[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-72568272 Closing this since #4014 has been merged. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel closed the pull request at: https://github.com/apache/spark/pull/4158 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel commented on a diff in the pull request:
https://github.com/apache/spark/pull/4158#discussion_r23514639
--- Diff: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveQl.scala ---
@@ -633,14 +633,28 @@
https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C
Token(script, Nil) ::
Token("TOK_SERDE", serdeClause) ::
Token("TOK_RECORDREADER", readerClause) ::
- outputClause :: Nil) :: Nil) =>
+ outputClause) :: Nil) =>
+// TODO the output should be bind with the output clause or
RecordReader
val output = outputClause match {
- case Token("TOK_ALIASLIST", aliases) =>
+ case Token("TOK_ALIASLIST", aliases) :: Nil =>
aliases.map { case Token(name, Nil) =>
AttributeReference(name, StringType)() }
- case Token("TOK_TABCOLLIST", attributes) =>
+ case Token("TOK_TABCOLLIST", attributes) :: Nil =>
attributes.map { case Token("TOK_TABCOL", Token(name, Nil)
:: dataType :: Nil) =>
AttributeReference(name, nodeToDataType(dataType))() }
+ case Nil => // Not specified the output field names, let it
be the same as input
+(0 to inputExprs.length - 1).map { idx =>
+ // Keep the same as Hive does, the first field names is
"key", and second is
+ // "value", however, Hive seems gives null string for
the rest of the
--- End diff --
OK, I see. thanks for the explanation. I will update that.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/4158#discussion_r23514311
--- Diff: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveQl.scala ---
@@ -633,14 +633,28 @@
https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C
Token(script, Nil) ::
Token("TOK_SERDE", serdeClause) ::
Token("TOK_RECORDREADER", readerClause) ::
- outputClause :: Nil) :: Nil) =>
+ outputClause) :: Nil) =>
+// TODO the output should be bind with the output clause or
RecordReader
val output = outputClause match {
- case Token("TOK_ALIASLIST", aliases) =>
+ case Token("TOK_ALIASLIST", aliases) :: Nil =>
aliases.map { case Token(name, Nil) =>
AttributeReference(name, StringType)() }
- case Token("TOK_TABCOLLIST", attributes) =>
+ case Token("TOK_TABCOLLIST", attributes) :: Nil =>
attributes.map { case Token("TOK_TABCOL", Token(name, Nil)
:: dataType :: Nil) =>
AttributeReference(name, nodeToDataType(dataType))() }
+ case Nil => // Not specified the output field names, let it
be the same as input
+(0 to inputExprs.length - 1).map { idx =>
+ // Keep the same as Hive does, the first field names is
"key", and second is
+ // "value", however, Hive seems gives null string for
the rest of the
--- End diff --
I think it is expected results as the Hive manual describes about
'Schema-less Map-reduce Scripts
' in
[transform](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Transform):
> If there is no AS clause after USING my_script, Hive assumes that the
output of the script contains 2 parts: key which is before the first tab, and
value which is the rest after the first tab.
So in your results, `value` column gets all query outputs after the first
tab. The results of table `test2` is just the alignment problem caused by tabs.
It should follow the same rule too.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71407251 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/26069/ Test PASSed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user SparkQA commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71407248 [Test build #26069 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/26069/consoleFull) for PR 4158 at commit [`5618fa7`](https://github.com/apache/spark/commit/5618fa7914fefee9ac6fbd6dba17ba8f6e1ff5bd). * This patch **passes all tests**. * This patch merges cleanly. * This patch adds no public classes. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel commented on a diff in the pull request:
https://github.com/apache/spark/pull/4158#discussion_r23509725
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/ScriptTransformation.scala
---
@@ -54,23 +55,47 @@ case class ScriptTransformation(
val outputStream = proc.getOutputStream
val reader = new BufferedReader(new InputStreamReader(inputStream))
+ // This projection outputs to the script, which runs in a single
process
+ // TODO a Writer SerDe will be placed here.
