[jira] [Assigned] (FLINK-33064) Improve the error message when the lookup source is used as the scan source
[ https://issues.apache.org/jira/browse/FLINK-33064?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shengkai Fang reassigned FLINK-33064: - Assignee: Yunhong Zheng > Improve the error message when the lookup source is used as the scan source > --- > > Key: FLINK-33064 > URL: https://issues.apache.org/jira/browse/FLINK-33064 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.18.0 >Reporter: Yunhong Zheng >Assignee: Yunhong Zheng >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > Improve the error message when the lookup source is used as the scan source. > Currently, if we use a source which only implement LookupTableSource but not > implement ScanTableSource, as a scan source, it cannot get a property plan > and give a ' > Cannot generate a valid execution plan for the given query' which can be > improved. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33064) Improve the error message when the lookup source is used as the scan source
[ https://issues.apache.org/jira/browse/FLINK-33064?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764498#comment-17764498 ] Shengkai Fang commented on FLINK-33064: --- Merged into master: be509e6d67471d886e58d3ddea6ddd3627a191a8 > Improve the error message when the lookup source is used as the scan source > --- > > Key: FLINK-33064 > URL: https://issues.apache.org/jira/browse/FLINK-33064 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.18.0 >Reporter: Yunhong Zheng >Assignee: Yunhong Zheng >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > Improve the error message when the lookup source is used as the scan source. > Currently, if we use a source which only implement LookupTableSource but not > implement ScanTableSource, as a scan source, it cannot get a property plan > and give a ' > Cannot generate a valid execution plan for the given query' which can be > improved. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-33064) Improve the error message when the lookup source is used as the scan source
[ https://issues.apache.org/jira/browse/FLINK-33064?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shengkai Fang closed FLINK-33064. - Resolution: Fixed > Improve the error message when the lookup source is used as the scan source > --- > > Key: FLINK-33064 > URL: https://issues.apache.org/jira/browse/FLINK-33064 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.18.0 >Reporter: Yunhong Zheng >Assignee: Yunhong Zheng >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > Improve the error message when the lookup source is used as the scan source. > Currently, if we use a source which only implement LookupTableSource but not > implement ScanTableSource, as a scan source, it cannot get a property plan > and give a ' > Cannot generate a valid execution plan for the given query' which can be > improved. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] reswqa commented on a diff in pull request #23404: [FLINK-33076][network] Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.
reswqa commented on code in PR #23404:
URL: https://github.com/apache/flink/pull/23404#discussion_r1324007518
##
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/BroadcastRecordWriterTest.java:
##
@@ -132,35 +132,34 @@ public void testRandomEmitAndBufferRecycling() throws
Exception {
List buffers =
Arrays.asList(bufferPool.requestBuffer(),
bufferPool.requestBuffer());
buffers.forEach(Buffer::recycleBuffer);
-assertEquals(3, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(3);
// fill first buffer
writer.broadcastEmit(new IntType(1));
writer.broadcastEmit(new IntType(2));
-assertEquals(2, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(2);
// simulate consumption of first buffer consumer; this should not free
buffers
-assertEquals(1, partition.getNumberOfQueuedBuffers(0));
+assertThat(partition.getNumberOfQueuedBuffers(0)).isEqualTo(1);
Review Comment:
Yes, good catch!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-33051) GlobalFailureHandler interface should be retired in favor of LabeledGlobalFailureHandler
[ https://issues.apache.org/jira/browse/FLINK-33051?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764496#comment-17764496 ] Panagiotis Garefalakis commented on FLINK-33051: Hey [~wangm92] – I already have a POC here but feel free to pick any of the remaining tickets. > GlobalFailureHandler interface should be retired in favor of > LabeledGlobalFailureHandler > > > Key: FLINK-33051 > URL: https://issues.apache.org/jira/browse/FLINK-33051 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Panagiotis Garefalakis >Priority: Minor > > FLIP-304 introduced `LabeledGlobalFailureHandler` interface that is an > extension of `GlobalFailureHandler` interface. The later can thus be removed > in the future to avoid the existence of interfaces with duplicate functions. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] huwh commented on a diff in pull request #23399: [FLINK-33061][docs] Translate failure-enricher documentation to Chinese
huwh commented on code in PR #23399:
URL: https://github.com/apache/flink/pull/23399#discussion_r1323974700
##
docs/content/docs/deployment/advanced/failure_enrichers.md:
##
@@ -42,7 +42,7 @@ To implement a custom FailureEnricher plugin, you need to:
Then, create a jar which includes your `FailureEnricher`,
`FailureEnricherFactory`, `META-INF/services/` and all external dependencies.
Make a directory in `plugins/` of your Flink distribution with an arbitrary
name, e.g. "failure-enrichment", and put the jar into this directory.
-See [Flink Plugin]({% link deployment/filesystems/plugins.md %}) for more
details.
+See [Flink Plugin]({{< ref "docs/deployment/filesystems/plugins" >}}) for more
details.
Review Comment:
I haven’t reviewed it in detail yet. Can you separate this fix change into
an independent commit? This is unrelated to translation work.
##
docs/content/docs/deployment/advanced/failure_enrichers.md:
##
@@ -42,7 +42,7 @@ To implement a custom FailureEnricher plugin, you need to:
Then, create a jar which includes your `FailureEnricher`,
`FailureEnricherFactory`, `META-INF/services/` and all external dependencies.
Make a directory in `plugins/` of your Flink distribution with an arbitrary
name, e.g. "failure-enrichment", and put the jar into this directory.
-See [Flink Plugin]({% link deployment/filesystems/plugins.md %}) for more
details.
+See [Flink Plugin]({{< ref "docs/deployment/filesystems/plugins" >}}) for more
details.
Review Comment:
I haven’t reviewed it in detail yet. Can you separate this fix change into
an independent commit? This is unrelated to translation work.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #23406: [FLINK-32884] [flink-clients] PyFlink remote execution should support URLs with paths and https scheme
flinkbot commented on PR #23406: URL: https://github.com/apache/flink/pull/23406#issuecomment-1716944631 ## CI report: * 291433141e0c930c751c3e990a159b1f1ab9823c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-32884) PyFlink remote execution should support URLs with paths and https scheme
[ https://issues.apache.org/jira/browse/FLINK-32884?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-32884: --- Labels: pull-request-available (was: ) > PyFlink remote execution should support URLs with paths and https scheme > > > Key: FLINK-32884 > URL: https://issues.apache.org/jira/browse/FLINK-32884 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Runtime / REST >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > Currently, the `SUBMIT_ARGS=remote -m http://:` format. For > local execution it works fine `SUBMIT_ARGS=remote -m http://localhost:8081/`, > but it does not support the placement of the JobManager behind a proxy or > using an Ingress for routing to a specific Flink cluster based on the URL > path. In the current scenario, it expects JobManager to access PyFlink jobs > at `http://:/v1/jobs` endpoint. Mapping to a non-root > location, > `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` > is not supported. > This will use changes from > [FLINK-32885](https://issues.apache.org/jira/browse/FLINK-32885)(https://issues.apache.org/jira/browse/FLINK-32885) > Since RestClusterClient talks to the JobManager via its REST endpoint, the > right format for `SUBMIT_ARGS` is a URL with a path (also support for https > scheme). -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] elkhand opened a new pull request, #23406: [FLINK-32884] [flink-clients] PyFlink remote execution should support URLs with paths and https scheme
elkhand opened a new pull request, #23406: URL: https://github.com/apache/flink/pull/23406 [FLINK-32884](https://issues.apache.org/jira/browse/FLINK-32884) PyFlink remote execution should support URLs with paths and https scheme ## What is the purpose of the change Currently, the `SUBMIT_ARGS=remote -m http://:` format. For local execution it works fine `SUBMIT_ARGS=remote -m http://localhost:8081/`, but it does not support the placement of the JobManager behind a proxy or using an Ingress for routing to a specific Flink cluster based on the URL path. In the current scenario, it expects JobManager to access PyFlink jobs at `http://:/v1/jobs` endpoint. Mapping to a non-root location, `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` is not supported. This will use changes from [FLINK-32885](https://issues.apache.org/jira/browse/FLINK-32885)(https://issues.apache.org/jira/browse/FLINK-32885) Since RestClusterClient talks to the JobManager via its REST endpoint, the right format for `SUBMIT_ARGS` is a URL with a path (also support for https scheme). ## Brief change log - Added 2 new options into RestOptions: RestOptions.PATH and RestOptions.PROTOCOL - Added `https` schema support and jobManagerUrl with path support to RestClusterClient - Added customHttpHeaders support to RestClusterClient (for example setting auth token from env variable) - Updated `NetUtils.validateHostPortString()` to handle both `http` and `https` schema for hostPort ## Verifying this change This change added tests and can be verified as follows: - Extended flink-clients/src/test/java/org/apache/flink/client/cli/DefaultCLITest.java to cover `http` and `https` schemes - Added unit test flink-core/src/test/java/org/apache/flink/util/NetUtilsTest.java to check `https` scheme and URL with path - Extended test flink-clients/src/test/java/org/apache/flink/client/program/rest/RestClusterClientTest.java to validate customHttpHeaders and jobmanagerUrl with path and `https` scheme ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-mongodb] Jiabao-Sun commented on a diff in pull request #15: [FLINK-33013][connectors/mongodb] Shade flink-connector-base into flink-sql-connector-mongodb
Jiabao-Sun commented on code in PR #15: URL: https://github.com/apache/flink-connector-mongodb/pull/15#discussion_r1323965537 ## flink-sql-connector-mongodb/pom.xml: ## @@ -60,6 +60,10 @@ under the License. *:* + org.apache.flink:flink-connector-base + org.apache.flink:flink-connector-mongodb + org.mongodb:* + org.bson:* Review Comment: Thanks @ruanhang1993 to remind me of this. The old shaded package does not include `flink-connector-base` is that has provided scope. I removed the useless includes and it works. Please help review it again when you have time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-mongodb] Jiabao-Sun commented on a diff in pull request #15: [FLINK-33013][connectors/mongodb] Shade flink-connector-base into flink-sql-connector-mongodb
Jiabao-Sun commented on code in PR #15: URL: https://github.com/apache/flink-connector-mongodb/pull/15#discussion_r1323965389 ## flink-sql-connector-mongodb/pom.xml: ## @@ -60,6 +60,10 @@ under the License. *:* + org.apache.flink:flink-connector-base + org.apache.flink:flink-connector-mongodb + org.mongodb:* + org.bson:* Review Comment: Thanks @ruanhang1993 to remind me of this. The old shaded package does not include `flink-connector-base` is that has provided scope. I removed the useless includes and it works. Please help review it again when you have time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764484#comment-17764484 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 4:44 AM: --- Let me see whether i can get a new machine for this purpose and re-set up the environment. was (Author: ym): Let me see whether i can get a new machine for this purpose. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Test Infrastructure >Reporter: Jing Ge >Assignee: Yuan Mei >Priority: Major > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-32884) PyFlink remote execution should support URLs with paths and https scheme
[ https://issues.apache.org/jira/browse/FLINK-32884?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Elkhan Dadashov updated FLINK-32884: Description: Currently, the `SUBMIT_ARGS=remote -m http://:` format. For local execution it works fine `SUBMIT_ARGS=remote -m http://localhost:8081/`, but it does not support the placement of the JobManager behind a proxy or using an Ingress for routing to a specific Flink cluster based on the URL path. In the current scenario, it expects JobManager to access PyFlink jobs at `http://:/v1/jobs` endpoint. Mapping to a non-root location, `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` is not supported. This will use changes from [FLINK-32885](https://issues.apache.org/jira/browse/FLINK-32885)(https://issues.apache.org/jira/browse/FLINK-32885) Since RestClusterClient talks to the JobManager via its REST endpoint, the right format for `SUBMIT_ARGS` is a URL with a path (also support for https scheme). was: Currently, the `SUBMIT_ARGS=remote -m http://:` format. For local execution it works fine `SUBMIT_ARGS=remote -m [http://localhost:8081|http://localhost:8081/]`, but it does not support the placement of the JobManager befind a proxy or using an Ingress for routing to a specific Flink cluster based on the URL path. In current scenario, it expects JobManager access PyFlink jobs at `http://:/v1/jobs` endpoint. Mapping to a non-root location, `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` is not supported. This will use changes from FLINK-32885(https://issues.apache.org/jira/browse/FLINK-32885) Since RestClusterClient talks to the JobManager via its REST endpoint, the right format for `SUBMIT_ARGS` is URL with path (also support for https scheme). > PyFlink remote execution should support URLs with paths and https scheme > > > Key: FLINK-32884 > URL: https://issues.apache.org/jira/browse/FLINK-32884 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Runtime / REST >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > Fix For: 1.19.0 > > > Currently, the `SUBMIT_ARGS=remote -m http://:` format. For > local execution it works fine `SUBMIT_ARGS=remote -m http://localhost:8081/`, > but it does not support the placement of the JobManager behind a proxy or > using an Ingress for routing to a specific Flink cluster based on the URL > path. In the current scenario, it expects JobManager to access PyFlink jobs > at `http://:/v1/jobs` endpoint. Mapping to a non-root > location, > `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` > is not supported. > This will use changes from > [FLINK-32885](https://issues.apache.org/jira/browse/FLINK-32885)(https://issues.apache.org/jira/browse/FLINK-32885) > Since RestClusterClient talks to the JobManager via its REST endpoint, the > right format for `SUBMIT_ARGS` is a URL with a path (also support for https > scheme). -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-31788) Add back Support emitValueWithRetract for TableAggregateFunction
[ https://issues.apache.org/jira/browse/FLINK-31788?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764485#comment-17764485 ] lincoln lee commented on FLINK-31788: - [~qingyue] assigned to you. > Add back Support emitValueWithRetract for TableAggregateFunction > > > Key: FLINK-31788 > URL: https://issues.apache.org/jira/browse/FLINK-31788 > Project: Flink > Issue Type: Bug > Components: Table SQL / Planner >Reporter: Feng Jin >Assignee: Jane Chan >Priority: Major > > This feature was originally implemented in the old planner: > [https://github.com/apache/flink/pull/8550/files] > However, this feature was not implemented in the new planner , the Blink > planner. > With the removal of the old planner in version 1.14 > [https://github.com/apache/flink/pull/16080] , this code was also removed. > > We should add it back. > > origin discuss link: > https://lists.apache.org/thread/rnvw8k3636dqhdttpmf1c9colbpw9svp -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-31788) Add back Support emitValueWithRetract for TableAggregateFunction
[ https://issues.apache.org/jira/browse/FLINK-31788?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lincoln lee reassigned FLINK-31788: --- Assignee: Jane Chan > Add back Support emitValueWithRetract for TableAggregateFunction > > > Key: FLINK-31788 > URL: https://issues.apache.org/jira/browse/FLINK-31788 > Project: Flink > Issue Type: Bug > Components: Table SQL / Planner >Reporter: Feng Jin >Assignee: Jane Chan >Priority: Major > > This feature was originally implemented in the old planner: > [https://github.com/apache/flink/pull/8550/files] > However, this feature was not implemented in the new planner , the Blink > planner. > With the removal of the old planner in version 1.14 > [https://github.com/apache/flink/pull/16080] , this code was also removed. > > We should add it back. > > origin discuss link: > https://lists.apache.org/thread/rnvw8k3636dqhdttpmf1c9colbpw9svp -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764484#comment-17764484 ] Yuan Mei commented on FLINK-33052: -- Let me see whether i can get a new machine for this purpose. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Test Infrastructure >Reporter: Jing Ge >Assignee: Yuan Mei >Priority: Major > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yuan Mei reassigned FLINK-33052: Assignee: Yuan Mei (was: Yanfei Lei) > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Test Infrastructure >Reporter: Jing Ge >Assignee: Yuan Mei >Priority: Major > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] swuferhong commented on a diff in pull request #23313: [FLINK-20767][table planner] Support filter push down on nested fields
swuferhong commented on code in PR #23313:
URL: https://github.com/apache/flink/pull/23313#discussion_r1323892173
##
flink-table/flink-table-planner/src/main/scala/org/apache/flink/table/planner/plan/utils/RexNodeExtractor.scala:
##
@@ -395,9 +397,19 @@ class RexNodeToExpressionConverter(
inputNames: Array[String],
functionCatalog: FunctionCatalog,
catalogManager: CatalogManager,
-timeZone: TimeZone)
+timeZone: TimeZone,
+relDataType: Option[RelDataType] = None)
extends RexVisitor[Option[ResolvedExpression]] {
+ def this(
+ rexBuilder: RexBuilder,
+ inputNames: Array[String],
+ functionCatalog: FunctionCatalog,
+ catalogManager: CatalogManager,
+ timeZone: TimeZone) = {
+this(rexBuilder, inputNames, functionCatalog, catalogManager, timeZone,
null)
Review Comment:
There is no need to add `null`. `this(rexBuilder, inputNames,
functionCatalog, catalogManager, timeZone)` is ok.
