[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22326 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220777535
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/python/BatchEvalPythonExecSuite.scala
---
@@ -100,6 +105,29 @@ class BatchEvalPythonExecSuite extends SparkPlanTest
with SharedSQLContext {
}
assert(qualifiedPlanNodes.size == 1)
}
+
+ test("SPARK-25314: Python UDF refers to the attributes from more than
one child " +
--- End diff --
Got it, I use this for IDE mock python UDF, will do this in a follow up PR
with a new test suites in `org.apache.spark.sql.catalyst.optimizer`, revert in
2b6977d.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220777383
--- Diff: python/pyspark/sql/tests.py ---
@@ -552,6 +552,96 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.assertRaisesRegexp(AnalysisException, 'Detected implicit
cartesian product'):
+df.collect()
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.assertRaisesRegexp(AnalysisException, 'Detected implicit
cartesian product'):
+df.collect()
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
--- End diff --
Make sense, just for checking during implement, delete both in 2b6977d.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220770012
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/python/BatchEvalPythonExecSuite.scala
---
@@ -100,6 +105,29 @@ class BatchEvalPythonExecSuite extends SparkPlanTest
with SharedSQLContext {
}
assert(qualifiedPlanNodes.size == 1)
}
+
+ test("SPARK-25314: Python UDF refers to the attributes from more than
one child " +
--- End diff --
This is still an end-to-end test, I don't think we need it
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220769336
--- Diff: python/pyspark/sql/tests.py ---
@@ -552,6 +552,96 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.assertRaisesRegexp(AnalysisException, 'Detected implicit
cartesian product'):
+df.collect()
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.assertRaisesRegexp(AnalysisException, 'Detected implicit
cartesian product'):
+df.collect()
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
--- End diff --
This test (and the corresponding one for left semi join) is not very
useful. The filter in join condition will be pushed down so this test is
basically same as the `test_udf_in_join_condition`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220628624
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/python/BatchEvalPythonExecSuite.scala
---
@@ -100,6 +104,28 @@ class BatchEvalPythonExecSuite extends SparkPlanTest
with SharedSQLContext {
}
assert(qualifiedPlanNodes.size == 1)
}
+
+ test("SPARK-25314: Python UDF refers to the attributes from more than
one child " +
+"in join condition") {
+def dummyPythonUDFTest(): Unit = {
+ val df = Seq(("Hello", 4)).toDF("a", "b")
+ val df2 = Seq(("Hello", 4)).toDF("c", "d")
+ val joinDF = df.join(df2,
+dummyPythonUDF(col("a"), col("c")) === dummyPythonUDF(col("d"),
col("c")))
+ val qualifiedPlanNodes = joinDF.queryExecution.executedPlan.collect {
+case b: BatchEvalPythonExec => b
+ }
+ assert(qualifiedPlanNodes.size == 1)
+}
+// Test without spark.sql.crossJoin.enabled set
+val errMsg = intercept[AnalysisException] {
+ dummyPythonUDFTest()
+}
+assert(errMsg.getMessage.startsWith("Detected implicit cartesian
product"))
+// Test with spark.sql.crossJoin.enabled=true
+spark.conf.set("spark.sql.crossJoin.enabled", "true")
--- End diff --
Thanks, done in 7f66954.
```
So I'd prefer having one or 2 end-to-end tests and create a new suite
testing only the rule and the plan transformation, both for having lower
testing time and finer grained tests checking that the output plan is indeed
the expected one (not only checking the result of the query).
```
Make sense, will add a plan test for this rule.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220586456
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/python/BatchEvalPythonExecSuite.scala
---
@@ -100,6 +104,28 @@ class BatchEvalPythonExecSuite extends SparkPlanTest
with SharedSQLContext {
}
assert(qualifiedPlanNodes.size == 1)
}
+
+ test("SPARK-25314: Python UDF refers to the attributes from more than
one child " +
+"in join condition") {
+def dummyPythonUDFTest(): Unit = {
+ val df = Seq(("Hello", 4)).toDF("a", "b")
+ val df2 = Seq(("Hello", 4)).toDF("c", "d")
+ val joinDF = df.join(df2,
+dummyPythonUDF(col("a"), col("c")) === dummyPythonUDF(col("d"),
col("c")))
+ val qualifiedPlanNodes = joinDF.queryExecution.executedPlan.collect {
+case b: BatchEvalPythonExec => b
+ }
+ assert(qualifiedPlanNodes.size == 1)
+}
+// Test without spark.sql.crossJoin.enabled set
+val errMsg = intercept[AnalysisException] {
+ dummyPythonUDFTest()
+}
+assert(errMsg.getMessage.startsWith("Detected implicit cartesian
product"))
+// Test with spark.sql.crossJoin.enabled=true
+spark.conf.set("spark.sql.crossJoin.enabled", "true")
--- End diff --
please use `withSQLConf`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220576239
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
+ // to cross join and the crossJoinEnable will be checked in
CheckCartesianProducts.
