[GitHub] [kafka] ijuma commented on a change in pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
ijuma commented on a change in pull request #10466:
URL: https://github.com/apache/kafka/pull/10466#discussion_r620886540
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
Review comment:
That line should be including test dependencies like log4j, etc. But I
don't know why that makes sense for streams. It does make sense for core. So, I
would remove it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vitojeng edited a comment on pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
vitojeng edited a comment on pull request #10597: URL: https://github.com/apache/kafka/pull/10597#issuecomment-827317919 @ableegoldman Got it, thank you for the explanation. :) I am fine with this change. Let me apply `StreamsNotStartedException` to `validateIsRunningOrRebalancing()` in this PR, and update the KIP and discussion thread. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng commented on pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
vitojeng commented on pull request #10597: URL: https://github.com/apache/kafka/pull/10597#issuecomment-827317919 @ableegoldman Got it, thank you for the explanation. :) I am fine with this change. Let me apply StreamsNotStartedException to `validateIsRunningOrRebalancing()` in this PR, and update the KIP and discussion thread. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
ableegoldman commented on pull request #10597: URL: https://github.com/apache/kafka/pull/10597#issuecomment-827302955 >It is a bit strange for me if use StreamsNotStartedException to replace IllegalStateException in the validateIsRunningOrRebalancing() Isn't that what we're doing with the `KafkaStreams#store` method, though? It also invokes `validateIsRunningOrRebalancing()` and thus presumably will throw an IllegalStateException if a user invokes this on a KafkaStreams that hasn't been started. Maybe you can run the test you added with the actual changes commented out and see what gets thrown. >I wonder if it worth to break the API compatibility? The trivial improvement will break the API compatibility(allMetadata(), allMetadataForStore(), queryMetadataForKey). It seems this change means that KIP-216 is no longer API Compatibility and the scope of the KIP will exceed Interactive Query related. WDYT? Those methods are all, ultimately at least, related to Interactive Queries. My understanding is that they would be used to find out where to route a query for a specific key, for example. Plus they do take a particular store as a parameter, thus even `InvalidStateStore` makes about as much sense for these methods as it does for KafkaStreams#store. Also just fyi, by sheer coincidence it seems this PR will end up landing in 3.0 which is a major version bump and thus (some) breaking changes are allowed. I think changing up exception handling in this way is acceptable (and as noted above it seems we are already doing so for the `#store` case, unless I'm missing something). Plus, it seems like compatibility is a bit nuanced in this particular case. Presumably a user will hit this case just because they forgot to call `start()` before invoking this API, therefore I would expect that any existing apps which are upgraded would already be sure to call start() first and it's only the new applications/new users which are likely to hit this particular exception. That's my read of the situation, anyway. Thoughts? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng commented on pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
vitojeng commented on pull request #10597: URL: https://github.com/apache/kafka/pull/10597#issuecomment-827296663 > LGTM, just some suggestions for the wording. Can we add a note to the section in the upgrade-guide that you added for the last exception? Sure, will do. Thank for your reminder. > By the way, I wonder if we should also throw this exception for the `allMetadata, `allMetadataForStore`, and `queryMetadataForKey`methods? It seems these methods along with`KafkaStreams#store`all do the same thing of calling`validateIsRunningOrRebalancing` which then checks on the KafkaStreams state and throws IllegalStateException if not in one of those two states. Imo all of these would benefit from the StreamsNotStartedException and it doesn't make sense to single that one out. One thing may need remind, in the KIP-216, `StreamsNotStartedException` is sub class of `InvalidStateStoreException`. That means `StreamsNotStartedException` is an exception related to the StateStore. It is a bit strange for me if use `StreamsNotStartedException` to replace `IllegalStateException` in the `validateIsRunningOrRebalancing()`. > Thoughts? I know it's not in the KIP but in this case it seems like a trivial improvement that would merit just a quick update on the KIP discussion thread but not a whole new KIP of its own I wonder if it worth to break the API compatibility? The trivial improvement will break the API compatibility(`allMetadata()`, `allMetadataForStore()`, `queryMetadataForKey`). It seems this change means that KIP-216 is no longer API Compatibility and the scope of the KIP will exceed Interactive Query related. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dielhennr commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
dielhennr commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620833566
##
File path:
raft/src/test/java/org/apache/kafka/raft/internals/BatchAccumulatorTest.java
##
@@ -65,6 +66,34 @@
);
}
+@Test
+public void testLeaderChangeMessageWritten() {
Review comment:
@hachikuji Why would 2 ever happen in practice? The accumulator is
created and then the leaderChangeMessage is written right after.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dielhennr commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
dielhennr commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620833566
##
File path:
raft/src/test/java/org/apache/kafka/raft/internals/BatchAccumulatorTest.java
##
@@ -65,6 +66,34 @@
);
}
+@Test
+public void testLeaderChangeMessageWritten() {
Review comment:
@hachikuji Why would 2 ever happen in practice?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] bruto1 commented on a change in pull request #10590: KAFKA-5761: support ByteBuffer as value in ProducerRecord and avoid redundant serialization when it's used
bruto1 commented on a change in pull request #10590: URL: https://github.com/apache/kafka/pull/10590#discussion_r620829421 ## File path: clients/src/main/java/org/apache/kafka/clients/producer/Partitioner.java ## @@ -34,10 +34,9 @@ * @param key The key to partition on (or null if no key) * @param keyBytes The serialized key to partition on( or null if no key) * @param value The value to partition on or null - * @param valueBytes The serialized value to partition on or null * @param cluster The current cluster metadata */ -public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); Review comment: I can pass a dummy byte array to the partitioner instead I guess -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-12713) Report "REAL" follower/consumer fetch latency
[ https://issues.apache.org/jira/browse/KAFKA-12713?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17331590#comment-17331590 ] Ming Liu edited comment on KAFKA-12713 at 4/27/21, 3:25 AM: The idea is: # Add waitTimeMs in FetchResponse # In processResponseCallback() of handleFetchRequest, set the waitTimeMs as the time spent in purgatory. # In FetcherStats, we will add a new meter to track the fetch latency, by deduct the waitTimeMs from the latency. Also, in FetchLatency, we should also report a time called TotalEffectiveTime = TotalTime-RemoteTime. Created KIP: https://cwiki.apache.org/confluence/display/KAFKA/KIP-736%3A+Track+the+real+fetch+latency was (Author: mingaliu): The idea is: # Add waitTimeMs in FetchResponse # In processResponseCallback() of handleFetchRequest, set the waitTimeMs as the time spent in purgatory. # In FetcherStats, we will add a new meter to track the fetch latency, by deduct the waitTimeMs from the latency. Also, in FetchLatency, we should also report a time called TotalEffectiveTime = TotalTime-RemoteTime. Let me know for any suggestion/feedback. I like to propose a KIP on that change. > Report "REAL" follower/consumer fetch latency > - > > Key: KAFKA-12713 > URL: https://issues.apache.org/jira/browse/KAFKA-12713 > Project: Kafka > Issue Type: Bug >Reporter: Ming Liu >Priority: Major > > The fetch latency is an important metrics to monitor for the cluster > performance. With ACK=ALL, the produce latency is affected primarily by > broker fetch latency. > However, currently the reported fetch latency didn't reflect the true fetch > latency because it sometimes need to stay in purgatory and wait for > replica.fetch.wait.max.ms when data is not available. This greatly affect the > real P50, P99 etc. > I like to propose a KIP to be able track the real fetch latency for both > broker follower and consumer. > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620802248
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
https://github.com/apache/kafka/pull/6592#discussion_r370513438
> However, to allow us to support different serialization format in the
future, we should add one more magic byte in the very beginning that encodes
the choose serialization format
As per ignoring the choice, also from @mjsax
https://github.com/apache/kafka/pull/6592#issuecomment-606277356:
> I guess it's called freedom of choice :) If we feel strong about it, we
could of course disallow the "negative size" strategy for primitive types.
However, it would have the disadvantage that we have a config that, depending
on the data type you are using, would either be ignored or even throw an error
if set incorrectly. From a usability point of view, this would be a
disadvantage. It's always a mental burden to users if they have to think about
if-then-else cases.
...
Personally, I have a slight preference to allow both strategies for all
types as I think easy of use is more important, but I am also fine otherwise.
Here is my thought process, if a user chooses a serialization strategy, then
she probably knows what she is doing. Ofc, the user will have a larger payload,
and we certainly will notify her that the serialization strategy she chose is
not optimal for the current type of data, but I don't think we should strictly
forbid the user from "shooting herself in the foot".
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620802248
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
https://github.com/apache/kafka/pull/6592#discussion_r370513438
> However, to allow us to support different serialization format in the
future, we should add one more magic byte in the very beginning that encodes
the choose serialization format
As per ignoring the choice, also from @mjsax
https://github.com/apache/kafka/pull/6592#issuecomment-606277356:
> I guess it's called freedom of choice :) If we feel strong about it, we
could of course disallow the "negative size" strategy for primitive types.
However, it would have the disadvantage that we have a config that, depending
on the data type you are using, would either be ignored or even throw an error
if set incorrectly. From a usability point of view, this would be a
disadvantage. It's always a mental burden to users if they have to think about
if-then-else cases.
...
Personally, I have a slight preference to allow both strategies for all
types as I think easy of use is more important, but I am also fine otherwise.
Here is my thought process, if a user chooses a serialization strategy, then
she probably knows what she is doing. Ofc, the user will have a larger payload,
and we certainly will notify her that the serialization strategy she chose is
not optimal for the current type of data, but I don't think we should simply
forbid the user from "shooting herself in the foot".
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620802248
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
https://github.com/apache/kafka/pull/6592#discussion_r370513438
> However, to allow us to support different serialization format in the
future, we should add one more magic byte in the very beginning that encodes
the choose serialization format
As per ignoring the choice, also from @mjsax
https://github.com/apache/kafka/pull/6592#issuecomment-606277356:
> I guess it's called freedom of choice :) If we feel strong about it, we
could of course disallow the "negative size" strategy for primitive types.
However, it would have the disadvantage that we have a config that, depending
on the data type you are using, would either be ignored or even throw an error
if set incorrectly. From a usability point of view, this would be a
disadvantage. It's always a mental burden to users if they have to think about
if-then-else cases.
...
Personally, I have a slight preference to allow both strategies for all
types as I think easy of use is more important, but I am also fine otherwise.
Here is my thought process, if a user chooses a serialization strategy, then
she probably knows what she is doing. Ofc, the user will have a larger payload,
and we certainly will notify her that the serialization strategy is not optimal
for the current type of data, but I don't think we should simply forbid the
user from "shooting herself in the foot".
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620804518
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
My feeling is, don't over-optimize for the future. If/when we do want to
add new serialization strategies it won't be that hard to pass a KIP that
deprecates the current API in favor of whatever new one they decide on. And it
won't be much work for users to migrate from the deprecated API. I'm all for
future-proofness but imo it's better to start out with the simplest and best
API for the current moment and then iterate on that, rather than try to address
all possible eventualities with the very first set of changes. The only
exception being cases where the overhead of migrating from the initial API to a
new and improved one would be really high, either for the devs or for the user
or both. But I don't think that applies here.
That's just my personal take. Maybe @mjsax would disagree, or maybe not.
I'll try to ping him and see what he thinks now, since it's been a while since
that last set of comments. Until then, what's your opinion here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620802248
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
https://github.com/apache/kafka/pull/6592#discussion_r370513438
> However, to allow us to support different serialization format in the
future, we should add one more magic byte in the very beginning that encodes
the choose serialization format
As per ignoring the choice, also from @mjsax
https://github.com/apache/kafka/pull/6592#issuecomment-606277356:
> I guess it's called freedom of choice :) If we feel strong about it, we
could of course disallow the "negative size" strategy for primitive types.
However, it would have the disadvantage that we have a config that, depending
on the data type you are using, would either be ignored or even throw an error
if set incorrectly. From a usability point of view, this would be a
disadvantage. It's always a mental burden to users if they have to think about
if-then-else cases.
...
Personally, I have a slight preference to allow both strategies for all
types as I think easy of use is more important, but I am also fine otherwise.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620802248
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
(https://github.com/apache/kafka/pull/6592#discussion_r370513438)
> However, to allow us to support different serialization format in the
future, we should add one more magic byte in the very beginning that encodes
the choose serialization format
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
https://github.com/apache/kafka/pull/6592#discussion_r370513438
> However, to allow us to support different serialization format in the
future, we should add one more magic byte in the very beginning that encodes
the choose serialization format
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620802248
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, @mjsax reasoning was that in the future we could introduce
**more** serialization strategies
(https://github.com/apache/kafka/pull/6592#discussion_r370513438)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #10554: Expand AdjustStreamThreadCountTest by writing some data to Kafka topics
ableegoldman commented on pull request #10554: URL: https://github.com/apache/kafka/pull/10554#issuecomment-827263009 Thanks for the PR, I think this is step forward since just processing some data at all may have caught that cache bug a while back. But I wonder if we can take it a step further in this PR and also try to validate that some data did get processed in each of the tests? I can think of two ways of doing this. One is obviously just to wait on some data showing up in the output topic. Not sure what topology all of these tests are running at the moment but if there's a 1:1 ratio between input records and output then you can just wait until however many records you pipe in. There should be some methods in IntegrationTestUtils that do this already, check out `waitUntilMinRecordsReceived` Another way would be to use a custom processor/transformer that sets a flag once all the expected data has been processed. But tbh that first method is probably the best since it tests end-to-end including writing to an output topic, plus you can use an existing IntegrationTestUtils method so there's less custom code needed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10554: Expand AdjustStreamThreadCountTest by writing some data to Kafka topics
ableegoldman commented on a change in pull request #10554:
URL: https://github.com/apache/kafka/pull/10554#discussion_r620794381
##
File path:
streams/src/test/java/org/apache/kafka/streams/integration/AdjustStreamThreadCountTest.java
##
@@ -121,6 +125,21 @@ public void setup() {
);
}
+
+private void publishDummyDataToTopic(final String inputTopic, final
EmbeddedKafkaCluster cluster) {
+final Properties props = new Properties();
+props.put("acks", "all");
+props.put("retries", 1);
+props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
cluster.bootstrapServers());
+props.put(ProducerConfig.CLIENT_ID_CONFIG, "test-client");
+props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
+props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
+final KafkaProducer dummyProducer = new
KafkaProducer<>(props);
+dummyProducer.send(new ProducerRecord(inputTopic,
Integer.toString(4), Integer.toString(4)));
Review comment:
It might be a good idea to send a slightly larger batch of data, for
example I think in other integration tests we did like 10,000 records. We don't
necessarily need that many here but Streams should be fast enough that we may
as well do something like 1,000 - 5,000
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ncliang commented on pull request #10475: KAFKA-12610: Implement PluginClassLoader::getResource
ncliang commented on pull request #10475: URL: https://github.com/apache/kafka/pull/10475#issuecomment-827234589 Ping @mageshn @gharris1727 , the failed tests don't seem to be related to this change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dielhennr commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
dielhennr commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620734980
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
+ByteBuffer buffer = memoryPool.tryAllocate(256);
+if (buffer != null) {
Review comment:
https://github.com/apache/kafka/blob/c8ee242811778be5c59bb1a8cdc92682eeececbc/raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java#L257
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
+ByteBuffer buffer = memoryPool.tryAllocate(256);
+if (buffer != null) {
Review comment:
Why doesn't an exception get thrown for `startNewBatch`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-12713) Report "REAL" follower/consumer fetch latency
[ https://issues.apache.org/jira/browse/KAFKA-12713?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17331590#comment-17331590 ] Ming Liu edited comment on KAFKA-12713 at 4/27/21, 12:17 AM: - The idea is: # Add waitTimeMs in FetchResponse # In processResponseCallback() of handleFetchRequest, set the waitTimeMs as the time spent in purgatory. # In FetcherStats, we will add a new meter to track the fetch latency, by deduct the waitTimeMs from the latency. Also, in FetchLatency, we should also report a time called TotalEffectiveTime = TotalTime-RemoteTime. Let me know for any suggestion/feedback. I like to propose a KIP on that change. was (Author: mingaliu): The idea is: 0. Add waitTimeMs in Request() 1. In delayedOperation DelayedFetch class, add some code to track the actual wait time. 2. In processResponseCallback() of handleFetchRequest, we can add additional parameter of waitTimeMs invoked from DelayedFetch. It will set request.waitTimeMs. 3. In updateRequestMetrics() function, if waitTimeMs is not zero, we will deduct that out of RemoteTime and TotalTime. Let me know for any suggestion/feedback. I like to propose a KIP on that change. > Report "REAL" follower/consumer fetch latency > - > > Key: KAFKA-12713 > URL: https://issues.apache.org/jira/browse/KAFKA-12713 > Project: Kafka > Issue Type: Bug >Reporter: Ming Liu >Priority: Major > > The fetch latency is an important metrics to monitor for the cluster > performance. With ACK=ALL, the produce latency is affected primarily by > broker fetch latency. > However, currently the reported fetch latency didn't reflect the true fetch > latency because it sometimes need to stay in purgatory and wait for > replica.fetch.wait.max.ms when data is not available. This greatly affect the > real P50, P99 etc. > I like to propose a KIP to be able track the real fetch latency for both > broker follower and consumer. > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dielhennr commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
dielhennr commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620734980
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
+ByteBuffer buffer = memoryPool.tryAllocate(256);
+if (buffer != null) {
Review comment:
https://github.com/apache/kafka/blob/c8ee242811778be5c59bb1a8cdc92682eeececbc/raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java#L257
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dielhennr commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
dielhennr commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620734462
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
+ByteBuffer buffer = memoryPool.tryAllocate(256);
+if (buffer != null) {
Review comment:
Why doesn't an exception get thrown for startNewBatch?
