[GitHub] [spark] AmplabJenkins commented on pull request #30883: [SPARK-33878][SQL][TESTS] Fix resolving of `spark_catalog` in v1 Hive catalog tests
AmplabJenkins commented on pull request #30883: URL: https://github.com/apache/spark/pull/30883#issuecomment-749397252 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37796/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30883: [SPARK-33878][SQL][TESTS] Fix resolving of `spark_catalog` in v1 Hive catalog tests
SparkQA commented on pull request #30883: URL: https://github.com/apache/spark/pull/30883#issuecomment-749396300 **[Test build #133199 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133199/testReport)** for PR 30883 at commit [`370d80b`](https://github.com/apache/spark/commit/370d80ba5a1494d8342c9dfbcc51fe3d4f6cd7f3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30212: [SPARK-33308][SQL] Refactor current grouping analytics
AmplabJenkins removed a comment on pull request #30212: URL: https://github.com/apache/spark/pull/30212#issuecomment-748607367 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30212: [SPARK-33308][SQL] Refactor current grouping analytics
maropu commented on a change in pull request #30212:
URL: https://github.com/apache/spark/pull/30212#discussion_r547116200
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -850,29 +850,62 @@ class AstBuilder extends SqlBaseBaseVisitor[AnyRef] with
SQLConfHelper with Logg
}
/**
- * Add an [[Aggregate]] or [[GroupingSets]] to a logical plan.
+ * Add an [[Aggregate]] to a logical plan.
*/
private def withAggregationClause(
ctx: AggregationClauseContext,
selectExpressions: Seq[NamedExpression],
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
-val groupByExpressions = expressionList(ctx.groupingExpressions)
-
-if (ctx.GROUPING != null) {
- // GROUP BY GROUPING SETS (...)
- val selectedGroupByExprs =
-ctx.groupingSet.asScala.map(_.expression.asScala.map(e =>
expression(e)).toSeq)
- GroupingSets(selectedGroupByExprs.toSeq, groupByExpressions, query,
selectExpressions)
-} else {
- // GROUP BY (WITH CUBE | WITH ROLLUP)?
- val mappedGroupByExpressions = if (ctx.CUBE != null) {
-Seq(Cube(groupByExpressions))
- } else if (ctx.ROLLUP != null) {
-Seq(Rollup(groupByExpressions))
+if (ctx.groupingExpressionsWithGroupingAnalytics.isEmpty) {
+ val groupByExpressions = expressionList(ctx.groupingExpressions)
+ if (ctx.GROUPING != null) {
+// GROUP BY GROUPING SETS (...)
+val selectedGroupByExprs =
+ ctx.groupingSet.asScala.map(_.expression.asScala.map(e =>
expression(e)).toSeq)
+Aggregate(Seq(GroupingSets(selectedGroupByExprs, groupByExpressions)),
+ selectExpressions, query)
} else {
-groupByExpressions
+// GROUP BY (WITH CUBE | WITH ROLLUP)?
+val mappedGroupByExpressions = if (ctx.CUBE != null) {
+ Seq(Cube(groupByExpressions.map(Seq(_
+} else if (ctx.ROLLUP != null) {
+ Seq(Rollup(groupByExpressions.map(Seq(_
+} else {
+ groupByExpressions
+}
+Aggregate(mappedGroupByExpressions, selectExpressions, query)
}
- Aggregate(mappedGroupByExpressions, selectExpressions, query)
+} else {
+ val groupByExpressions =
+ctx.groupingExpressionsWithGroupingAnalytics.asScala
+ .map(groupByExpr => {
+val groupingAnalytics = groupByExpr.groupingAnalytics
+if (groupingAnalytics != null) {
+ val selectedGroupByExprs = groupingAnalytics.groupingSet.asScala
+.map(_.expression.asScala.map(e => expression(e)).toSeq)
+ if (groupingAnalytics.CUBE != null) {
+// CUBE(A, B, (A, B), ()) is not supported.
+if (selectedGroupByExprs.exists(_.isEmpty)) {
+ throw new ParseException("Empty set in CUBE grouping sets is
not supported.",
+groupingAnalytics)
+}
+Cube(selectedGroupByExprs)
+ } else if (groupingAnalytics.ROLLUP != null) {
+// ROLLUP(A, B, (A, B), ()) is not supported.
+if (selectedGroupByExprs.exists(_.isEmpty)) {
+ throw new ParseException("Empty set in ROLLUP grouping sets
is not supported.",
+groupingAnalytics)
+}
+Rollup(selectedGroupByExprs)
+ } else {
+GroupingSets(selectedGroupByExprs,
selectedGroupByExprs.flatten.distinct)
Review comment:
Could you check `assert(groupingAnalytics.GROUPING != null)`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-745429482 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/132831/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-749395209 **[Test build #133198 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133198/testReport)** for PR 29966 at commit [`8c53b83`](https://github.com/apache/spark/commit/8c53b83d1650a69b4225cdbca4fd26d1d5537d94). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30863: [SPARK-33858][SQL][TESTS] Unify v1 and v2 ALTER TABLE .. RENAME PARTITION tests
AmplabJenkins removed a comment on pull request #30863: URL: https://github.com/apache/spark/pull/30863#issuecomment-749099159 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133152/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #30863: [SPARK-33858][SQL][TESTS] Unify v1 and v2 ALTER TABLE .. RENAME PARTITION tests
MaxGekk commented on a change in pull request #30863:
URL: https://github.com/apache/spark/pull/30863#discussion_r547114868
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/AlterTableRenamePartitionSuite.scala
##
@@ -0,0 +1,158 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import org.apache.spark.sql.{AnalysisException, Row}
+import org.apache.spark.sql.catalyst.analysis.{NoSuchPartitionException,
NoSuchTableException}
+import org.apache.spark.sql.execution.command
+import org.apache.spark.sql.internal.SQLConf
+
+trait AlterTableRenamePartitionSuiteBase extends
command.AlterTableRenamePartitionSuiteBase {
+ protected def createSinglePartTable(t: String): Unit = {
+sql(s"CREATE TABLE $t (id bigint, data string) $defaultUsing PARTITIONED
BY (id)")
+sql(s"INSERT INTO $t PARTITION (id = 1) SELECT 'abc'")
+ }
+
+ test("rename without explicitly specifying database") {
+val t = "tbl"
+withTable(t) {
+ createSinglePartTable(t)
+ checkPartitions(t, Map("id" -> "1"))
+
+ sql(s"ALTER TABLE $t PARTITION (id = 1) RENAME TO PARTITION (id = 2)")
+ checkPartitions(t, Map("id" -> "2"))
+ checkAnswer(sql(s"SELECT id, data FROM $t"), Row(2, "abc"))
+}
+ }
+
+ test("table to alter does not exist") {
+withNamespace(s"$catalog.ns") {
+ sql(s"CREATE NAMESPACE $catalog.ns")
+ val errMsg = intercept[NoSuchTableException] {
+sql(s"ALTER TABLE $catalog.ns.no_tbl PARTITION (id=1) RENAME TO
PARTITION (id=2)")
+ }.getMessage
