[jira] [Created] (FLINK-21180) Move the state module from 'pyflink.common' to 'pyflink.datastream'
Wei Zhong created FLINK-21180: - Summary: Move the state module from 'pyflink.common' to 'pyflink.datastream' Key: FLINK-21180 URL: https://issues.apache.org/jira/browse/FLINK-21180 Project: Flink Issue Type: Sub-task Components: API / Python Reporter: Wei Zhong Fix For: 1.13.0 Currently we put all the DataStream Functions to 'pyflink.datastream.functions' module and all the State API to 'pyflink.common.state' module. But the ReducingState and AggregatingState depend on ReduceFunction and AggregateFunction, which means the 'state' module will depend the 'functions' module. So we need to move the 'state' module to 'pyflink.datastream' package to avoid circular dependencies between 'pyflink.datastream' and 'pyflink.common'. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] KarmaGYZ commented on pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on pull request #14647: URL: https://github.com/apache/flink/pull/14647#issuecomment-768869214 @zentol I also glad to have a unified SlotManager. As the feature is not stable. I tend to put it out of the scope of this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14783: [FLINK-21169][kafka] flink-connector-base dependency should be scope compile
flinkbot edited a comment on pull request #14783: URL: https://github.com/apache/flink/pull/14783#issuecomment-768767423 ## CI report: * ea0fa2c3a97b2d2082b40732850ccc960ba7a09e Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12576) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on pull request #14647: URL: https://github.com/apache/flink/pull/14647#issuecomment-768868239 Thanks for the review @xintongsong . All your comments have been addressed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20838) Implement SlotRequestAdapter for the FineGrainedSlotManager
[ https://issues.apache.org/jira/browse/FLINK-20838?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273388#comment-17273388 ] Xintong Song commented on FLINK-20838: -- There a todo item from FLINK-20835, that should be addressed once this issue is resolved. https://github.com/apache/flink/pull/14647#discussion_r560716703 > Implement SlotRequestAdapter for the FineGrainedSlotManager > --- > > Key: FLINK-20838 > URL: https://issues.apache.org/jira/browse/FLINK-20838 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Yangze Guo >Priority: Major > > Implement an adapter for the deprecated slot request protocol. The adapter > will be removed along with the slot request protocol in the future. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-21174) Optimize the performance of ResourceAllocationStrategy
[
https://issues.apache.org/jira/browse/FLINK-21174?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yangze Guo updated FLINK-21174:
---
Parent: FLINK-14187
Issue Type: Sub-task (was: Improvement)
> Optimize the performance of ResourceAllocationStrategy
> --
>
> Key: FLINK-21174
> URL: https://issues.apache.org/jira/browse/FLINK-21174
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Reporter: Yangze Guo
>Priority: Major
>
> In FLINK-20835, we introduce the {{ResourceAllocationStrategy}} for
> fine-grained resource management, which matches resource requirements against
> available and pending resources and returns the allocation result.
> We need to optimize the computation logic of it, which is so complicated atm.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-21177) Introduce the counterpart of slotmanager.number-of-slots.max in fine-grained resource management
[ https://issues.apache.org/jira/browse/FLINK-21177?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yangze Guo updated FLINK-21177: --- Parent: FLINK-14187 Issue Type: Sub-task (was: New Feature) > Introduce the counterpart of slotmanager.number-of-slots.max in fine-grained > resource management > > > Key: FLINK-21177 > URL: https://issues.apache.org/jira/browse/FLINK-21177 > Project: Flink > Issue Type: Sub-task >Reporter: Yangze Guo >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14787: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
flinkbot edited a comment on pull request #14787: URL: https://github.com/apache/flink/pull/14787#issuecomment-768849685 ## CI report: * 43d7e4e3c23451fd7cf18cfaa7ba91d8ee47bd60 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12585) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14787: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
flinkbot commented on pull request #14787: URL: https://github.com/apache/flink/pull/14787#issuecomment-768849685 ## CI report: * 43d7e4e3c23451fd7cf18cfaa7ba91d8ee47bd60 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early
flinkbot edited a comment on pull request #14786: URL: https://github.com/apache/flink/pull/14786#issuecomment-768805034 ## CI report: * 0d544bd5e5eb4b7fa39a82da9aad46758d994faf Azure: [CANCELED](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12581) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14774: [FLINK-21163][python] Fix the issue that Python dependencies specified via CLI override the dependencies specified in configuration
flinkbot edited a comment on pull request #14774: URL: https://github.com/apache/flink/pull/14774#issuecomment-768234538 ## CI report: * 54a8354c03402cedbfe56f8e8e7336f2d9072e34 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12575) * 05847a0e4866d5eccf348c99a83113bedea27682 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12584) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21179) Make sure that the open/close methods of the Python DataStream Function are not implemented when using in ReducingState and AggregatingState
[ https://issues.apache.org/jira/browse/FLINK-21179?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Wei Zhong updated FLINK-21179: -- Description: As the ReducingState and AggregatingState only support non-rich functions, we need to make sure that the open/close methods of the Python DataStream Function are not implemented when using in ReducingState and AggregatingState. (was: As the ReducingState and AggregatingState only support non-rich functions, we need to split the base class of the DataStream Functions to 'Function' and 'RichFunction'.) Summary: Make sure that the open/close methods of the Python DataStream Function are not implemented when using in ReducingState and AggregatingState (was: Split the base class of Python DataStream Function to 'Function' and 'RichFunction') > Make sure that the open/close methods of the Python DataStream Function are > not implemented when using in ReducingState and AggregatingState > > > Key: FLINK-21179 > URL: https://issues.apache.org/jira/browse/FLINK-21179 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Reporter: Wei Zhong >Priority: Major > Fix For: 1.13.0 > > > As the ReducingState and AggregatingState only support non-rich functions, we > need to make sure that the open/close methods of the Python DataStream > Function are not implemented when using in ReducingState and AggregatingState. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #14787: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
flinkbot commented on pull request #14787: URL: https://github.com/apache/flink/pull/14787#issuecomment-768845020 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 43d7e4e3c23451fd7cf18cfaa7ba91d8ee47bd60 (Thu Jan 28 07:01:11 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] leonardBang opened a new pull request #14787: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
leonardBang opened a new pull request #14787: URL: https://github.com/apache/flink/pull/14787 ## What is the purpose of the change * This pull request aims to fix Blink planner does not ingest the row time timestamp into `StreamRecord` when leaving Table/SQL ## Brief change log - Improve the `OperatorCodeGenerator` for sink operator to deal the row time properly ## Verifying this change Add `TableToDataStreamITCase` to check the conversions between `Table` and `DataStream`. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): ( no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-18634) FlinkKafkaProducerITCase.testRecoverCommittedTransaction failed with "Timeout expired after 60000milliseconds while awaiting InitProducerId"
[
https://issues.apache.org/jira/browse/FLINK-18634?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273372#comment-17273372
]
Xintong Song commented on FLINK-18634:
--
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12577=results
> FlinkKafkaProducerITCase.testRecoverCommittedTransaction failed with "Timeout
> expired after 6milliseconds while awaiting InitProducerId"
>
>
> Key: FLINK-18634
> URL: https://issues.apache.org/jira/browse/FLINK-18634
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Tests
>Affects Versions: 1.11.0, 1.12.0, 1.13.0
>Reporter: Dian Fu
>Priority: Major
> Labels: test-stability
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=4590=logs=c5f0071e-1851-543e-9a45-9ac140befc32=684b1416-4c17-504e-d5ab-97ee44e08a20
> {code}
> 2020-07-17T11:43:47.9693015Z [ERROR] Tests run: 12, Failures: 0, Errors: 1,
> Skipped: 0, Time elapsed: 269.399 s <<< FAILURE! - in
> org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerITCase
> 2020-07-17T11:43:47.9693862Z [ERROR]
> testRecoverCommittedTransaction(org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerITCase)
> Time elapsed: 60.679 s <<< ERROR!
> 2020-07-17T11:43:47.9694737Z org.apache.kafka.common.errors.TimeoutException:
> org.apache.kafka.common.errors.TimeoutException: Timeout expired after
> 6milliseconds while awaiting InitProducerId
> 2020-07-17T11:43:47.9695376Z Caused by:
> org.apache.kafka.common.errors.TimeoutException: Timeout expired after
> 6milliseconds while awaiting InitProducerId
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] pengkangjing edited a comment on pull request #14779: [FLINK-21158][Runtime/Web Frontend] wrong jvm metaspace and overhead size show in taskmanager metric page
pengkangjing edited a comment on pull request #14779: URL: https://github.com/apache/flink/pull/14779#issuecomment-768836183 @xintongsong Another error seems to be not related to this change 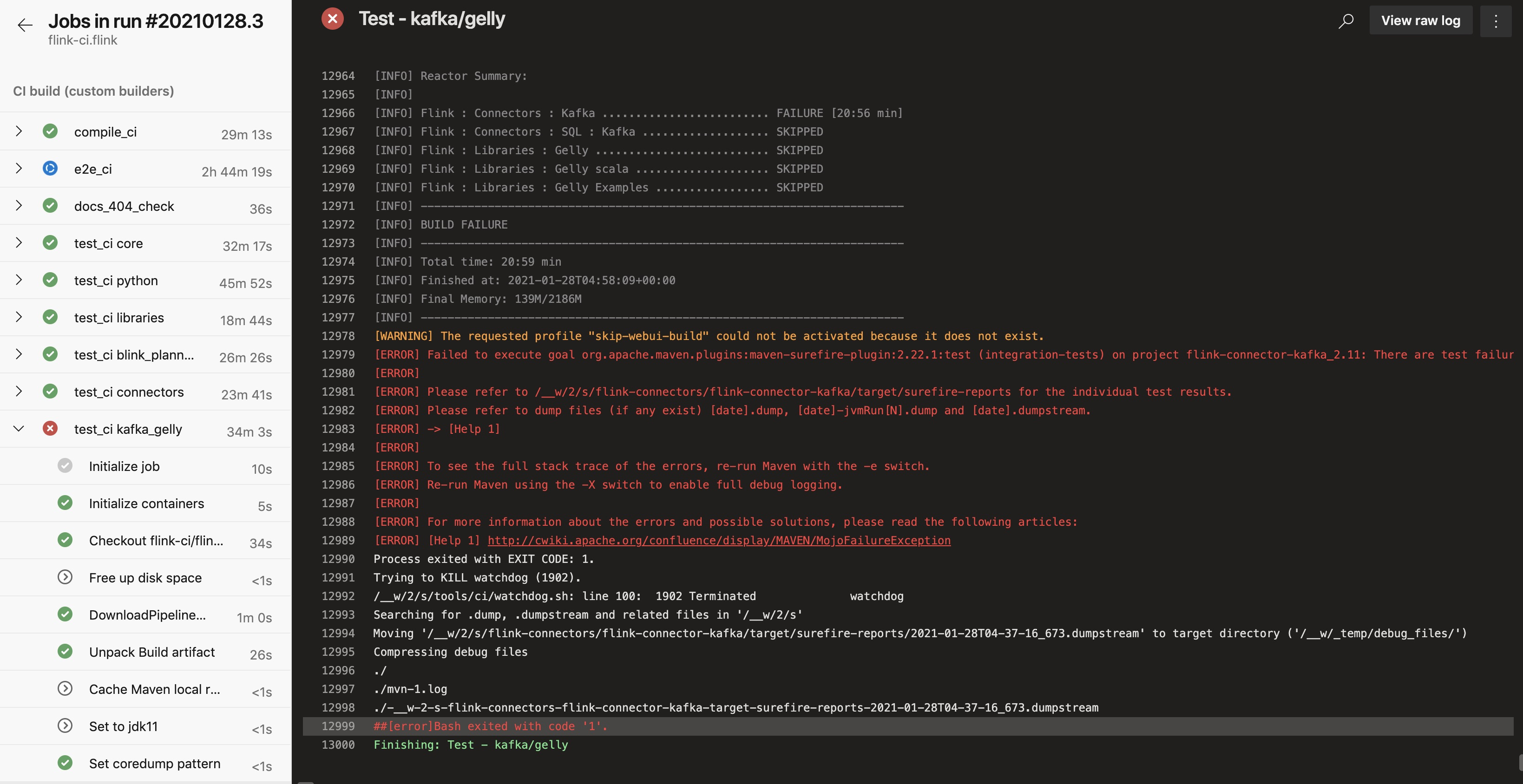 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-21138) KvStateServerHandler is not invoked with user code classloader
[ https://issues.apache.org/jira/browse/FLINK-21138?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273371#comment-17273371 ] Maciej Prochniak commented on FLINK-21138: -- I think using original.getClass().getClassLoader() won't work here - "original" is SerializableSerializer wrapper, which is probably loaded by framework classloader. I think with such custom serializers the part loaded by user classloader can hidden via quite a few wrappers/decorators and using contextClassloader is safer, it's done like that also here: [here|https://github.com/apache/flink/blob/master/flink-runtime/src/main/java/org/apache/flink/runtime/state/JavaSerializer.java#L59] I'll try to come up with PR with test > KvStateServerHandler is not invoked with user code classloader > -- > > Key: FLINK-21138 > URL: https://issues.apache.org/jira/browse/FLINK-21138 > Project: Flink > Issue Type: Bug > Components: Runtime / Queryable State >Affects Versions: 1.11.2 >Reporter: Maciej Prochniak >Priority: Major > Attachments: TestJob.java, stacktrace > > > When using e.g. custom Kryo serializers user code classloader has to be set > as context classloader during invocation of methods such as > TypeSerializer.duplicat() > KvStateServerHandler does not do this, which leads to exceptions like > ClassNotFound etc. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (FLINK-21134) Reactive mode: Introduce execution mode configuration key and check for supported ClusterEntrypoint type
[ https://issues.apache.org/jira/browse/FLINK-21134?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Robert Metzger reassigned FLINK-21134: -- Assignee: Robert Metzger > Reactive mode: Introduce execution mode configuration key and check for > supported ClusterEntrypoint type > > > Key: FLINK-21134 > URL: https://issues.apache.org/jira/browse/FLINK-21134 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Robert Metzger >Assignee: Robert Metzger >Priority: Major > Fix For: 1.13.0 > > > According to the FLIP, introduce a "execution-mode" configuration key, and > check in the ClusterEntrypoint if the chosen entry point type is supported by > the selected execution mode. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early
flinkbot edited a comment on pull request #14786: URL: https://github.com/apache/flink/pull/14786#issuecomment-768805034 ## CI report: * 0d544bd5e5eb4b7fa39a82da9aad46758d994faf Azure: [CANCELED](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12581) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14774: [FLINK-21163][python] Fix the issue that Python dependencies specified via CLI override the dependencies specified in configuration
flinkbot edited a comment on pull request #14774: URL: https://github.com/apache/flink/pull/14774#issuecomment-768234538 ## CI report: * 54a8354c03402cedbfe56f8e8e7336f2d9072e34 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12575) * 05847a0e4866d5eccf348c99a83113bedea27682 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-21179) Split the base class of Python DataStream Function to 'Function' and 'RichFunction'
