[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r191685596 --- Diff: python/pyspark/sql/dataframe.py --- @@ -351,8 +352,62 @@ def show(self, n=20, truncate=True, vertical=False): else: print(self._jdf.showString(n, int(truncate), vertical)) +def _get_repl_config(self): +"""Return the configs for eager evaluation each time when __repr__ or +_repr_html_ called by user or notebook. +""" +eager_eval = self.sql_ctx.getConf( +"spark.sql.repl.eagerEval.enabled", "false").lower() == "true" +console_row = int(self.sql_ctx.getConf( +"spark.sql.repl.eagerEval.maxNumRows", u"20")) +console_truncate = int(self.sql_ctx.getConf( +"spark.sql.repl.eagerEval.truncate", u"20")) +return (eager_eval, console_row, console_truncate) --- End diff -- OK. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21370 @viirya @gatorsmile @ueshin @felixcheung @HyukjinKwon The refactor about generating html code out of `Dataset.scala` was done in 94f3414. Please help to check whether it is appropriate when you have time. Thanks! @rdblue @rxin The lastest commit also include the logic of using `spark.sql.repl.eagerEval.enabled` both control \_\_repr\_\_ and \_repr\_html\_. Please have a look when you have time. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21445: [SPARK-24404][SS] Increase currentEpoch when meet a Epoc...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21445 ``` Looks like the patch is needed only with #21353 #21332 #21293 as of now, right? ``` @HeartSaVioR Yes, sorry for the late explanation. The background is we are running POC based on #21353 #21332 #21293 and the latest master, including the work of queue rdd reader/writer by @jose-torres. Greatly thanks for the work of #21239, we can complete all status operation after fix this bug. So we think we should report this to let you know. ``` Please note that I'm commenting on top of current implementation, not considering #21353 #21332 #21293. ``` Got it, owing to some pressure within internal requirement for CP, we running over these 3 patches, but we'll follow closely with all your works and hope to contribute into CP. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21385: [SPARK-24234][SS] Support multiple row writers in...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21385#discussion_r191149214
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/shuffle/UnsafeRowReceiver.scala
---
@@ -41,11 +50,15 @@ private[shuffle] case class ReceiverEpochMarker()
extends UnsafeRowReceiverMessa
*/
private[shuffle] class UnsafeRowReceiver(
queueSize: Int,
+ numShuffleWriters: Int,
+ checkpointIntervalMs: Long,
override val rpcEnv: RpcEnv)
extends ThreadSafeRpcEndpoint with ContinuousShuffleReader with
Logging {
// Note that this queue will be drained from the main task thread and
populated in the RPC
// response thread.
- private val queue = new
ArrayBlockingQueue[UnsafeRowReceiverMessage](queueSize)
+ private val queues = Array.fill(numShuffleWriters) {
--- End diff --
Hi TD, just a question here, what's the 'a non-RPC-endpoint-based transfer
mechanism' refers for?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r191080316 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.sql.repl.eagerEval.enabled + false + +Enable eager evaluation or not. If true and repl you're using supports eager evaluation, +dataframe will be ran automatically and html table will feedback the queries user have defined +(see https://issues.apache.org/jira/browse/SPARK-24215;>SPARK-24215 for more details). + + + + spark.sql.repl.eagerEval.showRows + 20 + +Default number of rows in HTML table. + + + + spark.sql.repl.eagerEval.truncate --- End diff -- Yep, I just want to keep the same behavior of `dataframe.show`. ``` That's useful for console output, but not so much for notebooks. ``` Notebooks aren't afraid for too many chaacters within a cell, so I just delete this? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r191080194 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala --- @@ -237,9 +238,13 @@ class Dataset[T] private[sql]( * @param truncate If set to more than 0, truncates strings to `truncate` characters and * all cells will be aligned right. * @param vertical If set to true, prints output rows vertically (one line per column value). + * @param html If set to true, return output as html table. --- End diff -- @viirya @gatorsmile @rdblue Sorry for the late commit, the refactor do in 94f3414. I spend some time on testing and implementing the transformation of rows between python and scala. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080082
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to
`truncate` characters and
+ *all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sbStringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+StringUtils.leftPad(cell, colWidths(i))
+ } else {
+StringUtils.rightPad(cell, colWidths(i))
+ }
+}
+(html, head) match {
+ case (true, true) =>
+data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "", "\n", "\n")
--- End diff --
I change the format in python \_repr\_html\_ in 94f3414.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r191080049 --- Diff: python/pyspark/sql/dataframe.py --- @@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False): name | Bob """ if isinstance(truncate, bool) and truncate: -print(self._jdf.showString(n, 20, vertical)) +print(self._jdf.showString(n, 20, vertical, False)) else: -print(self._jdf.showString(n, int(truncate), vertical)) +print(self._jdf.showString(n, int(truncate), vertical, False)) --- End diff -- Fix in 94f3414. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080066
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
+def _repr_html_(self):
+"""Returns a dataframe with html code when you enabled eager
evaluation
+by 'spark.sql.repl.eagerEval.enabled', this only called by repr
you're
--- End diff --
Thanks, change to REPL in 94f3414.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080057
--- Diff: python/pyspark/sql/tests.py ---
@@ -3040,6 +3040,50 @@ def test_csv_sampling_ratio(self):
.csv(rdd, samplingRatio=0.5).schema
self.assertEquals(schema, StructType([StructField("_c0",
IntegerType(), True)]))
+def _get_content(self, content):
+"""
+Strips leading spaces from content up to the first '|' in each
line.
+"""
+import re
+pattern = re.compile(r'^ *\|', re.MULTILINE)
--- End diff --
Thanks! Fix it in 94f3414.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r191080044 --- Diff: python/pyspark/sql/dataframe.py --- @@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False): name | Bob """ if isinstance(truncate, bool) and truncate: -print(self._jdf.showString(n, 20, vertical)) +print(self._jdf.showString(n, 20, vertical, False)) --- End diff -- Thanks, fix in 94f3414. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r191080037
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,30 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
--- End diff --
Thanks for your reply, this implement in 94f3414.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r191080026 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.sql.repl.eagerEval.enabled + false + +Enable eager evaluation or not. If true and repl you're using supports eager evaluation, +dataframe will be ran automatically and html table will feedback the queries user have defined +(see https://issues.apache.org/jira/browse/SPARK-24215;>SPARK-24215 for more details). + + + + spark.sql.repl.eagerEval.showRows --- End diff -- Thanks, change it in 94f3414. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21370 ``` Can we also do something a bit more generic that works for non-Jupyter notebooks as well? ``` Can we accept `spark.sql.repl.eagerEval.enabled` to control both \_\_repr\_\_ and \_repr\_html\_ ? The behavior like below: 1. If not support _repr_html_ and open eagerEval.enable, just call something like `show` and trigger `take` inside. 2. If support _repr_html_, use the html output. (Here need a small trick, we should add a var in python dataframe to check whether _repr_html_ called or not, otherwise in this mode _repr_html and __repr__ will both call showString). I test offline an it can work both python shell and Jupyter, if we agree this way, I'll add this support in next commit together will the refactor of showString in scala Dataset. 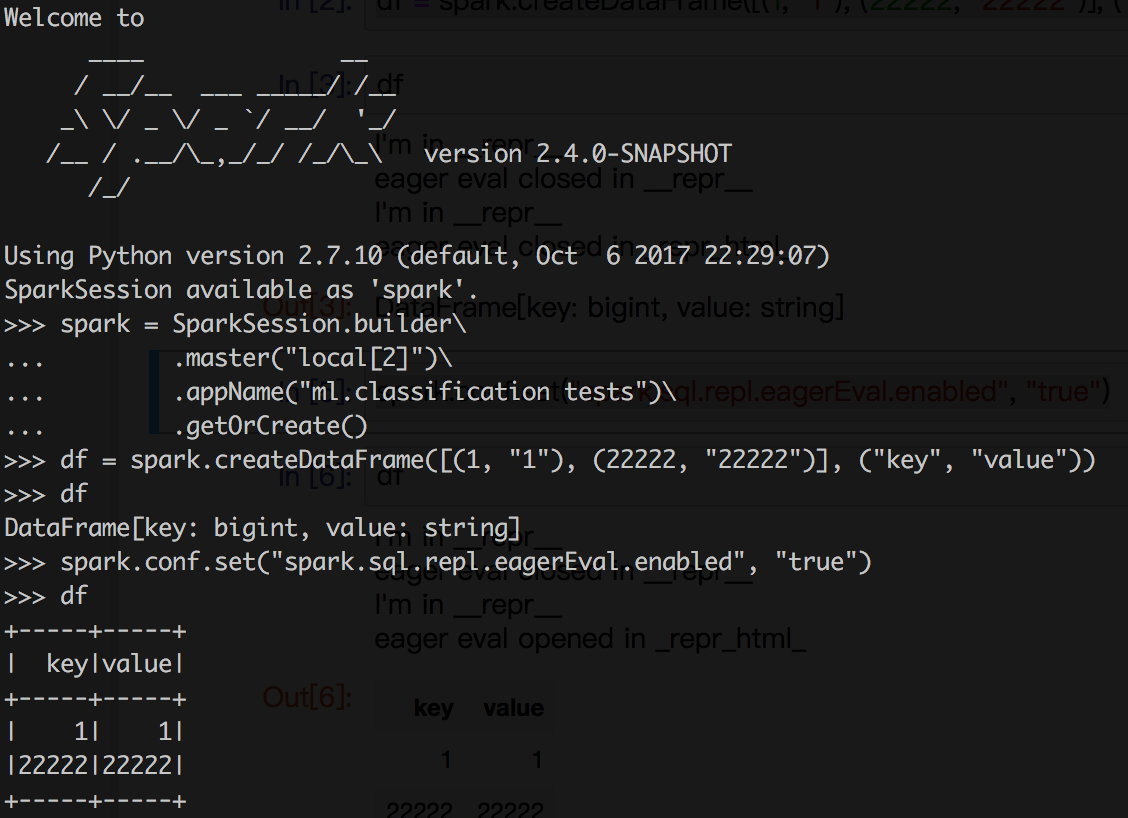 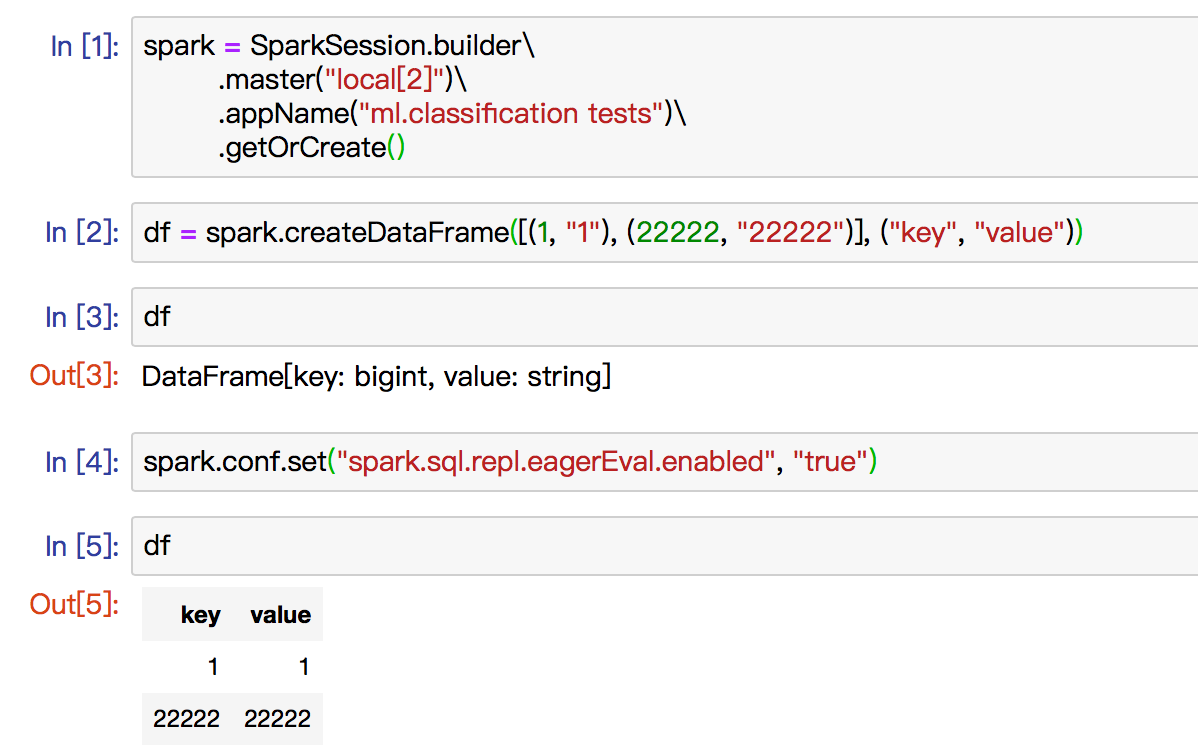 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190244648
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to
`truncate` characters and
+ *all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sbStringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+StringUtils.leftPad(cell, colWidths(i))
+ } else {
+StringUtils.rightPad(cell, colWidths(i))
+ }
+}
+(html, head) match {
+ case (true, true) =>
+data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "", "\n", "\n")
