[GitHub] [spark] LuciferYang commented on pull request #40283: [SPARK-42673][BUILD] Make `build/mvn` build Spark only with the verified maven version
LuciferYang commented on PR #40283: URL: https://github.com/apache/spark/pull/40283#issuecomment-1455648868 > https://issues.apache.org/jira/browse/MNG-7697 OK, let me test 3.9.1-SNAPSHOT later. @pan3793 Do you have any other issues besides those in GA task? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hboutemy commented on pull request #40283: [SPARK-42673][BUILD] Make `build/mvn` build Spark only with the verified maven version
hboutemy commented on PR #40283: URL: https://github.com/apache/spark/pull/40283#issuecomment-1455637895 [@cstamas ](https://github.com/cstamas) do you know if the lax parsing covers that `org.codehaus.plexus.util.xml.pull.XmlPullParserException: UTF-8 BOM plus xml decl of ISO-8859-1 is incompatible (position: START_DOCUMENT seen
[GitHub] [spark] hboutemy commented on pull request #40283: [SPARK-42673][BUILD] Make `build/mvn` build Spark only with the verified maven version
hboutemy commented on PR #40283: URL: https://github.com/apache/spark/pull/40283#issuecomment-1455633233 there is a known issue in Maven 3.9.0 (related to plexus-utils XML stricter reading https://github.com/codehaus-plexus/plexus-utils/issues/238 ) that is fixed in 3.9.1-SNAPSHOT: https://issues.apache.org/jira/browse/MNG-7697 3.9.1 will be released soon: can you eventually check with 3.9.1-SNAPSHOT if you're in a different case of this "too strict" XML parsing? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi commented on pull request #38358: [SPARK-40588] FileFormatWriter materializes AQE plan before accessing outputOrdering
EnricoMi commented on PR #38358: URL: https://github.com/apache/spark/pull/38358#issuecomment-1455620898 Yes, it looks like it removes the **empty** table location after **overwriting** the table failed due to the `ArithmeticException`. @cloud-fan do you consider the removal of an empty table location after overwriting the table fails is a regression? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #40280: [SPARK-42671][CONNECT] Fix bug for createDataFrame from complex type schema
itholic commented on PR #40280:
URL: https://github.com/apache/spark/pull/40280#issuecomment-1455567210
Thanks @panbingkun for the nice fix!
Btw, think I found another `createDataFrame` bug which is not working
properly with non-nullable schema as below:
```python
>>> from pyspark.sql.types import *
>>> schema_false = StructType([StructField("id", IntegerType(), False)])
>>> spark.createDataFrame([[1]], schema=schema_false)
Traceback (most recent call last):
...
pyspark.errors.exceptions.connect.AnalysisException:
[NULLABLE_COLUMN_OR_FIELD] Column or field `id` is nullable while it's required
to be non-nullable.
```
whereas working find with nullable schema as below:
```python
>>> schema_true = StructType([StructField("id", IntegerType(), True)])
>>> spark.createDataFrame([[1]], schema=schema_true)
DataFrame[id: int]
```
Do you have any idea what might be causing this? Could you take a look at it
if you're interested in? I have filed an issue at SPARK-42679.
Also cc @hvanhovell as an original author for `createDataFrame`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #40280: [SPARK-42671][CONNECT] Fix bug for createDataFrame from complex type schema
itholic commented on PR #40280:
URL: https://github.com/apache/spark/pull/40280#issuecomment-1455565581
Thanks @panbingkun for the nice fix!
Btw, think I found another `createDataFrame` bug which is not working
properly with non-nullable schema as below:
```python
>>> from pyspark.sql.types import *
>>> schema_false = StructType([StructField("id", IntegerType(), False)])
>>> spark.createDataFrame([[1]], schema=schema_false)
Traceback (most recent call last):
...
pyspark.errors.exceptions.connect.AnalysisException:
[NULLABLE_COLUMN_OR_FIELD] Column or field `id` is nullable while it's required
to be non-nullable.
```
whereas working find with nullable schema as below:
```python
>>> schema_true = StructType([StructField("id", IntegerType(), True)])
>>> spark.createDataFrame([[1]], schema=schema_true)
DataFrame[id: int]
```
Do you have any idea what might be causing this? Could you take a look at it
if you're interested in? I have filed an issue at SPARK-42679.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR closed pull request #40292: [SPARK-42676][SS] Write temp checkpoints for streaming queries to local filesystem even if default FS is set differently
HeartSaVioR closed pull request #40292: [SPARK-42676][SS] Write temp checkpoints for streaming queries to local filesystem even if default FS is set differently URL: https://github.com/apache/spark/pull/40292 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #40292: [SPARK-42676][SS] Write temp checkpoints for streaming queries to local filesystem even if default FS is set differently
HeartSaVioR commented on PR #40292: URL: https://github.com/apache/spark/pull/40292#issuecomment-1455549225 Thanks! Merging to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request, #40294: [SPARK-40610][SQL] Support unwrap date type to string type
wangyum opened a new pull request, #40294: URL: https://github.com/apache/spark/pull/40294 ### What changes were proposed in this pull request? This PR enhances `UnwrapCastInBinaryComparison` to support unwrapping date type to string type. ### Why are the changes needed? Avoid always fetching all partitions because the partition filters cannot be pushed down to the Hive metastore. For example: ```sql CREATE TABLE t1(id int, dt string) using parquet PARTITIONED BY (dt); EXPLAIN SELECT * FROM t1 WHERE dt > date_add(current_date(), -7); ``` Before SPARK-27638. It pushes partition filters to Hive metastore: ``` == Physical Plan == *(1) FileScan parquet default.t1[id#2,dt#3] Batched: true, Format: Parquet, Location: PrunedInMemoryFileIndex[], PartitionCount: 0, PartitionFilters: [isnotnull(dt#3), (dt#3 > 2023-02-27)], PushedFilters: [], ReadSchema: struct ``` After SPARK-27638. Because it will not [convert partition filters](https://github.com/apache/spark/blob/v3.0.0/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala#L794-L798) to hive metastore filters, it will not push partition filters to Hive metastore. As a result, it always takes all the parititons: ``` == Physical Plan == *(1) ColumnarToRow +- FileScan parquet default.t1[id#5,dt#6] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(0 paths)[], PartitionFilters: [isnotnull(dt#6), (cast(dt#6 as date) > 2023-02-27)], PushedFilters: [], ReadSchema: struct ``` After this PR. It unwraps date type to string type and then pushes partition filters to Hive metastore: ``` == Physical Plan == *(1) ColumnarToRow +- FileScan parquet spark_catalog.default.t1[id#0,dt#1] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(0 paths)[], PartitionFilters: [isnotnull(dt#1), (dt#1 > 2023-02-26)], PushedFilters: [], ReadSchema: struct ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40291: [WIP][SPARK-42578][CONNECT] Add JDBC to DataFrameWriter
LuciferYang commented on code in PR #40291:
URL: https://github.com/apache/spark/pull/40291#discussion_r1125957292
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/DataFrameWriter.scala:
##
@@ -345,6 +345,37 @@ final class DataFrameWriter[T] private[sql] (ds:
Dataset[T]) {
})
}
+ /**
+ * Saves the content of the `DataFrame` to an external database table via
JDBC. In the case the
+ * table already exists in the external database, behavior of this function
depends on the save
+ * mode, specified by the `mode` function (default to throwing an exception).
+ *
+ * Don't create too many partitions in parallel on a large cluster;
otherwise Spark might crash
+ * your external database systems.
+ *
+ * JDBC-specific option and parameter documentation for storing tables via
JDBC in https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html#data-source-option";>
+ * Data Source Option in the version you use.
+ *
+ * @param table
+ * Name of the table in the external database.
+ * @param connectionProperties
+ * JDBC database connection arguments, a list of arbitrary string
tag/value. Normally at least
+ * a "user" and "password" property should be included. "batchsize" can be
used to control the
+ * number of rows per insert. "isolationLevel" can be one of "NONE",
"READ_COMMITTED",
+ * "READ_UNCOMMITTED", "REPEATABLE_READ", or "SERIALIZABLE", corresponding
to standard
+ * transaction isolation levels defined by JDBC's Connection object, with
default of
+ * "READ_UNCOMMITTED".
+ * @since 3.4.0
+ */
+ def jdbc(url: String, table: String, connectionProperties: Properties): Unit
= {
+// connectionProperties should override settings in extraOptions.
Review Comment:
I have a question @hvanhovell @beliefer . For the connect-client api, should
we verify the parameters on the client side or on the server side?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40283: [SPARK-42673][BUILD] Make `build/mvn` build Spark only with the verified maven version
LuciferYang commented on PR #40283: URL: https://github.com/apache/spark/pull/40283#issuecomment-1455497586 also cc @HyukjinKwon -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40283: [SPARK-42673][BUILD] Make `build/mvn` build Spark only with the verified maven version
LuciferYang commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125949503
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
- if [ $(version $MVN_DETECTED_VERSION) -lt $(version $MVN_VERSION) ]; then
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-meng commented on a diff in pull request #40244: [WIP][SPARK-42643][CONNECT][PYTHON] Implement `spark.udf.registerJavaFunction`
xinrong-meng commented on code in PR #40244:
URL: https://github.com/apache/spark/pull/40244#discussion_r1125939747
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -303,14 +303,15 @@ message Expression {
message CommonInlineUserDefinedFunction {
// (Required) Name of the user-defined function.
string function_name = 1;
- // (Required) Indicate if the user-defined function is deterministic.