+ assert(errMsg.contains("Table or view 'no_tbl' not found"))
+}
+ }
+
+ test("partition to rename does not exist") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ createSinglePartTable(t)
+ checkPartitions(t, Map("id" -> "1"))
+ val errMsg = intercept[NoSuchPartitionException] {
+sql(s"ALTER TABLE $t PARTITION (id = 3) RENAME TO PARTITION (id = 2)")
+ }.getMessage
+ assert(errMsg.contains("Partition not found in table"))
+}
+ }
+}
+
+class AlterTableRenamePartitionSuite
+ extends AlterTableRenamePartitionSuiteBase
+ with CommandSuiteBase {
+
+ test("single part partition") {
Review comment:
@cloud-fan Here is the fix https://github.com/apache/spark/pull/30883
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request #30883: [SPARK-33878][SQL][TESTS] Fix resolving of `spark_catalog` in v1 Hive catalog tests
MaxGekk opened a new pull request #30883: URL: https://github.com/apache/spark/pull/30883 ### What changes were proposed in this pull request? 1. Recognize `spark_catalog` as the default session catalog in the checks of `TestHiveQueryExecution`. 2. Move v2 and v1 in-memory catalog test `"SPARK-33305: DROP TABLE should also invalidate cache"` to the common trait `command/DropTableSuiteBase`, and run it with v1 Hive external catalog. ### Why are the changes needed? To run In-memory catalog tests in Hive catalog. ### Does this PR introduce _any_ user-facing change? No, the changes influence only on tests. ### How was this patch tested? By running the affected test suites for `DROP TABLE`: ``` $ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DropTableSuite" ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30877: [SPARK-23862][SQL] Support Java enums from Scala Dataset API
AmplabJenkins removed a comment on pull request #30877: URL: https://github.com/apache/spark/pull/30877#issuecomment-749393606 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37794/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30865: [WIP][SPARK-33861][SQL] Simplify conditional in predicate
AmplabJenkins removed a comment on pull request #30865: URL: https://github.com/apache/spark/pull/30865#issuecomment-748820434 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133125/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30877: [SPARK-23862][SQL] Support Java enums from Scala Dataset API
AmplabJenkins commented on pull request #30877: URL: https://github.com/apache/spark/pull/30877#issuecomment-749393606 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37794/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #30865: [WIP][SPARK-33861][SQL] Simplify conditional in predicate
wangyum commented on pull request #30865: URL: https://github.com/apache/spark/pull/30865#issuecomment-749393504 It seems we need to add a new rule, this is because we can not add it to `ReplaceNullWithFalseInPredicate ` or `SimplifyConditionals`, example: `select if(null, true, false)` can not rewrite to `select null and true`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
SparkQA commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749393372 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37795/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r547110204
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveQuerySuite.scala
##
@@ -1219,6 +1219,22 @@ class HiveQuerySuite extends HiveComparisonTest with
SQLTestUtils with BeforeAnd
}
}
}
+
+ test("SPARK-33084: Add jar support ivy url in SQL") {
+val testData = TestHive.getHiveFile("data/files/sample.json").toURI
+sql("ADD JAR ivy://org.apache.hive.hcatalog:hive-hcatalog-core:2.3.7")
+sql(
+ """CREATE TABLE t1(a string, b string)
+|ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'""".stripMargin)
+sql(s"""LOAD DATA LOCAL INPATH "$testData" INTO TABLE t1""")
+sql("select * from src join t1 on src.key = t1.a")
+sql("DROP TABLE t1")
Review comment:
Done
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveQuerySuite.scala
##
@@ -1219,6 +1219,22 @@ class HiveQuerySuite extends HiveComparisonTest with
SQLTestUtils with BeforeAnd
}
}
}
+
+ test("SPARK-33084: Add jar support ivy url in SQL") {
+val testData = TestHive.getHiveFile("data/files/sample.json").toURI
+sql("ADD JAR ivy://org.apache.hive.hcatalog:hive-hcatalog-core:2.3.7")
+sql(
+ """CREATE TABLE t1(a string, b string)
Review comment:
DONE
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveQuerySuite.scala
##
@@ -1219,6 +1219,22 @@ class HiveQuerySuite extends HiveComparisonTest with
SQLTestUtils with BeforeAnd
}
}
}
+
+ test("SPARK-33084: Add jar support ivy url in SQL") {
+val testData = TestHive.getHiveFile("data/files/sample.json").toURI
+sql("ADD JAR ivy://org.apache.hive.hcatalog:hive-hcatalog-core:2.3.7")
+sql(
+ """CREATE TABLE t1(a string, b string)
+|ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'""".stripMargin)
+sql(s"""LOAD DATA LOCAL INPATH "$testData" INTO TABLE t1""")
+sql("select * from src join t1 on src.key = t1.a")
Review comment:
DONE
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -25,12 +25,140 @@ import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+case class IvyProperties(
+packagesExclusions: String,
+packages: String,
+repositories: String,
+ivyRepoPath: String,
+ivySettingsPath: String)
+
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): IvyProperties = {
+val Seq(packagesExclusions, packages, repositories, ivyRepoPath,
ivySettingsPath) = Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+IvyProperties(packagesExclusions, packages, repositories, ivyRepoPath,
ivySettingsPath)
+ }
+
+ private def isInvalidQueryString(tokens: Array[String]): Boolean = {
+tokens.length != 2 || StringUtils.isBlank(tokens(0)) ||
StringUtils.isBlank(tokens(1))
+ }
+
+ /**
+ * Parse URI query string's parameter value of `transitive` and `exclude`.
+ * Other invalid parameters will be ignored.
+ *
+ * @param uri Ivy uri need to be downloaded.
+ * @return Tuple value of parameter `transitive` and `exclude` value.
+ *
+ * 1. transitive: whether to download dependency jar of ivy URI,
default value is false
+ *and this parameter value is case-sensitive. Invalid value will
be treat as false.
+ *Example: Input:
exclude=org.mortbay.jetty:jetty&transitive=true
+ *Output: true
+ *
+ * 2. exclude: comma separated exclusions to apply when resolving
transitive dependencies,
+ *consists of `group:module` pairs separated by commas.
