[GitHub] spark issue #23262: [SPARK-26312][SQL]Replace RDDConversions.rowToRowRdd wit...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23262 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23262: [SPARK-26312][SQL]Replace RDDConversions.rowToRowRdd wit...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23262 @cloud-fan Updated, thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23262: [SPARK-26312][SQL]Replace RDDConversions.rowToRow...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/23262#discussion_r240188043
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceStrategy.scala
---
@@ -416,7 +416,12 @@ case class DataSourceStrategy(conf: SQLConf) extends
Strategy with Logging with
output: Seq[Attribute],
rdd: RDD[Row]): RDD[InternalRow] = {
if (relation.relation.needConversion) {
- execution.RDDConversions.rowToRowRdd(rdd, output.map(_.dataType))
+ val converters = RowEncoder(StructType.fromAttributes(output))
+ rdd.mapPartitions { iterator =>
+iterator.map { r =>
--- End diff --
Modified, thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23262: [SPARK-26312][SQL]Converting converters in RDDConversion...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23262 @HyukjinKwon Ok, removed it, thanks for review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23262: [SPARK-26312][SQL]Converting converters in RDDConversion...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23262 @HyukjinKwon @mgaido91 Thanks for review. @cloud-fan @kiszk Would you like to give some suggestions: remove the object `RDDConversions` , or leave it there? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23262: [SPARK-26312][SQL]Converting converters in RDDCon...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/23262#discussion_r240114106
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/ExistingRDD.scala ---
@@ -53,7 +53,7 @@ object RDDConversions {
data.mapPartitions { iterator =>
val numColumns = outputTypes.length
val mutableRow = new GenericInternalRow(numColumns)
- val converters =
outputTypes.map(CatalystTypeConverters.createToCatalystConverter)
+ val converters =
outputTypes.map(CatalystTypeConverters.createToCatalystConverter).toArray
--- End diff --
It has been modified, and the performance is the same as converting to
arrays.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23262: [SPARK-26312][SQL]Converting converters in RDDCon...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/23262#discussion_r240113822
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/ExistingRDD.scala ---
@@ -33,7 +33,7 @@ object RDDConversions {
data.mapPartitions { iterator =>
val numColumns = outputTypes.length
val mutableRow = new GenericInternalRow(numColumns)
- val converters =
outputTypes.map(CatalystTypeConverters.createToCatalystConverter)
+ val converters =
outputTypes.map(CatalystTypeConverters.createToCatalystConverter).toArray
--- End diff --
It is a good suggestion, and has been modified, would you like to review it
again, thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23262: [SPARK-26312][SQL]Converting converters in RDDConversion...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23262 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23262: [SPARK-26312][SQL]Converting converters in RDDCon...
GitHub user eatoncys opened a pull request: https://github.com/apache/spark/pull/23262 [SPARK-26312][SQL]Converting converters in RDDConversions into arrays to improve their access performance ## What changes were proposed in this pull request? `RDDConversions` would get disproportionately slower as the number of columns in the query increased. This PR converts the `converters` in `RDDConversions` into arrays to improve their access performance, the type of `converters` before is `scala.collection.immutable.::` which is a subtype of list. The test of `PrunedScanSuite` for 2000 columns and 20k rows takes 409 seconds before this PR, and 361 seconds after. ## How was this patch tested? Test case of `PrunedScanSuite` Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/eatoncys/spark toarray Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23262.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23262 commit ddb252892a439281b16bc14fdfdb7faf756f1067 Author: 10129659 Date: 2018-12-08T07:15:10Z Converting converters in RDDConversions into arrays to improve their access performance --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23010: [SPARK-26012][SQL]Null and '' values should not cause dy...
Github user eatoncys commented on the issue:
https://github.com/apache/spark/pull/23010
But we may forget to filter null values when we write sql. The following
function protects this situation and writes the value of null partitions as
__HIVE_DEFAULT_PARTITION__
def getPartitionPathString(col: String, value: String): String = {
val partitionString = if (value == null || value.isEmpty) {
DEFAULT_PARTITION_NAME
} else {
escapePathName(value)
}
escapePathName(col) + "=" + partitionString
}
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23010: [SPARK-26012][SQL]Null and '' values should not cause dy...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23010 @cloud-fan, Thanks for review, Do you mean we should filter out invalid partitions in sql before write? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user eatoncys closed the pull request at: https://github.com/apache/spark/pull/22561 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23010: [SPARK-26012][SQL]Null and '' values should not cause dy...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/23010 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23010: [SPARK-26012][SQL]Null and '' values should not c...
GitHub user eatoncys opened a pull request:
https://github.com/apache/spark/pull/23010
[SPARK-26012][SQL]Null and '' values should not cause dynamic partition
failure of string types
## What changes were proposed in this pull request?
Dynamic partition will fail when both '' and null values are taken as
dynamic partition values simultaneously.
For example, the test bellow will fail before this PR:
test("Null and '' values should not cause dynamic partition failure of
string types") {
withTable("t1", "t2") {
spark.range(3).write.saveAsTable("t1")
spark.sql("select id, cast(case when id = 1 then '' else null end as
string) as p" +
" from t1").write.partitionBy("p").saveAsTable("t2")
checkAnswer(spark.table("t2").sort("id"), Seq(Row(0, null), Row(1,
null), Row(2, null)))
}
}
The error is: 'org.apache.hadoop.fs.FileAlreadyExistsException: File
already exists'.
This PR adds exception protection to file conflicts, renaming the file when
files conflict.
(Please fill in changes proposed in this fix)
## How was this patch tested?
New added test.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/eatoncys/spark dynamicPartition
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/23010.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #23010
commit 1f18e2786a26eb64c52925d8ecff2d6a2295ca16
Author: 10129659
Date: 2018-11-12T04:41:53Z
Null and '' values should not cause dynamic partition failure of string
types
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22561: [SPARK-25548][SQL]In the PruneFileSourcePartitions optim...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/22561 @cloud-fan Yes, it has problems for Not expression, we need find some good ways. Thanks for review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22561: [SPARK-25548][SQL]In the PruneFileSourcePartitions optim...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/22561 @cloud-fan which should be proved is that: the partitions returned of p' shound contain the partitions returned by p. Here, let p' = p && x, if x is true then p' == p; else if x is false, the paritions returned we needed is none, so p' contains the partitions we needed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/22561#discussion_r225054113
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala
---
@@ -39,21 +40,31 @@ private[sql] object PruneFileSourcePartitions extends
Rule[LogicalPlan] {
_,
_))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined
=>
+
+ val sparkSession = fsRelation.sparkSession
+ val partitionColumns =
+logicalRelation.resolve(
+ partitionSchema, sparkSession.sessionState.analyzer.resolver)
+ val partitionSet = AttributeSet(partitionColumns)
// The attribute name of predicate could be different than the one
in schema in case of
// case insensitive, we should change them to match the one in
schema, so we donot need to
// worry about case sensitivity anymore.