+ // (Optional) Indicate if the user-defined function is deterministic.
bool deterministic = 2;
Review Comment:
JavaUDF has no `deterministic` field but the server doesn't have logic that
relies on that field. So only the comment is changed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40283: [SPARK-42673][BUILD] Ban Maven 3.9.x for Spark build
LuciferYang commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125934336
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
- if [ $(version $MVN_DETECTED_VERSION) -lt $(version $MVN_VERSION) ]; then
Review Comment:
Good idea
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on a diff in pull request #40283: [SPARK-42673][BUILD] Ban Maven 3.9.x for Spark build
pan3793 commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125930947
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
- if [ $(version $MVN_DETECTED_VERSION) -lt $(version $MVN_VERSION) ]; then
Review Comment:
I'm change `-lt` to `-ne`, and always respect `maven.version` defined in
`pom.xml`
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
- if [ $(version $MVN_DETECTED_VERSION) -lt $(version $MVN_VERSION) ]; then
Review Comment:
I mean change `-lt` to `-ne`, and always respect `maven.version` defined in
`pom.xml`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40283: [SPARK-42673][BUILD] Ban Maven 3.9.x for Spark build
LuciferYang commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125929900
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
- if [ $(version $MVN_DETECTED_VERSION) -lt $(version $MVN_VERSION) ]; then
Review Comment:
I am not sure when 3.9.x will be supported due to there is a pre-work need
to complete, if the pre-work cannot be completed, the version after 3.9.0 also
needs to be temporarily disabled
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on a diff in pull request #40283: [SPARK-42673][BUILD] Ban Maven 3.9.x for Spark build
pan3793 commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125927078
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
- if [ $(version $MVN_DETECTED_VERSION) -lt $(version $MVN_VERSION) ]; then
Review Comment:
why not use exact match here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #40228: [SPARK-41874][CONNECT][PYTHON] Support SameSemantics in Spark Connect
zhengruifeng commented on PR #40228: URL: https://github.com/apache/spark/pull/40228#issuecomment-1455466444 merged into master/branch-3.4 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng closed pull request #40228: [SPARK-41874][CONNECT][PYTHON] Support SameSemantics in Spark Connect
zhengruifeng closed pull request #40228: [SPARK-41874][CONNECT][PYTHON] Support SameSemantics in Spark Connect URL: https://github.com/apache/spark/pull/40228 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40291: [WIP][SPARK-42578][CONNECT] Add JDBC to DataFrameWriter
hvanhovell commented on PR #40291: URL: https://github.com/apache/spark/pull/40291#issuecomment-1455425240 hmmm - let me think about it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer opened a new pull request, #40293: [SPARK-42677][SQL] Fix the invalid tests for broadcast hint
beliefer opened a new pull request, #40293: URL: https://github.com/apache/spark/pull/40293 ### What changes were proposed in this pull request? Currently, there are a lot of test cases for broadcast hint is invalid. Because the data size is smaller than broadcast threshold. ### Why are the changes needed? Fix the invalid tests for broadcast hint. ### Does this PR introduce _any_ user-facing change? 'No'. Just modify the test cases. ### How was this patch tested? Correct test cases. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] anishshri-db commented on pull request #40292: [SPARK-42676] Write temp checkpoints for streaming queries to local filesystem even if default FS is set differently
anishshri-db commented on PR #40292: URL: https://github.com/apache/spark/pull/40292#issuecomment-1455397903 @HeartSaVioR - please take a look. Thx -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] anishshri-db opened a new pull request, #40292: [SPARK-42676] Write temp checkpoints for streaming queries to local filesystem even if default FS is set differently
anishshri-db opened a new pull request, #40292: URL: https://github.com/apache/spark/pull/40292 ### What changes were proposed in this pull request? Write temp checkpoints for streaming queries to local filesystem even if default FS is set differently ### Why are the changes needed? We have seen cases where the default FS could be a remote file system and since the path for streaming checkpoints is not specified explcitily, this could cause pileup under 2 cases: - query exits with exception and the flag to force checkpoint removal is not set - driver/cluster terminates without query being terminated gracefully ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Verified that the checkpoint is resolved and written to the local FS ``` 23/03/04 01:42:49 INFO ResolveWriteToStream: Checkpoint root file:/local_disk0/tmp/temporary-c97ab8bd-6b03-4c28-93ea-751d30a2d3f9 resolved to file:/local_disk0/tmp/temporary-c97ab8bd-6b03-4c28-93ea-751d30a2d3f9. ... 23/03/04 01:46:37 INFO MicroBatchExecution: [queryId = 66c4c] Deleting checkpoint file:/local_disk0/tmp/temporary-c97ab8bd-6b03-4c28-93ea-751d30a2d3f9. ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40287: [SPARK-42562][CONNECT] UnresolvedNamedLambdaVariable in python do not need unique names
beliefer commented on PR #40287: URL: https://github.com/apache/spark/pull/40287#issuecomment-1455392063 > I guess we will need to rewrite the lamda function in spark connect planner. Yeah. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40287: [SPARK-42562][CONNECT] UnresolvedNamedLambdaVariable in python do not need unique names
beliefer commented on PR #40287: URL: https://github.com/apache/spark/pull/40287#issuecomment-1455390728 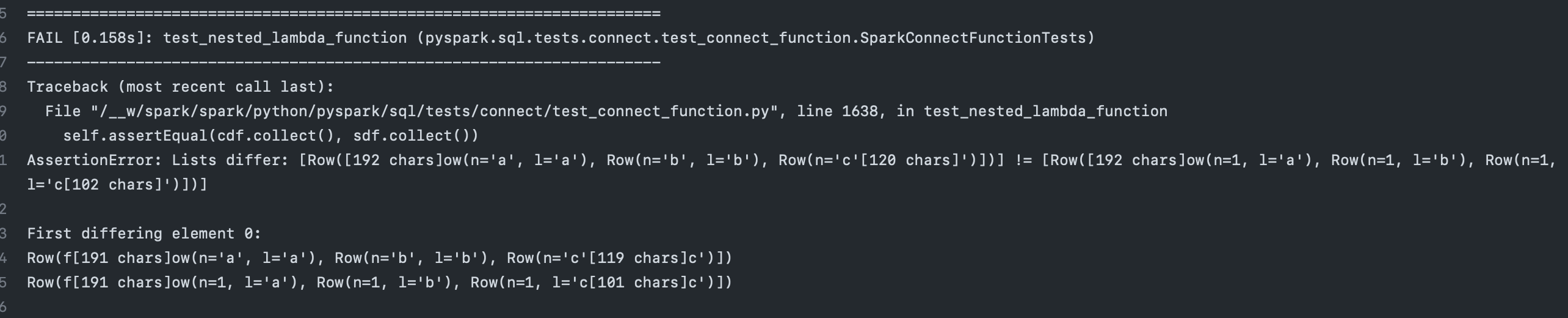 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #40277: [SPARK-42555][CONNECT][FOLLOWUP] Add the new proto msg to support the remaining jdbc API
beliefer commented on code in PR #40277:
URL: https://github.com/apache/spark/pull/40277#discussion_r1125854126
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -140,6 +141,21 @@ message Read {
// (Optional) A list of path for file-system backed data sources.
repeated string paths = 4;
}
+
+ message PartitionedJDBC {
+// (Required) JDBC URL.
+string url = 1;
+
+// (Required) Name of the table in the external database.
+string table = 2;
+
+// (Optional) Condition in the where clause for each partition.
+repeated string predicates = 3;
Review Comment:
But the transform path is very different from DataSource.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125854357
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -189,6 +190,11 @@ message Expression {
int32 days = 2;
int64 microseconds = 3;
}
+
+message Array {
+ DataType elementType = 1;
+ repeated Literal element = 2;
Review Comment:
Thanks for your confirmation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #40287: [SPARK-42562][CONNECT] UnresolvedNamedLambdaVariable in python do not need unique names
zhengruifeng commented on PR #40287: URL: https://github.com/apache/spark/pull/40287#issuecomment-1455388960 I guess we will need to rewrite the lamda function in spark connect planner. cc @ueshin as well, since existing implementation follows the fix in https://github.com/apache/spark/pull/32523 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huangxiaopingRD closed pull request #40196: [SPARK-42603][SQL] Set spark.sql.legacy.createHiveTableByDefault to false.
huangxiaopingRD closed pull request #40196: [SPARK-42603][SQL] Set spark.sql.legacy.createHiveTableByDefault to false. URL: https://github.com/apache/spark/pull/40196 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125852404
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.expressions
+
+import java.lang.{Boolean => JBoolean, Byte => JByte, Character => JChar,
Double => JDouble, Float => JFloat, Integer => JInteger, Long => JLong, Short
=> JShort}
+import java.math.{BigDecimal => JBigDecimal}
+import java.sql.{Date, Timestamp}
+import java.time._
+
+import com.google.protobuf.ByteString
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, IntervalUtils}
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.types.{DayTimeIntervalType, Decimal, DecimalType,
YearMonthIntervalType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+object LiteralProtoConverter {
+
+ private lazy val nullType =
+
proto.DataType.newBuilder().setNull(proto.DataType.NULL.getDefaultInstance).build()
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal.Builder`.