+ val inputProjection = new InterpretedProjection(input, child.output)
+
+ // This projection is casting the scripts output into user specified
data type
+ // TODO a Reader SerDe will be placed here for the casting the output
+ // data type into the required one
+ val outputProjection = new
InterpretedProjection(output.zipWithIndex.map {
+case (attr, idx) => if (attr.dataType == StringType) {
+BoundReference(idx, StringType, true)
--- End diff --
Thanks, Done.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user SparkQA commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71403889 [Test build #26069 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/26069/consoleFull) for PR 4158 at commit [`5618fa7`](https://github.com/apache/spark/commit/5618fa7914fefee9ac6fbd6dba17ba8f6e1ff5bd). * This patch merges cleanly. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel commented on a diff in the pull request:
https://github.com/apache/spark/pull/4158#discussion_r23509647
--- Diff: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveQl.scala ---
@@ -633,14 +633,28 @@
https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C
Token(script, Nil) ::
Token("TOK_SERDE", serdeClause) ::
Token("TOK_RECORDREADER", readerClause) ::
- outputClause :: Nil) :: Nil) =>
+ outputClause) :: Nil) =>
+// TODO the output should be bind with the output clause or
RecordReader
val output = outputClause match {
- case Token("TOK_ALIASLIST", aliases) =>
+ case Token("TOK_ALIASLIST", aliases) :: Nil =>
aliases.map { case Token(name, Nil) =>
AttributeReference(name, StringType)() }
- case Token("TOK_TABCOLLIST", attributes) =>
+ case Token("TOK_TABCOLLIST", attributes) :: Nil =>
attributes.map { case Token("TOK_TABCOL", Token(name, Nil)
:: dataType :: Nil) =>
AttributeReference(name, nodeToDataType(dataType))() }
+ case Nil => // Not specified the output field names, let it
be the same as input
+(0 to inputExprs.length - 1).map { idx =>
+ // Keep the same as Hive does, the first field names is
"key", and second is
+ // "value", however, Hive seems gives null string for
the rest of the
--- End diff --
Thanks for notice that. I think this's probably a bug in Hive.
I did the queries in Hive CLI:
```
set hive.cli.print.header=true;
select transform(key + 1, key - 1, key) using '/bin/cat' from src limit 4;
```
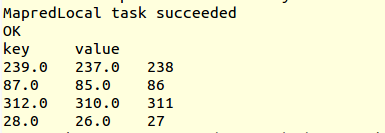
```
create table test2 as select transform(key + 1, key - 1, key) using
'/bin/cat' from src limit 4;
```
And print the result of the table `test2`:
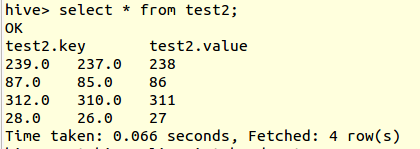
You will see, it's not the expected result, of `key` and `value`, that's
why I added the default field name for more than 2 columns.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user viirya commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71181584 @chenghao-intel overall it looks good for me except for small comments. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/4158#discussion_r23444792
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/ScriptTransformation.scala
---
@@ -54,23 +55,47 @@ case class ScriptTransformation(
val outputStream = proc.getOutputStream
val reader = new BufferedReader(new InputStreamReader(inputStream))
+ // This projection outputs to the script, which runs in a single
process
+ // TODO a Writer SerDe will be placed here.