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
+ByteBuffer buffer = memoryPool.tryAllocate(256);
+if (buffer != null) {
Review comment:
Why doesn't an exception get thrown for `startNewBatch`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #10542: KAFKA-12313: Streamling windowed Deserialiser configs.
ableegoldman commented on pull request #10542: URL: https://github.com/apache/kafka/pull/10542#issuecomment-827215366 Hey @vamossagar12 , I think we're good to go on the update you proposed to this KIP. Take a look at the other feedback I left and just ping me when the PR is ready for review again. Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573:
URL: https://github.com/apache/kafka/pull/10573#discussion_r620726308
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamThread.java
##
@@ -603,7 +606,7 @@ boolean runLoop() {
log.error("Shutting down because the Kafka cluster seems
to be on a too old version. " +
"Setting {}=\"{}\" requires broker version 2.5
or higher.",
StreamsConfig.PROCESSING_GUARANTEE_CONFIG,
- EXACTLY_ONCE_BETA);
+ StreamsConfig.EXACTLY_ONCE_V2);
Review comment:
I'll just put in both of them
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573: URL: https://github.com/apache/kafka/pull/10573#discussion_r620725616 ## File path: docs/streams/upgrade-guide.html ## @@ -93,6 +95,12 @@ Upgrade Guide and API Changes Streams API changes in 3.0.0 + + The StreamsConfig.EXACTLY_ONCE and StreamsConfig.EXACTLY_ONCE_BETA configs have been deprecated, and a new StreamsConfig.EXACTLY_ONCE_V2 config has been Review comment: I guess I'll just try to mention StreamsConfig in there somewhere... -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
hachikuji commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620722131
##
File path:
raft/src/test/java/org/apache/kafka/raft/internals/BatchAccumulatorTest.java
##
@@ -65,6 +66,34 @@
);
}
+@Test
+public void testLeaderChangeMessageWritten() {
Review comment:
A couple extra test cases to add:
1. Can we add a test case for `flush()` to ensure that it forces an
immediate drain?
2. Can we add a test case in which we have undrained data when
`appendLeaderChangeMessage` is called?
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
Review comment:
I think I was a little off in my suggestion to add this. I don't think
this is sufficient to ensure the current batch gets completed before we add the
leader change message since `maybeCompleteDrain` will only do so if a drain has
been started. Maybe the simple thing is to call `flush()`?
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -202,6 +203,25 @@ private void completeCurrentBatch() {
currentBatch = null;
}
+public void addControlBatch(MemoryRecords records) {
+appendLock.lock();
+try {
+drainStatus = DrainStatus.STARTED;
Review comment:
How about `forceDrain`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
ableegoldman commented on a change in pull request #10573: URL: https://github.com/apache/kafka/pull/10573#discussion_r620722055 ## File path: docs/streams/upgrade-guide.html ## @@ -93,6 +95,12 @@ Upgrade Guide and API Changes Streams API changes in 3.0.0 + + The StreamsConfig.EXACTLY_ONCE and StreamsConfig.EXACTLY_ONCE_BETA configs have been deprecated, and a new StreamsConfig.EXACTLY_ONCE_V2 config has been + introduced. This is the same feature as eos-beta, but renamed to highlight its production-readiness. Users of exactly-once semantics should plan to migrate to the eos-v2 config and prepare for the removal of the deprecated configs in 4.0 or after at least a year Review comment: Well, I kind of thought that we did intentionally choose to call it `beta` because we weren't completely confident in it when it was first released. But we are now, and looking back we can say with hindsight that it turned out to be production-ready back then. Still, I see your point, I'll make it more explicit with something like that suggestion -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620720140
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Ah, sorry if that wasn't clear. Yes I was proposing to ignore the choice
if a user selects the `VARIABLE_SIZE` strategy with primitive type data. And to
also log a warning in this case so at least we're not just silently ignoring it.
But I think you made a good point that perhaps we don't need to expose this
flag at all. There seems to be no reason for a user to explicitly opt-in to the
`VARIABLE_SIZE` strategy. Perhaps a better way of looking at this is to say
that this strategy is the default, where the default will be overridden in two
cases: data is a primitive/known type, or the data is a custom type that the
user knows to be constant size and thus chooses to opt-in to the
`CONSTANT_SIZE` strategy.
WDYT? We could simplify the API by making this a boolean parameter instead
of having them choose a `SerializationStrategy` directly, something like
`isConstantSize`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620720140
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Ah, sorry if that wasn't clear. Yes I was proposing to ignore the choice
if a user selects the `VARIABLE_SIZE` strategy with primitive type data. And to
also log a warning in this case so at least we're not just silently ignoring it.
But I think you may have a point that perhaps we don't need to expose this
flag at all. There seems to be no reason for a user to explicitly opt-in to the
`VARIABLE_SIZE` strategy. Perhaps a better way of looking at this is to say
that this strategy is the default, where the default will be overridden in two
cases: data is a primitive/known type, or the data is a custom type that the
user knows to be constant size and thus chooses to opt-in to the
`CONSTANT_SIZE` strategy.
WDYT? We could simplify the API by making this a boolean parameter instead
of having them choose a `SerializationStrategy` directly, something like
`isConstantSize`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
ableegoldman commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620716670
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
+mkEntry(UUIDDeserializer.class, 36)
+);
+
+public ListDeserializer() {}
+
+public > ListDeserializer(Class listClass,
Deserializer innerDeserializer) {
+this.listClass = listClass;
+this.inner = innerDeserializer;
+if (innerDeserializer != null) {
+this.primitiveSize =
fixedLengthDeserializers.get(innerDeserializer.getClass());
+}
+}
+
+public Deserializer getInnerDeserializer() {
+return inner;
+}
+
+@Override
+public void configure(Map configs, boolean isKey) {
+if (listClass == null) {
Review comment:
>Maybe, if a user tries to use the constructor when classes are already
defined in the configs, we simply throw an exception? Forcing the user to set
only one or the other
That works for me. Tbh I actually prefer this, but thought you might
consider it too harsh. Someone else had that reaction to a similar scenario in
the past. Let's do it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] junrao commented on a change in pull request #10534: KAFKA-806: Index may not always observe log.index.interval.bytes
junrao commented on a change in pull request #10534:
URL: https://github.com/apache/kafka/pull/10534#discussion_r620704283
##
File path: core/src/main/scala/kafka/log/LogSegment.scala
##
@@ -162,15 +162,43 @@ class LogSegment private[log] (val log: FileRecords,
// append the messages
val appendedBytes = log.append(records)
trace(s"Appended $appendedBytes to ${log.file} at end offset
$largestOffset")
+
+
+ def appendIndex(): Unit = {
+var validBytes = 0
+var maxTimestampSoFarTmp = RecordBatch.NO_TIMESTAMP
+var offsetOfMaxTimestampSoFarTmp = 0L
+var lastIndexEntry = 0
+val originalLastOffset = offsetIndex.lastOffset
+
+for (batch <- log.batches.asScala) {
+ batch.ensureValid()
+ ensureOffsetInRange(batch.lastOffset)
+
+ if (batch.maxTimestamp > maxTimestampSoFarTmp) {
+maxTimestampSoFarTmp = batch.maxTimestamp
+offsetOfMaxTimestampSoFarTmp = batch.lastOffset
+ }
+
+ if (validBytes - lastIndexEntry > indexIntervalBytes) {
+if (batch.lastOffset > originalLastOffset) {
+ offsetIndex.append(batch.lastOffset, validBytes)
+ timeIndex.maybeAppend(maxTimestampSoFarTmp,
offsetOfMaxTimestampSoFarTmp)
+}
+lastIndexEntry = validBytes
Review comment:
Could we just have a single val accumulatedBytes and reset it to 0 after
each index insertion?
##
File path: core/src/main/scala/kafka/log/LogSegment.scala
##
@@ -162,15 +162,43 @@ class LogSegment private[log] (val log: FileRecords,
// append the messages
val appendedBytes = log.append(records)
trace(s"Appended $appendedBytes to ${log.file} at end offset
$largestOffset")
+
+
+ def appendIndex(): Unit = {
+var validBytes = 0
+var maxTimestampSoFarTmp = RecordBatch.NO_TIMESTAMP
+var offsetOfMaxTimestampSoFarTmp = 0L
+var lastIndexEntry = 0
+val originalLastOffset = offsetIndex.lastOffset
+
+for (batch <- log.batches.asScala) {
+ batch.ensureValid()
+ ensureOffsetInRange(batch.lastOffset)
+
+ if (batch.maxTimestamp > maxTimestampSoFarTmp) {
+maxTimestampSoFarTmp = batch.maxTimestamp
+offsetOfMaxTimestampSoFarTmp = batch.lastOffset
+ }
+
+ if (validBytes - lastIndexEntry > indexIntervalBytes) {
Review comment:
It seems that we need to take bytesSinceLastIndexEntry into
consideration and we also need to update bytesSinceLastIndexEntry properly here
instead of the caller.
##
File path: core/src/main/scala/kafka/log/LogSegment.scala
##
@@ -162,15 +162,43 @@ class LogSegment private[log] (val log: FileRecords,
// append the messages
val appendedBytes = log.append(records)
trace(s"Appended $appendedBytes to ${log.file} at end offset
$largestOffset")
+
+
+ def appendIndex(): Unit = {
+var validBytes = 0
+var maxTimestampSoFarTmp = RecordBatch.NO_TIMESTAMP
+var offsetOfMaxTimestampSoFarTmp = 0L
+var lastIndexEntry = 0
+val originalLastOffset = offsetIndex.lastOffset
+
+for (batch <- log.batches.asScala) {
+ batch.ensureValid()
Review comment:
We already did validation in Log.analyzeAndValidateRecords(). So we
don't need to do this again here.
##
File path: core/src/main/scala/kafka/log/LogSegment.scala
##
@@ -162,15 +162,43 @@ class LogSegment private[log] (val log: FileRecords,
// append the messages
val appendedBytes = log.append(records)
trace(s"Appended $appendedBytes to ${log.file} at end offset
$largestOffset")
+
+
+ def appendIndex(): Unit = {
+var validBytes = 0
+var maxTimestampSoFarTmp = RecordBatch.NO_TIMESTAMP
+var offsetOfMaxTimestampSoFarTmp = 0L
+var lastIndexEntry = 0
+val originalLastOffset = offsetIndex.lastOffset
+
+for (batch <- log.batches.asScala) {
+ batch.ensureValid()
+ ensureOffsetInRange(batch.lastOffset)
+
+ if (batch.maxTimestamp > maxTimestampSoFarTmp) {
Review comment:
Since this is done in the caller for all batches, we don't need to do it
here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10480: KAFKA-12265: Move the BatchAccumulator in KafkaRaftClient to LeaderState
hachikuji commented on a change in pull request #10480:
URL: https://github.com/apache/kafka/pull/10480#discussion_r620708379
##
File path: raft/src/main/java/org/apache/kafka/raft/KafkaRaftClient.java
##
@@ -1876,12 +1836,12 @@ private void appendBatch(
}
private long maybeAppendBatches(
-LeaderState state,
+LeaderState state,
long currentTimeMs
) {
-long timeUnitFlush = accumulator.timeUntilDrain(currentTimeMs);
+long timeUnitFlush = state.accumulator().timeUntilDrain(currentTimeMs);
Review comment:
I was just interested in the spelling fix . I am fine with
`timeUntilDrain` as well.