+ *
+ * @return
+ * proto.Expression.Literal.Builder
+ */
+ @scala.annotation.tailrec
+ def toLiteralProtoBuilder(literal: Any): proto.Expression.Literal.Builder = {
+val builder = proto.Expression.Literal.newBuilder()
+
+def decimalBuilder(precision: Int, scale: Int, value: String) = {
+
builder.getDecimalBuilder.setPrecision(precision).setScale(scale).setValue(value)
+}
+
+def calendarIntervalBuilder(months: Int, days: Int, microseconds: Long) = {
+ builder.getCalendarIntervalBuilder
+.setMonths(months)
+.setDays(days)
+.setMicroseconds(microseconds)
+}
+
+def arrayBuilder(array: Array[_]) = {
+ val ab = builder.getArrayBuilder
+.setElementType(componentTypeToProto(array.getClass.getComponentType))
+ array.foreach(x => ab.addElement(toLiteralProto(x)))
+ ab
+}
+
+literal match {
+ case v: Boolean => builder.setBoolean(v)
+ case v: Byte => builder.setByte(v)
+ case v: Short => builder.setShort(v)
+ case v: Int => builder.setInteger(v)
+ case v: Long => builder.setLong(v)
+ case v: Float => builder.setFloat(v)
+ case v: Double => builder.setDouble(v)
+ case v: BigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: JBigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: String => builder.setString(v)
+ case v: Char => builder.setString(v.toString)
+ case v: Array[Char] => builder.setString(String.valueOf(v))
+ case v: Array[Byte] => builder.setBinary(ByteString.copyFrom(v))
+ case v: collection.mutable.WrappedArray[_] =>
toLiteralProtoBuilder(v.array)
+ case v: LocalDate => builder.setDate(v.toEpochDay.toInt)
+ case v: Decimal =>
+builder.setDecimal(decimalBuilder(Math.max(v.precision, v.scale),
v.scale, v.toString))
+ case v: Instant => builder.setTimestamp(DateTimeUtils.instantToMicros(v))
+ case v: Timestamp =>
builder.setTimestamp(DateTimeUtils.fromJavaTimestamp(v))
+ case v: LocalDateTime =>
builder.setTimestampNtz(DateTimeUtils.localDateTimeToMicros(v))
+ case v: Date => builder.setDate(DateTimeUtils.fromJavaDate(v))
+ case v: Duration =>
builder.setDayTimeInterval(IntervalUtils.durationToMicros(v))
+ case v: Period =>
builder.setYearMonthInterval(IntervalUtils.periodToMonths(v))
+ case v: Array[_] => builder.setArray(arrayBuilder(v))
+ case v: CalendarInterval =>
+builder.setCalendarInterval(calendarIntervalBuilder(v.months, v.days,
v.microseconds))
+ case null => builder.setNull(nullType)
+ case _ => unsupported(s"literal $literal not supported (yet).")
+}
+ }
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal`.
+ *
+ * @return
+ * proto.Expression.Literal
+ */
+ def toLiteralProto(literal: Any): proto.Expression.Literal =
+toLiteralProtoBuilder(litera
[GitHub] [spark] LuciferYang commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125852404
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.expressions
+
+import java.lang.{Boolean => JBoolean, Byte => JByte, Character => JChar,
Double => JDouble, Float => JFloat, Integer => JInteger, Long => JLong, Short
=> JShort}
+import java.math.{BigDecimal => JBigDecimal}
+import java.sql.{Date, Timestamp}
+import java.time._
+
+import com.google.protobuf.ByteString
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, IntervalUtils}
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.types.{DayTimeIntervalType, Decimal, DecimalType,
YearMonthIntervalType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+object LiteralProtoConverter {
+
+ private lazy val nullType =
+
proto.DataType.newBuilder().setNull(proto.DataType.NULL.getDefaultInstance).build()
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal.Builder`.
+ *
+ * @return
+ * proto.Expression.Literal.Builder
+ */
+ @scala.annotation.tailrec
+ def toLiteralProtoBuilder(literal: Any): proto.Expression.Literal.Builder = {
+val builder = proto.Expression.Literal.newBuilder()
+
+def decimalBuilder(precision: Int, scale: Int, value: String) = {
+
builder.getDecimalBuilder.setPrecision(precision).setScale(scale).setValue(value)
+}
+
+def calendarIntervalBuilder(months: Int, days: Int, microseconds: Long) = {
+ builder.getCalendarIntervalBuilder
+.setMonths(months)
+.setDays(days)
+.setMicroseconds(microseconds)
+}
+
+def arrayBuilder(array: Array[_]) = {
+ val ab = builder.getArrayBuilder
+.setElementType(componentTypeToProto(array.getClass.getComponentType))
+ array.foreach(x => ab.addElement(toLiteralProto(x)))
+ ab
+}
+
+literal match {
+ case v: Boolean => builder.setBoolean(v)
+ case v: Byte => builder.setByte(v)
+ case v: Short => builder.setShort(v)
+ case v: Int => builder.setInteger(v)
+ case v: Long => builder.setLong(v)
+ case v: Float => builder.setFloat(v)
+ case v: Double => builder.setDouble(v)
+ case v: BigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: JBigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: String => builder.setString(v)
+ case v: Char => builder.setString(v.toString)
+ case v: Array[Char] => builder.setString(String.valueOf(v))
+ case v: Array[Byte] => builder.setBinary(ByteString.copyFrom(v))
+ case v: collection.mutable.WrappedArray[_] =>
toLiteralProtoBuilder(v.array)
+ case v: LocalDate => builder.setDate(v.toEpochDay.toInt)
+ case v: Decimal =>
+builder.setDecimal(decimalBuilder(Math.max(v.precision, v.scale),
v.scale, v.toString))
+ case v: Instant => builder.setTimestamp(DateTimeUtils.instantToMicros(v))
+ case v: Timestamp =>
builder.setTimestamp(DateTimeUtils.fromJavaTimestamp(v))
+ case v: LocalDateTime =>
builder.setTimestampNtz(DateTimeUtils.localDateTimeToMicros(v))
+ case v: Date => builder.setDate(DateTimeUtils.fromJavaDate(v))
+ case v: Duration =>
builder.setDayTimeInterval(IntervalUtils.durationToMicros(v))
+ case v: Period =>
builder.setYearMonthInterval(IntervalUtils.periodToMonths(v))
+ case v: Array[_] => builder.setArray(arrayBuilder(v))
+ case v: CalendarInterval =>
+builder.setCalendarInterval(calendarIntervalBuilder(v.months, v.days,
v.microseconds))
+ case null => builder.setNull(nullType)
+ case _ => unsupported(s"literal $literal not supported (yet).")
+}
+ }
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal`.
+ *
+ * @return
+ * proto.Expression.Literal
+ */
+ def toLiteralProto(literal: Any): proto.Expression.Literal =
+toLiteralProtoBuilder(litera
[GitHub] [spark] LuciferYang commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125852404
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.expressions
+
+import java.lang.{Boolean => JBoolean, Byte => JByte, Character => JChar,
Double => JDouble, Float => JFloat, Integer => JInteger, Long => JLong, Short
=> JShort}
+import java.math.{BigDecimal => JBigDecimal}
+import java.sql.{Date, Timestamp}
+import java.time._
+
+import com.google.protobuf.ByteString
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, IntervalUtils}
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.types.{DayTimeIntervalType, Decimal, DecimalType,
YearMonthIntervalType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+object LiteralProtoConverter {
+
+ private lazy val nullType =
+
proto.DataType.newBuilder().setNull(proto.DataType.NULL.getDefaultInstance).build()
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal.Builder`.
