[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123426656
--- Diff: R/pkg/R/functions.R ---
@@ -2414,20 +2396,23 @@ setMethod("from_json", signature(x = "Column",
schema = "structType"),
column(jc)
})
-#' from_utc_timestamp
-#'
-#' Given a timestamp, which corresponds to a certain time of day in UTC,
returns another timestamp
-#' that corresponds to the same time of day in the given timezone.
+#' @details
+#' \code{from_utc_timestamp}: Given a timestamp, which corresponds to a
certain time of day in UTC,
+#' returns another timestamp that corresponds to the same time of day in
the given timezone.
#'
-#' @param y Column to compute on.
-#' @param x time zone to use.
+#' @rdname column_datetime_diff_functions
#'
-#' @family date time functions
-#' @rdname from_utc_timestamp
-#' @name from_utc_timestamp
-#' @aliases from_utc_timestamp,Column,character-method
+#' @aliases from_utc_timestamp from_utc_timestamp,Column,character-method
#' @export
-#' @examples \dontrun{from_utc_timestamp(df$t, 'PST')}
+#' @examples
+#'
+#' \dontrun{
+#' tmp <- mutate(df, from_utc = from_utc_timestamp(df$time, 'PST'),
+#' to_utc = to_utc_timestamp(df$time, 'PST'),
+#' to_unix = unix_timestamp(df$time),
+#' to_unix2 = unix_timestamp(df$time, '-MM-dd HH'),
+#' from_unix = from_unixtime(unix_timestamp(df$time)))
--- End diff --
Fixed. The examples for `unix_timestamp` and `from_unixtime` are now
documented in the correct file.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 @HyukjinKwon Great catch. Fixed all issues you pointed out. Thanks! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18371: [SPARK-20889][SparkR] Grouped documentation for M...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18371#discussion_r123425200
--- Diff: R/pkg/R/functions.R ---
@@ -34,6 +34,30 @@ NULL
#' df <- createDataFrame(cbind(model = rownames(mtcars), mtcars))}
NULL
+#' Math functions for Column operations
+#'
+#' Math functions defined for \code{Column}.
+#'
+#' @param x Column to compute on. In \code{shiftLeft}, \code{shiftRight}
and \code{shiftRightUnsigned},
+#' this is the number of bits to shift.
+#' @param y Column to compute on.
+#' @param ... additional argument(s).
+#' @name column_math_functions
+#' @rdname column_math_functions
+#' @family math functions
+#' @examples
+#' \dontrun{
+#' # Dataframe used throughout this doc
+#' df <- createDataFrame(cbind(model = rownames(mtcars), mtcars))
+#' tmp <- mutate(df, v1 = log(df$mpg), v2 = cbrt(df$disp),
+#' v3 = bround(df$wt, 1), v4 = bin(df$cyl),
+#' v5 = hex(df$wt), v6 = toDegrees(df$gear),
+#' v7 = atan2(df$cyl, df$am), v8 = hypot(df$cyl, df$am),
+#' v9 = pmod(df$hp, df$cyl), v10 = shiftLeft(df$disp, 1),
+#' v11 = conv(df$hp, 10, 16))
--- End diff --
Three more examples added.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18371: [SPARK-20889][SparkR] Grouped documentation for MATH col...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18371 Made another commit that addresses your comments. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18371: [SPARK-20889][SparkR] Grouped documentation for M...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18371#discussion_r123425179
--- Diff: R/pkg/R/functions.R ---
@@ -1405,18 +1309,12 @@ setMethod("sha1",
column(jc)
})
-#' signum
-#'
-#' Computes the signum of the given value.
-#'
-#' @param x Column to compute on.
+#' @details
+#' \code{signum}: Computes the signum of the given value.
--- End diff --
OK. fixed this.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18366: [SPARK-20889][SparkR] Grouped documentation for STRING c...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18366 jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18366: [SPARK-20889][SparkR] Grouped documentation for STRING c...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18366 Jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 @felixcheung Any idea what this message means? `This patch adds the following public classes (experimental): #' @Param x For class` --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18371: [SPARK-20889][SparkR] Grouped documentation for MATH col...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18371 jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123328728
--- Diff: R/pkg/R/functions.R ---
@@ -2774,27 +2724,16 @@ setMethod("format_string", signature(format =
"character", x = "Column"),
column(jc)
})
-#' from_unixtime
-#'
-#' Converts the number of seconds from unix epoch (1970-01-01 00:00:00
UTC) to a string
-#' representing the timestamp of that moment in the current system time
zone in the given
-#' format.
+#' @section Details:
+#' \code{from_unixtime}: Converts the number of seconds from unix epoch
(1970-01-01 00:00:00 UTC) to a
+#' string representing the timestamp of that moment in the current system
time zone in the given format.
--- End diff --
Done.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123328753
--- Diff: R/pkg/R/functions.R ---
@@ -2774,27 +2724,16 @@ setMethod("format_string", signature(format =
"character", x = "Column"),
column(jc)
})
-#' from_unixtime
-#'
-#' Converts the number of seconds from unix epoch (1970-01-01 00:00:00
UTC) to a string
-#' representing the timestamp of that moment in the current system time
zone in the given
-#' format.
+#' @section Details:
+#' \code{from_unixtime}: Converts the number of seconds from unix epoch
(1970-01-01 00:00:00 UTC) to a
+#' string representing the timestamp of that moment in the current system
time zone in the given format.
+#' See
\href{http://docs.oracle.com/javase/tutorial/i18n/format/simpleDateFormat.html}{
+#' Customizing Formats} for available options.
#'
-#' @param x a Column of unix timestamp.
-#' @param format the target format. See
-#'
\href{http://docs.oracle.com/javase/tutorial/i18n/format/simpleDateFormat.html}{
-#' Customizing Formats} for available options.
-#' @param ... further arguments to be passed to or from other methods.
-#' @family date time functions
-#' @rdname from_unixtime
-#' @name from_unixtime
-#' @aliases from_unixtime,Column-method
+#' @rdname column_datetime_functions
+#
--- End diff --
Fixed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123328685
--- Diff: R/pkg/R/functions.R ---
@@ -2458,111 +2441,78 @@ setMethod("instr", signature(y = "Column", x =
"character"),
column(jc)
})
-#' next_day
-#'
-#' Given a date column, returns the first date which is later than the
value of the date column
-#' that is on the specified day of the week.