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -194,14 +196,50 @@ private void completeCurrentBatch() {
MemoryRecords data = currentBatch.build();
completed.add(new CompletedBatch<>(
currentBatch.baseOffset(),
-currentBatch.records(),
+Optional.of(currentBatch.records()),
data,
memoryPool,
currentBatch.initialBuffer()
));
currentBatch = null;
}
+public void appendLeaderChangeMessage(LeaderChangeMessage
leaderChangeMessage, long currentTimeMs) {
+appendLock.lock();
+try {
+maybeCompleteDrain();
+ByteBuffer buffer = memoryPool.tryAllocate(256);
+if (buffer != null) {
Review comment:
How about in the `else` case? Probably we need to raise an exception?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] junrao merged pull request #10592: MINOR: Remove redudant test files and close LogSegment after test
junrao merged pull request #10592: URL: https://github.com/apache/kafka/pull/10592 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9441: KAFKA-10614: Ensure group state (un)load is executed in the submitted order
hachikuji commented on a change in pull request #9441:
URL: https://github.com/apache/kafka/pull/9441#discussion_r620695517
##
File path: core/src/main/scala/kafka/coordinator/group/GroupCoordinator.scala
##
@@ -905,19 +908,35 @@ class GroupCoordinator(val brokerId: Int,
*
* @param offsetTopicPartitionId The partition we are now leading
*/
- def onElection(offsetTopicPartitionId: Int): Unit = {
-info(s"Elected as the group coordinator for partition
$offsetTopicPartitionId")
-groupManager.scheduleLoadGroupAndOffsets(offsetTopicPartitionId,
onGroupLoaded)
+ def onElection(offsetTopicPartitionId: Int, coordinatorEpoch: Int): Unit = {
+epochForPartitionId.compute(offsetTopicPartitionId, (_, epoch) => {
+ val currentEpoch = Option(epoch)
+ if (currentEpoch.forall(currentEpoch => coordinatorEpoch >
currentEpoch)) {
Review comment:
One final thing I was considering is whether we should push this check
into `GroupMetadataManager.loadGroupsAndOffsets`. That would give us some
protection against any assumptions about ordering in `KafkaScheduler`.
##
File path: core/src/main/scala/kafka/coordinator/group/GroupCoordinator.scala
##
@@ -905,19 +908,32 @@ class GroupCoordinator(val brokerId: Int,
*
* @param offsetTopicPartitionId The partition we are now leading
*/
- def onElection(offsetTopicPartitionId: Int): Unit = {
-info(s"Elected as the group coordinator for partition
$offsetTopicPartitionId")
-groupManager.scheduleLoadGroupAndOffsets(offsetTopicPartitionId,
onGroupLoaded)
+ def onElection(offsetTopicPartitionId: Int, coordinatorEpoch: Int): Unit = {
+val currentEpoch = Option(epochForPartitionId.get(offsetTopicPartitionId))
+if (currentEpoch.forall(currentEpoch => coordinatorEpoch > currentEpoch)) {
+ info(s"Elected as the group coordinator for partition
$offsetTopicPartitionId in epoch $coordinatorEpoch")
+ groupManager.scheduleLoadGroupAndOffsets(offsetTopicPartitionId,
onGroupLoaded)
+ epochForPartitionId.put(offsetTopicPartitionId, coordinatorEpoch)
+} else {
+ warn(s"Ignored election as group coordinator for partition
$offsetTopicPartitionId " +
+s"in epoch $coordinatorEpoch since current epoch is $currentEpoch")
+}
}
/**
* Unload cached state for the given partition and stop handling requests
for groups which map to it.
*
* @param offsetTopicPartitionId The partition we are no longer leading
*/
- def onResignation(offsetTopicPartitionId: Int): Unit = {
-info(s"Resigned as the group coordinator for partition
$offsetTopicPartitionId")
-groupManager.removeGroupsForPartition(offsetTopicPartitionId,
onGroupUnloaded)
+ def onResignation(offsetTopicPartitionId: Int, coordinatorEpoch:
Option[Int]): Unit = {
+val currentEpoch = Option(epochForPartitionId.get(offsetTopicPartitionId))
+if (currentEpoch.forall(currentEpoch => currentEpoch <=
coordinatorEpoch.getOrElse(Int.MaxValue))) {
Review comment:
I have probably not been doing a good job of being clear. It is useful
to bump the epoch whenever we observe a larger value whether it is in
`onResignation` or `onElection`. This protects us from all potential
reorderings.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
ableegoldman commented on a change in pull request #10597:
URL: https://github.com/apache/kafka/pull/10597#discussion_r620653928
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1524,6 +1527,12 @@ public void cleanUp() {
*an InvalidStateStoreException is
thrown upon store access.
*/
public T store(final StoreQueryParameters storeQueryParameters) {
+synchronized (stateLock) {
+if (state == State.CREATED) {
+throw new StreamsNotStartedException("KafkaStreams is not
started, you can retry and wait until to running.");
Review comment:
Technically we don't need to wait for it to be running, they just need
to start it:
```suggestion
throw new StreamsNotStartedException("KafkaStreams has not
been started, you can retry after calling start()");
```
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1516,6 +1517,8 @@ public void cleanUp() {
*
* @param storeQueryParameters the parameters used to fetch a queryable
store
* @return A facade wrapping the local {@link StateStore} instances
+ * @throws StreamsNotStartedException if Kafka Streams state is {@link
KafkaStreams.State#CREATED CREATED}. Just
+ * retry and wait until to {@link KafkaStreams.State#RUNNING
RUNNING}
Review comment:
```suggestion
* @throws StreamsNotStartedException If user has not started the
KafkaStreams and it's still in {@link KafkaStreams.State#CREATED CREATED}.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (KAFKA-12718) SessionWindows are closed too early
[
https://issues.apache.org/jira/browse/KAFKA-12718?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-12718:
Labels: beginner easy-fix newbie (was: )
> SessionWindows are closed too early
> ---
>
> Key: KAFKA-12718
> URL: https://issues.apache.org/jira/browse/KAFKA-12718
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Reporter: Matthias J. Sax
>Priority: Major
> Labels: beginner, easy-fix, newbie
> Fix For: 3.0.0
>
>
> SessionWindows are defined based on a {{gap}} parameter, and also support an
> additional {{grace-period}} configuration to handle out-of-order data.
> To incorporate the session-gap a session window should only be closed at
> {{window-end + gap}} and to incorporate grace-period, the close time should
> be pushed out further to {{window-end + gap + grace}}.
> However, atm we compute the window close time as {{window-end + grace}}
> omitting the {{gap}} parameter.
> Because default grace-period is 24h most users might not notice this issues.
> Even if they set a grace period explicitly (eg, when using suppress()), they
> would most likely set a grace-period larger than gap-time not hitting the
> issue (or maybe only realize it when inspecting the behavior closely).
> However, if a user wants to disable the grace-period and sets it to zero (on
> any other value smaller than gap-time), sessions might be close too early and
> user might notice.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-12718) SessionWindows are closed too early
[
https://issues.apache.org/jira/browse/KAFKA-12718?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-12718:
Fix Version/s: 3.0.0
> SessionWindows are closed too early
> ---
>
> Key: KAFKA-12718
> URL: https://issues.apache.org/jira/browse/KAFKA-12718
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Reporter: Matthias J. Sax
>Priority: Major
> Fix For: 3.0.0
>
>
> SessionWindows are defined based on a {{gap}} parameter, and also support an
> additional {{grace-period}} configuration to handle out-of-order data.
> To incorporate the session-gap a session window should only be closed at
> {{window-end + gap}} and to incorporate grace-period, the close time should
> be pushed out further to {{window-end + gap + grace}}.
> However, atm we compute the window close time as {{window-end + grace}}
> omitting the {{gap}} parameter.
> Because default grace-period is 24h most users might not notice this issues.
> Even if they set a grace period explicitly (eg, when using suppress()), they
> would most likely set a grace-period larger than gap-time not hitting the
> issue (or maybe only realize it when inspecting the behavior closely).
> However, if a user wants to disable the grace-period and sets it to zero (on
> any other value smaller than gap-time), sessions might be close too early and
> user might notice.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-12718) SessionWindows are closed too early
Matthias J. Sax created KAFKA-12718:
---
Summary: SessionWindows are closed too early
Key: KAFKA-12718
URL: https://issues.apache.org/jira/browse/KAFKA-12718
Project: Kafka
Issue Type: Bug
Components: streams
Reporter: Matthias J. Sax
SessionWindows are defined based on a {{gap}} parameter, and also support an
additional {{grace-period}} configuration to handle out-of-order data.
To incorporate the session-gap a session window should only be closed at
{{window-end + gap}} and to incorporate grace-period, the close time should be
pushed out further to {{window-end + gap + grace}}.
However, atm we compute the window close time as {{window-end + grace}}
omitting the {{gap}} parameter.
Because default grace-period is 24h most users might not notice this issues.
Even if they set a grace period explicitly (eg, when using suppress()), they
would most likely set a grace-period larger than gap-time not hitting the issue
(or maybe only realize it when inspecting the behavior closely).
However, if a user wants to disable the grace-period and sets it to zero (on
any other value smaller than gap-time), sessions might be close too early and
user might notice.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] ableegoldman commented on a change in pull request #8923: KAFKA-6435: KIP-623 Add internal topics option to streamResetter
ableegoldman commented on a change in pull request #8923:
URL: https://github.com/apache/kafka/pull/8923#discussion_r620645865
##
File path:
streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationTest.java
##
@@ -151,6 +151,22 @@ public void
shouldNotAllowToResetWhenIntermediateTopicAbsent() {
Assert.assertEquals(1, exitCode);
}
+@Test
+public void shouldNotAllowToResetWhenSpecifiedInternalTopicAbsent() {
Review comment:
Just wondering, why put this test here instead of in
`AbstractResetIntegrationTest`?
##
File path:
streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationTest.java
##
@@ -151,6 +151,22 @@ public void
shouldNotAllowToResetWhenIntermediateTopicAbsent() {
Assert.assertEquals(1, exitCode);
}
+@Test
+public void shouldNotAllowToResetWhenSpecifiedInternalTopicAbsent() {
Review comment:
Also, can we add a test like this but for the case where the topic does
exist but just isn't a subset of inferred internal topics?
##
File path: docs/streams/developer-guide/app-reset-tool.html
##
@@ -78,6 +78,9 @@
Step 1: Run the application reset tool
Invoke the application reset tool from the command line
path-to-kafka/bin/kafka-streams-application-reset
+Warning! This tool makes irreversible changes to your
application. It is strongly recommended that you run this once with --dry-run to preview
your changes before making them.
+path-to-kafka/bin/kafka-streams-application-reset
Review comment:
You don't need to repeat this line, it's just printing an example of
running the app reset tool for the line above (`Invoke the application reset
tool from the command line`)
##
File path:
streams/src/test/java/org/apache/kafka/streams/integration/AbstractResetIntegrationTest.java
##
@@ -205,6 +206,34 @@ private void add10InputElements() {
}
}
+@Test
+public void testResetWhenInternalTopicsAreSpecified() throws Exception {
+final String appID =
IntegrationTestUtils.safeUniqueTestName(getClass(), testName);
+streamsConfig.put(StreamsConfig.APPLICATION_ID_CONFIG, appID);
+
+// RUN
+streams = new KafkaStreams(setupTopologyWithIntermediateTopic(true,
OUTPUT_TOPIC_2), streamsConfig);
+streams.start();
+
IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(resultConsumerConfig,
OUTPUT_TOPIC, 10);
+
+streams.close();
+waitForEmptyConsumerGroup(adminClient, appID, TIMEOUT_MULTIPLIER *
STREAMS_CONSUMER_TIMEOUT);
+
+// RESET
+streams.cleanUp();
+
+final List internalTopics =
cluster.getAllTopicsInCluster().stream()
+.filter(topic -> topic.startsWith(appID + "-"))
Review comment:
nit: we should also filter for internal topics specifically, like what's
done in `StreamsResetter#matchesInternalTopicFormat`. Actually you can probably
just invoke that method directly for the filter here (it can be made static if
necessary)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji opened a new pull request #10599: KAFKA-12716; Add `Admin` API to abort transactions
hachikuji opened a new pull request #10599: URL: https://github.com/apache/kafka/pull/10599 This patch adds the Admin API to abort transactions from KIP-664: https://cwiki.apache.org/confluence/display/KAFKA/KIP-664%3A+Provide+tooling+to+detect+and+abort+hanging+transactions. The `WriteTxnMarker` API needs to be sent to partition leaders, so we are able to reuse `PartitionLeaderStrategy`, which was introduced when support for `DescribeProducers` was added. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] JoelWee commented on pull request #8923: KAFKA-6435: KIP-623 Add internal topics option to streamResetter
JoelWee commented on pull request #8923: URL: https://github.com/apache/kafka/pull/8923#issuecomment-827122994 Hi @ableegoldman, have rebased now :). The failing tests are RaftClusterTests which don't seem related to the changes here? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-8147) Add changelog topic configuration to KTable suppress
[
https://issues.apache.org/jira/browse/KAFKA-8147?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17332711#comment-17332711
]
A. Sophie Blee-Goldman commented on KAFKA-8147:
---
[~philbour] that would be a bug, you should be able to set these configs in any
order. Seems like BufferConfigInternal#emitEarlyWhenFull creates a new
EagerBufferConfigImpl and passes the two original configs (maxRecords and
maxBytes) in to the constructor, but loses the logging configs at that point.
Same thing for BufferConfigInternal#shutDownWhenFull. Looks like the PR for
this feature just missed updating this, I notice that it did remember to add
this parameter in the constructor calls inside EagerBufferConfigImpl and
StrictBufferConfigImpl.
That said, this looks like kind of an abuse of this pattern so I'm not
surprised bugs slipped through. Maybe instead of just patching the current
problem by adding this parameter to the constructor calls in
BufferConfigInternal we can try to refactor things a bit so we aren't calling
constructors all over the place and making things vulnerable to future changes.
For example in Materialized all of the non-static .withXXX methods just set
that parameter directly instead of creating a new Materialized object every
time you set some configuration. But I'm sure there was a reason to do it this
way initially...
[~philbour] can you file a separate ticket for this? And would you be
interested in submitting a PR to fix the bug you found?
> Add changelog topic configuration to KTable suppress
>
>
> Key: KAFKA-8147
> URL: https://issues.apache.org/jira/browse/KAFKA-8147
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Affects Versions: 2.1.1
>Reporter: Maarten
>Assignee: highluck
>Priority: Minor
> Labels: kip
> Fix For: 2.6.0
>
>
> The streams DSL does not provide a way to configure the changelog topic
> created by KTable.suppress.
> From the perspective of an external user this could be implemented similar to
> the configuration of aggregate + materialized, i.e.,
> {code:java}
> changelogTopicConfigs = // Configs
> materialized = Materialized.as(..).withLoggingEnabled(changelogTopicConfigs)
> ..
