[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199286570
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingLimitExec.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.execution.streaming
+
+import java.util.concurrent.TimeUnit.NANOSECONDS
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow
+import org.apache.spark.sql.catalyst.expressions.UnsafeProjection
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+import org.apache.spark.sql.execution.streaming.state.StateStoreOps
+import org.apache.spark.sql.types.{LongType, NullType, StructField,
StructType}
+import org.apache.spark.util.CompletionIterator
+
+/**
+ * A physical operator for executing a streaming limit, which makes sure
no more than streamLimit
+ * rows are returned.
+ */
+case class StreamingLimitExec(
+streamLimit: Long,
+child: SparkPlan,
+stateInfo: Option[StatefulOperatorStateInfo] = None)
+ extends UnaryExecNode with StateStoreWriter {
+
+ private val keySchema = StructType(Array(StructField("key", NullType)))
+ private val valueSchema = StructType(Array(StructField("value",
LongType)))
+
+ override protected def doExecute(): RDD[InternalRow] = {
+metrics // force lazy init at driver
+
+child.execute().mapPartitionsWithStateStore(
+ getStateInfo,
+ keySchema,
+ valueSchema,
+ indexOrdinal = None,
+ sqlContext.sessionState,
+ Some(sqlContext.streams.stateStoreCoordinator)) { (store, iter) =>
+ val key = UnsafeProjection.create(keySchema)(new
GenericInternalRow(Array[Any](null)))
+ val numOutputRows = longMetric("numOutputRows")
+ val numUpdatedStateRows = longMetric("numUpdatedStateRows")
+ val allUpdatesTimeMs = longMetric("allUpdatesTimeMs")
+ val commitTimeMs = longMetric("commitTimeMs")
+ val updatesStartTimeNs = System.nanoTime
+
+ val startCount: Long =
Option(store.get(key)).map(_.getLong(0)).getOrElse(0L)
+ var rowCount = startCount
+
+ val result = iter.filter { r =>
+val x = rowCount < streamLimit
--- End diff --
Oh and we should be planning a `LocalLimit` before this and perhaps
`GlobalStreamingLimitExec` would be a better name to make the functionality
obvious.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199286349
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingLimitExec.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.execution.streaming
+
+import java.util.concurrent.TimeUnit.NANOSECONDS
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow
+import org.apache.spark.sql.catalyst.expressions.UnsafeProjection
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+import org.apache.spark.sql.execution.streaming.state.StateStoreOps
+import org.apache.spark.sql.types.{LongType, NullType, StructField,
StructType}
+import org.apache.spark.util.CompletionIterator
+
+/**
+ * A physical operator for executing a streaming limit, which makes sure
no more than streamLimit
+ * rows are returned.
+ */
+case class StreamingLimitExec(
+streamLimit: Long,
+child: SparkPlan,
+stateInfo: Option[StatefulOperatorStateInfo] = None)
+ extends UnaryExecNode with StateStoreWriter {
+
+ private val keySchema = StructType(Array(StructField("key", NullType)))
+ private val valueSchema = StructType(Array(StructField("value",
LongType)))
+
+ override protected def doExecute(): RDD[InternalRow] = {
+metrics // force lazy init at driver
+
+child.execute().mapPartitionsWithStateStore(
+ getStateInfo,
+ keySchema,
+ valueSchema,
+ indexOrdinal = None,
+ sqlContext.sessionState,
+ Some(sqlContext.streams.stateStoreCoordinator)) { (store, iter) =>
+ val key = UnsafeProjection.create(keySchema)(new
GenericInternalRow(Array[Any](null)))
+ val numOutputRows = longMetric("numOutputRows")
+ val numUpdatedStateRows = longMetric("numUpdatedStateRows")
+ val allUpdatesTimeMs = longMetric("allUpdatesTimeMs")
+ val commitTimeMs = longMetric("commitTimeMs")
+ val updatesStartTimeNs = System.nanoTime
+
+ val startCount: Long =
Option(store.get(key)).map(_.getLong(0)).getOrElse(0L)
+ var rowCount = startCount
+
+ val result = iter.filter { r =>
+val x = rowCount < streamLimit
--- End diff --
I think its okay due to `override def requiredChildDistribution:
Seq[Distribution] = AllTuples :: Nil`.
+1 to making sure there are tests with more than one partition though.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199279042
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingLimitExec.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.execution.streaming
+
+import java.util.concurrent.TimeUnit.NANOSECONDS
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow
+import org.apache.spark.sql.catalyst.expressions.UnsafeProjection
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+import org.apache.spark.sql.execution.streaming.state.StateStoreOps
+import org.apache.spark.sql.types.{LongType, NullType, StructField,
StructType}
+import org.apache.spark.util.CompletionIterator
+
+/**
+ * A physical operator for executing a streaming limit, which makes sure
no more than streamLimit
+ * rows are returned.
+ */
+case class StreamingLimitExec(
+streamLimit: Long,
+child: SparkPlan,
+stateInfo: Option[StatefulOperatorStateInfo] = None)
+ extends UnaryExecNode with StateStoreWriter {
+
+ private val keySchema = StructType(Array(StructField("key", NullType)))
+ private val valueSchema = StructType(Array(StructField("value",
LongType)))
+
+ override protected def doExecute(): RDD[InternalRow] = {
+metrics // force lazy init at driver
--- End diff --
Existing: Do we really do this in every operator? Why isn't this the
responsibility of the parent class?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199280992
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamSuite.scala ---
@@ -615,7 +615,7 @@ class StreamSuite extends StreamTest {
// Get an existing checkpoint generated by Spark v2.1.
// v2.1 does not record # shuffle partitions in the offset metadata.
val resourceUri =
-
this.getClass.getResource("/structured-streaming/checkpoint-version-2.1.0").toURI
+
this.getClass.getResource("/structured-streaming/checkpoint-version-2.1.0").toURI
--- End diff --
I'd undo these spurious changes.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199278369
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala ---
@@ -72,6 +72,8 @@ abstract class SparkStrategies extends
QueryPlanner[SparkPlan] {
case Limit(IntegerLiteral(limit), Project(projectList, Sort(order,
true, child)))
if limit < conf.topKSortFallbackThreshold =>
TakeOrderedAndProjectExec(limit, order, projectList,
planLater(child)) :: Nil
+case Limit(IntegerLiteral(limit), child) if plan.isStreaming =>
+ StreamingLimitExec(limit, planLater(child)) :: Nil
--- End diff --
I would create a different one only to continue the pattern of isolating
streaming specific Strategies. You'll then need to inject your new Strategy in
`IncrementalExecution`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199278041
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala
---
@@ -315,8 +315,10 @@ object UnsupportedOperationChecker {
case GroupingSets(_, _, child, _) if child.isStreaming =>
throwError("GroupingSets is not supported on streaming
DataFrames/Datasets")
-case GlobalLimit(_, _) | LocalLimit(_, _) if
subPlan.children.forall(_.isStreaming) =>
- throwError("Limits are not supported on streaming
DataFrames/Datasets")
+case GlobalLimit(_, _) | LocalLimit(_, _) if
+ subPlan.children.forall(_.isStreaming) && outputMode ==
InternalOutputModes.Update =>
--- End diff --
It is today (though as we discussed I think the query planner would be a
better place if we were to rearchitect).
Style nit: line break at the high syntactic level (i.e. before the if) and
indent 4 space for a continuation like this (to distinguish the guard from the
code executed when matched.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199278862
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingLimitExec.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.execution.streaming
+
+import java.util.concurrent.TimeUnit.NANOSECONDS
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow
+import org.apache.spark.sql.catalyst.expressions.UnsafeProjection
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+import org.apache.spark.sql.execution.streaming.state.StateStoreOps
+import org.apache.spark.sql.types.{LongType, NullType, StructField,
StructType}
+import org.apache.spark.util.CompletionIterator
+
+/**
+ * A physical operator for executing a streaming limit, which makes sure
no more than streamLimit
+ * rows are returned.
+ */
+case class StreamingLimitExec(
+streamLimit: Long,
+child: SparkPlan,
+stateInfo: Option[StatefulOperatorStateInfo] = None)
+ extends UnaryExecNode with StateStoreWriter {
+
+ private val keySchema = StructType(Array(StructField("key", NullType)))
+ private val valueSchema = StructType(Array(StructField("value",
LongType)))
+
+ override protected def doExecute(): RDD[InternalRow] = {
+metrics // force lazy init at driver
+
+child.execute().mapPartitionsWithStateStore(
+ getStateInfo,
+ keySchema,
+ valueSchema,
+ indexOrdinal = None,
+ sqlContext.sessionState,
+ Some(sqlContext.streams.stateStoreCoordinator)) { (store, iter) =>
+ val key = UnsafeProjection.create(keySchema)(new
GenericInternalRow(Array[Any](null)))
+ val numOutputRows = longMetric("numOutputRows")
+ val numUpdatedStateRows = longMetric("numUpdatedStateRows")
+ val allUpdatesTimeMs = longMetric("allUpdatesTimeMs")
+ val commitTimeMs = longMetric("commitTimeMs")
+ val updatesStartTimeNs = System.nanoTime
+
+ val startCount: Long =
Option(store.get(key)).map(_.getLong(0)).getOrElse(0L)
+ var rowCount = startCount
+
+ val result = iter.filter { r =>
+val x = rowCount < streamLimit
+if (x) {
+ rowCount += 1
+}
+x
+ }
+
+ CompletionIterator[InternalRow, Iterator[InternalRow]](result, {
--- End diff --
Do you need these type parameters?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21662: [SPARK-24662][SQL][SS] Support limit in structure...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/21662#discussion_r199279216
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingLimitExec.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.execution.streaming
+
+import java.util.concurrent.TimeUnit.NANOSECONDS
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow
+import org.apache.spark.sql.catalyst.expressions.UnsafeProjection
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+import org.apache.spark.sql.execution.streaming.state.StateStoreOps
+import org.apache.spark.sql.types.{LongType, NullType, StructField,
StructType}
+import org.apache.spark.util.CompletionIterator
+
+/**
+ * A physical operator for executing a streaming limit, which makes sure
no more than streamLimit
+ * rows are returned.