-#'
-#' For example, \code{next_day('2015-07-27', "Sunday")} returns 2015-08-02
because that is the first
-#' Sunday after 2015-07-27.
-#'
-#' Day of the week parameter is case insensitive, and accepts first three
or two characters:
-#' "Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun".
+#' @section Details:
+#' \code{next_day}: Given a date column, returns the first date which is
later than the value of
+#' the date column that is on the specified day of the week. For example,
+#' \code{next_day('2015-07-27', "Sunday")} returns 2015-08-02 because that
is the first Sunday
+#' after 2015-07-27. Day of the week parameter is case insensitive, and
accepts first three or
+#' two characters: "Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun".
#'
-#' @param y Column to compute on.
-#' @param x Day of the week string.
-#'
-#' @family date time functions
-#' @rdname next_day
-#' @name next_day
-#' @aliases next_day,Column,character-method
+#' @rdname column_datetime_diff_functions
+#' @aliases next_day next_day,Column,character-method
#' @export
-#' @examples
-#'\dontrun{
-#'next_day(df$d, 'Sun')
-#'next_day(df$d, 'Sunday')
-#'}
#' @note next_day since 1.5.0
setMethod("next_day", signature(y = "Column", x = "character"),
function(y, x) {
jc <- callJStatic("org.apache.spark.sql.functions",
"next_day", y@jc, x)
column(jc)
})
-#' to_utc_timestamp
-#'
-#' Given a timestamp, which corresponds to a certain time of day in the
given timezone, returns
-#' another timestamp that corresponds to the same time of day in UTC.
+#' @section Details:
+#' \code{to_utc_timestamp}: Given a timestamp, which corresponds to a
certain time of day
+#' in the given timezone, returns another timestamp that corresponds to
the same time of day in UTC.
#'
-#' @param y Column to compute on
-#' @param x timezone to use
-#'
-#' @family date time functions
-#' @rdname to_utc_timestamp
-#' @name to_utc_timestamp
-#' @aliases to_utc_timestamp,Column,character-method
+#' @rdname column_datetime_diff_functions
+#' @aliases to_utc_timestamp to_utc_timestamp,Column,character-method
#' @export
-#' @examples \dontrun{to_utc_timestamp(df$t, 'PST')}
#' @note to_utc_timestamp since 1.5.0
setMethod("to_utc_timestamp", signature(y = "Column", x = "character"),
function(y, x) {
jc <- callJStatic("org.apache.spark.sql.functions",
"to_utc_timestamp", y@jc, x)
column(jc)
})
-#' add_months
+#' @section Details:
+#' \code{add_months}: Returns the date that is numMonths after startDate.
--- End diff --
Yes, this was the original description. Updated to make it clearer. Also,
the examples now will help users figure out how to use these methods.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123328197
--- Diff: R/pkg/R/functions.R ---
@@ -34,6 +34,58 @@ NULL
#' df <- createDataFrame(cbind(model = rownames(mtcars), mtcars))}
NULL
+#' Date time functions for Column operations
+#'
+#' Date time functions defined for \code{Column}.
+#'
+#' @param x Column to compute on.
+#' @param format For \code{to_date} and \code{to_timestamp}, it is the
string to use to parse
+#' x Column to DateType or TimestampType. For \code{trunc},
it is the string used
+#' for specifying the truncation method. For example,
"year", "", "yy" for
+#' truncate by year, or "month", "mon", "mm" for truncate by
month.
+#' @param ... additional argument(s).
+#' @name column_datetime_functions
+#' @rdname column_datetime_functions
+#' @family data time functions
+#' @examples
+#' \dontrun{
+#' dts <- c("2005-01-02 18:47:22",
+#' "2005-12-24 16:30:58",
+#' "2005-10-28 07:30:05",
+#' "2005-12-28 07:01:05",
+#' "2006-01-24 00:01:10")
+#' y <- c(2.0, 2.2, 3.4, 2.5, 1.8)
+#' df <- createDataFrame(data.frame(time = as.POSIXct(dts), y = y))}
+NULL
+
+#' Date time arithmetic functions for Column operations
+#'
+#' Date time arithmetic functions defined for \code{Column}.
+#'
+#' @param y Column to compute on.
+#' @param x For class Column, it is used to perform arithmetic operations
with \code{y}.
+#' For class numeric, it is the number of months or days to be
added to \code{y}.
--- End diff --
updated. thx
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123328228
--- Diff: R/pkg/R/functions.R ---
@@ -546,18 +598,20 @@ setMethod("hash",
column(jc)
})
-#' dayofmonth
+#' @section Details:
--- End diff --
Done
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123328162
--- Diff: R/pkg/R/functions.R ---
@@ -34,6 +34,58 @@ NULL
#' df <- createDataFrame(cbind(model = rownames(mtcars), mtcars))}
NULL
+#' Date time functions for Column operations
+#'
+#' Date time functions defined for \code{Column}.
+#'
+#' @param x Column to compute on.
+#' @param format For \code{to_date} and \code{to_timestamp}, it is the
string to use to parse
+#' x Column to DateType or TimestampType. For \code{trunc},
it is the string used
--- End diff --
fixed
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 @felixcheung Thanks so much for the review and comments. Super helpful! I fixed all the issues you have pointed out in the new commit. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123327948
--- Diff: R/pkg/R/functions.R ---
@@ -2348,26 +2336,18 @@ setMethod("n", signature(x = "Column"),
count(x)
})
-#' date_format
-#'
-#' Converts a date/timestamp/string to a value of string in the format
specified by the date
-#' format given by the second argument.
-#'
-#' A pattern could be for instance \preformatted{dd.MM.} and could
return a string like '18.03.1993'. All
+#' @section Details:
+#' \code{date_format}: Converts a date/timestamp/string to a value of
string in the format
+#' specified by the date format given by the second argument. A pattern
could be for instance
+#' \code{dd.MM.} and could return a string like '18.03.1993'. All
#' pattern letters of \code{java.text.SimpleDateFormat} can be used.
-#'
#' Note: Use when ever possible specialized functions like \code{year}.