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF only, it will be moved out and the join plan will be
turned to cross " +
+ s"join. This plan shows below:\n $j")
+None
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike => Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
+j.left.output.map(_.toAttribute),
+ Filter(udf.reduceLeft(And), newJoin.copy(joinType = Inner)))
--- End diff --
Thanks, done in d2739af.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220576188
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
+ // to cross join and the crossJoinEnable will be checked in
CheckCartesianProducts.
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF only, it will be moved out and the join plan will be
turned to cross " +
+ s"join. This plan shows below:\n $j")
--- End diff --
Got it, done in d2739af.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220576115
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
+ // to cross join and the crossJoinEnable will be checked in
CheckCartesianProducts.
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
--- End diff --
Thanks, done in d2739af.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220576062
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
--- End diff --
Make sense, duplicate with log. Done in d2739af.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220575840
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
--- End diff --
Thanks, done in d2739af.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220569284
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
--- End diff --
I think we don't need here the second sentence, ie. the one startng with
`If join condition ...`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220570791
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
+ // to cross join and the crossJoinEnable will be checked in
CheckCartesianProducts.
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF only, it will be moved out and the join plan will be
turned to cross " +
+ s"join. This plan shows below:\n $j")
--- End diff --
can we at least remove the whole plan from the warning? Plans can be pretty
big...
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220568484
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
--- End diff --
nits:
- `they are`
- missing space before `(`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220570975
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
+ // to cross join and the crossJoinEnable will be checked in
CheckCartesianProducts.
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF only, it will be moved out and the join plan will be
turned to cross " +
+ s"join. This plan shows below:\n $j")
+None
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike => Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
+j.left.output.map(_.toAttribute),
+ Filter(udf.reduceLeft(And), newJoin.copy(joinType = Inner)))
--- End diff --
nit: indentation
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220570021
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,53 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * PythonUDF in join condition can not be evaluated, this rule will detect
the PythonUDF
+ * and pull them out from join condition. For python udf accessing
attributes from only one side,
+ * they would be pushed down by operation push down rules. If not(e.g.
user disables filter push
+ * down rules), we need to pull them out in this rule too.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // If condition expression contains python udf, it will be moved out
from
+ // the new join conditions. If join condition has python udf only,
it will be turned
+ // to cross join and the crossJoinEnable will be checked in
CheckCartesianProducts.
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
--- End diff --
nit: -> `splitConjunctivePredicates(condition.get).partition(...)` seems
more clear to me
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220568332
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
--- End diff --
Thanks, as our discussion in
https://github.com/apache/spark/pull/22326/files#r220518094.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220567623
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
--- End diff --
Got it, thanks :)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220567381
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
--- End diff --
Thanks, done in 87f0f50.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220567301
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
--- End diff --
Thanks, done in 87f0f50.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220567216
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
--- End diff --
Thanks, done in 87f0f50.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220564636
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
--- End diff --
ah, let's leave left anti join then, thanks for trying!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220562279
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
--- End diff --
I tried two ways to implement LeftAnti here:
1. Use the Except(join.left, left semi result, isAll=false) to simulate, it
is banned by strategy and actually also no plan for
Except.https://github.com/apache/spark/blob/89671a27e783d77d4bfaec3d422cc8dd468ef04c/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala#L557-L559
2. Also use cross join and filter to simulate, but maybe it can't reached
when there's only udf in anti join condition. Because after cross join, it's
hard to roll back to original status. UDF+ normal common condition can be
simulated by
```
Project(
j.left.output.map(_.toAttribute),
Filter(Not(udf.reduceLeft(And)),
newJoin.copy(joinType = Inner, condition = not(rest.reduceLeft(And)
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220526661
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
--- End diff --
No problem, I'll change it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220525992
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
--- End diff --
Then shall we make it better? e.g. only log warning if it really becomes a
cross join, i.e. the join condition is none.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220524866
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
--- End diff --
Let me try.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220524840
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
--- End diff --
Let me try.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220523238
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
--- End diff --
Can we keep this? As we discuss before, there's a little strange for user
to get a implicit cartesian product exception during python udf in join
condition, maybe left this log can give some clue. WDYT?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220522504
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
--- End diff --
```
can we then update the comment of this class in order to reflect what it
actually does?
```
I'll update the comment soon.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220518094
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
+case LeftSemi =>
+ Project(
--- End diff --
so we are simulating a left semi join here. Seems we can do the same thing
for left anti join.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220518059
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
--- End diff --
thanks for the explanation @cloud-fan , makes sense, can we then update the
comment of this class in order to reflect what it actually does?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220517587
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
--- End diff --
do we really need this warning? If it becomes cross join, users will get an
error anyway, if cross join is disabled.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220517383
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
--- End diff --
the comment is outdated
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220516732
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
--- End diff --
This doesn't matter. We can't evaluate python udf in the join condition,
and need to pull it out, that's all.
