[GitHub] spark issue #23211: [SPARK-19712][SQL] Move PullupCorrelatedPredicates and R...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23211 This file generated by [TPCDSQueryOptimizerTracker.scala](https://github.com/wangyum/spark/blob/SPARK-25872/sql/core/src/test/scala/org/apache/spark/sql/TPCDSQueryOptimizerTracker.scala). runtimes can generated by [TPCDSQueryBenchmark.scala](https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/TPCDSQueryBenchmark.scala). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23199: [SPARK-26245][SQL] Add Float literal
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/23199 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22683: [SPARK-25696] The storage memory displayed on spark Appl...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22683 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23211: [SPARK-19712][SQL] Move PullupCorrelatedPredicates and R...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23211 I generated the TPC-DS plans to compare the differences after this patch to help review: https://github.com/wangyum/spark/commit/7e7a1fe24e8970830c67f80604ce238caa035b85#diff-1a4e6beba801fa647e1dcbd61ed7e5bf --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-19784][SPARK-25403][SQL] Refresh the table...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r238891454
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
---
@@ -45,6 +45,8 @@ object CommandUtils extends Logging {
} else {
catalog.alterTableStats(table.identifier, None)
}
+} else {
+ catalog.refreshTable(table.identifier)
--- End diff --
Sure. move to DDLs is better.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23216: [SPARK-26264][CORE]It is better to add @transient to fie...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23216 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23219: [SPARK-26266][BUILD] Update to Scala 2.12.8
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23219 @srowen Sorry. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23219: [SPARK-26266][BUILD] Update to Scala 2.12.8
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/23219 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23219: [SPARK-26266][BUILD] Update to Scala 2.12.8
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23219 [SPARK-26266][BUILD] Update to Scala 2.12.8 ## What changes were proposed in this pull request? This pr update to Scala 2.12.8. It fixes two regressions that appeared in 2.12.7: ``` Don't reject views with result types which are TypeVars (#7295) Don't emit static forwarders (which simplify the use of methods in top-level objects from Java) for bridge methods (#7469) ``` More details: https://github.com/scala/scala/releases/tag/v2.12.8 ## How was this patch tested? Existing tests. You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-26266 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23219.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23219 commit 94f76e543c1b146d4d25d3e15b6efd4777af7652 Author: Yuming Wang Date: 2018-12-04T15:03:26Z Upgrade Scala to 2.12.8 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22600: [SPARK-25578][BUILD] Update to Scala 2.12.7
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22600 2.12.8 is out. Do we need to upgrade to 2.12.8? 2.12.8 fixes two regressions that appeared in 2.12.7: ``` Don't reject views with result types which are TypeVars (#7295) Don't emit static forwarders (which simplify the use of methods in top-level objects from Java) for bridge methods (#7469) ``` More details: https://github.com/scala/scala/releases/tag/v2.12.8 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23164: [SPARK-26198][SQL] Fix Metadata serialize null values th...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23164 I think we should back-port because we can [`putNull`](https://github.com/apache/spark/blob/630e25e35506c02a0b1e202ef82b1b0f69e50966/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Metadata.scala#L246), but can not serialize it without this patch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23199: [SPARK-26245][SQL] Add Float literal
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23199 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23199: [SPARK-26245][SQL] Add Float literal
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23199 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23199: [SPARK-26245][SQL] Add Float literal
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23199 [SPARK-26245][SQL] Add Float literal ## What changes were proposed in this pull request? This PR adds parser support for `Float` literals. Hive support this feature: 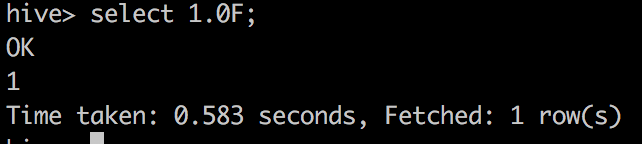 ## How was this patch tested? unit tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-26245 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23199.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23199 commit 57faa4160365e4ec7ef9847861882b469d4953d6 Author: Yuming Wang Date: 2018-12-02T08:56:56Z Add Float literal --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23164: [SPARK-26198][SQL] Fix Metadata serialize null values th...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23164 I used it here: https://github.com/apache/spark/compare/master...wangyum:default-value?expand=1#diff-9847f5cef7cf7fbc5830fbc6b779ee10R1827 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22683: [SPARK-25696] The storage memory displayed on spark Appl...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22683 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22683: [SPARK-25696] The storage memory displayed on spark Appl...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22683 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23164: [SPARK-26198][SQL] Fix Metadata serialize null values th...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23164 cc @srowen --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23170: [SPARK-24423][FOLLOW-UP][SQL] Fix error example
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23170 It's not a regression. The first check exists in [2.1.0](https://github.com/apache/spark/blob/v2.1.0/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCOptions.scala#L99-L102) and the second check is added in [2.4.0](https://github.com/apache/spark/blob/v2.4.0/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCOptions.scala#L133-L143). cc @dilipbiswal --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23170: [SPARK-24423][FOLLOW-UP][SQL] Fix error example
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23170 [SPARK-24423][FOLLOW-UP][SQL] Fix error example ## What changes were proposed in this pull request?  It will throw: ``` requirement failed: When reading JDBC data sources, users need to specify all or none for the following options: 'partitionColumn', 'lowerBound', 'upperBound', and 'numPartitions' ``` and ``` User-defined partition column subq.c1 not found in the JDBC relation ... ``` This PR fix this error example. ## How was this patch tested? manual tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-24499 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23170.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23170 commit e2d8229614ed232d1089c304cbc4bdb88292d213 Author: Yuming Wang Date: 2018-11-28T17:59:23Z Fix error example --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23164: [SPARK-26198][SQL] Fix Metadata serialize null va...
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/23164
[SPARK-26198][SQL] Fix Metadata serialize null values throw NPE
## What changes were proposed in this pull request?
How to reproduce this issue:
```scala
scala> val meta = new
org.apache.spark.sql.types.MetadataBuilder().putNull("key").build()
java.lang.NullPointerException
at
org.apache.spark.sql.types.Metadata$.org$apache$spark$sql$types$Metadata$$toJsonValue(Metadata.scala:196)
at
org.apache.spark.sql.types.Metadata$$anonfun$1.apply(Metadata.scala:180)
```
This pr fix `NullPointerException` when `Metadata` serialize `null` values.
