[GitHub] [spark] SparkQA commented on pull request #28511: [SPARK-31684][SQL] Overwrite partition failed with 'WRONG FS' when the target partition is not belong to the filesystem as same as the table
SparkQA commented on pull request #28511: URL: https://github.com/apache/spark/pull/28511#issuecomment-630599286 **[Test build #122830 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122830/testReport)** for PR 28511 at commit [`78e0972`](https://github.com/apache/spark/commit/78e097284096b27839928668a3deaf6a49cab336). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on a change in pull request #28511: [SPARK-31684][SQL] Overwrite partition failed with 'WRONG FS' when the target partition is not belong to the filesystem as same
yaooqinn commented on a change in pull request #28511:
URL: https://github.com/apache/spark/pull/28511#discussion_r427046165
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/execution/benchmark/InsertIntoHiveTableBenchmark.scala
##
@@ -0,0 +1,140 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.benchmark
+
+import org.apache.spark.benchmark.Benchmark
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.hive.HiveUtils
+import org.apache.spark.sql.hive.test.TestHive
+
+/**
+ * Benchmark to measure hive table write performance.
+ * To run this benchmark:
+ * {{{
+ * 1. without sbt: bin/spark-submit --class
+ *--jars ,,
+ *--packages org.spark-project.hive:hive-exec:1.2.1.spark2
+ *
+ * 2. build/sbt "hive/test:runMain " -Phive-1.2 or
+ * build/sbt "hive/test:runMain " -Phive-2.3
+ * 3. generate result:
+ * SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "hive/test:runMain "
+ * Results will be written to
"benchmarks/InsertIntoHiveTableBenchmark-hive2.3-results.txt".
+ * 4. -Phive-1.2 does not work for JDK 11
+ * }}}
+ */
+object InsertIntoHiveTableBenchmark extends SqlBasedBenchmark {
+
+ override def getSparkSession: SparkSession = TestHive.sparkSession
+
+ val tempView = "temp"
+ val numRows = 1024 * 10
+ val sql = spark.sql _
+
+ // scalastyle:off hadoopconfiguration
+ private val hadoopConf = spark.sparkContext.hadoopConfiguration
+ // scalastyle:on hadoopconfiguration
+ hadoopConf.set("hive.exec.dynamic.partition", "true")
+ hadoopConf.set("hive.exec.dynamic.partition.mode", "nonstrict")
+ hadoopConf.set("hive.exec.max.dynamic.partitions", numRows.toString)
+
+ def withTable(tableNames: String*)(f: => Unit): Unit = {
+tableNames.foreach { name =>
+ sql(s"CREATE TABLE $name(a INT) STORED AS TEXTFILE PARTITIONED BY (b
INT, c INT)")
+}
+try f finally {
+ tableNames.foreach { name =>
+spark.sql(s"DROP TABLE IF EXISTS $name")
+ }
+}
+ }
+
+ def insertOverwriteDynamic(table: String, benchmark: Benchmark): Unit = {
+benchmark.addCase("INSERT OVERWRITE DYNAMIC") { _ =>
+ sql(s"INSERT OVERWRITE TABLE $table SELECT CAST(id AS INT) AS a," +
+s" CAST(id % 10 AS INT) AS b, CAST(id % 100 AS INT) AS c FROM
$tempView DISTRIBUTE BY a")
Review comment:
the cause of the regression of hive is to copy files one by one, so I
use `DISTRIBUTE BY` to create a certain number of files to feed it.
BUT after rerun the test w/o `DISTRIBUTE BY`, the result seems ok to
illustrate the problem. I will rm that clause.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao commented on pull request #28525: [SPARK-27562][Shuffle] Complete the verification mechanism for shuffle transmitted data
jerryshao commented on pull request #28525: URL: https://github.com/apache/spark/pull/28525#issuecomment-630595693 I would suggest to describe the specs of shuffle index file somewhere in the code, and reduce the magical hard code numbers in everywhere. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
yaooqinn commented on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630592393 Currently, we don't have any page for builtin types yet, I don't know whether the current style looks good or not, cc @maropu @cloud-fan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on pull request #28523: [SPARK-31706][SQL] add back the support of streaming update mode
gatorsmile commented on pull request #28523: URL: https://github.com/apache/spark/pull/28523#issuecomment-630589229 This is the last blocker issue of Spark 3.0. Can we speed up the review? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on pull request #28523: [SPARK-31706][SQL] add back the support of streaming update mode
gatorsmile commented on pull request #28523: URL: https://github.com/apache/spark/pull/28523#issuecomment-63052 ping @tdas @rdblue @zsxwing @jose-torres This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28523: [SPARK-31706][SQL] add back the support of streaming update mode
cloud-fan commented on pull request #28523: URL: https://github.com/apache/spark/pull/28523#issuecomment-630589029 @rdblue @tdas @jose-torres tests pass and it's ready for review This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28462: [SPARK-31651][CORE] Improve handling the case where different barrier sync types in a single sync
AmplabJenkins removed a comment on pull request #28462: URL: https://github.com/apache/spark/pull/28462#issuecomment-630585266 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28462: [SPARK-31651][CORE] Improve handling the case where different barrier sync types in a single sync
AmplabJenkins commented on pull request #28462: URL: https://github.com/apache/spark/pull/28462#issuecomment-630585266 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28462: [SPARK-31651][CORE] Improve handling the case where different barrier sync types in a single sync
SparkQA removed a comment on pull request #28462: URL: https://github.com/apache/spark/pull/28462#issuecomment-630501075 **[Test build #122823 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122823/testReport)** for PR 28462 at commit [`8b192f1`](https://github.com/apache/spark/commit/8b192f12d765f9d94ebca73a4e7faa634bce8245). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28462: [SPARK-31651][CORE] Improve handling the case where different barrier sync types in a single sync
SparkQA commented on pull request #28462: URL: https://github.com/apache/spark/pull/28462#issuecomment-630584612 **[Test build #122823 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122823/testReport)** for PR 28462 at commit [`8b192f1`](https://github.com/apache/spark/commit/8b192f12d765f9d94ebca73a4e7faa634bce8245). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28568: [SPARK-31710][SQL]Add compatibility flag to cast long to timestamp
cloud-fan commented on pull request #28568: URL: https://github.com/apache/spark/pull/28568#issuecomment-630582721 > we need same sql to run on hive/spark during migrating,if spark failed or behaviored less expected. so with a compatibility flag ,as you said, we can easily migrate them and no need to change user's sqls We did something similar before, with the pgsql dialect. This project was canceled, because it's too much effort to keep 2 systems having exactly the same behaviors. And people may keep adding other dialects, which could increase maintenance costs dramatically. Hive is a bit different as Spark already provides a lot of Hive compatibility. But still, it's not the right direction for Spark to provide 100% compatibility with another system. For this particular case, I agree with @bart-samwel that we can fail by default for cast long to timestamp, and provide a legacy config to allow it with spark or hive behavior. This is a non-standard and weird behavior to allow cast long to timestamp, so for long-term we do want to forbid it, with clear error message to suggest using `TIMESTAMP_MILLIS` or `TIMESTAMP_MICROS` functions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #28208: [SPARK-31440][SQL] Improve SQL Rest API
gengliangwang commented on a change in pull request #28208:
URL: https://github.com/apache/spark/pull/28208#discussion_r427031360
##
File path:
sql/core/src/main/scala/org/apache/spark/status/api/v1/sql/SqlResource.scala
##
@@ -21,46 +21,55 @@ import java.util.Date
import javax.ws.rs._
import javax.ws.rs.core.MediaType
+import scala.util.{Failure, Success, Try}
+
import org.apache.spark.JobExecutionStatus
-import org.apache.spark.sql.execution.ui.{SQLAppStatusStore,
SQLExecutionUIData, SQLPlanMetric}
+import org.apache.spark.sql.execution.ui.{SparkPlanGraph,
SparkPlanGraphCluster, SparkPlanGraphNode, SQLAppStatusStore,
SQLExecutionUIData}
import org.apache.spark.status.api.v1.{BaseAppResource, NotFoundException}
@Produces(Array(MediaType.APPLICATION_JSON))
private[v1] class SqlResource extends BaseAppResource {
+ val WHOLE_STAGE_CODEGEN = "WholeStageCodegen"
+
@GET
def sqlList(
- @DefaultValue("false") @QueryParam("details") details: Boolean,
+ @DefaultValue("true") @QueryParam("details") details: Boolean,
+ @DefaultValue("true") @QueryParam("planDescription") planDescription:
Boolean,
Review comment:
@erenavsarogullari one last comment: why do we have extra option
"planDescription" here. It seems reasonable to be covered by the option
"details"
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28511: [SPARK-31684][SQL] Overwrite partition failed with 'WRONG FS' when the target partition is not belong to the filesystem as same
cloud-fan commented on a change in pull request #28511:
URL: https://github.com/apache/spark/pull/28511#discussion_r427027992
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/execution/benchmark/InsertIntoHiveTableBenchmark.scala
##
@@ -0,0 +1,140 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.benchmark
+
+import org.apache.spark.benchmark.Benchmark
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.hive.HiveUtils
+import org.apache.spark.sql.hive.test.TestHive
+
+/**
+ * Benchmark to measure hive table write performance.
