[GitHub] [spark] cloud-fan commented on a diff in pull request #36966: [SPARK-37753] [FOLLOWUP] [SQL] Fix unit tests sometimes failing
cloud-fan commented on code in PR #36966:
URL: https://github.com/apache/spark/pull/36966#discussion_r907040117
##
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala:
##
@@ -710,18 +711,20 @@ class AdaptiveQueryExecSuite
test("SPARK-37753: Inhibit broadcast in left outer join when there are many
empty" +
" partitions on outer/left side") {
-withSQLConf(
- SQLConf.ADAPTIVE_EXECUTION_ENABLED.key -> "true",
- SQLConf.NON_EMPTY_PARTITION_RATIO_FOR_BROADCAST_JOIN.key -> "0.5") {
- // `testData` is small enough to be broadcast but has empty partition
ratio over the config.
- withSQLConf(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "200") {
-val (plan, adaptivePlan) = runAdaptiveAndVerifyResult(
- "SELECT * FROM (select * from testData where value = '1') td" +
-" left outer join testData2 ON key = a")
-val smj = findTopLevelSortMergeJoin(plan)
-assert(smj.size == 1)
-val bhj = findTopLevelBroadcastHashJoin(adaptivePlan)
-assert(bhj.isEmpty)
+eventually(timeout(40.seconds), interval(500.milliseconds)) {
Review Comment:
the interval is 500 ms, do you know how long this test takes?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36985: [SPARK-39597][PYTHON] Make GetTable, TableExists and DatabaseExists in the python side support 3-layer-namespace
zhengruifeng commented on code in PR #36985: URL: https://github.com/apache/spark/pull/36985#discussion_r907041945 ## python/pyspark/sql/catalog.py: ## @@ -164,6 +169,65 @@ def listTables(self, dbName: Optional[str] = None) -> List[Table]: ) return tables +def getTable(self, tableName: str, dbName: Optional[str] = None) -> Table: Review Comment: I think it's a good idea. functions with `dbName` and `tableName` are now somewhat confusing, when `tableName` start to support 3L namespace. Let me update this PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
cloud-fan commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907049142
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala:
##
@@ -877,13 +879,18 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product with Tre
t.copy(properties = Utils.redact(t.properties).toMap,
options = Utils.redact(t.options).toMap) :: Nil
case table: CatalogTable =>
- table.storage.serde match {
-case Some(serde) => table.identifier :: serde :: Nil
-case _ => table.identifier :: Nil
- }
+ stringArgsForCatalogTable(table)
+
case other => other :: Nil
}.mkString(", ")
+ private def stringArgsForCatalogTable(table: CatalogTable): Seq[Any] = {
+table.storage.serde match {
+ case Some(serde) => table.identifier :: serde :: Nil
Review Comment:
I think quoted string is better, let's keep it as it was first.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
cloud-fan commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907049815
##
sql/catalyst/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala:
##
@@ -68,7 +68,11 @@ case class DataSourceV2Relation(
override def skipSchemaResolution: Boolean =
table.supports(TableCapability.ACCEPT_ANY_SCHEMA)
override def simpleString(maxFields: Int): String = {
-s"RelationV2${truncatedString(output, "[", ", ", "]", maxFields)} $name"
+val tableQualifier = (catalog, identifier) match {
Review Comment:
nit: qualifiedTableName
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mcdull-zhang commented on a diff in pull request #36966: [SPARK-37753] [FOLLOWUP] [SQL] Fix unit tests sometimes failing
mcdull-zhang commented on code in PR #36966:
URL: https://github.com/apache/spark/pull/36966#discussion_r907052628
##
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala:
##
@@ -710,18 +711,20 @@ class AdaptiveQueryExecSuite
test("SPARK-37753: Inhibit broadcast in left outer join when there are many
empty" +
" partitions on outer/left side") {
-withSQLConf(
- SQLConf.ADAPTIVE_EXECUTION_ENABLED.key -> "true",
- SQLConf.NON_EMPTY_PARTITION_RATIO_FOR_BROADCAST_JOIN.key -> "0.5") {
- // `testData` is small enough to be broadcast but has empty partition
ratio over the config.
- withSQLConf(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "200") {
-val (plan, adaptivePlan) = runAdaptiveAndVerifyResult(
- "SELECT * FROM (select * from testData where value = '1') td" +
-" left outer join testData2 ON key = a")
-val smj = findTopLevelSortMergeJoin(plan)
-assert(smj.size == 1)
-val bhj = findTopLevelBroadcastHashJoin(adaptivePlan)
-assert(bhj.isEmpty)
+eventually(timeout(40.seconds), interval(500.milliseconds)) {
Review Comment:
After communication, the unit test takes about 3s, the timeout is set to
15s, and it can be retried up to 5 times.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
cloud-fan commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907053973
##
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/WriteToMicroBatchDataSourceV1.scala:
##
@@ -0,0 +1,55 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.sources
+
+import org.apache.spark.sql.catalyst.catalog.CatalogTable
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, UnaryNode}
+import org.apache.spark.sql.execution.streaming.Sink
+import org.apache.spark.sql.streaming.OutputMode
+
+/**
+ * Marker node to represent a DSv1 sink on streaming query.
+ *
+ * Despite this is expected to be the top node, this node should behave like
"pass-through"
+ * since the DSv1 codepath on microbatch execution handles sink operation
separately.
+ *
+ * This node is eliminated in streaming specific optimization phase, which
means there is no
+ * matching physical node.
+ */
+case class WriteToMicroBatchDataSourceV1(
+catalogTable: Option[CatalogTable],
+sink: Sink,
+query: LogicalPlan,
+queryId: String,
+writeOptions: Map[String, String],
+outputMode: OutputMode,
+batchId: Option[Long] = None)
Review Comment:
where do we use this `batchId`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] panbingkun opened a new pull request, #36998: [SPARK-39613][BUILD] Upgrade shapeless to 2.3.9
panbingkun opened a new pull request, #36998: URL: https://github.com/apache/spark/pull/36998 ### What changes were proposed in this pull request? This PR aims to upgrade shapeless from 2.3.7 to 2.3.9. ### Why are the changes needed? This will bring some bug fix of shapeless ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Pass GA -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
HeartSaVioR commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907061291
##
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/WriteToMicroBatchDataSourceV1.scala:
##
@@ -0,0 +1,55 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.sources
+
+import org.apache.spark.sql.catalyst.catalog.CatalogTable
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, UnaryNode}
+import org.apache.spark.sql.execution.streaming.Sink
+import org.apache.spark.sql.streaming.OutputMode
+
+/**
+ * Marker node to represent a DSv1 sink on streaming query.
+ *
+ * Despite this is expected to be the top node, this node should behave like
"pass-through"
+ * since the DSv1 codepath on microbatch execution handles sink operation
separately.
+ *
+ * This node is eliminated in streaming specific optimization phase, which
means there is no
+ * matching physical node.
+ */
+case class WriteToMicroBatchDataSourceV1(
+catalogTable: Option[CatalogTable],
+sink: Sink,
+query: LogicalPlan,
+queryId: String,
+writeOptions: Map[String, String],
+outputMode: OutputMode,
+batchId: Option[Long] = None)
Review Comment:
This is to make this class be symmetric with WriteToMicroBatchDataSource.
Many of parameters are not actually used.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
dongjoon-hyun opened a new pull request, #36999: URL: https://github.com/apache/spark/pull/36999 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
HeartSaVioR commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907063933
##
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/WriteToMicroBatchDataSourceV1.scala:
##
@@ -0,0 +1,55 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.sources
+
+import org.apache.spark.sql.catalyst.catalog.CatalogTable
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, UnaryNode}
+import org.apache.spark.sql.execution.streaming.Sink
+import org.apache.spark.sql.streaming.OutputMode
+
+/**
+ * Marker node to represent a DSv1 sink on streaming query.
+ *
+ * Despite this is expected to be the top node, this node should behave like
"pass-through"
+ * since the DSv1 codepath on microbatch execution handles sink operation
separately.
+ *
+ * This node is eliminated in streaming specific optimization phase, which
means there is no
+ * matching physical node.
+ */
+case class WriteToMicroBatchDataSourceV1(
+catalogTable: Option[CatalogTable],
+sink: Sink,
+query: LogicalPlan,
+queryId: String,
+writeOptions: Map[String, String],
+outputMode: OutputMode,
+batchId: Option[Long] = None)
Review Comment:
Previous self-comment:
> It'd be nice if we can deal with
[SPARK-27484](https://issues.apache.org/jira/browse/SPARK-27484), but let's
defer it as of now as it may bring additional works/concerns.
These parameters could probably help us to go with SPARK-27484.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
dongjoon-hyun commented on PR #36999: URL: https://github.com/apache/spark/pull/36999#issuecomment-1166991352 cc @yaooqinn -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
HeartSaVioR commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907059119
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala:
##
@@ -877,13 +879,18 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product with Tre
t.copy(properties = Utils.redact(t.properties).toMap,
options = Utils.redact(t.options).toMap) :: Nil
case table: CatalogTable =>
- table.storage.serde match {
-case Some(serde) => table.identifier :: serde :: Nil
-case _ => table.identifier :: Nil
- }
+ stringArgsForCatalogTable(table)
+
case other => other :: Nil
}.mkString(", ")
+ private def stringArgsForCatalogTable(table: CatalogTable): Seq[Any] = {
+table.storage.serde match {
+ case Some(serde) => table.identifier :: serde :: Nil
Review Comment:
OK. Let me leave this as it is, and see whether I can make it consistent for
other places in the following work (out of this PR).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
dongjoon-hyun commented on code in PR #36999:
URL: https://github.com/apache/spark/pull/36999#discussion_r907065994
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Config.scala:
##
@@ -729,5 +729,6 @@ private[spark] object Config extends Logging {
val KUBERNETES_DRIVER_ENV_PREFIX = "spark.kubernetes.driverEnv."