These benefit from a
#' specialized implementation.
#'
-#' @param y Column to compute on.
-#' @param x date format specification.
+#' @rdname column_datetime_diff_functions
#'
-#' @family date time functions
-#' @rdname date_format
-#' @name date_format
-#' @aliases date_format,Column,character-method
+#' @aliases date_format date_format,Column,character-method
#' @export
-#' @examples \dontrun{date_format(df$t, 'MM/dd/yyy')}
--- End diff --
Added back.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r123327963
--- Diff: R/pkg/R/functions.R ---
@@ -1801,29 +1819,18 @@ setMethod("to_json", signature(x = "Column"),
column(jc)
})
-#' to_timestamp
-#'
-#' Converts the column into a TimestampType. You may optionally specify a
format
-#' according to the rules in:
+#' @section Details:
+#' \code{to_timestamp}: Converts the column into a TimestampType. You may
optionally specify
+#' a format according to the rules in:
#'
\url{http://docs.oracle.com/javase/tutorial/i18n/format/simpleDateFormat.html}.
#' If the string cannot be parsed according to the specified format (or
default),
#' the value of the column will be null.
#' By default, it follows casting rules to a TimestampType if the format
is omitted
#' (equivalent to \code{cast(df$x, "timestamp")}).
#'
-#' @param x Column to parse.
-#' @param format string to use to parse x Column to TimestampType.
(optional)
-#'
-#' @rdname to_timestamp
-#' @name to_timestamp
-#' @family date time functions
-#' @aliases to_timestamp,Column,missing-method
+#' @rdname column_datetime_functions
+#' @aliases to_timestamp to_timestamp,Column,missing-method
#' @export
-#' @examples
-#' \dontrun{
-#' to_timestamp(df$c)
-#' to_timestamp(df$c, '-MM-dd')
--- End diff --
Added back.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18367: [SQL][Doc] Fix documentation of lpad
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18367 OK. Updated the doc as suggested. Thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18366: [SPARK-20889][SparkR] Grouped documentation for STRING c...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18366 jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18371: [SPARK-20889][SparkR] Grouped documentation for MATH col...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18371 jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18371: [SPARK-20889][SparkR] Grouped documentation for MATH col...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18371 @felixcheung @HyukjinKwon This one is also fairly straightforward. See screenshots below.   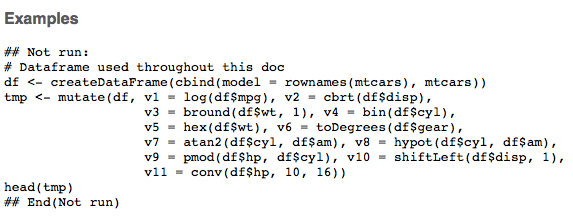 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18371: [SPARK-20889][SparkR] Grouped documentation for M...
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18371 [SPARK-20889][SparkR] Grouped documentation for MATH column methods ## What changes were proposed in this pull request? Grouped documentation for math column methods. You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRDocMath Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18371.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18371 commit 1b8880d2fe31a42949a947668f2d2927a094e941 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-20T21:44:32Z update doc for column math functions commit ee0a1f24c8a6c44770b13e9b805ca56a0bbe7f2f Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-20T21:58:26Z add examples --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18367: [SQL][Doc] Fix documentation of lpad
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18367 jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18367: [SQL][Doc] Fix documentation of lpad
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18367 [SQL][Doc] Fix documentation of lpad ## What changes were proposed in this pull request? Fix incomplete documentation for `lpad`. You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark SQLDoc Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18367.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18367 commit 42df330527663456a698f493ac611025f89e6d45 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-20T19:05:45Z fix doc of lpad --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18366: [SPARK-20889][SparkR] Grouped documentation for STRING c...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18366 @felixcheung @HyukjinKwon This one is pretty straightforward. See the screenshot below.    --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18366: [SPARK-20889][SparkR] Grouped documentation for S...
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18366 [SPARK-20889][SparkR] Grouped documentation for STRING column methods ## What changes were proposed in this pull request? Grouped documentation for string column methods. You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRDocString Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18366.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18366 commit 524c84aba5eeefddb2d139be76924a4cc88ca8de Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-20T06:28:42Z update doc for string functions commit 516a5536eb4b06c0faa8b6f47ca4ee0e36f0699e Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-20T07:42:35Z add examples commit d2c5b8d6993e9292020d19e95b555f1988a1efc4 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-20T17:12:32Z add more examples --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 Oh, great. Did that and checks passed now. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 For the `column_datetime_diff_functions`:   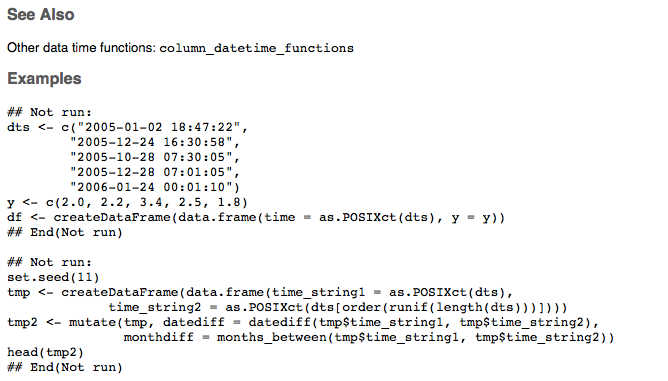 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 For the date time functions, I create two groups: one for arithmetic functions that work with two columns `column_datetime_diff_functions`, and the other for functions that work with only one column `column_datetime_functions`. Below is the screenshot for both.    --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18140: [SPARK-20917][ML][SparkR] SparkR supports string ...
Github user actuaryzhang closed the pull request at: https://github.com/apache/spark/pull/18140 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18140: [SPARK-20917][ML][SparkR] SparkR supports string ...