+ * To run this benchmark:
+ * {{{
+ * 1. without sbt: bin/spark-submit --class
+ *--jars ,,
+ *--packages org.spark-project.hive:hive-exec:1.2.1.spark2
+ *
+ * 2. build/sbt "hive/test:runMain " -Phive-1.2 or
+ * build/sbt "hive/test:runMain " -Phive-2.3
+ * 3. generate result:
+ * SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "hive/test:runMain "
+ * Results will be written to
"benchmarks/InsertIntoHiveTableBenchmark-hive2.3-results.txt".
+ * 4. -Phive-1.2 does not work for JDK 11
+ * }}}
+ */
+object InsertIntoHiveTableBenchmark extends SqlBasedBenchmark {
+
+ override def getSparkSession: SparkSession = TestHive.sparkSession
+
+ val tempView = "temp"
+ val numRows = 1024 * 10
+ val sql = spark.sql _
+
+ // scalastyle:off hadoopconfiguration
+ private val hadoopConf = spark.sparkContext.hadoopConfiguration
+ // scalastyle:on hadoopconfiguration
+ hadoopConf.set("hive.exec.dynamic.partition", "true")
+ hadoopConf.set("hive.exec.dynamic.partition.mode", "nonstrict")
+ hadoopConf.set("hive.exec.max.dynamic.partitions", numRows.toString)
+
+ def withTable(tableNames: String*)(f: => Unit): Unit = {
+tableNames.foreach { name =>
+ sql(s"CREATE TABLE $name(a INT) STORED AS TEXTFILE PARTITIONED BY (b
INT, c INT)")
+}
+try f finally {
+ tableNames.foreach { name =>
+spark.sql(s"DROP TABLE IF EXISTS $name")
+ }
+}
+ }
+
+ def insertOverwriteDynamic(table: String, benchmark: Benchmark): Unit = {
+benchmark.addCase("INSERT OVERWRITE DYNAMIC") { _ =>
+ sql(s"INSERT OVERWRITE TABLE $table SELECT CAST(id AS INT) AS a," +
+s" CAST(id % 10 AS INT) AS b, CAST(id % 100 AS INT) AS c FROM
$tempView DISTRIBUTE BY a")
Review comment:
why does the number of files matter? `DISTRIBUTE BY a` will add shuffle
AFAIK, then the perf is not purely about table insertion and may be less
accurate.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28362: [SPARK-31570][R][DOCS] R combine gapply dapply
AmplabJenkins removed a comment on pull request #28362: URL: https://github.com/apache/spark/pull/28362#issuecomment-630577457 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28362: [SPARK-31570][R][DOCS] R combine gapply dapply
AmplabJenkins commented on pull request #28362: URL: https://github.com/apache/spark/pull/28362#issuecomment-630577457 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28362: [SPARK-31570][R][DOCS] R combine gapply dapply
SparkQA commented on pull request #28362: URL: https://github.com/apache/spark/pull/28362#issuecomment-630577030 **[Test build #122829 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122829/testReport)** for PR 28362 at commit [`6ad2085`](https://github.com/apache/spark/commit/6ad20856a3b242bf7f139eaee10a98ceabadf29f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #28362: [SPARK-31570][R][DOCS] R combine gapply dapply
HyukjinKwon commented on pull request #28362: URL: https://github.com/apache/spark/pull/28362#issuecomment-630575435 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26624: [SPARK-8981][CORE][test-hadoop3.2][test-java11] Add MDC support in Executor
cloud-fan commented on a change in pull request #26624: URL: https://github.com/apache/spark/pull/26624#discussion_r427025412 ## File path: docs/configuration.md ## @@ -2955,6 +2955,12 @@ Spark uses [log4j](http://logging.apache.org/log4j/) for logging. You can config `log4j.properties` file in the `conf` directory. One way to start is to copy the existing `log4j.properties.template` located there. +By default, Spark adds 1 record to the MDC: `taskName`, which shows something Review comment: do we have the full name of `MDC`? maybe some users don't know very well about it and we should give them something that they can get the general meaning. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26624: [SPARK-8981][CORE][test-hadoop3.2][test-java11] Add MDC support in Executor
cloud-fan commented on a change in pull request #26624:
URL: https://github.com/apache/spark/pull/26624#discussion_r427024955
##
File path: core/src/main/scala/org/apache/spark/executor/Executor.scala
##
@@ -395,6 +401,9 @@ private[spark] class Executor(
}
override def run(): Unit = {
+
+ setMDCForTask(taskDescription.name, mdcProperties)
Review comment:
nit: taskDescription.name -> taskName
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26624: [SPARK-8981][CORE][test-hadoop3.2][test-java11] Add MDC support in Executor
cloud-fan commented on a change in pull request #26624:
URL: https://github.com/apache/spark/pull/26624#discussion_r427024809
##
File path: core/src/main/scala/org/apache/spark/executor/Executor.scala
##
@@ -320,7 +321,12 @@ private[spark] class Executor(
val taskId = taskDescription.taskId
val threadName = s"Executor task launch worker for task $taskId"
-private val taskName = taskDescription.name
+val taskName = taskDescription.name
+val mdcProperties = taskDescription.properties.asScala
+ .filter(_._1.startsWith("mdc.")).map { item =>
+val key = item._1.substring(4)
+(key, item._2)
+ }.toMap
Review comment:
we don't really need to look up the resulting map. Seems calling `toSeq`
and keeping it as `Seq[(String, String)]` is good enough.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26624: [SPARK-8981][CORE][test-hadoop3.2][test-java11] Add MDC support in Executor
cloud-fan commented on a change in pull request #26624:
URL: https://github.com/apache/spark/pull/26624#discussion_r427024406
##
File path: core/src/main/scala/org/apache/spark/util/ThreadUtils.scala
##
@@ -133,6 +133,14 @@ private[spark] object ThreadUtils {
Executors.newCachedThreadPool(threadFactory).asInstanceOf[ThreadPoolExecutor]
}
+ /**
+ * Wrapper over newCachedThreadPool. Thread names are formatted as
prefix-ID, where ID is a
Review comment:
This doesn't really have a prefix in the name. Can we inline this
method? It's only called once, and the change itself is not related to the MDC
stuff
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26624: [SPARK-8981][CORE][test-hadoop3.2][test-java11] Add MDC support in Executor
cloud-fan commented on a change in pull request #26624:
URL: https://github.com/apache/spark/pull/26624#discussion_r427024406
##
File path: core/src/main/scala/org/apache/spark/util/ThreadUtils.scala
##
@@ -133,6 +133,14 @@ private[spark] object ThreadUtils {
Executors.newCachedThreadPool(threadFactory).asInstanceOf[ThreadPoolExecutor]
}
+ /**
+ * Wrapper over newCachedThreadPool. Thread names are formatted as
prefix-ID, where ID is a
Review comment:
This doesn't really have a prefix in the name. Can we inline this
method? It's only called once.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28575: [SPARK-31705][SQL] Push predicate through join by rewriting join condition to conjunctive normal form
AmplabJenkins removed a comment on pull request #28575: URL: https://github.com/apache/spark/pull/28575#issuecomment-630571645 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28572: [SPARK-31750][SQL] Eliminate UpCast if child's dataType is DecimalType
cloud-fan commented on a change in pull request #28572:
URL: https://github.com/apache/spark/pull/28572#discussion_r427022894
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -3071,15 +3071,31 @@ class Analyzer(
case p => p transformExpressions {
case u @ UpCast(child, _, _) if !child.resolved => u
-case UpCast(child, dt: AtomicType, _)
+case u @ UpCast(child, _, _)
if SQLConf.get.getConf(SQLConf.LEGACY_LOOSE_UPCAST) &&
+ u.dataType.isInstanceOf[AtomicType] &&
child.dataType == StringType =>
- Cast(child, dt.asNullable)
-
-case UpCast(child, dataType, walkedTypePath) if
!Cast.canUpCast(child.dataType, dataType) =>
- fail(child, dataType, walkedTypePath)
-
-case UpCast(child, dataType, _) => Cast(child, dataType.asNullable)
+ Cast(child, u.dataType.asNullable)
+
+case u @ UpCast(child, _, walkedTypePath)
+ if child.dataType.isInstanceOf[DecimalType]
+&& u.dataType.isInstanceOf[DecimalType]
+&& walkedTypePath.nonEmpty =>
+ // SPARK-31750: there are two cases: 1. for local BigDecimal
collection,
+ // e.g. Seq(BigDecimal(12.34), BigDecimal(1)).toDF("a"), we will have
+ // UpCast(child, Decimal(38, 18)) where child's data type is always
Decimal(38, 18).
