[GitHub] spark issue #16418: [SPARK-18993][BUILD] Unable to build/compile Spark in In...
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16418 good catch, thx --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 Thanks @vanzin ! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 Thanks @vanzin; do you have a cmdline handy that will reproduce the problem with the tags not being found? It'd be nice to sanity-check this for myself but I don't see what to do with the configs in `dev/sparktestsupport/modules.py`. Sorry if you've described it already and I missed it, still glazing over at some parts of the whole menagerie ð. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 OK, I looked at what the more-correct-but-invasive POM-refactoring would take and could not stomach it, so I pasted a spark-tags test-dep into every relevant submodule's POM*. *Actually I only did POMs that already had a compile-scope dep on spark-tags; these POMs were skipped: ``` assembly/pom.xml examples/pom.xml external/flume-assembly/pom.xml external/kafka-0-10-assembly/pom.xml external/kafka-0-8-assembly/pom.xml external/kinesis-asl-assembly/pom.xml external/spark-ganglia-lgpl/pom.xml resource-managers/mesos/pom.xml tools/pom.xml ``` lmkwyt --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 Thx for that info. Are these test-gated tags ever run? If so, when? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 @srowen thx, one comment: > It does indeed require editing all the POMs but it's straightforward. The other option that I described [above](https://github.com/apache/spark/pull/16311#issuecomment-267657034) is to express the "each module needs a spark-tags test-dep" requirement once, in the spark-parent POM's `` tag. @vanzin on that note, I guess I am proximally blocked on this question of whether to just hard-code a spark-tags dep into every submodule's POM, or try to factor it out a little more cleanly, albeit with a bit more pom-inheritance contortions. I'm also balking at a higher-level at some apparent messiness of the overall build landscape that this has run into: - we have submodule-specific tags that have been module-sharded by their tag-ness instead of by their submodule-relevance, which are used to manually control whether to run certain tests in certain situations (as opposed to, say, the build system understanding when they'd need to be run based on changes to things they depend on). - apparently the way they are used is broken by this PR, but the already-3hr build does not know about that, and passes. So I'm not really sure what the best way to proceed is; I could almost squint and say the requirement for all possible tags to be on the classpath when running unrelated modules' tests is a problem with Scalatest, or Scalatest's interactions with Spark's submodule-landscape, or something else altogether. Anyway we can keep discussing or someone is welcome to fork this PR themselves and push through some seemingly-least-evil solution. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 I suppose that build-pass above can be considered erroneous since I'd not actually removed the compile-scope scalatest-dep from spark-tags in the first commit in this PR⦠let's see how the second build fares. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 OK, well lmk if I should make a version of this that: - un-inherits spark-tags from spark-parent, - copies the test-jar-publishing config into spark-tags, and - adds a spark-tags test-dep to all modules in spark-parent. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 > if you make a change, but you don't change any files under the YARN module, then some slower YARN tests are skipped by excluding that tag. I don't remember exactly what the code does, so it might add the exclusion in more cases, but that is the idea at least. Interesting, where is the code that does this that you referred to? Some kind of hard-coded rules about what has to be rebuilt/re-tested when various things change? > It would require some duplication (e.g. version of shared dependencies) but is probably doable. Don't know if there are any other implications. Looking at the spark-tags pom and libraries, it has no dependencies other than scalatest (test scope; I had missed changing this from "compile" to "test" scope in this PR, just updated, thanks!) which it gets from the root POM. It does get at least some necessary configuration from the root POM for publishing a `test-jar`; if that's all there is, we could duplicate it and remove the root-POM inheritance, or we could factor it into a root-root-POM that spark-tags and spark-parent inherit from. Obviously this is all pretty sticky, but while we're here I'm interested in at least discussing what the most idiomatic solution would be, whether or not we ultimately decide that it's worth the trouble. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 > And you can't just declare that in the root pom's dependencies because then "spark-tags" cannot inherit from the root pom... fun all around. Should spark-tags not inherit from the root POM? it seems like it barely does anything as a module, does it need the root POM? > if you make a SQL change, that will trigger the exclusion of "ExtendedYarnTest" Can you elaborate on why the second part of this follows from the first? Can we add a test-jar-test-dep to the root POM? Wouldn't that be picked up by every module? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 @vanzin interesting, so at what level do they have to be brought in as dependencies in order to avoid that? Is that why spark-core needs to depend on the test-tags? I didn't see a reason for it to so I did not add such a dep here, I wonder if that will cause some tests to fail? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16303: [SPARK-17807][core] Demote scalatest to "provided" in sp...
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16303 I filed #16311 splitting out a spark-tags test-jar; turns out my second bullet above is a no-op since all Spark modules' test-jars are already automatically published, so that's neat. As I noted over on #16311, I now feel that we should just move each of the three test-tags to the modules they are pretty explicitly scoped to (in name and usage), and do away with spark-tags' containing these test-tags altogether, but we can discuss that further over there. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16311: [SPARK-17807][core] split test-tags into test-JAR
Github user ryan-williams commented on the issue: https://github.com/apache/spark/pull/16311 While preparing this PR, I noted that spark-tags has 3 test-tags that are each specifically directed at each of three modules' tests: - `DockerTest` -> external/docker-integration-tests - `ExtendedHiveTest` -> sql/hive - `ExtendedYarnTest` -> resource-managers/yarn It may make more sense to just move each test-tag to its corresponding module, and do away with the spark-tags test-JAR altogether; I don't see that their status as "tags" is the most important axis on which to physically group them. LMK if anyone would prefer that and I'll do it. cc @vanzin @srowen --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #16311: [SPARK-17807][core] split test-tags into test-JAR
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/16311 [SPARK-17807][core] split test-tags into test-JAR Remove spark-tag's compile-scope dependency (and, indirectly, spark-core's compile-scope transitive-dependency) on scalatest by splitting test-oriented tags into spark-tags' test JAR. Alternative to #16303. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark tt Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/16311.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #16311 commit fe7711726feaa70fb79f7f79e33c76fb17f32a92 Author: Ryan Williams <ryan.blake.willi...@gmail.com> Date: 2016-12-16T16:11:22Z [SPARK-17807][core] split test-tags into test-JAR --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16303: [SPARK-17807][core] Demote scalatest to "provided" in sp...
Github user ryan-williams commented on the issue:
https://github.com/apache/spark/pull/16303
I appreciate the quick turn-around on this, though it seems like a mis-use
of the `provided` scope.
FWIW, I am advocating for:
- `mv common/tags/src/{main,test}/java/org/apache/spark/tags`;
- publish the `test-jar` for the spark-tags module.
- I know this is trivial in SBT, and I've seen Maven modules do this
- bdgenomics:utils-misc does it with [this config
blob](https://github.com/bigdatagenomics/utils/blob/utils-parent_2.11-0.2.10/utils-misc/pom.xml#L46-L56)
afaict?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8582][Core]Optimize checkpointing to av...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9258#discussion_r42951707
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -258,6 +258,16 @@ abstract class RDD[T: ClassTag](
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T]
= {
+if (!isCheckpointedAndMaterialized) {
--- End diff --
just out of curiosity, any reason not to do an `if`/`else` here?
```
if (!isCheckpointedAndMaterialized &&
checkpointData.exists(_.isInstanceOf[ReliableRDDCheckpointData[T]])) {
SparkEnv.get.checkpointMananger.getOrCompute(
this, checkpointData.get.asInstanceOf[ReliableRDDCheckpointData[T]],
split, context)
} else {
computeOrReadCache(split, context)
}
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8582][Core]Optimize checkpointing to av...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9258#discussion_r42951772
--- Diff: core/src/main/scala/org/apache/spark/SparkEnv.scala ---
@@ -81,6 +81,8 @@ class SparkEnv (
@deprecated("Actor system is no longer supported as of 1.4.0", "1.4.0")
val actorSystem: ActorSystem = _actorSystem
+ private[spark] val checkpointMananger = new CheckpointManager
--- End diff --
typo: `s/Mananger/Manager/g`, jfyi
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8582][Core]Optimize checkpointing to av...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9258#discussion_r42951830
--- Diff: core/src/main/scala/org/apache/spark/CheckpointManager.scala ---
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark
+
+import scala.collection.mutable
+import scala.reflect.ClassTag
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.rdd.{ReliableRDDCheckpointData,
ReliableCheckpointRDD, RDD}
+import org.apache.spark.storage._
+
+class CheckpointManager extends Logging {
+
+ /** Keys of RDD partitions that are being checkpointed. */
+ private val checkpointingRDDPartitions = new mutable.HashSet[RDDBlockId]
+
+ /** Gets or computes an RDD partition. Used by RDD.iterator() when an
RDD is cached. */
--- End diff --
does "cached" still make sense here?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42387794
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala ---
@@ -430,17 +430,20 @@ private[yarn] class YarnAllocator(
for (completedContainer <- completedContainers) {
val containerId = completedContainer.getContainerId
val alreadyReleased = releasedContainers.remove(containerId)
+ val hostOpt = allocatedContainerToHostMap.get(containerId)
+ val onHostStr = hostOpt.map(host => s" on host: $host").getOrElse("")
val exitReason = if (!alreadyReleased) {
// Decrement the number of executors running. The next iteration of
// the ApplicationMaster's reporting thread will take care of
allocating.
numExecutorsRunning -= 1
-logInfo("Completed container %s (state: %s, exit status:
%s)".format(
+logInfo("Completed container %s%s (state: %s, exit status:
%s)".format(
--- End diff --
Yea I originally did some more aggressive converting to
interpolated-strings here because that seems like a better way to do things in
general, but such strings often make for absurdly long lines, and I don't have
a solution I like to that (e.g. breaking onto multiple lines with `+`s seems
gross), so I think I reverted that here and went for the more minimal change.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42271853
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,23 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to numExecutors * 2 (maxExecutors in the case that we are
+ // dynamically allocating executors), with minimum of 3.