> KGroupedStream.aggregate(..,materialized)
> {code}
> [KIP-446:
> https://cwiki.apache.org/confluence/display/KAFKA/KIP-446%3A+Add+changelog+topic+configuration+to+KTable+suppress|https://cwiki.apache.org/confluence/display/KAFKA/KIP-446%3A+Add+changelog+topic+configuration+to+KTable+suppress]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] jolshan commented on a change in pull request #10590: KAFKA-5761: support ByteBuffer as value in ProducerRecord and avoid redundant serialization when it's used
jolshan commented on a change in pull request #10590: URL: https://github.com/apache/kafka/pull/10590#discussion_r620608169 ## File path: clients/src/main/java/org/apache/kafka/clients/producer/Partitioner.java ## @@ -34,10 +34,9 @@ * @param key The key to partition on (or null if no key) * @param keyBytes The serialized key to partition on( or null if no key) * @param value The value to partition on or null - * @param valueBytes The serialized value to partition on or null * @param cluster The current cluster metadata */ -public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); Review comment: This is a public interface, so we can't change the parameters without a KIP. We need to consider compatibility with others who may be using the old interface. This is likely why this parameter still exists. See https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dejan2609 commented on a change in pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
dejan2609 commented on a change in pull request #10466:
URL: https://github.com/apache/kafka/pull/10466#discussion_r620603149
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
Review comment:
So... I will test full Gradle build (across all Scala versions and with
all tests) with and without this clause.
If turns out that build results are comparable I will remove that clause.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jolshan commented on pull request #10598: MINOR: rename wrong topic id variable name and description
jolshan commented on pull request #10598: URL: https://github.com/apache/kafka/pull/10598#issuecomment-827098023 Looks like "topic ID" was language used in in kafka 9+ years ago. But good to clarify now since we have a topic ID for topics now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dejan2609 commented on a change in pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
dejan2609 commented on a change in pull request #10466:
URL: https://github.com/apache/kafka/pull/10466#discussion_r620594758
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
Review comment:
One more note: @vvcephei didn't introduced/changed `copyDependentLibs`
Gradle task. I just mentioned him above while I was investigating changes
related to a `streams` sub-module dependencies block (at the time when I just
started to look for an approach).
That specific Gradle task was introduced as a part of this (big)
improvement:
https://cwiki.apache.org/confluence/display/KAFKA/KIP-28+-+Add+a+processor+client
Related (pretty large) commit:
https://github.com/apache/kafka/commit/263c10ab7c8e8fde9d3566bf59dccaa454ee2605
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dejan2609 commented on a change in pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
dejan2609 commented on a change in pull request #10466:
URL: https://github.com/apache/kafka/pull/10466#discussion_r620580912
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
Review comment:
Hint/note: this **_'from'_** clause could be redundant now:
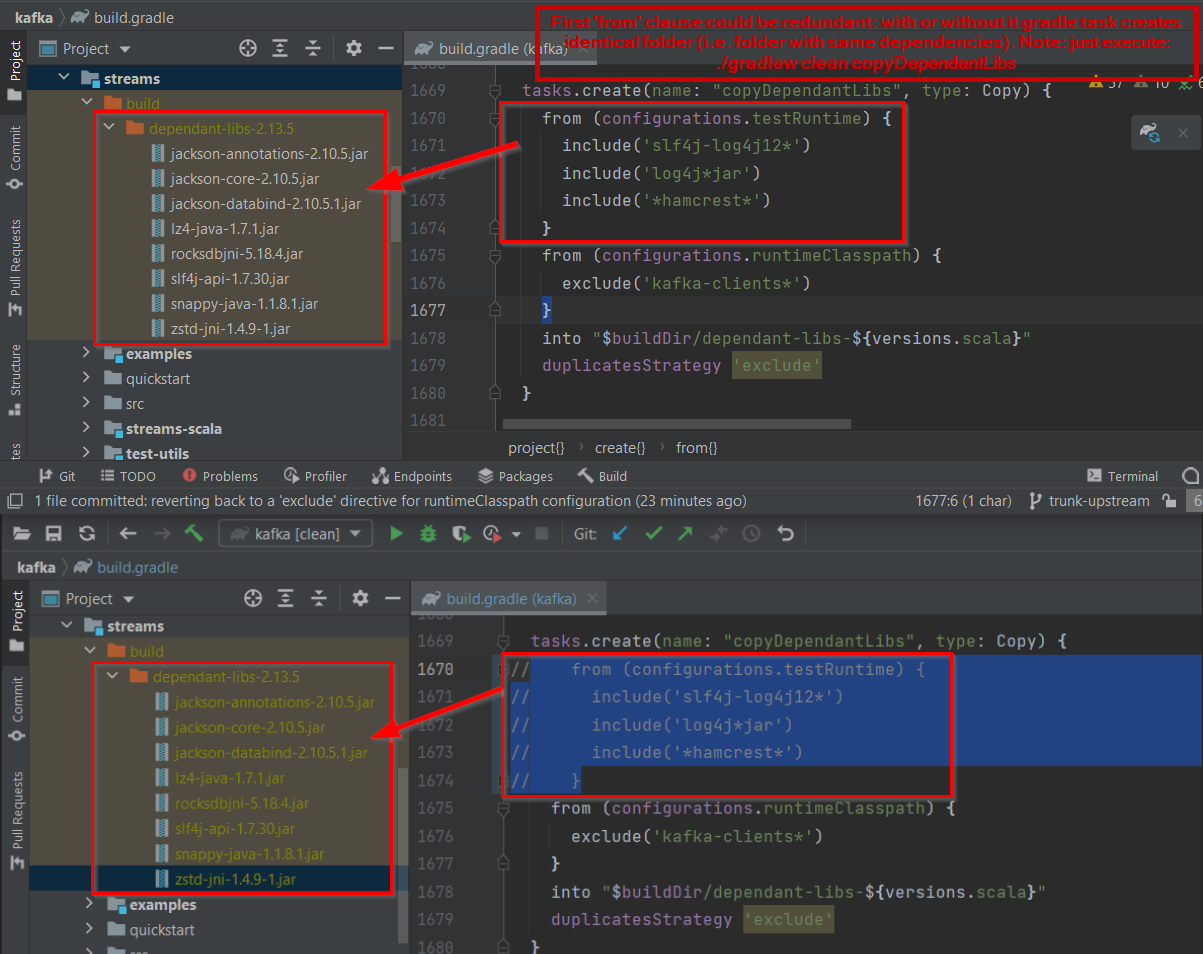
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-9861) Process Simplification - Community Validation of Kafka Release Candidates
[ https://issues.apache.org/jira/browse/KAFKA-9861?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17332683#comment-17332683 ] Israel Ekpo commented on KAFKA-9861: I am resuming work on this task in a few weeks. I will report back soon. > Process Simplification - Community Validation of Kafka Release Candidates > - > > Key: KAFKA-9861 > URL: https://issues.apache.org/jira/browse/KAFKA-9861 > Project: Kafka > Issue Type: Improvement > Components: build, documentation, system tests > Environment: Linux, Java 8/11, Scala 2.x >Reporter: Israel Ekpo >Assignee: Israel Ekpo >Priority: Minor > > When new KAFKA release candidates are published and there is a solicitation > for the community to get involved in testing and verifying the release > candidates, it would be great to have the test process thoroughly documented > for newcomers to participate effectively. > For new contributors, this can be very daunting and it would be great to have > this process clearly documented in a way that lowers the level of effort > necessary to get started. > The goal of this task is to create the documentation and supporting artifacts > that would make this goal a reality. > Going forward for future releases, it would be great to have the link to this > documentation included in the RC announcements so that the community > (especially end users) can help test and participate in the voting process > effectively. > These are the items that I believe should be included in this documentation > * How to set up test environment for unit and functional tests > * Java version(s) needed for the tests > * Scala version(s) needed for the tests > * Gradle version needed > * Sample script for running sanity checks and unit tests > * Sample Helm Charts for running all the basic components on a Kubernetes > * Sample Ansible Script for running all the basic components on Virtual > Machines > The first 4 items will be part of the documentation that shows how to install > these dependencies in a Linux VM. The 5th item is a script that will download > PGP keys, check signatures, validate checksums and run unit/integration > tests. The 6th item is a Helm chart with basic components necessary to > validate critical components in the ecosystem (Zookeeper, Brokers, Streams > etc) within a Kubernetes cluster. The last item is similar to the 6th item > but installs these components on virtual machines instead. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dejan2609 commented on pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
dejan2609 commented on pull request #10466: URL: https://github.com/apache/kafka/pull/10466#issuecomment-827067268 @ijuma branch is rebased onto trunk (I can also squash all commits into one). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dejan2609 commented on a change in pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
dejan2609 commented on a change in pull request #10466:
URL: https://github.com/apache/kafka/pull/10466#discussion_r620558374
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
- include('slf4j-log4j12*')
- include('log4j*jar')
- include('*hamcrest*')
+from (configurations.testCompileClasspath) {
+ include('jackson*')
+ include('slf4j-api*')
}
from (configurations.runtimeClasspath) {
- exclude('kafka-clients*')
+ include('connect*')
+ include('*java*')
+ include('*jni*')
Review comment:
Nice catch @ijuma ! Thing is that my intention was to put forward some
solution that just **_works_** (in a same way that previous, see attached
snapshots below).
So, I moved around **_java_** and **_java-library_** plugins configurations
and after scrapping something I just left solution as-is... of course,
**_exclude_** declaration is an optimal solution (because it handles
dependencies that will be included into related configuration in the future).
All-in-all: reverting back to an **_'exclude'_** directive.
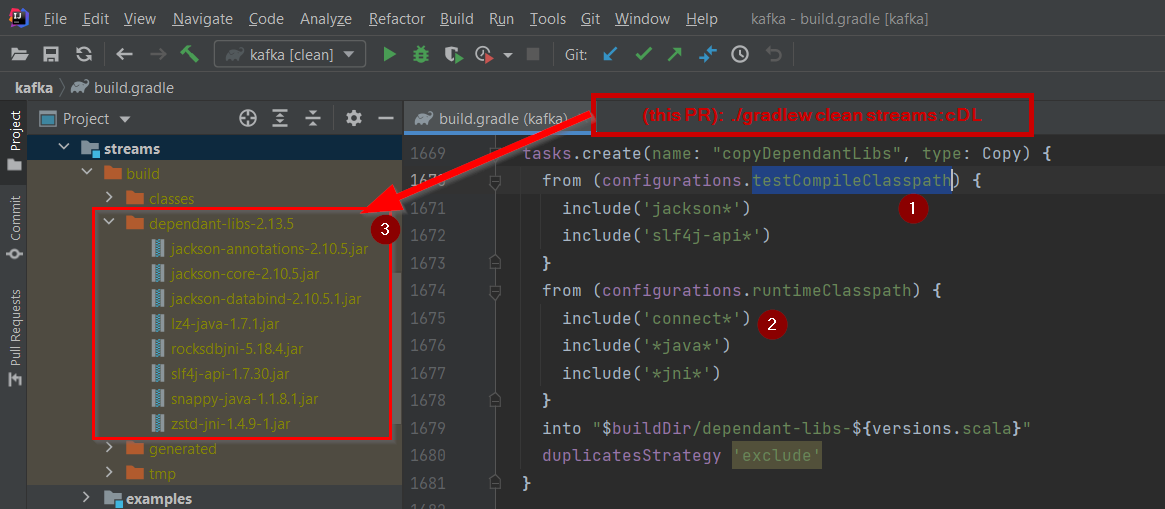
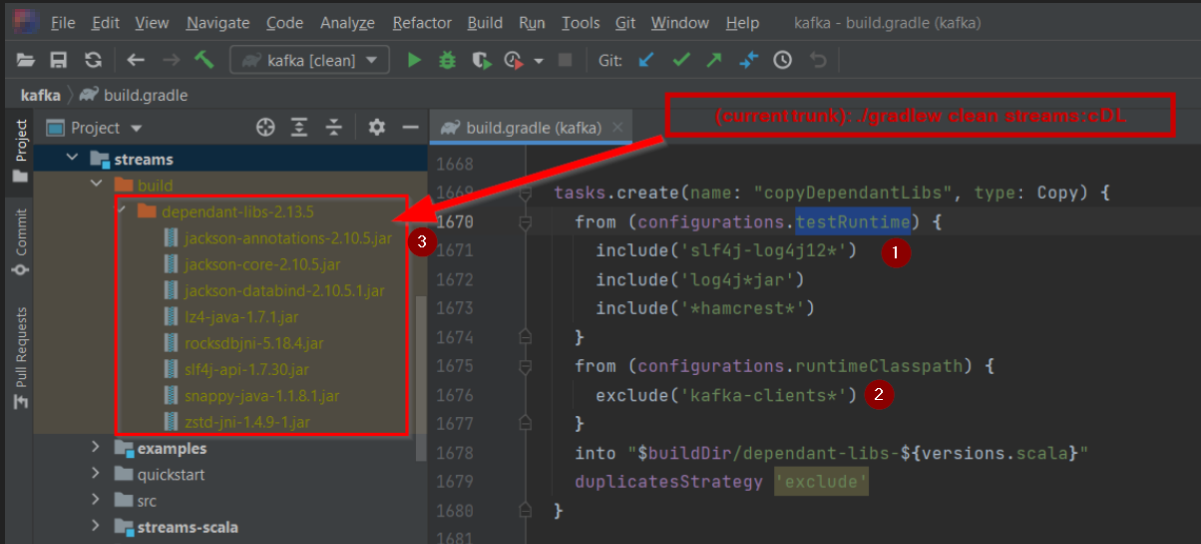
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Resolved] (KAFKA-12344) Support SlidingWindows in the Scala API
[ https://issues.apache.org/jira/browse/KAFKA-12344?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] A. Sophie Blee-Goldman resolved KAFKA-12344. Fix Version/s: 3.0.0 Resolution: Fixed > Support SlidingWindows in the Scala API > --- > > Key: KAFKA-12344 > URL: https://issues.apache.org/jira/browse/KAFKA-12344 > Project: Kafka > Issue Type: Improvement > Components: streams >Affects Versions: 2.7.0 >Reporter: Leah Thomas >Assignee: Ketul Gupta >Priority: Major > Labels: newbie, scala > Fix For: 3.0.0 > > > in KIP-450 we implemented sliding windows for the Java API but left out a few > crucial methods to allow sliding windows to work through the Scala API. We > need to add those methods to make the Scala API fully leverage sliding windows -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] ableegoldman commented on pull request #10519: KAFKA-12344 Support SlidingWindows in the Scala API
ableegoldman commented on pull request #10519: URL: https://github.com/apache/kafka/pull/10519#issuecomment-827060742 Merged to trunk. Thanks for the PR @ketulgupta1995 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman merged pull request #10519: KAFKA-12344 Support SlidingWindows in the Scala API
ableegoldman merged pull request #10519: URL: https://github.com/apache/kafka/pull/10519 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-12717) Remove internal converter config properties
[
https://issues.apache.org/jira/browse/KAFKA-12717?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chris Egerton updated KAFKA-12717:
--
Labels: needs-kip (was: )
> Remove internal converter config properties
> ---
>
> Key: KAFKA-12717
> URL: https://issues.apache.org/jira/browse/KAFKA-12717
> Project: Kafka
> Issue Type: Bug
> Components: KafkaConnect
>Reporter: Chris Egerton
>Assignee: Chris Egerton
>Priority: Major
> Labels: needs-kip
>
> KAFKA-5540 /
> [KIP-174|https://cwiki.apache.org/confluence/display/KAFKA/KIP-174+-+Deprecate+and+remove+internal+converter+configs+in+WorkerConfig]
> deprecated but did not officially remove Connect's internal converter worker
> config properties. With the upcoming 3.0 release, we can make the
> backwards-incompatible change of completely removing these properties once
> and for all.