+ *Example: Input:
excludeorg.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ *Output: [org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http]
+ */
+ private def parseQueryParams(uri: URI): (Boolean, String) = {
+val uriQuery = uri.getQuery
+if (uriQuery == null) {
+ (false, "")
+} else {
+ val mapTokens = uriQuery.split("&").map(_.split("="))
+ if (mapTokens.exists(isInvalidQueryString)) {
+throw new IllegalArgumentException(
+ s"Invalid query string in ivy uri ${uri.toString}: $uriQuery")
+ }
+ val groupedParams = mapTokens.map(kv => (kv(0), kv(1))).groupBy(_._1)
+
+ // Parse transitive parameters (e.g., transitive=true) in an ivy U
[GitHub] [spark] maropu commented on pull request #29893: [SPARK-32976][SQL]Support column list in INSERT statement
maropu commented on pull request #29893: URL: https://github.com/apache/spark/pull/29893#issuecomment-749381388 @yaooqinn kindly ping: I've filed jira so that we don't forget to do it. https://issues.apache.org/jira/browse/SPARK-33877 `branch-3.1` includes this commit, so I think its better to document it until v3.1.0 released. cc: @HyukjinKwon This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30484: [SPARK-33532][SQL] Remove unreachable branch in SpecificParquetRecordReaderBase.initialize method
LuciferYang commented on pull request #30484: URL: https://github.com/apache/spark/pull/30484#issuecomment-749380105 > @LuciferYang I am very sorry but do you mind pointing out which commit added that codes and removed the usages? It would be much easier to review with that. @HyukjinKwon OK, let me investigate ~ I think it's a very interesting thing ~ haha ~ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
SparkQA removed a comment on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-749303793 **[Test build #133190 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133190/testReport)** for PR 30243 at commit [`a1024f2`](https://github.com/apache/spark/commit/a1024f27b73a9dc41b4fbd246f4a468d79f3222c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
LuciferYang commented on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749378837 thx @HyukjinKwon @dongjoon-hyun This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
LuciferYang commented on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749378207 @HyukjinKwon @dongjoon-hyun It seems that it is not easy to prove this optimization through UT. I did the following test, taking DataSourceV1 as an example: 1. 10 files and each file has 1100 columns , each file about 400m 2. Execute a simple query without filter `select count(xxx) from orc_table` The key results are as follows: **without this pr** 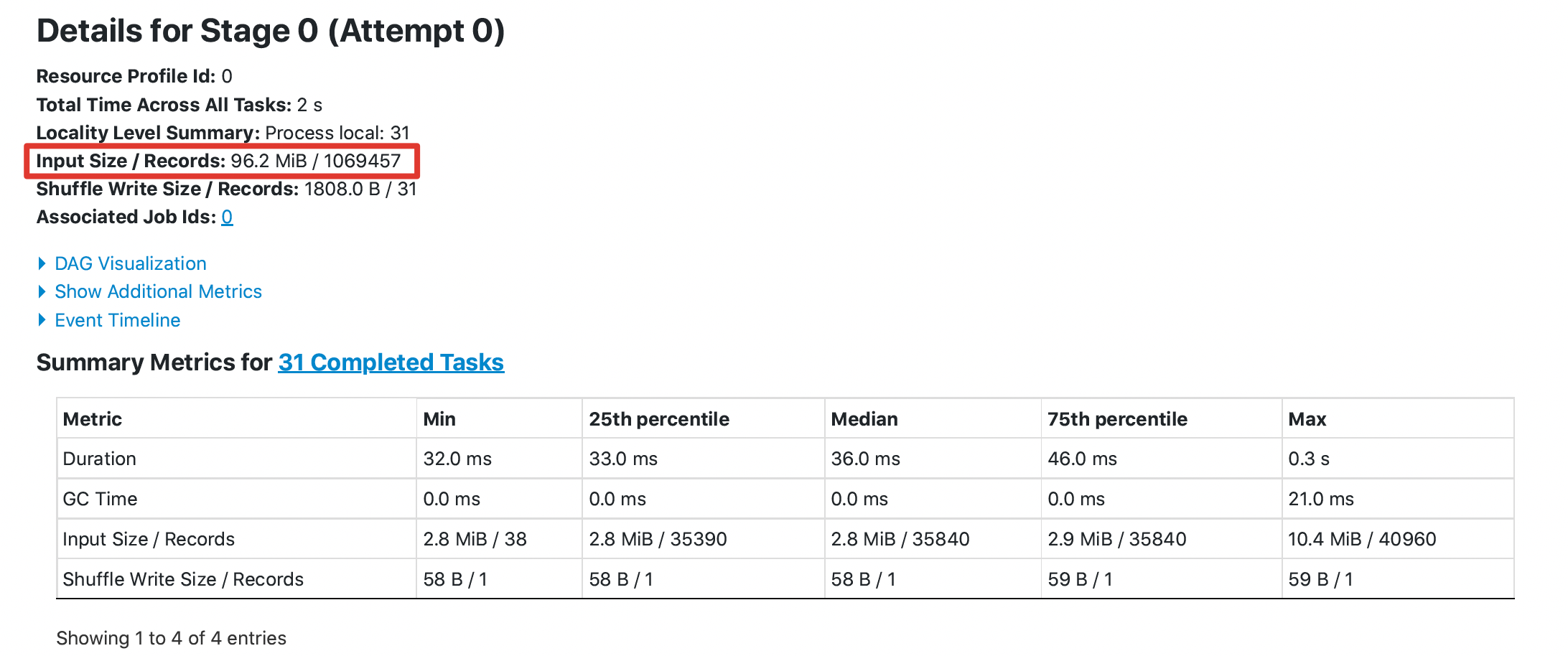 **with this pr** 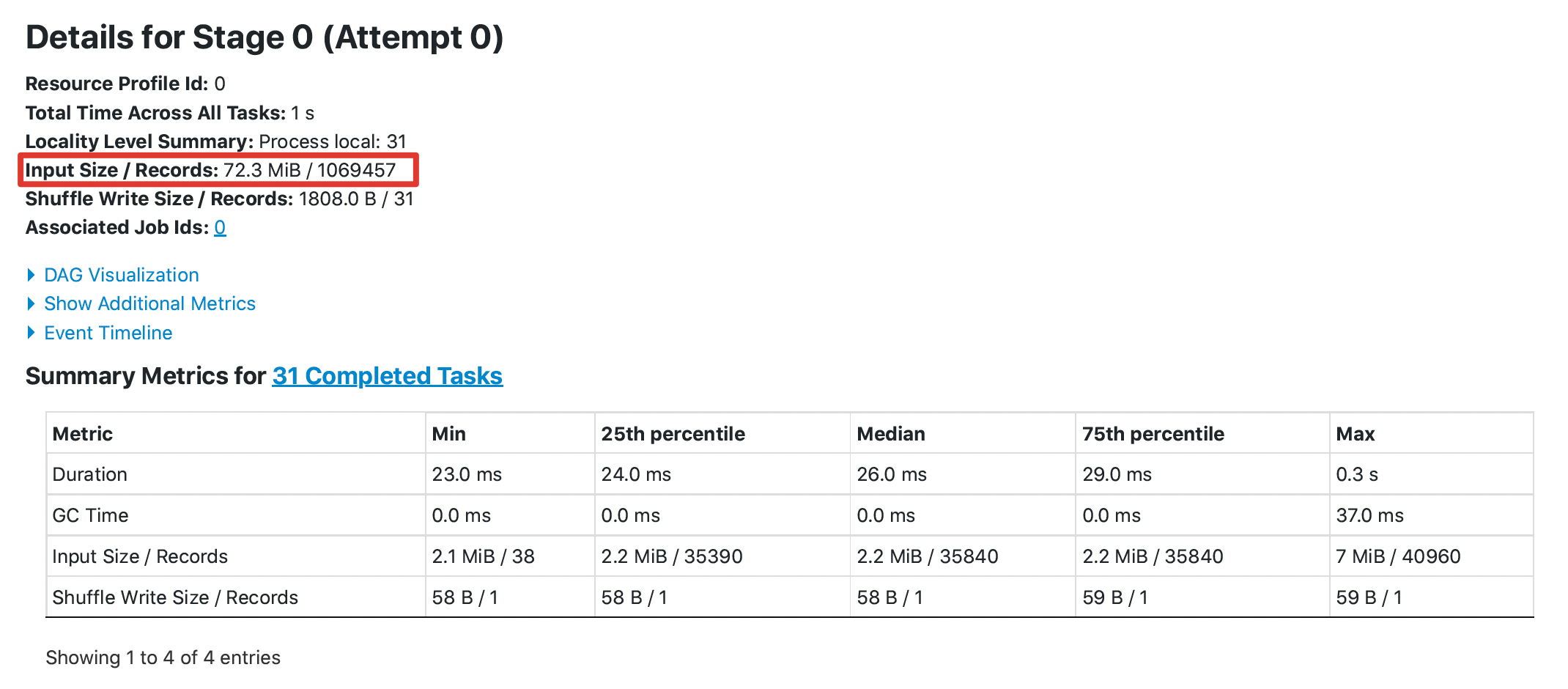 The `Input Size` from `96.2 MiB` to `72.3 MiB`, the `Total Time Across All Tasks` from 2s to 1s This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
AmplabJenkins commented on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-749377852 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133190/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] weixiuli commented on a change in pull request #30716: [SPARK-33747][CORE] Avoid calling unregisterMapOutput when the map stage is being rerunning.