+ *
+ * @return
+ * proto.Expression.Literal.Builder
+ */
+ @scala.annotation.tailrec
+ def toLiteralProtoBuilder(literal: Any): proto.Expression.Literal.Builder = {
+val builder = proto.Expression.Literal.newBuilder()
+
+def decimalBuilder(precision: Int, scale: Int, value: String) = {
+
builder.getDecimalBuilder.setPrecision(precision).setScale(scale).setValue(value)
+}
+
+def calendarIntervalBuilder(months: Int, days: Int, microseconds: Long) = {
+ builder.getCalendarIntervalBuilder
+.setMonths(months)
+.setDays(days)
+.setMicroseconds(microseconds)
+}
+
+def arrayBuilder(array: Array[_]) = {
+ val ab = builder.getArrayBuilder
+.setElementType(componentTypeToProto(array.getClass.getComponentType))
+ array.foreach(x => ab.addElement(toLiteralProto(x)))
+ ab
+}
+
+literal match {
+ case v: Boolean => builder.setBoolean(v)
+ case v: Byte => builder.setByte(v)
+ case v: Short => builder.setShort(v)
+ case v: Int => builder.setInteger(v)
+ case v: Long => builder.setLong(v)
+ case v: Float => builder.setFloat(v)
+ case v: Double => builder.setDouble(v)
+ case v: BigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: JBigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: String => builder.setString(v)
+ case v: Char => builder.setString(v.toString)
+ case v: Array[Char] => builder.setString(String.valueOf(v))
+ case v: Array[Byte] => builder.setBinary(ByteString.copyFrom(v))
+ case v: collection.mutable.WrappedArray[_] =>
toLiteralProtoBuilder(v.array)
+ case v: LocalDate => builder.setDate(v.toEpochDay.toInt)
+ case v: Decimal =>
+builder.setDecimal(decimalBuilder(Math.max(v.precision, v.scale),
v.scale, v.toString))
+ case v: Instant => builder.setTimestamp(DateTimeUtils.instantToMicros(v))
+ case v: Timestamp =>
builder.setTimestamp(DateTimeUtils.fromJavaTimestamp(v))
+ case v: LocalDateTime =>
builder.setTimestampNtz(DateTimeUtils.localDateTimeToMicros(v))
+ case v: Date => builder.setDate(DateTimeUtils.fromJavaDate(v))
+ case v: Duration =>
builder.setDayTimeInterval(IntervalUtils.durationToMicros(v))
+ case v: Period =>
builder.setYearMonthInterval(IntervalUtils.periodToMonths(v))
+ case v: Array[_] => builder.setArray(arrayBuilder(v))
+ case v: CalendarInterval =>
+builder.setCalendarInterval(calendarIntervalBuilder(v.months, v.days,
v.microseconds))
+ case null => builder.setNull(nullType)
+ case _ => unsupported(s"literal $literal not supported (yet).")
+}
+ }
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal`.
+ *
+ * @return
+ * proto.Expression.Literal
+ */
+ def toLiteralProto(literal: Any): proto.Expression.Literal =
+toLiteralProtoBuilder(litera
[GitHub] [spark] beliefer commented on pull request #40291: [WIP][SPARK-42578][CONNECT] Add JDBC to DataFrameWriter
beliefer commented on PR #40291: URL: https://github.com/apache/spark/pull/40291#issuecomment-1455384866 @hvanhovell It seems that add test cases no way. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40287: [SPARK-42562][CONNECT] UnresolvedNamedLambdaVariable in python do not need unique names
beliefer commented on PR #40287: URL: https://github.com/apache/spark/pull/40287#issuecomment-1455384317 @hvanhovell After my test, `python/run-tests --testnames 'pyspark.sql.connect.dataframe'` will not passed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer opened a new pull request, #40291: [WIP][SPARK-42578][CONNECT] Add JDBC to DataFrameWriter
beliefer opened a new pull request, #40291: URL: https://github.com/apache/spark/pull/40291 ### What changes were proposed in this pull request? Currently, the connect project have the new `DataFrameWriter` API which is corresponding to Spark `DataFrameWriter` API. But the connect's `DataFrameWriter` missing the jdbc API. ### Why are the changes needed? This PR try to add JDBC to `DataFrameWriter`. ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? @hvanhovell It seems that add test cases no way. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40290: [SPARK-42478][SQL][3.3] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory
Yikf commented on PR #40290: URL: https://github.com/apache/spark/pull/40290#issuecomment-1455380079 cc @cloud-fan @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40289: [SPARK-42478][SQL][3.2] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory
Yikf commented on PR #40289: URL: https://github.com/apache/spark/pull/40289#issuecomment-1455379959 cc @cloud-fan @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf opened a new pull request, #40290: [SPARK-42478][SQL][3.3] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory
Yikf opened a new pull request, #40290: URL: https://github.com/apache/spark/pull/40290 This is a backport of https://github.com/apache/spark/pull/40064 for branch-3.3 ### What changes were proposed in this pull request? Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory ### Why are the changes needed? [SPARK-41448](https://issues.apache.org/jira/browse/SPARK-41448) make consistent MR job IDs in FileBatchWriter and FileFormatWriter, but it breaks a serializable issue, JobId is non-serializable. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? GA -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf opened a new pull request, #40289: [SPARK-42478][SQL][3.2] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory
Yikf opened a new pull request, #40289: URL: https://github.com/apache/spark/pull/40289 This is a backport of https://github.com/apache/spark/pull/40064 ### What changes were proposed in this pull request? Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory ### Why are the changes needed? [SPARK-41448](https://issues.apache.org/jira/browse/SPARK-41448) make consistent MR job IDs in FileBatchWriter and FileFormatWriter, but it breaks a serializable issue, JobId is non-serializable. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? GA -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #38358: [SPARK-40588] FileFormatWriter materializes AQE plan before accessing outputOrdering
wangyum commented on PR #38358:
URL: https://github.com/apache/spark/pull/38358#issuecomment-1455371977
@EnricoMi It seems it will remove the table location if a
`java.lang.ArithmeticException` is thrown after this change.
How to reproduce:
```scala
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.QueryTest
import org.apache.spark.sql.catalyst.TableIdentifier
sql("CREATE TABLE IF NOT EXISTS spark32_overwrite(amt1 int) STORED AS ORC")
sql("CREATE TABLE IF NOT EXISTS spark32_overwrite2(amt1 long) STORED AS ORC")
sql("INSERT OVERWRITE TABLE spark32_overwrite2 select 644164")
sql("set spark.sql.ansi.enabled=true")
val loc =
spark.sessionState.catalog.getTableMetadata(TableIdentifier("spark32_overwrite")).location
val fs = FileSystem.get(loc, spark.sparkContext.hadoopConfiguration)
println("Location exists: " + fs.exists(new Path(loc)))
try {
sql("INSERT OVERWRITE TABLE spark32_overwrite select amt1 from " +
"(select cast(amt1 as int) as amt1 from spark32_overwrite2 distribute by
amt1)")
} finally {
println("Location exists: " + fs.exists(new Path(loc)))
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125837371
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.expressions
+
+import java.lang.{Boolean => JBoolean, Byte => JByte, Character => JChar,
Double => JDouble, Float => JFloat, Integer => JInteger, Long => JLong, Short
=> JShort}
+import java.math.{BigDecimal => JBigDecimal}
+import java.sql.{Date, Timestamp}
+import java.time._
+
+import com.google.protobuf.ByteString
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, IntervalUtils}
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.types.{DayTimeIntervalType, Decimal, DecimalType,
YearMonthIntervalType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+object LiteralProtoConverter {
+
+ private lazy val nullType =
+
proto.DataType.newBuilder().setNull(proto.DataType.NULL.getDefaultInstance).build()
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal.Builder`.
+ *
+ * @return
+ * proto.Expression.Literal.Builder
+ */
+ @scala.annotation.tailrec
+ def toLiteralProtoBuilder(literal: Any): proto.Expression.Literal.Builder = {
+val builder = proto.Expression.Literal.newBuilder()
+
+def decimalBuilder(precision: Int, scale: Int, value: String) = {
+
builder.getDecimalBuilder.setPrecision(precision).setScale(scale).setValue(value)
+}
+
+def calendarIntervalBuilder(months: Int, days: Int, microseconds: Long) = {
+ builder.getCalendarIntervalBuilder
+.setMonths(months)
+.setDays(days)
+.setMicroseconds(microseconds)
+}
+
+def arrayBuilder(array: Array[_]) = {
+ val ab = builder.getArrayBuilder
+.setElementType(componentTypeToProto(array.getClass.getComponentType))
+ array.foreach(x => ab.addElement(toLiteralProto(x)))
+ ab
+}
+
+literal match {
+ case v: Boolean => builder.setBoolean(v)
+ case v: Byte => builder.setByte(v)
+ case v: Short => builder.setShort(v)
+ case v: Int => builder.setInteger(v)
+ case v: Long => builder.setLong(v)
+ case v: Float => builder.setFloat(v)
+ case v: Double => builder.setDouble(v)
+ case v: BigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: JBigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: String => builder.setString(v)
+ case v: Char => builder.setString(v.toString)
+ case v: Array[Char] => builder.setString(String.valueOf(v))
+ case v: Array[Byte] => builder.setBinary(ByteString.copyFrom(v))
+ case v: collection.mutable.WrappedArray[_] =>
toLiteralProtoBuilder(v.array)
+ case v: LocalDate => builder.setDate(v.toEpochDay.toInt)
+ case v: Decimal =>
+builder.setDecimal(decimalBuilder(Math.max(v.precision, v.scale),
v.scale, v.toString))
+ case v: Instant => builder.setTimestamp(DateTimeUtils.instantToMicros(v))
+ case v: Timestamp =>
builder.setTimestamp(DateTimeUtils.fromJavaTimestamp(v))
+ case v: LocalDateTime =>
builder.setTimestampNtz(DateTimeUtils.localDateTimeToMicros(v))
+ case v: Date => builder.setDate(DateTimeUtils.fromJavaDate(v))
+ case v: Duration =>
builder.setDayTimeInterval(IntervalUtils.durationToMicros(v))
+ case v: Period =>
builder.setYearMonthInterval(IntervalUtils.periodToMonths(v))
+ case v: Array[_] => builder.setArray(arrayBuilder(v))
+ case v: CalendarInterval =>
+builder.setCalendarInterval(calendarIntervalBuilder(v.months, v.days,
v.microseconds))
+ case null => builder.setNull(nullType)
+ case _ => unsupported(s"literal $literal not supported (yet).")
