ThomasDelteil commented on a change in pull request #10955: [MXNET-422] Distributed training tutorial URL: https://github.com/apache/incubator-mxnet/pull/10955#discussion_r188729724
########## File path: example/distributed_training/README.md ########## @@ -0,0 +1,231 @@ +# Distributed Training using Gluon + +Deep learning models are usually trained using GPUs because GPUs can do a lot more computations in parallel that CPUs. But even with the modern GPUs, it could take several days to train big models. Training can be done faster by using multiple GPUs like described in [this](https://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html) tutorial. However only a certain number of GPUs can be attached to one host (typically 8 or 16). To make the training even faster, we can use multiple GPUs attached to multiple hosts. + +In this tutorial, we will show how to train a model faster using multi-host distributed training. + +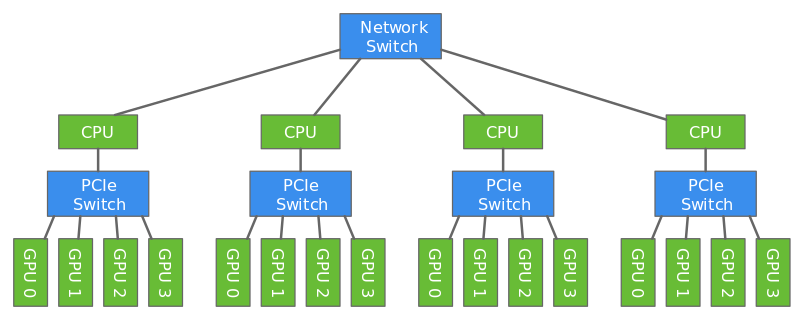 + +We will use data parallelism to distribute the training which involves splitting the training data across GPUs attached to multiple hosts. Since the hosts are working with different subset of the training data in parallel, the training completes lot faster. + +In this tutorial, we will train a LeNet network using MNIST dataset using two hosts each having four GPUs. + +## Distributed Training Architecture: + +Multihost distributed training involves working with three different types of processes - worker, parameter server and scheduler. + +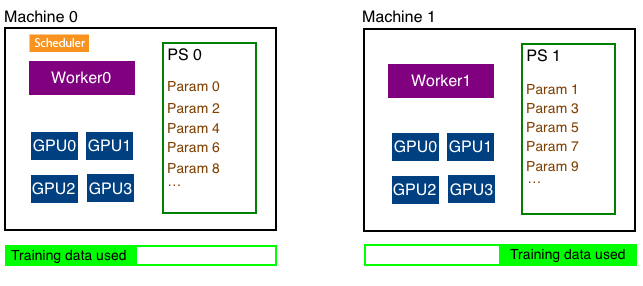 + +### Parameter Server: +The parameters of the model needs to be shared with all hosts since multiple hosts are working together to train one model. To make this sharing efficient, the parameters are split across multiple hosts. A parameter server in each host stores a subset of parameters. In the figure above, parameters are split evenly between the two hosts. At the end of every iteration, each host communicates with every other host to update all parameters of the model. + +### Worker: +Each host has a worker process which in each iteration fetches a batch of data, runs forward and backward pass on all GPUs in the host, computes the parameter updates and sends those updates to the parameter servers in each host. Since we have multiple workers to train the model, each worker only needs to process 1/N part of the training data where N is the number of workers. + +### Scheduler: +Scheduler is responsible for scheduling the workers and parameter servers. There is only one scheduler in the entire cluster. + +## Moving to distributed training: + +[mnist_dist.py](mnist_dist.py) contains code that trains a LeNet network using distributed training. In this section we'll walk through parts of that file that are unique to distributed training. + +### Step 1: Use a distributed key-value store: + +Like mentioned above, in distributed training, parameters are split into N parts and distributed across N hosts. This is done automatically by the [distributed key-value store](https://mxnet.incubator.apache.org/tutorials/python/kvstore.html). User only needs to create the distributed kv store and ask the `Trainer` to use the created store. + +```python +store = mxnet.kv.create('dist') +``` + +It is the job of the trainer to take the gradients computed in the backward pass and update the parameters of the model. We'll tell the trainer to store and update the parameters in the distributed kv store we just created instead of doing it in GPU of CPU memory. For example, + +```python +trainer = gluon.Trainer(net.collect_params(), + 'sgd', {'learning_rate': .1}, + kvstore=store) +``` + +## Step 2: Split the training data: + +In distributed training (using data parallelism), training data is split into equal parts across all workers and each worker uses its subset of the training data for training. For example, if we had two machines, each running a worker, each worker managing four GPUs we'll split the data like shown below. Note that we don't split the data depending on the number of GPUs but split it depending on the number of workers. + + + +Each worker can find out the total number of workers in the cluster and its own rank which is an integer between 0 and N-1 where N is the number of workers. + +```python +store = kv.create('dist') +print("Total number of workers: %d" % store.num_workers) +print("This worker's rank: %d" % store.rank) Review comment: it would be nice to have an example of the output of these functions in the `.md` file as well ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
{kind=link}
{kind=link}
{kind=link}