LuciferYang commented on PR #40283:
URL: https://github.com/apache/spark/pull/40283#issuecomment-1455648868
> https://issues.apache.org/jira/browse/MNG-7697
OK, let me test 3.9.1-SNAPSHOT later. @pan3793 Do you have any other issues
besides those in GA task?
--
This is an a
hboutemy commented on PR #40283:
URL: https://github.com/apache/spark/pull/40283#issuecomment-1455637895
[@cstamas ](https://github.com/cstamas) do you know if the lax parsing
covers that `org.codehaus.plexus.util.xml.pull.XmlPullParserException: UTF-8
BOM plus xml decl of ISO-8859-1 is inc
hboutemy commented on PR #40283:
URL: https://github.com/apache/spark/pull/40283#issuecomment-1455633233
there is a known issue in Maven 3.9.0 (related to plexus-utils XML stricter
reading https://github.com/codehaus-plexus/plexus-utils/issues/238 ) that is
fixed in 3.9.1-SNAPSHOT: https://
EnricoMi commented on PR #38358:
URL: https://github.com/apache/spark/pull/38358#issuecomment-1455620898
Yes, it looks like it removes the **empty** table location after
**overwriting** the table failed due to the `ArithmeticException`.
@cloud-fan do you consider the removal of an emp
itholic commented on PR #40280:
URL: https://github.com/apache/spark/pull/40280#issuecomment-1455567210
Thanks @panbingkun for the nice fix!
Btw, think I found another `createDataFrame` bug which is not working
properly with non-nullable schema as below:
```python
>>> from pyspark.s
itholic commented on PR #40280:
URL: https://github.com/apache/spark/pull/40280#issuecomment-1455565581
Thanks @panbingkun for the nice fix!
Btw, think I found another `createDataFrame` bug which is not working
properly with non-nullable schema as below:
```python
>>> from pyspark.s
HeartSaVioR closed pull request #40292: [SPARK-42676][SS] Write temp
checkpoints for streaming queries to local filesystem even if default FS is set
differently
URL: https://github.com/apache/spark/pull/40292
--
This is an automated message from the Apache Git Service.
To respond to the mess
HeartSaVioR commented on PR #40292:
URL: https://github.com/apache/spark/pull/40292#issuecomment-1455549225
Thanks! Merging to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
wangyum opened a new pull request, #40294:
URL: https://github.com/apache/spark/pull/40294
### What changes were proposed in this pull request?
This PR enhances `UnwrapCastInBinaryComparison` to support unwrapping date
type to string type.
### Why are the changes needed?
LuciferYang commented on code in PR #40291:
URL: https://github.com/apache/spark/pull/40291#discussion_r1125957292
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/DataFrameWriter.scala:
##
@@ -345,6 +345,37 @@ final class DataFrameWriter[T] private[sql] (ds:
LuciferYang commented on PR #40283:
URL: https://github.com/apache/spark/pull/40283#issuecomment-1455497586
also cc @HyukjinKwon
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comm
LuciferYang commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125949503
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
xinrong-meng commented on code in PR #40244:
URL: https://github.com/apache/spark/pull/40244#discussion_r1125939747
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -303,14 +303,15 @@ message Expression {
message CommonInlineUserDefinedFuncti
LuciferYang commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125934336
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
pan3793 commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125930947
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
-
LuciferYang commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125929900
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
pan3793 commented on code in PR #40283:
URL: https://github.com/apache/spark/pull/40283#discussion_r1125927078
##
build/mvn:
##
@@ -119,7 +119,8 @@ install_mvn() {
if [ "$MVN_BIN" ]; then
local MVN_DETECTED_VERSION="$(mvn --version | head -n1 | awk '{print $3}')"
fi
-
zhengruifeng commented on PR #40228:
URL: https://github.com/apache/spark/pull/40228#issuecomment-1455466444
merged into master/branch-3.4
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the spec
zhengruifeng closed pull request #40228: [SPARK-41874][CONNECT][PYTHON] Support
SameSemantics in Spark Connect
URL: https://github.com/apache/spark/pull/40228
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above
hvanhovell commented on PR #40291:
URL: https://github.com/apache/spark/pull/40291#issuecomment-1455425240
hmmm - let me think about it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specif
beliefer opened a new pull request, #40293:
URL: https://github.com/apache/spark/pull/40293
### What changes were proposed in this pull request?
Currently, there are a lot of test cases for broadcast hint is invalid.