+}
+ }
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal`.
+ *
+ * @return
+ * proto.Expression.Literal
+ */
+ def toLiteralProto(literal: Any): proto.Expression.Literal =
+toLiteralProtoBuilder(litera
[GitHub] [spark] anishshri-db commented on pull request #40273: [SPARK-42668][SS] Catch exception while trying to close compressed stream in HDFSStateStoreProvider abort
anishshri-db commented on PR #40273: URL: https://github.com/apache/spark/pull/40273#issuecomment-1455371384 > Mind retriggering the build, please? Probably simplest way to do is pushing an empty commit. You can retrigger the build in your fork but it won't be reflected here. Sure done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125837371
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.expressions
+
+import java.lang.{Boolean => JBoolean, Byte => JByte, Character => JChar,
Double => JDouble, Float => JFloat, Integer => JInteger, Long => JLong, Short
=> JShort}
+import java.math.{BigDecimal => JBigDecimal}
+import java.sql.{Date, Timestamp}
+import java.time._
+
+import com.google.protobuf.ByteString
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, IntervalUtils}
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.types.{DayTimeIntervalType, Decimal, DecimalType,
YearMonthIntervalType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+object LiteralProtoConverter {
+
+ private lazy val nullType =
+
proto.DataType.newBuilder().setNull(proto.DataType.NULL.getDefaultInstance).build()
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal.Builder`.
+ *
+ * @return
+ * proto.Expression.Literal.Builder
+ */
+ @scala.annotation.tailrec
+ def toLiteralProtoBuilder(literal: Any): proto.Expression.Literal.Builder = {
+val builder = proto.Expression.Literal.newBuilder()
+
+def decimalBuilder(precision: Int, scale: Int, value: String) = {
+
builder.getDecimalBuilder.setPrecision(precision).setScale(scale).setValue(value)
+}
+
+def calendarIntervalBuilder(months: Int, days: Int, microseconds: Long) = {
+ builder.getCalendarIntervalBuilder
+.setMonths(months)
+.setDays(days)
+.setMicroseconds(microseconds)
+}
+
+def arrayBuilder(array: Array[_]) = {
+ val ab = builder.getArrayBuilder
+.setElementType(componentTypeToProto(array.getClass.getComponentType))
+ array.foreach(x => ab.addElement(toLiteralProto(x)))
+ ab
+}
+
+literal match {
+ case v: Boolean => builder.setBoolean(v)
+ case v: Byte => builder.setByte(v)
+ case v: Short => builder.setShort(v)
+ case v: Int => builder.setInteger(v)
+ case v: Long => builder.setLong(v)
+ case v: Float => builder.setFloat(v)
+ case v: Double => builder.setDouble(v)
+ case v: BigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: JBigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: String => builder.setString(v)
+ case v: Char => builder.setString(v.toString)
+ case v: Array[Char] => builder.setString(String.valueOf(v))
+ case v: Array[Byte] => builder.setBinary(ByteString.copyFrom(v))
+ case v: collection.mutable.WrappedArray[_] =>
toLiteralProtoBuilder(v.array)
+ case v: LocalDate => builder.setDate(v.toEpochDay.toInt)
+ case v: Decimal =>
+builder.setDecimal(decimalBuilder(Math.max(v.precision, v.scale),
v.scale, v.toString))
+ case v: Instant => builder.setTimestamp(DateTimeUtils.instantToMicros(v))
+ case v: Timestamp =>
builder.setTimestamp(DateTimeUtils.fromJavaTimestamp(v))
+ case v: LocalDateTime =>
builder.setTimestampNtz(DateTimeUtils.localDateTimeToMicros(v))
+ case v: Date => builder.setDate(DateTimeUtils.fromJavaDate(v))
+ case v: Duration =>
builder.setDayTimeInterval(IntervalUtils.durationToMicros(v))
+ case v: Period =>
builder.setYearMonthInterval(IntervalUtils.periodToMonths(v))
+ case v: Array[_] => builder.setArray(arrayBuilder(v))
+ case v: CalendarInterval =>
+builder.setCalendarInterval(calendarIntervalBuilder(v.months, v.days,
v.microseconds))
+ case null => builder.setNull(nullType)
+ case _ => unsupported(s"literal $literal not supported (yet).")
+}
+ }
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal`.
+ *
+ * @return
+ * proto.Expression.Literal
+ */
+ def toLiteralProto(literal: Any): proto.Expression.Literal =
+toLiteralProtoBuilder(litera
[GitHub] [spark] hvanhovell commented on a diff in pull request #40277: [SPARK-42555][CONNECT][FOLLOWUP] Add the new proto msg to support the remaining jdbc API
hvanhovell commented on code in PR #40277:
URL: https://github.com/apache/spark/pull/40277#discussion_r1125835789
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -140,6 +141,21 @@ message Read {
// (Optional) A list of path for file-system backed data sources.
repeated string paths = 4;
}
+
+ message PartitionedJDBC {
+// (Required) JDBC URL.
+string url = 1;
+
+// (Required) Name of the table in the external database.
+string table = 2;
+
+// (Optional) Condition in the where clause for each partition.
+repeated string predicates = 3;
Review Comment:
Can we just put the predicates into the DataSource message?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40287: [SPARK-42562][CONNECT] UnresolvedNamedLambdaVariable in python do not need unique names
hvanhovell commented on PR #40287: URL: https://github.com/apache/spark/pull/40287#issuecomment-1455366786 @HyukjinKwon @zhengruifeng the rationale for this change is that analyzer takes care of making lambda variables unique. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40064: [SPARK-42478] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory
Yikf commented on PR #40064: URL: https://github.com/apache/spark/pull/40064#issuecomment-1455364691 > @Yikf can you help to open a backport PR for 3.2/3.3? Thanks! Sure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement `DataFrame.observe`
beliefer commented on PR #39091: URL: https://github.com/apache/spark/pull/39091#issuecomment-1455360592 @hvanhovell @grundprinzip @HyukjinKwon @zhengruifeng @amaliujia Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #40228: [SPARK-41874][CONNECT][PYTHON] Support SameSemantics in Spark Connect
amaliujia commented on PR #40228: URL: https://github.com/apache/spark/pull/40228#issuecomment-1455359011 @hvanhovell waiting for CI -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40275: [SPARK-42557][CONNECT] Add Broadcast to functions
beliefer commented on PR #40275: URL: https://github.com/apache/spark/pull/40275#issuecomment-1455357573 @hvanhovell @LuciferYang Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40228: [SPARK-41874][CONNECT][PYTHON] Support SameSemantics in Spark Connect
hvanhovell commented on PR #40228: URL: https://github.com/apache/spark/pull/40228#issuecomment-1455352755 @amaliujia can you update the PR? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on a diff in pull request #40217: [SPARK-42559][CONNECT] Implement DataFrameNaFunctions
hvanhovell commented on code in PR #40217:
URL: https://github.com/apache/spark/pull/40217#discussion_r1125825287
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/DataFrameNaFunctionSuite.scala:
##
@@ -0,0 +1,377 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.sql.connect.client.util.QueryTest
+
+class DataFrameNaFunctionSuite extends QueryTest {
Review Comment:
Is this a line for line copy of the original test?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40217: [SPARK-42559][CONNECT] Implement DataFrameNaFunctions
hvanhovell commented on PR #40217: URL: https://github.com/apache/spark/pull/40217#issuecomment-1455351159 @panbingkun can you update the CompatibilitySuite? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40254: [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17
LuciferYang commented on PR #40254: URL: https://github.com/apache/spark/pull/40254#issuecomment-1455349598 Thanks @srowen -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #40288: [SPARK-42496][CONNECT][DOCS] Introduction Spark Connect at main page.
itholic commented on PR #40288: URL: https://github.com/apache/spark/pull/40288#issuecomment-1455348864 cc @tgravescs since this is a Spark Connect introduction including note about built in authentication you mentioned in JIRA ticket before. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40217: [SPARK-42559][CONNECT] Implement DataFrameNaFunctions
hvanhovell commented on PR #40217: URL: https://github.com/apache/spark/pull/40217#issuecomment-1455348717 @panbingkun can you update your PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
hvanhovell commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125820525
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.expressions
+
+import java.lang.{Boolean => JBoolean, Byte => JByte, Character => JChar,
Double => JDouble, Float => JFloat, Integer => JInteger, Long => JLong, Short
=> JShort}
+import java.math.{BigDecimal => JBigDecimal}
+import java.sql.{Date, Timestamp}
+import java.time._
+
+import com.google.protobuf.ByteString
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.catalyst.util.{DateTimeUtils, IntervalUtils}
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.types.{DayTimeIntervalType, Decimal, DecimalType,
YearMonthIntervalType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+object LiteralProtoConverter {
+
+ private lazy val nullType =
+
proto.DataType.newBuilder().setNull(proto.DataType.NULL.getDefaultInstance).build()
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal.Builder`.