val normalizedFilters = filters.map { e =>
-e transform {
+e transformUp {
case a: AttributeReference =>
a.withName(logicalRelation.output.find(_.semanticEquals(a)).get.name)
+ // Replace the nonPartitionOps field with true in the
And(partitionOps, nonPartitionOps)
+ // to make the partition can be pruned
+ case and @And(left, right) =>
+val leftPartition =
left.references.filter(partitionSet.contains(_))
+val rightPartition =
right.references.filter(partitionSet.contains(_))
+if (leftPartition.size == left.references.size &&
rightPartition.size == 0) {
--- End diff --
Ok, I will add a UT latter, thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/22561#discussion_r225053437
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala
---
@@ -39,21 +40,31 @@ private[sql] object PruneFileSourcePartitions extends
Rule[LogicalPlan] {
_,
_))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined
=>
+
+ val sparkSession = fsRelation.sparkSession
+ val partitionColumns =
+logicalRelation.resolve(
+ partitionSchema, sparkSession.sessionState.analyzer.resolver)
+ val partitionSet = AttributeSet(partitionColumns)
// The attribute name of predicate could be different than the one
in schema in case of
// case insensitive, we should change them to match the one in
schema, so we donot need to
// worry about case sensitivity anymore.
val normalizedFilters = filters.map { e =>
-e transform {
+e transformUp {
case a: AttributeReference =>
a.withName(logicalRelation.output.find(_.semanticEquals(a)).get.name)
+ // Replace the nonPartitionOps field with true in the
And(partitionOps, nonPartitionOps)
+ // to make the partition can be pruned
+ case and @And(left, right) =>
+val leftPartition =
left.references.filter(partitionSet.contains(_))
+val rightPartition =
right.references.filter(partitionSet.contains(_))
+if (leftPartition.size == left.references.size &&
rightPartition.size == 0) {
+ and.withNewChildren(Seq(left, Literal(true, BooleanType)))
+} else if (leftPartition.size == 0 && rightPartition.size ==
right.references.size) {
+ and.withNewChildren(Seq(Literal(true, BooleanType), right))
+} else and
}
}
-
- val sparkSession = fsRelation.sparkSession
- val partitionColumns =
-logicalRelation.resolve(
- partitionSchema, sparkSession.sessionState.analyzer.resolver)
- val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters =
--- End diff --
@cloud-fan Sorry, I don't understand very clearly, the function of
splitConjunctivePredicates can only split and(a,b); if there is a or expression
in the filter , for example 'where (p_d=2 and key=2) or (p_d=3 and key=3)', the
result of splitConjunctivePredicates is '(((p_d#2 = 2) && (key#0 = 2)) ||
((p_d#2 = 3) && (key#0 = 3)))', the partition expression could not be split out.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/22561#discussion_r225050369
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala
---
@@ -39,21 +40,31 @@ private[sql] object PruneFileSourcePartitions extends
Rule[LogicalPlan] {
_,
_))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined
=>
+
+ val sparkSession = fsRelation.sparkSession
+ val partitionColumns =
+logicalRelation.resolve(
+ partitionSchema, sparkSession.sessionState.analyzer.resolver)
+ val partitionSet = AttributeSet(partitionColumns)
// The attribute name of predicate could be different than the one
in schema in case of
// case insensitive, we should change them to match the one in
schema, so we donot need to
// worry about case sensitivity anymore.
val normalizedFilters = filters.map { e =>
-e transform {
+e transformUp {
case a: AttributeReference =>
a.withName(logicalRelation.output.find(_.semanticEquals(a)).get.name)
+ // Replace the nonPartitionOps field with true in the
And(partitionOps, nonPartitionOps)
+ // to make the partition can be pruned
+ case and @And(left, right) =>
+val leftPartition =
left.references.filter(partitionSet.contains(_))
+val rightPartition =
right.references.filter(partitionSet.contains(_))
+if (leftPartition.size == left.references.size &&
rightPartition.size == 0) {
--- End diff --
Ok, thanks for review.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22561: [SPARK-25548][SQL]In the PruneFileSourcePartitions optim...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/22561 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22561: [SPARK-25548][SQL]In the PruneFileSourcePartitions optim...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/22561 cc @gatorsmile @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
GitHub user eatoncys opened a pull request:
https://github.com/apache/spark/pull/22561
[SPARK-25548][SQL]In the PruneFileSourcePartitions optimizer, replace the
nonPartitionOps field with true in the And(partitionOps, nonPartitionOps) to
make the partition can be pruned
## What changes were proposed in this pull request?
In the PruneFileSourcePartitions optimizer, the partition files will not be
pruned if we use partition filter and non partition filter together, for
example:
sql("CREATE TABLE IF NOT EXISTS src_par (key INT, value STRING)
partitioned by(p_d int) stored as parquet ")
sql("insert overwrite table src_par partition(p_d=2) select 2 as key,
'4' as value")
sql("insert overwrite table src_par partition(p_d=3) select 3 as key,
'4' as value")
sql("insert overwrite table src_par partition(p_d=4) select 4 as key,
'4' as value")
Before this PR, the sql below will scan all the partition files, in which,
the partition **p_d=4** should be pruned.
**sql("select * from src_par where (p_d=2 and key=2) or (p_d=3 and
key=3)").show**
After this PR, the partition **p_d=4** will be pruned
## How was this patch tested?
exist test
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/eatoncys/spark partitionFilter
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22561.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22561
commit 6acb460381c96fe71f807f94bb617f3928f41694
Author: 10129659
Date: 2018-09-27T01:04:20Z
In the PruneFileSourcePartitions optimizer, replace the nonPartitionOps
field with true in the And(partitionOps, nonPartitionOps) to make the partition
can be pruned
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22053: [SPARK-25069][CORE]Using UnsafeAlignedOffset to make the...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/22053 @cloud-fan Unaligned accesses are not supported on SPARC architecture, which is discussed on the issure: https://issues.apache.org/jira/browse/SPARK-16962. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22053: [SPARK-25069][CORE]Using UnsafeAlignedOffset to make the...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/22053 @kiszk The comments updated , Thanks for review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22053: [SPARK-25069][Core]Using UnsafeAlignedOffset to m...
GitHub user eatoncys opened a pull request: https://github.com/apache/spark/pull/22053 [SPARK-25069][Core]Using UnsafeAlignedOffset to make the entire record of 8 byte Items aligned like which is used in UnsafeExternalSorter ## What changes were proposed in this pull request? The class of UnsafeExternalSorter used UnsafeAlignedOffset to make the entire record of 8 byte Items aligned, but ShuffleExternalSorter not. The SPARC platform requires this because using a 4 byte Int for record lengths causes the entire record of 8 byte Items to become misaligned by 4 bytes. Using a 8 byte long for record length keeps things 8 byte aligned. ## How was this patch tested? Existing Test. You can merge this pull request into a Git repository by running: $ git pull https://github.com/eatoncys/spark UnsafeAlignedOffset Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22053.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22053 commit 8559c454127904ad2d25930d6b743238f0fff46d Author: 10129659 Date: 2018-08-09T08:53:59Z Aligned Offset for ShuffleExternalSorter --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21823: [SPARK-24870][SQL]Cache can't work normally if th...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/21823#discussion_r204597636
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/SameResultSuite.scala ---
@@ -58,4 +61,16 @@ class SameResultSuite extends QueryTest with
SharedSQLContext {
val df4 = spark.range(10).agg(sumDistinct($"id"))
assert(df3.queryExecution.executedPlan.sameResult(df4.queryExecution.executedPlan))
}
+
+ test("Canonicalized result is not case-insensitive") {
--- End diff --
Modified, thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21823: [SPARK-24870][SQL]Cache can't work normally if there are...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21823 Can we merge it to master? @cloud-fan @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21823: [SPARK-24870][SQL]Cache can't work normally if th...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/21823#discussion_r204199119
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/SameResultSuite.scala ---
@@ -58,4 +61,16 @@ class SameResultSuite extends QueryTest with
SharedSQLContext {
val df4 = spark.range(10).agg(sumDistinct($"id"))
assert(df3.queryExecution.executedPlan.sameResult(df4.queryExecution.executedPlan))
}
+
+ test("Canonicalized result is not case-insensitive") {
+val a = AttributeReference("A", IntegerType)()
+val b = AttributeReference("B", IntegerType)()
+val planUppercase = Project(Seq(a, b), LocalRelation(a))
--- End diff --
Ok,thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21823: [SPARK-24870][SQL]Cache can't work normally if th...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/21823#discussion_r203990617
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CanonicalizeSuite.scala
---
@@ -50,4 +52,30 @@ class CanonicalizeSuite extends SparkFunSuite {
assert(range.where(arrays1).sameResult(range.where(arrays2)))
assert(!range.where(arrays1).sameResult(range.where(arrays3)))
}
+
+ test("Canonicalized result is not case-insensitive") {
--- End diff --
Ok,modified,thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21823: [SPARK-24870][SQL]Cache can't work normally if th...