+ */
+case class StreamingLimitExec(
+streamLimit: Long,
+child: SparkPlan,
+stateInfo: Option[StatefulOperatorStateInfo] = None)
+ extends UnaryExecNode with StateStoreWriter {
+
+ private val keySchema = StructType(Array(StructField("key", NullType)))
+ private val valueSchema = StructType(Array(StructField("value",
LongType)))
+
+ override protected def doExecute(): RDD[InternalRow] = {
+metrics // force lazy init at driver
+
+child.execute().mapPartitionsWithStateStore(
+ getStateInfo,
+ keySchema,
+ valueSchema,
+ indexOrdinal = None,
+ sqlContext.sessionState,
+ Some(sqlContext.streams.stateStoreCoordinator)) { (store, iter) =>
--- End diff --
Nit: I'd indent 4 above to distinguish these two blocks visually.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20647: [SPARK-23303][SQL] improve the explain result for...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/20647#discussion_r170185948
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
---
@@ -77,31 +79,32 @@ class MicroBatchExecution(
sparkSession.sqlContext.conf.disabledV2StreamingMicroBatchReaders.split(",")
val _logicalPlan = analyzedPlan.transform {
- case streamingRelation@StreamingRelation(dataSourceV1, sourceName,
output) =>
-toExecutionRelationMap.getOrElseUpdate(streamingRelation, {
+ case s @ StreamingRelation(dsV1, sourceName, output) =>
--- End diff --
If you are touching that specific code then its fine to fix the style, but
in general I tend to agree that it makes the diff harder to read and commit
harder to back port if you include spurious changes.
I've even seen guidelines that specifically prohibit fixing style just to
fix style since it obfuscates the history.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20647: [SPARK-23303][SQL] improve the explain result for...
Github user marmbrus commented on a diff in the pull request: https://github.com/apache/spark/pull/20647#discussion_r170115965 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala --- @@ -415,12 +418,14 @@ class MicroBatchExecution( case v1: SerializedOffset => reader.deserializeOffset(v1.json) case v2: OffsetV2 => v2 } - reader.setOffsetRange( -toJava(current), -Optional.of(availableV2)) + reader.setOffsetRange(toJava(current), Optional.of(availableV2)) logDebug(s"Retrieving data from $reader: $current -> $availableV2") - Some(reader -> -new StreamingDataSourceV2Relation(reader.readSchema().toAttributes, reader)) + Some(reader -> StreamingDataSourceV2Relation( --- End diff -- @rdblue There was a doc as part of this SPIP: https://issues.apache.org/jira/browse/SPARK-20928, but it has definitely evolved enough past that we should update and send to the dev list again. Things like the logical plan requirement in execution will likely be significantly easier to remove once we have a full V2 API and can remove the legacy internal API for streaming. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20598: [SPARK-23406] [SS] Enable stream-stream self-joins
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20598 Yeah, this seems risky at RC5. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20647: [SPARK-23303][SQL] improve the explain result for...
Github user marmbrus commented on a diff in the pull request: https://github.com/apache/spark/pull/20647#discussion_r169799465 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala --- @@ -107,17 +106,24 @@ case class DataSourceV2Relation( } /** - * A specialization of DataSourceV2Relation with the streaming bit set to true. Otherwise identical - * to the non-streaming relation. + * A specialization of [[DataSourceV2Relation]] with the streaming bit set to true. + * + * Note that, this plan has a mutable reader, so Spark won't apply operator push-down for this plan, + * to avoid making the plan mutable. We should consolidate this plan and [[DataSourceV2Relation]] + * after we figure out how to apply operator push-down for streaming data sources. --- End diff -- @rdblue as well. I agree that we really need to define the contract here, and personally I would really benefit from seeing a life cycle diagram for all of the different pieces of the API. @tdas and @jose-torres made one for just the write side of streaming and it was super useful for me as someone at a distance that wants to understand what was going on. 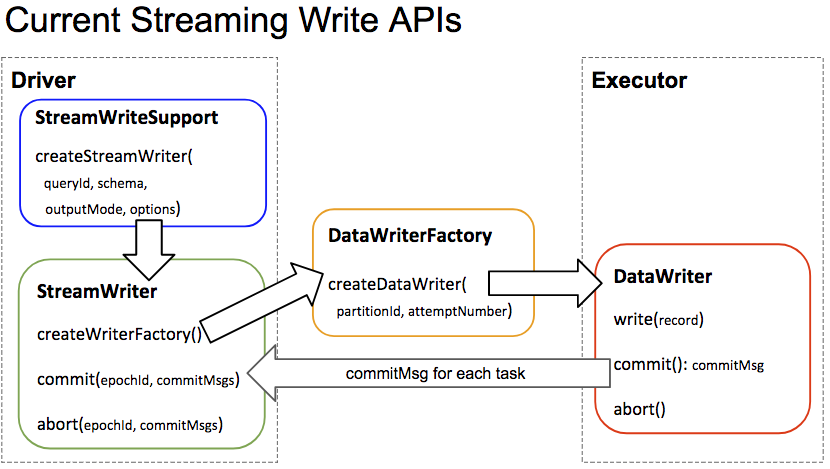 Something like this diagram that also covered when things are resolved, when pushdown happens, and that shows the differences between read/write, microbatch, batch and continuous would be awesome. Regarding the actual question, I'm not a huge fan of option 2 as it still seems like an implicit contract with this mutable object (assuming I understand the proposal correctly). Option 1 at least means that we could say, "whenever its time to do pushdown: call `reset()`, do pushdown in some defined order, then call `createX()`. It is invalid to do more pushdown after createX has been called". Even better than a `reset()` might be a `cleanClone()` method that gives you a fresh copy. As I said above, I don't really understand the lifecycle of the API, but given how we reuse query plan fragments I'm really nervous about mutable objects that are embedded in operators. I also agree with @jose-torres point that this mechanism looks like action at a distance, but the `reset()` contract at least localizes it to some degree, and I don't have a better suggestion for a way to support evolvable pushdown. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20511: [SPARK-23340][SQL] Upgrade Apache ORC to 1.4.3
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20511 Unfortunately, dependency changes are not typically allowed in patch releases. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20598: [SPARK-23406] [SS] Enable stream-stream self-join...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/20598#discussion_r168011671
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
---
@@ -431,7 +431,11 @@ class MicroBatchExecution(
s"Invalid batch: ${Utils.truncatedString(output, ",")} != " +
s"${Utils.truncatedString(dataPlan.output, ",")}")
replacements ++= output.zip(dataPlan.output)
--- End diff --
I think this is no longer used.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20598: [SPARK-23406] [SS] Enable stream-stream self-join...
Github user marmbrus commented on a diff in the pull request: https://github.com/apache/spark/pull/20598#discussion_r168011940 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala --- @@ -440,8 +444,6 @@ class MicroBatchExecution( // Rewire the plan to use the new attributes that were returned by the source. val replacementMap = AttributeMap(replacements) --- End diff -- Same --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20511: [SPARK-23340][SQL] Upgrade Apache ORC to 1.4.3
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20511 Sorry if I'm missing some context here, but our typical process this late in the release (we are over a month since the branch was cut) would be to disable any new features that still have regressions. I'm generally not okay with any dependency changes this far into QA unless there is no other option. Should we be considering turning this off so that we can GA Spark 2.3 soon? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20387: [SPARK-23203][SQL]: DataSourceV2: Use immutable logical ...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20387 Regarding, `computeStats`, the logical plan seems like it might not be the right place. As we move towards more CBO it seems like we are going to need to pick physical operators before we can really reason about the cost of a subplan. With the caveat that I haven't though hard about this, I'd be supportive of moving these kinds of metrics to physical plan. +1 that we need to be able to consider pushdown when producing stats either way. On the second point, I don't think I understand DataSourceV2 enough yet to know the answer, but you ask a lot of questions that I think need to be defined as part of the API (if we haven't already). What is the contract for ordering and interactions between different types of pushdown? Is it valid to pushdown in pieces or will we only call the method once? (sorry if this is written down and I've just missed it). My gut feeling is that we don't really want to fuse incrementally. Its seems hard to reason about correctness and interactions between different things that have been pushed. As I hinted at before, I think its most natural to split the concerns of pushdown within a query plan and fusing of operators. But maybe this is limited in someway I don't realize. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20387: [SPARK-23203][SQL]: DataSourceV2: Use immutable l...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/20387#discussion_r165751660
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala
---
@@ -17,15 +17,149 @@
package org.apache.spark.sql.execution.datasources.v2
-import org.apache.spark.sql.catalyst.expressions.AttributeReference
+import java.util.UUID
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable
+
+import org.apache.spark.sql.{AnalysisException, SaveMode}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.expressions.{AttributeReference,
Expression}
import org.apache.spark.sql.catalyst.plans.logical.{LeafNode, Statistics}
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.sources.{DataSourceRegister, Filter}
+import org.apache.spark.sql.sources.v2.{DataSourceV2, DataSourceV2Options,
ReadSupport, ReadSupportWithSchema, WriteSupport}
import org.apache.spark.sql.sources.v2.reader._
+import org.apache.spark.sql.sources.v2.writer.DataSourceV2Writer
+import org.apache.spark.sql.types.StructType
case class DataSourceV2Relation(
-fullOutput: Seq[AttributeReference],
-reader: DataSourceV2Reader) extends LeafNode with
DataSourceReaderHolder {
+source: DataSourceV2,
+options: Map[String, String],
+path: Option[String] = None,
+table: Option[TableIdentifier] = None,
+projection: Option[Seq[AttributeReference]] = None,
+filters: Option[Seq[Expression]] = None,
--- End diff --
I like this pattern. I think it is important that the arguments to a query
plan node are comprehensive so that it is easy to understand what is going on
in the output of `explain()`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20085: [SPARK-22739][Catalyst][WIP] Additional Expression Suppo...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20085 This blocks better support for encoders on spark-avro, and seems safe, so I'd really like to include it in possible. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20219: [SPARK-23025][SQL] Support Null type in scala reflection
Github user marmbrus commented on the issue:
https://github.com/apache/spark/pull/20219
This seems reasonable to me. You can already do `sql("SELECT null")`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20010: [SPARK-22826][SQL] findWiderTypeForTwo Fails over Struct...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20010 /cc @cloud-fan @sameeragarwal --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20085: [SPARK-22739][Catalyst][WIP] Additional Expression Suppo...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/20085 /cc @cloud-fan @sameeragarwal --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16578: [SPARK-4502][SQL] Parquet nested column pruning
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/16578 I agree that this PR needs to be allocated more review bandwidth, and it is unfortunate that it has been blocked on that. However, I am -1 on merging a change this large after branch cut. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20048: [SPARK-22862] Docs on lazy elimination of columns...