+ *
+ * @return
+ * proto.Expression.Literal.Builder
+ */
+ @scala.annotation.tailrec
+ def toLiteralProtoBuilder(literal: Any): proto.Expression.Literal.Builder = {
+val builder = proto.Expression.Literal.newBuilder()
+
+def decimalBuilder(precision: Int, scale: Int, value: String) = {
+
builder.getDecimalBuilder.setPrecision(precision).setScale(scale).setValue(value)
+}
+
+def calendarIntervalBuilder(months: Int, days: Int, microseconds: Long) = {
+ builder.getCalendarIntervalBuilder
+.setMonths(months)
+.setDays(days)
+.setMicroseconds(microseconds)
+}
+
+def arrayBuilder(array: Array[_]) = {
+ val ab = builder.getArrayBuilder
+.setElementType(componentTypeToProto(array.getClass.getComponentType))
+ array.foreach(x => ab.addElement(toLiteralProto(x)))
+ ab
+}
+
+literal match {
+ case v: Boolean => builder.setBoolean(v)
+ case v: Byte => builder.setByte(v)
+ case v: Short => builder.setShort(v)
+ case v: Int => builder.setInteger(v)
+ case v: Long => builder.setLong(v)
+ case v: Float => builder.setFloat(v)
+ case v: Double => builder.setDouble(v)
+ case v: BigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: JBigDecimal =>
+builder.setDecimal(decimalBuilder(v.precision, v.scale, v.toString))
+ case v: String => builder.setString(v)
+ case v: Char => builder.setString(v.toString)
+ case v: Array[Char] => builder.setString(String.valueOf(v))
+ case v: Array[Byte] => builder.setBinary(ByteString.copyFrom(v))
+ case v: collection.mutable.WrappedArray[_] =>
toLiteralProtoBuilder(v.array)
+ case v: LocalDate => builder.setDate(v.toEpochDay.toInt)
+ case v: Decimal =>
+builder.setDecimal(decimalBuilder(Math.max(v.precision, v.scale),
v.scale, v.toString))
+ case v: Instant => builder.setTimestamp(DateTimeUtils.instantToMicros(v))
+ case v: Timestamp =>
builder.setTimestamp(DateTimeUtils.fromJavaTimestamp(v))
+ case v: LocalDateTime =>
builder.setTimestampNtz(DateTimeUtils.localDateTimeToMicros(v))
+ case v: Date => builder.setDate(DateTimeUtils.fromJavaDate(v))
+ case v: Duration =>
builder.setDayTimeInterval(IntervalUtils.durationToMicros(v))
+ case v: Period =>
builder.setYearMonthInterval(IntervalUtils.periodToMonths(v))
+ case v: Array[_] => builder.setArray(arrayBuilder(v))
+ case v: CalendarInterval =>
+builder.setCalendarInterval(calendarIntervalBuilder(v.months, v.days,
v.microseconds))
+ case null => builder.setNull(nullType)
+ case _ => unsupported(s"literal $literal not supported (yet).")
+}
+ }
+
+ /**
+ * Transforms literal value to the `proto.Expression.Literal`.
+ *
+ * @return
+ * proto.Expression.Literal
+ */
+ def toLiteralProto(literal: Any): proto.Expression.Literal =
+toLiteralProtoBuilder(literal
[GitHub] [spark] hvanhovell commented on a diff in pull request #40218: [SPARK-42579][CONNECT] Part-1: `function.lit` support `Array[_]` dataType
hvanhovell commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125817796
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/LiteralValueProtoConverter.scala:
##
@@ -130,4 +138,61 @@ object LiteralValueProtoConverter {
case o => throw new Exception(s"Unsupported value type: $o")
}
}
+
+ private def toArrayData(array: proto.Expression.Literal.Array): Any = {
+def makeArrayData[T](converter: proto.Expression.Literal => T)(implicit
+tag: ClassTag[T]): Array[T] = {
Review Comment:
yes
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #40288: [SPARK-42496][CONNECT][DOCS] Introduction Spark Connect at main page.
itholic opened a new pull request, #40288: URL: https://github.com/apache/spark/pull/40288 ### What changes were proposed in this pull request? This PR proposes to add a brief description of Spark Connect to the PySpark main page. https://user-images.githubusercontent.com/44108233/223006571-42fccf6f-cb7b-479c-9f11-5c246b442fac.png";> ### Why are the changes needed? Spark Connect is a new and experimental feature of PySpark that enables Spark to run anywhere and work with different data stores and services. Adding a brief description of Spark Connect to the main page will inform users about this feature and how it can benefit their use cases. Additionally, the note about the experimental nature of this feature will help users understand the potential risks of using Spark Connect in production environments. ### Does this PR introduce _any_ user-facing change? No for API usage, but this PR introduces a user-facing documents by adding a new section about Spark Connect to the PySpark main page. ### How was this patch tested? To ensure that the documentation builds correctly, the `make clean html` command was executed to test the build process. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on a diff in pull request #40270: [SPARK-42662][CONNECT][PYTHON][PS] Support `withSequenceColumn` as PySpark DataFrame internal function.
hvanhovell commented on code in PR #40270:
URL: https://github.com/apache/spark/pull/40270#discussion_r1125815690
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -781,3 +782,10 @@ message FrameMap {
CommonInlineUserDefinedFunction func = 2;
}
+message WithSequenceColumn {
Review Comment:
Well my argument against this is that it is just a project with a specific
type of expression attached to it. There is no need to complicate the protocol,
it is just that.
As for what this does, and this comment is more aimed at the original PR,
two things:
- The IDs are not stable at all. This is an order based, and well we
basically do not guarantee that the order is stable during processing.
- The IDs can contain gaps or duplicates if any of the shuffles of the input
contains a non-deterministic column, and a retry of one of the input
tasks/stages occurs. This is a result of the double scanning that
RDD.zipWithIndex requires.
- Finally two scans can be slow.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #40254: [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17
srowen commented on PR #40254: URL: https://github.com/apache/spark/pull/40254#issuecomment-1455341403 Merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen closed pull request #40254: [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17
srowen closed pull request #40254: [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17 URL: https://github.com/apache/spark/pull/40254 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #40064: [SPARK-42478] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory
cloud-fan commented on PR #40064: URL: https://github.com/apache/spark/pull/40064#issuecomment-1455335925 @Yikf can you help to open a backport PR for 3.2/3.3? Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40254: [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17
LuciferYang commented on PR #40254: URL: https://github.com/apache/spark/pull/40254#issuecomment-1455328473 friendly ping @srowen -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell closed pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement `DataFrame.observe`
hvanhovell closed pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement `DataFrame.observe` URL: https://github.com/apache/spark/pull/39091 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement `DataFrame.observe`
hvanhovell commented on PR #39091: URL: https://github.com/apache/spark/pull/39091#issuecomment-1455327845 Merging to master/3.4 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40285: [SPARK-42675][CONNECT][TESTS] Drop temp view after test `test temp view`
LuciferYang commented on PR #40285: URL: https://github.com/apache/spark/pull/40285#issuecomment-1455325164 Thanks @wangyum -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40255: [SPARK-42558][CONNECT] Implement `DataFrameStatFunctions` except `bloomFilter` functions
LuciferYang commented on PR #40255: URL: https://github.com/apache/spark/pull/40255#issuecomment-1455324716 Thanks @hvanhovell @HyukjinKwon @zhengruifeng @amaliujia -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell closed pull request #40255: [SPARK-42558][CONNECT] Implement `DataFrameStatFunctions` except `bloomFilter` functions
hvanhovell closed pull request #40255: [SPARK-42558][CONNECT] Implement `DataFrameStatFunctions` except `bloomFilter` functions URL: https://github.com/apache/spark/pull/40255 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40255: [SPARK-42558][CONNECT] Implement `DataFrameStatFunctions` except `bloomFilter` functions
hvanhovell commented on PR #40255: URL: https://github.com/apache/spark/pull/40255#issuecomment-1455323028 Merging. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell closed pull request #40275: [SPARK-42557][CONNECT] Add Broadcast to functions
hvanhovell closed pull request #40275: [SPARK-42557][CONNECT] Add Broadcast to functions URL: https://github.com/apache/spark/pull/40275 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #40275: [SPARK-42557][CONNECT] Add Broadcast to functions
hvanhovell commented on PR #40275: URL: https://github.com/apache/spark/pull/40275#issuecomment-1455321694 Merging. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell closed pull request #40279: [MINOR][CONNECT] Remove unused protobuf imports to eliminate build warnings
hvanhovell closed pull request #40279: [MINOR][CONNECT] Remove unused protobuf imports to eliminate build warnings URL: https://github.com/apache/spark/pull/40279 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell closed pull request #40280: [SPARK-42671][CONNECT] Fix bug for createDataFrame from complex type schema
hvanhovell closed pull request #40280: [SPARK-42671][CONNECT] Fix bug for createDataFrame from complex type schema URL: https://github.com/apache/spark/pull/40280 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on a diff in pull request #40280: [SPARK-42671][CONNECT] Fix bug for createDataFrame from complex type schema
hvanhovell commented on code in PR #40280:
URL: https://github.com/apache/spark/pull/40280#discussion_r1125800378
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/SparkSession.scala:
##
@@ -115,7 +115,7 @@ class SparkSession private[sql] (
private def createDataset[T](encoder: AgnosticEncoder[T], data:
Iterator[T]): Dataset[T] = {
newDataset(encoder) { builder =>
val localRelationBuilder = builder.getLocalRelationBuilder
-.setSchema(encoder.schema.catalogString)
Review Comment:
json is ok
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a diff in pull request #40286: [SPARK-42577][CORE] Add max attempts limitation for stages to avoid potential infinite retry
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790750
##
core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala:
##
@@ -232,6 +232,13 @@ private[spark] class DAGScheduler(
sc.getConf.getInt("spark.stage.maxConsecutiveAttempts",
DAGScheduler.DEFAULT_MAX_CONSECUTIVE_STAGE_ATTEMPTS)
+ /**
+ * Max stage attempts allowed before a stage is aborted.