For python udf accessing attributes from only one side, these would be
pushed down by other rules. If they don't (e.g. user disables filter pushdown
rule), we need to pull them out here, too. Anyway it's orthogonal to this rule.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220482709
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
--- End diff --
I see no check that this requires attributes from both sides, shall we add
it? I see that if this is not true the predicate should have been already
pushed down, but an additional sanity check is worth IMHO
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220482278
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
+ } else {
+Some(rest.reduceLeft(And))
+ }
+ val newJoin = j.copy(condition = newCondition)
+ joinType match {
+case _: InnerLike =>
+ Filter(udf.reduceLeft(And), newJoin)
--- End diff --
nit: this can go on the line above
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220481529
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ // if condition expression contains python udf, it will be moved out
from
+ // the new join conditions, and the join type will be changed to
CrossJoin.
+ logWarning(s"The join condition:$condition of the join plan contains
" +
+"PythonUDF, it will be moved out and the join plan will be turned
to cross " +
+s"join when its the only condition. This plan shows below:\n $j")
+ val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+ val newCondition = if (rest.isEmpty) {
+Option.empty
--- End diff --
`None`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220484279
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,51 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object PullOutPythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+if condition.isDefined && hasPythonUDF(condition.get) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
--- End diff --
can't we support `LeftAnti` too?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220479127
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
--- End diff --
```
@xuanyuanking Oh.. is it because the UDFS referring to single leg would
have been pushed down and we will only have UDFs referring to both legs in the
join condition when we come here ?
```
Yea that's right.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220478633
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
@mgaido91 Yea, I revert the changes for `CheckCartesianProducts` and delete
the check in new rule in d1db33a.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220463070
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
@mgaido91 Its probably because this suite only exercises one rule of the
optimizer ? :-)
```
object Optimize extends RuleExecutor[LogicalPlan] {
val batches = Batch("Check Cartesian Products", Once,
CheckCartesianProducts) :: Nil
}
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220453684
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
> the udf check in CheckCartesianProducts is not work because we have
pulled out the udf in join condition.
yes, but the point is exactly that we don't need that check if we just do
the change here.
> It will also break the UT add in BatchEvalPythonExecSuite.
This is interesting, why?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220440612
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
--- End diff --
@cloud-fan Just saw your comment that validated my understanding on this
rule relying on pushing down predicates through join. However, the
pushdownPredicateThroughJoin is not in the nonExcludableRules list. So can we
rely on this rule being fired always here ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220438880
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
--- End diff --
@xuanyuanking Oh.. it is because the UDFS referring to single leg would
have been pushed down and we will only have UDFs referring to both legs in the
join condition when we come here ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220437721
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1308,6 +1312,16 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, condition)
+ if condition.isDefined &&
PullOutPythonUDFInJoinCondition.hasPythonUDF(condition.get) =>
+// if the crossJoinEnabled is false, a RuntimeException will be
thrown later while
+// the PythonUDF need to access both side of join, we throw
firstly here for better
+// readable information.
+throw new AnalysisException(s"Detected the join
condition:${j.condition} of this join " +
--- End diff --
The reason for can't be pulled out in the case
https://github.com/apache/spark/pull/22326#discussion_r220418201 is not because
of join type problem. The screenshot is I do a test to do the check by
`havePythonUDFInAllConditions`, and the test result shows it returned by
getting a RuntimeException even though its a inner join.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220436983
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
--- End diff --
@xuanyuanking So here we are finding out if the join condition has a python
UDF. I am trying to understand where we are making the determination that this
python UDF is referring to attributes of both legs of the join ? Can you please
let me know. Thank you.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220436485
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1308,6 +1312,16 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, condition)
+ if condition.isDefined &&
PullOutPythonUDFInJoinCondition.hasPythonUDF(condition.get) =>
+// if the crossJoinEnabled is false, a RuntimeException will be
thrown later while
+// the PythonUDF need to access both side of join, we throw
firstly here for better
+// readable information.
+throw new AnalysisException(s"Detected the join
condition:${j.condition} of this join " +
--- End diff --
when will we hit it? If the python udf can't be pulled out because of join
type problems, we already throw exception at `PullOutPythonUDFInJoinCondition`.
Did I miss something?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220433980
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
--- End diff --
Maybe Wenchen means PullOutPythonUDFInJoinCondition, done in 98cd3cc.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220433916
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
+// if condition expression contains python udf, it will be moved
out from
+// the new join conditions, and the join type will be changed to
CrossJoin.