GitHub user marmbrus opened a pull request: https://github.com/apache/spark/pull/20048 [SPARK-22862] Docs on lazy elimination of columns missing from an encoder This behavior has confused some users, so lets clarify it. You can merge this pull request into a Git repository by running: $ git pull https://github.com/marmbrus/spark datasetAsDocs Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20048.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20048 commit 2f4e7b04f8d62d73225f00c12a95136c556a15d7 Author: Michael Armbrust Date: 2017-12-21T19:48:46Z [SPARK-22862] Docs on lazy elimination of columns missing from an encoder --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19925: [SPARK-22732] Add Structured Streaming APIs to DataSourc...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/19925 I would probably do ... streaming.reader/writer if we are going to namespace it. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19771: [SPARK-22544][SS]FileStreamSource should use its own had...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/19771 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19461: [SPARK-22230] Swap per-row order in state store restore.
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/19461 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19314: [SPARK-22094][SS]processAllAvailable should check the qu...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/19314 LGTM! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19240: [SPARK-22018][SQL]Preserve top-level alias metadata when...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/19240 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19240: [SPARK-22018][SQL]Preserve top-level alias metada...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/19240#discussion_r139042816
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2256,7 +2256,10 @@ object CleanupAliases extends Rule[LogicalPlan] {
def trimNonTopLevelAliases(e: Expression): Expression = e match {
case a: Alias =>
- a.withNewChildren(trimAliases(a.child) :: Nil)
--- End diff --
Is there anywhere else in the code base where we call `withNewChildren` on
an alias? Should we just override that?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19080: [SPARK-21865][SQL] simplify the distribution sema...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/19080#discussion_r136213945
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/physical/partitioning.scala
---
@@ -30,18 +30,43 @@ import org.apache.spark.sql.types.{DataType,
IntegerType}
* - Intra-partition ordering of data: In this case the distribution
describes guarantees made
*about how tuples are distributed within a single partition.
*/
-sealed trait Distribution
+sealed trait Distribution {
+ /**
+ * The required number of partitions for this distribution. If it's
None, then any number of
+ * partitions is allowed for this distribution.
+ */
+ def requiredNumPartitions: Option[Int]
+
+ /**
+ * Creates a default partitioning for this distribution, which can
satisfy this distribution while
+ * matching the given number of partitions.
+ */
+ def createPartitioning(numPartitions: Int): Partitioning
+}
/**
* Represents a distribution where no promises are made about co-location
of data.
*/
-case object UnspecifiedDistribution extends Distribution
+case object UnspecifiedDistribution extends Distribution {
+ override def requiredNumPartitions: Option[Int] = None
+
+ override def createPartitioning(numPartitions: Int): Partitioning = {
+throw new IllegalStateException("UnspecifiedDistribution does not have
default partitioning.")
+ }
+}
/**
* Represents a distribution that only has a single partition and all
tuples of the dataset
* are co-located.
*/
-case object AllTuples extends Distribution
+case object AllTuples extends Distribution {
--- End diff --
It seems we should be moving towards CBO, not away from it.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19080: [SPARK-21865][SQL] simplify the distribution sema...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/19080#discussion_r136213879
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/physical/partitioning.scala
---
@@ -30,18 +30,43 @@ import org.apache.spark.sql.types.{DataType,
IntegerType}
* - Intra-partition ordering of data: In this case the distribution
describes guarantees made
*about how tuples are distributed within a single partition.
*/
-sealed trait Distribution
+sealed trait Distribution {
+ /**
+ * The required number of partitions for this distribution. If it's
None, then any number of
+ * partitions is allowed for this distribution.
+ */
+ def requiredNumPartitions: Option[Int]
+
+ /**
+ * Creates a default partitioning for this distribution, which can
satisfy this distribution while
+ * matching the given number of partitions.
+ */
+ def createPartitioning(numPartitions: Int): Partitioning
+}
/**
* Represents a distribution where no promises are made about co-location
of data.
*/
-case object UnspecifiedDistribution extends Distribution
+case object UnspecifiedDistribution extends Distribution {
+ override def requiredNumPartitions: Option[Int] = None
+
+ override def createPartitioning(numPartitions: Int): Partitioning = {
+throw new IllegalStateException("UnspecifiedDistribution does not have
default partitioning.")
+ }
+}
/**
* Represents a distribution that only has a single partition and all
tuples of the dataset
* are co-located.
*/
-case object AllTuples extends Distribution
+case object AllTuples extends Distribution {
--- End diff --
Sure you can make that argument (I'm not sure I buy it), but then why does
this PR still have two different concepts?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19080: [SPARK-21865][SQL] simplify the distribution sema...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/19080#discussion_r136209980
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/physical/partitioning.scala
---
@@ -30,18 +30,43 @@ import org.apache.spark.sql.types.{DataType,
IntegerType}
* - Intra-partition ordering of data: In this case the distribution
describes guarantees made
*about how tuples are distributed within a single partition.
*/
-sealed trait Distribution
+sealed trait Distribution {
+ /**
+ * The required number of partitions for this distribution. If it's
None, then any number of
+ * partitions is allowed for this distribution.
+ */
+ def requiredNumPartitions: Option[Int]
+
+ /**
+ * Creates a default partitioning for this distribution, which can
satisfy this distribution while
+ * matching the given number of partitions.
+ */
+ def createPartitioning(numPartitions: Int): Partitioning
+}
/**
* Represents a distribution where no promises are made about co-location
of data.
*/
-case object UnspecifiedDistribution extends Distribution
+case object UnspecifiedDistribution extends Distribution {
+ override def requiredNumPartitions: Option[Int] = None
+
+ override def createPartitioning(numPartitions: Int): Partitioning = {
+throw new IllegalStateException("UnspecifiedDistribution does not have
default partitioning.")
+ }
+}
/**
* Represents a distribution that only has a single partition and all
tuples of the dataset
* are co-located.
*/
-case object AllTuples extends Distribution
+case object AllTuples extends Distribution {
--- End diff --
So I spoke with @sameeragarwal about this a little. The whole point here
was to have a logical / physical separation. `AllTuples` could be `SingleNode`
or it could be `Broadcast`. All the operation wants to know is that its seeing
all of them and it shouldn't care about how that is being accomplished.
Now, since the first version, we have started to deviate from that. I'm
not sure if this is still the right thing to do, but I wanted to give a little
context.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18923: [SPARK-21710][StSt] Fix OOM on ConsoleSink with l...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18923#discussion_r132801760
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
---
@@ -49,7 +49,7 @@ class ConsoleSink(options: Map[String, String]) extends
Sink with Logging {
println("---")
// scalastyle:off println
data.sparkSession.createDataFrame(
- data.sparkSession.sparkContext.parallelize(data.collect()),
data.schema)
--- End diff --
I don't think this means we can't do anything. I just think that we need
to fix the query plan and call take without changing the plan. Its kind of a
hack but it would work until we make the planner smarter.
I think something like `data.queryExecution.executedPlan.executeTake(...)`
would be safe.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18923: [SPARK-21710][StSt] Fix OOM on ConsoleSink with l...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18923#discussion_r132792708
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
---
@@ -49,7 +49,7 @@ class ConsoleSink(options: Map[String, String]) extends
Sink with Logging {
println("---")
// scalastyle:off println
data.sparkSession.createDataFrame(
- data.sparkSession.sparkContext.parallelize(data.collect()),
data.schema)
--- End diff --
This might not be safe unfortunately. Anything that changes the query plan
might cause it to get replanned (and we don't do this correctly).
Can you make sure that there is a test case that uses the console sink and
does aggregation across more than one batch?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18925: [SPARK-21713][SC] Replace streaming bit with Outp...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18925#discussion_r132791950
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
---
@@ -779,10 +780,16 @@ case object OneRowRelation extends LeafNode {
}
/** A logical plan for `dropDuplicates`. */
+case object Deduplicate {
+ def apply(keys: Seq[Attribute], child: LogicalPlan): Deduplicate = {
+Deduplicate(keys, child, child.outputMode)
+ }
+}
+
case class Deduplicate(
keys: Seq[Attribute],
child: LogicalPlan,
-streaming: Boolean) extends UnaryNode {
+originalOutputMode: OutputMode) extends UnaryNode {
--- End diff --
Can we drop this? Can it just preserve the output mode of its child?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18925: [SPARK-21713][SC] Replace streaming bit with Outp...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18925#discussion_r132791711
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1185,7 +1186,7 @@ object ReplaceDistinctWithAggregate extends
Rule[LogicalPlan] {
*/
object ReplaceDeduplicateWithAggregate extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
-case Deduplicate(keys, child, streaming) if !streaming =>
+case d @ Deduplicate(keys, child, _) if d.originalOutputMode !=
OutputMode.Append() =>
--- End diff --
existing: It's kind of odd that this decision is made in the optimizer and
not the query planner. I think our aggregate operator is actually worse than
the specialized deduplication operator (since the specialized one is
non-blocking).
It doesn't have to be in this PR, but we should probably move this to the
planner eventually.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18925: [SPARK-21713][SC] Replace streaming bit with OutputMode
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18925 ok to test --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18925: [SPARK-21713][SC] Replace streaming bit with OutputMode
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18925 add to whitelist --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18828: [SPARK-21619][SQL] Fail the execution of canonica...