--- End diff --
Got it, I'll change it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r190154145 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala --- @@ -237,9 +238,13 @@ class Dataset[T] private[sql]( * @param truncate If set to more than 0, truncates strings to `truncate` characters and * all cells will be aligned right. * @param vertical If set to true, prints output rows vertically (one line per column value). + * @param html If set to true, return output as html table. --- End diff -- Thanks for guidance, I will do this in next commit. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190154231
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to
`truncate` characters and
+ *all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sbStringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+StringUtils.leftPad(cell, colWidths(i))
+ } else {
+StringUtils.rightPad(cell, colWidths(i))
+ }
+}
+(html, head) match {
+ case (true, true) =>
+data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "", "", "")
--- End diff --
Thanks, done. feb5f4a.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r190153907 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled --- End diff -- Thanks, done. feb5f4a. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190153833
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
+def _repr_html_(self):
--- End diff --
Thanks, done. feb5f4a.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r190153812
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
+def _repr_html_(self):
--- End diff --
Thanks, done. feb5f4a.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189614136 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled --- End diff -- Got it, fix it in next commit. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189614067
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
+def _repr_html_(self):
--- End diff --
No problem, I'll added in `SQLTests` in next commit.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189613358
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -292,31 +297,25 @@ class Dataset[T] private[sql](
}
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+",
"+\n").toString()
+ val sep: String = if (html) {
+// Initial append table label
+sb.append("\n")
+"\n"
+ } else {
+colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ }
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
-if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
-} else {
- StringUtils.rightPad(cell, colWidths(i))
-}
- }.addString(sb, "|", "|", "|\n")
-
+ appendRowString(rows.head, truncate, colWidths, html, true, sb)
sb.append(sep)
// data
- rows.tail.foreach {
-_.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
-StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
-StringUtils.rightPad(cell.toString, colWidths(i))
- }
-}.addString(sb, "|", "|", "|\n")
+ rows.tail.foreach { row =>
+appendRowString(row.map(_.toString), truncate, colWidths, html,
false, sb)
--- End diff --
I see, the `cell.toString` has been called here.
https://github.com/apache/spark/pull/21370/files/f2bb8f334631734869ddf5d8ef1eca1fa29d334a#diff-7a46f10c3cedbf013cf255564d9483cdR271
Got it, I'll fix this in next commit.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189611792
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to
`truncate` characters and
+ *all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sbStringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+StringUtils.leftPad(cell, colWidths(i))
+ } else {
+StringUtils.rightPad(cell, colWidths(i))
+ }
+}
+(html, head) match {
+ case (true, true) =>
+data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "", "", "")
--- End diff --
Ah, I understand your consideration. I'll add this in next commit.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189603851
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +347,26 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
+def _repr_html_(self):
--- End diff --
No problem, is the SQLTests in pyspark/sql/tests.py the right place?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21370 Thanks all reviewer's comments, I address all comments in this commit. Please have a look. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189574938 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala --- @@ -237,9 +238,13 @@ class Dataset[T] private[sql]( * @param truncate If set to more than 0, truncates strings to `truncate` characters and * all cells will be aligned right. * @param vertical If set to true, prints output rows vertically (one line per column value). + * @param html If set to true, return output as html table. --- End diff -- We can do this in python side, I implement it in scala side mainly consider to reuse the code and logic of `show()`, maybe it's more natural in `show df as html` call showString. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189570764
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -358,6 +357,43 @@ class Dataset[T] private[sql](
sb.toString()
}
+ /**
+ * Transform current row string and append to builder
+ *
+ * @param row Current row of string
+ * @param truncate If set to more than 0, truncates strings to
`truncate` characters and
+ *all cells will be aligned right.
+ * @param colWidths The width of each column
+ * @param html If set to true, return output as html table.
+ * @param head Set to true while current row is table head.
+ * @param sbStringBuilder for current row.
+ */
+ private[sql] def appendRowString(
+ row: Seq[String],
+ truncate: Int,
+ colWidths: Array[Int],
+ html: Boolean,
+ head: Boolean,
+ sb: StringBuilder): Unit = {
+val data = row.zipWithIndex.map { case (cell, i) =>
+ if (truncate > 0) {
+StringUtils.leftPad(cell, colWidths(i))
+ } else {
+StringUtils.rightPad(cell, colWidths(i))
+ }
+}
+(html, head) match {
+ case (true, true) =>
+data.map(StringEscapeUtils.escapeHtml).addString(
+ sb, "", "", "")
--- End diff --
the "\n" added in
seperatedLine:https://github.com/apache/spark/pull/21370/files#diff-7a46f10c3cedbf013cf255564d9483cdR300
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189570479
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -292,31 +297,25 @@ class Dataset[T] private[sql](
}
// Create SeparateLine
- val sep: String = colWidths.map("-" * _).addString(sb, "+", "+",
"+\n").toString()
+ val sep: String = if (html) {
+// Initial append table label
+sb.append("\n")
+"\n"
+ } else {
+colWidths.map("-" * _).addString(sb, "+", "+", "+\n").toString()
+ }
// column names
- rows.head.zipWithIndex.map { case (cell, i) =>
-if (truncate > 0) {
- StringUtils.leftPad(cell, colWidths(i))
-} else {
- StringUtils.rightPad(cell, colWidths(i))
-}
- }.addString(sb, "|", "|", "|\n")
-
+ appendRowString(rows.head, truncate, colWidths, html, true, sb)
sb.append(sep)
// data
- rows.tail.foreach {
-_.zipWithIndex.map { case (cell, i) =>
- if (truncate > 0) {
-StringUtils.leftPad(cell.toString, colWidths(i))
- } else {
-StringUtils.rightPad(cell.toString, colWidths(i))
- }
-}.addString(sb, "|", "|", "|\n")
+ rows.tail.foreach { row =>
+appendRowString(row.map(_.toString), truncate, colWidths, html,
false, sb)
--- End diff --
I think we need this toString, because the appendRowString method including
both column names and data in original logic, which call `toString` in data
part.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189569952 --- Diff: python/pyspark/sql/dataframe.py --- @@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx): self.is_cached = False self._schema = None # initialized lazily self._lazy_rdd = None +self._eager_eval = sql_ctx.getConf( +"spark.jupyter.eagerEval.enabled", "false").lower() == "true" +self._default_console_row = int(sql_ctx.getConf( +"spark.jupyter.default.showRows", u"20")) +self._default_console_truncate = int(sql_ctx.getConf( +"spark.jupyter.default.showRows", u"20")) --- End diff -- Yep, I'll fix it in next commit.  --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189569437
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -347,13 +353,18 @@ def show(self, n=20, truncate=True, vertical=False):
name | Bob
"""
if isinstance(truncate, bool) and truncate:
-print(self._jdf.showString(n, 20, vertical))
+print(self._jdf.showString(n, 20, vertical, False))
else:
-print(self._jdf.showString(n, int(truncate), vertical))
+print(self._jdf.showString(n, int(truncate), vertical, False))
def __repr__(self):
return "DataFrame[%s]" % (", ".join("%s: %s" % c for c in
self.dtypes))
+def _repr_html_(self):
+if self._eager_eval:
+return self._jdf.showString(
+self._default_console_row, self._default_console_truncate,
False, True)
--- End diff --
```
What will be shown if spark.jupyter.eagerEval.enabled is False? Fallback
the original automatically?
```
Yes, it will fallback to call __repr__.
```
We need to return None if self._eager_eval is False.