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF, it will be moved out and the join plan will be " +
+ s"turned to cross join. This plan shows below:\n $j")
+val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+val newCondition = if (rest.isEmpty) {
+ Option.empty
+} else {
+ Some(rest.reduceLeft(And))
+}
+val newJoin = j.copy(joinType = Cross, condition = newCondition)
+joinType match {
+ case _: InnerLike =>
+Filter(udf.reduceLeft(And), newJoin)
+ case LeftSemi =>
+Project(
--- End diff --
Yes, that's right.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220433940
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
--- End diff --
ah yes, thanks, done in 98cd3cc.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220433995
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -165,6 +165,8 @@ abstract class Optimizer(sessionCatalog: SessionCatalog)
Batch("LocalRelation", fixedPoint,
ConvertToLocalRelation,
PropagateEmptyRelation) :+
+Batch("Extract PythonUDF From JoinCondition", Once,
+HandlePythonUDFInJoinCondition) :+
// The following batch should be executed after batch "Join Reorder"
and "LocalRelation".
--- End diff --
Thanks, done in 98cd3cc.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220433896
--- Diff: python/pyspark/sql/tests.py ---
@@ -552,6 +552,92 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
--- End diff --
Sorry for the old comment, done in 98cd3cc.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220433190
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
It will also break the UT add in `BatchEvalPythonExecSuite`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220432728
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
```
What about just doing the change?
```
If just do the change here, the udf check in `CheckCartesianProducts` is
not work because we have pulled out the udf in join condition.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220432468
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1304,10 +1307,27 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+ /**
+ * Check if a join contains PythonUDF in join condition.
+ */
+ def hasPythonUDFInJoinCondition(join: Join): Boolean = {
+val conditions =
join.condition.map(splitConjunctivePredicates).getOrElse(Nil)
+conditions.exists(HandlePythonUDFInJoinCondition.hasPythonUDF)
+ }
+
def apply(plan: LogicalPlan): LogicalPlan =
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, _) if hasPythonUDFInJoinCondition(j) =>
--- End diff --
I mean as our discussion in
https://github.com/apache/spark/pull/22326#discussion_r220198104,
`HandlePythonUDFInJoinCondition` no longer throw the AnalysisException. If I do
the check work by `havePythonUDFInAllConditions`, the above case will throw an
RuntimeException.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220428377
--- Diff: python/pyspark/sql/tests.py ---
@@ -552,6 +552,92 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2])
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1, b=2,
b1=1, b2=2)])
+
+def test_udf_and_filter_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2],
"left_semi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_common_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and common filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=1,
b1=3, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
--- End diff --
same question as above ..
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220428290
--- Diff: python/pyspark/sql/tests.py ---
@@ -552,6 +552,92 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
--- End diff --
is this udf non-deterministic ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user dilipbiswal commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220428332
--- Diff: python/pyspark/sql/tests.py ---
@@ -552,6 +552,92 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2])
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1, b=2,
b1=1, b2=2)])
+
+def test_udf_and_filter_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
--- End diff --
is this udf non-deterministic ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220424663
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1304,10 +1307,27 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+ /**
+ * Check if a join contains PythonUDF in join condition.
+ */
+ def hasPythonUDFInJoinCondition(join: Join): Boolean = {
+val conditions =
join.condition.map(splitConjunctivePredicates).getOrElse(Nil)
+conditions.exists(HandlePythonUDFInJoinCondition.hasPythonUDF)
+ }
+
def apply(plan: LogicalPlan): LogicalPlan =
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, _) if hasPythonUDFInJoinCondition(j) =>
--- End diff --
I don't get it. The error means we didn't pull out python udf, but we
should already throw exception in `HandlePythonUDFInJoinCondition`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220418201
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1304,10 +1307,27 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+ /**
+ * Check if a join contains PythonUDF in join condition.
+ */
+ def hasPythonUDFInJoinCondition(join: Join): Boolean = {