+ private val maxNumExecutorFailures =
+sparkConf.getInt("spark.yarn.max.executor.failures",
+ sparkConf.getInt("spark.yarn.max.worker.failures",
+math.max(
+ 3,
+ 2 * sparkConf.getInt(
+if (Utils.isDynamicAllocationEnabled(sparkConf))
+ "spark.dynamicAllocation.maxExecutors"
--- End diff --
To be clear, this change does not place any additional requirements on a
user to set `maxExecutors` to get sane dynamic allocation (DA) default behavior.
It merely alleviates one class of "gotcha" that caused me some trouble this
week: when setting standard DA params, the `val maxNumExecutorFailures` here
becomes `3` by default, which does not seem sensible for apps that are going up
to many 100s of executors.
It seems to me that the extant
`math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)` expression
is not _intentionally_ making DA apps have a limit of `3` failures, but that it
simply wasn't taking into account the fact that `spark.executor.instances` is
not set in DA mode.
It's true that we could also "resolve" this by declaring
`spark.yarn.max.worker.failures` to be yet another configuration param that
must be set to a non-default value in order to get sane DA behavior.
Off the top of my head, there is already one param
(`spark.shuffle.service.enabled=true`) that is not named in a way that suggests
that it is important for DA apps to set, and we could make
`spark.yarn.max.worker.failures` a second.
My belief is that it would be better to not require yet another parameter
(especially one that is not named in a way that makes it obvious that it is or
could be important for DA to not fail in unexpected ways) for sane DA behavior,
but to just fix the clearly-inadvertently-missed setting of a good default
value here.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42284143
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,24 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to numExecutors * 2 (maxExecutors in the case that we are
+ // dynamically allocating executors), with minimum of 3.
+ private val maxNumExecutorFailures =
+sparkConf.getInt("spark.yarn.max.executor.failures",
+ sparkConf.getInt("spark.yarn.max.worker.failures",
--- End diff --
ah, hadn't seen that, done
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42292614
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,26 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to numExecutors * 2 (maxExecutors in the case that we are
+ // dynamically allocating executors), with minimum of 3.
+ private val maxNumExecutorFailures = {
+val effectiveNumExecutors =
+ sparkConf.getInt(
+if (Utils.isDynamicAllocationEnabled(sparkConf)) {
+ "spark.dynamicAllocation.maxExecutors"
+} else {
+ "spark.executor.instances"
+},
+0
+ )
+
+val defaultMaxNumExecutorFailures = math.max(3, 2 *
effectiveNumExecutors)
+
+sparkConf.getInt(
--- End diff --
OK I addressed this so the tests will run one more time
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42284385
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,24 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to numExecutors * 2 (maxExecutors in the case that we are
+ // dynamically allocating executors), with minimum of 3.
+ private val maxNumExecutorFailures =
+sparkConf.getInt("spark.yarn.max.executor.failures",
+ sparkConf.getInt("spark.yarn.max.worker.failures",
+math.max(
+ 3,
+ 2 * sparkConf.getInt(
--- End diff --
cool, done with some slightly more verbose `val`-names, lmk if you want me
to change
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42301156
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,23 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to numExecutors * 2 (maxExecutors in the case that we are
+ // dynamically allocating executors), with minimum of 3.
+ private val maxNumExecutorFailures = {
+val effectiveNumExecutors =
+ sparkConf.getInt(
+if (Utils.isDynamicAllocationEnabled(sparkConf)) {
+ "spark.dynamicAllocation.maxExecutors"
+} else {
+ "spark.executor.instances"
+},
+0
+ )
+
+val defaultMaxNumExecutorFailures = math.max(3, 2 *
effectiveNumExecutors)
+
--- End diff --
done
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42301346
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,19 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to twice the number of executors (twice the maximum number of
executors if dynamic
+ // allocation is enabled), with a minimum of 3.
+ val defaultKey =
+if (Utils.isDynamicAllocationEnabled(sparkConf)) {
+ "spark.dynamicAllocation.maxExecutors"
+} else {
+ "spark.executor.instances"
+}
+ val effectiveNumExecutors = sparkConf.getInt(defaultKey, 0)
+ val defaultMaxNumExecutorFailures = math.max(3, 2 *
effectiveNumExecutors)
--- End diff --
woops, didn't notice that you still wanted that scoping, fixed
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/9147#issuecomment-148848610 Test failure above looks like a jenkinsâ·git issue? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/9147#discussion_r42301088
--- Diff:
yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala ---
@@ -62,10 +62,23 @@ private[spark] class ApplicationMaster(
.asInstanceOf[YarnConfiguration]
private val isClusterMode = args.userClass != null
- // Default to numExecutors * 2, with minimum of 3
- private val maxNumExecutorFailures =
sparkConf.getInt("spark.yarn.max.executor.failures",
-sparkConf.getInt("spark.yarn.max.worker.failures",
- math.max(sparkConf.getInt("spark.executor.instances", 0) * 2, 3)))
+ // Default to numExecutors * 2 (maxExecutors in the case that we are
+ // dynamically allocating executors), with minimum of 3.
--- End diff --
done (a version of that anyway)
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/9147#issuecomment-148867212 not super excited to write a test for this, tbh. what kind of test are you imagining? `ApplicationMaster*Suite` doesn't even exist atm... --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-11120] Allow sane default number of exe...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/9147 [SPARK-11120] Allow sane default number of executor failures when dynamically allocating in YARN I also added some information to container-failure error msgs about what host they failed on, which would have helped me identify the problem that lead me to this JIRA and PR sooner. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark dyn-exec-failures Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/9147.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #9147 commit 5b91832ce3d7b813af62825ac6e01bebc5ed57c5 Author: Ryan Williams <ryan.blake.willi...@gmail.com> Date: 2015-10-15T00:40:03Z allow 2*maxExecutors failures when dyn-alloc'ing commit 46633e74d0f732a293e8ca4cbfc6a5d683d6cc99 Author: Ryan Williams <ryan.blake.willi...@gmail.com> Date: 2015-10-15T02:05:16Z add host info to container-failure log msgs --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-10871] include number of executor failu...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/8939 [SPARK-10871] include number of executor failures in error msg You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark errmsg Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/8939.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #8939 commit 52ad7f30ac8667cac06bdebfd76f3f7def18b7f3 Author: Ryan Williams <ryan.blake.willi...@gmail.com> Date: 2015-09-29T14:48:00Z include number of executor failures in error msg --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5847] Allow for namespacing metrics by ...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4632#issuecomment-140235859 I'm not sure how to figure out what test failed from the Jenkins output here https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/42444/consoleFull all I see is ``` [info] Run completed in 1 hour, 58 minutes, 26 seconds. [info] Total number of tests run: 667 [info] Suites: completed 136, aborted 0 [info] Tests: succeeded 667, failed 0, canceled 0, ignored 0, pending 0 [info] All tests passed. [info] Passed: Total 774, Failed 0, Errors 0, Passed 774 [error] (core/test:test) sbt.TestsFailedException: Tests unsuccessful [error] Total time: 7320 s, completed Sep 14, 2015 4:38:56 PM [error] running /home/jenkins/workspace/SparkPullRequestBuilder@2/build/sbt -Pyarn -Phadoop-2.3 -Dhadoop.version=2.3.0 -Phive -Pkinesis-asl -Phive-thriftserver test ; received return code 1 ``` at the end and what looks like many passing tests --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-9851] Support submitting map stages ind...