## How was this patch tested?
unit tests
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/wangyum/spark SPARK-26198
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/23164.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #23164
commit 03101868a72b5ae68bf6324e627f1874af32f040
Author: Yuming Wang
Date: 2018-11-28T12:22:09Z
Fix Metadata serialize null values throw NPE
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/23027 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
GitHub user wangyum reopened a pull request: https://github.com/apache/spark/pull/23027 [SPARK-26049][SQL][TEST] FilterPushdownBenchmark add InMemoryTable case ## What changes were proposed in this pull request? `FilterPushdownBenchmark` add InMemoryTable case. ## How was this patch tested? manual tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-26049 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23027.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23027 commit d0a2a3f4af492fbf69f7774e03d67d4af39cd5c7 Author: Yuming Wang Date: 2018-11-14T00:35:35Z Add InMemoryTable filter benchmark commit 01d01e7995ecb72705d0d610892dc99a6c3f4621 Author: Yuming Wang Date: 2018-11-19T07:59:19Z cache inMemoryTable from file commit b8c54ea5048524f7df0b750a11a8fb109b43f479 Author: Yuming Wang Date: 2018-11-19T12:44:46Z Fix path --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23027#discussion_r235259340
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -2,669 +2,809 @@
Pushdown for many distinct value case
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row (value IS NULL): Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
-Parquet Vectorized 11405 / 11485 1.4
725.1 1.0X
-Parquet Vectorized (Pushdown) 675 / 690 23.3
42.9 16.9X
-Native ORC Vectorized 7127 / 7170 2.2
453.1 1.6X
-Native ORC Vectorized (Pushdown) 519 / 541 30.3
33.0 22.0X
+Parquet Vectorized7823 / 7996 2.0
497.4 1.0X
+Parquet Vectorized (Pushdown) 460 / 468 34.2
29.2 17.0X
+Native ORC Vectorized 5412 / 5550 2.9
344.1 1.4X
+Native ORC Vectorized (Pushdown) 551 / 563 28.6
35.0 14.2X
+InMemoryTable Vectorized 6 /6 2859.1
0.31422.0X
+InMemoryTable Vectorized (Pushdown) 5 /6 3023.0
0.31503.6X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row ('7864320' < value < '7864320'): Best/Avg Time(ms)
Rate(M/s) Per Row(ns) Relative
-Parquet Vectorized 11457 / 11473 1.4
728.4 1.0X
-Parquet Vectorized (Pushdown) 656 / 686 24.0
41.7 17.5X
-Native ORC Vectorized 7328 / 7342 2.1
465.9 1.6X
-Native ORC Vectorized (Pushdown) 539 / 565 29.2
34.2 21.3X
+Parquet Vectorized 8322 / 11160 1.9
529.1 1.0X
+Parquet Vectorized (Pushdown) 463 / 472 34.0
29.4 18.0X
+Native ORC Vectorized 5622 / 5635 2.8
357.4 1.5X
+Native ORC Vectorized (Pushdown) 563 / 595 27.9
35.8 14.8X
+InMemoryTable Vectorized 4831 / 4881 3.3
307.2 1.7X
+InMemoryTable Vectorized (Pushdown) 1980 / 2027 7.9
125.9 4.2X
--- End diff --
I think the reason is
[SPARK-22599](https://issues.apache.org/jira/browse/SPARK-22599). But if we
cached all data to memory, the result is:
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row ('7864320' < value < '7864320'): Best/Avg Time(ms)
Rate(M/s) Per Row(ns) Relative
Parquet Vectorized6491 / 6716 2.4
412.7 1.0X
Parquet Vectorized (Pushdown) 491 / 496 32.0
31.2 13.2X
Native ORC Vectorized 5849 / 6103 2.7
371.9 1.1X
Native ORC Vectorized (Pushdown) 533 / 572 29.5
33.9 12.2X
InMemoryTable Vectorized 2788 / 2854 5.6
177.2 2.3X
InMemoryTable Vectorized (Pushdown)370 / 408 42.5
23.5 17.5X
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/23027 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22879: [SPARK-25872][SQL][TEST] Add an optimizer tracker...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/22879 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23004: [SPARK-26004][SQL] InMemoryTable support StartsWi...
Github user wangyum commented on a diff in the pull request: https://github.com/apache/spark/pull/23004#discussion_r234857747 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryTableScanExec.scala --- @@ -237,6 +237,13 @@ case class InMemoryTableScanExec( if list.forall(ExtractableLiteral.unapply(_).isDefined) && list.nonEmpty => list.map(l => statsFor(a).lowerBound <= l.asInstanceOf[Literal] && l.asInstanceOf[Literal] <= statsFor(a).upperBound).reduce(_ || _) + +case StartsWith(a: AttributeReference, ExtractableLiteral(l)) => --- End diff -- Added to pr description. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22683: [SPARK-25696] The storage memory displayed on spark Appl...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22683 @srowen Thanks for ping me. I agree with you. If @httfighter willing, updating all usages in the UI to indicate units like `KiB`, `MiB`, `GiB`. @httfighter you can check details here: https://en.wikipedia.org/wiki/Kilobyte https://en.wikipedia.org/wiki/Kibibyte --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23027#discussion_r234521489
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/FilterPushdownBenchmark.scala
---
@@ -104,6 +107,10 @@ object FilterPushdownBenchmark extends BenchmarkBase
with SQLHelper {
df.write.mode("overwrite")
.option("parquet.block.size", blockSize).parquet(parquetPath)
spark.read.parquet(parquetPath).createOrReplaceTempView("parquetTable")
+
+df.write.mode("overwrite").save(inMemoryTablePath)
--- End diff --
Cache `inMemoryTable` from file to avoid the performance issue:
https://github.com/apache/spark/pull/23027#pullrequestreview-175054485
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23027#discussion_r234482766
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -2,669 +2,809 @@
Pushdown for many distinct value case
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row (value IS NULL): Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
-Parquet Vectorized 11405 / 11485 1.4
725.1 1.0X
-Parquet Vectorized (Pushdown) 675 / 690 23.3
42.9 16.9X
-Native ORC Vectorized 7127 / 7170 2.2
453.1 1.6X
-Native ORC Vectorized (Pushdown) 519 / 541 30.3
33.0 22.0X
+Parquet Vectorized7823 / 7996 2.0
497.4 1.0X
+Parquet Vectorized (Pushdown) 460 / 468 34.2
29.2 17.0X
+Native ORC Vectorized 5412 / 5550 2.9
344.1 1.4X