Because the data size is smaller than broadcast threshold.
##
anishshri-db commented on PR #40292:
URL: https://github.com/apache/spark/pull/40292#issuecomment-1455397903
@HeartSaVioR - please take a look. Thx
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to
anishshri-db opened a new pull request, #40292:
URL: https://github.com/apache/spark/pull/40292
### What changes were proposed in this pull request?
Write temp checkpoints for streaming queries to local filesystem even if
default FS is set differently
### Why are the changes needed
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455392063
> I guess we will need to rewrite the lamda function in spark connect
planner.
Yeah.
--
This is an automated message from the Apache Git Service.
To respond to the message, plea
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455390728
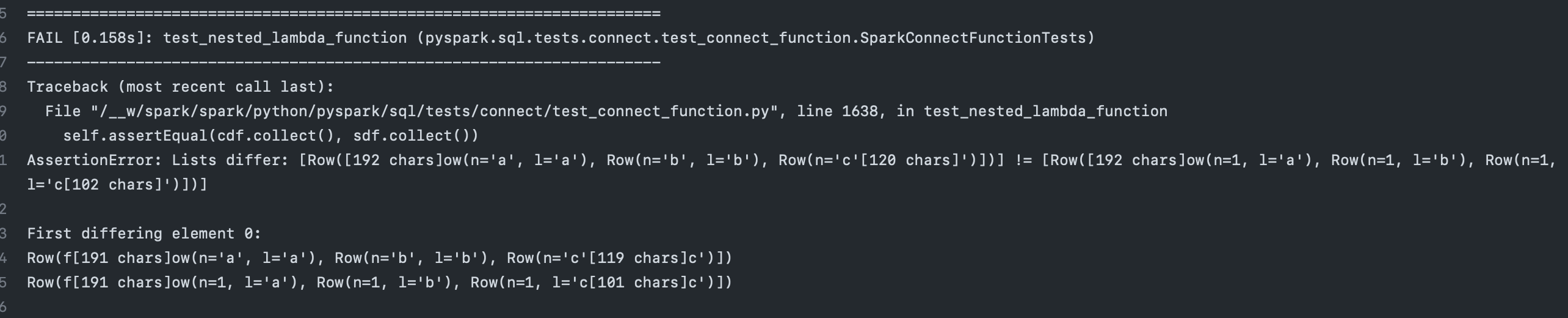
--
This is an automated message from the Apache Git Service.
To respo
beliefer commented on code in PR #40277:
URL: https://github.com/apache/spark/pull/40277#discussion_r1125854126
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -140,6 +141,21 @@ message Read {
// (Optional) A list of path for file-system b
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125854357
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -189,6 +190,11 @@ message Expression {
int32 days = 2;
int64 micr
zhengruifeng commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455388960
I guess we will need to rewrite the lamda function in spark connect planner.
cc @ueshin as well, since existing implementation follows the fix in
https://github.com/apache/spar
huangxiaopingRD closed pull request #40196: [SPARK-42603][SQL] Set
spark.sql.legacy.createHiveTableByDefault to false.
URL: https://github.com/apache/spark/pull/40196
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
U
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125852404
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Sof
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125852404
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Sof
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125852404
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Sof
beliefer commented on PR #40291:
URL: https://github.com/apache/spark/pull/40291#issuecomment-1455384866
@hvanhovell It seems that add test cases no way.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455384317
@hvanhovell After my test, `python/run-tests --testnames
'pyspark.sql.connect.dataframe'` will not passed.
--
This is an automated message from the Apache Git Service.
To respond to th
beliefer opened a new pull request, #40291:
URL: https://github.com/apache/spark/pull/40291
### What changes were proposed in this pull request?
Currently, the connect project have the new `DataFrameWriter` API which is
corresponding to Spark `DataFrameWriter` API. But the connect's
`Dat
Yikf commented on PR #40290:
URL: https://github.com/apache/spark/pull/40290#issuecomment-1455380079
cc @cloud-fan @dongjoon-hyun
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific com
Yikf commented on PR #40289:
URL: https://github.com/apache/spark/pull/40289#issuecomment-1455379959
cc @cloud-fan @dongjoon-hyun
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific com
Yikf opened a new pull request, #40290:
URL: https://github.com/apache/spark/pull/40290
This is a backport of https://github.com/apache/spark/pull/40064 for
branch-3.3
### What changes were proposed in this pull request?
Make a serializable jobTrackerId instead of a non-ser
Yikf opened a new pull request, #40289:
URL: https://github.com/apache/spark/pull/40289
This is a backport of https://github.com/apache/spark/pull/40064
### What changes were proposed in this pull request?
Make a serializable jobTrackerId instead of a non-serializable JobID
wangyum commented on PR #38358:
URL: https://github.com/apache/spark/pull/38358#issuecomment-1455371977
@EnricoMi It seems it will remove the table location if a
`java.lang.ArithmeticException` is thrown after this change.
How to reproduce:
```scala
import org.apache.hadoop.fs.{File
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125837371
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Sof
anishshri-db commented on PR #40273:
URL: https://github.com/apache/spark/pull/40273#issuecomment-1455371384
> Mind retriggering the build, please? Probably simplest way to do is
pushing an empty commit. You can retrigger the build in your fork but it won't
be reflected here.
Sure do
LuciferYang commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125837371
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Sof
hvanhovell commented on code in PR #40277:
URL: https://github.com/apache/spark/pull/40277#discussion_r1125835789
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -140,6 +141,21 @@ message Read {
// (Optional) A list of path for file-system
hvanhovell commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455366786
@HyukjinKwon @zhengruifeng the rationale for this change is that analyzer
takes care of making lambda variables unique.
--
This is an automated message from the Apache Git Service.
T
Yikf commented on PR #40064:
URL: https://github.com/apache/spark/pull/40064#issuecomment-1455364691
> @Yikf can you help to open a backport PR for 3.2/3.3? Thanks!
Sure
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub a
beliefer commented on PR #39091:
URL: https://github.com/apache/spark/pull/39091#issuecomment-1455360592
@hvanhovell @grundprinzip @HyukjinKwon @zhengruifeng @amaliujia Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHu
amaliujia commented on PR #40228:
URL: https://github.com/apache/spark/pull/40228#issuecomment-1455359011
@hvanhovell waiting for CI
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific c
beliefer commented on PR #40275:
URL: https://github.com/apache/spark/pull/40275#issuecomment-1455357573
@hvanhovell @LuciferYang Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the sp
hvanhovell commented on PR #40228:
URL: https://github.com/apache/spark/pull/40228#issuecomment-1455352755
@amaliujia can you update the PR?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the sp
hvanhovell commented on code in PR #40217:
URL: https://github.com/apache/spark/pull/40217#discussion_r1125825287
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/DataFrameNaFunctionSuite.scala:
##
@@ -0,0 +1,377 @@
+/*
+ * Licensed to the Apache Software Foun
hvanhovell commented on PR #40217:
URL: https://github.com/apache/spark/pull/40217#issuecomment-1455351159
@panbingkun can you update the CompatibilitySuite?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL abov
LuciferYang commented on PR #40254:
URL: https://github.com/apache/spark/pull/40254#issuecomment-1455349598
Thanks @srowen
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
itholic commented on PR #40288:
URL: https://github.com/apache/spark/pull/40288#issuecomment-1455348864
cc @tgravescs since this is a Spark Connect introduction including note
about built in authentication you mentioned in JIRA ticket before.
--
This is an automated message from the Apach
hvanhovell commented on PR #40217:
URL: https://github.com/apache/spark/pull/40217#issuecomment-1455348717
@panbingkun can you update your PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
hvanhovell commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125820525
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/expressions/LiteralProtoConverter.scala:
##
@@ -0,0 +1,297 @@
+/*
+ * Licensed to the Apache Soft
hvanhovell commented on code in PR #40218:
URL: https://github.com/apache/spark/pull/40218#discussion_r1125817796
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/LiteralValueProtoConverter.scala:
##
@@ -130,4 +138,61 @@ object LiteralValueProtoCon
itholic opened a new pull request, #40288:
URL: https://github.com/apache/spark/pull/40288
### What changes were proposed in this pull request?
This PR proposes to add a brief description of Spark Connect to the PySpark
main page.