```
Got it, more clear in code logic.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189567614 --- Diff: python/pyspark/sql/dataframe.py --- @@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx): self.is_cached = False self._schema = None # initialized lazily self._lazy_rdd = None +self._eager_eval = sql_ctx.getConf( +"spark.jupyter.eagerEval.enabled", "false").lower() == "true" +self._default_console_row = int(sql_ctx.getConf( +"spark.jupyter.default.showRows", u"20")) +self._default_console_truncate = int(sql_ctx.getConf( +"spark.jupyter.default.showRows", u"20")) --- End diff -- My bad, sorry for this. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189567350 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled + false + +Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically +and html table will feedback the queries user have defined (see +https://issues.apache.org/jira/browse/SPARK-24215;>SPARK-24215 for more details). + + + + spark.jupyter.default.showRows + 20 + +Default number of rows in jupyter html table. + + + + spark.jupyter.default.truncate --- End diff -- Yep, change to spark.jupyter.eagerEval.truncate --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189567315 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled + false + +Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically +and html table will feedback the queries user have defined (see +https://issues.apache.org/jira/browse/SPARK-24215;>SPARK-24215 for more details). + + + + spark.jupyter.default.showRows --- End diff -- change to spark.jupyter.eagerEval.showRows,thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189567259 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled + false + +Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically --- End diff -- Got it, thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189483903 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled + false + +Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically +and html table will feedback the queries user have defined (see --- End diff -- Got it. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189483894 --- Diff: docs/configuration.md --- @@ -456,6 +456,29 @@ Apart from these, the following properties are also available, and may be useful from JVM to Python worker for every task. + + spark.jupyter.eagerEval.enabled + false + +Open eager evaluation on jupyter or not. If yes, dataframe will be ran automatically --- End diff -- Copy. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21370 ``` this will need to escape the values to make sure it is legal html too right? ``` Yes you're right, thanks for your guidance, the new patch consider the escape and add new UT. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21370#discussion_r189463652
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -237,9 +236,13 @@ class Dataset[T] private[sql](
* @param truncate If set to more than 0, truncates strings to
`truncate` characters and
* all cells will be aligned right.
* @param vertical If set to true, prints output rows vertically (one
line per column value).
+ * @param html If set to true, return output as html table.
*/
private[sql] def showString(
- _numRows: Int, truncate: Int = 20, vertical: Boolean = false):
String = {
+ _numRows: Int,
+ truncate: Int = 20,
--- End diff --
Yes, the truncated string will be showed in table row and controlled by
`spark.jupyter.default.truncate`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189463098 --- Diff: python/pyspark/sql/dataframe.py --- @@ -78,6 +78,12 @@ def __init__(self, jdf, sql_ctx): self.is_cached = False self._schema = None # initialized lazily self._lazy_rdd = None +self._eager_eval = sql_ctx.getConf( +"spark.jupyter.eagerEval.enabled", "false").lower() == "true" --- End diff -- Got it. Do it in next commit. Thanks for reminding. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21370#discussion_r189463079 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala --- @@ -3056,7 +3059,6 @@ class Dataset[T] private[sql]( * view, e.g. `SELECT * FROM global_temp.view1`. * * @throws AnalysisException if the view name is invalid or already exists - * --- End diff -- Sorry for this, I'll revert the IDE changes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21370: [SPARK-24215][PySpark] Implement _repr_html_ for datafra...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21370 Not sure who is the right reviewer, maybe @rdblue @gatorsmile ? Could you help me check whether it is the right implementation for the discussion in the dev list? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21370: [SPARK-24215][PySpark] Implement _repr_html_ for ...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/21370 [SPARK-24215][PySpark] Implement _repr_html_ for dataframes in PySpark ## What changes were proposed in this pull request? Implement _repr_html_ for PySpark while in notebook and add config named "spark.jupyter.eagerEval.enabled" to control this. The dev list thread for context: http://apache-spark-developers-list.1001551.n3.nabble.com/eager-execution-and-debuggability-td23928.html ## How was this patch tested? New ut in DataFrameSuite and manual test in jupyter. Some screenshot below:   You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-24215 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21370.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21370 commit ebc0b11fd006386d32949f56228e2671297373fc Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-19T11:56:02Z SPARK-24215: Implement __repr__ and _repr_html_ for dataframes in PySpark --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21353: [SPARK-24036][SS] Scheduler changes for continuou...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21353#discussion_r188975680 --- Diff: core/src/main/scala/org/apache/spark/scheduler/ContinuousShuffleMapTask.scala --- @@ -0,0 +1,139 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.scheduler + +import java.lang.management.ManagementFactory +import java.nio.ByteBuffer +import java.util.Properties + +import scala.language.existentials + +import org.apache.spark._ +import org.apache.spark.broadcast.Broadcast +import org.apache.spark.internal.Logging +import org.apache.spark.rdd.RDD +import org.apache.spark.shuffle.ShuffleWriter + +/** + * A ShuffleMapTask divides the elements of an RDD into multiple buckets (based on a partitioner + * specified in the ShuffleDependency). + * + * See [[org.apache.spark.scheduler.Task]] for more information. + * + * @param stageId id of the stage this task belongs to + * @param stageAttemptId attempt id of the stage this task belongs to + * @param taskBinary broadcast version of the RDD and the ShuffleDependency. Once deserialized, + * the type should be (RDD[_], ShuffleDependency[_, _, _]). + * @param partition partition of the RDD this task is associated with + * @param locs preferred task execution locations for locality scheduling + * @param localProperties copy of thread-local properties set by the user on the driver side. + * @param serializedTaskMetrics a `TaskMetrics` that is created and serialized on the driver side + * and sent to executor side. + * @param totalShuffleNum total shuffle number for current job. + * + * The parameters below are optional: + * @param jobId id of the job this task belongs to + * @param appId id of the app this task belongs to + * @param appAttemptId attempt id of the app this task belongs to + */ +private[spark] class ContinuousShuffleMapTask( --- End diff -- Implementation about ContinuousShuffleMapTask same with #21293 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21353: [SPARK-24036][SS] Scheduler changes for continuou...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21353#discussion_r188974718
--- Diff: core/src/main/scala/org/apache/spark/SparkEnv.scala ---
@@ -140,6 +140,7 @@ object SparkEnv extends Logging {
private[spark] val driverSystemName = "sparkDriver"
private[spark] val executorSystemName = "sparkExecutor"
+ private[spark] val START_EPOCH_KEY = "__continuous_start_epoch"
--- End diff --
Changes about SparkEnv same in #21293
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21353: [SPARK-24036][SS] Scheduler changes for continuou...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21353#discussion_r188974568 --- Diff: core/src/main/scala/org/apache/spark/MapOutputTracker.scala --- @@ -213,6 +213,12 @@ private[spark] sealed trait MapOutputTrackerMessage private[spark] case class GetMapOutputStatuses(shuffleId: Int) extends MapOutputTrackerMessage private[spark] case object StopMapOutputTracker extends MapOutputTrackerMessage +private[spark] case class CheckNoMissingPartitions(shuffleId: Int) --- End diff -- Changes about MapOutputTracker same in #21293 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21353: [SPARK-24036][SS] Scheduler changes for continuou...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21353#discussion_r188974319
--- Diff: core/src/main/scala/org/apache/spark/Dependency.scala ---
@@ -88,14 +96,53 @@ class ShuffleDependency[K: ClassTag, V: ClassTag, C:
ClassTag](
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
- val shuffleId: Int = _rdd.context.newShuffleId()
+ val shuffleId: Int = if (isContinuous) {
+// This will not be reset in continuous processing, set an invalid
value for now.
+Int.MinValue
+ } else {
+_rdd.context.newShuffleId()
+ }
- val shuffleHandle: ShuffleHandle =
_rdd.context.env.shuffleManager.registerShuffle(
-shuffleId, _rdd.partitions.length, this)
+ val shuffleHandle: ShuffleHandle = if (isContinuous) {
+null
+ } else {
+_rdd.context.env.shuffleManager.registerShuffle(
+ shuffleId, _rdd.partitions.length, this)
+ }
- _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
+ if (!isContinuous) {
+_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
+ }
}
+/**
+ * :: DeveloperApi ::
+ * Represents a dependency on the output of a shuffle stage of continuous
type.
+ * Different with ShuffleDependency, the continuous dependency only create
on Executor side,
+ * so the rdd in param is deserialized from taskBinary.
+ */
+@DeveloperApi
+class ContinuousShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
--- End diff --
Changes about ShuffleDependency same in #21293
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21353: [SPARK-24036][SS] Scheduler changes for continuou...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/21353 [SPARK-24036][SS] Scheduler changes for continuous processing shuffle support ## What changes were proposed in this pull request? This is the last part of the preview PRs, the mainly change is in DAGScheduler, we added a interface to submit whole job at once. In order to work and compile properly, this also including several parts in #21332 and #21293. I will marked the duplicated part for convenient review. Sorry about this... ## How was this patch tested? Added new UT You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-24304 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21353.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21353 commit fbcc88bfb0d2fb6dbaae9664d6f0852b71e64f2b Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-10T09:18:16Z commit for continuous map output tracker commit 44ae9d917c354d780071a8e112a118674865143d Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-04T03:58:06Z INF-SPARK-1382: Continuous shuffle map task implementation and output trackder support commit af2d60854856e669f40a03b76fffe02dac7b79c2 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-10T13:23:39Z Address comments commit 56442dc1c7450518d9bc84b4bfeddb017daa967b Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-11T12:12:29Z Fix mima test commit 2ac9980f30b8b50809aa780035281f6a62ad9573 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-17T13:01:33Z add inteface to submit all stages of one job in DAGScheduler commit 0f070fc5b26a3e2d5c30fdd7d59c4dd8896255ac Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-17T13:05:29Z fix commit 42e2a63f68ba12264f001ed53ff33c27c1287de8 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-17T13:36:32Z Merge SPARK-24304 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21332: [SPARK-24236][SS] Continuous replacement for ShuffleExch...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21332 > As discussed in the other PR, I'm not sure about how we're integrating with the scheduler here, so I can't really give a more detailed review at this point. My bad, I'm preparing the part about integrating with scheduler first. That's the last part for our preview PR. I will marked the duplicated part of #21293 for convenient review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21114: [SPARK-22371][CORE] Return None instead of throwing an e...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21114 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21337: [SPARK-24234][SS] Reader for continuous processin...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21337#discussion_r188604001
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/shuffle/ContinuousShuffleReadRDD.scala
---
@@ -0,0 +1,64 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.continuous.shuffle
+
+import java.util.UUID
+
+import org.apache.spark.{Partition, SparkContext, SparkEnv, TaskContext}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.util.NextIterator
+
+case class ContinuousShuffleReadPartition(index: Int) extends Partition {
+ // Initialized only on the executor, and only once even as we call
compute() multiple times.