Wei Zhong created FLINK-21179: - Summary: Split the base class of Python DataStream Function to 'Function' and 'RichFunction' Key: FLINK-21179 URL: https://issues.apache.org/jira/browse/FLINK-21179 Project: Flink Issue Type: Sub-task Components: API / Python Reporter: Wei Zhong Fix For: 1.13.0 As the ReducingState and AggregatingState only support non-rich functions, we need to split the base class of the DataStream Functions to 'Function' and 'RichFunction'. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] CPS794 commented on pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early state evi
CPS794 commented on pull request #14786: URL: https://github.com/apache/flink/pull/14786#issuecomment-768836986 @flinkbot run azure This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] pengkangjing commented on pull request #14779: [FLINK-21158][Runtime/Web Frontend] wrong jvm metaspace and overhead size show in taskmanager metric page
pengkangjing commented on pull request #14779: URL: https://github.com/apache/flink/pull/14779#issuecomment-768836183 @xintongsong Another error seem to be not related to this change  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-21178) Task failure will not trigger master hook's reset()
Brian Zhou created FLINK-21178: -- Summary: Task failure will not trigger master hook's reset() Key: FLINK-21178 URL: https://issues.apache.org/jira/browse/FLINK-21178 Project: Flink Issue Type: Bug Components: Runtime / Checkpointing Affects Versions: 1.11.3, 1.12.0 Reporter: Brian Zhou In Pravega Flink connector integration with Flink 1.12, we found an issue with our no-checkpoint recovery test case [1]. We expect the recovery will call the ReaderCheckpointHook::reset() function which was the behaviour before 1.12. However FLINK-20222 changes the logic, the reset() call will only be called along with a global recovery. This causes Pravega source data loss when failure happens before the first checkpoint. [1] [https://github.com/crazyzhou/flink-connectors/blob/da9f76d04404071471ebd86bf6889b307c9122ff/src/test/java/io/pravega/connectors/flink/FlinkPravegaReaderRGStateITCase.java#L78] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] PatrickRen commented on pull request #14783: [FLINK-21169][kafka] flink-connector-base dependency should be scope compile
PatrickRen commented on pull request #14783: URL: https://github.com/apache/flink/pull/14783#issuecomment-768833202 Hello @tweise and @becketqin ~ I think putting flink-connector-base JAR under lib directory of Flink distribution might be a better choice. After eventually all connectors are migrated to the new source and sink API, almost every job will reference this module as long as the job uses any type of connector, which would be a kind of duplication among all Flink job JARs. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14774: [FLINK-21163][python] Fix the issue that Python dependencies specified via CLI override the dependencies specified in configuration
flinkbot edited a comment on pull request #14774: URL: https://github.com/apache/flink/pull/14774#issuecomment-768234538 ## CI report: * 54a8354c03402cedbfe56f8e8e7336f2d9072e34 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12575) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565849050
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/FineGrainedSlotManager.java
##
@@ -0,0 +1,790 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.api.common.time.Time;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.runtime.clusterframework.types.AllocationID;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.clusterframework.types.SlotID;
+import org.apache.flink.runtime.concurrent.FutureUtils;
+import org.apache.flink.runtime.concurrent.ScheduledExecutor;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.metrics.MetricNames;
+import org.apache.flink.runtime.metrics.groups.SlotManagerMetricGroup;
+import org.apache.flink.runtime.resourcemanager.ResourceManagerId;
+import org.apache.flink.runtime.resourcemanager.WorkerResourceSpec;
+import
org.apache.flink.runtime.resourcemanager.registration.TaskExecutorConnection;
+import org.apache.flink.runtime.slots.ResourceCounter;
+import org.apache.flink.runtime.slots.ResourceRequirement;
+import org.apache.flink.runtime.slots.ResourceRequirements;
+import org.apache.flink.runtime.taskexecutor.SlotReport;
+import org.apache.flink.util.FlinkException;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nullable;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.Comparator;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.Executor;
+import java.util.concurrent.ScheduledFuture;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+
+/** Implementation of {@link SlotManager} supporting fine-grained resource
management. */
+public class FineGrainedSlotManager implements SlotManager {
+private static final Logger LOG =
LoggerFactory.getLogger(FineGrainedSlotManager.class);
+
+private final TaskManagerTracker taskManagerTracker;
+private final ResourceTracker resourceTracker;
+private final ResourceAllocationStrategy resourceAllocationStrategy;
+
+private final SlotStatusSyncer slotStatusSyncer;
+
+/** Scheduled executor for timeouts. */
+private final ScheduledExecutor scheduledExecutor;
+
+/** Timeout after which an unused TaskManager is released. */
+private final Time taskManagerTimeout;
+
+private final SlotManagerMetricGroup slotManagerMetricGroup;
+
+private final Map jobMasterTargetAddresses = new
HashMap<>();
+
+/** Defines the max limitation of the total number of task executors. */
+private final int maxTaskManagerNum;
+
+/** Defines the number of redundant task executors. */
+private final int redundantTaskManagerNum;
+
+/**
+ * Release task executor only when each produced result partition is
either consumed or failed.
+ */
+private final boolean waitResultConsumedBeforeRelease;
+
+/** The default resource spec of workers to request. */
+private final WorkerResourceSpec defaultWorkerResourceSpec;
+
+/** The resource profile of default slot. */
+private final ResourceProfile defaultSlotResourceProfile;
+
+private boolean sendNotEnoughResourceNotifications = true;
+
+/** ResourceManager's id. */
+@Nullable private ResourceManagerId resourceManagerId;
+
+/** Executor for future callbacks which have to be "synchronized". */
+@Nullable private Executor mainThreadExecutor;
+
+/** Callbacks for resource (de-)allocations. */
+@Nullable private ResourceActions resourceActions;
+
+private ScheduledFuture
[jira] [Created] (FLINK-21177) Introduce the counterpart of slotmanager.number-of-slots.max in fine-grained resource management
Yangze Guo created FLINK-21177: -- Summary: Introduce the counterpart of slotmanager.number-of-slots.max in fine-grained resource management Key: FLINK-21177 URL: https://issues.apache.org/jira/browse/FLINK-21177 Project: Flink Issue Type: Improvement Reporter: Yangze Guo -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-21177) Introduce the counterpart of slotmanager.number-of-slots.max in fine-grained resource management
[ https://issues.apache.org/jira/browse/FLINK-21177?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yangze Guo updated FLINK-21177: --- Issue Type: New Feature (was: Improvement) > Introduce the counterpart of slotmanager.number-of-slots.max in fine-grained > resource management > > > Key: FLINK-21177 > URL: https://issues.apache.org/jira/browse/FLINK-21177 > Project: Flink > Issue Type: New Feature >Reporter: Yangze Guo >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565846698
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/ResourceAllocationResult.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.slots.ResourceCounter;
+
+import java.util.ArrayList;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/** Contains the results of the {@link ResourceAllocationStrategy}. */
+public class ResourceAllocationResult {
+private final Set unfulfillableJobs;
+private final Map>
registeredResourceAllocationResult;
+private final List pendingTaskManagersToBeAllocated;
+private final Map>
+pendingResourceAllocationResult;
+
+private ResourceAllocationResult(
+Set unfulfillableJobs,
+Map>
registeredResourceAllocationResult,
+List pendingTaskManagersToBeAllocated,
+Map>
+pendingResourceAllocationResult) {
+this.unfulfillableJobs = unfulfillableJobs;
+this.registeredResourceAllocationResult =
registeredResourceAllocationResult;
+this.pendingTaskManagersToBeAllocated =
pendingTaskManagersToBeAllocated;
+this.pendingResourceAllocationResult = pendingResourceAllocationResult;
+}
+
+public List getPendingTaskManagersToBeAllocated() {
+return Collections.unmodifiableList(pendingTaskManagersToBeAllocated);
+}
+
+public Set getUnfulfillableJobs() {
+return Collections.unmodifiableSet(unfulfillableJobs);
+}
+
+public Map>
getRegisteredResourceAllocationResult() {
+return Collections.unmodifiableMap(registeredResourceAllocationResult);
Review comment:
That's a good point. I agree that the strict unmodifiability is not
necessary for this PR, given that it is more than 5000 lines now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565846698
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/ResourceAllocationResult.java
##
@@ -0,0 +1,121 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.slots.ResourceCounter;
+
+import java.util.ArrayList;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+
+/** Contains the results of the {@link ResourceAllocationStrategy}. */
+public class ResourceAllocationResult {
+private final Set unfulfillableJobs;
+private final Map>
registeredResourceAllocationResult;
+private final List pendingTaskManagersToBeAllocated;
+private final Map>
+pendingResourceAllocationResult;
+
+private ResourceAllocationResult(
+Set unfulfillableJobs,
+Map>
registeredResourceAllocationResult,
+List pendingTaskManagersToBeAllocated,
+Map>
+pendingResourceAllocationResult) {
+this.unfulfillableJobs = unfulfillableJobs;
+this.registeredResourceAllocationResult =
registeredResourceAllocationResult;
+this.pendingTaskManagersToBeAllocated =
pendingTaskManagersToBeAllocated;
+this.pendingResourceAllocationResult = pendingResourceAllocationResult;
+}
+
+public List getPendingTaskManagersToBeAllocated() {
+return Collections.unmodifiableList(pendingTaskManagersToBeAllocated);
+}
+
+public Set getUnfulfillableJobs() {
+return Collections.unmodifiableSet(unfulfillableJobs);
+}
+
+public Map>
getRegisteredResourceAllocationResult() {
+return Collections.unmodifiableMap(registeredResourceAllocationResult);
Review comment:
That's a good point. I agree that it is not necessary for this PR,
given that it is more than 5000 lines now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Assigned] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu reassigned FLINK-21172:
---
Assignee: Nicholas Jiang
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile), Table
> SQL / Ecosystem
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Assignee: Nicholas Jiang
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> {code:json}
> {
> "data": [
> {
> "id": "111",
> "name": "scooter",
> "description": "Big 2-wheel scooter",
> "weight": "5.18"
> }
> ],
> "database": "inventory",
> "es": 158937356,
> "id": 9,
> "isDdl": false,
> "mysqlType": {
> "id": "INTEGER",
> "name": "VARCHAR(255)",
> "description": "VARCHAR(512)",
> "weight": "FLOAT"
> },
> "old": [
> {
> "weight": "5.15"
> }
> ],
> "pkNames": [
> "id"
> ],
> "sql": "",
> "sqlType": {
> "id": 4,
> "name": 12,
> "description": 12,
> "weight": 7
> },
> "table": "products",
> "ts": 1589373560798,
> "type": "UPDATE"
> }
> {code}
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273356#comment-17273356
]
Jark Wu commented on FLINK-21172:
-
What metadata key do you want to propose? [~nicholasjiang]
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile), Table
> SQL / Ecosystem
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> {code:json}
> {
> "data": [
> {
> "id": "111",
> "name": "scooter",
> "description": "Big 2-wheel scooter",
> "weight": "5.18"
> }
> ],
> "database": "inventory",
> "es": 158937356,
> "id": 9,
> "isDdl": false,
> "mysqlType": {
> "id": "INTEGER",
> "name": "VARCHAR(255)",
> "description": "VARCHAR(512)",
> "weight": "FLOAT"
> },
> "old": [
> {
> "weight": "5.15"
> }
> ],
> "pkNames": [
> "id"
> ],
> "sql": "",
> "sqlType": {
> "id": 4,
> "name": 12,
> "description": 12,
> "weight": 7
> },
> "table": "products",
> "ts": 1589373560798,
> "type": "UPDATE"
> }
> {code}
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-21176) Translate updates on Confluent Avro Format page
Jark Wu created FLINK-21176: --- Summary: Translate updates on Confluent Avro Format page Key: FLINK-21176 URL: https://issues.apache.org/jira/browse/FLINK-21176 Project: Flink Issue Type: Task Components: chinese-translation, Documentation Reporter: Jark Wu We have updated examples in FLINK-20999 in commit 2596c12f7fe6b55bfc8708e1f61d3521703225b3. We should translate the updates to Chinese. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565845168
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DefaultResourceAllocationStrategy.java
##
@@ -0,0 +1,233 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.slots.ResourceCounter;
+import org.apache.flink.runtime.slots.ResourceRequirement;
+
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.stream.Collectors;
+
+import static
org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerUtils.getEffectiveResourceProfile;
+
+/**
+ * The default implementation of {@link ResourceAllocationStrategy}, which
always allocate pending
+ * task managers with the fixed profile.