##
flink-table/flink-table-common/src/main/java/org/apache/flink/table/expressions/NestedFieldReferenceExpression.java:
##
@@ -0,0 +1,126 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.expressions;
+
+import org.apache.flink.annotation.PublicEvolving;
+import org.apache.flink.table.types.DataType;
+
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.Objects;
+
+/**
+ * A reference to a nested field in an input. The reference contains.
Review Comment:
`contains.` -> `contains:`
##
flink-table/flink-table-common/src/main/java/org/apache/flink/table/expressions/NestedFieldReferenceExpression.java:
##
@@ -0,0 +1,126 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.expressions;
+
+import org.apache.flink.annotation.PublicEvolving;
+import org.apache.flink.table.types.DataType;
+
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.Objects;
+
+/**
+ * A reference to a nested field in an input. The reference contains.
+ *
+ *
+ * nested field names to traverse from the top level column to the
nested leaf column.
+ * nested field indices to traverse from the top level column to the
nested leaf column.
+ * type
+ *
+ */
+@PublicEvolving
+public class NestedFieldReferenceExpression implements ResolvedExpression {
+
+/** Nested field names to traverse from the top level column to the nested
leaf column. */
+private final String[] fieldNames;
+
+/** Nested field index to traverse from the top level column to the nested
leaf column. */
+private final int[] fieldIndices;
+
+private final DataType dataType;
+
+public NestedFieldReferenceExpression(
+String[] fieldNames, int[] fieldIndices, DataType dataType) {
+this.fieldNames = fieldNames;
+this.fieldIndices = fieldIndices;
+this.dataType = dataType;
+}
+
+public String[] getFieldNames() {
+return fieldNames;
+}
+
+public int[] getFieldIndices() {
+return fieldIndices;
+}
+
+public String getName() {
+return String.format(
+"`%s`",
+String.join(
+".",
+Arrays.stream(fieldNames)
+.map(this::quoteIdentifier)
+
[jira] [Resolved] (FLINK-33034) Incorrect StateBackendTestBase#testGetKeysAndNamespaces
[
https://issues.apache.org/jira/browse/FLINK-33034?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Hangxiang Yu resolved FLINK-33034.
--
Fix Version/s: 1.19.0
Resolution: Fixed
merged 36b9da50da9405b5b79f0d4da9393921982ab040 into master
> Incorrect StateBackendTestBase#testGetKeysAndNamespaces
> ---
>
> Key: FLINK-33034
> URL: https://issues.apache.org/jira/browse/FLINK-33034
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Affects Versions: 1.12.2, 1.15.0, 1.17.1
>Reporter: Dmitriy Linevich
>Assignee: Dmitriy Linevich
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.19.0
>
> Attachments: image-2023-09-05-12-51-28-203.png
>
>
> In this test first namespace 'ns1' doesn't exist in state, because creating
> ValueState is incorrect for test (When creating the 2nd value state namespace
> 'ns1' is overwritten by namespace 'ns2'). Need to fix it, to change creating
> ValueState or to change process of updating this state.
>
> If to add following code for checking count of adding namespaces to state
> [here|https://github.com/apache/flink/blob/3e6a1aab0712acec3e9fcc955a28f2598f019377/flink-runtime/src/test/java/org/apache/flink/runtime/state/StateBackendTestBase.java#L501C28-L501C28]
> {code:java}
> assertThat(keysByNamespace.size(), is(2)); {code}
> then
> !image-2023-09-05-12-51-28-203.png!
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] huwh commented on a diff in pull request #23386: [FLINK-33022] Log an error when enrichers defined as part of the configuration can not be found/loaded
huwh commented on code in PR #23386:
URL: https://github.com/apache/flink/pull/23386#discussion_r1323944084
##
flink-runtime/src/test/java/org/apache/flink/runtime/failure/FailureEnricherUtilsTest.java:
##
@@ -109,6 +109,15 @@ public void testGetFailureEnrichers() {
assertThat(enrichers).hasSize(1);
// verify that the failure enricher was created and returned
assertThat(enrichers.iterator().next()).isInstanceOf(TestEnricher.class);
+
+// Valid plus Invalid Name combination
+configuration.set(
+JobManagerOptions.FAILURE_ENRICHERS_LIST,
+FailureEnricherUtilsTest.class.getName() + "," +
TestEnricher.class.getName());
+final Collection validInvalidEnrichers =
+FailureEnricherUtils.getFailureEnrichers(configuration,
createPluginManager());
+assertThat(validInvalidEnrichers).hasSize(1);
+
assertThat(enrichers.iterator().next()).isInstanceOf(TestEnricher.class);
Review Comment:
It's appreciated if you could update line 109~111.
##
flink-runtime/src/test/java/org/apache/flink/runtime/failure/FailureEnricherUtilsTest.java:
##
@@ -109,6 +109,15 @@ public void testGetFailureEnrichers() {
assertThat(enrichers).hasSize(1);
// verify that the failure enricher was created and returned
assertThat(enrichers.iterator().next()).isInstanceOf(TestEnricher.class);
+
+// Valid plus Invalid Name combination
+configuration.set(
+JobManagerOptions.FAILURE_ENRICHERS_LIST,
+FailureEnricherUtilsTest.class.getName() + "," +
TestEnricher.class.getName());
+final Collection validInvalidEnrichers =
+FailureEnricherUtils.getFailureEnrichers(configuration,
createPluginManager());
+assertThat(validInvalidEnrichers).hasSize(1);
+
assertThat(enrichers.iterator().next()).isInstanceOf(TestEnricher.class);
Review Comment:
It is recommended to verify this way to make it clearer.
```suggestion
assertThat(validInvalidEnrichers)
.satisfiesExactly(
enricher ->
assertThat(enricher).isInstanceOf(TestEnricher.class));
```
##
flink-runtime/src/main/java/org/apache/flink/runtime/failure/FailureEnricherUtils.java:
##
@@ -105,6 +105,16 @@ static Collection getFailureEnrichers(
includedEnrichers);
}
}
+includedEnrichers.removeAll(
Review Comment:
We could remove the found enricher after line 91.
And shall we change the name of `includedEnrichers` to `enrichersToLoad`.
From the perspective of naming, the `includedEnrichers` is meaning the
enrichers that user configured, and it shouldn't be modified. But the
`enrichersToLoad` means the enrichers that should be load, when some of it is
loaded, it could be removed from this set since it's not need load any more.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] masteryhx closed pull request #23355: [FLINK-33034][runtime] Correct ValueState creating for StateBackendTestBase#testGetKeysAndNamespaces
masteryhx closed pull request #23355: [FLINK-33034][runtime] Correct ValueState creating for StateBackendTestBase#testGetKeysAndNamespaces URL: https://github.com/apache/flink/pull/23355 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323925122
##
flink-kubernetes-operator/src/test/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilderTest.java:
##
@@ -478,6 +478,50 @@ public void testTaskManagerSpec() {
Double.valueOf(1),
configuration.get(KubernetesConfigOptions.TASK_MANAGER_CPU));
}
+@Test
+public void testApplyJobManagerSpecWithBiByteMemorySetting() {
Review Comment:
Could you please break up that large test case to smaller ones? You can
follow the logic in the table you put together in the description.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on PR #670: URL: https://github.com/apache/flink-kubernetes-operator/pull/670#issuecomment-1716915082 What happens when users overwrite the configuration with standard memory parameters? Could you please handle these cases and cover with tests? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-23411) Expose Flink checkpoint details metrics
[ https://issues.apache.org/jira/browse/FLINK-23411?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Hangxiang Yu updated FLINK-23411: - Component/s: Runtime / Checkpointing > Expose Flink checkpoint details metrics > --- > > Key: FLINK-23411 > URL: https://issues.apache.org/jira/browse/FLINK-23411 > Project: Flink > Issue Type: Improvement > Components: Runtime / Checkpointing, Runtime / Metrics >Affects Versions: 1.13.1, 1.12.4 >Reporter: Jun Qin >Assignee: Hangxiang Yu >Priority: Major > Labels: pull-request-available, stale-assigned > Fix For: 1.18.0 > > > The checkpoint metrics as shown in the Flink Web UI like the > sync/async/alignment/start delay are not exposed to the metrics system. This > makes problem investigation harder when Web UI is not enabled: those numbers > can not get in the DEBUG logs. I think we should see how we can expose > metrics. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323925122
##
flink-kubernetes-operator/src/test/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilderTest.java:
##
@@ -478,6 +478,50 @@ public void testTaskManagerSpec() {
Double.valueOf(1),
configuration.get(KubernetesConfigOptions.TASK_MANAGER_CPU));
}
+@Test
+public void testApplyJobManagerSpecWithBiByteMemorySetting() {
Review Comment:
Could you please break up that large test case to smaller ones? You can
follow the table you put together in the description.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-23411) Expose Flink checkpoint details metrics
[
https://issues.apache.org/jira/browse/FLINK-23411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764477#comment-17764477
]
Hangxiang Yu commented on FLINK-23411:
--
Thanks for the quick reply.
{quote}Anyway, I think best way would be to first think through OTEL/Traces
integration, add support for that, and then add those new checkpointing metrics
from this ticket in this new model. However it's indeed much more work
(including writing and voting on a FLIP)
{quote}
Yeah, Supprting OTEL/Traces integration makes sense.