Github user ryan-williams commented on a diff in the pull request: https://github.com/apache/spark/pull/8180#discussion_r38893879 --- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala --- @@ -45,17 +45,65 @@ import org.apache.spark.storage.BlockManagerMessages.BlockManagerHeartbeat * The high-level scheduling layer that implements stage-oriented scheduling. It computes a DAG of * stages for each job, keeps track of which RDDs and stage outputs are materialized, and finds a * minimal schedule to run the job. It then submits stages as TaskSets to an underlying - * TaskScheduler implementation that runs them on the cluster. + * TaskScheduler implementation that runs them on the cluster. A TaskSet contains fully independent + * tasks that can run right away based on the data that's already on the cluster (e.g. map output + * files from previous stages), though it may fail if this data becomes unavailable. * - * In addition to coming up with a DAG of stages, this class also determines the preferred + * Spark stages are created by breaking the RDD graph at shuffle boundaries. RDD operations with + * "narrow" dependencies, like map() and filter(), are pipelined together into one set of tasks + * in each stage, but operations with shuffle dependencies require multiple stages (one to write a + * set of map output files, and another to read those files after a barrier). In the end, every + * stage will have only shuffle dependencies on other stages, and may compute multiple operations + * inside it. The actual pipelining of these operations happens in the RDD.compute() functions of + * various RDDs (MappedRDD, FilteredRDD, etc). + * + * In addition to coming up with a DAG of stages, the DAGScheduler also determines the preferred * locations to run each task on, based on the current cache status, and passes these to the * low-level TaskScheduler. Furthermore, it handles failures due to shuffle output files being * lost, in which case old stages may need to be resubmitted. Failures *within* a stage that are * not caused by shuffle file loss are handled by the TaskScheduler, which will retry each task * a small number of times before cancelling the whole stage. * + * When looking through this code, there are several key concepts: + * + * - Jobs (represented by [[ActiveJob]]) are the top-level work items submitted to the scheduler. + *For example, when the user calls an action, like count(), a job will be submitted through + *submitJob. Each Job may require the execution of multiple stages to build intermediate data. + * + * - Stages ([[Stage]]) are sets of tasks that compute intermediate results in jobs, where each + *task computes the same function on partitions of the same RDD. Stages are separated at shuffle + *boundaries, which introduce a barrier (where we must wait for the previous stage to finish to + *fetch outputs). There are two types of stages: [[ResultStage]], for the final stage that + *executes an action, and [[ShuffleMapStage]], which writes map output files for a shuffle. + *Stages are often shared across multiple jobs, if these jobs reuse the same RDDs. + * + * - Tasks are individual units of work, each sent to one machine. + * + * - Cache tracking: the DAGScheduler figures out which RDDs are cached to avoid recomputing them + *and likewise remembers which shuffle map stages have already produced output files to avoid + *redoing the map side of a shuffle. + * + * - Preferred locations: the DAGScheduler also computes where to run each task in a stage based + *on the preferred locations of its underlying RDDs, or the location of cached or shuffle data. + * + * - Cleanup: all data structures are cleared when the running jobs that depend on them finish, + *to prevent memory leaks in a long-running application. + * + * To recover from failures, the same stage might need to run multiple times, which are called + * "attempts". If the TaskScheduler reports that a task failed because a map output file from a + * previous stage was lost, the DAGScheduler resubmits that lost stage. This is detected through a + * through a CompletionEvent with FetchFailed, or an ExecutorLost event. The DAGScheduler will wait + * a small amount of time to see whether other nodes or tasks fail, then resubmit TaskSets for any + * lost stage(s) that compute the missing tasks. As part of this process, we might also have to + * create Stage objects for old (finished) stages where we previously cleaned up the Stage object. + * Since tasks from the old attempt of a stage could still be running, care must be taken to map + * any events rec
[GitHub] spark pull request: [SPARK-1517] Refactor release scripts to facil...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/7411#discussion_r36684398
--- Diff: dev/create-release/release-build.sh ---
@@ -0,0 +1,320 @@
+#!/usr/bin/env bash
+
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the License); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an AS IS BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+function exit_with_usage {
+ cat EOF
+usage: release-build.sh package|docs|publish-snapshot|publish-release
+Creates build deliverables from a Spark commit.
+
+Top level targets are
+ package: Create binary packages and copy them to people.apache
+ docs: Build docs and copy them to people.apache
+ publish-snapshot: Publish snapshot release to Apache snapshots
+ publish-release: Publish a release to Apache release repo
+
+All other inputs are environment variables
+
+GIT_REF - Release tag or commit to build from
+SPARK_VERSION - Release identifier used when publishing
+SPARK_PACKAGE_VERSION - Release identifier in top level package directory
+REMOTE_PARENT_DIR - Parent in which to create doc or release builds.
+REMOTE_PARENT_MAX_LENGTH - If set, parent directory will be cleaned to only
+ have this number of subdirectories (by deleting old ones). WARNING: This
deletes data.
+
+ASF_USERNAME - Username of ASF committer account
+ASF_PASSWORD - Password of ASF committer account
+ASF_RSA_KEY - RSA private key file for ASF committer account
+
+GPG_KEY - GPG key used to sign release artifacts
+GPG_PASSPHRASE - Passphrase for GPG key
+EOF
+ exit 1
+}
+
+set -e
+
+if [ $# -eq 0 ]; then
+ exit_with_usage
+fi
+
+if [[ $@ == *help* ]]; then
+ exit_with_usage
+fi
+
+for env in ASF_USERNAME ASF_RSA_KEY GPG_PASSPHRASE GPG_KEY; do
+ if [ -z ${!env} ]; then
+echo ERROR: $env must be set to run this script
+exit_with_usage
+ fi
+done
+
+# Commit ref to checkout when building
+GIT_REF=${GIT_REF:-master}
+
+# Destination directory parent on remote server
+REMOTE_PARENT_DIR=${REMOTE_PARENT_DIR:-/home/$ASF_USERNAME/public_html}
+
+SSH=ssh -o StrictHostKeyChecking=no -i $ASF_RSA_KEY
+GPG=gpg --no-tty --batch
+NEXUS_ROOT=https://repository.apache.org/service/local/staging
+NEXUS_PROFILE=d63f592e7eac0 # Profile for Spark staging uploads
+BASE_DIR=$(pwd)
+
+PUBLISH_PROFILES=-Pyarn -Phive -Phadoop-2.2
+PUBLISH_PROFILES=$PUBLISH_PROFILES -Pspark-ganglia-lgpl -Pkinesis-asl
+
+rm -rf spark
+git clone https://git-wip-us.apache.org/repos/asf/spark.git
+cd spark
+git checkout $GIT_REF
+git_hash=`git rev-parse --short HEAD`
+echo Checked out Spark git hash $git_hash
+
+if [ -z $SPARK_VERSION ]; then
+ SPARK_VERSION=$(mvn help:evaluate -Dexpression=project.version \
+| grep -v INFO | grep -v WARNING | grep -v Download)
+fi
+
+if [ -z $SPARK_PACKAGE_VERSION ]; then
+ SPARK_PACKAGE_VERSION=${SPARK_VERSION}-$(date
+%Y_%m_%d_%H_%M)-${git_hash}
+fi
+
+DEST_DIR_NAME=spark-$SPARK_PACKAGE_VERSION
+USER_HOST=$asf_usern...@people.apache.org
+
+rm .gitignore
+rm -rf .git
+cd ..
+
+if [ -n $REMOTE_PARENT_MAX_LENGTH ]; then
+ old_dirs=$($SSH $USER_HOST ls -t $REMOTE_PARENT_DIR | tail -n
+$REMOTE_PARENT_MAX_LENGTH)
+ for old_dir in $old_dirs; do
+echo Removing directory: $old_dir
+$SSH $USER_HOST rm -r $REMOTE_PARENT_DIR/$old_dir
+ done
+fi
+
+if [[ $1 == package ]]; then
+ # Source and binary tarballs
+ echo Packaging release tarballs
+ cp -r spark spark-$SPARK_VERSION
+ tar cvzf spark-$SPARK_VERSION.tgz spark-$SPARK_VERSION
+ echo $GPG_PASSPHRASE | $GPG --passphrase-fd 0 --armour --output
spark-$SPARK_VERSION.tgz.asc \
+--detach-sig spark-$SPARK_VERSION.tgz
+ echo $GPG_PASSPHRASE | $GPG --passphrase-fd 0 --print-md MD5
spark-$SPARK_VERSION.tgz \
+spark-$SPARK_VERSION.tgz.md5
+ echo $GPG_PASSPHRASE | $GPG --passphrase-fd 0 --print-md \
+SHA512 spark-$SPARK_VERSION.tgz spark
[GitHub] spark pull request: [SPARK-9607] [SPARK-9608] fix zinc-port handli...