+ */
+public class DefaultResourceAllocationStrategy implements
ResourceAllocationStrategy {
+private final ResourceProfile defaultSlotResourceProfile;
+private final ResourceProfile totalResourceProfile;
+
+public DefaultResourceAllocationStrategy(
+ResourceProfile defaultSlotResourceProfile, int numSlotsPerWorker)
{
+this.defaultSlotResourceProfile = defaultSlotResourceProfile;
+this.totalResourceProfile =
defaultSlotResourceProfile.multiply(numSlotsPerWorker);
+}
+
+/**
+ * Matches resource requirements against available and pending resources.
For each job, in a
+ * first round requirements are matched against registered resources. The
remaining unfulfilled
+ * requirements are matched against pending resources, allocating more
workers if no matching
+ * pending resources could be found. If the requirements for a job could
not be fulfilled then
+ * it will be recorded in {@link
ResourceAllocationResult#getUnfulfillableJobs()}.
+ *
+ * Performance notes: At it's core this method loops, for each job,
over all resources for
+ * each required slot, trying to find a matching registered/pending task
manager. One should
+ * generally go in with the assumption that this runs in
numberOfJobsRequiringResources *
+ * numberOfRequiredSlots * numberOfFreeOrPendingTaskManagers.
+ *
+ * In the absolute worst case, with J jobs, requiring R slots each with
a unique resource
+ * profile such each pair of these profiles is not matching, and T
registered/pending task
+ * managers that don't fulfill any requirement, then this method does a
total of J*R*T resource
+ * profile comparisons.
+ */
+@Override
+public ResourceAllocationResult tryFulfillRequirements(
+Map> missingResources,
+Map>
registeredResources,
+List pendingTaskManagers) {
+final ResourceAllocationResult.Builder resultBuilder =
ResourceAllocationResult.builder();
+final Map pendingResources =
+pendingTaskManagers.stream()
+.collect(
+Collectors.toMap(
+
PendingTaskManager::getPendingTaskManagerId,
+
PendingTaskManager::getTotalResourceProfile));
+for (Map.Entry>
resourceRequirements :
+missingResources.entrySet()) {
+final JobID jobId = resourceRequirements.getKey();
+
+final ResourceCounter unfulfilledJobRequirements =
+tryFulfillRequirementsForJobWithRegisteredResources(
+jobId,
+resourceRequirements.getValue(),
+registeredResources,
+resultBuilder);
+
+if (!unfulfilledJobRequirements.isEmpty()) {
+tryFulfillRequirementsForJobWithPendingResources(
+jobId, unfulfilledJobRequirements,
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565845168
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DefaultResourceAllocationStrategy.java
##
@@ -0,0 +1,233 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.slots.ResourceCounter;
+import org.apache.flink.runtime.slots.ResourceRequirement;
+
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.stream.Collectors;
+
+import static
org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerUtils.getEffectiveResourceProfile;
+
+/**
+ * The default implementation of {@link ResourceAllocationStrategy}, which
always allocate pending
+ * task managers with the fixed profile.
+ */
+public class DefaultResourceAllocationStrategy implements
ResourceAllocationStrategy {
+private final ResourceProfile defaultSlotResourceProfile;
+private final ResourceProfile totalResourceProfile;
+
+public DefaultResourceAllocationStrategy(
+ResourceProfile defaultSlotResourceProfile, int numSlotsPerWorker)
{
+this.defaultSlotResourceProfile = defaultSlotResourceProfile;
+this.totalResourceProfile =
defaultSlotResourceProfile.multiply(numSlotsPerWorker);
+}
+
+/**
+ * Matches resource requirements against available and pending resources.
For each job, in a
+ * first round requirements are matched against registered resources. The
remaining unfulfilled
+ * requirements are matched against pending resources, allocating more
workers if no matching
+ * pending resources could be found. If the requirements for a job could
not be fulfilled then
+ * it will be recorded in {@link
ResourceAllocationResult#getUnfulfillableJobs()}.
+ *
+ * Performance notes: At it's core this method loops, for each job,
over all resources for
+ * each required slot, trying to find a matching registered/pending task
manager. One should
+ * generally go in with the assumption that this runs in
numberOfJobsRequiringResources *
+ * numberOfRequiredSlots * numberOfFreeOrPendingTaskManagers.
+ *
+ * In the absolute worst case, with J jobs, requiring R slots each with
a unique resource
+ * profile such each pair of these profiles is not matching, and T
registered/pending task
+ * managers that don't fulfill any requirement, then this method does a
total of J*R*T resource
+ * profile comparisons.
+ */
+@Override
+public ResourceAllocationResult tryFulfillRequirements(
+Map> missingResources,
+Map>
registeredResources,
+List pendingTaskManagers) {
+final ResourceAllocationResult.Builder resultBuilder =
ResourceAllocationResult.builder();
+final Map pendingResources =
+pendingTaskManagers.stream()
+.collect(
+Collectors.toMap(
+
PendingTaskManager::getPendingTaskManagerId,
+
PendingTaskManager::getTotalResourceProfile));
+for (Map.Entry>
resourceRequirements :
+missingResources.entrySet()) {
+final JobID jobId = resourceRequirements.getKey();
+
+final ResourceCounter unfulfilledJobRequirements =
+tryFulfillRequirementsForJobWithRegisteredResources(
+jobId,
+resourceRequirements.getValue(),
+registeredResources,
+resultBuilder);
+
+if (!unfulfilledJobRequirements.isEmpty()) {
+tryFulfillRequirementsForJobWithPendingResources(
+jobId, unfulfilledJobRequirements,
[jira] [Closed] (FLINK-20999) Confluent Avro Format should document how to serialize kafka keys
[
https://issues.apache.org/jira/browse/FLINK-20999?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu closed FLINK-20999.
---
Resolution: Fixed
Fixed in master: 2596c12f7fe6b55bfc8708e1f61d3521703225b3
> Confluent Avro Format should document how to serialize kafka keys
> -
>
> Key: FLINK-20999
> URL: https://issues.apache.org/jira/browse/FLINK-20999
> Project: Flink
> Issue Type: Improvement
> Components: Documentation, Table SQL / Ecosystem
>Affects Versions: 1.12.0
>Reporter: Svend Vanderveken
>Assignee: Svend Vanderveken
>Priority: Minor
> Fix For: 1.13.0
>
>
> The [Confluent Avro
> Format|https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/formats/avro-confluent.html]
> only shows example of how to serialize/deserialize Kafka values. Also,
> parameter description is not always clear what is influencing the source and
> the sink behaviour, IMHO.
> This seems surprising especially in the context of a sink kafka connector
> since keys are such an important concept in that case.
> Adding examples of how to serialize/deserialize Kafka keys would add clarity.
> While it can be argued that a connector format is independent from the
> underlying storage, probably showing kafka-oriented examples in this case
> (i.e, with a concept of "key" and "value") makes senses here since this
> connector is very much thought with Kafka in mind.
>
> I'm happy to submit a PR with all if this suggested change is approved?
>
> I suggest to add this:
> h3. writing to Kafka while keeping the keys in "raw" big endian format:
> {code:java}
> CREATE TABLE OUTPUT_TABLE (
> user_id BIGINT,
> item_id BIGINT,
> category_id BIGINT,
> behavior STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'user_behavior',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'key.format' = 'raw',
> 'key.raw.endianness' = 'big-endian',
> 'key.fields' = 'user_id',
> 'value.format' = 'avro-confluent',
> 'value.avro-confluent.schema-registry.url' = 'http://localhost:8081',
> 'value.avro-confluent.schema-registry.subject' = 'user_behavior'
> )
>
> {code}
>
> h3. writing to Kafka while registering both the key and the value to the
> schema registry
> {code:java}
> CREATE TABLE OUTPUT_TABLE (
> user_id BIGINT,
> item_id BIGINT,
> category_id BIGINT,
> behavior STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'user_behavior',
> 'properties.bootstrap.servers' = 'localhost:9092',
> -- => this will register a {user_id: long} Avro type in the schema registry.
> -- Watch out: schema evolution in the context of a Kafka key is almost never
> backward nor
> -- forward compatible in practice due to hash partitioning.
> 'key.avro-confluent.schema-registry.url' = 'http://localhost:8081',
> 'key.avro-confluent.schema-registry.subject' = 'user_behavior_key',
> 'key.format' = 'avro-confluent',
> 'key.fields' = 'user_id',
> 'value.format' = 'avro-confluent',
> 'value.avro-confluent.schema-registry.url' = 'http://localhost:8081',
> 'value.avro-confluent.schema-registry.subject' = 'user_behavior_value'
> )
>
> {code}
>
> h3. reading form Kafka with both the key and value schema in the registry
> while resolving field name clashes:
> {code:java}
> CREATE TABLE INPUT_TABLE (
> -- user_id as read from the kafka key:
> from_kafka_key_user_id BIGINT,
>
> -- user_id, and other fields, as read from the kafka value-
> user_id BIGINT,
> item_id BIGINT,
> category_id BIGINT,
> behavior STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'user_behavior',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'key.format' = 'avro-confluent',
> 'key.avro-confluent.schema-registry.url' = 'http://localhost:8081',
> 'key.fields' = 'from_kafka_key_user_id',
> -- Adds a column prefix when mapping the avro fields of the kafka key to
> columns of this Table
> -- to avoid clashes with avro fields of the value (both contain 'user_id' in
> this example)
> 'key.fields-prefix' = 'from_kafka_key_',
> 'value.format' = 'avro-confluent',
> -- cannot include key here since dealt with above
> 'value.fields-include' = 'EXCEPT_KEY',
> 'value.avro-confluent.schema-registry.url' = 'http://localhost:8081'
> )
>
> {code}
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] wuchong merged pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
wuchong merged pull request #14764: URL: https://github.com/apache/flink/pull/14764 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20659) YARNSessionCapacitySchedulerITCase.perJobYarnClusterOffHeap test failed with NPE
[
https://issues.apache.org/jira/browse/FLINK-20659?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273349#comment-17273349
]
Guowei Ma commented on FLINK-20659:
---
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12572=logs=298e20ef-7951-5965-0e79-ea664ddc435e=8560c56f-9ec1-5c40-4ff5-9d3e882d
> YARNSessionCapacitySchedulerITCase.perJobYarnClusterOffHeap test failed with
> NPE
>
>
> Key: FLINK-20659
> URL: https://issues.apache.org/jira/browse/FLINK-20659
> Project: Flink
> Issue Type: Bug
> Components: Deployment / YARN
>Affects Versions: 1.11.0, 1.12.0, 1.13.0
>Reporter: Huang Xingbo
>Assignee: Matthias
>Priority: Major
> Labels: test-stability
>
> [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=10989=logs=fc5181b0-e452-5c8f-68de-1097947f6483=6b04ca5f-0b52-511d-19c9-52bf0d9fbdfa]
> {code:java}
> 2020-12-17T22:57:58.1994352Z Test
> perJobYarnClusterOffHeap(org.apache.flink.yarn.YARNSessionCapacitySchedulerITCase)
> failed with:
> 2020-12-17T22:57:58.1994893Z java.lang.NullPointerException:
> java.lang.NullPointerException
> 2020-12-17T22:57:58.1995439Z at
> org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptMetrics.getAggregateAppResourceUsage(RMAppAttemptMetrics.java:128)
> 2020-12-17T22:57:58.1996185Z at
> org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl.getApplicationResourceUsageReport(RMAppAttemptImpl.java:900)
> 2020-12-17T22:57:58.1996919Z at
> org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl.createAndGetApplicationReport(RMAppImpl.java:660)
> 2020-12-17T22:57:58.1997526Z at
> org.apache.hadoop.yarn.server.resourcemanager.ClientRMService.getApplications(ClientRMService.java:930)
> 2020-12-17T22:57:58.1998193Z at
> org.apache.hadoop.yarn.api.impl.pb.service.ApplicationClientProtocolPBServiceImpl.getApplications(ApplicationClientProtocolPBServiceImpl.java:273)
> 2020-12-17T22:57:58.1998960Z at
> org.apache.hadoop.yarn.proto.ApplicationClientProtocol$ApplicationClientProtocolService$2.callBlockingMethod(ApplicationClientProtocol.java:507)
> 2020-12-17T22:57:58.1999876Z at
> org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:447)
> 2020-12-17T22:57:58.2000346Z at
> org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
> 2020-12-17T22:57:58.2000744Z at
> org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:847)
> 2020-12-17T22:57:58.2001532Z at
> org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:790)
> 2020-12-17T22:57:58.2001915Z at
> java.security.AccessController.doPrivileged(Native Method)
> 2020-12-17T22:57:58.2002286Z at
> javax.security.auth.Subject.doAs(Subject.java:422)
> 2020-12-17T22:57:58.2002734Z at
> org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836)
> 2020-12-17T22:57:58.2003185Z at
> org.apache.hadoop.ipc.Server$Handler.run(Server.java:2486)
> 2020-12-17T22:57:58.2003447Z
> 2020-12-17T22:57:58.2003708Z at
> sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
> 2020-12-17T22:57:58.2004233Z at
> sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
> 2020-12-17T22:57:58.2004810Z at
> sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
> 2020-12-17T22:57:58.2005468Z at
> java.lang.reflect.Constructor.newInstance(Constructor.java:423)
> 2020-12-17T22:57:58.2005907Z at
> org.apache.hadoop.yarn.ipc.RPCUtil.instantiateException(RPCUtil.java:53)
> 2020-12-17T22:57:58.2006387Z at
> org.apache.hadoop.yarn.ipc.RPCUtil.instantiateRuntimeException(RPCUtil.java:85)
> 2020-12-17T22:57:58.2006920Z at
> org.apache.hadoop.yarn.ipc.RPCUtil.unwrapAndThrowException(RPCUtil.java:122)
> 2020-12-17T22:57:58.2007515Z at
> org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplications(ApplicationClientProtocolPBClientImpl.java:291)
> 2020-12-17T22:57:58.2008082Z at
> sun.reflect.GeneratedMethodAccessor39.invoke(Unknown Source)
> 2020-12-17T22:57:58.2008518Z at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> 2020-12-17T22:57:58.2008964Z at
> java.lang.reflect.Method.invoke(Method.java:498)
> 2020-12-17T22:57:58.2009430Z at
> org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:409)
> 2020-12-17T22:57:58.2010002Z at
> org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163)
> 2020-12-17T22:57:58.2010554Z at
> org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155)
> 2020-12-17T22:57:58.2011301Z at
>
[jira] [Created] (FLINK-21175) OneInputStreamTaskTest.testWatermarkMetrics:914 expected:<1> but was:<-9223372036854775808>
Guowei Ma created FLINK-21175: - Summary: OneInputStreamTaskTest.testWatermarkMetrics:914 expected:<1> but was:<-9223372036854775808> Key: FLINK-21175 URL: https://issues.apache.org/jira/browse/FLINK-21175 Project: Flink Issue Type: Bug Components: API / Core Affects Versions: 1.13.0 Reporter: Guowei Ma [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12572=logs=d89de3df-4600-5585-dadc-9bbc9a5e661c=66b5c59a-0094-561d-0e44-b149dfdd586d] [ERROR] OneInputStreamTaskTest.testWatermarkMetrics:914 expected:<1> but was:<-9223372036854775808> -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-21174) Optimize the performance of ResourceAllocationStrategy
Yangze Guo created FLINK-21174:
--
Summary: Optimize the performance of ResourceAllocationStrategy
Key: FLINK-21174
URL: https://issues.apache.org/jira/browse/FLINK-21174
Project: Flink
Issue Type: Improvement
Components: Runtime / Coordination
Reporter: Yangze Guo
In FLINK-20835, we introduce the {{ResourceAllocationStrategy}} for
fine-grained resource management, which matches resource requirements against
available and pending resources and returns the allocation result.