GitHub user actuaryzhang reopened a pull request: https://github.com/apache/spark/pull/18140 [SPARK-20917][ML][SparkR] SparkR supports string encoding consistent with R ## What changes were proposed in this pull request? Add `stringIndexerOrderType` to `spark.glm` and `spark.survreg` to support string encoding that is consistent with default R. ## How was this patch tested? new tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRFormula Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18140.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18140 commit aba1429c48580ed19ae0a653830d065c681b7150 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-28T01:39:51Z add stringIndexerOrderType to SparkR glm and test result consistency with R commit 49e50849ac7566aad9eb251535a29a59b659a68a Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-30T01:36:39Z add stringIndexerOrderType to survreg commit cdc6c377ada3187111cdf984e8cd595ba78b69dc Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-30T02:52:22Z fix test commit 18cbeb79b7cbf12a6d77110673312b82edbed92a Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-30T07:39:49Z address comments on doc commit 6ae4d56592aef607a9e6d29b11fbb703bc4b971c Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-31T16:50:44Z add match arg commit 3c1b85eb4db97723576927a2f972543c7ae69678 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-31T18:31:43Z add match arg in survreg commit f33d0eafa5fc2a0b806c7016b42574045c3261af Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-19T17:08:10Z address comments --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 How do I do that? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 OK. Updated the doc for the cov method for SparkDataFrame. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 Thanks for the comments. Fixed them all in the new commit. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 This is how the doc for column_aggregate_functions looks like (only snapshot of the main parts): 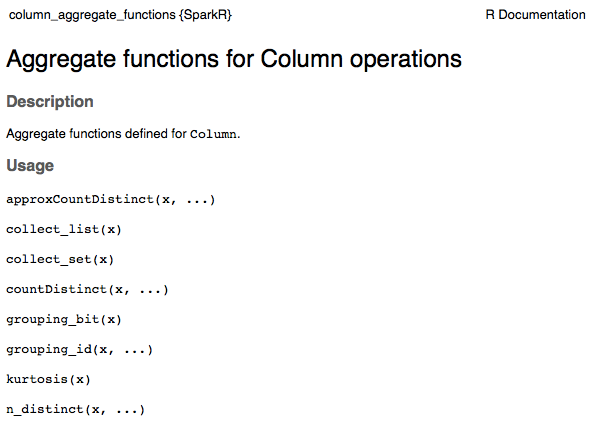   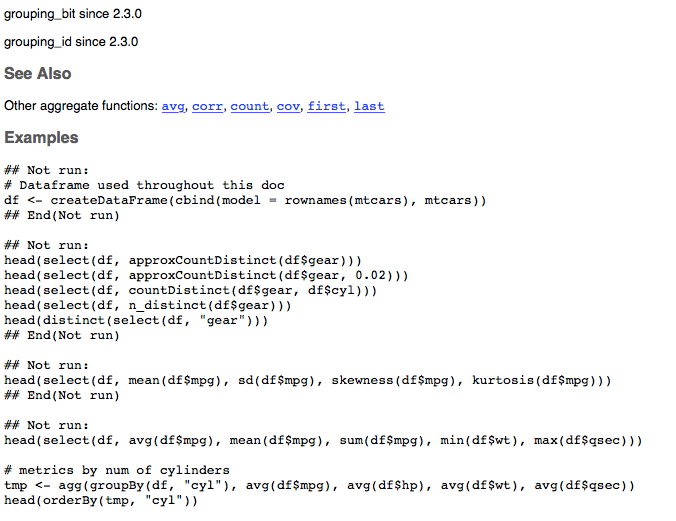 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122617531
--- Diff: R/pkg/R/stats.R ---
@@ -52,22 +52,17 @@ setMethod("crosstab",
collect(dataFrame(sct))
})
-#' Calculate the sample covariance of two numerical columns of a
SparkDataFrame.
-#'
#' @param colName1 the name of the first column
#' @param colName2 the name of the second column
-#' @return The covariance of the two columns.
--- End diff --
OK. I added this back. The doc should be very clear even without this
return value. Indeed, most functions do not document return value in SparkR.
See what it looks like in the image attached in the next comment.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122617405
--- Diff: R/pkg/R/stats.R ---
@@ -52,22 +52,17 @@ setMethod("crosstab",
collect(dataFrame(sct))
})
-#' Calculate the sample covariance of two numerical columns of a
SparkDataFrame.
-#'
#' @param colName1 the name of the first column
#' @param colName2 the name of the second column
-#' @return The covariance of the two columns.
#'
#' @rdname cov
-#' @name cov
#' @aliases cov,SparkDataFrame-method
#' @family stat functions
#' @export
#' @examples
-#'\dontrun{
-#' df <- read.json("/path/to/file.json")
-#' cov <- cov(df, "title", "gender")
-#' }
+#'
+#' \dontrun{
--- End diff --
No. The newline should be between `@example` and `\dontrun` to separate
multiple `dontruns`.

---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122616787
--- Diff: R/pkg/R/stats.R ---
@@ -52,22 +52,17 @@ setMethod("crosstab",
collect(dataFrame(sct))
})
-#' Calculate the sample covariance of two numerical columns of a
SparkDataFrame.
--- End diff --
The method for SparkDataFrame is still there. I'm just removing redundant
doc here.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122609690
--- Diff: R/pkg/R/functions.R ---
@@ -361,10 +361,13 @@ setMethod("column",
#'
#' @rdname corr
#' @name corr
-#' @family math functions
+#' @family aggregate functions
#' @export
#' @aliases corr,Column-method
-#' @examples \dontrun{corr(df$c, df$d)}
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(cbind(model = rownames(mtcars), mtcars))
--- End diff --
this one does not need the extra newline since it's in its own Rd and there
are no examples before it.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 @felixcheung It's up to date now. Any additional comments on this one? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18291: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18291 @felixcheung Anything else needed for this PR? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 @HyukjinKwon Thanks for catching this. They were incorrectly labeled as math functions instead of aggregate functions in SparkR. And that's why I did not change them. New commit fixed this now. Note they are still documented in their own Rd because there is also a method defined for SparkDataFrame. I made some cleaning and updated the example to be runnable. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 @felixcheung Could you take another look and let me know if there is anything else needed? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 @felixcheung Your comments are all addressed now. Please let me know if there is anything else needed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122358689
--- Diff: R/pkg/R/generics.R ---
@@ -919,10 +920,9 @@ setGeneric("array_contains", function(x, value) {
standardGeneric("array_contain
#' @export
setGeneric("ascii", function(x) { standardGeneric("ascii") })
-#' @param x Column to compute on or a GroupedData object.