Besides some task-level metrics like this, users could also report their
own-defined operator metrics to their own distributed tracing system which may
be traced together with other jobs or systems.
I could also try to improve this when I'm free if you also think it's helpful
for users.
{quote}One thing is that in order to not bloat metric system too much, we
should implement this as an opt-in feature, hidden behind a feature toggle,
that users would have to manually enable in order to see those metrics.
{quote}
Sure, I aggree. Thanks for the advice.
> Expose Flink checkpoint details metrics
> ---
>
> Key: FLINK-23411
> URL: https://issues.apache.org/jira/browse/FLINK-23411
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Metrics
>Affects Versions: 1.13.1, 1.12.4
>Reporter: Jun Qin
>Assignee: Hangxiang Yu
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.18.0
>
>
> The checkpoint metrics as shown in the Flink Web UI like the
> sync/async/alignment/start delay are not exposed to the metrics system. This
> makes problem investigation harder when Web UI is not enabled: those numbers
> can not get in the DEBUG logs. I think we should see how we can expose
> metrics.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] morhidi commented on pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on PR #670: URL: https://github.com/apache/flink-kubernetes-operator/pull/670#issuecomment-1716912377 The last column looks good to me, we're not failing on any previous values which is important for backward compatibility reasons. I'm leaning towards accepting the corrected logic, while loosing the difference between `2147483648 b` vs `20 b`, where users intention was probably was to have `20 b` anyways. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-33013) Shade flink-connector-base info flink-sql-connector-connector
[ https://issues.apache.org/jira/browse/FLINK-33013?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-33013: --- Labels: pull-request-available (was: ) > Shade flink-connector-base info flink-sql-connector-connector > - > > Key: FLINK-33013 > URL: https://issues.apache.org/jira/browse/FLINK-33013 > Project: Flink > Issue Type: Improvement > Components: Connectors / MongoDB >Affects Versions: mongodb-1.0.2 >Reporter: Jiabao Sun >Priority: Major > Labels: pull-request-available > > Shade flink-connector-base info flink-sql-connector-connector -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-connector-mongodb] ruanhang1993 commented on a diff in pull request #15: [FLINK-33013][connectors/mongodb] Shade flink-connector-base into flink-sql-connector-mongodb
ruanhang1993 commented on code in PR #15: URL: https://github.com/apache/flink-connector-mongodb/pull/15#discussion_r1323913992 ## flink-sql-connector-mongodb/pom.xml: ## @@ -60,6 +60,10 @@ under the License. *:* + org.apache.flink:flink-connector-base + org.apache.flink:flink-connector-mongodb + org.mongodb:* + org.bson:* Review Comment: I think these new includes are useless as `*:*` already contains them. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] TanYuxin-tyx commented on a diff in pull request #23404: [FLINK-33076][network] Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.
TanYuxin-tyx commented on code in PR #23404:
URL: https://github.com/apache/flink/pull/23404#discussion_r1323910378
##
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/BroadcastRecordWriterTest.java:
##
@@ -132,35 +132,34 @@ public void testRandomEmitAndBufferRecycling() throws
Exception {
List buffers =
Arrays.asList(bufferPool.requestBuffer(),
bufferPool.requestBuffer());
buffers.forEach(Buffer::recycleBuffer);
-assertEquals(3, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(3);
// fill first buffer
writer.broadcastEmit(new IntType(1));
writer.broadcastEmit(new IntType(2));
-assertEquals(2, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(2);
// simulate consumption of first buffer consumer; this should not free
buffers
-assertEquals(1, partition.getNumberOfQueuedBuffers(0));
+assertThat(partition.getNumberOfQueuedBuffers(0)).isEqualTo(1);
Review Comment:
We can simplify this.
```suggestion
assertThat(partition.getNumberOfQueuedBuffers(0)).isOne();
```
##
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/api/writer/BroadcastRecordWriterTest.java:
##
@@ -132,35 +132,34 @@ public void testRandomEmitAndBufferRecycling() throws
Exception {
List buffers =
Arrays.asList(bufferPool.requestBuffer(),
bufferPool.requestBuffer());
buffers.forEach(Buffer::recycleBuffer);
-assertEquals(3, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(3);
// fill first buffer
writer.broadcastEmit(new IntType(1));
writer.broadcastEmit(new IntType(2));
-assertEquals(2, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(2);
// simulate consumption of first buffer consumer; this should not free
buffers
-assertEquals(1, partition.getNumberOfQueuedBuffers(0));
+assertThat(partition.getNumberOfQueuedBuffers(0)).isEqualTo(1);
ResultSubpartitionView view0 =
partition.createSubpartitionView(0, new
NoOpBufferAvailablityListener());
closeConsumer(view0, 2 * recordSize);
-assertEquals(2, bufferPool.getNumberOfAvailableMemorySegments());
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(2);
// use second buffer
writer.emit(new IntType(3), 0);
-assertEquals(1, bufferPool.getNumberOfAvailableMemorySegments());
-
+
assertThat(bufferPool.getNumberOfAvailableMemorySegments()).isEqualTo(1);
// fully free first buffer
-assertEquals(1, partition.getNumberOfQueuedBuffers(1));
+assertThat(partition.getNumberOfQueuedBuffers(1)).isEqualTo(1);
Review Comment:
```suggestion
assertThat(partition.getNumberOfQueuedBuffers(1)).isOne();
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (FLINK-31788) Add back Support emitValueWithRetract for TableAggregateFunction
[ https://issues.apache.org/jira/browse/FLINK-31788?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764475#comment-17764475 ] Jane Chan edited comment on FLINK-31788 at 9/13/23 3:49 AM: Hi, according to the discussion, we're on the consensus that we should support this feature, please assign the ticket to me, thanks. was (Author: qingyue): Hi, according to the discussion, we're one the consensus that we should support this feature, please assign the ticket to me, thanks. > Add back Support emitValueWithRetract for TableAggregateFunction > > > Key: FLINK-31788 > URL: https://issues.apache.org/jira/browse/FLINK-31788 > Project: Flink > Issue Type: Bug > Components: Table SQL / Planner >Reporter: Feng Jin >Priority: Major > > This feature was originally implemented in the old planner: > [https://github.com/apache/flink/pull/8550/files] > However, this feature was not implemented in the new planner , the Blink > planner. > With the removal of the old planner in version 1.14 > [https://github.com/apache/flink/pull/16080] , this code was also removed. > > We should add it back. > > origin discuss link: > https://lists.apache.org/thread/rnvw8k3636dqhdttpmf1c9colbpw9svp -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-31788) Add back Support emitValueWithRetract for TableAggregateFunction
[ https://issues.apache.org/jira/browse/FLINK-31788?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764475#comment-17764475 ] Jane Chan commented on FLINK-31788: --- Hi, according to the discussion, we're one the consensus that we should support this feature, please assign the ticket to me, thanks. > Add back Support emitValueWithRetract for TableAggregateFunction > > > Key: FLINK-31788 > URL: https://issues.apache.org/jira/browse/FLINK-31788 > Project: Flink > Issue Type: Bug > Components: Table SQL / Planner >Reporter: Feng Jin >Priority: Major > > This feature was originally implemented in the old planner: > [https://github.com/apache/flink/pull/8550/files] > However, this feature was not implemented in the new planner , the Blink > planner. > With the removal of the old planner in version 1.14 > [https://github.com/apache/flink/pull/16080] , this code was also removed. > > We should add it back. > > origin discuss link: > https://lists.apache.org/thread/rnvw8k3636dqhdttpmf1c9colbpw9svp -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33065) Optimize the exception message when the program plan could not be fetched
[ https://issues.apache.org/jira/browse/FLINK-33065?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764472#comment-17764472 ] Rui Fan commented on FLINK-33065: - Merged via d5b2cdb618cd7a50818d7eaa575c0fac6aaeac9a > Optimize the exception message when the program plan could not be fetched > - > > Key: FLINK-33065 > URL: https://issues.apache.org/jira/browse/FLINK-33065 > Project: Flink > Issue Type: Improvement >Reporter: Rui Fan >Assignee: Rui Fan >Priority: Major > Labels: pull-request-available > > When the program plan could not be fetched, the root cause may be: the main > method doesn't call the `env.execute()`. > > We can optimize the message to help user find this root cause. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Resolved] (FLINK-33065) Optimize the exception message when the program plan could not be fetched
[ https://issues.apache.org/jira/browse/FLINK-33065?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Rui Fan resolved FLINK-33065. - Fix Version/s: 1.19.0 Resolution: Fixed > Optimize the exception message when the program plan could not be fetched > - > > Key: FLINK-33065 > URL: https://issues.apache.org/jira/browse/FLINK-33065 > Project: Flink > Issue Type: Improvement >Reporter: Rui Fan >Assignee: Rui Fan >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > When the program plan could not be fetched, the root cause may be: the main > method doesn't call the `env.execute()`. > > We can optimize the message to help user find this root cause. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33051) GlobalFailureHandler interface should be retired in favor of LabeledGlobalFailureHandler
[ https://issues.apache.org/jira/browse/FLINK-33051?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764473#comment-17764473 ] Matt Wang commented on FLINK-33051: --- [~pgaref] Have you started this tricket? If you agree, I will be happy to contribute this. > GlobalFailureHandler interface should be retired in favor of > LabeledGlobalFailureHandler > > > Key: FLINK-33051 > URL: https://issues.apache.org/jira/browse/FLINK-33051 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Panagiotis Garefalakis >Priority: Minor > > FLIP-304 introduced `LabeledGlobalFailureHandler` interface that is an > extension of `GlobalFailureHandler` interface. The later can thus be removed > in the future to avoid the existence of interfaces with duplicate functions. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #23405: [FLINK-31895] Add End-to-end integration tests for failure labels
flinkbot commented on PR #23405: URL: https://github.com/apache/flink/pull/23405#issuecomment-1716894944 ## CI report: * 6ec84c4729ced192747cff0778d42fa69dc68a39 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wangzzu commented on pull request #23405: [FLINK-31895] Add End-to-end integration tests for failure labels
wangzzu commented on PR #23405: URL: https://github.com/apache/flink/pull/23405#issuecomment-1716892702 @huwh @pgaref when you have time, help me review this -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-31895) End-to-end integration tests for failure labels
[ https://issues.apache.org/jira/browse/FLINK-31895?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-31895: --- Labels: pull-request-available (was: ) > End-to-end integration tests for failure labels > --- > > Key: FLINK-31895 > URL: https://issues.apache.org/jira/browse/FLINK-31895 > Project: Flink > Issue Type: Sub-task >Reporter: Panagiotis Garefalakis >Assignee: Matt Wang >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] wangzzu opened a new pull request, #23405: [FLINK-31895] Add End-to-end integration tests for failure labels
wangzzu opened a new pull request, #23405: URL: https://github.com/apache/flink/pull/23405 ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log - Add an end-to-end failure enricher test ## Verifying this change - run the test in local, the test is expected. 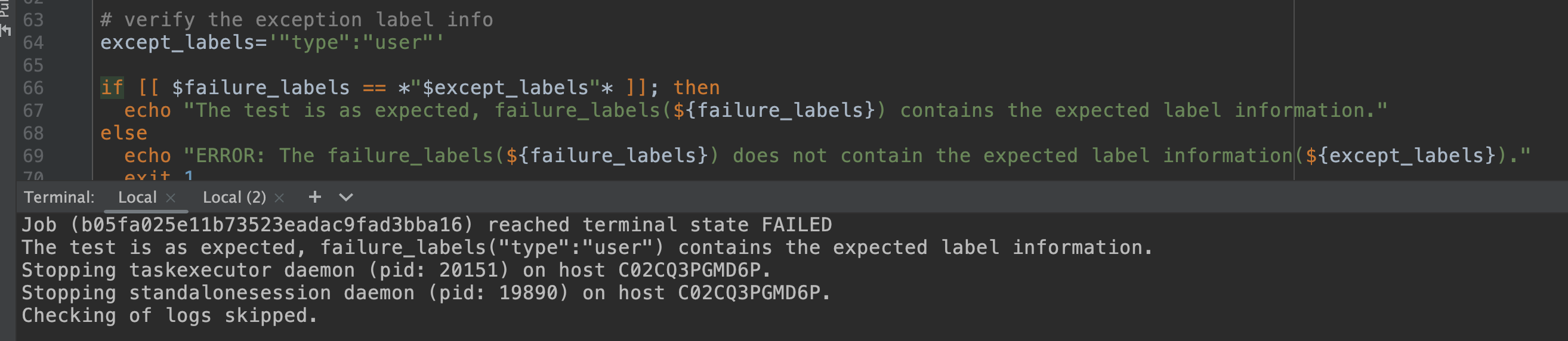 ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-32863) Improve Flink UI's time precision from second level to millisecond level
[ https://issues.apache.org/jira/browse/FLINK-32863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764464#comment-17764464 ] Jufang He commented on FLINK-32863: --- Hi [~guoyangze], I have created a PR([https://github.com/apache/flink/pull/23403)] for this issue, could you assign this to me? > Improve Flink UI's time precision from second level to millisecond level > > > Key: FLINK-32863 > URL: https://issues.apache.org/jira/browse/FLINK-32863 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Web Frontend >Affects Versions: 1.17.1 >Reporter: Runkang He >Priority: Major > Labels: pull-request-available > > This an UI improvement for OLAP jobs. > OLAP queries are generally small queries which will finish at the seconds or > milliseconds, but currently the time precision displayed is second level and > not enough for OLAP queries. Millisecond part of time is very important for > users and developers, to see accurate time, for performance measurement and > optimization. The displayed time includes job duration, task duration, task > start time, end time and so on. > It would be nice to improve this for better OLAP user experience. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] masteryhx commented on a diff in pull request #14611: [FLINK-13194][docs] Add explicit clarification about thread-safety of state
masteryhx commented on code in PR #14611: URL: https://github.com/apache/flink/pull/14611#discussion_r1323873654 ## flink-runtime/src/main/java/org/apache/flink/runtime/state/KeyedStateBackend.java: ## @@ -30,6 +30,11 @@ /** * A keyed state backend provides methods for managing keyed state. * + * Not Thread-Safe + * + * State access in keyed state backend dose not require thread safety as each task is executed by + * one thread. Current implementations (Heap/RocksDB keyed state backend) are not thread-safe. + * Review Comment: Sure, I aggree. Could you update your pr as we disscussed? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #23404: [FLINK-33076][network] Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.