We need to optimize the computation logic of it, which is so complicated atm.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565842059
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DefaultResourceAllocationStrategy.java
##
@@ -0,0 +1,233 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.slots.ResourceCounter;
+import org.apache.flink.runtime.slots.ResourceRequirement;
+
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.stream.Collectors;
+
+import static
org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerUtils.getEffectiveResourceProfile;
+
+/**
+ * The default implementation of {@link ResourceAllocationStrategy}, which
always allocate pending
+ * task managers with the fixed profile.
+ */
+public class DefaultResourceAllocationStrategy implements
ResourceAllocationStrategy {
+private final ResourceProfile defaultSlotResourceProfile;
+private final ResourceProfile totalResourceProfile;
+
+public DefaultResourceAllocationStrategy(
+ResourceProfile defaultSlotResourceProfile, int numSlotsPerWorker)
{
+this.defaultSlotResourceProfile = defaultSlotResourceProfile;
+this.totalResourceProfile =
defaultSlotResourceProfile.multiply(numSlotsPerWorker);
+}
+
+/**
+ * Matches resource requirements against available and pending resources.
For each job, in a
+ * first round requirements are matched against registered resources. The
remaining unfulfilled
+ * requirements are matched against pending resources, allocating more
workers if no matching
+ * pending resources could be found. If the requirements for a job could
not be fulfilled then
+ * it will be recorded in {@link
ResourceAllocationResult#getUnfulfillableJobs()}.
+ *
+ * Performance notes: At it's core this method loops, for each job,
over all resources for
+ * each required slot, trying to find a matching registered/pending task
manager. One should
+ * generally go in with the assumption that this runs in
numberOfJobsRequiringResources *
+ * numberOfRequiredSlots * numberOfFreeOrPendingTaskManagers.
+ *
+ * In the absolute worst case, with J jobs, requiring R slots each with
a unique resource
+ * profile such each pair of these profiles is not matching, and T
registered/pending task
+ * managers that don't fulfill any requirement, then this method does a
total of J*R*T resource
+ * profile comparisons.
+ */
Review comment:
I open https://issues.apache.org/jira/browse/FLINK-21174 for it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273347#comment-17273347
]
Nicholas Jiang commented on FLINK-21172:
I agree with the point of [~jiabao.sun][~jark]. [~jark], could you please
assign this ticket to me?
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile), Table
> SQL / Ecosystem
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> {code:json}
> {
> "data": [
> {
> "id": "111",
> "name": "scooter",
> "description": "Big 2-wheel scooter",
> "weight": "5.18"
> }
> ],
> "database": "inventory",
> "es": 158937356,
> "id": 9,
> "isDdl": false,
> "mysqlType": {
> "id": "INTEGER",
> "name": "VARCHAR(255)",
> "description": "VARCHAR(512)",
> "weight": "FLOAT"
> },
> "old": [
> {
> "weight": "5.15"
> }
> ],
> "pkNames": [
> "id"
> ],
> "sql": "",
> "sqlType": {
> "id": 4,
> "name": 12,
> "description": 12,
> "weight": 7
> },
> "table": "products",
> "ts": 1589373560798,
> "type": "UPDATE"
> }
> {code}
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-18634) FlinkKafkaProducerITCase.testRecoverCommittedTransaction failed with "Timeout expired after 60000milliseconds while awaiting InitProducerId"
[
https://issues.apache.org/jira/browse/FLINK-18634?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273344#comment-17273344
]
Guowei Ma commented on FLINK-18634:
---
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12571=logs=72d4811f-9f0d-5fd0-014a-0bc26b72b642=c1d93a6a-ba91-515d-3196-2ee8019fbda7
> FlinkKafkaProducerITCase.testRecoverCommittedTransaction failed with "Timeout
> expired after 6milliseconds while awaiting InitProducerId"
>
>
> Key: FLINK-18634
> URL: https://issues.apache.org/jira/browse/FLINK-18634
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Tests
>Affects Versions: 1.11.0, 1.12.0, 1.13.0
>Reporter: Dian Fu
>Priority: Major
> Labels: test-stability
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=4590=logs=c5f0071e-1851-543e-9a45-9ac140befc32=684b1416-4c17-504e-d5ab-97ee44e08a20
> {code}
> 2020-07-17T11:43:47.9693015Z [ERROR] Tests run: 12, Failures: 0, Errors: 1,
> Skipped: 0, Time elapsed: 269.399 s <<< FAILURE! - in
> org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerITCase
> 2020-07-17T11:43:47.9693862Z [ERROR]
> testRecoverCommittedTransaction(org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerITCase)
> Time elapsed: 60.679 s <<< ERROR!
> 2020-07-17T11:43:47.9694737Z org.apache.kafka.common.errors.TimeoutException:
> org.apache.kafka.common.errors.TimeoutException: Timeout expired after
> 6milliseconds while awaiting InitProducerId
> 2020-07-17T11:43:47.9695376Z Caused by:
> org.apache.kafka.common.errors.TimeoutException: Timeout expired after
> 6milliseconds while awaiting InitProducerId
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-20329) Elasticsearch7DynamicSinkITCase hangs
[
https://issues.apache.org/jira/browse/FLINK-20329?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273341#comment-17273341
]
Guowei Ma commented on FLINK-20329:
---
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12571=logs=961f8f81-6b52-53df-09f6-7291a2e4af6a=60581941-0138-53c0-39fe-86d62be5f407
> Elasticsearch7DynamicSinkITCase hangs
> -
>
> Key: FLINK-20329
> URL: https://issues.apache.org/jira/browse/FLINK-20329
> Project: Flink
> Issue Type: Bug
> Components: Connectors / ElasticSearch
>Affects Versions: 1.12.0
>Reporter: Dian Fu
>Priority: Critical
> Labels: test-stability
> Fix For: 1.13.0
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=10052=logs=d44f43ce-542c-597d-bf94-b0718c71e5e8=03dca39c-73e8-5aaf-601d-328ae5c35f20
> {code}
> 2020-11-24T16:04:05.9260517Z [INFO] Running
> org.apache.flink.streaming.connectors.elasticsearch.table.Elasticsearch7DynamicSinkITCase
> 2020-11-24T16:19:25.5481231Z
> ==
> 2020-11-24T16:19:25.5483549Z Process produced no output for 900 seconds.
> 2020-11-24T16:19:25.5484064Z
> ==
> 2020-11-24T16:19:25.5484498Z
> ==
> 2020-11-24T16:19:25.5484882Z The following Java processes are running (JPS)
> 2020-11-24T16:19:25.5485475Z
> ==
> 2020-11-24T16:19:25.5694497Z Picked up JAVA_TOOL_OPTIONS:
> -XX:+HeapDumpOnOutOfMemoryError
> 2020-11-24T16:19:25.7263048Z 16192 surefirebooter5057948964630155904.jar
> 2020-11-24T16:19:25.7263515Z 18566 Jps
> 2020-11-24T16:19:25.7263709Z 959 Launcher
> 2020-11-24T16:19:25.7411148Z
> ==
> 2020-11-24T16:19:25.7427013Z Printing stack trace of Java process 16192
> 2020-11-24T16:19:25.7427369Z
> ==
> 2020-11-24T16:19:25.7484365Z Picked up JAVA_TOOL_OPTIONS:
> -XX:+HeapDumpOnOutOfMemoryError
> 2020-11-24T16:19:26.0848776Z 2020-11-24 16:19:26
> 2020-11-24T16:19:26.0849578Z Full thread dump OpenJDK 64-Bit Server VM
> (25.275-b01 mixed mode):
> 2020-11-24T16:19:26.0849831Z
> 2020-11-24T16:19:26.0850185Z "Attach Listener" #32 daemon prio=9 os_prio=0
> tid=0x7fc148001000 nid=0x48e7 waiting on condition [0x]
> 2020-11-24T16:19:26.0850595Zjava.lang.Thread.State: RUNNABLE
> 2020-11-24T16:19:26.0850814Z
> 2020-11-24T16:19:26.0851375Z "testcontainers-ryuk" #31 daemon prio=5
> os_prio=0 tid=0x7fc251232000 nid=0x3fb0 in Object.wait()
> [0x7fc1012c4000]
> 2020-11-24T16:19:26.0854688Zjava.lang.Thread.State: TIMED_WAITING (on
> object monitor)
> 2020-11-24T16:19:26.0855379Z at java.lang.Object.wait(Native Method)
> 2020-11-24T16:19:26.0855844Z at
> org.testcontainers.utility.ResourceReaper.lambda$null$1(ResourceReaper.java:142)
> 2020-11-24T16:19:26.0857272Z - locked <0x8e2bd2d0> (a
> java.util.ArrayList)
> 2020-11-24T16:19:26.0857977Z at
> org.testcontainers.utility.ResourceReaper$$Lambda$93/1981729428.run(Unknown
> Source)
> 2020-11-24T16:19:26.0858471Z at
> org.rnorth.ducttape.ratelimits.RateLimiter.doWhenReady(RateLimiter.java:27)
> 2020-11-24T16:19:26.0858961Z at
> org.testcontainers.utility.ResourceReaper.lambda$start$2(ResourceReaper.java:133)
> 2020-11-24T16:19:26.0859422Z at
> org.testcontainers.utility.ResourceReaper$$Lambda$92/40191541.run(Unknown
> Source)
> 2020-11-24T16:19:26.0859788Z at java.lang.Thread.run(Thread.java:748)
> 2020-11-24T16:19:26.0860030Z
> 2020-11-24T16:19:26.0860371Z "process reaper" #24 daemon prio=10 os_prio=0
> tid=0x7fc0f803b800 nid=0x3f92 waiting on condition [0x7fc10296e000]
> 2020-11-24T16:19:26.0860913Zjava.lang.Thread.State: TIMED_WAITING
> (parking)
> 2020-11-24T16:19:26.0861387Z at sun.misc.Unsafe.park(Native Method)
> 2020-11-24T16:19:26.0862495Z - parking to wait for <0x8814bf30> (a
> java.util.concurrent.SynchronousQueue$TransferStack)
> 2020-11-24T16:19:26.0863253Z at
> java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
> 2020-11-24T16:19:26.0863760Z at
> java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:460)
> 2020-11-24T16:19:26.0864274Z at
> java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:362)
> 2020-11-24T16:19:26.0864762Z at
> java.util.concurrent.SynchronousQueue.poll(SynchronousQueue.java:941)
> 2020-11-24T16:19:26.0865299Z at
>
[jira] [Created] (FLINK-21173) "Streaming SQL end-to-end test (Old planner)" e2e test failed
Guowei Ma created FLINK-21173: - Summary: "Streaming SQL end-to-end test (Old planner)" e2e test failed Key: FLINK-21173 URL: https://issues.apache.org/jira/browse/FLINK-21173 Project: Flink Issue Type: Bug Components: Table SQL / Planner Affects Versions: 1.12.0 Reporter: Guowei Ma Jan 28 00:03:37 FAIL StreamSQL: Output hash mismatch. Got e7a02d99d5ac2a4ef4792b3b7e6f54bf, expected b29f14ed221a936211202ff65b51ee26. https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12573=logs=c88eea3b-64a0-564d-0031-9fdcd7b8abee=ff888d9b-cd34-53cc-d90f-3e446d355529 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-21173) "Streaming SQL end-to-end test (Old planner)" e2e test failed
[ https://issues.apache.org/jira/browse/FLINK-21173?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guowei Ma updated FLINK-21173: -- Labels: test-stability (was: ) > "Streaming SQL end-to-end test (Old planner)" e2e test failed > - > > Key: FLINK-21173 > URL: https://issues.apache.org/jira/browse/FLINK-21173 > Project: Flink > Issue Type: Bug > Components: Table SQL / Planner >Affects Versions: 1.12.0 >Reporter: Guowei Ma >Priority: Major > Labels: test-stability > > Jan 28 00:03:37 FAIL StreamSQL: Output hash mismatch. Got > e7a02d99d5ac2a4ef4792b3b7e6f54bf, expected b29f14ed221a936211202ff65b51ee26. > > https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12573=logs=c88eea3b-64a0-564d-0031-9fdcd7b8abee=ff888d9b-cd34-53cc-d90f-3e446d355529 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
flinkbot edited a comment on pull request #14764: URL: https://github.com/apache/flink/pull/14764#issuecomment-767576041 ## CI report: * 038ad0d6915e874ca32cce0da55184a436737a53 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12582) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-21104) UnalignedCheckpointITCase.execute failed with "IllegalStateException"
[
https://issues.apache.org/jira/browse/FLINK-21104?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273339#comment-17273339
]
Guowei Ma commented on FLINK-21104:
---
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12573=logs=2c3cbe13-dee0-5837-cf47-3053da9a8a78=2c7d57b9-7341-5a87-c9af-2cf7cc1a37dc
> UnalignedCheckpointITCase.execute failed with "IllegalStateException"
> -
>
> Key: FLINK-21104
> URL: https://issues.apache.org/jira/browse/FLINK-21104
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing
>Affects Versions: 1.13.0, 1.12.2
>Reporter: Huang Xingbo
>Assignee: Arvid Heise
>Priority: Blocker
> Labels: pull-request-available, test-stability
> Fix For: 1.13.0, 1.12.2
>
>
> [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=12383=logs=5c8e7682-d68f-54d1-16a2-a09310218a49=f508e270-48d6-5f1e-3138-42a17e0714f0]
> {code:java}
> 2021-01-22T15:17:34.6711152Z [ERROR] execute[Parallel union, p =
> 10](org.apache.flink.test.checkpointing.UnalignedCheckpointITCase) Time
> elapsed: 3.903 s <<< ERROR!