Github user eatoncys commented on a diff in the pull request: https://github.com/apache/spark/pull/21823#discussion_r203972375 --- Diff: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/QueryPlan.scala --- @@ -237,7 +239,7 @@ abstract class QueryPlan[PlanType <: QueryPlan[PlanType]] extends TreeNode[PlanT // Top level `AttributeReference` may also be used for output like `Alias`, we should // normalize the epxrId too. id += 1 -ar.withExprId(ExprId(id)).canonicalized + ar.withExprId(ExprId(id)).withName(ar.name.toLowerCase(Locale.ROOT)).canonicalized --- End diff -- I think it is Ok, and it erase the attribute name in spark version 2.0.2. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21823: [SPARK-24870][SQL]Cache can't work normally if there are...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21823 @cloud-fan why not fix this in doCanonicalize? I think it is better to fix it in doCanonicalize, but I'm not very sure. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21823: [SPARK-24870][SQL]Cache can't work normally if there are...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21823 @cloud-fan fix this in dedupRight is Ok, but maybe there are other operations like dedupRight to change the case of the word. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21823: [SPARK-24870][SQL]Cache can't work normally if there are...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21823 @cloud-fan case j @ Join(left, right, _, _) if !j.duplicateResolved => j.copy(right = dedupRight(left, right)) dedupRight generate a new logical plan for the right child, which get the 'key' from the original table 'src', but left not. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21823: [SPARK-24870][SQL]Cache can't work normally if there are...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21823 @cloud-fan Cast 'Key' to lower case is done by rule of ResolveReferences: 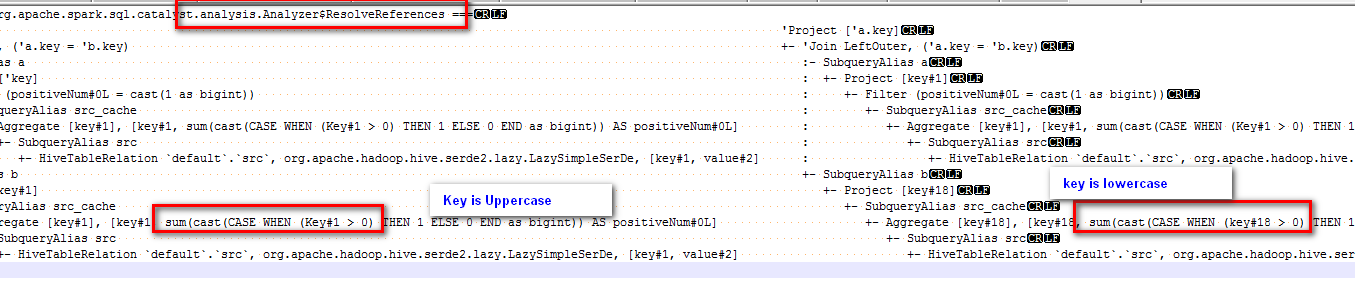 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21823: [SPARK-24870][SQL]Cache can't work normally if there are...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21823 cc @cloud-fan @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21823: [SPARK-24870][SQL]Cache can't work normally if th...
GitHub user eatoncys opened a pull request:
https://github.com/apache/spark/pull/21823
[SPARK-24870][SQL]Cache can't work normally if there are case letters in SQL
## What changes were proposed in this pull request?
Modified the canonicalized to not case-insensitive.
Before the PR, cache can't work normally if there are case letters in SQL,
for example:
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING
hive")
sql("select key, sum(case when Key > 0 then 1 else 0 end) as
positiveNum " +
"from src group by key").cache().createOrReplaceTempView("src_cache")
sql(
s"""select a.key
from
(select key from src_cache where positiveNum = 1)a
left join
(select key from src_cache )b
on a.key=b.key
""").explain
The physical plan of the sql is:

The subquery "select key from src_cache where positiveNum = 1" on the left
of join can use the cache data, but the subquery "select key from src_cache" on
the right of join cannot use the cache data.
## How was this patch tested?
new added test
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/eatoncys/spark canonicalized
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21823.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21823
commit 2b2a5a33ed58ce07fd2515eb01e80acbedeb8b2a
Author: 10129659
Date: 2018-07-20T01:43:53Z
Cache can't work normally if there are case letters in SQL
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19819: [SPARK-22606][Streaming]Add threadId to the Cache...
Github user eatoncys closed the pull request at: https://github.com/apache/spark/pull/19819 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21084: [SPARK-23998][Core]It may be better to add @trans...
Github user eatoncys closed the pull request at: https://github.com/apache/spark/pull/21084 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21084: [SPARK-23998][Core]It may be better to add @transient to...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21084 @jerryshao @hvanhovell Ok, I will close it, thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21084: [SPARK-23998][Core]It may be better to add @transient to...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21084 @jerryshao , There is not any issue without transient, but I think it is better to keep same to other fields, and make it clearly which fields do not need to be serialized. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21084: [SPARK-23998][Core]It may be better to add @transient to...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21084 @jiangxb1987 It does not take significant time to serialize the taskMemoryManager, because the value is null in driver side, but I think it is better to keep same to other fields in the Task class, which are only used in executor side, like '@volatile @transient private var _reasonIfKilled: String = null'. In my test, the serialized size reduced from 8392 bytes to 8325 bytes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21084: [SPARK-23998][Core]It may be better to add @transient to...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/21084 @hvanhovell The field 'taskMemoryManager' is only used in executor side, so it is not needed to serialize it when sending the task from driver to executor --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21084: [SPARK-23998][Core]It may be better to add @trans...
GitHub user eatoncys opened a pull request: https://github.com/apache/spark/pull/21084 [SPARK-23998][Core]It may be better to add @transient to field 'taskMemoryManager' in class Task, for it is only be set and used in executor side Add @transient to field 'taskMemoryManager' in class Task, for it is only be set and used in executor side and it will be set before used in class Executor like this: task.setTaskMemoryManager(taskMemoryManager) before task.run ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/eatoncys/spark transient Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21084.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21084 commit 283e1ac91996e375cb9d1775fef39ea29eb85325 Author: 10129659 <chen.yanshan@...> Date: 2018-04-17T08:20:38Z It may be better to add @transient to field 'taskMemoryManager' in class Task, for it is only be setted and used in executor --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19819: [SPARK-22606][Streaming]Add threadId to the Cache...