--- End diff --
In this case, we will have to document `avg` on its own, like `count`,
`first` and `last`. I cannot document the `x` param here since it will show up
in the doc for the column class. Interestingly, there is not even a doc of the
`avg` method from the `GroupedData` class
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122356625
--- Diff: R/pkg/R/generics.R ---
@@ -1403,20 +1416,25 @@ setGeneric("unix_timestamp", function(x, format) {
standardGeneric("unix_timesta
#' @export
setGeneric("upper", function(x) { standardGeneric("upper") })
-#' @rdname var
+#' @rdname column_aggregate_functions
+#' @param y,na.rm,use currently not used.
--- End diff --
Good point. Moved to `column_aggregate_functions`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122322352
--- Diff: R/pkg/R/functions.R ---
@@ -2254,18 +2198,12 @@ setMethod("approxCountDistinct",
column(jc)
})
-#' Count Distinct Values
+#' @section Details:
+#' \code{countDistinct}: Returns the number of distinct items in a group.
#'
-#' @param x Column to compute on
-#' @param ... other columns
--- End diff --
I agree it is less clear, but the impact is very minor if we have examples
to illustrate passing additional columns. I now updated the doc of the argument
as
`#' @param ... additional argument(s). For example, it could be used to
pass additional Columns. `
And update the example to have multiple columns:
`head(select(df, countDistinct(df$gear, df$cyl)))`
Do the above changes address your concern?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122318874
--- Diff: R/pkg/R/functions.R ---
@@ -85,17 +100,20 @@ setMethod("acos",
column(jc)
})
-#' Returns the approximate number of distinct items in a group
+#' @section Details:
+#' \code{approxCountDistinct}: Returns the approximate number of distinct
items in a group.
#'
-#' Returns the approximate number of distinct items in a group. This is a
column
-#' aggregate function.
-#'
-#' @rdname approxCountDistinct
-#' @name approxCountDistinct
-#' @return the approximate number of distinct items in a group.
+#' @rdname column_aggregate_functions
#' @export
-#' @aliases approxCountDistinct,Column-method
-#' @examples \dontrun{approxCountDistinct(df$c)}
+#' @aliases approxCountDistinct approxCountDistinct,Column-method
+#' @examples
+#'
--- End diff --
Yes, this newline is needed to separate blocks of examples.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r122312290
--- Diff: R/pkg/R/functions.R ---
@@ -85,17 +100,20 @@ setMethod("acos",
column(jc)
})
-#' Returns the approximate number of distinct items in a group
+#' @section Details:
--- End diff --
Yes, changed. Thanks for the suggestion.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18291: [SPARK-20892][SparkR] Add SQL trunc function to S...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18291#discussion_r122298526
--- Diff: R/pkg/NAMESPACE ---
@@ -357,6 +357,7 @@ exportMethods("%<=>%",
"to_utc_timestamp",
"translate",
"trim",
+ "trunc",
--- End diff --
And yes, it doesn't mask base. You can still do `trunc(10.5)`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18291: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18291 Added your suggested change. Thanks! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18291: [SPARK-20892][SparkR] Add SQL trunc function to S...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18291#discussion_r122270206
--- Diff: R/pkg/NAMESPACE ---
@@ -357,6 +357,7 @@ exportMethods("%<=>%",
"to_utc_timestamp",
"translate",
"trim",
+ "trunc",
--- End diff --
It is part of the internally S4 methods and there is already generics.
This is similar to math functions like `abs`.
https://stat.ethz.ch/R-manual/R-devel/library/base/html/groupGeneric.html
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18291: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18291 jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18291: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18291 @felixcheung @zero323 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18116: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18116 Sorry, I messed up git. Close and reopen in another PR. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18291: [SPARK-20892][SparkR] Add SQL trunc function to S...
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18291 [SPARK-20892][SparkR] Add SQL trunc function to SparkR ## What changes were proposed in this pull request? Add SQL trunc function ## How was this patch tested? standard test You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRTrunc2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18291.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18291 commit ef70cee9a64c0d2e274cf228e27723083dbd691e Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-06-13T17:00:27Z add trunc function to SparkR SQL --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18116: [SPARK-20892][SparkR] Add SQL trunc function to S...
Github user actuaryzhang closed the pull request at: https://github.com/apache/spark/pull/18116 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 @HyukjinKwon Thanks much for the review. New commit now fixes the issues you pointed out. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r119538499
--- Diff: R/pkg/R/functions.R ---
@@ -1630,18 +1609,12 @@ setMethod("sqrt",
column(jc)
})
-#' sum
-#'
-#' Aggregate function: returns the sum of all values in the expression.
+#' @section Details:
+#' \code{sum}: Returns the sum of all values in the expression.
#'
-#' @param x Column to compute on.
-#'
-#' @rdname sum
-#' @name sum
-#' @family aggregate functions
-#' @aliases sum,Column-method
+#' @rdname column_aggregate_functions
+#' @aliases sum sum,Column-method
#' @export
-#' @examples \dontrun{sum(df$c)}
--- End diff --
Good catch. Added to example.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r119538471
--- Diff: R/pkg/R/functions.R ---
@@ -1081,19 +1098,12 @@ setMethod("md5",
column(jc)
})
-#' mean
-#'
-#' Aggregate function: returns the average of the values in a group.
-#' Alias for avg.
-#'
-#' @param x Column to compute on.
+#' @section Details:
+#' \code{mean}: Returns the average of the values in a group. Alias for
avg.