> 2021-01-22T15:17:34.6711736Z
> org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
> 2021-01-22T15:17:34.6712204Z at
> org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:144)
> 2021-01-22T15:17:34.6712779Z at
> org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:117)
> 2021-01-22T15:17:34.6713344Z at
> java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
> 2021-01-22T15:17:34.6713816Z at
> java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
> 2021-01-22T15:17:34.6714454Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2021-01-22T15:17:34.6714952Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2021-01-22T15:17:34.6715472Z at
> org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$0(AkkaInvocationHandler.java:238)
> 2021-01-22T15:17:34.6716026Z at
> java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
> 2021-01-22T15:17:34.6716631Z at
> java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
> 2021-01-22T15:17:34.6717128Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2021-01-22T15:17:34.6717616Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2021-01-22T15:17:34.6718105Z at
> org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:1046)
> 2021-01-22T15:17:34.6718596Z at
> akka.dispatch.OnComplete.internal(Future.scala:264)
> 2021-01-22T15:17:34.6718973Z at
> akka.dispatch.OnComplete.internal(Future.scala:261)
> 2021-01-22T15:17:34.6719364Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
> 2021-01-22T15:17:34.6719748Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
> 2021-01-22T15:17:34.6720155Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2021-01-22T15:17:34.6720641Z at
> org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:73)
> 2021-01-22T15:17:34.6721236Z at
> scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44)
> 2021-01-22T15:17:34.6721706Z at
> scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252)
> 2021-01-22T15:17:34.6722205Z at
> akka.pattern.PromiseActorRef.$bang(AskSupport.scala:572)
> 2021-01-22T15:17:34.6722663Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
> 2021-01-22T15:17:34.6723214Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
> 2021-01-22T15:17:34.6723723Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:436)
> 2021-01-22T15:17:34.6724146Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:435)
> 2021-01-22T15:17:34.6724726Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2021-01-22T15:17:34.6725198Z at
> akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
> 2021-01-22T15:17:34.6725861Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply$mcV$sp(BatchingExecutor.scala:91)
> 2021-01-22T15:17:34.6726525Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
> 2021-01-22T15:17:34.6727278Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
>
[GitHub] [flink] flinkbot edited a comment on pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early
flinkbot edited a comment on pull request #14786: URL: https://github.com/apache/flink/pull/14786#issuecomment-768805034 ## CI report: * 0d544bd5e5eb4b7fa39a82da9aad46758d994faf Azure: [CANCELED](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12581) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early state e
flinkbot commented on pull request #14786: URL: https://github.com/apache/flink/pull/14786#issuecomment-768805034 ## CI report: * 0d544bd5e5eb4b7fa39a82da9aad46758d994faf UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14779: [FLINK-21158][Runtime/Web Frontend] wrong jvm metaspace and overhead size show in taskmanager metric page
flinkbot edited a comment on pull request #14779: URL: https://github.com/apache/flink/pull/14779#issuecomment-768302027 ## CI report: * 9863d9e8363e2c6bf2e32394f04579ace32a88fc Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12577) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early state e
flinkbot commented on pull request #14786: URL: https://github.com/apache/flink/pull/14786#issuecomment-768802041 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 0d544bd5e5eb4b7fa39a82da9aad46758d994faf (Thu Jan 28 05:05:12 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-19592) MiniBatchGroupAggFunction should emit messages to prevent too early state eviction of downstream operators
[
https://issues.apache.org/jira/browse/FLINK-19592?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-19592:
---
Labels: pull-request-available (was: )
> MiniBatchGroupAggFunction should emit messages to prevent too early state
> eviction of downstream operators
> --
>
> Key: FLINK-19592
> URL: https://issues.apache.org/jira/browse/FLINK-19592
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.12.0
>Reporter: Smile
>Assignee: Smile
>Priority: Minor
> Labels: pull-request-available
>
> Currently,
> [GroupAggFunction|https://github.com/apache/flink/blob/master/flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/operators/aggregate/GroupAggFunction.java#L183]
> will emit a retract and a new insert message when a new message with the
> same key arrives. According to
> [Flink-8566|https://issues.apache.org/jira/browse/FLINK-8566], it's a feature
> to prevent too early state eviction of downstream operators.
> However,
> [MiniBatchGroupAggFunction|https://github.com/apache/flink/blob/master/flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/operators/aggregate/MiniBatchGroupAggFunction.java#L206]
> doesn't. Before
> [Flink-8566|https://issues.apache.org/jira/browse/FLINK-8566] being resolved,
> it should also emit these messages.
> *GroupAggFunction.java:*
> {code:java}
> if (!stateCleaningEnabled && equaliser.equals(prevAggValue, newAggValue)) {
> // newRow is the same as before and state cleaning is not enabled.
> // We do not emit retraction and acc message.
> // If state cleaning is enabled, we have to emit messages to prevent
> too early
> // state eviction of downstream operators.
> return;
> } else {
> // retract previous result
> if (generateUpdateBefore) {
> // prepare UPDATE_BEFORE message for previous row
> resultRow.replace(currentKey,
> prevAggValue).setRowKind(RowKind.UPDATE_BEFORE);
> out.collect(resultRow);
> }
> // prepare UPDATE_AFTER message for new row
> resultRow.replace(currentKey,
> newAggValue).setRowKind(RowKind.UPDATE_AFTER);
> }
> {code}
> *MiniBatchGroupAggFunction.java:*
>
> {code:java}
> if (!equaliser.equals(prevAggValue, newAggValue)) {
> // new row is not same with prev row
> if (generateUpdateBefore) {
> // prepare UPDATE_BEFORE message for previous row
> resultRow.replace(currentKey,
> prevAggValue).setRowKind(RowKind.UPDATE_BEFORE);
> out.collect(resultRow);
> }
> // prepare UPDATE_AFTER message for new row
> resultRow.replace(currentKey,
> newAggValue).setRowKind(RowKind.UPDATE_AFTER);
> out.collect(resultRow);
> }
> // new row is same with prev row, no need to output
> {code}
>
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] CPS794 opened a new pull request #14786: [FLINK-19592] [Table SQL / Runtime] MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages to prevent too early state evi
CPS794 opened a new pull request #14786: URL: https://github.com/apache/flink/pull/14786 … of downstream operators when state cleaning is enabled ## What is the purpose of the change This pull request makes MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction emit messages when state cleaning is enabled. That way we avoid too early state eviction of the downstream operators. ## Brief change log - GroupAggFunction is currently doing so and we implement the same way for MiniBatchGroupAggFunction and MiniBatchGlobalGroupAggFunction. - If state cleaning is enabled, emit messages even if it's the same with a previous row to prevent too early state eviction of downstream operators. ## Verifying this change This change is already covered by existing tests, such as org.apache.flink.table.planner.runtime.harness.GroupAggregateHarnessTest. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduces a new feature? no This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14785: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
flinkbot edited a comment on pull request #14785: URL: https://github.com/apache/flink/pull/14785#issuecomment-768793784 ## CI report: * e101240afc9b86f44866e6ea126e3686182677e9 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12580) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
flinkbot edited a comment on pull request #14764: URL: https://github.com/apache/flink/pull/14764#issuecomment-767576041 ## CI report: * 72b7c0d03d710be89bc6e7bdcff7c6a27980323c Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12579) * 038ad0d6915e874ca32cce0da55184a436737a53 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14785: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
flinkbot commented on pull request #14785: URL: https://github.com/apache/flink/pull/14785#issuecomment-768793784 ## CI report: * e101240afc9b86f44866e6ea126e3686182677e9 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14784: [FLINK-21160][connector/kafka] Fix bug of referencing uninitialized deserializer when using KafkaRecordDeserializer#valueOnly
flinkbot edited a comment on pull request #14784: URL: https://github.com/apache/flink/pull/14784#issuecomment-768786978 ## CI report: * c327e27872f782274cab4e10692ef1d913f85c5d Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12578) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
flinkbot edited a comment on pull request #14764: URL: https://github.com/apache/flink/pull/14764#issuecomment-767576041 ## CI report: * e5106da1732cba93446aa63fc61cdf7e74b29271 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12519) * 72b7c0d03d710be89bc6e7bdcff7c6a27980323c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-21172:
Component/s: Table SQL / Ecosystem
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile), Table
> SQL / Ecosystem
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> {code:json}
> {
> "data": [
> {
> "id": "111",
> "name": "scooter",
> "description": "Big 2-wheel scooter",
> "weight": "5.18"
> }
> ],
> "database": "inventory",
> "es": 158937356,
> "id": 9,
> "isDdl": false,
> "mysqlType": {
> "id": "INTEGER",
> "name": "VARCHAR(255)",
> "description": "VARCHAR(512)",
> "weight": "FLOAT"
> },
> "old": [
> {
> "weight": "5.15"
> }
> ],
> "pkNames": [
> "id"
> ],
> "sql": "",
> "sqlType": {
> "id": 4,
> "name": 12,
> "description": 12,
> "weight": 7
> },
> "table": "products",
> "ts": 1589373560798,
> "type": "UPDATE"
> }
> {code}
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273299#comment-17273299
]
Jark Wu commented on FLINK-21172:
-
We can support this by a new metadata column. What do you think
[~nicholasjiang]?
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> {code:json}
> {
> "data": [
> {
> "id": "111",
> "name": "scooter",
> "description": "Big 2-wheel scooter",
> "weight": "5.18"
> }
> ],
> "database": "inventory",
> "es": 158937356,
> "id": 9,
> "isDdl": false,
> "mysqlType": {
> "id": "INTEGER",
> "name": "VARCHAR(255)",
> "description": "VARCHAR(512)",
> "weight": "FLOAT"
> },
> "old": [
> {
> "weight": "5.15"
> }
> ],
> "pkNames": [
> "id"
> ],
> "sql": "",
> "sqlType": {
> "id": 4,
> "name": 12,
> "description": 12,
> "weight": 7
> },
> "table": "products",
> "ts": 1589373560798,
> "type": "UPDATE"
> }
> {code}
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] wuchong commented on a change in pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
wuchong commented on a change in pull request #14764:
URL: https://github.com/apache/flink/pull/14764#discussion_r565813102
##
File path: docs/dev/table/connectors/formats/avro-confluent.zh.md
##
@@ -52,20 +52,126 @@ Avro Schema Registry 格式只能与[Apache Kafka SQL连接器]({% link
dev/tabl
+
+||TODO: TRANSLATION:||
Review comment:
We dont' need the tag. It's fine just place English content in Chinese
docs.
##
File path: docs/dev/table/connectors/formats/avro-confluent.zh.md
##
@@ -35,7 +35,7 @@ Avro Schema Registry (``avro-confluent``) 格式能让你读取被
``io.confluen
当以这种格式写入(序列化)记录时,Avro schema 是从 table schema 中推断出来的,并会用来检索要与数据一起编码的 schema
id。我们会在配置的 Confluent Schema Registry 中配置的
[subject](https://docs.confluent.io/current/schema-registry/index.html#schemas-subjects-and-topics)
下,检索 schema id。subject 通过 `avro-confluent.schema-registry.subject` 参数来制定。
-Avro Schema Registry 格式只能与[Apache Kafka SQL连接器]({% link
dev/table/connectors/kafka.zh.md %})结合使用。
+Avro Schema Registry 格式只能与[Apache Kafka SQL连接器]({% link
dev/table/connectors/kafka.zh.md %})结合使用。||TODO: TRANSLATION:|| or the [Upsert
Kafka SQL Connector]({% link dev/table/connectors/upsert-kafka.zh.md %}).
Review comment:
We can just repalce the whole sentence use the new English sentence.
```
The Avro Schema Registry format can only be used in conjunction with the
[Apache Kafka SQL connector]({% link dev/table/connectors/kafka.zh.md %}) or
the [Upsert Kafka SQL Connector]({% link
dev/table/connectors/upsert-kafka.zh.md %}).
