Hello world!
Okay, I have satisfied my curiosity in this matter.
Bill Freeman <[EMAIL PROTECTED]>, who replied to me off-list quickly after my
original post, was correct in that the overhead I was seeing is due to
indirect blocks. Credit also to Derek Martin <[EMAIL PROTECTED]>, for
providing very nice empirical evidence (and saving me the trouble of
producing it).
Once I knew what I was looking for, finding it with Google was easy enough
to do. ;-)
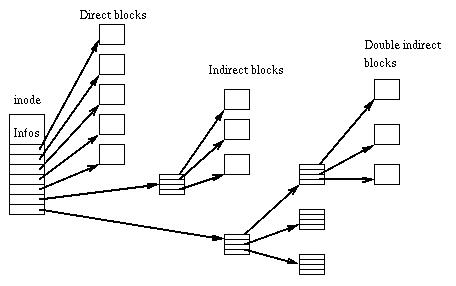
A good brief explanation:
An inode stores up to 12 "direct" block numbers, summing up
to a file size of 48 kByte. Number 13 points to a block with up to
1024 block numbers of 32 Bit size each ("indirect blocks"), summing
up to a file size of 4 MByte. Number 14 points to a block with
numbers of blocks containing numbers of data blocks ("double
indirect", up to 4 GByte); and number 15 points to "triple indirect"
blocks (up to 4 TByte).
-- from http://e2undel.sourceforge.net/how.html
A good diagram:
http://e2fsprogs.sourceforge.net/ext2-inode.gif
Additional references:
http://www.nongnu.org/ext2-doc/
http://e2fsprogs.sourceforge.net/ext2intro.html
Finally, Mr. Freeman's reply to my original post was sufficiently
informative and well-written then I asked for and received his permission to
repost it here (thanks Bill!). His post is about UFS (the original(?) Unix
File System), but most of the concepts (if not the numbers) apply to EXT2/3
as well.
---------- Begin forwarded message ----------
Date: Mon, 28 Jul 2003 13:24:16 -0400
From: Bill Freeman <[EMAIL PROTECTED]>
To: [EMAIL PROTECTED]
Subject: Filesystem overhead
Ben,
I'd guess that du is counting the indirect blocks, except then
the overhead that you see is too small, unless things have gotten a
lot better than early Unix days. Actually, they probably have gotten
better, having some scheme to allocate most of a large file from
contiguous sets of blocks that only needs a single pointer in an inode
or indirect block. But whatever the allocation unit is, you need at
least an index into the allocation space plus an indication of which
space, and more likely a block offset within the filesystem, for each
unit of data. If 32 bit offsets are enough (maybe not for the new
extra large filesystems), then to see the approximate 0.1% overhead
you're describing would need 4k allocation units, which seems
reasonable to me.
Actually, I assume that you know the stuff below, but I'm
going to say it anyway. This is all from UFS: I've never studied extN
stuff internally. In old Unix systems, blocks were 512 bytes. An
inode was a block, and after things like permissions, size, fragment
allocation in the last block, owner, group, etc., there was room for
13 disk pointers (index of block within the partition). The first 10
of these were used to point to the first 10 data blocks of the file.
If a file was bigger than 5k (needed more than 10 blocks), then the
11th pointer pointed to a block that was used for nothing but
pointers. With 32 bit (4 byte) pointers, 128 pointers would fit in a
block, so this "single indirect block" could handle the next 64k of
the file. If the file was larger than 69k (more than fills the single
indirect block), then the 12th pointer in the inode points to a
"double indirect block", a block of pointers to blocks of pointers to
blocks of data. In the 4 byte pointer 512 byte block world, this
handles the next 8Mb of the file. Finally, if the file was too big
for that, the last inode pointer pointed to a triple indirect block, a
pointer to a block of pointers to blocks of pointers to blocks of
pointers to data blocks. That handled the next 1Gb of the file.
This size comfortably exceeds the wildest dreams of a PDP-11,
the original implementation platform for Unix. The washing machine
sided drives of the day only held between 2.5Mb and 10Mb. Even when
we started being able to get 40Mb drives the choice wasn't a concern.
By the mid 1980's, however, big system vendors (I was at Alliant, who
made so called mini-super-computers) were scrambling to find creative
ways to expand the limits on both filesystems and individual files
without breaking too many things.
Linux has clearly been using 1k blocks, and I wouldn't be
surprised by the allocation of 4 block clusters for all but the last
(fragmented) blocks. One to one thousand overhead to data sounds
pretty reasonable to me.
Bill
---------- End forwarded message ----------
Thanks to everyone who responded. I hope other people have found this
thread as informative and useful as I have.
Clear skies!
--
Ben Scott <[EMAIL PROTECTED]>
| The opinions expressed in this message are those of the author and do |
| not represent the views or policy of any other person or organization. |
| All information is provided without warranty of any kind. |
_______________________________________________
gnhlug-discuss mailing list
[EMAIL PROTECTED]
http://mail.gnhlug.org/mailman/listinfo/gnhlug-discuss
{kind=link}