[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22533#discussion_r220218715 --- Diff: python/pyspark/sql/column.py --- @@ -54,6 +54,22 @@ def _to_java_column(col): return jcol +def _to_sorted_java_columns(cols, ascending=True): +if len(cols) == 1 and isinstance(cols[0], list): +cols = cols[0] +jcols = [_to_java_column(c) for c in cols] +if isinstance(ascending, (bool, int)): +if not ascending: +jcols = [jc.desc() for jc in jcols] +elif isinstance(ascending, list): +jcols = [jc if asc else jc.desc() + for asc, jc in zip(ascending, jcols)] --- End diff -- Btw this can be easily worked around. I think we don't need to add this argument --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r220218332
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
We match it to the equivalent API. If it's not in Scale side; we should add
it in Scale side first.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user annamolchanova commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r220169775
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
You're right, it does not. As well as DataSet.orderBy() in Scala api.
So there's no any inconsistency between similar methods of 2 packages.
I guess this was the main point of the ticket.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r220122281
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
`orderBy` looks not taking `ascending` in the API documentation.
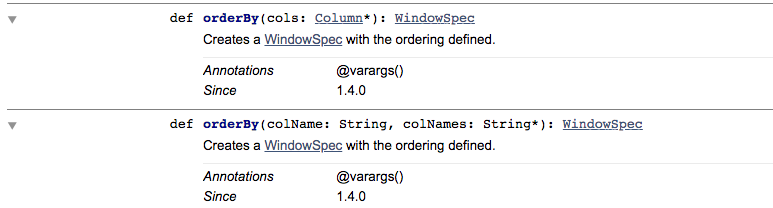
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user annamolchanova commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r220089447
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
It's in the expressions pachage:
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.expressions.Window$
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r219902083
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
Would you mind if I ask to point out the corresponding API in Scala side?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user annamolchanova commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r219898548
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
As I can see orderBy is implemented in scala.
It accepts sorting order via string query, something like 'col_name desc'
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user annamolchanova commented on a diff in the pull request: https://github.com/apache/spark/pull/22533#discussion_r219898059 --- Diff: python/pyspark/sql/window.py --- @@ -76,12 +79,37 @@ def partitionBy(*cols): @staticmethod @since(1.4) -def orderBy(*cols): +def orderBy(*cols, **kwargs): """ Creates a :class:`WindowSpec` with the ordering defined. + +:param cols: names of columns or expressions. --- End diff -- Hi @HyukjinKwon , I've added version directive. Thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22533#discussion_r219811169 --- Diff: python/pyspark/sql/window.py --- @@ -76,12 +79,37 @@ def partitionBy(*cols): @staticmethod @since(1.4) -def orderBy(*cols): +def orderBy(*cols, **kwargs): """ Creates a :class:`WindowSpec` with the ordering defined. + +:param cols: names of columns or expressions. --- End diff -- We should add ` ... versionchanged:: 2.5 blah blah` BTW --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r219812531
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
-def orderBy(*cols):
+def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+:param cols: names of columns or expressions.
+:param ascending: boolean or list of boolean (default True).
+Sort ascending vs. descending. Specify list for multiple sort
orders.
+If a list is specified, length of the list must equal length
of the `cols`.
+
+>>> from pyspark.sql import functions as F, SparkSession, Window
+>>> spark = SparkSession.builder.getOrCreate()
+>>> df = spark.createDataFrame(
+... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+>>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+... Window.unboundedPreceding, Window.currentRow)
+>>> df.withColumn("sum", F.sum("id").over(window)).show()
++---++---+
+| id|category|sum|
++---++---+
+| 3| b| 3|
+| 2| b| 5|
+| 1| b| 6|
+| 2| a| 2|
+| 1| a| 3|
+| 1| a| 4|
++---++---+
"""
sc = SparkContext._active_spark_context
-jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ascending = kwargs.get('ascending', True)
+jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+_to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
Does Scala side have `orderBy` as well?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter t...
GitHub user annamolchanova opened a pull request: https://github.com/apache/spark/pull/22533 [SPARK-18818][PYTHON] Add 'ascending' parameter to Window.orderBy() ## What changes were proposed in this pull request? Pass `ascending` parameter to Window's orderBy() function the same like DataFrame's orderBy() accepts. This allows to specify descending order without building Column object. It makes this function more consistent and convenient. ## How was this patch tested? Unit tests were run. Docstring tests were added to Window.orderBy() You can merge this pull request into a Git repository by running: $ git pull https://github.com/annamolchanova/spark SPARK-18818-window_ascending_parameter Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22533.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22533 commit 40f8295b97e887108e96a6b4a39cc6781ebb406d Author: Anna Molchanova Date: 2018-09-23T19:11:42Z Implement ascending parameter in window orderBy --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org