+val conditions =
join.condition.map(splitConjunctivePredicates).getOrElse(Nil)
+conditions.exists(HandlePythonUDFInJoinCondition.hasPythonUDF)
+ }
+
def apply(plan: LogicalPlan): LogicalPlan =
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, _) if hasPythonUDFInJoinCondition(j) =>
--- End diff --
Maybe not, we should keep the current logic, as the test below:
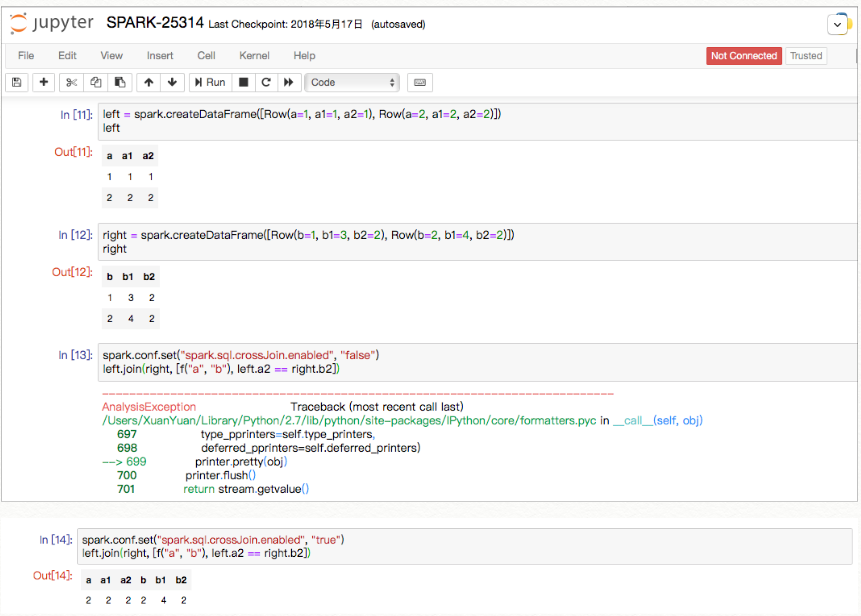
In the join condition, only one python udf but we still need this
AnalysisException. If the logic here change to `havePythonUDFInAllConditions`,
you'll get a runtime exception of `requires attributes from more than one
child.` like:
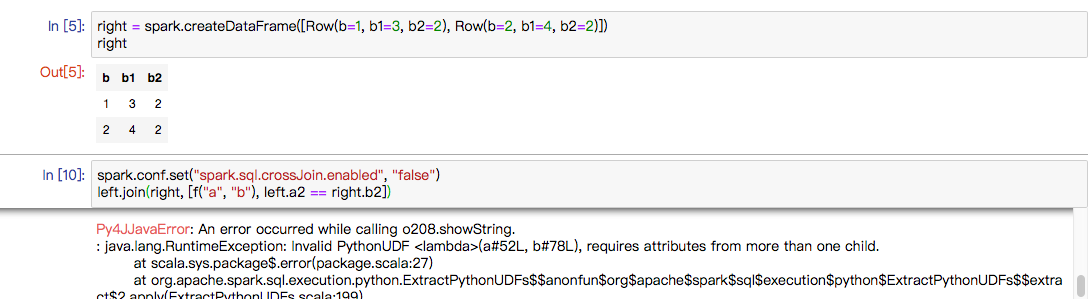
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220289897
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
+// if condition expression contains python udf, it will be moved
out from
+// the new join conditions, and the join type will be changed to
CrossJoin.
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF, it will be moved out and the join plan will be " +
+ s"turned to cross join. This plan shows below:\n $j")
+val (udf, rest) =
+
condition.map(splitConjunctivePredicates).get.partition(hasPythonUDF)
+val newCondition = if (rest.isEmpty) {
+ Option.empty
+} else {
+ Some(rest.reduceLeft(And))
+}
+val newJoin = j.copy(joinType = Cross, condition = newCondition)
+joinType match {
+ case _: InnerLike =>
+Filter(udf.reduceLeft(And), newJoin)
+ case LeftSemi =>
+Project(
--- End diff --
we don't need to add the project if we don't change the join type, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220289293
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
+1
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220289231
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
--- End diff --
why not just `if hasPythonUDF(condition)`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220288991
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
--- End diff --
nit: PullOutputPythonUDFInJoinCondition
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220273079
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,56 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ def hasPythonUDF(expression: Expression): Boolean = {
+expression.collectFirst { case udf: PythonUDF => udf }.isDefined
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if
condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(hasPythonUDF) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
why are you doing this? What about just doing the change? if the result is
a cartesian product, then it will be detected by the relative check
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220272571
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1304,10 +1307,27 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+ /**
+ * Check if a join contains PythonUDF in join condition.
+ */
+ def hasPythonUDFInJoinCondition(join: Join): Boolean = {
+val conditions =
join.condition.map(splitConjunctivePredicates).getOrElse(Nil)
+conditions.exists(HandlePythonUDFInJoinCondition.hasPythonUDF)
+ }
+
def apply(plan: LogicalPlan): LogicalPlan =
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, _) if hasPythonUDFInJoinCondition(j) =>
--- End diff --
if there are other conditions, the presence of a pythoUDF doesn't imply a
cartesian product. I think this should be a `havePythonUDFInAllConditions`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220272683
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -165,6 +165,8 @@ abstract class Optimizer(sessionCatalog: SessionCatalog)
Batch("LocalRelation", fixedPoint,
ConvertToLocalRelation,
PropagateEmptyRelation) :+
+Batch("Extract PythonUDF From JoinCondition", Once,
+HandlePythonUDFInJoinCondition) :+
// The following batch should be executed after batch "Join Reorder"
and "LocalRelation".
--- End diff --
please update this comment too with the new rule
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220267389
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1304,10 +1307,27 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+ /**
+ * Check if a join contains PythonUDF in join condition.
+ */
+ def hasPythonUDFInJoinCondition(join: Join): Boolean = {
+val conditions =
join.condition.map(splitConjunctivePredicates).getOrElse(Nil)
+conditions.exists(HandlePythonUDFInJoinCondition.hasPythonUDF)
+ }
+
def apply(plan: LogicalPlan): LogicalPlan =
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, _) if hasPythonUDFInJoinCondition(j) =>
--- End diff --
Move the check logic only in `CheckCartesianProducts ` as our discussion in
https://github.com/apache/spark/pull/22326#discussion_r220236374 and add
corresponding UT in CheckCartesianProductsSuite, the checking order is
PythonUDF first and then the original checking for cartesian products.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220236374
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,60 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
+// if condition expression contains python udf, it will be moved
out from
+// the new join conditions, and the join type will be changed to
CrossJoin.