GitHub user ryan-williams opened a pull request:
https://github.com/apache/spark/pull/7944
[SPARK-9607] [SPARK-9608] fix zinc-port handling in build/mvn
- pass `$ZINC_PORT` to zinc status/shutdown commands
- fix path check that sets `$ZINC_INSTALL_FLAG`, which was incorrectly
causing zinc to be shutdown and restarted every time (with mismatched
ports on those commands to boot)
- pass `-DzincPort=${ZINC_PORT}` to maven, to use the correct zinc port
when building
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/ryan-williams/spark zinc-status
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/7944.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #7944
commit 619c520002c8d1d18853f52a2efdbe289979f990
Author: Ryan Williams ryan.blake.willi...@gmail.com
Date: 2015-08-04T21:15:51Z
fix zinc status/shutdown commands
also:
- fix path check that sets ZINC_INSTALL_FLAG, which was incorrectly
causing zinc to be shutdown and restarted every time (with incorrect
ports on those commands)
- pass -DzincPort=${ZINC_PORT} to maven, to use the correct zinc port
when building
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-9607] [SPARK-9608] fix zinc-port handli...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/7944#issuecomment-127801789 Just catching up here, yea @pwendell the `-DzincPort` bit was kind of an afterthought but I guess is really the most useful thing here :) it's also not really covered by either JIRA but they're all such trivial changes that I'm not going to file it separately unless you say to --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-1301] add navigation links to StagePage...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/5121#issuecomment-126434455 using collapsible tables in [Spree](https://github.com/hammerlab/spree/) to get this, closing --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-1301] add navigation links to StagePage...
Github user ryan-williams closed the pull request at: https://github.com/apache/spark/pull/5121 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-9366] use task's stageAttemptId in Task...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/7681 [SPARK-9366] use task's stageAttemptId in TaskEnd event You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark task-stage-attempt Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/7681.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #7681 commit d6d5f0fb4b243d2dd07213f17d10de19dfa61005 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-07-26T01:11:34Z use task's stageAttemptId in TaskEnd event --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3525#issuecomment-123487287 I've lost state on this, closing, thanks all --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams closed the pull request at: https://github.com/apache/spark/pull/3525 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-9036][Core] SparkListenerExecutorMetric...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/7555#discussion_r35066320
--- Diff: core/src/main/scala/org/apache/spark/util/JsonProtocol.scala ---
@@ -224,6 +224,19 @@ private[spark] object JsonProtocol {
(Spark Version - SPARK_VERSION)
}
+ def executorMetricsUpdateToJson(metricsUpdate:
SparkListenerExecutorMetricsUpdate): JValue = {
+val execId = metricsUpdate.execId
+val taskMetrics = metricsUpdate.taskMetrics
+(Event - Utils.getFormattedClassName(metricsUpdate)) ~
+(Executor ID - execId) ~
+(Metrics Updated - taskMetrics.map(s =
+ (Task ID - s._1) ~
+(Stage ID - s._2) ~
+(Stage Attempt - s._3) ~
--- End diff --
This should probably be Stage Attempt ID to match similar JSON, right?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8088] don't attempt to lower number of ...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/6624#discussion_r31677433
--- Diff:
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala ---
@@ -266,10 +266,12 @@ private[spark] class ExecutorAllocationManager(
// executors and inform the cluster manager to cancel the extra
pending requests
val oldNumExecutorsTarget = numExecutorsTarget
numExecutorsTarget = math.max(maxNeeded, minNumExecutors)
- client.requestTotalExecutors(numExecutorsTarget)
- numExecutorsToAdd = 1
- logInfo(sLowering target number of executors to $numExecutorsTarget
because +
-snot all requests are actually needed (previously
$oldNumExecutorsTarget))
+ if (numExecutorsTarget oldNumExecutorsTarget) {
--- End diff --
@sryza I thought about that, but wasn't sure it was necessary.
You're worried about the case where, after executing L268, we have
`maxNeeded oldNumExecutorsTarget == numExecutorsTarget == minNumExecutors`,
i.e. we need fewer than the minimum, we were already at the minimum, and will
continue to be at the minimum.
If we're already at the minimum, we must have actually decreased to it at
some point (and therefore set `numExecutorsToAdd = 1`), or we just started, in
which case `numExecutorsToAdd == 1`).
@andrewor14 sure I'll add the comment
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8088] don't attempt to lower number of ...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/6624 [SPARK-8088] don't attempt to lower number of executors by 0 You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark execs Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/6624.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6624 commit 695d3c504b0e7f7ed2742d8e7419e1b2a4cf Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-06-03T21:38:05Z don't attempt to lower number of executors by 0 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8088] don't attempt to lower number of ...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/6624#issuecomment-108633719 [previous test failure](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/34121/console) seems like Jenkins had some kind of hiccup fwiw --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8088] don't attempt to lower number of ...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/6624#discussion_r31679678
--- Diff:
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala ---
@@ -266,10 +266,12 @@ private[spark] class ExecutorAllocationManager(
// executors and inform the cluster manager to cancel the extra
pending requests
val oldNumExecutorsTarget = numExecutorsTarget
numExecutorsTarget = math.max(maxNeeded, minNumExecutors)
- client.requestTotalExecutors(numExecutorsTarget)
- numExecutorsToAdd = 1
- logInfo(sLowering target number of executors to $numExecutorsTarget
because +
-snot all requests are actually needed (previously
$oldNumExecutorsTarget))
+ if (numExecutorsTarget oldNumExecutorsTarget) {
--- End diff --
@andrewor14 makes sense, done
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8088] don't attempt to lower number of ...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/6624#discussion_r31677556
--- Diff:
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala ---
@@ -266,10 +266,12 @@ private[spark] class ExecutorAllocationManager(
// executors and inform the cluster manager to cancel the extra
pending requests
val oldNumExecutorsTarget = numExecutorsTarget
numExecutorsTarget = math.max(maxNeeded, minNumExecutors)
- client.requestTotalExecutors(numExecutorsTarget)
- numExecutorsToAdd = 1
- logInfo(sLowering target number of executors to $numExecutorsTarget
because +
-snot all requests are actually needed (previously
$oldNumExecutorsTarget))
+ if (numExecutorsTarget oldNumExecutorsTarget) {
--- End diff --
basically, if the contract is we start `numExecutorsToAdd` at 1, and every
time we decrease we reset it to 1, then I think we get everything we want, no?
obvs it's a nit to pick, just want to be sure we're all agreed about the
semantics and more importantly that I understand the code I'm modifying :)
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8057][Core]Call TaskAttemptContext.getT...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/6599#issuecomment-108484037 @srowen has convinced me that, rather than try to publish one Spark that works for Hadoops 1 **and** 2, we should publish individual artifacts for the Hadoop versions that are not compatible with each other (hopefully just a 1.* and a 2.*). Conveniently, such artifacts are already built and published at [https://spark.apache.org/downloads.html](https://spark.apache.org/downloads.html), they're just not published anywhere that can be easily programmatically built against, e.g. a Maven repository. It seems to me that the correct solution is to take those already-published artifacts, which people can manually download and run against today, and also publish them to a Maven repository. Maybe I don't fully understand what is meant by embedded Spark, but shouldn't [people that want to embed Spark and run against Hadoop 1] simply embed one of the Spark JARs that is already built for Hadoop 1 and published and hosted at apache.org? Is it important that they embed it via a Maven dependency? If so, again, we should publish Maven JARs that are built to support Hadoop 1. Thanks, let me know if I'm misunderstanding something. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-8057][Core]Call TaskAttemptContext.getT...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/6599#discussion_r31646975
--- Diff:
core/src/main/scala/org/apache/spark/mapred/SparkHadoopMapRedUtil.scala ---
@@ -22,8 +22,10 @@ import java.lang.reflect.Modifier
import org.apache.hadoop.mapred._
import org.apache.hadoop.mapreduce.{TaskAttemptContext =
MapReduceTaskAttemptContext}
+import org.apache.hadoop.mapreduce.{TaskAttemptID =
MapReduceTaskAttemptID}
--- End diff --
nit: this import isn't used, is it?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5784] Add StatsD adapter to MetricsSyst...
Github user ryan-williams closed the pull request at: https://github.com/apache/spark/pull/4574 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5847] Allow for namespacing metrics by ...
Github user ryan-williams commented on the pull request:
https://github.com/apache/spark/pull/4632#issuecomment-85180665
Thanks @pwendell. I had stumbled across that
[SPARK-3377](https://issues.apache.org/jira/browse/SPARK-3377) work as well.
I think there are solid arguments for each of these use-cases being
supported:
* `app.id`-prefixing can be pathologically hard on Graphite's disk I/O /
for short-running jobs.
