Hmm, I've never seen such scheduling (doesn't mean it doesn't exist of course) for OoO cores. Besides what Aleksey said about macro fusion, what happens to the flags register in between the cmp and the jmp?
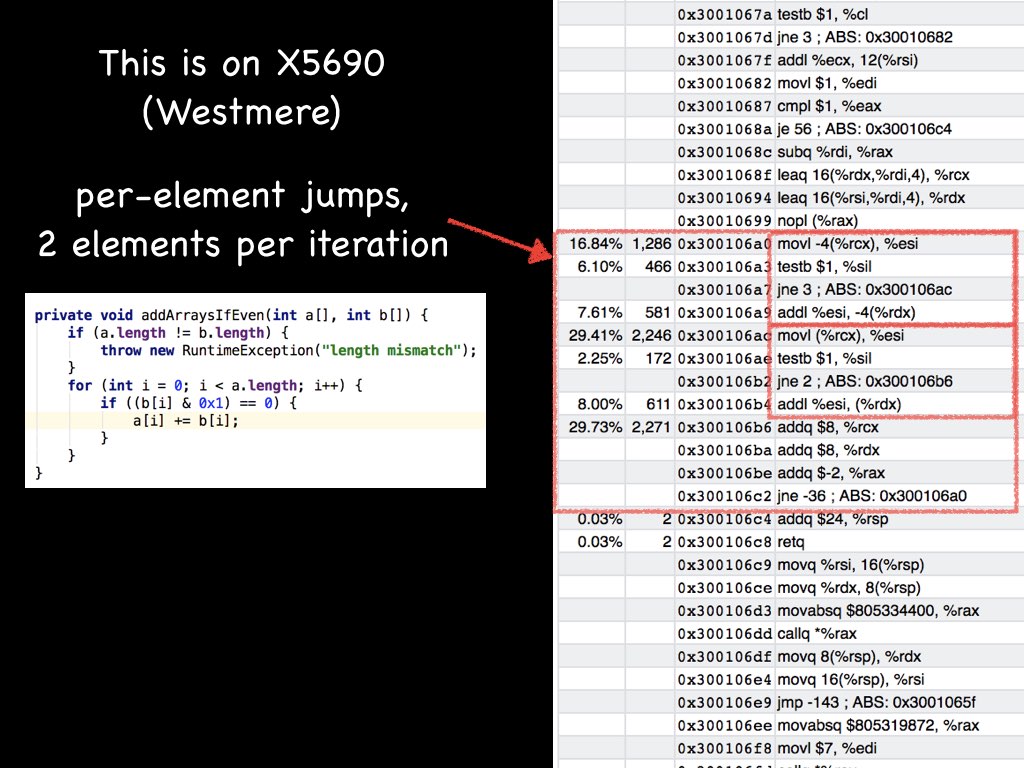
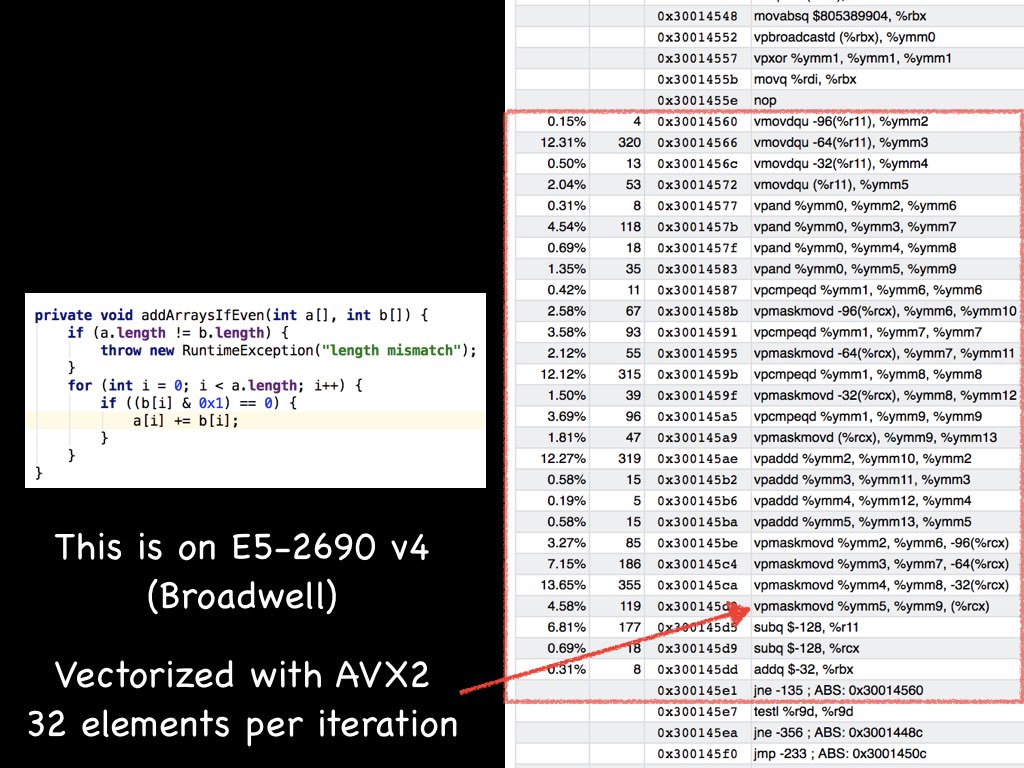
It's also hard to look at these few instructions in isolation. For example, the mov+cmp+jmp sequence itself may start executing "ahead of time". The only scheduling type of thing I've seen by compilers is breaking dependency chains to enable super scalar execution (e.g. loop unrolling and doing reassociative operations in parallel). I also recall Mike Pall (of LuaJIT fame) mentioning that he doesn't think manual OoO scheduling makes sense for modern OoO chips. I'm no expert on this, but breaking cmp+jmp sequences like that seems strange. Particularly the cmp+jmp due to fusion and flags being set. On Tue, Jan 17, 2017 at 6:33 PM Sergey Melnikov <melnikov.serge...@gmail.com> wrote: > >> Pretty sure OOO cores will do a good job themselves for scheduling > > provided you don't bottleneck in instruction fetch/decode phases or > > create other pipeline hazards. If you artificially increase distance > > between dependent instructions, you may cause instructions to hang out > > in the reorder buffers longer before they can retire. > > As usual, corner cases may have worse performance. And it's a tricky > compromise between locality and OOO scheduling. But in general case, good > instruction scheduling (out-of-order enabled) may bring additional up to > dozen per cent of performance. It's important even for modern BigCores > (HSW) besides Atom (Silvermont). > > For example, if you have something like > > mov (%rax), %rbx > cmp %rbx, %rdx > jxx Lxxx > > It's difficult to execute these instructions in OOO-manner. > But if you schedule them this way > > mov (%rax), %rbx > ... few instructions > cmp %rbx, %rdx > ... few instructions > jxx Lxxx > > It would be possible to execute them out-of-order and calculate something > additional. > > Anyway, ICC does this kind of scheduling. > > > --Sergey > > On Wed, Jan 18, 2017 at 12:11 AM, Vitaly Davidovich <vita...@gmail.com> > wrote: > > > > On Tue, Jan 17, 2017 at 3:55 PM, Sergey Melnikov < > melnikov.serge...@gmail.com> wrote: > > Hi Gil, > > Your slides are really inspiring, especially for JIT code. Now, it's > comparable with code produced by static C/C++ compilers. Have you compared > a performance of this code with a code produced by ICC (Intel's compiler) > for example? > > I believe the Falcon JIT that Gil refers to is Azul's LLVM-based JIT, so > you get the same middle/backend as Clang. > > As for ICC, I'm not even sure