6da`](https://github.com/apache/spark/commit/540d6daef3cecbec195333d5aec7595853f2c94d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans
AmplabJenkins commented on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans URL: https://github.com/apache/spark/pull/25434#issuecomment-521077853 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
AmplabJenkins commented on issue #25443: [WIP][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#issuecomment-521077792 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans
AmplabJenkins commented on issue #25434: [SPARK-28716][SQL] Add id to Exchange and Subquery's stringArgs method for easier identifying their reuses in query plans URL: https://github.com/apache/spark/pull/25434#issuecomment-521077856 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109067/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org