+ */
+ private[scheduler] val maxStageAttempts: Int = {
+Math.max(maxConsecutiveStageAttempts,
sc.getConf.get(config.STAGE_MAX_ATTEMPTS))
Review Comment:
Modify this suitably to return an `Option` if using optin
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a diff in pull request #40286: [SPARK-42577][CORE] Add max attempts limitation for stages to avoid potential infinite retry
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790378
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2479,4 +2479,14 @@ package object config {
.version("3.4.0")
.booleanConf
.createWithDefault(false)
+
+ private[spark] val STAGE_MAX_ATTEMPTS =
+ConfigBuilder("spark.stage.maxAttempts")
+ .doc("The max attempts for a stage, the spark job will be aborted if any
of its stages is " +
+"resubmitted multiple times beyond the limitation. The value should be
no less " +
+"than `spark.stage.maxConsecutiveAttempts` which defines the max
attempts for " +
+"fetch failures.")
+ .version("3.5.0")
+ .intConf
+ .createWithDefault(16)
Review Comment:
Since this is a behavior change, let us make this an optional parameter -
and preserve current behavior when not configured (or make default int max
value).
We can change this to a more restrictive default value in a future release.
Given cascading stage retries and deployments where decom is not applicable
(yarn for example), particularly due to `INDETERMINATE` stage, this minimizes
application failures.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a diff in pull request #40286: [SPARK-42577][CORE] Add max attempts limitation for stages to avoid potential infinite retry
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790378
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2479,4 +2479,14 @@ package object config {
.version("3.4.0")
.booleanConf
.createWithDefault(false)
+
+ private[spark] val STAGE_MAX_ATTEMPTS =
+ConfigBuilder("spark.stage.maxAttempts")
+ .doc("The max attempts for a stage, the spark job will be aborted if any
of its stages is " +
+"resubmitted multiple times beyond the limitation. The value should be
no less " +
+"than `spark.stage.maxConsecutiveAttempts` which defines the max
attempts for " +
+"fetch failures.")
+ .version("3.5.0")
+ .intConf
+ .createWithDefault(16)
Review Comment:
Since this is a behavior change, let us make this an optional parameter -
and preserve current behavior when not configured (or make default int max
value).
We can change this to a more restrictive default value in a future release.
Given cascading stage retries, particularly due to `INDETERMINATE` stage,
this minimizes application failures.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer opened a new pull request, #40287: [SPARK-42562][CONNECT] UnresolvedNamedLambdaVariable in python do not need unique names
beliefer opened a new pull request, #40287: URL: https://github.com/apache/spark/pull/40287 ### What changes were proposed in this pull request? UnresolvedNamedLambdaVariable do not need unique names in python. We already did this for the scala client, and it is good to have parity between the two implementations. ### Why are the changes needed? Try to avoid unique names for UnresolvedNamedLambdaVariable. ### Does this PR introduce _any_ user-facing change? 'No'. New feature ### How was this patch tested? N/A -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a diff in pull request #40286: [SPARK-42577][CORE] Add max attempts limitation for stages to avoid potential infinite retry
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790378
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2479,4 +2479,14 @@ package object config {
.version("3.4.0")
.booleanConf
.createWithDefault(false)
+
+ private[spark] val STAGE_MAX_ATTEMPTS =
+ConfigBuilder("spark.stage.maxAttempts")
+ .doc("The max attempts for a stage, the spark job will be aborted if any
of its stages is " +
+"resubmitted multiple times beyond the limitation. The value should be
no less " +
+"than `spark.stage.maxConsecutiveAttempts` which defines the max
attempts for " +
+"fetch failures.")
+ .version("3.5.0")
+ .intConf
+ .createWithDefault(16)
Review Comment:
Since this is a behavior change, let us make this an optional paraeter - and
preserve current behavior when not configured.
We can change this to a default value in a future release.
Given cascading stage retries, particularly due to `INDETERMINATE` stage,
this minimizes application failures.
##
core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala:
##
@@ -232,6 +232,13 @@ private[spark] class DAGScheduler(
sc.getConf.getInt("spark.stage.maxConsecutiveAttempts",
DAGScheduler.DEFAULT_MAX_CONSECUTIVE_STAGE_ATTEMPTS)
+ /**
+ * Max stage attempts allowed before a stage is aborted.
+ */
+ private[scheduler] val maxStageAttempts: Int = {
+Math.max(maxConsecutiveStageAttempts,
sc.getConf.get(config.STAGE_MAX_ATTEMPTS))
Review Comment:
Modify this suitably to return an `Option`.
##
core/src/main/scala/org/apache/spark/scheduler/Stage.scala:
##
@@ -70,6 +70,7 @@ private[scheduler] abstract class Stage(
/** The ID to use for the next new attempt for this stage. */
private var nextAttemptId: Int = 0
+ private[scheduler] def getNextAttemptId(): Int = nextAttemptId
Review Comment:
`getNextAttemptId()` -> `getNextAttemptId`
##
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:
##
@@ -406,12 +406,13 @@ class DAGSchedulerSuite extends SparkFunSuite with
TempLocalSparkContext with Ti
blockManagerMaster = spy(new MyBlockManagerMaster(sc.getConf))
doNothing().when(blockManagerMaster).updateRDDBlockVisibility(any(), any())
scheduler = new MyDAGScheduler(
+scheduler = spy(new MyDAGScheduler(
Review Comment:
This should cause a compilation failure - remove the prev line ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #40262: [SPARK-42651][SQL] Optimize global sort to driver sort
ulysses-you commented on PR #40262: URL: https://github.com/apache/spark/pull/40262#issuecomment-1455303198 cc @cloud-fan @viirya thank you -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement `DataFrame.observe`
beliefer commented on code in PR #39091:
URL: https://github.com/apache/spark/pull/39091#discussion_r1125777299
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -338,6 +340,22 @@ class SparkConnectPlanner(session: SparkSession) {
}
}
+ private def transformCollectMetrics(rel: proto.CollectMetrics): LogicalPlan
= {
+val metrics = rel.getMetricsList.asScala.map { expr =>
+ Column(transformExpression(expr))
+}
+
+if (rel.getIsObservation) {
Review Comment:
@hvanhovell is_observation has been removed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40275: [SPARK-42557][CONNECT] Add Broadcast to functions
beliefer commented on PR #40275: URL: https://github.com/apache/spark/pull/40275#issuecomment-1455280706 ping @HyukjinKwon @zhengruifeng @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40277: [SPARK-42555][CONNECT][FOLLOWUP] Add the new proto msg to support the remaining jdbc API
beliefer commented on PR #40277: URL: https://github.com/apache/spark/pull/40277#issuecomment-1455280396 ping @hvanhovell @HyukjinKwon @dongjoon-hyun cc @LuciferYang -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement `DataFrame.observe`
beliefer commented on PR #39091: URL: https://github.com/apache/spark/pull/39091#issuecomment-1455279364 > @beliefer can you please remove the is_observation code path? And take another look at the protocol. Otherwise I think it looks good. is_observation code path has been removed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #40271: [WIP][SPARK-42258][PYTHON] pyspark.sql.functions should not expose typing.cast
itholic commented on PR #40271: URL: https://github.com/apache/spark/pull/40271#issuecomment-1455275958 Looks good otherwise. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #40271: [WIP][SPARK-42258][PYTHON] pyspark.sql.functions should not expose typing.cast
itholic commented on code in PR #40271:
URL: https://github.com/apache/spark/pull/40271#discussion_r1125771590
##
python/pyspark/sql/tests/test_functions.py:
##
@@ -1268,6 +1268,12 @@ def test_bucket(self):
message_parameters={"arg_name": "numBuckets", "arg_type": "str"},
)
+def test_no_cast(self):
Review Comment:
How about add a `test_cast` with practical cases?