flinkbot commented on PR #23404: URL: https://github.com/apache/flink/pull/23404#issuecomment-1716849649 ## CI report: * ae67b21f40ba17fb643acd1e5a410e37562e7119 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-33076) broadcastEmit of ChannelSelectorRecordWriter should reuse the serialized record
[ https://issues.apache.org/jira/browse/FLINK-33076?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-33076: --- Labels: pull-request-available (was: ) > broadcastEmit of ChannelSelectorRecordWriter should reuse the serialized > record > --- > > Key: FLINK-33076 > URL: https://issues.apache.org/jira/browse/FLINK-33076 > Project: Flink > Issue Type: Bug > Components: Runtime / Network >Reporter: Weijie Guo >Assignee: Weijie Guo >Priority: Major > Labels: pull-request-available > > ChannelSelectorRecordWriter#broadcastEmit serialize the record to ByteBuffer > but didn't use it. It will re-serialize this record per-channel. We should > allows all channels to reuse the serialized buffer. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] reswqa opened a new pull request, #23404: [FLINK-33076][network] Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.
reswqa opened a new pull request, #23404: URL: https://github.com/apache/flink/pull/23404 ## What is the purpose of the change *ChannelSelectorRecordWriter#broadcastEmit serialize the record to ByteBuffer but didn't use it. It will re-serialize this record per-channel. We should allows all channels to reuse the serialized buffer.* ## Brief change log - *Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.* ## Verifying this change This change is already covered by existing tests, such as `RecordWriterTest`*. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-33066) Enable to inject environment variable from secret/configmap to operatorPod
[
https://issues.apache.org/jira/browse/FLINK-33066?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764455#comment-17764455
]
dongwoo.kim commented on FLINK-33066:
-
Thanks [~gyfora], I have opened the pr :)
> Enable to inject environment variable from secret/configmap to operatorPod
> --
>
> Key: FLINK-33066
> URL: https://issues.apache.org/jira/browse/FLINK-33066
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: dongwoo.kim
>Assignee: dongwoo.kim
>Priority: Minor
> Labels: pull-request-available
>
> Hello, I've been working with the Flink Kubernetes operator and noticed that
> the {{operatorPod.env}} only allows for simple key-value pairs and doesn't
> support Kubernetes {{valueFrom}} syntax.
> How about changing template to support more various k8s syntax?
> *Current template*
> {code:java}
> {{- range $k, $v := .Values.operatorPod.env }}
> - name: {{ $v.name | quote }}
> value: {{ $v.value | quote }}
> {{- end }}{code}
>
> *Proposed template*
> 1) Modify template like below
> {code:java}
> {{- with .Values.operatorPod.env }}
> {{- toYaml . | nindent 12 }}
> {{- end }}
> {code}
> 2) create extra config, *Values.operatorPod.envFrom* and utilize this
>
> I'd be happy to implement this update if it's approved.
> Thanks in advance.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-33066) Enable to inject environment variable from secret/configmap to operatorPod
[
https://issues.apache.org/jira/browse/FLINK-33066?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-33066:
---
Labels: pull-request-available (was: )
> Enable to inject environment variable from secret/configmap to operatorPod
> --
>
> Key: FLINK-33066
> URL: https://issues.apache.org/jira/browse/FLINK-33066
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: dongwoo.kim
>Assignee: dongwoo.kim
>Priority: Minor
> Labels: pull-request-available
>
> Hello, I've been working with the Flink Kubernetes operator and noticed that
> the {{operatorPod.env}} only allows for simple key-value pairs and doesn't
> support Kubernetes {{valueFrom}} syntax.
> How about changing template to support more various k8s syntax?
> *Current template*
> {code:java}
> {{- range $k, $v := .Values.operatorPod.env }}
> - name: {{ $v.name | quote }}
> value: {{ $v.value | quote }}
> {{- end }}{code}
>
> *Proposed template*
> 1) Modify template like below
> {code:java}
> {{- with .Values.operatorPod.env }}
> {{- toYaml . | nindent 12 }}
> {{- end }}
> {code}
> 2) create extra config, *Values.operatorPod.envFrom* and utilize this
>
> I'd be happy to implement this update if it's approved.
> Thanks in advance.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] dongwoo6kim opened a new pull request, #671: [FLINK-33066] Support all k8s methods to configure env variable in operatorPod
dongwoo6kim opened a new pull request, #671: URL: https://github.com/apache/flink-kubernetes-operator/pull/671 ## What is the purpose of the change To enhance Helm chart by adding full support for setting environment variables in values.yaml, including valueFrom and envFrom options, to align closely with native Kubernetes features and reduce user confusion. ## Brief change log - *Add support for valueFrom in env field* - *Add envFrom field* ## Verifying this change This change is a trivial work, locally checked the generation of manifest files. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changes to the `CustomResourceDescriptors`: (yes / no) - Core observer or reconciler logic that is regularly executed: (yes / no) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (not documented) **Q)** Should I open a new PR to document about ```envFrom``` field if this PR is merged? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dalelane commented on pull request #23395: [FLINK-33058][formats] Add encoding option to Avro format
dalelane commented on PR #23395: URL: https://github.com/apache/flink/pull/23395#issuecomment-1716773854 Apologies for the flurry of follow-on commits - this is my first contribution to Flink so I'd missed the checkstyle and spotless rules when testing locally. I think it's ready to review now, but I'm sure there are still other things I've unwittingly missed! Please let me know if there is anything else that I should do to get this PR into an acceptable state. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] architgyl commented on a diff in pull request #23164: [FLINK- 32775]Add parent dir of files to classpath using yarn.provided.lib.dirs
architgyl commented on code in PR #23164:
URL: https://github.com/apache/flink/pull/23164#discussion_r1323745882
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -143,6 +165,22 @@ private static Map getLibJars() {
return libJars;
}
+private static Map getFilesWithParentDir() {
+final Map filesWithParentDir = new HashMap<>(2);
+final String xmlContent = "XML Content";
+
+filesWithParentDir.put("conf/hive-site.xml", xmlContent);
+filesWithParentDir.put("conf/ivysettings.xml", xmlContent);
+
+return filesWithParentDir;
+}
+
+private static List getExpectedClassPathWithParentDir() {
Review Comment:
Done.
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -143,6 +165,22 @@ private static Map getLibJars() {
return libJars;
}
+private static Map getFilesWithParentDir() {
Review Comment:
Done.
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -73,6 +73,28 @@ void testRegisterProvidedLocalResources(@TempDir File
flinkLibDir) throws IOExce
}
}
+@Test
+void testRegisterProvidedLocalResourcesWithParentDir(@TempDir File
flinkLibDir)
+throws IOException {
+final Map filesWithParentDir = getFilesWithParentDir();
Review Comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] venkata91 commented on a diff in pull request #23164: [FLINK- 32775]Add parent dir of files to classpath using yarn.provided.lib.dirs
venkata91 commented on code in PR #23164:
URL: https://github.com/apache/flink/pull/23164#discussion_r1323679045
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -143,6 +165,22 @@ private static Map getLibJars() {
return libJars;
}
+private static Map getFilesWithParentDir() {
+final Map filesWithParentDir = new HashMap<>(2);
+final String xmlContent = "XML Content";
+
+filesWithParentDir.put("conf/hive-site.xml", xmlContent);
+filesWithParentDir.put("conf/ivysettings.xml", xmlContent);
+
+return filesWithParentDir;
+}
+
+private static List getExpectedClassPathWithParentDir() {
Review Comment:
nit: Currently this is used only by one test, why not just inline it?
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -73,6 +73,28 @@ void testRegisterProvidedLocalResources(@TempDir File
flinkLibDir) throws IOExce
}
}
+@Test
+void testRegisterProvidedLocalResourcesWithParentDir(@TempDir File
flinkLibDir)
+throws IOException {
+final Map filesWithParentDir = getFilesWithParentDir();
Review Comment:
nit: `s/filesWithParentDir/xmlResources`?
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -143,6 +165,22 @@ private static Map getLibJars() {
return libJars;
}
+private static Map getFilesWithParentDir() {
+final Map filesWithParentDir = new HashMap<>(2);
+final String xmlContent = "XML Content";
+
+filesWithParentDir.put("conf/hive-site.xml", xmlContent);
+filesWithParentDir.put("conf/ivysettings.xml", xmlContent);
+
+return filesWithParentDir;
+}
+
+private static List getExpectedClassPathWithParentDir() {
Review Comment:
It can be rewritten as:
```
List expectedClassPathWithParentDir = Arrays.asList("conf");
```
##
flink-yarn/src/test/java/org/apache/flink/yarn/YarnApplicationFileUploaderTest.java:
##
@@ -143,6 +165,22 @@ private static Map getLibJars() {
return libJars;
}
+private static Map getFilesWithParentDir() {
Review Comment:
Inline as below?
```
Map xmlResources = ImmutableMap.of("conf/hive-site.xml",
xmlContent, "conf/ivysettings.xml", xmlContent);
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] srpraneeth commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
srpraneeth commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323676402
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
@morhidi The issue is that Flink interprets values only in Bibytes (gi, mi,
ki) format. For instance, a simple value like '2g' is currently interpreted as
'2gi = 2147483648 b' and there is no way to use both Bibyte and decimal byte
formats as in K8s Spec.
This change will ensure that '2gi' is interpreted as '2g' accordingly, and
the appropriate memory will be used. I assume that by 'backward change,' here
means that the existing CR memory configuration should remain functional and
not be disrupted, even though the values interpreted by the operator will
change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-33018) GCP Pubsub PubSubConsumingTest.testStoppingConnectorWhenDeserializationSchemaIndicatesEndOfStream failed
[
https://issues.apache.org/jira/browse/FLINK-33018?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-33018:
---
Labels: pull-request-available stale-blocker (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as a
Blocker but is unassigned and neither itself nor its Sub-Tasks have been
updated for 1 days. I have gone ahead and marked it "stale-blocker". If this
ticket is a Blocker, please either assign yourself or give an update.
Afterwards, please remove the label or in 7 days the issue will be
deprioritized.
> GCP Pubsub
> PubSubConsumingTest.testStoppingConnectorWhenDeserializationSchemaIndicatesEndOfStream
> failed
>
>
> Key: FLINK-33018
> URL: https://issues.apache.org/jira/browse/FLINK-33018
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Google Cloud PubSub
>Affects Versions: gcp-pubsub-3.0.2
>Reporter: Martijn Visser
>Priority: Blocker
> Labels: pull-request-available, stale-blocker
>
> https://github.com/apache/flink-connector-gcp-pubsub/actions/runs/6061318336/job/16446392844#step:13:507
> {code:java}
> [INFO]
> [INFO] Results:
> [INFO]
> Error: Failures:
> Error:
> PubSubConsumingTest.testStoppingConnectorWhenDeserializationSchemaIndicatesEndOfStream:119
>
> expected: ["1", "2", "3"]
> but was: ["1", "2"]
> [INFO]
> Error: Tests run: 30, Failures: 1, Errors: 0, Skipped: 0
> [INFO]
> [INFO]
>
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-30774) Introduce flink-utils module
[
https://issues.apache.org/jira/browse/FLINK-30774?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-30774:
---
Labels: auto-deprioritized-major starter (was: stale-major starter)
Priority: Minor (was: Major)
This issue was labeled "stale-major" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Major, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Introduce flink-utils module
>
>
> Key: FLINK-30774
> URL: https://issues.apache.org/jira/browse/FLINK-30774
> Project: Flink
> Issue Type: Improvement
> Components: Build System
>Affects Versions: 1.17.0
>Reporter: Matthias Pohl
>Priority: Minor
> Labels: auto-deprioritized-major, starter
>
> Currently, utility methods generic utility classes like {{Preconditions}} or
> {{AbstractAutoCloseableRegistry}} are collected in {{flink-core}}. The flaw
> of this approach is that we cannot use those classes in modules like
> {{fink-migration-test-utils}}, {{flink-test-utils-junit}},
> {{flink-metrics-core}} or {{flink-annotations}}.