weixiuli commented on a change in pull request #30716:
URL: https://github.com/apache/spark/pull/30716#discussion_r546631296
##
File path:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
##
@@ -2035,6 +2040,107 @@ class DAGSchedulerSuite extends SparkFunSuite with
TempLocalSparkContext with Ti
assert(scheduler.activeJobs.isEmpty)
}
+ def reInit(): Unit = {
+assert(sc != null)
+val dagOutputTracker = mapOutputTracker
+val taskSchedulerImpl = new TaskSchedulerImpl(sc) {
+ override def submitTasks(taskSet: TaskSet) = {
+super.submitTasks(taskSet)
+taskSet.tasks.foreach(_.epoch = dagOutputTracker.getEpoch)
+taskSets += taskSet
+ }
+
+ override def cancelTasks(stageId: Int, interruptThread: Boolean) {
+cancelledStages += stageId
+ }
+}
+taskSchedulerImpl.initialize(new FakeSchedulerBackend)
+scheduler = new DAGScheduler(
+ sc,
+ taskSchedulerImpl,
+ sc.listenerBus,
+ mapOutputTracker,
+ blockManagerMaster,
+ sc.env)
+dagEventProcessLoopTester = new
DAGSchedulerEventProcessLoopTester(scheduler)
+ }
+
+ test("Test dagScheduler.shouldUnregisterMapOutput with map stage not
running") {
+reInit()
+val shuffleMapRdd = new MyRDD(sc, 2, Nil)
+val shuffleDep = new ShuffleDependency(shuffleMapRdd, new
HashPartitioner(2))
+val shuffleId = shuffleDep.shuffleId
+val reduceRdd = new MyRDD(sc, 2, List(shuffleDep), tracker =
mapOutputTracker)
+submit(reduceRdd, Array(0, 1))
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", reduceRdd.partitions.length)),
+ (Success, makeMapStatus("hostB", reduceRdd.partitions.length
+// The MapOutputTracker should know about both map output locations.
+assert(mapOutputTracker.getMapSizesByExecutorId(shuffleId,
0).map(_._1.host).toSet ===
+ HashSet("hostA", "hostB"))
+
+// The first result task fails, with a fetch failure for the output from
the first mapper.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleId, 0, 0, 0, "ignored"),
+ null))
+assert(sparkListener.failedStages.contains(1))
+
+val mapStatuses = mapOutputTracker.shuffleStatuses(shuffleId).mapStatuses
+// unregisterMapOutput with a fetchFailed.
+assert(mapStatuses.count(_ != null) === 1)
+assert(mapStatuses(1).location === makeBlockManagerId("hostB"))
+ }
+
+ test("Test dagScheduler.shouldUnregisterMapOutput with map stage
re-running") {
+reInit()
+val shuffleMapRdd = new MyRDD(sc, 3, Nil)
+val shuffleDep = new ShuffleDependency(shuffleMapRdd, new
HashPartitioner(2))
+val shuffleId = shuffleDep.shuffleId
+val reduceRdd = new MyRDD(sc, 2, List(shuffleDep), tracker =
mapOutputTracker)
+submit(reduceRdd, Array(0, 1))
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", reduceRdd.partitions.length)),
+ (Success, makeMapStatus("hostB", reduceRdd.partitions.length)),
+ (Success, makeMapStatus("hostC", reduceRdd.partitions.length
+// The MapOutputTracker should know about both map output locations.
+assert(mapOutputTracker.getMapSizesByExecutorId(shuffleId,
0).map(_._1.host).toSet ===
+ HashSet("hostA", "hostB", "hostC"))
+
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleId, 0, 0, 0, "ignored"),
+ null))
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostB"), shuffleId, 1, 1, 0, "ignored"),
+ null))
+
+assert(sparkListener.failedStages.contains(1))
+
+// Wait for a long time to make sure the map stage was resubmitted.
+eventually(timeout(1000 milliseconds), interval(10 milliseconds)) {
+ assert(scheduler.runningStages.nonEmpty && taskSets.size == 3)
+}
+
+runEvent(makeCompletionEvent(
+ taskSets(2).tasks(0),
+ Success,
+ makeMapStatus("hostA", reduceRdd.partitions.length)))
+
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
Review comment:
Oh, I'm sorry,i have updated my ut, thanks, PTAL.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
SparkQA commented on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-749377070 **[Test build #133190 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133190/testReport)** for PR 30243 at commit [`a1024f2`](https://github.com/apache/spark/commit/a1024f27b73a9dc41b4fbd246f4a468d79f3222c). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class SparkPod(pod: Pod, container: Container) ` * `trait KubernetesFeatureConfigStep ` * `public class Distributions ` * `trait CheckAnalysis extends PredicateHelper with LookupCatalog ` * `case class UnresolvedView(` * `case class TemporaryViewRelation(tableMeta: CatalogTable) extends LeafNode ` * `case class Decode(params: Seq[Expression], child: Expression) extends RuntimeReplaceable ` * `case class StringDecode(bin: Expression, charset: Expression)` * `case class NoopCommand(` * `case class ShowTableExtended(` * `case class AlterTableRenamePartition(` * `case class AlterTableRecoverPartitions(child: LogicalPlan) extends Command ` * `case class DropView(` * `case class RepairTable(child: LogicalPlan) extends Command ` * `case class AlterViewAs(` * `case class AlterViewSetProperties(` * `case class AlterViewUnsetProperties(` * `case class AlterTableSerDeProperties(` * `case class CacheTable(` * `case class CacheTableAsSelect(` * `case class UncacheTable(` * `case class SubqueryExec(name: String, child: SparkPlan, maxNumRows: Option[Int] = None)` * `trait BaseCacheTableExec extends V2CommandExec ` * `case class CacheTableExec(` * `case class CacheTableAsSelectExec(` * `case class UncacheTableExec(` * `class JDBCTableCatalog extends TableCatalog with SupportsNamespaces with Logging ` * `case class StateSchemaNotCompatible(message: String) extends Exception(message)` * `class StateSchemaCompatibilityChecker(` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
imback82 commented on a change in pull request #30881:
URL: https://github.com/apache/spark/pull/30881#discussion_r547097927
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveAttribute.scala
##
@@ -0,0 +1,35 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.analysis
+
+import org.apache.spark.sql.catalyst.plans.logical.{DescribeColumn,
LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.connector.catalog.V1Table
+
+/**
+ * Resolve [[UnresolvedAttribute]] in column related commands.