- val KUBERNETES_DNSNAME_MAX_LENGTH = 63
+ val KUBERNETES_DNS_SUBDOMAIN_NAME_MAX_LENGTH = 253
+ val KUBERNETES_DNS_LABEL_NAME_MAX_LENGTH = 63
Review Comment:
K8s have two DNS name rules: DNS Subdomain and DNS Label.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
HeartSaVioR commented on code in PR #36963:
URL: https://github.com/apache/spark/pull/36963#discussion_r907066953
##
sql/catalyst/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala:
##
@@ -68,7 +68,11 @@ case class DataSourceV2Relation(
override def skipSchemaResolution: Boolean =
table.supports(TableCapability.ACCEPT_ANY_SCHEMA)
override def simpleString(maxFields: Int): String = {
-s"RelationV2${truncatedString(output, "[", ", ", "]", maxFields)} $name"
+val tableQualifier = (catalog, identifier) match {
Review Comment:
[4ae4b81](https://github.com/apache/spark/pull/36963/commits/4ae4b813e295fda8f6c0dab4ffee43fef0761496)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36774: [SPARK-39388][SQL] Reuse `orcSchema` when push down Orc predicates
cloud-fan commented on PR #36774: URL: https://github.com/apache/spark/pull/36774#issuecomment-1167008944 is `OrcUtils.readCatalystSchema` still needed anywhere? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on a diff in pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
yaooqinn commented on code in PR #36999:
URL: https://github.com/apache/spark/pull/36999#discussion_r907082125
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala:
##
@@ -38,7 +38,7 @@ private[spark] object KubernetesClientUtils extends Logging {
// Config map name can be 63 chars at max.
def configMapName(prefix: String): String = {
val suffix = "-conf-map"
-s"${prefix.take(KUBERNETES_DNSNAME_MAX_LENGTH - suffix.length)}$suffix"
+s"${prefix.take(KUBERNETES_DNS_SUBDOMAIN_NAME_MAX_LENGTH -
suffix.length)}$suffix"
Review Comment:
nit: update L38
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #36774: [SPARK-39388][SQL] Reuse `orcSchema` when push down Orc predicates
LuciferYang commented on PR #36774: URL: https://github.com/apache/spark/pull/36774#issuecomment-1167015535 > readCatalystSchema Yes, it's useless. [05707f2](https://github.com/apache/spark/pull/36774/commits/05707f2654e20d191c7e8ba8b5640eedc685bf17) deleted it -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request, #37000: [SPARK-39615][SQL][WIP] Make listColumns be compatible with 3 layer namespace
zhengruifeng opened a new pull request, #37000: URL: https://github.com/apache/spark/pull/37000 ### What changes were proposed in this pull request? Make listColumns be compatible with 3 layer namespace ### Why are the changes needed? for 3 layer namespace compatiblity ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? added UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #36774: [SPARK-39388][SQL] Reuse `orcSchema` when push down Orc predicates
LuciferYang commented on PR #36774: URL: https://github.com/apache/spark/pull/36774#issuecomment-1167018893 > > readCatalystSchema > > Yes, it's useless. [05707f2](https://github.com/apache/spark/pull/36774/commits/05707f2654e20d191c7e8ba8b5640eedc685bf17) deleted it Let's check this with GitHub Actions -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
dongjoon-hyun commented on code in PR #36999:
URL: https://github.com/apache/spark/pull/36999#discussion_r907113328
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala:
##
@@ -38,7 +38,7 @@ private[spark] object KubernetesClientUtils extends Logging {
// Config map name can be 63 chars at max.
def configMapName(prefix: String): String = {
val suffix = "-conf-map"
-s"${prefix.take(KUBERNETES_DNSNAME_MAX_LENGTH - suffix.length)}$suffix"
+s"${prefix.take(KUBERNETES_DNS_SUBDOMAIN_NAME_MAX_LENGTH -
suffix.length)}$suffix"
Review Comment:
Oh, right. Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #36965: [SPARK-39567][SQL] Support ANSI intervals in the percentile functions
MaxGekk closed pull request #36965: [SPARK-39567][SQL] Support ANSI intervals in the percentile functions URL: https://github.com/apache/spark/pull/36965 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
dongjoon-hyun commented on PR #36999: URL: https://github.com/apache/spark/pull/36999#issuecomment-1167045418 Thank you, @yaooqinn . K8s UT passed at the first comment and the second commit is only changing comments. Merged to master/3.3. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule
dongjoon-hyun closed pull request #36999: [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule URL: https://github.com/apache/spark/pull/36999 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] chenzhx commented on a diff in pull request #36663: [SPARK-38899][SQL]DS V2 supports push down datetime functions
chenzhx commented on code in PR #36663:
URL: https://github.com/apache/spark/pull/36663#discussion_r907122926
##
sql/core/src/main/scala/org/apache/spark/sql/catalyst/util/V2ExpressionBuilder.scala:
##
@@ -254,6 +254,55 @@ class V2ExpressionBuilder(e: Expression, isPredicate:
Boolean = false) {
} else {
None
}
+case date: DateAdd =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_ADD",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: DateDiff =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_DIFF",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: TruncDate =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("TRUNC",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case Second(child, _) =>
+ generateExpression(child).map(v => new V2Extract("SECOND", v))
+case Minute(child, _) =>
+ generateExpression(child).map(v => new V2Extract("MINUTE", v))
+case Hour(child, _) =>
+ generateExpression(child).map(v => new V2Extract("HOUR", v))
+case Month(child) =>
+ generateExpression(child).map(v => new V2Extract("MONTH", v))
+case Quarter(child) =>
+ generateExpression(child).map(v => new V2Extract("QUARTER", v))
+case Year(child) =>
+ generateExpression(child).map(v => new V2Extract("YEAR", v))
+// The DAY_OF_WEEK function in Spark returns the day of the week for
date/timestamp.
+// Database dialects should avoid to follow ISO semantics when handling
DAY_OF_WEEK.
+case DayOfWeek(child) =>
+ generateExpression(child).map(v => new V2Extract("DAY_OF_WEEK", v))
+case DayOfMonth(child) =>
+ generateExpression(child).map(v => new V2Extract("DAY_OF_MONTH", v))
+case DayOfYear(child) =>
+ generateExpression(child).map(v => new V2Extract("DAY_OF_YEAR", v))
+// The WEEK_OF_YEAR function in Spark returns the ISO week from a
date/timestamp.
+// Database dialects need to follow ISO semantics when handling
WEEK_OF_YEAR.
+case WeekOfYear(child) =>
+ generateExpression(child).map(v => new V2Extract("WEEK_OF_YEAR", v))
+// The YEAR_OF_WEEK function in Spark returns the ISO week year from a
date/timestamp.
+// Database dialects need to follow ISO semantics when handling
YEAR_OF_WEEK.
+case YearOfWeek(child) =>
+ generateExpression(child).map(v => new V2Extract("YEAR_OF_WEEK", v))
Review Comment:
Yes. We can replace "Week_Of_Year" with "WEEK", "Day_Of_Year" with "DOY",
and "Day_Of_Month" with "DAY"
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer opened a new pull request, #37001: [SPARK-39148][SQL] DS V2 aggregate push down can work with OFFSET or LIMIT
beliefer opened a new pull request, #37001: URL: https://github.com/apache/spark/pull/37001 ### What changes were proposed in this pull request? Currently, DS V2 aggregate push-down cannot work with OFFSET and LIMIT. If it can work with OFFSET or LIMIT, it will be better performance. ### Why are the changes needed? Let DS V2 aggregate push down can work with OFFSET push down or LIMIT push down. ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? Update tests cases. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36997: [SPARK-39394][SPARK-39253][DOCS][FOLLOW-UP] Fix the PySpark API reference links in the documentation
dongjoon-hyun closed pull request #36997: [SPARK-39394][SPARK-39253][DOCS][FOLLOW-UP] Fix the PySpark API reference links in the documentation URL: https://github.com/apache/spark/pull/36997 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36997: [SPARK-39394][SPARK-39253][DOCS][FOLLOW-UP] Fix the PySpark API reference links in the documentation
dongjoon-hyun commented on PR #36997: URL: https://github.com/apache/spark/pull/36997#issuecomment-1167067833 Could you make a backport to branch-3.3? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36936: [SPARK-39503][SQL] Add session catalog name for v1 database table and function
cloud-fan commented on code in PR #36936:
URL: https://github.com/apache/spark/pull/36936#discussion_r907136211
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/identifiers.scala:
##
@@ -34,13 +38,35 @@ sealed trait IdentifierWithDatabase {
private def quoteIdentifier(name: String): String = name.replace("`", "``")
def quotedString: String = {
+if (SQLConf.get.getConf(LEGACY_IDENTIFIER_OUTPUT_CATALOG_NAME) &&
database.isDefined) {
+ val replacedId = quoteIdentifier(identifier)
+ val replacedDb = database.map(quoteIdentifier(_))
Review Comment:
```suggestion
val replacedDb = quoteIdentifier(database.get)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36936: [SPARK-39503][SQL] Add session catalog name for v1 database table and function
cloud-fan commented on code in PR #36936:
URL: https://github.com/apache/spark/pull/36936#discussion_r907137742
##
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##
@@ -3848,6 +3848,15 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val LEGACY_IDENTIFIER_OUTPUT_CATALOG_NAME =
+buildConf("spark.sql.legacy.identifierOutputCatalogName")
+ .internal()
+ .doc("When set to true, the identifier will output catalog name if
database is defined. " +
+"When set to false, it restores the legacy behavior that does not
output catalog name.")