* `app.name`-prefixing is no good if you have jobs running simultaneously.
Here are three options for supporting both (all defaulting to `app.id` but
providing an escape hatch):
1. Only admit `id` and `name` values here, and use the value from the
appropriate config key. The main downside is that we would essentially
introduce two new, made-up magic strings to do this; id and name?
app.id and app.name? At that point, we're basically atâ¦
2. Allow usage of any existing conf value as the metrics prefix, which is
what this PR currently does.
3. Default to `app.id` but allow the user to specify a string that is used
as the metrics' prefix (as opposed to a string that keys into `SparkConfig`),
e.g. `--conf spark.metrics.prefix=my-app-name`;
* this could be a `--conf` param or happen in the `MetricsConfig`'s
file.
I feel like doing this via the `MetricsConfig`'s `spark.metrics.conf` file
makes more sense than adding another `--conf` param, but I could be persuaded
otherwise.
It seems a bit weird to hard code handling of this particular
configuration in the MetricsConfig class.
This bit I disagree with; plenty of config params are {read by, relevant
to} just one class.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6449][YARN] Report failure status if dr...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/5130#issuecomment-85333531 It seems like I was running a pre-#4773 Spark. I just ran a job from `v1.3.0` that OOMs and it correctly reported `FAILED`. For good measure I'm building+running again from right before #4773, but in the meantime I'll close this, thanks all. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6449][YARN] Report failure status if dr...
Github user ryan-williams closed the pull request at: https://github.com/apache/spark/pull/5130 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: Report failure status if driver throws excepti...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/5130 Report failure status if driver throws exception e.g. OutOfMemoryError on the driver was leading to application reporting SUCCESS on history server and to YARN RM. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark oom Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/5130.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5130 commit 5c315229f646374e6a4a45353c46b0be901c4001 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-03-21T22:15:55Z Report failure status if driver throws exception e.g. OutOfMemoryError on the driver was leading to application reporting SUCCESS on history server and to YARN RM. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6449][YARN] Report failure status if dr...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/5130#issuecomment-84780737 oh yea, sry I forgot to do that @rxin --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6448] Make history server log parse exc...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/5122#issuecomment-84462788 oof, line length, fixing --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6447] add navigation links to StagePage...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/5121#discussion_r26897637
--- Diff: core/src/main/resources/org/apache/spark/ui/static/webui.css ---
@@ -194,6 +194,24 @@ span.additional-metric-title {
color: #777;
}
+#additional-metrics {
+ float: left;
+ padding-bottom: 10px;
+}
+
+#links {
+ float: left;
+ padding-left: 100px;
--- End diff --
My understanding has always been that using `table`s to lay out things
that are not tabular but that you merely want to be horizontally adjacent is
hacky and should be avoided. If you're adamant I can do it though.
I triedy `display: inline` since that is maybe supposed to directly address
this kind of use case:

that lets me kill the `clear:both` on the Summary metrics ⦠lt;h4gt;,
but it gets in to trouble when I expand the additional metrics:
re: adding it under the title, it would be nice to not have this push the
actual important info on the page further below the fold. There is a
preponderance of unused horizontal space on the page currently, and the row it
is being added to is a fairly underutilized one since the additional metrics
dropdown is presumably not frequently engaged with.
Here it is full-screen on my macbook:
The Summary Metrics ⦠lt;h4gt; is 31% of the way down the screen.
With additional metrics open it is 50% of the way down:
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6448] Make history server log parse exc...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/5122 [SPARK-6448] Make history server log parse exceptions This helped me to debug a parse error that was due to the event log format changing recently. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark histerror Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/5122.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5122 commit c3742ae7d248c20b1b7111e7a190f23c93acd3bc Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-03-21T22:12:34Z Make history server log parse exceptions --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6447] add navigation links to StagePage...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/5121 [SPARK-6447] add navigation links to StagePage for 3 tables Executors table, accumulators table, tasks table. If there are no accumulators then that link is not displayed. Here are some screenshots of their appearance:  With Show additional metrics expanded: 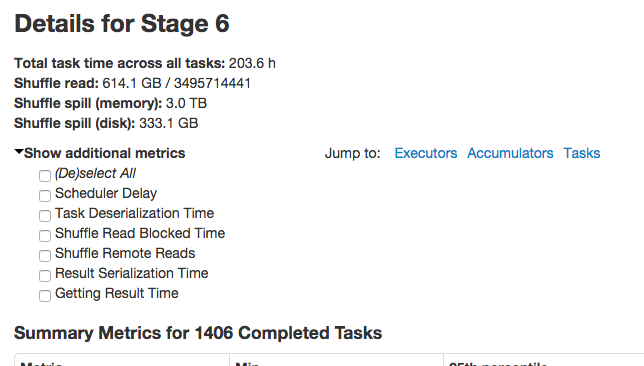 Without Accumulators link: 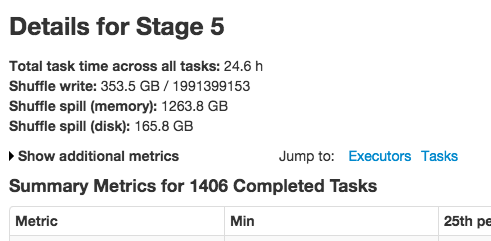 You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark links Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/5121.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5121 commit a1307b40be0bb5e2907c8594876f678732c673cb Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-03-21T22:14:54Z add navigation links to StagePage for 3 tables Executors table, accumulators table, tasks table. If there are no accumulators then that link is not displayed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6447] add navigation links to StagePage...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/5121#discussion_r26897520
--- Diff: core/src/main/resources/org/apache/spark/ui/static/webui.css ---
@@ -194,6 +194,24 @@ span.additional-metric-title {
color: #777;
}
+#additional-metrics {
+ float: left;
+ padding-bottom: 10px;
+}
+
+#links {
+ float: left;
+ padding-left: 100px;
+}
+
+#links a {
+ padding-left: 10px;
+}
+
+.clear {
--- End diff --
no, it's added to the Summary Metrics ⦠h4 element
[here](https://github.com/apache/spark/pull/5121/files#diff-fa4cfb2cce1b925f55f41f2dfa8c8501R450)
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6447] add navigation links to StagePage...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/5121#discussion_r26898355
--- Diff: core/src/main/resources/org/apache/spark/ui/static/webui.css ---
@@ -194,6 +194,24 @@ span.additional-metric-title {
color: #777;
}
+#additional-metrics {
+ float: left;
+ padding-bottom: 10px;
+}
+
+#links {
+ float: left;
+ padding-left: 100px;
--- End diff --
Calling this absolute layout seems misleading, given what `absolute`
usually means in this context (e.g. `position: absolute`). These links are
positioned relatively, to the right of the additional metrics `div`, with
a fixed amount of padding.
I'm also not sure what you mean by inline layout like the rest of this;
again, inline has a specific meaning in CSS, e.g. `display: inline`, that I
don't think anything else on the page is using. Everything else is basically
structured as `div`s and `table`s that are `display: block` by default
meaning that they don't fall next to each other on the same line but each get
their own lines, hence the horizontal wasted space.
I'm open to trying something like a `float: right` for the links, though
relative to this that would mostly serve to make them farther away from the LHS
where the user's eyes and mouse are likely to start out.