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF, it will be moved out and the join plan will be " +
+ s"turned to cross join. This plan shows below:\n $j")
+val (udf, rest) =
+ condition.map(splitConjunctivePredicates).get.partition(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined)
+val newCondition = if (rest.isEmpty) {
+ Option.empty
+} else {
+ Some(rest.reduceLeft(And))
+}
+val newJoin = j.copy(joinType = Cross, condition = newCondition)
+joinType match {
+ case _: InnerLike =>
+Filter(udf.reduceLeft(And), newJoin)
+ case LeftSemi =>
+Project(
+ j.left.output.map(_.toAttribute),
Filter(udf.reduceLeft(And), newJoin))
+ case _ =>
+throw new AnalysisException("Using PythonUDF in join condition
of join type" +
+ s" $joinType is not supported.")
+}
+ } else {
+// if the crossJoinEnabled is false, a RuntimeException will be
thrown later while
+// the PythonUDF need to access both side of join, we throw
firstly here for better
+// readable information.
+throw new AnalysisException(s"Detected the join
condition:$condition of this join " +
--- End diff --
Got it, I'll move the cross join detection logic only into
`CheckCartesianProducts` for safety.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220198104
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/joins.scala
---
@@ -152,3 +153,60 @@ object EliminateOuterJoin extends Rule[LogicalPlan]
with PredicateHelper {
if (j.joinType == newJoinType) f else Filter(condition,
j.copy(joinType = newJoinType))
}
}
+
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ override def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
+case j @ Join(_, _, joinType, condition)
+ if condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because for other type,
+// it breaks SQL semantic if we run the join condition as a filter
after join. If we pass
+// the plan here, it'll still get a an invalid PythonUDF
RuntimeException with message
+// `requires attributes from more than one child`, we throw
firstly here for better
+// readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
+// if condition expression contains python udf, it will be moved
out from
+// the new join conditions, and the join type will be changed to
CrossJoin.
+logWarning(s"The join condition:$condition of the join plan
contains " +
+ "PythonUDF, it will be moved out and the join plan will be " +
+ s"turned to cross join. This plan shows below:\n $j")
+val (udf, rest) =
+ condition.map(splitConjunctivePredicates).get.partition(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined)
+val newCondition = if (rest.isEmpty) {
+ Option.empty
+} else {
+ Some(rest.reduceLeft(And))
+}
+val newJoin = j.copy(joinType = Cross, condition = newCondition)
+joinType match {
+ case _: InnerLike =>
+Filter(udf.reduceLeft(And), newJoin)
+ case LeftSemi =>
+Project(
+ j.left.output.map(_.toAttribute),
Filter(udf.reduceLeft(And), newJoin))
+ case _ =>
+throw new AnalysisException("Using PythonUDF in join condition
of join type" +
+ s" $joinType is not supported.")
+}
+ } else {
+// if the crossJoinEnabled is false, a RuntimeException will be
thrown later while
+// the PythonUDF need to access both side of join, we throw
firstly here for better
+// readable information.
+throw new AnalysisException(s"Detected the join
condition:$condition of this join " +
--- End diff --
I agree the error message is better than just saying cross join is
detected. But I'm worried about duplicating the cross join detection logic in
multiple rules. e.g. what if after pulling out python udf from join condition,
we still have other join conditions so it's not cross join?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220128279
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1234,6 +1237,59 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ override def apply(plan: LogicalPlan): LogicalPlan =
plan.resolveOperatorsUp {
+case j @ Join(_, _, joinType, condition)
+ if condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because other type
+// can not simply be resolved by adding a Cross join. If we pass
the plan here, it'll
+// still get a an invalid PythonUDF RuntimeException with message
`requires attributes
+// from more than one child`, we throw firstly here for better
readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
Maybe the currently `CheckCartesianProducts` could not reuse because it
only match the case of `Join(left, right, Inner | LeftOuter | RightOuter |
FullOuter, _)`, while moving new batch before it, here will got a CrossJoin.
If it is permitted adding the python udf check log in
`CheckCartesianProducts` I think your proposal can be achieved, but maybe the
current logic is better than above method? Because we can log the detail why
we need cross join here. WDYT?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220111919
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1234,6 +1237,59 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ override def apply(plan: LogicalPlan): LogicalPlan =
plan.resolveOperatorsUp {
+case j @ Join(_, _, joinType, condition)
+ if condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because other type
+// can not simply be resolved by adding a Cross join. If we pass
the plan here, it'll
--- End diff --
Yes, will modify the comment more accurate.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220110490
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1234,6 +1237,59 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ override def apply(plan: LogicalPlan): LogicalPlan =
plan.resolveOperatorsUp {
+case j @ Join(_, _, joinType, condition)
+ if condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because other type
+// can not simply be resolved by adding a Cross join. If we pass
the plan here, it'll
+// still get a an invalid PythonUDF RuntimeException with message
`requires attributes
+// from more than one child`, we throw firstly here for better
readable information.