+ lazy val (receiver, endpoint) = {
+val env = SparkEnv.get.rpcEnv
+val receiver = new UnsafeRowReceiver(env)
+val endpoint = env.setupEndpoint(UUID.randomUUID().toString, receiver)
+TaskContext.get().addTaskCompletionListener { ctx =>
+ env.stop(endpoint)
+}
+(receiver, endpoint)
+ }
+}
+
+/**
+ * RDD at the bottom of each continuous processing shuffle task, reading
from the
--- End diff --
"Bottom is a bit ambiguous" +1 for this.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21337: [SPARK-24234][SS] Reader for continuous processin...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21337#discussion_r188601016
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/shuffle/UnsafeRowReceiver.scala
---
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.continuous.shuffle
+
+import java.util.concurrent.{ArrayBlockingQueue, BlockingQueue}
+import java.util.concurrent.atomic.AtomicBoolean
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.rpc.{RpcCallContext, RpcEnv, ThreadSafeRpcEndpoint}
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+
+/**
+ * Messages for the UnsafeRowReceiver endpoint. Either an incoming row or
an epoch marker.
+ */
+private[shuffle] sealed trait UnsafeRowReceiverMessage extends Serializable
+private[shuffle] case class ReceiverRow(row: UnsafeRow) extends
UnsafeRowReceiverMessage
+private[shuffle] case class ReceiverEpochMarker() extends
UnsafeRowReceiverMessage
+
+/**
+ * RPC endpoint for receiving rows into a continuous processing shuffle
task.
+ */
+private[shuffle] class UnsafeRowReceiver(val rpcEnv: RpcEnv)
--- End diff --
override val rpcEnv here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21332: [SPARK-24236][SS] Continuous replacement for ShuffleExch...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21332 cc @jose-torres As we discussion in #21293, the main difference between us is whether we can reuse current implementation of scheduler and shuffle, but in this part about the implementation of ShuffleExchangeExec, we may have the same imagine. Can you give a review about this? Great thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21332: [SPARK-24236][SS] Continuous replacement for Shuf...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/21332 [SPARK-24236][SS] Continuous replacement for ShuffleExchangeExec ## What changes were proposed in this pull request? 1. New RDD named ContinuousShuffleRowRDD 2. New case class ContinuousShuffleExchangeExec 3. The rule named ReplaceShuffleExchange to replace original ShuffleExchange to ContinuousShuffleExhcange ## How was this patch tested? Existing UT. Add more UT later. Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-24236 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21332.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21332 commit 09e5ec9dcf3b1822eee02d10f29eb3f02d806485 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-15T13:20:59Z Add ContinuousShuffledRowRDD for cp shuffle commit 70c2a2b3016703950746142823fec147041b5158 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-08T12:41:46Z INF-SPARK-1388: Implementation of ContinuousShuffleExchange and corresponding rule commit bd05db1344e5d89136f9bda51f2c0cf292abe4cc Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-09T10:04:01Z INF-SPARK-1388: Refactor commit 91d1bab0eeea612565b701166070d88b2e36882e Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-15T13:41:59Z ContinuouShuffleRowRDD support multi compute calls commit 42c7b29ce49650c79f06d2269d4f2bff029ffe9e Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-11T08:42:27Z INF-SPARK-1392: fix mima test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21293: [SPARK-24237][SS] Continuous shuffle dependency and map ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21293 @jose-torres Great thanks for you advise and guidance for us! I found the main difference between us is whether we can reuse current implementation of scheduler and shuffle. I marked in your design here:https://docs.google.com/document/d/1IL4kJoKrZWeyIhklKUJqsW-yEN7V7aL05MmM65AYOfE/edit?disco=B4z058g --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r188277683
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/ContinuousShuffleMapTask.scala
---
@@ -0,0 +1,139 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.scheduler
+
+import java.lang.management.ManagementFactory
+import java.nio.ByteBuffer
+import java.util.Properties
+
+import scala.language.existentials
+
+import org.apache.spark._
+import org.apache.spark.broadcast.Broadcast
+import org.apache.spark.internal.Logging
+import org.apache.spark.rdd.RDD
+import org.apache.spark.shuffle.ShuffleWriter
+
+/**
+ * A ShuffleMapTask divides the elements of an RDD into multiple buckets
(based on a partitioner
+ * specified in the ShuffleDependency).
+ *
+ * See [[org.apache.spark.scheduler.Task]] for more information.
+ *
+ * @param stageId id of the stage this task belongs to
+ * @param stageAttemptId attempt id of the stage this task belongs to
+ * @param taskBinary broadcast version of the RDD and the
ShuffleDependency. Once deserialized,
+ * the type should be (RDD[_], ShuffleDependency[_, _,
_]).
+ * @param partition partition of the RDD this task is associated with
+ * @param locs preferred task execution locations for locality scheduling
+ * @param localProperties copy of thread-local properties set by the user
on the driver side.
+ * @param serializedTaskMetrics a `TaskMetrics` that is created and
serialized on the driver side
+ * and sent to executor side.
+ * @param totalShuffleNum total shuffle number for current job.
+ *
+ * The parameters below are optional:
+ * @param jobId id of the job this task belongs to
+ * @param appId id of the app this task belongs to
+ * @param appAttemptId attempt id of the app this task belongs to
+ */
+private[spark] class ContinuousShuffleMapTask(
+stageId: Int,
+stageAttemptId: Int,
+taskBinary: Broadcast[Array[Byte]],
+partition: Partition,
+@transient private var locs: Seq[TaskLocation],
+localProperties: Properties,
+serializedTaskMetrics: Array[Byte],
+totalShuffleNum: Int,
+jobId: Option[Int] = None,
+appId: Option[String] = None,
+appAttemptId: Option[String] = None)
+ extends Task[Unit](stageId, stageAttemptId, partition.index,
localProperties,
+serializedTaskMetrics, jobId, appId, appAttemptId)
+with Logging {
+
+ /** A constructor used only in test suites. This does not require
passing in an RDD. */
+ def this(partitionId: Int, totalShuffleNum: Int) {
+this(0, 0, null, new Partition { override def index: Int = 0 }, null,
new Properties,
+ null, totalShuffleNum)
+ }
+
+ @transient private val preferredLocs: Seq[TaskLocation] = {
+if (locs == null) Nil else locs.toSet.toSeq
+ }
+
+ // TODO: Get current epoch from epoch coordinator while task restart,
also epoch is Long, we
+ // should deal with it.
+ var currentEpoch =
context.getLocalProperty(SparkEnv.START_EPOCH_KEY).toInt
+
+ override def runTask(context: TaskContext): Unit = {
+// Deserialize the RDD using the broadcast variable.
+val threadMXBean = ManagementFactory.getThreadMXBean
+val deserializeStartTime = System.currentTimeMillis()
+val deserializeStartCpuTime = if
(threadMXBean.isCurrentThreadCpuTimeSupported) {
+ threadMXBean.getCurrentThreadCpuTime
+} else 0L
+val ser = SparkEnv.get.closureSerializer.newInstance()
+// TODO: rdd here should be a wrap of ShuffledRowRDD which never stop
+val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
+ ByteBuffer.wrap(taskBinary.value),
Thread.currentThread.getContextClassLoader)
+_executorDeserializeTime = System.currentTimeMillis() -
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21293#discussion_r188273722 --- Diff: core/src/main/scala/org/apache/spark/MapOutputTracker.scala --- @@ -769,6 +796,43 @@ private[spark] class MapOutputTrackerWorker(conf: SparkConf) extends MapOutputTr } } +/** + * MapOutputTrackerWorker for continuous processing, the main difference with MapOutputTracker + * is waiting for a time when the upstream's map output status not ready. --- End diff -- The current implement of ContinuousShuffleMapOutputTracker didn't change existing behavior, just choose the corresponding output tracker instance by the job type. After we use a better way of mark a job is continuous mode(discuss in https://github.com/apache/spark/pull/21293#discussion-diff-187368178R231), they do different things and not use same codepath. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r188270290
--- Diff: core/src/main/scala/org/apache/spark/Dependency.scala ---
@@ -88,14 +90,53 @@ class ShuffleDependency[K: ClassTag, V: ClassTag, C:
ClassTag](
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
- val shuffleId: Int = _rdd.context.newShuffleId()
+ val shuffleId: Int = if (isContinuous) {
+// This will not be reset in continuous processing, set an invalid
value for now.
+Int.MinValue
+ } else {
+_rdd.context.newShuffleId()
+ }
- val shuffleHandle: ShuffleHandle =
_rdd.context.env.shuffleManager.registerShuffle(
-shuffleId, _rdd.partitions.length, this)
+ val shuffleHandle: ShuffleHandle = if (isContinuous) {
+null
+ } else {
+_rdd.context.env.shuffleManager.registerShuffle(
+ shuffleId, _rdd.partitions.length, this)
+ }
- _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
+ if (!isContinuous) {
+_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
+ }
}
+/**
+ * :: DeveloperApi ::
+ * Represents a dependency on the output of a shuffle stage of continuous
type.
+ * Different with ShuffleDependency, the continuous dependency only create
on Executor side,
+ * so the rdd in param is deserialized from taskBinary.
+ */
+@DeveloperApi
+class ContinuousShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
+rdd: RDD[_ <: Product2[K, V]],
+dep: ShuffleDependency[K, V, C],
+continuousEpoch: Int,
+totalShuffleNum: Int,
+shuffleNumMaps: Int)
+ extends ShuffleDependency[K, V, C](
+rdd,
+dep.partitioner,
+dep.serializer,
+dep.keyOrdering,
+dep.aggregator,
+dep.mapSideCombine, true) {
+
+ val baseShuffleId: Int = dep.shuffleId
+
+ override val shuffleId: Int = continuousEpoch * totalShuffleNum +
baseShuffleId
--- End diff --
Got it, if we move EpochCoordinator to SparkEnv, I think we can
re-implement the shuffle register on driver side, totally controlled by
EpochCoordinator. Even if the EpochCoordinator doesn't manage the shuffle
register work, I think EpochCoordinator should move to SparkEnv and take more
work in shuffle support in your design, am I right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r188269208
--- Diff: core/src/main/scala/org/apache/spark/Dependency.scala ---
@@ -65,15 +65,17 @@ abstract class NarrowDependency[T](_rdd: RDD[T])
extends Dependency[T] {
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also
known as map-side combine)
+ * @param isContinuous mark the dependency is base for continuous
processing or not
--- End diff --
Got it, if we think currently implementation is tricky here, we can change
the implementation by getting rid of the ContinuousShuffleDependency, just as
you said in jira comments :"We might not need this to be an actual
org.apache.spark.Dependency."