+Native ORC Vectorized (Pushdown) 551 / 563 28.6
35.0 14.2X
+InMemoryTable Vectorized 6 /6 2859.1
0.31422.0X
+InMemoryTable Vectorized (Pushdown) 5 /6 3023.0
0.31503.6X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row ('7864320' < value < '7864320'): Best/Avg Time(ms)
Rate(M/s) Per Row(ns) Relative
-Parquet Vectorized 11457 / 11473 1.4
728.4 1.0X
-Parquet Vectorized (Pushdown) 656 / 686 24.0
41.7 17.5X
-Native ORC Vectorized 7328 / 7342 2.1
465.9 1.6X
-Native ORC Vectorized (Pushdown) 539 / 565 29.2
34.2 21.3X
+Parquet Vectorized 8322 / 11160 1.9
529.1 1.0X
+Parquet Vectorized (Pushdown) 463 / 472 34.0
29.4 18.0X
+Native ORC Vectorized 5622 / 5635 2.8
357.4 1.5X
+Native ORC Vectorized (Pushdown) 563 / 595 27.9
35.8 14.8X
+InMemoryTable Vectorized 4831 / 4881 3.3
307.2 1.7X
+InMemoryTable Vectorized (Pushdown) 1980 / 2027 7.9
125.9 4.2X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 1 string row (value = '7864320'): Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
-Parquet Vectorized 11878 / 11888 1.3
755.2 1.0X
-Parquet Vectorized (Pushdown) 630 / 654 25.0
40.1 18.9X
-Native ORC Vectorized 7342 / 7362 2.1
466.8 1.6X
-Native ORC Vectorized (Pushdown) 519 / 537 30.3
33.0 22.9X
+Parquet Vectorized8322 / 8386 1.9
529.1 1.0X
+Parquet Vectorized (Pushdown) 434 / 441 36.2
27.6 19.2X
+Native ORC Vectorized 5659 / 5944 2.8
359.8 1.5X
+Native ORC Vectorized (Pushdown) 535 / 567 29.4
34.0 15.6X
+InMemoryTable Vectorized 4784 / 4879 3.3
304.1 1.7X
+InMemoryTable Vectorized (Pushdown) 1950 / 1985 8.1
124.0 4.3X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Ser
[GitHub] spark pull request #23030: [MINOR][YARN] Make memLimitExceededLogMessage mor...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23030#discussion_r234386679
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala
---
@@ -598,13 +597,25 @@ private[yarn] class YarnAllocator(
(false, s"Container ${containerId}${onHostStr} was preempted.")
// Should probably still count memory exceeded exit codes
towards task failures
case VMEM_EXCEEDED_EXIT_CODE =>
-(true, memLimitExceededLogMessage(
- completedContainer.getDiagnostics,
- VMEM_EXCEEDED_PATTERN))
+val vmemExceededPattern = raw"$MEM_REGEX of $MEM_REGEX virtual
memory used".r
+val diag =
vmemExceededPattern.findFirstIn(completedContainer.getDiagnostics)
+ .map(_.concat(".")).getOrElse("")
+val additional = if
(conf.getBoolean(YarnConfiguration.NM_VMEM_CHECK_ENABLED,
--- End diff --
I see.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23030: [MINOR][YARN] Make memLimitExceededLogMessage mor...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23030#discussion_r234233444
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala
---
@@ -735,18 +744,8 @@ private[yarn] class YarnAllocator(
private object YarnAllocator {
val MEM_REGEX = "[0-9.]+ [KMG]B"
- val PMEM_EXCEEDED_PATTERN =
-Pattern.compile(s"$MEM_REGEX of $MEM_REGEX physical memory used")
- val VMEM_EXCEEDED_PATTERN =
-Pattern.compile(s"$MEM_REGEX of $MEM_REGEX virtual memory used")
+ val PMEM_EXCEEDED_PATTERN = raw"$MEM_REGEX of $MEM_REGEX physical memory
used".r
--- End diff --
Yes. I will do it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22999: [SPARK-20319][SQL] Already quoted identifiers are gettin...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22999 cc @gatorsmile @maropu --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23027#discussion_r233689556
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -2,669 +2,809 @@
Pushdown for many distinct value case
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row (value IS NULL): Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
-Parquet Vectorized 11405 / 11485 1.4
725.1 1.0X
-Parquet Vectorized (Pushdown) 675 / 690 23.3
42.9 16.9X
-Native ORC Vectorized 7127 / 7170 2.2
453.1 1.6X
-Native ORC Vectorized (Pushdown) 519 / 541 30.3
33.0 22.0X
+Parquet Vectorized7823 / 7996 2.0
497.4 1.0X
+Parquet Vectorized (Pushdown) 460 / 468 34.2
29.2 17.0X
+Native ORC Vectorized 5412 / 5550 2.9
344.1 1.4X
+Native ORC Vectorized (Pushdown) 551 / 563 28.6
35.0 14.2X
+InMemoryTable Vectorized 6 /6 2859.1
0.31422.0X
+InMemoryTable Vectorized (Pushdown) 5 /6 3023.0
0.31503.6X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row ('7864320' < value < '7864320'): Best/Avg Time(ms)
Rate(M/s) Per Row(ns) Relative
-Parquet Vectorized 11457 / 11473 1.4
728.4 1.0X
-Parquet Vectorized (Pushdown) 656 / 686 24.0
41.7 17.5X
-Native ORC Vectorized 7328 / 7342 2.1
465.9 1.6X
-Native ORC Vectorized (Pushdown) 539 / 565 29.2
34.2 21.3X
+Parquet Vectorized 8322 / 11160 1.9
529.1 1.0X
+Parquet Vectorized (Pushdown) 463 / 472 34.0
29.4 18.0X
+Native ORC Vectorized 5622 / 5635 2.8
357.4 1.5X
+Native ORC Vectorized (Pushdown) 563 / 595 27.9
35.8 14.8X
+InMemoryTable Vectorized 4831 / 4881 3.3
307.2 1.7X
+InMemoryTable Vectorized (Pushdown) 1980 / 2027 7.9
125.9 4.2X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 1 string row (value = '7864320'): Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
-Parquet Vectorized 11878 / 11888 1.3
755.2 1.0X
-Parquet Vectorized (Pushdown) 630 / 654 25.0
40.1 18.9X
-Native ORC Vectorized 7342 / 7362 2.1
466.8 1.6X
-Native ORC Vectorized (Pushdown) 519 / 537 30.3
33.0 22.9X
+Parquet Vectorized8322 / 8386 1.9
529.1 1.0X
+Parquet Vectorized (Pushdown) 434 / 441 36.2
27.6 19.2X
+Native ORC Vectorized 5659 / 5944 2.8
359.8 1.5X
+Native ORC Vectorized (Pushdown) 535 / 567 29.4
34.0 15.6X
+InMemoryTable Vectorized 4784 / 4879 3.3
304.1 1.7X
+InMemoryTable Vectorized (Pushdown) 1950 / 1985 8.1
124.0 4.3X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Ser
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23027#discussion_r233687968
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -2,669 +2,809 @@
Pushdown for many distinct value case
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row (value IS NULL): Best/Avg Time(ms)Rate(M/s)
Per Row(ns) Relative
-Parquet Vectorized 11405 / 11485 1.4
725.1 1.0X
-Parquet Vectorized (Pushdown) 675 / 690 23.3
42.9 16.9X
-Native ORC Vectorized 7127 / 7170 2.2
453.1 1.6X
-Native ORC Vectorized (Pushdown) 519 / 541 30.3
33.0 22.0X
+Parquet Vectorized7823 / 7996 2.0
497.4 1.0X