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-21045) Support 'load module' and 'unload module' SQL syntax
[ https://issues.apache.org/jira/browse/FLINK-21045?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273295#comment-17273295 ] Jark Wu commented on FLINK-21045: - It seems that we still have many different thoughts on this topic. What do you think about restart a discussion on mailing list for the SQL syntax of modules to collect more opinions? Do you want to start this discussion [~qingyue]? > Support 'load module' and 'unload module' SQL syntax > > > Key: FLINK-21045 > URL: https://issues.apache.org/jira/browse/FLINK-21045 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.13.0 >Reporter: Nicholas Jiang >Assignee: Jane Chan >Priority: Major > Fix For: 1.13.0 > > > At present, Flink SQL doesn't support the 'load module' and 'unload module' > SQL syntax. It's necessary for uses in the situation that users load and > unload user-defined module through table api or sql client. > SQL syntax has been proposed in FLIP-68: > https://cwiki.apache.org/confluence/display/FLINK/FLIP-68%3A+Extend+Core+Table+System+with+Pluggable+Modules -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] sv3ndk commented on pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
sv3ndk commented on pull request #14764: URL: https://github.com/apache/flink/pull/14764#issuecomment-768791368 Thanks for the feed-back @wuchong . I copied the code examples to the Chinese version of the documentation, although they contain some English sentences at the moment, which I'm not capable of translating. Please let me know if I should open a ticket for that part or if we can handle it as part of this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
jiabao sun updated FLINK-21172:
---
Description:
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but was ignored during deserialization.
{code:json}
{
"data": [
{
"id": "111",
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": "5.18"
}
],
"database": "inventory",
"es": 158937356,
"id": 9,
"isDdl": false,
"mysqlType": {
"id": "INTEGER",
"name": "VARCHAR(255)",
"description": "VARCHAR(512)",
"weight": "FLOAT"
},
"old": [
{
"weight": "5.15"
}
],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": 4,
"name": 12,
"description": 12,
"weight": 7
},
"table": "products",
"ts": 1589373560798,
"type": "UPDATE"
}
{code}
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
was:
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but was ignored during deserialization.
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> {code:json}
> {
> "data": [
> {
> "id": "111",
> "name": "scooter",
> "description": "Big 2-wheel scooter",
> "weight": "5.18"
> }
> ],
> "database": "inventory",
> "es": 158937356,
> "id": 9,
> "isDdl": false,
> "mysqlType": {
> "id": "INTEGER",
> "name": "VARCHAR(255)",
> "description": "VARCHAR(512)",
> "weight": "FLOAT"
> },
> "old": [
> {
> "weight": "5.15"
> }
> ],
> "pkNames": [
> "id"
> ],
> "sql": "",
> "sqlType": {
> "id": 4,
> "name": 12,
> "description": 12,
> "weight": 7
> },
> "table": "products",
> "ts": 1589373560798,
> "type": "UPDATE"
> }
> {code}
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian
[jira] [Updated] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
jiabao sun updated FLINK-21172:
---
Description:
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but was ignored during deserialization.
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
was:
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but is ignored during deserialization.
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but was ignored during deserialization.
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-21172) canal-json format include es field
[
https://issues.apache.org/jira/browse/FLINK-21172?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
jiabao sun updated FLINK-21172:
---
Description:
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but is ignored during deserialization.
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
was:
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but is ignored during deserialization.
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
[Canal Flat Message|https://github.com/alibaba/canal/issues/2170]
> canal-json format include es field
> --
>
> Key: FLINK-21172
> URL: https://issues.apache.org/jira/browse/FLINK-21172
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.12.0, 1.12.1
>Reporter: jiabao sun
>Priority: Minor
>
> Canal flat message json format has an 'es' field extracted from mysql binlog
> which means the row data real change time in mysql. It expressed the event
> time naturally but is ignored during deserialization.
> org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
> {code:java}
> private static RowType createJsonRowType(DataType databaseSchema) {
> // Canal JSON contains other information, e.g. "ts", "sql", but we
> don't need them
> return (RowType)
> DataTypes.ROW(
> DataTypes.FIELD("data",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("old",
> DataTypes.ARRAY(databaseSchema)),
> DataTypes.FIELD("type", DataTypes.STRING()),
> DataTypes.FIELD("database",
> DataTypes.STRING()),
> DataTypes.FIELD("table", DataTypes.STRING()))
> .getLogicalType();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-21045) Support 'load module' and 'unload module' SQL syntax
[ https://issues.apache.org/jira/browse/FLINK-21045?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273292#comment-17273292 ] Jark Wu commented on FLINK-21045: - Good points [~lirui], I also found it's really hard to use "load" + "unload" to reorder modules, especially they may don't know the original properties. Maybe we should downplay the reorder ability of load/unload or create/drop, and use "use modules" instead. > Support 'load module' and 'unload module' SQL syntax > > > Key: FLINK-21045 > URL: https://issues.apache.org/jira/browse/FLINK-21045 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.13.0 >Reporter: Nicholas Jiang >Assignee: Jane Chan >Priority: Major > Fix For: 1.13.0 > > > At present, Flink SQL doesn't support the 'load module' and 'unload module' > SQL syntax. It's necessary for uses in the situation that users load and > unload user-defined module through table api or sql client. > SQL syntax has been proposed in FLIP-68: > https://cwiki.apache.org/confluence/display/FLINK/FLIP-68%3A+Extend+Core+Table+System+with+Pluggable+Modules -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-21172) canal-json format include es field
jiabao sun created FLINK-21172:
--
Summary: canal-json format include es field
Key: FLINK-21172
URL: https://issues.apache.org/jira/browse/FLINK-21172
Project: Flink
Issue Type: Improvement
Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
Affects Versions: 1.12.1, 1.12.0
Reporter: jiabao sun
Canal flat message json format has an 'es' field extracted from mysql binlog
which means the row data real change time in mysql. It expressed the event time
naturally but is ignored during deserialization.
org.apache.flink.formats.json.canal. CanalJsonDeserializationSchema
{code:java}
private static RowType createJsonRowType(DataType databaseSchema) {
// Canal JSON contains other information, e.g. "ts", "sql", but we
don't need them
return (RowType)
DataTypes.ROW(
DataTypes.FIELD("data",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("old",
DataTypes.ARRAY(databaseSchema)),
DataTypes.FIELD("type", DataTypes.STRING()),
DataTypes.FIELD("database", DataTypes.STRING()),
DataTypes.FIELD("table", DataTypes.STRING()))
.getLogicalType();
}
{code}
[Canal Flat Message|https://github.com/alibaba/canal/issues/2170]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #14785: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
flinkbot commented on pull request #14785: URL: https://github.com/apache/flink/pull/14785#issuecomment-768788506 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit e101240afc9b86f44866e6ea126e3686182677e9 (Thu Jan 28 04:18:29 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21013) Blink planner does not ingest timestamp into StreamRecord
[
https://issues.apache.org/jira/browse/FLINK-21013?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-21013:
---
Labels: pull-request-available (was: )
> Blink planner does not ingest timestamp into StreamRecord
> -
>
> Key: FLINK-21013
> URL: https://issues.apache.org/jira/browse/FLINK-21013
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner, Table SQL / Runtime
>Affects Versions: 1.12.0
>Reporter: Timo Walther
>Assignee: Leonard Xu
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 1.12.2
>
>
> Currently, the rowtime attribute is not put into the StreamRecord when
> leaving the Table API to DataStream API. The legacy planner supports this,
> but the timestamp is null when using the Blink planner.
> {code}
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment();
> env.setParallelism(1);
> EnvironmentSettings settings =
>
> EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();
> StreamTableEnvironment tEnv = StreamTableEnvironment.create(env,
> settings);
> DataStream orderA =
> env.fromCollection(
> Arrays.asList(
> new Order(1L, "beer", 3),
> new Order(1L, "diaper", 4),
> new Order(3L, "rubber", 2)));
> DataStream orderB =
> orderA.assignTimestampsAndWatermarks(
> new AssignerWithPunctuatedWatermarks() {
> @Nullable
> @Override
> public Watermark checkAndGetNextWatermark(
> Order lastElement, long
> extractedTimestamp) {
> return new Watermark(extractedTimestamp);
> }
> @Override
> public long extractTimestamp(Order element, long
> recordTimestamp) {
> return element.user;
> }
> });
> Table tableA = tEnv.fromDataStream(orderB, $("user").rowtime(),
> $("product"), $("amount"));
> // union the two tables
> Table result = tEnv.sqlQuery("SELECT * FROM " + tableA);
> tEnv.toAppendStream(result, Row.class)
> .process(
> new ProcessFunction() {
> @Override
> public void processElement(Row value, Context
> ctx, Collector out)
> throws Exception {
> System.out.println("TIMESTAMP" +
> ctx.timestamp());
> }
> })
> .print();
> env.execute();
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] leonardBang opened a new pull request #14785: [FLINK-21013][table-planner-blink] Ingest row time into StreamRecord in Blink planner
leonardBang opened a new pull request #14785: URL: https://github.com/apache/flink/pull/14785 ## What is the purpose of the change * This pull request aims to fix Blink planner does not ingest the row time timestamp into `StreamRecord` when leaving Table/SQL ## Brief change log - Improve the `OperatorCodeGenerator` for sink operator to deal the row time properly ## Verifying this change Add `TableToDataStreamITCase` to check the conversions between `Table` and `DataStream`. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): ( no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on a change in pull request #14748: [FLINK-20894][Table SQL / API] Introduce SupportsAggregatePushDown interface
wuchong commented on a change in pull request #14748:
URL: https://github.com/apache/flink/pull/14748#discussion_r565805854
##
File path:
flink-table/flink-table-common/src/main/java/org/apache/flink/table/connector/source/abilities/SupportsAggregatePushDown.java
##
@@ -0,0 +1,165 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.connector.source.abilities;
+
+import org.apache.flink.annotation.PublicEvolving;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.connector.source.ScanTableSource;
+import org.apache.flink.table.expressions.AggregateExpression;
+import org.apache.flink.table.types.DataType;
+
+import java.util.List;
+
+/**
+ * Enables to push down local aggregates into a {@link ScanTableSource}.
+ *
+ * Given the following example inventory table:
+ *
+ * {@code
+ * CREATE TABLE inventory (
+ * id INT,
+ * name STRING,
+ * amount INT,
+ * price DOUBLE,
+ * type STRING,
+ * )
+ * }
+ *
+ * And we have a simple aggregate sql:
+ *
+ * {@code
+ * SELECT
+ * sum(amount),
+ * max(price),
+ * avg(price),
+ * count(1),
+ * name,
+ * type
+ * FROM inventory
+ * group by name, type
+ * }
+ *
+ * In the example above, {@code sum(amount), max(price), avg(price),
count(1)} and {@code group
+ * by name, type} are aggregate functions and grouping sets. By default, if
this interface is not
+ * implemented, local aggregates are applied in a subsequent operation after
the source. The
+ * optimized plan will be the following without local aggregate push down:
+ *
+ * {@code
+ * Calc(select=[EXPR$0, EXPR$1, EXPR$2, EXPR$3, name, type])
+ * +- HashAggregate(groupBy=[name, type], select=[name, type, Final_SUM(sum$0)
AS EXPR$0, Final_MAX(max$1) AS EXPR$1, Final_AVG(sum$2, count$3) AS EXPR$2,
Final_COUNT(count1$4) AS EXPR$3])
+ *+- Exchange(distribution=[hash[name, type]])
+ * +- LocalHashAggregate(groupBy=[name, type], select=[name, type,
Partial_SUM(amount) AS sum$0, Partial_MAX(price) AS max$1, Partial_AVG(price)
AS (sum$2, count$3), Partial_COUNT(*) AS count1$4])
+ * +- TableSourceScan(table=[[inventory, project=[name, type, amount,
price]]], fields=[name, type, amount, price])
+ * }
+ *
+ * For efficiency, a source can push local aggregates further down in order
to reduce the network
+ * and computing overhead. The passed aggregate functions and grouping sets
are in the original
+ * order. The downstream storage which has aggregation capability can directly
return the aggregated
+ * values if the underlying database or storage system has aggregation
capability. The optimized
+ * plan will change to the following pattern with local aggregate push down:
Review comment:
```suggestion
* For efficiency, a source can push local aggregates further down into
underlying database or storage system to reduce the network
* and computing overhead. The passed aggregate functions and grouping sets
are in the order defined by the query.
* The source can directly return the aggregated
* values if the underlying database or storage system has aggregation
capability. The optimized
* plan will be changed to the following pattern with local aggregate push
down:
```
##
File path:
flink-table/flink-table-common/src/main/java/org/apache/flink/table/connector/source/abilities/SupportsAggregatePushDown.java
##
@@ -0,0 +1,165 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+
[GitHub] [flink] flinkbot commented on pull request #14784: [FLINK-21160][connector/kafka] Fix bug of referencing uninitialized deserializer when using KafkaRecordDeserializer#valueOnly
flinkbot commented on pull request #14784: URL: https://github.com/apache/flink/pull/14784#issuecomment-768786978 ## CI report: * c327e27872f782274cab4e10692ef1d913f85c5d UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14779: [FLINK-21158][Runtime/Web Frontend] wrong jvm metaspace and overhead size show in taskmanager metric page
flinkbot edited a comment on pull request #14779: URL: https://github.com/apache/flink/pull/14779#issuecomment-768302027 ## CI report: * 87fab35cbddf22b2479969188eca5a9a3767c098 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12561) * 9863d9e8363e2c6bf2e32394f04579ace32a88fc Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12577) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] sv3ndk commented on a change in pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
sv3ndk commented on a change in pull request #14764:
URL: https://github.com/apache/flink/pull/14764#discussion_r565808097
##
File path: docs/dev/table/connectors/formats/avro-confluent.md
##
@@ -45,29 +45,132 @@ Dependencies
connector=connector
%}
-How to create a table with Avro-Confluent format
-
-
-Here is an example to create a table using Kafka connector and Confluent Avro
format.