>
> One migration path for users who may still be running Connect clusters with
> different internal converters can be:
> # Stop all workers on the cluster
> # For each internal topic (config, offsets, and status):
> ## Create a new topic to take the place of the existing one
> ## For every message in the existing topic:
> ### Deserialize the message's key and value using the Connect cluster's old
> internal key and value converters
> ### Serialize the message's key and value using the [JSON
> converter|https://github.com/apache/kafka/blob/trunk/connect/json/src/main/java/org/apache/kafka/connect/json/JsonConverter.java]
> with schemas disabled (by setting the {{schemas.enable}} property to
> {{false}})
> ### Write a message with the new key and value to the new internal topic
> # Reconfigure each Connect worker to use the newly-created internal topics
> from step 2
> # Start all workers on the cluster
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-12717) Remove internal converter config properties
Chris Egerton created KAFKA-12717:
-
Summary: Remove internal converter config properties
Key: KAFKA-12717
URL: https://issues.apache.org/jira/browse/KAFKA-12717
Project: Kafka
Issue Type: Bug
Components: KafkaConnect
Reporter: Chris Egerton
Assignee: Chris Egerton
KAFKA-5540 /
[KIP-174|https://cwiki.apache.org/confluence/display/KAFKA/KIP-174+-+Deprecate+and+remove+internal+converter+configs+in+WorkerConfig]
deprecated but did not officially remove Connect's internal converter worker
config properties. With the upcoming 3.0 release, we can make the
backwards-incompatible change of completely removing these properties once and
for all.
One migration path for users who may still be running Connect clusters with
different internal converters can be:
# Stop all workers on the cluster
# For each internal topic (config, offsets, and status):
## Create a new topic to take the place of the existing one
## For every message in the existing topic:
### Deserialize the message's key and value using the Connect cluster's old
internal key and value converters
### Serialize the message's key and value using the [JSON
converter|https://github.com/apache/kafka/blob/trunk/connect/json/src/main/java/org/apache/kafka/connect/json/JsonConverter.java]
with schemas disabled (by setting the {{schemas.enable}} property to {{false}})
### Write a message with the new key and value to the new internal topic
# Reconfigure each Connect worker to use the newly-created internal topics
from step 2
# Start all workers on the cluster
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620541346
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/RemoteLogMetadataSerde.java
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage.serialization;
+
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import
org.apache.kafka.server.log.remote.metadata.storage.generated.RemoteLogSegmentMetadataRecord;
+import
org.apache.kafka.server.log.remote.metadata.storage.generated.RemoteLogSegmentMetadataUpdateRecord;
+import
org.apache.kafka.server.log.remote.metadata.storage.generated.RemotePartitionDeleteMetadataRecord;
+import org.apache.kafka.server.log.remote.storage.RemoteLogSegmentMetadata;
+import
org.apache.kafka.server.log.remote.storage.RemoteLogSegmentMetadataUpdate;
+import
org.apache.kafka.server.log.remote.storage.RemotePartitionDeleteMetadata;
+import org.apache.kafka.server.log.remote.storage.RemoteLogMetadata;
+
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * This class provides serialization and deserialization for {@link
RemoteLogMetadata}. This is the root serde
+ * for the messages that are stored in internal remote log metadata topic.
+ */
+public class RemoteLogMetadataSerde {
+private static final short REMOTE_LOG_SEGMENT_METADATA_API_KEY = new
RemoteLogSegmentMetadataRecord().apiKey();
+private static final short REMOTE_LOG_SEGMENT_METADATA_UPDATE_API_KEY =
new RemoteLogSegmentMetadataUpdateRecord().apiKey();
+private static final short REMOTE_PARTITION_DELETE_API_KEY = new
RemotePartitionDeleteMetadataRecord().apiKey();
+
+private static final Map
REMOTE_LOG_STORAGE_CLASS_TO_API_KEY = createRemoteLogStorageClassToApiKeyMap();
Review comment:
I initially had `Class` as a key but later I changed it to class name
viz `String`. `Class` instances may not be equal if they are not loaded from
the same classloader. String(Class name) was taken as the key to avoid such
remote possible scenarios in the future.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620531772
##
File path:
storage/src/test/java/org/apache/kafka/server/log/remote/metadata/storage/RemoteLogMetadataSerdeTest.java
##
@@ -0,0 +1,113 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage;
+
+import org.apache.kafka.common.TopicIdPartition;
+import org.apache.kafka.common.TopicPartition;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.utils.MockTime;
+import org.apache.kafka.common.utils.Time;
+import
org.apache.kafka.server.log.remote.metadata.storage.serialization.RemoteLogMetadataSerde;
+import org.apache.kafka.server.log.remote.storage.RemoteLogSegmentId;
+import org.apache.kafka.server.log.remote.storage.RemoteLogSegmentMetadata;
+import
org.apache.kafka.server.log.remote.storage.RemoteLogSegmentMetadataUpdate;
+import org.apache.kafka.server.log.remote.storage.RemoteLogSegmentState;
+import
org.apache.kafka.server.log.remote.storage.RemotePartitionDeleteMetadata;
+import org.apache.kafka.server.log.remote.storage.RemotePartitionDeleteState;
+import org.apache.kafka.server.log.remote.storage.RemoteLogMetadata;
+import org.junit.jupiter.api.Assertions;
+import org.junit.jupiter.api.Test;
+
+import java.util.HashMap;
+import java.util.Map;
+
+public class RemoteLogMetadataSerdeTest {
+
+public static final String TOPIC = "foo";
+private static final TopicIdPartition TP0 = new
TopicIdPartition(Uuid.randomUuid(), new TopicPartition(TOPIC, 0));
+private final Time time = new MockTime(1);
+
+@Test
+public void testRemoteLogSegmentMetadataSerde() {
+RemoteLogSegmentMetadata remoteLogSegmentMetadata =
createRemoteLogSegmentMetadata();
+
+doTestRemoteLogMetadataSerde(remoteLogSegmentMetadata);
+}
+
+@Test
+public void testRemoteLogSegmentMetadataUpdateSerde() {
+// Create RemoteLogSegmentMetadataUpdate for
RemoteLogSegmentMetadataUpdate
+RemoteLogSegmentMetadataUpdate remoteLogSegmentMetadataUpdate =
createRemoteLogSegmentMetadataUpdate();
+
+doTestRemoteLogMetadataSerde(remoteLogSegmentMetadataUpdate);
+}
+
+@Test
+public void testRemotePartitionDeleteMetadataSerde() {
+// Create RemoteLogMetadataContext for RemotePartitionDeleteMetadata
Review comment:
sorry for running the wrong find/replace just before the commit. :(
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620531430
##
File path:
raft/src/main/java/org/apache/kafka/raft/metadata/AbstractMetadataRecordSerde.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.metadata;
+
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.common.protocol.Readable;
+import org.apache.kafka.common.protocol.Writable;
+import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.raft.RecordSerde;
+
+/**
+ * This is an implementation of {@code RecordSerde} with {@code
ApiMessageAndVersion} but implementors need to implement
+ * {@link #apiMessageFor(short)} to return a {@code ApiMessage} instance for
the given {@code apiKey}.
+ *
+ * This can be used as the underlying serialization mechanism for any metadata
kind of log storage.
+ */
+public abstract class AbstractMetadataRecordSerde implements
RecordSerde {
+private static final short DEFAULT_FRAME_VERSION = 0;
+private static final int DEFAULT_FRAME_VERSION_SIZE =
ByteUtils.sizeOfUnsignedVarint(DEFAULT_FRAME_VERSION);
+
+@Override
+public int recordSize(ApiMessageAndVersion data,
+ ObjectSerializationCache serializationCache) {
+int size = DEFAULT_FRAME_VERSION_SIZE;
+size += ByteUtils.sizeOfUnsignedVarint(data.message().apiKey());
+size += ByteUtils.sizeOfUnsignedVarint(data.version());
+size += data.message().size(serializationCache, data.version());
+return size;
+}
+
+@Override
+public void write(ApiMessageAndVersion data,
+ ObjectSerializationCache serializationCache,
+ Writable out) {
+out.writeUnsignedVarint(DEFAULT_FRAME_VERSION);
+out.writeUnsignedVarint(data.message().apiKey());
+out.writeUnsignedVarint(data.version());
+data.message().write(out, serializationCache, data.version());
+}
+
+@Override
+public ApiMessageAndVersion read(Readable input,
+ int size) {
+short frameVersion = (short) input.readUnsignedVarint();
+if (frameVersion != DEFAULT_FRAME_VERSION) {
+throw new SerializationException("Could not deserialize metadata
record due to unknown frame version "
+ + frameVersion + "(only
frame version " + DEFAULT_FRAME_VERSION + " is supported)");
+}
+
+short apiKey = (short) input.readUnsignedVarint();
+short version = (short) input.readUnsignedVarint();
+ApiMessage record = apiMessageFor(apiKey);
+record.read(input, version);
+return new ApiMessageAndVersion(record, version);
+}
+
+/**
+ * Return {@code ApiMessage} instance for the given {@code apiKey}. This
is used while deserializing the bytes
+ * payload into the respective {@code ApiMessage} in {@link
#read(Readable, int)} method.
+ *
+ * @param apiKey apiKey for which a {@code ApiMessage} to be created.
+ */
+public abstract ApiMessage apiMessageFor(short apiKey);
Review comment:
I guess it very unlikely to have such a use case in the future.
If we encounter such a use case in the future, we can have a workaround to
define a message in another topic and create a converter for one message
definition to the other.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rondagostino edited a comment on pull request #10550: MINOR: Add support for ZK Authorizer with KRaft
rondagostino edited a comment on pull request #10550:
URL: https://github.com/apache/kafka/pull/10550#issuecomment-827040926
> we need to start forwarding the ACL operations to the controller
We forward the Create/Remove operations to the controller, but this patch
actually short-circuits that if we are using KRaft with the ZooKeeper-based
`AclAuthorizer` via the changes to `RaftSupport.maybeForward()`. The reason
for short-circuiting it is because the KRaft controller doesn't have the code
to create or remove ACLs (`handle{Create,Delete}Acls` in `KafkaApis`). We
could add it, of course, in which case the changes to the `maybeForward()`
method would be unnecessary. Perhaps it would be simpler to do that instead of
delaying it to an additional PR -- is that what you were suggesting?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rondagostino commented on pull request #10550: MINOR: Add support for ZK Authorizer with KRaft
rondagostino commented on pull request #10550:
URL: https://github.com/apache/kafka/pull/10550#issuecomment-827040926
> we need to start forwarding the ACL operations to the controller
We forward the Create/Remove operations to the controller, BUT this patch
actually short-circuits that if we are using KRaft with the ZooKeeper-based
`AclAuthorizer` via the changes to `RaftSupport.maybeForward()`. The reason
for short-circuiting it is because the KRaft controller doesn't have the code
to create or remove ACLs (`handle{Create,Delete}Acls` in `KafkaApis`). We
could add it, of course, in which case the changes to the `maybeForward()`
method would be unnecessary. Perhaps it would be simpler to do that instead of
delaying it to an additional PR -- is that what you were suggesting?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620529858
##
File path:
raft/src/main/java/org/apache/kafka/raft/metadata/AbstractMetadataRecordSerde.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.metadata;
+
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.common.protocol.Readable;
+import org.apache.kafka.common.protocol.Writable;
+import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.raft.RecordSerde;
+
+/**
+ * This is an implementation of {@code RecordSerde} with {@code
ApiMessageAndVersion} but implementors need to implement
+ * {@link #apiMessageFor(short)} to return a {@code ApiMessage} instance for
the given {@code apiKey}.
+ *
+ * This can be used as the underlying serialization mechanism for any metadata
kind of log storage.
+ */
+public abstract class AbstractMetadataRecordSerde implements
RecordSerde {
+private static final short DEFAULT_FRAME_VERSION = 0;
+private static final int DEFAULT_FRAME_VERSION_SIZE =
ByteUtils.sizeOfUnsignedVarint(DEFAULT_FRAME_VERSION);
+
+@Override
+public int recordSize(ApiMessageAndVersion data,
+ ObjectSerializationCache serializationCache) {
+int size = DEFAULT_FRAME_VERSION_SIZE;
+size += ByteUtils.sizeOfUnsignedVarint(data.message().apiKey());
+size += ByteUtils.sizeOfUnsignedVarint(data.version());
+size += data.message().size(serializationCache, data.version());
+return size;
+}
+
+@Override
+public void write(ApiMessageAndVersion data,
+ ObjectSerializationCache serializationCache,
+ Writable out) {
+out.writeUnsignedVarint(DEFAULT_FRAME_VERSION);
+out.writeUnsignedVarint(data.message().apiKey());
+out.writeUnsignedVarint(data.version());
+data.message().write(out, serializationCache, data.version());
+}
+
+@Override
+public ApiMessageAndVersion read(Readable input,
+ int size) {
+short frameVersion = (short) input.readUnsignedVarint();
+if (frameVersion != DEFAULT_FRAME_VERSION) {
+throw new SerializationException("Could not deserialize metadata
record due to unknown frame version "
+ + frameVersion + "(only
frame version " + DEFAULT_FRAME_VERSION + " is supported)");
+}
+
+short apiKey = (short) input.readUnsignedVarint();
+short version = (short) input.readUnsignedVarint();
+ApiMessage record = apiMessageFor(apiKey);
+record.read(input, version);
+return new ApiMessageAndVersion(record, version);
+}
+
+/**
+ * Return {@code ApiMessage} instance for the given {@code apiKey}. This
is used while deserializing the bytes
+ * payload into the respective {@code ApiMessage} in {@link
#read(Readable, int)} method.
+ *
+ * @param apiKey apiKey for which a {@code ApiMessage} to be created.
+ */
+public abstract ApiMessage apiMessageFor(short apiKey);
Review comment:
I guess it very unlikely to have such a use case in the future.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rondagostino commented on pull request #10550: MINOR: Add support for ZK Authorizer with KRaft
rondagostino commented on pull request #10550: URL: https://github.com/apache/kafka/pull/10550#issuecomment-827032633 > It might be helpful to move the znode setup code into KafkaZkClient @cmccabe One possibility is that the first time we connect to ZooKeeper we connect without the chroot path, create that path if it doesn't exist, and then disconnect -- then (and thereafter)we connect with the chroot path? If we did that then I think it would have to happen in `kafka.zookeeper.ZooKeeperClient` rather than in `KafkaZkClient` since the former is where we provide the chroot path -- the latter seems to simply use the former with no concept of a chroot path. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-8147) Add changelog topic configuration to KTable suppress
[
https://issues.apache.org/jira/browse/KAFKA-8147?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17332630#comment-17332630
]
Philip Bourke edited comment on KAFKA-8147 at 4/26/21, 5:34 PM:
I'm looking to implement this fix but it seems like it only works depending on
the order of the
{{BufferConfig}}
If I do this it works -
{code:java}
.suppress(Suppressed.untilTimeLimit(Duration.ofMillis(maxIdleIntervalMs),
BufferConfig.maxRecords(
maxBufferRecords).emitEarlyWhenFull().withLoggingEnabled(changelogConfig)){code}
But not if I set the {{withLoggingEnabled}} before {{emitEarlyWhenFull}}.