+Parquet Vectorized (Pushdown) 460 / 468 34.2
29.2 17.0X
+Native ORC Vectorized 5412 / 5550 2.9
344.1 1.4X
+Native ORC Vectorized (Pushdown) 551 / 563 28.6
35.0 14.2X
+InMemoryTable Vectorized 6 /6 2859.1
0.31422.0X
+InMemoryTable Vectorized (Pushdown) 5 /6 3023.0
0.31503.6X
-OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64
-Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz
+Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6
+Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 0 string row ('7864320' < value < '7864320'): Best/Avg Time(ms)
Rate(M/s) Per Row(ns) Relative
-Parquet Vectorized 11457 / 11473 1.4
728.4 1.0X
-Parquet Vectorized (Pushdown) 656 / 686 24.0
41.7 17.5X
-Native ORC Vectorized 7328 / 7342 2.1
465.9 1.6X
-Native ORC Vectorized (Pushdown) 539 / 565 29.2
34.2 21.3X
+Parquet Vectorized 8322 / 11160 1.9
529.1 1.0X
+Parquet Vectorized (Pushdown) 463 / 472 34.0
29.4 18.0X
+Native ORC Vectorized 5622 / 5635 2.8
357.4 1.5X
+Native ORC Vectorized (Pushdown) 563 / 595 27.9
35.8 14.8X
+InMemoryTable Vectorized 4831 / 4881 3.3
307.2 1.7X
+InMemoryTable Vectorized (Pushdown) 1980 / 2027 7.9
125.9 4.2X
--- End diff --
Yes. This is the current benchmark result. I plan to improve it step by
step. Example: [SPARK-26004](https://issues.apache.org/jira/browse/SPARK-26004)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23027#discussion_r233686986
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/FilterPushdownBenchmark.scala
---
@@ -131,6 +134,15 @@ object FilterPushdownBenchmark extends BenchmarkBase
with SQLHelper {
}
}
+Seq(false, true).foreach { pushDownEnabled =>
+ val name = s"InMemoryTable Vectorized ${if (pushDownEnabled)
s"(Pushdown)" else ""}"
+ benchmark.addCase(name) { _ =>
+withSQLConf(SQLConf.IN_MEMORY_PARTITION_PRUNING.key ->
s"$pushDownEnabled") {
--- End diff --
I think the InMemoryTable's partition same to Parquet RowGroup(@kiszk
please correct if I'm wrong). We put them together and it's easy to compare
performance.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23030 cc @vanzin --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23030: [MINOR][YARN] Make memLimitExceededLogMessage mor...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23030 [MINOR][YARN] Make memLimitExceededLogMessage more clean ## What changes were proposed in this pull request? Current `memLimitExceededLogMessage`: https://user-images.githubusercontent.com/5399861/48467789-ec8e1000-e824-11e8-91fc-280d342e1bf3.png; width="360"> Itâs not very clear, because physical memory exceeds but suggestion contains virtual memory config. This pr makes it more clear and replace deprecated config: ```spark.yarn.executor.memoryOverhead```. ## How was this patch tested? manual tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark EXECUTOR_MEMORY_OVERHEAD Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23030.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23030 commit e7ff43d0056e38033ae2a2edf81b296797bb46e0 Author: Yuming Wang Date: 2018-11-14T07:46:58Z Make memLimitExceededLogMessage more clean --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23028: [SPARK-26053][SQL] Enhance LikeSimplification
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23028#discussion_r233317201
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
---
@@ -504,6 +504,19 @@ object LikeSimplification extends Rule[LogicalPlan] {
Like(input, Literal.create(pattern, StringType))
}
}
+
+case Like(Literal(pattern, StringType), input) =>
+ if (pattern == null) {
+// If pattern is null, return null value directly, since "null
like col" == null.
+Literal(null, BooleanType)
+ } else {
+pattern.toString match {
+ case equalTo(str) =>
+EqualTo(Literal(str), input)
--- End diff --
Yes.
```
select "abc" like "%abc%" -> true
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23028: [SPARK-26053][SQL] Enhance LikeSimplification
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/23028 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23027: [SPARK-26049][SQL][TEST] FilterPushdownBenchmark add InM...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23027 cc @HyukjinKwon @dongjoon-hyun --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23028: [SPARK-26053][SQL] Enhance LikeSimplification
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23028 [SPARK-26053][SQL] Enhance LikeSimplification ## What changes were proposed in this pull request? This PR enhance `LikeSimplification` in 2 cases: 1. null like col -> null 2. 'str' like col -> col = 'str' It difficult to handle these cases: 1. 'str%' like col 2. '%str' like col 3. 'str%str' like col 4. '%' like col for example: ```sql select '8%' like '8%'; -- true select '8%' like '%8%'; -- true select '8%' like '%%8%%'; -- true select '8%' like '%%5%%8%%'; --false select '%8' like '%8%'; -- true select '%8' like '%8%'; -- true select '%8' like '%%8%'; -- true select '%8' like '%%5%%8%'; -- false select '%' like '%'; -- true select '%' like '%%'; -- true select '%' like '%%8%'; -- false ``` ## How was this patch tested? unit tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-26053 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23028.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23028 commit 56a02eaaa63f297d3dbaf0ca183e4248d4882834 Author: Yuming Wang Date: 2018-11-14T02:55:25Z Enhance LikeSimplification --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23027: [SPARK-26049][SQL][TEST] Add InMemoryTable filter...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23027 [SPARK-26049][SQL][TEST] Add InMemoryTable filter benchmark to FilterPushdownBenchmark ## What changes were proposed in this pull request? Add InMemoryTable filter benchmark to `FilterPushdownBenchmark`. ## How was this patch tested? manual tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-26049 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23027.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23027 commit d0a2a3f4af492fbf69f7774e03d67d4af39cd5c7 Author: Yuming Wang Date: 2018-11-14T00:35:35Z Add InMemoryTable filter benchmark --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23004: [SPARK-26004][SQL] InMemoryTable support StartsWi...