Review Comment:
nit: usually true means legacy behavior, we probably need to rename the
config a little bit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36984: [SPARK-39594][CORE] Improve logs to show addresses in addition to ports
dongjoon-hyun commented on PR #36984: URL: https://github.com/apache/spark/pull/36984#issuecomment-1167069520 Rebased to the master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36965: [SPARK-39567][SQL] Support ANSI intervals in the percentile functions
MaxGekk commented on PR #36965: URL: https://github.com/apache/spark/pull/36965#issuecomment-1167040364 Merging to master. Thank you, @cloud-fan for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36936: [SPARK-39503][SQL] Add session catalog name for v1 database table and function
cloud-fan commented on PR #36936: URL: https://github.com/apache/spark/pull/36936#issuecomment-1167076595 looks good in general. I'm taking a closer look at where we use `unquotedStringWithoutCatalog` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] martin-g commented on a diff in pull request #36980: [POC][SPARK-39522][INFRA] Uses Docker image cache over a custom image
martin-g commented on code in PR #36980:
URL: https://github.com/apache/spark/pull/36980#discussion_r907146312
##
.github/workflows/build_and_test.yml:
##
@@ -251,13 +254,59 @@ jobs:
name: unit-tests-log-${{ matrix.modules }}-${{ matrix.comment }}-${{
matrix.java }}-${{ matrix.hadoop }}-${{ matrix.hive }}
path: "**/target/unit-tests.log"
- pyspark:
+ infra-image:
needs: precondition
+if: >-
+ fromJson(needs.precondition.outputs.required).pyspark == 'true'
+ || fromJson(needs.precondition.outputs.required).sparkr == 'true'
+ || fromJson(needs.precondition.outputs.required).lint == 'true'
+runs-on: ubuntu-latest
+steps:
+ - name: Login to GitHub Container Registry
+uses: docker/login-action@v2
+with:
+ registry: ghcr.io
+ username: ${{ github.actor }}
+ password: ${{ secrets.GITHUB_TOKEN }}
+ - name: Checkout Spark repository
+uses: actions/checkout@v2
+# In order to fetch changed files
+with:
+ fetch-depth: 0
+ repository: apache/spark
+ ref: ${{ inputs.branch }}
+ - name: Sync the current branch with the latest in Apache Spark
+if: github.repository != 'apache/spark'
+run: |
+ echo "APACHE_SPARK_REF=$(git rev-parse HEAD)" >> $GITHUB_ENV
+ git fetch https://github.com/$GITHUB_REPOSITORY.git
${GITHUB_REF#refs/heads/}
+ git -c user.name='Apache Spark Test Account' -c
user.email='sparktest...@gmail.com' merge --no-commit --progress --squash
FETCH_HEAD
+ git -c user.name='Apache Spark Test Account' -c
user.email='sparktest...@gmail.com' commit -m "Merged commit" --allow-empty
+ -
+name: Set up QEMU
+uses: docker/setup-qemu-action@v1
+ -
+name: Set up Docker Buildx
+uses: docker/setup-buildx-action@v1
+ -
+name: Build and push
+id: docker_build
+uses: docker/build-push-action@v2
+with:
+ context: ./dev/infra/
+ push: true
+ tags: ghcr.io/${{ needs.precondition.outputs.user
}}/apache-spark-github-action-image:latest
+ # TODO: Change yikun to apache
+ # Use the infra image cache of build_infra_images_cache.yml
+ cache-from:
type=registry,ref=ghcr.io/yikun/apache-spark-github-action-image-cache:${{
inputs.branch }}
+
+ pyspark:
+needs: [precondition, infra-image]
if: fromJson(needs.precondition.outputs.required).pyspark == 'true'
name: "Build modules: ${{ matrix.modules }}"
runs-on: ubuntu-20.04
container:
- image: dongjoon/apache-spark-github-action-image:20220207
+ image: ghcr.io/${{ needs.precondition.outputs.user
}}/apache-spark-github-action-image:latest
Review Comment:
I think you could use `options: --user ${{
needs.preconditions.outputs.os_user }}` to avoid the steps for ` Github Actions
permissions workaround` later.
where `os_user` is defined earlier as:
`echo ::set-output name=os_user::$(id -u)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36998: [SPARK-39613][BUILD] Upgrade shapeless to 2.3.9
AmplabJenkins commented on PR #36998: URL: https://github.com/apache/spark/pull/36998#issuecomment-1167095745 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] chenzhx commented on a diff in pull request #36663: [SPARK-38899][SQL]DS V2 supports push down datetime functions
chenzhx commented on code in PR #36663: URL: https://github.com/apache/spark/pull/36663#discussion_r907162042 ## sql/catalyst/src/main/java/org/apache/spark/sql/connector/expressions/Extract.java: ## @@ -0,0 +1,47 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.sql.connector.expressions; + +import org.apache.spark.annotation.Evolving; + +import java.io.Serializable; + +/** + * Represent an extract expression, which contains a field to be extracted + * and a source expression where the field should be extracted. Review Comment: OK -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36663: [SPARK-38899][SQL]DS V2 supports push down datetime functions
cloud-fan commented on code in PR #36663:
URL: https://github.com/apache/spark/pull/36663#discussion_r907164502
##
sql/core/src/main/scala/org/apache/spark/sql/catalyst/util/V2ExpressionBuilder.scala:
##
@@ -254,6 +254,55 @@ class V2ExpressionBuilder(e: Expression, isPredicate:
Boolean = false) {
} else {
None
}
+case date: DateAdd =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_ADD",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: DateDiff =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_DIFF",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: TruncDate =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("TRUNC",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case Second(child, _) =>
+ generateExpression(child).map(v => new V2Extract("SECOND", v))
+case Minute(child, _) =>
+ generateExpression(child).map(v => new V2Extract("MINUTE", v))
+case Hour(child, _) =>
+ generateExpression(child).map(v => new V2Extract("HOUR", v))
+case Month(child) =>
+ generateExpression(child).map(v => new V2Extract("MONTH", v))
+case Quarter(child) =>
+ generateExpression(child).map(v => new V2Extract("QUARTER", v))
+case Year(child) =>
+ generateExpression(child).map(v => new V2Extract("YEAR", v))
+// The DAY_OF_WEEK function in Spark returns the day of the week for
date/timestamp.
+// Database dialects should avoid to follow ISO semantics when handling
DAY_OF_WEEK.
+case DayOfWeek(child) =>
+ generateExpression(child).map(v => new V2Extract("DAY_OF_WEEK", v))
+case DayOfMonth(child) =>
+ generateExpression(child).map(v => new V2Extract("DAY_OF_MONTH", v))
+case DayOfYear(child) =>
+ generateExpression(child).map(v => new V2Extract("DAY_OF_YEAR", v))
+// The WEEK_OF_YEAR function in Spark returns the ISO week from a
date/timestamp.
+// Database dialects need to follow ISO semantics when handling
WEEK_OF_YEAR.
+case WeekOfYear(child) =>
+ generateExpression(child).map(v => new V2Extract("WEEK_OF_YEAR", v))
+// The YEAR_OF_WEEK function in Spark returns the ISO week year from a
date/timestamp.
+// Database dialects need to follow ISO semantics when handling
YEAR_OF_WEEK.
+case YearOfWeek(child) =>
+ generateExpression(child).map(v => new V2Extract("YEAR_OF_WEEK", v))
Review Comment:
SGMT. My only concern is the non-standard ones: `DAY_OF_WEEK`. One idea is
to translate the spark expression to standard functions. ISO DOW is 1 (Monday)
to 7 (Sunday)
Spark `DayOfWeek` -> `(EXTACT(DOW FROM ...) + 5) % 7 + 1`
Spark `WeekDay` -> `EXTACT(DOW FROM ...) + 1`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
HeartSaVioR commented on PR #36963: URL: https://github.com/apache/spark/pull/36963#issuecomment-1167101071 Just rebased to pick up the fixes on GA. No changes during rebase. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request, #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0
zhengruifeng opened a new pull request, #37002: URL: https://github.com/apache/spark/pull/37002 ### What changes were proposed in this pull request? Upgrade Breeze to 2.0 ### Why are the changes needed? since 1.3, breeze has replaced `com.github.fommil.netlib` with `dev.ludovic.netlib` after upgrade to 2.0: 1, breeze should be faster because of this replacement; 2, avoid the licensing issue related to `com.github.fommil.netlib:all` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36976: [SPARK-39577][SQL][DOCS] Add SQL reference for built-in functions
cloud-fan commented on code in PR #36976:
URL: https://github.com/apache/spark/pull/36976#discussion_r907179775
##
docs/sql-ref-functions-builtin.md:
##
@@ -77,3 +77,93 @@ license: |
{% endif %}
{% endfor %}
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-math-funcs-table.html' %}
+### Mathematical Functions
+{% include_relative generated-math-funcs-table.html %}
+ Examples
+{% include_relative generated-math-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-string-funcs-table.html' %}
+### String Functions
+{% include_relative generated-string-funcs-table.html %}
+ Examples
+{% include_relative generated-string-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-conditional-funcs-table.html' %}
+### Conditional Functions
+{% include_relative generated-conditional-funcs-table.html %}
+ Examples
+{% include_relative generated-conditional-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-bitwise-funcs-table.html' %}
+### Bitwise Functions
+{% include_relative generated-bitwise-funcs-table.html %}
+ Examples
+{% include_relative generated-bitwise-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-conversion-funcs-table.html' %}
+### Conversion Functions
+{% include_relative generated-conversion-funcs-table.html %}
+ Examples
+{% include_relative generated-conversion-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-predicate-funcs-table.html' %}
+### Predicate Functions
+{% include_relative generated-predicate-funcs-table.html %}
+ Examples
+{% include_relative generated-predicate-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-generator-funcs-table.html' %}
+### Generator Functions
Review Comment:
This is not scalar function and should be put in a new section. Shall we do
it in a new PR?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] chenzhx commented on a diff in pull request #36663: [SPARK-38899][SQL]DS V2 supports push down datetime functions
chenzhx commented on code in PR #36663:
URL: https://github.com/apache/spark/pull/36663#discussion_r907173999
##
sql/core/src/main/scala/org/apache/spark/sql/catalyst/util/V2ExpressionBuilder.scala:
##
@@ -254,6 +254,55 @@ class V2ExpressionBuilder(e: Expression, isPredicate:
Boolean = false) {
} else {
None
}
+case date: DateAdd =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_ADD",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: DateDiff =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_DIFF",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: TruncDate =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("TRUNC",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case Second(child, _) =>
+ generateExpression(child).map(v => new V2Extract("SECOND", v))
+case Minute(child, _) =>
+ generateExpression(child).map(v => new V2Extract("MINUTE", v))
+case Hour(child, _) =>
+ generateExpression(child).map(v => new V2Extract("HOUR", v))
+case Month(child) =>
+ generateExpression(child).map(v => new V2Extract("MONTH", v))
+case Quarter(child) =>
+ generateExpression(child).map(v => new V2Extract("QUARTER", v))
+case Year(child) =>
+ generateExpression(child).map(v => new V2Extract("YEAR", v))
+// The DAY_OF_WEEK function in Spark returns the day of the week for
date/timestamp.
+// Database dialects should avoid to follow ISO semantics when handling
DAY_OF_WEEK.
Review Comment:
OK
##
sql/core/src/main/scala/org/apache/spark/sql/catalyst/util/V2ExpressionBuilder.scala:
##
@@ -254,6 +254,55 @@ class V2ExpressionBuilder(e: Expression, isPredicate:
Boolean = false) {
} else {
None
}
+case date: DateAdd =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_ADD",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: DateDiff =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("DATE_DIFF",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case date: TruncDate =>
+ val childrenExpressions = date.children.flatMap(generateExpression(_))
+ if (childrenExpressions.length == date.children.length) {
+Some(new GeneralScalarExpression("TRUNC",
childrenExpressions.toArray[V2Expression]))
+ } else {
+None
+ }
+case Second(child, _) =>
+ generateExpression(child).map(v => new V2Extract("SECOND", v))
+case Minute(child, _) =>
+ generateExpression(child).map(v => new V2Extract("MINUTE", v))
+case Hour(child, _) =>
+ generateExpression(child).map(v => new V2Extract("HOUR", v))
+case Month(child) =>
+ generateExpression(child).map(v => new V2Extract("MONTH", v))
+case Quarter(child) =>
+ generateExpression(child).map(v => new V2Extract("QUARTER", v))
+case Year(child) =>
+ generateExpression(child).map(v => new V2Extract("YEAR", v))
+// The DAY_OF_WEEK function in Spark returns the day of the week for
date/timestamp.