Clang+LLVM (or even GCC) autovectorize as > well as ICC (at least that used to be the case). > > > BTW, it may be better for performance to schedule instruction in > out-of-order manner (interchange independent instructions in order to > maximize a distance between dependent instructions and so utilize as many > execution ports as possible). > > Pretty sure OOO cores will do a good job themselves for scheduling > provided you don't bottleneck in instruction fetch/decode phases or create > other pipeline hazards. If you artificially increase distance between > dependent instructions, you may cause instructions to hang out in the > reorder buffers longer before they can retire. > > > And small hint: there is no need to have rbx register calculations here, > so, it may be hoisted out of loop (it would reduce register pressure); more > sophisticated addressing mode may help for reduction rcx calculation. > > P.S. It's great to see nop instruction at 0x3001455e address for proper > code alignment ;-) > > -- > Sergey > > > On Jan 17, 2017 11:48 AM, "Gil Tene" <g...@azul.com> wrote: > > I'm all for experimenting and digging into what the generated code > actually looks like. Just remember that it's a moving target, and that you > should not assume that the code choices will look similar in the future. > > E.g. I'm working on a presentation that demonstrations of how our JITs > make use of the capabilities of newer Intel cores. To study machine code, I > generally "make it hot" (e.g. with jmh, using DONT_INLINE directives) and > then look at it with ZVision (a feature of Zing), which is very useful > because the instruction-level profiling ticks allow me quickly identify and > zoom into the actual loop with the code I want to study (and ignore the > 90%+ rest of the machine code that is not the actual hot loop). > > Below is a short sequence from my work-in-progress slide deck. It > demonstrates how much of a moving target code-gen is for the exact same > code, and even the exact same compiler (e.g. varying according to the core > you are running on). In this case you are looking at what Zing's Falcon JIT > generates fro Westmere vs. Broadwell for the same simple loop. But the same > sort of variance and adaptability will probably be there for other JITs and > static compilers. > > > <https://lh3.googleusercontent.com/-eAa-Lluz1Ss/WH3YsAlHKtI/AAAAAAAAAPY/Yn3sJQv50kA5Bjrlp7imxfn2u60WXYIoACLcB/s1600/Java_Intel_Jan2017%2Btmp.001.jpeg> > > > > <https://lh3.googleusercontent.com/-qbYzAVA2eIk/WH3YxHl5WTI/AAAAAAAAAPc/CJpm7YZbLpAR-fGBgrs_xD-Oz3XkqqSfwCLcB/s1600/Java_Intel_Jan2017%2Btmp.002.jpeg> > > > > <https://lh3.googleusercontent.com/-WlLoyCc3zsg/WH3Y1hoPIKI/AAAAAAAAAPg/jyLk8DNvpv4RJe41XAj18rbIeXZDKFRtgCLcB/s1600/Java_Intel_Jan2017%2Btmp.003.jpeg> > > > <https://lh3.googleusercontent.com/-eTbu9Jt6SHI/WH3Y7FfyckI/AAAAAAAAAPk/cMGUBGYd3x4BiWb_W7VZRUl8ZzOqlUrmgCLcB/s1600/Java_Intel_Jan2017%2Btmp.004.jpeg> > > > Here