Github user marmbrus commented on a diff in the pull request: https://github.com/apache/spark/pull/18828#discussion_r131250896 --- Diff: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/QueryPlan.scala --- @@ -181,17 +181,38 @@ abstract class QueryPlan[PlanType <: QueryPlan[PlanType]] extends TreeNode[PlanT override def innerChildren: Seq[QueryPlan[_]] = subqueries /** + * A private mutable variable to indicate whether this plan is the result of canonicalization. + * This is used solely for making sure we wouldn't execute a canonicalized plan. + * See [[canonicalized]] on how this is set. + */ + @transient --- End diff -- I guess plans are already not valid on executors, by why `@transient`? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18822: [SPARK-21546][SS] dropDuplicates should ignore watermark...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18822 LGTM --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18803: [SPARK-21597][SS]Fix a potential overflow issue in Event...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18803 LGTM --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18780: [INTRA] Close stale PRs
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18780 I'm in favor of fairly aggressive closing of inactive pull requests. The cost of reopening them is small, and the benefits of having a clear view of what is in progress are large. I think as long as the notification is clear and polite, it won't discourage contribution. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18658: [SPARK-20871][SQL] only log Janino code at debug level
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18658 That seems reasonable. I'm kind of pro-truncation for very very large code. Even though its not great to have something truncated, outputting GBs of logs is also pretty bad for downstream consumers. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18658: [SPARK-20871][SQL] only log Janino code at debug level
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18658 I don't have super strong opinions here, but in my experience its not always easy to get users to rerun a failed query with a different logging level. Have we considered truncating or special casing the 64k limitation instead? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18638: [SPARK-21421][SS]Add the query id as a local property to...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18638 LGTM --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18426: [SPARK-21216][SS] Hive strategies missed in Struc...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18426#discussion_r124127512
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/IncrementalExecution.scala
---
@@ -47,11 +47,19 @@ class IncrementalExecution(
sparkSession.sparkContext,
sparkSession.sessionState.conf,
sparkSession.sessionState.experimentalMethods) {
-override def extraPlanningStrategies: Seq[Strategy] =
- StatefulAggregationStrategy ::
- FlatMapGroupsWithStateStrategy ::
- StreamingRelationStrategy ::
- StreamingDeduplicationStrategy :: Nil
+
+// We shouldn't miss the parent's strategies
+val parentPlanner = sparkSession.sessionState.planner
--- End diff --
Is there a reason to create this val rather than use
`sparkSession.sessionState.planner`. I'm just not sure if its okay to freeze
this (probably it is?).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123638453
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TimeWindow.scala
---
@@ -152,17 +152,21 @@ object TimeWindow {
}
/**
- * Expression used internally to convert the TimestampType to Long without
losing
+ * Expression used internally to convert the TimestampType to Long and
back without losing
* precision, i.e. in microseconds. Used in time windowing.
*/
-case class PreciseTimestamp(child: Expression) extends UnaryExpression
with ExpectsInputTypes {
- override def inputTypes: Seq[AbstractDataType] = Seq(TimestampType)
- override def dataType: DataType = LongType
+case class PreciseTimestampConversion(
+child: Expression,
+fromType: DataType,
--- End diff --
Maybe we shouldn't be using it then? This is a purely internal expression?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123588018
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2562,37 +2563,63 @@ object TimeWindowing extends Rule[LogicalPlan] {
case a: Attribute => a.metadata
case _ => Metadata.empty
}
-val windowAttr =
- AttributeReference("window", window.dataType, metadata =
metadata)()
-val maxNumOverlapping = math.ceil(window.windowDuration * 1.0 /
window.slideDuration).toInt
-val windows = Seq.tabulate(maxNumOverlapping + 1) { i =>
- val windowId = Ceil((PreciseTimestamp(window.timeColumn) -
window.startTime) /
-window.slideDuration)
+def getWindow(i: Int, maxNumOverlapping: Int): Expression = {
+ val division = (PreciseTimestampConversion(
+window.timeColumn, TimestampType, LongType) -
window.startTime) / window.slideDuration
+ val ceil = Ceil(division)
+ // if the division is equal to the ceiling, our record is the
start of a window
+ val windowId = CaseWhen(Seq((ceil === division, ceil + 1)),
Some(ceil))
val windowStart = (windowId + i - maxNumOverlapping) *
- window.slideDuration + window.startTime
+window.slideDuration + window.startTime
val windowEnd = windowStart + window.windowDuration
CreateNamedStruct(
-Literal(WINDOW_START) :: windowStart ::
-Literal(WINDOW_END) :: windowEnd :: Nil)
+Literal(WINDOW_START) ::
+ PreciseTimestampConversion(windowStart, LongType,
TimestampType) ::
+ Literal(WINDOW_END) ::
+ PreciseTimestampConversion(windowEnd, LongType,
TimestampType) ::
+ Nil)
}
-val projections = windows.map(_ +: p.children.head.output)
+val windowAttr = AttributeReference(
+ WINDOW_COL_NAME, window.dataType, metadata = metadata)()
-val filterExpr =
- window.timeColumn >= windowAttr.getField(WINDOW_START) &&
- window.timeColumn < windowAttr.getField(WINDOW_END)
+if (window.windowDuration == window.slideDuration) {
+ val windowStruct = Alias(getWindow(0, 1), WINDOW_COL_NAME)(
+exprId = windowAttr.exprId, explicitMetadata = Some(metadata))
--- End diff --
nit: Wrapping is off. Prefer to break at `=` and if you wrap args, wrap
all of them.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123589167
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2562,37 +2563,63 @@ object TimeWindowing extends Rule[LogicalPlan] {
case a: Attribute => a.metadata
case _ => Metadata.empty
}
-val windowAttr =
- AttributeReference("window", window.dataType, metadata =
metadata)()
-val maxNumOverlapping = math.ceil(window.windowDuration * 1.0 /
window.slideDuration).toInt
-val windows = Seq.tabulate(maxNumOverlapping + 1) { i =>
- val windowId = Ceil((PreciseTimestamp(window.timeColumn) -
window.startTime) /
-window.slideDuration)
+def getWindow(i: Int, maxNumOverlapping: Int): Expression = {
+ val division = (PreciseTimestampConversion(
+window.timeColumn, TimestampType, LongType) -
window.startTime) / window.slideDuration
+ val ceil = Ceil(division)
+ // if the division is equal to the ceiling, our record is the
start of a window
+ val windowId = CaseWhen(Seq((ceil === division, ceil + 1)),
Some(ceil))
val windowStart = (windowId + i - maxNumOverlapping) *
- window.slideDuration + window.startTime
+window.slideDuration + window.startTime
val windowEnd = windowStart + window.windowDuration
CreateNamedStruct(
-Literal(WINDOW_START) :: windowStart ::
-Literal(WINDOW_END) :: windowEnd :: Nil)
+Literal(WINDOW_START) ::
+ PreciseTimestampConversion(windowStart, LongType,
TimestampType) ::
+ Literal(WINDOW_END) ::
+ PreciseTimestampConversion(windowEnd, LongType,
TimestampType) ::
+ Nil)
}
-val projections = windows.map(_ +: p.children.head.output)
+val windowAttr = AttributeReference(
+ WINDOW_COL_NAME, window.dataType, metadata = metadata)()
-val filterExpr =
- window.timeColumn >= windowAttr.getField(WINDOW_START) &&
- window.timeColumn < windowAttr.getField(WINDOW_END)
+if (window.windowDuration == window.slideDuration) {
+ val windowStruct = Alias(getWindow(0, 1), WINDOW_COL_NAME)(
+exprId = windowAttr.exprId, explicitMetadata = Some(metadata))
-val expandedPlan =
- Filter(filterExpr,
+ val replacedPlan = p transformExpressions {
+case t: TimeWindow => windowAttr
+ }
+
+ // For backwards compatibility we add a filter to filter out
nulls
+ val filterExpr = IsNotNull(window.timeColumn)
+
+ replacedPlan.withNewChildren(Filter(filterExpr,
--- End diff --
Actually, should we even be doing a projection here? If its just a
substitution / filter, perhaps we should just replace it inline?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123588431
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2562,37 +2563,63 @@ object TimeWindowing extends Rule[LogicalPlan] {
case a: Attribute => a.metadata
case _ => Metadata.empty
}
-val windowAttr =
- AttributeReference("window", window.dataType, metadata =
metadata)()
-val maxNumOverlapping = math.ceil(window.windowDuration * 1.0 /
window.slideDuration).toInt
-val windows = Seq.tabulate(maxNumOverlapping + 1) { i =>
- val windowId = Ceil((PreciseTimestamp(window.timeColumn) -
window.startTime) /
-window.slideDuration)
+def getWindow(i: Int, maxNumOverlapping: Int): Expression = {
+ val division = (PreciseTimestampConversion(
+window.timeColumn, TimestampType, LongType) -
window.startTime) / window.slideDuration
+ val ceil = Ceil(division)
+ // if the division is equal to the ceiling, our record is the
start of a window
+ val windowId = CaseWhen(Seq((ceil === division, ceil + 1)),
Some(ceil))
val windowStart = (windowId + i - maxNumOverlapping) *
- window.slideDuration + window.startTime
+window.slideDuration + window.startTime
val windowEnd = windowStart + window.windowDuration
CreateNamedStruct(
-Literal(WINDOW_START) :: windowStart ::
-Literal(WINDOW_END) :: windowEnd :: Nil)
+Literal(WINDOW_START) ::
+ PreciseTimestampConversion(windowStart, LongType,
TimestampType) ::
+ Literal(WINDOW_END) ::
+ PreciseTimestampConversion(windowEnd, LongType,
TimestampType) ::
+ Nil)
}
-val projections = windows.map(_ +: p.children.head.output)
+val windowAttr = AttributeReference(
+ WINDOW_COL_NAME, window.dataType, metadata = metadata)()
-val filterExpr =
- window.timeColumn >= windowAttr.getField(WINDOW_START) &&
- window.timeColumn < windowAttr.getField(WINDOW_END)
+if (window.windowDuration == window.slideDuration) {
+ val windowStruct = Alias(getWindow(0, 1), WINDOW_COL_NAME)(
+exprId = windowAttr.exprId, explicitMetadata = Some(metadata))
-val expandedPlan =
- Filter(filterExpr,
+ val replacedPlan = p transformExpressions {
+case t: TimeWindow => windowAttr
+ }
+
+ // For backwards compatibility we add a filter to filter out
nulls
+ val filterExpr = IsNotNull(window.timeColumn)
+
+ replacedPlan.withNewChildren(Filter(filterExpr,
+Project(windowStruct +: child.output, child)) :: Nil)
+} else {
+
--- End diff --
nit: no blank line
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123594063
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TimeWindow.scala
---
@@ -152,17 +152,21 @@ object TimeWindow {
}
/**
- * Expression used internally to convert the TimestampType to Long without
losing
+ * Expression used internally to convert the TimestampType to Long and
back without losing
* precision, i.e. in microseconds. Used in time windowing.