https://user-images.githubusercontent.com/44108
hvanhovell commented on code in PR #40270:
URL: https://github.com/apache/spark/pull/40270#discussion_r1125815690
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -781,3 +782,10 @@ message FrameMap {
CommonInlineUserDefinedFunction func = 2;
srowen commented on PR #40254:
URL: https://github.com/apache/spark/pull/40254#issuecomment-1455341403
Merged to master
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To u
srowen closed pull request #40254: [SPARK-42654][BUILD] Upgrade dropwizard
metrics 4.2.17
URL: https://github.com/apache/spark/pull/40254
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
cloud-fan commented on PR #40064:
URL: https://github.com/apache/spark/pull/40064#issuecomment-1455335925
@Yikf can you help to open a backport PR for 3.2/3.3? Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use th
LuciferYang commented on PR #40254:
URL: https://github.com/apache/spark/pull/40254#issuecomment-1455328473
friendly ping @srowen
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific com
hvanhovell closed pull request #39091: [SPARK-41527][CONNECT][PYTHON] Implement
`DataFrame.observe`
URL: https://github.com/apache/spark/pull/39091
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to th
hvanhovell commented on PR #39091:
URL: https://github.com/apache/spark/pull/39091#issuecomment-1455327845
Merging to master/3.4
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comme
LuciferYang commented on PR #40285:
URL: https://github.com/apache/spark/pull/40285#issuecomment-1455325164
Thanks @wangyum
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
LuciferYang commented on PR #40255:
URL: https://github.com/apache/spark/pull/40255#issuecomment-1455324716
Thanks @hvanhovell @HyukjinKwon @zhengruifeng @amaliujia
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
hvanhovell closed pull request #40255: [SPARK-42558][CONNECT] Implement
`DataFrameStatFunctions` except `bloomFilter` functions
URL: https://github.com/apache/spark/pull/40255
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and u
hvanhovell commented on PR #40255:
URL: https://github.com/apache/spark/pull/40255#issuecomment-1455323028
Merging.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsub
hvanhovell closed pull request #40275: [SPARK-42557][CONNECT] Add Broadcast to
functions
URL: https://github.com/apache/spark/pull/40275
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
hvanhovell commented on PR #40275:
URL: https://github.com/apache/spark/pull/40275#issuecomment-1455321694
Merging.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsub
hvanhovell closed pull request #40279: [MINOR][CONNECT] Remove unused protobuf
imports to eliminate build warnings
URL: https://github.com/apache/spark/pull/40279
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL ab
hvanhovell closed pull request #40280: [SPARK-42671][CONNECT] Fix bug for
createDataFrame from complex type schema
URL: https://github.com/apache/spark/pull/40280
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL ab
hvanhovell commented on code in PR #40280:
URL: https://github.com/apache/spark/pull/40280#discussion_r1125800378
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/SparkSession.scala:
##
@@ -115,7 +115,7 @@ class SparkSession private[sql] (
private def creat
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790750
##
core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala:
##
@@ -232,6 +232,13 @@ private[spark] class DAGScheduler(
sc.getConf.getInt("spark.stage.max
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790378
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2479,4 +2479,14 @@ package object config {
.version("3.4.0")
.booleanConf
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790378
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2479,4 +2479,14 @@ package object config {
.version("3.4.0")
.booleanConf
beliefer opened a new pull request, #40287:
URL: https://github.com/apache/spark/pull/40287
### What changes were proposed in this pull request?
UnresolvedNamedLambdaVariable do not need unique names in python. We already
did this for the scala client, and it is good to have parity betwee
mridulm commented on code in PR #40286:
URL: https://github.com/apache/spark/pull/40286#discussion_r1125790378
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2479,4 +2479,14 @@ package object config {
.version("3.4.0")
.booleanConf
ulysses-you commented on PR #40262:
URL: https://github.com/apache/spark/pull/40262#issuecomment-1455303198
cc @cloud-fan @viirya thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the spe
beliefer commented on code in PR #39091:
URL: https://github.com/apache/spark/pull/39091#discussion_r1125777299
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -338,6 +340,22 @@ class SparkConnectPlanner(session: S
beliefer commented on PR #40275:
URL: https://github.com/apache/spark/pull/40275#issuecomment-1455280706
ping @HyukjinKwon @zhengruifeng @dongjoon-hyun
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
beliefer commented on PR #40277:
URL: https://github.com/apache/spark/pull/40277#issuecomment-1455280396
ping @hvanhovell @HyukjinKwon @dongjoon-hyun cc @LuciferYang
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use th
beliefer commented on PR #39091:
URL: https://github.com/apache/spark/pull/39091#issuecomment-1455279364
> @beliefer can you please remove the is_observation code path? And take
another look at the protocol. Otherwise I think it looks good.