+// Database dialects should avoid to follow ISO semantics when handling
DAY_OF_WEEK.
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #36976: [SPARK-39577][SQL][DOCS] Add SQL reference for built-in functions
beliefer commented on code in PR #36976:
URL: https://github.com/apache/spark/pull/36976#discussion_r907186103
##
docs/sql-ref-functions-builtin.md:
##
@@ -77,3 +77,93 @@ license: |
{% endif %}
{% endfor %}
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-math-funcs-table.html' %}
+### Mathematical Functions
+{% include_relative generated-math-funcs-table.html %}
+ Examples
+{% include_relative generated-math-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-string-funcs-table.html' %}
+### String Functions
+{% include_relative generated-string-funcs-table.html %}
+ Examples
+{% include_relative generated-string-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-conditional-funcs-table.html' %}
+### Conditional Functions
+{% include_relative generated-conditional-funcs-table.html %}
+ Examples
+{% include_relative generated-conditional-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-bitwise-funcs-table.html' %}
+### Bitwise Functions
+{% include_relative generated-bitwise-funcs-table.html %}
+ Examples
+{% include_relative generated-bitwise-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-conversion-funcs-table.html' %}
+### Conversion Functions
+{% include_relative generated-conversion-funcs-table.html %}
+ Examples
+{% include_relative generated-conversion-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-predicate-funcs-table.html' %}
+### Predicate Functions
+{% include_relative generated-predicate-funcs-table.html %}
+ Examples
+{% include_relative generated-predicate-funcs-examples.html %}
+{% break %}
+{% endif %}
+{% endfor %}
+
+{% for static_file in site.static_files %}
+{% if static_file.name == 'generated-generator-funcs-table.html' %}
+### Generator Functions
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #36877: [SPARK-39479][SQL] DS V2 supports push down math functions(non ANSI)
beliefer commented on PR #36877: URL: https://github.com/apache/spark/pull/36877#issuecomment-1167157368 ping @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36996: [SPARK-34305][SQL] Unify v1 and v2 ALTER TABLE .. SET SERDE tests
AmplabJenkins commented on PR #36996: URL: https://github.com/apache/spark/pull/36996#issuecomment-1167200348 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36995: [SPARK-39607][SQL][DSV2] Distribution and ordering support V2 function in writing
AmplabJenkins commented on PR #36995: URL: https://github.com/apache/spark/pull/36995#issuecomment-1167200402 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36993: [SPARK-39604][SQL][TESTS] Add UT for DerbyDialect getCatalystType method
AmplabJenkins commented on PR #36993: URL: https://github.com/apache/spark/pull/36993#issuecomment-1167292134 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi closed pull request #36888: [CI] Check if tests are to be run for build and pyspark matrix jobs
EnricoMi closed pull request #36888: [CI] Check if tests are to be run for build and pyspark matrix jobs URL: https://github.com/apache/spark/pull/36888 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun opened a new pull request, #37003: [WIP][SPARK-39522][INFRA] Add Apache Spark infra GA image cache
Yikun opened a new pull request, #37003: URL: https://github.com/apache/spark/pull/37003 ### What changes were proposed in this pull request? 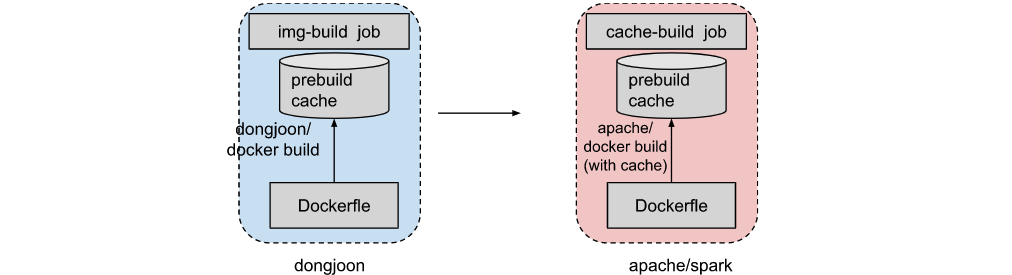 This patch added github action yaml to build infra image cache, this image cache would be used by pyspark/sparkr/lint job later. See more in: https://docs.google.com/document/d/1_uiId-U1DODYyYZejAZeyz2OAjxcnA-xfwjynDF6vd0 ### Why are the changes needed? Help to speed up docker infra image build in each PR. ### Does this PR introduce _any_ user-facing change? No, dev only ### How was this patch tested? local test in my repo -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #37004: [WIP][SQL] Add the `REGEXP_COUNT` function
MaxGekk opened a new pull request, #37004: URL: https://github.com/apache/spark/pull/37004 ### What changes were proposed in this pull request? In the PR, I propose to add new expression `RegExpCount` as a runtime replaceable expression. ### Why are the changes needed? To make the migration process from other systems to Spark SQL easier, and achieve feature parity to such systems. For example, ... supports the `REGEXP_COUNT` function, see ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By running new tests: ``` $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z regexp-functions.sql" $ build/sbt "sql/testOnly *ExpressionsSchemaSuite" $ build/sbt "sql/test:testOnly org.apache.spark.sql.expressions.ExpressionInfoSuite" ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun opened a new pull request, #37005: [SPARK-39522][INFRA]Uses Docker image cache over a custom image in pyspark job
Yikun opened a new pull request, #37005: URL: https://github.com/apache/spark/pull/37005 ### What changes were proposed in this pull request? 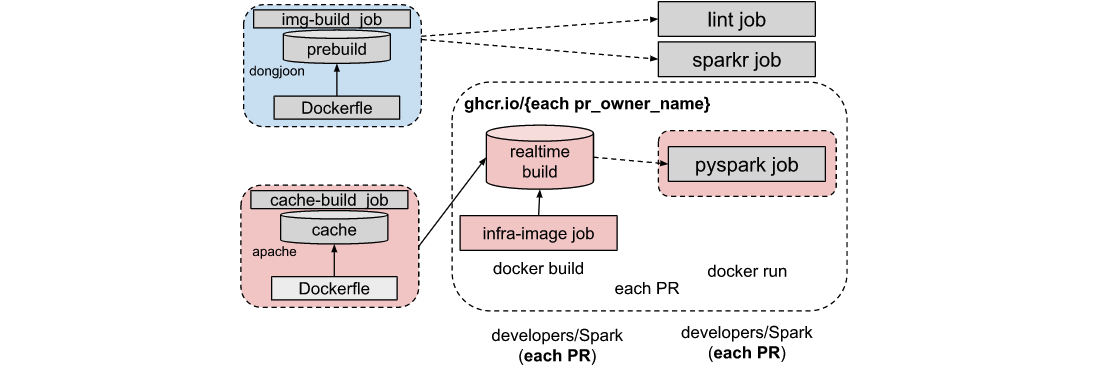 Change pyspark container from original static image to just-in-time build image from cache. ### Why are the changes needed? Help to speed up docker infra image build in each PR. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on a diff in pull request #37005: [SPARK-39522][INFRA]Uses Docker image cache over a custom image in pyspark job
Yikun commented on code in PR #37005:
URL: https://github.com/apache/spark/pull/37005#discussion_r907371578
##
.github/workflows/build_and_test.yml:
##
@@ -251,13 +256,57 @@ jobs:
name: unit-tests-log-${{ matrix.modules }}-${{ matrix.comment }}-${{
matrix.java }}-${{ matrix.hadoop }}-${{ matrix.hive }}
path: "**/target/unit-tests.log"
- pyspark:
+ infra-image:
needs: precondition
if: fromJson(needs.precondition.outputs.required).pyspark == 'true'
+runs-on: ubuntu-latest
+steps:
+ - name: Login to GitHub Container Registry
+uses: docker/login-action@v2
+with:
+ registry: ghcr.io
+ username: ${{ github.actor }}
+ password: ${{ secrets.GITHUB_TOKEN }}
+ - name: Checkout Spark repository
+uses: actions/checkout@v2
+# In order to fetch changed files
+with:
+ fetch-depth: 0
+ repository: apache/spark
+ ref: ${{ inputs.branch }}
+ - name: Sync the current branch with the latest in Apache Spark
+if: github.repository != 'apache/spark'
+run: |
+ echo "APACHE_SPARK_REF=$(git rev-parse HEAD)" >> $GITHUB_ENV
+ git fetch https://github.com/$GITHUB_REPOSITORY.git
${GITHUB_REF#refs/heads/}
+ git -c user.name='Apache Spark Test Account' -c
user.email='sparktest...@gmail.com' merge --no-commit --progress --squash
FETCH_HEAD
+ git -c user.name='Apache Spark Test Account' -c
user.email='sparktest...@gmail.com' commit -m "Merged commit" --allow-empty
+ -
+name: Set up QEMU
+uses: docker/setup-qemu-action@v1
+ -
+name: Set up Docker Buildx
+uses: docker/setup-buildx-action@v1
+ -
+name: Build and push
+id: docker_build
+uses: docker/build-push-action@v2
+with:
+ context: ./dev/infra/
+ push: true
+ # TODO: Cleanup the latest image
+ tags: ghcr.io/${{ needs.precondition.outputs.user
}}/apache-spark-github-action-image:${{ needs.precondition.outputs.img_tag }}
+ # TODO: Change yikun cache to apache cache
Review Comment:
Change this when https://github.com/apache/spark/pull/37003 ready
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on a diff in pull request #37005: [SPARK-39522][INFRA]Uses Docker image cache over a custom image in pyspark job
Yikun commented on code in PR #37005: URL: https://github.com/apache/spark/pull/37005#discussion_r907374687 ## dev/infra/Dockerfile: ## @@ -0,0 +1,55 @@ +# Review Comment: cleanup(rebase) this when #37003 ready -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #36966: [SPARK-37753] [FOLLOWUP] [SQL] Fix unit tests sometimes failing
cloud-fan closed pull request #36966: [SPARK-37753] [FOLLOWUP] [SQL] Fix unit tests sometimes failing URL: https://github.com/apache/spark/pull/36966 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36966: [SPARK-37753] [FOLLOWUP] [SQL] Fix unit tests sometimes failing
cloud-fan commented on PR #36966: URL: https://github.com/apache/spark/pull/36966#issuecomment-1167374600 thanks, merging to master/3.3! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36966: [SPARK-37753] [FOLLOWUP] [SQL] Fix unit tests sometimes failing
cloud-fan commented on code in PR #36966:
URL: https://github.com/apache/spark/pull/36966#discussion_r907411473
##
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala:
##
@@ -710,18 +711,20 @@ class AdaptiveQueryExecSuite
test("SPARK-37753: Inhibit broadcast in left outer join when there are many
empty" +
" partitions on outer/left side") {
-withSQLConf(
- SQLConf.ADAPTIVE_EXECUTION_ENABLED.key -> "true",
- SQLConf.NON_EMPTY_PARTITION_RATIO_FOR_BROADCAST_JOIN.key -> "0.5") {
- // `testData` is small enough to be broadcast but has empty partition
ratio over the config.