+ // 2. for other cases where data type is explicitly known, e.g,
spark.read
+ // .parquet("/tmp/file").as[BigDecimal]. We will have UpCast(child,
Decimal(38, 18)),
+ // where child's data type can be, e.g. Decimal(38, 0). In this
case, we actually
+ // should not do cast otherwise there will be precision lost.
+ // Thus, we eliminate the UpCast here to avoid precision lost for
case 2 and do
+ // no hurt for case 1.
Review comment:
We can simplify the comment to only mention case 2
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28575: [SPARK-31705][SQL] Push predicate through join by rewriting join condition to conjunctive normal form
AmplabJenkins commented on pull request #28575: URL: https://github.com/apache/spark/pull/28575#issuecomment-630571645 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28572: [SPARK-31750][SQL] Eliminate UpCast if child's dataType is DecimalType
cloud-fan commented on a change in pull request #28572:
URL: https://github.com/apache/spark/pull/28572#discussion_r427022612
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -3071,15 +3071,31 @@ class Analyzer(
case p => p transformExpressions {
case u @ UpCast(child, _, _) if !child.resolved => u
-case UpCast(child, dt: AtomicType, _)
+case u @ UpCast(child, _, _)
if SQLConf.get.getConf(SQLConf.LEGACY_LOOSE_UPCAST) &&
+ u.dataType.isInstanceOf[AtomicType] &&
child.dataType == StringType =>
- Cast(child, dt.asNullable)
-
-case UpCast(child, dataType, walkedTypePath) if
!Cast.canUpCast(child.dataType, dataType) =>
- fail(child, dataType, walkedTypePath)
-
-case UpCast(child, dataType, _) => Cast(child, dataType.asNullable)
+ Cast(child, u.dataType.asNullable)
+
+case u @ UpCast(child, _, walkedTypePath)
+ if child.dataType.isInstanceOf[DecimalType]
+&& u.dataType.isInstanceOf[DecimalType]
+&& walkedTypePath.nonEmpty =>
Review comment:
why do we need to check `walkedTypePath`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28575: [SPARK-31705][SQL] Push predicate through join by rewriting join condition to conjunctive normal form
SparkQA commented on pull request #28575: URL: https://github.com/apache/spark/pull/28575#issuecomment-630571286 **[Test build #122828 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122828/testReport)** for PR 28575 at commit [`21fb7c5`](https://github.com/apache/spark/commit/21fb7c5844f43ec0b9190ac6e823aba2854ba2bd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28572: [SPARK-31750][SQL] Eliminate UpCast if child's dataType is DecimalType
cloud-fan commented on a change in pull request #28572:
URL: https://github.com/apache/spark/pull/28572#discussion_r427022539
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -3071,15 +3071,31 @@ class Analyzer(
case p => p transformExpressions {
case u @ UpCast(child, _, _) if !child.resolved => u
-case UpCast(child, dt: AtomicType, _)
+case u @ UpCast(child, _, _)
if SQLConf.get.getConf(SQLConf.LEGACY_LOOSE_UPCAST) &&
+ u.dataType.isInstanceOf[AtomicType] &&
child.dataType == StringType =>
- Cast(child, dt.asNullable)
-
-case UpCast(child, dataType, walkedTypePath) if
!Cast.canUpCast(child.dataType, dataType) =>
- fail(child, dataType, walkedTypePath)
-
-case UpCast(child, dataType, _) => Cast(child, dataType.asNullable)
+ Cast(child, u.dataType.asNullable)
+
+case u @ UpCast(child, _, walkedTypePath)
+ if child.dataType.isInstanceOf[DecimalType]
+&& u.dataType.isInstanceOf[DecimalType]
Review comment:
nit: `u.targetType == DecimalType`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #28575: [SPARK-31705][SQL] Push predicate through join by rewriting join condition to conjunctive normal form
wangyum opened a new pull request #28575: URL: https://github.com/apache/spark/pull/28575 ### What changes were proposed in this pull request? This PR add a new rule to support push predicate through join by rewriting join condition to conjunctive normal form. For example: ```sql create table x as select * from (values (1, 2, 3, 4)) as x(a, b, c, d); create table y as select * from (values (1, 2, 3, 4)) as x(a, b, c, d); ``` ```sql postgres=# explain select x.* from x, y where x.b = y.b and ((x.a > 3 and y.a > 13) or (x.a > 1)); QUERY PLAN -- Merge Join (cost=218.07..437.16 rows=6973 width=16) Merge Cond: (x.b = y.b) Join Filter: (((x.a > 3) AND (y.a > 13)) OR (x.a > 1)) -> Sort (cost=89.18..91.75 rows=1028 width=16) Sort Key: x.b -> Seq Scan on x (cost=0.00..37.75 rows=1028 width=16) Filter: ((a > 3) OR (a > 1)) -> Sort (cost=128.89..133.52 rows=1850 width=8) Sort Key: y.b -> Seq Scan on y (cost=0.00..28.50 rows=1850 width=8) (10 rows) ``` `x.b = y.b and ((x.a > 3 and y.a > 13) or (x.a > 1))` can be rewritten to `x.b = y.b and (((x.a > 3) or (x.a > 1)) and ((y.a > 13) or (x.a > 1`, and then we can push down `((x.a > 3) or (x.a > 1))`. ### Why are the changes needed? Improve query performance. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test and benchmark test. SQL | Before this PR | After this PR --- | --- | --- TPCDS 5T q85 | 66s | 34s TPCH 1T q7 | 37s | 32s This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28572: [SPARK-31750][SQL] Eliminate UpCast if child's dataType is DecimalType
cloud-fan commented on a change in pull request #28572:
URL: https://github.com/apache/spark/pull/28572#discussion_r427022169
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DeserializerBuildHelper.scala
##
@@ -161,6 +161,7 @@ object DeserializerBuildHelper {
case _: StructType => expr
case _: ArrayType => expr
case _: MapType => expr
+case _: DecimalType => UpCast(expr, DecimalType, walkedTypePath.getPaths)
Review comment:
let's add a comment:
```
// For Scala/Java `BigDecimal`, we accept decimal types of any valid
precision/scale. Here we use
// the `DecimalType` object to indicate it.