is_observation code path has been removed.
itholic commented on PR #40271:
URL: https://github.com/apache/spark/pull/40271#issuecomment-1455275958
Looks good otherwise.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
itholic commented on code in PR #40271:
URL: https://github.com/apache/spark/pull/40271#discussion_r1125771590
##
python/pyspark/sql/tests/test_functions.py:
##
@@ -1268,6 +1268,12 @@ def test_bucket(self):
message_parameters={"arg_name": "numBuckets", "arg_type": "
itholic commented on code in PR #40271:
URL: https://github.com/apache/spark/pull/40271#discussion_r1125771590
##
python/pyspark/sql/tests/test_functions.py:
##
@@ -1268,6 +1268,12 @@ def test_bucket(self):
message_parameters={"arg_name": "numBuckets", "arg_type": "
HyukjinKwon closed pull request #40281: [SPARK-41497][CORE][Follow UP]Modify
config `spark.rdd.cache.visibilityTracking.enabled` support version to 3.5.0
URL: https://github.com/apache/spark/pull/40281
--
This is an automated message from the Apache Git Service.
To respond to the message, ple
HyukjinKwon commented on PR #40282:
URL: https://github.com/apache/spark/pull/40282#issuecomment-1455270795
cc @MaxGekk and @srielau
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
HyukjinKwon closed pull request #40284: [SPARK-42674][BUILD] Upgrade scalafmt
from 3.7.1 to 3.7.2
URL: https://github.com/apache/spark/pull/40284
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
HyukjinKwon commented on PR #40284:
URL: https://github.com/apache/spark/pull/40284#issuecomment-1455270404
Merged to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
github-actions[bot] closed pull request #36265: [SPARK-38951][SQL] Aggregate
aliases override field names in ResolveAggregateFunctions
URL: https://github.com/apache/spark/pull/36265
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHu
github-actions[bot] commented on PR #38736:
URL: https://github.com/apache/spark/pull/38736#issuecomment-1455262719
We're closing this PR because it hasn't been updated in a while. This isn't
a judgement on the merit of the PR in any way. It's just a way of keeping the
PR queue manageable.
wangyum commented on PR #40285:
URL: https://github.com/apache/spark/pull/40285#issuecomment-1455258629
Merged to master and branch-3.4.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specif
wangyum closed pull request #40285: [SPARK-42675][CONNECT][TESTS] Drop temp
view after test `test temp view`
URL: https://github.com/apache/spark/pull/40285
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
FurcyPin commented on code in PR #40271:
URL: https://github.com/apache/spark/pull/40271#discussion_r1125698656
##
python/pyspark/sql/functions.py:
##
@@ -22,20 +22,10 @@
import sys
import functools
import warnings
-from typing import (
-Any,
-cast,
Review Comment:
FurcyPin commented on code in PR #40271:
URL: https://github.com/apache/spark/pull/40271#discussion_r1125695676
##
python/pyspark/sql/functions.py:
##
@@ -22,20 +22,10 @@
import sys
import functools
import warnings
-from typing import (
-Any,
-cast,
Review Comment:
itholic commented on code in PR #40236:
URL: https://github.com/apache/spark/pull/40236#discussion_r1125682909
##
sql/core/src/test/scala/org/apache/spark/sql/errors/QueryExecutionErrorsSuite.scala:
##
@@ -765,6 +770,58 @@ class QueryExecutionErrorsSuite
)
}
}
+
+
LuciferYang commented on PR #40274:
URL: https://github.com/apache/spark/pull/40274#issuecomment-1455105130
There is another problem that needs to be confirmed, which may not related
to current pr: if other Suites inherit `RemoteSparkSession`, they will share
the same connect server, right?
ivoson opened a new pull request, #40286:
URL: https://github.com/apache/spark/pull/40286
### What changes were proposed in this pull request?
Currently a stage will be resubmitted in a few scenarios:
1. Task failed with `FetchFailed` will trigger stage re-submit;
2. Barrier task fai
1 - 100 of 125 matches
Mail list logo