*/
-case class PreciseTimestamp(child: Expression) extends UnaryExpression
with ExpectsInputTypes {
- override def inputTypes: Seq[AbstractDataType] = Seq(TimestampType)
- override def dataType: DataType = LongType
+case class PreciseTimestampConversion(
+child: Expression,
+fromType: DataType,
--- End diff --
The from type should just come from the child right?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123587631
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2562,37 +2563,63 @@ object TimeWindowing extends Rule[LogicalPlan] {
case a: Attribute => a.metadata
case _ => Metadata.empty
}
-val windowAttr =
- AttributeReference("window", window.dataType, metadata =
metadata)()
-val maxNumOverlapping = math.ceil(window.windowDuration * 1.0 /
window.slideDuration).toInt
-val windows = Seq.tabulate(maxNumOverlapping + 1) { i =>
- val windowId = Ceil((PreciseTimestamp(window.timeColumn) -
window.startTime) /
-window.slideDuration)
+def getWindow(i: Int, maxNumOverlapping: Int): Expression = {
--- End diff --
I'm not sure I understand `maxNumOverlapping` as a name that we tabulate
over. Isn't it like the `overlapNumber` or something?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123588323
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2562,37 +2563,63 @@ object TimeWindowing extends Rule[LogicalPlan] {
case a: Attribute => a.metadata
case _ => Metadata.empty
}
-val windowAttr =
- AttributeReference("window", window.dataType, metadata =
metadata)()
-val maxNumOverlapping = math.ceil(window.windowDuration * 1.0 /
window.slideDuration).toInt
-val windows = Seq.tabulate(maxNumOverlapping + 1) { i =>
- val windowId = Ceil((PreciseTimestamp(window.timeColumn) -
window.startTime) /
-window.slideDuration)
+def getWindow(i: Int, maxNumOverlapping: Int): Expression = {
+ val division = (PreciseTimestampConversion(
+window.timeColumn, TimestampType, LongType) -
window.startTime) / window.slideDuration
+ val ceil = Ceil(division)
+ // if the division is equal to the ceiling, our record is the
start of a window
+ val windowId = CaseWhen(Seq((ceil === division, ceil + 1)),
Some(ceil))
val windowStart = (windowId + i - maxNumOverlapping) *
- window.slideDuration + window.startTime
+window.slideDuration + window.startTime
val windowEnd = windowStart + window.windowDuration
CreateNamedStruct(
-Literal(WINDOW_START) :: windowStart ::
-Literal(WINDOW_END) :: windowEnd :: Nil)
+Literal(WINDOW_START) ::
+ PreciseTimestampConversion(windowStart, LongType,
TimestampType) ::
+ Literal(WINDOW_END) ::
+ PreciseTimestampConversion(windowEnd, LongType,
TimestampType) ::
+ Nil)
}
-val projections = windows.map(_ +: p.children.head.output)
+val windowAttr = AttributeReference(
+ WINDOW_COL_NAME, window.dataType, metadata = metadata)()
-val filterExpr =
- window.timeColumn >= windowAttr.getField(WINDOW_START) &&
- window.timeColumn < windowAttr.getField(WINDOW_END)
+if (window.windowDuration == window.slideDuration) {
+ val windowStruct = Alias(getWindow(0, 1), WINDOW_COL_NAME)(
+exprId = windowAttr.exprId, explicitMetadata = Some(metadata))
-val expandedPlan =
- Filter(filterExpr,
+ val replacedPlan = p transformExpressions {
+case t: TimeWindow => windowAttr
+ }
+
+ // For backwards compatibility we add a filter to filter out
nulls
+ val filterExpr = IsNotNull(window.timeColumn)
+
+ replacedPlan.withNewChildren(Filter(filterExpr,
--- End diff --
Nit: wrapping, indent query plans like trees.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18364: [SPARK-21153] Use project instead of expand in tu...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18364#discussion_r123587244
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -2562,37 +2563,63 @@ object TimeWindowing extends Rule[LogicalPlan] {
case a: Attribute => a.metadata
--- End diff --
existing: There is a comment above that says "not correct"?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18381: [SPARK-21167][SS]Decode the path generated by File sink ...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18381 LGTM --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18306: [SPARK-21029][SS] All StreamingQuery should be stopped w...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18306 Seems okay to me. /cc @zsxwing --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15306: [SPARK-17740] Spark tests should mock / interpose HDFS t...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/15306 This is good thing for us to test. However, If you throw an exception in your test that opens a file, it seems that it swallows the exception just telling you that you are leaking files. Is there anyway we could make this less confusing? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18207: [MINOR][DOC] Update deprecation notes on Python/Hadoop/S...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18207 /cc @joshrosen --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17371: [SPARK-19903][PYSPARK][SS] window operator miss the `wat...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17371 Can we add an analysis rule that just pulls up missing metadata from attributes in the child? It could run once after other rules. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18104: [SPARK-20877][SPARKR][WIP] add timestamps to test runs
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18104 Ping? I'd like to cut the next RC. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17770: [SPARK-20392][SQL] Set barrier to prevent re-entering a ...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17770 Whoa, I do not think we should back porting a large change to the inner workings of the analyzer. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18119: [BACKPORT-2.2][SPARK-19372][SQL] Fix throwing a Java exc...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18119 Since this is purely a fallback for a case that would error, it seems possibly okay to include in 2.2. @zsxwing could you take a look and make sure I'm right? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18065: [SPARK-20844] Remove experimental from Structured Stream...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18065 Good catch on python! Fixed but please help me make sure I didn't miss anything. Leaving all the GroupState stuff experimental was on purpose, since this will be the first release including it. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18065: [SPARK-20844] Remove experimental from Structured...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/18065#discussion_r118390750
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -2800,8 +2800,6 @@ object functions {
* @group datetime_funcs
* @since 2.0.0
*/
- @Experimental
- @InterfaceStability.Evolving
--- End diff --
Yes, I did. This has been out since 2.0, so I don't think we can change it
at this point.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18065: [SPARK-20844] Remove experimental from Structured...
Github user marmbrus commented on a diff in the pull request: https://github.com/apache/spark/pull/18065#discussion_r118390436 --- Diff: docs/structured-streaming-programming-guide.md --- @@ -10,7 +10,7 @@ title: Structured Streaming Programming Guide # Overview Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the [Dataset/DataFrame API](sql-programming-guide.html) in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The computation is executed on the same optimized Spark SQL engine. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write Ahead Logs. In short, *Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.* --- End diff -- haha, good catch --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r118389082
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+import java.util.concurrent.{ConcurrentMap, TimeUnit}
+import javax.annotation.concurrent.GuardedBy
+
+import com.google.common.cache.{Cache, CacheBuilder, RemovalListener,
RemovalNotification}
+import org.apache.kafka.clients.producer.KafkaProducer
+import scala.collection.JavaConverters._
+import scala.collection.immutable.SortedMap
+import scala.collection.mutable
+import scala.util.control.NonFatal
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.util.ShutdownHookManager
+
+private[kafka010] object CachedKafkaProducer extends Logging {
+
+ private type Producer = KafkaProducer[Array[Byte], Array[Byte]]
+
+ private lazy val cacheExpireTimeout: Long =
+SparkEnv.get.conf.getTimeAsMs("spark.kafka.producer.cache.timeout",
"10m")
+
+ private val removalListener = new RemovalListener[String, Producer]() {
+override def onRemoval(notification: RemovalNotification[String,
Producer]): Unit = {
+ val uid: String = notification.getKey
+ val producer: Producer = notification.getValue
+ logDebug(s"Evicting kafka producer $producer uid: $uid, due to
${notification.getCause}")
+ close(uid, producer)
+}
+ }
+
+ private lazy val guavaCache: Cache[String, Producer] =
CacheBuilder.newBuilder()
+.expireAfterAccess(cacheExpireTimeout, TimeUnit.MILLISECONDS)
+.removalListener(removalListener)
+.build[String, Producer]()
+
+ ShutdownHookManager.addShutdownHook { () =>
+clear()
+ }
+
+ private def createKafkaProducer(
+producerConfiguration: ju.Map[String, Object]): Producer = {
--- End diff --
nit: indent 4 here
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r118389504
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+import java.util.concurrent.{ConcurrentMap, TimeUnit}
+import javax.annotation.concurrent.GuardedBy
+
+import com.google.common.cache.{Cache, CacheBuilder, RemovalListener,
RemovalNotification}
+import org.apache.kafka.clients.producer.KafkaProducer
+import scala.collection.JavaConverters._
+import scala.collection.immutable.SortedMap
+import scala.collection.mutable
+import scala.util.control.NonFatal
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.util.ShutdownHookManager
+
+private[kafka010] object CachedKafkaProducer extends Logging {
+
+ private type Producer = KafkaProducer[Array[Byte], Array[Byte]]
+
+ private lazy val cacheExpireTimeout: Long =
+SparkEnv.get.conf.getTimeAsMs("spark.kafka.producer.cache.timeout",
"10m")
+
+ private val removalListener = new RemovalListener[String, Producer]() {
+override def onRemoval(notification: RemovalNotification[String,
Producer]): Unit = {
+ val uid: String = notification.getKey
+ val producer: Producer = notification.getValue
+ logDebug(s"Evicting kafka producer $producer uid: $uid, due to
${notification.getCause}")
+ close(uid, producer)
+}
+ }
+
+ private lazy val guavaCache: Cache[String, Producer] =
CacheBuilder.newBuilder()
+.expireAfterAccess(cacheExpireTimeout, TimeUnit.MILLISECONDS)
+.removalListener(removalListener)
+.build[String, Producer]()
+
+ ShutdownHookManager.addShutdownHook { () =>
+clear()
+ }
+
+ private def createKafkaProducer(
+producerConfiguration: ju.Map[String, Object]): Producer = {
+val uid = getUniqueId(producerConfiguration)
+val kafkaProducer: Producer = new Producer(producerConfiguration)
+guavaCache.put(uid.toString, kafkaProducer)
+logDebug(s"Created a new instance of KafkaProducer for
$producerConfiguration.")
+kafkaProducer
+ }
+
+ private def getUniqueId(kafkaParams: ju.Map[String, Object]): String = {
+val uid =
kafkaParams.get(CanonicalizeKafkaParams.sparkKafkaParamsUniqueId)
+assert(uid != null, s"KafkaParams($kafkaParams) not canonicalized.")
+uid.toString
+ }
+
+ /**
+ * Get a cached KafkaProducer for a given configuration. If matching
KafkaProducer doesn't
+ * exist, a new KafkaProducer will be created. KafkaProducer is thread
safe, it is best to keep
+ * one instance per specified kafkaParams.