+ */
+case class ResolveAttribute(resolver: Resolver) extends Rule[LogicalPlan] {
+ def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
+case r @ DescribeColumn(ResolvedTable(_, _, table),
UnresolvedAttribute(colNameParts), _)
+if !table.isInstanceOf[V1Table] =>
Review comment:
This is so that `ResolveSessionCatalog` can pass column name parts
directly to `DescribeColumnCommand` without resolving columns in the analyzer.
If we want to resolve columns for both v1 and v2 here, we can introduce
`UnresolvedAttr` and `ResolvedAttr` in `v2ResolutionPlans.scala`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30243: [SPARK-33335][SQL] Support `has_all` func
AngersZh commented on a change in pull request #30243:
URL: https://github.com/apache/spark/pull/30243#discussion_r547096480
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
##
@@ -3999,3 +3999,203 @@ case class ArrayExcept(left: Expression, right:
Expression) extends ArrayBinaryL
override def prettyName: String = "array_except"
}
+
+/**
+ * Checks if the array (left) has the array (right)
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(array1, array2) - Returns true if array1 contains all
element in array2." +
+" Ignore duplicates and element order in array.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(1, 2, 3), array(2));
+ true
+ > SELECT _FUNC_(array(1, 2, 3), array(1, 2, 2));
+ true
+ > SELECT _FUNC_(array(1, 2, null), array(null));
+ true
+ """,
+ group = "array_funcs",
+ since = "3.2.0")
+case class HasAll(left: Expression, right: Expression)
+ extends BinaryArrayExpressionWithImplicitCast with ArraySetLike with
NullIntolerant {
+
+ override def dataType: DataType = BooleanType
+
+ override def et: DataType = elementType
+
+ override def dt: DataType = dataType
+
+ override def checkInputDataTypes(): TypeCheckResult = {
+val typeCheckResult = super.checkInputDataTypes()
+if (typeCheckResult.isSuccess) {
+ TypeUtils.checkForOrderingExpr(et, s"function $prettyName")
Review comment:
Yea, similar as `ArrayContains`
https://github.com/apache/spark/blob/a1024f27b73a9dc41b4fbd246f4a468d79f3222c/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala#L4102-L4109
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
SparkQA commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749374255 **[Test build #133197 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133197/testReport)** for PR 30881 at commit [`66fa611`](https://github.com/apache/spark/commit/66fa61149a9363d8da135a8c07f66b6b38311200). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30484: [SPARK-33532][SQL] Remove unreachable branch in SpecificParquetRecordReaderBase.initialize method
HyukjinKwon commented on pull request #30484: URL: https://github.com/apache/spark/pull/30484#issuecomment-749372549 @LuciferYang I am very sorry but do you mind pointing out which commit added that codes and removed the usages? It would be much easier to review with that. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
AmplabJenkins removed a comment on pull request #30882: URL: https://github.com/apache/spark/pull/30882#issuecomment-749370232 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37792/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27019: [SPARK-30027][SQL] Support codegen for aggregate filters in HashAggregateExec
AmplabJenkins removed a comment on pull request #27019: URL: https://github.com/apache/spark/pull/27019#issuecomment-749370234 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133188/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30880: [MINOR][CORE] Remove unused variable CompressionCodec.DEFAULT_COMPRESSION_CODEC
AmplabJenkins removed a comment on pull request #30880: URL: https://github.com/apache/spark/pull/30880#issuecomment-749320394 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
AmplabJenkins removed a comment on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749370231 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133191/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
AmplabJenkins removed a comment on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749370233 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37793/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30880: [MINOR][CORE] Remove unused variable CompressionCodec.DEFAULT_COMPRESSION_CODEC
AmplabJenkins commented on pull request #30880: URL: https://github.com/apache/spark/pull/30880#issuecomment-749370229 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133192/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
AmplabJenkins commented on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749370233 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37793/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
AmplabJenkins commented on pull request #30882: URL: https://github.com/apache/spark/pull/30882#issuecomment-749370232 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37792/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27019: [SPARK-30027][SQL] Support codegen for aggregate filters in HashAggregateExec
AmplabJenkins commented on pull request #27019: URL: https://github.com/apache/spark/pull/27019#issuecomment-749370234 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133188/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
AmplabJenkins commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749370231 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133191/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya edited a comment on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
viirya edited a comment on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749356702 > I see. This makes sense. But why do we need to avoid this? > What's the cost did you mean? The execution memory used by states? > It would be great if you can explain your case and what issue you would like to solve in the PR description. To avoid skew memory usage on an executor. Yes, it is mainly for memory. For streaming queries that store large states, memory usage is severe. Skew state store distribution means there are times of memory usage on one or few executors than others. So streaming query can fail due to OOM on these executors. I will update the PR description to make it more clear. > Ideally, we should let the Spark task scheduler to do its work rather than doing the task scheduling work in SS because we don't have the full context of the executors. For example, this PR has to assume each executor has the same capability, while the task scheduler knows more about slow and fast executors. Preferred location doesn't replace the task scheduler, it is just a suggestion and task scheduler can choose to use it or not. For example we already asked later batch to schedule tasks on same executors that store states in previous batch. This is how the preferred locations work, isn't? This PR doesn't assume executor capacity but suggests the task scheduler to evenly distribute statuful tasks across executors if possible, when no store location is available. The task scheduling is still decided by the task scheduler. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #30864: [SPARK-33857][SQL] Unify random functions and make Uuid Shuffle support seed in SQL
ulysses-you commented on pull request #30864: URL: https://github.com/apache/spark/pull/30864#issuecomment-749364673 thanks @maropu @dongjoon-hyun , will to narrow the goal and make this PR focus on one thing. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya edited a comment on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
viirya edited a comment on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749356702 > I see. This makes sense. But why do we need to avoid this? > What's the cost did you mean? The execution memory used by states? > It would be great if you can explain your case and what issue you would like to solve in the PR description. To avoid skew memory usage on an executor. Yes, it is mainly for memory. For streaming queries that store large states, memory usage is severe. Skew state store distribution means there are times of memory usage on one or few executors than others. I will update the PR description to make it more clear. > Ideally, we should let the Spark task scheduler to do its work rather than doing the task scheduling work in SS because we don't have the full context of the executors. For example, this PR has to assume each executor has the same capability, while the task scheduler knows more about slow and fast executors. Preferred location doesn't replace the task scheduler, it is just a suggestion and task scheduler can choose to use it or not. For example we already asked later batch to schedule tasks on same executors that store states in previous batch. This is how the preferred locations work, isn't? This PR doesn't assume executor capacity but suggests the task scheduler to evenly distribute statuful tasks across executors if possible, when no store location is available. The task scheduling is still decided by the task scheduler. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