Github user wangyum commented on a diff in the pull request: https://github.com/apache/spark/pull/23004#discussion_r233272718 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryTableScanExec.scala --- @@ -237,6 +237,13 @@ case class InMemoryTableScanExec( if list.forall(ExtractableLiteral.unapply(_).isDefined) && list.nonEmpty => list.map(l => statsFor(a).lowerBound <= l.asInstanceOf[Literal] && l.asInstanceOf[Literal] <= statsFor(a).upperBound).reduce(_ || _) + +case StartsWith(a: AttributeReference, ExtractableLiteral(l)) => + statsFor(a).lowerBound.substr(0, Length(l)) <= l && +l <= statsFor(a).upperBound.substr(0, Length(l)) +case StartsWith(ExtractableLiteral(l), a: AttributeReference) => --- End diff -- Good question, The last one should be removed, `DataSourceStrategy` has the same logic: https://github.com/apache/spark/blob/3d6b68b030ee85a0f639dd8e9b68aedf5f27b46f/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceStrategy.scala#L512-L513 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23014: [MINOR][SQL] Add disable bucketedRead workaround when th...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23014 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23004: [SPARK-26004][SQL] InMemoryTable support StartsWith pred...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23004 cc @cloud-fan @HyukjinKwon @kiszk --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23014: [MINOR][SQL] Add disable bucketedRead workaround when th...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23014 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23014: [MINOR][SQL] Add disable bucketedRead workaround when th...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23014 Yes. The `filePartitions` are the same as the bucket number when `BucketedRead`: https://github.com/apache/spark/blob/ab5752cb952e6536a68a988289e57100fdbba142/sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala#L382-L414 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23018: [SPARK-26023][SQL] Dumping truncated plans and ge...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/23018#discussion_r232871356
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
---
@@ -469,7 +471,21 @@ abstract class TreeNode[BaseType <:
TreeNode[BaseType]] extends Product {
def treeString: String = treeString(verbose = true)
def treeString(verbose: Boolean, addSuffix: Boolean = false): String = {
-generateTreeString(0, Nil, new StringBuilder, verbose = verbose,
addSuffix = addSuffix).toString
+val writer = new StringBuilderWriter()
+try {
+ treeString(writer, verbose, addSuffix, None)
+ writer.toString
+} finally {
+ writer.close()
+}
+ }
+
+ def treeString(
+ writer: Writer,
+ verbose: Boolean,
+ addSuffix: Boolean,
+ maxFields: Option[Int]): Unit = {
+generateTreeString(0, Nil, writer, verbose, "", addSuffix)
--- End diff --
How about add another function only save `nodeName`? I'll use it in another
PR: https://github.com/apache/spark/pull/22879
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22419: [SPARK-23906][SQL] Add built-in UDF TRUNCATE(numb...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/22419 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22941: [SPARK-25936][SQL] Fix InsertIntoDataSourceComman...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/22941 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22930: [SPARK-24869][SQL] Fix SaveIntoDataSourceCommand'...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/22930 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23014: [MINOR][SQL] Add disable bucketedRead workaround ...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23014 [MINOR][SQL] Add disable bucketedRead workaround when throw RuntimeException ## What changes were proposed in this pull request? It will throw `RuntimeException` when read from bucketed table(about 1.7G per bucket file):  Default(enable bucket read):  Disable bucket read:  ## How was this patch tested? manual tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark anotherWorkaround Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23014.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23014 commit a41551efd667f3ed6c30b0a2b262818e37d00884 Author: Yuming Wang Date: 2018-11-12T12:06:35Z Add new workaround --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22721: [SPARK-19784][SPARK-25403][SQL] Refresh the table even t...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22721 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23004: [SPARK-26004][SQL] InMemoryTable support StartsWi...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23004 [SPARK-26004][SQL] InMemoryTable support StartsWith predicate push down ## What changes were proposed in this pull request? [SPARK-24638](https://issues.apache.org/jira/browse/SPARK-24638) adds support for Parquet file `StartsWith` predicate push down. `InMemoryTable` can also support this feature. ## How was this patch tested? unit tests and benchmark tests benchmark test result: ``` Pushdown benchmark for StringStartsWith Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6 Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz StringStartsWith filter: (value like '10%'): Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative InMemoryTable Vectorized12068 / 14198 1.3 767.3 1.0X InMemoryTable Vectorized (Pushdown) 5457 / 8662 2.9 347.0 2.2X Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6 Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz StringStartsWith filter: (value like '1000%'): Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative InMemoryTable Vectorized 5246 / 5355 3.0 333.5 1.0X InMemoryTable Vectorized (Pushdown) 2185 / 2346 7.2 138.9 2.4X Java HotSpot(TM) 64-Bit Server VM 1.8.0_191-b12 on Mac OS X 10.12.6 Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz StringStartsWith filter: (value like '786432%'): Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative InMemoryTable Vectorized 5112 / 5312 3.1 325.0 1.0X InMemoryTable Vectorized (Pushdown) 2292 / 2522 6.9 145.7 2.2X ``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-26004 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23004.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23004 commit 7bbdb0713056f387e49cf3921a226554e9af5557 Author: Yuming Wang Date: 2018-11-11T03:56:36Z InMemoryTable support StartsWith predicate push down --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23001: [INFRA] Close stale PRs
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/23001 cc @srowen @dongjoon-hyun @HyukjinKwon --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23001: [INFRA] Close stale PRs
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/23001 [INFRA] Close stale PRs Closes https://github.com/apache/spark/pull/21766 Closes https://github.com/apache/spark/pull/21679 Closes https://github.com/apache/spark/pull/21161 Closes https://github.com/apache/spark/pull/20846 Closes https://github.com/apache/spark/pull/19434 Closes https://github.com/apache/spark/pull/18080 Closes https://github.com/apache/spark/pull/17648 Closes https://github.com/apache/spark/pull/17169 You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark CloseStalePRs Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23001.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23001 commit 45855463c6c5c0ee1183cc8d011b691add948f9f Author: Yuming Wang Date: 2018-11-10T13:01:45Z Close stale PRs --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17169: [SPARK-19714][ML] Bucketizer.handleInvalid docs improved