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28488: [SPARK-29083][CORE] Prefetch elements in rdd.toLocalIterator
AmplabJenkins removed a comment on pull request #28488: URL: https://github.com/apache/spark/pull/28488#issuecomment-630564778 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/122822/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28488: [SPARK-29083][CORE] Prefetch elements in rdd.toLocalIterator
AmplabJenkins removed a comment on pull request #28488: URL: https://github.com/apache/spark/pull/28488#issuecomment-630564771 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28488: [SPARK-29083][CORE] Prefetch elements in rdd.toLocalIterator
AmplabJenkins commented on pull request #28488: URL: https://github.com/apache/spark/pull/28488#issuecomment-630564771 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao commented on a change in pull request #28525: [SPARK-27562][Shuffle] Complete the verification mechanism for shuffle transmitted data
jerryshao commented on a change in pull request #28525:
URL: https://github.com/apache/spark/pull/28525#discussion_r427016625
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/ShuffleIndexInformation.java
##
@@ -31,17 +34,44 @@
public class ShuffleIndexInformation {
/** offsets as long buffer */
private final LongBuffer offsets;
+ private final boolean hasDigest;
+ /** digests as long buffer */
+ private final LongBuffer digests;
private int size;
public ShuffleIndexInformation(File indexFile) throws IOException {
+ByteBuffer offsetsBuffer, digestsBuffer;
size = (int)indexFile.length();
-ByteBuffer buffer = ByteBuffer.allocate(size);
-offsets = buffer.asLongBuffer();
+int offsetsSize, digestsSize;
+if (size % 8 == 0) {
+ hasDigest = false;
+ offsetsSize = size;
+ digestsSize = 0;
+} else {
+ hasDigest = true;
+ offsetsSize = ((size - 8 - 1) / (8 + DigestUtils.getDigestLength()) + 1)
* 8;
Review comment:
Can you explain a bit about this line?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28488: [SPARK-29083][CORE] Prefetch elements in rdd.toLocalIterator
SparkQA removed a comment on pull request #28488: URL: https://github.com/apache/spark/pull/28488#issuecomment-630501057 **[Test build #122822 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122822/testReport)** for PR 28488 at commit [`6c3856d`](https://github.com/apache/spark/commit/6c3856d5d82de3f98cd0dd93e951b8355e93fe7f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao commented on a change in pull request #28525: [SPARK-27562][Shuffle] Complete the verification mechanism for shuffle transmitted data
jerryshao commented on a change in pull request #28525:
URL: https://github.com/apache/spark/pull/28525#discussion_r427016499
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/ShuffleIndexInformation.java
##
@@ -31,17 +34,44 @@
public class ShuffleIndexInformation {
/** offsets as long buffer */
private final LongBuffer offsets;
+ private final boolean hasDigest;
+ /** digests as long buffer */
+ private final LongBuffer digests;
private int size;
public ShuffleIndexInformation(File indexFile) throws IOException {
+ByteBuffer offsetsBuffer, digestsBuffer;
size = (int)indexFile.length();
-ByteBuffer buffer = ByteBuffer.allocate(size);
-offsets = buffer.asLongBuffer();
+int offsetsSize, digestsSize;
+if (size % 8 == 0) {
Review comment:
Would you please explain more about why using `size % 8` to check
whether the index file has digest or not?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28488: [SPARK-29083][CORE] Prefetch elements in rdd.toLocalIterator
SparkQA commented on pull request #28488: URL: https://github.com/apache/spark/pull/28488#issuecomment-630564401 **[Test build #122822 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122822/testReport)** for PR 28488 at commit [`6c3856d`](https://github.com/apache/spark/commit/6c3856d5d82de3f98cd0dd93e951b8355e93fe7f). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #28106: [SPARK-31335][SQL] Add try function support
yaooqinn commented on pull request #28106: URL: https://github.com/apache/spark/pull/28106#issuecomment-630564036 @bart-samwel thanks for your explanations. [this](https://github.com/google/zetasql/blob/79adcd0fe227173e68ed7aa88f580a691ebe82c2/docs/functions-reference.md#safe-prefix) seems to have much lower cognitive cost for the end-users and maintenance cost for the community This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #28571: Add compatibility flag to cast long to timestamp
HyukjinKwon commented on pull request #28571: URL: https://github.com/apache/spark/pull/28571#issuecomment-630562207 @GuoPhilipse, it's a matter of coherence in Apache Spark instead of fixing this one case alone. Also, you should open a PR against the master branch if you want to change something newly. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #28571: Add compatibility flag to cast long to timestamp
HyukjinKwon closed pull request #28571: URL: https://github.com/apache/spark/pull/28571 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao commented on a change in pull request #28525: [SPARK-27562][Shuffle] Complete the verification mechanism for shuffle transmitted data
jerryshao commented on a change in pull request #28525:
URL: https://github.com/apache/spark/pull/28525#discussion_r427013351
##
File path:
common/network-common/src/main/java/org/apache/spark/network/util/DigestUtils.java
##
@@ -0,0 +1,69 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.network.util;
+
+import java.io.*;
+import java.nio.ByteBuffer;
+import java.nio.MappedByteBuffer;
+import java.nio.channels.FileChannel;
+import java.util.zip.CRC32;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class DigestUtils {
+private static final Logger LOG =
LoggerFactory.getLogger(DigestUtils.class);
+private static final int STREAM_BUFFER_LENGTH = 8192;
+private static final int DIGEST_LENGTH = 8;
+
+public static int getDigestLength() {
+ return DIGEST_LENGTH;
+}
+
+public static long getDigest(InputStream data) throws IOException {
+CRC32 crc32 = new CRC32();
+byte[] buffer = new byte[STREAM_BUFFER_LENGTH];
+int len;
+while ((len = data.read(buffer)) >= 0) {
+crc32.update(buffer, 0, len);
+}
+return crc32.getValue();
+}
+
+public static long getDigest(File file, long offset, long length) {
+if (length <= 0) {
+return -1L;
+}
+try (RandomAccessFile rf = new RandomAccessFile(file, "r")) {
+MappedByteBuffer data =
rf.getChannel().map(FileChannel.MapMode.READ_ONLY, offset,
+ length);
+CRC32 crc32 = new CRC32();
+byte[] buffer = new byte[STREAM_BUFFER_LENGTH];
+int len;
+while ((len = Math.min(STREAM_BUFFER_LENGTH, data.remaining())) >
0) {
+data.get(buffer, 0, len);
+crc32.update(buffer, 0, len);
+}
+return crc32.getValue();
+} catch (IOException e) {
+LOG.error(String.format("Exception while computing digest for file
segment: " +
+ "%s(offset:%d, length:%d)", file.getName(), offset, length ));
+return -1L;
+}
+}
+}
Review comment:
I think the indention here is not correct. In Spark we typically use 2
space idention.
##
File path:
common/network-common/src/main/java/org/apache/spark/network/util/DigestUtils.java
##
@@ -0,0 +1,69 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.network.util;
+
+import java.io.*;
+import java.nio.ByteBuffer;
+import java.nio.MappedByteBuffer;
+import java.nio.channels.FileChannel;
+import java.util.zip.CRC32;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class DigestUtils {
+private static final Logger LOG =
LoggerFactory.getLogger(DigestUtils.class);
+private static final int STREAM_BUFFER_LENGTH = 8192;
+private static final int DIGEST_LENGTH = 8;
+
+public static int getDigestLength() {
+ return DIGEST_LENGTH;
+}
+
+public static long getDigest(InputStream data) throws IOException {
+CRC32 crc32 = new CRC32();
+byte[] buffer = new byte[STREAM_BUFFER_LENGTH];
+int len;
+while ((len = data.read(buffer)) >= 0) {
+crc32.update(buffer, 0, len);
+}
+return crc32.getValue();
+}
+
+public static long getDigest(File file, long offset, long length) {
+if (length <= 0) {
+return -1L;
+
[GitHub] [spark] GuoPhilipse commented on pull request #28571: Add compatibility flag to cast long to timestamp
GuoPhilipse commented on pull request #28571:
URL: https://github.com/apache/spark/pull/28571#issuecomment-630558198
hi HyukjinKwon
it will take effect only when converting long to timestamp, other cases
currently seems no need to change. we want to keep compatibility back with
hive sql,
Do you have any cases? we can discuss more.
Thanls.
At 2020-05-19 10:44:13, "Hyukjin Kwon" wrote:
@HyukjinKwon commented on this pull request.