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r188152980
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -237,6 +236,65 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
acc.merge("kindness")
assert(acc.value === "kindness")
}
+
+ test("updating garbage collected accumulators") {
--- End diff --
This test can reproduce the crush scenario in original code base and
successful ended after this patch. I think @cloud-fan is worrying about this
test shouldn't commit in code base because it complexityï¼
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21114: [SPARK-22371][CORE] Return None instead of throwing an e...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21114 cc @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187823469
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -237,6 +236,65 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
acc.merge("kindness")
assert(acc.value === "kindness")
}
+
+ test("updating garbage collected accumulators") {
+// Simulate FetchFailedException in the first attempt to force a retry.
+// Then complete remaining task from the first attempt after the second
+// attempt started, but before it completes. Completion event for the
first
+// attempt will try to update garbage collected accumulators.
+val numPartitions = 2
+sc = new SparkContext("local[2]", "test")
+
+val attempt0Latch = new TestLatch("attempt0")
+val attempt1Latch = new TestLatch("attempt1")
+
+val x = sc.parallelize(1 to 100, numPartitions).groupBy(identity)
+val sid = x.dependencies.head.asInstanceOf[ShuffleDependency[_, _,
_]].shuffleHandle.shuffleId
+val rdd = x.mapPartitionsWithIndex { case (i, iter) =>
+ val taskContext = TaskContext.get()
+ if (taskContext.stageAttemptNumber() == 0) {
+if (i == 0) {
+ // Fail the first task in the first stage attempt to force retry.
+ throw new FetchFailedException(
+SparkEnv.get.blockManager.blockManagerId,
+sid,
+taskContext.partitionId(),
+taskContext.partitionId(),
+"simulated fetch failure")
+} else {
+ // Wait till the second attempt starts.
+ attempt0Latch.await()
+ iter
+}
+ } else {
+if (i == 0) {
+ // Wait till the first attempt completes.
+ attempt1Latch.await()
+}
+iter
+ }
+}
+
+sc.addSparkListener(new SparkListener {
+ override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = {
+if (taskStart.stageId == 1 && taskStart.stageAttemptId == 1) {
--- End diff --
Got it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187763308
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -237,6 +236,65 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
acc.merge("kindness")
assert(acc.value === "kindness")
}
+
+ test("updating garbage collected accumulators") {
+// Simulate FetchFailedException in the first attempt to force a retry.
+// Then complete remaining task from the first attempt after the second
+// attempt started, but before it completes. Completion event for the
first
+// attempt will try to update garbage collected accumulators.
+val numPartitions = 2
+sc = new SparkContext("local[2]", "test")
+
+val attempt0Latch = new TestLatch("attempt0")
+val attempt1Latch = new TestLatch("attempt1")
+
+val x = sc.parallelize(1 to 100, numPartitions).groupBy(identity)
+val sid = x.dependencies.head.asInstanceOf[ShuffleDependency[_, _,
_]].shuffleHandle.shuffleId
+val rdd = x.mapPartitionsWithIndex { case (i, iter) =>
+ val taskContext = TaskContext.get()
+ if (taskContext.stageAttemptNumber() == 0) {
+if (i == 0) {
+ // Fail the first task in the first stage attempt to force retry.
+ throw new FetchFailedException(
+SparkEnv.get.blockManager.blockManagerId,
+sid,
+taskContext.partitionId(),
+taskContext.partitionId(),
+"simulated fetch failure")
+} else {
+ // Wait till the second attempt starts.
+ attempt0Latch.await()
+ iter
+}
+ } else {
+if (i == 0) {
+ // Wait till the first attempt completes.
+ attempt1Latch.await()
+}
+iter
+ }
+}
+
+sc.addSparkListener(new SparkListener {
+ override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = {
+if (taskStart.stageId == 1 && taskStart.stageAttemptId == 1) {
--- End diff --
Should we add 'taskStart.taskInfo.index == 0' here to make sure it's the
partition 0?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187763285
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -209,10 +209,8 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
System.gc()
assert(ref.get.isEmpty)
-// Getting a garbage collected accum should throw error
-intercept[IllegalStateException] {
- AccumulatorContext.get(accId)
-}
+// Getting a garbage collected accum should return None.
+assert(AccumulatorContext.get(accId).isEmpty)
--- End diff --
Cool!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21293#discussion_r187599741 --- Diff: core/src/main/scala/org/apache/spark/MapOutputTracker.scala --- @@ -769,6 +796,43 @@ private[spark] class MapOutputTrackerWorker(conf: SparkConf) extends MapOutputTr } } +/** + * MapOutputTrackerWorker for continuous processing, the main difference with MapOutputTracker + * is waiting for a time when the upstream's map output status not ready. --- End diff -- Maybe we didn't change here, IIUC in batch mode, child stage only submitted while no missing partition of parent stage. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r187598787
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/ContinuousShuffleMapTask.scala
---
@@ -0,0 +1,139 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.scheduler
+
+import java.lang.management.ManagementFactory
+import java.nio.ByteBuffer
+import java.util.Properties
+
+import scala.language.existentials
+
+import org.apache.spark._
+import org.apache.spark.broadcast.Broadcast
+import org.apache.spark.internal.Logging
+import org.apache.spark.rdd.RDD
+import org.apache.spark.shuffle.ShuffleWriter
+
+/**
+ * A ShuffleMapTask divides the elements of an RDD into multiple buckets
(based on a partitioner
+ * specified in the ShuffleDependency).
+ *
+ * See [[org.apache.spark.scheduler.Task]] for more information.
+ *
+ * @param stageId id of the stage this task belongs to
+ * @param stageAttemptId attempt id of the stage this task belongs to
+ * @param taskBinary broadcast version of the RDD and the
ShuffleDependency. Once deserialized,
+ * the type should be (RDD[_], ShuffleDependency[_, _,
_]).
+ * @param partition partition of the RDD this task is associated with
+ * @param locs preferred task execution locations for locality scheduling
+ * @param localProperties copy of thread-local properties set by the user
on the driver side.
+ * @param serializedTaskMetrics a `TaskMetrics` that is created and
serialized on the driver side
+ * and sent to executor side.
+ * @param totalShuffleNum total shuffle number for current job.
+ *
+ * The parameters below are optional:
+ * @param jobId id of the job this task belongs to
+ * @param appId id of the app this task belongs to
+ * @param appAttemptId attempt id of the app this task belongs to
+ */
+private[spark] class ContinuousShuffleMapTask(
+stageId: Int,
+stageAttemptId: Int,
+taskBinary: Broadcast[Array[Byte]],
+partition: Partition,
+@transient private var locs: Seq[TaskLocation],
+localProperties: Properties,
+serializedTaskMetrics: Array[Byte],
+totalShuffleNum: Int,
+jobId: Option[Int] = None,
+appId: Option[String] = None,
+appAttemptId: Option[String] = None)
+ extends Task[Unit](stageId, stageAttemptId, partition.index,
localProperties,
+serializedTaskMetrics, jobId, appId, appAttemptId)
+with Logging {
+
+ /** A constructor used only in test suites. This does not require
passing in an RDD. */
+ def this(partitionId: Int, totalShuffleNum: Int) {
+this(0, 0, null, new Partition { override def index: Int = 0 }, null,
new Properties,
+ null, totalShuffleNum)
+ }
+
+ @transient private val preferredLocs: Seq[TaskLocation] = {
+if (locs == null) Nil else locs.toSet.toSeq
+ }
+
+ // TODO: Get current epoch from epoch coordinator while task restart,
also epoch is Long, we
+ // should deal with it.
+ var currentEpoch =
context.getLocalProperty(SparkEnv.START_EPOCH_KEY).toInt
+
+ override def runTask(context: TaskContext): Unit = {
+// Deserialize the RDD using the broadcast variable.
+val threadMXBean = ManagementFactory.getThreadMXBean
+val deserializeStartTime = System.currentTimeMillis()
+val deserializeStartCpuTime = if
(threadMXBean.isCurrentThreadCpuTimeSupported) {
+ threadMXBean.getCurrentThreadCpuTime
+} else 0L
+val ser = SparkEnv.get.closureSerializer.newInstance()
+// TODO: rdd here should be a wrap of ShuffledRowRDD which never stop
+val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
+ ByteBuffer.wrap(taskBinary.value),
Thread.currentThread.getContextClassLoader)
+_executorDeserializeTime = System.currentTimeMillis() -
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r187598365
--- Diff: core/src/main/scala/org/apache/spark/SparkEnv.scala ---
@@ -227,6 +228,7 @@ object SparkEnv extends Logging {
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] =
None): SparkEnv = {
val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER
+val isContinuous = conf.getBoolean("spark.streaming.continuousMode",
false)
--- End diff --
Yep, I agree, we are now trying to set this in physical plan, not in user
config.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r187598100
--- Diff: core/src/main/scala/org/apache/spark/MapOutputTracker.scala ---
@@ -233,6 +239,28 @@ private[spark] class MapOutputTrackerMasterEndpoint(
logInfo("MapOutputTrackerMasterEndpoint stopped!")
context.reply(true)
stop()
+
+case CheckNoMissingPartitions(shuffleId: Int) =>
+ logInfo(s"Checking missing partitions for $shuffleId")
+ // If get None from findMissingPartitions, just return a non-empty
Seq
+ val missing =
tracker.findMissingPartitions(shuffleId).getOrElse(Seq(0))
+ if (missing.isEmpty) {
+context.reply(true)
+ } else {
+context.reply(false)
+ }
+
+case CheckAndRegisterShuffle(shuffleId: Int, numMaps: Int) =>
--- End diff --
As the usage of ContinuousShuffleDependency, we only use it on executor
side, the original shuffle register only on driver side.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r187597922
--- Diff: core/src/main/scala/org/apache/spark/Dependency.scala ---
@@ -88,14 +90,53 @@ class ShuffleDependency[K: ClassTag, V: ClassTag, C:
ClassTag](
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
- val shuffleId: Int = _rdd.context.newShuffleId()
+ val shuffleId: Int = if (isContinuous) {
+// This will not be reset in continuous processing, set an invalid
value for now.