Seems like the test for `functions.cast` is missing (And that's also the
root reason why we haven't noticed this is wrong until now)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #40271: [WIP][SPARK-42258][PYTHON] pyspark.sql.functions should not expose typing.cast
itholic commented on code in PR #40271:
URL: https://github.com/apache/spark/pull/40271#discussion_r1125771590
##
python/pyspark/sql/tests/test_functions.py:
##
@@ -1268,6 +1268,12 @@ def test_bucket(self):
message_parameters={"arg_name": "numBuckets", "arg_type": "str"},
)
+def test_no_cast(self):
Review Comment:
How about add a `test_cast`?
Seems like the test for `functions.cast` is missing (And that's also the
root reason why we haven't noticed this is wrong until now)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #40281: [SPARK-41497][CORE][Follow UP]Modify config `spark.rdd.cache.visibilityTracking.enabled` support version to 3.5.0
HyukjinKwon closed pull request #40281: [SPARK-41497][CORE][Follow UP]Modify config `spark.rdd.cache.visibilityTracking.enabled` support version to 3.5.0 URL: https://github.com/apache/spark/pull/40281 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #40282: [SPARK-42672][PYTHON][DOCS] Document error class list
HyukjinKwon commented on PR #40282: URL: https://github.com/apache/spark/pull/40282#issuecomment-1455270795 cc @MaxGekk and @srielau -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #40284: [SPARK-42674][BUILD] Upgrade scalafmt from 3.7.1 to 3.7.2
HyukjinKwon closed pull request #40284: [SPARK-42674][BUILD] Upgrade scalafmt from 3.7.1 to 3.7.2 URL: https://github.com/apache/spark/pull/40284 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #40284: [SPARK-42674][BUILD] Upgrade scalafmt from 3.7.1 to 3.7.2
HyukjinKwon commented on PR #40284: URL: https://github.com/apache/spark/pull/40284#issuecomment-1455270404 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #36265: [SPARK-38951][SQL] Aggregate aliases override field names in ResolveAggregateFunctions
github-actions[bot] closed pull request #36265: [SPARK-38951][SQL] Aggregate aliases override field names in ResolveAggregateFunctions URL: https://github.com/apache/spark/pull/36265 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #38736: [SPARK-41214][SQL] - SQL Metrics are missing from Spark UI when AQE for Cached DataFrame is enabled
github-actions[bot] commented on PR #38736: URL: https://github.com/apache/spark/pull/38736#issuecomment-1455262719 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #40285: [SPARK-42675][CONNECT][TESTS] Drop temp view after test `test temp view`
wangyum commented on PR #40285: URL: https://github.com/apache/spark/pull/40285#issuecomment-1455258629 Merged to master and branch-3.4. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum closed pull request #40285: [SPARK-42675][CONNECT][TESTS] Drop temp view after test `test temp view`
wangyum closed pull request #40285: [SPARK-42675][CONNECT][TESTS] Drop temp view after test `test temp view` URL: https://github.com/apache/spark/pull/40285 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] FurcyPin commented on a diff in pull request #40271: [WIP][SPARK-42258][PYTHON] pyspark.sql.functions should not expose typing.cast
FurcyPin commented on code in PR #40271: URL: https://github.com/apache/spark/pull/40271#discussion_r1125698656 ## python/pyspark/sql/functions.py: ## @@ -22,20 +22,10 @@ import sys import functools import warnings -from typing import ( -Any, -cast, Review Comment: In the end, I went for `from typing import cast as _cast` which makes the intent even more explicit, I think. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] FurcyPin commented on a diff in pull request #40271: [WIP][SPARK-42258][PYTHON] pyspark.sql.functions should not expose typing.cast
FurcyPin commented on code in PR #40271: URL: https://github.com/apache/spark/pull/40271#discussion_r1125695676 ## python/pyspark/sql/functions.py: ## @@ -22,20 +22,10 @@ import sys import functools import warnings -from typing import ( -Any, -cast, Review Comment: I agree that the change seemed quite cumbersome. It made me wish Python had some kind of "private import" keyword to handle such cases more easily. I agree with you that `cast` is the only name that might be confusing (perhaps `overload` too, but all the other names start with an uppercase). The `functions` module feels a little special to me because it is the module I use the most as a Spark user, it's definitely a public API. The 201 other modules don't require such change. It's out of the scope of this MR, but perhaps for the long term you could consider reorganizing this module [the same way as I did in one of my projects](https://github.com/FurcyPin/spark-frame/blob/main/spark_frame/transformations.py), which had two advantages: - the code of each method was isolated in a separate file (that would prevent having a 10 000-lines files) - there was no import pollution For now, I'll do as you suggest: only handle `typing.cast` as a special case and add a unit test to make sure it does not get imported again. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #40236: [SPARK-38735][SQL][TESTS] Add tests for the error class: INTERNAL_ERROR
itholic commented on code in PR #40236:
URL: https://github.com/apache/spark/pull/40236#discussion_r1125682909
##
sql/core/src/test/scala/org/apache/spark/sql/errors/QueryExecutionErrorsSuite.scala:
##
@@ -765,6 +770,58 @@ class QueryExecutionErrorsSuite
)
}
}
+
+ test("INTERNAL_ERROR: Calling eval on Unevaluable expression") {
+val e = intercept[SparkException] {
+ Parameter("foo").eval()
+}
+checkError(
+ exception = e,
+ errorClass = "INTERNAL_ERROR",
+ parameters = Map("message" -> "Cannot evaluate expression:
parameter(foo)"),
+ sqlState = "XX000")
+ }
+
+ test("INTERNAL_ERROR: Calling doGenCode on unresolved") {
+val e = intercept[SparkException] {
+ val ctx = new CodegenContext
+ Grouping(Parameter("foo")).genCode(ctx)
+}
+checkError(
+ exception = e,
+ errorClass = "INTERNAL_ERROR",
+ parameters = Map(
+"message" -> ("Cannot generate code for expression: " +
+ "grouping(parameter(foo))")),
+ sqlState = "XX000")
+ }
+
+ test("INTERNAL_ERROR: Calling terminate on UnresolvedGenerator") {
+val e = intercept[SparkException] {
+ UnresolvedGenerator(FunctionIdentifier("foo"), Seq.empty).terminate()
+}
+checkError(
+ exception = e,
+ errorClass = "INTERNAL_ERROR",
+ parameters = Map("message" -> "Cannot terminate expression: 'foo()"),
+ sqlState = "XX000")
+ }
+
+ test("INTERNAL_ERROR: Initializing JavaBean with non existing method") {
+val e = intercept[SparkException] {
+ val initializeWithNonexistingMethod = InitializeJavaBean(
+Literal.fromObject(new java.util.LinkedList[Int]),
+Map("nonexistent" -> Literal(1)))
+ initializeWithNonexistingMethod.eval()
+}
+checkError(
+ exception = e,
+ errorClass = "INTERNAL_ERROR",
+ parameters = Map(
+"message" -> ("""A method named "nonexistent" is not declared in """ +
+ "any enclosing class nor any supertype")),
+ sqlState = "XX000")
Review Comment:
It's fine if it's already tested :-)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40274: [SPARK-42215][CONNECT] Simplify Scala Client IT tests
LuciferYang commented on PR #40274: URL: https://github.com/apache/spark/pull/40274#issuecomment-1455105130 There is another problem that needs to be confirmed, which may not related to current pr: if other Suites inherit `RemoteSparkSession`, they will share the same connect server, right? (`SparkConnectServerUtils` is an object, so `SparkConnect` will only submit once) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ivoson opened a new pull request, #40286: [SPARK-42577][CORE] Add max attempts limitation for stages to avoid potential infinite retry
ivoson opened a new pull request, #40286: URL: https://github.com/apache/spark/pull/40286 ### What changes were proposed in this pull request? Currently a stage will be resubmitted in a few scenarios: 1. Task failed with `FetchFailed` will trigger stage re-submit; 2. Barrier task failed; 3. Shuffle data loss due to executor/host decommissioned; For the first 2 scenarios, there is a config `spark.stage.maxConsecutiveAttempts` to limit the retry times. While for the 3rd scenario, there'll be potential risks for inifinite retry if there are always executors hosting the shuffle data from successful tasks got killed/lost, the stage will be re-run again and again. To avoid the potential risk, the proposal in this PR is to add a new config `spark.stage.maxConsecutiveAttempts` to limit the overall max attempts number for each stage, the stage will be aborted once the retry times beyond the limitation. ### Why are the changes needed? To avoid the potential risks for stage infinite retry. ### Does this PR introduce _any_ user-facing change? Added limitation for stage retry times, so jobs may fail if they need to retry for mutiplte times beyond the limitation. ### How was this patch tested? Added new UT. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org