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/17169 It seems has improved: https://github.com/apache/spark/blob/v2.4.0/mllib/src/main/scala/org/apache/spark/ml/feature/Bucketizer.scala#L91-L104 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18323: [SPARK-21117][SQL] Built-in SQL Function Support ...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/18323 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21339: [SPARK-24287][Core] Spark -packages option should suppor...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/21339 ping @fangshil --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21783: [SPARK-24799]A solution of dealing with data skew in lef...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/21783 @marymwu Could you make a PR against `master` branch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22092: [SPARK-25101][CORE]Creating leaderLatch with id f...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22092#discussion_r232449802
--- Diff:
core/src/main/scala/org/apache/spark/deploy/master/ZooKeeperLeaderElectionAgent.scala
---
@@ -19,7 +19,6 @@ package org.apache.spark.deploy.master
import org.apache.curator.framework.CuratorFramework
import org.apache.curator.framework.recipes.leader.{LeaderLatch,
LeaderLatchListener}
-
--- End diff --
Do not remove this line.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22999: [SPARK-20319][SQL] Already quoted identifiers are...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/22999 [SPARK-20319][SQL] Already quoted identifiers are getting wrapped with additional quotes ## What changes were proposed in this pull request? Currently JDBC Writer uses dialects to quote the field names but when the quotes are explicitly wrapped with the column names, JDBC driver fails to parse columns with two double quotes. e.g. ```""columnName""```. This pr fix this issue. ## How was this patch tested? unit tests Closes https://github.com/apache/spark/pull/17631 You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-20319 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22999.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22999 commit b2af6b33e5289c07b1c70d4eb96c721cc7db8cea Author: Yuming Wang Date: 2018-11-10T11:05:38Z SPARK-20319 Already quoted identifiers are getting wrapped with additional quotes --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17631: [SPARK-20319][SQL] Already quoted identifiers are gettin...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/17631 @gatorsmile @maropu I took over. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21161: [SPARK-21645]left outer join synchronize the condition f...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/21161 I think it has fixed by [SPARK-21479](https://issues.apache.org/jira/browse/SPARK-21479). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22855: [SPARK-25839] [Core] Implement use of KryoPool in...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22855#discussion_r232203634
--- Diff:
core/src/test/scala/org/apache/spark/serializer/KryoSerializerBenchmark.scala
---
@@ -0,0 +1,90 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.serializer
+
+import scala.concurrent._
+import scala.concurrent.ExecutionContext.Implicits.global
+import scala.concurrent.duration._
+
+import org.apache.spark.{SparkConf, SparkContext}
+import org.apache.spark.benchmark.{Benchmark, BenchmarkBase}
+import org.apache.spark.serializer.KryoTest._
+import org.apache.spark.util.ThreadUtils
+
+/**
+ * Benchmark for KryoPool vs old "pool of 1".
+ * To run this benchmark:
+ * {{{
+ * 1. without sbt:
+ * bin/spark-submit --class --jars
+ * 2. build/sbt "core/test:runMain "
+ * 3. generate result:
+ * SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "core/test:runMain
"
+ * Results will be written to
"benchmarks/KryoSerializerBenchmark-results.txt".
+ * }}}
+ */
+object KryoSerializerBenchmark extends BenchmarkBase {
--- End diff --
cc @dongjoon-hyun for Benchmark change.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22683: [SPARK-25696] The storage memory displayed on spark Appl...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22683 cc @srowen Cloud we merge this PR? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22982: Spark 25973 - Spark History Main page performance improv...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22982 @Willymontaz Please update PR title to ```[SPARK-25973][CORE] Spark History Main page performance improvement```. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22985: [SPARK-25510][SQL][TEST][FOLLOW-UP] Remove Benchm...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/22985 [SPARK-25510][SQL][TEST][FOLLOW-UP] Remove BenchmarkWithCodegen ## What changes were proposed in this pull request? Remove `BenchmarkWithCodegen` as we don't use it anymore. More details: https://github.com/apache/spark/pull/22484#discussion_r221397904 ## How was this patch tested? N/A You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-25510 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22985.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22985 commit 9ced28d6b28c631440865d3510394a0e95cc2da8 Author: Yuming Wang Date: 2018-11-08T15:11:18Z Remove BenchmarkWithCodegen --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22981 Do you know which PR fixed this issue? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22981 @Willymontaz Could you make a PR against `master` branch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22980: Spark 25973 - Spark History Main page performance improv...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22980 @Willymontaz Could you make a PR against `master` branch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20944: [SPARK-23831][SQL] Add org.apache.derby to IsolatedClien...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/20944 This fix for testing only, production won't use derby as their matestore database. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231791936
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
May be we should fixed it by: https://github.com/apache/spark/pull/20430
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789027
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
Good catch. new created table's stats is empty, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20944: [SPARK-23831][SQL] Add org.apache.derby to IsolatedClien...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/20944 Sorry @HyukjinKwon It's difficult reproduce. I am not sure whether it is caused by multithreading. But you can verify it by: https://github.com/apache/spark/blob/a75571b46f813005a6d4b076ec39081ffab11844/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogSuite.scala#L117-L120 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22617: [SPARK-25484][SQL][TEST] Refactor ExternalAppendOnlyUnsa...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22617 Retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22943: [SPARK-25098][SQL] Trim the string when cast stri...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22943#discussion_r230970713
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
---
@@ -359,7 +359,7 @@ case class Cast(child: Expression, dataType: DataType,
timeZoneId: Option[String
// TimestampConverter
private[this] def castToTimestamp(from: DataType): Any => Any = from
match {
case StringType =>
- buildCast[UTF8String](_, utfs =>
DateTimeUtils.stringToTimestamp(utfs, timeZone).orNull)
+ buildCast[UTF8String](_, s =>
DateTimeUtils.stringToTimestamp(s.trim(), timeZone).orNull)
--- End diff --
How about change `stringToDate` to `trimStringToDate` and update
`trimStringToDate` to:

---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22949: [minor] update known_translations