+ */
+ private[kafka010] def getOrCreate(kafkaParams: ju.Map[String, Object]):
Producer = synchronized {
+val params = if
(!CanonicalizeKafkaParams.isCanonicalized(kafkaParams)) {
+ CanonicalizeKafkaParams.computeUniqueCanonicalForm(kafkaParams)
+} else {
+ kafkaParams
+}
+val uid = getUniqueId(params)
+
Option(guavaCache.getIfPresent(uid)).getOrElse(createKafkaProducer(params))
+ }
+
+ /** For explicitly closing kafka producer */
+ private[kafka010] def close(kafkaParams: ju.Map[String, Object]): Unit =
{
+val params = if
(!CanonicalizeKafkaParams.isCanonicalized(kafkaParams)) {
+ CanonicalizeKafkaParams.computeUniqueCanonicalForm(kafkaParams)
+} else kafkaParams
+val uid = getUniqueId(params)
+guavaCache.invalidate(uid)
+ }
+
+ /** Auto close on cache evict */
+ private def close(uid: String, producer: Producer): Unit = {
+try {
+ val outcome = CanonicalizeKa
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r118387956
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+import java.util.concurrent.{ConcurrentMap, TimeUnit}
+import javax.annotation.concurrent.GuardedBy
+
+import com.google.common.cache.{Cache, CacheBuilder, RemovalListener,
RemovalNotification}
+import org.apache.kafka.clients.producer.KafkaProducer
+import scala.collection.JavaConverters._
+import scala.collection.immutable.SortedMap
+import scala.collection.mutable
+import scala.util.control.NonFatal
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.util.ShutdownHookManager
+
+private[kafka010] object CachedKafkaProducer extends Logging {
+
+ private type Producer = KafkaProducer[Array[Byte], Array[Byte]]
+
+ private lazy val cacheExpireTimeout: Long =
+SparkEnv.get.conf.getTimeAsMs("spark.kafka.producer.cache.timeout",
"10m")
+
+ private val removalListener = new RemovalListener[String, Producer]() {
+override def onRemoval(notification: RemovalNotification[String,
Producer]): Unit = {
+ val uid: String = notification.getKey
+ val producer: Producer = notification.getValue
+ logDebug(s"Evicting kafka producer $producer uid: $uid, due to
${notification.getCause}")
+ close(uid, producer)
+}
+ }
+
+ private lazy val guavaCache: Cache[String, Producer] =
CacheBuilder.newBuilder()
+.expireAfterAccess(cacheExpireTimeout, TimeUnit.MILLISECONDS)
+.removalListener(removalListener)
+.build[String, Producer]()
+
+ ShutdownHookManager.addShutdownHook { () =>
+clear()
--- End diff --
+1, this seems complicated. What exactly does shutdown do? Is it just
cleaning up thread pools?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18065: [SPARK-20844] Remove experimental from Structured Stream...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/18065 test this please --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18065: [SPARK-20844] Remove experimental from Structured...
GitHub user marmbrus opened a pull request: https://github.com/apache/spark/pull/18065 [SPARK-20844] Remove experimental from Structured Streaming APIs Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3. You can merge this pull request into a Git repository by running: $ git pull https://github.com/marmbrus/spark streamingGA Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18065.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18065 commit fe03241d56899af9fa9cc4e63f4f97061bbb8b74 Author: Michael Armbrust Date: 2017-05-22T19:55:31Z [SPARK-20844] Remove experimental from Structured Streaming APIs --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17957: [SPARK-20717][SS] Minor tweaks to the MapGroupsWithState...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17957 LGTM --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17958: [SPARK-20716][SS] StateStore.abort() should not t...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17958#discussion_r116288688
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/HDFSBackedStateStoreProvider.scala
---
@@ -202,13 +203,22 @@ private[state] class HDFSBackedStateStoreProvider(
/** Abort all the updates made on this store. This store will not be
usable any more. */
override def abort(): Unit = {
verify(state == UPDATING || state == ABORTED, "Cannot abort after
already committed")
+ try {
+state = ABORTED
+if (tempDeltaFileStream != null) {
+ tempDeltaFileStream.close()
+}
+if (tempDeltaFile != null) {
+ fs.delete(tempDeltaFile, true)
+}
+ } catch {
+case c: ClosedChannelException =>
--- End diff --
Its debug though for the expected case.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17958: [SPARK-20716][SS] StateStore.abort() should not t...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17958#discussion_r116283013
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/HDFSBackedStateStoreProvider.scala
---
@@ -202,13 +203,22 @@ private[state] class HDFSBackedStateStoreProvider(
/** Abort all the updates made on this store. This store will not be
usable any more. */
override def abort(): Unit = {
verify(state == UPDATING || state == ABORTED, "Cannot abort after
already committed")
+ try {
+state = ABORTED
+if (tempDeltaFileStream != null) {
+ tempDeltaFileStream.close()
+}
+if (tempDeltaFile != null) {
+ fs.delete(tempDeltaFile, true)
+}
+ } catch {
+case c: ClosedChannelException =>
+ // This can happen when underlying file output stream has been
closed before the
+ // compression stream.
+ logDebug(s"Error aborting version $newVersion into $this", c)
- state = ABORTED
- if (tempDeltaFileStream != null) {
-tempDeltaFileStream.close()
- }
- if (tempDeltaFile != null) {
-fs.delete(tempDeltaFile, true)
+case e: Exception =>
+ logWarning(s"Error aborting version $newVersion into $this")
--- End diff --
Include the exception.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17770: [SPARK-20392][SQL] Set barrier to prevent re-entering a ...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17770 It might be a good idea to look at [the time spent](https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules/RuleExecutor.scala#L37) before and after this change for all the unit tests in core / hive. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17770: [SPARK-20392][SQL] Set barrier to prevent re-entering a ...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17770 Okay, I can be convinced. Lets do eliminate the other path then though and make sure there are no performance regressions. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SS] Use a cached instance of `Kafka...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r114841425
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -0,0 +1,70 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+
+import scala.collection.mutable
+
+import org.apache.kafka.clients.producer.KafkaProducer
+
+import org.apache.spark.internal.Logging
+
+private[kafka010] object CachedKafkaProducer extends Logging {
+
+ private val cacheMap = new mutable.HashMap[Int,
KafkaProducer[Array[Byte], Array[Byte]]]()
+
+ private def createKafkaProducer(
+producerConfiguration: ju.HashMap[String, Object]):
KafkaProducer[Array[Byte], Array[Byte]] = {
+val kafkaProducer: KafkaProducer[Array[Byte], Array[Byte]] =
+ new KafkaProducer[Array[Byte], Array[Byte]](producerConfiguration)
+cacheMap.put(producerConfiguration.hashCode(), kafkaProducer)
+kafkaProducer
+ }
+
+ /**
+ * Get a cached KafkaProducer for a given configuration. A new
KafkaProducer will be created,
+ * if matching KafkaProducer doesn't exist. KafkaProducer is thread
safe, it is best to keep
+ * one instance per specified kafkaParams.
+ */
+ def getOrCreate(kafkaParams: ju.HashMap[String, Object])
+ : KafkaProducer[Array[Byte], Array[Byte]] = synchronized {
--- End diff --
nit: Typically we wrap the arguments rather than the return type
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SS] Use a cached instance of `Kafka...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r11484
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -0,0 +1,70 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+
+import scala.collection.mutable
+
+import org.apache.kafka.clients.producer.KafkaProducer
+
+import org.apache.spark.internal.Logging
+
+private[kafka010] object CachedKafkaProducer extends Logging {
+
+ private val cacheMap = new mutable.HashMap[Int,
KafkaProducer[Array[Byte], Array[Byte]]]()
+
+ private def createKafkaProducer(
+producerConfiguration: ju.HashMap[String, Object]):
KafkaProducer[Array[Byte], Array[Byte]] = {
+val kafkaProducer: KafkaProducer[Array[Byte], Array[Byte]] =
+ new KafkaProducer[Array[Byte], Array[Byte]](producerConfiguration)
+cacheMap.put(producerConfiguration.hashCode(), kafkaProducer)
--- End diff --
Yeah, I don't think this is a good key for the hashmap. There could be
collisions. We should either assign a unique ID to the sink and thread that
through, or come up with some way to canoncicalize the set of parameters that
create the sink. The latter might better since you could maybe reuse the same
producer for more than one query.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SS] Use a cached instance of `Kafka...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r114841245
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSink.scala
---
@@ -30,14 +30,19 @@ private[kafka010] class KafkaSink(
@volatile private var latestBatchId = -1L
override def toString(): String = "KafkaSink"
+ private val kafkaParams = new ju.HashMap[String,
Object](executorKafkaParams)
override def addBatch(batchId: Long, data: DataFrame): Unit = {
if (batchId <= latestBatchId) {
logInfo(s"Skipping already committed batch $batchId")
} else {
KafkaWriter.write(sqlContext.sparkSession,
-data.queryExecution, executorKafkaParams, topic)
+data.queryExecution, kafkaParams, topic)
latestBatchId = batchId
}
}
+
+ override def stop(): Unit = {
+CachedKafkaProducer.close(kafkaParams)
--- End diff --
This is only closing the producer on the driver, right? Do we even create
on there?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17770: [SPARK-20392][SQL] Set barrier to prevent re-entering a ...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17770 Some thoughts: - We shouldn't have multiple optimizations for avoiding repeated analysis. So if we decide to go this way then we should get rid of `resolveOperators`. - I agree with Reynold, that the dummy operator could have confusing side-effects down the road. - The proposed generalization of `resolveOperators` to take a generic stopping condition is reasonable, but I would only do it if we have more than one use case. Have we tried just using `resolveOperators` in more places? Does that fix the performance issue? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17838: [SPARK-20567] Lazily bind in GenerateExec
GitHub user marmbrus opened a pull request: https://github.com/apache/spark/pull/17838 [SPARK-20567] Lazily bind in GenerateExec It is not valid to eagerly bind with the child's output as this causes failures when we attempt to canonicalize the plan (replacing the attribute references with dummies). You can merge this pull request into a Git repository by running: $ git pull https://github.com/marmbrus/spark fixBindExplode Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/17838.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #17838 commit 7c86b0e997e87bce77cdf6064975ff5cab245c08 Author: Michael Armbrust Date: 2017-05-03T00:13:52Z [SPARK-20567] Lazily bind in GenerateExec --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17765: [SPARK-20464][SS] Add a job group and description...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17765#discussion_r113827924
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamExecution.scala
---
@@ -825,6 +832,11 @@ class StreamExecution(
}
}
+ private def getBatchDescriptionString: String = {
+val batchDescription = if (currentBatchId < 0) "init" else
currentBatchId.toString
+Option(name).map(_ + " ").getOrElse("") +
+ s"[batch = $batchDescription,id = $id,runId = $runId]"
--- End diff --
I would get rid of the `[]` if you are going to use newlines
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17765: [SPARK-20464][SS] Add a job group and description...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17765#discussion_r113593037
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamExecution.scala
---
@@ -252,6 +252,7 @@ class StreamExecution(
*/
private def runBatches(): Unit = {
try {
+ sparkSession.sparkContext.setJobGroup(runId.toString,
getBatchDescriptionString)
--- End diff --
when would you want to set this to true or false?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17765: [SPARK-20464][SS] Add a job group and description...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17765#discussion_r113560170
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamExecution.scala
---
@@ -825,6 +833,11 @@ class StreamExecution(
}
}
+ private def getBatchDescriptionString: String = {
+val batchDescription = if (currentBatchId < 0) "init" else
currentBatchId.toString
+Option(name).map(_ + " ").getOrElse("") +
+ s"[batch = $batchDescription, id = $id, runId = $runId]"
--- End diff --
LGTM
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17765: [SPARK-20464][SS] Add a job group and description...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17765#discussion_r113560096
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamExecution.scala
---
@@ -252,6 +252,7 @@ class StreamExecution(
*/
private def runBatches(): Unit = {
try {
+ sparkSession.sparkContext.setJobGroup(runId.toString,
getBatchDescriptionString)
--- End diff --
@brkyvz is this okay?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17594: [SPARK-20282][SS][Tests]Write the commit log first to fi...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17594 LGTM, for fixing the issue with the test. We should separately decide if this is really the behavior we want for the commit log. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17594: [SPARK-20282][SS][Tests]Write the commit log firs...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17594#discussion_r110735241
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamExecution.scala
---
@@ -304,8 +304,8 @@ class StreamExecution(
finishTrigger(dataAvailable)
if (dataAvailable) {
// Update committed offsets.