In
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala:
>// converting seconds to us
- private[this] def longToTimestamp(t: Long): Long = t * 100L
+ private[this] def longToTimestamp(t: Long): Long = {
+if (SQLConf.get.getConf(SQLConf.LONG_TIMESTAMP_CONVERSION_IN_SECONDS))
t * 100L
Let's don't do this. It will require to add the compatibility across all the
date time functionality in Spark, e.g.) from_unixtime.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
AmplabJenkins removed a comment on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630556941 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
SparkQA removed a comment on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630553566 **[Test build #122826 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122826/testReport)** for PR 28574 at commit [`ab56a3b`](https://github.com/apache/spark/commit/ab56a3b3911adee8de8dc7b0dd7e44b29e339e1f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
SparkQA commented on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630556817 **[Test build #122826 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122826/testReport)** for PR 28574 at commit [`ab56a3b`](https://github.com/apache/spark/commit/ab56a3b3911adee8de8dc7b0dd7e44b29e339e1f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
AmplabJenkins commented on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630556941 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28527: [SPARK-31709][SQL] Proper base path for database/table location when it is a relative path
AmplabJenkins removed a comment on pull request #28527: URL: https://github.com/apache/spark/pull/28527#issuecomment-63060 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28527: [SPARK-31709][SQL] Proper base path for database/table location when it is a relative path
AmplabJenkins commented on pull request #28527: URL: https://github.com/apache/spark/pull/28527#issuecomment-63060 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28527: [SPARK-31709][SQL] Proper base path for database/table location when it is a relative path
SparkQA commented on pull request #28527: URL: https://github.com/apache/spark/pull/28527#issuecomment-630555292 **[Test build #122827 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122827/testReport)** for PR 28527 at commit [`3fbe65a`](https://github.com/apache/spark/commit/3fbe65a0c3f1e59e5af1f5d3f3b7beb13c0636f6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
AmplabJenkins removed a comment on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630553799 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
AmplabJenkins commented on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630553799 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
SparkQA commented on pull request #28574: URL: https://github.com/apache/spark/pull/28574#issuecomment-630553566 **[Test build #122826 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122826/testReport)** for PR 28574 at commit [`ab56a3b`](https://github.com/apache/spark/commit/ab56a3b3911adee8de8dc7b0dd7e44b29e339e1f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn opened a new pull request #28574: [SPARK-31752][SQL][DOCS] Add sql doc for interval type
yaooqinn opened a new pull request #28574: URL: https://github.com/apache/spark/pull/28574 ### What changes were proposed in this pull request? This PR adds SQL doc for interval datatype to describe its keyword, definition, and related operators and functions. ### Why are the changes needed? Provide a detailed SQL doc for interval type ### Does this PR introduce _any_ user-facing change? yes, new doc added ### How was this patch tested? Passing doc generation and locally verified.  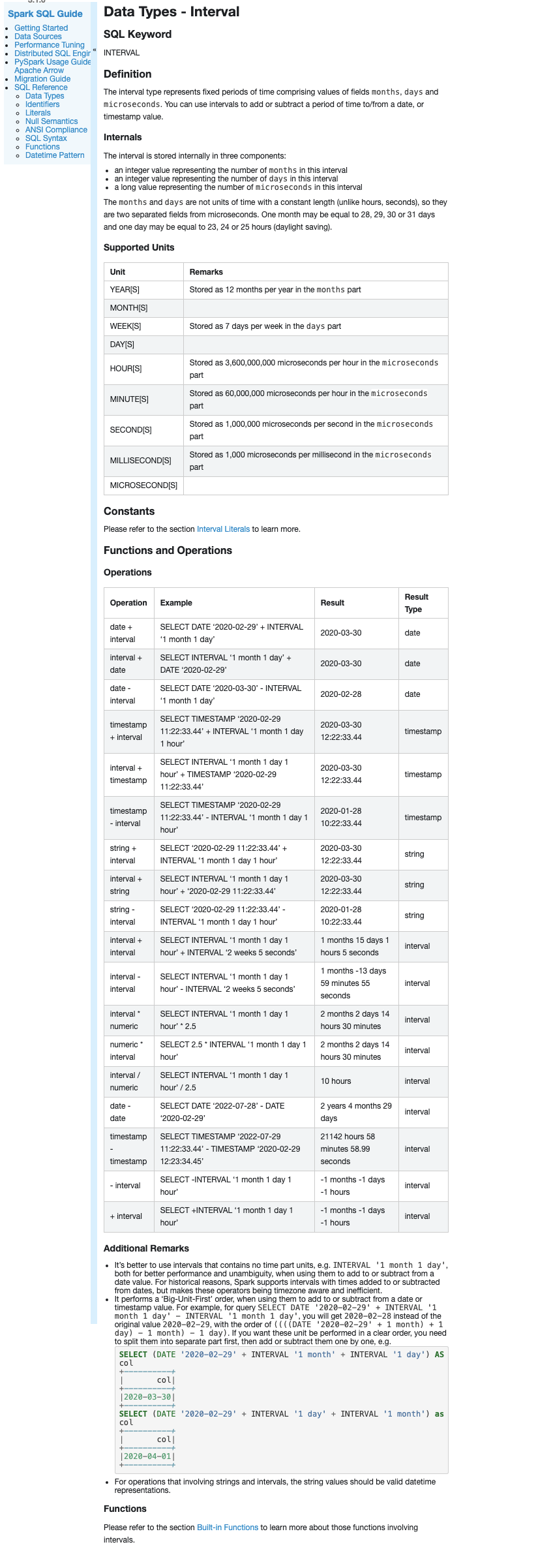 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #28290: [SPARK-29458][SQL][DOCS] Add a paragraph for scalar function in sql getting started
maropu commented on pull request #28290: URL: https://github.com/apache/spark/pull/28290#issuecomment-630551973 note: I've filed jira so that we wouldn't forget to add them in the documents: https://issues.apache.org/jira/browse/SPARK-31753 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rednaxelafx commented on a change in pull request #28463: [SPARK-31399][CORE][test-hadoop3.2][test-java11] Support indylambda Scala closure in ClosureCleaner
rednaxelafx commented on a change in pull request #28463:
URL: https://github.com/apache/spark/pull/28463#discussion_r426999033
##
File path: core/src/main/scala/org/apache/spark/util/ClosureCleaner.scala
##
@@ -414,6 +434,312 @@ private[spark] object ClosureCleaner extends Logging {
}
}
+private[spark] object IndylambdaScalaClosures extends Logging {
+ // internal name of java.lang.invoke.LambdaMetafactory
+ val LambdaMetafactoryClassName = "java/lang/invoke/LambdaMetafactory"
+ // the method that Scala indylambda use for bootstrap method
+ val LambdaMetafactoryMethodName = "altMetafactory"
+ val LambdaMetafactoryMethodDesc = "(Ljava/lang/invoke/MethodHandles$Lookup;"
+
+"Ljava/lang/String;Ljava/lang/invoke/MethodType;[Ljava/lang/Object;)" +
+"Ljava/lang/invoke/CallSite;"
+
+ /**
+ * Check if the given reference is a indylambda style Scala closure.
+ * If so (e.g. for Scala 2.12+ closures), return a non-empty serialization
proxy
+ * (SerializedLambda) of the closure;
+ * otherwise (e.g. for Scala 2.11 closures) return None.
+ *
+ * @param maybeClosure the closure to check.
+ */
+ def getSerializationProxy(maybeClosure: AnyRef): Option[SerializedLambda] = {
+def isClosureCandidate(cls: Class[_]): Boolean = {
+ // TODO: maybe lift this restriction to support other functional
interfaces in the future
+ val implementedInterfaces = ClassUtils.getAllInterfaces(cls).asScala
+ implementedInterfaces.exists(_.getName.startsWith("scala.Function"))
+}
+
+maybeClosure.getClass match {
+ // shortcut the fast check:
+ // 1. indylambda closure classes are generated by Java's
LambdaMetafactory, and they're
+ //always synthetic.