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22949 Update line 132: ``` wangyum - Yuming Wang ``` How about add: ``` lipzhu - Lipeng Zhu daviddingly - David Ding laskfla - Keith Sun ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22502: [SPARK-25474][SQL]When the "fallBackToHdfsForStat...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22502#discussion_r230734089
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/HadoopFsRelation.scala
---
@@ -86,10 +89,28 @@ case class HadoopFsRelation(
}
override def sizeInBytes: Long = {
--- End diff --
May be you need to implement a rule similar to `DetermineTableStats` for
the datasource table?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22590: [SPARK-25574][SQL]Add an option `keepQuotes` for parsing...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22590 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22943: [SPARK-25098][SQL] Trim the string when cast stringToTim...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22943 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22943: [SPARK-25098][SQL] Trim the string when cast stringToTim...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22943 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22693: [SPARK-25701][SQL] Supports calculation of table ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22693#discussion_r230639634
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala ---
@@ -115,26 +116,45 @@ class ResolveHiveSerdeTable(session: SparkSession)
extends Rule[LogicalPlan] {
class DetermineTableStats(session: SparkSession) extends Rule[LogicalPlan]
{
override def apply(plan: LogicalPlan): LogicalPlan = plan
resolveOperators {
+case filterPlan @ Filter(_, SubqueryAlias(_, relation:
HiveTableRelation)) =>
+ val predicates =
PhysicalOperation.unapply(filterPlan).map(_._2).getOrElse(Nil)
+ computeTableStats(relation, predicates)
case relation: HiveTableRelation
if DDLUtils.isHiveTable(relation.tableMeta) &&
relation.tableMeta.stats.isEmpty =>
- val table = relation.tableMeta
- val sizeInBytes = if
(session.sessionState.conf.fallBackToHdfsForStatsEnabled) {
-try {
- val hadoopConf = session.sessionState.newHadoopConf()
- val tablePath = new Path(table.location)
- val fs: FileSystem = tablePath.getFileSystem(hadoopConf)
- fs.getContentSummary(tablePath).getLength
-} catch {
- case e: IOException =>
-logWarning("Failed to get table size from hdfs.", e)
-session.sessionState.conf.defaultSizeInBytes
-}
- } else {
-session.sessionState.conf.defaultSizeInBytes
+ computeTableStats(relation)
+ }
+
+ private def computeTableStats(
+ relation: HiveTableRelation,
+ predicates: Seq[Expression] = Nil): LogicalPlan = {
+val table = relation.tableMeta
+val sizeInBytes = if
(session.sessionState.conf.fallBackToHdfsForStatsEnabled) {
+ try {
+val hadoopConf = session.sessionState.newHadoopConf()
+val tablePath = new Path(table.location)
+val fs: FileSystem = tablePath.getFileSystem(hadoopConf)
+BigInt(fs.getContentSummary(tablePath).getLength)
+ } catch {
+case e: IOException =>
+ logWarning("Failed to get table size from hdfs.", e)
+ getSizeInBytesFromTablePartitions(table.identifier, predicates)
}
+} else {
+ getSizeInBytesFromTablePartitions(table.identifier, predicates)
+}
+val withStats = table.copy(stats = Some(CatalogStatistics(sizeInBytes
= sizeInBytes)))
+relation.copy(tableMeta = withStats)
+ }
- val withStats = table.copy(stats =
Some(CatalogStatistics(sizeInBytes = BigInt(sizeInBytes
- relation.copy(tableMeta = withStats)
+ private def getSizeInBytesFromTablePartitions(
+ tableIdentifier: TableIdentifier,
+ predicates: Seq[Expression] = Nil): BigInt = {
+session.sessionState.catalog.listPartitionsByFilter(tableIdentifier,
predicates) match {
--- End diff --
After [this refactor](https://github.com/apache/spark/pull/22743). We can
avoid compute stats if `LogicalRelation` already cached. because the computed
stats will not take effect.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22943: [SPARK-25098][SQL] Trim the string when cast stri...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/22943 [SPARK-25098][SQL] Trim the string when cast stringToTimestamp and stringToDate ## What changes were proposed in this pull request? **Hive** and **Oracle** trim the string when cast `stringToTimestamp` and `stringToDate`. this PR support this feature:   ## How was this patch tested? unit tests Closes https://github.com/apache/spark/pull/22089 You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-25098 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22943.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22943 commit d297817b7457fef40eb78b803542aed213afb7fc Author: Yuming Wang Date: 2018-11-05T05:31:22Z trim() the string when cast stringToTimestamp and stringToDate --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22941: [SPARK-25936][SQL] Fix InsertIntoDataSourceComman...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22941#discussion_r230622708
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/sources/InsertSuite.scala ---
@@ -589,4 +590,33 @@ class InsertSuite extends DataSourceTest with
SharedSQLContext {
sql("INSERT INTO TABLE test_table SELECT 2, null")
}
}
+
+ test("SPARK-25936 InsertIntoDataSourceCommand does not use Cached Data")
{
--- End diff --
It works. Do we need to fix this plan issue?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22903: [SPARK-24196][SQL] Implement Spark's own GetSchemasOpera...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22903 cc @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22089: [SPARK-25098][SQL]‘Cast’ will return NULL when input...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22089 Sure, @gatorsmile . --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22908: [MINOR][SQL] Replace all TreeNode's node name in ...
Github user wangyum closed the pull request at: https://github.com/apache/spark/pull/22908 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22941: [SPARK-25936][SQL] Fix InsertIntoDataSourceComman...
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/22941
[SPARK-25936][SQL] Fix InsertIntoDataSourceCommand does not use Cached Data
## What changes were proposed in this pull request?
```java
spark.sql("""
CREATE TABLE jdbcTable
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:mysql://localhost:3306/test",
dbtable "test.InsertIntoDataSourceCommand",
user "hive",
password "hive"
)""")
spark.range(2).createTempView("test_view")
spark.catalog.cacheTable("test_view")
spark.sql("INSERT INTO TABLE jdbcTable SELECT * FROM test_view").explain
```
Before this PR:
```
== Physical Plan ==
Execute InsertIntoDataSourceCommand
+- InsertIntoDataSourceCommand
+- Project
+- SubqueryAlias
+- Range (0, 2, step=1, splits=Some(8))
```
After this PR:
```
== Physical Plan ==
Execute InsertIntoDataSourceCommand InsertIntoDataSourceCommand
Relation[id#8L] JDBCRelation(test.InsertIntoDataSourceCommand)
[numPartitions=1], false, [id]
+- *(1) InMemoryTableScan [id#0L]
+- InMemoryRelation [id#0L], StorageLevel(disk, memory, deserialized,
1 replicas)
+- *(1) Range (0, 2, step=1, splits=8)
```
## How was this patch tested?
unit tests
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/wangyum/spark SPARK-25936
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22941.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22941
commit 2968b2c34f42f6b0bcb5e373a400377abfd09e86
Author: Yuming Wang
Date: 2018-11-04T10:36:20Z
Fix InsertIntoDataSourceCommand does not use Cached Data
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22889: [SPARK-25882][SQL] Added a function to join two d...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22889#discussion_r230570164
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -883,6 +883,31 @@ class Dataset[T] private[sql](
join(right, Seq(usingColumn))
}
+ /**
+* Equi-join with another `DataFrame` using the given column.