+throw new AnalysisException("Using PythonUDF in join condition of
join type" +
+ s" $joinType is not supported.")
+ }
+ if (SQLConf.get.crossJoinEnabled) {
--- End diff --
Can we simplify it if we move the new batch before `Check Cartesian
Products`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220109700
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1234,6 +1237,59 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
+ override def apply(plan: LogicalPlan): LogicalPlan =
plan.resolveOperatorsUp {
+case j @ Join(_, _, joinType, condition)
+ if condition.map(splitConjunctivePredicates).getOrElse(Nil).exists(
+_.collectFirst { case udf: PythonUDF => udf }.isDefined) =>
+ if (!joinType.isInstanceOf[InnerLike] && joinType != LeftSemi) {
+// The current strategy only support InnerLike and LeftSemi join
because other type
+// can not simply be resolved by adding a Cross join. If we pass
the plan here, it'll
--- End diff --
it's not about cross join. It breaks SQL semantic if we run the join
condition as a filter after join, for non-inner joins.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220109689
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1234,6 +1237,59 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
--- End diff --
No problem, will do this together with rebasing work.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220108380
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1234,6 +1237,59 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+/**
+ * Correctly handle PythonUDF which need access both side of join side by
changing the new join
+ * type to Cross.
+ */
+object HandlePythonUDFInJoinCondition extends Rule[LogicalPlan] with
PredicateHelper {
--- End diff --
can we move it to `org/apache/spark/sql/catalyst/optimizer/joins.scala`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220102842
--- Diff: python/pyspark/sql/tests.py ---
@@ -547,6 +547,92 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2])
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1, b=2,
b1=1, b2=2)])
+
+def test_udf_and_filter_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2],
"left_semi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_common_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and common filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=1,
b1=3, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b"), left.a1 == right.b1])
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1, b=1,
b1=1, b2=1)])
+
+def test_udf_and_common_filter_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and common filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=1,
b1=3, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b"), left.a1 == right.b1],
"left_semi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_not_supported_in_join_condition(self):
--- End diff --
Add this test for
https://github.com/apache/spark/pull/22326/files#diff-a636a87d8843eeccca90140be91d4fafR1249.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r219675105
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -995,7 +995,8 @@ class Dataset[T] private[sql](
// After the cloning, left and right side will have distinct
expression ids.
val plan = withPlan(
Join(logicalPlan, right.logicalPlan, JoinType(joinType),
Some(joinExprs.expr)))
- .queryExecution.analyzed.asInstanceOf[Join]
+ .queryExecution.analyzed
+val joinPlan = plan.collectFirst { case j: Join => j }.get
--- End diff --
For reviewer, we need this change cause the rule
`HandlePythonUDFInJoinCondition` will break the assumption about the join plan
after analyzing will only return Join. After we add the rule of handling python
udf, we'll add filter or project node on top of Join.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216606555
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/FilterPushdownSuite.scala
---
@@ -1153,12 +1154,35 @@ class FilterPushdownSuite extends PlanTest {
"x.a".attr === Rand(10) && "y.b".attr === 5))
val correctAnswer =
x.where("x.a".attr === 5).join(y.where("y.a".attr === 5 &&
"y.b".attr === 5),
-condition = Some("x.a".attr === Rand(10)))
+joinType = Cross).where("x.a".attr === Rand(10))
--- End diff --
Thanks @mgaido91 for the detailed review and advise, for me, I maybe choose
only limited the change scope to pythonUDF only or at lease Unevaluable only.
Waiting for others advice.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216592676
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/FilterPushdownSuite.scala
---
@@ -1153,12 +1154,35 @@ class FilterPushdownSuite extends PlanTest {
"x.a".attr === Rand(10) && "y.b".attr === 5))
val correctAnswer =
x.where("x.a".attr === 5).join(y.where("y.a".attr === 5 &&
"y.b".attr === 5),
-condition = Some("x.a".attr === Rand(10)))
+joinType = Cross).where("x.a".attr === Rand(10))
--- End diff --
cc @cloud-fan @gatorsmile for advice on this. It may probably be ok, as it
lets supporting a case which was not supported before. But I am not sure about
the added value as performing a cross join is often an impossible operation.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216585000
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/FilterPushdownSuite.scala
---
@@ -1153,12 +1154,35 @@ class FilterPushdownSuite extends PlanTest {
"x.a".attr === Rand(10) && "y.b".attr === 5))
val correctAnswer =
x.where("x.a".attr === 5).join(y.where("y.a".attr === 5 &&
"y.b".attr === 5),
-condition = Some("x.a".attr === Rand(10)))
+joinType = Cross).where("x.a".attr === Rand(10))
--- End diff --
As the code in canEvaluateWithinJoin, we can get the scope relation :
(CannotEvaluateWithinJoin = nonDeterminstic + Unevaluable) > Unevaluable >
PythonUDF.