Here's a screen fwiw:
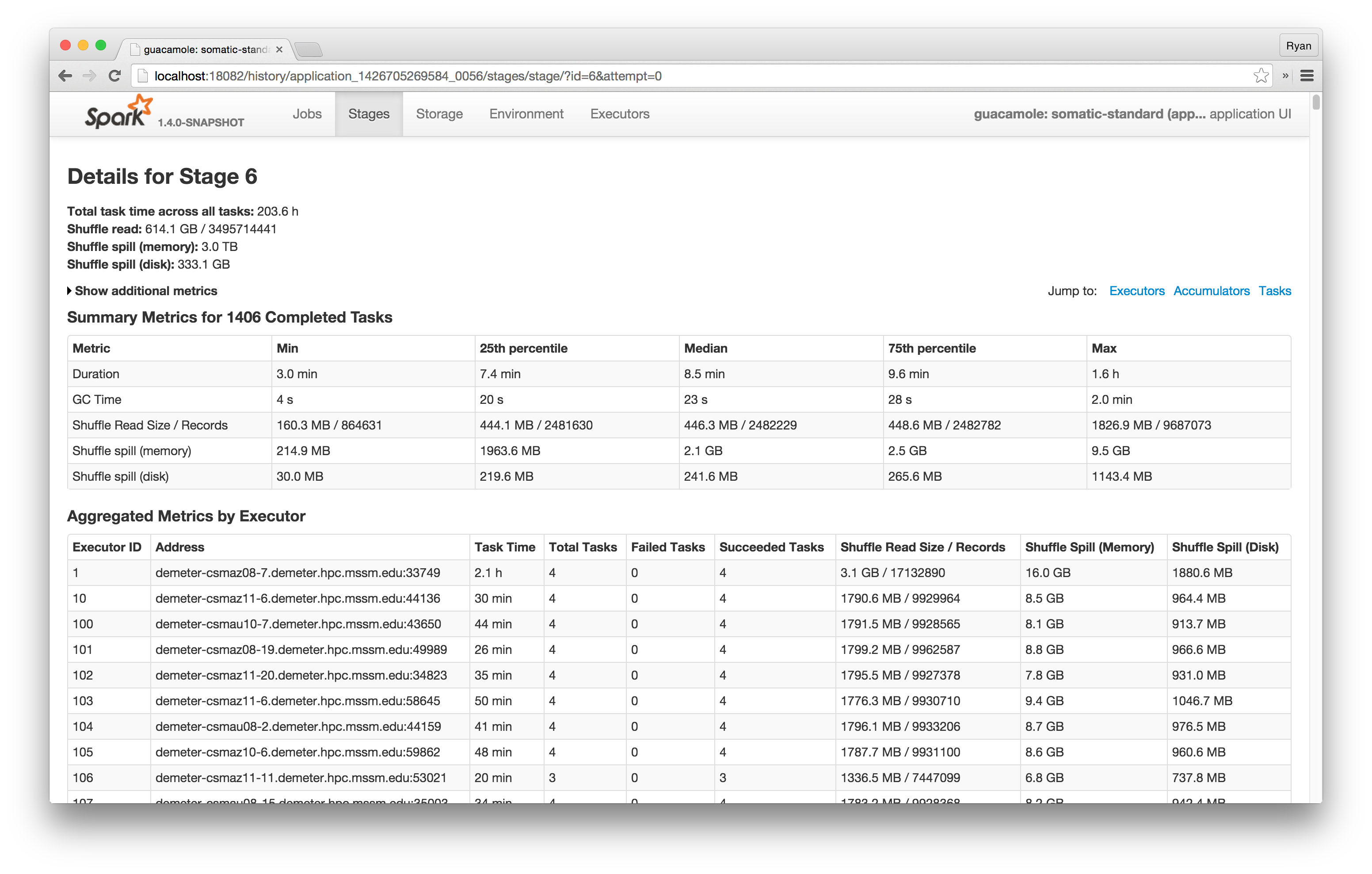
Lmk what you think.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-6448][Core]Added exception log in Histo...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/5123#issuecomment-84510815 Weird, I think this duplicates #5122 which didn't get added to the JIRA... JIRA seemed to have gone down for a while this afternoon so maybe it was lost during that? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5847] Allow for namespacing metrics by ...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4632#issuecomment-82420712 bump, @pwendell any ideas who would be a good reviewer for this? This is a pretty important piece of my [`grafana-spark-dashboards`](https://github.com/hammerlab/grafana-spark-dashboards) setup that it would be good to allow others to benefit from. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5847] Allow for namespacing metrics by ...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4632#issuecomment-76444840 This one is ready for review, I think --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5134] Bump default hadoop.version to 2....
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3917#issuecomment-74556639 np @pwendell, I understand there's some complicated stability concerns here. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5847] Allow for namespacing metrics by ...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4632#issuecomment-74578411 scala style check should pass now --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5784] Add StatsD adapter to MetricsSyst...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4574#issuecomment-74574885 yea I could see that making more sense @pwendell. From a cursory look I don't see how to proceed doing that; any pointers? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5847] Allow for namespacing metrics by ...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/4632 [SPARK-5847] Allow for namespacing metrics by conf params other than spark.app.id You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark metrics-namespace Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/4632.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4632 commit f2cd257d23dbf7d4cabe072ae5b5f0834c1f5782 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-13T23:51:48Z rename propertyCategories - perInstanceProperties commit ffdc06a6af1c2060053f817c7d631ddd619a3097 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-16T21:17:14Z allow configuring of MetricsSystem namespace previously always namespaced metrics with app ID; now metrics- config-file can specify a different Spark conf param to use, e.g. app name. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5134] Bump default hadoop.version to 2....
Github user ryan-williams closed the pull request at: https://github.com/apache/spark/pull/3917 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5134] Bump default hadoop.version to 2....
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3917#issuecomment-74394491 k, thanks for following up @srowen --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5778] throw if nonexistent metrics conf...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4571#issuecomment-74395577 seems like another spurious failure to me. That one passed in the previous build --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5783] Better eventlog-parsing error mes...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4573#issuecomment-74298311 thanks @andrewor14! OOC, what was your calculus for judging build [27379](https://github.com/apache/spark/pull/4573#issuecomment-74163534) above to have been a spurious failure and asking for a retest? I'd looked at it and optimistically thought that maybe that was the situation, but was not sure. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5778] throw if nonexistent metrics conf...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4571#issuecomment-74346703 I just rebased and tacked a couple of trivial commits to `MetricsConfig` onto the end of this, jfyi --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5778] throw if nonexistent metrics conf...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4571#issuecomment-74354106 looks like similar sorts of probably-spurious to those that I saw on #4573; thoughts, @rxin? re-test? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5783] Better eventlog-parsing error mes...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/4573 [SPARK-5783] Better eventlog-parsing error messages You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark history Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/4573.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4573 commit b668b529d57e7963f2f08384f1fc5f24587cf989 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-12T19:00:49Z add log info line to history-eventlog parsing commit 8deecf06face194d500c36e6dcfdd6a4e74cb604 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-12T19:02:04Z add line number to history-parsing error message commit 98aa3fe1fcfc6ffafbd8481761dea1acd82e99c5 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-12T19:02:30Z include filename in history-parsing error message --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5522] Accelerate the Histroty Server st...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/4525#discussion_r24613574
--- Diff:
core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala ---
@@ -119,14 +138,79 @@ private[history] class FsHistoryProvider(conf:
SparkConf) extends ApplicationHis
if (!conf.contains(spark.testing)) {
logCheckingThread.setDaemon(true)
logCheckingThread.start()
+ logLazyReplayThread.setDaemon(true)
+ logLazyReplayThread.start()
+} else {
+ logLazyReplay()
}
}
- override def getListing() = applications.values
+ /**
+ * Fetch and Parse the log files
+ */
+ private[history] def logLazyReplay() {
+if(lazyApplications.isEmpty) return
+
+logDebug(start doLazyReplay)
--- End diff --
`s/doLazyReplay/logLazyReplay/`?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5522] Accelerate the Histroty Server st...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/4525#discussion_r24613618
--- Diff:
core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala ---
@@ -119,14 +138,79 @@ private[history] class FsHistoryProvider(conf:
SparkConf) extends ApplicationHis
if (!conf.contains(spark.testing)) {
logCheckingThread.setDaemon(true)
logCheckingThread.start()
+ logLazyReplayThread.setDaemon(true)
+ logLazyReplayThread.start()
+} else {
+ logLazyReplay()
}
}
- override def getListing() = applications.values
+ /**
+ * Fetch and Parse the log files
+ */
+ private[history] def logLazyReplay() {
+if(lazyApplications.isEmpty) return
+
+logDebug(start doLazyReplay)
+val mergeSize = 20
+val bufferedApps = new ArrayBuffer[FsApplicationHistoryInfo](mergeSize)
+
+def addIfAbsent(newApps: mutable.LinkedHashMap[String,
FsApplicationHistoryInfo],
+info: FsApplicationHistoryInfo) {
+ if (!newApps.contains(info.id) ||
+
newApps(info.id).logPath.endsWith(EventLoggingListener.IN_PROGRESS)
+ !info.logPath.endsWith(EventLoggingListener.IN_PROGRESS)) {
+newApps += (info.id - info)
+ }
+}
+
+def mergeApps(): mutable.LinkedHashMap[String,
FsApplicationHistoryInfo] = {
+ val newApps = new mutable.LinkedHashMap[String,
FsApplicationHistoryInfo]()
+ bufferedApps.sortWith(compareAppInfo)
+
+ val newIterator = bufferedApps.iterator.buffered
+ val oldIterator = applications.values.iterator.buffered
+ while (newIterator.hasNext oldIterator.hasNext) {
+if (compareAppInfo(newIterator.head, oldIterator.head)) {
+ addIfAbsent(newApps, newIterator.next())
+} else {
+ addIfAbsent(newApps, oldIterator.next())
+}
+ }
+ newIterator.foreach(addIfAbsent(newApps, _))
+ oldIterator.foreach(addIfAbsent(newApps, _))
+
+ newApps
+}
+
+val bus = new ReplayListenerBus()
+while(lazyApplications.nonEmpty){
+ lazyApplications.iterator.take(mergeSize).foreach(keyValue = {
+try{
+ val lazyInfo = keyValue._2
+ val info = replay(lazyInfo.eventLog, bus)
+ bufferedApps += info
+ logDebug(replay application + lazyInfo.id + successfully)
+} catch {
+ case e: Exception =
+}
+ })
+ applications = mergeApps()
+ for(i - 1 to bufferedApps.size)
lazyApplications.remove(lazyApplications.head._1)
+ bufferedApps.clear()
+}
+logDebug(finish doLazyReplay)
--- End diff --
ditto
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5778] throw if nonexistent metrics conf...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/4571 [SPARK-5778] throw if nonexistent metrics config file provided previous behavior was to log an error; this is fine in the general case where no `spark.metrics.conf` parameter was specified, in which case a default `metrics.properties` is looked for, and the execption logged and suppressed if it doesn't exist. if the user has purposefully specified a metrics.conf file, however, it makes more sense to show them an error when said file doesn't exist. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark metrics Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/4571.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4571 commit 105288e2c661ed631e64cfdc3aeb79b2aea858eb Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-12T19:06:25Z throw if nonexistent metrics config file provided previous behavior was to log an error; this is fine in the general case where no `spark.metrics.conf` parameter was specified, in which case a default `metrics.properties` is looked for, and the execption logged and suppressed if it doesn't exist. if the user has purposefully specified a metrics.conf file, however, it makes more sense to show them an error when said file doesn't exist. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5778] throw if nonexistent metrics conf...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4571#issuecomment-74151752 I threw in a couple of other trivial things: * `throw` if a bad `Sink` class is specified * exclude `conf/metrics.properties`, if present, from RAT checks lmk if you want me to make those separate JIRAs/PRs --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5784] Add StatsD adapter to MetricsSyst...