> We might want to have a generic {{flink-utils}} analogously to
> {{flink-test-utils}} that collects Flink-independent utility functionality
> that can be access by any module {{flink-core}} is depending on to make this
> utility functionality available in any Flink-related module.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-32564) Support cast from BYTES to NUMBER
[
https://issues.apache.org/jira/browse/FLINK-32564?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-32564:
---
Labels: pull-request-available stale-assigned (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issue is assigned but has not
received an update in 30 days, so it has been labeled "stale-assigned".
If you are still working on the issue, please remove the label and add a
comment updating the community on your progress. If this issue is waiting on
feedback, please consider this a reminder to the committer/reviewer. Flink is a
very active project, and so we appreciate your patience.
If you are no longer working on the issue, please unassign yourself so someone
else may work on it.
> Support cast from BYTES to NUMBER
> -
>
> Key: FLINK-32564
> URL: https://issues.apache.org/jira/browse/FLINK-32564
> Project: Flink
> Issue Type: Sub-task
>Reporter: Hanyu Zheng
>Assignee: Hanyu Zheng
>Priority: Major
> Labels: pull-request-available, stale-assigned
>
> We are dealing with a task that requires casting from the BYTES type to
> BIGINT. Specifically, we have a string '00T1p'. Our approach is to convert
> this string to BYTES and then cast the result to BIGINT with the following
> SQL query:
> {code:java}
> SELECT CAST((CAST('00T1p' as BYTES)) as BIGINT);{code}
> However, an issue arises when executing this query, likely due to an error in
> the conversion between BYTES and BIGINT. We aim to identify and rectify this
> issue so our query can run correctly. The tasks involved are:
> # Investigate and identify the specific reason for the failure of conversion
> from BYTES to BIGINT.
> # Design and implement a solution to ensure our query can function correctly.
> # Test this solution across all required scenarios to guarantee its
> functionality.
>
> see also
> 1. PostgreSQL: PostgreSQL supports casting from BYTES type (BYTEA) to NUMBER
> types (INTEGER, BIGINT, DECIMAL, etc.). In PostgreSQL, you can use CAST or
> type conversion operator (::) for performing the conversion. URL:
> [https://www.postgresql.org/docs/current/sql-expressions.html#SQL-SYNTAX-TYPE-CASTS]
> 2. MySQL: MySQL supports casting from BYTES type (BLOB or BINARY) to NUMBER
> types (INTEGER, BIGINT, DECIMAL, etc.). In MySQL, you can use CAST or CONVERT
> functions for performing the conversion. URL:
> [https://dev.mysql.com/doc/refman/8.0/en/cast-functions.html]
> 3. Microsoft SQL Server: SQL Server supports casting from BYTES type
> (VARBINARY, IMAGE) to NUMBER types (INT, BIGINT, NUMERIC, etc.). You can use
> CAST or CONVERT functions for performing the conversion. URL:
> [https://docs.microsoft.com/en-us/sql/t-sql/functions/cast-and-convert-transact-sql]
> 4. Oracle Database: Oracle supports casting from RAW type (equivalent to
> BYTES) to NUMBER types (NUMBER, INTEGER, FLOAT, etc.). You can use the
> TO_NUMBER function for performing the conversion. URL:
> [https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/TO_NUMBER.html]
> 5. Apache Spark: Spark DataFrame supports casting binary types (BinaryType or
> ByteType) to numeric types (IntegerType, LongType, DecimalType, etc.) by
> using the {{cast}} function. URL:
> [https://spark.apache.org/docs/latest/api/sql/#cast]
>
> for the problem of bytes order may arise (little vs big endian).
>
> 1. Apache Hadoop: Hadoop, being an open-source framework, has to deal with
> byte order issues across different platforms and architectures. The Hadoop
> File System (HDFS) uses a technique called "sequence files," which include
> metadata to describe the byte order of the data. This metadata ensures that
> data is read and written correctly, regardless of the endianness of the
> platform.
> 2. Apache Avro: Avro is a data serialization system used by various big data
> frameworks like Hadoop and Apache Kafka. Avro uses a compact binary encoding
> format that includes a marker for the byte order. This allows Avro to handle
> endianness issues seamlessly when data is exchanged between systems with
> different byte orders.
> 3. Apache Parquet: Parquet is a columnar storage format used in big data
> processing frameworks like Apache Spark. Parquet uses a little-endian format
> for encoding numeric values, which is the most common format on modern
> systems. When reading or writing Parquet data, data processing engines
> typically handle any necessary byte order conversions transparently.
> 4. Apache Spark: Spark is a popular big data processing engine that can
> handle data on distributed systems. It relies on the underlying data formats
> it reads (e.g., Avro, Parquet, ORC) to manage byte order issues.
[jira] [Updated] (FLINK-31689) Filesystem sink fails when parallelism of compactor operator changed
[
https://issues.apache.org/jira/browse/FLINK-31689?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-31689:
---
Labels: pull-request-available stale-assigned (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issue is assigned but has not
received an update in 30 days, so it has been labeled "stale-assigned".
If you are still working on the issue, please remove the label and add a
comment updating the community on your progress. If this issue is waiting on
feedback, please consider this a reminder to the committer/reviewer. Flink is a
very active project, and so we appreciate your patience.
If you are no longer working on the issue, please unassign yourself so someone
else may work on it.
> Filesystem sink fails when parallelism of compactor operator changed
>
>
> Key: FLINK-31689
> URL: https://issues.apache.org/jira/browse/FLINK-31689
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem
>Affects Versions: 1.16.1
>Reporter: jirawech.s
>Assignee: jirawech.s
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Attachments: HelloFlinkHadoopSink.java
>
>
> I encounter this error when i tried to use Filesystem sink with Table SQL. I
> have not tested with Datastream API tho. You may refers to the error as below
> {code:java}
> // code placeholder
> java.util.NoSuchElementException
> at java.util.ArrayList$Itr.next(ArrayList.java:864)
> at
> org.apache.flink.connector.file.table.stream.compact.CompactOperator.initializeState(CompactOperator.java:119)
> at
> org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.initializeOperatorState(StreamOperatorStateHandler.java:122)
> at
> org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:286)
> at
> org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.initializeStateAndOpenOperators(RegularOperatorChain.java:106)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:700)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.restoreInternal(StreamTask.java:676)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:643)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:917)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563)
> at java.lang.Thread.run(Thread.java:750) {code}
> I cannot attach the full reproducible code here, but you may follow my pseudo
> code in attachment and reproducible steps below
> 1. Create Kafka source
> 2. Set state.savepoints.dir
> 3. Set Job parallelism to 1
> 4. Create FileSystem Sink
> 5. Run the job and trigger savepoint with API
> {noformat}
> curl -X POST localhost:8081/jobs/:jobId/savepoints -d '{"cancel-job":
> false}'{noformat}
> {color:#172b4d}6. Cancel job, change parallelism to 2, and resume job from
> savepoint{color}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] srpraneeth commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
srpraneeth commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323659448
##
flink-kubernetes-operator/src/test/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilderTest.java:
##
@@ -478,6 +478,50 @@ public void testTaskManagerSpec() {
Double.valueOf(1),
configuration.get(KubernetesConfigOptions.TASK_MANAGER_CPU));
}
+@Test
+public void testApplyJobManagerSpecWithBiByteMemorySetting() {
Review Comment:
Added more tests.
Please refer to the PR description for all list of handled cases and tests.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] architgyl commented on a diff in pull request #23164: [FLINK- 32775]Add parent dir of files to classpath using yarn.provided.lib.dirs
architgyl commented on code in PR #23164:
URL: https://github.com/apache/flink/pull/23164#discussion_r1323653567
##
flink-yarn/src/main/java/org/apache/flink/yarn/YarnApplicationFileUploader.java:
##
@@ -360,11 +362,27 @@ List registerProvidedLocalResources() {
envShipResourceList.add(descriptor);
if (!isFlinkDistJar(filePath.getName()) &&
!isPlugin(filePath)) {
-classPaths.add(fileName);
+URI parentDirectoryUri = new
Path(fileName).getParent().toUri();
+String relativeParentDirectory =
Review Comment:
Makes sense. This way we can limit the values in the classPath also. Updated
the code.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-32884) PyFlink remote execution should support URLs with paths and https scheme
[ https://issues.apache.org/jira/browse/FLINK-32884?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Elkhan Dadashov updated FLINK-32884: Fix Version/s: 1.19.0 > PyFlink remote execution should support URLs with paths and https scheme > > > Key: FLINK-32884 > URL: https://issues.apache.org/jira/browse/FLINK-32884 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Runtime / REST >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > Fix For: 1.19.0 > > > Currently, the `SUBMIT_ARGS=remote -m http://:` format. For > local execution it works fine `SUBMIT_ARGS=remote -m > [http://localhost:8081|http://localhost:8081/]`, but it does not support the > placement of the JobManager befind a proxy or using an Ingress for routing to > a specific Flink cluster based on the URL path. In current scenario, it > expects JobManager access PyFlink jobs at `http://:/v1/jobs` > endpoint. Mapping to a non-root location, > `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` > is not supported. > This will use changes from > FLINK-32885(https://issues.apache.org/jira/browse/FLINK-32885) > Since RestClusterClient talks to the JobManager via its REST endpoint, the > right format for `SUBMIT_ARGS` is URL with path (also support for https > scheme). -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-32884) PyFlink remote execution should support URLs with paths and https scheme
[ https://issues.apache.org/jira/browse/FLINK-32884?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Elkhan Dadashov updated FLINK-32884: Description: Currently, the `SUBMIT_ARGS=remote -m http://:` format. For local execution it works fine `SUBMIT_ARGS=remote -m [http://localhost:8081|http://localhost:8081/]`, but it does not support the placement of the JobManager befind a proxy or using an Ingress for routing to a specific Flink cluster based on the URL path. In current scenario, it expects JobManager access PyFlink jobs at `http://:/v1/jobs` endpoint. Mapping to a non-root location, `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` is not supported. This will use changes from FLINK-32885(https://issues.apache.org/jira/browse/FLINK-32885) Since RestClusterClient talks to the JobManager via its REST endpoint, the right format for `SUBMIT_ARGS` is URL with path (also support for https scheme). was: Currently, the `SUBMIT_ARGS=remote -m http://:` format. For local execution it works fine `SUBMIT_ARGS=remote -m [http://localhost:8081|http://localhost:8081/]`, but it does not support the placement of the JobManager befind a proxy or using an Ingress for routing to a specific Flink cluster based on the URL path. In current scenario, it expects JobManager access PyFlink jobs at `http://:/v1/jobs` endpoint. Mapping to a non-root location, `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` is not supported. This will use changes from [FLINK-32885](https://issues.apache.org/jira/browse/FLINK-32885) Since RestClusterClient talks to the JobManager via its REST endpoint, the right format for `SUBMIT_ARGS` is URL with path (also support for https scheme). I intend to change these classes in a backward compatible way flink-clients/src/main/java/org/apache/flink/client/ClientUtils.java flink-clients/src/main/java/org/apache/flink/client/cli/DefaultCLI.java flink-clients/src/main/java/org/apache/flink/client/program/rest/RestClusterClient.java flink-core/src/main/java/org/apache/flink/configuration/RestOptions.java flink-core/src/main/java/org/apache/flink/util/NetUtils.java > PyFlink remote execution should support URLs with paths and https scheme > > > Key: FLINK-32884 > URL: https://issues.apache.org/jira/browse/FLINK-32884 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Runtime / REST >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > > Currently, the `SUBMIT_ARGS=remote -m http://:` format. For > local execution it works fine `SUBMIT_ARGS=remote -m > [http://localhost:8081|http://localhost:8081/]`, but it does not support the > placement of the JobManager befind a proxy or using an Ingress for routing to > a specific Flink cluster based on the URL path. In current scenario, it > expects JobManager access PyFlink jobs at `http://:/v1/jobs` > endpoint. Mapping to a non-root location, > `https://:/flink-clusters/namespace/flink_job_deployment/v1/jobs` > is not supported. > This will use changes from > FLINK-32885(https://issues.apache.org/jira/browse/FLINK-32885) > Since RestClusterClient talks to the JobManager via its REST endpoint, the > right format for `SUBMIT_ARGS` is URL with path (also support for https > scheme). -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-32885) Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient for PyFlink remote execution
[ https://issues.apache.org/jira/browse/FLINK-32885?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Elkhan Dadashov closed FLINK-32885. --- > Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used > by RestClusterClient for PyFlink remote execution > - > > Key: FLINK-32885 > URL: https://issues.apache.org/jira/browse/FLINK-32885 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Table SQL / Gateway >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > UrlPrefixDecorator is introduced in `flink-sql-gateway` module, which has > dependency on `flink-clients` module. RestClusterClient will also need to use > UrlPrefixDecorator for supporting PyFlink remote execution. Will refactor > related classes to achieve this. > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Resolved] (FLINK-32885) Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient for PyFlink remote execution