GitHub user eatoncys opened a pull request:
https://github.com/apache/spark/pull/19819
[SPARK-22606][Streaming]Add threadId to the CachedKafkaConsumer key
## What changes were proposed in this pull request?
If the value of param 'spark.streaming.concurrentJobs' is more than one,
and the value of param 'spark.executor.cores' is more than one, there may be
two or more tasks in one executor will use the same kafka consumer at the same
time, then it will throw an exception: "KafkaConsumer is not safe for
multi-threaded access";
for example:
spark.streaming.concurrentJobs=2
spark.executor.cores=2
spark.cores.max=2
if there is only one topic with one partition('topic1',0) to consume, there
will be two jobs to run at the same time, and they will use the same
cacheKey('groupid','topic1',0) to get the CachedKafkaConsumer from the cache
list of' private var cache: ju.LinkedHashMap[CacheKey, CachedKafkaConsumer[_,
_]]' , then it will get the same CachedKafkaConsumer.
this PR add threadId to the CachedKafkaConsumer key to prevent two thread
using a consumer at the same time.
## How was this patch tested?
existing ut test
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/eatoncys/spark kafka
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/19819.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #19819
commit aa02d8904fcbaa91df47ac224d90345bd555a372
Author: 10129659 <chen.yans...@zte.com.cn>
Date: 2017-11-25T08:15:17Z
Add threadId to CachedKafkaConsumer key
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19022: [Spark-21807][SQL]Override ++ operation in Expres...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/19022#discussion_r134905955
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ExpressionSetSuite.scala
---
@@ -210,4 +210,13 @@ class ExpressionSetSuite extends SparkFunSuite {
assert((initialSet - (aLower + 1)).size == 0)
}
+
+ test("add multiple elements to set") {
+val initialSet = ExpressionSet(aUpper + 1 :: Nil)
+val setToAddWithSameExpression = ExpressionSet(aUpper + 1 :: aUpper +
2 :: Nil)
+val setToAdd = ExpressionSet(aUpper + 2 :: aUpper + 3 :: Nil)
--- End diff --
Yes, I have modified the name to setToAddWithOutSameExpression.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19022: [Spark-21807][SQL]Override ++ operation in Expres...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/19022#discussion_r134905739
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/ExpressionSet.scala
---
@@ -17,7 +17,7 @@
package org.apache.spark.sql.catalyst.expressions
-import scala.collection.mutable
+import scala.collection.{GenTraversableOnce, mutable}
--- End diff --
Ok, modified it, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19022: [Spark-21807][SQL]The getAliasedConstraints funct...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/19022#discussion_r134703026
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/ExpressionSet.scala
---
@@ -59,6 +59,12 @@ class ExpressionSet protected(
}
}
+ def addMultiExpressions(elems: Set[Expression]): ExpressionSet = {
--- End diff --
Ok, Added, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19022: [Spark-21807][SQL]The getAliasedConstraints funct...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/19022#discussion_r134695982
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/ExpressionSet.scala
---
@@ -59,6 +59,12 @@ class ExpressionSet protected(
}
}
+ def addMultiExpressions(elems: Set[Expression]): ExpressionSet = {
--- End diff --
Ok, Modified it, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19022: [Spark-21807][SQL]The getAliasedConstraints funct...
GitHub user eatoncys opened a pull request:
https://github.com/apache/spark/pull/19022
[Spark-21807][SQL]The getAliasedConstraints function in LogicalPlan will
take a long time when number of expressions is greater than 100
## What changes were proposed in this pull request?
The getAliasedConstraints fuction in LogicalPlan.scala will clone the
expression set when an element added,
and it will take a long time. This PR add a function to add multiple
elements at once to reduce the clone time.
Before modified, the cost of getAliasedConstraints is:
100 expressions: 41 seconds
150 expressions: 466 seconds
After modified, the cost of getAliasedConstraints is:
100 expressions: 1.8 seconds
150 expressions: 6.5 seconds
The test is like this:
test("getAliasedConstraints") {
val expressionNum = 150
val aggExpression = (1 to expressionNum).map(i =>
Alias(Count(Literal(1)), s"cnt$i")())
val aggPlan = Aggregate(Nil, aggExpression, LocalRelation())
val beginTime = System.currentTimeMillis()
val expressions = aggPlan.validConstraints
println(s"validConstraints cost: ${System.currentTimeMillis() -
beginTime}ms")
// The size of Aliased expression is n * (n - 1) / 2 + n
assert( expressions.size === expressionNum * (expressionNum - 1) / 2 +
expressionNum)
}
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Run new added test.
Please review http://spark.apache.org/contributing.html before opening a
pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/eatoncys/spark getAliasedConstraints
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/19022.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #19022
commit 80af01add6c0169c7cad0286afc748d845cd1327
Author: 10129659 <chen.yans...@zte.com.cn>
Date: 2017-08-22T07:47:27Z
The getAliasedConstraints function will take a long time when expression is
greater than 100
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132806724
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -572,6 +572,14 @@ object SQLConf {
"disable logging or -1 to apply no limit.")
.createWithDefault(1000)
+ val WHOLESTAGE_MAX_LINES_PER_FUNCTION =
buildConf("spark.sql.codegen.maxLinesPerFunction")
+.internal()
+.doc("The maximum lines of a single Java function generated by
whole-stage codegen. " +
+ "When the generated function exceeds this threshold, " +
+ "the whole-stage codegen is deactivated for this subtree of the
current query plan.")
+.intConf
+.createWithDefault(1500)
--- End diff --
@kiszk, you're right, it depends on how much byte code per line.
@gatorsmile, ok, we take a conservative value 2730 (8192 / 3) first.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132616342
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -572,6 +572,14 @@ object SQLConf {
"disable logging or -1 to apply no limit.")
.createWithDefault(1000)
+ val WHOLESTAGE_MAX_LINES_PER_FUNCTION =
buildConf("spark.sql.codegen.maxLinesPerFunction")
+.internal()
+.doc("The maximum lines of a single Java function generated by
whole-stage codegen. " +
+ "When the generated function exceeds this threshold, " +
+ "the whole-stage codegen is deactivated for this subtree of the
current query plan.")
+.intConf
+.createWithDefault(1500)
--- End diff --
@gatorsmile, Which do you think better to use for the default value, 1500
or Int.Max ?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132616033
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/WholeStageCodegenSuite.scala
---
@@ -149,4 +150,56 @@ class WholeStageCodegenSuite extends SparkPlanTest
with SharedSQLContext {
assert(df.collect() === Array(Row(1), Row(2)))
}
}
+
+ def genGroupByCodeGenContext(caseNum: Int, maxLinesPerFunction: Int):
CodegenContext = {
+val caseExp = (1 to caseNum).map { i =>
+ s"case when id > $i and id <= ${i + 1} then 1 else 0 end as v$i"
+}.toList
+
+spark.conf.set("spark.sql.codegen.maxLinesPerFunction",
maxLinesPerFunction)
--- End diff --
Ok, modified, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132610861
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -572,6 +572,14 @@ object SQLConf {
"disable logging or -1 to apply no limit.")