GitHub user ryan-williams opened a pull request: https://github.com/apache/spark/pull/4574 [SPARK-5784] Add StatsD adapter to MetricsSystem You can merge this pull request into a Git repository by running: $ git pull https://github.com/ryan-williams/spark statsd Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/4574.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4574 commit 39c5e41d6baa2cd9f2a5a7a4a7bfc32095df1839 Author: Ryan Williams ryan.blake.willi...@gmail.com Date: 2015-02-02T14:50:33Z Add StatsD adapter to MetricsSystem --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5783] Better eventlog-parsing error mes...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4573#issuecomment-74152600 hopefully fixed now --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5522] Accelerate the Histroty Server st...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4525#issuecomment-74157026 my command was `mvn '-Dsuites=*FsHistory*' test` after a `build/sbt -Pyarn -Phadoop-2.3 clean assembly/assembly` --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5778] throw if nonexistent metrics conf...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/4571#discussion_r24619183
--- Diff: core/src/main/scala/org/apache/spark/metrics/MetricsConfig.scala
---
@@ -47,21 +47,27 @@ private[spark] class MetricsConfig(val configFile:
Option[String]) extends Loggi
setDefaultProperties(properties)
// If spark.metrics.conf is not set, try to get file in class path
-var is: InputStream = null
-try {
- is = configFile match {
-case Some(f) = new FileInputStream(f)
-case None =
Utils.getSparkClassLoader.getResourceAsStream(METRICS_CONF)
+(configFile match {
--- End diff --
cool, thanks, went with the first one.
incidentally I had a `Some()` where I should have had an `Option()`, which
your candidates all fix, that I think was breaking the tests
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5522] Accelerate the Histroty Server st...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4525#issuecomment-74156847 fwiw @marsishandsome I ran `FsHistoryProviderSuite` on this PR and got a similar failure: ``` FsHistoryProviderSuite: - Parse new and old application logs *** FAILED *** ApplicationHistoryInfo(old1,old-app-complete,2,3,1423776491000,test,true) was not equal to ApplicationHistoryInfo(new1,new-app-complete,1,4,1423776491000,test,true) (FsHistoryProviderSuite.scala:97) ``` The failure you referenced above was: ``` [info] - Parse new and old application logs *** FAILED *** (32 milliseconds) [info] ApplicationHistoryInfo(old2,old-app-incomplete,2,-1,1423744927000,test,false) was not equal to ApplicationHistoryInfo(old1,old-app-complete,2,3,1423744927000,test,true) (FsHistoryProviderSuite.scala:99) [info] org.scalatest.exceptions.TestFailedException: [info] at org.scalatest.MatchersHelper$.newTestFailedException(MatchersHelper.scala:160) [info] at org.scalatest.Matchers$ShouldMethodHelper$.shouldMatcher(Matchers.scala:6231) [info] at org.scalatest.Matchers$AnyShouldWrapper.should(Matchers.scala:6265) [info] at org.apache.spark.deploy.history.FsHistoryProviderSuite$$anonfun$3.apply$mcV$sp(FsHistoryProviderSuite.scala:99) [info] at org.apache.spark.deploy.history.FsHistoryProviderSuite$$anonfun$3.apply(FsHistoryProviderSuite.scala:48) [info] at org.apache.spark.deploy.history.FsHistoryProviderSuite$$anonfun$3.apply(FsHistoryProviderSuite.scala:48) [info] at org.scalatest.Transformer$$anonfun$apply$1.apply$mcV$sp(Transformer.scala:22) [info] at org.scalatest.OutcomeOf$class.outcomeOf(OutcomeOf.scala:85) [info] at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) [info] at org.scalatest.Transformer.apply(Transformer.scala:22) [info] at org.scalatest.Transformer.apply(Transformer.scala:20) [info] at org.scalatest.FunSuiteLike$$anon$1.apply(FunSuiteLike.scala:166) [info] at org.scalatest.Suite$class.withFixture(Suite.scala:1122) [info] at org.scalatest.FunSuite.withFixture(FunSuite.scala:1555) [info] at org.scalatest.FunSuiteLike$class.invokeWithFixture$1(FunSuiteLike.scala:163) [info] at org.scalatest.FunSuiteLike$$anonfun$runTest$1.apply(FunSuiteLike.scala:175) [info] at org.scalatest.FunSuiteLike$$anonfun$runTest$1.apply(FunSuiteLike.scaAttempting to post to Github... ``` Could the applications be getting read in a nondeterministic order somehow? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5783] Better eventlog-parsing error mes...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4573#issuecomment-74150113 ha yea, need to update test call-sites, brb --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/3525#discussion_r24633577
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -203,6 +203,28 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging {
getOption(key).map(_.toBoolean).getOrElse(defaultValue)
}
+ // Limit of bytes for total size of results (default is 1GB)
--- End diff --
hm, I'd vote we put it back in `Utils` over un-factoring those two calls
that are doing the same thing as one another
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3525#issuecomment-73783538 OK I think it is back to you @srowen --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on a diff in the pull request: https://github.com/apache/spark/pull/3525#discussion_r24450366 --- Diff: docs/running-on-yarn.md --- @@ -113,9 +113,9 @@ Most of the configs are the same for Spark on YARN as for other deployment modes /tr tr tdcodespark.yarn.executor.memoryOverhead/code/td - tdexecutorMemory * 0.07, with minimum of 384 /td + tdexecutorMemory * 0.07, with minimum of 384 megabytes /td --- End diff -- good catch, updated the other similar strings in this file --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/3525#discussion_r24449997
--- Diff: core/src/main/scala/org/apache/spark/util/Utils.scala ---
@@ -980,33 +980,77 @@ private[spark] object Utils extends Logging {
)
}
+
+ private val TB = 1L 40
+ private val GB = 1L 30
+ private val MB = 1L 20
+ private val KB = 1L 10
+
+ private val scaleCharToFactor: Map[Char, Long] = Map(
+'b' - 1L,
+'k' - KB,
+'m' - MB,
+'g' - GB,
+'t' - TB
+ )
+
/**
- * Convert a Java memory parameter passed to -Xmx (such as 300m or 1g)
to a number of megabytes.
- */
- def memoryStringToMb(str: String): Int = {
+ * Convert a Java memory parameter passed to -Xmx (such as 300m or
1g) to a number of
+ * megabytes (or other byte-scale denominations as specified by
@outputScaleChar).
+ *
+ * For @defaultInputScaleChar and @outputScaleChar, valid values are:
'b' (bytes), 'k'
+ * (kilobytes), 'm' (megabytes), 'g' (gigabytes), and 't' (terabytes).
+ *
+ * @param str String to parse an amount of memory out of
+ * @param defaultInputScaleChar if no scale is provided on the end of
@str (i.e. @str is a
+ * plain numeric value), assume this scale
(default: 'b' for
+ * 'bytes')
+ * @param outputScaleChar express the output in this scale, i.e. number
of bytes, kilobytes,
+ *megabytes, or gigabytes.