So for the safety maybe I just limit the change scope to the smallest
PythonUDF only. Need some advise from you thanks :)
https://github.com/apache/spark/blob/0736e72a66735664b191fc363f54e3c522697dba/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/predicates.scala#L104-L120
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216583509
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/FilterPushdownSuite.scala
---
@@ -1153,12 +1154,35 @@ class FilterPushdownSuite extends PlanTest {
"x.a".attr === Rand(10) && "y.b".attr === 5))
val correctAnswer =
x.where("x.a".attr === 5).join(y.where("y.a".attr === 5 &&
"y.b".attr === 5),
-condition = Some("x.a".attr === Rand(10)))
+joinType = Cross).where("x.a".attr === Rand(10))
--- End diff --
Yes, I changed this to let the test passing. The original thought is
nondeterministic expression in join condition is not supported yet, so that's
no big
problem.https://github.com/apache/spark/blob/0736e72a66735664b191fc363f54e3c522697dba/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/predicates.scala#L105
https://github.com/apache/spark/blob/0736e72a66735664b191fc363f54e3c522697dba/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/FilterPushdownSuite.scala#L1158-L1159
But now I think I should more carefully about this and just limit the cross
join changes only in PythonUDF case. WDYT? @mgaido91 .Thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216151151
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1149,6 +1149,51 @@ object PushPredicateThroughJoin extends
Rule[LogicalPlan] with PredicateHelper {
(leftEvaluateCondition, rightEvaluateCondition, commonCondition ++
nonDeterministic)
}
+ private def tryToGetCrossType(commonJoinCondition: Seq[Expression], j:
LogicalPlan) = {
+if (SQLConf.get.crossJoinEnabled) {
+ // if condition expression is unevaluable, it will be removed from
+ // the new join conditions, if all conditions is unevaluable, we
should
+ // change the join type to CrossJoin.
+ logWarning(s"The whole commonJoinCondition:$commonJoinCondition of
the join " +
+"plan is unevaluable, it will be ignored and the join plan will be
" +
+s"turned to cross join. This plan shows below:\n $j")
+ Cross
+} else {
+ // if the crossJoinEnabled is false, an AnalysisException will throw
by
+ // CheckCartesianProducts, we throw firstly here for better readable
information.
+ throw new AnalysisException("Detected the whole
commonJoinCondition:" +
+s"$commonJoinCondition of the join plan is unevaluable, we need to
cast the " +
+"join to cross join by setting the configuration variable " +
+s"${SQLConf.CROSS_JOINS_ENABLED.key}=true")
+}
+ }
+
+ /**
+ * Generate new join by pushing down the side only join filter, split
commonJoinCondition
--- End diff --
nit: `filters`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216151223
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/FilterPushdownSuite.scala
---
@@ -1153,12 +1154,35 @@ class FilterPushdownSuite extends PlanTest {
"x.a".attr === Rand(10) && "y.b".attr === 5))
val correctAnswer =
x.where("x.a".attr === 5).join(y.where("y.a".attr === 5 &&
"y.b".attr === 5),
-condition = Some("x.a".attr === Rand(10)))
+joinType = Cross).where("x.a".attr === Rand(10))
--- End diff --
this is not a change we want, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22326: [SPARK-25314][SQL] Fix Python UDF accessing attri...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r216127932
--- Diff: python/pyspark/sql/tests.py ---
@@ -547,6 +547,74 @@ def test_udf_in_filter_on_top_of_join(self):
df = left.crossJoin(right).filter(f("a", "b"))
self.assertEqual(df.collect(), [Row(a=1, b=1)])
+def test_udf_in_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1)])
+right = self.spark.createDataFrame([Row(b=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"))
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, b=1)])
+
+def test_udf_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, f("a", "b"), "leftsemi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_filter_in_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2])
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1, b=2,
b1=1, b2=2)])
+
+def test_udf_and_filter_in_left_semi_join_condition(self):
+# regression test for SPARK-25314
+# test the complex scenario with both udf(non-deterministic)
+# and normal filter(deterministic)
+from pyspark.sql.functions import udf
+left = self.spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2,
a1=2, a2=2)])
+right = self.spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=2,
b1=1, b2=2)])
+f = udf(lambda a, b: a == b, BooleanType())
+df = left.join(right, [f("a", "b1"), left.a == 1, right.b == 2],
"left_semi")
+with self.sql_conf({"spark.sql.crossJoin.enabled": True}):
+self.assertEqual(df.collect(), [Row(a=1, a1=1, a2=1)])
+
+def test_udf_and_common_filter_in_join_condition(self):
--- End diff --
Add these two test for the comment in
https://github.com/apache/spark/pull/22326#discussion_r216127673.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org