-committedOffsets ++= availableOffsets
batchCommitLog.add(currentBatchId)
--- End diff --
This is existing, but do we not write to the commit log if there is no new
data in the next batch?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17488: [SPARK-20165][SS] Resolve state encoder's deseria...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17488#discussion_r109070462
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamTest.scala ---
@@ -490,6 +490,18 @@ trait StreamTest extends QueryTest with
SharedSQLContext with Timeouts {
try {
// Add data and get the source where it was added, and the
expected offset of the
// added data.
+ if (currentStream != null &&
--- End diff --
Can you comment here too. I had no idea what this was doing until read the
PR description.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17488: [SPARK-20165][SS] Resolve state encoder's deseria...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17488#discussion_r109069839
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FlatMapGroupsWithStateExec.scala
---
@@ -68,6 +68,17 @@ case class FlatMapGroupsWithStateExec(
val encSchemaAttribs = stateEncoder.schema.toAttributes
if (isTimeoutEnabled) encSchemaAttribs :+ timestampTimeoutAttribute
else encSchemaAttribs
}
+ // Converter for translating state Java objects to rows
+ private val stateSerializer = {
+val encoderSerializer = stateEncoder.namedExpressions
+if (isTimeoutEnabled) {
+ encoderSerializer :+ Literal(GroupStateImpl.NO_TIMESTAMP)
+} else {
+ encoderSerializer
+}
+ }
+ private val stateDeserializer =
stateEncoder.resolveAndBind().deserializer
--- End diff --
Can you comment that this has to happen on the driver so we don't forget
why its here and move it?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17398: [SPARK-19716][SQL] support by-name resolution for...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17398#discussion_r107985278
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/encoders/EncoderResolutionSuite.scala
---
@@ -62,6 +66,54 @@ class EncoderResolutionSuite extends PlanTest {
encoder.resolveAndBind(attrs).fromRow(InternalRow(InternalRow(str,
1.toByte), 2))
}
+ test("real type doesn't match encoder schema but they are compatible:
array") {
--- End diff --
Is there a reason we don't have any `encodeDecodeTest`?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17252: [SPARK-19913][SS] Log warning rather than throw Analysis...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17252 Thanks for working on this, but I think this is inconsistent with other APIs in Spark. Also for things like the foreach sink, you might actually be expecting the option to affect the partitioning for some correctness reason. As such I think we should close this issue. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17361: [SPARK-20030][SS] Event-time-based timeout for MapGroups...
Github user marmbrus commented on the issue: https://github.com/apache/spark/pull/17361 LGTM --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107307806
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/streaming/KeyedStateTimeout.java
---
@@ -34,9 +32,20 @@
@InterfaceStability.Evolving
public class KeyedStateTimeout {
- /** Timeout based on processing time. */
+ /**
+ * Timeout based on processing time. The duration of timeout can be set
for each group in
+ * `map/flatMapGroupsWithState` by calling
`KeyedState.setTimeoutDuration()`.
+ */
public static KeyedStateTimeout ProcessingTimeTimeout() { return
ProcessingTimeTimeout$.MODULE$; }
--- End diff --
I'd probably still remove it.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107307722
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala
---
@@ -147,49 +147,68 @@ object UnsupportedOperationChecker {
throwError("Commands like CreateTable*, AlterTable*, Show* are
not supported with " +
"streaming DataFrames/Datasets")
-// mapGroupsWithState: Allowed only when no aggregation + Update
output mode
-case m: FlatMapGroupsWithState if m.isStreaming &&
m.isMapGroupsWithState =>
- if (collectStreamingAggregates(plan).isEmpty) {
-if (outputMode != InternalOutputModes.Update) {
- throwError("mapGroupsWithState is not supported with " +
-s"$outputMode output mode on a streaming
DataFrame/Dataset")
-} else {
- // Allowed when no aggregation + Update output mode
-}
- } else {
-throwError("mapGroupsWithState is not supported with
aggregation " +
- "on a streaming DataFrame/Dataset")
- }
-
-// flatMapGroupsWithState without aggregation
-case m: FlatMapGroupsWithState
- if m.isStreaming && collectStreamingAggregates(plan).isEmpty =>
- m.outputMode match {
-case InternalOutputModes.Update =>
- if (outputMode != InternalOutputModes.Update) {
-throwError("flatMapGroupsWithState in update mode is not
supported with " +
+// mapGroupsWithState and flatMapGroupsWithState
+case m: FlatMapGroupsWithState if m.isStreaming =>
+
+ // Check compatibility with output modes and aggregations in
query
+ val aggsAfterFlatMapGroups = collectStreamingAggregates(plan)
+
+ if (m.isMapGroupsWithState) { // check
mapGroupsWithState
+// allowed only in update query output mode and without
aggregation
+if (aggsAfterFlatMapGroups.nonEmpty) {
+ throwError(
+"mapGroupsWithState is not supported with aggregation " +
+ "on a streaming DataFrame/Dataset")
+} else if (outputMode != InternalOutputModes.Update) {
+ throwError(
+"mapGroupsWithState is not supported with " +
s"$outputMode output mode on a streaming
DataFrame/Dataset")
+}
+ } else { // check
latMapGroupsWithState
+if (aggsAfterFlatMapGroups.isEmpty) {
+ // flatMapGroupsWithState without aggregation: operation's
output mode must
+ // match query output mode
+ m.outputMode match {
+case InternalOutputModes.Update if outputMode !=
InternalOutputModes.Update =>
+ throwError(
+"flatMapGroupsWithState in update mode is not
supported with " +
+ s"$outputMode output mode on a streaming
DataFrame/Dataset")
+
+case InternalOutputModes.Append if outputMode !=
InternalOutputModes.Append =>
+ throwError(
+"flatMapGroupsWithState in append mode is not
supported with " +
+ s"$outputMode output mode on a streaming
DataFrame/Dataset")
+
+case _ =>
}
-case InternalOutputModes.Append =>
- if (outputMode != InternalOutputModes.Append) {
-throwError("flatMapGroupsWithState in append mode is not
supported with " +
- s"$outputMode output mode on a streaming
DataFrame/Dataset")
+} else {
+ // flatMapGroupsWithState with aggregation: update operation
mode not allowed, and
+ // *groupsWithState after aggregation not allowed
+ if (m.outputMode == InternalOutputModes.Update) {
+throwError(
+ "flatMapGroupsWithState in update mode is not supported
with " +
+"aggregation on a streaming DataFrame/Dataset")
+ } else if (collectStreamingAggregates(m).nonEmpty) {
+throwError(
+ "flatMapGroupsWithState in append mode is not supported
after " +
+s"aggregation on a streaming DataFrame/Dataset&
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107307617
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/FlatMapGroupsWithStateSuite.scala
---
@@ -519,6 +588,52 @@ class FlatMapGroupsWithStateSuite extends
StateStoreMetricsTest with BeforeAndAf
)
}
+ test("flatMapGroupsWithState - streaming with event time timeout") {
+// Function to maintain the max event time
+// Returns the max event time in the state, or -1 if the state was
removed by timeout
+val stateFunc = (
+key: String,
+values: Iterator[(String, Long)],
+state: KeyedState[Long]) => {
+ val timeoutDelay = 5
+ if (key != "a") {
+Iterator.empty
+ } else {
+if (state.hasTimedOut) {
+ state.remove()
+ Iterator((key, -1))
+} else {
+ val valuesSeq = values.toSeq
+ val maxEventTime = math.max(valuesSeq.map(_._2).max,
state.getOption.getOrElse(0L))
+ val timeoutTimestampMs = maxEventTime + timeoutDelay
+ state.update(maxEventTime)
+ state.setTimeoutTimestamp(timeoutTimestampMs * 1000)
+ Iterator((key, maxEventTime.toInt))
+}
+ }
+}
+val inputData = MemoryStream[(String, Int)]
+val result =
+ inputData.toDS
+.select($"_1".as("key"), $"_2".cast("timestamp").as("eventTime"))
+.withWatermark("eventTime", "10 seconds")
+.as[(String, Long)]
+.groupByKey[String]((x: (String, Long)) => x._1)
+.flatMapGroupsWithState[Long, (String, Int)](Update,
EventTimeTimeout)(stateFunc)
--- End diff --
As long as they aren't required its okay.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107307367
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/KeyedStateImpl.scala
---
@@ -17,37 +17,45 @@
package org.apache.spark.sql.execution.streaming
+import java.sql.Date
+
import org.apache.commons.lang3.StringUtils
-import org.apache.spark.sql.streaming.KeyedState
+import org.apache.spark.sql.catalyst.plans.logical.{EventTimeTimeout,
ProcessingTimeTimeout}
+import org.apache.spark.sql.execution.streaming.KeyedStateImpl._
+import org.apache.spark.sql.streaming.{KeyedState, KeyedStateTimeout}
import org.apache.spark.unsafe.types.CalendarInterval
+
/**
* Internal implementation of the [[KeyedState]] interface. Methods are
not thread-safe.
* @param optionalValue Optional value of the state
* @param batchProcessingTimeMs Processing time of current batch, used to
calculate timestamp
* for processing time timeouts
- * @param isTimeoutEnabled Whether timeout is enabled. This will be used
to check whether the user
- * is allowed to configure timeouts.