+Usage examples
+--
+
+Example of a table using raw UTF-8 string as Kafka key and Avro records
registered in the Schema Registry as Kafka values:
+
{% highlight sql %}
-CREATE TABLE user_behavior (
- user_id BIGINT,
- item_id BIGINT,
- category_id BIGINT,
- behavior STRING,
- ts TIMESTAMP(3)
+CREATE TABLE user_created (
+
+ -- one column mapped to the Kafka raw UTF-8 key
+ the_kafka_key STRING,
+
+ -- a few columns mapped to the Avro fields of the Kafka value
+ id STRING,
+ name STRING,
+ email STRING
+
) WITH (
+
'connector' = 'kafka',
+ 'topic' = 'user_events_example1',
'properties.bootstrap.servers' = 'localhost:9092',
- 'topic' = 'user_behavior',
- 'format' = 'avro-confluent',
- 'avro-confluent.schema-registry.url' = 'http://localhost:8081',
- 'avro-confluent.schema-registry.subject' = 'user_behavior'
+
+ -- UTF-8 string as Kafka keys, using the 'the_kafka_key' table column
+ 'key.format' = 'raw',
+ 'key.fields' = 'the_kafka_key',
+
+ 'value.format' = 'avro-confluent',
+ 'value.avro-confluent.schema-registry.url' = 'http://localhost:8082',
+ 'value.fields-include' = 'EXCEPT_KEY'
)
{% endhighlight %}
+
+To which we can write as follows):
Review comment:
Thanks for the suggestion. Yes, indeed, that's what I meant.
I'll add a commit to use your version, it's clearer.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565806651
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DefaultSlotStatusSyncer.java
##
@@ -0,0 +1,258 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.api.common.time.Time;
+import org.apache.flink.runtime.clusterframework.types.AllocationID;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import org.apache.flink.runtime.clusterframework.types.SlotID;
+import org.apache.flink.runtime.concurrent.FutureUtils;
+import org.apache.flink.runtime.instance.InstanceID;
+import org.apache.flink.runtime.messages.Acknowledge;
+import org.apache.flink.runtime.resourcemanager.ResourceManagerId;
+import org.apache.flink.runtime.taskexecutor.SlotReport;
+import org.apache.flink.runtime.taskexecutor.SlotStatus;
+import org.apache.flink.runtime.taskexecutor.TaskExecutorGateway;
+import org.apache.flink.runtime.taskexecutor.exceptions.SlotOccupiedException;
+import org.apache.flink.util.Preconditions;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.util.HashSet;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.Executor;
+
+/** Default implementation of {@link SlotStatusSyncer} for fine-grained slot
management. */
+public class DefaultSlotStatusSyncer implements SlotStatusSyncer {
+private static final Logger LOG =
LoggerFactory.getLogger(DefaultSlotStatusSyncer.class);
+
+private final TaskManagerTracker taskManagerTracker;
+private final ResourceTracker resourceTracker;
+private final Set pendingSlotAllocations;
+/** Timeout for slot requests to the task manager. */
+private final Time taskManagerRequestTimeout;
+
+public DefaultSlotStatusSyncer(
+TaskManagerTracker taskManagerTracker,
+ResourceTracker resourceTracker,
+Time taskManagerRequestTimeout) {
+this.taskManagerTracker =
Preconditions.checkNotNull(taskManagerTracker);
+this.resourceTracker = Preconditions.checkNotNull(resourceTracker);
+this.taskManagerRequestTimeout =
Preconditions.checkNotNull(taskManagerRequestTimeout);
+
+this.pendingSlotAllocations = new HashSet<>(16);
+}
+
+@Override
+public CompletableFuture allocateSlot(
+InstanceID instanceId,
+JobID jobId,
+String targetAddress,
+ResourceProfile resourceProfile,
+ResourceManagerId resourceManagerId,
+Executor mainThreadExecutor) {
+final AllocationID allocationId = new AllocationID();
+final Optional taskManager =
+taskManagerTracker.getRegisteredTaskManager(instanceId);
+Preconditions.checkState(
+taskManager.isPresent(),
+"Could not find a registered task manager for instance id " +
instanceId + '.');
+final TaskExecutorGateway gateway =
+
taskManager.get().getTaskExecutorConnection().getTaskExecutorGateway();
+
+taskManagerTracker.notifySlotStatus(
+allocationId, jobId, instanceId, resourceProfile,
SlotState.PENDING);
+resourceTracker.notifyAcquiredResource(jobId, resourceProfile);
+pendingSlotAllocations.add(allocationId);
+
+// RPC call to the task manager
+CompletableFuture requestFuture =
+gateway.requestSlot(
+SlotID.getDynamicSlotID(
+
taskManager.get().getTaskExecutorConnection().getResourceID()),
+jobId,
+allocationId,
+resourceProfile,
+targetAddress,
+resourceManagerId,
+taskManagerRequestTimeout);
+
+CompletableFuture returnedFuture = new CompletableFuture<>();
+
+FutureUtils.assertNoException(
+
[jira] [Updated] (FLINK-21171) Introduce TypedValue to the StateFun request-reply protocol
[
https://issues.apache.org/jira/browse/FLINK-21171?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tzu-Li (Gordon) Tai updated FLINK-21171:
Description:
Currently, all values being passed around via the request-reply protocol, are
of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
other functions, and also state values.
This has a few shortcomings:
* All user records are strictly required to be modeled and wrapped as a
Protobuf message - even for simple primitive types. This makes it awkward to
work with for many common types of messages, for example JSON.
* For data persisted as state, with each state value being a Protobuf {{Any}},
each value would also redundantly store the type urls associated with each
Protobuf message.
Instead, we'd like to introduce a {{TypedValue}} construct that replaces
{{Any}} everywhere in the protocol, for both messages and state values:
{code}
message TypedValue {
string typename = 1;
bytes value = 2;
}
{code}
The {{typename}} here directly maps to the type concept introduced in
FLINK-21061.
For state, we directly write the value bytes of a {{TypedValue}} into state,
and the {{typename}} is the meta information snapshotted by the state
serializer (see FLINK-21061).
For messages, the new {{TypedValue}} opens up the possibility for user-defined
types. For example, a user can serialize a JSON string as the value bytes, and
define a custom typename to indentify the type.
We can also leverage this to define built-in types, for example a
cross-language unification of primitive types. This would be an extended scope
of this ticket and will be separately handled.
was:
Currently, all values being passed around via the request-reply protocol, are
of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
other functions, and also state values.
This has a few shortcomings:
* All user records are strictly required to be modeled and wrapped as a
Protobuf message - even for simple primitive types. This makes it awkward to
work with for many common types of messages, for example JSON.
* For data persisted as state, with each state value being a Protobuf {{Any}},
each value would also redundantly store the type urls associated with each
Protobuf message.
Instead, we'd like to introduced a {{TypedValue}} construct that replaces
{{Any}} everywhere in the protocol, for both messages and state values:
{code}
message TypedValue {
string typename = 1;
bytes value = 2;
}
{code}
The {{typename}} here directly maps to the type concept introduced in
FLINK-21061.
For state, we directly write the value bytes of a {{TypedValue}} into state,
and the {{typename}} is the meta information snapshotted by the state
serializer (see FLINK-21061).
> Introduce TypedValue to the StateFun request-reply protocol
> ---
>
> Key: FLINK-21171
> URL: https://issues.apache.org/jira/browse/FLINK-21171
> Project: Flink
> Issue Type: New Feature
> Components: Stateful Functions
>Reporter: Tzu-Li (Gordon) Tai
>Assignee: Tzu-Li (Gordon) Tai
>Priority: Major
> Fix For: statefun-3.0.0
>
>
> Currently, all values being passed around via the request-reply protocol, are
> of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
> other functions, and also state values.
> This has a few shortcomings:
> * All user records are strictly required to be modeled and wrapped as a
> Protobuf message - even for simple primitive types. This makes it awkward to
> work with for many common types of messages, for example JSON.
> * For data persisted as state, with each state value being a Protobuf
> {{Any}}, each value would also redundantly store the type urls associated
> with each Protobuf message.
> Instead, we'd like to introduce a {{TypedValue}} construct that replaces
> {{Any}} everywhere in the protocol, for both messages and state values:
> {code}
> message TypedValue {
> string typename = 1;
> bytes value = 2;
> }
> {code}
> The {{typename}} here directly maps to the type concept introduced in
> FLINK-21061.
> For state, we directly write the value bytes of a {{TypedValue}} into state,
> and the {{typename}} is the meta information snapshotted by the state
> serializer (see FLINK-21061).
> For messages, the new {{TypedValue}} opens up the possibility for
> user-defined types. For example, a user can serialize a JSON string as the
> value bytes, and define a custom typename to indentify the type.
> We can also leverage this to define built-in types, for example a
> cross-language unification of primitive types. This would be an extended
> scope of this ticket and will be separately handled.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-21171) Introduce TypedValue to the StateFun request-reply protocol
[
https://issues.apache.org/jira/browse/FLINK-21171?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tzu-Li (Gordon) Tai updated FLINK-21171:
Description:
Currently, all values being passed around via the request-reply protocol, are
of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
other functions, and also state values.
This has a few shortcomings:
* All user records are strictly required to be modeled and wrapped as a
Protobuf message - even for simple primitive types. This makes it awkward to
work with for many common types of messages, for example JSON.
* For data persisted as state, with each state value being a Protobuf {{Any}},
each value would also redundantly store the type urls associated with each
Protobuf message.
Instead, we'd like to introduced a {{TypedValue}} construct that replaces
{{Any}} everywhere in the protocol, for both messages and state values:
{code}
message TypedValue {
string typename = 1;
bytes value = 2;
}
{code}
The {{typename}} here directly maps to the type concept introduced in
FLINK-21061.
For state, we directly write the value bytes of a {{TypedValue}} into state,
and the {{typename}} is the meta information snapshotted by the state
serializer (see FLINK-21061).
was:
Currently, all values being passed around via the request-reply protocol, are
of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
other functions, and also state values.
This has a few shortcomings:
* All user records are strictly required to be modeled and wrapped as a
Protobuf message - even for simple primitive type. This makes it awkward to
work with for many common types of messages, for example JSON.
* For data persisted as state, with each state value being a Protobuf {{Any}},
each value would also redundantly store the type urls associated with each
Protobuf message.
Instead, we'd like to introduced a {{TypedValue}} construct that replaces
{{Any}} everywhere in the protocol, for both messages and state values:
{code}
message TypedValue {
string typename = 1;
bytes value = 2;
}
{code}
The {{typename}} here directly maps to the type concept introduced in
FLINK-21061.
For state, we directly write the value bytes of a {{TypedValue}} into state,
and the {{typename}} is the meta information snapshotted by the state
serializer (see FLINK-21061).
> Introduce TypedValue to the StateFun request-reply protocol
> ---
>
> Key: FLINK-21171
> URL: https://issues.apache.org/jira/browse/FLINK-21171
> Project: Flink
> Issue Type: New Feature
> Components: Stateful Functions
>Reporter: Tzu-Li (Gordon) Tai
>Assignee: Tzu-Li (Gordon) Tai
>Priority: Major
> Fix For: statefun-3.0.0
>
>
> Currently, all values being passed around via the request-reply protocol, are
> of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
> other functions, and also state values.
> This has a few shortcomings:
> * All user records are strictly required to be modeled and wrapped as a
> Protobuf message - even for simple primitive types. This makes it awkward to
> work with for many common types of messages, for example JSON.
> * For data persisted as state, with each state value being a Protobuf
> {{Any}}, each value would also redundantly store the type urls associated
> with each Protobuf message.
> Instead, we'd like to introduced a {{TypedValue}} construct that replaces
> {{Any}} everywhere in the protocol, for both messages and state values:
> {code}
> message TypedValue {
> string typename = 1;
> bytes value = 2;
> }
> {code}
> The {{typename}} here directly maps to the type concept introduced in
> FLINK-21061.
> For state, we directly write the value bytes of a {{TypedValue}} into state,
> and the {{typename}} is the meta information snapshotted by the state
> serializer (see FLINK-21061).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-21045) Support 'load module' and 'unload module' SQL syntax
[
https://issues.apache.org/jira/browse/FLINK-21045?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273285#comment-17273285
]
Rui Li commented on FLINK-21045:
Thanks for looping me in. I don't have a strong opinion regarding
{{CREATE/DROP}} vs {{LOAD/UNLOAD}} either.
But I do believe introducing {{USE MODULES}} is very useful (and perhaps we
should add similar function to the API). My reasons are 1) it's very tedious to
unload old modules just to reorder them 2) users may not even know how to
"re-load" an old module if it was not initially loaded by the user, e.g. don't
know which type to use.
> Support 'load module' and 'unload module' SQL syntax
>
>
> Key: FLINK-21045
> URL: https://issues.apache.org/jira/browse/FLINK-21045
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Affects Versions: 1.13.0
>Reporter: Nicholas Jiang
>Assignee: Jane Chan
>Priority: Major
> Fix For: 1.13.0
>
>
> At present, Flink SQL doesn't support the 'load module' and 'unload module'
> SQL syntax. It's necessary for uses in the situation that users load and
> unload user-defined module through table api or sql client.