+ */
+ def parseMemoryString(
+ str: String,
+ defaultInputScaleChar: Char = 'b',
+ outputScaleChar: Char = 'm'): Long = {
+
val lower = str.toLowerCase
-if (lower.endsWith(k)) {
- (lower.substring(0, lower.length-1).toLong / 1024).toInt
-} else if (lower.endsWith(m)) {
- lower.substring(0, lower.length-1).toInt
-} else if (lower.endsWith(g)) {
- lower.substring(0, lower.length-1).toInt * 1024
-} else if (lower.endsWith(t)) {
- lower.substring(0, lower.length-1).toInt * 1024 * 1024
-} else {// no suffix, so it's just a number in bytes
- (lower.toLong / 1024 / 1024).toInt
-}
+val lastChar = lower(lower.length - 1)
+val (num, inputScaleChar) =
+ if (lastChar.isDigit) {
+(lower.toLong, defaultInputScaleChar)
+ } else {
+(lower.substring(0, lower.length - 1).toLong, lastChar)
+ }
+
+(for {
--- End diff --
Why is a for construction used here? just to handle the invalid in / out
scale param?
`for` comprehensions are commonly used when `map`ing over 2 or more monads
to avoid arguably-ugly `.flatMap`-chaining; the syntax just removes some
boilerplate, e.g.:
```
scaleCharToFactor.get(inputScaleChar).flatMap(inputScale =
scaleCharToFactor.get(outputScaleChar).map(outputScale =
inputScale * num / outputScale
)
).getOrElse(
// throw
)
```
vs.
```
(for {
inputScale - scaleCharToFactor.get(inputScaleChar)
outputScale - scaleCharToFactor.get(outputScaleChar)
} yield {
inputScale * num / outputScale
}).getOrElse(
// throw
)
```
(I collapsed the `scale` wrapper line in the latter for apples-to-apples
brevity, and can do that in the PR as well).
So, it's not a looping construct so much as a mapping one, commonly
used on `Option`s, `List`s, and [even things like twitter
`Future`s](https://twitter.github.io/scala_school/finagle.html) (search for
for {).
However, it does get better as the number of chained `map`s increases, e.g.
especially when there are 3 or more, so I'm not that tied to it here.
Of course, handling such situations using a `match` is also possible:
```
(scaleCharToFactor.get(inputScaleChar),
scaleCharToFactor.get(outputScaleChar)) match {
case (Some(inputScale), Some(outputScale)) =
inputScale * num / outputScale
case _ =
// throw
}
```
I prefer all of these to, say, the following straw-man that doesn't take
advantage of any of the nice things that come from using `Option`s:
```
if (scaleCharToFactor.get(inputScaleChar).isDefined
scaleCharToFactor.get(outputScaleChar).isDefined)
scaleCharToFactor.get(inputScaleChar).get * num /
scaleCharToFactor.get(outputScaleChar).get
else
// throw
```
but I'll defer to you on the approach you like best.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3525#issuecomment-73783554 (thanks for the review!) --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/3525#discussion_r24446161
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -203,6 +203,28 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging {
getOption(key).map(_.toBoolean).getOrElse(defaultValue)
}
+ // Limit of bytes for total size of results (default is 1GB)
--- End diff --
I weighed two options:
1. have a method in `Utils` that takes a `SparkConf` as a parameter and
thinly wraps a method call on said `SparkConf`
1. make the aforementioned wrapper a method on `SparkConf` that delegates
to another method on `SparkConf`
..and felt like the latter was better/cleaner. My feeling was that a
kitchen-sink / generically-named `Utils` class that wraps methods for
`SparkConf` (and possibly other classes?) to maintain an illusion of simplicity
in the `SparkConf` API is not helping code clarity.
Of course, this is subjective and I'm open to putting it back in `Utils`,
lmk.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/3525#discussion_r24448450
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -203,6 +203,28 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging {
getOption(key).map(_.toBoolean).getOrElse(defaultValue)
}
+ // Limit of bytes for total size of results (default is 1GB)
--- End diff --
Option 3. could be: Put such methods in a `SparkConfUtils` object that
would be less prone to kitchen-sink-iness.
I'm impartial, I'll let you make the call between these three.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on a diff in the pull request:
https://github.com/apache/spark/pull/3525#discussion_r24446286
--- Diff: core/src/main/scala/org/apache/spark/SparkConf.scala ---
@@ -203,6 +203,28 @@ class SparkConf(loadDefaults: Boolean) extends
Cloneable with Logging {
getOption(key).map(_.toBoolean).getOrElse(defaultValue)
}
+ // Limit of bytes for total size of results (default is 1GB)
--- End diff --
NB: that was an answer to why this property is special-cased here, as
opposed to over in `Utils`. You may be more interested in the question of why
it's special-cased at all, but that seems reasonable to me given the couple
magic strings and its greater-than-1 call-sites (namely: 2).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4666] Improve YarnAllocator's parsing o...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3525#issuecomment-73625367 OK, this is ready to go again. Changes: * removed SPARK-4665 from the title and closed that JIRA * in the process of rebasing this change I found myself wanting MB suffixes on various `Int` variables that represent numbers of megabytes; I've included several commits here that perform such renames, but they're separate and easy to remove from this PR if that's controversial * I made `Utils.getMaxResultSize(SparkConf)` a method of `SparkConf` instead. * I cleaned up the semantics around which `Utils` and `SparkConf` methods assume `Int`s to represent numbers of megabytes, vs. ones that are generic across memory-size orders-of-magnitude. Let me know what you think. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4665] [SPARK-4666] Improve YarnAllocato...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3525#issuecomment-73589151 Thanks for resurrecting this, @srowen. I think there are 3 potentially separable changes here, in rough order of increasing controversial-ness: 1. Make `spark.yarn.executor.memoryOverhead` take a memory string (e.g. `1g` or `100m`) * defaulting to `m` as the unit for backwards-compatibility. 1. General refactoring of memory string handling in conf parameters in some other parts of the codebase. 1. Addition of `spark.yarn.executor.memoryOverheadFraction` If people prefer, I can make a separate PR with 1âª2 or individual PRs for each of 1 and 2. Re: 3, I am sympathetic to @tgravescs's arguments, but worry that we are conflating [wishing Spark's configuration surface area was smaller] with [forcing users to build custom Sparks to get at real, existing niches of said configuration surface area (in this case to change a hard-coded `.07` that reasonable people can disagree on the ideal value of)]. Additionally, the arguments about possible confusion around interplay between `memoryOverhead` and `memoryOverheadFraction` are applicable to the status quo, imho. However, I don't mind much one way or another at this point, so I'm fine dropping 3 if that's what consensus here prefers. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4665] [SPARK-4666] Improve YarnAllocato...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/3525#issuecomment-73594255 (until I hear otherwise I am pulling/rebasing 1âª2, roughly the SPARK-4666 bits, into their own PR) --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-4665] [SPARK-4666] Improve YarnAllocato...
Github user ryan-williams commented on a diff in the pull request: https://github.com/apache/spark/pull/3525#discussion_r24373338 --- Diff: core/src/main/scala/org/apache/spark/scheduler/local/LocalBackend.scala --- @@ -20,6 +20,7 @@ package org.apache.spark.scheduler.local import java.nio.ByteBuffer import scala.concurrent.duration._ +import scala.language.postfixOps --- End diff -- Saw this while compiling: [WARNING] /Users/ryan/c/spark/streaming/src/main/scala/org/apache/spark/streaming/util/WriteAheadLogManager.scala:156: postfix operator second should be enabled by making the implicit value scala.language.postfixOps visible. This can be achieved by adding the import clause 'import scala.language.postfixOps' or by setting the compiler option -language:postfixOps. See the Scala docs for value scala.language.postfixOps for a discussion why the feature should be explicitly enabled. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5413] bump metrics dependency to v3.1.0
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4209#issuecomment-72396380 oh, cool, sure thanks --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5413] bump metrics dependency to v3.1.0
Github user ryan-williams closed the pull request at: https://github.com/apache/spark/pull/4209 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5413] bump metrics dependency to v3.1.0
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4209#issuecomment-71878471 ah interesting. I had run into graphite struggling with the `driver` token previously, that would be great if this also fixes that for free --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request: [SPARK-5417] Remove redundant executor-id set(...
Github user ryan-williams commented on the pull request: https://github.com/apache/spark/pull/4213#issuecomment-71920785 thanks @andrewor14, to be clear, afaik the removed line here only became redundant on Sunday with #4194; did you mean you've been wanting to do the same since then? Or has this been redundant for longer, unbeknownst to me? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org