are two different > > > On Tuesday, January 17, 2017 at 2:41:21 AM UTC-5, Francesco Nigro wrote: > > Thanks, > > "Assume nothing" is a pretty scientific approach,I like it :) > But this (absence of) assumption lead me to think about another couple of > things: what about all the encoders/decoders or any program that rely on > data access patterns to pretend to be and remain "fast"? > Writing mechanichal sympathetic code means being smart enough to trick the > compiler in new and more creative ways or check what a compiler doesn't > handle so well,trying to manage it by yourself? > The last one is a very strong statement just for the sake of > discussion..But I'm curious to know what the guys of this group think about > it :) > > > > > > > > > > -- > > > You received this message because you are subscribed to the Google Groups > "mechanical-sympathy" group. > > > To unsubscribe from this group and stop receiving emails from it, send an > email to mechanical-sympathy+unsubscr...@googlegroups.com. > > > For more options, visit https://groups.google.com/d/optout. > > > > > > > > > > > > > > -- > > > You received this message because you are subscribed to the Google Groups > "mechanical-sympathy" group. > > > To unsubscribe from this group and stop receiving emails from it, send an > email to mechanical-sympathy+unsubscr...@googlegroups.com. > > > For more options, visit https://groups.google.com/d/optout. > > > > > > > > > > > > -- > > > You received this message because you are subscribed to the Google Groups > "mechanical-sympathy" group. > > > To unsubscribe from this group and stop receiving emails from it, send an > email to mechanical-sympathy+unsubscr...@googlegroups.com. > > > For more options, visit https://groups.google.com/d/optout. > > > > > > -- > > --Sergey > > > > > > > > > > > -- > > > You received this message because you are subscribed to the Google Groups > "mechanical-sympathy" group. > > > To unsubscribe from this group and stop receiving emails from it, send an > email to mechanical-sympathy+unsubscr...@googlegroups.com. > > > For more options, visit https://groups.google.com/d/optout. > > > -- Sent from my phone -- You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group. To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsubscr...@googlegroups.com. For more options, visit https://groups.google.com/d/optout.
{kind=link}
{kind=link}
{kind=link}
{kind=link}