Is it expected that the {{BufferConfig}} should be set in a particular order?
was (Author: philbour):
I'm looking to implement this fix but it seems like it only works depending on
the order of the {{BufferConfig}}
If I do this it works -
.suppress(Suppressed.untilTimeLimit(Duration.ofMillis(maxIdleIntervalMs),
BufferConfig.maxRecords(
maxBufferRecords).emitEarlyWhenFull().withLoggingEnabled(changelogConfig))
But not if I set the {{withLoggingEnabled }}before {{emitEarlyWhenFull}}.
Is it expected that the {{BufferConfig }}should be set in a particular order?
> Add changelog topic configuration to KTable suppress
>
>
> Key: KAFKA-8147
> URL: https://issues.apache.org/jira/browse/KAFKA-8147
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Affects Versions: 2.1.1
>Reporter: Maarten
>Assignee: highluck
>Priority: Minor
> Labels: kip
> Fix For: 2.6.0
>
>
> The streams DSL does not provide a way to configure the changelog topic
> created by KTable.suppress.
> From the perspective of an external user this could be implemented similar to
> the configuration of aggregate + materialized, i.e.,
> {code:java}
> changelogTopicConfigs = // Configs
> materialized = Materialized.as(..).withLoggingEnabled(changelogTopicConfigs)
> ..
> KGroupedStream.aggregate(..,materialized)
> {code}
> [KIP-446:
> https://cwiki.apache.org/confluence/display/KAFKA/KIP-446%3A+Add+changelog+topic+configuration+to+KTable+suppress|https://cwiki.apache.org/confluence/display/KAFKA/KIP-446%3A+Add+changelog+topic+configuration+to+KTable+suppress]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620457633
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, I thought you wanted to simply warn the user that the
serialization strategy she chose is not optimal. But seems like you want to
ignore the choice completely.
Then it doesn't make sense to expose this flag at all for the user to
change. Me and @mjsax were discussing it earlier
https://github.com/apache/kafka/pull/6592#issuecomment-606277356
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620449322
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
+mkEntry(UUIDDeserializer.class, 36)
+);
+
+public ListDeserializer() {}
+
+public > ListDeserializer(Class listClass,
Deserializer innerDeserializer) {
+this.listClass = listClass;
+this.inner = innerDeserializer;
+if (innerDeserializer != null) {
+this.primitiveSize =
fixedLengthDeserializers.get(innerDeserializer.getClass());
+}
+}
+
+public Deserializer getInnerDeserializer() {
+return inner;
+}
+
+@Override
+public void configure(Map configs, boolean isKey) {
+if (listClass == null) {
Review comment:
Now, I am thinking about it. It seems a bit extra to compare the classes
defined between the constructor and configs.
Maybe, if a user tries to use the constructor when classes are already
defined in the configs, we simply throw an exception? Forcing the user to set
only one or the other.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-8147) Add changelog topic configuration to KTable suppress
[
https://issues.apache.org/jira/browse/KAFKA-8147?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17332630#comment-17332630
]
Philip Bourke commented on KAFKA-8147:
--
I'm looking to implement this fix but it seems like it only works depending on
the order of the {{BufferConfig}}
If I do this it works -
.suppress(Suppressed.untilTimeLimit(Duration.ofMillis(maxIdleIntervalMs),
BufferConfig.maxRecords(
maxBufferRecords).emitEarlyWhenFull().withLoggingEnabled(changelogConfig))
But not if I set the {{withLoggingEnabled }}before {{emitEarlyWhenFull}}.
Is it expected that the {{BufferConfig }}should be set in a particular order?
> Add changelog topic configuration to KTable suppress
>
>
> Key: KAFKA-8147
> URL: https://issues.apache.org/jira/browse/KAFKA-8147
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Affects Versions: 2.1.1
>Reporter: Maarten
>Assignee: highluck
>Priority: Minor
> Labels: kip
> Fix For: 2.6.0
>
>
> The streams DSL does not provide a way to configure the changelog topic
> created by KTable.suppress.
> From the perspective of an external user this could be implemented similar to
> the configuration of aggregate + materialized, i.e.,
> {code:java}
> changelogTopicConfigs = // Configs
> materialized = Materialized.as(..).withLoggingEnabled(changelogTopicConfigs)
> ..
> KGroupedStream.aggregate(..,materialized)
> {code}
> [KIP-446:
> https://cwiki.apache.org/confluence/display/KAFKA/KIP-446%3A+Add+changelog+topic+configuration+to+KTable+suppress|https://cwiki.apache.org/confluence/display/KAFKA/KIP-446%3A+Add+changelog+topic+configuration+to+KTable+suppress]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-5540) Deprecate internal converter configs
[ https://issues.apache.org/jira/browse/KAFKA-5540?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chris Egerton updated KAFKA-5540: - Summary: Deprecate internal converter configs (was: Deprecate and remove internal converter configs) > Deprecate internal converter configs > > > Key: KAFKA-5540 > URL: https://issues.apache.org/jira/browse/KAFKA-5540 > Project: Kafka > Issue Type: Bug > Components: KafkaConnect >Affects Versions: 0.11.0.0 >Reporter: Ewen Cheslack-Postava >Assignee: Chris Egerton >Priority: Major > Labels: needs-kip > Fix For: 2.0.0 > > > The internal.key.converter and internal.value.converter were original exposed > as configs because a) they are actually pluggable and b) providing a default > would require relying on the JsonConverter always being available, which > until we had classloader isolation it was possible might be removed for > compatibility reasons. > However, this has ultimately just caused a lot more trouble and confusion > than it is worth. We should deprecate the configs, give them a default of > JsonConverter (which is also kind of nice since it results in human-readable > data in the internal topics), and then ultimately remove them in the next > major version. > These are all public APIs so this will need a small KIP before we can make > the change. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] junrao commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
junrao commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620461362
##
File path:
storage/api/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogMetadata.java
##
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+/**
+ * Base class for remote log metadata objects like {@link
RemoteLogSegmentMetadata}, {@link RemoteLogSegmentMetadataUpdate},
+ * and {@link RemotePartitionDeleteMetadata}.
+ */
+@InterfaceStability.Evolving
+public class RemoteLogMetadata {
Review comment:
Should this class be abstract?
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/RemoteLogMetadataSerde.java
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage.serialization;
+
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import
org.apache.kafka.server.log.remote.metadata.storage.generated.RemoteLogSegmentMetadataRecord;
+import
org.apache.kafka.server.log.remote.metadata.storage.generated.RemoteLogSegmentMetadataUpdateRecord;
+import
org.apache.kafka.server.log.remote.metadata.storage.generated.RemotePartitionDeleteMetadataRecord;
+import org.apache.kafka.server.log.remote.storage.RemoteLogSegmentMetadata;
+import
org.apache.kafka.server.log.remote.storage.RemoteLogSegmentMetadataUpdate;
+import
org.apache.kafka.server.log.remote.storage.RemotePartitionDeleteMetadata;
+import org.apache.kafka.server.log.remote.storage.RemoteLogMetadata;
+
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * This class provides serialization and deserialization for {@link
RemoteLogMetadata}. This is the root serde
+ * for the messages that are stored in internal remote log metadata topic.
+ */
+public class RemoteLogMetadataSerde {
+private static final short REMOTE_LOG_SEGMENT_METADATA_API_KEY = new
RemoteLogSegmentMetadataRecord().apiKey();
+private static final short REMOTE_LOG_SEGMENT_METADATA_UPDATE_API_KEY =
new RemoteLogSegmentMetadataUpdateRecord().apiKey();
+private static final short REMOTE_PARTITION_DELETE_API_KEY = new
RemotePartitionDeleteMetadataRecord().apiKey();
+
+private static final Map
REMOTE_LOG_STORAGE_CLASS_TO_API_KEY = createRemoteLogStorageClassToApiKeyMap();
+private static final Map
KEY_TO_TRANSFORM = createRemoteLogMetadataTransforms();
+
+private static final BytesApiMessageSerde BYTES_API_MESSAGE_SERDE = new
BytesApiMessageSerde() {
+@Override
+public ApiMessage apiMessageFor(short apiKey) {
Review comment:
Could we generate this mapping using MetadataRecordTypeGenerator like
what raft did?
##
File path:
storage/src/test/java/org/apache/kafka/server/log/remote/metadata/storage/RemoteLogMetadataSerdeTest.java
##
@@ -0,0 +1,113 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ *
[jira] [Updated] (KAFKA-12713) Report "REAL" follower/consumer fetch latency
[ https://issues.apache.org/jira/browse/KAFKA-12713?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ming Liu updated KAFKA-12713: - Summary: Report "REAL" follower/consumer fetch latency (was: Report "REAL" broker/consumer fetch latency) > Report "REAL" follower/consumer fetch latency > - > > Key: KAFKA-12713 > URL: https://issues.apache.org/jira/browse/KAFKA-12713 > Project: Kafka > Issue Type: Bug >Reporter: Ming Liu >Priority: Major > > The fetch latency is an important metrics to monitor for the cluster > performance. With ACK=ALL, the produce latency is affected primarily by > broker fetch latency. > However, currently the reported fetch latency didn't reflect the true fetch > latency because it sometimes need to stay in purgatory and wait for > replica.fetch.wait.max.ms when data is not available. This greatly affect the > real P50, P99 etc. > I like to propose a KIP to be able track the real fetch latency for both > broker follower and consumer. > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] mjsax commented on pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
mjsax commented on pull request #10548: URL: https://github.com/apache/kafka/pull/10548#issuecomment-826998394 To avoid checkstyle and test issues, and reduce review turn-around time, I would recommend to run unit tests and checkstyle locally before pushing update: `./gradlew clean stream:unitTest streams:checkstyleMain streams:checkstyleTest` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] lct45 commented on pull request #10519: KAFKA-12344 Support SlidingWindows in the Scala API
lct45 commented on pull request #10519: URL: https://github.com/apache/kafka/pull/10519#issuecomment-826998105 bumping - @mjsax @ableegoldman @vvcephei -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on a change in pull request #10548: KAFKA-12396 added a nullcheck before trying to retrieve a key
mjsax commented on a change in pull request #10548:
URL: https://github.com/apache/kafka/pull/10548#discussion_r620479940
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/RocksDBStoreTest.java
##
@@ -402,6 +402,11 @@ public void shouldReturnKeysWithGivenPrefix() {
assertThat(valuesWithPrefix.get(2), is("b"));
}
+@Test
+public void shouldThrowNullPointerIfPrefixKeySerializerIsNull() {
Review comment:
This test fails now, as the check was removed. No need to add this test
any longer in this class.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on pull request #10271: URL: https://github.com/apache/kafka/pull/10271#issuecomment-826991751 @junrao: I will have a followup PR for moving `RecordSerde`, `AbstractApiMessageSerde`, `BytesApiMessageSerde` into clients modules as I discussed earlier. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] satishd commented on pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on pull request #10271: URL: https://github.com/apache/kafka/pull/10271#issuecomment-826988567 Thanks @junrao for the review. Addressed them with the inline replies, and with the commit https://github.com/apache/kafka/pull/10271/commits/265b72692f590ab5760776f2b5176066c08e959d. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620457633
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListSerializer.java
##
@@ -77,21 +87,39 @@ public void configure(Map configs, boolean
isKey) {
}
}
+private void serializeNullIndexList(final DataOutputStream out,
List data) throws IOException {
+List nullIndexList = IntStream.range(0, data.size())
+.filter(i -> data.get(i) == null)
+.boxed().collect(Collectors.toList());
+out.writeInt(nullIndexList.size());
+for (int i : nullIndexList) out.writeInt(i);
+}
+
@Override
public byte[] serialize(String topic, List data) {
if (data == null) {
return null;
}
-final int size = data.size();
try (final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final DataOutputStream out = new DataOutputStream(baos)) {
+out.writeByte(serStrategy.ordinal()); // write serialization
strategy flag
+if (serStrategy == SerializationStrategy.NULL_INDEX_LIST) {
+serializeNullIndexList(out, data);
+}
+final int size = data.size();
out.writeInt(size);
for (Inner entry : data) {
-final byte[] bytes = inner.serialize(topic, entry);
-if (!isFixedLength) {
-out.writeInt(bytes.length);
+if (entry == null) {
+if (serStrategy == SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(Serdes.ListSerde.NEGATIVE_SIZE_VALUE);
+}
+} else {
+final byte[] bytes = inner.serialize(topic, entry);
+if (!isFixedLength || serStrategy ==
SerializationStrategy.NEGATIVE_SIZE) {
+out.writeInt(bytes.length);
Review comment:
Hmmm, I thought you want to simply warn the user that the serialization
strategy she chose is not optimal. But seems like you want to ignore the choice
completely.
Then it doesn't make sense to expose this flag at all for the user to
change. Me and @mjsax were discussing it earlier
https://github.com/apache/kafka/pull/6592#issuecomment-606277356
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Assigned] (KAFKA-12716) Admin API for aborting transactions
[ https://issues.apache.org/jira/browse/KAFKA-12716?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jason Gustafson reassigned KAFKA-12716: --- Assignee: Jason Gustafson > Admin API for aborting transactions > --- > > Key: KAFKA-12716 > URL: https://issues.apache.org/jira/browse/KAFKA-12716 > Project: Kafka > Issue Type: Sub-task >Reporter: Jason Gustafson >Assignee: Jason Gustafson >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12716) Admin API for aborting transactions
Jason Gustafson created KAFKA-12716: --- Summary: Admin API for aborting transactions Key: KAFKA-12716 URL: https://issues.apache.org/jira/browse/KAFKA-12716 Project: Kafka Issue Type: Sub-task Reporter: Jason Gustafson -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] junrao commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
junrao commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620455106
##
File path:
raft/src/main/java/org/apache/kafka/raft/metadata/AbstractMetadataRecordSerde.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.metadata;
+
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.common.protocol.Readable;
+import org.apache.kafka.common.protocol.Writable;
+import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.raft.RecordSerde;
+
+/**
+ * This is an implementation of {@code RecordSerde} with {@code
ApiMessageAndVersion} but implementors need to implement
+ * {@link #apiMessageFor(short)} to return a {@code ApiMessage} instance for
the given {@code apiKey}.
+ *
+ * This can be used as the underlying serialization mechanism for any metadata
kind of log storage.