ulysses-you commented on pull request #30868: URL: https://github.com/apache/spark/pull/30868#issuecomment-749363672 thanks for merging ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon commented on pull request #30868: URL: https://github.com/apache/spark/pull/30868#issuecomment-749362580 It has a conflict with branch-2.4 but I think we don't have to bother. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon edited a comment on pull request #30868: URL: https://github.com/apache/spark/pull/30868#issuecomment-749361814 Merged to master, branch-3.1 and branch-3.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon commented on pull request #30868: URL: https://github.com/apache/spark/pull/30868#issuecomment-749361814 Merged to master, branch-3.1, branch-3.0 and branch-2.4. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon closed pull request #30868: URL: https://github.com/apache/spark/pull/30868 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon commented on a change in pull request #30868:
URL: https://github.com/apache/spark/pull/30868#discussion_r547087403
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/CatalystTypeConverters.scala
##
@@ -457,7 +457,9 @@ object CatalystTypeConverters {
case d: JavaBigDecimal => new DecimalConverter(DecimalType(d.precision,
d.scale)).toCatalyst(d)
case seq: Seq[Any] => new
GenericArrayData(seq.map(convertToCatalyst).toArray)
case r: Row => InternalRow(r.toSeq.map(convertToCatalyst): _*)
-case arr: Array[Any] => new GenericArrayData(arr.map(convertToCatalyst))
+case arr: Array[Byte] => arr
+case arr: Array[Char] => StringConverter.toCatalyst(arr)
+case arr: Array[_] => new GenericArrayData(arr.map(convertToCatalyst))
Review comment:
Oh, gotya.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on a change in pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
ulysses-you commented on a change in pull request #30868:
URL: https://github.com/apache/spark/pull/30868#discussion_r547086735
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/CatalystTypeConverters.scala
##
@@ -457,7 +457,9 @@ object CatalystTypeConverters {
case d: JavaBigDecimal => new DecimalConverter(DecimalType(d.precision,
d.scale)).toCatalyst(d)
case seq: Seq[Any] => new
GenericArrayData(seq.map(convertToCatalyst).toArray)
case r: Row => InternalRow(r.toSeq.map(convertToCatalyst): _*)
-case arr: Array[Any] => new GenericArrayData(arr.map(convertToCatalyst))
+case arr: Array[Byte] => arr
+case arr: Array[Char] => StringConverter.toCatalyst(arr)
+case arr: Array[_] => new GenericArrayData(arr.map(convertToCatalyst))
Review comment:
Seems missed a param `ArrayType(IntegerType)`, they use the different
code path.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya edited a comment on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
viirya edited a comment on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749356702 > I see. This makes sense. But why do we need to avoid this? > What's the cost did you mean? The execution memory used by states? > It would be great if you can explain your case and what issue you would like to solve in the PR description. To avoid skew memory usage on an executor. Yes, it is mainly for memory. For streaming queries that store large states, memory usage is severe. Skew state store distribution means there are times of memory usage on one or few executors than others. I will update the PR description to make it more clear. > Ideally, we should let the Spark task scheduler to do its work rather than doing the task scheduling work in SS because we don't have the full context of the executors. For example, this PR has to assume each executor has the same capability, while the task scheduler knows more about slow and fast executors. Preferred location doesn't replace the task scheduler, it is just a suggestion and task scheduler can choose to use it or not. For example we already asked later batch to schedule tasks on same executors that store states in previous batch. This is how the preferred locations work, isn't? This PR doesn't assume executor capacity but suggests the task scheduler to evenly distribute statuful tasks across executors if possible, when no store location is available. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30880: [MINOR][CORE] Remove unused variable CompressionCodec.DEFAULT_COMPRESSION_CODEC
SparkQA removed a comment on pull request #30880: URL: https://github.com/apache/spark/pull/30880#issuecomment-749318866 **[Test build #133192 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133192/testReport)** for PR 30880 at commit [`fcd3e17`](https://github.com/apache/spark/commit/fcd3e17d7f540d07daa2c35b3c21ed27e13d9335). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
SparkQA removed a comment on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749319402 **[Test build #133191 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133191/testReport)** for PR 30881 at commit [`ec2b57b`](https://github.com/apache/spark/commit/ec2b57b0400cdb7a2f1c7dd02ca349b6eaed9b24). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30880: [MINOR][CORE] Remove unused variable CompressionCodec.DEFAULT_COMPRESSION_CODEC
SparkQA commented on pull request #30880: URL: https://github.com/apache/spark/pull/30880#issuecomment-749358204 **[Test build #133192 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133192/testReport)** for PR 30880 at commit [`fcd3e17`](https://github.com/apache/spark/commit/fcd3e17d7f540d07daa2c35b3c21ed27e13d9335). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon commented on a change in pull request #30868:
URL: https://github.com/apache/spark/pull/30868#discussion_r547084623
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/CatalystTypeConverters.scala
##
@@ -457,7 +457,9 @@ object CatalystTypeConverters {
case d: JavaBigDecimal => new DecimalConverter(DecimalType(d.precision,
d.scale)).toCatalyst(d)
case seq: Seq[Any] => new
GenericArrayData(seq.map(convertToCatalyst).toArray)
case r: Row => InternalRow(r.toSeq.map(convertToCatalyst): _*)
-case arr: Array[Any] => new GenericArrayData(arr.map(convertToCatalyst))
+case arr: Array[Byte] => arr
+case arr: Array[Char] => StringConverter.toCatalyst(arr)
+case arr: Array[_] => new GenericArrayData(arr.map(convertToCatalyst))
Review comment:
It already works without this change.
```scala
scala> Literal.create(Array(1, 2, 3))
res0: org.apache.spark.sql.catalyst.expressions.Literal = [1,2,3]
scala> Literal(Array(1, 2, 3))
res1: org.apache.spark.sql.catalyst.expressions.Literal = [1,2,3]
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
SparkQA commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749358016 **[Test build #133191 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133191/testReport)** for PR 30881 at commit [`ec2b57b`](https://github.com/apache/spark/commit/ec2b57b0400cdb7a2f1c7dd02ca349b6eaed9b24). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
SparkQA commented on pull request #30882: URL: https://github.com/apache/spark/pull/30882#issuecomment-749357902 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37792/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30868: [SPARK-33860][SQL] Make CatalystTypeConverters.convertToCatalyst match special Array value
HyukjinKwon commented on a change in pull request #30868:
URL: https://github.com/apache/spark/pull/30868#discussion_r547084623
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/CatalystTypeConverters.scala
##
@@ -457,7 +457,9 @@ object CatalystTypeConverters {
case d: JavaBigDecimal => new DecimalConverter(DecimalType(d.precision,
d.scale)).toCatalyst(d)
case seq: Seq[Any] => new
GenericArrayData(seq.map(convertToCatalyst).toArray)
case r: Row => InternalRow(r.toSeq.map(convertToCatalyst): _*)
-case arr: Array[Any] => new GenericArrayData(arr.map(convertToCatalyst))
+case arr: Array[Byte] => arr
+case arr: Array[Char] => StringConverter.toCatalyst(arr)
+case arr: Array[_] => new GenericArrayData(arr.map(convertToCatalyst))
Review comment:
It already works without this change.