.createWithDefault(1000)
+ val WHOLESTAGE_MAX_LINES_PER_FUNCTION =
buildConf("spark.sql.codegen.maxLinesPerFunction")
+.internal()
+.doc("The maximum lines of a single Java function generated by
whole-stage codegen. " +
+ "When the generated function exceeds this threshold, " +
+ "the whole-stage codegen is deactivated for this subtree of the
current query plan.")
+.intConf
+.createWithDefault(1500)
--- End diff --
I think it applies to other Java programs using JAVA HotSpot VM.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132610543
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/WholeStageCodegenSuite.scala
---
@@ -149,4 +149,75 @@ class WholeStageCodegenSuite extends SparkPlanTest
with SharedSQLContext {
assert(df.collect() === Array(Row(1), Row(2)))
}
}
+
+ test("SPARK-21603 check there is a too long generated function") {
+val ds = spark.range(10)
--- End diff --
Ok, I have modified it as you suggested above all, would you like to review
it again, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132388819
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -370,6 +370,14 @@ case class WholeStageCodegenExec(child: SparkPlan)
extends UnaryExecNode with Co
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
+if (ctx.isTooLongGeneratedFunction) {
+ logWarning("Found too long generated codes and JIT optimization
might not work, " +
+"Whole-stage codegen disabled for this plan, " +
+"You can change the config spark.sql.codegen.MaxFunctionLength " +
+"to adjust the function length limit:\n "
++ s"$treeString")
+ return child.execute()
+}
--- End diff --
Ok ,I have added a test, would you like to review it again, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132376473
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -370,6 +370,14 @@ case class WholeStageCodegenExec(child: SparkPlan)
extends UnaryExecNode with Co
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
+if (ctx.isTooLongGeneratedFunction) {
+ logWarning("Found too long generated codes and JIT optimization
might not work, " +
+"Whole-stage codegen disabled for this plan, " +
+"You can change the config spark.sql.codegen.MaxFunctionLength " +
+"to adjust the function length limit:\n "
++ s"$treeString")
+ return child.execute()
+}
--- End diff --
When we check "ctx.isTooLongGeneratedFunction" in doExecute, the
WholeStageCodegenExec node is generated alreay, so there must be
WholeStageCodegenExec node at this point.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132374541
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -370,6 +370,14 @@ case class WholeStageCodegenExec(child: SparkPlan)
extends UnaryExecNode with Co
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
+if (ctx.isTooLongGeneratedFunction) {
+ logWarning("Found too long generated codes and JIT optimization
might not work, " +
+"Whole-stage codegen disabled for this plan, " +
+"You can change the config spark.sql.codegen.MaxFunctionLength " +
+"to adjust the function length limit:\n "
++ s"$treeString")
+ return child.execute()
+}
--- End diff --
@viirya, it is hard to check if whole-stage codegen is disabled or not for
me, would you like to give me some suggestion, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][SQL]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132370096
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeFormatter.scala
---
@@ -89,6 +89,14 @@ object CodeFormatter {
}
new CodeAndComment(code.result().trim(), map)
}
+
+ def stripExtraNewLinesAndComments(input: String): String = {
+val commentReg =
+ ("""([ |\t]*?\/\*[\s|\S]*?\*\/[ |\t]*?)|""" + // strip /*comment*/
+"""([ |\t]*?\/\/[\s\S]*?\n)""").r // strip //comment
--- End diff --
Ok,modified, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132368646
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -572,6 +572,14 @@ object SQLConf {
"disable logging or -1 to apply no limit.")
.createWithDefault(1000)
+ val WHOLESTAGE_MAX_LINES_PER_FUNCTION =
buildConf("spark.sql.codegen.maxLinesPerFunction")
+.internal()
+.doc("The maximum lines of a single Java function generated by
whole-stage codegen. " +
+ "When the generated function exceeds this threshold, " +
+ "the whole-stage codegen is deactivated for this subtree of the
current query plan.")
+.intConf
+.createWithDefault(1500)
--- End diff --
When I modified it to 1600, the result is:
max function length of wholestagecodegen: Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
codegen = F467 / 507 1.4
712.7 1.0X
codegen = T maxLinesPerFunction = 16003191 / 3238 0.2
4868.7 0.1X
codegen = T maxLinesPerFunction = 1500 449 / 482 1.5
685.2 1.0X
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132368484
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -370,6 +370,14 @@ case class WholeStageCodegenExec(child: SparkPlan)
extends UnaryExecNode with Co
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
+if (ctx.isTooLongGeneratedFunction) {
+ logWarning("Found too long generated codes and JIT optimization
might not work, " +
+"Whole-stage codegen disabled for this plan, " +
+"You can change the config spark.sql.codegen.MaxFunctionLength " +
+"to adjust the function length limit:\n "
++ s"$treeString")
+ return child.execute()
+}
--- End diff --
I think it can tested by " max function length of wholestagecodegen" added
in AggregateBenchmark.scala, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132365359
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -572,6 +572,13 @@ object SQLConf {
"disable logging or -1 to apply no limit.")
.createWithDefault(1000)
+ val WHOLESTAGE_MAX_LINES_PER_FUNCTION =
buildConf("spark.sql.codegen.maxLinesPerFunction")
+.internal()
+.doc("The maximum lines of a function that will be supported before" +
+ " deactivating whole-stage codegen.")
--- End diff --
Ok,updated,thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132365401
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,19 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns if there is a codegen function the lines of which is greater
than maxLinesPerFunction
+ * It will count the lines of every codegen function, if there is a
function of length
+ * greater than spark.sql.codegen.maxLinesPerFunction, it will return
true.
+ */
+ def existTooLongFunction(): Boolean = {
--- End diff --
Ok,updated,thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132365436
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,19 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns if there is a codegen function the lines of which is greater
than maxLinesPerFunction
+ * It will count the lines of every codegen function, if there is a
function of length
+ * greater than spark.sql.codegen.maxLinesPerFunction, it will return
true.
+ */
+ def existTooLongFunction(): Boolean = {
+classFunctions.exists { case (className, functions) =>
+ functions.exists{ case (name, code) =>
+val codeWithoutComments =
CodeFormatter.stripExtraNewLinesAndComments(code)
+codeWithoutComments.count(_ == '\n') >
SQLConf.get.maxLinesPerFunction
+ }
+}
+ }
+ /**
--- End diff --
Ok, added, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132347436
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,18 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns if the length of codegen function is too long or not
--- End diff --
Ok, I have modified it, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132347148
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,18 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns if the length of codegen function is too long or not
+ * It will count the lines of every codegen function, if there is a
function of length
+ * greater than spark.sql.codegen.MaxFunctionLength, it will return true.
+ */
+ def existTooLongFunction(): Boolean = {
+classFunctions.exists { case (className, functions) =>
+ functions.exists{ case (name, code) =>
+CodeFormatter.stripExtraNewLines(code).count(_ == '\n') >
SQLConf.get.maxFunctionLength
--- End diff --
Ok, I have modified it to count lines without comments and extra new lines
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132347198
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -572,6 +572,13 @@ object SQLConf {
"disable logging or -1 to apply no limit.")
