ThomasDelteil commented on a change in pull request #10955: [MXNET-422] Distributed training tutorial URL: https://github.com/apache/incubator-mxnet/pull/10955#discussion_r188728964
########## File path: example/distributed_training/README.md ########## @@ -0,0 +1,231 @@ +# Distributed Training using Gluon + +Deep learning models are usually trained using GPUs because GPUs can do a lot more computations in parallel that CPUs. But even with the modern GPUs, it could take several days to train big models. Training can be done faster by using multiple GPUs like described in [this](https://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html) tutorial. However only a certain number of GPUs can be attached to one host (typically 8 or 16). To make the training even faster, we can use multiple GPUs attached to multiple hosts. + +In this tutorial, we will show how to train a model faster using multi-host distributed training. + +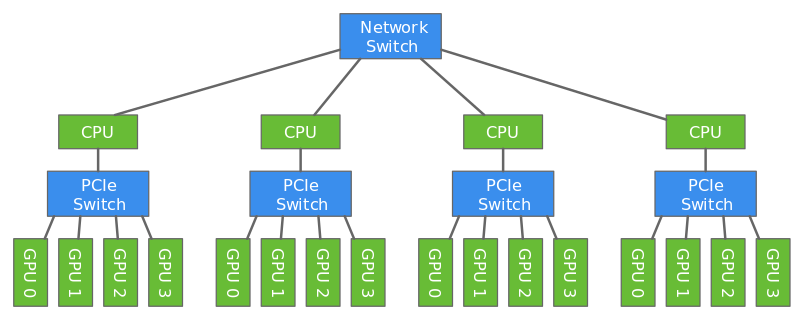 + +We will use data parallelism to distribute the training which involves splitting the training data across GPUs attached to multiple hosts. Since the hosts are working with different subset of the training data in parallel, the training completes lot faster. + +In this tutorial, we will train a LeNet network using MNIST dataset using two hosts each having four GPUs. Review comment: could we use CIFAR10 instead? Because multi host multi gpu for mnist is a bit overkill since it trains in 2-3 seconds on a single GPU already? ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
{kind=link}