--- End diff --
Fixed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 Thanks for the update. Look forward to your feedback. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 @felixcheung Yes, the first one is the default. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18140: [SPARK-20917][ML][SparkR] SparkR supports string ...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18140#discussion_r119438348
--- Diff: R/pkg/R/mllib_regression.R ---
@@ -110,7 +125,8 @@ setClass("IsotonicRegressionModel", representation(jobj
= "jobj"))
#' @seealso \link{glm}, \link{read.ml}
setMethod("spark.glm", signature(data = "SparkDataFrame", formula =
"formula"),
function(data, formula, family = gaussian, tol = 1e-6, maxIter =
25, weightCol = NULL,
- regParam = 0.0, var.power = 0.0, link.power = 1.0 -
var.power) {
+ regParam = 0.0, var.power = 0.0, link.power = 1.0 -
var.power,
+ stringIndexerOrderType = "frequencyDesc") {
--- End diff --
I see. Added argument matching in the new commit.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 Simple example to illustrate: ``` > df <- createDataFrame(as.data.frame(Titanic, stringsAsFactors = FALSE)) > rModel <- stats::glm(Freq ~ Sex + Age, family = "gaussian", data = as.data.frame(df)) > summary(rModel)$coefficients Estimate Std. Error t valuePr(>|t|) (Intercept) 91.34375 35.99417 2.537737 0.016790098 SexMale 78.81250 41.56249 1.896241 0.067931094 AgeChild-123.93750 41.56249 -2.981956 0.005752153 > model <- spark.glm(df, Freq ~ Sex + Age, family = "gaussian") > summary(model)$coefficients Estimate Std. Errort valuePr(>|t|) (Intercept) -32.59375 35.99417 -0.9055286 0.372647658 Sex_Male 78.81250 41.56249 1.8962412 0.067931094 Age_Adult 123.93750 41.56249 2.9819558 0.005752153 > model2 <- spark.glm(df, Freq ~ Sex + Age, family = "gaussian", + stringIndexerOrderType = "alphabetDesc") > summary(model2)$coefficients Estimate Std. Error t valuePr(>|t|) (Intercept) 91.34375 35.99417 2.537737 0.016790098 Sex_Male 78.81250 41.56249 1.896241 0.067931094 Age_Child -123.93750 41.56249 -2.981956 0.005752153 ``` --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18140: [SPARK-20917][ML][SparkR] SparkR supports string ...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18140#discussion_r119285081
--- Diff: R/pkg/inst/tests/testthat/test_mllib_regression.R ---
@@ -379,6 +379,49 @@ test_that("glm save/load", {
unlink(modelPath)
})
+test_that("spark.glm and glm with string encoding", {
--- End diff --
Added. Thank you!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18116: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18116 Thanks @zero323. Anything else needed for this one? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18116: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18116 @dongjoon-hyun Thanks for pointing this out. Fixed now. I thought the `@export` tag will instruct roxygen to export this method automatically in the namespace. Or was this namespace file always manually edited? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18140: [SPARK-20917][ML][SparkR] SparkR supports string ...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18140#discussion_r119029879
--- Diff: R/pkg/R/mllib_regression.R ---
@@ -110,7 +125,8 @@ setClass("IsotonicRegressionModel", representation(jobj
= "jobj"))
#' @seealso \link{glm}, \link{read.ml}
setMethod("spark.glm", signature(data = "SparkDataFrame", formula =
"formula"),
function(data, formula, family = gaussian, tol = 1e-6, maxIter =
25, weightCol = NULL,
- regParam = 0.0, var.power = 0.0, link.power = 1.0 -
var.power) {
+ regParam = 0.0, var.power = 0.0, link.power = 1.0 -
var.power,
+ stringIndexerOrderType = "frequencyDesc") {
--- End diff --
I don't think there are corresponding R options for this. One can convert
the string into a factor and manipulate the factor easily. It's just the
default approach is dropping the first alphabetical category.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 Thanks for the comments. Addressed them in the new commit. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18140: [SPARK-20917][ML][SparkR] SparkR supports string encodin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18140 @felixcheung Please take a look. Thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18122: [SPARK-20899][PySpark] PySpark supports stringIndexerOrd...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18122 @yanboliang I have moved the tests to the test file. Please let me know if there is anything else needed. Thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18140: Spark r formula
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18140 Spark r formula ## What changes were proposed in this pull request? Add `stringIndexerOrderType` to `spark.glm` and `spark.survreg` to support string encoding that is consistent with default R. ## How was this patch tested? new tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRFormula Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18140.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18140 commit be7a0fb993ad1fbe60576cd39ca86b20d45289a6 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-28T01:39:51Z add stringIndexerOrderType to SparkR glm and test result consistency with R commit 826e784e3bf83c3b9a84fc7d9500d15971a7ffd8 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-30T01:36:39Z add stringIndexerOrderType to survreg --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 Jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 @felixcheung The new commit addresses your concern by splitting methods with two arguments into a separate doc. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for D...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r118803557
--- Diff: R/pkg/R/functions.R ---
@@ -2095,26 +2061,28 @@ setMethod("atan2", signature(y = "Column"),
column(jc)
})
-#' datediff
+#' @section Details:
+#' \code{datediff}: Returns the number of days from \code{start} to
\code{end}.
#'
-#' Returns the number of days from \code{start} to \code{end}.
-#'
-#' @param x start Column to use.
-#' @param y end Column to use.
--- End diff --
@felixcheung These names `start` and `end` are from the original doc. I now
changed it to `x` and `y`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18122: [SPARK-20899][PySpark] PySpark supports stringInd...
Github user actuaryzhang commented on a diff in the pull request: https://github.com/apache/spark/pull/18122#discussion_r118796569 --- Diff: python/pyspark/ml/feature.py --- @@ -3043,26 +3055,35 @@ class RFormula(JavaEstimator, HasFeaturesCol, HasLabelCol, JavaMLReadable, JavaM "Force to index label whether it is numeric or string", typeConverter=TypeConverters.toBoolean) +stringIndexerOrderType = Param(Params._dummy(), "stringIndexerOrderType", + "How to order categories of a string FEATURE column used by " + --- End diff -- Changed it to lower case now. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18122: [SPARK-20899][PySpark] PySpark supports stringInd...
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18122 [SPARK-20899][PySpark] PySpark supports stringIndexerOrderType in RFormula ## What changes were proposed in this pull request? PySpark supports stringIndexerOrderType in RFormula as in #17967. ## How was this patch tested? docstring test You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark PythonRFormula Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18122.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18122 commit 4bca4d95613e6e18361de8fe0a36667182c2d446 Author: actuaryzhang <actuaryzhan...@gmail.com> Date: 2017-05-26T07:40:22Z Pyhton port for Rformula stringIndexerOrderType --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18122: [SPARK-20899][PySpark] PySpark supports stringIndexerOrd...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18122 @felixcheung @yanboliang @viirya --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR] Grouped documentation for AGGREGAT...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 Jenkins, retest this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18025: [SPARK-20889][SparkR] Grouped documentation for A...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18025#discussion_r118643715
--- Diff: R/pkg/R/generics.R ---
@@ -1403,20 +1416,25 @@ setGeneric("unix_timestamp", function(x, format) {
standardGeneric("unix_timesta
#' @export
setGeneric("upper", function(x) { standardGeneric("upper") })
-#' @rdname var
+#' @rdname column_aggregate_functions
+#' @param y,na.rm,use currently not used.