.createWithDefault(1000)
+ val WHOLESTAGE_MAX_FUNCTION_LEN =
buildConf("spark.sql.codegen.MaxFunctionLength")
--- End diff --
Ok, I have modified it, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r132347018
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/AggregateBenchmark.scala
---
@@ -301,6 +301,61 @@ class AggregateBenchmark extends BenchmarkBase {
*/
}
+ ignore("max function length of wholestagecodegen") {
+val N = 20 << 15
+
+val benchmark = new Benchmark("max function length of
wholestagecodegen", N)
+def f(): Unit = sparkSession.range(N)
+ .selectExpr(
+"id",
+"(id & 1023) as k1",
+"cast(id & 1023 as double) as k2",
+"cast(id & 1023 as int) as k3",
+"case when id > 100 and id <= 200 then 1 else 0 end as v1",
+"case when id > 200 and id <= 300 then 1 else 0 end as v2",
+"case when id > 300 and id <= 400 then 1 else 0 end as v3",
+"case when id > 400 and id <= 500 then 1 else 0 end as v4",
+"case when id > 500 and id <= 600 then 1 else 0 end as v5",
+"case when id > 600 and id <= 700 then 1 else 0 end as v6",
+"case when id > 700 and id <= 800 then 1 else 0 end as v7",
+"case when id > 800 and id <= 900 then 1 else 0 end as v8",
+"case when id > 900 and id <= 1000 then 1 else 0 end as v9",
+"case when id > 1000 and id <= 1100 then 1 else 0 end as v10",
+"case when id > 1100 and id <= 1200 then 1 else 0 end as v11",
+"case when id > 1200 and id <= 1300 then 1 else 0 end as v12",
+"case when id > 1300 and id <= 1400 then 1 else 0 end as v13",
+"case when id > 1400 and id <= 1500 then 1 else 0 end as v14",
+"case when id > 1500 and id <= 1600 then 1 else 0 end as v15",
+"case when id > 1600 and id <= 1700 then 1 else 0 end as v16",
+"case when id > 1700 and id <= 1800 then 1 else 0 end as v17",
+"case when id > 1800 and id <= 1900 then 1 else 0 end as v18")
+ .groupBy("k1", "k2", "k3")
+ .sum()
+ .collect()
+
+benchmark.addCase(s"codegen = F") { iter =>
+ sparkSession.conf.set("spark.sql.codegen.wholeStage", "false")
+ f()
+}
+
+benchmark.addCase(s"codegen = T") { iter =>
+ sparkSession.conf.set("spark.sql.codegen.wholeStage", "true")
+ sparkSession.conf.set("spark.sql.codegen.MaxFunctionLength", "1")
--- End diff --
Ok, I have added a test use the default number 1500, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18810: [SPARK-21603][sql]The wholestage codegen will be much sl...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18810 cc @gatorsmile --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r131585903
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,16 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns the length of codegen function is too long or not
+ */
+ def existTooLongFunction(): Boolean = {
--- End diff --
Ok, I have modified it, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r131593593
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -370,6 +370,12 @@ case class WholeStageCodegenExec(child: SparkPlan)
extends UnaryExecNode with Co
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
+val existLongFunction = ctx.existTooLongFunction
+if (existLongFunction) {
+ logWarning(s"Function is too long, Whole-stage codegen disabled for
this plan:\n "
++ s"$treeString")
--- End diff --
@gatorsmile , thank you for review, the treeString not contains the code,
it only contains the tree string of the Physical plan like below:
*HashAggregate(keys=[k1#2395L, k2#2396, k3#2397],
functions=[partial_sum(id#2392L)...
+- *Project [id#2392L, (id#2392L & 1023) AS k1#2395L, cast((id#2392L &
1023) as double) AS k2#2396...
+- *Range (0, 655360, step=1, splits=1)
So, I think it will not be very big.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r131585857
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,18 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns the length of codegen function is too long or not
--- End diff --
Ok, I have modified it, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18810#discussion_r131340166
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
---
@@ -356,6 +356,16 @@ class CodegenContext {
private val placeHolderToComments = new mutable.HashMap[String, String]
/**
+ * Returns the length of codegen function is too long or not
+ */
+ def existTooLongFunction(): Boolean = {
+classFunctions.exists { case (className, functions) =>
+ functions.exists{ case (name, code) =>
+CodeFormatter.stripExtraNewLines(code).count(_ == '\n') >
SQLConf.get.maxFunctionLength
--- End diff --
@kiszk Because when the JVM parameter -XX:+DontCompileHugeMethods is true,
it can not get the JIT optimization when the byte code of a function is longer
than 8000, here I just estimate a function lines by 8000 byte code, maybe there
are some other good ways.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18810: [SPARK-21603][sql]The wholestage codegen will be ...
GitHub user eatoncys opened a pull request:
https://github.com/apache/spark/pull/18810
[SPARK-21603][sql]The wholestage codegen will be much slower then
wholestage codegen is closed when the function is too long
## What changes were proposed in this pull request?
Close the whole stage codegen when the function lines is longer than the
maxlines which will be setted by
spark.sql.codegen.MaxFunctionLength parameter, because when the function is
too long , it will not get the JIT optimizing.
A benchmark test result is 10x slower when the generated function is too
long :
ignore("max function length of wholestagecodegen") {
val N = 20 << 15
val benchmark = new Benchmark("max function length of
wholestagecodegen", N)
def f(): Unit = sparkSession.range(N)
.selectExpr(
"id",
"(id & 1023) as k1",
"cast(id & 1023 as double) as k2",
"cast(id & 1023 as int) as k3",
"case when id > 100 and id <= 200 then 1 else 0 end as v1",
"case when id > 200 and id <= 300 then 1 else 0 end as v2",
"case when id > 300 and id <= 400 then 1 else 0 end as v3",
"case when id > 400 and id <= 500 then 1 else 0 end as v4",
"case when id > 500 and id <= 600 then 1 else 0 end as v5",
"case when id > 600 and id <= 700 then 1 else 0 end as v6",
"case when id > 700 and id <= 800 then 1 else 0 end as v7",
"case when id > 800 and id <= 900 then 1 else 0 end as v8",
"case when id > 900 and id <= 1000 then 1 else 0 end as v9",
"case when id > 1000 and id <= 1100 then 1 else 0 end as v10",
"case when id > 1100 and id <= 1200 then 1 else 0 end as v11",
"case when id > 1200 and id <= 1300 then 1 else 0 end as v12",
"case when id > 1300 and id <= 1400 then 1 else 0 end as v13",
"case when id > 1400 and id <= 1500 then 1 else 0 end as v14",
"case when id > 1500 and id <= 1600 then 1 else 0 end as v15",
"case when id > 1600 and id <= 1700 then 1 else 0 end as v16",
"case when id > 1700 and id <= 1800 then 1 else 0 end as v17",
"case when id > 1800 and id <= 1900 then 1 else 0 end as v18")
.groupBy("k1", "k2", "k3")
.sum()
.collect()
benchmark.addCase(s"codegen = F") { iter =>
sparkSession.conf.set("spark.sql.codegen.wholeStage", "false")
f()
}
benchmark.addCase(s"codegen = T") { iter =>
sparkSession.conf.set("spark.sql.codegen.wholeStage", "true")
sparkSession.conf.set("spark.sql.codegen.MaxFunctionLength", "1")
f()
}
benchmark.run()
/*
Java HotSpot(TM) 64-Bit Server VM 1.8.0_111-b14 on Windows 7 6.1
Intel64 Family 6 Model 58 Stepping 9, GenuineIntel
max function length of wholestagecodegen: Best/Avg Time(ms)