+Int.MinValue
+ } else {
+_rdd.context.newShuffleId()
+ }
- val shuffleHandle: ShuffleHandle =
_rdd.context.env.shuffleManager.registerShuffle(
-shuffleId, _rdd.partitions.length, this)
+ val shuffleHandle: ShuffleHandle = if (isContinuous) {
+null
+ } else {
+_rdd.context.env.shuffleManager.registerShuffle(
+ shuffleId, _rdd.partitions.length, this)
+ }
- _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
+ if (!isContinuous) {
+_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
+ }
}
+/**
+ * :: DeveloperApi ::
+ * Represents a dependency on the output of a shuffle stage of continuous
type.
+ * Different with ShuffleDependency, the continuous dependency only create
on Executor side,
+ * so the rdd in param is deserialized from taskBinary.
+ */
+@DeveloperApi
+class ContinuousShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
+rdd: RDD[_ <: Product2[K, V]],
+dep: ShuffleDependency[K, V, C],
+continuousEpoch: Int,
+totalShuffleNum: Int,
+shuffleNumMaps: Int)
+ extends ShuffleDependency[K, V, C](
+rdd,
+dep.partitioner,
+dep.serializer,
+dep.keyOrdering,
+dep.aggregator,
+dep.mapSideCombine, true) {
+
+ val baseShuffleId: Int = dep.shuffleId
+
+ override val shuffleId: Int = continuousEpoch * totalShuffleNum +
baseShuffleId
--- End diff --
Here we use the generated shuffleId only for shuffle registering and
identifying, can we consider the DAG never change and each epoch will has same
dependency just with diff shuffleId?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21293#discussion_r187596748
--- Diff: core/src/main/scala/org/apache/spark/Dependency.scala ---
@@ -65,15 +65,17 @@ abstract class NarrowDependency[T](_rdd: RDD[T])
extends Dependency[T] {
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also
known as map-side combine)
+ * @param isContinuous mark the dependency is base for continuous
processing or not
--- End diff --
Actually we can implement ContinuousShuffleDependency by inheriting
Dependency. In current way few interface can be changed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21293: [SPARK-24237][SS] Continuous shuffle dependency and map ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21293 cc @jose-torres @zsxwing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21293: [SPARK-24237][SS] Continuous shuffle dependency a...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/21293 [SPARK-24237][SS] Continuous shuffle dependency and map output tracker ## What changes were proposed in this pull request? As our disscussion in [jira comment](https://issues.apache.org/jira/browse/SPARK-24036?focusedCommentId=16470067=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16470067) and [design comment](https://docs.google.com/document/d/1IL4kJoKrZWeyIhklKUJqsW-yEN7V7aL05MmM65AYOfE/edit?disco=B4X1H_E) and [design doc](https://docs.google.com/document/d/14cGJ75v9myznywtB35ytEqL9wHy9xfZRv06B6g2tUgI/edit#bookmark=id.2lfv2glj7ny0), this pr including the following changes: 1. Add ContinuousShuffleDependency support, which can allow shuffleId generated from epoch and re-register shuffleHandle with new shuffleId. 2. Add ContinuousMapOutputTrackerWorker, which can get shuffle status by a blocking way, and support register shuffle\map ouput in tracker worker. 3. Add ContinuousShuffleMapTask. ## How was this patch tested? Add a new UT for ContinuousMapOutputTracker. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-24237 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21293.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21293 commit fbcc88bfb0d2fb6dbaae9664d6f0852b71e64f2b Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-10T09:18:16Z commit for continuous map output tracker commit 44ae9d917c354d780071a8e112a118674865143d Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-04T03:58:06Z INF-SPARK-1382: Continuous shuffle map task implementation and output trackder support commit af2d60854856e669f40a03b76fffe02dac7b79c2 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-05-10T13:23:39Z Address comments --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21199: [SPARK-24127][SS] Continuous text socket source
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21199#discussion_r186764630
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousTextSocketSource.scala
---
@@ -0,0 +1,304 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.continuous
+
+import java.io.{BufferedReader, InputStreamReader, IOException}
+import java.net.Socket
+import java.sql.Timestamp
+import java.text.SimpleDateFormat
+import java.util.{Calendar, List => JList, Locale}
+import javax.annotation.concurrent.GuardedBy
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+import org.json4s.{DefaultFormats, NoTypeHints}
+import org.json4s.jackson.Serialization
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.rpc.{RpcCallContext, RpcEndpointRef, RpcEnv,
ThreadSafeRpcEndpoint}
+import org.apache.spark.sql._
+import
org.apache.spark.sql.execution.streaming.continuous.TextSocketContinuousReader.GetRecord
+import org.apache.spark.sql.sources.v2.DataSourceOptions
+import org.apache.spark.sql.sources.v2.reader.{DataReader,
DataReaderFactory}
+import
org.apache.spark.sql.sources.v2.reader.streaming.{ContinuousDataReader,
ContinuousReader, Offset, PartitionOffset}
+import org.apache.spark.sql.types.{StringType, StructField, StructType,
TimestampType}
+import org.apache.spark.util.RpcUtils
+
+
+object TextSocketContinuousReader {
+ val SCHEMA_REGULAR = StructType(StructField("value", StringType) :: Nil)
+ val SCHEMA_TIMESTAMP = StructType(
+StructField("value", StringType)
+ :: StructField("timestamp", TimestampType) :: Nil)
+ val DATE_FORMAT = new SimpleDateFormat("-MM-dd HH:mm:ss", Locale.US)
+
+ case class GetRecord(offset: TextSocketPartitionOffset)
+
+}
+
+/**
+ * A ContinuousReader that reads text lines through a TCP socket, designed
only for tutorials and
+ * debugging. This ContinuousReader will *not* work in production
applications due to multiple
+ * reasons, including no support for fault recovery.
+ *
+ * The driver maintains a socket connection to the host-port, keeps the
received messages in
+ * buckets and serves the messages to the executors via a RPC endpoint.
+ */
+class TextSocketContinuousReader(options: DataSourceOptions) extends
ContinuousReader with Logging {
+ implicit val defaultFormats: DefaultFormats = DefaultFormats
+
+ private val host: String = options.get("host").get()
+ private val port: Int = options.get("port").get().toInt
+
+ assert(SparkSession.getActiveSession.isDefined)
+ private val spark = SparkSession.getActiveSession.get
+ private val numPartitions = spark.sparkContext.defaultParallelism
+
+ @GuardedBy("this")
+ private var socket: Socket = _
+
+ @GuardedBy("this")
+ private var readThread: Thread = _
+
+ @GuardedBy("this")
+ private val buckets = Seq.fill(numPartitions)(new ListBuffer[(String,
Timestamp)])
+
+ @GuardedBy("this")
+ private var currentOffset: Int = -1
+
+ private var startOffset: TextSocketOffset = _
+
+ private val recordEndpoint = new RecordEndpoint()
+ @volatile private var endpointRef: RpcEndpointRef = _
+
+ initialize()
+
+ override def mergeOffsets(offsets: Array[PartitionOffset]): Offset = {
+assert(offsets.length == numPartitions)
+val offs = offsets
+ .map(_.asInstanceOf[TextSocketPartitionOffset])
+ .sortBy(_.partitionId)
+ .map(_.offset)
+ .toList
+TextSocketOffset(offs)
+ }
+
+ override def deserializeOffset(json: String): Offset = {
+TextSocketOffset(Seria
[GitHub] spark pull request #21199: [SPARK-24127][SS] Continuous text socket source
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21199#discussion_r186765402
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousTextSocketSource.scala
---
@@ -0,0 +1,304 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.continuous
+
+import java.io.{BufferedReader, InputStreamReader, IOException}
+import java.net.Socket
+import java.sql.Timestamp
+import java.text.SimpleDateFormat
+import java.util.{Calendar, List => JList, Locale}
+import javax.annotation.concurrent.GuardedBy
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+import org.json4s.{DefaultFormats, NoTypeHints}
+import org.json4s.jackson.Serialization
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.rpc.{RpcCallContext, RpcEndpointRef, RpcEnv,
ThreadSafeRpcEndpoint}
+import org.apache.spark.sql._
+import
org.apache.spark.sql.execution.streaming.continuous.TextSocketContinuousReader.GetRecord
+import org.apache.spark.sql.sources.v2.DataSourceOptions
+import org.apache.spark.sql.sources.v2.reader.{DataReader,
DataReaderFactory}
+import
org.apache.spark.sql.sources.v2.reader.streaming.{ContinuousDataReader,
ContinuousReader, Offset, PartitionOffset}
+import org.apache.spark.sql.types.{StringType, StructField, StructType,
TimestampType}
+import org.apache.spark.util.RpcUtils
+
+
+object TextSocketContinuousReader {
+ val SCHEMA_REGULAR = StructType(StructField("value", StringType) :: Nil)
+ val SCHEMA_TIMESTAMP = StructType(
+StructField("value", StringType)
+ :: StructField("timestamp", TimestampType) :: Nil)
+ val DATE_FORMAT = new SimpleDateFormat("-MM-dd HH:mm:ss", Locale.US)
+
+ case class GetRecord(offset: TextSocketPartitionOffset)
+
+}
+
+/**
+ * A ContinuousReader that reads text lines through a TCP socket, designed
only for tutorials and
+ * debugging. This ContinuousReader will *not* work in production
applications due to multiple
+ * reasons, including no support for fault recovery.
+ *
+ * The driver maintains a socket connection to the host-port, keeps the
received messages in
+ * buckets and serves the messages to the executors via a RPC endpoint.