- withSQLConf(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "200") {
-val (plan, adaptivePlan) = runAdaptiveAndVerifyResult(
- "SELECT * FROM (select * from testData where value = '1') td" +
-" left outer join testData2 ON key = a")
-val smj = findTopLevelSortMergeJoin(plan)
-assert(smj.size == 1)
-val bhj = findTopLevelBroadcastHashJoin(adaptivePlan)
-assert(bhj.isEmpty)
+eventually(timeout(15.seconds), interval(500.milliseconds)) {
Review Comment:
ah missed one thing: can we add some comments to explain the reason?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36976: [SPARK-39577][SQL][DOCS] Add SQL reference for built-in functions
cloud-fan commented on PR #36976: URL: https://github.com/apache/spark/pull/36976#issuecomment-1167379746 thanks, merging to master/3.3! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #36976: [SPARK-39577][SQL][DOCS] Add SQL reference for built-in functions
cloud-fan closed pull request #36976: [SPARK-39577][SQL][DOCS] Add SQL reference for built-in functions URL: https://github.com/apache/spark/pull/36976 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907421453
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/expressions/GeneralScalarExpression.java:
##
@@ -249,12 +249,12 @@ public int hashCode() {
@Override
public String toString() {
-V2ExpressionSQLBuilder builder = new V2ExpressionSQLBuilder();
+ToStringSQLBuilder builder = new ToStringSQLBuilder();
try {
return builder.build(this);
} catch (Throwable e) {
- return name + "(" +
-Arrays.stream(children).map(child -> child.toString()).reduce((a,b) ->
a + "," + b) + ")";
+ return name + "(" + Arrays.stream(children)
+.map(child -> child.toString()).reduce((a,b) -> a + "," + b +
")").get();
Review Comment:
unnecessary change?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907422117
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/expressions/UserDefinedScalarFunc.java:
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.connector.expressions;
+
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Objects;
+
+import org.apache.spark.annotation.Evolving;
+import org.apache.spark.sql.connector.util.ToStringSQLBuilder;
+
+/**
+ * The general representation of user defined scalar function, which contains
the upper-cased
+ * function name, canonical function name and all the children expressions.
+ *
+ * @since 3.4.0
+ */
+@Evolving
+public class UserDefinedScalarFunc implements Expression, Serializable {
+ private String name;
+ private String canonicalName;
+ private Expression[] children;
+
+ public UserDefinedScalarFunc(String name, String canonicalName, Expression[]
children) {
+this.name = name;
+this.canonicalName = canonicalName;
+this.children = children;
+ }
+
+ public String name() { return name; }
+ public String canonicalName() { return canonicalName; }
+
+ @Override
+ public Expression[] children() { return children; }
+
+ @Override
+ public boolean equals(Object o) {
+if (this == o) return true;
+if (o == null || getClass() != o.getClass()) return false;
+UserDefinedScalarFunc that = (UserDefinedScalarFunc) o;
+return Objects.equals(name, that.name) && Objects.equals(canonicalName,
that.canonicalName) &&
+ Arrays.equals(children, that.children);
+ }
+
+ @Override
+ public int hashCode() {
+return Objects.hash(name, canonicalName, children);
+}
Review Comment:
nit: indentation is wrong
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907422685
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/expressions/aggregate/GeneralAggregateFunc.java:
##
@@ -47,27 +47,31 @@ public final class GeneralAggregateFunc implements
AggregateFunc {
private final boolean isDistinct;
private final Expression[] children;
- public String name() { return name; }
- public boolean isDistinct() { return isDistinct; }
Review Comment:
unnecessary change?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907423331
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/expressions/UserDefinedScalarFunc.java:
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.connector.expressions;
+
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Objects;
+
+import org.apache.spark.annotation.Evolving;
+import org.apache.spark.sql.connector.util.ToStringSQLBuilder;
+
+/**
+ * The general representation of user defined scalar function, which contains
the upper-cased
+ * function name, canonical function name and all the children expressions.
+ *
+ * @since 3.4.0
+ */
+@Evolving
+public class UserDefinedScalarFunc implements Expression, Serializable {
+ private String name;
+ private String canonicalName;
+ private Expression[] children;
+
+ public UserDefinedScalarFunc(String name, String canonicalName, Expression[]
children) {
+this.name = name;
+this.canonicalName = canonicalName;
+this.children = children;
+ }
+
+ public String name() { return name; }
+ public String canonicalName() { return canonicalName; }
+
+ @Override
+ public Expression[] children() { return children; }
+
+ @Override
+ public boolean equals(Object o) {
+if (this == o) return true;
+if (o == null || getClass() != o.getClass()) return false;
+UserDefinedScalarFunc that = (UserDefinedScalarFunc) o;
+return Objects.equals(name, that.name) && Objects.equals(canonicalName,
that.canonicalName) &&
+ Arrays.equals(children, that.children);
+ }
+
+ @Override
+ public int hashCode() {
+return Objects.hash(name, canonicalName, children);
+}
+
+ @Override
+ public String toString() {
+ToStringSQLBuilder builder = new ToStringSQLBuilder();
+try {
+ return builder.build(this);
+} catch (Throwable e) {
+ return name + "(" + Arrays.stream(children)
+.map(child -> child.toString()).reduce((a,b) -> a + "," + b +
")").get();
Review Comment:
is this really corrected? won't it output too many `")"`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907424914
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/expressions/UserDefinedScalarFunc.java:
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.connector.expressions;
+
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Objects;
+
+import org.apache.spark.annotation.Evolving;
+import org.apache.spark.sql.connector.util.ToStringSQLBuilder;
+
+/**
+ * The general representation of user defined scalar function, which contains
the upper-cased
+ * function name, canonical function name and all the children expressions.
+ *
+ * @since 3.4.0
+ */
+@Evolving
+public class UserDefinedScalarFunc implements Expression, Serializable {
+ private String name;
+ private String canonicalName;
+ private Expression[] children;
+
+ public UserDefinedScalarFunc(String name, String canonicalName, Expression[]
children) {
+this.name = name;
+this.canonicalName = canonicalName;
+this.children = children;
+ }
+
+ public String name() { return name; }
+ public String canonicalName() { return canonicalName; }
+
+ @Override
+ public Expression[] children() { return children; }
+
+ @Override
+ public boolean equals(Object o) {
+if (this == o) return true;
+if (o == null || getClass() != o.getClass()) return false;
+UserDefinedScalarFunc that = (UserDefinedScalarFunc) o;
+return Objects.equals(name, that.name) && Objects.equals(canonicalName,
that.canonicalName) &&
+ Arrays.equals(children, that.children);
+ }
+
+ @Override
+ public int hashCode() {
+return Objects.hash(name, canonicalName, children);
+}
+
+ @Override
+ public String toString() {
+ToStringSQLBuilder builder = new ToStringSQLBuilder();
+try {
+ return builder.build(this);
+} catch (Throwable e) {
Review Comment:
what error do we expect to hit?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907427189
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/H2Dialect.scala:
##
@@ -41,6 +43,45 @@ private[sql] object H2Dialect extends JdbcDialect {
override def isSupportedFunction(funcName: String): Boolean =
supportedFunctions.contains(funcName)
+ class H2SQLBuilder extends JDBCSQLBuilder {
+override def visitUserDefinedScalarFunction(
+funcName: String, canonicalName: String, inputs: Array[String]):
String = {
+ funcName match {
+case "CHAR_LENGTH" =>
Review Comment:
let's match `canonicalName` to be safe
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/H2Dialect.scala:
##
@@ -41,6 +43,45 @@ private[sql] object H2Dialect extends JdbcDialect {
override def isSupportedFunction(funcName: String): Boolean =
supportedFunctions.contains(funcName)
+ class H2SQLBuilder extends JDBCSQLBuilder {
+override def visitUserDefinedScalarFunction(
+funcName: String, canonicalName: String, inputs: Array[String]):
String = {
+ funcName match {
+case "CHAR_LENGTH" =>
+ s"$funcName(${inputs.mkString(", ")})"
+case _ => super.visitUserDefinedScalarFunction(funcName,
canonicalName, inputs)
+ }
+}
+
+override def visitUserDefinedAggregateFunction(
+funcName: String,
+canonicalName: String,
+isDistinct: Boolean,
+inputs: Array[String]): String = {
+ funcName match {
Review Comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907428693
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/H2Dialect.scala:
##
@@ -41,6 +43,45 @@ private[sql] object H2Dialect extends JdbcDialect {
override def isSupportedFunction(funcName: String): Boolean =
supportedFunctions.contains(funcName)
+ class H2SQLBuilder extends JDBCSQLBuilder {
+override def visitUserDefinedScalarFunction(
+funcName: String, canonicalName: String, inputs: Array[String]):
String = {
+ funcName match {
+case "CHAR_LENGTH" =>
+ s"$funcName(${inputs.mkString(", ")})"
+case _ => super.visitUserDefinedScalarFunction(funcName,
canonicalName, inputs)
+ }
+}
+
+override def visitUserDefinedAggregateFunction(
+funcName: String,
+canonicalName: String,
+isDistinct: Boolean,
+inputs: Array[String]): String = {
+ funcName match {
+case "IAVG" =>
+ if (isDistinct) {
+s"$funcName(DISTINCT ${inputs.mkString(", ")})"
+ } else {
+s"$funcName(${inputs.mkString(", ")})"
+ }
+case _ =>
+ super.visitUserDefinedAggregateFunction(funcName, canonicalName,
isDistinct, inputs)
+ }
+}
+ }
+
+ override def compileExpression(expr: Expression): Option[String] = {
+val h2SQLBuilder = new H2SQLBuilder()
+try {
+ Some(h2SQLBuilder.build(expr))
+} catch {
+ case NonFatal(e) =>
+logWarning("Error occurs while compiling V2 expression", e)
+None
+}
+ }
+
override def compileAggregate(aggFunction: AggregateFunc): Option[String] = {
Review Comment:
when do we call `compileExpression` and when do we call `compileAggregate`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36593: [SPARK-39139][SQL] DS V2 supports push down DS V2 UDF