--- End diff --
Good catch. But I think this one makes more sense to stay here because all
these arguments are specific to the `var` generic, which is not used anywhere
else. I moved the `...` in `avg` to `column_aggregate_functions` to avoid
duplicated doc for `...`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for DATETIME...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 @felixcheung Thank you. This is great suggestion. I will split it into two help files which should make the doc much cleaner without changing the functions. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18116: [SPARK-20892][SparkR] Add SQL trunc function to S...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18116#discussion_r118634921
--- Diff: R/pkg/R/functions.R ---
@@ -4015,3 +4015,29 @@ setMethod("input_file_name", signature("missing"),
jc <- callJStatic("org.apache.spark.sql.functions",
"input_file_name")
column(jc)
})
+
+#' trunc
+#'
+#' Returns date truncated to the unit specified by the format.
+#'
+#' @param x Column to compute on.
+#' @param format string used for specify the truncation method. For
example, "year", "",
+#' "yy" for truncate by year, or "month", "mon", "mm" for truncate by
month.
+#'
+#' @rdname trunc
+#' @name trunc
+#' @family date time functions
+#' @aliases trunc,Column-method
+#' @export
+#' @examples
+#' \dontrun{
+#' trunc(df$c, "year")
+#' trunc(df$c, "month")
+#' }
+#' @note trunc since 2.3.0
+setMethod("trunc",
+ signature(x = "Column"),
+ function(x, format = "year") {
--- End diff --
Sure. Removed the default value.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18116: [SPARK-20892][SparkR] Add SQL trunc function to S...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18116#discussion_r118634873
--- Diff: R/pkg/inst/tests/testthat/test_sparkSQL.R ---
@@ -1404,6 +1404,8 @@ test_that("column functions", {
c20 <- to_timestamp(c) + to_timestamp(c, "") + to_date(c, "")
c21 <- posexplode_outer(c) + explode_outer(c)
c22 <- not(c)
+ c23 <- trunc(c) + trunc(c, "year") + trunc(c, "") + trunc(c, "yy") +
--- End diff --
Got it. Thank you!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18116: [SPARK-20892][SparkR] Add SQL trunc function to S...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18116#discussion_r118612551
--- Diff: R/pkg/inst/tests/testthat/test_sparkSQL.R ---
@@ -1404,6 +1404,8 @@ test_that("column functions", {
c20 <- to_timestamp(c) + to_timestamp(c, "") + to_date(c, "")
c21 <- posexplode_outer(c) + explode_outer(c)
c22 <- not(c)
+ c23 <- trunc(c) + trunc(c, "year") + trunc(c, "") + trunc(c, "yy") +
--- End diff --
Not sure what this does. Is this the current test for these SQL functions?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18116: [SPARK-20892][SparkR] Add SQL trunc function
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18116 [SPARK-20892][SparkR] Add SQL trunc function ## What changes were proposed in this pull request? Add SQL trunc function ## How was this patch tested? standard test You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRTrunc Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18116.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18116 commit 95e032c9c3d71aa9095c8193361f3eefb91e9a0c Author: Wayne Zhang <actuaryzh...@uber.com> Date: 2017-05-26T00:09:12Z add SQL trunc function --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18116: [SPARK-20892][SparkR] Add SQL trunc function to SparkR
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18116 @felixcheung @wangmiao1981 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for d...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r118605422
--- Diff: R/pkg/R/functions.R ---
@@ -2476,24 +2430,27 @@ setMethod("from_json", signature(x = "Column",
schema = "structType"),
column(jc)
})
-#' from_utc_timestamp
+#' @section Details:
+#' \code{from_utc_timestamp}: Given a timestamp, which corresponds to a
certain time of day in UTC,
+#' returns another timestamp that corresponds to the same time of day in
the given timezone.
#'
-#' Given a timestamp, which corresponds to a certain time of day in UTC,
returns another timestamp
-#' that corresponds to the same time of day in the given timezone.
+#' @rdname column_datetime_functions
#'
-#' @param y Column to compute on.
-#' @param x time zone to use.
-#'
-#' @family date time functions
-#' @rdname from_utc_timestamp
-#' @name from_utc_timestamp
-#' @aliases from_utc_timestamp,Column,character-method
+#' @aliases from_utc_timestamp from_utc_timestamp,Column,character-method
#' @export
-#' @examples \dontrun{from_utc_timestamp(df$t, 'PST')}
+#' @examples
+#'
+#' \dontrun{
+#' tmp <- mutate(df, from_utc = from_utc_timestamp(df$time, 'PST'),
+#' to_utc = to_utc_timestamp(df$time, 'PST'),
+#' to_unix = unix_timestamp(df$time),
+#' to_unix2 = unix_timestamp(df$time, '-MM-dd HH'),
+#' from_unix = from_unixtime(unix_timestamp(df$time)))
+#' head(tmp)}
#' @note from_utc_timestamp since 1.5.0
-setMethod("from_utc_timestamp", signature(y = "Column", x = "character"),
- function(y, x) {
-jc <- callJStatic("org.apache.spark.sql.functions",
"from_utc_timestamp", y@jc, x)
+setMethod("from_utc_timestamp", signature(x = "Column", tz = "character"),
+ function(x, tz) {
--- End diff --
Changed the second argument to `tz` to be consistent with Scala, which also
makes it less confusing in the doc since other methods also have `y` as
argument.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for d...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/18114#discussion_r118605244
--- Diff: R/pkg/R/functions.R ---
@@ -2095,26 +2061,28 @@ setMethod("atan2", signature(y = "Column"),
column(jc)
})
-#' datediff
+#' @section Details:
+#' \code{datediff}: Returns the number of days from \code{start} to
\code{end}.
#'
-#' Returns the number of days from \code{start} to \code{end}.