```scala
scala> Literal(Array(1, 2, 3))
res1: org.apache.spark.sql.catalyst.expressions.Literal = [1,2,3]
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #27019: [SPARK-30027][SQL] Support codegen for aggregate filters in HashAggregateExec
SparkQA removed a comment on pull request #27019: URL: https://github.com/apache/spark/pull/27019#issuecomment-749287847 **[Test build #133188 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133188/testReport)** for PR 27019 at commit [`86d89ba`](https://github.com/apache/spark/commit/86d89ba79bd2d0a86a791d77bdde3eda00271561). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27019: [SPARK-30027][SQL] Support codegen for aggregate filters in HashAggregateExec
SparkQA commented on pull request #27019: URL: https://github.com/apache/spark/pull/27019#issuecomment-749357196 **[Test build #133188 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133188/testReport)** for PR 27019 at commit [`86d89ba`](https://github.com/apache/spark/commit/86d89ba79bd2d0a86a791d77bdde3eda00271561). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `trait GeneratePredicateHelper extends PredicateHelper ` * `case class FilterExec(condition: Expression, child: SparkPlan)` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
viirya commented on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749356702 > I see. This makes sense. But why do we need to avoid this? > What's the cost did you mean? The execution memory used by states? > It would be great if you can explain your case and what issue you would like to solve in the PR description. To avoid skew memory usage on an executor. Yes, it is mainly for memory. For streaming queries that store large states, memory usage is severe. I will update the PR description to make it more clear. > Ideally, we should let the Spark task scheduler to do its work rather than doing the task scheduling work in SS because we don't have the full context of the executors. For example, this PR has to assume each executor has the same capability, while the task scheduler knows more about slow and fast executors. Preferred location doesn't replace the task scheduler, it is just a suggestion and task scheduler can choose to use it or not. For example we already asked later batch to schedule tasks on same executors that store states in previous batch. This is how the preferred locations work, isn't? This PR doesn't assume executor capacity but suggests the task scheduler to evenly distribute statuful tasks across executors if possible, when no store location is available. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
SparkQA commented on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749356083 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37793/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30877: [SPARK-23862][SQL] Support Java enums from Scala Dataset API
SparkQA commented on pull request #30877: URL: https://github.com/apache/spark/pull/30877#issuecomment-749352528 **[Test build #133196 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133196/testReport)** for PR 30877 at commit [`88b7b3c`](https://github.com/apache/spark/commit/88b7b3c3528e0e127e88db98b4ff15cff21ddcef). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xkrogen commented on a change in pull request #30877: [SPARK-23862][SQL] Support Java enums from Scala Dataset API
xkrogen commented on a change in pull request #30877:
URL: https://github.com/apache/spark/pull/30877#discussion_r547079407
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/ScalaReflection.scala
##
@@ -232,6 +232,11 @@ object ScalaReflection extends ScalaReflection {
case t if isSubtype(t, localTypeOf[java.time.Instant]) =>
createDeserializerForInstant(path)
+ case t if t <:< localTypeOf[java.lang.Enum[_]] =>
Review comment:
Good catch! I fixed most of the references to `<:<` from the original PR
but it looks like I missed this one. Updated now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30851: [SPARK-33846][SQL] Include Comments for a nested schema in StructType.toDDL
AmplabJenkins removed a comment on pull request #30851: URL: https://github.com/apache/spark/pull/30851#issuecomment-749347995 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
AmplabJenkins removed a comment on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749347996 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37789/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
AmplabJenkins commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749347996 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37789/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30851: [SPARK-33846][SQL] Include Comments for a nested schema in StructType.toDDL
AmplabJenkins commented on pull request #30851: URL: https://github.com/apache/spark/pull/30851#issuecomment-749347995 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
SparkQA commented on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749346069 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37793/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
SparkQA commented on pull request #30882: URL: https://github.com/apache/spark/pull/30882#issuecomment-749345887 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37792/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
dongjoon-hyun commented on pull request #30472: URL: https://github.com/apache/spark/pull/30472#issuecomment-749345172 Please let me know if this is ready back, @ScrapCodes . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] weixiuli commented on pull request #30716: [SPARK-33747][CORE] Avoid calling unregisterMapOutput when the map stage is being rerunning.
weixiuli commented on pull request #30716: URL: https://github.com/apache/spark/pull/30716#issuecomment-749343263 @Ngone51 @mridulm @jiangxb1987 @dongjoon-hyun PTAL. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
zsxwing commented on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749343031 > When the first batch takes payload from latest offsets, this batch possibly finishes very quick. An executor might be assigned more than one task because the executor finishes previous task very quickly and becomes available again. I see. This makes sense. But why do we need to avoid this? > This is an issue for stateful operations because the expected high cost for maintaining multiple states in same executor. What's the cost did you mean? The execution memory used by states? It would be great if you can explain your case and what issue you would like to solve in the PR description. Ideally, we should let the Spark task scheduler to do its work rather than doing the task scheduling work in SS because we don't have the full context of the executors. For example, this PR has to assume each executor has the same capability, while the task scheduler knows more about slow and fast executors. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dungdm93 commented on pull request #30738: [SPARK-33759][K8S] docker entrypoint should using `spark-class` for spark executor
dungdm93 commented on pull request #30738: URL: https://github.com/apache/spark/pull/30738#issuecomment-749341877 @dongjoon-hyun Yes, It's OK. So feel free to close this MR if it is not suitable for you. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
SparkQA commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749341419 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37789/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30851: [SPARK-33846][SQL] Include Comments for a nested schema in StructType.toDDL
SparkQA commented on pull request #30851: URL: https://github.com/apache/spark/pull/30851#issuecomment-749340702 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37791/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #30852: [SPARK-33847][SQL] Replace None of elseValue inside CaseWhen if all branches are FalseLiteral
wangyum commented on a change in pull request #30852:
URL: https://github.com/apache/spark/pull/30852#discussion_r547069637
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/ReplaceNullWithFalseInPredicate.scala
##
@@ -94,6 +94,7 @@ object ReplaceNullWithFalseInPredicate extends
Rule[LogicalPlan] {
replaceNullWithFalse(cond) -> replaceNullWithFalse(value)
}
val newElseValue = cw.elseValue.map(replaceNullWithFalse)
+.orElse(if (newBranches.forall(_._2 == FalseLiteral))
Some(FalseLiteral) else None)
Review comment:
The result will not change. We will not push foldable into branches for
`EqualTo(CaseWhen(Seq((a, b)), None), Literal(1))` before this pr, but we will
push foldable into branches after this pr, because we will rewrite it to
`EqualTo(CaseWhen(Seq((a, b)), null), Literal(1))`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30851: [SPARK-33846][SQL] Include Comments for a nested schema in StructType.toDDL
SparkQA removed a comment on pull request #30851: URL: https://github.com/apache/spark/pull/30851#issuecomment-749321404 **[Test build #133193 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133193/testReport)** for PR 30851 at commit [`7414d90`](https://github.com/apache/spark/commit/7414d90ce3f262700f4c90f0d1109b6473c745d9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30851: [SPARK-33846][SQL] Include Comments for a nested schema in StructType.toDDL
SparkQA commented on pull request #30851: URL: https://github.com/apache/spark/pull/30851#issuecomment-749338745 **[Test build #133193 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133193/testReport)** for PR 30851 at commit [`7414d90`](https://github.com/apache/spark/commit/7414d90ce3f262700f4c90f0d1109b6473c745d9). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #30852: [SPARK-33847][SQL] Replace None of elseValue inside CaseWhen if all branches are FalseLiteral
wangyum commented on a change in pull request #30852:
URL: https://github.com/apache/spark/pull/30852#discussion_r547000365
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/ReplaceNullWithFalseInPredicate.scala
##
@@ -94,6 +94,7 @@ object ReplaceNullWithFalseInPredicate extends
Rule[LogicalPlan] {
replaceNullWithFalse(cond) -> replaceNullWithFalse(value)
}
val newElseValue = cw.elseValue.map(replaceNullWithFalse)
+.orElse(if (newBranches.forall(_._2 == FalseLiteral))
Some(FalseLiteral) else None)
Review comment:
~~sorry, it is incorrect.~~
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #30852: [SPARK-33847][SQL] Replace None of elseValue inside CaseWhen if all branches are FalseLiteral
wangyum commented on a change in pull request #30852:
URL: https://github.com/apache/spark/pull/30852#discussion_r546997382
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/ReplaceNullWithFalseInPredicate.scala
##
@@ -94,6 +94,7 @@ object ReplaceNullWithFalseInPredicate extends
Rule[LogicalPlan] {
replaceNullWithFalse(cond) -> replaceNullWithFalse(value)
}
val newElseValue = cw.elseValue.map(replaceNullWithFalse)
+.orElse(if (newBranches.forall(_._2 == FalseLiteral))
Some(FalseLiteral) else None)
Review comment:
~~How about another approach, just add this to `SimplifyConditionals`?