cloud-fan commented on code in PR #36593:
URL: https://github.com/apache/spark/pull/36593#discussion_r907429393
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/H2Dialect.scala:
##
@@ -41,6 +43,45 @@ private[sql] object H2Dialect extends JdbcDialect {
override def isSupportedFunction(funcName: String): Boolean =
supportedFunctions.contains(funcName)
+ class H2SQLBuilder extends JDBCSQLBuilder {
+override def visitUserDefinedScalarFunction(
+funcName: String, canonicalName: String, inputs: Array[String]):
String = {
+ funcName match {
+case "CHAR_LENGTH" =>
Review Comment:
BTW, does h2 dialect have the `CHAR_LENGTH` UDF yet?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun opened a new pull request, #37006: [SPARK-39522][INFRA] Uses Docker image cache over a custom image in sparkr job
Yikun opened a new pull request, #37006: URL: https://github.com/apache/spark/pull/37006 ### What changes were proposed in this pull request? 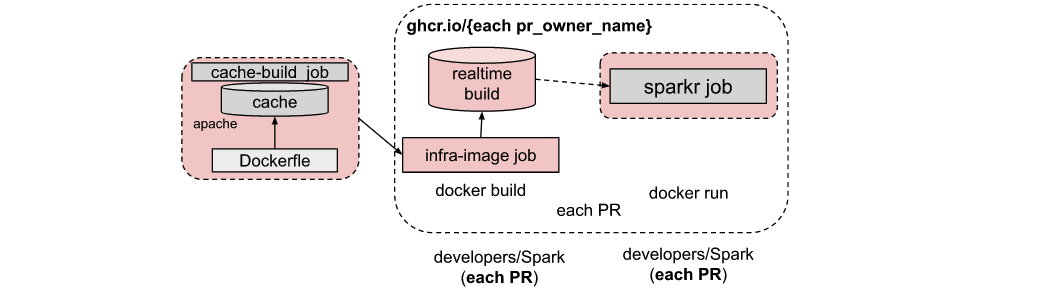 Change sparkr container from original static image to just-in-time build image from cache. See also: https://docs.google.com/document/d/1_uiId-U1DODYyYZejAZeyz2OAjxcnA-xfwjynDF6vd0 ### Why are the changes needed? Help to speed up docker infra image build in each PR. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on pull request #37006: [SPARK-39522][INFRA] Uses Docker image cache over a custom image in sparkr job
Yikun commented on PR #37006: URL: https://github.com/apache/spark/pull/37006#issuecomment-1167414803 sparkr job related changes: https://github.com/apache/spark/pull/37006/commits/1077a230e6d35c949e610d586a929a30b27d83f7 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on a diff in pull request #36980: [POC][SPARK-39522][INFRA] Uses Docker image cache over a custom image
Yikun commented on code in PR #36980:
URL: https://github.com/apache/spark/pull/36980#discussion_r907450964
##
.github/workflows/build_and_test.yml:
##
@@ -251,13 +254,59 @@ jobs:
name: unit-tests-log-${{ matrix.modules }}-${{ matrix.comment }}-${{
matrix.java }}-${{ matrix.hadoop }}-${{ matrix.hive }}
path: "**/target/unit-tests.log"
- pyspark:
+ infra-image:
needs: precondition
+if: >-
+ fromJson(needs.precondition.outputs.required).pyspark == 'true'
+ || fromJson(needs.precondition.outputs.required).sparkr == 'true'
+ || fromJson(needs.precondition.outputs.required).lint == 'true'
+runs-on: ubuntu-latest
+steps:
+ - name: Login to GitHub Container Registry
+uses: docker/login-action@v2
+with:
+ registry: ghcr.io
+ username: ${{ github.actor }}
+ password: ${{ secrets.GITHUB_TOKEN }}
+ - name: Checkout Spark repository
+uses: actions/checkout@v2
+# In order to fetch changed files
+with:
+ fetch-depth: 0
+ repository: apache/spark
+ ref: ${{ inputs.branch }}
+ - name: Sync the current branch with the latest in Apache Spark
+if: github.repository != 'apache/spark'
+run: |
+ echo "APACHE_SPARK_REF=$(git rev-parse HEAD)" >> $GITHUB_ENV
+ git fetch https://github.com/$GITHUB_REPOSITORY.git
${GITHUB_REF#refs/heads/}
+ git -c user.name='Apache Spark Test Account' -c
user.email='sparktest...@gmail.com' merge --no-commit --progress --squash
FETCH_HEAD
+ git -c user.name='Apache Spark Test Account' -c
user.email='sparktest...@gmail.com' commit -m "Merged commit" --allow-empty
+ -
+name: Set up QEMU
+uses: docker/setup-qemu-action@v1
+ -
+name: Set up Docker Buildx
+uses: docker/setup-buildx-action@v1
+ -
+name: Build and push
+id: docker_build
+uses: docker/build-push-action@v2
+with:
+ context: ./dev/infra/
+ push: true
+ tags: ghcr.io/${{ needs.precondition.outputs.user
}}/apache-spark-github-action-image:latest
+ # TODO: Change yikun to apache
+ # Use the infra image cache of build_infra_images_cache.yml
+ cache-from:
type=registry,ref=ghcr.io/yikun/apache-spark-github-action-image-cache:${{
inputs.branch }}
+
+ pyspark:
+needs: [precondition, infra-image]
if: fromJson(needs.precondition.outputs.required).pyspark == 'true'
name: "Build modules: ${{ matrix.modules }}"
runs-on: ubuntu-20.04
container:
- image: dongjoon/apache-spark-github-action-image:20220207
+ image: ghcr.io/${{ needs.precondition.outputs.user
}}/apache-spark-github-action-image:latest
Review Comment:
Looks like original job didn't use user, so maybe just keep same first.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on pull request #36980: [POC][SPARK-39522][INFRA] Uses Docker image cache over a custom image
Yikun commented on PR #36980: URL: https://github.com/apache/spark/pull/36980#issuecomment-1167423479 In order easy to review and complete step by step, I splited the PR to: Step 1: https://github.com/apache/spark/pull/37003 Step 2: https://github.com/apache/spark/pull/37005 Step 3: https://github.com/apache/spark/pull/37006 Step 4: TBD -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Eugene-Mark commented on a diff in pull request #36993: [SPARK-39604][SQL][TESTS] Add UT for DerbyDialect getCatalystType method
Eugene-Mark commented on code in PR #36993:
URL: https://github.com/apache/spark/pull/36993#discussion_r907475109
##
sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala:
##
@@ -924,6 +924,13 @@ class JDBCSuite extends QueryTest
assert(derbyDialect.getJDBCType(BooleanType).map(_.databaseTypeDefinition).get
== "BOOLEAN")
}
+ test("SPARK-39604: DerbyDialect catalyst type mapping") {
+val derbyDialect = JdbcDialects.get("jdbc:derby:db")
+val metadata = new MetadataBuilder().putString("name", "test_column")
+assert(derbyDialect.getCatalystType(java.sql.Types.REAL, "real",
+ 0, metadata) == Some(FloatType))
Review Comment:
Good point about the consistency! However, currently we have MysqlDialects,
TerdataDialects and DerbyDialects that have separated UT for `getJDBCType` and
`getCatalystType`. It seems not bad to separate them since the two methods
serves as different goal.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Eugene-Mark commented on a diff in pull request #36993: [SPARK-39604][SQL][TESTS] Add UT for DerbyDialect getCatalystType method
Eugene-Mark commented on code in PR #36993:
URL: https://github.com/apache/spark/pull/36993#discussion_r907478695
##
sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala:
##
@@ -924,6 +924,13 @@ class JDBCSuite extends QueryTest
assert(derbyDialect.getJDBCType(BooleanType).map(_.databaseTypeDefinition).get
== "BOOLEAN")
}
+ test("SPARK-39604: DerbyDialect catalyst type mapping") {
+val derbyDialect = JdbcDialects.get("jdbc:derby:db")
+val metadata = new MetadataBuilder().putString("name", "test_column")
+assert(derbyDialect.getCatalystType(java.sql.Types.REAL, "real",
+ 0, metadata) == Some(FloatType))
Review Comment:
I'm Okay to put them all together or separate the others just like how
MysqlDialacts did. But I'm neutral to which one is better, may I kindly know
your preference about it? @wangyum
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36984: [SPARK-39594][CORE] Improve logs to show addresses in addition to ports
dongjoon-hyun commented on PR #36984: URL: https://github.com/apache/spark/pull/36984#issuecomment-1167484757 Could you review this please, @viirya ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kuwii opened a new pull request, #37007: [SPARK-38056][Web UI][WIP] Use same condition in history server page and API to filter applications
kuwii opened a new pull request, #37007: URL: https://github.com/apache/spark/pull/37007 ### What changes were proposed in this pull request? Updated REST API `/api/v1/applications`, to use the same condition as history server page to filter completed/incomplete applications. ### Why are the changes needed? When opening summary page, history server follows this logic: If there's completed/incomplete application, page will add script in response, using AJAX to call the REST API to get the filtered list. - If there's no such application, page will only return a message telling nothing found. - Issue is that page and REST API are using different conditions to filter applications. In `HistoryPage`, an application is considered as completed as long as the last attempt is completed. But in `ApplicationListResource`, all attempts should be completed. This brings inconsistency and will cause issue in a corner case. In driver, event queues have capacity to protect memory. When there's too many events, some of them will be dropped and the event log file will be incomplete. For an application with multiple attempts, there's possibility that the last attempt is completed, but the previous attempts is considered as incomplete due to loss of application end event. For this type of application, page thinks it is completed, but the API thinks it is still running. When opening summary page: - When checking completed applications, page will call script, but API returns nothing. - When checking incomplete applications, page returns nothing. So the user won't be able to see this app in history server. ### Does this PR introduce _any_ user-facing change? Yes, there will be a change on `/api/v1/applications` API. For application mentioned above, previously it is considered as running. After the change it is considered as completed. So the result will be different using same filter. But I think this change should be OK. Because attempts are executed sequentially and incrementally. So if an attempt with bigger ID is completed, the previous attempts should also be completed. ### How was this patch tested? WIP -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36998: [SPARK-39613][BUILD] Upgrade shapeless to 2.3.9
dongjoon-hyun closed pull request #36998: [SPARK-39613][BUILD] Upgrade shapeless to 2.3.9 URL: https://github.com/apache/spark/pull/36998 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36998: [SPARK-39613][BUILD] Upgrade shapeless to 2.3.9
dongjoon-hyun commented on PR #36998: URL: https://github.com/apache/spark/pull/36998#issuecomment-1167507002 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kuwii commented on pull request #37007: [SPARK-39620][Web UI][WIP] Use same condition in history server page and API to filter applications
kuwii commented on PR #37007: URL: https://github.com/apache/spark/pull/37007#issuecomment-1167531301 Linked to wrong JIRA. Will recreate a new one. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kuwii closed pull request #37007: [SPARK-39620][Web UI][WIP] Use same condition in history server page and API to filter applications