> SQL syntax has been proposed in FLIP-68:
> https://cwiki.apache.org/confluence/display/FLINK/FLIP-68%3A+Extend+Core+Table+System+with+Pluggable+Modules
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-20740) Use managed memory (network memory) to avoid direct memory OOM error for sort-merge shuffle
[ https://issues.apache.org/jira/browse/FLINK-20740?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yingjie Cao updated FLINK-20740: Summary: Use managed memory (network memory) to avoid direct memory OOM error for sort-merge shuffle (was: Use managed memory to avoid direct memory OOM error for sort-merge shuffle) > Use managed memory (network memory) to avoid direct memory OOM error for > sort-merge shuffle > --- > > Key: FLINK-20740 > URL: https://issues.apache.org/jira/browse/FLINK-20740 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Network >Affects Versions: 1.12.0 >Reporter: Yingjie Cao >Priority: Major > Fix For: 1.13.0 > > > Currently, sort-merge blocking shuffle uses some unmanaged memory for data > writing and reading, which means users must increase the size of direct > memory, otherwise, one may encounter direct memory OOM error, which is really > bad for usability. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #14784: [FLINK-21160][connector/kafka] Fix bug of referencing uninitialized deserializer when using KafkaRecordDeserializer#valueOnly
flinkbot commented on pull request #14784: URL: https://github.com/apache/flink/pull/14784#issuecomment-768782077 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit c327e27872f782274cab4e10692ef1d913f85c5d (Thu Jan 28 03:55:21 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-21160).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14779: [FLINK-21158][Runtime/Web Frontend] wrong jvm metaspace and overhead size show in taskmanager metric page
flinkbot edited a comment on pull request #14779: URL: https://github.com/apache/flink/pull/14779#issuecomment-768302027 ## CI report: * 87fab35cbddf22b2479969188eca5a9a3767c098 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12561) * 9863d9e8363e2c6bf2e32394f04579ace32a88fc UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21160) ValueDeserializerWrapper throws NullPointerException when getProducedType is invoked
[
https://issues.apache.org/jira/browse/FLINK-21160?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-21160:
---
Labels: pull-request-available (was: )
> ValueDeserializerWrapper throws NullPointerException when getProducedType is
> invoked
>
>
> Key: FLINK-21160
> URL: https://issues.apache.org/jira/browse/FLINK-21160
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Reporter: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
> The variable {{deserializer}} in class {{ValueDeserializerWrapper}} won't be
> instantiated until method {{deserialize()}} is invoked in runtime, so in the
> job compiling stage when invoking {{getProducedType()}}, NPE will be thrown
> because of referencing the uninstantiated variable {{deserializer}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] wuchong commented on a change in pull request #14764: [Flink-20999][docs] - adds usage examples to the Kafka Avro Confluent connector format
wuchong commented on a change in pull request #14764:
URL: https://github.com/apache/flink/pull/14764#discussion_r565802781
##
File path: docs/dev/table/connectors/formats/avro-confluent.md
##
@@ -45,29 +45,132 @@ Dependencies
connector=connector
%}
-How to create a table with Avro-Confluent format
-
-
-Here is an example to create a table using Kafka connector and Confluent Avro
format.
+Usage examples
+--
+
+Example of a table using raw UTF-8 string as Kafka key and Avro records
registered in the Schema Registry as Kafka values:
+
{% highlight sql %}
-CREATE TABLE user_behavior (
- user_id BIGINT,
- item_id BIGINT,
- category_id BIGINT,
- behavior STRING,
- ts TIMESTAMP(3)
+CREATE TABLE user_created (
+
+ -- one column mapped to the Kafka raw UTF-8 key
+ the_kafka_key STRING,
+
+ -- a few columns mapped to the Avro fields of the Kafka value
+ id STRING,
+ name STRING,
+ email STRING
+
) WITH (
+
'connector' = 'kafka',
+ 'topic' = 'user_events_example1',
'properties.bootstrap.servers' = 'localhost:9092',
- 'topic' = 'user_behavior',
- 'format' = 'avro-confluent',
- 'avro-confluent.schema-registry.url' = 'http://localhost:8081',
- 'avro-confluent.schema-registry.subject' = 'user_behavior'
+
+ -- UTF-8 string as Kafka keys, using the 'the_kafka_key' table column
+ 'key.format' = 'raw',
+ 'key.fields' = 'the_kafka_key',
+
+ 'value.format' = 'avro-confluent',
+ 'value.avro-confluent.schema-registry.url' = 'http://localhost:8082',
+ 'value.fields-include' = 'EXCEPT_KEY'
)
{% endhighlight %}
+
+To which we can write as follows):
Review comment:
I don't fully understand this sentence. Do you mean "We can write data
into the kafka table as follows" ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
KarmaGYZ commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565802712
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/resourcemanager/slotmanager/FineGrainedTaskManagerTrackerTest.java
##
@@ -0,0 +1,254 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.runtime.clusterframework.types.AllocationID;
+import org.apache.flink.runtime.clusterframework.types.ResourceID;
+import org.apache.flink.runtime.clusterframework.types.ResourceProfile;
+import
org.apache.flink.runtime.resourcemanager.registration.TaskExecutorConnection;
+import org.apache.flink.runtime.slots.ResourceCounter;
+import org.apache.flink.runtime.taskexecutor.TestingTaskExecutorGatewayBuilder;
+import org.apache.flink.util.TestLogger;
+
+import org.junit.Test;
+
+import java.util.Collections;
+
+import static org.hamcrest.Matchers.empty;
+import static org.hamcrest.core.Is.is;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.assertThat;
+import static org.junit.Assert.assertTrue;
+
+/** Tests for the {@link FineGrainedTaskManagerTracker}. */
+public class FineGrainedTaskManagerTrackerTest extends TestLogger {
Review comment:
> Try to allocate slot from a (pending) task manager that does not have
enough resource
I'll put it into the `FineGrainedTaskManagerRegistrationTest`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] PatrickRen opened a new pull request #14784: [FLINK-21160][connector/kafka] Fix bug of referencing uninitialized deserializer when using KafkaRecordDeserializer#valueOnly
PatrickRen opened a new pull request #14784: URL: https://github.com/apache/flink/pull/14784 ## What is the purpose of the change This pull request fixes bug of referencing uninitialized deserializer in ```ValueDeserializerWrapper``` when using ```KafkaRecordDeserializer#valueOnly```, which would lead to NPE at job compiling stage. ## Brief change log - Keep the ```deserializeClass``` directly in the instance of ```ValueDeserializerWrapper``` as a member instead of storing the name of the class - Add an IT case for testing value only deserializer. ## Verifying this change - *Added integration tests for using ```KafkaRecordDeserializer#valueOnly``` to build a KafkaSource* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-21171) Introduce TypedValue to the StateFun request-reply protocol
Tzu-Li (Gordon) Tai created FLINK-21171:
---
Summary: Introduce TypedValue to the StateFun request-reply
protocol
Key: FLINK-21171
URL: https://issues.apache.org/jira/browse/FLINK-21171
Project: Flink
Issue Type: New Feature
Components: Stateful Functions
Reporter: Tzu-Li (Gordon) Tai
Assignee: Tzu-Li (Gordon) Tai
Fix For: statefun-3.0.0
Currently, all values being passed around via the request-reply protocol, are
of the Protobuf {{Any}} type. This includes payloads of outgoing messages to
other functions, and also state values.
This has a few shortcomings:
* All user records are strictly required to be modeled and wrapped as a
Protobuf message - even for simple primitive type. This makes it awkward to
work with for many common types of messages, for example JSON.
* For data persisted as state, with each state value being a Protobuf {{Any}},
each value would also redundantly store the type urls associated with each
Protobuf message.
Instead, we'd like to introduced a {{TypedValue}} construct that replaces
{{Any}} everywhere in the protocol, for both messages and state values:
{code}
message TypedValue {
string typename = 1;
bytes value = 2;
}
{code}
The {{typename}} here directly maps to the type concept introduced in
FLINK-21061.
For state, we directly write the value bytes of a {{TypedValue}} into state,
and the {{typename}} is the meta information snapshotted by the state
serializer (see FLINK-21061).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-21170) Add internal state hierarchy in PyFlink
Huang Xingbo created FLINK-21170: Summary: Add internal state hierarchy in PyFlink Key: FLINK-21170 URL: https://issues.apache.org/jira/browse/FLINK-21170 Project: Flink Issue Type: Sub-task Components: API / Python Affects Versions: 1.13.0 Reporter: Huang Xingbo Fix For: 1.13.0 Attachments: InternalKvState.png !InternalKvState.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] xintongsong commented on a change in pull request #14647: [FLINK-20835] Implement FineGrainedSlotManager
xintongsong commented on a change in pull request #14647:
URL: https://github.com/apache/flink/pull/14647#discussion_r565798745
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/PendingTaskManagerId.java
##
@@ -0,0 +1,30 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.resourcemanager.slotmanager;
+
+import org.apache.flink.util.AbstractID;
+
+/** Id of {@link PendingTaskManager}. */
+public class PendingTaskManagerId extends AbstractID {
Review comment:
> This ID should only be used inside the slotmanager.
This is an assumption rather than an explicit contract, while `Serializable`
is a contract.
The assumption is true now, but might be changed in future. In that case,
people can easily overlook that `PendingTaskManagerId` as a `Serializable` is
originally not expected to be serialized and they need to add a
`serialVersionUID` to make it properly work.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-20416) Need a cached catalog for HiveCatalog
[
https://issues.apache.org/jira/browse/FLINK-20416?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273279#comment-17273279
]
Rui Li commented on FLINK-20416:
[~shared_ptr] Thanks for the update. LGTM, please go ahead with the PR :)
> Need a cached catalog for HiveCatalog
> -
>
> Key: FLINK-20416
> URL: https://issues.apache.org/jira/browse/FLINK-20416
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / Common, Connectors / Hive, Table SQL / API,
> Table SQL / Planner
>Reporter: Sebastian Liu
>Assignee: Sebastian Liu
>Priority: Major
> Labels: pull-request-available
> Attachments: hms cache.jpg, hms cache.jpg
>
>
> For OLAP scenarios, There are usually some analytical queries which running
> time is relatively short. These queries are also sensitive to latency. In the
> current Blink sql processing, parse/validate/optimize stages are all need
> meta data from catalog API. But each request to the catalog requires re-run
> of the underlying meta query.
>
> We may need a cached catalog which can cache the table schema and statistic
> info to avoid unnecessary repeated meta requests.
> Design
> doc:[https://docs.google.com/document/d/1oL8HUpv2WaF6OkFvbH5iefXkOJB__Dal_bYsIZJA_Gk/edit?usp=sharing]
> I have submitted a related PR for adding a genetic cached catalog, which can
> delegate other implementations of {{AbstractCatalog. }}
> {{[https://github.com/apache/flink/pull/14260]}}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14783: [FLINK-21169][kafka] flink-connector-base dependency should be scope compile
flinkbot edited a comment on pull request #14783: URL: https://github.com/apache/flink/pull/14783#issuecomment-768767423 ## CI report: * ea0fa2c3a97b2d2082b40732850ccc960ba7a09e Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=12576) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-21005) Introduce new provider for unified Sink API and implement in planner
[
https://issues.apache.org/jira/browse/FLINK-21005?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17273278#comment-17273278
]
Jark Wu commented on FLINK-21005:
-
Sure. Assigned to you [~nicholasjiang]
> Introduce new provider for unified Sink API and implement in planner
>
>
> Key: FLINK-21005
> URL: https://issues.apache.org/jira/browse/FLINK-21005
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / API, Table SQL / Planner
>Reporter: Jark Wu
>Assignee: Huajie Wang
>Priority: Major
> Fix For: 1.13.0
>
>
> FLIP-143 [1] introduced the unified sink API, we should add a
> {{SinkRuntimeProvider}} for it and support it in planner. So that Table SQL
> users can also use the unified sink APIs.
> [1]:
> https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (FLINK-21005) Introduce new provider for unified Sink API and implement in planner
[
https://issues.apache.org/jira/browse/FLINK-21005?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu reassigned FLINK-21005:
---
Assignee: Nicholas Jiang (was: Huajie Wang)
> Introduce new provider for unified Sink API and implement in planner
>
>
> Key: FLINK-21005
> URL: https://issues.apache.org/jira/browse/FLINK-21005
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / API, Table SQL / Planner
>Reporter: Jark Wu
>Assignee: Nicholas Jiang
>Priority: Major
> Fix For: 1.13.0
>
>
> FLIP-143 [1] introduced the unified sink API, we should add a
> {{SinkRuntimeProvider}} for it and support it in planner. So that Table SQL
> users can also use the unified sink APIs.
> [1]:
> https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] xintongsong edited a comment on pull request #14591: FLINK-20359 Added Owner Reference to Job Manager in native kubernetes
xintongsong edited a comment on pull request #14591: URL: https://github.com/apache/flink/pull/14591#issuecomment-768770142 Sorry, closed the PR by mistake. @blublinsky, you have not addressed my comment. > * Why is the owner reference only set for JobManager. Are other resources guaranteed to be cleaned up? We might want to make it more explicit that "delete the actual cluster" means all resources are cleaned up. > * How exactly to use the configuration option. I would suggest to add an example (with multiple owner references). The above should be explained in the configuration option description. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] blublinsky opened a new pull request #14591: FLINK-20359 Added Owner Reference to Job Manager in native kubernetes
blublinsky opened a new pull request #14591: URL: https://github.com/apache/flink/pull/14591 ## What is the purpose of the change Flink implementation is often a part of the larger application. As a result a synchronized management - clean up of Flink resources, when a main application is deleted is important. In Kubernetes, a common approach for such clean up is usage of the owner's reference (https://kubernetes.io/docs/concepts/workloads/controllers/garbage-collection/) This PR allows adding owner reference support to Flink Job manager ## Brief change log - Add configuration for owner reference - Add Owner manager resource - Add Owner manager support to KubernetesJobManagerParameters - Updated Job Manager factory to process owner's reference - Updated Job Manager factory unit test ## Verifying this change This change added tests and can be verified as follows: Running job manager factory unit test ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with @Public(Evolving): (yes / no) yes - The serializers: (yes / no / don't know) no - The runtime per-record code paths (performance sensitive): (yes / no / don't know) no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: (yes / no / don't know) yes - The S3 file system connector: (yes / no / don't know)no ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) java doc This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] xintongsong commented on pull request #14591: FLINK-20359 Added Owner Reference to Job Manager in native kubernetes
xintongsong commented on pull request #14591: URL: https://github.com/apache/flink/pull/14591#issuecomment-768770142 @blublinsky, This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] xintongsong closed pull request #14591: FLINK-20359 Added Owner Reference to Job Manager in native kubernetes
xintongsong closed pull request #14591: URL: https://github.com/apache/flink/pull/14591 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14783: [FLINK-21169][kafka] flink-connector-base dependency should be scope compile
flinkbot commented on pull request #14783: URL: https://github.com/apache/flink/pull/14783#issuecomment-768767423 ## CI report: * ea0fa2c3a97b2d2082b40732850ccc960ba7a09e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org