Rate(M/s) Per Row(ns) Relative
----
codegen = F443 / 507 1.5
676.0 1.0X
codegen = T 3279 / 3283 0.2
5002.6 0.1X
*/
}
## How was this patch tested?
Run the unit test
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/eatoncys/spark codegen
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/18810.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #18810
commit ca9eff68424511fa11cc2bd695f1fddaae178e3c
Author: 10129659 <chen.yans...@zte.com.cn>
Date: 2017-08-02T03:48:21Z
The wholestage codegen will be slower when the function is too long
commit 1b0ac5ed896136df3579a61d7ef93980c0647e97
Author: 10129659 <chen.yans...@zte.com.cn>
Date: 2017-08-02T04:41:24Z
The wholestage codegen will be slower when the function is too long
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r123475601
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -543,6 +543,30 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging with Seria
}
}
+if (contains("spark.cores.max")) {
+ val totalCores = getInt("spark.cores.max", -1)
+ if (totalCores <= 0) {
+throw new IllegalArgumentException(s"spark.cores.max (was
${get("spark.cores.max")})" +
+ s" can only be a positive number")
+ }
+}
+if (contains("spark.executor.cores")) {
+ val executorCores = getInt("spark.executor.cores", -1)
+ if (executorCores <= 0) {
+throw new IllegalArgumentException(s"spark.executor.cores " +
+ s"(was ${get("spark.executor.cores")}) can only be a positive
number")
+ }
+}
+if (contains("spark.cores.max") && contains("spark.executor.cores")) {
+ val totalCores = getInt("spark.cores.max", 1)
--- End diff --
@srowen @jiangxb1987 Ok, I have removed the argument checking code, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r123461583
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -543,6 +543,30 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging with Seria
}
}
+if (contains("spark.cores.max")) {
+ val totalCores = getInt("spark.cores.max", -1)
+ if (totalCores <= 0) {
+throw new IllegalArgumentException(s"spark.cores.max (was
${get("spark.cores.max")})" +
+ s" can only be a positive number")
+ }
+}
+if (contains("spark.executor.cores")) {
+ val executorCores = getInt("spark.executor.cores", -1)
+ if (executorCores <= 0) {
+throw new IllegalArgumentException(s"spark.executor.cores " +
+ s"(was ${get("spark.executor.cores")}) can only be a positive
number")
+ }
+}
+if (contains("spark.cores.max") && contains("spark.executor.cores")) {
+ val totalCores = getInt("spark.cores.max", 1)
--- End diff --
@srowen Users may set these configuration via SparkConf object in a
programmatic way after arg checking for spark-submit. For example, an app code
may be like this: "val conf = new SparkConf().set("spark.executor.cores","-1")"
before SparkContext created, the checkings here can get the error and exit
directly.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 cc @srowen --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r123420930
--- Diff:
core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala ---
@@ -258,23 +256,7 @@ private[deploy] class SparkSubmitArguments(args:
Seq[String], env: Map[String, S
if (mainClass == null && SparkSubmit.isUserJar(primaryResource)) {
SparkSubmit.printErrorAndExit("No main class set in JAR; please
specify one with --class")
}
-if (driverMemory != null
-&& Try(JavaUtils.byteStringAsBytes(driverMemory)).getOrElse(-1L)
<= 0) {
- SparkSubmit.printErrorAndExit("Driver Memory must be a positive
number")
-}
-if (executorMemory != null
-&& Try(JavaUtils.byteStringAsBytes(executorMemory)).getOrElse(-1L)
<= 0) {
- SparkSubmit.printErrorAndExit("Executor Memory cores must be a
positive number")
-}
-if (executorCores != null && Try(executorCores.toInt).getOrElse(-1) <=
0) {
- SparkSubmit.printErrorAndExit("Executor cores must be a positive
number")
-}
-if (totalExecutorCores != null &&
Try(totalExecutorCores.toInt).getOrElse(-1) <= 0) {
- SparkSubmit.printErrorAndExit("Total executor cores must be a
positive number")
-}
-if (numExecutors != null && Try(numExecutors.toInt).getOrElse(-1) <=
0) {
- SparkSubmit.printErrorAndExit("Number of executors must be a
positive number")
-}
--- End diff --
@jerryshao Ok ,I have moved them back, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r123420644
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -543,6 +545,42 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging with Seria
}
}
+if (contains("spark.driver.memory")) {
+ val driverMemory = get("spark.driver.memory")
+ if (Try(JavaUtils.byteStringAsBytes(driverMemory)).getOrElse(-1L) <=
0) {
+throw new IllegalArgumentException(s"spark.driver.memory " +
+ s"(was ${driverMemory}) can only be a positive number")
+ }
+}
+if (contains("spark.executor.memory")) {
+ val executorMemory = get("spark.executor.memory")
+ if (Try(JavaUtils.byteStringAsBytes(executorMemory)).getOrElse(-1L)
<= 0) {
+throw new IllegalArgumentException(s"spark.executor.memory " +
+ s"(was ${executorMemory}) can only be a positive number")
+ }
--- End diff --
@jerryshao Ok ,I have moved them back, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r123420083
--- Diff:
core/src/test/scala/org/apache/spark/deploy/master/MasterSuite.scala ---
@@ -704,6 +707,43 @@ class MasterSuite extends SparkFunSuite
private def getState(master: Master): RecoveryState.Value = {
master.invokePrivate(_state())
}
+
+ test("Total cores is not divisible by cores per executor") {
--- End diff --
@jerryshao Ok, I have removed them out, thanks
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18351: [SPARK-21135][WEB UI] On history server page,duration ...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18351 I think it is better to hide it. @fjh100456 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18351: [SPARK-21135][WEB UI] On history server page,duration ...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18351 I think it is better to hide it. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18351: [SPARK-21135][WEB UI] On history server page,duration ...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18351 I think it is better to hide it. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122942651
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -543,6 +543,30 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging with Seria
}
}
+if (contains("spark.cores.max")) {
+ val totalCores = getInt("spark.cores.max", -1)
+ if (totalCores <= 0) {
+throw new IllegalArgumentException(s"spark.cores.max (was
${get("spark.cores.max")})" +
+ s" can only be a positive number")
+ }
+}
+if (contains("spark.executor.cores")) {
+ val executorCores = getInt("spark.executor.cores", -1)
+ if (executorCores <= 0) {
+throw new IllegalArgumentException(s"spark.executor.cores " +
+ s"(was ${get("spark.executor.cores")}) can only be a positive
number")
+ }
+}
+if (contains("spark.cores.max") && contains("spark.executor.cores")) {
--- End diff --
@jerryshao I put the negative check here first, but I think the app should
exit directly if the cores is negative, so I move them out. And @srowen thinks
these checks for negative numbers are redundant with arg checking for
spark-submit, it may be a good way to move the checkings from spark-submit to
here.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122939834
--- Diff:
core/src/test/scala/org/apache/spark/deploy/master/MasterSuite.scala ---
@@ -704,6 +707,43 @@ class MasterSuite extends SparkFunSuite
private def getState(master: Master): RecoveryState.Value = {
master.invokePrivate(_state())
}
+
+ test("Total cores is not divisible by cores per executor") {
--- End diff --
@jerryshao I have not any good way to test like this, any good suggestion?