kuwii closed pull request #37007: [SPARK-39620][Web UI][WIP] Use same condition in history server page and API to filter applications URL: https://github.com/apache/spark/pull/37007 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kuwii opened a new pull request, #37008: [SPARK-39620][Web UI][WIP] Use same condition in history server page and API to filter applications
kuwii opened a new pull request, #37008: URL: https://github.com/apache/spark/pull/37008 ### What changes were proposed in this pull request? Updated REST API `/api/v1/applications`, to use the same condition as history server page to filter completed/incomplete applications. ### Why are the changes needed? When opening summary page, history server follows this logic: If there's completed/incomplete application, page will add script in response, using AJAX to call the REST API to get the filtered list. - If there's no such application, page will only return a message telling nothing found. - Issue is that page and REST API are using different conditions to filter applications. In `HistoryPage`, an application is considered as completed as long as the last attempt is completed. But in `ApplicationListResource`, all attempts should be completed. This brings inconsistency and will cause issue in a corner case. In driver, event queues have capacity to protect memory. When there's too many events, some of them will be dropped and the event log file will be incomplete. For an application with multiple attempts, there's possibility that the last attempt is completed, but the previous attempts is considered as incomplete due to loss of application end event. For this type of application, page thinks it is completed, but the API thinks it is still running. When opening summary page: - When checking completed applications, page will call script, but API returns nothing. - When checking incomplete applications, page returns nothing. So the user won't be able to see this app in history server. ### Does this PR introduce _any_ user-facing change? Yes, there will be a change on `/api/v1/applications` API. For application mentioned above, previously it is considered as running. After the change it is considered as completed. So the result will be different using same filter. But I think this change should be OK. Because attempts are executed sequentially and incrementally. So if an attempt with bigger ID is completed, the previous attempts should also be completed. ### How was this patch tested? WIP -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on pull request #36950: [SPARK-38796][SQL] Update documentation for number format strings with the {try_}to_number functions
dtenedor commented on PR #36950: URL: https://github.com/apache/spark/pull/36950#issuecomment-1167544715 friendly ping when you have a moment @cloud-fan :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on pull request #36960: [SPARK-39557][SQL] Support ARRAY, STRUCT, MAP types as DEFAULT values
dtenedor commented on PR #36960: URL: https://github.com/apache/spark/pull/36960#issuecomment-1167545360 friendly ping when you have a moment @gengliangwang and/or @HyukjinKwon :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #36150: [SPARK-38864][SQL] Add melt / unpivot to Dataset
srielau commented on code in PR #36150:
URL: https://github.com/apache/spark/pull/36150#discussion_r907584961
##
core/src/main/resources/error/error-classes.json:
##
@@ -256,6 +256,18 @@
"Key does not exist. Use `try_element_at` to tolerate
non-existent key and return NULL instead. If necessary set to
\"false\" to bypass this error."
]
},
+ "MELT_REQUIRES_VALUE_COLUMNS" : {
Review Comment:
Given that even pandas using UNPIVOT in the description. Can we use that
verb instead of
met?https://pandas.pydata.org/docs/reference/api/pandas.melt.html
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/CheckAnalysis.scala:
##
@@ -422,6 +426,15 @@ trait CheckAnalysis extends PredicateHelper with
LookupCatalog {
}
metrics.foreach(m => checkMetric(m, m))
+ // see Analyzer.ResolveMelt
+ case m: Melt if m.childrenResolved && m.ids.forall(_.resolved) &&
m.values.isEmpty =>
+failAnalysis("MELT_REQUIRES_VALUE_COLUMNS",
Array(m.ids.mkString(", ")))
Review Comment:
I think toSQLId() is need to make sure the ids are properly decorated with
back-ticks.
##
core/src/main/resources/error/error-classes.json:
##
@@ -256,6 +256,18 @@
"Key does not exist. Use `try_element_at` to tolerate
non-existent key and return NULL instead. If necessary set to
\"false\" to bypass this error."
]
},
+ "MELT_REQUIRES_VALUE_COLUMNS" : {
+"message" : [
+ "At least one non-id column is required to melt. All columns are id
columns: []"
Review Comment:
I don't understand this restriction. What does it mean?
##
core/src/main/resources/error/error-classes.json:
##
@@ -256,6 +256,18 @@
"Key does not exist. Use `try_element_at` to tolerate
non-existent key and return NULL instead. If necessary set to
\"false\" to bypass this error."
]
},
+ "MELT_REQUIRES_VALUE_COLUMNS" : {
+"message" : [
+ "At least one non-id column is required to melt. All columns are id
columns: []"
+],
+"sqlState" : "42000"
+ },
+ "MELT_VALUE_DATA_TYPE_MISMATCH" : {
+"message" : [
+ "Melt value columns must have compatible data types, some data types are
not compatible: []"
Review Comment:
I think "share a least-common type" is the term that is well defined.
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/CheckAnalysis.scala:
##
@@ -422,6 +426,15 @@ trait CheckAnalysis extends PredicateHelper with
LookupCatalog {
}
metrics.foreach(m => checkMetric(m, m))
+ // see Analyzer.ResolveMelt
+ case m: Melt if m.childrenResolved && m.ids.forall(_.resolved) &&
m.values.isEmpty =>
+failAnalysis("MELT_REQUIRES_VALUE_COLUMNS",
Array(m.ids.mkString(", ")))
+ // see TypeCoercionBase.MeltCoercion
+ case m: Melt if m.values.nonEmpty && m.values.forall(_.resolved) &&
m.valueType.isEmpty =>
+failAnalysis("MELT_VALUE_DATA_TYPE_MISMATCH", Array(
+ m.values.map(_.dataType).toSet.mkString(", ")
Review Comment:
I think the types need to be decorated/cleaned up @MaxGekk
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] holdenk commented on pull request #36434: [SPARK-38969][K8S] Fix Decom reporting
holdenk commented on PR #36434: URL: https://github.com/apache/spark/pull/36434#issuecomment-1167605217 @yeachan153 Do you have decommissioning enabled in the executor our sending the kill to? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] holdenk commented on a diff in pull request #36434: [SPARK-38969][K8S] Fix Decom reporting
holdenk commented on code in PR #36434:
URL: https://github.com/apache/spark/pull/36434#discussion_r907595853
##
resource-managers/kubernetes/docker/src/main/dockerfiles/spark/decom.sh:
##
@@ -18,17 +18,24 @@
#
-set -ex
+set +e
+set -x
echo "Asked to decommission"
# Find the pid to signal
date | tee -a ${LOG}
-WORKER_PID=$(ps -o pid -C java | tail -n 1| awk '{ sub(/^[ \t]+/, ""); print
}')
+WORKER_PID=$(ps x -o pid,cmd -C java |grep Executor \
Review Comment:
Intresting, can you send me the ps aux for the container?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] holdenk commented on a diff in pull request #36434: [SPARK-38969][K8S] Fix Decom reporting
holdenk commented on code in PR #36434:
URL: https://github.com/apache/spark/pull/36434#discussion_r907597398
##
resource-managers/kubernetes/docker/src/main/dockerfiles/spark/decom.sh:
##
@@ -18,17 +18,24 @@
#
-set -ex
+set +e
+set -x
echo "Asked to decommission"
# Find the pid to signal
date | tee -a ${LOG}
-WORKER_PID=$(ps -o pid -C java | tail -n 1| awk '{ sub(/^[ \t]+/, ""); print
}')
+WORKER_PID=$(ps x -o pid,cmd -C java |grep Executor \
Review Comment:
We could also do a `killall java` instead but I'm hesistant incase someones
runing another java process inside the executor container.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pralabhkumar opened a new pull request, #37009: [SPARK-38292][PYTHON]na_filter added to csv
pralabhkumar opened a new pull request, #37009:
URL: https://github.com/apache/spark/pull/37009
### What changes were proposed in this pull request?
na filter is added in the read csv option . This is similar to na filter
option in pandas
data.csv
A,B,C
,val1,val2
val3
from pyspark import pandas as ps
import pandas as pd
ps.read_csv("data.csv")
A B C
0 None val1 val2
1 val3 None None
ps.read_csv("data.csv", na_filter=False)
A B C
0val1 val2
1 val3
pd.read_csv("/Users/pralkuma/Desktop/rk_read_panda_csv/data.csv",
na_filter=False)
A B C
0val1 val2
1 val3
pd.read_csv("/Users/pralkuma/Desktop/rk_read_panda_csv/data.csv")
A B C
0 NaN val1 val2
1 val3 NaN NaN
### Why are the changes needed?
Added na_filter option
### Does this PR introduce _any_ user-facing change?
yes
### How was this patch tested?
Unit test cases
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #36968: [SPARK-39235][SQL] Make getDatabase and listDatabases compatible with 3 layer namespace
amaliujia commented on code in PR #36968:
URL: https://github.com/apache/spark/pull/36968#discussion_r907636962
##
sql/core/src/test/scala/org/apache/spark/sql/internal/CatalogSuite.scala:
##
@@ -743,4 +743,25 @@ class CatalogSuite extends SharedSparkSession with
AnalysisTest with BeforeAndAf
val catalogName2 = "catalog_not_exists"
assert(!spark.catalog.databaseExists(Array(catalogName2,
dbName).mkString(".")))
}
+
+ test("three layer namespace compatibility - get database") {
+Seq(("testcat", "somedb"), ("testcat", "ns.somedb")).foreach { case
(catalog, dbName) =>
+ val qualifiedDb = s"$catalog.$dbName"
+ // TODO test properties? WITH DBPROPERTIES (prop='val')
Review Comment:
If there is no properties returned in the `Database` object, then it is ok
to skip such properties test.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] schuermannator commented on a diff in pull request #36968: [SPARK-39235][SQL] Make getDatabase and listDatabases compatible with 3 layer namespace
schuermannator commented on code in PR #36968:
URL: https://github.com/apache/spark/pull/36968#discussion_r907641599
##
sql/core/src/test/scala/org/apache/spark/sql/internal/CatalogSuite.scala:
##
@@ -743,4 +743,25 @@ class CatalogSuite extends SharedSparkSession with
AnalysisTest with BeforeAndAf
val catalogName2 = "catalog_not_exists"
assert(!spark.catalog.databaseExists(Array(catalogName2,
dbName).mkString(".")))