The logic is clear and simple:~~
```scala
case cw @ CaseWhen(_, elseValue) if cw.dataType == BooleanType &&
elseValue.isEmpty =>
cw.copy(elseValue = Some(FalseLiteral))
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30738: [SPARK-33759][K8S] docker entrypoint should using `spark-class` for spark executor
dongjoon-hyun commented on pull request #30738:
URL: https://github.com/apache/spark/pull/30738#issuecomment-749337595
Hi, @dungdm93 . Apache Spark distributions provide docker files and build
scripts instead of docker image. It seems that you can do the following to
achieve your use cases. How do you think about that? It's just one line before
you build your docker image.
```bash
$ sed -i.bak 's/${JAVA_HOME}\/bin\/java/\"\$SPARK_HOME\/bin\/spark-class\"/'
kubernetes/dockerfiles/spark/entrypoint.sh
$ bin/docker-image-tool.sh -p
kubernetes/dockerfiles/spark/bindings/python/Dockerfile -n build
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30881: [SPARK-33875][SQL] Implement DESCRIBE COLUMN for v2 tables
SparkQA commented on pull request #30881: URL: https://github.com/apache/spark/pull/30881#issuecomment-749333100 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37789/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
SparkQA commented on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749332723 **[Test build #133195 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133195/testReport)** for PR 30443 at commit [`85d971b`](https://github.com/apache/spark/commit/85d971b0387b2f7e0bd93b2c18a3ceb65c0811b9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30851: [SPARK-33846][SQL] Include Comments for a nested schema in StructType.toDDL
SparkQA commented on pull request #30851: URL: https://github.com/apache/spark/pull/30851#issuecomment-749332132 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37791/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
SparkQA commented on pull request #30882: URL: https://github.com/apache/spark/pull/30882#issuecomment-749332139 **[Test build #133194 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133194/testReport)** for PR 30882 at commit [`4c92503`](https://github.com/apache/spark/commit/4c92503116e3b4b35913ab6d48abf227beac91ae). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
AmplabJenkins removed a comment on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-749306881 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
AmplabJenkins removed a comment on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749331841 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133185/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
AmplabJenkins removed a comment on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749331843 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133184/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
AmplabJenkins removed a comment on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749331838 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30812: [SPARK-33814][SS] Provide preferred locations for stateful operations without reported state store locations
AmplabJenkins commented on pull request #30812: URL: https://github.com/apache/spark/pull/30812#issuecomment-749331843 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133184/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
AmplabJenkins commented on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-749331840 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37788/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
AmplabJenkins commented on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749331838 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
AmplabJenkins commented on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749331841 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133185/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30864: [SPARK-33857][SQL] Unify random functions and make Uuid Shuffle support seed in SQL
dongjoon-hyun commented on pull request #30864: URL: https://github.com/apache/spark/pull/30864#issuecomment-749331667 Oh, I commented before reading @maropu 's last comment. Ya. This looks like two orthogonal purposes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
yaooqinn commented on pull request #30882: URL: https://github.com/apache/spark/pull/30882#issuecomment-749330997 cc @cloud-fan @maropu @HyukjinKwon thanks for checking this This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
dongjoon-hyun closed pull request #30663: URL: https://github.com/apache/spark/pull/30663 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn opened a new pull request #30882: [SPARK-33876][SQL] Add length-check for reading char/varchar from tables w/ a external location
yaooqinn opened a new pull request #30882:
URL: https://github.com/apache/spark/pull/30882
### What changes were proposed in this pull request?
### Why are the changes needed?
```sql
spark-sql> INSERT INTO t2 VALUES ('1', 'b12345');
Time taken: 0.141 seconds
spark-sql> alter table t set location '/tmp/hive_one/t2';
Time taken: 0.095 seconds
spark-sql> select * from t;
1 b1234
1 a
1 b
```
the above case should fail rather than implicitly applying truncation
This PR adds the length check to the existing ApplyCharPadding rule. Tables
will have external locations when users execute
SET LOCATION or CREATE TABLE ... LOCATION. If the location contains over
length values we should fail on read.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #30443: [SPARK-33497][SQL] Override maxRows in some LogicalPlan
ulysses-you commented on pull request #30443: URL: https://github.com/apache/spark/pull/30443#issuecomment-749327611 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30876: [SPARK-33870][CORE] Enable spark.storage.replication.proactive by default
dongjoon-hyun commented on pull request #30876: URL: https://github.com/apache/spark/pull/30876#issuecomment-749327332 Also, cc @mridulm . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29414: [SPARK-32106][SQL] Implement script transform in sql/core
dongjoon-hyun commented on pull request #29414: URL: https://github.com/apache/spark/pull/29414#issuecomment-749327113 Thank you for informing, @maropu ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
SparkQA removed a comment on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749304279 **[Test build #133189 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133189/testReport)** for PR 30663 at commit [`dc04cff`](https://github.com/apache/spark/commit/dc04cff134136561e6e5822d25758356cdd653e3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30663: [SPARK-33700][SQL] Avoid file meta reading when enableFilterPushDown is true and filters is empty for Orc
SparkQA commented on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749325825 **[Test build #133189 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133189/testReport)** for PR 30663 at commit [`dc04cff`](https://github.com/apache/spark/commit/dc04cff134136561e6e5822d25758356cdd653e3). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org