+ // 2. We only care about Serializable closures, so let's check that as
well
+ case c if !c.isSynthetic || !maybeClosure.isInstanceOf[Serializable] =>
None
+
+ case c if isClosureCandidate(c) =>
+try {
+ Option(inspect(maybeClosure)).filter(isIndylambdaScalaClosure)
+} catch {
+ case e: Exception =>
+logDebug("The given reference is not an indylambda Scala
closure.", e)
+None
+}
+
+ case _ => None
+}
+ }
+
+ def isIndylambdaScalaClosure(lambdaProxy: SerializedLambda): Boolean = {
+lambdaProxy.getImplMethodKind == MethodHandleInfo.REF_invokeStatic &&
+ lambdaProxy.getImplMethodName.contains("$anonfun$")
+ }
+
+ def inspect(closure: AnyRef): SerializedLambda = {
+val writeReplace = closure.getClass.getDeclaredMethod("writeReplace")
+writeReplace.setAccessible(true)
+writeReplace.invoke(closure).asInstanceOf[SerializedLambda]
+ }
+
+ /**
+ * Check if the handle represents the LambdaMetafactory that indylambda
Scala closures
+ * use for creating the lambda class and getting a closure instance.
+ */
+ def isLambdaMetafactory(bsmHandle: Handle): Boolean = {
+bsmHandle.getOwner == LambdaMetafactoryClassName &&
+ bsmHandle.getName == LambdaMetafactoryMethodName &&
+ bsmHandle.getDesc == LambdaMetafactoryMethodDesc
+ }
+
+ /**
+ * Check if the handle represents a target method that is:
+ * - a STATIC method that implements a Scala lambda body in the indylambda
style
+ * - captures the enclosing `this`, i.e. the first argument is a reference
to the same type as
+ * the owning class.
+ * Returns true if both criteria above are met.
+ */
+ def isLambdaBodyCapturingOuter(handle: Handle, ownerInternalName: String):
Boolean = {
+handle.getTag == H_INVOKESTATIC &&
+ handle.getName.contains("$anonfun$") &&
+ handle.getOwner == ownerInternalName &&
+ handle.getDesc.startsWith(s"(L$ownerInternalName;")
+ }
+
+ /**
+ * Check if the callee of a call site is a inner class constructor.
+ * - A constructor has to be invoked via INVOKESPECIAL
+ * - A constructor's internal name is "init" and the return type is
"V" (void)
+ * - An inner class' first argument in the signature has to be a reference
to the
+ * enclosing "this", aka `$outer` in Scala.
+ */
+ def isInnerClassCtorCapturingOuter(
+ op: Int, owner: String, name: String, desc: String, callerInternalName:
String): Boolean = {
Review comment:
Good point! Thanks for the suggestion, I'll remove the unused parameter
when I gather enough changes for a follow-up change.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rednaxelafx commented on a change in pull request #28463: [SPARK-31399][CORE][test-hadoop3.2][test-java11] Support indylambda Scala closure in ClosureCleaner
rednaxelafx commented on a change in pull request #28463:
URL: https://github.com/apache/spark/pull/28463#discussion_r426998824
##
File path: core/src/main/scala/org/apache/spark/util/ClosureCleaner.scala
##
@@ -414,6 +434,312 @@ private[spark] object ClosureCleaner extends Logging {
}
}
+private[spark] object IndylambdaScalaClosures extends Logging {
+ // internal name of java.lang.invoke.LambdaMetafactory
+ val LambdaMetafactoryClassName = "java/lang/invoke/LambdaMetafactory"
+ // the method that Scala indylambda use for bootstrap method
+ val LambdaMetafactoryMethodName = "altMetafactory"
+ val LambdaMetafactoryMethodDesc = "(Ljava/lang/invoke/MethodHandles$Lookup;"
+
+"Ljava/lang/String;Ljava/lang/invoke/MethodType;[Ljava/lang/Object;)" +
+"Ljava/lang/invoke/CallSite;"
+
+ /**
+ * Check if the given reference is a indylambda style Scala closure.
+ * If so (e.g. for Scala 2.12+ closures), return a non-empty serialization
proxy
+ * (SerializedLambda) of the closure;
+ * otherwise (e.g. for Scala 2.11 closures) return None.
+ *
+ * @param maybeClosure the closure to check.
+ */
+ def getSerializationProxy(maybeClosure: AnyRef): Option[SerializedLambda] = {
+def isClosureCandidate(cls: Class[_]): Boolean = {
+ // TODO: maybe lift this restriction to support other functional
interfaces in the future
+ val implementedInterfaces = ClassUtils.getAllInterfaces(cls).asScala
+ implementedInterfaces.exists(_.getName.startsWith("scala.Function"))
+}
+
+maybeClosure.getClass match {
+ // shortcut the fast check:
+ // 1. indylambda closure classes are generated by Java's
LambdaMetafactory, and they're
+ //always synthetic.
+ // 2. We only care about Serializable closures, so let's check that as
well
+ case c if !c.isSynthetic || !maybeClosure.isInstanceOf[Serializable] =>
None
+
+ case c if isClosureCandidate(c) =>
+try {
+ Option(inspect(maybeClosure)).filter(isIndylambdaScalaClosure)
+} catch {
+ case e: Exception =>
+logDebug("The given reference is not an indylambda Scala
closure.", e)
+None
+}
+
+ case _ => None
+}
+ }
+
+ def isIndylambdaScalaClosure(lambdaProxy: SerializedLambda): Boolean = {
+lambdaProxy.getImplMethodKind == MethodHandleInfo.REF_invokeStatic &&
+ lambdaProxy.getImplMethodName.contains("$anonfun$")
+ }
+
+ def inspect(closure: AnyRef): SerializedLambda = {
+val writeReplace = closure.getClass.getDeclaredMethod("writeReplace")
+writeReplace.setAccessible(true)
+writeReplace.invoke(closure).asInstanceOf[SerializedLambda]
+ }
+
+ /**
+ * Check if the handle represents the LambdaMetafactory that indylambda
Scala closures
+ * use for creating the lambda class and getting a closure instance.
+ */
+ def isLambdaMetafactory(bsmHandle: Handle): Boolean = {
+bsmHandle.getOwner == LambdaMetafactoryClassName &&
+ bsmHandle.getName == LambdaMetafactoryMethodName &&
+ bsmHandle.getDesc == LambdaMetafactoryMethodDesc
+ }
+
+ /**
+ * Check if the handle represents a target method that is:
+ * - a STATIC method that implements a Scala lambda body in the indylambda
style
+ * - captures the enclosing `this`, i.e. the first argument is a reference
to the same type as
+ * the owning class.
+ * Returns true if both criteria above are met.
+ */
+ def isLambdaBodyCapturingOuter(handle: Handle, ownerInternalName: String):
Boolean = {
+handle.getTag == H_INVOKESTATIC &&
+ handle.getName.contains("$anonfun$") &&
+ handle.getOwner == ownerInternalName &&
+ handle.getDesc.startsWith(s"(L$ownerInternalName;")
+ }
+
+ /**
+ * Check if the callee of a call site is a inner class constructor.
+ * - A constructor has to be invoked via INVOKESPECIAL
+ * - A constructor's internal name is "init" and the return type is
"V" (void)
+ * - An inner class' first argument in the signature has to be a reference
to the
+ * enclosing "this", aka `$outer` in Scala.
+ */
+ def isInnerClassCtorCapturingOuter(
+ op: Int, owner: String, name: String, desc: String, callerInternalName:
String): Boolean = {
+op == INVOKESPECIAL && name == "" &&
desc.startsWith(s"(L$callerInternalName;")
+ }
+
+ /**
+ * Scans an indylambda Scala closure, along with its lexically nested
closures, and populate
+ * the accessed fields info on which fields on the outer object are accessed.
+ *
+ * This is equivalent to getInnerClosureClasses() + InnerClosureFinder +
FieldAccessFinder fused
+ * into one for processing indylambda closures. The traversal order along
the call graph is the
+ * same for all three combined, so they can be fused together easily while
maintaining the same
+ * ordering as the existing implementation.