}
+
+ test("three layer namespace compatibility - get database") {
+Seq(("testcat", "somedb"), ("testcat", "ns.somedb")).foreach { case
(catalog, dbName) =>
+ val qualifiedDb = s"$catalog.$dbName"
+ // TODO test properties? WITH DBPROPERTIES (prop='val')
+ sql(s"CREATE NAMESPACE $qualifiedDb COMMENT 'test comment' LOCATION
'/test/location'")
+ val db = spark.catalog.getDatabase(qualifiedDb)
+ assert(db.name === dbName)
+ assert(db.description === "test comment")
+ assert(db.locationUri === "file:/test/location")
+}
+intercept[AnalysisException](spark.catalog.getDatabase("randomcat.db10"))
+ }
+
+ test("get database when there is `default` catalog") {
+spark.conf.set("spark.sql.catalog.default",
classOf[InMemoryCatalog].getName)
+val db = "testdb"
+val qualified = s"default.$db"
+sql(s"CREATE NAMESPACE $qualified")
Review Comment:
I've implemented this test but currently just verifying based on setting the
'comment' of the Database. Let me know if there is some `Database.catalog` API
i am not aware of
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #37010: [SPARK-39621][PYTHON][TESTS] Make run-tests.py robust by avoiding `rmtree` usage
dongjoon-hyun opened a new pull request, #37010: URL: https://github.com/apache/spark/pull/37010 … ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerrypeng commented on pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
jerrypeng commented on PR #36963: URL: https://github.com/apache/spark/pull/36963#issuecomment-1167689731 @HeartSaVioR in regard to the UI screen shots you provided for DSv2 read and write, the logical plan before the patch already contained the src and target catalog tables. What is the difference to the logical after the this patch is applied for DSv2 connectors? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37010: [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS
dongjoon-hyun commented on PR #37010: URL: https://github.com/apache/spark/pull/37010#issuecomment-1167701941 Hi, @huaxingao . Could you review this Python Test PR when you have some time, please? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36950: [SPARK-38796][SQL] Update documentation for number format strings with the {try_}to_number functions
cloud-fan commented on code in PR #36950:
URL: https://github.com/apache/spark/pull/36950#discussion_r907666826
##
docs/sql-ref-number-pattern.md:
##
@@ -19,4 +19,165 @@ license: |
limitations under the License.
---
-TODO: Add the content of Number Patterns for Formatting and Parsing
+### Description
+
+Functions such as `to_number` and `to_char` support converting between values
of string and
+Decimal type. Such functions accept format strings indicating how to map
between these types.
+
+### Syntax
+
+Number format strings support the following syntax:
+
+```
+ { ' [ S ] [ $ ]
+ [ 0 | 9 | G | , ] [...]
+ [ . | D ]
+ [ 0 | 9 ] [...]
+ [ $ ] [ PR | MI | S ] ' }
+```
+
+### Elements
+
+Each number format string can contain the following elements (case
insensitive):
+
+- **`0`** or **`9`**
+
+ Specifies an expected digit between `0` and `9`.
+
+ A sequence of 0 or 9 in the format string matches a sequence of digits with
the same or smaller
+ size. If the 0/9 sequence starts with 0 and is before the decimal point, it
requires matching the
+ number of digits: when parsing, it matches only a digit sequence of the same
size; when
+ formatting, the result string adds left-padding with zeros to the digit
sequence to reach the
+ same size. Otherwise, the 0/9 sequence matches any digit sequence with the
same or smaller size
+ when parsing, and pads the digit sequence with spaces in the result string
when formatting. Note
+ that the digit sequence will become a '#' sequence if the size is larger
than the 0/9 sequence.
+
+- **`.`** or **`D`**
+
+ Specifies the position of the decimal point.
+
+ The input value does not need to include a decimal point.
+
+- **`,`** or **`G`**
+
+ Specifies the position of the `,` grouping (thousands) separator.
+
+ There must be a `0` or `9` to the left and right of each grouping separator.
+
+- **`$`**
+
+ Specifies the location of the `$` currency sign. This character may only be
specified once.
+
+- **`S`**
+
+ Specifies the position of an optional '+' or '-' sign. This character may
only be specified once.
+
+- **`MI`**
+
+ Specifies an optional `-` sign at the end, but no `+`.
Review Comment:
Seems our implementation allows `MI` at the beginning. Is it intentional and
we should fix the doc, or it's a mistake?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] schuermannator commented on a diff in pull request #36968: [SPARK-39235][SQL] Make getDatabase and listDatabases compatible with 3 layer namespace
schuermannator commented on code in PR #36968:
URL: https://github.com/apache/spark/pull/36968#discussion_r907669226
##
sql/core/src/test/scala/org/apache/spark/sql/internal/CatalogSuite.scala:
##
@@ -743,4 +743,25 @@ class CatalogSuite extends SharedSparkSession with
AnalysisTest with BeforeAndAf
val catalogName2 = "catalog_not_exists"
assert(!spark.catalog.databaseExists(Array(catalogName2,
dbName).mkString(".")))
}
+
+ test("three layer namespace compatibility - get database") {
+Seq(("testcat", "somedb"), ("testcat", "ns.somedb")).foreach { case
(catalog, dbName) =>
+ val qualifiedDb = s"$catalog.$dbName"
+ // TODO test properties? WITH DBPROPERTIES (prop='val')
Review Comment:
correct, i will skip
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36984: [SPARK-39594][CORE] Improve logs to show addresses in addition to ports
dongjoon-hyun commented on PR #36984: URL: https://github.com/apache/spark/pull/36984#issuecomment-1167721183 Thank you so much, @viirya . Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36984: [SPARK-39594][CORE] Improve logs to show addresses in addition to ports
dongjoon-hyun closed pull request #36984: [SPARK-39594][CORE] Improve logs to show addresses in addition to ports URL: https://github.com/apache/spark/pull/36984 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #36968: [SPARK-39235][SQL] Make getDatabase and listDatabases compatible with 3 layer namespace
amaliujia commented on code in PR #36968:
URL: https://github.com/apache/spark/pull/36968#discussion_r907680192
##
sql/core/src/test/scala/org/apache/spark/sql/internal/CatalogSuite.scala:
##
@@ -749,4 +756,39 @@ class CatalogSuite extends SharedSparkSession with
AnalysisTest with BeforeAndAf
assert(spark.catalog.currentCatalog().equals("spark_catalog"))
assert(spark.catalog.listCatalogs().collect().map(c => c.name).toSet ==
Set("testcat"))
}
+
+ test("three layer namespace compatibility - get database") {
+val catalogsAndDatabases =
+ Seq(("testcat", "somedb"), ("testcat", "ns.somedb"), ("spark_catalog",
"somedb"))
+catalogsAndDatabases.foreach { case (catalog, dbName) =>
+ val qualifiedDb = s"$catalog.$dbName"
+ sql(s"CREATE NAMESPACE $qualifiedDb COMMENT 'test comment' LOCATION
'/test/location'")
+ val db = spark.catalog.getDatabase(qualifiedDb)
+ assert(db.name === dbName)
+ assert(db.description === "test comment")
+ assert(db.locationUri === "file:/test/location")
+}
+intercept[AnalysisException](spark.catalog.getDatabase("randomcat.db10"))
+ }
+
+ test("three layer namespace compatibility - get database, same in hive and
testcat") {
+// create 'testdb' in hive and testcat
+val dbName = "testdb"
+sql(s"CREATE NAMESPACE spark_catalog.$dbName COMMENT 'hive database'")
+sql(s"CREATE NAMESPACE testcat.$dbName COMMENT 'testcat namespace'")
+sql("SET CATALOG testcat")
+// should still return the database in Hive
+val db = spark.catalog.getDatabase(dbName)
+assert(db.name === dbName)
+assert(db.description === "hive database")
+// TODO catalog check API?
Review Comment:
There is no `Catalog` field from the Database object so this comment check
seems to be good.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao commented on pull request #37010: [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS
huaxingao commented on PR #37010: URL: https://github.com/apache/spark/pull/37010#issuecomment-1167753792 LGTM. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37010: [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS
dongjoon-hyun commented on PR #37010: URL: https://github.com/apache/spark/pull/37010#issuecomment-1167755211 Thank you so much, @huaxingao ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #36963: [SPARK-39564][SS] Expose the information of catalog table to the logical plan in streaming query
HeartSaVioR commented on PR #36963: URL: https://github.com/apache/spark/pull/36963#issuecomment-1167799733 @jerrypeng Please see the screenshot of "after the change". I described where they come and why they are not something we can rely on. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37010: [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS
dongjoon-hyun commented on PR #37010: URL: https://github.com/apache/spark/pull/37010#issuecomment-1167814195 All tests passed. Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #37010: [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS
dongjoon-hyun closed pull request #37010: [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS URL: https://github.com/apache/spark/pull/37010 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] JoshRosen commented on pull request #36885: [WIP][SPARK-39489][CORE] Improve event logging JsonProtocol performance by using Jackson instead of Json4s
JoshRosen commented on PR #36885: URL: https://github.com/apache/spark/pull/36885#issuecomment-1167840285 > @JoshRosen Would you consider using [jsoniter-scala](https://github.com/plokhotnyuk/jsoniter-scala) instead of Jackson? @plokhotnyuk, I don't think that `jsoniter-scala` will easily address our current use-case: it looks like that library is focused on object mapping but Spark's `JsonProtocol` does not currently use object mapping to serialize its JSON events. I think that one of the reasons for this is the fact that `JsonProtocol` events have fields which aren't Scala classes or POJOs and thus can't easily be object mapped. For example, `taskMetricsFromJson` extracts fields from the JSON and then calls "increment metric" setter methods on a `new TaskMetrics` instance. If we wanted to use object mapping, we could define a separate set of case classes for events' JSON representations and could have a helper function for translating from those intermediate classes into the actual `SparkListenerEvent` classes. We'd have to be careful to properly handle all of the backwards- and forwards-compatibility constraints, including supplying default values for missing fields. We'd also have to weight the costs / benefits of adding another external dependency to Spark: Spark's dependency on libraries can cause library conflicts if users also depend on those same libraries in their own code. I think it's certainly possible that we could re-architect this code in order to let an object mapping library do more of the heavy lifting, but I don't don't want to make that change in this PR: my short-term goal is to land an easy-to-understand, easy-to-verify patch in order to achieve large performance improvements over the JSON4s-based status quo. I would be open to reviewing a patch that does the refactoring work needed to use object mapping libraries in case that results in significant performance improvements or code simplification, but I don't have the time to develop such a patch myself. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org