[ https://issues.apache.org/jira/browse/FLINK-32885?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Elkhan Dadashov resolved FLINK-32885. - Resolution: Fixed > Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used > by RestClusterClient for PyFlink remote execution > - > > Key: FLINK-32885 > URL: https://issues.apache.org/jira/browse/FLINK-32885 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Table SQL / Gateway >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > UrlPrefixDecorator is introduced in `flink-sql-gateway` module, which has > dependency on `flink-clients` module. RestClusterClient will also need to use > UrlPrefixDecorator for supporting PyFlink remote execution. Will refactor > related classes to achieve this. > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] tweise merged pull request #23383: [FLINK-32885 ] [flink-clients] Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient for PyFlink remote e
tweise merged PR #23383: URL: https://github.com/apache/flink/pull/23383 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-33078) Enhance ParameterTool to support múltiple environments
Oscar Perez created FLINK-33078: --- Summary: Enhance ParameterTool to support múltiple environments Key: FLINK-33078 URL: https://issues.apache.org/jira/browse/FLINK-33078 Project: Flink Issue Type: New Feature Reporter: Oscar Perez I would like to see a new class e.g. EnvironmentParameterTool which can be made of composition of 2 parametertool instances and works by retrieving the value in a properties file environment specific and if not found falls back to global properties file. This would work in the same fashion than, for instance, spring boot works with properties.yaml and properties-dev.yaml -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323483540
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
What are we solving with the current implementation exactly? Do we want to
be backward compatible with an originally flawed logic?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323483540
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
What are we handling with the current implementation exactly?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323483540
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
What are we solving with the current implementation exactly?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] gyfora commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
gyfora commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323424948
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
This change has to be backward compatible so I think @srpraneeth took the
right approach here
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-32885) Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient for PyFlink remote execution
[ https://issues.apache.org/jira/browse/FLINK-32885?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Elkhan Dadashov updated FLINK-32885: Fix Version/s: 1.19.0 Description: UrlPrefixDecorator is introduced in `flink-sql-gateway` module, which has dependency on `flink-clients` module. RestClusterClient will also need to use UrlPrefixDecorator for supporting PyFlink remote execution. Will refactor related classes to achieve this. was: UrlPrefixDecorator is introduced in `flink-sql-gateway` module, which has dependency on `flink-clients` module. RestClusterClient will also need to use UrlPrefixDecorator for supporting PyFlink remote execution. Will refactor related classes to achieve this. I intend to change these classes in a backward compatible way flink-clients/src/main/java/org/apache/flink/client/program/rest/UrlPrefixDecorator.java flink-table/flink-sql-gateway/src/main/java/org/apache/flink/table/gateway/rest/header/util/SQLGatewayUrlPrefixDecorator.java flink-clients/src/main/java/org/apache/flink/client/program/rest/MonitoringAPIMessageHeaders.java flink-table/flink-sql-client/src/main/java/org/apache/flink/table/client/gateway/ExecutorImpl.java > Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used > by RestClusterClient for PyFlink remote execution > - > > Key: FLINK-32885 > URL: https://issues.apache.org/jira/browse/FLINK-32885 > Project: Flink > Issue Type: New Feature > Components: Client / Job Submission, Table SQL / Gateway >Affects Versions: 1.17.1 >Reporter: Elkhan Dadashov >Assignee: Elkhan Dadashov >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > UrlPrefixDecorator is introduced in `flink-sql-gateway` module, which has > dependency on `flink-clients` module. RestClusterClient will also need to use > UrlPrefixDecorator for supporting PyFlink remote execution. Will refactor > related classes to achieve this. > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323381133
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
@gyfora @tweise @mxm wdyt?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on PR #670: URL: https://github.com/apache/flink-kubernetes-operator/pull/670#issuecomment-1716182195 Thanks for contributing @srpraneeth. Could you please update the PR and help understand the goal here with specific examples CR examples? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323382871
##
flink-kubernetes-operator/src/test/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilderTest.java:
##
@@ -478,6 +478,50 @@ public void testTaskManagerSpec() {
Double.valueOf(1),
configuration.get(KubernetesConfigOptions.TASK_MANAGER_CPU));
}
+@Test
+public void testApplyJobManagerSpecWithBiByteMemorySetting() {
Review Comment:
We'll probably need a bit more test cases here once we understand what do we
exactly want, see my comments above.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] venkata91 commented on a diff in pull request #23164: [FLINK- 32775]Add parent dir of files to classpath using yarn.provided.lib.dirs
venkata91 commented on code in PR #23164:
URL: https://github.com/apache/flink/pull/23164#discussion_r1323383321
##
flink-yarn/src/main/java/org/apache/flink/yarn/YarnApplicationFileUploader.java:
##
@@ -360,11 +362,27 @@ List registerProvidedLocalResources() {
envShipResourceList.add(descriptor);
if (!isFlinkDistJar(filePath.getName()) &&
!isPlugin(filePath)) {
-classPaths.add(fileName);
+URI parentDirectoryUri = new
Path(fileName).getParent().toUri();
+String relativeParentDirectory =
Review Comment:
+1 to @wangyang0918 suggestion.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764321#comment-17764321
]
Tzu-Li (Gordon) Tai edited comment on FLINK-33017 at 9/12/23 5:55 PM:
--
Lets only resolve this ticket once we have a green light on the nightly build:
Manually triggered one here -
[https://github.com/apache/flink-connector-kafka/actions/runs/6163109229]
was (Author: tzulitai):
Lets only resolve this ticket once we have a green light on the nightly build:
https://github.com/apache/flink-connector-kafka/actions/runs/6163109229
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Assignee: Alex Sorokoumov
>Priority: Blocker
> Labels: pull-request-available
> Fix For: kafka-3.0.1, kafka-3.1.0
>
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
[jira] [Comment Edited] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764321#comment-17764321
]
Tzu-Li (Gordon) Tai edited comment on FLINK-33017 at 9/12/23 5:55 PM:
--
Lets only resolve this ticket once we have a green light on the nightly build:
https://github.com/apache/flink-connector-kafka/actions/runs/6163109229
was (Author: tzulitai):
Lets only resolve this ticket once we have a green light on the nightly builds.
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Assignee: Alex Sorokoumov
>Priority: Blocker
> Labels: pull-request-available
> Fix For: kafka-3.0.1, kafka-3.1.0
>
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949673Z [ERROR] Run 6: Could not initialize class
>
[jira] [Commented] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764321#comment-17764321
]
Tzu-Li (Gordon) Tai commented on FLINK-33017:
-
Lets only resolve this ticket once we have a green light on the nightly builds.
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Assignee: Alex Sorokoumov
>Priority: Blocker
> Labels: pull-request-available
> Fix For: kafka-3.0.1, kafka-3.1.0
>
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949673Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949913Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8950155Z [ERROR] Run 8:
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323381133
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
@mxm wdyt?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764320#comment-17764320
]
Tzu-Li (Gordon) Tai commented on FLINK-33017:
-
Fixed via:
apache/flink-connector-kafka:main - 818d1fdedaad63631eab5d44ec90c748cfcf299f
apache/flink-connector-kafka:v3.0 - a81cbeb62b1f12a3f80ff6f2380047a2d7400194
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Assignee: Alex Sorokoumov
>Priority: Blocker
> Labels: pull-request-available
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949673Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949913Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
>
[jira] [Updated] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tzu-Li (Gordon) Tai updated FLINK-33017:
Fix Version/s: kafka-3.0.1
kafka-3.1.0
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Assignee: Alex Sorokoumov
>Priority: Blocker
> Labels: pull-request-available
> Fix For: kafka-3.0.1, kafka-3.1.0
>
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949673Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949913Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8950155Z [ERROR] Run 8: Could not initialize class
>
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
morhidi commented on code in PR #670:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/670#discussion_r1323380347
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/config/FlinkConfigBuilder.java:
##
@@ -420,13 +421,24 @@ private void setResource(Resource resource, Configuration
effectiveConfig, boole
? JobManagerOptions.TOTAL_PROCESS_MEMORY
: TaskManagerOptions.TOTAL_PROCESS_MEMORY;
if (resource.getMemory() != null) {
-effectiveConfig.setString(memoryConfigOption.key(),
resource.getMemory());
+effectiveConfig.setString(
+memoryConfigOption.key(),
parseResourceMemoryString(resource.getMemory()));
}
configureCpu(resource, effectiveConfig, isJM);
}
}
+// Using the K8s units specification for the JM and TM memory settings
+private String parseResourceMemoryString(String memory) {
+try {
+return MemorySize.parse(memory).toString();
Review Comment:
Mmm in my head we should aim to support all memory configurations and
notations kubernetes supports and convert them to Flinks proprietary settings
unless those are specifically provided by Flink properties.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Assigned] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tzu-Li (Gordon) Tai reassigned FLINK-33017:
---
Assignee: Alex Sorokoumov
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Assignee: Alex Sorokoumov
>Priority: Blocker
> Labels: pull-request-available
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949673Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949913Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8950155Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8950518Z [ERROR]
[jira] [Updated] (FLINK-33017) Nightly run for Flink Kafka connector fails
[
https://issues.apache.org/jira/browse/FLINK-33017?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-33017:
---
Labels: pull-request-available (was: )
> Nightly run for Flink Kafka connector fails
> ---
>
> Key: FLINK-33017
> URL: https://issues.apache.org/jira/browse/FLINK-33017
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: kafka-3.1.0
>Reporter: Martijn Visser
>Priority: Blocker
> Labels: pull-request-available
>
> https://github.com/apache/flink-connector-kafka/actions/runs/6061283403/job/16446313350#step:13:54462
> {code:java}
> 2023-09-03T00:29:28.8942615Z [ERROR] Errors:
> 2023-09-03T00:29:28.8942799Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestore
> 2023-09-03T00:29:28.8943079Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943342Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943604Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8943903Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944164Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944419Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944714Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8944970Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945221Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8945294Z [INFO]
> 2023-09-03T00:29:28.8945577Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateNoPartitions
> 2023-09-03T00:29:28.8945769Z [ERROR] Run 1:
> org/apache/flink/shaded/guava31/com/google/common/collect/ImmutableList
> 2023-09-03T00:29:28.8946019Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946266Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946525Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8946778Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947027Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947269Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947516Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947765Z [ERROR] Run 9: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8947834Z [INFO]
> 2023-09-03T00:29:28.8948117Z [ERROR]
> FlinkKafkaConsumerBaseMigrationTest.testRestoreFromEmptyStateWithPartitions
> 2023-09-03T00:29:28.8948407Z [ERROR] Run 1: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948660Z [ERROR] Run 2: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8948949Z [ERROR] Run 3: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949192Z [ERROR] Run 4: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949433Z [ERROR] Run 5: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949673Z [ERROR] Run 6: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8949913Z [ERROR] Run 7: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8950155Z [ERROR] Run 8: Could not initialize class
> org.apache.flink.runtime.util.config.memory.ManagedMemoryUtils
> 2023-09-03T00:29:28.8950518Z [ERROR] Run 9: Could not initialize class
>
[jira] [Commented] (FLINK-32818) Support region failover for adaptive scheduler
