On Thu, 2013-11-28 at 00:20 -0500, Igor Tandetnik wrote:
> On 11/27/2013 11:52 PM, Tristan Van Berkom wrote:
> > ================================================
> > SELECT DISTINCT summary.uid, summary.vcard FROM 'folder_id' AS summary
> > LEFT OUTER JOIN 'folder_id_phone_list' AS phone_list
> > ON phone_list.uid = summary.uid
> > LEFT OUTER JOIN 'folder_id_email_list' AS email_list
> > ON email_list.uid = summary.uid
> > WHERE (phone_list.value IS NOT NULL AND phone_list.value LIKE '%0505')
> > AND (email_list.value IS NOT NULL AND email_list.value LIKE 'eddie%')
>
> Why are you using outer joins when your WHERE clause discards unmatched
> records anyway? If you replace LEFT OUTER with INNER, the end result
> would be exactly the same.
I was afraid someone might ask this, but I had already put a lot
of detail into this email so I left it out.
When using an INNER join, the engine does something like this:
o Create a data set that is table_1 * table_2 * table_3 rows
large
o Run the constraints on what might be multiple matching rows
in the resulting huge data set (even if I nest the selects,
there can be other constraints to sort out on the main table).
This is extremely slow for addressbooks with 200,000 contacts,
however the INNER join allows me to drop the nested select foolery
for smaller addressbooks as the indexes can still be leveraged
in a query similar to the first version above.
This bug comment has a good detailed description of the reason
why we shifted from regular joins to LEFT OUTER joins:
https://bugzilla.gnome.org/show_bug.cgi?id=699597#c6
> I have a strong feeling that, once you replace outer joins with regular
> joins, this statement would run just as fast as your convoluted one with
> nested selects. By using outer joins, you prevent SQLite from reordering
> the conditions and using the most efficient search strategy - it is
> forced to perform those joins left to right, which results in bad
> performance because, apparently, you don't have indexes on
> phone_list.uid or email_list.uid.
Indeed I avoided creating an index for phone_list.uid and
email_list.uid, and indeed I'm unsure of how that will effect
performance.
If I were to create indexes on the uid column of the auxiliary
tables, would that cause the INNER join to not create such a
huge dataset before checking the constraints ?
> Try this straightforward query:
>
> SELECT DISTINCT summary.uid, summary.vcard FROM folder_id AS summary
> JOIN folder_id_phone_list AS phone_list
> ON phone_list.uid = summary.uid
> JOIN folder_id_email_list AS email_list
> ON email_list.uid = summary.uid
> WHERE phone_list.value LIKE '%0505' AND email_list.value LIKE 'eddie%';
This looks stunningly similar to what we had originally, which indeed
returns results in less than 10ms for addressbooks up to around 800
contacts.
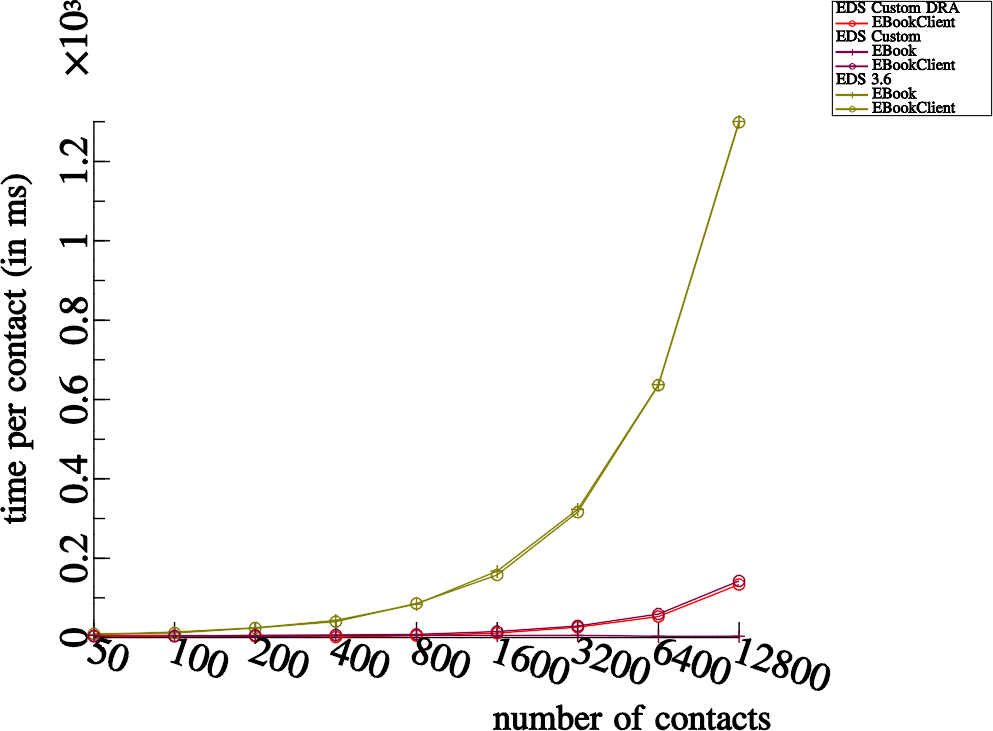
This graph shows performance of INNER joins actually:
http://blogs.gnome.org/tvb/files/2013/01/filter-by-long-phone-number-prefix.png
As you can see, things start to get bad with > 800 contacts (the red
line is what we're looking at here).
>
> > o Leverage the index which I've created on 'folder_id_email_list'
> > (I am using case insensitive LIKE statements so the indexes
> > work in that statement).
>
> Normally, you need case-sensitive LIKE in order to use the index, unless
> the index is created with COLLATE NOCASE. You could use EXPLAIN QUERY
> PLAN to confirm that the index is indeed being utilized.
Oh sorry, I totally mistyped that, LIKE is case insensitive by default
and we override that indeed, using "PRAGMA case_sensitive_like=ON" at
initialization time.
Thank you for taking the time to try and understand this with me :)
Cheers,
-Tristan
_______________________________________________
sqlite-users mailing list
[email protected]
http://sqlite.org:8080/cgi-bin/mailman/listinfo/sqlite-users
{kind=link}