-#'
-#' @param x start Column to use.
-#' @param y end Column to use.
-#'
-#' @rdname datediff
-#' @name datediff
-#' @aliases datediff,Column-method
-#' @family date time functions
+#' @rdname column_datetime_functions
+#' @aliases datediff datediff,Column-method
#' @export
-#' @examples \dontrun{datediff(df$c, x)}
+#' @examples
+#'
+#' \dontrun{
+#' set.seed(11)
+#' tmp <- createDataFrame(data.frame(time_string1 = as.POSIXct(dts),
+#' time_string2 = as.POSIXct(dts[order(runif(length(dts)))])))
+#' tmp2 <- mutate(tmp, timediff = datediff(tmp$time_string1,
tmp$time_string2),
+#'monthdiff = months_between(tmp$time_string1,
tmp$time_string2))
+#' head(tmp2)}
#' @note datediff since 1.5.0
-setMethod("datediff", signature(y = "Column"),
- function(y, x) {
-if (class(x) == "Column") {
- x <- x@jc
+setMethod("datediff", signature(x = "Column"),
+ function(x, y) {
--- End diff --
Here, `x` and `y` are reversed for easy documentation. Similarly for other
methods that take two arguments.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18114: [SPARK-20889][SparkR] Grouped documentation for datetime...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18114 @felixcheung Created this PR to update the doc for the date time methods, similar to #18114. About 27 date time methods are documented into one page. I'm attaching the snapshot of part of the new help page.    --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18114: [SPARK-20889][SparkR] Grouped documentation for d...
GitHub user actuaryzhang opened a pull request: https://github.com/apache/spark/pull/18114 [SPARK-20889][SparkR] Grouped documentation for datetime column methods ## What changes were proposed in this pull request? Grouped documentation for datetime column methods. You can merge this pull request into a Git repository by running: $ git pull https://github.com/actuaryzhang/spark sparkRDocDate Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18114.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18114 commit 2c2fa800bb0f4c7f2503a08a9565a8b9ac135d69 Author: Wayne Zhang <actuaryzh...@uber.com> Date: 2017-05-25T21:07:20Z start working on datetime functions commit 0d2853d0cff6cbd92fcbb68cebaee0729d25eb8f Author: Wayne Zhang <actuaryzh...@uber.com> Date: 2017-05-25T22:07:57Z fix issue in generics and example --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17864: [SPARK-20604][ML] Allow imputer to handle numeric...
Github user actuaryzhang commented on a diff in the pull request:
https://github.com/apache/spark/pull/17864#discussion_r118600408
--- Diff: mllib/src/main/scala/org/apache/spark/ml/feature/Imputer.scala ---
@@ -94,12 +94,13 @@ private[feature] trait ImputerParams extends Params
with HasInputCols {
* :: Experimental ::
* Imputation estimator for completing missing values, either using the
mean or the median
* of the columns in which the missing values are located. The input
columns should be of
- * DoubleType or FloatType. Currently Imputer does not support categorical
features
+ * numeric type. Currently Imputer does not support categorical features
* (SPARK-15041) and possibly creates incorrect values for a categorical
feature.
*
* Note that the mean/median value is computed after filtering out missing
values.
* All Null values in the input columns are treated as missing, and so are
also imputed. For
* computing median, DataFrameStatFunctions.approxQuantile is used with a
relative error of 0.001.
+ * The output column is always of Double type regardless of the input
column type.
--- End diff --
@MLnick Here is the note on always returning Double type.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17864: [SPARK-20604][ML] Allow imputer to handle numeric types
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/17864 @MLnick Thanks much for your comments. Yes, I think always returning Double is consistent with Python and R and also other transformers in ML. Plus, as @hhbyyh mentioned, this makes the implementation easier. Would you mind taking a look at the code and let me know if there is any suggestion for improvement? The doc is already updated to make it clear that it always returns Double regardless of the input type. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18051: [SPARK-18825][SPARKR][DOCS][WIP] Eliminate duplicate lin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18051 That makes sense! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18051: [SPARK-18825][SPARKR][DOCS][WIP] Eliminate duplicate lin...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18051 @zero323 I really like your thoughts on the docs. As @felixcheung mentioned above, we are doing some cleaning in #18025, which will improve readability and fix the SeeAlso issue. Regarding making the examples runnable, I would really like to do that. This is not an issue for Jenkins since the examples are tiny. However, that will increase the cran check time significantly and I'm not sure CRAN will allow that. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [SPARK-20889][SparkR][WIP] Grouped documentation for agg...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 Opened a JIRA. We would need several PRs to fix all doc issues. Also, not sure why Jenkins failed as the error msg is not clear and all tests passed on my computer. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [WIP][SparkR] Grouped documentation for sql functions
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 @felixcheung All comments are addressed now and I think this is ready for review. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [WIP][SparkR] Grouped documentation for sql functions
Github user actuaryzhang commented on the issue:
https://github.com/apache/spark/pull/18025
- New commit now resolves the Name issue. `@title` does not work, which is
the header in the second line `\title{Aggregate functions for Column
operations}`. The solution is to use `@name NULL` for the generics. Now we
have:

- Also added several more practical examples. But most of these functions
are very straightforward to use.

---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18025: [WIP][SparkR] Grouped documentation for sql functions
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/18025 @felixcheung - The links to `stddev_samp` etc are already removed in the latest commit. - About collecting all the example into one, I think that'll work for this particular one. But I'm not sure about this in general. These methods are still spread out in `.R` file. And if we decide to change the grouping of these functions later on, it will be very difficult if we don't have examples in those methods. - For a method that is defined for multiple classes but meaning are drastically different, I agree that it's best to document by class. One downside is a generic `?coalesce` can only go to one help page, e.g., the help for SparkDataFrame, not the other classed. However, we can add links to the `coalesce` methods for the other classes in the `SeeAlso` section. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17967: [SPARK-14659][ML] RFormula consistent with R when handli...
Github user actuaryzhang commented on the issue: https://github.com/apache/spark/pull/17967 @felixcheung @yanboliang I'm fine with either the ascii table or the html table. It's your call. Hope to get over this minor doc issue and get this PR in soon. I can update the doc later if we find a better way. Thanks much. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org