[ https://issues.apache.org/jira/browse/FLINK-32818?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764298#comment-17764298 ] Talat Uyarer commented on FLINK-32818: -- Thank you [~fanrui] I look forward your PR :) > Support region failover for adaptive scheduler > -- > > Key: FLINK-32818 > URL: https://issues.apache.org/jira/browse/FLINK-32818 > Project: Flink > Issue Type: Improvement > Components: Runtime / Coordination >Reporter: Rui Fan >Assignee: Rui Fan >Priority: Major > > The region failover strategy is useful for fast failover, and reduce the > impact for business side. However, the adaptive scheduler doesn't support it > so far. > https://nightlies.apache.org/flink/flink-docs-master/docs/ops/state/task_failure_recovery/#restart-pipelined-region-failover-strategy -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-31871) Interpret Flink MemoryUnits according to the actual user input
[ https://issues.apache.org/jira/browse/FLINK-31871?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764296#comment-17764296 ] Praneeth Ramesh commented on FLINK-31871: - [~gyfora] Can you please help review https://github.com/apache/flink-kubernetes-operator/pull/670 > Interpret Flink MemoryUnits according to the actual user input > -- > > Key: FLINK-31871 > URL: https://issues.apache.org/jira/browse/FLINK-31871 > Project: Flink > Issue Type: Improvement > Components: API / Core, Kubernetes Operator >Reporter: Alexander Fedulov >Assignee: Praneeth Ramesh >Priority: Major > Labels: pull-request-available > > Currently all MemorySize.MemoryUnits are interpreted in "bibyte" notation, > regardless of the units that users specify: > [https://github.com/apache/flink/blob/release-1.17/flink-core/src/main/java/org/apache/flink/configuration/MemorySize.java#L352-L356] > (i.e. G = Gi) > Flink Kubernetes Operator utilizes these units for specifying resources in > user-facing CR API (taskManager.resource.memory, jobManager.resource.memory). > In other places this CR requires native K8S units specification (i.e. > spec.containers[*].ephemeral-storage). > There are two issues with this: > * users cannot rely on the same units notation (taskManager.resource.memory > = 16Gi fails) > * taskManager.resource.memory = 16G is not interpreted as other units in the > spec (16G is implicitly converted into 16Gi) -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-31871) Interpret Flink MemoryUnits according to the actual user input
[ https://issues.apache.org/jira/browse/FLINK-31871?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-31871: --- Labels: pull-request-available (was: ) > Interpret Flink MemoryUnits according to the actual user input > -- > > Key: FLINK-31871 > URL: https://issues.apache.org/jira/browse/FLINK-31871 > Project: Flink > Issue Type: Improvement > Components: API / Core, Kubernetes Operator >Reporter: Alexander Fedulov >Assignee: Praneeth Ramesh >Priority: Major > Labels: pull-request-available > > Currently all MemorySize.MemoryUnits are interpreted in "bibyte" notation, > regardless of the units that users specify: > [https://github.com/apache/flink/blob/release-1.17/flink-core/src/main/java/org/apache/flink/configuration/MemorySize.java#L352-L356] > (i.e. G = Gi) > Flink Kubernetes Operator utilizes these units for specifying resources in > user-facing CR API (taskManager.resource.memory, jobManager.resource.memory). > In other places this CR requires native K8S units specification (i.e. > spec.containers[*].ephemeral-storage). > There are two issues with this: > * users cannot rely on the same units notation (taskManager.resource.memory > = 16Gi fails) > * taskManager.resource.memory = 16G is not interpreted as other units in the > spec (16G is implicitly converted into 16Gi) -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] srpraneeth opened a new pull request, #670: [FLINK-31871] Interpret Flink MemoryUnits according to the actual user input
srpraneeth opened a new pull request, #670: URL: https://github.com/apache/flink-kubernetes-operator/pull/670 ## What is the purpose of the change JM and TM memory settings is only supported in bibytes format. This change will help interpreting the flink memory according to the actual user input. ## Brief change log - Added the implementation - Added tests ## Verifying this change This change is already covered by existing tests ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changes to the `CustomResourceDescriptors`: no - Core observer or reconciler logic that is regularly executed: no ## Documentation - Does this pull request introduce a new feature? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-31163) Unexpected correlate variable $cor0 in the plan error in where clause
[
https://issues.apache.org/jira/browse/FLINK-31163?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764293#comment-17764293
]
Sergey Nuyanzin edited comment on FLINK-31163 at 9/12/23 4:52 PM:
--
--[~rohankrao] it seems after upgrade to Calcite 1.32.0 and some other fixes
it is not an issue anymore for 1.18-
-Could you please double check it?--
yes, seems still an issue, will have a look
was (Author: sergey nuyanzin):
-[~rohankrao] it seems after upgrade to Calcite 1.32.0 and some other fixes
it is not an issue anymore for 1.18
Could you please double check it?-
yes, seems still an issue, will have a look
> Unexpected correlate variable $cor0 in the plan error in where clause
> -
>
> Key: FLINK-31163
> URL: https://issues.apache.org/jira/browse/FLINK-31163
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API
>Affects Versions: 1.16.0
>Reporter: P Rohan Kumar
>Priority: Major
>
> {code:java}
> val env: StreamExecutionEnvironment =
> StreamExecutionEnvironment.getExecutionEnvironment
> val tableEnv = StreamTableEnvironment.create(env)
> val accountsTd =
> TableDescriptor.forConnector("datagen").option("rows-per-second", "10")
> .option("number-of-rows", "10")
> .schema(Schema
> .newBuilder()
> .column("account_num", DataTypes.VARCHAR(2147483647))
> .column("acc_name", DataTypes.VARCHAR(2147483647))
> .column("acc_phone_num", DataTypes.VARCHAR(2147483647))
> .build())
> .build()
> val accountsTable = tableEnv.from(accountsTd)
> tableEnv.createTemporaryView("accounts", accountsTable)
> val transactionsTd =
> TableDescriptor.forConnector("datagen").option("rows-per-second", "10")
> .option("number-of-rows", "10")
> .schema(Schema
> .newBuilder()
> .column("account_num", DataTypes.VARCHAR(2147483647))
> .column("transaction_place", DataTypes.VARCHAR(2147483647))
> .column("transaction_time", DataTypes.BIGINT())
> .column("amount", DataTypes.INT())
> .build())
> .build()
> val transactionsTable = tableEnv.from(transactionsTd)
> tableEnv.createTemporaryView("transaction_data", transactionsTable)
> val newTable = tableEnv.sqlQuery("select acc.account_num, (select count(*)
> from transaction_data where transaction_place = trans.transaction_place and
> account_num = acc.account_num) from accounts acc,transaction_data trans")
> tableEnv.toChangelogStream(newTable).print()
> env.execute() {code}
> I get the following error if I run the above code.
>
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.TableException:
> unexpected correlate variable $cor0 in the plan
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkDecorrelateProgram.checkCorrelVariableExists(FlinkDecorrelateProgram.scala:59)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkDecorrelateProgram.optimize(FlinkDecorrelateProgram.scala:42)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$2(FlinkGroupProgram.scala:59)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at scala.collection.Iterator.foreach(Iterator.scala:943)
> at scala.collection.Iterator.foreach$(Iterator.scala:943)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
> at scala.collection.IterableLike.foreach(IterableLike.scala:74)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
> at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:189)
> at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:184)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$1(FlinkGroupProgram.scala:56)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$1$adapted(FlinkGroupProgram.scala:51)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at scala.collection.immutable.Range.foreach(Range.scala:158)
> at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:189)
> at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:184)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.optimize(FlinkGroupProgram.scala:51)
> at
>
[jira] [Comment Edited] (FLINK-31163) Unexpected correlate variable $cor0 in the plan error in where clause
[
https://issues.apache.org/jira/browse/FLINK-31163?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764293#comment-17764293
]
Sergey Nuyanzin edited comment on FLINK-31163 at 9/12/23 4:52 PM:
--
-[~rohankrao] it seems after upgrade to Calcite 1.32.0 and some other fixes
it is not an issue anymore for 1.18
Could you please double check it?-
yes, seems still an issue, will have a look
was (Author: sergey nuyanzin):
[~rohankrao] it seems after upgrade to Calcite 1.32.0 and some other fixes it
is not an issue anymore for 1.18
Could you please double check it?
> Unexpected correlate variable $cor0 in the plan error in where clause
> -
>
> Key: FLINK-31163
> URL: https://issues.apache.org/jira/browse/FLINK-31163
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API
>Affects Versions: 1.16.0
>Reporter: P Rohan Kumar
>Priority: Major
>
> {code:java}
> val env: StreamExecutionEnvironment =
> StreamExecutionEnvironment.getExecutionEnvironment
> val tableEnv = StreamTableEnvironment.create(env)
> val accountsTd =
> TableDescriptor.forConnector("datagen").option("rows-per-second", "10")
> .option("number-of-rows", "10")
> .schema(Schema
> .newBuilder()
> .column("account_num", DataTypes.VARCHAR(2147483647))
> .column("acc_name", DataTypes.VARCHAR(2147483647))
> .column("acc_phone_num", DataTypes.VARCHAR(2147483647))
> .build())
> .build()
> val accountsTable = tableEnv.from(accountsTd)
> tableEnv.createTemporaryView("accounts", accountsTable)
> val transactionsTd =
> TableDescriptor.forConnector("datagen").option("rows-per-second", "10")
> .option("number-of-rows", "10")
> .schema(Schema
> .newBuilder()
> .column("account_num", DataTypes.VARCHAR(2147483647))
> .column("transaction_place", DataTypes.VARCHAR(2147483647))
> .column("transaction_time", DataTypes.BIGINT())
> .column("amount", DataTypes.INT())
> .build())
> .build()
> val transactionsTable = tableEnv.from(transactionsTd)
> tableEnv.createTemporaryView("transaction_data", transactionsTable)
> val newTable = tableEnv.sqlQuery("select acc.account_num, (select count(*)
> from transaction_data where transaction_place = trans.transaction_place and
> account_num = acc.account_num) from accounts acc,transaction_data trans")
> tableEnv.toChangelogStream(newTable).print()
> env.execute() {code}
> I get the following error if I run the above code.
>
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.TableException:
> unexpected correlate variable $cor0 in the plan
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkDecorrelateProgram.checkCorrelVariableExists(FlinkDecorrelateProgram.scala:59)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkDecorrelateProgram.optimize(FlinkDecorrelateProgram.scala:42)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$2(FlinkGroupProgram.scala:59)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at scala.collection.Iterator.foreach(Iterator.scala:943)
> at scala.collection.Iterator.foreach$(Iterator.scala:943)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
> at scala.collection.IterableLike.foreach(IterableLike.scala:74)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
> at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:189)
> at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:184)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$1(FlinkGroupProgram.scala:56)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$1$adapted(FlinkGroupProgram.scala:51)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at scala.collection.immutable.Range.foreach(Range.scala:158)
> at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:189)
> at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:184)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.optimize(FlinkGroupProgram.scala:51)
> at
>
[jira] [Commented] (FLINK-31163) Unexpected correlate variable $cor0 in the plan error in where clause
[
https://issues.apache.org/jira/browse/FLINK-31163?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764293#comment-17764293
]
Sergey Nuyanzin commented on FLINK-31163:
-
[~rohankrao] it seems after upgrade to Calcite 1.32.0 and some other fixes it
is not an issue anymore for 1.18
Could you please double check it?
> Unexpected correlate variable $cor0 in the plan error in where clause
> -
>
> Key: FLINK-31163
> URL: https://issues.apache.org/jira/browse/FLINK-31163
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API
>Affects Versions: 1.16.0
>Reporter: P Rohan Kumar
>Priority: Major
>
> {code:java}
> val env: StreamExecutionEnvironment =
> StreamExecutionEnvironment.getExecutionEnvironment
> val tableEnv = StreamTableEnvironment.create(env)
> val accountsTd =
> TableDescriptor.forConnector("datagen").option("rows-per-second", "10")
> .option("number-of-rows", "10")
> .schema(Schema
> .newBuilder()
> .column("account_num", DataTypes.VARCHAR(2147483647))
> .column("acc_name", DataTypes.VARCHAR(2147483647))
> .column("acc_phone_num", DataTypes.VARCHAR(2147483647))
> .build())
> .build()
> val accountsTable = tableEnv.from(accountsTd)
> tableEnv.createTemporaryView("accounts", accountsTable)
> val transactionsTd =
> TableDescriptor.forConnector("datagen").option("rows-per-second", "10")
> .option("number-of-rows", "10")
> .schema(Schema
> .newBuilder()
> .column("account_num", DataTypes.VARCHAR(2147483647))
> .column("transaction_place", DataTypes.VARCHAR(2147483647))
> .column("transaction_time", DataTypes.BIGINT())
> .column("amount", DataTypes.INT())
> .build())
> .build()
> val transactionsTable = tableEnv.from(transactionsTd)
> tableEnv.createTemporaryView("transaction_data", transactionsTable)
> val newTable = tableEnv.sqlQuery("select acc.account_num, (select count(*)
> from transaction_data where transaction_place = trans.transaction_place and
> account_num = acc.account_num) from accounts acc,transaction_data trans")
> tableEnv.toChangelogStream(newTable).print()
> env.execute() {code}
> I get the following error if I run the above code.