+ */
+public abstract class AbstractMetadataRecordSerde implements
RecordSerde {
+private static final short DEFAULT_FRAME_VERSION = 0;
+private static final int DEFAULT_FRAME_VERSION_SIZE =
ByteUtils.sizeOfUnsignedVarint(DEFAULT_FRAME_VERSION);
+
+@Override
+public int recordSize(ApiMessageAndVersion data,
+ ObjectSerializationCache serializationCache) {
+int size = DEFAULT_FRAME_VERSION_SIZE;
+size += ByteUtils.sizeOfUnsignedVarint(data.message().apiKey());
+size += ByteUtils.sizeOfUnsignedVarint(data.version());
+size += data.message().size(serializationCache, data.version());
+return size;
+}
+
+@Override
+public void write(ApiMessageAndVersion data,
+ ObjectSerializationCache serializationCache,
+ Writable out) {
+out.writeUnsignedVarint(DEFAULT_FRAME_VERSION);
+out.writeUnsignedVarint(data.message().apiKey());
+out.writeUnsignedVarint(data.version());
+data.message().write(out, serializationCache, data.version());
+}
+
+@Override
+public ApiMessageAndVersion read(Readable input,
+ int size) {
+short frameVersion = (short) input.readUnsignedVarint();
+if (frameVersion != DEFAULT_FRAME_VERSION) {
+throw new SerializationException("Could not deserialize metadata
record due to unknown frame version "
+ + frameVersion + "(only
frame version " + DEFAULT_FRAME_VERSION + " is supported)");
+}
+
+short apiKey = (short) input.readUnsignedVarint();
+short version = (short) input.readUnsignedVarint();
+ApiMessage record = apiMessageFor(apiKey);
+record.read(input, version);
+return new ApiMessageAndVersion(record, version);
+}
+
+/**
+ * Return {@code ApiMessage} instance for the given {@code apiKey}. This
is used while deserializing the bytes
+ * payload into the respective {@code ApiMessage} in {@link
#read(Readable, int)} method.
+ *
+ * @param apiKey apiKey for which a {@code ApiMessage} to be created.
+ */
+public abstract ApiMessage apiMessageFor(short apiKey);
Review comment:
One potential benefit of shared id space is that an ApiMessage could be
used in more than one topic. There is no such use case now. I am wondering if
there is such a use case in the future. If there is no such usage, we could
choose not to share the id space.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] yeralin commented on a change in pull request #6592: KAFKA-8326: Introduce List Serde
yeralin commented on a change in pull request #6592:
URL: https://github.com/apache/kafka/pull/6592#discussion_r620449322
##
File path:
clients/src/main/java/org/apache/kafka/common/serialization/ListDeserializer.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common.serialization;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.KafkaException;
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.utils.Utils;
+
+import java.io.ByteArrayInputStream;
+import java.io.DataInputStream;
+import java.io.IOException;
+import java.lang.reflect.Constructor;
+import java.lang.reflect.InvocationTargetException;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import static
org.apache.kafka.common.serialization.Serdes.ListSerde.SerializationStrategy;
+import static org.apache.kafka.common.utils.Utils.mkEntry;
+import static org.apache.kafka.common.utils.Utils.mkMap;
+
+public class ListDeserializer implements Deserializer> {
+
+private Deserializer inner;
+private Class listClass;
+private Integer primitiveSize;
+
+static private Map>, Integer>
fixedLengthDeserializers = mkMap(
+mkEntry(ShortDeserializer.class, 2),
+mkEntry(IntegerDeserializer.class, 4),
+mkEntry(FloatDeserializer.class, 4),
+mkEntry(LongDeserializer.class, 8),
+mkEntry(DoubleDeserializer.class, 8),
+mkEntry(UUIDDeserializer.class, 36)
+);
+
+public ListDeserializer() {}
+
+public > ListDeserializer(Class listClass,
Deserializer innerDeserializer) {
+this.listClass = listClass;
+this.inner = innerDeserializer;
+if (innerDeserializer != null) {
+this.primitiveSize =
fixedLengthDeserializers.get(innerDeserializer.getClass());
+}
+}
+
+public Deserializer getInnerDeserializer() {
+return inner;
+}
+
+@Override
+public void configure(Map configs, boolean isKey) {
+if (listClass == null) {
Review comment:
Now, I am thinking about it. It seems a bit extra to compare the classes
defined between the constructor and configs.
Maybe, we simply throw an exception, if a user tries to use the constructor
when classes are already defined in the configs?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] junrao commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
junrao commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620449297
##
File path:
raft/src/main/java/org/apache/kafka/raft/metadata/AbstractMetadataRecordSerde.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.metadata;
+
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.common.protocol.Readable;
+import org.apache.kafka.common.protocol.Writable;
+import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.raft.RecordSerde;
+
+/**
+ * This is an implementation of {@code RecordSerde} with {@code
ApiMessageAndVersion} but implementors need to implement
+ * {@link #apiMessageFor(short)} to return a {@code ApiMessage} instance for
the given {@code apiKey}.
+ *
+ * This can be used as the underlying serialization mechanism for any metadata
kind of log storage.
+ */
+public abstract class AbstractMetadataRecordSerde implements
RecordSerde {
Review comment:
(1) Perhaps we could call this one AbstractApiMessageSerde and the other
one BytesApiMessageSerde?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620438864
##
File path:
raft/src/main/java/org/apache/kafka/raft/metadata/AbstractMetadataRecordSerde.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.metadata;
+
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.common.protocol.Readable;
+import org.apache.kafka.common.protocol.Writable;
+import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.raft.RecordSerde;
+
+/**
+ * This is an implementation of {@code RecordSerde} with {@code
ApiMessageAndVersion} but implementors need to implement
+ * {@link #apiMessageFor(short)} to return a {@code ApiMessage} instance for
the given {@code apiKey}.
+ *
+ * This can be used as the underlying serialization mechanism for any metadata
kind of log storage.
Review comment:
Added more details.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620438317
##
File path:
raft/src/main/java/org/apache/kafka/raft/metadata/AbstractMetadataRecordSerde.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.metadata;
+
+import org.apache.kafka.common.errors.SerializationException;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.protocol.ObjectSerializationCache;
+import org.apache.kafka.common.protocol.Readable;
+import org.apache.kafka.common.protocol.Writable;
+import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.raft.RecordSerde;
+
+/**
+ * This is an implementation of {@code RecordSerde} with {@code
ApiMessageAndVersion} but implementors need to implement
+ * {@link #apiMessageFor(short)} to return a {@code ApiMessage} instance for
the given {@code apiKey}.
+ *
+ * This can be used as the underlying serialization mechanism for any metadata
kind of log storage.
+ */
+public abstract class AbstractMetadataRecordSerde implements
RecordSerde {
Review comment:
(1) ReadableWritableApiMessageSerde instead of WritableApiMessageSerde?
(2) Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10271: KAFKA-12429: Added serdes for the default implementation of RLMM based on an internal topic as storage.
satishd commented on a change in pull request #10271:
URL: https://github.com/apache/kafka/pull/10271#discussion_r620437193
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/serialization/AbstractMetadataMessageSerde.java
##
@@ -19,52 +19,41 @@
import org.apache.kafka.common.protocol.ApiMessage;
import org.apache.kafka.common.protocol.ByteBufferAccessor;
import org.apache.kafka.common.protocol.ObjectSerializationCache;
-import org.apache.kafka.common.utils.ByteUtils;
+import org.apache.kafka.common.protocol.Readable;
import org.apache.kafka.metadata.ApiMessageAndVersion;
-
+import org.apache.kafka.raft.metadata.AbstractMetadataRecordSerde;
import java.nio.ByteBuffer;
/**
- * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}.
+ * This class provides serialization/deserialization of {@code
ApiMessageAndVersion}. This can be used as
+ * serialization/deserialization protocol for any metadata records derived of
{@code ApiMessage}s.
*
* Implementors need to extend this class and implement {@link
#apiMessageFor(short)} method to return a respective
* {@code ApiMessage} for the given {@code apiKey}. This is required to
deserialize the bytes to build the respective
* {@code ApiMessage} instance.
*/
-public abstract class AbstractApiMessageAndVersionSerde {
+public abstract class AbstractMetadataMessageSerde {
Review comment:
`ReadableWritableApiMessageSerde` instead of `WritableApiMessageSerde`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rondagostino commented on pull request #10550: MINOR: Add support for ZK Authorizer with KRaft
rondagostino commented on pull request #10550: URL: https://github.com/apache/kafka/pull/10550#issuecomment-826903361 @cmccabe Thanks for taking a look. I agree in principle with your statement that `KafkaRaftServer` should know nothing about ZooKeeper or AclAuthorizer. My reasoning for violating that idea was due to a specific issue: nothing will work with ZooKeeper when there is a chroot path in the `zk.connect` configuration value unless that chroot path exists. Currently `KafkaServer` checks for and creates any non-existing chroot path upon startup, and the ZooKeeper initialization being done in `KafkaRaftServer` is the same thing -- the PR refactored that ability out into its own function so that it could be called from both `KafkaServer` and `KafkaRaftServer`. It is conceivable that we could move this check into `AclAuthorizer`, but then the ZooKeeper-based broker won't run if there is no authorizer configured (and it might not work anyway due to race conditions -- who's to say that the authorizer will win the race and create the chroot path before anything else tries to connect?) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #10593: KAFKA-10800 Validate the snapshot id when the state machine creates a snapshot
jsancio commented on a change in pull request #10593:
URL: https://github.com/apache/kafka/pull/10593#discussion_r620232416
##
File path: raft/src/main/java/org/apache/kafka/raft/KafkaRaftClient.java
##
@@ -2268,6 +2269,20 @@ private Long append(int epoch, List records, boolean
isAtomic) {
);
}
+private void validateSnapshotId(OffsetAndEpoch snapshotId) {
+Optional highWatermarkOpt =
quorum().highWatermark();
+if (!highWatermarkOpt.isPresent() || highWatermarkOpt.get().offset <=
snapshotId.offset) {
+throw new KafkaException("Trying to creating snapshot with
snapshotId: " + snapshotId + " whose offset is larger than the high-watermark:
" +
+highWatermarkOpt + ". This may necessarily mean a bug in
the caller, since the there should be a minimum " +
+"size of records between the latest snapshot and the
high-watermark when creating snapshot");
+}
+int leaderEpoch = quorum().epoch();
+if (snapshotId.epoch > leaderEpoch) {
+throw new KafkaException("Trying to creating snapshot with
snapshotId: " + snapshotId + " whose epoch is" +
+" larger than the current leader epoch: " + leaderEpoch);
+}
Review comment:
Yeah, This is not strictly required for correctness. Oh, I see, the
check in 2280 is checking that the `epoch > current epoch`.
I mistakenly read it as `epoch != current epoch`. If we perform this check
we are basically saying that the caller of `createSnapshot` needs to catch up
to the current quorum epoch before it can generate a snapshot. Yes, I think
epoch <= quorum epoch` is fine. Let me think about it and I'll update the Jira.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] bruto1 edited a comment on pull request #10590: KAFKA-5761: support ByteBuffer as value in ProducerRecord and avoid redundant serialization when it's used
bruto1 edited a comment on pull request #10590: URL: https://github.com/apache/kafka/pull/10590#issuecomment-826126350 I guess failing tests are par for the course here pls review! @chia7712 ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] feyman2016 edited a comment on pull request #10593: KAFKA-10800 Validate the snapshot id when the state machine creates a snapshot
feyman2016 edited a comment on pull request #10593: URL: https://github.com/apache/kafka/pull/10593#issuecomment-826653099 @jsancio Thanks for the review! I updated the PR, and the failed tests should be unrelated, thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] feyman2016 commented on pull request #10593: KAFKA-10800 Validate the snapshot id when the state machine creates a snapshot
feyman2016 commented on pull request #10593: URL: https://github.com/apache/kafka/pull/10593#issuecomment-826653099 @jsancio I updated the PR, and the failed tests should be unrelated, thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng edited a comment on pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
vitojeng edited a comment on pull request #10597: URL: https://github.com/apache/kafka/pull/10597#issuecomment-826589358 @ableegoldman Please take a look. BTW, I encounter a [ClassDataAbstractionCoupling](https://checkstyle.org/config_metrics.html#ClassDataAbstractionCoupling) check style failure, so I update the **checkstyle/suppressions.xml** to avoid this failure. If there have a better way to solve this check style failure, please let me know. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dengziming opened a new pull request #10598: MINOR: rename wrong topic id variable name and description
dengziming opened a new pull request #10598: URL: https://github.com/apache/kafka/pull/10598 *More detailed description of your change*  1. The argument description "The topic id to produce messages to" is not right, currently we do not support topicId when producing messages, maybe 3.0.0. 2. also rename deprecaed `Class.newInstance` to `class.getDeclaredConstructor().newInstance()` 3. rename `Map` to `JMap` for better reading. *Summary of testing strategy (including rationale)* Test locally. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng commented on pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
vitojeng commented on pull request #10597: URL: https://github.com/apache/kafka/pull/10597#issuecomment-826589358 @ableegoldman Please take a look. BTW, I encounter a [ClassDataAbstractionCoupling](https://checkstyle.org/config_metrics.html#ClassDataAbstractionCoupling) check style failure, so I update the **checkstyle/suppressions.xml** to avoid this failure. I am not sure that there have a better way to solve this failure. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng opened a new pull request #10597: KAFKA-5876: Apply StreamsNotStartedException for Interactive Queries
vitojeng opened a new pull request #10597: URL: https://github.com/apache/kafka/pull/10597 follow-up #8200 KAFKA-5876's PR break into multiple parts, this PR is part 3 - apply StreamsNotStartedException ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
ijuma commented on pull request #10466: URL: https://github.com/apache/kafka/pull/10466#issuecomment-826400303 @dejan2609 can you please rebase on trunk? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10466: KAFKA-12417 "streams" module: switch deprecated Gradle configuration `testRuntime`
ijuma commented on a change in pull request #10466:
URL: https://github.com/apache/kafka/pull/10466#discussion_r619888968
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
- include('slf4j-log4j12*')
- include('log4j*jar')
- include('*hamcrest*')
+from (configurations.testCompileClasspath) {
+ include('jackson*')
+ include('slf4j-api*')
}
from (configurations.runtimeClasspath) {
- exclude('kafka-clients*')
+ include('connect*')
+ include('*java*')
+ include('*jni*')
Review comment:
Why did we switch from exclude to include?