+ *
+ * Precondition: this function expects the `accessedFields` to be populated
with all known
+ *
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28571: Add compatibility flag to cast long to timestamp
HyukjinKwon commented on a change in pull request #28571:
URL: https://github.com/apache/spark/pull/28571#discussion_r426998182
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
##
@@ -390,8 +390,12 @@ case class Cast(child: Expression, dataType: DataType,
timeZoneId: Option[String
if (d.isNaN || d.isInfinite) null else (d * 100L).toLong
}
+ // SPARK-31710.Add compatibility flag to cast long to timestamp,
// converting seconds to us
- private[this] def longToTimestamp(t: Long): Long = t * 100L
+ private[this] def longToTimestamp(t: Long): Long = {
+if (SQLConf.get.getConf(SQLConf.LONG_TIMESTAMP_CONVERSION_IN_SECONDS)) t *
100L
Review comment:
Let's don't do this. It will require to add the compatibility across all
the date time functionality in Spark, e.g.) `from_unixtime`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #28544: [SPARK-31387][SQL][test-maven] Handle unknown operation/session ID in HiveThriftServer2Listener
maropu commented on a change in pull request #28544:
URL: https://github.com/apache/spark/pull/28544#discussion_r426997661
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/ui/HiveThriftServer2Listener.scala
##
@@ -131,60 +132,81 @@ private[thriftserver] class HiveThriftServer2Listener(
updateLiveStore(session)
}
- private def onSessionClosed(e: SparkListenerThriftServerSessionClosed): Unit
= {
-val session = sessionList.get(e.sessionId)
-session.finishTimestamp = e.finishTime
-updateStoreWithTriggerEnabled(session)
-sessionList.remove(e.sessionId)
- }
+ private def onSessionClosed(e: SparkListenerThriftServerSessionClosed): Unit
=
+Option(sessionList.get(e.sessionId)) match {
+ case None => logWarning(s"onSessionClosed called with unknown session
id: ${e.sessionId}")
+ case Some(sessionData) =>
+val session = sessionData
+session.finishTimestamp = e.finishTime
+updateStoreWithTriggerEnabled(session)
+sessionList.remove(e.sessionId)
+}
- private def onOperationStart(e: SparkListenerThriftServerOperationStart):
Unit = {
-val info = getOrCreateExecution(
- e.id,
- e.statement,
- e.sessionId,
- e.startTime,
- e.userName)
-
-info.state = ExecutionState.STARTED
-executionList.put(e.id, info)
-sessionList.get(e.sessionId).totalExecution += 1
-executionList.get(e.id).groupId = e.groupId
-updateLiveStore(executionList.get(e.id))
-updateLiveStore(sessionList.get(e.sessionId))
- }
+ private def onOperationStart(e: SparkListenerThriftServerOperationStart):
Unit =
+Option(sessionList.get(e.sessionId)) match {
+ case None => logWarning(s"onOperationStart called with unknown session
id: ${e.sessionId}")
Review comment:
> @maropu this code is in a listener that executes on the listener bus.
The listener bus can drop events if it becomes to busy.
So it might happen that events are dropped, and id is unavailable. It will
not affect query execution.
Does a server get back to a normal state by just ignoring the case? What I a
bit worry about is that users can get the same warning message repeatedly if a
session id gets lost (I'm not sure the case can happen in event sequences).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630543560 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630543560 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
SparkQA commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630543079 **[Test build #122825 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122825/testReport)** for PR 28569 at commit [`6beeca7`](https://github.com/apache/spark/commit/6beeca79435cbfe6c1acecf8eb898efe84faf1f4). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
SparkQA removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630529795 **[Test build #122825 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122825/testReport)** for PR 28569 at commit [`6beeca7`](https://github.com/apache/spark/commit/6beeca79435cbfe6c1acecf8eb898efe84faf1f4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28540: [SPARK-31719][SQL] Refactor JoinSelection
AmplabJenkins removed a comment on pull request #28540: URL: https://github.com/apache/spark/pull/28540#issuecomment-630541237 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28540: [SPARK-31719][SQL] Refactor JoinSelection
AmplabJenkins commented on pull request #28540: URL: https://github.com/apache/spark/pull/28540#issuecomment-630541237 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28540: [SPARK-31719][SQL] Refactor JoinSelection
SparkQA removed a comment on pull request #28540: URL: https://github.com/apache/spark/pull/28540#issuecomment-630419853 **[Test build #122820 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122820/testReport)** for PR 28540 at commit [`8a2d0ee`](https://github.com/apache/spark/commit/8a2d0ee8ac1cf97d5f4bf2b46306be6b90128159). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28540: [SPARK-31719][SQL] Refactor JoinSelection
SparkQA commented on pull request #28540: URL: https://github.com/apache/spark/pull/28540#issuecomment-630540660 **[Test build #122820 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122820/testReport)** for PR 28540 at commit [`8a2d0ee`](https://github.com/apache/spark/commit/8a2d0ee8ac1cf97d5f4bf2b46306be6b90128159). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #28558: [SPARK-31738][SQL][DOCS] Describe 'L' and 'M' month pattern letters
HyukjinKwon commented on pull request #28558: URL: https://github.com/apache/spark/pull/28558#issuecomment-630536486 +1 seems good to me too This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #28541: [SPARK-31720][CORE] TaskMemoryManager allocate failed when new task comming
AngersZh commented on a change in pull request #28541:
URL: https://github.com/apache/spark/pull/28541#discussion_r426989811
##
File path: core/src/main/scala/org/apache/spark/memory/ExecutionMemoryPool.scala
##
@@ -138,6 +140,11 @@ private[memory] class ExecutionMemoryPool(
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName
pool to be free")
lock.wait()
+ } else if (toGrant == 0 && memoryFree > 0) {
Review comment:
> Or, if one specific pattern of tasks take significantly more memory
than other tasks, maybe you should tune the tasks themselves, instead of
modifying the Spark internal for a specific case.
yea, ad-hoc query sort with big key, spill 20G +. only run that query will
success, run with other sql with high concurrency , failed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #28541: [SPARK-31720][CORE] TaskMemoryManager allocate failed when new task comming
AngersZh commented on a change in pull request #28541:
URL: https://github.com/apache/spark/pull/28541#discussion_r426988749
##
File path: core/src/main/scala/org/apache/spark/memory/ExecutionMemoryPool.scala
##
@@ -138,6 +140,11 @@ private[memory] class ExecutionMemoryPool(
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName
pool to be free")
lock.wait()
+ } else if (toGrant == 0 && memoryFree > 0) {
Review comment:
> That's exactly what I mean, the executor is oversubscribed by tasks.
The task OOM because the executor memory is not enough, the choice here is
either to launch worker node with more memory, or change the value of
`spark.task.cpus` to allow less tasks run in parallel.
In our case, spark.task.cpus is default value, but core per executor is 4.
Active Task not use too much memory decrease the limit of task which use more
memory. So want heavy task wait a little for other task release. A little
corner case
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on a change in pull request #28541: [SPARK-31720][CORE] TaskMemoryManager allocate failed when new task comming
jiangxb1987 commented on a change in pull request #28541:
URL: https://github.com/apache/spark/pull/28541#discussion_r426988698
##
File path: core/src/main/scala/org/apache/spark/memory/ExecutionMemoryPool.scala
##
@@ -138,6 +140,11 @@ private[memory] class ExecutionMemoryPool(
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName
pool to be free")
lock.wait()
+ } else if (toGrant == 0 && memoryFree > 0) {
Review comment:
Or, if one specific pattern of tasks take significantly more memory than
other tasks, maybe you should tune the tasks themselves, instead of modifying
the Spark internal for a specific case.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
HyukjinKwon commented on a change in pull request #28569: URL: https://github.com/apache/spark/pull/28569#discussion_r426478018 ## File path: python/pyspark/resource/information.py ## @@ -26,8 +26,10 @@ class ResourceInformation(object): One example is GPUs, where the addresses would be the indices of the GPUs -@param name the name of the resource -@param addresses an array of strings describing the addresses of the resource +:param name: the name of the resource +:param addresses: an array of strings describing the addresses of the resource + +.. versionadded:: 3.0.0 Review comment: Will open a PR to backport for this change specifically for branch-3.0. This PR itself should go to master only. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on a change in pull request #28541: [SPARK-31720][CORE] TaskMemoryManager allocate failed when new task comming
jiangxb1987 commented on a change in pull request #28541:
URL: https://github.com/apache/spark/pull/28541#discussion_r426987592
##
File path: core/src/main/scala/org/apache/spark/memory/ExecutionMemoryPool.scala
##
@@ -138,6 +140,11 @@ private[memory] class ExecutionMemoryPool(
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName
pool to be free")
lock.wait()
+ } else if (toGrant == 0 && memoryFree > 0) {
Review comment:
That's exactly what I mean, the executor is oversubscribed by tasks. The
task OOM because the executor memory is not enough, the choice here is either
to launch worker node with more memory, or change the value of
`spark.task.cpus` to allow less tasks run in parallel.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #28559: [SPARK-31739][PYSPARK][DOCS][MINOR] Fix docstring syntax issues and misplaced space characters.