>
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.TableException:
> unexpected correlate variable $cor0 in the plan
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkDecorrelateProgram.checkCorrelVariableExists(FlinkDecorrelateProgram.scala:59)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkDecorrelateProgram.optimize(FlinkDecorrelateProgram.scala:42)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$2(FlinkGroupProgram.scala:59)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at scala.collection.Iterator.foreach(Iterator.scala:943)
> at scala.collection.Iterator.foreach$(Iterator.scala:943)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
> at scala.collection.IterableLike.foreach(IterableLike.scala:74)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
> at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:189)
> at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:184)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$1(FlinkGroupProgram.scala:56)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.$anonfun$optimize$1$adapted(FlinkGroupProgram.scala:51)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at scala.collection.immutable.Range.foreach(Range.scala:158)
> at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:189)
> at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:184)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkGroupProgram.optimize(FlinkGroupProgram.scala:51)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.$anonfun$optimize$1(FlinkChainedProgram.scala:59)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:187)
> at
> scala.collection.TraversableOnce$folder$1$.apply(TraversableOnce.scala:185)
> at
[GitHub] [flink] flinkbot commented on pull request #23403: [FLINK-32863][runtime-web] Improve Flink UI's time precision from sec…
flinkbot commented on PR #23403: URL: https://github.com/apache/flink/pull/23403#issuecomment-1715992250 ## CI report: * 4f3ce28635392bcaf72db7e63627c7cfe5e709c0 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-32863) Improve Flink UI's time precision from second level to millisecond level
[ https://issues.apache.org/jira/browse/FLINK-32863?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-32863: --- Labels: pull-request-available (was: ) > Improve Flink UI's time precision from second level to millisecond level > > > Key: FLINK-32863 > URL: https://issues.apache.org/jira/browse/FLINK-32863 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Web Frontend >Affects Versions: 1.17.1 >Reporter: Runkang He >Priority: Major > Labels: pull-request-available > > This an UI improvement for OLAP jobs. > OLAP queries are generally small queries which will finish at the seconds or > milliseconds, but currently the time precision displayed is second level and > not enough for OLAP queries. Millisecond part of time is very important for > users and developers, to see accurate time, for performance measurement and > optimization. The displayed time includes job duration, task duration, task > start time, end time and so on. > It would be nice to improve this for better OLAP user experience. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] hejufang opened a new pull request, #23403: [FLINK-32863][runtime-web] Improve Flink UI's time precision from sec…
hejufang opened a new pull request, #23403: URL: https://github.com/apache/flink/pull/23403 ## What is the purpose of the change Improve Flink UI's time precision from second level to millisecond level. ## Brief change log Improve Flink UI's time precision from second level to millisecond level, includes job duration, task duration, task start time, end time. https://github.com/apache/flink/assets/28342990/f6fd85d3-4d0c-4d12-9aeb-1ecb504708e8;> ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? yes - If yes, how is the feature documented? not documented -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-32804) Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink
[ https://issues.apache.org/jira/browse/FLINK-32804?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764255#comment-17764255 ] Panagiotis Garefalakis edited comment on FLINK-32804 at 9/12/23 3:38 PM: - Hey [~wangm92] closing this ticket at the main functionality was validated as discussed above. Linking the follow-up tickets as discussed was (Author: pgaref): Hey [~wangm92] closing this ticket at the main functionality was validated as discussed above. Linking the follow-up tickets as discussed: https://issues.apache.org/jira/browse/FLINK-33051 https://issues.apache.org/jira/browse/FLINK-33022 and https://issues.apache.org/jira/browse/FLINK-31895 > Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink > - > > Key: FLINK-32804 > URL: https://issues.apache.org/jira/browse/FLINK-32804 > Project: Flink > Issue Type: Sub-task > Components: Tests >Affects Versions: 1.18.0 >Reporter: Qingsheng Ren >Assignee: Matt Wang >Priority: Major > Fix For: 1.18.0 > > Attachments: image-2023-09-04-16-58-29-329.png, > image-2023-09-04-17-00-16-413.png, image-2023-09-04-17-02-41-760.png, > image-2023-09-04-17-03-25-452.png, image-2023-09-04-17-04-21-682.png > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Resolved] (FLINK-32804) Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink
[ https://issues.apache.org/jira/browse/FLINK-32804?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Panagiotis Garefalakis resolved FLINK-32804. Resolution: Fixed > Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink > - > > Key: FLINK-32804 > URL: https://issues.apache.org/jira/browse/FLINK-32804 > Project: Flink > Issue Type: Sub-task > Components: Tests >Affects Versions: 1.18.0 >Reporter: Qingsheng Ren >Assignee: Matt Wang >Priority: Major > Fix For: 1.18.0 > > Attachments: image-2023-09-04-16-58-29-329.png, > image-2023-09-04-17-00-16-413.png, image-2023-09-04-17-02-41-760.png, > image-2023-09-04-17-03-25-452.png, image-2023-09-04-17-04-21-682.png > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-32804) Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink
[ https://issues.apache.org/jira/browse/FLINK-32804?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17764255#comment-17764255 ] Panagiotis Garefalakis commented on FLINK-32804: Hey [~wangm92] closing this ticket at the main functionality was validated as discussed above. Linking the follow-up tickets as discussed: https://issues.apache.org/jira/browse/FLINK-33051 https://issues.apache.org/jira/browse/FLINK-33022 and https://issues.apache.org/jira/browse/FLINK-31895 > Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink > - > > Key: FLINK-32804 > URL: https://issues.apache.org/jira/browse/FLINK-32804 > Project: Flink > Issue Type: Sub-task > Components: Tests >Affects Versions: 1.18.0 >Reporter: Qingsheng Ren >Assignee: Matt Wang >Priority: Major > Fix For: 1.18.0 > > Attachments: image-2023-09-04-16-58-29-329.png, > image-2023-09-04-17-00-16-413.png, image-2023-09-04-17-02-41-760.png, > image-2023-09-04-17-03-25-452.png, image-2023-09-04-17-04-21-682.png > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] afedulov commented on a diff in pull request #23383: [FLINK-32885 ] [flink-clients] Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient fo
afedulov commented on code in PR #23383:
URL: https://github.com/apache/flink/pull/23383#discussion_r1323172674
##
flink-clients/src/main/java/org/apache/flink/client/program/rest/UrlPrefixDecorator.java:
##
@@ -100,4 +105,11 @@ public Class getRequestClass() {
public M getUnresolvedMessageParameters() {
return decorated.getUnresolvedMessageParameters();
}
+
+@Override
+public Collection> getSupportedAPIVersions() {
Review Comment:
How about simply doing this:
```
@Override
public Collection> getSupportedAPIVersions()
{
return decorated.getSupportedAPIVersions();
}
```
this class has a clear purpose of only decorating the URL, without dealing
with anything related to the features of the decorated object. This change
would also make the `SQLGatewayUrlPrefixDecorator` redundant - the SQL headers
that get decorated will simply pass their `SqlGatewayRestAPIVersion.values()`
from `SqlGatewayMessageHeaders` which they already extend.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (FLINK-32804) Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink
[
https://issues.apache.org/jira/browse/FLINK-32804?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17762443#comment-17762443
]
Panagiotis Garefalakis edited comment on FLINK-32804 at 9/12/23 3:32 PM:
-
Hey [~wangm92] – thanks for the detailed update! Answers inline
{quote}1. When FailureEnricherUtils loads FailureEnricher, if
`jobmanager.failure-enrichers` is configured but not loaded, I think it should
throw an exception or print some ERROR logs. I created
Jira(https://issues.apache.org/jira/browse/FLINK-33022) a to follow up;
{quote}
Happy to take care of this
{quote}2. FLIP-304 introduces the `LabeledGlobalFailureHandler` interface. I
think the `GlobalFailureHandler` interface can be removed in the future to
avoid the existence of interfaces with duplicate functions. This can be
promoted in future versions;
{quote}
Opened FLINK-33051 to work on this
{quote}3. Regarding the user documentation, I left some comments. The user
documentation is very helpful, and the code integration needs to be promoted as
soon as possible; [~pgaref]
{quote}
Updated documentation PR – let me know what you think
{quote}4. https://issues.apache.org/jira/browse/FLINK-31895 about E2E test
Here I think it needs to be promoted as soon as possible. If there is a Demo
example, it will be more helpful to users.
{quote}
Lets split this to 2 tickets, one about e2e tests and one adding a demo
was (Author: pgaref):
Hey [~wangm92] – thanks for the detailed update! Answers inline
{quote}1. When FailureEnricherUtils loads FailureEnricher, if
`jobmanager.failure-enrichers` is configured but not loaded, I think it should
throw an exception or print some ERROR logs. I created
Jira(https://issues.apache.org/jira/browse/FLINK-33022) a to follow up;
{quote}
Happy to take care of this
{quote}2. FLIP-304 introduces the `LabeledGlobalFailureHandler` interface. I
think the `GlobalFailureHandler` interface can be removed in the future to
avoid the existence of interfaces with duplicate functions. This can be
promoted in future versions;
{quote}
Opened FLINK-31508 to work on this
{quote}3. Regarding the user documentation, I left some comments. The user
documentation is very helpful, and the code integration needs to be promoted as
soon as possible; [~pgaref]
{quote}
Updated documentation PR – let me know what you think
{quote}4. https://issues.apache.org/jira/browse/FLINK-31895 about E2E test
Here I think it needs to be promoted as soon as possible. If there is a Demo
example, it will be more helpful to users.
{quote}
Lets split this to 2 tickets, one about e2e tests and one adding a demo
> Release Testing: Verify FLIP-304: Pluggable failure handling for Apache Flink
> -
>
> Key: FLINK-32804
> URL: https://issues.apache.org/jira/browse/FLINK-32804
> Project: Flink
> Issue Type: Sub-task
> Components: Tests
>Affects Versions: 1.18.0
>Reporter: Qingsheng Ren
>Assignee: Matt Wang
>Priority: Major
> Fix For: 1.18.0
>
> Attachments: image-2023-09-04-16-58-29-329.png,
> image-2023-09-04-17-00-16-413.png, image-2023-09-04-17-02-41-760.png,
> image-2023-09-04-17-03-25-452.png, image-2023-09-04-17-04-21-682.png
>
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Closed] (FLINK-32777) Upgrade Okhttp version to support IPV6
[ https://issues.apache.org/jira/browse/FLINK-32777?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gyula Fora closed FLINK-32777. -- Fix Version/s: kubernetes-operator-1.7.0 Resolution: Fixed merged to main 8978dde3facd3094a2cbb1a7706588c3fa7ef5fb > Upgrade Okhttp version to support IPV6 > -- > > Key: FLINK-32777 > URL: https://issues.apache.org/jira/browse/FLINK-32777 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Zhenqiu Huang >Assignee: Zhenqiu Huang >Priority: Minor > Labels: pull-request-available > Fix For: kubernetes-operator-1.7.0 > > > It is reported by user: > I was testing flink-kubernetes-operator in an IPv6 cluster and found out the > below issues: > Caused by: javax.net.ssl.SSLPeerUnverifiedException: Hostname > fd70:e66a:970d::1 not verified: > certificate: sha256/EmX0EhNn75iJO353Pi+1rClwZyVLe55HN3l5goaneKQ= > DN: CN=kube-apiserver > subjectAltNames: [fd70:e66a:970d:0:0:0:0:1, > 2406:da14:2:770b:3b82:51d7:9e89:76ce, 10.0.170.248, > c0c813eaff4f9d66084de428125f0b9c.yl4.ap-northeast-1.eks.amazonaws.com, > ip-10-0-170-248.ap-northeast-1.compute.internal, kubernetes, > kubernetes.default, kubernetes.default.svc, > kubernetes.default.svc.cluster.local] > Which seemed to be related to a known issue of okhttp. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] afedulov commented on a diff in pull request #23383: [FLINK-32885 ] [flink-clients] Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient fo
afedulov commented on code in PR #23383:
URL: https://github.com/apache/flink/pull/23383#discussion_r1323172674
##
flink-clients/src/main/java/org/apache/flink/client/program/rest/UrlPrefixDecorator.java:
##
@@ -100,4 +105,11 @@ public Class getRequestClass() {
public M getUnresolvedMessageParameters() {
return decorated.getUnresolvedMessageParameters();
}
+
+@Override
+public Collection> getSupportedAPIVersions() {
Review Comment:
How about simply doing this:
```
@Override
public Collection> getSupportedAPIVersions()
{
return decorated.getSupportedAPIVersions();
}
```
this class has a clear purpose of only decorating the URL, without dealing
with anything delated to the features of the decorated object. This change
would also make the `SQLGatewayUrlPrefixDecorator` redundant - the SQL headers
that get decorated will simply pass their `SqlGatewayRestAPIVersion.values()`
from `SqlGatewayMessageHeaders` which they already extend.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] afedulov commented on a diff in pull request #23383: [FLINK-32885 ] [flink-clients] Refactoring: Moving UrlPrefixDecorator into flink-clients so it can be used by RestClusterClient fo
afedulov commented on code in PR #23383:
URL: https://github.com/apache/flink/pull/23383#discussion_r1323172674
##
flink-clients/src/main/java/org/apache/flink/client/program/rest/UrlPrefixDecorator.java:
##
@@ -100,4 +105,11 @@ public Class getRequestClass() {
public M getUnresolvedMessageParameters() {
return decorated.getUnresolvedMessageParameters();
}
+
+@Override
+public Collection> getSupportedAPIVersions() {
Review Comment:
How about simply doing this:
```
@Override
public Collection> getSupportedAPIVersions()
{
return decorated.getSupportedAPIVersions();
}
```
this class has a clear purpose of only decorating the URL, without dealing
with anything delated to the features of the decorated object. That would make
the `SQLGatewayUrlPrefixDecorator` redundant - the SQL headers that get
decorated will simply pass their `SqlGatewayRestAPIVersion.values()` from
`SqlGatewayMessageHeaders` which they already extend.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-connector-rabbitmq] RocMarshal commented on a diff in pull request #16: [FLINK-20628] Port RabbitMQ Connector using unified Source & Sink API
RocMarshal commented on code in PR #16:
URL:
https://github.com/apache/flink-connector-rabbitmq/pull/16#discussion_r1323168285
##
flink-connector-rabbitmq/src/main/java/org/apache/flink/connector/rabbitmq/common/ConsistencyMode.java:
##
@@ -0,0 +1,39 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connector.rabbitmq.common;
+
+/**
+ * The different consistency modes that can be defined for the sink and source
individually.
+ *
+ * The available consistency modes are as follows.
+ *
+ *
+ * AT_MOST_ONCE Messages are consumed by the output once or
never.
+ * AT_LEAST_ONCE Messages are consumed by the output at
least once.
+ * EXACTLY_ONCE Messages are consumed by the output exactly
once.
+ *
+ *
+ * Note that the higher the consistency guarantee gets, fewer messages can
be processed by the
+ * system. At-least-once and exactly-once should only be used if necessary.
+ */
+public enum ConsistencyMode {
Review Comment:
Should we use `DeliveryGuarantee` to replace the `ConsistencyMode` ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org