+ * @param timeoutConf Type of timeout configured. Based on this,
different operations will
+ *be supported.
--- End diff --
nit: indent is inconsistent
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107304893
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/FlatMapGroupsWithStateSuite.scala
---
@@ -519,6 +588,52 @@ class FlatMapGroupsWithStateSuite extends
StateStoreMetricsTest with BeforeAndAf
)
}
+ test("flatMapGroupsWithState - streaming with event time timeout") {
+// Function to maintain the max event time
+// Returns the max event time in the state, or -1 if the state was
removed by timeout
+val stateFunc = (
+key: String,
+values: Iterator[(String, Long)],
+state: KeyedState[Long]) => {
+ val timeoutDelay = 5
+ if (key != "a") {
+Iterator.empty
+ } else {
+if (state.hasTimedOut) {
+ state.remove()
+ Iterator((key, -1))
+} else {
+ val valuesSeq = values.toSeq
+ val maxEventTime = math.max(valuesSeq.map(_._2).max,
state.getOption.getOrElse(0L))
+ val timeoutTimestampMs = maxEventTime + timeoutDelay
+ state.update(maxEventTime)
+ state.setTimeoutTimestamp(timeoutTimestampMs * 1000)
+ Iterator((key, maxEventTime.toInt))
+}
+ }
+}
+val inputData = MemoryStream[(String, Int)]
+val result =
+ inputData.toDS
+.select($"_1".as("key"), $"_2".cast("timestamp").as("eventTime"))
+.withWatermark("eventTime", "10 seconds")
+.as[(String, Long)]
+.groupByKey[String]((x: (String, Long)) => x._1)
+.flatMapGroupsWithState[Long, (String, Int)](Update,
EventTimeTimeout)(stateFunc)
--- End diff --
These types are just here for testing? (i.e. we didn't break inference
right?)
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107304618
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala
---
@@ -147,49 +147,68 @@ object UnsupportedOperationChecker {
throwError("Commands like CreateTable*, AlterTable*, Show* are
not supported with " +
"streaming DataFrames/Datasets")
-// mapGroupsWithState: Allowed only when no aggregation + Update
output mode
-case m: FlatMapGroupsWithState if m.isStreaming &&
m.isMapGroupsWithState =>
- if (collectStreamingAggregates(plan).isEmpty) {
-if (outputMode != InternalOutputModes.Update) {
- throwError("mapGroupsWithState is not supported with " +
-s"$outputMode output mode on a streaming
DataFrame/Dataset")
-} else {
- // Allowed when no aggregation + Update output mode
-}
- } else {
-throwError("mapGroupsWithState is not supported with
aggregation " +
- "on a streaming DataFrame/Dataset")
- }
-
-// flatMapGroupsWithState without aggregation
-case m: FlatMapGroupsWithState
- if m.isStreaming && collectStreamingAggregates(plan).isEmpty =>
- m.outputMode match {
-case InternalOutputModes.Update =>
- if (outputMode != InternalOutputModes.Update) {
-throwError("flatMapGroupsWithState in update mode is not
supported with " +
+// mapGroupsWithState and flatMapGroupsWithState
+case m: FlatMapGroupsWithState if m.isStreaming =>
+
+ // Check compatibility with output modes and aggregations in
query
+ val aggsAfterFlatMapGroups = collectStreamingAggregates(plan)
+
+ if (m.isMapGroupsWithState) { // check
mapGroupsWithState
+// allowed only in update query output mode and without
aggregation
+if (aggsAfterFlatMapGroups.nonEmpty) {
+ throwError(
+"mapGroupsWithState is not supported with aggregation " +
+ "on a streaming DataFrame/Dataset")
+} else if (outputMode != InternalOutputModes.Update) {
+ throwError(
+"mapGroupsWithState is not supported with " +
s"$outputMode output mode on a streaming
DataFrame/Dataset")
+}
+ } else { // check
latMapGroupsWithState
+if (aggsAfterFlatMapGroups.isEmpty) {
+ // flatMapGroupsWithState without aggregation: operation's
output mode must
+ // match query output mode
+ m.outputMode match {
+case InternalOutputModes.Update if outputMode !=
InternalOutputModes.Update =>
+ throwError(
+"flatMapGroupsWithState in update mode is not
supported with " +
+ s"$outputMode output mode on a streaming
DataFrame/Dataset")
+
+case InternalOutputModes.Append if outputMode !=
InternalOutputModes.Append =>
+ throwError(
+"flatMapGroupsWithState in append mode is not
supported with " +
+ s"$outputMode output mode on a streaming
DataFrame/Dataset")
+
+case _ =>
}
-case InternalOutputModes.Append =>
- if (outputMode != InternalOutputModes.Append) {
-throwError("flatMapGroupsWithState in append mode is not
supported with " +
- s"$outputMode output mode on a streaming
DataFrame/Dataset")
+} else {
+ // flatMapGroupsWithState with aggregation: update operation
mode not allowed, and
+ // *groupsWithState after aggregation not allowed
+ if (m.outputMode == InternalOutputModes.Update) {
+throwError(
+ "flatMapGroupsWithState in update mode is not supported
with " +
+"aggregation on a streaming DataFrame/Dataset")
+ } else if (collectStreamingAggregates(m).nonEmpty) {
+throwError(
+ "flatMapGroupsWithState in append mode is not supported
after " +
+s"aggregation on a streaming DataFrame/Dataset&
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107304531
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala
---
@@ -147,49 +147,68 @@ object UnsupportedOperationChecker {
throwError("Commands like CreateTable*, AlterTable*, Show* are
not supported with " +
"streaming DataFrames/Datasets")
-// mapGroupsWithState: Allowed only when no aggregation + Update
output mode
-case m: FlatMapGroupsWithState if m.isStreaming &&
m.isMapGroupsWithState =>
- if (collectStreamingAggregates(plan).isEmpty) {
-if (outputMode != InternalOutputModes.Update) {
- throwError("mapGroupsWithState is not supported with " +
-s"$outputMode output mode on a streaming
DataFrame/Dataset")
-} else {
- // Allowed when no aggregation + Update output mode
-}
- } else {
-throwError("mapGroupsWithState is not supported with
aggregation " +
- "on a streaming DataFrame/Dataset")
- }
-
-// flatMapGroupsWithState without aggregation
-case m: FlatMapGroupsWithState
- if m.isStreaming && collectStreamingAggregates(plan).isEmpty =>
- m.outputMode match {
-case InternalOutputModes.Update =>
- if (outputMode != InternalOutputModes.Update) {
-throwError("flatMapGroupsWithState in update mode is not
supported with " +
+// mapGroupsWithState and flatMapGroupsWithState
+case m: FlatMapGroupsWithState if m.isStreaming =>
+
+ // Check compatibility with output modes and aggregations in
query
+ val aggsAfterFlatMapGroups = collectStreamingAggregates(plan)
+
+ if (m.isMapGroupsWithState) { // check
mapGroupsWithState
+// allowed only in update query output mode and without
aggregation
+if (aggsAfterFlatMapGroups.nonEmpty) {
+ throwError(
+"mapGroupsWithState is not supported with aggregation " +
+ "on a streaming DataFrame/Dataset")
+} else if (outputMode != InternalOutputModes.Update) {
+ throwError(
+"mapGroupsWithState is not supported with " +
s"$outputMode output mode on a streaming
DataFrame/Dataset")
+}
+ } else { // check
latMapGroupsWithState
+if (aggsAfterFlatMapGroups.isEmpty) {
+ // flatMapGroupsWithState without aggregation: operation's
output mode must
+ // match query output mode
+ m.outputMode match {
+case InternalOutputModes.Update if outputMode !=
InternalOutputModes.Update =>
+ throwError(
+"flatMapGroupsWithState in update mode is not
supported with " +
+ s"$outputMode output mode on a streaming
DataFrame/Dataset")
+
+case InternalOutputModes.Append if outputMode !=
InternalOutputModes.Append =>
+ throwError(
+"flatMapGroupsWithState in append mode is not
supported with " +
+ s"$outputMode output mode on a streaming
DataFrame/Dataset")
+
+case _ =>
}
-case InternalOutputModes.Append =>
- if (outputMode != InternalOutputModes.Append) {
-throwError("flatMapGroupsWithState in append mode is not
supported with " +
- s"$outputMode output mode on a streaming
DataFrame/Dataset")
+} else {
+ // flatMapGroupsWithState with aggregation: update operation
mode not allowed, and
+ // *groupsWithState after aggregation not allowed
+ if (m.outputMode == InternalOutputModes.Update) {
+throwError(
+ "flatMapGroupsWithState in update mode is not supported
with " +
+"aggregation on a streaming DataFrame/Dataset")
+ } else if (collectStreamingAggregates(m).nonEmpty) {
+throwError(
+ "flatMapGroupsWithState in append mode is not supported
after " +
+s"aggregation on a streaming DataFrame/Dataset&
[GitHub] spark pull request #17361: [SPARK-20030][SS] Event-time-based timeout for Ma...
Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/17361#discussion_r107304196
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala
---
@@ -147,49 +147,68 @@ object UnsupportedOperationChecker {
throwError("Commands like CreateTable*, AlterTable*, Show* are
not supported with " +
"streaming DataFrames/Datasets")
-// mapGroupsWithState: Allowed only when no aggregation + Update
output mode
-case m: FlatMapGroupsWithState if m.isStreaming &&
m.isMapGroupsWithState =>
- if (collectStreamingAggregates(plan).isEmpty) {
-if (outputMode != InternalOutputModes.Update) {
- throwError("mapGroupsWithState is not supported with " +
-s"$outputMode output mode on a streaming
DataFrame/Dataset")
-} else {
- // Allowed when no aggregation + Update output mode
-}
- } else {
-throwError("mapGroupsWithState is not supported with
aggregation " +
- "on a streaming DataFrame/Dataset")
- }
-
-// flatMapGroupsWithState without aggregation
-case m: FlatMapGroupsWithState
- if m.isStreaming && collectStreamingAggregates(plan).isEmpty =>
- m.outputMode match {
-case InternalOutputModes.Update =>
- if (outputMode != InternalOutputModes.Update) {
-throwError("flatMapGroupsWithState in update mode is not
supported with " +
+// mapGroupsWithState and flatMapGroupsWithState
+case m: FlatMapGroupsWithState if m.isStreaming =>
--- End diff --
Wow, this is getting complicated...
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org