+*
+* Different from other join functions, the join column will only
appear once in the output,
+* i.e. similar to SQL's `JOIN USING` syntax.
+*
+* {{{
+* // Left join of df1 and df2 using the column "user_id"
+* df1.join(df2, "user_id", "left")
+* }}}
+*
+* @param right Right side of the join operation.
+* @param usingColumn Name of the column to join on. This column must
exist on both sides.
+* @param joinType Type of join to perform. Default `inner`. Must be
one of:
+* `inner`, `cross`, `outer`, `full`, `full_outer`,
`left`, `left_outer`,
+* `right`, `right_outer`, `left_semi`, `left_anti`.
+* @note If you perform a self-join using this function without
aliasing the input
+* `DataFrame`s, you will NOT be able to reference any columns after
the join, since
+* there is no way to disambiguate which side of the join you would
like to reference.
+* @group untypedrel
+*/
+ def join(right: Dataset[_], usingColumn: String, joinType: String):
DataFrame = {
--- End diff --
cc @dongjoon-hyun
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22930: [SPARK-24869][SQL] Fix SaveIntoDataSourceCommand's input...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22930 cc @gatorsmile @gengliangwang @maropu --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22889: [SPARK-25882][SQL] Added a function to join two d...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22889#discussion_r230559647
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -883,6 +883,31 @@ class Dataset[T] private[sql](
join(right, Seq(usingColumn))
}
+ /**
+* Equi-join with another `DataFrame` using the given column.
+*
+* Different from other join functions, the join column will only
appear once in the output,
+* i.e. similar to SQL's `JOIN USING` syntax.
+*
+* {{{
+* // Left join of df1 and df2 using the column "user_id"
+* df1.join(df2, "user_id", "left")
+* }}}
+*
+* @param right Right side of the join operation.
+* @param usingColumn Name of the column to join on. This column must
exist on both sides.
+* @param joinType Type of join to perform. Default `inner`. Must be
one of:
+* `inner`, `cross`, `outer`, `full`, `full_outer`,
`left`, `left_outer`,
+* `right`, `right_outer`, `left_semi`, `left_anti`.
+* @note If you perform a self-join using this function without
aliasing the input
+* `DataFrame`s, you will NOT be able to reference any columns after
the join, since
+* there is no way to disambiguate which side of the join you would
like to reference.
+* @group untypedrel
+*/
+ def join(right: Dataset[_], usingColumn: String, joinType: String):
DataFrame = {
--- End diff --
Cloud we close this?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22889: [SPARK-25882][SQL] Added a function to join two d...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22889#discussion_r230557937
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -883,6 +883,31 @@ class Dataset[T] private[sql](
join(right, Seq(usingColumn))
}
+ /**
+* Equi-join with another `DataFrame` using the given column.
+*
+* Different from other join functions, the join column will only
appear once in the output,
+* i.e. similar to SQL's `JOIN USING` syntax.
+*
+* {{{
+* // Left join of df1 and df2 using the column "user_id"
+* df1.join(df2, "user_id", "left")
+* }}}
+*
+* @param right Right side of the join operation.
+* @param usingColumn Name of the column to join on. This column must
exist on both sides.
+* @param joinType Type of join to perform. Default `inner`. Must be
one of:
+* `inner`, `cross`, `outer`, `full`, `full_outer`,
`left`, `left_outer`,
+* `right`, `right_outer`, `left_semi`, `left_anti`.
+* @note If you perform a self-join using this function without
aliasing the input
+* `DataFrame`s, you will NOT be able to reference any columns after
the join, since
+* there is no way to disambiguate which side of the join you would
like to reference.
+* @group untypedrel
+*/
+ def join(right: Dataset[_], usingColumn: String, joinType: String):
DataFrame = {
--- End diff --
@arman1371 What do you think? ```def join(right: Dataset[_], usingColumn:
String, joinType: String)``` only support one column. right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22935: Branch 2.2
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22935 @litao1223 Please close this. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22089: [SPARK-25098][SQL]‘Cast’ will return NULL when input...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22089 ping @bingbai0912 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22088: [SPARK-24931][CORE]CoarseGrainedExecutorBackend send wro...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22088 cc @jiangxb1987 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22934: [BUILD] Close stale PRs
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/22934 [BUILD] Close stale PRs Closes https://github.com/apache/spark/pull/22859 Closes https://github.com/apache/spark/pull/22591 Closes https://github.com/apache/spark/pull/22322 Closes https://github.com/apache/spark/pull/22312 Closes https://github.com/apache/spark/pull/19590 You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark CloseStalePRs Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22934.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22934 commit 322e21c29919cb7dcfc2e088cd5d605e1f4bb5a7 Author: Yuming Wang Date: 2018-11-03T12:34:05Z Close stale PRs --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22889: [SPARK-25882][SQL] Added a function to join two d...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22889#discussion_r230555316
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -883,6 +883,31 @@ class Dataset[T] private[sql](
join(right, Seq(usingColumn))
}
+ /**
+* Equi-join with another `DataFrame` using the given column.
+*
+* Different from other join functions, the join column will only
appear once in the output,
+* i.e. similar to SQL's `JOIN USING` syntax.
+*
+* {{{
+* // Left join of df1 and df2 using the column "user_id"
+* df1.join(df2, "user_id", "left")
+* }}}
+*
+* @param right Right side of the join operation.
+* @param usingColumn Name of the column to join on. This column must
exist on both sides.
+* @param joinType Type of join to perform. Default `inner`. Must be
one of:
+* `inner`, `cross`, `outer`, `full`, `full_outer`,
`left`, `left_outer`,
+* `right`, `right_outer`, `left_semi`, `left_anti`.
+* @note If you perform a self-join using this function without
aliasing the input
+* `DataFrame`s, you will NOT be able to reference any columns after
the join, since
+* there is no way to disambiguate which side of the join you would
like to reference.
+* @group untypedrel
+*/
+ def join(right: Dataset[_], usingColumn: String, joinType: String):
DataFrame = {
--- End diff --
So in your case. Could you replace ```df1.join(df2, "user_id", "left")```
with ```df1.join(df2, Seq("user_id"), "left")```?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22683: [SPARK-25696] The storage memory displayed on spark Appl...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22683 cc @ajbozarth --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org