HyukjinKwon commented on pull request #28559: URL: https://github.com/apache/spark/pull/28559#issuecomment-630531082 Merged to branch-3.0 as well. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630530241 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630530241 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
SparkQA commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630529795 **[Test build #122825 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122825/testReport)** for PR 28569 at commit [`6beeca7`](https://github.com/apache/spark/commit/6beeca79435cbfe6c1acecf8eb898efe84faf1f4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #28541: [SPARK-31720][CORE] TaskMemoryManager allocate failed when new task comming
AngersZh commented on a change in pull request #28541:
URL: https://github.com/apache/spark/pull/28541#discussion_r426984333
##
File path: core/src/main/scala/org/apache/spark/memory/ExecutionMemoryPool.scala
##
@@ -138,6 +140,11 @@ private[memory] class ExecutionMemoryPool(
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName
pool to be free")
lock.wait()
+ } else if (toGrant == 0 && memoryFree > 0) {
Review comment:
> I don't see why it's still required to wait for more memory here. If
your executor memory is not sufficient to support so many tasks, either
increase your executor memory or reduce the slots per executor.
Sometimes required 0 then cause Task throw OOM, in this case always task is
heavy, re-compute cost a lot.
For normal Spark job, we can change config to increase memory or change
slot, but for long running Spark such as Thrift server, we can't always restart
it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
viirya commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630527564 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630523156 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/122824/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630523152 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630523152 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
SparkQA removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630512946 **[Test build #122824 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122824/testReport)** for PR 28569 at commit [`6beeca7`](https://github.com/apache/spark/commit/6beeca79435cbfe6c1acecf8eb898efe84faf1f4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
SparkQA commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630522970 **[Test build #122824 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122824/testReport)** for PR 28569 at commit [`6beeca7`](https://github.com/apache/spark/commit/6beeca79435cbfe6c1acecf8eb898efe84faf1f4). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] TJX2014 commented on a change in pull request #28534: [SPARK-31710][SQL]Fix millisecond and microsecond convert to timestamp in to_timestamp
TJX2014 commented on a change in pull request #28534: URL: https://github.com/apache/spark/pull/28534#discussion_r426973155 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala ## @@ -789,7 +789,7 @@ abstract class ToTimestamp protected def downScaleFactor: Long override def inputTypes: Seq[AbstractDataType] = -Seq(TypeCollection(StringType, DateType, TimestampType), StringType) +Seq(TypeCollection(StringType, DateType, TimestampType, LongType ), StringType) Review comment: Yes, `IntegerType` should also be considered. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28543: [SPARK-31721][SQL] Assert optimized is initialized before tracking the planning time
AmplabJenkins removed a comment on pull request #28543: URL: https://github.com/apache/spark/pull/28543#issuecomment-630513775 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28543: [SPARK-31721][SQL] Assert optimized is initialized before tracking the planning time
AmplabJenkins commented on pull request #28543: URL: https://github.com/apache/spark/pull/28543#issuecomment-630513775 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins removed a comment on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630513352 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
AmplabJenkins commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630513352 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28543: [SPARK-31721][SQL] Assert optimized is initialized before tracking the planning time
SparkQA removed a comment on pull request #28543: URL: https://github.com/apache/spark/pull/28543#issuecomment-630360910 **[Test build #122819 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122819/testReport)** for PR 28543 at commit [`41ea1a9`](https://github.com/apache/spark/commit/41ea1a91b8741c9af60cd927c64da863ea893cdc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28569: [SPARK-31748][CORE][PYTHON] Document resource module in PySpark doc and rename/move classes
SparkQA commented on pull request #28569: URL: https://github.com/apache/spark/pull/28569#issuecomment-630512946 **[Test build #122824 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122824/testReport)** for PR 28569 at commit [`6beeca7`](https://github.com/apache/spark/commit/6beeca79435cbfe6c1acecf8eb898efe84faf1f4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28543: [SPARK-31721][SQL] Assert optimized is initialized before tracking the planning time
SparkQA commented on pull request #28543: URL: https://github.com/apache/spark/pull/28543#issuecomment-630512988 **[Test build #122819 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122819/testReport)** for PR 28543 at commit [`41ea1a9`](https://github.com/apache/spark/commit/41ea1a91b8741c9af60cd927c64da863ea893cdc). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on a change in pull request #28541: [SPARK-31720][CORE] TaskMemoryManager allocate failed when new task comming
jiangxb1987 commented on a change in pull request #28541:
URL: https://github.com/apache/spark/pull/28541#discussion_r426963366
##
File path: core/src/main/scala/org/apache/spark/memory/ExecutionMemoryPool.scala
##
@@ -138,6 +140,11 @@ private[memory] class ExecutionMemoryPool(
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName
pool to be free")
lock.wait()
+ } else if (toGrant == 0 && memoryFree > 0) {
Review comment:
This simply means the task has already got assigned the amount of memory
that is above average, I don't see why it's still required to wait for more
memory here. If your executor memory is not sufficient to support so many
tasks, either increase your executor memory or reduce the slots per executor.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] GuoPhilipse commented on pull request #28571: Add compatibility flag to cast long to timestamp
GuoPhilipse commented on pull request #28571: URL: https://github.com/apache/spark/pull/28571#issuecomment-630503356 thanks Takeshi ,i will read the rules. At 2020-05-19 07:43:14, "Takeshi Yamamuro" wrote: Hi, @GuoPhilipse. Could you pelase read the Pull Request section in the our contribution guide first? Then, plz follow the rules there. https://spark.apache.org/contributing.html Thanks for your contribution, anyway. — You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or unsubscribe. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Sudhar287 commented on pull request #28573: [WIP][SPARK-31579][SQL] Floor div to div
Sudhar287 commented on pull request #28573: URL: https://github.com/apache/spark/pull/28573#issuecomment-630503124 Right. Got it! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Sudhar287 closed pull request #28573: [WIP][SPARK-31579][SQL] Floor div to div
Sudhar287 closed pull request #28573: URL: https://github.com/apache/spark/pull/28573 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #28573: [WIP][SPARK-31579][SQL] Floor div to div
maropu commented on pull request #28573: URL: https://github.com/apache/spark/pull/28573#issuecomment-630502891 If you want to discuss this topic, I think you should do in the JIRA side by showing your PoF patch in your local (forked) repository. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28462: [SPARK-31651][CORE] Improve handling the case where different barrier sync types in a single sync
AmplabJenkins removed a comment on pull request #28462: URL: https://github.com/apache/spark/pull/28462#issuecomment-630501468 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28462: [SPARK-31651][CORE] Improve handling the case where different barrier sync types in a single sync
AmplabJenkins commented on pull request #28462: URL: https://github.com/apache/spark/pull/28462#issuecomment-630501468 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28488: [SPARK-29083][CORE] Prefetch elements in rdd.toLocalIterator
SparkQA commented on pull request #28488: URL: https://github.com/apache/spark/pull/28488#issuecomment-630501057 **[Test build #122822 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122822/testReport)** for PR 28488 at commit [`6c3856d`](https://github.com/apache/spark/commit/6c3856d5d82de3f98cd0dd93e951b8355e93fe7f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org