##
File path: build.gradle
##
@@ -1491,13 +1491,14 @@ project(':streams') {
}
tasks.create(name: "copyDependantLibs", type: Copy) {
-from (configurations.testRuntime) {
Review comment:
@vvcephei do you know why we're copying test dependencies here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] feyman2016 commented on a change in pull request #10593: KAFKA-10800 Validate the snapshot id when the state machine creates a snapshot
feyman2016 commented on a change in pull request #10593:
URL: https://github.com/apache/kafka/pull/10593#discussion_r619793709
##
File path: raft/src/main/java/org/apache/kafka/raft/internals/BatchBuilder.java
##
@@ -96,7 +96,7 @@ public BatchBuilder(
}
/**
- * Append a record to this patch. The caller must first verify there is
room for the batch
+ * Append a record to this batch. The caller must first verify there is
room for the batch
Review comment:
Side fix
##
File path: raft/src/test/java/org/apache/kafka/snapshot/SnapshotWriterTest.java
##
@@ -38,7 +38,7 @@
@Test
public void testWritingSnapshot() throws IOException {
-OffsetAndEpoch id = new OffsetAndEpoch(10L, 3);
+OffsetAndEpoch id = new OffsetAndEpoch(0L, 1);
Review comment:
The highwatermark here is 1, so we need to make the snapshotId's
endOffset < 1.
##
File path:
raft/src/test/java/org/apache/kafka/raft/KafkaRaftClientSnapshotTest.java
##
@@ -1335,6 +1313,51 @@ public void
testFetchSnapshotRequestClusterIdValidation() throws Exception {
context.assertSentFetchSnapshotResponse(Errors.INCONSISTENT_CLUSTER_ID);
}
+@Test
+public void testCreateSnapshotWithInvalidSnapshotId() throws Exception {
+int localId = 0;
+int otherNodeId = localId + 1;
+Set voters = Utils.mkSet(localId, otherNodeId);
+int epoch = 2;
+
+List appendRecords = Arrays.asList("a", "b", "c");
+OffsetAndEpoch invalidSnapshotId1 = new OffsetAndEpoch(3, epoch);
+
+RaftClientTestContext context = new
RaftClientTestContext.Builder(localId, voters)
+.appendToLog(epoch, appendRecords)
+.withAppendLingerMs(1)
+.build();
+
+context.becomeLeader();
+int currentEpoch = context.currentEpoch();
+
+// When creating snapshot:
+// 1. high watermark cannot be empty
+assertEquals(OptionalLong.empty(), context.client.highWatermark());
+assertThrows(KafkaException.class, () ->
context.client.createSnapshot(invalidSnapshotId1));
+
+// 2. high watermark must larger than the snapshotId's endOffset
+advanceHighWatermark(context, currentEpoch, currentEpoch, otherNodeId,
localId);
+assertNotEquals(OptionalLong.empty(), context.client.highWatermark());
+OffsetAndEpoch invalidSnapshotId2 = new
OffsetAndEpoch(context.client.highWatermark().getAsLong(), currentEpoch);
+assertThrows(KafkaException.class, () ->
context.client.createSnapshot(invalidSnapshotId2));
+
+// 3. the current leader epoch cache must larger than the snapshotId's
epoch
+OffsetAndEpoch invalidSnapshotId3 = new
OffsetAndEpoch(context.client.highWatermark().getAsLong() - 1, currentEpoch +
1);
+assertThrows(KafkaException.class, () ->
context.client.createSnapshot(invalidSnapshotId3));
+}
+
+private void advanceHighWatermark(RaftClientTestContext context,
Review comment:
Extract the functionality to avoid duplicate
##
File path: raft/src/main/java/org/apache/kafka/raft/KafkaRaftClient.java
##
@@ -2268,6 +2269,20 @@ private Long append(int epoch, List records, boolean
isAtomic) {
);
}
+private void validateSnapshotId(OffsetAndEpoch snapshotId) {
+Optional highWatermarkOpt =
quorum().highWatermark();
+if (!highWatermarkOpt.isPresent() || highWatermarkOpt.get().offset <=
snapshotId.offset) {
Review comment:
Conceptually, the `snapshotId.offset=highWatermarkOpt.get().offset` is
ok, because the record at `snapshotId.offset` is not included in the snapshot,
but I'm not sure if there are other restrictions because in the Jira
description, it says: `The end offset and epoch of the snapshot is less than
the high-watermark`, please kindly advice @jsancio
##
File path: raft/src/main/java/org/apache/kafka/raft/KafkaRaftClient.java
##
@@ -2268,6 +2269,20 @@ private Long append(int epoch, List records, boolean
isAtomic) {
);
}
+private void validateSnapshotId(OffsetAndEpoch snapshotId) {
+Optional highWatermarkOpt =
quorum().highWatermark();
+if (!highWatermarkOpt.isPresent() || highWatermarkOpt.get().offset <=
snapshotId.offset) {
+throw new KafkaException("Trying to creating snapshot with
snapshotId: " + snapshotId + " whose offset is larger than the high-watermark:
" +
+highWatermarkOpt + ". This may necessarily mean a bug in
the caller, since the there should be a minimum " +
+"size of records between the latest snapshot and the
high-watermark when creating snapshot");
+}
+int leaderEpoch = quorum().epoch();
+if (snapshotId.epoch > leaderEpoch) {
+throw new KafkaException("Trying to creating snapshot with
snapshotId: " + snapshotId + " whose epoch is" +
+
[GitHub] [kafka] chia7712 commented on pull request #9627: KAFKA-10746: Change to Warn logs when necessary to notify users
chia7712 commented on pull request #9627: URL: https://github.com/apache/kafka/pull/9627#issuecomment-826320025 @showuon thanks for this patch! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on a change in pull request #10573: KAFKA-12574: KIP-732, Deprecate eos-alpha and replace eos-beta with eos-v2
mjsax commented on a change in pull request #10573:
URL: https://github.com/apache/kafka/pull/10573#discussion_r619875764
##
File path: docs/streams/upgrade-guide.html
##
@@ -93,6 +95,12 @@ Upgrade Guide and API Changes
Streams API changes in 3.0.0
+
+ The StreamsConfig.EXACTLY_ONCE and
StreamsConfig.EXACTLY_ONCE_BETA configs have been deprecated, and
a new StreamsConfig.EXACTLY_ONCE_V2 config has been
+ introduced. This is the same feature as eos-beta, but renamed to
highlight its production-readiness. Users of exactly-once semantics should plan
to migrate to the eos-v2 config and prepare for the removal of the deprecated
configs in 4.0 or after at least a year
Review comment:
I would be very bolt about it:
```
We deprecated processing.guarantee configuration value
"exactly_once"
(for EOS version 1) in favor of the improved EOS version 2, formerly
configured via
"exactly_once_beta. To avoid the confusion about the term
"beta" in the config value
(it was never meant to imply it's not production ready), we furthermore
renamed
"exactly_once_beta" to "exactly_once_v2".
```
Or something similar.
##
File path: docs/streams/upgrade-guide.html
##
@@ -93,6 +95,12 @@ Upgrade Guide and API Changes
Streams API changes in 3.0.0
+
+ The StreamsConfig.EXACTLY_ONCE and
StreamsConfig.EXACTLY_ONCE_BETA configs have been deprecated, and
a new StreamsConfig.EXACTLY_ONCE_V2 config has been
Review comment:
Well, we do deprecate `StreamsConfig.EXACTLY_ONCE`, too, but user might
just do `config.put("processing.guarantee", "exactly_once");` (or have a config
file with `"exactly_once"`) in it. To me, the main change is that the config
itself is deprecated and the deprecation of variable is just a "side effect".
##
File path: docs/streams/upgrade-guide.html
##
@@ -93,6 +95,12 @@ Upgrade Guide and API Changes
Streams API changes in 3.0.0
+
+ The StreamsConfig.EXACTLY_ONCE and
StreamsConfig.EXACTLY_ONCE_BETA configs have been deprecated, and
a new StreamsConfig.EXACTLY_ONCE_V2 config has been
+ introduced. This is the same feature as eos-beta, but renamed to
highlight its production-readiness. Users of exactly-once semantics should plan
to migrate to the eos-v2 config and prepare for the removal of the deprecated
configs in 4.0 or after at least a year
+ from the release of 3.0, whichever comes last. Note that eos-v2 requires
broker version 2.5 or higher, like eos-beta, so users should begin to upgrade
their kafka cluster if necessary. See
Review comment:
Fair enough.
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamThread.java
##
@@ -603,7 +606,7 @@ boolean runLoop() {
log.error("Shutting down because the Kafka cluster seems
to be on a too old version. " +
"Setting {}=\"{}\" requires broker version 2.5
or higher.",
StreamsConfig.PROCESSING_GUARANTEE_CONFIG,
- EXACTLY_ONCE_BETA);
+ StreamsConfig.EXACTLY_ONCE_V2);
Review comment:
SGTM -- if the required code changes to get the actual value are to
much, I am fine with hard-coding the value, too.
##
File path:
streams/src/test/java/org/apache/kafka/streams/processor/internals/RecordCollectorTest.java
##
@@ -111,6 +113,7 @@
private final StringSerializer stringSerializer = new StringSerializer();
private final ByteArraySerializer byteArraySerializer = new
ByteArraySerializer();
+private final UUID processId = UUID.randomUUID();
Review comment:
> only for eos-v2 for some reason
That is weird -- if `StreamsProducer` requires the `processID` it should
have required it for `_beta` already? Would be good to understand -- maybe we
unmasked a bug?
##
File path:
streams/src/test/java/org/apache/kafka/streams/processor/internals/RecordCollectorTest.java
##
@@ -126,10 +129,10 @@ public void setup() {
clientSupplier.setCluster(cluster);
streamsProducer = new StreamsProducer(
config,
-"threadId",
+processId + "-StreamThread-1",
Review comment:
This PR does not change `StreamsProducer` so this parsing should have
happened for `_beta` already -- what do I miss?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] feyman2016 commented on pull request #10593: KAFKA-10800 Validate the snapshot id when the state machine creates a snapshot
feyman2016 commented on pull request #10593: URL: https://github.com/apache/kafka/pull/10593#issuecomment-826304130 @jsancio Could you please help to review? Thanks! Locally verified, all the failed tests should not be related. See failed tests in https://ci-builds.apache.org/job/Kafka/job/kafka-pr/job/PR-10593/2/testReport/?cloudbees-analytics-link=scm-reporting%2Ftests%2Ffailed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #10593: KAFKA-10800 Validate the snapshot id when the state machine creates a snapshot
jsancio commented on a change in pull request #10593:
URL: https://github.com/apache/kafka/pull/10593#discussion_r619882084
##
File path: raft/src/main/java/org/apache/kafka/raft/KafkaRaftClient.java
##
@@ -2268,6 +2269,20 @@ private Long append(int epoch, List records, boolean
isAtomic) {
);
}
+private void validateSnapshotId(OffsetAndEpoch snapshotId) {
+Optional highWatermarkOpt =
quorum().highWatermark();
+if (!highWatermarkOpt.isPresent() || highWatermarkOpt.get().offset <=
snapshotId.offset) {
Review comment:
You are correct. I think when I created the Jira I overlooked that both
snapshot id's end offset and the high-watermark are exclusive values. Update
the Jira's description.
##
File path: raft/src/main/java/org/apache/kafka/raft/KafkaRaftClient.java
##
@@ -2268,6 +2269,20 @@ private Long append(int epoch, List records, boolean
isAtomic) {
);
}
+private void validateSnapshotId(OffsetAndEpoch snapshotId) {
+Optional highWatermarkOpt =
quorum().highWatermark();
+if (!highWatermarkOpt.isPresent() || highWatermarkOpt.get().offset <=
snapshotId.offset) {
+throw new KafkaException("Trying to creating snapshot with
snapshotId: " + snapshotId + " whose offset is larger than the high-watermark:
" +
+highWatermarkOpt + ". This may necessarily mean a bug in
the caller, since the there should be a minimum " +
+"size of records between the latest snapshot and the
high-watermark when creating snapshot");
+}
+int leaderEpoch = quorum().epoch();
+if (snapshotId.epoch > leaderEpoch) {
+throw new KafkaException("Trying to creating snapshot with
snapshotId: " + snapshotId + " whose epoch is" +
+" larger than the current leader epoch: " + leaderEpoch);
+}
Review comment:
From the Jira:
> The end offset and epoch of the snapshot is valid based on the leader
epoch cache.
How about also validating against the leader epoch cache? See
https://github.com/apache/kafka/blob/trunk/raft/src/main/java/org/apache/kafka/raft/ReplicatedLog.java#L124.
This is important because both the snapshot and the leader epoch cache are
used to validate offsets. See
https://github.com/apache/kafka/blob/trunk/raft/src/main/java/org/apache/kafka/raft/ReplicatedLog.java#L85.
The term leader epoch cache comes the variable name `leaderEpochCache` used in
`kafka.log.Log`.
##
File path:
raft/src/test/java/org/apache/kafka/raft/KafkaRaftClientSnapshotTest.java
##
@@ -1335,6 +1313,51 @@ public void
testFetchSnapshotRequestClusterIdValidation() throws Exception {
context.assertSentFetchSnapshotResponse(Errors.INCONSISTENT_CLUSTER_ID);
}
+@Test
+public void testCreateSnapshotWithInvalidSnapshotId() throws Exception {
+int localId = 0;
+int otherNodeId = localId + 1;
+Set voters = Utils.mkSet(localId, otherNodeId);
+int epoch = 2;
+
+List appendRecords = Arrays.asList("a", "b", "c");
+OffsetAndEpoch invalidSnapshotId1 = new OffsetAndEpoch(3, epoch);
+
+RaftClientTestContext context = new
RaftClientTestContext.Builder(localId, voters)
+.appendToLog(epoch, appendRecords)
+.withAppendLingerMs(1)
+.build();
+
+context.becomeLeader();
+int currentEpoch = context.currentEpoch();
+
+// When creating snapshot:
+// 1. high watermark cannot be empty
+assertEquals(OptionalLong.empty(), context.client.highWatermark());
+assertThrows(KafkaException.class, () ->
context.client.createSnapshot(invalidSnapshotId1));
+
+// 2. high watermark must larger than the snapshotId's endOffset
+advanceHighWatermark(context, currentEpoch, currentEpoch, otherNodeId,
localId);
+assertNotEquals(OptionalLong.empty(), context.client.highWatermark());
+OffsetAndEpoch invalidSnapshotId2 = new
OffsetAndEpoch(context.client.highWatermark().getAsLong(), currentEpoch);
+assertThrows(KafkaException.class, () ->
context.client.createSnapshot(invalidSnapshotId2));
+
+// 3. the current leader epoch cache must larger than the snapshotId's
epoch
+OffsetAndEpoch invalidSnapshotId3 = new
OffsetAndEpoch(context.client.highWatermark().getAsLong() - 1, currentEpoch +
1);
+assertThrows(KafkaException.class, () ->
context.client.createSnapshot(invalidSnapshotId3));
+}
+
+private void advanceHighWatermark(RaftClientTestContext context,
Review comment:
Thanks for clean up the code duplication.
##
File path:
raft/src/test/java/org/apache/kafka/raft/KafkaRaftClientSnapshotTest.java
##
@@ -1335,6 +1313,51 @@ public void
testFetchSnapshotRequestClusterIdValidation() throws Exception {