+ */
+class TextSocketContinuousReader(options: DataSourceOptions) extends
ContinuousReader with Logging {
+ implicit val defaultFormats: DefaultFormats = DefaultFormats
+
+ private val host: String = options.get("host").get()
+ private val port: Int = options.get("port").get().toInt
+
+ assert(SparkSession.getActiveSession.isDefined)
+ private val spark = SparkSession.getActiveSession.get
+ private val numPartitions = spark.sparkContext.defaultParallelism
+
+ @GuardedBy("this")
+ private var socket: Socket = _
+
+ @GuardedBy("this")
+ private var readThread: Thread = _
+
+ @GuardedBy("this")
+ private val buckets = Seq.fill(numPartitions)(new ListBuffer[(String,
Timestamp)])
+
+ @GuardedBy("this")
+ private var currentOffset: Int = -1
+
+ private var startOffset: TextSocketOffset = _
+
+ private val recordEndpoint = new RecordEndpoint()
+ @volatile private var endpointRef: RpcEndpointRef = _
+
+ initialize()
+
+ override def mergeOffsets(offsets: Array[PartitionOffset]): Offset = {
+assert(offsets.length == numPartitions)
+val offs = offsets
+ .map(_.asInstanceOf[TextSocketPartitionOffset])
+ .sortBy(_.partitionId)
+ .map(_.offset)
+ .toList
+TextSocketOffset(offs)
+ }
+
+ override def deserializeOffset(json: String): Offset = {
+TextSocketOffset(Seria
[GitHub] spark issue #21188: [SPARK-24046][SS] Fix rate source rowsPerSecond <= rampU...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21188 @maasg as comment in #21194, I just consider we should not change the behavior while `seconds > rampUpTimeSeconds`. Maybe it more important than smooth. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21188: [SPARK-24046][SS] Fix rate source rowsPerSecond <...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21188#discussion_r185852663
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProvider.scala
---
@@ -107,14 +107,25 @@ object RateStreamProvider {
// seconds = 0 1 2 3 4 5 6
// speed = 0 2 4 6 8 10 10 (speedDeltaPerSecond * seconds)
// end value = 0 2 6 12 20 30 40 (0 + speedDeltaPerSecond * seconds) *
(seconds + 1) / 2
-val speedDeltaPerSecond = rowsPerSecond / (rampUpTimeSeconds + 1)
+val speedDeltaPerSecond = math.max(1, rowsPerSecond /
(rampUpTimeSeconds + 1))
--- End diff --
Keep at-least 1 per second and leave other seconds to 0 is ok IMOP.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21194: [SPARK-24046][SS] Fix rate source when rowsPerSec...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21194#discussion_r185851172
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProviderSuite.scala
---
@@ -173,55 +173,154 @@ class RateSourceSuite extends StreamTest {
assert(readData.map(_.getLong(1)).sorted == Range(0, 33))
}
- test("valueAtSecond") {
+ test("valueAtSecond without ramp-up") {
import RateStreamProvider._
+val rowsPerSec = Seq(1,10,50,100,1000,1)
+val secs = Seq(1, 10, 100, 1000, 1, 10)
+for {
+ sec <- secs
+ rps <- rowsPerSec
+} yield {
+ assert(valueAtSecond(seconds = sec, rowsPerSecond = rps,
rampUpTimeSeconds = 0) === sec * rps)
+}
+ }
-assert(valueAtSecond(seconds = 0, rowsPerSecond = 5, rampUpTimeSeconds
= 0) === 0)
-assert(valueAtSecond(seconds = 1, rowsPerSecond = 5, rampUpTimeSeconds
= 0) === 5)
+ test("valueAtSecond with ramp-up") {
+import RateStreamProvider._
+val rowsPerSec = Seq(1, 5, 10, 50, 100, 1000, 1)
+val rampUpSec = Seq(10, 100, 1000)
+
+// for any combination, value at zero = 0
+for {
+ rps <- rowsPerSec
+ rampUp <- rampUpSec
+} yield {
+ assert(valueAtSecond(seconds = 0, rowsPerSecond = rps,
rampUpTimeSeconds = rampUp) === 0)
+}
-assert(valueAtSecond(seconds = 0, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 0)
-assert(valueAtSecond(seconds = 1, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 1)
-assert(valueAtSecond(seconds = 2, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 3)
-assert(valueAtSecond(seconds = 3, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 8)
--- End diff --
I try your implement local and it changes the original behavior
```
valueAtSecond(seconds = 1, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 1
valueAtSecond(seconds = 2, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 5
valueAtSecond(seconds = 3, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 10
valueAtSecond(seconds = 4, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 15
```
I think the bug fix should not change the value on `seconds >
rampUpTimeSeconds`, just my opinion, you can ping other committers to review.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21194: [SPARK-24046][SS] Fix rate source when rowsPerSec...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21194#discussion_r185252544
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProvider.scala
---
@@ -101,25 +101,10 @@ object RateStreamProvider {
/** Calculate the end value we will emit at the time `seconds`. */
def valueAtSecond(seconds: Long, rowsPerSecond: Long, rampUpTimeSeconds:
Long): Long = {
-// E.g., rampUpTimeSeconds = 4, rowsPerSecond = 10
-// Then speedDeltaPerSecond = 2
-//
-// seconds = 0 1 2 3 4 5 6
-// speed = 0 2 4 6 8 10 10 (speedDeltaPerSecond * seconds)
-// end value = 0 2 6 12 20 30 40 (0 + speedDeltaPerSecond * seconds) *
(seconds + 1) / 2
-val speedDeltaPerSecond = rowsPerSecond / (rampUpTimeSeconds + 1)
-if (seconds <= rampUpTimeSeconds) {
- // Calculate "(0 + speedDeltaPerSecond * seconds) * (seconds + 1) /
2" in a special way to
- // avoid overflow
- if (seconds % 2 == 1) {
-(seconds + 1) / 2 * speedDeltaPerSecond * seconds
- } else {
-seconds / 2 * speedDeltaPerSecond * (seconds + 1)
- }
-} else {
- // rampUpPart is just a special case of the above formula:
rampUpTimeSeconds == seconds
- val rampUpPart = valueAtSecond(rampUpTimeSeconds, rowsPerSecond,
rampUpTimeSeconds)
- rampUpPart + (seconds - rampUpTimeSeconds) * rowsPerSecond
-}
+val delta = rowsPerSecond.toDouble / rampUpTimeSeconds
+val rampUpSeconds = if (seconds <= rampUpTimeSeconds) seconds else
rampUpTimeSeconds
+val afterRampUpSeconds = if (seconds > rampUpTimeSeconds ) seconds -
rampUpTimeSeconds else 0
+// Use classic distance formula based on accelaration: ut + ½at2
+Math.floor(rampUpSeconds * rampUpSeconds * delta / 2).toLong +
afterRampUpSeconds * rowsPerSecond
--- End diff --
nit: >100 characters
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21194: [SPARK-24046][SS] Fix rate source when rowsPerSec...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21194#discussion_r185252360
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProvider.scala
---
@@ -101,25 +101,10 @@ object RateStreamProvider {
/** Calculate the end value we will emit at the time `seconds`. */
def valueAtSecond(seconds: Long, rowsPerSecond: Long, rampUpTimeSeconds:
Long): Long = {
-// E.g., rampUpTimeSeconds = 4, rowsPerSecond = 10
-// Then speedDeltaPerSecond = 2
-//
-// seconds = 0 1 2 3 4 5 6
-// speed = 0 2 4 6 8 10 10 (speedDeltaPerSecond * seconds)
-// end value = 0 2 6 12 20 30 40 (0 + speedDeltaPerSecond * seconds) *
(seconds + 1) / 2
-val speedDeltaPerSecond = rowsPerSecond / (rampUpTimeSeconds + 1)
-if (seconds <= rampUpTimeSeconds) {
- // Calculate "(0 + speedDeltaPerSecond * seconds) * (seconds + 1) /
2" in a special way to
- // avoid overflow
- if (seconds % 2 == 1) {
-(seconds + 1) / 2 * speedDeltaPerSecond * seconds
- } else {
-seconds / 2 * speedDeltaPerSecond * (seconds + 1)
- }
-} else {
- // rampUpPart is just a special case of the above formula:
rampUpTimeSeconds == seconds
- val rampUpPart = valueAtSecond(rampUpTimeSeconds, rowsPerSecond,
rampUpTimeSeconds)
- rampUpPart + (seconds - rampUpTimeSeconds) * rowsPerSecond
-}
+val delta = rowsPerSecond.toDouble / rampUpTimeSeconds
+val rampUpSeconds = if (seconds <= rampUpTimeSeconds) seconds else
rampUpTimeSeconds
+val afterRampUpSeconds = if (seconds > rampUpTimeSeconds ) seconds -
rampUpTimeSeconds else 0
+// Use classic distance formula based on accelaration: ut + ½at2
--- End diff --
nit: acceleration
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21175: [SPARK-24107][CORE] ChunkedByteBuffer.writeFully ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21175#discussion_r184882338
--- Diff:
core/src/test/scala/org/apache/spark/io/ChunkedByteBufferSuite.scala ---
@@ -20,12 +20,12 @@ package org.apache.spark.io
import java.nio.ByteBuffer
import com.google.common.io.ByteStreams
-
-import org.apache.spark.SparkFunSuite
+import org.apache.spark.{SparkFunSuite, SharedSparkContext}
--- End diff --
move SharedSparkContext before SparkFunSuite
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21175: [SPARK-24107][CORE] ChunkedByteBuffer.writeFully ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21175#discussion_r184882396 --- Diff: core/src/test/scala/org/apache/spark/io/ChunkedByteBufferSuite.scala --- @@ -20,12 +20,12 @@ package org.apache.spark.io import java.nio.ByteBuffer import com.google.common.io.ByteStreams --- End diff -- add an empty line behind 22 to separate spark and third-party group. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21177: [SPARK-24111][SQL] Add the TPCDS v2.7 (latest) qu...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21177#discussion_r184725980
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/TPCDSQueryBenchmark.scala
---
@@ -78,7 +81,7 @@ object TPCDSQueryBenchmark extends Logging {
}
val numRows = queryRelations.map(tableSizes.getOrElse(_, 0L)).sum
val benchmark = new Benchmark(s"TPCDS Snappy", numRows, 5)
- benchmark.addCase(name) { i =>
+ benchmark.addCase(s"$name$nameSuffix") { _ =>
--- End diff --
how about
```
benchmark.addCase(s"$name$nameSuffix")(_ =>
spark.sql(queryString).collect())
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21177: [SPARK-24111][SQL] Add the TPCDS v2.7 (latest) qu...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21177#discussion_r184724132
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/TPCDSQueryBenchmark.scala
---
@@ -87,10 +90,20 @@ object TPCDSQueryBenchmark extends Logging {
}
}
+ def filterQueries(
+ origQueries: Seq[String],
+ args: TPCDSQueryBenchmarkArguments): Seq[String] = {
+if (args.queryFilter.nonEmpty) {
+ origQueries.filter { case queryName =>
args.queryFilter.contains(queryName) }
--- End diff --
```
origQueries.filter(args.queryFilter.contains)
```
maybe better? :)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 > Have you applied this patch: #17955 ? No, this happened on Spark 2.1. Thanks xingbo & wenchen, I'll port back this patch to our internal Spark 2.1. > That PR seems to be addressing the issue you described: Yeah, the description is similar with currently scenario, but there's also a puzzle about the wrong ShuffleId, I'm trying to find the reason. Thanks again for your help, I'll first port back this patch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184276403
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
--- End diff --
Yep, you're right. The success completely event in UT was treated as normal
success task. I fixed this by ignore this event at the beginning of
handleTaskCompletion.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184274946
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+assertDataStructuresEmpty()
--- End diff --
Ah, it's used for check job successful complete and all temp structure
empty.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184260597
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
--- End diff --
The success task will be ignored by
`OutputCommitCoordinator.taskCompleted`, in the taskCompleted logic,
stageStates.getOrElse will return because the current stage is in failed set.
