> On Jul 8, 2019, at 3:53 PM, ermouth <[email protected]> wrote:
>
>> disabling clustering (i.e., setting Q=N=1)
>
> Let’s start with this one, because it’s about installation process. To set
> q=1 you should install Couch manually. Built-in installer sets up q=8 for
> single node setup.
That’s a good point. I guess we were trying to find a “goldilocks” option since
shard counts have always been fixed at creation time, but now that we can split
shards in a running server this default could be worth revisiting.
> Compared to Futon, Fauxton is at least uncomfortable. There are two obvious
> accountable metrics: 1) how many clicks you need to do this or that, 2) how
> far you need to move mouse to make next click in a logical sequence of
> actions.
I did expect to see this one on your list :) I thought some of those issues
have improved over time, but I’ll admit I haven’t paid terribly close attention
to it.
>
> Also, as for our experience, protecting Couch admin from administering by
> hard-disabling write for some _config/*/* endpoints, is a mistake. This
> kind of role separation isn’t reasonable for single-node scenario (which
> often is ‘I gonna make something small’).
OK. I think we grew tired of having to issue CVEs for unforeseen
vulnerabilities in this part of the codebase, but it’s definitely true we’ve
dropped functionality here.
> As for stability – unfortunately 2.x bites without notice, patterns are
> hard to grasp. However, there are at least two: unpredictable RAM
> footprint, and also unpredictable recoverability after crash. Also 2.x
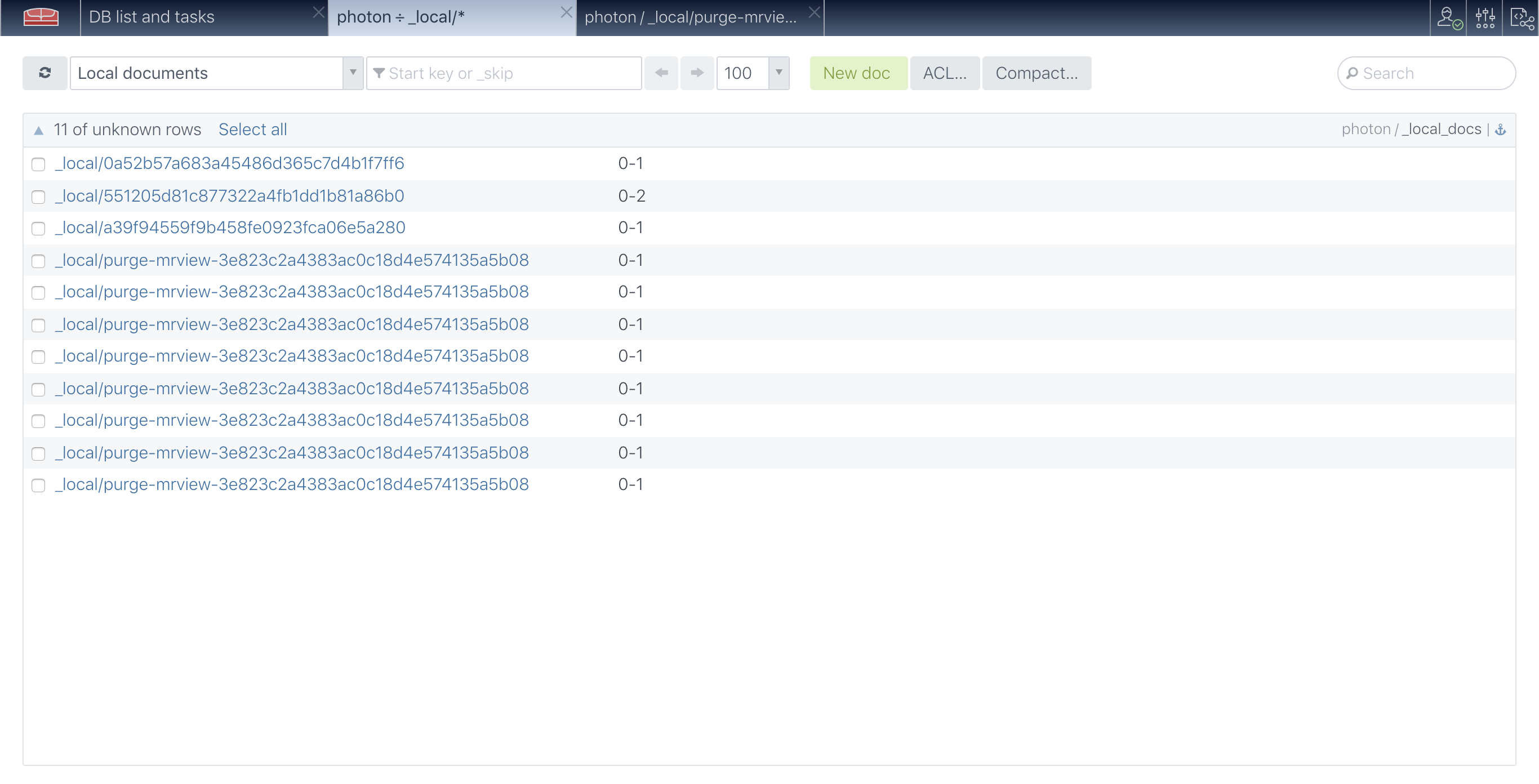
> tends to eat disk space slowly (spams in _local docs, sometimes creating
> strange things like this http://ermouth.com/dl/couch_local_doc_dupes.png).
Ah, that’s strange-looking for sure. I guess there’s one of those
“purge-mrview” docs per shard, per view group on a database with purge enabled,
but the shard name is not encoded into the ID so you get that crazy-looking
“duplication". That seems worthy of a bug report, although I imagine the actual
space consumption is pretty minimal and it’s not actually causing any incorrect
behavior of the database.
What do you mean by “unpredictable recoverability”? That after a crash the
database needs operator intervention in order to become available to serve
requests?
Adam
>
> Best regards,
> ermouth
{kind=link}