+ val inputProjection = new InterpretedProjection(input, child.output)
+
+ // This projection is casting the scripts output into user specified
data type
+ // TODO a Reader SerDe will be placed here for the casting the output
+ // data type into the required one
+ val outputProjection = new
InterpretedProjection(output.zipWithIndex.map {
+case (attr, idx) => if (attr.dataType == StringType) {
+BoundReference(idx, StringType, true)
--- End diff --
`BoundReference` can be out of the if block.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/4158#discussion_r23444732
--- Diff: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveQl.scala ---
@@ -633,14 +633,28 @@
https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C
Token(script, Nil) ::
Token("TOK_SERDE", serdeClause) ::
Token("TOK_RECORDREADER", readerClause) ::
- outputClause :: Nil) :: Nil) =>
+ outputClause) :: Nil) =>
+// TODO the output should be bind with the output clause or
RecordReader
val output = outputClause match {
- case Token("TOK_ALIASLIST", aliases) =>
+ case Token("TOK_ALIASLIST", aliases) :: Nil =>
aliases.map { case Token(name, Nil) =>
AttributeReference(name, StringType)() }
- case Token("TOK_TABCOLLIST", attributes) =>
+ case Token("TOK_TABCOLLIST", attributes) :: Nil =>
attributes.map { case Token("TOK_TABCOL", Token(name, Nil)
:: dataType :: Nil) =>
AttributeReference(name, nodeToDataType(dataType))() }
+ case Nil => // Not specified the output field names, let it
be the same as input
+(0 to inputExprs.length - 1).map { idx =>
+ // Keep the same as Hive does, the first field names is
"key", and second is
+ // "value", however, Hive seems gives null string for
the rest of the
--- End diff --
According to Hive manual, there should be only two outputs `key` and
`value` when no output schema is defined. So I am not sure if it is a bug
because it is explictly described in the manual. I suppose that it is a
well-known and expected behavior?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user SparkQA commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71153531 [Test build #25996 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/25996/consoleFull) for PR 4158 at commit [`a7b6989`](https://github.com/apache/spark/commit/a7b698945856eb3412aeef92ba22e4956371eb66). * This patch **passes all tests**. * This patch merges cleanly. * This patch adds no public classes. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71153535 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/25996/ Test PASSed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71149913 @viirya I've updated the code, which is a block issue for our partner, it's would be great if you can review this for me. And definitely the TODOs I leave there can be done in your PR #4014 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user SparkQA commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71149756 [Test build #25996 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/25996/consoleFull) for PR 4158 at commit [`a7b6989`](https://github.com/apache/spark/commit/a7b698945856eb3412aeef92ba22e4956371eb66). * This patch merges cleanly. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user chenghao-intel commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-71128096 Thank you @viirya . This is just a quick fix in my use case. Hope it merge soon. And I will give some comment in your PR. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-70992965 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/25959/ Test PASSed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user SparkQA commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-70992962 [Test build #25959 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/25959/consoleFull) for PR 4158 at commit [`c8fe7fc`](https://github.com/apache/spark/commit/c8fe7fc37471c38b24e52a5d170fa0741b50c791). * This patch **passes all tests**. * This patch merges cleanly. * This patch adds no public classes. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user viirya commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-70989376 Hi @chenghao-intel, I already did this and support for custom field delimiter and SerDe in PR #4014. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
Github user SparkQA commented on the pull request: https://github.com/apache/spark/pull/4158#issuecomment-70986035 [Test build #25959 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/25959/consoleFull) for PR 4158 at commit [`c8fe7fc`](https://github.com/apache/spark/commit/c8fe7fc37471c38b24e52a5d170fa0741b50c791). * This patch merges cleanly. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5364] [SQL] HiveQL transform doesn't su...
GitHub user chenghao-intel opened a pull request: https://github.com/apache/spark/pull/4158 [SPARK-5364] [SQL] HiveQL transform doesn't support the non output clause This is a quick fix for query (in HiveContext) like: ``` SELECT transform(key + 1, value) USING '/bin/cat' FROM src ``` Ideally, we need to refactor the `ScriptTransformation`, which should support the custom SerDe for reader & writer. Will do that in the follow up. You can merge this pull request into a Git repository by running: $ git pull https://github.com/chenghao-intel/spark transform Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/4158.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4158 commit c8fe7fc37471c38b24e52a5d170fa0741b50c791 Author: Cheng Hao Date: 2015-01-22T08:09:00Z fix bug of transform in HiveQL --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org