@srowen
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122926099
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -543,6 +543,30 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging with Seria
}
}
+if (contains("spark.cores.max")) {
+ val totalCores = getInt("spark.cores.max", -1)
--- End diff --
@jerryshao I don't understand very cleanly, if we don't set this
configuration ,the "if (contains("spark.cores.max")) " will not got into.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122925526
--- Diff:
core/src/test/scala/org/apache/spark/deploy/master/MasterSuite.scala ---
@@ -704,6 +707,43 @@ class MasterSuite extends SparkFunSuite
private def getState(master: Master): RecoveryState.Value = {
master.invokePrivate(_state())
}
+
+ test("Total cores is not divisible by cores per executor") {
--- End diff --
@jerryshao The result is same before and after my change, how to test them
differently, any suggestion? thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122676148
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -543,6 +543,30 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging with Seria
}
}
+if (contains("spark.cores.max")) {
--- End diff --
@srowen Users may set these configuration via SparkConf object in a
programmatic way, can I move the checkings from sparkâsubmit to here, or
removed it here directly,which is better?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 @jerryshao, I have added a unit test in MasterSuite, would you like to review it again, thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122638913
--- Diff:
core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala ---
@@ -278,6 +278,14 @@ private[deploy] class SparkSubmitArguments(args:
Seq[String], env: Map[String, S
if (pyFiles != null && !isPython) {
SparkSubmit.printErrorAndExit("--py-files given but primary resource
is not a Python script")
}
+if (totalExecutorCores != null && executorCores != null) {
--- End diff --
Ok, I have moved it to SparkConf, would you like to review it again, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122562905
--- Diff: core/src/main/scala/org/apache/spark/deploy/master/Master.scala
---
@@ -658,19 +658,22 @@ private[deploy] class Master(
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to
fit in the first app
// in the queue, then the second app, etc.
-for (app <- waitingApps if app.coresLeft > 0) {
+for (app <- waitingApps) {
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
- // Filter out workers that don't have enough resources to launch an
executor
- val usableWorkers = workers.toArray.filter(_.state ==
WorkerState.ALIVE)
-.filter(worker => worker.memoryFree >=
app.desc.memoryPerExecutorMB &&
- worker.coresFree >= coresPerExecutor.getOrElse(1))
-.sortBy(_.coresFree).reverse
- val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers,
spreadOutApps)
-
- // Now that we've decided how many cores to allocate on each worker,
let's allocate them
- for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
-allocateWorkerResourceToExecutors(
- app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
+ // If the cores left is less than the coresPerExecutor,the cores
left will not be allocated
+ if (app.coresLeft >= coresPerExecutor.getOrElse(1)) {
--- End diff --
Ok, I've modified the expression "val coresPerExecutor =
app.desc.coresPerExecutor" to "val coresPerExecutor =
app.desc.coresPerExecutor.getOrElse(1)" and reused it. And then using
"app.desc.coresPerExecutor" directly in the function
allocateWorkerResourceToExecutors. Thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122562797
--- Diff:
core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala ---
@@ -278,6 +278,12 @@ private[deploy] class SparkSubmitArguments(args:
Seq[String], env: Map[String, S
if (pyFiles != null && !isPython) {
SparkSubmit.printErrorAndExit("--py-files given but primary resource
is not a Python script")
}
+if (totalExecutorCores != null && executorCores != null
+&& (totalExecutorCores.toInt % executorCores.toInt) != 0) {
--- End diff --
Ok, I've modified the mod expression repeated to a val param and reused
it,thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122439758
--- Diff: core/src/main/scala/org/apache/spark/deploy/master/Master.scala
---
@@ -658,19 +658,22 @@ private[deploy] class Master(
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to
fit in the first app
// in the queue, then the second app, etc.
-for (app <- waitingApps if app.coresLeft > 0) {
+for (app <- waitingApps) {
--- End diff --
@srowen If the total cores is not divisible by cores per executor, the
compare app.coresLeft>0 will be always true, so it is better to compare
app.coresLeft with coresPerExecutor than compare with 0.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122424679
--- Diff: core/src/main/scala/org/apache/spark/deploy/master/Master.scala
---
@@ -658,19 +658,22 @@ private[deploy] class Master(
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to
fit in the first app
// in the queue, then the second app, etc.
-for (app <- waitingApps if app.coresLeft > 0) {
+for (app <- waitingApps) {
--- End diff --
Is not be better to compare app.coresLeft whih coresPerExecutor? If the
coresLeft less than coresPerExecutor, it will return directly
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
Github user eatoncys commented on a diff in the pull request:
https://github.com/apache/spark/pull/18322#discussion_r122424299
--- Diff:
core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala ---
@@ -278,6 +278,15 @@ private[deploy] class SparkSubmitArguments(args:
Seq[String], env: Map[String, S
if (pyFiles != null && !isPython) {
SparkSubmit.printErrorAndExit("--py-files given but primary resource
is not a Python script")
}
+if (totalExecutorCores != null && executorCores != null) {
+ val totalCores = Try(totalExecutorCores.toInt).getOrElse(-1)
--- End diff --
Ok, I will remove the Try block, thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 @jerryshao I have added warning logs in SparkSubmit , would you like to review it again, thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 @jerryshao Ok, I will add warning logs in SparkSubmit, thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 @jerryshao I have modified the "app.coresLeft>0" to "app.coresLeft >= coresPerExecutor.getOrElse(1)". And another question is : is it will be better to allocate another executor with 1 core for the cores left? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 @jerryshao The problem is: If we start an app with the param --total-executor-cores=4 and spark.executor.cores=3, the code "app.coresLeft>0" is always true in "org.apache.spark.deploy.master.startExecutorsOnWorkers" and it will try to allocate executor for this app and it will allocate nothing, it is better to compare the app.coresLeft whih coresPerExecutor, if the coresLeft less than coresPerExecutor, it will return directly. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18322: [SPARK-21115][Core]If the cores left is less than the co...
Github user eatoncys commented on the issue: https://github.com/apache/spark/pull/18322 @jerryshao I have not see any issue here, and I have tested this again using the latest Master code, the problem also exists. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18322: [SPARK-21115][Core]If the cores left is less than...
GitHub user eatoncys opened a pull request: https://github.com/apache/spark/pull/18322 [SPARK-21115][Core]If the cores left is less than the coresPerExecutor,the cores left will not be allocated, so it should not to check in every schedule ## What changes were proposed in this pull request? If we start an app with the param --total-executor-cores=4 and spark.executor.cores=3, the cores left is always 1, so it will try to allocate executors in the function org.apache.spark.deploy.master.startExecutorsOnWorkers in every schedule. Another question is, is it will be better to allocate another executor with 1 core for the cores left. ## How was this patch tested? unit test You can merge this pull request into a Git repository by running: $ git pull https://github.com/eatoncys/spark leftcores Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18322.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18322 commit 5f5f01fb55ec827d0053de2b574929520ff73406 Author: 10129659 <chen.yans...@zte.com.cn> Date: 2017-06-16T05:46:47Z If the cores left is less than the coresPerExecutor,the cores left will not be allocated, so it should not to check in every schedule --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org