The detailed log providing below:
```
18/04/26 10:50:24.524 ScalaTest-run-running-DAGSchedulerSuite INFO
DAGScheduler: Resubmitting ShuffleMapStage 0 (RDD at
DAGSchedulerSuite.scala:74) and ResultStage 1 () due to fetch failure
18/04/26 10:50:24.535 ScalaTest-run-running-DAGSchedulerSuite DEBUG
DAGSchedulerSuite$$anon$6: Increasing epoch to 2
18/04/26 10:50:24.538 ScalaTest-run-running-DAGSchedulerSuite INFO
DAGScheduler: Executor lost: exec-hostA (epoch 1)
18/04/26 10:50:24.540 ScalaTest-run-running-DAGSchedulerSuite INFO
DAGScheduler: Shuffle files lost for execut
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184260210
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+assertDataStructuresEmpty()
--- End diff --
I add this test for answering your previous question "Can you simulate what
happens to result task if FechFaileded comes before task success?". This test
can pass without my code changing in DAGScheduler.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184109204
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
---
@@ -1266,6 +1266,9 @@ class DAGScheduler(
}
if (failedEpoch.contains(execId) && smt.epoch <=
failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from
executor $execId")
+} else if (failedStages.contains(shuffleStage)) {
--- End diff --
Added the UT for simulating this scenario happens to result task.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r183772627
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -209,10 +209,8 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
System.gc()
assert(ref.get.isEmpty)
-// Getting a garbage collected accum should throw error
-intercept[IllegalStateException] {
- AccumulatorContext.get(accId)
-}
+// Getting a garbage collected accum should return None.
+assert(AccumulatorContext.get(accId).isEmpty)
--- End diff --
Do we have a way to simulate the scenario in description by a new test?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r183770468
--- Diff: core/src/main/scala/org/apache/spark/util/AccumulatorV2.scala ---
@@ -258,14 +258,8 @@ private[spark] object AccumulatorContext {
* Returns the [[AccumulatorV2]] registered with the given ID, if any.
*/
def get(id: Long): Option[AccumulatorV2[_, _]] = {
-Option(originals.get(id)).map { ref =>
- // Since we are storing weak references, we must check whether the
underlying data is valid.
- val acc = ref.get
- if (acc eq null) {
-throw new IllegalStateException(s"Attempted to access garbage
collected accumulator $id")
- }
- acc
-}
+val ref = originals.get(id)
+Option(if (ref != null) ref.get else null)
--- End diff --
As the discussion in
[JIRA](https://issues.apache.org/jira/browse/SPARK-22371), here should not
raise an Exception, but we may also need some warning logs?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21136: [SPARK-24061][SS]Add TypedFilter support for continuous ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21136 +1 for this. We find this by CP app use filter with functions, this can be supported by current implement. cc @jose-torres @zsxwing @tdas --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21136: [SPARK-24061][SS]Add TypedFilter support for cont...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21136#discussion_r183604217
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationsSuite.scala
---
@@ -771,7 +778,16 @@ class UnsupportedOperationsSuite extends SparkFunSuite
{
}
}
- /**
+ /** Assert that the logical plan is not supportd for continuous
procsssing mode */
+ def assertSupportedForContinuousProcessing(
+name: String,
+plan: LogicalPlan,
+outputMode: OutputMode): Unit = {
+test(s"continuous processing - $name: supported") {
+ UnsupportedOperationChecker.checkForContinuous(plan, outputMode)
+}
+ }
+ /**
--- End diff --
nits: Indent here
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20946: [SPARK-23565] [SQL] New error message for structu...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20946#discussion_r183447816
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/OffsetSeq.scala
---
@@ -39,7 +39,9 @@ case class OffsetSeq(offsets: Seq[Option[Offset]],
metadata: Option[OffsetSeqMet
* cannot be serialized).
*/
def toStreamProgress(sources: Seq[BaseStreamingSource]): StreamProgress
= {
-assert(sources.size == offsets.size)
+assert(sources.size == offsets.size, s"There are [${offsets.size}]
sources in the " +
+ s"checkpoint offsets and now there are [${sources.size}] sources
requested by the query. " +
--- End diff --
nit: extra blank in the end
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20946: [SPARK-23565] [SQL] New error message for structu...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20946#discussion_r183447988
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/OffsetSeqLogSuite.scala
---
@@ -125,6 +125,19 @@ class OffsetSeqLogSuite extends SparkFunSuite with
SharedSQLContext {
assert(offsetSeq.metadata === Some(OffsetSeqMetadata(0L,
1480981499528L)))
}
+ test("assertion that number of checkpoint offsets match number of
sources") {
--- End diff --
maybe no need add UT for the log change.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21116: [SPARK-24038][SS] Refactor continuous writing to ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21116#discussion_r183224838
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/WriteToContinuousDataSourceExec.scala
---
@@ -0,0 +1,126 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.continuous
+
+import scala.util.control.NonFatal
+
+import org.apache.spark.{SparkEnv, SparkException, TaskContext}
+import org.apache.spark.internal.Logging
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.execution.SparkPlan
+import
org.apache.spark.sql.execution.datasources.v2.{DataWritingSparkTask,
InternalRowDataWriterFactory}
+import
org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask.{logError,
logInfo}
+import org.apache.spark.sql.execution.streaming.StreamExecution
+import org.apache.spark.sql.sources.v2.writer._
+import org.apache.spark.sql.sources.v2.writer.streaming.StreamWriter
+import org.apache.spark.util.Utils
+
+/**
+ * The physical plan for writing data into a continuous processing
[[StreamWriter]].
+ */
+case class WriteToContinuousDataSourceExec(writer: StreamWriter, query:
SparkPlan)
+extends SparkPlan with Logging {
+ override def children: Seq[SparkPlan] = Seq(query)
+ override def output: Seq[Attribute] = Nil
+
+ override protected def doExecute(): RDD[InternalRow] = {
+val writerFactory = writer match {
+ case w: SupportsWriteInternalRow =>
w.createInternalRowWriterFactory()
+ case _ => new
InternalRowDataWriterFactory(writer.createWriterFactory(), query.schema)
+}
+
+val rdd = query.execute()
+val messages = new Array[WriterCommitMessage](rdd.partitions.length)
+
+logInfo(s"Start processing data source writer: $writer. " +
+ s"The input RDD has ${messages.length} partitions.")
+// Let the epoch coordinator know how many partitions the write RDD
has.
+EpochCoordinatorRef.get(
+
sparkContext.getLocalProperty(ContinuousExecution.EPOCH_COORDINATOR_ID_KEY),
+sparkContext.env)
+ .askSync[Unit](SetWriterPartitions(rdd.getNumPartitions))
+
+try {
+ // Force the RDD to run so continuous processing starts; no data is
actually being collected
+ // to the driver, as ContinuousWriteRDD outputs nothing.
+ sparkContext.runJob(
+rdd,
+(context: TaskContext, iter: Iterator[InternalRow]) =>
+ WriteToContinuousDataSourceExec.run(writerFactory, context,
iter),
+rdd.partitions.indices)
+} catch {
+ case _: InterruptedException =>
+// Interruption is how continuous queries are ended, so accept and
ignore the exception.
+ case cause: Throwable =>
+cause match {
+ // Do not wrap interruption exceptions that will be handled by
streaming specially.
+ case _ if StreamExecution.isInterruptionException(cause) =>
throw cause
+ // Only wrap non fatal exceptions.
+ case NonFatal(e) => throw new SparkException("Writing job
aborted.", e)
+ case _ => throw cause
+}
+}
+
+sparkContext.emptyRDD
+ }
+}
+
+object WriteToContinuousDataSourceExec extends Logging {
+ def run(
+ writeTask: DataWriterFactory[InternalRow],
+ context: TaskContext,
+ iter: Iterator[InternalRow]): Unit = {
+val epochCoordinator = EpochCoordinatorRef.get(
+
context.getLocalProperty(ContinuousExecution.EPOCH_COORDINATOR_ID_KEY),
+ SparkEnv.get)
+val currentMsg: WriterCommitMessage = null
--- End diff --
currentMsg is no longer needed?
---
-
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930  Stage 0\1\2\3 same with 20\21\22\23 in this screenshot, stage2's shuffleId is 1 but stage3's is 0 can't happen. Good description for the scenario, can't get a FetchFailed because we can get the MapStatus, but get a 'null'. If I'm not mistaken, this also because the ExecutorLost trigger `removeOutputsOnExecutor`. Happy to discuss with all guys and sorry for can't giving more detailed log after checking the root case, this happened in Baidu online env and can't keep all logs for 1 month. I'll keep fixing the case and catching details log as mush as possible. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 @Ngone51 Ah, maybe I know how the description misleading you, the in the description 5, 'this stage' refers to 'Stage 2' in screenshot, thanks for your check, I modified the description to avoid misleading others. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 @Ngone51 You can check the screenshot in detail, stage 2's shuffleID is 1, but stage 3 failed by missing an output for shuffle '0'! So here the stage 2's skip cause stage 3 got an error shuffleId, the root case is this patch wants to fix, missing task should have, but actually not. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r183198368
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
---
@@ -1266,6 +1266,9 @@ class DAGScheduler(
}
if (failedEpoch.contains(execId) && smt.epoch <=
failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from
executor $execId")
+} else if (failedStages.contains(shuffleStage)) {
--- End diff --
>Sorry I may nitpick here.
No, that's necessary, I should have to make sure about this, thanks for
your advice! :)
> Can you simulate what happens to result task if FechFaileded comes before
task success?
Sure, but it maybe hardly to reproduce this in real env, I'll try to fake
it on UT first ASAP.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org